实验三编译原理综合实验报告——(LR(0)语法分析的实现)
《编译原理》中LR(0)语法分析动态演示系统分析与设计

《编译原理》中LR(0)语法分析动态演示系统分析与设计1. 引言1.1 研究背景编译原理是计算机科学领域的重要基础课程,而LR(0)语法分析是编译原理中一个关键的内容。
LR(0)语法分析是一种自底向上的语法分析方法,能够准确地判断一个输入串是否是给定文法的句子,同时可以生成句子对应的语法树。
LR(0)语法分析比上下文无关文法分析更为强大,因此被广泛应用于编译器的设计和实现中。
对于学习者来说,理解和掌握LR(0)语法分析并不是一件容易的事情。
传统的教学方法往往是通过讲解和演示来进行,但存在一定的局限性,学生很难深入理解其中的逻辑和原理。
设计一个LR(0)语法分析动态演示系统是十分必要和有意义的。
这样的系统可以通过图形化的界面展示LR(0)语法分析的每个步骤和过程,帮助学生更直观地理解LR(0)语法分析的原理和实现。
1.2 研究目的研究目的是为了通过设计和实现一个LR(0)语法分析动态演示系统,帮助学生和从业者更好地理解和应用LR(0)语法分析算法。
具体来说,研究目的包括但不限于以下几点:通过分析LR(0)语法分析算法的原理和流程,深入探讨其在编译原理中的重要性和应用价值,为用户提供一个直观、动态的学习工具,帮助他们更好地理解和掌握这一算法的核心概念。
通过设计和实现一个功能齐全、易于操作的LR(0)语法分析动态演示系统,提供用户友好的界面和交互功能,使用户可以通过实际操作和观察,加深对LR(0)语法分析算法的认识,并在实践中掌握其使用方法和技巧。
通过系统测试和优化,不断改进系统性能和用户体验,确保系统稳定运行并具有良好的可用性和可靠性,为用户提供一个高质量的学习工具和应用工具。
通过这些努力,旨在提高用户对LR(0)语法分析算法的理解和应用能力,促进编译原理领域的教学和研究工作的发展。
1.3 研究意义编译原理是计算机专业的重要基础课程,而LR(0)语法分析是编译原理中一项重要的内容。
通过设计和实现一个LR(0)语法分析动态演示系统,可以帮助学生更加直观地理解和掌握LR(0)语法分析的原理和算法。
《编译原理》中LR(0)语法分析动态演示系统分析与设计

《编译原理》中LR(0)语法分析动态演示系统分析与设计一、引言随着计算机科学领域的不断发展,编译原理作为计算机科学的核心课程之一,对于理解编程语言和编译器的原理和技术具有重要意义。
LR(0)语法分析作为编译器中的重要组成部分,在编译原理课程中具有重要的地位。
为了更好地理解与掌握LR(0)语法分析,本文将课程中的相关理论与实践相结合,提出了一个LR(0)语法分析动态演示系统的设计与分析。
二、LR(0)语法分析概述在编译器的构建中,语法分析是非常重要的一环。
而LR(0)语法分析是一种常用的语法分析方法之一。
LR(0)语法分析使用的是LR(0)自动机进行分析,它是一种自底向上的语法分析方法,它的优势在于可以处理大部分的上下文无关文法(Context-Free Grammar, CFG),并且可以准确地进行语法分析。
LR(0)语法分析是通过构建状态机的方式,根据文法产生式中的右部项目来进行状态转换并最终得到文法的推导序列。
为了更好地理解LR(0)语法分析的原理与过程,我们需要深入学习LR(0)自动机的构建过程、状态转换的规则以及分析过程的具体步骤。
仅仅通过理论学习,学生们往往难以深刻理解LR(0)语法分析的工作原理与流程。
我们需要设计一个能够直观演示LR(0)语法分析过程的系统,通过动态的展示来帮助学生更好地理解LR(0)语法分析的过程和原理。
三、LR(0)语法分析动态演示系统的需求分析为了实现LR(0)语法分析动态演示系统,首先需要进行系统需求分析,明确系统的功能需要和用户需求。
根据LR(0)语法分析的原理与过程,系统的主要功能需求包括:1. 文法输入:能够接受用户输入的文法表达式,包括非终结符、终结符及产生式。
2. LR(0)自动机构建:根据用户输入的文法表达式自动生成LR(0)自动机,并进行展示。
3. 状态转换展示:根据LR(0)自动机中的状态转换规则,动态展示状态之间的转换过程及转换规则。
4. 分析过程展示:根据LR(0)自动机和输入的句子,展示分析过程中状态的变化和产生式的规约过程。
lr语法分析实验报告

lr语法分析实验报告LR语法分析实验报告引言在计算机科学领域,语法分析是编译器设计中非常重要的一个环节。
它负责将输入的源代码按照给定的文法规则进行解析,并生成语法树或分析表。
本实验报告将介绍LR语法分析器的设计与实现,并通过实验结果进行分析和评估。
一、背景知识1.1 语法分析语法分析是编译器的一个重要组成部分,它负责将输入的源代码转化为抽象语法树或分析表。
语法分析器根据给定的文法规则,逐个读取输入的字符并进行规约或移进操作,最终确定输入串是否符合给定的文法。
1.2 LR语法分析LR语法分析是一种自底向上的语法分析方法,它利用有限状态自动机进行分析。
LR分析器根据输入的文法规则和状态转移表,逐步推导输入串,直到达到最终的语法树或分析表。
二、实验设计2.1 实验目标本实验旨在设计和实现一个LR语法分析器,包括以下主要内容:- 设计和实现文法规则- 构建LR分析表- 实现LR分析器的状态转移和语法规约操作2.2 实验环境本实验使用Python语言进行实现,使用了Python的语法分析库PLY(Python Lex-Yacc)。
三、实验过程3.1 文法规则设计在本实验中,选择了一个简单的算术表达式文法作为示例:```E -> E + T| E - T| TT -> T * F| T / F| FF -> ( E )| number```该文法规则描述了四则运算表达式的语法结构,其中E表示表达式,T表示项,F表示因子。
3.2 构建LR分析表根据给定的文法规则,我们可以构建LR分析表。
该表记录了分析器在不同状态下的状态转移和规约操作。
3.3 实现LR分析器基于PLY库,我们可以很方便地实现LR分析器的状态转移和规约操作。
首先,我们需要定义文法规则的各个产生式对应的处理函数。
然后,通过PLY库提供的API,我们可以构建分析器对象,并进行状态转移和规约操作。
四、实验结果与分析4.1 实验结果经过实验,我们成功地实现了LR语法分析器,并对多个测试用例进行了分析。
编译原理语法分析实验报告

编译原理语法分析实验报告编译原理语法分析实验报告引言编译原理是计算机科学中的重要课程,它研究的是如何将高级语言转化为机器语言的过程。
语法分析是编译过程中的一个关键步骤,它负责将输入的源代码转化为抽象语法树,为后续的语义分析和代码生成提供便利。
本实验旨在通过实践,加深对语法分析的理解,并掌握常见的语法分析算法。
实验环境本次实验使用的是Python编程语言,因为Python具有简洁的语法和强大的库支持,非常适合用于编译原理的实验。
实验步骤1. 词法分析在进行语法分析之前,需要先进行词法分析,将源代码划分为一个个的词法单元。
词法分析器的实现可以使用正则表达式或有限自动机等方式。
在本实验中,我们选择使用正则表达式来进行词法分析。
2. 文法定义在进行语法分析之前,需要先定义源代码的文法。
文法是一种形式化的表示,它描述了源代码中各个语法成分之间的关系。
常见的文法表示方法有巴科斯范式(BNF)和扩展巴科斯范式(EBNF)。
在本实验中,我们选择使用BNF来表示文法。
3. 自顶向下语法分析自顶向下语法分析是一种基于产生式的语法分析方法,它从文法的起始符号开始,逐步展开产生式,直到生成目标字符串。
自顶向下语法分析的关键是选择合适的产生式进行展开。
在本实验中,我们选择使用递归下降分析法进行自顶向下语法分析。
4. 自底向上语法分析自底向上语法分析是一种基于移进-归约的语法分析方法,它从输入串的左端开始,逐步将输入符号移入分析栈,并根据产生式进行归约。
自底向上语法分析的关键是选择合适的归约规则。
在本实验中,我们选择使用LR(1)分析法进行自底向上语法分析。
实验结果经过实验,我们成功实现了自顶向下和自底向上两种语法分析算法,并对比了它们的优缺点。
自顶向下语法分析的优点是易于理解和实现,可以直接根据产生式进行展开,但缺点是对左递归和回溯的处理比较困难,而且效率较低。
自底向上语法分析的优点是可以处理任意文法,对左递归和回溯的处理较为方便,而且效率较高,但缺点是实现相对复杂,需要构建分析表和使用分析栈。
编译原理实验报告-语法分析

编译原理课程实验报告实验2:语法分析
(2)输出针对此测试程序对应的语法错误报告;
四、实验中遇到的问题总结
(一)实验过程中遇到的问题如何解决的?
问题1:关于action表中需要存储空‘#’以代表在某个状态读入空后所应该进行的动作,如何在action表中安排空这一列?
答:以0代表空,所以action表的列数为终结符数量加1,其中第0列表示某状态读入空时应该执行的动作。
问题2:关于数据结构,显然,文法中的终结符和非终结符都应该有一个唯一的标号来标识这是哪个文法符号,如何进行存储(文件和内存中)?用什么约束使得处理得到简化?答:我是通过一个short型的整型数标识文法符号的;文法输入文件的约束是,以终极符的数量加一为第一个非终结符的标识值,之后依次加一,必须连续且不重复。
对于终结符,从1开始为第1个终结符的标识值(0代表空),以后依次加一,必须连续且不重复;如此设计可以方便后续的action表和goto表的构建和查询操作。
问题3:构建项目集规范族或计算first集和follow集的过程中常常需要用到集合操作,如何编写相关代码?
答:可以直接使用现有的库或者自己实现一个set数据结构。
编译原理-语法分析实验报告

课程实验报告课程名称:编译原理(语法分析)专业班级:信息安全1001班学号:U201014608姓名:指导教师:骆婷报告日期:2010/11/8计算机科学与技术学院1、实验目的1)设计并编制一个语法分析程序,加深对语法分析程序中递归下降分析方法的理解;2)巩固对代码生成及报错处理等理论的认识;3)培养对完整系统独立分析和设计的能力;4)培养学生独立编程的能力;2、实验要求利用C语言编制递归下降分析程序,并对简单语言进行语法分析。
2.1 待分析的简单语法的语法用扩充的BNF表示如下:(1)<程序>::=begin <语句串> end(2)<语句串>::=<语句>{:语句}(3)<语句>::=<赋值语句>(4)<赋值语句>::=ID := <表达式>(5)<表达死>::=<项>{+<项>|-<项>}(6)<项>::=<因子>{*<因子>|/<因子>}(7)<因子>::=ID | NUM | ( <表达式> )2.2语法分析程序的功能输入单词串,以”#”结束,如果是文法正确的句子,则输出成功信息,打印“success”,否则输出”error”例如:输入: begin a:=9;b:=0 end #输出: success输入: begin a=9 end #输出:error3、词法分析程序的算法思想算法的基本任务是从字符串中表示的源程序中识别出具有独立意义的单词符号,并通过其基本文法,正确规约到开始符号。
1)全局变量的设置在此程序中,需要设置两个个全局变量:关键字表retab[6]、当前识别的种别号syn。
其中retab中元素为“begin”“if”“then”“while”“do”“end”,在程序会扫描出标识符时,首先查关键字表。
编译原理 LR分析法实验报告

实验五、LR分析法实验报告计算机与信息技术学院程序功能描述通过设计、编写和构造LR(0)项目集规范簇和LR 分析表、对给定的符号串进行LR 分析的程序,了解构造LR(0)分析表的步骤,对文法的要求,能够从文法G 出发生成LR(0)分析表,并对给定的符号串进行分析。
要求以表格或图形的方式实现。
G[E]:E→aA∣bBA→cA∣dB→cB∣d设计要求:(1)构造LR(0)项目集规范簇;要求输入LR(0)文法时,可以直接输入,也可以读取文件,并能够以表格的形式输出项目集规范簇集识别活前缀的有穷自动机(2)构造LR(0)分析表。
要求要求输入LR(0)文法时,可以直接输入,也可以读取文件;输出项目集规范簇,可以调用前一处理部分的结果,输出为LR(0)分析表(3)LR(0)分析过程【移进、归约、接受、报错】的实现。
要求调用前一部分处理结果的分析表,输入一个符号串,依据LR(0)分析表输出与句子对应的语法树,或直接以表格形式输出分析过程。
主要数据结构描述程序结构描述1.首先要求用户输入规则,并保存,分析出规则的数目,规则里的非终结符号和终结符号等信息,为下一步分析备用。
2.根据产生式构造分析表,首先分析每个状态里有哪些产生式,逐步将状态构造完整,最后的规约状态数应该等于产生式的个数。
3.在构造状态的时候,首先将所有的内容均填为出错情况,在每一步状态转换时可以将移进项目填进action表中,对于最后的规约项目,则再用规约覆盖掉之前填的移进。
4.要求用户输入分析串,并保存在输入序列数组中。
5.每一步根据当前的状态栈栈顶状态和输入符号查分析表,若是移进,则直接将符号和相应的状态添进栈中,否则弹出与产生式右部相同个数的字符和状态,并用剩下的状态和产生式的左部在goto表中进行查找,将非终结符和得到的状态压入两个栈内。
6.无论是规约还是移进都要输出当前三个栈内保存内容的情况。
7.如果碰到acc则输出accept,若碰到error则输出error,否则则继续进行规约和移进,不进行结果输出,直至输出接受或出错。
LR(0)语法分析

淮阴工学院编译原理课程设计报告选题名称:LR(0) 语法分析系(院):计算机工程学院专业:计算机科学与技术班级:计算机1075(单招)姓名:赵俊丽学号: 1071308114指导老师:于长辉王文豪高丽夏森学年学期:2009 ~2010 学年第 2 学期设计任务书指导教师(签章):年月日编译原理课程设计报告摘要:编译程序是现代计算机系统的基本组成部分之一,语法分析是编译程序的核心部分,识别由语法分析给出的单词符号序列是否是给定文法的正确句子,把词法记号流按语言的语法结构层次地分组,以形成语法短语。
一个编译程序的工作过程一般可以划分为五个阶段:词法分析、语法分析、语义分析与中间代码生成、优化、目标代码生成。
LR(0)是一种自底向上的语法分析方法,是已知的最一般的无回溯的移近—归约方法,这一方法能够识别所有能用上下文无关文法描述的程序语言的结构.本文主要讨论LR(0)语法分析的构造.着重分析LR(0)分析器的一般原理、实现思想、基本设计方法以及主要实现技术和工具。
操作员录入合法的LR(0)文法,则自动生成LR(0)分析表,并对任一输入串进行分析。
判断其是否是给定文法的句子。
还可以对输入的句子进行语法分析。
关键词:自底向上分析;移进;规约目录1课题综述 (1)1.1课题来源 (1)1.2意义 (1)1.3预期目标 (1)1.4面对的问题 (2)2系统分析 (3)2.1涉及的基础知识 (3)2.2 总体方案 (5)3 系统设计 (5)3.1 算法描述 (6)3.3 详细流程图 (9)4代码编写 (10)5程序调试 (15)总结 (19)致谢 (20)参考文献 (21)1课题综述1.1课题来源编译器设计的编译程序涉及到编译五个阶段中的三个,即词法分析器、语法分析器和中间代码生成器。
编译程序的输出结果包括词法分析后的二元式序列、变量名表、状态栈分析过程显示及四元式序列程序。
整个编译程序分为三部分:词法分析部分、语法分析处理及四元式生成部分、输出显示部分。
编译原理实验三-自下而上语法分析报告及语义分析报告.docx

上海电力学院编译原理课程实验报告实验名称:实验三自下而上语法分析及语义分析院系:计算机科学与技术学院专业年级:学生姓名:学号:指导老师:实验日期:实验三自上而下的语法分析一、实验目的:通过本实验掌握LR分析器的构造过程,并根据语法制导翻译,掌握属性文法的自下而上计算的过程。
二、实验学时:4学时。
三、实验内容根据给出的简单表达式的语法构成规则(见五),编制LR分析程序,要求能对用给定的语法规则书写的源程序进行语法分析和语义分析。
对于正确的表达式,给出表达式的值。
对于错误的表达式,给出出错位置。
四、实验方法采用LR分析法。
首先给出S-属性文法的定义(为简便起见,每个文法符号只设置一个综合属性,即该文法符号所代表的表达式的值。
属性文法的定义可参照书137页表6.1),并将其改造成用LR分析实现时的语义分析动作(可参照书145页表6.5)。
接下来给出LR分析表。
然后程序的具体实现:●LR分析表可用二维数组(或其他)实现。
●添加一个val栈作为语义分析实现的工具。
●编写总控程序,实现语法分析和语义分析的过程。
注:对于整数的识别可以借助实验1。
五、文法定义简单的表达式文法如下:(1)E->E+T(2)E->E-T(3)E->T(4)T->T*F(5)T->T/F(6)T->F(7)F->(E)(8)F->i五、处理程序例和处理结果例示例1:20133191*(20133191+3191)+ 3191#六、源代码【cifa.h】//cifa.h#include<string> using namespace std;//单词结构定义struct WordType{int code;string pro;};//函数声明WordType get_w();void getch();void getBC();bool isLetter();bool isDigit();void retract();int Reserve(string str); string concat(string str); 【Table.action.h】//table_action.hclass Table_action{int row_num,line_num;int lineName[8];string tableData[16][8]; public:Table_action(){row_num=16;line_num=8;lineName[0]=30;lineName[1]=7;lineName[2]=13;lineName[3]=8;lineName[4]=14;lineName[5]=1;lineName[6]=2;lineName[7]=15;lineName[8]=0;for(int m=0;m<row_num;m++) for(int n=0;n<line_num;n++) tableData[m][n]="";tableData[0][0]="S5";tableData[0][5]="S4";tableData[1][1]="S6";tableData[1][2]="S12";tableData[1][7]="acc";tableData[2][1]="R3";tableData[2][2]="R3";tableData[2][3]="S7";tableData[2][6]="R3"; tableData[2][7]="R3"; tableData[3][1]="R6"; tableData[3][2]="R6"; tableData[3][3]="R6"; tableData[3][4]="R6"; tableData[3][6]="R6"; tableData[3][7]="R6"; tableData[4][0]="S5"; tableData[4][5]="S4"; tableData[5][1]="R8"; tableData[5][2]="R8"; tableData[5][3]="R8"; tableData[5][4]="R8"; tableData[5][6]="R8"; tableData[5][7]="R8"; tableData[6][0]="S5"; tableData[6][5]="S4"; tableData[7][0]="S5"; tableData[7][5]="S4"; tableData[8][1]="S6";tableData[8][6]="S11"; tableData[9][1]="R1"; tableData[9][2]="R1"; tableData[9][3]="S7"; tableData[9][4]="S13"; tableData[9][6]="R1"; tableData[9][7]="R1"; tableData[10][1]="R4"; tableData[10][2]="R4"; tableData[10][3]="R4"; tableData[10][4]="R4"; tableData[10][6]="R4"; tableData[10][7]="R4"; tableData[11][1]="R7"; tableData[11][2]="R7"; tableData[11][3]="R7"; tableData[11][4]="R7"; tableData[11][6]="R7"; tableData[11][7]="R7"; tableData[12][0]="S5"; tableData[12][5]="S4";tableData[13][5]="S4";tableData[14][1]="R2";tableData[14][2]="R2";tableData[14][3]="S7";tableData[14][4]="S13";tableData[14][6]="R2";tableData[14][7]="R2";tableData[15][1]="R5";tableData[15][2]="R5";tableData[15][3]="R5";tableData[15][4]="R5";tableData[15][5]="R5";tableData[15][6]="R5";tableData[15][7]="R5";}string getCell(int rowN,int lineN){int row=rowN;int line=getLineNumber(lineN);if(row>=0&&row<row_num&&line>=0&&line<=line_num) return tableData[row][line];elsereturn"";}int getLineNumber(int lineN){for(int i=0;i<line_num;i++)if(lineName[i]==lineN)return i;return -1;}};【Table_go.h】//table_go.hclass Table_go{int row_num,line_num;//行数、列数string lineName[3];int tableData[16][3];public:Table_go(){row_num=16;line_num=3;lineName[0]="E";lineName[1]="T";lineName[2]="F";for(int m=0;m<row_num;m++) for(int n=0;n<line_num;n++)tableData[m][n]=0;tableData[0][0]=1;tableData[0][1]=2;tableData[0][2]=3;tableData[4][0]=8;tableData[4][1]=2;tableData[4][2]=3;tableData[6][1]=9;tableData[6][2]=3;tableData[7][2]=10;tableData[12][1]=14;tableData[12][2]=3;tableData[13][2]=15;}int getCell(int rowN,string lineNa){int row=rowN;int line=getLineNumber(lineNa);if(row>=0&&row<row_num&&line<=line_num) return tableData[row][line];elsereturn -1;}int getLineNumber(string lineNa){for(int i=0;i<line_num;i++)if(lineName[i]==lineNa)return i;return -1;}};【Stack_num.h】class Stack_num{int i; //栈顶标记int *data; //栈结构public:Stack_num() //构造函数{data=new int[100];i=-1;}int push(int m) //进栈操作{i++;data[i]=m;return i;}int pop() //出栈操作{i--;return data[i+1];}int getTop() //返回栈顶{return data[i];}~Stack_num() //析构函数{delete []data;}int topNumber(){return i;}void outStack(){for(int m=0;m<=i;m++)cout<<data[m];}};【Stack_str.h】class Stack_str{int i; //栈顶标记string *data; //栈结构public:Stack_str() //构造函数{data=new string[50];i=-1;}int push(string m) //进栈操作{i++;data[i]=m;return i;}int pop() //出栈操作{data[i]="";i--;return i;}string getTop() //返回栈顶{return data[i];}~Stack_str() //析构函数{delete []data;int topNumber(){return i;}void outStack(){for(int m=0;m<=i;m++)cout<<data[m];}};【cifa.cpp】//cifa.cpp#include<iostream>#include<string>#include"cifa.h"using namespace std;//关键字表和对应的编码stringcodestring[10]={"main","int","if","then","else","return","void","cout","endlint codebook[10]={26,21,22,23,24,25,27,28,29};//全局变量char ch;int flag=0;/*//主函数int main(){WordType word;cout<<"请输入源程序序列:";word=get_w();while(word.pro!="#")//#为自己设置的结束标志{cout<<"("<<word.code<<","<<"“"<<word.pro<<"”"<<")"<<endl;word=get_w();};return 0;}*/WordType get_w(){string str="";int code;WordType wordtmp;getch();//读一个字符getBC();//去掉空白符if(isLetter()){ //以字母开头while(isLetter()||isDigit()){str=concat(str);getch();}retract();code=Reserve(str);if(code==-1){wordtmp.code=0;wordtmp.pro=str;}//不是关键字else{wordtmp.code=code;wordtmp.pro=str;}//是关键字}else if(isDigit()){ //以数字开头while(isDigit()){str=concat(str);getch();}retract();wordtmp.code=30;wordtmp.pro=str;}else if(ch=='(') {wordtmp.code=1;wordtmp.pro="(";} else if(ch==')') {wordtmp.code=2;wordtmp.pro=")";} else if(ch=='{') {wordtmp.code=3;wordtmp.pro="{";} else if(ch=='}') {wordtmp.code=4;wordtmp.pro="}";} else if(ch==';') {wordtmp.code=5;wordtmp.pro=";";} else if(ch=='=') {wordtmp.code=6;wordtmp.pro="=";} else if(ch=='+') {wordtmp.code=7;wordtmp.pro="+";} else if(ch=='*') {wordtmp.code=8;wordtmp.pro="*";} else if(ch=='>') {wordtmp.code=9;wordtmp.pro=">";} else if(ch=='<') {wordtmp.code=10;wordtmp.pro="<";} else if(ch==',') {wordtmp.code=11;wordtmp.pro=",";} else if(ch=='\'') {wordtmp.code=12;wordtmp.pro="\'";} else if(ch=='-') {wordtmp.code=13;wordtmp.pro="-";} else if(ch=='/') {wordtmp.code=14;wordtmp.pro="/";} else if(ch=='#') {wordtmp.code=15;wordtmp.pro="#";} else if(ch=='|') {wordtmp.code=16;wordtmp.pro="|";}else {wordtmp.code=100;wordtmp.pro=ch;}return wordtmp;}void getch(){if(flag==0) //没有回退的字符ch=getchar();else //有回退字符,用回退字符,并设置标志flag=0;}void getBC(){while(ch==' '||ch=='\t'||ch=='\n')ch=getchar();}bool isLetter(){if(ch>='a'&&ch<='z'||ch>='A'&&ch<='Z')return true;elsereturn false;}bool isDigit(){if(ch>='0'&&ch<='9')return true;elsereturn false;}string concat(string str){return str+ch;}void retract(){flag=1;}int Reserve(string str){int i;for(i=0;i<=8;i++){if(codestring[i]==str) //是某个关键字,返回对应的编码return codebook[i];}if(i==9) //不是关键字return -1;}【LR.cpp】#include<iostream>#include<string>#include<cstdlib>#include"cifa.h"#include"stack_num.h"#include"stack_str.h"#include"table_action.h"#include"table_go.h"using namespace std;void process(){int stepNum=1;int topStat;Stack_num statusSTK; //状态栈Stack_str symbolSTK; //符号栈Stack_num valueSTK; //值栈WordType word;Table_action actionTAB; //行为表Table_go goTAB; //转向表cout<<"请输入源程序,以#结束:";word=get_w();//总控程序初始化操作symbolSTK.push("#");statusSTK.push(0);valueSTK.push(0);cout<<"步骤\t状态栈\t符号栈\t值栈\t当前词\t动作\t转向"<<endl;//分析while(1){topStat=statusSTK.getTop(); //当前状态栈顶string act=actionTAB.getCell(topStat,word.code);//根据状态栈顶和当前单词查到的动作//输出cout<<stepNum++<<"\t";statusSTK.outStack(); cout<<"\t";symbolSTK.outStack(); cout<<"\t";valueSTK.outStack(); cout<<"\t";cout<<word.pro<<"\t";//行为为“acc”,且当前处理的单词为#,且状态栈里就两个状态//说明正常分析结束if(act=="acc"&&word.pro=="#"&&statusSTK.topNumber()==1){cout<<act<<endl;cout<<"分析成功!"<<endl;cout<<"结果为:"<<valueSTK.getTop()<<endl;return;}//读到act表里标记为错误的单元格else if(act==""){cout<<endl<<"不是文法的句子!"<<endl;cout<<"错误的位置为单词"<<word.pro<<"附近。
编译原理实验报告-语法分析

编译原理课程实验报告实验2:语法分析
三、系统设计得分
要求:分为系统概要设计和系统详细设计。
(1)系统概要设计:给出必要的系统宏观层面设计图,如系统框架图、数据流图、功能模块结构图等以及相应的文字说明。
1)系统的数据流图:
说明
说明:本语法分析器是基于上一个实验词法分析器的基础上,通过在界面写或者是导入源程序,词法分析器将源程序识别的词法单元传递给语法分析器,语法分析器验证这个词法单元组成的串是否可以由源语言的文法生成,能够输出语法分析的结果,文法的first集、follow 集和预测分析表,当然也可以以易于理解的方式报告语法错误。
2)系统框架图
本系统框架主要是三部分,一部分是词法分析,负责识别源程序的词法单元识别,并将其存
因为预测分析表实在是过于庞大,因此本处分段截取预测分析表,下面的表是接在上面表的右侧。
(3)针对一测试程序输出其句法分析结果;
测试程序:
语法分析结果:
语法分析树:
(4)输出针对此测试程序对应的语法错误报告;
带错误的测试程序:
语法错误报告:
(5)对实验结果进行分析。
总结:
本语法分析器具有强大的语法分析功能
●允许变量的连续声明,比如int a,b,c;
●允许声明的同时赋值,比如string c = “你好”;
●允许对数组的声明和引用,同时进行赋值,比如char[4] a = {‘a’,’b’,’c’,’d’};a[0] = ‘m’;
●支持多种类型的声明和赋值,比如int,short,long,flaot,double,char,string,boolean
的声明和赋值;
●允许声明和使用一个过程函数,比如:。
编译原理语法分析实验报告

编译原理语法分析实验报告一、实验目的本实验主要目的是学习和掌握编译原理中的语法分析方法,通过实验了解和实践LR(1)分析器的实现过程,并对比不同的文法对语法分析的影响。
二、实验内容1.实现一个LR(1)的语法分析器2.使用不同的文法进行语法分析3.对比不同文法对语法分析的影响三、实验原理1.背景知识LR(1)分析器是一种自底向上(bottom-up)的语法分析方法。
它使用一个分析栈(stack)和一个输入缓冲区(input buffer)来处理输入文本,并通过移进(shift)和规约(reduce)操作进行语法分析。
2.实验步骤1)构建文法的LR(1)分析表2)读取输入文本3)初始化分析栈和输入缓冲区4)根据分析表进行移进或规约操作,直至分析过程结束四、实验过程与结果1.实验环境本实验使用Python语言进行实现,使用了语法分析库ply来辅助实验。
2.实验步骤1)构建文法的LR(1)分析表通过给定的文法,根据LR(1)分析表的构造算法,构建出分析表。
2)实现LR(1)分析器使用Python语言实现LR(1)分析器,包括读取输入文本、初始化分析栈和输入缓冲区、根据分析表进行移进或规约操作等功能。
3)使用不同的文法进行语法分析选择不同的文法对编写的LR(1)分析器进行测试,观察语法分析的结果。
3.实验结果通过不同的测试案例,实验结果表明编写的LR(1)分析器能够正确地进行语法分析,能够识别出输入文本是否符合给定文法。
五、实验分析与总结1.实验分析本实验通过实现LR(1)分析器,对不同文法进行语法分析,通过实验结果可以观察到不同文法对语法分析的影响。
2.实验总结本实验主要学习和掌握了编译原理中的语法分析方法,了解了LR(1)分析器的实现过程,并通过实验提高了对语法分析的理解。
六、实验心得通过本次实验,我深入学习了编译原理中的语法分析方法,了解了LR(1)分析器的实现过程。
在实验过程中,我遇到了一些问题,但通过查阅资料和请教老师,最终解决了问题,并完成了实验。
LR0语法分析报告

《编译原理》课程实验报告题目语法分析专业班级学号姓名指导教师南京理工大学计算机学院2010年6月实验2:语法分析一、实验目的1.巩固对语法分析的基本功能和原理的认识。
2.通过对语法分析表的自动生成加深语法分析表的认识。
3.理解并处理语法分析中的异常和错误。
二、实验内容(1)掌握语法分析程序的总体框架,并将其实现。
(2) 在手工构造的文法的基础上实现LR(1)分析,给出其语法分析表的生成程序及其数据结构和查找算法。
分析表生成程序:char* StackStateToString(int stackLen,int *stateStack){int i;char pstr[5];char *kunchar=new char[256];kunchar[0]=0;for(i=0;i<stackLen;i++){itoa(stateStack[i],pstr,10);if(strlen(pstr)>1){strcat(kunchar,"(");strcat(kunchar,pstr);strcat(kunchar,")");}else{strcat(kunchar,pstr);}}return kunchar;}void initial(){int i;actionTable[0][0].doWhat='S';actionTable[0][0].number=2;actionTable[1][5].doWhat='A';。
actionTable[10][5].doWhat='r';actionTable[10][5].number=2;actionTable[11][5].doWhat='r';actionTable[11][5].number=4;GoTo[0][0]=1;GoTo[2][1]=4;GoTo[3][1]=6;}数据结构相对简单,利用二维数组存放当前状态下的Action和Goto字符查找算法:char* ActionToString(Action nowAction){char *pstr=new char[20];pstr[0]=0;char temp[4];if(nowAction.doWhat=='A')strcat(pstr,"Acc");else if(nowAction.doWhat=='S'||nowAction.doWhat=='R'){pstr[0]=nowAction.doWhat;pstr[1]=0;itoa(nowAction.number,temp,10);strcat(pstr,temp);}return pstr;}char* GotoToString(int goTo){char *temp=new char[4];temp[0]=0;if(goTo>0)itoa(goTo,temp,10);return temp;}(3)给出错误处理方法。
编译原理编译器综合实验报告

编译原理编译器综合实验报告
本次综合实验的目标是设计和实现一个简单的编译器,用于将一种高级程序语言转化为等效的目标代码。
该编译器的设计基于编译原理的相关知识和技术。
在实验中,我们首先进行了语法分析的设计与实现。
通过使用自顶向下的递归下降方法,我们构建了一个语法分析器,该分析器能够识别源代码中的语法结构,并生成相应的语法树。
为了提高语法分析的效率,我们还使用了一些常见的优化技术,如LL(1)文法的设计和FIRST集合的计算。
接下来,我们进行了语义分析的设计与实现。
在语义分析阶段,我们对语法树进行了类型检查和语义检查。
通过遍历语法树,我们检查了变量的声明和使用情况,以及表达式的合法性。
同时,我们还进行了符号表的设计与管理,用于记录变量和函数的相关信息。
我们进行了中间代码生成的设计与实现,在中间代码生成阶段,我们将语法树转化为一种中间表示形式,以方便后续的优化和目标代码生成。
为了提高中间代码的质量,我们使用了一些常见的优化技术,如常量折叠和公共子表达式消除。
我们进行了目标代码生成的设计与实现,在目标代码生成阶段,我们将中间代码转化为目标代码,以便于在特定的硬件平台上执行。
为了生成高效的目标代码,我们使用了一些常见的优化技术,如寄存器分配和指令选择。
通过本次综合实验,我们深入了解了编译器的各个阶段,了解了
编译原理的基本原理和技术。
同时,我们也学会了如何设计和实现一个简单的编译器,并通过实践掌握了相关的编程技能。
这对我们进一步学习和研究编译原理以及相关领域的知识具有重要意义。
编译原理 实验报告实验三 语法分析(LR分析程序)
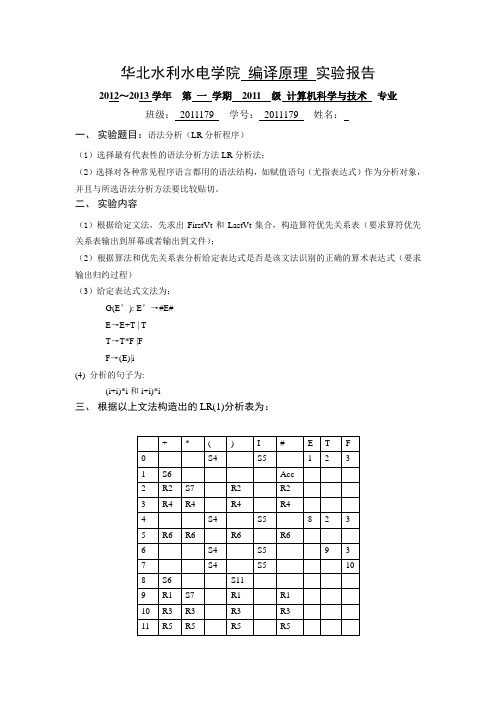
华北水利水电学院编译原理实验报告2012~2013学年第一学期2011 级计算机科学与技术专业班级:2011179 学号:2011179 姓名:一、实验题目:语法分析(LR分析程序)(1)选择最有代表性的语法分析方法LR分析法;(2)选择对各种常见程序语言都用的语法结构,如赋值语句(尤指表达式)作为分析对象,并且与所选语法分析方法要比较贴切。
二、实验内容(1)根据给定文法,先求出FirstVt和LastVt集合,构造算符优先关系表(要求算符优先关系表输出到屏幕或者输出到文件);(2)根据算法和优先关系表分析给定表达式是否是该文法识别的正确的算术表达式(要求输出归约过程)(3)给定表达式文法为:G(E’): E’→#E#E→E+T | TT→T*F |FF→(E)|i(4) 分析的句子为:(i+i)*i和i+i)*i三、根据以上文法构造出的LR(1)分析表为:四、程序源代using System;using System.Text;using System.IO;namespace Syntax_Analyzer{class Syntax{StreamReader myStreamReader;int t;int[] lengh;int l =0;string[] grammar;int s=0;string[] Word;int w=0;int[] wordNum ;int n =0;int[,] LR;public Syntax(){lengh = new int[7];grammar=new string[7];Word=new string[100];wordNum = new int[100];LR=new int[30,30];}public void analyzer(){//读入grammarSyntax myTextRead=new Syntax();Console.WriteLine("-----------------------------语法分析开始---------------------------------\n");//***************************//循环读取文法//***************************string strStart;strStart="grammar.txt";myTextRead.myStreamReader=new StreamReader(strStart);string strBufferStart;int uu=0;do{strBufferStart =myTextRead.myStreamReader.ReadLine();if(strBufferStart==null)break;foreach (String subString in strBufferStart.Split()){grammar[uu]=subString; //每行文法存入grammar[]uu++;}}while (strBufferStart!=null);myTextRead.myStreamReader.Close();//***************************//循环读取lengh//***************************strStart="lengh.txt";myTextRead.myStreamReader=new StreamReader(strStart);uu=0;do{strBufferStart =myTextRead.myStreamReader.ReadLine();if(strBufferStart==null)break;foreach (String subString in strBufferStart.Split()){lengh[uu]=Convert.ToInt32(subString); //每行文法存入grammar[]uu++;}}while (strBufferStart!=null);myTextRead.myStreamReader.Close();//****************************// 读入文件,进行语法分析////****************************string strReadFile;strReadFile="input.txt";myTextRead.myStreamReader=new StreamReader(strReadFile);string strBufferText;int wid =0;Console.WriteLine("分析读入程序(记号ID):\n");do{strBufferText =myTextRead.myStreamReader.ReadLine();if(strBufferText==null)break;foreach (String subString in strBufferText.Split()){if(subString!=""){int ll;if(subString!=null){ll= subString.Length; //每一个长度}else{break;}int a=ll+1;char[] b = new char[a];StringReader sr = new StringReader(subString);sr.Read(b, 0, ll); //把substring 读到char[]数组里int sort=(int)b[0];// word[i] 和wordNum[i]对应//先识别出一整个串,再根据开头识别是数字还是字母Word[wid]=subString;if(subString.Equals("+")){wordNum[wid]=0;}else{if(subString.Equals("*")){wordNum[wid]=1;}else{if(subString.Equals("(")){wordNum[wid]=2;}else{if(subString.Equals(")")){wordNum[wid]=3;}else{if(subString.Equals("i")){wordNum[wid]=4;}}}}}Console.Write(subString+"("+wordNum[wid]+")"+" ");wid++;}}Console.WriteLine("\n");}while (strBufferText!=null);wordNum[wid]=5;myTextRead.myStreamReader.Close();//*********************************//读入LR分析表////***********************************string strLR;strLR="LR-table.txt";myTextRead.myStreamReader=new StreamReader(strLR);string strBufferLR;int pp=0;do{strBufferLR =myTextRead.myStreamReader.ReadLine();if(strBufferLR==null)break;else{int j=0;foreach (String subString in strBufferLR.Split()){if(subString!=null){int lllr=Convert.ToInt16(subString);LR[pp,j]=lllr; //把行与列读入数组j++;}}}pp++;}while (strBufferLR!=null);myTextRead.myStreamReader.Close();int[] state = new int[100];string[] symbol =new string[100];state[0]=0;symbol[0]="#";int p1=0;int p2=0;Console.WriteLine("\n按文法规则归约顺序如下:\n");//***************//归约算法//***************while(true){int j,k;j=state[p2];k=wordNum[p1];t=LR[j,k]; //当出现t为的时候if(t==0){//错误类型string error = "" ;if (k == 0)error = "+";elseif (k == 1)error = "*";elseif (k == 2)error = "(";elseif (k == 3)error = ")";elseif (k == 4)error = "i";elseerror = " 其它错误!";Console.WriteLine("\n检测结果:");Console.WriteLine("代码中存在语法错误");Console.WriteLine("错误状况:错误状态编号为"+j+" 读头下符号为"+error);break;}else{if(t==-100) //-100为达到接受状态{Console.WriteLine("\n");Console.WriteLine("\n检测结果:");Console.WriteLine("代码通过语法检测");break;}if(t<0&&t!=-100) //归约{string m=grammar[-t];Console.Write(m+" "); //输出开始符int length=lengh[-t];p2=p2-(length-1);Search mySearch=new Search();int right=mySearch.search(m);if(right==0){Console.WriteLine("\n");Console.WriteLine("代码中有语法错误");break;}int a=state[p2-1];int LRresult= LR[a,right];state[p2]=LRresult;symbol[p2]=m;}if(t>0){p2=p2+1;state[p2]=t;symbol[p2]=Convert.ToString(wordNum[p1]);p1=p1+1;}}}myTextRead.myStreamReader.Close();Console.WriteLine("-----------------------------语法分析结束---------------------------------\n");Console.Read();}}class Search{public int search(string x){string[] mysymbol=new string[3];mysymbol[0]="E";mysymbol[1]="T";mysymbol[2]="F";int r = 0;for(int s=0;s<=2;s++){if(mysymbol[s].Equals(x))r=s+6 ;}return r;}}}五、测试结果输入”( i + i ) * i”字符串,分析如下图所示输入”i + i ”字符串,分析如下图所示六、小结(包括收获、心得体会、存在的问题及解决问题的方法、建议等)本次实验是LR分析法,LR分析法是一种有效的自上而下分析技术,在自左向右扫描输入串时就能发现其中的任何错误。
编译原理-LR语法分析器的控制程序实验报告

编译原理实验报告学号姓名时间专业班级实验题目:LR语法分析器的控制程序实验目的:手工模拟控制程序计算,对源程序进行LR 语法分析主要是分析表的构造实验内容与步骤:1.将要进行LR 语法分析的源程序和LR 语法分析器控制程序放在同一文件夹中。
2.用 C 语言编写 LR 语法分析器控制程序,程序代码如下:#include <fstream.h>#include <iostream.h>#include <stdlib.h>#include <string.h>struct code_val{char code;char val[20];};const char *p[]={//产生式"S→ E","E → E+T","E → T","T → T*F","T → F","F → (E)","F → i"};const char TNT[ ]="+*()i#ETF";//LR 分析表列的字符const int M[][9]={//LR 分析表数字化,列字符 +*()i#ETF用数字 012345678 标识。
{ 0, 0, 4, 0, 5,0, 1, 2, 3},//0 表示出错, s4 用 4 表示。
{ 6, 0, 0, 0, 0,99},//Acc 用 99 表示{-2, 7, 0,-2, 0,-2},//r2 用 -2 表示{-4,-4, 0,-4, 0,-4},{ 0, 0, 4, 0, 5, 0, 8, 2, 3},{-6,-6, 0,-6, 0,-6}, { 0, 0,4, 0, 5, 0, 0, 9, 3},{ 0, 0, 4, 0, 5, 0, 0, 0,10},{ 6, 0, 0,11},{-1, 7, 0,-1, 0,-1},{-3,-3, 0,-3, 0,-3},{-5,-5, 0,-5, 0,-5}};int col(char);void main(){//列定位函数原型int state[50]={0};//状态栈初值char symbol[50]={'#'};//符号栈初值int top=0;//栈顶指针初值ofstream cout("par_r.txt");//语法分析结果输出至文件par_r.txtifstream cin("lex_r.txt");// lex_r.txt 存放词法分析结果,语法分析器从该文件输入数据。
北邮编译原理实验 LR语法分析 实验报告

LR语法分析实验报告班级:2010211308 姓名:杨娜学号:10211369一.题目:LR语法分析程序的设计与实现二.设计目的:(1)了解语法分析器的生成工具和编译器的设计。
(2)了解自上而下语法分析器的构造过程。
(3). 理解和掌握LR语法分析方法的基本原理;根据给出的LR)文法,掌握LR分析表的构造及分析过程的实现。
(4)掌握预测分析程序如何使用分析表和栈联合控制实现LR分析。
三.实验内容:编写语法分析程序,实现对算术表达式的语法分析,要求所分析算数表达式由如下的文法产生:E->E+T|E-T|TT->T/F|T*F|FF->i|n|(E)四.实验要求:编写LR语法分析程序,要求如下:(1)构造识别所有活动的DFA(2)构造LR分析表(3)编程实现算法4.3,构造LR分析程序五.算法流程分析程序可分为如下几步:六.算法设计1.数据结构s :文法开始符号line :产生式的个数G[i][0] :产生式的标号Vt[] :终结符Vn[] :非终结符id :项目集编号Prjt *next :指示下一个项目集Prjt[]:存储项目的编号,prjt[0]项目编号的个数Pointafter[] :圆点后的字符,pointafter[0]为字符个数Prjset*actorgo[]:存储出度Pointbefore:圆点前面的字符Form:动态数组下标,同时作为符号的编号Vn[] :非终结符序列Vt[]:终结符序列2.LR分析器由三个部分组成(1)总控程序,也可以称为驱动程序。
对所有的LR分析器总控程序都是相同的。
(2)分析表或分析函数,不同的文法分析表将不同,同一个文法采用的LR分析器不同时,分析表将不同,分析表又可以分为动作表(ACTION)和状态转换(GOTO)表两个部分,它们都可用二维数组表示。
(3)分析栈,包括文法符号栈和相应的状态栈,它们均是先进后出栈。
分析器的动作就是由栈顶状态和当前输入符号所决定。
编译原理LR(0)分析过程的实现

编译原理LR(0)分析过程的实现淮北师范大学编译原理课程设计课题名称:LR(0)分析过程的实现班级:2014级非师2班学号:20141202109姓名: 夏涛目录1.课程设计的目的 (2)2.课程设计的内容及要求 (2)3.实现原理 (2)3.1 LR分析器结构 (2)3.2 LR分析法寻找可归约句柄的依据 (3)3.3 LR分析器的核心 (3)3.4 LR分析器的总控程序 (4)3.5 具体过程分析如下: (4)3.6 LR(0)分析表构造基本思想 (4)3.7 构造LR(0)分析表的方法 (5)3.7.1生成文法G的LR(0)项目 (5)3.7.2 由项目构成识别文法活前缀的DFA (5) 3.7.3将所得DFA确定化 (5)3.7.4 LR(0)项目集规范簇的自动构造 (6)3.7.5 LR(0)分析表的构造算法 (7)4.算法实现流程图 (7)5.测试数据 (8)6.结果输出及分析 (9)7.软件运行环境及限制 (12)8.心得体会 (13)9.参考文献 (13)1.课程设计的目的通过课程设计进一步理解高级语言在计算机中的执行过程,加深对编译原理中重点算法和编译技术的理解,提高自己的编程能力,培养好的程序设计风格。
同时通过某种可视化编程语言的应用,具备初步的Windows环境下的编程思想。
2.课程设计的内容及要求1.可以使用任何语言来完成,例如:Java、C、C++。
2.文法采用常用的方式进行描述,例如:S→aA。
3.以文件方式读取文法。
4.求出项目集规范族(即所有的状态)。
5.给出状态间的关系。
6.给出LR(0)分析表。
7.给定的任意符号串判定是否是文法中的句子,将分析过程用计算机打印出来。
3.实现原理3.1 LR分析器结构LR分析器由三个部分组成:(1) 总控程序,也可称驱动程序。
对所有的LR分析器总控程序都是相同的。
(2) 分析表或分析函数,不同的文法分析表将不同,同一个文法采用的LR分析器不同时,分析表将不同,分析表又可以分为动作表(ACTION)和状态转换(GOTO)表两个部分,它们都可用二维数组表示。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
m_pTree->SetControlInfo(IDC_TREE1, RESIZE_BOTH);
m_pTree->SetControlInfo(IDOK, ANCHORE_BOTTOM | ANCHORE_RIGHT);
void CAnalyzeDlg::OnOK()
{
// TODO: Add extra validation here
//CDialog::OnOK();
}
void CAnalyzeDlg::OnCancel()
{
// TODO: Add extra cleanup here
六、实验原理、数据(程序)记录
(一)实验原理:
利用LR(k)类分析算法的四个步骤,分别实现"移进"、"归约"、"成功"、"报错"的分析能力。同时采用相应的数据结构实现分析表的描述。
(二)程序框架:
#include "stdafx.h"
#include "GoData.h"
GoData::GoData()
assert(j != -1);
out.WriteString(GetStepInfo(iStep, Status, Symbol, m_input.Right(m_input.GetLength() - iPos), ToDo, j));
for(i = 0; i < m_g.GetPrecept(ToDo.two).GetRight().length(); i++)
//{{AFX_DATA_MAP(CAnalyzeDlg)
DDX_Control(pDX, IDC_EDIT1, m_edit1);
DDX_Control(pDX, IDC_EXPLORER1, m_web);
DDX_Text(pDX, IDC_EDIT1, m_input);
//}}AFX_DATA_MAP
}
CAnalyzeDlg::~CAnalyzeDlg()
{
m_pTree->DestroyWindow();
delete m_pTree;
}
void CAnalyzeDlg::DoDataExchange(CDataExchange* pDX)
{
CResizingDialog::DoDataExchange(pDX);
bool bGoOn = true;
while ((bGoOn) && (!bErrorFlag))
{
assert(iPos < m_input.GetLength());
assert(Status.size() == Symbol.size());
ToDo = m_g.GetAction(Status.back(), m_input.GetAt(iPos));
{
Status.pop_back();
Symbol.pop_back();
}
Symbol.push_back(m_g.GetPrecept(ToDo.two).GetLeft()[0]);
Status.push_back(j);
TreeStack.push(ToDo.two);
vector <int> Status;
vector <char> Symbol;
int iStep = 1;
int iPos = 0;
Status.push_back(0);
Symbol.push_back('#');
Pair ToDo;
bool bErrorFlag = false;
out.WriteString("<meta http-equiv=\"Content-Type\" content=\"text/html; charset=gb2312\">\n");
out.WriteString("</head>\n");
out.WriteString("<body bgcolor=\"#FFFFFF\" text=\"#000000\">\n");
UpdateData(TRUE);
m_pTree->m_tree.DeleteAllItems();
for(int i = 0; i < m_input.GetLength(); i ++)
{
if (!m_g.IsInVt(m_input.GetAt(i)))
{
MessageBox("输入的句子不全部由终结符组成", "错误", MB_OK | MB_ICONSTOP);
⑶ 输出
对于所输入的LR(0)文法,不论对错,都应有明确的信息告诉外界。对于符合规则的LR(0)文法,将输出LR(0)分析表,并可以对输入的句子进行语法分析输出相应语法树。
⑷ 扩充
有余力的同学,可适当扩大分析算法。譬如:
① SLR(1)分析方法的实现
② LR(1)分析方法的实现
ON_WM_ACTIVATE()
//}}AFX_MSG_MAP
END_MESSAGE_MAP()
/////////////////////////////////////////////////////////////////////////////
// CAnalyzeDlg message handlers
: CResizingDialog(CAnalyzeDlg::IDD, pParent)
{
//{{AFX_DATA_INIT(CAnalyzeDlg)
m_input = _T("");
//}}AFX_DATA_INIT
m_strTempFilename = "";
m_pTree = new CTreeDlg;
#include "AnalyzeDlg.h"
#include <vector>
#include <cassert>
#include "Pair.h"
using namespace std;
#ifdef _DEBUG
#define new DEBUG_NEW
#undef THIS_FILE
::DeleteFile(m_strTempFilename.c_str());
::GetTempPath(100,szTempPath);
::GetTempFileName(szTempPath,"LR0",0,szTempName);
m_strTempFilename = szTempName;
CStdioFile out;
out.Open(szTempName, CFile::modeCreate | CFile::modeWrite);
out.WriteString("<html>\n");
out.WriteString("<head>\n");
out.WriteString("<title>Untitled Document</title>\n");
static char THIS_FILE[] = __FILE__;
#endif
/////////////////////////////////////////////////////////////////////////////
// CAnalyzeDlg dialog
CAnalyzeDlg::CAnalyzeDlg(CWnd* pParent /*=NULL*/)
if (m_strTempFilename != "")
DeleteFile(m_strTempFilename.c_str());
CResizingDialog::OnCancel();
}
void CAnalyzeDlg::OnButton1()
{
// TODO: Add your control notification handler code here
return;
}
}
assert(TreeStack.empty());
m_input += "#";
char szTempPath[MAX_PATH];
char szTempName[MAX_PATH];
if (m_strTempFilename != "")
out.WriteString("<table border=\"1\" cellpadding=\"0\" cellspacing=\"0\" style=\"border-collapse: collapse\" bordercolor=\"#111111\">\n");
out.WriteString("<tr>\n<td nowrap> 步骤 </td>\n<td nowrap> 状态栈</td>\n<td nowrap> 符号栈 </td>\n<td nowrap> 输入串 </td>\n<td nowrap> ACTION </td>\n<td nowrap > GOTO </td>\n </tr>\n");