模式识别试题2
模式识别第二篇习题解答
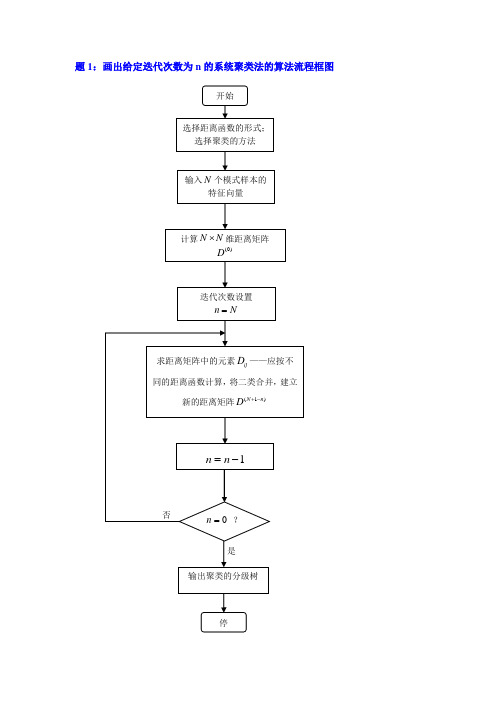
题1:画出给定迭代次数为n的系统聚类法的算法流程框图题2:对如下5个6维模式样本,用最小聚类准那么进行系统聚类分析x1: 0, 1, 3, 1, 3, 4x2: 3, 3, 3, 1, 2, 1 x3: 1, 0, 0, 0, 1, 1 x4: 2, 1, 0, 2, 2, 1 x5: 0, 0, 1, 0, 1, 0第1步:将每一样本看成单唯一类,得(0)(0)(0)112233(0)(0)4455{},{},{}{},{}G x G x G x Gx Gx =====计算各类之间的欧式距离,可得距离矩阵(0)D第2步:矩阵(0)D 中最小元素为(0)3G 和(0)5G 之间的距离,将他们归并为一类,得新的分类为(1)(0)(1)(0)(1)(0)(0)(1)(0)112233544{},{},{,},{}G G G G G G G G G ====计算聚类后的距离矩阵(1)D第3步:由于(1)D 它是(1)3G 与(1)4G 之间的距离,于是归并(1)3G 和(1)4G ,得新的分类为(2)(1)(2)(2)(2)(1)(1)1122334{},{},{,}G G G G G G G ===一样,按最小距离准那么计算距离矩阵(2)D ,得第4步:同理得(3)(2)(3)(2)(2)11223{},{,}G G G G G ==知足聚类要求,如聚为2类,聚类完毕。
题3:选2k =,11210(1),(1)z x z x ==,用K-均值算法进行聚类分析第一步:选取1121007(1),(1)06z x z x ⎛⎫⎛⎫==== ⎪ ⎪⎝⎭⎝⎭第二步:依照聚类中心进行聚类,取得1123456782910111220(1){,,,,,,,}(1){,,,,}S x x x x x x x x S x x x x x ==第三步:计算新的聚类中心121128(1)1291020(1)2 1.250011(2)() 1.125087.666711(2)()7.333312x S x S z x x x x N z x x x x N ∈∈⎛⎫==+++= ⎪⎝⎭⎛⎫==+++= ⎪⎝⎭∑∑第四步:因(2)(1),1,2j j z z j ≠=,故回到第二步 第二步:依照新的聚类中心从头进行聚类,取得1123456782910111220(2){,,,,,,,}(2){,,,,}S x x x x x x x x S x x x x x ==第三步:计算新的聚类中心121128(2)1291020(2)2 1.250011(3)() 1.125087.666711(3)()7.333312x S x S z x x x x N z x x x x N ∈∈⎛⎫==+++= ⎪⎝⎭⎛⎫==+++= ⎪⎝⎭∑∑第四步:(3)(2),1,2j j z z j ==,因此算法收敛,得聚类中心为121.25007.6667,1.12507.3333z z ⎛⎫⎛⎫== ⎪ ⎪⎝⎭⎝⎭迭代终止。
模式识别作业题(2)

答:不是最小的。首先要明确当我们谈到最小最大损失判决规则时,先验概率是未知的, 而先验概率的变化会导致错分概率变化, 故错分概率也是一个变量。 使用最小最大损 失判决规则的目的就是保证在先验概率任意变化导致错分概率变化时, 错分概率的最 坏(即最大)情况在所有判决规则中是最好的(即最小)。 4、 若 λ11 = λ22 =0, λ12 = λ21 ,证明此时最小最大决策面是来自两类的错误率相等。 证明:最小最大决策面满足 ( λ11 - λ22 )+( λ21 - λ11 ) 容易得到
λ11 P(ω1 | x) + λ12 P(ω2 | x) < λ21 P(ω1 | x) + λ22 P(ω2 | x) ( λ21 - λ11 ) P (ω1 | x) >( λ12 - λ22 ) P (ω2 | x) ( λ21 - λ11 ) P (ω1 ) P ( x | ω1 ) >( λ12 - λ22 ) P (ω2 ) P ( x | ω2 ) p( x | ω1 ) (λ 12 − λ 22) P(ω2 ) > 即 p( x | ω2 ) ( λ 21 − λ 11) P (ω1 )
6、设总体分布密度为 N( μ ,1),-∞< μ <+∞,并设 X={ x1 , x2 ,… xN },分别用最大似然 估计和贝叶斯估计计算 μ 。已知 μ 的先验分布 p( μ )~N(0,1)。 解:似然函数为:
∧Байду номын сангаас
L( μ )=lnp(X|u)=
∑ ln p( xi | u) = −
i =1
N
模式识别第三章作业及其解答
模式识别试卷及答案

模式识别试卷及答案一、选择题(每题5分,共30分)1. 以下哪一项不是模式识别的主要任务?A. 分类B. 回归C. 聚类D. 预测答案:B2. 以下哪种算法不属于监督学习?A. 支持向量机(SVM)B. 决策树C. K最近邻(K-NN)D. K均值聚类答案:D3. 在模式识别中,以下哪一项是特征选择的目的是?A. 减少特征维度B. 增强模型泛化能力C. 提高模型计算效率D. 所有上述选项答案:D4. 以下哪种模式识别方法适用于非线性问题?A. 线性判别分析(LDA)B. 主成分分析(PCA)C. 支持向量机(SVM)D. 线性回归答案:C5. 在神经网络中,以下哪种激活函数常用于输出层?A. SigmoidB. TanhC. ReLUD. Softmax答案:D6. 以下哪种聚类算法是基于密度的?A. K均值聚类B. 层次聚类C. DBSCAND. 高斯混合模型答案:C二、填空题(每题5分,共30分)1. 模式识别的主要任务包括______、______、______。
答案:分类、回归、聚类2. 在监督学习中,训练集通常分为______和______两部分。
答案:训练集、测试集3. 支持向量机(SVM)的基本思想是找到一个______,使得不同类别的数据点被最大化地______。
答案:最优分割超平面、间隔4. 主成分分析(PCA)是一种______方法,用于降维和特征提取。
答案:线性变换5. 神经网络的反向传播算法用于______。
答案:梯度下降6. 在聚类算法中,DBSCAN算法的核心思想是找到______。
答案:密度相连的点三、简答题(每题10分,共30分)1. 简述模式识别的基本流程。
答案:模式识别的基本流程包括以下几个步骤:(1)数据预处理:对原始数据进行清洗、标准化和特征提取。
(2)模型选择:根据问题类型选择合适的模式识别算法。
(3)模型训练:使用训练集对模型进行训练,学习数据特征和规律。
模式识别第二版答案完整版

模式识别(第二版)习题解答
目录
1 绪论
2
2 贝叶斯决策理论
2
j=1,...,c
类条件概率相联系的形式,即 如果 p(x|wi)P (wi) = max p(x|wj)P (wj),则x ∈ wi。
j=1,...,c
• 2.6 对两类问题,证明最小风险贝叶斯决策规则可表示为,若
p(x|w1) > (λ12 − λ22)P (w2) , p(x|w2) (λ21 − λ11)P (w1)
max P (wj|x),则x ∈ wj∗。另外一种形式为j∗ = max p(x|wj)P (wj),则x ∈ wj∗。
j=1,...,c
j=1,...,c
考虑两类问题的分类决策面为:P (w1|x) = P (w2|x),与p(x|w1)P (w1) = p(x|w2)P (w2)
是相同的。
• 2.9 写出两类和多类情况下最小风险贝叶斯决策判别函数和决策面方程。
λ11P (w1|x) + λ12P (w2|x) < λ21P (w1|x) + λ22P (w2|x) (λ21 − λ11)P (w1|x) > (λ12 − λ22)P (w2|x)
(λ21 − λ11)P (w1)p(x|w1) > (λ12 − λ22)P (w2)p(x|w2) p(x|w1) > (λ12 − λ22)P (w2) p(x|w2) (λ21 − λ11)P (w1)
模式识别第二章(线性判别函数法)

2类判别区域 d21(x)>0 d23(x)>0 3类判别区域 d31(x)>0 d32(x)>0
0 1 2 3 4 5 6 7 8 9
x1
d23(x)为正
d32(x)为正
d12(x)为正
d21(x)为正
32
i j 两分法例题图示
33
3、第三种情况(续)
d1 ( x) d2 ( x)
12
2.2.1 线性判别函数的基本概念
• 如果采用增广模式,可以表达如下
g ( x) w x
T
x ( x1 , x 2 , , x d ,1)
w ( w1 , w 2 , , w d , w d 1 ) T
T
增广加权向量
2016/12/3
模式识别导论
13
2.1 判别函数(discriminant function) 1.判别函数的定义 直接用来对模式进行分类的准则函数。
模式识别导论
11
2.2.1 线性判别函数的基本概念
• 在一个d维的特征空间中,线性判别函数的
一般表达式如下
g ( x ) w1 x1 w 2 x 2 w d x d w d 1
g ( x ) w x w d 1
T
w为 加 权 向 量
2016/12/3
模式识别导论
1
d1 ( x ) d3 ( x )
2
3
d2 ( x) d3 ( x)
34
多类问题图例(第三种情况)
35
上述三种方法小结:
当c
但是
3 时,i j
法比
i i
法需要更多
模式识别试题2

《模式识别》试题库一、基本概念题 1模式识别的三大核心问题是:( )、( )、( )。
2、模式分布为团状时,选用( )聚类算法较好。
3 欧式距离具有( )。
马式距离具有( )。
(1)平移不变性(2)旋转不变性(3)尺度缩放不变性(4)不受量纲影响的特性4 描述模式相似的测度有( )。
(1)距离测度 (2)模糊测度 (3)相似测度 (4)匹配测度5 利用两类方法处理多类问题的技术途径有:(1) (2)(3) 。
其中最常用的是第( )个技术途径。
6 判别函数的正负和数值大小在分类中的意义是:( )。
7 感知器算法 ( )。
(1)只适用于线性可分的情况;(2)线性可分、不可分都适用。
8 积累位势函数法的判别界面一般为( )。
(1)线性界面;(2)非线性界面。
9 基于距离的类别可分性判据有:( ).(1)1[]w B Tr S S - (2) BW S S (3) B W B S S S +10 作为统计判别问题的模式分类,在( )情况下,可使用聂曼-皮尔逊判决准则。
11 确定性模式非线形分类的势函数法中,位势函数K(x,xk)与积累位势函数K(x)的关系为( )。
12 用作确定性模式非线形分类的势函数法,通常,两个n 维向量x 和xk 的函数K(x,xk)若同时满足下列三个条件,都可作为势函数。
①( );②( );③ K(x,xk)是光滑函数,且是x 和xk 之间距离的单调下降函数。
13 散度Jij 越大,说明i 类模式与j 类模式的分布( )。
当i 类模式与j 类模式的分布相同时,Jij=( )。
14 若用Parzen 窗法估计模式的类概率密度函数,窗口尺寸h1过小可能产生的问题是( ),h1过大可能产生的问题是( )。
15 信息熵可以作为一种可分性判据的原因是:( )。
16作为统计判别问题的模式分类,在( )条件下,最小损失判决规则与最小错误判决规则是等价的。
17 随机变量l(x )=p(x 1)/p(x 2),l(x )又称似然比,则E l( x )2=( )。
模式识别习题及答案

模式识别习题及答案模式识别习题及答案【篇一:模式识别题目及答案】p> t,方差?1?(2,0)-1/2??11/2??1t,第二类均值为,方差,先验概率??(2,2)?122???1??1/21??-1/2p(?1)?p(?2),试求基于最小错误率的贝叶斯决策分界面。
解根据后验概率公式p(?ix)?p(x?i)p(?i)p(x),(2’)及正态密度函数p(x?i)?t(x??)?i(x??i)/2] ,i?1,2。
(2’) i?1基于最小错误率的分界面为p(x?1)p(?1)?p(x?2)p(?2),(2’) 两边去对数,并代入密度函数,得(x??1)t?1(x??1)/2?ln?1??(x??2)t?2(x??2)/2?ln?2(1) (2’)1?14/3-2/3??4/32/3??1由已知条件可得?1??2,?1,?2??2/34/3?,(2’)-2/34/31设x?(x1,x2)t,把已知条件代入式(1),经整理得x1x2?4x2?x1?4?0,(5’)二、(15分)设两类样本的类内离散矩阵分别为s1??11/2?, ?1/21?-1/2??1tt,各类样本均值分别为?1?,?2?,试用fisher准(1,0)(3,2)s2-1/21??(2,2)的类别。
则求其决策面方程,并判断样本x?解:s?s1?s2??t20?(2’) ??02?1/20??-2??-1?*?1w?s()?投影方向为12?01/22?1? (6’) ???阈值为y0?w(?1??2)/2??-1-13 (4’)*t2?1?给定样本的投影为y?w*tx??2-1?24?y0,属于第二类(3’) ??1?三、(15分)给定如下的训练样例实例 x0 x1 x2 t(真实输出) 1 1 1 1 1 2 1 2 0 1 3 1 0 1 -1 4 1 1 2 -1用感知器训练法则求感知器的权值,设初始化权值为w0?w1?w2?0;1 第1次迭代2 第2次迭代(4’)(2’)3 第3和4次迭代四、(15分)i. 推导正态分布下的最大似然估计;ii. 根据上步的结论,假设给出如下正态分布下的样本,估计该部分的均值和方差两个参数。
模式识别习题答案

将 w0 代入由 (∗∗) 得到的第二个等式得到:
1 [ N
Sw
+
N1N2 N2
(m1
−
m2)(m1
−
m2)T ]w
=
m1
−
m2
显然,
N1 N2 N2
(m1
−
m2
)(m1
−
m2
)T
w
在
m1 − m2
方向上,不妨令
N1 N2 N2
(m1
−
m2)(m1 − m2)T w = (1 − λ)(m1 − m2) 代入上式可得
g(x) = aT y, a = (1, 2, −2)T , y = (x1, x2, 1)T
(3)事实上, X 是 Y 中的一个 y3 = 1 超平面,两者有相同的表达式,因此对 原空间的划分相同。 4.8 证明在正态等协方差条件下,Fisher线性判别准则等价于贝叶斯判别。 证明: 在正态等协方差条件( Σ1 = Σ2 = Σ )下,贝叶斯判别的决策面方程为:
w xp = x ∓ r ∥w∥
根据超平面的定向,将 r 代入可得,
g(x) xp = x − ∥w∥2 w
4.4 对于二维线性判别函数
g(x) = x1 + 2x2 − 2
(1)将判别函数写成 g(x) = wT x + w0 的形式,并画出 g(x) = 0 的几何图形; (2)映射成广义齐次线性判别函数
∥∇J (a)∥2 ρk = ∇JT (a)D∇J(a)
时,梯度下降算法的迭代公式为
证明:
ak+1
=
ak
+
b
− aTk y1 ∥y1∥2
y1
模式识别郝旷荣Chap2(MSSB-HKR)

§2.1 引 言 §2.2 几种常用的决策规则 §2.3 正态分布时的统计决策 §本章小节 §本章习题
1
第二章 贝叶斯决策理论与 统计判别方法
本章要点 1. 机器自动识别出现错分类的条件,错分类的
可能性如何计算,如何实现使错分类出现可能 性最小——基于最小错误率的Bayes决策理论 2. 如何减小危害大的错分类情况——基于最小 错误风险的Bayes决策理论 3. 模式识别的基本计算框架——制定准则函数, 实现准则函数极值化的分类器设计方法
如果我们把作出ω1决策的所有观测值区域称为R1, 则在R1区内的每个x值,条件错误概率为p(ω2|x)。另 一个区R2中的x,条件错误概率为p(ω1|x)。
24
2.2.1 基于最小错误率的贝叶斯决策
因此平均错误率P(e)可表示成
(2-8) 由于在R1区内任一个x值都有P(ω2|x)<P(ω1|x),同样
8
§2.2 几种常用的决策规则
本节将讨论几种常用的决策规则。 不同的决策规则反映了分类器设计者的不同考虑,
对决策结果有不同的影响。 最有代表性的是基于最小错误率的贝叶斯决策与基
于最小风险的贝叶斯决策,下面分别加以讨论。
9
2.2.1 基于最小错误率的贝叶斯决策
一般说来,c类不同的物体应该具有各不相同的属性, 在d维特征空间,各自有不同的分布。
(2-9) 因此错误率为图中两个划线部分之和,显而易见只有
这种划分才能使对应的错误率区域面积为最小。
27
2.2.1 基于最小错误率的贝叶斯决策
在C类别情况下,很容易写成相应的最小错误率贝叶 斯决策规则:如果 ,
(2-10) 也可将其写成用先验概率与类条件概率密度相联系的 形式,得:
大学模式识别考试题及答案详解完整版

大学模式识别考试题及答案详解HUA system office room 【HUA16H-TTMS2A-HUAS8Q8-HUAH1688】一、填空与选择填空(本题答案写在此试卷上,30分)1、模式识别系统的基本构成单元包括:模式采集、特征提取与选择和模式分类。
2、统计模式识别中描述模式的方法一般使用特真矢量;句法模式识别中模式描述方法一般有串、树、网。
3、聚类分析算法属于(1);判别域代数界面方程法属于(3)。
(1)无监督分类 (2)有监督分类(3)统计模式识别方法(4)句法模式识别方法4、若描述模式的特征量为0-1二值特征量,则一般采用(4)进行相似性度量。
(1)距离测度(2)模糊测度(3)相似测度(4)匹配测度5、下列函数可以作为聚类分析中的准则函数的有(1)(3)(4)。
(1)(2) (3)(4)6、Fisher线性判别函数的求解过程是将N维特征矢量投影在(2)中进行。
(1)二维空间(2)一维空间(3)N-1维空间7、下列判别域界面方程法中只适用于线性可分情况的算法有(1);线性可分、不可分都适用的有(3)。
(1)感知器算法(2)H-K算法(3)积累位势函数法8、下列四元组中满足文法定义的有(1)(2)(4)。
(1)({A, B}, {0, 1}, {A01, A 0A1 , A 1A0 , B BA , B 0}, A)(2)({A}, {0, 1}, {A0, A 0A}, A)(3)({S}, {a, b}, {S 00S, S 11S, S 00, S 11}, S)(4)({A}, {0, 1}, {A01, A 0A1, A 1A0}, A)二、(15分)简答及证明题(1)影响聚类结果的主要因素有那些?(2)证明马氏距离是平移不变的、非奇异线性变换不变的。
答:(1)分类准则,模式相似性测度,特征量的选择,量纲。
(2)证明:(2分)(2分)(1分)设,有非奇异线性变换:(1分)(4分)三、(8分)说明线性判别函数的正负和数值大小在分类中的意义并证明之。
模式识别作业题(2)
=α
∏ p( x | μ ) p( μ )
i =1 i
N
=α
∏
i =1
N
⎡ 1 ⎢ exp ⎢ − 2πσ ⎢ ⎣
( xi − μ )
2σ
2
2
⎤ ⎡ 1 ⎥ ⎢ ⎥ • 2πσ exp ⎢ − 0 ⎥ ⎢ ⎦ ⎣
( μ − μ0 ) ⎤⎥ ⎥ 2σ ⎥ 0 ⎦
2 2
= α exp ⎢ − [⎜
''
⎡ 1 ⎛ N ⎛ 1 1 ⎞ 2 μ + − 2 ⎟ ⎜ 2 2 σ 02 ⎟ 2 ⎜ ⎢ ⎝σ σ ⎝ ⎠ ⎣
2 1 N +C ( x − μ ) ∑ 2 i =1 i
似然函数 μ 求导
∂L( μ ) N = ∑ x -N μ =0 i ∂μ i =1
∧
所以 μ 的最大似然估计: μ =
1 N
∑ xi
i =1
N
贝叶斯估计: p( μ |X)=
p( X | μ ) p( μ )
∫ p( X | μ ) p(μ )du
2 σn =
σ 02σ 2 2 Nσ 0 +σ 2
其中, mN =
1 N
∑x ,μ
i =1 i
N
n
就是贝叶斯估计。
7 略
得证。 3、使用最小最大损失判决规则的错分概率是最小吗?为什么?
答:不是最小的。首先要明确当我们谈到最小最大损失判决规则时,先验概率是未知的, 而先验概率的变化会导致错分概率变化, 故错分概率也是一个变量。 使用最小最大损 失判决规则的目的就是保证在先验概率任意变化导致错分概率变化时, 错分概率的最 坏(即最大)情况在所有判决规则中是最好的(即最小)。 4、 若 λ11 = λ22 =0, λ12 = λ21 ,证明此时最小最大决策面是来自两类的错误率相等。 证明:最小最大决策面满足 ( λ11 - λ22 )+( λ21 - λ11 ) 容易得到
模式识别期末考试题及答案

模式识别期末考试题及答案一、填空题1. 模式识别是研究通过_________从观测数据中自动识别和分类模式的一种学科。
答案:计算机算法2. 在模式识别中,特征选择的主要目的是_________。
答案:降低数据的维度3. 支持向量机(SVM)的基本思想是找到一个最优的超平面,使得两类数据的_________最大化。
答案:间隔4. 主成分分析(PCA)是一种_________方法,用于降低数据的维度。
答案:线性降维5. 隐马尔可夫模型(HMM)是一种用于处理_________数据的统计模型。
答案:时序二、选择题6. 以下哪种方法不属于模式识别的监督学习方法?()A. 线性判别分析B. 支持向量机C. 神经网络D. K-means聚类答案:D7. 在以下哪种情况下,可以使用主成分分析(PCA)进行特征降维?()A. 数据维度较高,且特征之间存在线性关系B. 数据维度较高,且特征之间存在非线性关系C. 数据维度较低,且特征之间存在线性关系D. 数据维度较低,且特征之间存在非线性关系答案:A8. 以下哪个算法不属于聚类算法?()A. K-meansB. 层次聚类C. 判别分析D. 密度聚类答案:C三、判断题9. 模式识别的目的是将输入数据映射到事先定义的类别中。
()答案:正确10. 在模式识别中,特征提取和特征选择是两个不同的概念,其中特征提取是将原始特征转换为新的特征,而特征选择是从原始特征中筛选出有用的特征。
()答案:正确四、简答题11. 简述模式识别的主要任务。
答案:模式识别的主要任务包括:分类、回归、聚类、异常检测等。
其中,分类和回归任务属于监督学习,聚类和异常检测任务属于无监督学习。
12. 简述支持向量机(SVM)的基本原理。
答案:支持向量机的基本原理是找到一个最优的超平面,使得两类数据的间隔最大化。
具体来说,SVM通过求解一个凸二次规划问题来确定最优超平面,使得训练数据中的正类和负类数据点尽可能远离这个超平面。
模式识别第2章 模式识别的基本理论(2)
(步长系数 )
33
算法
1)给定初始权向量a(k) ,k=0;
( 如a(0)=[1,1,….,1]T)
2)利用a(k)对对样本集分类,设错分类样本集为yk 3)若yk是空集,则a=a(k),迭代结束;否则,转4) 或 ||a(k)-a(k-1)||<=θ, θ是预先设定的一个小的阈值 (线性可分, θ =0) ( y) a(k 1) a(k) k J p 4)计算:ρ k, J p (a) y y 令k=k+1 5)转2)
1)g(x)>0, 决策:X∈ ω1 决策面的法向量指向ω1的决 策域R1,R1在H的正侧 2) g(x)<0, 决策:X∈ ω2, ω2的决策域R2在H的负侧
6
X g(X) / ||W|| R0=w0 / ||W|| Xp R2: g<0 H: g=0 r 正侧 R1: g>0 负侧
g(X)、 w0的意义 g(X)是d维空间任一点X到决策面H的距离的代数度量 w0体现该决策面在特征空间中的位置 1) w0=0时,该决策面过特征空间坐标系原点 2)否则,r0=w0/||W||表示坐标原点到决策面的距离
否则,按如下方法确定: 1、 2、 3、 m m ln[ P( ) / P( )]
~ ~
w0
1
2
2
1
2
N1 N 2 2
(P(W1)、P(W2) 已知时)
24
分类规则
25
5 感知准则函数
感知准则函数是五十年代由Rosenblatt提出的一种 自学习判别函数生成方法,企图将其用于脑模型感 知器,因此被称为感知准则函数。 特点:随意确定判别函数的初始值,在对样本分类 训练过程中逐步修正直至最终确定。 感知准则函数:是设计线性分类器的重要方法 感知准则函数使用增广样本向量与增广权向量
北航2019-2020学年第二学期期末《模式识别基础》试题

2019-2020学年第二学期期末《模式识别基础》试题考试日期:2020年6月17日,上午9:50–12:20 (满分100分)考试科目:《模式识别基础》学号:姓名:注意事项:1、请大家仔细审题,不要漏掉题目2、不要互相交流答案,杜绝试卷雷同一、单选题(每题2分,共10题)1. 下列不属于模式识别系统的基本构成单元的是( )A. 模式采集B. 特征选择与提取C. 模式分类D. 软件界面设计2. 下列不属于模式识别应用范畴的是()A. 利用书写板向计算机输入汉字B. 利用扫描仪向计算机输入图片C. 利用指纹来鉴定人的身份D. 利用语音向计算机输入汉字3. 哪条是贝叶斯分类器必须满足的先决条件( )A. 类别数已知且一定B. 每个类别的样本数已知C. 所有样本的总样本数已知D. 样本特征维度已知且一定4. Parzen窗法做概率密度估计时,当窗宽度变得很小时,容易出现( )A.噪声变弱B. 稳定性变差C. 分辨率变低D. 连续性变好5. 下面不属于非参数估计方法的是( )A. 直方图估计B. Parzen窗估计C. 贝叶斯估计D. K近邻估计6. Fisher线性判别函数的求解过程是将N维特征矢量投影在( )中进行A. 二维空间B. 一维空间C. (N-1)维空间D. N维空间7. 影响聚类算法结果的主要因素不包括( )A. 分类准则B. 已知类别的样本质量C. 特征选取D. 模式相似性测度8. 下列不属于估计量评价标准的是( )A. 无偏性B. 有效性C. 一致性D. 收敛性9. 关于感知器准则,以下说法错误的是( )A. 要求样本是线性可分的B. 可以用梯度下降法求解C. 当样本线性不可分时,感知器算法不能收敛D. 不能随意确定初始权向量10. 对于k均值(C均值)聚类算法,初始类心的选取非常重要,相比较而言,当对数据有一定了解时,如何选择c个样本作为初始类心较好( )A. 按输入顺序选B. 选相距最远的C. 随机挑选D. 选分布密度最高处的二、判断题(正确用“T”表示,错误用“F”表示;每题2分,共10题)1.模式所指的不是事物本身,而是从事物获得的信息,因此,模式往往表现为具有时间和空间分布的信息。
模式识别作业_2
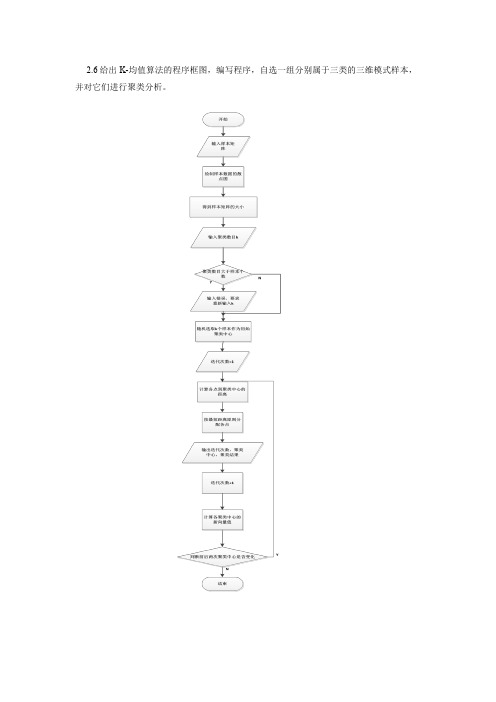
2.6给出K-均值算法的程序框图,编写程序,自选一组分别属于三类的三维模式样本,并对它们进行聚类分析。
MATLAB程序代码clear all;clc;data=input('请输入样本数据矩阵:');X=data(:,1);Y=data(:,2);figure(1);plot(X,Y,'r*','LineWidth',3);axis([0908])xlabel('x');ylabel('y');hold on;grid on;m=size(data,1);n=size(data,2);counter=0;k=input('请输入聚类数目:');if k>mdisp('输入的聚类数目过大,请输入正确的k值');k=input('请输入聚类数目:');endM=cell(1,m);for i=1:kM{1,i}=zeros(1,n);endMold=cell(1,m);for i=1:kMold{1,i}=zeros(1,n);end%随机选取k个样本作为初始聚类中心%第一次聚类,使用初始聚类中心p=randperm(m);%产生m个不同的随机数for i=1:kM{1,i}=data(p(i),:);while truecounter=counter+1;disp('第');disp(counter);disp('次迭代');count=zeros(1,k);%初始化聚类CC=cell(1,k);for i=1:kC{1,i}=zeros(m,n);end%聚类for i=1:mgap=zeros(1,k);for d=1:kfor j=1:ngap(d)=gap(d)+(M{1,d}(j)-data(i,j))^2;endend[y,l]=min(sqrt(gap));count(l)=count(l)+1;C{1,l}(count(l),:)=data(i,:);endMold=M;disp('聚类中心为:');for i=1:kdisp(M{1,i});enddisp('聚类结果为:');for i=1:kdisp(C{1,i});sumvar=0;for i=1:kE=0;disp('单个误差平方和为:');for j=1:count(i)for h=1:nE=E+(M{1,i}(h)-C{1,i}(j,h))^2;endenddisp(E);sumvar=sumvar+E;enddisp('总体误差平方和为:');disp(sumvar);%计算新的聚类中心,更新M,并保存旧的聚类中心for i=1:kM{1,i}=sum(C{1,i})/count(i);end%检查前后两次聚类中心是否变化,若变化则继续迭代;否则算法停止;tally=0;for i=1:kif abs(Mold{1,i}-M{1,i})<1e-5*ones(1,n)tally=tally+1;continue;elsebreak;endendif tally==kbreak;endEnd3.11给出感知器算法程序框图,编写算法程序.MATLAB程序代码clear all;clc;disp('感知器算法求解两类训练样本的判别函数'); Data1=input('请输入第一类样本数据:');Data2=input('请输入第二类样本数据:');W=input('请输入权向量初始值W(1)='); Expand=cat(1,Data1,Data2); ExpandData1=cat(2,Data1,ones(4,1)); ExpandData2=cat(2,Data2.*-1,ones(4,1).*-1); ExpandData=cat(1,ExpandData1,ExpandData2); X=Expand(:,1);Y=Expand(:,2);Z=Expand(:,3);[ro,co]=size(ExpandData);Step=0;CountError=1;while CountError>0;CountError=0;for i=1:roTemp=W*ExpandData(i,:)';if Temp<=0W=W+ExpandData(i,:);disp(W)CounterError=CountError+1;endendStep=Step+1;enddisp(W)figure(1)plot3(X,Y,Z,'ks','LineWidth',2);grid on;hold on;xlabel('x');ylabel('y');zlabel('z');f=@(x,y,z)W(1)*x+W(2)*y+W(3)*z+W(4); [x,y,z]=meshgrid(-1:.2:1,-1:.2:1,0:.2:1);v=f(x,y,z);h=patch(isosurface(x,y,z,v));isonormals(x,y,z,v,h)set(h,'FaceColor','r','EdgeColor','none');。
模式识别作业第三章2

第三章作业已知两类训练样本为1:(0 0 0 )',(1 0 0)' ,(1 0 1)',(1 1 0)'ω2:(0 0 1)',(0 1 1)' ,(0 1 0)',(1 1 1)'ω设0)'(-1,-2,-2,)1(=W,用感知器算法求解判别函数,并绘出判别界面。
$解:matlab程序如下:clear%感知器算法求解判别函数x1=[0 0 0]';x2=[1 0 0]';x3=[1 0 1]';x4=[1 1 0]';x5=[0 0 1]';x6=[0 1 1]';x7=[0 1 0]';x8=[1 1 1]';%构成增广向量形式,并进行规范化处理[x=[0 1 1 1 0 0 0 -1;0 0 0 1 0 -1 -1 -1;0 0 1 0 -1 -1 0 -1;1 1 1 1 -1 -1 -1 -1];plot3(x1(1),x1(2),x1(3),'ro',x2(1),x2(2),x2(3),'ro',x3(1),x3(2),x3(3),'ro',x4(1),x4(2),x4(3),'ro');hold on; plot3(x5(1),x5(2),x5(3),'rx',x6(1),x6(2),x6(3),'rx',x7(1),x7(2),x7(3),'rx',x8(1),x8(2),x8(3),'rx');grid on; w=[-1,-2,-2,0]';c=1;N=2000;for k=1:N|t=[];for i=1:8d=w'*x(:,i);if d>0w=w;、t=[t 1];elsew=w+c*x(:,i);t=[t -1];end-endif i==8&t==ones(1,8)w=wsyms x yz=-w(1)/w(3)*x-w(2)/w(3)*y-1/w(3);《ezmesh(x,y,z,[ 1 2]);axis([,,,,,]);title('感知器算法')break;else{endend运行结果:w =3]-2-31判别界面如下图所示:!若有样本123[,,]'x x x x =;其增广]1,,,[321x x x X =;则判别函数可写成: 1323')(321+*-*-*=*=x x x X w X d若0)(>X d ,则1ω∈x ,否则2ω∈x已知三类问题的训练样本为123:(-1 -1)', (0 0)' , :(1 1)'ωωω<试用多类感知器算法求解判别函数。
模式识别第二版答案完整版
1. 对c类情况推广最小错误率率贝叶斯决策规则; 2. 指出此时使错误率最小等价于后验概率最大,即P (wi|x) > P (wj|x) 对一切j ̸= i
成立时,x ∈ wi。
2
模式识别(第二版)习题解答
解:对于c类情况,最小错误率贝叶斯决策规则为: 如果 P (wi|x) = max P (wj|x),则x ∈ wi。利用贝叶斯定理可以将其写成先验概率和
(2) Σ为半正定矩阵所以r(a, b) = (a − b)T Σ−1(a − b) ≥ 0,只有当a = b时,才有r(a, b) = 0。
(3) Σ−1可对角化,Σ−1 = P ΛP T
h11 h12 · · · h1d
• 2.17 若将Σ−1矩阵写为:Σ−1 = h...12
h22 ...
P (w1) P (w2)
= 0。所以判别规则为当(x−u1)T (x−u1) > (x−u2)T (x−u2)则x ∈ w1,反
之则s ∈ w2。即将x判给离它最近的ui的那个类。
[
• 2.24 在习题2.23中若Σ1 ̸= Σ2,Σ1 =
1
1
2
策规则。
1]
2
1
,Σ2
=
[ 1
−
1 2
−
1 2
] ,写出负对数似然比决
1
6
模式识别(第二版)习题解答
解:
h(x) = − ln [l(x)]
= − ln p(x|w1) + ln p(x|w2)
=
1 2 (x1
−
u1)T
Σ−1 1(x1
−
u1)
−
1 2 (x2
模式识别试题及总结.doc

《模式识别》试卷( A)一、填空与选择填空(本题答案写在此试卷上,30 分)1、模式识别系统的基本构成单元包括:模式采集、特征提取与选择和模式分类。
2、统计模式识别中描述模式的方法一般使用特真矢量;句法模式识别中模式描述方法一般有串、树、网。
3、聚类分析算法属于(1);判别域代数界面方程法属于(3)。
(1)无监督分类(2)有监督分类(3)统计模式识别方法(4)句法模式识别方法4、若描述模式的特征量为0-1 二值特征量,则一般采用(4)进行相似性度量。
(1)距离测度(2)模糊测度(3)相似测度(4)匹配测度5、下列函数可以作为聚类分析中的准则函数的有(1)(3)(4)。
(1)(2)(3)(4)6、Fisher 线性判别函数的求解过程是将N 维特征矢量投影在(2)中进行。
(1)二维空间(2)一维空间(3)N-1维空间7、下列判别域界面方程法中只适用于线性可分情况的算法有(1);线性可分、不可分都适用的有(3)。
(1)感知器算法(2)H-K算法(3)积累位势函数法8、下列四元组中满足文法定义的有(1)(2)(4)。
(1)({A, B}, {0, 1}, {A 01, A0A1 ,A1A0 , B BA , B0}, A)(2)({A}, {0, 1}, {A 0, A0A}, A)(3)({S}, {a, b}, {S 00S, S11S, S00, S11},S)(4)({A}, {0, 1}, {A 01, A0A1, A1A0}, A)9、影响层次聚类算法结果的主要因素有(计算模式距离的测度、(聚类准则、类间距离门限、预定的类别数目))。
10、欧式距离具有(1、 2);马式距离具有(1、2、3、 4)。
(1)平移不变性( 2)旋转不变性( 3)尺度缩放不变性( 4)不受量纲影响的特性11、线性判别函数的正负和数值大小的几何意义是(正(负)表示样本点位于判别界面法向量指向的正(负)半空间中;绝对值正比于样本点到判别界面的距离。
模式识别试题答案最终版

模式识别非学位课考试试题考试科目:模式识别考试时间考生姓名:考生学号任课教师考试成绩一、简答题(每题6分,12题共72分):1、监督学习和非监督学习有什么区别?参考答案:监督学习与非监督学习的区别:监督学习方法用来对数据实现分类,分类规则通过训练获得。
该训练集由带分类号的数据集组成,因此监督学习方法的训练过程是离线的。
非监督学习方法不需要单独的离线训练过程,也没有带分类号(标号)的训练数据集,一般用来对数据集进行分析,如聚类,确定其分布的主分量等。
2、你如何理解特征空间?表示样本有哪些常见方法?参考答案:由利用某些特征描述的所有样本组成的集合称为特征空间或者样本空间,特征空间的维数是描述样本的特征数量。
描述样本的常见方法:矢量、矩阵、列表等。
3、什么是分类器?有哪些常见的分类器?参考答案:将特征空中的样本以某种方式区分开来的算法、结构等。
例如:贝叶斯分类器、神经网络等。
4、进行模式识别在选择特征时应该注意哪些问题?参考答案:特征要能反映样本的本质;特征不能太少,也不能太多;要注意量纲。
5、聚类分析中,有哪些常见的表示样本相似性的方法?参考答案:距离测度、相似测度和匹配测度。
距离测度例如欧氏距离、绝对值距离、明氏距离、马氏距离等。
相似测度有角度相似系数、相关系数、指数相似系数等。
6、SVM的主要思想可以概括为两点:(1) 它是针对线性可分情况进行分析,对于线性不可分的情况,通过使用非线性映射算法将低维输入空间线性不可分的样本转化为高维特征空间使其线性可分,从而使得高维特征空间采用线性算法对样本的非线性特征进行线性分析成为可能;(2) 它基于结构风险最小化理论之上在特征空间中建构最优分割超平面,使得学习器得到全局最优化,并且在整个样本空间的期望风险以某个概率满足一定上界。
7、请论述模式识别系统的主要组成部分及其设计流程,并简述各组成部分中常用方法的主要思想。
特征空间信息获取:通过测量、采样和量化,可以用矩阵或向量表示二维图像或以为波形。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
9 基于距离的类别可分性判据有: (
SB SB Tr[ S S B ] (2) SW (3) SW S B ). (1)
1 w
10 作为统计判别问题的模式分类, 在 ( ) 情况下, 可使用聂曼-皮尔逊判决准则。 11 确定性模式非线形分类的势函数法中,位势函数 K(x,xk)与积累位势函数 K(x)的关系为 ( ) 。 12 用作确定性模式非线形分类的势函数法,通常,两个 n 维向量 x 和 xk 的函数 K(x,xk)若 同时满足下列三个条件,都可作为势函数。①( ) ; ②( ) ;③ K(x,xk)是光滑函数,且是 x 和 xk 之间距离的单调下降函数。 13 散度 Jij 越大,说明i 类模式与j 类模式的分布( ) 。当i 类模 式与j 类模式的分布相同时,Jij=( ) 。 14 若用 Parzen 窗法估计模式的类概率密度函数,窗口尺寸 h1 过小可能产生的问题是 ( ) ,h1 过大可能产生的问题是( ) 。 15 信息熵可以作为一种可分性判据的原因是:( )。 16 作为统计判别问题的模式分类,在( )条件下,最小损失判决规则与最 小错误判决规则是等价的。 17 随机变量 l( x )=p( x 1)/p( x 2), l( x )又称似然比, 则 El( x )2= ( 在最小误判概率准则下,对数似然比 Bayes 判决规则为( 18 影响类概率密度估计质量的最重要因素( ) 。 ) 。
*
试用 LMSE 算法判断其线性可分性。
x 3.4 已知二维样本: x1 =(-1,0)T, x2 =(0,-1)T,=(0,0)T, x4 =(2,0)T 和 5 =(0,2)T, {x1 , x 2 , x3 } 1 , {x 4 , x5 } 2 。试用感知器算法求出分类决策函数,并判断 x6 =(1,1)T
属于哪一类? 3.4. 已 知 模 式 样 本 x1=(0,0)T,x2=(1,0)T,x3=(-1,1)T 分 别 属 于 三 个 模 式 类 别 , 即 , x11,x22,x33, (1)试用感知器算法求判别函数 gi(x),使之满足,若 xii 则 gi(x)>0,i=1,2,3; (2)求出相应的判决界面方程,并画出解区域的示意图。给定校正增量因子 C=1,初始值 可以取: w1(1)=(4,-9,-4)T,w2(1)=(4,1,-4,)T,w3(1)=(-4,-1,-6)T。 3.5 已知1:{(0,0)T},2:{(1,1)T},3:{(-1,1)T}。用感知器算法求该三类问题的判 别函数,并画出解区域。 第四章 统计判决 4.1 使用最小最大损失判决规则的错分概率是最小吗?为什么? 4.3 假设在某个地区的细胞识别中正常
J (k )
j 1
c
xi (j k )
(x
i
z (j k ) ) T ( xi z (j k ) )
最小。
其中,k 是迭代次数;
z (j k )
是
(j k )
的样本均值。
0 0 4 4 5 5 1 { 0 , 1 , 4 , 5 , 4 , 5 , 0 } ,试用谱系聚类算法对其分类。 2.12 有样本集
《模式识别》试题库 一、基本概念题 1 模式识别的三大核心问题是: ( ) 、 ( ) 、 ( ) 。 2、模式分布为团状时,选用( )聚类算法较好。 3 欧式距离具有( ) 。马式距离具有( ) 。 (1)平移不变性(2)旋转不 变性(3)尺度缩放不变性(4)不受量纲影响的特性 4 描述模式相似的测度有( )。 (1) 距离测度 (2) 模糊测度 (3) 相似测度 (4) 匹配测度 5 利用两类方法处理多类问题的技术途径有: (1) (2) (3) 。其中最常用的是第( )个技术途径。 6 判别函数的正负和数值大小在分类中的意义是:( )。 7 感知器算法 ( )。 (1)只适用于线性可分的情况; (2)线性可分、不可分都适用。 8 积累位势函数法的判别界面一般为( )。 (1)线性界面; (2)非线性界面。
第三章 判别域代数界面方程法 3.1 证明感知器算法在训练模式是线性可分的情况下, 经过有限次迭代后可以收敛到正确的 解矢量 w 。 3.2(1)试给出 LMSE 算法(H-K 算法)的算法流程图; (2)试证明 X#e(k)=0,这里, X#是伪逆矩阵;e(k)为第 k 次迭代的误差向量; (3)已知两类模式样本1:x1=(-1,0)T, x2=(1,0)T;2:x3=(0,0)T,x4=(0,-1)T。
ቤተ መጻሕፍቲ ባይዱ
1 和异常 2 两类的先验概率分别为 正常状态 :
P (1 ) 0.9 异常状态: P (2 ) 0.1
现有一待识的细胞,其观测值为 x ,从类条件概率密度分布曲线上查得
p ( x 1 ) 0.2 , p ( x 2 ) 0.4
并且已知损失系数为11=0,12=1,21=6,22=0。试对该细胞以以下两种方法进行分类: ①基于最小错误概率准则的贝叶斯判决; ②基于最小损失准则的贝叶斯判决。 请分析两种分 类结果的异同及原因。 4.4 试用最大似然估计的方法估计单变量正态分布的均值 和方差 。
) 。
19 基于熵的可分性判据定义为
c J H E x [ P ( i | x ) log P ( i | x )] i 1
,JH 越(
) ,说
明模式的可分性越强。当 P(i| x ) =(
)(i=1,2,…,c)时,JH 取极大值。
20 Kn 近邻元法较之于 Parzen 窗法的优势在于( ) 。上 述两种算法的共同弱点主要是( ) 。 21 已知有限状态自动机 Af=(,Q,,q0,F),={0,1};Q={q0,q1};:(q0,0)= q1, (q0,1)= q1,(q1,0)=q0,(q1,1)=q0;q0=q0;F={q0}。 现有输入字符串:(a) 00011101011,(b) 1100110011,(c) 101100111000,(d)0010011, 试问,用 Af 对上述字符串进行分类的结果为( ) 。
2
4.5 已知两个一维模式类别的类概率密度函数为 x x1 0≤x<1 1≤x<2 p(x2)= 3-x 2≤x≤3 p(x1)= 2-x 1≤x≤2 0 0 其它 其它 先验概率 P(1)=0.6,P(2)=0.4, (1)求 0-1 代价 Bayes 判决函数; (2)求总错误概率 P(e); (3)判断样本x1=1.35,x2=1.45,x3=1.55,x4=1.65各属于哪一类别。 4.16 在两类分类问题中,限定其中一类的错分误概率为1=,证明,使另一类的错分概率2 最小等价于似然比判决:如果 P(1)/P(2)> ,则判 x1,这里,是使1=成立的似然 比判决门限。 注:这就是 Neyman-Pearson 判决准则, 它类似于贝叶斯最小风险准则。 提示:该问题等价于用 Langrange 乘子法,使 q=(1-)+2 最小化。 第五章 特征提取与选择 5.1 设有 M 类模式i,i=1,2,...,M,试证明总体散布矩阵 St 是总类内散布矩阵 Sw 与类间 散布矩阵 Sb 之和,即 St=Sw+Sb 。
22 句法模式识别中模式描述方法有: ( )。 (1) 符号串 (2) 树 (3) 图 (4) 特征向量 23 设 集 合 X= a,b,c,d 上 的 关 系 ,R= (a,a),(a,b),(a,d),(b,b),(b,a),(b,d),(c,c),(d,d),(d,a),(d,b) , 则 a,b,c,d 生成的 R 等价类分别为 ( [a]R= , [b]R= , [c]R= [d]R= ) 。 24 如果集合 X 上的关系 R 是传递的、 ( )和( )的,则称 R 是一个等价关系。 25 一个模式识别系统由那几部分组成?画出其原理框图。 26 统计模式识别中,模式是如何描述的。 27 简述随机矢量之间的统计关系:不相关,正交,独立的定义及它们之间的关系。 28 试证明,对于正态分布,不相关与独立是等价的。 29 试证明,多元正态随机矢量的线性变换仍为多元正态随机矢量。 30 试证明,多元正态随机矢量 X 的分量的线性组合是一正态随机变量。 第二部分 分析、证明、计算题 第二章 聚类分析 2.1 影响聚类结果的主要因素有那些? 2.2 马氏距离有那些优点? 2.3 如果各模式类呈现链状分布,衡量其类间距离用最小距离还是用最大距离?为什么? 2.4 动态聚类算法较之于简单聚类算法的改进之处何在?层次聚类算法是动态聚类算法 吗?比较层次聚类算法与 c-均值算法的优劣。 2.5 ISODATA 算法较之于 c-均值算法的优势何在? 2.9 (1)设有 M 类模式i,i=1,2,...,M,试证明总体散布矩阵 ST 是总类内散布矩阵 SW 与类间散布矩阵 SB 之和,即 ST=SW+SB。 (2)设有二维样本:x1=(-1,0)T,x2=(0,-1)T,x3=(0,0)T,x4=(2,0)T 和 x5=(0,2)T。试 选用一种合适的方法进行一维特征特征提取 yi = WTxi 。 要求求出变换矩阵 W,并求出变换结果 yi ,(i=1,2,3,4,5)。 (3)根据(2)特征提取后的一维特征,选用一种合适的聚类算法将这些样本分为两类,要 求每类样本个数不少于两个,并写出聚类过程。 2.10 (1)试给出 c-均值算法的算法流程图;(2)试证明 c-均值算法可使误差平方和准则