数据结构课后习题答案第九章
数据结构第九章排序习题与答案

习题九排序一、单项选择题1.下列内部排序算法中:A.快速排序 B.直接插入排序C. 二路归并排序D.简单选择排序E. 起泡排序F.堆排序(1)其比较次数与序列初态无关的算法是()(2)不稳定的排序算法是()(3)在初始序列已基本有序(除去n 个元素中的某 k 个元素后即呈有序, k<<n)的情况下,排序效率最高的算法是()(4)排序的平均时间复杂度为O(n?logn)的算法是()为 O(n?n) 的算法是()2.比较次数与排序的初始状态无关的排序方法是( )。
A.直接插入排序B.起泡排序C.快速排序D.简单选择排序3.对一组数据( 84, 47, 25, 15, 21)排序,数据的排列次序在排序的过程中的变化为(1) 84 47 25 15 21(2) 15 47 25 84 21(3) 15 21 25 84 47(4) 15 21 25 47 84则采用的排序是 ()。
A. 选择B.冒泡C.快速D.插入4.下列排序算法中 ( )排序在一趟结束后不一定能选出一个元素放在其最终位置上。
A. 选择B.冒泡C.归并D.堆5.一组记录的关键码为(46,79,56, 38,40, 84),则利用快速排序的方法,以第一个记录为基准得到的一次划分结果为()。
A. (38,40,46,56,79,84) B. (40,38,46,79,56,84)C. (40,38,46,56,79,84) D. (40,38,46,84,56,79)6.下列排序算法中,在待排序数据已有序时,花费时间反而最多的是()排序。
A.冒泡 B. 希尔C. 快速D. 堆7.就平均性能而言,目前最好的内排序方法是() 排序法。
A. 冒泡B.希尔插入C.交换D.快速8.下列排序算法中,占用辅助空间最多的是:()A. 归并排序B.快速排序C.希尔排序D.堆排序9.若用冒泡排序方法对序列 {10,14,26,29,41,52}从大到小排序,需进行()次比较。
数据结构 第9章答案

第9章 查找参考答案一、填空题(每空1分,共10分)1. 在数据的存放无规律而言的线性表中进行检索的最佳方法是 顺序查找(线性查找) 。
2. 线性有序表(a 1,a 2,a 3,…,a 256)是从小到大排列的,对一个给定的值k ,用二分法检索表中与k 相等的元素,在查找不成功的情况下,最多需要检索 8 次。
设有100个结点,用二分法查找时,最大比较次数是 7 。
3. 假设在有序线性表a[20]上进行折半查找,则比较一次查找成功的结点数为1;比较两次查找成功的结点数为 2 ;比较四次查找成功的结点数为 8 ;平均查找长度为 3.7 。
解:显然,平均查找长度=O (log 2n )<5次(25)。
但具体是多少次,则不应当按照公式)1(log 12++=n nn ASL 来计算(即(21×log 221)/20=4.6次并不正确!)。
因为这是在假设n =2m -1的情况下推导出来的公式。
应当用穷举法罗列:全部元素的查找次数为=(1+2×2+4×3+8×4+5×5)=74; ASL =74/20=3.7 !!!4.【计研题2000】折半查找有序表(4,6,12,20,28,38,50,70,88,100),若查找表中元素20,它将依次与表中元素 28,6,12,20 比较大小。
5. 在各种查找方法中,平均查找长度与结点个数n 无关的查找方法是 散列查找 。
6. 散列法存储的基本思想是由 关键字的值 决定数据的存储地址。
7. 有一个表长为m 的散列表,初始状态为空,现将n (n<m )个不同的关键码插入到散列表中,解决冲突的方法是用线性探测法。
如果这n 个关键码的散列地址都相同,则探测的总次数是 n(n-1)/2=( 1+2+…+n-1) 。
(而任一元素查找次数 ≤n-1)二、单项选择题(每小题1分,共27分)( B )1.在表长为n的链表中进行线性查找,它的平均查找长度为A. ASL=n; B. ASL=(n+1)/2;C. ASL=n +1; D. ASL≈log2(n+1)-1( A )2.【计研题2001】折半查找有序表(4,6,10,12,20,30,50,70,88,100)。
数据结构(C语言版)9-12章练习 答案 清华大学出版社

数据结构(C语言版)9-12章练习答案清华大学出版社9-12章数据结构作业答案第九章查找选择题1、对n个元素的表做顺序查找时,若查找每个元素的概率相同,则平均查找长度为( A )A.(n+1)/2 B. n/2 C. n D. [(1+n)*n ]/2 2. 下面关于二分查找的叙述正确的是 ( D )A. 表必须有序,表可以顺序方式存储,也可以链表方式存储B. 表必须有序且表中数据必须是整型,实型或字符型 C. 表必须有序,而且只能从小到大排列 D. 表必须有序,且表只能以顺序方式存储3. 二叉查找树的查找效率与二叉树的( (1)C)有关, 在 ((2)C )时其查找效率最低 (1): A. 高度 B. 结点的多少 C. 树型 D. 结点的位置(2): A. 结点太多 B. 完全二叉树 C. 呈单枝树 D. 结点太复杂。
4. 若采用链地址法构造散列表,散列函数为H(key)=key MOD 17,则需 ((1)A)个链表。
这些链的链首指针构成一个指针数组,数组的下标范围为 ((2)C) (1) A.17 B. 13 C. 16 D. 任意(2) A.0至17 B. 1至17 C. 0至16 D. 1至16判断题1.Hash表的平均查找长度与处理冲突的方法无关。
(错) 2. 若散列表的负载因子α<1,则可避免碰撞的产生。
(错)3. 就平均查找长度而言,分块查找最小,折半查找次之,顺序查找最大。
(错)填空题1. 在顺序表(8,11,15,19,25,26,30,33,42,48,50)中,用二分(折半)法查找关键码值20,需做的关键码比较次数为 4 .算法应用题1. 设有一组关键字{9,01,23,14,55,20,84,27},采用哈希函数:H(key)=key mod7 ,表长为10,用开放地址法的二次探测再散列方法Hi=(H(key)+di) mod 10解决冲突。
要求:对该关键字序列构造哈希表,并计算查找成功的平均查找长度。
数据结构第9章作业 查找答案

第9章 查找答案一、填空题1. 在数据的存放无规律而言的线性表中进行检索的最佳方法是 顺序查找(线性查找) 。
2. 线性有序表(a 1,a 2,a 3,…,a 256)是从小到大排列的,对一个给定的值k ,用二分法检索表中与k 相等的元素,在查找不成功的情况下,最多需要检索 9 次。
设有100个结点,用二分法查找时,最大比较次数是 7 。
3. 假设在有序线性表a[20]上进行折半查找,则比较一次查找成功的结点数为1;比较两次查找成功的结点数为 2 ;比较四次查找成功的结点数为 8 ;平均查找长度为 3.7 。
解:显然,平均查找长度=O (log 2n )<5次(25)。
但具体是多少次,则不应当按照公式)1(log 12++=n nn ASL 来计算(即(21×log 221)/20=4.6次并不正确!)。
因为这是在假设n =2m-1的情况下推导出来的公式。
应当用穷举法罗列:全部元素的查找次数为=(1+2×2+4×3+8×4+5×5)=74; ASL =74/20=3.7 !!!4.折半查找有序表(4,6,12,20,28,38,50,70,88,100),若查找表中元素20,它将依次与表中元素 28,6,12,20 比较大小。
5. 在各种查找方法中,平均查找长度与结点个数n 无关的查找方法是 散列查找 。
6. 散列法存储的基本思想是由 关键字的值 决定数据的存储地址。
7. 有一个表长为m 的散列表,初始状态为空,现将n (n<m )个不同的关键码插入到散列表中,解决冲突的方法是用线性探测法。
如果这n 个关键码的散列地址都相同,则探测的总次数是 n(n-1)/2=( 1+2+…+n-1) 。
(而任一元素查找次数 ≤n-1)二、单项选择题( B )1.在表长为n的链表中进行线性查找,它的平均查找长度为A. ASL=n; B. ASL=(n+1)/2;C. ASL=n +1; D. ASL≈log2(n+1)-1( A )2. 折半查找有序表(4,6,10,12,20,30,50,70,88,100)。
数据结构第三版第九章课后习题参考答案
}
}
设计如下主函数:
void main()
{ BSTNode *bt;
KeyType k=3;
int a[]={5,2,1,6,7,4,8,3,9},n=9;
bt=CreatBST(a,n);
//创建《教程》中图 9.4(a)所示的二叉排序树
printf("BST:");DispBST(bt);printf("\n");
#define M 26 int H(char *s)
//求字符串 s 的哈希函数值
{
return(*s%M);
}
构造哈希表 void Hash(char *s[]) //
{ int i,j;
char HT[M][10]; for (i=0;i<M;i++)
//哈希表置初值
HT[i][0]='\0'; for (i=0;i<N;i++) { j=H(s[i]);
//求每个关键字的位置 求 // s[i]的哈希函数值
while (1)
不冲突时 直接放到该处 { if (HT[j][0]=='\0') //
,
{ strcpy(HT[j],s[i]);
break;
}
else
//冲突时,采用线性线性探测法求下一个地址
j=(j+1)%M;
}
} for (i=0;i<M;i++)
printf("%2d",path[j]);
printf("\n");
}
else { path[i+1]=bt->key;
(完整word版)数据结构第九章查找

第九章查找:习题习题一、选择题1.散列表查找中k个关键字具有同一散列值,若用线性探测法将这k个关键字对应的记录存入散列表中,至少要进行( )次探测。
A. k B。
k+l C. k(k+l)/2 D. l+k (k+l)/22.下述命题( )是不成立的。
A。
m阶B-树中的每一个结点的子树个数都小于或等于mB。
m阶B-树中的每一个结点的子树个数都大于或等于『m/2-1C。
m阶B-树中的每一个结点的子树高度都相等D。
m阶B—树具有k个子树的非叶子结点含有(k-l)个关键字3.如果要求一个基本线性表既能较快地查找,又能适应动态变化的要求,可以采用( )查找方法.A。
分块 B. 顺序 C. 二分 D.散列4.设有100个元素,用折半查找法进行查找时,最大比较次数是( ),最小比较次数是( ).A。
7,1 B.6,l C.5,1 D. 8,15.散列表长m=15,散列表函数H(key)=key%13。
表中已有4个结点:addr(18)=5;addr(32)=6; addr(59)=7;addr(73)=8;其余地址为空,如果用二次探测再散列处理冲突,关键字为109的结点的地址是( )。
A. 8 B。
3 C. 5 D。
46.用分块查找时,若线性表中共有729个元素,查找每个元素的概率相同,假设采用顺序查找来确定结点所在的块时,每块应分( )个结点最佳。
A。
15 B. 27 C。
25 D。
307.散列函数有一个共同性质,即函数值应当以( )取其值域的每个值。
A.同等概率B。
最大概率C。
最小概率D。
平均概率8.设散列地址空间为O.。
m—1,k为关键字,假定散列函数为h(k)=k%p,为了减少冲突,一般应取p为( )。
A.小于m的最大奇数B. 小于m的最大素数C.小于m的最大偶数D.小于m的最大合数9.当向一棵m阶的B-树做插入操作时,若使一个结点中的关键字个数等于( ),则必须分裂成两个结点。
A。
m B。
m-l C.m+l D。
《数据结构》习题集:第9章查找(第1次更新2019-5)

第9章查找一、选择题1.顺序查找一个共有n个元素的线性表,其时间复杂度为(),折半查找一个具有n个元素的有序表,其时间复杂度为()。
【*,★】A.O(n)B. O(log2n)C. O(n2)D. O(nlog2n)2.在对长度为n的顺序存储的有序表进行折半查找,对应的折半查找判定树的高度为()。
【*,★】A.nB.C.D.3.采用顺序查找方式查找长度为n的线性表时,平均查找长度为()。
【*】A.nB. n/2C. (n+1)/2D. (n-1)/24.采用折半查找方法检索长度为n的有序表,检索每个元素的平均比较次数()对应判定树的高度(设高度大于等于2)。
【**】A.小于B. 大于C. 等于D. 大于等于5.已知有序表(13,18,24,35,47,50,62,83,90,115,134),当折半查找值为90的元素时,查找成功的比较次数为()。
【*】A. 1B. 2C. 3D. 46.对线性表进行折半查找时,要求线性表必须()。
【*】A.以顺序方式存储B. 以链接方式存储C.以顺序方式存储,且结点按关键字有序排序D. 以链接方式存储,且结点按关键字有序排序7.顺序查找法适合于存储结构为()的查找表。
【*】A.散列存储B. 顺序或链接存储C. 压缩存储D. 索引存储8.采用分块查找时,若线性表中共有625个元素,查找每个元素的概率相同,假设采用顺序查找来确定结点所在的块时,每块应分()个结点最佳。
【**】A.10B. 25C. 6D. 6259.从键盘依次输入关键字的值:t、u、r、b、o、p、a、s、c、l,建立二叉排序树,则其先序遍历序列为(),中序遍历序列为()。
【**,★】A.abcloprstuB. alcpobsrutC. trbaoclpsuD. trubsaocpl10.折半查找和二叉排序树的时间性能()。
【*】A.相同B. 不相同11.一棵深度为k的平衡二叉树,其每个非终端结点的平衡因子均为0,则该树共有()个结点。
第九章 严蔚敏数据结构课后答案-查找

else if(key<r[mid].key) high=mid; else low=mid; } //本算法不存在查找失败的情况,不需要 return 0; }//Locate_Bin
while(p->data>key) p=p->pre; L.sp=p;
} else if(p->data<key) { while(p->data<key) p=p->next;
L.sp=p; } return p; }//Search_DSList 分析:本题的平均查找长度与上一题相同,也是 n/3.
}//while //借助中序遍历找到元素 x 及其前驱和后继结点 if(!ptr) return ERROR; //未找到待删结点 Delete_BSTree(ptr); //删除 x 结点 if(pre&&pre->rtag) pre->rchild=suc; //修改线索 return OK; }//BSTree_Delete_key
printf("a=%d\n",last); if(last<=x&&T->data>x) //找到了大于 x 的最小元素 printf("b=%d\n",T->data); last=T->data; if(T->rchild) MaxLT_MinGT(T->rchild,x); }//MaxLT_MinGT
数据结构第九章--查找-习题及答案

第九章查找一、选择题1。
若查找每个记录的概率均等,则在具有n个记录的连续顺序文件中采用顺序查找法查找一个记录,其平均查找长度ASL为( )。
A. (n—1)/2 B. n/2 C。
(n+1)/2 D。
n2. 下面关于二分查找的叙述正确的是( )A。
表必须有序,表可以顺序方式存储,也可以链表方式存储 C. 表必须有序,而且只能从小到大排列B。
表必须有序且表中数据必须是整型,实型或字符型 D. 表必须有序,且表只能以顺序方式存储3. 用二分(对半)查找表的元素的速度比用顺序法( )A.必然快 B. 必然慢 C. 相等 D. 不能确定4. 具有12个关键字的有序表,折半查找的平均查找长度( )A. 3。
1 B。
4 C. 2。
5 D. 55.当采用分块查找时,数据的组织方式为 ( )A.数据分成若干块,每块内数据有序B.数据分成若干块,每块内数据不必有序,但块间必须有序,每块内最大(或最小)的数据组成索引块C。
数据分成若干块,每块内数据有序,每块内最大(或最小)的数据组成索引块D. 数据分成若干块,每块(除最后一块外)中数据个数需相同6。
二叉查找树的查找效率与二叉树的( (1))有关, 在((2))时其查找效率最低(1): A。
高度 B。
结点的多少 C. 树型 D. 结点的位置(2): A。
结点太多 B. 完全二叉树 C。
呈单枝树 D. 结点太复杂。
7. 对大小均为n的有序表和无序表分别进行顺序查找,在等概率查找的情况下,对于查找失败,它们的平均查找长度是((1)) ,对于查找成功,他们的平均查找长度是((2))供选择的答案:A。
相同的 B。
不同的9.分别以下列序列构造二叉排序树,与用其它三个序列所构造的结果不同的是()A.(100,80, 90, 60, 120,110,130) B。
(100,120,110,130,80, 60, 90) C。
(100,60, 80, 90, 120,110,130) D。
算法与数据结构课后答案9-11章

算法与数据结构课后答案9-11章第9章集合一、基础知识题9.1 若对长度均为n 的有序的顺序表和无序的顺序表分别进行顺序查找,试在下列三种情况下分别讨论二者在等概率情况下平均查找长度是否相同?(1)查找不成功,即表中没有和关键字K 相等的记录;(2)查找成功,且表中只有一个和关键字K 相等的记录;(3)查找成功,且表中有多个和关键字K 相等的记录,要求计算有多少个和关键字K 相等的记录。
【解答】(1)平均查找长度不相同。
前者在n+1个位置均可能失败,后者失败时的查找长度都是n+1。
(2)平均查找长度相同。
在n 个位置上均可能成功。
(3)平均查找长度不相同。
前者在某个位置上(1<=i<=n)查找成功时,和关键字K 相等的记录是连续的,而后者要查找完顺序表的全部记录。
9.2 在查找和排序算法中,监视哨的作用是什么?【解答】监视哨的作用是免去查找过程中每次都要检测整个表是否查找完毕,提高了查找效率。
9.3 用分块查找法,有2000项的表分成多少块最理想?每块的理想长度是多少?若每块长度为25 ,平均查找长度是多少?【解答】分成45块,每块的理想长度为45(最后一块长20)。
若每块长25,则平均查找长度为ASL=(80+1)/2+(25+1)/2=53.5(顺序查找确定块),或ASL=19(折半查找确定块)。
9.4 用不同的输入顺序输入n 个关键字,可能构造出的二叉排序树具有多少种不同形态? 【解答】 9.5 证明若二叉排序树中的一个结点存在两个孩子,则它的中序后继结点没有左孩子,中序前驱结点没有右孩子。
【证明】根据中序遍历的定义,该结点的中序后继是其右子树上按中序遍历的第一个结点,即右子树上值最小的结点:叶子结点或仅有右子树的结点,没有左孩子;而其中序前驱是其左子树上按中序遍历的最后个结点,即左子树上值最大的结点:叶子结点或仅有左子树的结点,没有右孩子。
命题得证。
9.6 对于一个高度为h 的A VL 树,其最少结点数是多少?反之,对于一个有n 个结点的A VL 树,其最大高度是多少? 最小高度是多少?【解答】设以N h 表示深度为h 的A VL 树中含有的最少结点数。
中南大学数据结构与算法第9章查找课后作业答案

第9章查找习题练习答案1.对含有n个互不相同元素的集合,同时找最大元和最小元至少需进行多少次比较?答:设变量max和min用于存放最大元和最小元(的位置),第一次取两个元素进行比较,大的放入max,小的放入min。
从第2次开始,每次取一个元素先和max比较,如果大于max 则以它替换max,并结束本次比较;若小于max则再与min相比较,在最好的情况下,一路比较下去都不用和min相比较,所以这种情况下,至少要进行n-1次比较就能找到最大元和最小元。
2.若对具有n个元素的有序的顺序表和无序的顺序表分别进行顺序查找,试在下述两种情况下分别讨论两者在等概率时的平均查找长度:(1)查找不成功,即表中无关键字等于给定值K的记录;(2)查找成功,即表中有关键字等于给定值K的记录。
答:查找不成功时,需进行n+1次比较才能确定查找失败。
因此平均查找长度为n+1,这时有序表和无序表是一样的。
查找成功时,平均查找长度为(n+1)/2,有序表和无序表也是一样的。
因为顺序查找与表的初始序列状态无关。
3.画出对长度为18的有序的顺序表进行二分查找的判定树,并指出在等概率时查找成功的平均查找长度,以及查找失败时所需的最多的关键字比较次数。
答:等概率情况下,查找成功的平均查找长度为:ASL=(1+2*2+3*4+4*8+5*3)/18=3.556查找失败时,最多的关键字比较次树不超过判定树的深度,此处为5.4.为什么有序的单链表不能进行折半查找?答:因为链表无法进行随机访问,如果要访问链表的中间结点,就必须先从头结点开始进行依次访问,这就要浪费很多时间,还不如进行顺序查找,而且,用链存储结构将无法判定二分的过程是否结束,因此无法用链表实现二分查找。
5.设有序表为(a,b,c,e,f,g,i,j,k,p,q),请分别画出对给定值b,g和n进行折半查找的过程。
解:(1)查找b的过程如下(其中方括号表示当前查找区间,圆括号表示当前比较的关键字)下标: 1 2 3 4 5 6 7 8 9 10 11 12 13第一次比较: [a b c d e f (g) h i j k p q]第二次比较: [a b (c) d e f] g h i j k p q第三次比较: [a (b)]c d e f g h i j k p q经过三次比较,查找成功。
数据结构习题及答案(3)

数据结构习题及答案(3)第九章排序⼀、选择题1.在所有排序⽅法中,关键字⽐较的次数与记录得初始排列次序⽆关的是()(A)希尔排序(B)起泡排序(C)插⼊排序(D)选择排序参考答案:D2.设有1000个⽆序的元素,希望⽤最快的速度挑选出其中前10个最⼤的元素,最好()排序法。
(A)起泡排序(B)快速排序(C)堆排序(D)基数排序参考答案:C3.在待排序的元素序列基本有序的前提下,效率最⾼的排序⽅法是()(A)插⼊排序(B)选择排序(C)快速排序(D)归并排序参考答案:A4.⼀组记录的排序码为(46,79,56,38,40,84),则利⽤堆排序的⽅法建⽴的初始推为()。
(A)79,46,56,38,40,80 (B)84,79,56,38,40,46(C)84,79,56,46,40,38 (D)84,56,79,40,46,38参考答案:B5.⼀组记录的关键码为(46,79,56,38,40,84),则利⽤快速排序的⽅法,以第⼀个记录为基准得到的⼀次划分结果为()。
(A)38,40,46,56,79,84(B)40,38,46,79,56,84(C)40,38,46,56,79,84(D)40,38,46,84,56,79参考答案:C6.⼀组记录的排序码为(25,48,16,35,79,82,23,40,36,72),其中含有5个长度为2的有序表,按归并排序的⽅法对该序列进⾏⼀趟归并后的结果为()。
(A)16,25,35,48,23,40,79,82,36,72(B)16,25,35,48,79,82,23,36,40,72(C)16,25,48,35,79,82,23,36,40,72(D)16,25,35,48,79,23,36,40,72,82参考答案:A7.排序⽅法中,从未排序序列中依次取出元素与⼰排序序列(初始时为空)中的元素进⾏⽐较,将其放⼊⼰排序序列的正确位置上的⽅法,称为()(A)希尔排序(B)起泡排序(C)插⼊排序(D)选择排序参考答案:C8.排序⽅法中,从未排序序列中挑选元素并将其依次放⼊⼰排序序列(初始为空)的⼀端的⽅法,称为()(A)希尔排序(B)归并排序(C)插⼊排序(D)选择排序参考答案:D9.⽤某种排序⽅法对线性表(25,84,21,47,15,27,68,35,20)进⾏排序时,元素序列的变化情况如下:(1)25,84,21,47,15,27,68,35,20 (2)20,15,21,25,47,27,68,35,84(3)15,20,21,25,35,27,47,68,84 (4)15,20,21,25,27,35,47,68,845则所采⽤的排序⽅法是()。
数据结构 第九章测验 测验答案 慕课答案 UOOC优课 课后练习 深圳大学

数据结构第九章测验一、单选题 (共100.00分)1. 以下属于插入排序的算法是()A. 希尔排序B. 堆排序C. 冒泡排序D. 基数排序正确答案:A2. 以下排序算法时间复杂度最小的是()A. 冒泡排序B. 直接插入排序C. 简单选择排序D. 堆排序正确答案:D3. 以下排序算法稳定的是()A. 希尔排序B. 归并排序C. 简单选择排序D. 堆排序正确答案:B4. 以下排序算法空间复杂度最大的是()A. 堆排序B. 快速排序C. 归并排序D. 直接插入排序正确答案:C5. 现有100万个数据,需要找出最大的前10个数据,最快的算法是()A. 快速排序B. 归并排序C. 简单选择排序D. 希尔排序正确答案:C6. 时间复杂度小于n平方的排序算法是()A. 冒泡排序B. 快速排序C. 简单选择排序D. 直接插入排序正确答案:B7. 已知数列为125、45、88、72、165、33、 28、64,采用起泡排序算法递增排序,第一趟排序共发生()次交换A. 8B. 7C. 6D. 5正确答案:C8. 以下排序算法不稳定的是()A. 直接插入排序B. 归并排序C. 起泡排序D. 堆排序正确答案:D9. 序列19 11 23 14 55 68,采用希尔排序gap为n/2,则第一趟排序()A. 14 19 11 55 23 68B. 19 23 11 14 55 68C. 11 14 19 23 55 68D. 14 19 11 55 33 68正确答案:A10. 序列21 25 49 25* 16 08,采用快速排序,枢轴为序列首元素,则第一趟排序()A. 08 16 21 25 25* 49B. 08 16 21 25* 25 49C. 16 08 21 25* 49 25D. 08 16 21 25* 49 25正确答案:D。
数据结构(C语言版)习题及答案第九章

习题一、选择题1、一组记录的排序码为(46,79,56,38,40,84),则利用堆排序的方法建立的初始堆为( B )。
A、79,46,56,38,40,80B、84,79,56,38,40,46C、84,79,56,46,40,38D、84,56,79,40,46,382、排序趟数与序列原始状态(原始排列)有关的排序方法是(ACD)方法。
A、插入排序B、选择排序C、冒泡排序D、快速排序3 、下列排序方法中,(B)是稳定的排序方法。
A、直接选择排序B、二分法插入排序C、希尔排序D、快速排序4、数据序列(8,9,10,4,5,6,20,1,2)只能是下列排序算法中( C )的两趟排序后的结果。
A、选择排序B、冒泡排序C、插入排序D、堆排序5、对序列(15,9,7,8,20,-1,4)进行排序,进行一趟排序后,数据的排列变为(4,9,-1,8,20,7,15),则采用的是(C)排序。
A、选择B、快速C、希尔D、冒泡6 、一组待排序记录的关键字为(46,79,56,38,40,84),则利用快速排序,以第一个记录为基准元素得到的一次划分结果为( C)。
A、(38,40,46,56,79,84)B、(40,38,46,79,56,84)C、(40,38,46,56,79,84)D、(40,38,46,84,56,79)7、用直接插入排序对下面四个序列进行排序(由小到大),元素比较次数最少的是( C )。
A、94,32,40,90,80,46,21,69B、32,40,21,46,69,94,90,80C、21,32,46,40,80,69,90,94D、90,69,80,46,21,32,94,408、若用冒泡排序对关键字序列(18,16,14,12,10,8)进行从小到大的排序,所需进行的关键字比较总次数是(B)。
A、10B、15C、21D、349、就排序算法所用的辅助空间而言,堆排序、快速排序和归并排序的关系( A)。
《数据结构》第九章习题 参考答案

《数据结构》第九章习题参考答案一、判断题(在正确说法的题后括号中打“√”,错误说法的题后括号中打“×”)1、快速排序是一种稳定的排序方法。
(×)2、在任何情况下,归并排序都比简单插入排序快。
(×)3、当待排序的元素很大时,为了交换元素的位置,移动元素要占用较多的时间,这是影响时间复杂度的主要因素。
(√)4、内排序要求数据一定要以顺序方式存储。
(×)5、直接选择排序算法在最好情况下的时间复杂度为O(n)。
( ×)6、快速排序总比简单排序快。
( ×)二、单项选择题1.在已知待排序文件已基本有序的前提下,效率最高的排序方法是(A)。
A.直接插入排序B.直接选择排序C.快速排序D.归并排序2.下列排序方法中,哪一个是稳定的排序方法?(B)A.直接选择排序B.折半插入排序C.希尔排序D.快速排序3、比较次数与排序的初始状态无关的排序方法是( B)。
A.直接插入排序B.起泡排序(时间复杂度O(n2))C.快速排序D.简单选择排序4、对一组数据(84,47,25,15,21)排序,数据的排列次序在排序的过程中的变化为(1)84 47 25 15 21 (2)15 47 25 84 21 (3)15 21 25 84 47 (4)15 21 25 47 84 则采用的排序是( A)。
A. 选择B. 冒泡C. 快速D. 插入5、快速排序方法在(D)情况下最不利于发挥其长处。
A. 要排序的数据量太大B. 要排序的数据中含有多个相同值C. 要排序的数据个数为奇数D. 要排序的数据已基本有序6、用某种排序方法对线性表{25,84,21,47,15,27,68,35,20}进行排序,各趟排序结束时的结果为:(基准)20,21,15,25,84,27,68,35,47(25)15,20,21,25,47,27,68,35,84(左20右47)15,20,21,25,35,27,47,68,84(左35右68)15,20,21,25,27,35,47,68,84 ;则采用的排序方法为(C)。
数据结构课后习题答案第九章 查找

第九章9.1 若对大小均为n的有序顺序表和无序顺序表分别进行顺序查找,试在下列三种情况下分别讨论两者在等概率时平均查找长度是否相同?(1)查找不成功,即表中没有关键字等于给的值K的记录;(2)查找成功,且表中只有一个关键字等于给定值K的记录;(3)查找成功,且表中有若干关键字等于给定值K的记录,要求找出所有这些记录。
答:(1)相同,有序n+1; 无序n+1(2)相同,有序12n+;无序12n+(3)不相同,对于有序表,找到了第一个与K相同的元素后,只要再找到与K 不同的元素,即可停止查找;对于无序表,则要一直查找到最后一个元素。
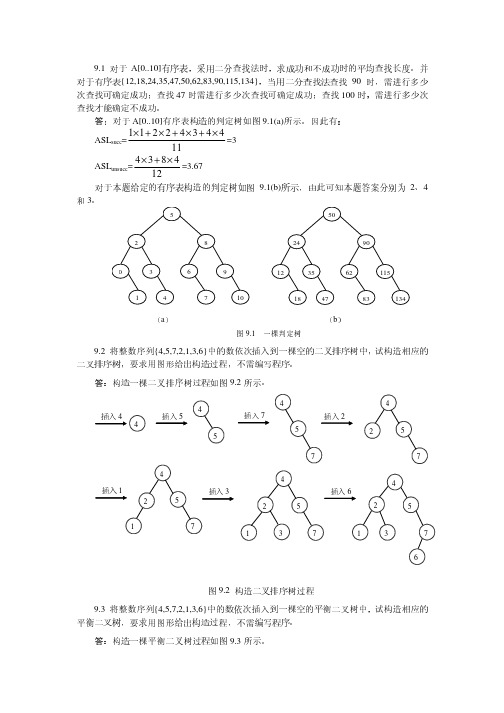
9.3 画出对长度为10的有序表进行折半查找的判定树,并分别求其等概率时查找成功和查找不成功的ASL。
查找成功:ASL=1/10(1*1+2*2+3*4+4*3)=2.92.设顺序表中关键字是递增有序的,试写一顺序查找算法,将哨兵设在表的高下标端。
然后求出等概率情况下查找成功与失败时的ASL。
【分析】因为顺序表中关键字是递增有序的,所以从低下标端开始顺序查找,若当前的关键码比要查找的关键码大,说明查找失败,终止查找。
【解答】(1)算法int seqsearch(SeqList R,KeyType K){int i;R[n]=K; // 设置哨兵i=0;while (R[i].key<K)i++;if (R[i].key==K)return i% n;elsereturn 0;}(2)查找长度成功情况:ASL succ=(1+2+3+……+n)/n=(n+1)/2失败情况:K<R[0].key时,比较1次,就终止查找;R[0].key<K< R[1].key时,比较2次,就终止查找;R[1].key<K< R[2].key时,比较3次,就终止查找;…R[n-2].key<K< R[n-1].key时,比较n次,就终止查找;R[n-1].key<K时,比较n+1次,就终止查找;所以ASL unsucc=((1+2+3+……+n+(n+1))/(n+1)=(n+2)/2。
数据结构第九章查找习题解答

第九章查找 习题解答9.5 画出对长度为10的有序表进行折半查找的判定树,并求其等概率时查找成功的平均查找长度。
解:求得的判定树如下: 57109643182ASL 成功=(1+2*2+4*3+3*4)/10 =2.99.9 已知如下所示长度为12的表(Jan,Feb,Mar,Apr,May,June,July,Aug,Sep,Oct,Nov,Dec )(1)试按表中元素的顺序依次插入一查初始为空的二叉排序树,画出插入完成之后的二叉排序树,并求其在等概率的情况下查找成功的平均查找长度。
(2)若对表中元素先进行排序构成有序表,求在等概率的情况下对此有序表进行折半查找时查找成功的平均查找长度。
解:(1)求得的二叉排序树如下图所示:JanFeb MarApr Aug Dec June July MaySeptOctNov在等概率情况下查找成功的平均查找长度为:ASL 成功=(1+2*2+3*3+4*3+5*2+6*1)/12=42/12=3.5(2)分析:对表中元素进行排序后,其实就变成了对长度为12的有序表进行折半查找了,那么在等概率的情况下的平均查找长度只要根据折半查找的判定树就很容易求出。
长度为12的有序表进行折半查找的判定树如下图所示:681211754193210所以可求出:ASL 成功=(1+2*2+4*3+5*4)/12=37/129.19 选取哈希函数H(k)=(3k) MOD 11。
用开放定址法处理冲突,di=i((7k)MOD 10+1)(i=1,2,3,…)。
试在0~10的散列地址空间中对关键字序列(22,41,53,46,30,13,01,67)造哈希表,并求等概率情况下查找成功时的平均查找长度。
解:因为H(22)=0;H(41)=2;H(53)=5;H(46)=6;H(30)=2;H 1(30)=3;H(13)=6;H 1(13)=8;H(01)=3;H 1(01)=0;H 2(01)=8;H 3(01)=5;H 4(01)=2;H 5(01)=10H(67)=3;H 1(67)=2;H 2(67)=1所以:构造的哈希表如下图所示:并求得等概率情况下查找成功的平均查找长度为:ASL 成功=(1*4+2*2+3+6)/8=17/89.21 在地址空间为0~16的散列区中,对以下关键字序列构造两哈希表: (Jan,Feb,Mar,Apr,May,June,July,Aug,Sep,Oct,Nov,Dec )(1)用线性探测开放定址法处理冲突;(2)用链地址法处理。
数据结构第九章--查找-习题及答案

第九章查找一、选择题1.若查找每个记录的概率均等,则在具有n个记录的连续顺序文件中采用顺序查找法查找一个记录,其平均查找长度ASL为( )。
A. (n-1)/2 B. n/2 C. (n+1)/2 D. n2. 下面关于二分查找的叙述正确的是 ( )A. 表必须有序,表可以顺序方式存储,也可以链表方式存储 C. 表必须有序,而且只能从小到大排列B. 表必须有序且表中数据必须是整型,实型或字符型 D. 表必须有序,且表只能以顺序方式存储3. 用二分(对半)查找表的元素的速度比用顺序法( )A.必然快 B. 必然慢 C. 相等 D. 不能确定4. 具有12个关键字的有序表,折半查找的平均查找长度()A. 3.1B. 4C. 2.5D. 55.当采用分块查找时,数据的组织方式为 ( )A.数据分成若干块,每块内数据有序B.数据分成若干块,每块内数据不必有序,但块间必须有序,每块内最大(或最小)的数据组成索引块C. 数据分成若干块,每块内数据有序,每块内最大(或最小)的数据组成索引块D. 数据分成若干块,每块(除最后一块外)中数据个数需相同6. 二叉查找树的查找效率与二叉树的( (1))有关, 在 ((2))时其查找效率最低(1): A. 高度 B. 结点的多少 C. 树型 D. 结点的位置(2): A. 结点太多 B. 完全二叉树 C. 呈单枝树 D. 结点太复杂。
7. 对大小均为n的有序表和无序表分别进行顺序查找,在等概率查找的情况下,对于查找失败,它们的平均查找长度是((1)) ,对于查找成功,他们的平均查找长度是((2))供选择的答案:A. 相同的B.不同的9.分别以下列序列构造二叉排序树,与用其它三个序列所构造的结果不同的是( ) A.(100,80, 90, 60, 120,110,130) B.(100,120,110,130,80, 60, 90)C.(100,60, 80, 90, 120,110,130)D. (100,80, 60, 90, 120,130,110)10. 在平衡二叉树中插入一个结点后造成了不平衡,设最低的不平衡结点为A,并已知A的左孩子的平衡因子为0右孩子的平衡因子为1,则应作( ) 型调整以使其平衡。
数据结构第九章查找练习及答案

数据结构第九章查找练习及答案一、选择题1、对线性表进行二分查找时,要求线性表必须()A、以顺序方式存储B、以链表方式存储C、以顺序方式存储,且结点按关键字有序排列D、以链表方式存储,且结点按关键字有序排列2、采用顺序查找方法查找长度为n的线性表时,每个元素的平均查找长度为()A、nB、n/2C、(n+1)/2D、(n-1)/23、采用二分查找方法查找长度为n的线性表时,每个元素的平均查找长度为()A、n2B、nlog2nC、nD、log2n4、二分查找和二叉排序树的时间性能()A、相同B、不相同C、有时相同D、有时不相同5、有一个有序表为{1,3,9,12,32,41,45,62,75,77,82,95,100},当二分查找值为82的结点时,()次比较后查找成功。
A、1B、2C、4D、86、哈希表长m=14,哈希表函数H(key)=key%11,表中已有4个结点:ADDR(15)=4,ADDR(38)=5;ADDR(61)=6;ADDR(84)=7;其余地址为空,如果用二次探测再散列处理冲突,关键字为49的结点的地址是()A、8B、3C、5D、97、一个长度为12的有序表,按二分查找法对该表进行查找,在表内每个元素等概率情况下查找成功所需的平均比较次数()A、35/12B、37/12C、39/12D、43/128、用分块查找时,若线性表中共有625个元素,查找每个元素的概率相同,假设采用顺序查找来确定结点所在的块时,每块应分()结点最佳。
A、10B、25C、6D、6259、如果要求一个线性表既能较快的查找,又能适应动态变化的要求,可以采用()查找方法。
A、分块B、顺序C、二分D、散列10、有100个元素,用折半查找法进行查找时,最大比较次数是()A、25B、50C、10D、711、有100个元素,用折半查找法进行查找时,最小比较次数是()A、7B、4C、2D、112、散列函数有一个共同性质,即函数值应当以()取其值域的每个值。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
return(binsearch(s,low,mid-1,k)
else return(mid);
}
else return(0);
} // 算法结束
9.5 int level(bstnode *bst, keytype K)
// 在二叉排序树bst中,求关键字K所在结点的层次
q->next=p->next;
while (q!=L && q->freq<p-freq) q=q->prior; // 找p结点位置
q->next->prior=p; // 将p结点插入链表
p->next=q->next;
p->prior=q;
q->next=p;
} // 算法结束
void locate(snode L[],int n;keytype X)
else { freq=L[i].freq;
while ( L[i-1].freq<freq) { L[i].freq=L[l-1].freq; i--; }
L[i+1].freq=freq;
}
} // 算法结束
9.3
注:判定树中的编号为元素在有序表中的序号
9.4 int binsearch(rectype s[],int low,int high, keytype k)
if(p= =null){printf(“没有关键字k”);return(null);}
else{pre->next=p->next;free(p);return(k);}
}
}//hashdelete
9.12(1)
0 1 2 3 4 5 6 7 8 9 10 11 12
14
01
68
27
55
19
20
84
{bstnode *p; // p为工作指针
int num=0; // 记层数
p=bst;
while (p && p->key!=K) // 二叉排序树不空 且关键字不等
if (p->key<K) { num++; p=p->rchild; } // 沿右子树
else { num++; p=p->lchild; } // 沿左子树
if (i>0 && r[i].key==k) return(i);
else 过程的判定树是单支树。
查找成功的平均查找长度为
ASL=∑PICI =1/n*∑i = 1/2*(n+1)
查找不成功的平均查找长度为 ASL=1/(n+1)(∑i+(n+1))=(n+2)/2.
// 为1,调用本函数后,若仍为1,是二叉排序树,否则,不是二叉排序树。
{if (bst!=null)
{bstree(bst->lchild,pre);
if (pre==null) pre=bst;
else if (pre->key>bst->key)
{printf (“非二叉排序树\n”);flag=0; return 0;}
// 有序的顺序表s,其元素的低端和高端下标分别为low和 high.
// 本算法递归地折半查找关键字为k的数据元素,若存在,则返回其在有序
// 顺序表中的位置,否则,返回0。
{ if (low<=high)
{mid=(low+high)/2;
if (s[mid].key<k )
return binsearch(s,mid+1,high,k);
(2)
0
1
2
3
4
5
6
7
8
9
10
11
12
查找成功时平均查找长度=(1*6+4*2+1*3+1*4)/12=21/12
查找不成功时的平均查找长度=(1*7+2*2+3*3+1*5)/13=25/13
9.13各种查找方法均有优点和缺点,不能笼统地说某种方法的好坏。
顺序查找的时间为o(n),在n较小时使用较好,它对数据元素的排列没有要求;二分查找时间为o(log2n),效率高但它要求数据元素有序排列;散查找时间为o(1),它只能按关键字随机查找(使用散列函数),不能顺序查找,也不能折半查找。
else pre=p;
bstree(bst->rchild,pre);
}
}
9.8(1)
ASL=(1*1+2*2+3*3+3*4+2*5+1*6)/12=42/12
(2)
L
R
(一)
R
L
(二)
R
R
(三)
(四)
ASL=(1*1+2*2+4*3+4*4+1*5)/12=38/12
9.9
L
LR
L
RL
(LL型)(LR型)(RL型)
R
R
(RR型)
9.10
(1)插入关键字B后,B-树的结点无变化
(2)插入关键字L后,结点E和G产生分裂
(3)插入关键字P后,结点H产生分裂
(4)插入关键字Q后,结点不变
(5)插入关键字R后,三个层次结点产生分裂,使B-树增高
9.11hegtype hashdelete(hashtable ht,hegtype k)
H(11)=11%13=11
H(10)=10%13=10冲突,3次成功
H(79)=79%13=1冲突,9次成功
成功时的平均查找长度=(1*6+1*2+3*3+1*4+1*9)/12=30/12
查找不成功时的平均查找长度=(1+13+12+11+10+9+8+7+6+5+4+3+2+1)/13=92/13
else return(ancestor(p->rchild)); // 沿右子树
} // 算法结束
9.7 int bstree(bstnode *bst, bstnode *pre)
// bst是二叉树根结点的指针,pre总指向当前访问结点的前驱,调用本函数
// 时为null。本算法判断bst是否是二叉排序树。设一全程变量flag,初始值
else if (p->key==b) { printf(“B 是A的祖先。\n”); return(p); }
else if (p-key>a && p->key<b) return(p);/ p是A和B的最近公共祖先
else if (p->key>b) return(ancestor(p->lchild)); // 沿左子树
if (p->key==K) return (++num); // 查找成功
else return(0); // 查找失败
} // 算法结束
其递归算法如下:
int level(bstnode *bst, keytype K,int num)
// 在二叉排序树中,求关键字K所在结点的层次的递归算法,调用时num=0
{if (bst==null) return 0;
else if (bst->key==K) return ++num;
else if (bst->key<K) return(bst->rchild,K,num++);
else return(bst->lchild,K,num++);
} // 算法结束
//ht是拉链法解决冲突的散列表,本算法删除关键字
//为k的指定结点,若删除成功,返回K;否则
//返回null
{设I=H(heg);//I为关键字k用指定哈希函数计算的哈希地址
if(ht[i]=null) {printf(“没有关键字k”);return(null);}
else{p=ht[i];pre=p;while(p&&p->data!=k){pre=p;p=p->next;}
79
23
11
10
121431139113
H(19)=19%13=6
H(14)=14%13=1
H(23)=23%13=10
H(01)=01%13=1冲突,2次成功
H(68)=68%13=3
H(20)=20%13=7
H(84)=84%13=6冲突,3次成功
H(27)=27%13=1冲突,4次成功
H(55)=55%13=3冲突,3次成功
9.6 bstnode *ancestor(bstnode *bst)
// bst是非空二叉排序树根结点的指针。
// A和B是bst树上的两个不同结点,本算法求A和B的最近公共祖先。
// 设A和B的关键字分别为a和b,不失一般性,设a<b。
{bstnode *p=bst;
if (p->key==a) { printf(“A 是B的祖先。\n”); return(p); }
keytype key; // 关键字
ElemType other;
}snode;
void locate(seqlist L,keytype X)
// 在链表中查找给定值为X的结点,并保持访问频繁的结点在前