字符汉字数字【提取】
在文字中提取数字的函数

在文字中提取数字的函数提取数字是在文本中获取数字的过程。
在计算机科学中,有很多方法可以实现这个目标。
本文将介绍一些常用的方法和算法,以及如何使用它们来提取数字。
一、正则表达式正则表达式是一种强大的模式匹配工具,可以用来匹配特定的文本模式。
通过使用适当的正则表达式,可以很容易地从文本中提取数字。
例如,使用\d+正则表达式可以匹配一个或多个连续的数字。
二、字符串处理另一种常用的方法是使用字符串处理函数来提取数字。
这些函数通常包括查找和替换操作,可以根据特定的规则来查找并提取数字。
例如,可以使用isdigit()函数检查字符串中的每个字符是否是数字,并将它们组合在一起形成一个数字。
三、分词分词是将文本分解成单个词语或标记的过程。
在分词过程中,可以将数字作为一个独立的标记进行提取。
这可以通过使用适当的分词库或算法来实现,例如NLTK(自然语言工具包)中的分词函数。
四、机器学习机器学习是一种强大的技术,可以用来识别和提取文本中的特定模式。
通过训练一个机器学习模型,可以让计算机自动学习如何提取数字。
例如,可以使用支持向量机(SVM)或循环神经网络(RNN)等算法来训练一个模型,使其能够自动提取数字。
五、深度学习深度学习是机器学习的一种特殊形式,它使用多个神经网络层来学习和提取数据中的模式。
通过训练一个深度学习模型,可以实现更准确和高效的数字提取。
例如,可以使用卷积神经网络(CNN)或循环神经网络(RNN)等深度学习算法来训练一个模型,使其能够自动提取数字。
六、图像处理在某些情况下,数字可能以图像的形式出现在文本中。
为了提取这些图像中的数字,可以使用图像处理技术,如图像分割、字符识别等。
例如,可以使用OpenCV库中的函数来处理图像,并使用OCR (光学字符识别)算法来提取数字。
无论使用哪种方法,提取数字的关键是准确地识别数字出现的模式和规律。
在处理文本时,需要注意不要将其他类型的字符或文本错误地识别为数字。
excel 提取字母+数字的数字 公式

在Excel中,提取字母和数字的公式是非常常见的需求。
它可以帮助我们从混合的单元格中提取出我们需要的数据,例如提取出数字、提取出字母等。
在Excel中,有很多种方式可以实现这个功能,我们可以通过使用函数、公式、宏等方法来实现。
下面将详细介绍如何在Excel中提取字母和数字的公式。
1. 使用 MID 函数提取字母和数字MID 函数可以从文本字符串的任意位置开始,返回指定长度的字符。
如果我们知道需要提取的字符在文本中的位置,可以使用 MID 函数来提取。
具体公式为:```=MID(文本, 起始位置, 长度)```其中,文本是要提取的文本字符串,起始位置是要提取的起始位置,长度是要提取的字符的长度。
如果我们想要从单元格A1中提取第2到第5个字符,我们可以使用以下公式:```=MID(A1, 2, 4)```2. 使用 LEFT 和 RIGHT 函数提取字母和数字除了使用MID函数,我们还可以使用LEFT和RIGHT函数来提取文本字符串的前几个字符或者后几个字符。
具体公式为:LEFT函数:```=LEFT(文本, 长度)```RIGHT函数:```=RIGHT(文本, 长度)```如果我们想要从单元格A1中提取前5个字符,我们可以使用以下公式:```=LEFT(A1, 5)3. 使用 SUBSTITUTE 函数去除非数字字符在提取字母和数字的过程中,有时候单元格中会夹杂一些非数字字符,对于这些非数字字符,我们可以使用SUBSTITUTE函数将其替换为空,从而得到纯数字的结果。
具体公式为:```=SUBSTITUTE(文本, 要替换的字符, 替换为空的字符)```如果我们想要将单元格A1中的非数字字符都替换为空,我们可以使用以下公式:```=SUBSTITUTE(A1, "非数字字符", "")```通过以上三种常见的方法,我们可以在Excel中轻松提取字母和数字的公式。
提取excel中的一段数字、文字、符号方法

提取excel中的⼀段数字、⽂字、符号⽅法⼀、单元格A1中有如下内容:要提取出数字经测试下列公式好⽤提取Excel单元格中连续的数字的函数公式是:=LOOKUP(9E+307,--MID(A1,MIN(FIND({1,2,3,4,5,6,7,8,9,0},A1&1234567890)),ROW($1:$8)))或者=LOOKUP(9E+307,--MID(H2,MIN(FIND({0;1;2;3;4;5;6;7;8;9},H2&1234567890)),ROW(INDIRECT("1:"&LEN(H2)))))解释⼀下这个公式FIND函数——查询⽂本所在位置FIND(find_text,within_text,[start_num])FIND(需查找的⽂本,包含查找⽂本的单元格,开始查找单元格的字符位置(可选))此处FIND函数是搜索{1,2,3,4,5,6,7,8,9,0}数字在“A1&1234567890”中所在的位置;A1&1234567890的⽬的是在⽤FIND函数查询时,不出现错误值,使之后的MIN函数可以正常运⾏。
即FIND({1,2,3,4,5,6,7,8,9,0},“⼩王联系电话58670098负责财务1234567890”)选取划⿊后按F9,得出的位置为:{19,20,21,22,7,9,10,8,13,11}MIN函数——返回列表中的最⼩值MIN(number1,number2,……)MIN(数字1,数字2,……)将FIND所得结果{19,20,21,22,7,9,10,8,13,11}带⼊MIN函数,最⼩值所得为7,正是第⼀个数值出现的位置;也正是之前FIND函数中使⽤A1&1234567890的原因。
MID函数——返回⽂本字符串从指定位置开始特定数⽬的字符,即提取某段字符。
MID(text,start_num,num_chars)MID(被提取的⽂本或单元格,开始提取的字符位置,提取的字符个数)将上述MIN函数所得带⼊MID(A1,7,ROW($1:$8);ROW($1:$8)使⽤row函数不是⽤来计算⾏,⽽是借⽤其作为常量。
提取字符串中的数字(进阶版)
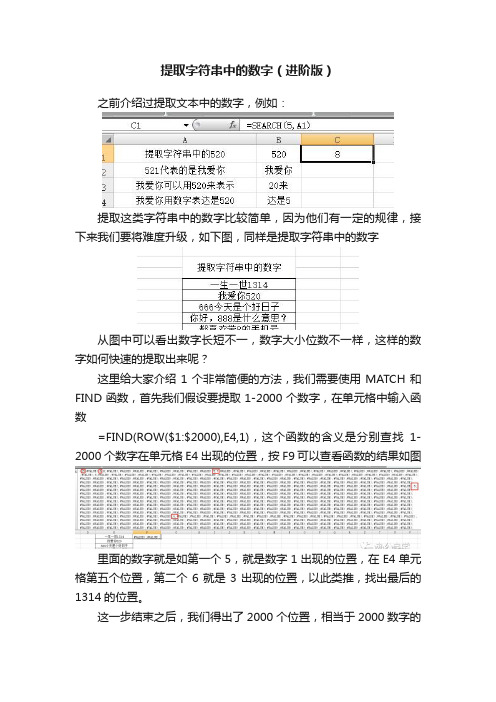
提取字符串中的数字(进阶版)
之前介绍过提取文本中的数字,例如:
提取这类字符串中的数字比较简单,因为他们有一定的规律,接下来我们要将难度升级,如下图,同样是提取字符串中的数字
从图中可以看出数字长短不一,数字大小位数不一样,这样的数字如何快速的提取出来呢?
这里给大家介绍1个非常简便的方法,我们需要使用MATCH和FIND函数,首先我们假设要提取1-2000个数字,在单元格中输入函数
=FIND(ROW($1:$2000),E4,1),这个函数的含义是分别查找1-2000个数字在单元格E4出现的位置,按F9可以查看函数的结果如图
里面的数字就是如第一个5,就是数字1出现的位置,在E4单元格第五个位置,第二个6就是3出现的位置,以此类推,找出最后的1314的位置。
这一步结束之后,我们得出了2000个位置,相当于2000数字的
区域,然后在结合MATCH函数,即可得出最终的结果
MATCH函数是查找字符串在数组中出现的位置,所以我们可以在FIND函数在套用MATCH函数,如图
按CTRL+SHIFT+ENTER得出结果
在往下填充,得出所有的值
这个函数是通用的,在一般的公式可以直接套用,效率很高,但是有个缺点,因为最多只支持查找1-1000000直接的数字,超出则会出错,所以在数字小于100万的数字都可以快速查找出来,大于7位数字则不适应。
wps从混合文本中提取数字的万能公式

wps从混合文本中提取数字的万能公式在日常工作和生活中,我们经常会遇到需要从一段文字中提取数字的情况,比如提取报告中的数据、整理统计信息等。
使用WPS软件,我们可以轻松完成这个任务,而不需要手动逐字筛选。
下面,我将介绍几种方法,帮助您从混合文本中提取数字。
方法一:使用WPS的查找功能WPS软件内置了强大的查找功能,可以帮助我们快速定位到文本中的数字。
具体操作如下:1. 打开需要提取数字的文档,点击菜单栏上的“编辑”按钮,选择“查找”。
2. 在弹出的查找对话框中,点击“数字”选项卡,输入要查找的数字范围,比如从1到1000。
3. 点击“查找下一个”按钮,WPS会自动定位到第一个符合条件的数字。
4. 可以点击“替换”按钮,将找到的数字替换为其他内容,或者点击“全部替换”按钮,一次性替换所有符合条件的数字。
方法二:使用WPS的正则表达式功能正则表达式是一种强大的文本匹配工具,可以用来识别特定的文本模式。
在WPS中,我们可以利用正则表达式来提取数字。
具体操作如下:1. 打开需要提取数字的文档,点击菜单栏上的“编辑”按钮,选择“查找”。
2. 在弹出的查找对话框中,点击“高级”按钮,在“查找模式”中选择“正则表达式”。
3. 在“查找内容”中输入以下正则表达式:\d+,表示匹配一个或多个数字。
4. 点击“查找下一个”按钮,WPS会自动定位到第一个符合条件的数字。
5. 可以点击“替换”按钮,将找到的数字替换为其他内容,或者点击“全部替换”按钮,一次性替换所有符合条件的数字。
方法三:使用WPS的自定义公式功能WPS还提供了自定义公式的功能,可以根据特定的文本模式提取数字。
具体操作如下:1. 打开需要提取数字的文档,点击菜单栏上的“插入”按钮,选择“公式”。
2. 在弹出的公式编辑器中,输入以下公式:=VALUE(LEFT(A1,LEN(A1)-1)),其中A1为待提取数字的单元格。
3. 按下回车键,WPS会自动计算提取的数字,并显示在公式所在的单元格中。
提取 中文+数字 之间部分 正则

在撰写文章之前,先简要介绍一下提取中文和数字之间部分的正则表达式。
正则表达式是一种用来匹配字符串的强大工具,它可以帮助我们从文本中提取出符合特定模式的内容。
提取中文和数字之间部分的正则表达式可以帮助我们在处理中文文本或含数字信息的文本时,高效地筛选出我们感兴趣的部分。
我们需要明确中文和数字的Unicode取值范围。
中文的Unicode范围大致在[\u4e00-\u9fa5]之间,数字的Unicode范围在[\u0030-\u0039]之间。
基于这个范围,我们可以使用正则表达式来匹配中文和数字之间的部分。
下面简要介绍一些常用的正则表达式符号:1. \d:匹配一个数字字符,等价于[0-9]。
2. \u4e00-\u9fa5:匹配中文字符的范围。
3. *:匹配前面的子表达式零次或多次。
4. +:匹配前面的子表达式一次或多次。
基于以上的符号,我们可以使用如下正则表达式来提取中文和数字之间的部分:```(?:[\u4e00-\u9fa5])+([\d]+)(?:[\u4e00-\u9fa5])+```其中,(?:[\u4e00-\u9fa5])+表示匹配一个或多个中文字符,([\d]+)表示匹配一个或多个数字字符,并且最后的(?:[\u4e00-\u9fa5])+表示再匹配一个或多个中文字符。
这样,我们就可以从文本中提取出中文和数字之间的部分。
以上是简要的介绍,接下来我将按照深度和广度的要求,以从简到繁的方式来探讨提取中文和数字之间部分的正则表达式的主题。
希望这篇文章可以帮助你更深入地理解这个主题。
【深度和广度要求下的探讨】1. 简单介绍:提取中文和数字之间部分的正则表达式的基本原理和常用符号。
2. 深入解析:进一步讲解每个符号的作用,以及如何通过组合运用来精确提取需要的部分。
3. 应用举例:通过实际的案例,展示如何使用提取中文和数字之间部分的正则表达式来处理实际文本。
4. 个人观点:共享我对这个主题的个人理解和使用体会。
【技巧】Excel快速批量提取字符

【技巧】Excel快速批量提取字符
以下的演示均使用快速填充快捷键Ctrl+E,使用步骤:
第一步:先手动有规律的提取字符或数字,最好是操作2次以上,让Excel知晓你所要求的规则;
第二步:选中要填充的区域(包含手动操作输入的单元格),按下快速填充快捷键Ctrl+E即可。
1提取固定位置字符
从名字中分离姓氏(第一个字符)和名字。
2按符号拆分
快速填充能根据文本与特定字符(或符号)的位置进行提取。
3提取数字
快速填充可以识别文本中的数字,用于分离数字特别方便。
4日期拆分
可以自动识别年、月、日。
5日期合并
提取月和日与姓名合并。
6字符合并
对于一个示例不能明确规律的,可以写两个(也可多个)示例再做快速填充。
利用通配符将Excel中英文字母、中文、数字提取出来

利⽤通配符将Excel中英⽂字母、中⽂、数字提取出来
混乱数据中包含了中⽂、数据、⼤⼩写英⽂字母这些内容,我们如何单独分离获取呢?之前易
⽼师有讲过【ExcelVBA在混合数据单元格中快速提取英⽂、数字、中⽂】⽅法,主要是利⽤
VBA来快速获取。
今天,易⽼师再来给⼤家分享⼀篇技巧,我们利⽤通配符也可以单独分离获
取。
不同的⽅法,结果相同。
有的同学可能就会说了,可以利⽤快速填充来搞定,这⾥我要告诉⼤家的是快速填充功能还不
是很完善,对于部分数据⽆法做到百分百准确获取。
01 获取数据
我们先将Excel中的数据复制到Word中来,然后使⽤快捷键【Ctrl + H】打开查找替换,然后勾
选通配符。
查找:[!0-9]
替换:空
说明:通配符,我之前的⽂章都有讲过哦。
在通配符中感叹号[!]代表“否”或“⾮”,所以,我们查
找的内容是⾮0到9这些字符。
02 获取⼤⼩写英⽂字母
查找:[!a-zA-Z]
替换:空
说明:[a-z]是包含了所有的⼩写字母,[A-Z]是包含了所有的⼤写字母,[a-zA-Z]包含了所有⼩写
和⼤写字母。
再加上⼀个感叹号!就是⾮。
03 获取中⽂
查找:[!⼀-龥] 或者 [!⼀-﨩]
替换:空
说明:[!⼀-龥] 或者 [!⼀-﨩],是什么意思呢,都是包含了所有的中⽂,属于2.0和3.0字符集⾥⾯
的顺序,你可以理解为数字中的从0到9,或者字母中的a到z就⾏了,也就是包含了所有的中⽂
汉字。
如何快速从混杂着文字的信息中提取数字?看这里,轻松搞定!

如何快速从混杂着文字的信息中提取数字?看这里,轻松搞定!如何快速从混杂着文字的信息中提取数字?彭怀文对于非财务人员,记录经济业务信息,不会像财务人员一样在Excel表格中记录,把数字信息单独用一列单元格记录。
非财务人员记录,有的是在word文档中记录,有的是在手机上的一些日记簿等记录,反正就是一句话:不能用来直接计算。
因为:文字和数字经常是混在一起的!如果要计算,则必须将数字从混杂的字符信息中提取出来。
对于这种混杂的字符信息,有三种情况,下面我分别介绍如何提取:一、数字统一在前面的图-1方法1:在单元格B2输入函数公式:=-LOOKUP(1,-LEFT(A2,ROW($1:29)))方法2:在单元格C2输入函数公式:=VALUE(LEFT(A2,2*LEN(A2)-LENB(A2)))然后批量填充。
二、数字统一在后面图-2方法1:在单元格B2输入函数公式:=-LOOKUP(1,-RIGHT(A2,ROW($1:29)))方法2:在单元格C2输入函数公式:=VALUE(RIGHT(A2,2*LEN(A2)-LENB(A2)))然后批量填充。
三、数字在中间不规则位置图-3方法:在单元格B2输入函数公式:=VALUE(MIDB(A2,SEARCHB("?",A2),2*LEN(A2)-LENB(A2))) 然后批量填充。
【说明】其实第三种情况的方法,也可以用于数字在前和数字在后,如果要记住这些公式用于实务工作,就记住最后一个即可。
最好的办法建议大家动手试试。
如果需要文中案例的模板(Excel文档),请在后台留下您的邮箱。
excel提取某指定字符后的所有数字

excel提取某指定字符后的所有数字使用Excel提取指定字符后的所有数字为标题在日常工作中,我们经常需要处理大量的数据,而Excel是一个非常实用的工具,可以帮助我们高效地进行数据处理和分析。
其中,提取指定字符后的所有数字是一项常见的需求。
本文将介绍如何使用Excel来实现这一功能,并给出一些实际应用场景。
我们需要准备一份包含了一定数量文字和数字的文本数据。
假设我们有一个单元格内容如下的表格:"A1: 在2021年7月1日,公司A的销售额达到100万美元;在2021年8月1日,销售额达到200万美元;在2021年9月1日,销售额达到300万美元。
"我们的目标是从这段文本中提取出所有的数字作为标题。
下面是具体的操作步骤:步骤1:选中需要提取的文本数据所在的单元格(在本例中为A1单元格)。
步骤2:点击Excel菜单栏中的“数据”选项卡,找到“文本到列”命令,并点击该命令。
步骤3:在弹出的“文本向导”对话框中,选择“分隔符号”选项,然后点击“下一步”按钮。
步骤4:在下一个界面中,取消选择所有的分隔符,然后在“其他”文本框中输入一个空格,最后点击“下一步”按钮。
步骤5:在最后一个界面中,选择“常规”列格式,并点击“完成”按钮。
除了上述的基本操作外,Excel还提供了一些其他的功能,可以帮助我们更加灵活地提取指定字符后的数字。
例如,使用Excel的函数可以实现更复杂的文本处理操作。
下面是一些常用的函数:1. LEFT函数:提取字符串的左侧指定长度的字符。
2. RIGHT函数:提取字符串的右侧指定长度的字符。
3. MID函数:提取字符串的指定位置和长度的字符。
4. FIND函数:查找一个字符串在另一个字符串中的位置。
5. SUBSTITUTE函数:替换字符串中的指定字符。
通过灵活运用这些函数,我们可以根据具体的需求进行更加精细化的数据提取和处理。
例如,如果我们需要提取的数字位数不固定,可以使用MID函数结合FIND函数来实现。
excel数字汉字分离整理
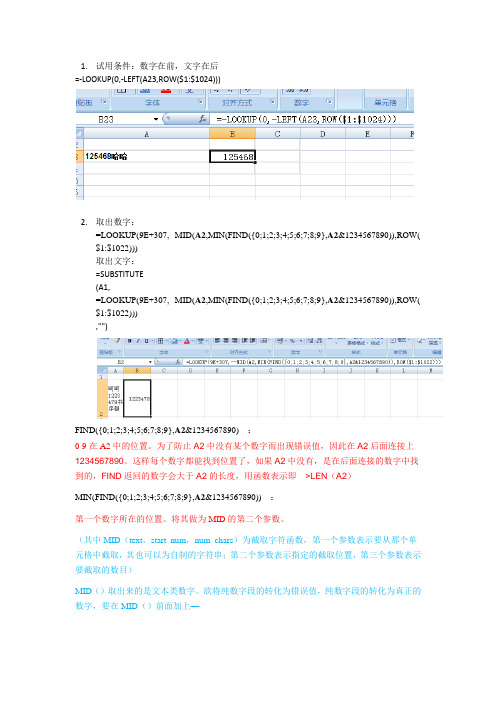
1.试用条件:数字在前,文字在后=-LOOKUP(0,-LEFT(A23,ROW($1:$1024)))2.取出数字:=LOOKUP(9E+307,--MID(A2,MIN(FIND({0;1;2;3;4;5;6;7;8;9},A2&1234567890)),ROW( $1:$1022)))取出文字:=SUBSTITUTE(A1,=LOOKUP(9E+307,--MID(A2,MIN(FIND({0;1;2;3;4;5;6;7;8;9},A2&1234567890)),ROW( $1:$1022))),"")FIND({0;1;2;3;4;5;6;7;8;9},A2&1234567890) :0-9在A2中的位置。
为了防止A2中没有某个数字而出现错误值,因此在A2后面连接上1234567890。
这样每个数字都能找到位置了,如果A2中没有,是在后面连接的数字中找到的,FIND返回的数字会大于A2的长度,用函数表示即>LEN(A2)MIN(FIND({0;1;2;3;4;5;6;7;8;9},A2&1234567890)) :第一个数字所在的位置。
将其做为MID的第二个参数。
(其中MID(text,start_num,num_chars)为截取字符函数,第一个参数表示要从那个单元格中截取,其也可以为自制的字符串;第二个参数表示指定的截取位置,第三个参数表示要截取的数目)MID()取出来的是文本类数字。
欲将纯数字段的转化为错误值,纯数字段的转化为真正的数字,要在MID()前面加上—整个MID()计算出来的值作为lookup的第二个参数,即取小于9E+307(工作表中的最大数值)的最大值ROW($1:$1022) :Row($1:$1022)返回1到1022的行号分别取一个,二个,三个,一直到1022个Lookup向量形式用法:LOOKUP(lookup_value, lookup_vector, [result_vector])=LOOKUP(4.19, A2:A6, B2:B6)在A 列中查找4.19,然后返回B 列中同一行内的值。
提取文本中数字的函数

提取文本中数字的函数提取文本中的数字是一种常见的数据处理操作,它能够从一段文字中提取出所有的数字,包括整数、小数和负数等。
通过使用合适的函数或算法,我们可以轻松地实现这一任务。
首先,让我们来编写一个用于提取数字的函数。
我们可以使用正则表达式来匹配并提取文本中的数字。
以下是一个示例代码:```pythonimport redef extract_numbers(text):pattern = r"[-+]?\d*\.\d+|\d+" # 正则表达式模式,匹配整数、小数和负数numbers = re.findall(pattern, text)return [float(number) for number in numbers] # 转换为浮点数并返回```上面的代码中,我们使用了`re.findall()`函数来匹配模式,并返回所有匹配的结果。
`findall()`函数会返回一个列表,其中包含了所有匹配的字符串。
我们将这些字符串转换为浮点数,并将其返回。
在实际应用中,提取文本中的数字有着广泛的应用。
以下是一些常见的应用场景:1. 数据清洗:在处理结构化或非结构化数据时,我们常常需要将文本中的数字提取出来,并进行进一步的分析或处理。
例如,在金融领域中,我们可能需要提取公司财务报表中的数字。
2. 自然语言处理:在自然语言处理任务中,提取文本中的数字可以帮助我们获取一些与数量或比例相关的信息,例如提取新闻文章中的统计数据或百分比指标。
3. 文字识别:在文字识别任务中,我们常常需要将图像中的文字转换为可处理的文本数据。
提取其中的数字可以用于识别价格、身份证号码等信息。
4. 数据分析和统计:在数据分析和统计任务中,我们常常会处理大量的数据。
因此,通过提取文本中的数字,我们可以更方便地进行数据分析和统计,并得出有用的结论。
总之,提取文本中的数字是一项重要的数据处理任务,它在许多领域中都有着广泛的应用。
excel文本提取数字方法

在 Excel 中提取文本中的数字可以使用多种方法,以下是几种常见的方法:1. 使用文本函数:如果要提取文本中的数字,可以使用 Excel 的文本函数,如 MID、LEFT、RIGHT 等。
这些函数可以用于截取字符串的指定部分。
例如,假设要从单元格 A1 中的文本中提取数字,可以使用以下公式:```=MID(A1,MIN(FIND({0,1,2,3,4,5,6,7,8,9},A1&"0123456789")),SUMPRODUCT(--ISNUMBER(--MID(A1,ROW($1:$100),1)))*2)```2. 使用正则表达式:如果需要更复杂的提取操作,可以使用正则表达式。
Excel 的正则表达式函数是通过“Microsoft VBScript Regular Expressions 5.5”引擎实现的。
例如,假设要从单元格 A1 中的文本中提取数字,可以使用以下公式:```=SUMPRODUCT(--(ISNUMBER(--TRIM(MID(SUBSTITUTE(A1,ROW($1:$100)," "),ROW($1:$100),LEN(A1)))))*(10^(LEN(A1)-1-ROW($1:$100))))```3. 使用辅助列和函数:另一种方法是使用辅助列,并结合一些Excel 函数来提取数字。
步骤如下:- 在一个空白列中输入公式 `=SUBSTITUTE(A1," ","")`,去除文本中的空格。
- 在下一个空白列中输入公式 `=IFERROR(VALUE(B1),"")`,提取数字。
- 将公式应用到需要提取数字的单元格范围。
- 最后,复制提取后的数字,粘贴为值以去除公式。
这些方法可以根据具体情况进行调整和组合使用。
请根据您的需求选择适合的方法。
在Excel表格中,数字、汉字、字母混在一起的情况下,应该如何把数字提取出来?

在Excel表格中,数字、汉字、字母混在⼀起的情况下,应该如何把数字提取出
来?
你没有具体举例说明,我就按照我常⽤的三种情况下为例⼦给你操作师范下,你看下你是属于
哪⼀种情况,如果都不在下列情况中,你可以再评论区留⾔,我接着回答。
第⼀种情况:
单元格内左边⽂字规律,数字不规律,并且数字位数⽐较短,那么可以⽤MID函数来解决,⽤法
MID(⽂本中要提取的第⼀个字符的位置,指定希望 MID 从⽂本中返回字符的个数,指定希望
MIDB 从⽂本中返回字符的个数(字节数)。
如下图⼀所⽰
第⼆种情况,
单元格内容⽂字不规律,可以这样分两步操作:
第⼀步.在B1单元格输⼊第⼀个想要的数字200,
第⼆步,同时按住键盘上的Ctrl+E
两步操作完成以后,单元格中的201和0356同步提取出来了,如下图所⽰
第三种情况;
单元格内左边⽂字规律,数字不规律,并且数字位数⽐较长,那么可以通过“数据-分列”来实
现,具体操作如下:。
一串字符中提取其中的数字

一串字符中提取其中的数字如何从一串字符中提取数字?在日常生活中,我们经常需要从一些字符串中提取数字,比如从一段文本中提取出电话号码、身份证号码、银行卡号码等等。
这时候,我们就需要用到一些字符串处理的技巧,来提取出我们需要的数字。
我们需要了解一下什么是字符串。
字符串是由一系列字符组成的序列,可以包含数字、字母、符号等等。
在Python中,字符串是一种基本的数据类型,可以使用单引号或双引号来表示。
接下来,我们来看一下如何从字符串中提取数字。
假设我们有一个字符串s,其中包含了一些数字和其他字符,我们想要提取出其中的数字。
我们可以使用Python中的正则表达式来实现。
正则表达式是一种用来匹配字符串的模式,可以用来查找、替换、分割字符串等等。
在Python中,我们可以使用re模块来操作正则表达式。
下面是一个简单的例子,假设我们有一个字符串s,其中包含了一些数字和其他字符:s = 'hello 123 world 456'我们想要提取出其中的数字,可以使用re模块中的findall函数来实现:import reresult = re.findall('\d+', s)print(result)运行结果为:['123', '456']可以看到,findall函数返回了一个列表,其中包含了所有匹配到的数字。
在上面的例子中,我们使用了正则表达式中的\d+来匹配数字。
其中,\d表示匹配任意一个数字,+表示匹配一个或多个数字。
因此,\d+可以匹配任意一个或多个数字。
除了\d+之外,还有很多其他的正则表达式可以用来匹配不同的字符串。
在实际应用中,我们需要根据具体的需求来选择合适的正则表达式。
从一串字符中提取数字并不是一件难事,只需要使用正则表达式来匹配即可。
当然,如果我们需要提取的数字比较复杂,可能需要使用更加复杂的正则表达式来匹配。
但是,只要我们掌握了正则表达式的基本用法,就可以轻松地从字符串中提取出我们需要的数字了。
提取文字数字中的数字函数

提取文字数字中的数字函数
在Python中,你可以使用正则表达式(regex)来提取字符串中的数字。
下面
是一个简单的例子:
python
import re
def extract_numbers(s):
return re.findall(r'\d+', s)
# 测试函数
s = "我有100个苹果和20个香蕉"
print(extract_numbers(s)) # 输出: ['100', '20']
在这个例子中,\d匹配任何数字,+表示前面的字符可以出现一次或多次,所
以\d+匹配一个或多个数字。
re.findall函数则返回所有匹配的子串。
如果你想要提取的是数字字符,包括整数和小数,你可以稍微修改一下正则表达式:python
import re
def extract_numbers(s):
return re.findall(r'[0-9.\-]+', s)
# 测试函数
s = "我有100个苹果和20.5个香蕉"
print(extract_numbers(s)) # 输出: ['100', '20.5']
在这个例子中,[0-9.\-]匹配任何数字、小数点或负号。
注意这个表达式只能处理简单的情况,例如它不会处理科学计数法(例如1e3)。
如果你需要处理更复杂的情况,你可能需要使用更复杂的正则表达式。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
15 15 9 10 19 14 9 21 14 大数式 错误
15 15 9 7 15 12 9 21 14 大数0/条件式 正确
多次测试才能慎重选择某个正确方式
同是使用lookup公式的 E列用的是数组形式,区别在于返回的 形式和数值形式,使用时根据需要选择 提示:经测试,使用 数式”,左边框框讨论的“ 都不能使用,会报错。
提取数字(lookup)
right,用于确定“数字都在文本串最后”的情况
lookup矢量形式 结果为文本串 #N/A #N/A #N/A 4.5 018 35 #N/A #N/A #N/A #N/A #N/A #N/A #N/A #N/A #N/A 4.5 4.5 18 018 35 35 #N/A #N/A #N/A lookup数组形式 结果为数值 #N/A #N/A #N/A 12.3 00175 10000 4.5 018 35 8.0 0188 1245
回最后一个符合
处模糊查找不是跟 )都能但可以
或最后一个满足条件的位置或者值,分别用精确查找和模糊查找
几个(10、00、11、大数、大数0/条件等等),要根据不同情况选择,还有经过多次测试才能慎重选
12 15 9 7 12 12 9 16 14 lookup 11式 错误
字在文本串中位置不确定“的 公式较left或right复杂
lookup数组形式 结果为数值 12.3 00175 10000 4.5 018 35 8.0 0188 1245
个人认为自定义公 式是提取英文、中 文字最好的方法。 但本例子主要研究 match、lookup查找 方法,因此自定义 公式仅作一种方法 分享,不作讨论。
:经测试,使用lookup的数组形式,就只能用“大 ”,左边框框讨论的“00式”、“10式”、“11式” 能使用,会报错。
个人认为自定义公 式是提取英文、中 文字最好的方法。 但本例子主要研究 match 方法,因此自定义 公式仅作一种方法 分享,不作讨论。
提取英文
分解公式 自定义公式 #NAME? #NAME? #NAME? #NAME? #NAME? #NAME? #NAME? #NAME? #NAME? mid(B,N,O-N) Invtid Transfer bb Begin PM Receipt PM Sentout PP PO Receipt Transfer match取得首字母的 位置 5 6 6 1 1 1 1 1 1
lookup或match模糊查找返回最后一个符合 条件的值的位置 我在试算过程中发现,此处模糊查找不是跟 前面一样,每个方式(00、11……)都能返 回正确的结果,经过右表测试,只有10 大数0/条件式才能返回正确位置,而且错误 的位置各有小差异(黑色highlight) 对于这个现象,本人还未透彻理解,但可以 总结出以下经验
同是使用lookup公式的矢量形式,但lookup_value和 lookup_vector使用的参数有不同,C列用的是在“0/ (条件)”中查找“0”,D列用的是在“--(条件)” 中查找9E+306,返回的结果是完全一样的。
经过多次测试,以下lookup公式(矢量形式)返回的结 果是一样的: lookup(,0/(条件),返回值);(00式) lookup(1,0/(条件),返回值);(10式) lookup(1,1/(条件),返回值);(11式) lookup(9E+307,--(条件),返回值);(大数式) 值得注意的是: lookup(1,1/(条件),返回值),(01式)是不能 用的,会报错。
提取数字
例:分别提取下列单 元格中的数字、英文 、中文
12.3Invtid存货/代码 00175Transfer移出 10000bb宝贝 Begin期初4.5 PM Receipt生产(入库)018 PM Sentout出库35 PP8.0采购入库 PO Receipt0188采购/其他入库 Transfer1245移入
=mid(单元格,首字母的位置,末字母的位置—首字母的位置)
长度
这里必须用match公式 match模糊查找返回最后一个符合条件的位置,但在此处要返回 没有报错的值的位置,因此使用了精确查找的方法: =MATCH(1,((MID(B4,ROW(INDIRECT("1:"&LEN(B4))),1)<="z")*(MID(B4,ROW( INDIRECT("1:"&LEN(B4))),1)>="a")),0) 思路分析:(mid()<="z")*(mid()>="a")返回的值是数组 以match(1,{0,0,0,0,1,1……},0)就能返回第一个符合条件的值的位置。
match取得首中文 字的位置 11 14 8 6 11 11 6 15 13
首字母的位置)
长度
条件的位置,但在此处要返回第一个 查找的方法: T("1:"&LEN(B4))),1)<="z")*(MID(B4,ROW(
返回的值是数组{0,0,0,0,1,1……},所 返回第一个符合条件的值的位置。
left,用于确定“数字都在文本串最前”的情况
lookup矢量形式 结果为文本串 12.3 00175 10000 #N/A #N/A #N/A #N/A #N/A #N/A 12.3 00175 10000 #N/A #N/A #N/A #N/A #N/A #N/A #N/A #N/A #N/A #N/A #N/A #N/A lookup数组形式 结果为数值 12.3 175 10000
mid,用于”数字在文本串中位置不确定“的 情况,当然公式较left或right复杂
lookup矢量形式 结果为文本串 12.3 175 10000 4.5 18 35 8 188 1245
lookup公式的9E+307方法,D列用的是矢量形式, 用的是数组形式,区别在于返回的结果,分别是文本 和数值形式,使用时根据需要选择。
本次思考总结: 1.从数列中返回第一个或最后一个满足条件的位置或者
2.模糊查找的方式有几个(10、00、11、大数、大数0/
lookup或match取得末 中文字的位置 15 15 9 7 15 12 9 21 14 10式 正确 00式 错误 12 15 9 7 12 12 9 16 14 match 11式 错误 大数式 错误 大数0/条件式 正确 10式 正确 00式 错误 12 15 9 7 12 12 9 16 14 15 15 9 10 19 14 9 21 14 15 15 9 7 15 12 9 21 14 15 15 9 7 15 12 9 21 14 12 15 9 7 12 12 9 16 14 lookup
提取中文
lookup或match取得末 字母的位置 10 13 7 5 10 10 2 10 8
自定义公式 #NAME? #NAME? #NAME? #NAME? #NAME? #NAME? #NAME? #NAME? #NAME?
mid(B,R,S-R) 存货/代码 移出 宝贝 期初 生产(入库 出库 采购入库 采购/其他入库 移入