(参考资料)词法分析器(含完整源码)
实验一、词法分析器(含源代码)

词法分析器实验报告一、实验目的及要求本次实验通过用C语言设计、编制、调试一个词法分析子程序,识别单词,实现一个C语言词法分析器,经过此过程可以加深对编译器解析单词流的过程的了解。
运行环境:硬件:windows xp软件:visual c++6.0二、实验步骤1.查询资料,了解词法分析器的工作过程与原理。
2.分析题目,整理出基本设计思路。
3.实践编码,将设计思想转换用c语言编码实现,编译运行。
4.测试功能,多次设置包含不同字符,关键字的待解析文件,仔细察看运行结果,检测该分析器的分析结果是否正确。
通过最终的测试发现问题,逐渐完善代码中设置的分析对象与关键字表,拓宽分析范围提高分析能力。
三、实验内容本实验中将c语言单词符号分成了四类:关键字key(特别的将main说明为主函数)、普通标示符、常数和界符。
将关键字初始化在一个字符型指针数组*key[]中,将界符分别由程序中的case列出。
在词法分析过程中,关键字表和case列出的界符的内容是固定不变的(由程序中的初始化确定),因此,从源文件字符串中识别出现的关键字,界符只能从其中选取。
标识符、常数是在分析过程中不断形成的。
对于一个具体源程序而言,在扫描字符串时识别出一个单词,若这个单词的类型是关键字、普通标示符、常数或界符中之一,那么就将此单词以文字说明的形式输出.每次调用词法分析程序,它均能自动继续扫描下去,形成下一个单词,直到整个源程序全部扫描完毕,从而形成相应的单词串。
输出形式例如:void $关键字流程图 、程序流程图:开始 输入源文件路径路径是否有效是初始化文件指针否将字符加入字符数组Word[]是空格,空白或换行吗是字母吗是数字吗否否是界符吗否打开源文件跳过该字符是是文件结束?否将字符加入字符数组Word[]否将字符加入字符数组Word[]是指向下一字符识别指针内容指向下一字符是字母惑数字吗是将word 与关键字表key 进行匹配否匹配?是输出word 为关键字输出word 为普通标示符否将字符加入字符数组Word[]指向下一字符输出word 为常数识别指针内容回退是数字吗是否输出word 为界符指向下一字符结束是输出Word 内容为不可识别将字符加入字符数组Word[]程序:#include<string.h>#include<stdio.h>#include<stdlib.h>#include<ctype.h>//定义关键字char*Key[10]={"main","void","int","char","printf","scanf","else","if","return"}; char Word[20],ch; // 存储识别出的单词流int IsAlpha(char c) { //判断是否为字母if(((c<='z')&&(c>='a'))||((c<='Z')&&(c>='A'))) return 1;else return 0;}int IsNum(char c){ //判断是否为数字if(c>='0'&&c<='9') return 1;else return 0;}int IsKey(char *Word){ //识别关键字函数int m,i;for(i=0;i<9;i++){if((m=strcmp(Word,Key[i]))==0){if(i==0)return 2;return 1;}}return 0;}void scanner(FILE *fp){ //扫描函数char Word[20]={'\0'};char ch;int i,c;ch=fgetc(fp); //获取字符,指针fp并自动指向下一个字符if(IsAlpha(ch)){ //判断该字符是否是字母Word[0]=ch;ch=fgetc(fp);i=1;while(IsNum(ch)||IsAlpha(ch)){ //判断该字符是否是字母或数字Word[i]=ch;i++;ch=fgetc(fp);}Word[i]='\0'; //'\0' 代表字符结束(空格)fseek(fp,-1,1); //回退一个字符c=IsKey(Word); //判断是否是关键字if(c==0) printf("%s\t$普通标识符\n\n",Word);//不是关键字else if(c==2) printf("%s\t$主函数\n\n",Word);else printf("%s\t$关键字\n\n",Word); //输出关键字 }else //开始判断的字符不是字母if(IsNum(ch)){ //判断是否是数字Word[0]=ch;ch=fgetc(fp);i=1;while(IsNum(ch)){Word[i]=ch;i++;ch=fgetc(fp);}Word[i]='\0';fseek(fp,-1,1); //回退printf("%s\t$无符号实数\n\n",Word);}else //开始判断的字符不是字母也不是数字{Word[0]=ch;switch(ch){case'[':case']':case'(':case')':case'{':case'}':case',':case'"':case';':printf("%s\t$界符\n\n",Word); break;case'+':ch=fgetc(fp);Word[1]=ch;if(ch=='='){printf("%s\t$运算符\n\n",Word);//运算符“+=”}else if(ch=='+'){printf("%s\t$运算符\n\n",Word); //判断结果为“++”}else {fseek(fp,-1,1);printf("%s\t$运算符\n\n",Word); //判断结果为“+”}break;case'-':ch=fgetc(fp);Word[1]=ch;if(ch=='='){printf("%s\t$运算符\n\n",Word); }else if(ch=='-'){printf("%s\t$运算符\n\n",Word); //判断结果为“--”}else {fseek(fp,-1,1);printf("%s\t$运算符\n\n",Word); //判断结果为“-”}break;case'*':case'/':case'!':case'=':ch=fgetc(fp);if(ch=='='){printf("%s\t$运算符\n\n",Word);}else {fseek(fp,-1,1);printf("%s\t$运算符\n\n",Word);}break;case'<':ch=fgetc(fp);Word[1]=ch;if(ch=='='){printf("%s\t$运算符\n\n",Word); //判断结果为运算符“<=”}else if(ch=='<'){printf("%s\t$运算符\n\n",Word); //判断结果为“<<”}else {fseek(fp,-1,1);printf("%s\t$运算符\n\n",Word); //判断结果为“<”}break;case'>':ch=fgetc(fp);Word[1]=ch;if(ch=='=') printf("%s\t$运算符\n\n",Word);else {fseek(fp,-1,1);printf("%s\t$运算符\n\n",Word);}break;case'%':ch=fgetc(fp);Word[1]=ch;if(ch=='='){printf("%s\t$运算符\n\n",Word);}if(IsAlpha(ch)) printf("%s\t$类型标识符\n\n",Word);else {fseek(fp,-1,1);printf("%s\t$取余运算符\n\n",Word);}break;default:printf("无法识别字符!\n\n"); break;}}}main(){char in_fn[30]; //文件路径FILE *fp;printf("\n请输入源文件名(包括路径和后缀名):");while(1){gets(in_fn);//scanf("%s",in_fn);if((fp=fopen(in_fn,"r"))!=NULL) break; //读取文件内容,并返回文件指针,该指针指向文件的第一个字符else printf("文件路径错误!请重新输入:");}printf("\n******************* 词法分析结果如下 *******************\n");do{ch=fgetc(fp);if(ch=='#') break; //文件以#结尾,作为扫描结束条件else if(ch==' '||ch=='\t'||ch=='\n'){} //忽略空格,空白,和换行else{fseek(fp,-1,1); //回退一个字节开始识别单词流scanner(fp);}}while(ch!='#');return(0);}4.实验结果解析源文件:void main(){int a=3;a+=b;printf("%d",a);return;}#解析结果:5.实验总结分析通过本次实验,让再次浏览了有关c语言的一些基本知识,特别是对文件,字符串进行基本操作的方法。
编译原理词法分析器代码

#include <stdio.h>#include <string.h>#include <stdlib.h>#include <ctype.h>#include <conio.h>#define KEYWORD_LEN 32 //保留字个数#define STR_MAX_LEN 300 //标识符最大长度#define PRO_MAX_LEN 20480 //源程序最大长度#define STB_MAX_LEN 1000 //符号表最大容量#define CTB_MAX_LEN 1000 //常数表最大容量#define ERROR 0 //错误#define ID (KEYWORD_LEN+1) //标识符#define CONST (KEYWORD_LEN+2) //常量#define OPERAT (KEYWORD_LEN+3) //运算符#define DIVIDE (KEYWORD_LEN+4) //界符int errorLine=0; char proBuffer[PRO_MAX_LEN] = ""; //存储程序代码的全局缓冲区char ch; //读出来的当前字符char wordget[STR_MAX_LEN]; //标识符或常量int point = 0; //源程序当前位置指针char signTab[STB_MAX_LEN][STR_MAX_LEN]; //符号表int pointSTB = 0; //符号表指针char constTab[CTB_MAX_LEN][STR_MAX_LEN]; //常量表int pointCTB = 0; //常数表指针char kwTab[KEYWORD_LEN][10]={ //保留字表C语言一共有32个保留字[关键字]"auto", "break", "case", "char","const", "continue", "default","do", "double", "else", "enum","extern", "float", "for", "goto","if", "int", "long", "register","return", "short", "signed", "sizeof","static", "struct", "switch", "typedef","union", "unsigned", "void", "volatile", "while"};char errorTab[][50]={ //错误代码表/*0*/"未知错误", /*1*/"非法的字符", /*2*/"不正确的字符常量表达",/*3*/"不正确的字符串表达", /*4*/"不正确的数字表达", /*5*/"注释丢失'*/'"};typedef struct signDuality{int kind;int value;}*pDualistic, Dualistic;void pretreatment(); //预处理void ProcError(int id); //错误bool GetChar(); //获得一个字符不包括结束标记bool GetBC(); //获得一个非空白字符void Concat(char *str); //将ch连接到str后int Reserve(char *str); //对str字符串查找保留字表若是一个保留字-返回其编码否则返回0void Retract(); //将搜索指示器回调一个字符位置int InsertId(char *str);//将str串以标识符插入符号表,并返回符号表指针int InsertConst(char *str); //将str串以常数插入符号表,并返回常数表指针bool wordAnalyse(pDualistic pDu); //词法分析true正常//预处理将缓冲区内的源代码去掉注释和无效空格void pretreatment(){int lines=0;char tmp[PRO_MAX_LEN]; //先将处理结果保存到临时空间int tmpp = 0; //这个临时空间的末尾指针bool flg;char tmpc; //去掉注释先//注释有两种一种是// 另一种是/**/point = 0;do{flg = GetChar();if(ch == '/'){flg = GetChar();switch(ch){case '/':do{flg = GetChar();}while(!(ch == '\n' || flg == false));//注释一直到行尾或文件结束if(ch == '\n')Retract(); //归还换行break;case '*':do{flg = GetChar();tmpc = ch;//为了保证出错处理程序能正确定位出错位置保留注释中的换行if(tmpc == '\n')tmp[tmpp++] = tmpc;flg = GetChar();Retract(); //归还一个字符}while(flg && !(flg && tmpc == '*' && ch == '/'));flg = GetChar();if (!flg){ProcError(5);}break;default: //不是任何一种注释Retract();Retract();GetChar();tmp[tmpp++] = ch;flg = GetChar();tmp[tmpp++] = ch;}}else{tmp[tmpp++] = ch;}}while(flg);tmp[tmpp] = '\0';strcpy(proBuffer,tmp);}//错误void ProcError(int id){printf("\nError:第%d行,%s\n",errorLine, errorTab[id]);}//获得一个字符bool GetChar(){if(point < PRO_MAX_LEN && proBuffer[point] != '\0'){//如果当前下标合法且当前字符为结束标记则取字符增游标ch = proBuffer[point++];if (ch == '\n')errorLine ++;return true;}ch = '\0';return false;}//获得一个非空白字符bool GetBC(){do{if(!GetChar()) //获取字符失败{ch = '\0';return false;}}while(isspace(ch)); //直到获得一个非空白字符return true;}//将ch连接到str后void Concat(char *str){int i;for(i=0; str[i]; ++i);str[i] = ch;str[i+1] = '\0';}//对str字符串查找保留字表若是一个保留字-返回其编码否则返回0int Reserve(char *str){int i;for(i=0; i<KEYWORD_LEN; ++i) //从保留字表中查找str串{if(0 == strcmp(kwTab[i], str))return i+1; //注意,这里加一原因是0值被错误标记占用}return 0;}//将搜索指示器回调一个字符位置void Retract()///char *ch{if(proBuffer[point] == '\n' && errorLine > 0)errorLine --;point --;}//将str串以标识符插入符号表,并返回符号表指针int InsertId(char *str){int i;for(i=0; i < pointSTB; ++i)if(0 == strcmp(signTab[i], str))return i;strcpy(signTab[pointSTB++], str);return (pointSTB-1);}//将str串以常数插入常量表,并返回常数表指针int InsertConst(char *str){int i;for(i=0; i < pointCTB; ++i)if(0 == strcmp(constTab[i], str))return i;strcpy(constTab[pointCTB++], str);return (pointCTB-1);}//词法分析false--分析结束bool wordAnalyse(pDualistic pDu){int code, value;char judge; //这里有个技巧借用此变量巧妙的运用SWITCH结构int i = 0; //辅助GetBC();judge = ch;if (isalpha(ch) || ch == '_')judge='L';if (isdigit(ch))judge='D';switch(judge){case 'L':while(isalnum(ch) || ch == '_'){ //标识符wordget[i++] = ch;GetChar();}wordget[i] = '\0';Retract(); //回退一个字符code = Reserve(wordget);if(code == 0){value = InsertId(wordget);pDu->kind = ID;pDu->value = value;}else{pDu->kind = code;pDu->value = -1;}return true;case 'D':while(isdigit(ch)){wordget[i++] = ch;GetChar();}wordget[i] = '\0';Retract();value = InsertConst(wordget);pDu->kind = CONST;pDu->value= value;return true;//( ) [ ] . , ! != ~ sizeof < << <= > >> >= = == & && &= | || |= ?: + ++ +=// --> ---= * *= / /= % %= >>= <<= ^ ^=case '"': //字符串常量do{wordget[i++] = ch;GetChar();}while(ch != '"' && ch != '\0');wordget[i++] = ch;wordget[i] = '\0';if(ch == '\0'){printf("%s",wordget);ProcError(3);pDu->kind = ERROR;pDu->value = 0;}else{value = InsertConst(wordget);pDu->kind = CONST;pDu->value = value;}return true; //字符常量case '\'':wordget[i++] = ch; // 'GetChar();wordget[i++] = ch;if(ch == '\\') // '\n'{//如果是转义字符则要多接收一个字符GetChar(); // ch = 'wordget[i++] = ch;}GetChar();wordget[i++] = ch;wordget[i] = '\0';if(ch != '\''){//'\b'printf("%s",wordget);ProcError(2);pDu->kind = ERROR;pDu->value = 0;}else{value = InsertConst(wordget);pDu->kind = CONST;pDu->value = value;}return true;case '(':case ')':case '[':case ']':case '.':case ',':case '~':case '?':case ':':case ';':case '{':case '}':case '#':wordget[i++] = ch;wordget[i] = '\0';pDu->kind = DIVIDE; //界符pDu->value = -1;return true;case '!': //!=wordget[i++] = ch;GetChar();if (ch=='=')wordget[i++] = ch;elseRetract();wordget[i]='\0';break;case '<': // << <=wordget[i++] = ch;GetChar();if (ch == '<' || ch == '=')wordget[i++] = ch;elseRetract();wordget[i]='\0';break;case '>': // >> >=wordget[i++] = ch;GetChar();if (ch == '>' || ch == '=')wordget[i++] = ch;elseRetract();wordget[i]='\0';break;case '=': // ==wordget[i++] = ch;GetChar();if (ch == '=')wordget[i++] = ch;elseRetract();wordget[i]='\0';break;case '&': // && &=wordget[i++] = ch;GetChar();if (ch == '&' || ch == '=')wordget[i++] = ch;elseRetract();wordget[i]='\0';break; case '|': // || |=wordget[i++] = ch;GetChar();if (ch == '|' || ch == '=')wordget[i++] = ch;elseRetract();wordget[i]='\0';break;case '+': // ++ +=wordget[i++] = ch;GetChar();if (ch == '+' || ch == '=')wordget[i++] = ch;else Retract();wordget[i]='\0';break;case '-': // ---= ->wordget[i++] = ch;GetChar();if (ch == '-' || ch == '=' || ch == '>')wordget[i++] = ch;elseRetract();wordget[i]='\0';break;case '*':// ** *=wordget[i++] = ch;GetChar();if (ch == '*' || ch == '=')wordget[i++] = ch;elseRetract();wordget[i]='\0';break;case '/': // /=wordget[i++] = ch;GetChar();if (ch == '=')wordget[i++] = ch;elseRetract();wordget[i]='\0';break;case '%': // %=wordget[i++] = ch;GetChar();if (ch == '=')wordget[i++] = ch;elseRetract();wordget[i]='\0';break;case '^': // ^=wordget[i++] = ch;GetChar();if (ch == '=')wordget[i++] = ch;elseRetract();wordget[i]='\0';break;case '\0':return false;default:ProcError(1);return false;}pDu->kind = OPERAT;return true;}//主函数int main(){Dualistic tmp;pDualistic ptmp = &tmp;FILE *fin, *fout;int i;char c;char filename[20];printf("源代码读入\n");//scanf("%s",filename);//将源程序读入缓冲区if ((fin=fopen("Test.txt","r")) == NULL){printf("Cannot open infile\n");return 0;}i = 0;//c = fgetc(fin);while((c = fgetc(fin)) != EOF){if(i >= PRO_MAX_LEN-1){printf("\n程序代码太长,无法处理\a");return 0;}proBuffer[i++] = c;}fclose(fin); //关闭文件proBuffer[i++] = '\0';printf("\n***************************\n源代码读入成功,源代码如下:\n%s",proBuffer);printf("\n按任意键继续\n");getch(); //预处理printf("\n预处理\n");pretreatment();printf("\n***************************\n预处理成功,去掉注释后的源代码为:\n%s*",proBuffer);printf("\n按任意键继续\n");getch();printf("\n词法分析\n");point = 0;//词法分析if ((fout=fopen("Result.txt","wb")) == NULL){printf("建立文件Result.txt失败。
简单的词法分析器
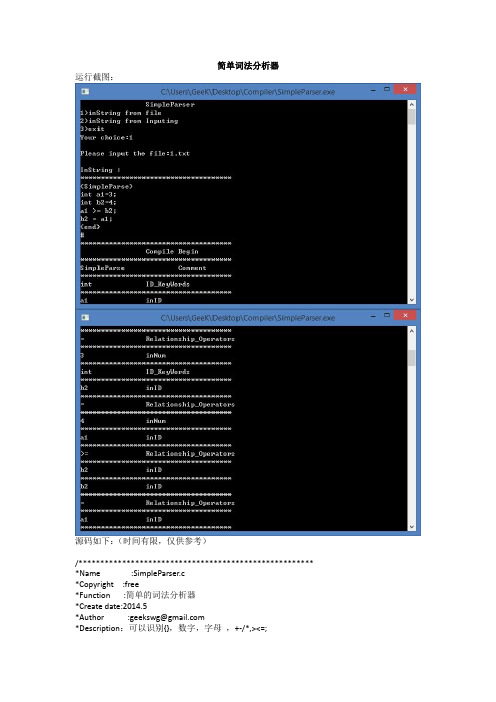
简单词法分析器运行截图:源码如下:(时间有限,仅供参考)/****************************************************** *Name :SimpleParser.c*Copyright :free*Function :简单的词法分析器*Create date:2014.5*Author :geekswg@*Description:可以识别{},数字,字母,+-/*,><=;******************************************************/ #include<stdio.h>//#include<stdbool.h>//C99包含bool头文件,VC6.0报错#include<memory.h>#include<string.h>//包含strcmp()函数//宏定义bool类型兼容VC6.0#define bool char#define true 1#define false 0#define MAXSIZE 500#define SOC '{' //start of comment#define EOC '}' //end of comment/*#define ADD +#define MIN -#define MUL *#define DIV /*/char inStr[MAXSIZE];//bool型,是否是关键字,是返回truebool isKeyword(char s1[],char s2[]){if(!strcmp(s1,s2))return true;elsereturn false;}//bool型,是否是数字,是返回truebool isDigit(char c){if(c > 47 && c<58){//ASCII(0-9)return true;}elsereturn false;}//bool型,是否是字符,是返回truebool isLetter(char c){if((c > 64 && c < 91) || (c >96 && c <123)){//A-Z,a-z)return true;}elsereturn false;}//读入待分析的字符串;void inFile(char inStr[]){FILE *fp;//文件指针int i = 0;char filename[50]; //文件名memset(filename,0,sizeof(filename)); //清空数组;printf("\nPlease input the file:");scanf("%s",&filename);// printf("\n%s",filename);while((fp = fopen(filename,"r"))==NULL){//以只读方式打开文件printf("\nCan't Find file!Input again:");scanf("%s",&filename);}while(!feof(fp)){//直到文件结束符停止fscanf(fp,"%c",&inStr[i]);//将文件中的数据写到inStr中i++;}inStr[i]='\0';fclose(fp);}//录入待分析的字符串;void inString(char inStr[]){//录入函数int i=0;char inchar;printf("SimpleParser For Test \n");printf("Please Inpuet Strings:(End of '#')\n:");while( inchar !='#'){//以#为结束符标志;scanf("%c",&inchar);inStr[i++] = inchar;}}/**********************************//打印数组//参数待分析字符串,备注信息字符串//***********************************/void display(char inStr[],char info[]){//打印数组int i = 0;printf("\n*************************************\n");while( inStr[i] != '\0' ){//直到数组结束标志printf("%c",inStr[i++]);//打印元素}printf("\t\t%s",info);// printf("\n*************************************\n");// printf("#\n");}/**********************************//parser for comment//参数待分析字符串,位置下标int i// 返回值位置下标int i***********************************/int parser_com(char inStr[],int i){//parser for comment"{}"char temp[MAXSIZE] ;//存放{}内的字符串memset(temp,0,sizeof(temp)); //清空数组,以防止第二次调用时有上次的字符串;int t=0;while(inStr[++i] != EOC){temp[t]=inStr[i];t++;}// printf("Comment \t:");display(temp,"Comment");return i;}/**********************************//parser for letter//参数待分析字符串,位置下标int i// 返回值位置下标int i***********************************/int parser_letter(char inStr[],int i){int t = 0;char temp[MAXSIZE];memset(temp,0,sizeof(temp)); //清空数组;while(isDigit(inStr[i]) || isLetter(inStr[i])){//如果是数字或字母temp[t++] = inStr[i];i++;}//判断是否是关键字,如需添加关键字添加else if即可//若使用关键字表应该效果更好if(isKeyword(temp,"int")){display(temp,"ID_KeyWords");}else if(isKeyword(temp,"char")){display(temp,"ID_KeyWords");}// printf("Letter \t:");else{display(temp,"inID");}return --i;}int parser_digit(char inStr[],int i){int t = 0;char temp[MAXSIZE];memset(temp,0,sizeof(temp)); //清空数组;while(inStr[i] != ' ' && inStr[i] != '\n' && isDigit(inStr[i])){ temp[t++] = inStr[i];i++;}// printf("Digit \t:");display(temp,"inNum");return --i;}/*// prasers for operators like "+,-,* /"//之后放入了parser()中了int parser_ops(char inStr[],int i){int t = 0;char temp[MAXSIZE];memset(temp,0,sizeof(temp)); 清空数组;return i;}*/// prasers for relationship operators like ">,<,="int parser_rel(char inStr[],int i){int t = 0;char temp[MAXSIZE];memset(temp,0,sizeof(temp)); //清空数组;while(inStr[i]=='>' || inStr[i]=='<' || inStr[i]=='='){temp[t] = inStr[i];t++;i++;}// printf("\nRelationship_Operator\t:");display(temp,"Relationship_Operators");return --i;}/**********************************//词法分析主程序,//参数待分析字符串//***********************************/void parser(char inStr[]){int i = 0;while(inStr[i] != '#'){/*switch(inStr[i]){case '{': i = pareser_com(inStr,i);break;//如果是{,使用case ' ': ;break; //如果是空格跳过case '+':;break;default:;break; //}*///之前使用switch,后来觉得if ,else更方便if(inStr[i] == SOC){//SOC'{'-start of commenti = parser_com(inStr,i);//如果是{,使用pareser_com;}else if(inStr[i] == '+'){display("+","Operator");}else if(inStr[i] == '-'){display("-","Operator");}else if(inStr[i] == '*'){display("*","Operator");}else if(inStr[i] == '/'){display("/","Operator");}else if(inStr[i]=='>' || inStr[i]=='=' || inStr[i]=='<'){i = parser_rel(inStr,i);//parser for relationship;}/*else if(inStr[i] > 47 && inStr[i] <58){//0-9;i = parser_digit(inStr,i);}*/else if(isDigit(inStr[i])){i = parser_digit(inStr,i);}/*else if((inStr[i] >64 && inStr[i]<91)|| (inStr[i]>96 && inStr[i] <123)){//A-Z,a-zi = parser_letter(inStr,i);}*/else if(isLetter(inStr[i])){i = parser_letter(inStr,i);}i++;}memset(inStr,0,sizeof(inStr));//清空数组;}//主菜单;void menu(){char choice;printf("\t\tSimpleParser\n");printf("1)inString from file\n2)inString from Inputing\n3)exit\n");printf("Your choice:");scanf("%c",&choice);while(choice!='1'&& choice!='2' && choice!='0' ){printf("\nerror,Your choice:");scanf("%c",&choice);}switch(choice){case '0':{system("PAUSE");exit(0);};break;case '1':inFile(inStr); break;case '2':inString(inStr); break;default:;break;}}int main(){/*inString(inStr);inFile(inStr);*/menu();printf("\nInString :");display(inStr,"\n*************************************");printf("\n\t\tCompile Begin");parser(inStr);system("PAUSE"); //调用系统暂停return 0;}。
词法分析器(C语言版)

#include <stdlib.h>
#include <assert.h>
#define LENGTH1 10//type reserved word size
FILE * fp=NULL;//outstream Pointer
FILE * fw=NULL;//instream pointer
if(character=='=')
returntofile(9,0,id,con);
else
{
retract(fp);
returntofile(8,0,id,con);
}
break;
case '>':
getNextChar(fp);
if(character=='=')
returntofile(11,0,id,con);
{
char s[3];
int i=num/10;
while(i>0)
{
char c=i+'0';
strcat(s,&c);
}
return s;
}
//将结果写入到文件并且输出到屏幕。
void returntofile(int num,int val,identifier *id,constnumber *con)
//存入常数表中,并返回它在常数表中的位置编号。
int constant(constnumber * con)
{
con->cont[con->len]=strtonumber();
con->len++;
(完整版)词法分析器(c语言实现)

词法分析c实现一、实验目的设计、编制并调试一个词法分析程序,加深对词法分析原理的理解。
二、实验要求2.1 待分析的简单的词法(1)关键字:begin if then while do end所有的关键字都是小写。
(2)运算符和界符:= + - * / < <= <> > >= = ; ( ) #(3)其他单词是标识符(ID)和整型常数(SUM),通过以下正规式定义:ID = letter (letter | digit)*NUM = digit digit*(4)空格有空白、制表符和换行符组成。
空格一般用来分隔ID、SUM、运算符、界符和关键字,词法分析阶段通常被忽略。
2.2 各种单词符号对应的种别码:输入:所给文法的源程序字符串。
输出:二元组(syn,token或sum)构成的序列。
其中:syn为单词种别码;token为存放的单词自身字符串;sum为整型常数。
例如:对源程序begin x:=9: if x>9 then x:=2*x+1/3; end #的源文件,经过词法分析后输出如下序列:(1,begin)(10,x)(18,:=)(11,9)(26,;)(2,if)……三、词法分析程序的C语言程序源代码:#include <stdio.h>#include <string.h>char prog[80],token[8],ch;int syn,p,m,n,sum;char *rwtab[6]={"begin","if","then","while","do","end"};scaner();main(){p=0;printf("\n please input a string(end with '#'):/n");do{scanf("%c",&ch);prog[p++]=ch;}while(ch!='#');p=0;do{scaner();switch(syn){case 11:printf("( %-10d%5d )\n",sum,syn);break;case -1:printf("you have input a wrong string\n");getch();exit(0);default: printf("( %-10s%5d )\n",token,syn);break;}}while(syn!=0);getch();}scaner(){ sum=0;for(m=0;m<8;m++)token[m++]=NULL;ch=prog[p++];m=0;while((ch==' ')||(ch=='\n'))ch=prog[p++];if(((ch<='z')&&(ch>='a'))||((ch<='Z')&&(ch>='A'))){ while(((ch<='z')&&(ch>='a'))||((ch<='Z')&&(ch>='A'))||((ch>='0')&&(ch<='9'))) {token[m++]=ch;ch=prog[p++];}p--;syn=10;for(n=0;n<6;n++)if(strcmp(token,rwtab[n])==0){ syn=n+1;break;}}else if((ch>='0')&&(ch<='9')) { while((ch>='0')&&(ch<='9')) { sum=sum*10+ch-'0';ch=prog[p++];}p--;syn=11;}else switch(ch){ case '<':token[m++]=ch;ch=prog[p++];if(ch=='='){ syn=22;token[m++]=ch;}else{ syn=20;p--;}break;case '>':token[m++]=ch;ch=prog[p++];if(ch=='='){ syn=24;token[m++]=ch;}else{ syn=23;p--;}break;case '+': token[m++]=ch;ch=prog[p++];if(ch=='+'){ syn=17;token[m++]=ch;}else{ syn=13;p--;}break;ch=prog[p++];if(ch=='-'){ syn=29;token[m++]=ch;}else{ syn=14;p--;}break;case '!':ch=prog[p++];if(ch=='='){ syn=21;token[m++]=ch;}else{ syn=31;p--;}break;case '=':token[m++]=ch;ch=prog[p++];if(ch=='='){ syn=25;token[m++]=ch;}else{ syn=18;p--;}break;case '*': syn=15;token[m++]=ch;break;case '/': syn=16;token[m++]=ch;break;case '(': syn=27;token[m++]=ch;break;case ')': syn=28;break;case '{': syn=5;token[m++]=ch;break;case '}': syn=6;token[m++]=ch;break;case ';': syn=26;token[m++]=ch;break;case '\"': syn=30;token[m++]=ch;break;case '#': syn=0;token[m++]=ch;break;case ':':syn=17;token[m++]=ch;break;default: syn=-1;break;}token[m++]='\0';}四、结果分析:输入begin x:=9: if x>9 then x:=2*x+1/3; end # 后经词法分析输出如下序列:(begin 1)(x 10)(:17)(= 18)(9 11)(;26)(if 2)……如图5-1所示:。
词法分析器源代码

词法分析器源代码#include <iostream> #include <vector> #include <string> #include<fstream>/*单词种别码*/#define _CHAR 1 #define _INT 2#define _SHORT 3 #define _LONG 4 #define _SIGNED 5 #define _UNSIGNED 6 #define _FLOAT 7 #define _DOUBLE 8 #define _CONST 9 #define _VOID 10 #define _VOLATILE 11 #define _ENUM 12 #define _STRUCT 13 #define _UNION 14 #define _TYPEDEF 15 #define _AUTO 16 #define _EXTERN 17 #define_STATIC 18 #define _REGISTER 19 #define _IF 20#define _ELSE 21 #define _SWITCH 22 #define _CASE 23 #define_DEFAULT 24 #define _WHILE 25 #define _DO 26#define _FOR 27 #define _BREAK 28 #define _CONTINUE 29 #define _GOTO 30 #define _RETURN 31 #define _SIZEOF 32 #define _INCLUDE 33 #define_DEFINE 34 /*以上为关键字的种别码*/#define _ID 40 //标识符#define _NUM 50 //数#define _AS 51 //= #define _PLUS 52 //+ #define _SUB 53 //- #define _TIMES 54 // * #define _DIV 55 // / #define _LP 56 // ( #define _RP 57 // ) #define _LB1 58 // [ #define _RB1 59 // ] #define _LB2 60 //{ #define _RB2 61 // } #define _COM 62 // , #define _COL 63 // : #define_SEM 64 // #define _POINT 65 // . #define _LG 66 // > #define _LT 67 // < #define _ME 68 // >= #define _LE 69 // <= #define _EQ 70 // == #define _NE 71 // != #define _A 72 // >> #define _B 73 // >>= #define _C 74 // << #define _D 75 // <<= #define _E 76 // & #define _F 76 // && #define _G 77 // &= #define _H 78 // | #define _I 79 // || #define _J 80 // |= #define _K 81 // ~ #define _L 82 // ++ #define _M 83 // -- #define _N 84 // -> #define _O 85 // += #define _P 86 // -= #define _Q 87 // *=#define _R 88 // /= #define _S 89 // %=#define _T 90 // ^=#define _U 91 // %#define _V 92 // "#define _W 93 // '#define _X 94 // ?#define _EROOR -1 // 错误using namespace std;int ERROR_NUM=0; //记载词法编译错误个数bool isnum(string str) //判断是不是合法的数字{int y;int i;int j=0;int k=0;for(i=0;i<str.size();i++){if(!(str[i]<='9'&&str[i]>='0')){k++;if((k-j)>1){cout<<"数字串"<<str<<"出现词法错误~"<<endl;return false;} if(str[i]=='.') {j++;if(j>1) {cout<<"数字串"<<str<<"出现词法错误~"<<endl;return false;} }else if((str[i]=='E'||str[i]=='e')&&(str[i-1]<='9'&&str[i-1]>='0')&&((str[i+1]<='9'&&str[i+1]>='0')||(y=i+1)==str.size())) continue;else{cout<<"数字串"<<str<<"出现词法错误~"<<endl;return false;} }}return true;}/*该函数用来略过空格和换行符,找到有效字符的位置第一个参数为目标字符串,第二个参数为开始位置返回值为连续的空格和换行后的第一个有效字符在字符串的位置*/int valuable(string str,int i) {while(true){if(str[i]!=' '&&str[i]!='\n')return i;i++;}}int isexp(string str,int i) {if(str[i]=='/'&&str[i+1]=='/'){while(str[i]!='\n'){i++;}}return i;}int iskey(string str) //判断是不是关键字{stringp[34]={"char","int","short","long","signed","unsigned","float","double", "const","void","volatile","enum","struct","union","typedef","auto"," extern","static","register","if","else","switch","case","default","while","do", "for","break","continue","goto","return","size of","#include","#define"};vector<string> ppp(p,p+34); int u;for(u=0;u<ppp.size();u++)if(!pare(ppp[u]))return u+1;return 0;}vector<pair<int,string> > scan(vector<string> vec)//本次程序的主要分析程序 {vector<pair<int,string> > temp;int i;for(i=0;i<vec.size();i++){if(vec[i].size()==1){if(vec[i]==">"){if(vec[i+1]=="="){string jk=vec[i];jk.append(vec[++i],0,1);pair<int,string> pp(_ME,jk);temp.push_back(pp);continue;}else if(vec[i+1]==">"&&vec[i+2]!="=") { string jk=vec[i];jk.append(vec[++i],0,1);pair<int,string> pp(_A,jk);temp.push_back(pp);continue; }else if(vec[i+1]==">"&&vec[i+2]=="="){ string jk=vec[i];jk.append(vec[++i],0,1);jk.append(vec[++i],0,1);pair<int,string> pp(_B,jk);temp.push_back(pp);continue;}else {pair<int,string> pp(_LG,vec[i]);//标识符temp.push_back(pp);}}else if(vec[i]=="<") {if(vec[i+1]=="=") {string jk=vec[i];jk.append(vec[++i],0,1);pair<int,string> pp(_LE,jk);temp.push_back(pp);continue; }else if(vec[i+1]=="<"&&vec[i+2]!="=") { string jk=vec[i];jk.append(vec[++i],0,1);pair<int,string> pp(_C,jk);temp.push_back(pp);continue;}else if(vec[i+1]=="<"&&vec[i+2]=="=") { string jk=vec[i];jk.append(vec[++i],0,1);jk.append(vec[++i],0,1);pair<int,string> pp(_D,jk);temp.push_back(pp);continue; }else {pair<int,string> pp(_LT,vec[i]);//标识符temp.push_back(pp);}}else if(vec[i]=="!") {if(vec[i+1]=="=") {string jk=vec[i];jk.append(vec[++i],0,1);pair<int,string> pp(_LE,jk);temp.push_back(pp);continue;}else {pair<int,string> pp(_NE,vec[i]);//标识符temp.push_back(pp);}else if(vec[i]=="=") {if(vec[i+1]=="="){string jk=vec[i];jk.append(vec[++i],0,1);pair<int,string> pp(_EQ,jk);temp.push_back(pp);continue; }else {pair<int,string> pp(_AS,vec[i]);//标识符temp.push_back(pp); }}else if(vec[i]=="&") {if(vec[i+1]=="&") {string jk=vec[i];jk.append(vec[++i],0,1);pair<int,string> pp(_F,jk);temp.push_back(pp);continue;}else if(vec[i+1]=="=") {string jk=vec[i];jk.append(vec[++i],0,1);pair<int,string> pp(_G,jk);temp.push_back(pp);continue;}else {pair<int,string> pp(_E,vec[i]);//标识符temp.push_back(pp);}}else if(vec[i]=="|"){if(vec[i+1]=="|") {string jk=vec[i];jk.append(vec[++i],0,1);pair<int,string> pp(_I,jk);temp.push_back(pp);continue;}else if(vec[i+1]=="="){string jk=vec[i];jk.append(vec[++i],0,1);pair<int,string> pp(_J,jk);temp.push_back(pp);continue;}else {pair<int,string> pp(_H,vec[i]);//标识符temp.push_back(pp);}}else if(vec[i]=="(") {{pair<int,string> pp(_LP,vec[i]);//标识符temp.push_back(pp);}}else if(vec[i]==")"){{pair<int,string> pp(_RP,vec[i]);//标识符temp.push_back(pp); }}else if(vec[i]=="["){{pair<int,string> pp(_LB1,vec[i]);//标识符temp.push_back(pp); } }else if(vec[i]=="]") {{pair<int,string> pp(_RB1,vec[i]);//标识符temp.push_back(pp); } }else if(vec[i]=="~") {{pair<int,string> pp(_K,vec[i]);//标识符temp.push_back(pp); } }else if(vec[i]==",") {{pair<int,string> pp(_COM,vec[i]);//标识符temp.push_back(pp); } }else if(vec[i]=="{") {{pair<int,string> pp(_LB2,vec[i]);//标识符temp.push_back(pp);} }else if(vec[i]==":") {{pair<int,string> pp(_COL,vec[i]);//标识符temp.push_back(pp); } }else if(vec[i]==";") {{pair<int,string> pp(_SEM,vec[i]);//标识符temp.push_back(pp); } }else if(vec[i]=="}") {{pair<int,string> pp(_RB2,vec[i]);//标识符temp.push_back(pp); } }else if(vec[i]=="*") {if(vec[i+1]=="="){string jk=vec[i];jk.append(vec[++i],0,1);pair<int,string> pp(_Q,jk);temp.push_back(pp);continue; }else {pair<int,string> pp(_TIMES,vec[i]);//标识符temp.push_back(pp); } }else if(vec[i]=="/") {if(vec[i+1]=="=") {string jk=vec[i];jk.append(vec[++i],0,1);pair<int,string> pp(_R,jk);temp.push_back(pp);continue; }else if(vec[i+1]=="*") {i=i+4;while(i<vec.size()&&(vec[i-1]!="*"||vec[i]!="/"))i++; cont inue; }else {pair<int,string> pp(_DIV,vec[i]);//标识符temp.push_back(pp); }}else if(vec[i]=="%") {if(vec[i+1]=="=") {string jk=vec[i];jk.append(vec[++i],0,1);pair<int,string> pp(_S,jk);temp.push_back(pp);continue; }else {pair<int,string> pp(_U,vec[i]);//标识符temp.push_back(pp); } }else if(vec[i][0]=='"') {pair<int,string> pp(_V,vec[i]);//标识符temp.push_back(pp);}else if(vec[i][0]=='\'') {pair<int,string> pp(_W,vec[i]);//标识符temp.push_back(pp);}else if(vec[i][0]=='?'){pair<int,string> pp(_X,vec[i]);//标识符temp.push_back(pp); }else if(vec[i]=="+") {if(vec[i+1]=="=") {string jk=vec[i];jk.append(vec[++i],0,1);pair<int,string> pp(_O,jk);temp.push_back(pp);continue; }else if(vec[i+1]=="+") {string jk=vec[i];jk.append(vec[++i],0,1);pair<int,string> pp(_L,jk);temp.push_back(pp);continue; }else if((vec[i-1]=="="||vec[i-1]=="(")&&isnum(vec[i+1])) {string jk=vec[i]; jk.append(vec[++i]);pair<int,string> pp(_NUM,jk);temp.push_back(pp);continue; }else{pair<int,string> pp(_PLUS,vec[i]);//标识符temp.push_back(pp); } }else if(vec[i]=="-"){if(vec[i+1]=="=") {string jk=vec[i];jk.append(vec[++i],0,1);pair<int,string> pp(_P,jk);temp.push_back(pp);continue;}else if(vec[i+1]=="-") {string jk=vec[i];jk.append(vec[++i],0,1);pair<int,string> pp(_M,jk);temp.push_back(pp);continue; }else if(vec[i+1]==">") {string jk=vec[i];jk.append(vec[++i],0,1);pair<int,string> pp(_N,jk);temp.push_back(pp);continue;} else if((vec[i-1]=="="||vec[i-1]=="(")&&isnum(vec[i+1])) { string jk=vec[i]; jk.append(vec[++i]);pair<int,string> pp(_NUM,jk);temp.push_back(pp);continue; }else {pair<int,string> pp(_SUB,vec[i]);//标识符temp.push_back(pp);}}else if(vec[i][0]<='9'&&vec[i][0]>='0'){pair<int,string> pp(_NUM,vec[i]);temp.push_back(pp);}else{pair<int,string> pp(_ID,vec[i]);//标识符temp.push_back(pp);}}else if((vec[i][0]<='9'&&vec[i][0]>='0')||vec[i][0]=='.'){if(!isnum(vec[i]))ERROR_NUM++;else if((vec[i+1][0]=='+'||vec[i+1][0]=='-')&&isnum(vec[i+2])) { string jk=vec[i];jk.append(vec[++i]);jk.append(vec[++i]);pair<int,string> pp(_NUM,jk);temp.push_back(pp);continue;}else{pair<int,string> pp(_NUM,vec[i]);temp.push_back(pp);}}else if(iskey(vec[i])){pair<int,string> pp(iskey(vec[i]),vec[i]);temp.push_back(pp);}else{pair<int,string> pp(_ID,vec[i]);temp.push_back(pp);}}return temp;}void OutFile(vector<pair<int,string> > v) {int i;for(i=0;i<v.size();i++)outfile<<"<"<<v[i].first<<" , \""<<v[i].second<<"\">"<<endl; return;}。
实验一、词法分析器(含源代码)

词法分析器实验报告一、实验目的及要求本次实验通过用C语言设计、编制、调试一个词法分析子程序,识别单词,实现一个C语言词法分析器,经过此过程可以加深对编译器解析单词流的过程的了解。
运行环境:硬件:windows xp软件:visual c++6.0二、实验步骤1.查询资料,了解词法分析器的工作过程与原理。
2.分析题目,整理出基本设计思路。
3.实践编码,将设计思想转换用c语言编码实现,编译运行。
4.测试功能,多次设置包含不同字符,关键字的待解析文件,仔细察看运行结果,检测该分析器的分析结果是否正确。
通过最终的测试发现问题,逐渐完善代码中设置的分析对象与关键字表,拓宽分析范围提高分析能力。
三、实验内容本实验中将c语言单词符号分成了四类:关键字key(特别的将main说明为主函数)、普通标示符、常数和界符。
将关键字初始化在一个字符型指针数组*key[]中,将界符分别由程序中的case列出。
在词法分析过程中,关键字表和case列出的界符的内容是固定不变的(由程序中的初始化确定),因此,从源文件字符串中识别出现的关键字,界符只能从其中选取。
标识符、常数是在分析过程中不断形成的。
对于一个具体源程序而言,在扫描字符串时识别出一个单词,若这个单词的类型是关键字、普通标示符、常数或界符中之一,那么就将此单词以文字说明的形式输出.每次调用词法分析程序,它均能自动继续扫描下去,形成下一个单词,直到整个源程序全部扫描完毕,从而形成相应的单词串。
输出形式例如:void $关键字流程图、程序流程图:程序:#include<string.h>#include<stdio.h>#include<stdlib.h>#include<ctype.h>//定义关键字char*Key[10]={"main","void","int","char","printf","scanf","else","if","return"}; char Word[20],ch; // 存储识别出的单词流int IsAlpha(char c) { //判断是否为字母if(((c<='z')&&(c>='a'))||((c<='Z')&&(c>='A'))) return 1;else return 0;}int IsNum(char c){ //判断是否为数字if(c>='0'&&c<='9') return 1;else return 0;}int IsKey(char *Word){ //识别关键字函数int m,i;for(i=0;i<9;i++){if((m=strcmp(Word,Key[i]))==0){if(i==0)return 2;return 1;}}return 0;}void scanner(FILE *fp){ //扫描函数char Word[20]={'\0'};char ch;int i,c;ch=fgetc(fp); //获取字符,指针fp并自动指向下一个字符if(IsAlpha(ch)){ //判断该字符是否是字母Word[0]=ch;ch=fgetc(fp);i=1;while(IsNum(ch)||IsAlpha(ch)){ //判断该字符是否是字母或数字Word[i]=ch;i++;ch=fgetc(fp);}Word[i]='\0'; //'\0' 代表字符结束(空格)fseek(fp,-1,1); //回退一个字符c=IsKey(Word); //判断是否是关键字if(c==0) printf("%s\t$普通标识符\n\n",Word);//不是关键字else if(c==2) printf("%s\t$主函数\n\n",Word);else printf("%s\t$关键字\n\n",Word); //输出关键字 }else //开始判断的字符不是字母if(IsNum(ch)){ //判断是否是数字Word[0]=ch;ch=fgetc(fp);i=1;while(IsNum(ch)){Word[i]=ch;i++;ch=fgetc(fp);}Word[i]='\0';fseek(fp,-1,1); //回退printf("%s\t$无符号实数\n\n",Word);}else //开始判断的字符不是字母也不是数字{Word[0]=ch;switch(ch){case'[':case']':case'(':case')':case'{':case'}':case',':case'"':case';':printf("%s\t$界符\n\n",Word); break;case'+':ch=fgetc(fp);Word[1]=ch;if(ch=='='){printf("%s\t$运算符\n\n",Word);//运算符“+=”}else if(ch=='+'){printf("%s\t$运算符\n\n",Word); //判断结果为“++”}else {fseek(fp,-1,1);printf("%s\t$运算符\n\n",Word); //判断结果为“+”}break;case'-':ch=fgetc(fp);Word[1]=ch;if(ch=='='){printf("%s\t$运算符\n\n",Word); }else if(ch=='-'){printf("%s\t$运算符\n\n",Word); //判断结果为“--”}else {fseek(fp,-1,1);printf("%s\t$运算符\n\n",Word); //判断结果为“-”}break;case'*':case'/':case'!':case'=':ch=fgetc(fp);if(ch=='='){printf("%s\t$运算符\n\n",Word);}else {fseek(fp,-1,1);printf("%s\t$运算符\n\n",Word);}break;case'<':ch=fgetc(fp);Word[1]=ch;if(ch=='='){printf("%s\t$运算符\n\n",Word); //判断结果为运算符“<=”}else if(ch=='<'){printf("%s\t$运算符\n\n",Word); //判断结果为“<<”}else {fseek(fp,-1,1);printf("%s\t$运算符\n\n",Word); //判断结果为“<”}break;case'>':ch=fgetc(fp);Word[1]=ch;if(ch=='=') printf("%s\t$运算符\n\n",Word);else {fseek(fp,-1,1);printf("%s\t$运算符\n\n",Word);}break;case'%':ch=fgetc(fp);Word[1]=ch;if(ch=='='){printf("%s\t$运算符\n\n",Word);}if(IsAlpha(ch)) printf("%s\t$类型标识符\n\n",Word);else {fseek(fp,-1,1);printf("%s\t$取余运算符\n\n",Word);}break;default:printf("无法识别字符!\n\n"); break;}}}main(){char in_fn[30]; //文件路径FILE *fp;printf("\n请输入源文件名(包括路径和后缀名):");while(1){gets(in_fn);//scanf("%s",in_fn);if((fp=fopen(in_fn,"r"))!=NULL) break; //读取文件内容,并返回文件指针,该指针指向文件的第一个字符else printf("文件路径错误!请重新输入:");}printf("\n******************* 词法分析结果如下 *******************\n");do{ch=fgetc(fp);if(ch=='#') break; //文件以#结尾,作为扫描结束条件else if(ch==' '||ch=='\t'||ch=='\n'){} //忽略空格,空白,和换行else{fseek(fp,-1,1); //回退一个字节开始识别单词流scanner(fp);}}while(ch!='#');return(0);}4.实验结果解析源文件:void main(){int a=3;a+=b;printf("%d",a);return;}#解析结果:5.实验总结分析通过本次实验,让再次浏览了有关c语言的一些基本知识,特别是对文件,字符串进行基本操作的方法。
词法分析器

词法分析器以下是一个简单的词法分析器的完整源码(使用Python语言实现):```pythonimport redef lexer(input_string):#定义关键字列表keywords = ['if', 'else', 'while', 'for']#定义正则表达式匹配规则pattern = r'\bif\b,\belse\b,\bwhile\b,\bfor\b,\b\d+(\.\d+)?\b,\b\w+\b,[+=\-*/(],\s+'#利用正则表达式进行词法分析tokens = re.findall(pattern, input_string)#过滤空格和注释tokens = [token for token in tokens if nottoken.isspace( and not token.startswith('#')]#过滤关键字tokens = [token if token not in keywords elsetoken.upper( for token in tokens]return tokens#测试词法分析器input_string = '''# This is a simple programa=1+2if a == 3:print("Hello, world!")else:print("Invalid input!")'''tokens = lexer(input_string)for token in tokens:print(token)```这个词法分析器根据正则表达式对输入字符串进行词法分析,并返回一个包含所有词法单元的列表。
该分析器识别整数,浮点数,变量名,关键字,运算符和括号等词法单元。
词法分析器

}
}
//***************其它 ************
void IsOther()
{
char ch1;
int i;
for(i=0;i<30;i++)
{[i]='\0';}//将缓冲区初始化
int var_count; //类型种数
int label_count; //序号总数
int addr_count; //内码编址
int LineOfPro; //错误出现的行号
char filename[30];
FILE *SourceFin; //源文件
FILE *TokenFout; //输出文件
void Scanner(); //主程序
void IsAlpha(); //关键字
void IsNumber(); //数字
void IsOther(); //其它
void OutPut(); //输出
void Error(int a); //错误类型
char name[30];//单词本身
int code;//对应机内码
int addr;//入口地址
}token;
typedef struct KeyWord
{
char name[30];
int code;
}KeyWord;
typedef struct symble
{
printf("无法打开文件%s!\n",filename);
exit(1);
}
if((TokenFout=fopen("d:/Token.txt","w"))==NULL)
编译原理实验报告——词法分析器(内含源代码)

编译原理实验(一)——词法分析器一.实验描述运行环境:vc++2008对某特定语言A ,构造其词法规则。
该语言的单词符号包括:12状态转换图3程序流程:词法分析作成一个子程序,由另一个主程序调用,每次调用返回一个单词对应的二元组,输出标识符表、常数表由主程序来完成。
二.实验目的通过动手实践,使学生对构造编译系统的基本理论、编译程序的基本结构有更为深入的理解和掌握;使学生掌握编译程序设计的基本方法和步骤;能够设计实现编译系统的重要环节。
同时增强编写和调试程序的能力。
三.实验任务编制程序实现要求的功能,并能完成对测试样例程序的分析。
四.实验原理char set[1000],str[500],strtaken[20];//set[]存储代码,strtaken[]存储当前字符char sign[50][10],constant[50][10];//存储标识符和常量定义了一个Analyzer类class Analyzer{public:Analyzer(); //构造函数 ~Analyzer(); //析构函数int IsLetter(char ch); //判断是否是字母,是则返回 1,否则返回 0。
int IsDigit(char ch); //判断是否为数字,是则返回 1,否则返回 0。
void GetChar(char *ch); //将下一个输入字符读到ch中。
void GetBC(char *ch); //检查ch中的字符是否为空白,若是,则调用GetChar直至ch进入一个非空白字符。
void Concat(char *strTaken, char *ch); //将ch中的字符连接到strToken之后。
int Reserve(char *strTaken); //对strTaken中的字符串查找保留字表,若是一个保留字返回它的数码,否则返回0。
void Retract(char *ch) ; //将搜索指针器回调一个字符位置,将ch置为空白字符。
词法分析器(含完整源码)

void Scanner(char ch[],int chLen,Table table[Max],int nLine) {
int chIndex = 0;
while(chIndex < chLen) //对输入的字符扫描 { /**************************处理空格和 tab ************************/
六、总结:
词法分析是构造编译器的起始阶段,也是相应比较简单的一个环节。词法分析的主要任 务是:根据构造的状态转换图,从左到右逐个字符地対源程序进行扫描,识别开源程序中具 有独立含义的最小语法单位——符号或单词,如变量标识符,关键字,常量,运算符,界符 等。
然后将提取出的标识符以内码的形式表示,即用 int 类型的数字来表示其类型和在 display 表中的位置,而无须保留原来标识符本身的字符串,这不仅节省了内存空间,也有 利于下一阶段的分析工作。
typedef struct DisplayTable {
int Index; //标识符所在表的下标 int type; //标识符的类型 int line; //标识符所在表的行数 char symbol[20]; //标识符所在表的名称 }Table;
int TableNum = 0; //display 表的下标 char Word[WordMaxNum][20]; //标识符表 char Digit[WordMaxNum][20]; //数字表 int WordNum = 0; //变量表的下标 int DigNum = 0; //常量表的下标 bool errorFlag = 0; //错误标志
当然,在扫描源程序串的同时,进行一些简单的处理,如删除空格、tab、换行等无效 字符,也进行了一些基本的错误处理,如变量长度的判别,有些不合词法规则的标识符判别 等。总之,严格说来,词法分析程序只进行和词法分析相关的工作。
《C语言词法分析器》开发文档及源代码

《C语言词法分析器》开发文档Powered By 萌萌的玉雪一、实验题目编制并调试C词法分析程序。
二、实验目的全面深入理解高级语言程序设计知识,掌握应用技巧,提高应用与分析能力。
三、主要函数四、设计1.主函数void main ( )2. 初始化函数void load ( )3. 保留字及标识符判断函数void char_search(char *word)4. 整数类型判断函数void inta_search(char *word)5. 浮点类型判断函数void intb_search(char *word)6. 字符串常量判断函数void cc_search(char *word)7. 字符常量判断函数void c_search(char *word)同4、5函数图8.主扫描函数void scan ( )五、关键代码#include <stdio.h>#include <string.h>#include <stdlib.h>char *key0[]={" ","auto","break","case","char","const","continue","default","do","double","else","enum","extern","float","for","goto","if" ,"int","long","register","return","short","signed","sizeof","static","struct","switch","typedef","_Complex","_Imaginary"," union","unsigned","void","volatile","while"};/*保留字表*/char *key1[]={" ","(",")","[","]","{","}",",",";","'"};/*分隔符表*/char *key2[]={" ","+","-","*","/","%","<",">","==",">=","<=","!=","!","&&","||","<<",">>","~","|","^","&","=","?:","->","++","--",".","+ =","-=","*=","/="};/*运算符表*/int xx0[35],xx1[10],xx2[31];int temp_key3=0,temp_c40=0,temp_c41=0,temp_c42=0,temp_c43=0; /******* 初始化函数*******/void load(){int mm;for (mm=0;mm<=34;mm++){xx0[mm]=0;}for (mm=0;mm<=9;mm++){xx1[mm]=0;}for (mm=0;mm<=30;mm++){xx2[mm]=0;}FILE *floading;if ((floading=fopen("key0.txt","w"))==NULL){printf("Error! Can't create file : key0.txt");return;}fclose (floading);/*建立保留字表文件:key0.txt*/if ((floading=fopen("key1.txt","w"))==NULL){printf("Error! Can't create file : key1.txt");return;}/*建立分隔符表文件:key1.txt*/if ((floading=fopen("key2.txt","w"))==NULL){printf("Error! Can't create file : key2.txt");return;}fclose(floading);/*建立运算符表文件:key2.txt*/if ((floading=fopen("key3.txt","w"))==NULL){printf("Error! Can't create file : key3.txt");return;}fclose (floading);/*建立标识符表文件:key3.txt*/if ((floading=fopen("c40.txt","w"))==NULL){printf("Error! Can't create file : c40.txt");return;}fclose (floading);/*建立整数类型常量表文件:c40.txt*/if ((floading=fopen("c41.txt","w"))==NULL){printf("Error! Can't create file : c41.txt");return;}fclose (floading);/*建立浮点类型常量表文件:c41.txt*/if ((floading=fopen("c42.txt","w"))==NULL){printf("Error! Can't create file : c42.txt");return;}fclose (floading);/*建立字符类型常量表文件:c42.txt*/if ((floading=fopen("c43.txt","w"))==NULL){printf("Error! Can't create file : c43.txt");return;}fclose (floading);/*建立字符串类型常量表文件:c43.txt*/if ((floading=fopen("defination.txt","w"))==NULL) {printf("Error! Can't create file : defination.txt");return;}fclose (floading);/*建立注释文件:defination.txt*/if ((floading=fopen("output.txt","w"))==NULL) {printf("Error! Can't create file : output.txt");return;}fclose (floading);/*建立内部码文件:output.txt*/if ((floading=fopen("temp_key1","w"))==NULL) {printf("Error! Can't create file : temp_key1");return;}fclose (floading);/*建立保留字临时表文件:temp_key1*/if ((floading=fopen("temp_key3","w"))==NULL) {printf("Error! Can't create file : temp_key3");return;}fclose (floading);/*建立标识符临时文件:temp_key3*/if ((floading=fopen("temp_c40","w"))==NULL){printf("Error! Can't create file : temp_c40");return;}fclose (floading);/*建立整数类型常量临时文件:temp_c40*/if ((floading=fopen("temp_c41","w"))==NULL){printf("Error! Can't create file : temp_c41");return;}fclose (floading);/*建立浮点类型常量临时文件:temp_c41*/if ((floading=fopen("temp_c42","w"))==NULL){printf("Error! Can't create file : temp_c42");return;}fclose (floading);/*建立字符类型常量临时文件:temp_c42*/if ((floading=fopen("temp_c43","w"))==NULL){printf("Error! Can't create file : temp_c43");return;}fclose (floading);/*建立字符串类型常量临时文件:temp_c43*/ }/******* 保留字及标识符判断函数*******/void char_search(char *word){int m,line=0,csi=0;int value=0;int value2=0;char c,cs[100];FILE *foutput,*finput;for (m=1;m<=34;m++){if (strcmp(word,key0[m])==0){value=1;break;}}if (value==1){if (xx0[m]==0){foutput=fopen("key0.txt","a");fprintf(foutput,"0\t%d\t\t%s\n",m,word);fclose(foutput);xx0[m]=1;}foutput=fopen("output.txt","a");fprintf(foutput,"0\t%d\t\t%s\n",m,word);fclose(foutput);}else{if (temp_key3==0){foutput=fopen("temp_key3","a");fprintf(foutput,"%s\n",word);fclose(foutput);temp_key3++;foutput=fopen("key3.txt","a");fprintf(foutput,"3\t1\t\t%s\n",word);fclose(foutput);}finput=fopen("temp_key3","r");c=fgetc(finput);while (c!=EOF){while (c!='\n'){cs[csi++]=c;c=fgetc(finput);}cs[csi]='\0';csi=0;line++;if ((strcmp(cs,word))==0){value2=1;break;}else{value2=0;c=fgetc(finput);}}fclose(finput);if (value2==1){foutput=fopen("output.txt","a");fprintf(foutput,"3\t%d\t\t%s\n",line,word);fclose(foutput);}else{foutput=fopen("temp_key3","a");fprintf(foutput,"%s\n",word);fclose(foutput);temp_key3++;foutput=fopen("output.txt","a");fprintf(foutput,"3\t%d\t\t%s\n",temp_key3,word);fclose(foutput);foutput=fopen("key3.txt","a");fprintf(foutput,"3\t%d\t\t%s\n",temp_key3,word);fclose(foutput);}}}/******* 整数类型判断函数*******/void inta_search(char *word){FILE *foutput,*finput;char c;char cs[100];int csi=0;int line=0;int value2=0;if (temp_c40==0)foutput=fopen("temp_c40","a");fprintf(foutput,"%s\n",word);fclose(foutput);temp_c40++;foutput=fopen("c40.txt","a");fprintf(foutput,"4\t0\t1\t%s\n",word);fclose(foutput);}finput=fopen("temp_c40","r");c=fgetc(finput);while (c!=EOF){while (c!='\n'){cs[csi++]=c;c=fgetc(finput);}cs[csi]='\0';csi=0;line++;if (strcmp(cs,word)==0){value2=1;break;}c=fgetc(finput);}fclose(finput);if (value2==1){foutput=fopen("output.txt","a");fprintf(foutput,"4\t0\t%d\t%s\n",line,word);fclose(foutput);}else{foutput=fopen("temp_c40","a");fprintf(foutput,"%s\n",word);fclose(foutput);temp_c40++;foutput=fopen("output.txt","a");fprintf(foutput,"4\t0\t%d\t%s\n",temp_c40,word);fclose(foutput);foutput=fopen("c40.txt","a");fprintf(foutput,"4\t0\t%d\t%s\n",temp_c40,word);fclose(foutput);}/******* 浮点类型判断函数*******/void intb_search(char *word){FILE *foutput,*finput;char c;char cs[100];int csi=0;int line=0;int value2=0;if (temp_c41==0){foutput=fopen("temp_c41","a");fprintf(foutput,"%s\n",word);fclose(foutput);temp_c41++;foutput=fopen("c41.txt","a");fprintf(foutput,"4\t1\t1\t%s\n",word);fclose(foutput);}finput=fopen("temp_c41","r");c=fgetc(finput);while (c!=EOF){while (c!='\n'){cs[csi++]=c;c=fgetc(finput);}cs[csi]='\0';csi=0;line++;if (strcmp(cs,word)==0){value2=1;break;}c=fgetc(finput);}fclose(finput);if (value2==1){foutput=fopen("output.txt","a");fprintf(foutput,"4\t1\t%d\t%s\n",line,word);fclose(foutput);}else{foutput=fopen("temp_c41","a");fprintf(foutput,"%s\n",word);fclose(foutput);temp_c41++;foutput=fopen("output.txt","a");fprintf(foutput,"4\t1\t%d\t%s\n",temp_c41,word);fclose(foutput);foutput=fopen("c40.txt","a");fprintf(foutput,"4\t1\t%d\t%s\n",temp_c41,word);fclose(foutput);}}/******* 字符串常量判断函数*******/void cc_search(char *word){FILE *foutput,*finput;char c;char cs[100];int csi=0;int line=0;int value2=0;if (temp_c43==0){foutput=fopen("temp_c43","a");fprintf(foutput,"%s\n",word);fclose(foutput);temp_c43++;foutput=fopen("c43.txt","a");fprintf(foutput,"4\t3\t1\t%s\n",word);fclose(foutput);}finput=fopen("temp_c43","r");c=fgetc(finput);while (c!=EOF){while (c!='\n'){cs[csi++]=c;c=fgetc(finput);}cs[csi]='\0';csi=0;line++;if (strcmp(cs,word)==0){value2=1;break;}c=fgetc(finput);}fclose(finput);if (value2==1){foutput=fopen("output.txt","a");fprintf(foutput,"4\t3\t%d\t%s\n",line,word);fclose(foutput);}else{foutput=fopen("temp_c43","a");fprintf(foutput,"%s\n",word);fclose(foutput);temp_c43++;foutput=fopen("output.txt","a");fprintf(foutput,"4\t3\t%d\t%s\n",temp_c43,word);fclose(foutput);foutput=fopen("c43.txt","a");fprintf(foutput,"4\t3\t%d\t%s\n",temp_c43,word);fclose(foutput);}}/******* 字符常量判断函数*******/void c_search(char *word){FILE *foutput,*finput;char c;char cs[100];int csi=0;int line=0;int value2=0;if (temp_c42==0){foutput=fopen("temp_c42","a");fprintf(foutput,"%s\n",word);fclose(foutput);temp_c42++;foutput=fopen("c42.txt","a");fprintf(foutput,"4\t2\t1\t%s\n",word);fclose(foutput);}finput=fopen("temp_c42","r");c=fgetc(finput);while (c!=EOF){while (c!='\n'){cs[csi++]=c;c=fgetc(finput);}cs[csi]='\0';csi=0;line++;if (strcmp(cs,word)==0){value2=1;break;}c=fgetc(finput);}fclose(finput);if (value2==1){foutput=fopen("output.txt","a");fprintf(foutput,"4\t2\t%d\t%s\n",line,word);fclose(foutput);}else{foutput=fopen("temp_c42","a");fprintf(foutput,"%s\n",word);fclose(foutput);temp_c42++;foutput=fopen("output.txt","a");fprintf(foutput,"4\t2\t%d\t%s\n",temp_c42,word);fclose(foutput);foutput=fopen("c42.txt","a");fprintf(foutput,"4\t2\t%d\t%s\n",temp_c42,word);fclose(foutput);}}/******* 主扫描函数*******/void scan(){int count;char chin;FILE *fin;FILE *fout;char filename[50];char temp[100];char target[3]="'";printf("请输入文件名:");scanf("%s",filename);if ((fin=fopen(filename,"r"))==NULL){printf("Error! Can't open file : %s\n",filename);return;}chin=fgetc(fin);while (chin!=EOF){/*对文件包含、宏定义进行处理*/if (chin=='#'){while (chin!='>')chin=fgetc(fin);/*chin=fgetc(fin);*/}/*对空格符、水平制表符进行处理*/else if ((chin==' ')||(chin=='\t')){;}/*对回车符进行处理*/else if (chin=='\n'){;}/*对单引号内的字符常量进行处理*/else if (chin==target[0]){if (xx1[9]==0){fout=fopen("key1.txt","a");fprintf(fout,"1\t9\t\t%c\n",target[0]);fclose(fout);xx1[9]=1;}temp[0]=chin;chin=fgetc(fin);temp[1]=chin;chin=fgetc(fin);if (chin!=target[0]){temp[2]=chin;chin=fgetc(fin);temp[3]=chin;temp[4]='\0';}else{temp[2]=chin;temp[3]='\0';}c_search(temp);}/*对双引号内的字符串常量进行处理*/else if (chin=='"'){int i=0;temp[i++]='"';chin=fgetc(fin);while (chin!='"'){temp[i++]=chin;chin=fgetc(fin);}temp[i]='"';temp[i+1]='\0';cc_search(temp);}/*对保留字、标识符进行处理*/else if (((chin>='A')&&(chin<='Z'))||((chin>='a')&&(chin<='z'))||(chin=='_')){int i=0;while(((chin>='A')&&(chin<='Z'))||((chin>='a')&&(chin<='z'))||(chin=='_')||((chin>='0')&&(chin<='9'))) {temp[i++]=chin;chin=fgetc(fin);}temp[i]='\0';char_search(temp);if (chin!=EOF)fseek (fin,-1L,SEEK_CUR);}/*对整型、浮点型数据进行处理*/else if ((chin>='0')&&(chin<='9')){int dotcount=0;int i=0;while (((chin>='0')&&(chin<='9'))||(chin=='.')) {if (chin=='.')dotcount++;if (dotcount==2)break;temp[i++]=chin;chin=fgetc(fin);}temp[i]='\0';if (dotcount==1)intb_search(temp);elseinta_search(temp);if (chin!=EOF)fseek (fin,-1L,SEEK_CUR);}/*对注释进行处理*/else if (chin=='/'){chin=fgetc(fin);if (chin=='='){fout=fopen("output.txt","a");fprintf(fout,"2\t30\t\t/=\n");fclose(fout);}else if (chin!='*'){fout=fopen("output.txt","a");fprintf(fout,"2\t4\t\t/\n");fclose(fout);fseek(fin,-1L,SEEK_CUR);}else if (chin=='*'){count=0;chin=fgetc(fin);fout=fopen("defination.txt","a");fprintf(fout,"/*");while (count!=2){count=0;while (chin!='*'){fprintf(fout,"%c",chin);chin=fgetc(fin);}count++;fprintf(fout,"%c",chin);chin=fgetc(fin);if (chin=='/'){count++;fprintf(fout,"%c\n",chin);}else{fprintf(fout,"%c",chin);chin=fgetc(fin);}}}}/*对运算符、分隔符进行处理*/else{int time=0;int firstblood=0;temp[0]=chin;chin=fgetc(fin);if (chin!=EOF){temp[1]=chin;temp[2]='\0';for (time=1;time<=30;time++){if (strcmp(temp,key2[time])==0){firstblood=1;if (xx2[time]==0){fout=fopen("key2.txt","a");fprintf(fout,"2\t%d\t\t%s\n",time,temp);fclose(fout);xx2[time]=1;}fout=fopen("output.txt","a");fprintf(fout,"2\t%d\t\t%s\n",time,temp);fclose(fout);break;}}if (firstblood!=1){fseek(fin,-1L,SEEK_CUR);temp[1]='\0';for (time=1;time<=9;time++){if (strcmp(temp,key1[time])==0){if (xx1[time]==0){fout=fopen("key1.txt","a");fprintf(fout,"1\t%d\t\t%s\n",time,temp);fclose(fout);xx1[time]=1;}fout=fopen("output.txt","a");fprintf(fout,"1\t%d\t\t%s\n",time,temp);fclose(fout);break;}}for (time=1;time<=30;time++){if (strcmp(temp,key2[time])==0){if (xx2[time]==0){fout=fopen("key2.txt","a");fprintf(fout,"2\t%d\t\t%s\n",time,temp);fclose(fout);xx2[time]=1;}fout=fopen("output.txt","a");fprintf(fout,"2\t%d\t\t%s\n",time,temp);fclose(fout);break;}}}}}chin=fgetc(fin);}fout=fopen("output.txt","a");fprintf(fout,"1\t6\t\t}\n");fclose(fout);}/******* Main函数*******/void main(){FILE *fread;char charin;char command='Q';printf("\n");printf("******************** C语言词法分析工具********************\n");printf("* *\n");printf("* *\n");printf("* 命令如下:*\n");printf("* 0 --> 查看保留字表文件*\n");printf("* 1 --> 查看分隔符表文件*\n");printf("* 2 --> 查看运算符表文件*\n");printf("* 3 --> 查看标识符表文件*\n");printf("* 4 --> 查看整数类型常量表*\n");printf("* 5 --> 查看浮点类型常量表*\n");printf("* 6 --> 查看字符类型常量表*\n");printf("* 7 --> 查看字符串类型常量表*\n");printf("* 8 --> 查看注释文件*\n");printf("* 9 --> 查看内部码文件*\n");printf("* -------------------------- *\n");printf("* Q --> 退出*\n");printf("***************************************************************\n");printf("\n");load();scan();printf("\n");printf("分析完成!\n");getchar();printf("\n");printf("请输入命令:");command=getchar();while ((command!='Q')&&(command!='q')){switch (command){case '0':{printf("*************************\n");printf("\n");fread=fopen("key0.txt","r");charin=fgetc(fread);while (charin!=EOF){putchar(charin);charin=fgetc(fread);}printf("\n");printf("*************************\n");printf("\n");printf("请输入命令:");break;}case '1':{printf("*************************\n");printf("\n");fread=fopen("key1.txt","r");charin=fgetc(fread);while (charin!=EOF){putchar(charin);charin=fgetc(fread);}printf("\n");printf("*************************\n");printf("\n");printf("请输入命令:");break;}case '2':{printf("*************************\n");printf("\n");fread=fopen("key2.txt","r");charin=fgetc(fread);while (charin!=EOF){putchar(charin);charin=fgetc(fread);}printf("\n");printf("*************************\n");printf("\n");printf("请输入命令:");break;}case '3':{printf("*************************\n");printf("\n");fread=fopen("key3.txt","r");charin=fgetc(fread);while (charin!=EOF){putchar(charin);charin=fgetc(fread);}printf("\n");printf("*************************\n");printf("\n");printf("请输入命令:");break;}case '4':{printf("*************************\n");printf("\n");fread=fopen("c40.txt","r");charin=fgetc(fread);while (charin!=EOF){putchar(charin);charin=fgetc(fread);}printf("\n");printf("*************************\n");printf("\n");printf("请输入命令:");break;}case '5':{printf("*************************\n");printf("\n");fread=fopen("c41.txt","r");charin=fgetc(fread);while (charin!=EOF){putchar(charin);charin=fgetc(fread);}printf("\n");printf("*************************\n");printf("\n");21printf("请输入命令:");break;}case '6':{printf("*************************\n");printf("\n");fread=fopen("c42.txt","r");charin=fgetc(fread);while (charin!=EOF){putchar(charin);charin=fgetc(fread);}printf("\n");printf("*************************\n");printf("\n");printf("请输入命令:");break;}case '7':{printf("*************************\n");printf("\n");fread=fopen("c43.txt","r");charin=fgetc(fread);while (charin!=EOF){putchar(charin);charin=fgetc(fread);}printf("\n");printf("*************************\n");printf("\n");printf("请输入命令:");break;}case '8':{printf("*************************\n");printf("\n");fread=fopen("defination.txt","r");charin=fgetc(fread);while (charin!=EOF){putchar(charin);charin=fgetc(fread);22}printf("\n");printf("*************************\n");printf("\n");printf("请输入命令:");break;}case '9':{printf("*************************\n");printf("\n");fread=fopen("output.txt","r");charin=fgetc(fread);while (charin!=EOF){putchar(charin);charin=fgetc(fread);}printf("\n");printf("*************************\n");printf("\n");printf("请输入命令:");break;}}command=getchar();}}23。
(完整版)词法分析器(c语言实现)
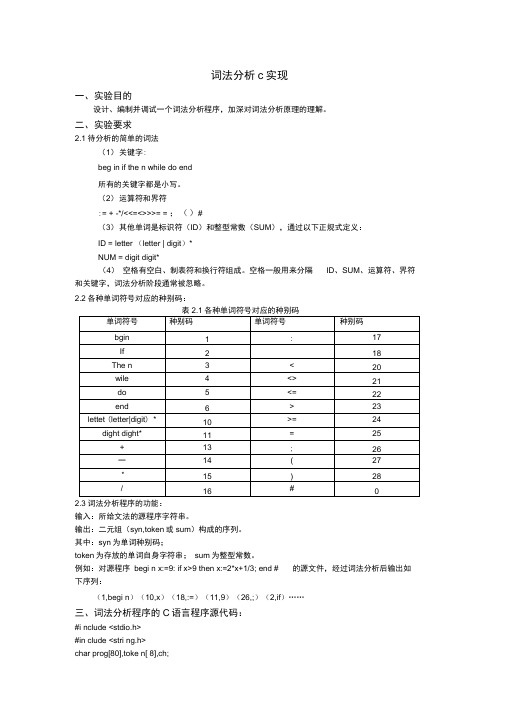
词法分析c实现一、实验目的设计、编制并调试一个词法分析程序,加深对词法分析原理的理解。
二、实验要求2.1待分析的简单的词法(1)关键字:beg in if the n while do end所有的关键字都是小写。
(2)运算符和界符:= + -*/<<=<>>>= = ;()#(3)其他单词是标识符(ID)和整型常数(SUM),通过以下正规式定义:ID = letter (letter | digit)*NUM = digit digit*(4)空格有空白、制表符和换行符组成。
空格一般用来分隔ID、SUM、运算符、界符和关键字,词法分析阶段通常被忽略。
2.2各种单词符号对应的种别码:2.3词法分析程序的功能:输入:所给文法的源程序字符串。
输出:二元组(syn,token或sum)构成的序列。
其中:syn为单词种别码;token为存放的单词自身字符串;sum为整型常数。
例如:对源程序begi n x:=9: if x>9 then x:=2*x+1/3; end # 的源文件,经过词法分析后输出如下序列:(1,begi n)(10,x)(18,:=)(11,9)(26,;)(2,if)……三、词法分析程序的C语言程序源代码:#i nclude <stdio.h>#in clude <stri ng.h>char prog[80],toke n[ 8],ch;int syn,p,m,n,sum;char *rwtab[6]={"begin","if","then","while","do","end"};scaner();main(){p=0;printf("\n please input a string(end with '#'):/n");do{ scanf("%c",&ch); prog[p++]=ch; }while(ch!='#');p=0;do{scaner();switch(syn){case 11:printf("( %-10d%5d )\n",sum,syn);break;case -1:printf("you have input a wrong string\n");getch();exit(0);default: printf("( %-10s%5d )\n",token,syn); break;} }while(syn!=0); getch();}scaner(){ sum=0; for(m=0;m<8;m++)token[m++]=NULL; ch=prog[p++];m=0;while((ch==' ')||(ch=='\n'))ch=prog[p++]; if(((ch<='z')&&(ch>='a'))||((ch<='Z')&&(ch>='A'))) { while(((ch<='z')&&(ch>='a'))||((ch<='Z')&&(ch>='A'))||((ch>='0')&&(ch<='9'))){token[m++]=ch;ch=prog[p++];}p--;syn=10;for(n=0;n<6;n++) if(strcmp(token,rwtab[n])==0){ syn=n+1;break;}else if((ch>='0')&&(ch<='9')){ while((ch>='0')&&(ch<='9')){ sum=sum*10+ch-'0';ch=prog[p++];}p--;syn=11;}else switch(ch){ case '<':token[m++]=ch; ch=prog[p++]; if(ch=='='){ syn=22;}token[m++]=ch;}else{ syn=20; p--;}break;case '>':token[m++]=ch; ch=prog[p++]; if(ch=='=') { syn=24; token[m++]=ch;}else{ syn=23; p--;}break;case '+': token[m++]=ch; ch=prog[p++]; if(ch=='+') { syn=17; token[m++]=ch;}else{ syn=13;p--;}break;case '-':token[m++]=ch; ch=prog[p++]; if(ch=='-'){ syn=29; token[m++]=ch;}else{ syn=14;p--;}break;case '!':ch=prog[p++]; if(ch=='=') { syn=21; token[m++]=ch; } else { syn=31; p--;}break;case '=':token[m++]=ch; ch=prog[p++]; if(ch=='='){ syn=25; token[m++]=ch;}else{ syn=18;p--;}break; case '*': syn=15; token[m++]=ch; break;case '/': syn=16; token[m++]=ch; break;case '(': syn=27; token[m++]=ch; break;case ')': syn=28;toke n[ m++]=ch; break;case '{': syn=5;toke n[ m++]=ch; break;case '}': syn=6;toke n[ m++]=ch; break;case ';': syn=26; toke n[ m++]=ch; break; case '、"': syn=30; toke n[ m++]=ch; break; case '#': syn=0; toke n[ m++]=ch; break; case ':':s yn=17;toke n[ m++]=ch; break;default: syn=-1;break; }toke n[ m++]='\0'; }四、结果分析:输入 beg in x:=9: if x>9 then x:=2*x+1/3; end # 后经词法分析输出如下序列: (begin 1)(x 10)(: 17)(=11)(; 26)(if2)1 y 10) 17〉 is y 11〉 26、2 ?IH 、 23 ) 11 y 3〉 io y 17〉 18 \ II 、15 > 10 ) 13 ? 11〉 16 ) 11〉 2£ 〉 m 、 u y;HC 三卜TV®译原理比IFAFE" ・exe如图5-1所示:X9Xend ttbegin Xx>0。
词法分析器文档

}
else if(chf==',')
{printf("48,%c\n",chf);
fprintf(fpout,"%d\t%s\n",48,",");
}
else if(chf==':')
{printf("49,%c\n",chf);
fprintf(fpout,"%d\t%s\n",49,":");
}
}
}
scan(FILE *fp)
{ char chf;
while((chf=fgetc(fp))!=EOF&&chf!='#') /*文件未结束就执行循环判断输入的字符串*/
{
if(isalpha(chf)) /*标示符和关键字的判断*/
{ int p=0;
char str1[20];
do
{str1[p++]=chf;
}
else if(chf=='=')
{chf=getc(fp);
if(chf=='=')
{printf("56,%c\n",chf);
fprintf(fpout,"%d\t%s\n",56,"==");
}
else{printf("47,%c\n",chf);
fprintf(fpout,"%d\t%s\n",47,"=");
}
str2[--j]='\0';
fseek(fp,-2L,1);
词法分析器原代码

// 456.cpp : 定义控制台应用程序的入口点。
//#include "stdafx.h"#include<iostream>#include<fstream>#include<string.h>using namespace std;bool Isnoshow(char ch){ //判断是不是空格、回车、换行符if(ch=='\n'||ch=='\t'||ch==' ')return true;return false;}bool Isletter(char ch){ //判断是不是字母if((ch>='a'&&ch<='z')||(ch>='A '&&ch<='Z'))return true;return false;}bool Isdigital(char ch){ //判断是不是数字if(ch>='0'&&ch<='9')return true;return false;}bool Isunline(char ch){ //判断是不是下划线if(ch=='_')return true;return false;}bool Iscacus(char ch){ //判断是不是运算符if(ch=='+'||ch=='-'||ch=='*'|| ch=='/'||ch=='%'||ch=='<'||ch=='>'||ch=='&'||ch= ='|'||ch=='!'||ch=='=')return true;return false;}bool Issplits(char ch){ //判断是不是分界符if(ch=='{'||ch=='}'||ch=='['|| ch==']'||ch=='('||ch==')'||ch==';'||ch==','||ch= ='.'||ch==':'||ch=='"')return true;return false;}int _tmain(int argc, _TCHAR* argv[]){char b[1000];ifstream ifile;ifile.open("d:\\1.txt");int i=0;while(ifile.get(b[i])){{int a=i+1;if(ifile.eof()==1) break;if(Isletter(b[i])||Isunline(b[i ]))cout<<b[i];else if(Isnoshow(b[i])){if(Isletter(b[i-1])||Isunline(b [i-1]))cout<<"是标识符"<<endl;elseif( Isdigital(b[i-1]))cout<<"是数字"<<endl;elseif(Issplits(b[i-1]))cout<<"是分界符"<<endl;else if(Iscacus(b[i-1]))cout<<"是运算符"<<endl;}else if(Isdigital(b[i])){if(Isletter(b[i-1])||Isunline( b[i-1]))cout<<"是标识符"<<endl; elseif(Issplits(b[i-1]))cout<<b[i-1]<<"是分界符"<<endl;else if(Iscacus(b[i-1]))cout<<"是运算符"<<endl; cout<<b[i];}else if(Iscacus(b[i]))//运算符{if(Isletter(b[i-1])||Isunline(b [i-1]))cout<<"是标识符"<<endl;elseif( Isdigital(b[i-1]))cout<<"是数字"<<endl;else if(Issplits(b[i-1]))cout<<"是分界符"<<endl;cout<<b[i];}else if(Issplits(b[i]))//分界符{if(Isletter(b[i-1])||Isunline( b[i-1]))cout<<"是标识符"<<endl;elseif( Isdigital(b[i-1]))cout<<"是数字"<<endl;else if(Iscacus(b[i-1]))cout<<"是运算符"<<endl;cout<<b[i];}i++;}}if(b[i]='/0'){if(Isletter(b[i-1])||Isunline( b[i-1]))cout<<"是标识符"<<endl;else if( Isdigital(b[i-1]))cout<<"是数字"<<endl;else if(Issplits(b[i-1]))cout<<"是分界符"<<endl;else if(Iscacus(b[i-1]))cout<<"是运算符"<<endl;}ifile.close(); return 0;}。
编译原理实验报告——词法分析器(内含源代码)

#include "string.h"
#include "iostream"
using namespace std;
char set[1000],str[500],strtaken[20]; char sign[50][10],constant[50][10];
//int Words[500][10]; char ch;//当前读入字符int sr,to=0;//数组str, strtaken int st=0,dcount=0;
{
printf( "cannot open file.\n");
void input();//向存放输入结果的字符数组输入一句语句。
void display();//输出一些程序结束字符显示样式
int analyzerSubFun();//词法分析器子程序,为了实现词法分析的主要功能。
五. 代码实现
//cifa.cpp:定义控制台应用程序的入口点
//#include "stdafx Nhomakorabeah"
3.实验任务
编制程序实现要求的功能,并能完成对测试样例程序的分析。
四. 实验原理
int Reserve(char *strTaken);//对strTaken中的字符串查找保留字表,若是一个保留
字返回它的数码,否则返回0。
void Retract(char *ch); //将搜索指针器回调一个字符位置,将ch置为空白字符。
};
typedef struct keytable{
char name[20]; int kind;
编译原理课程设计-词法分析器(附含源代码).doc

编译原理 -词法分析器的设计一.设计说明及设计要求一般来说,编译程序的整个过程可以划分为五个阶段:词法分析、语法分析、中间代码生成、优化和目标代码生成。
本课程设计即为词法分析阶段。
词法分析阶段是编译过程的第一个阶段。
这个阶段的任务是从左到右一个字符一个字符地读入源程序,对构成源程序的字符流进行扫描和分解,从而识别出一个个单词(也称单词符号或符号)。
如保留字(关键字或基本字)、标志符、常数、算符和界符等等。
二.设计中相关关键字说明1.基本字:也称关键字,如 C 语言中的 if , else , while , do ,for,case,break, return 等。
2.标志符:用来表示各种名字,如常量名、变量名和过程名等。
3.常数:各种类型的常数,如12,,和“ ABC”等。
4.运算符:如+ ,- , * , / ,%, < , > ,<= , >=等。
5.界符,如逗点,冒号,分号,括号,# ,〈〈,〉〉等。
三、程序分析词法分析是编译的第一个阶段,它的主要任务是从左到右逐个字符地对源程序进行扫描,产生一个个单词序列,用以语法分析。
词法分析工作可以是独立的一遍,把字符流的源程序变为单词序列,输出在一个中间文件上,这个文件做为语法分析程序的输入而继续编译过程。
然而,更一般的情况,常将词法分析程序设计成一个子程序,每当语法分析程序需要一个单词时,则调用该子程序。
词法分析程序每得到一次调用,便从源程序文件中读入一些字符,直到识别出一个单词,或说直到下一个单词的第一个字符为止。
四、模块设计下面是程序的流程图五、程序介绍在程序当前目录里建立一个文本文档,取名为 ,所有需要分析的程序都写在此文本文档里,程序的结尾必须以“@”标志符结束。
程序结果输出在同一个目录下,文件名为,此文件为自动生成。
本程序所输出的单词符号采用以下二元式表示:(单词种别,单词自身的值)如程序输出结果(57,"#")(33,"include")(52,"<")(33,"iostream") 等。
词法分析程序源代码

词法分析程序源代码#include<stdio.h>#include<string.h>#include<stdlib.h>char TOken[10];//分开进⾏⽐较char ch;char r1[]={"auto"};char r2[]={"break"};char r3[]={"case"};char r4[]={"char"};char r5[]={"const"};char r6[]={"continue"};char r7[]={"default"};char r8[]={"do"};char r9[]={"double"};char r10[]={"else"};char r11[]={"enum"};char r12[]={"extern"};char r13[]={"float"};char r14[]={"for"};char r15[]={"goto"};char r16[]={"if"};char r17[]={"int"};char r18[]={"long"};char r19[]={"register"};char r20[]={"return"};char r21[]={"short"};char r22[]={"signed"};char r23[]={"sizeof"};char r24[]={"static"};char r25[]={"struct"};char r26[]={"switch"};char r27[]={"typedef"};char r28[]={"union"};char r29[]={"unsigned"};char r30[]={"void"};char r31[]={"volatile"};char r32[]={"while"};char r33[]={"end"};char r34[]={"include"};char r35[]={"stdio"};char r36[]={"string"};char r37[]={"main"};char r38[]={"stdlib"};//这是我定义的char A[10000];//输⼊的所有值int syn,row;int n,m,p,sum,j;static int i = 0;void scaner();int main(){row = 0 ;p = 0 ;printf("Please input string:(end of '@')\n");do{scanf("%c",&ch);A[p]=ch;p++;}//输⼊值到数组A【】中,以@结束while(ch!='@');do{scaner();//进⼊函数进⾏判定switch(syn){case40: printf("(%d,%d)\n",syn,sum); break;//如果是40,那么就是数字case0: printf("(%d,%c)\n",syn,TOken[0]);break;//如果是0,那么是@ 结束case -2: row=row++;break;default: printf("(%d,%s)\n",syn,TOken);break;//否则,就是变量名、关键词}}while (syn!=0);}void scaner(){/*共分为三⼤块,分别是标⽰符、数字、符号,对应下⾯的 if else if 和 else */for(n=0;n<7;n++)TOken[n]=0;//每次循环完就清零ch=A[i];while(ch==''||ch=='\n')//如果字符是空格或者回车,跳过ch=A[i];}if((ch>='a'&&ch<='z')||(ch>='A'&&ch<='Z')) //可能是标⽰符或者变量名{m=0;while((ch>='0'&&ch<='9')||(ch>='a'&&ch<='z')||(ch>='A'&&ch<='Z'))//找到⼀个变量名或者关键字,直到遇到空格为⽌ {TOken[m]=ch;m++;i++;ch=A[i];}TOken[m]='\0';//将识别出来的字符和已定义的标⽰符作⽐较, //因为定义的begin为1,if为2......if(strcmp(TOken,r1)==0){syn=1;}else if(strcmp(TOken,r2)==0){syn=2; }else if(strcmp(TOken,r3)==0){syn=3;}else if(strcmp(TOken,r4)==0){syn=4;}else if(strcmp(TOken,r5)==0){syn=5;}else if(strcmp(TOken,r6)==0){syn=6;}else if(strcmp(TOken,r7)==0){syn=7;}else if(strcmp(r8,TOken)==0){syn=8;}else if(strcmp(r9,TOken)==0){syn=9;}else if(strcmp(r10,TOken)==0){syn=10;}else if(strcmp(r11,TOken)==0){syn=11;}else if(strcmp(r12,TOken)==0){syn=12;}else if(strcmp(r13,TOken)==0){syn=13;}else if(strcmp(r14,TOken)==0){syn=14;}else if(strcmp(r15,TOken)==0){syn=15;}else if(strcmp(r16,TOken)==0){syn=16;}else if(strcmp(r17,TOken)==0){syn=17;}else if(strcmp(r18,TOken)==0){syn=18;}else if(strcmp(r19,TOken)==0){syn=19;}else if(strcmp(r20,TOken)==0){syn=20;}else if(strcmp(r21,TOken)==0){syn=21;}else if(strcmp(r22,TOken)==0){syn=22;}else if(strcmp(r23,TOken)==0){syn=23;}else if(strcmp(r24,TOken)==0){syn=24;}else if(strcmp(r25,TOken)==0){syn=25;}else if(strcmp(r26,TOken)==0){syn=26;}else if(strcmp(r27,TOken)==0){syn=27;}else if(strcmp(r28,TOken)==0){syn=28;}else if(strcmp(r29,TOken)==0){syn=29;}else if(strcmp(r30,TOken)==0){syn=30;}else if(strcmp(r31,TOken)==0){syn=31;}else if(strcmp(r32,TOken)==0){syn=32;}else if(strcmp(r33,TOken)==0){syn=33;}else if(strcmp(r34,TOken)==0){syn=34;}else if(strcmp(r35,TOken)==0){syn=35;}else if(strcmp(r36,TOken)==0){syn=36;}else if(strcmp(r37,TOken)==0){syn=37;}else if(strcmp(r38,TOken)==0){syn=38;}else{syn=100;} //变量名}else if((ch>='0'&&ch<='9')) //数字{sum=0;while((ch>='0'&&ch<='9')){sum=sum*10+ch-'0';//显⽰其数字sumi++;ch=A[i];}syn=40;}else switch(ch) //其他字符{case'<':m=0;TOken[m]=ch;m++;i++;ch=A[i];if(ch=='=')//<>为22{syn=41;TOken[m]=ch;m++;i++;}else{syn=46;}break;case'>':m=0;TOken[m]=ch;m++;i++;ch=A[i];if(ch=='='){syn=42;TOken[m]=ch;m++;i++;{syn=47;}break;case':':m=0;TOken[m]=ch;m++; i++;ch=A[i];if(ch=='='){syn=44;TOken[m]=ch;m++;i++; }else{syn=49;}break;case'@':syn=0;TOken[0]=ch;i++;break;case'=':syn=48;TOken[0]=ch;i++;break;case'#':syn=50;TOken[0]=ch;i++;break;case'+':syn=50;TOken[0]=ch;i++;break;case'-':syn=51;TOken[0]=ch;i++;break;case'*':syn=52;TOken[0]=ch;i++;break;case'/':syn=53;TOken[0]=ch;i++;break;case'(':syn=54;TOken[0]=ch;i++;break;case')':syn=55;TOken[0]=ch;i++;break;case'{':syn=56;TOken[0]=ch;i++;break;case'}':syn=57;TOken[0]=ch;i++;break;case';':syn=58;TOken[0]=ch;i++;break;case'.':syn=59;TOken[0]=ch;i++;break;case'\'':syn=60;TOken[0]=ch;i++;break;case'\n':syn=-2;break;default: syn=-1;break;}}。
词法分析源代码

#include <stdio.h>#include <stdlib.h>#include <string.h>#define _KEY_WORD_END "waiting for your expanding"typedef struct{int typenum;char * word;} WORD;char input[255];char token[255]="";int p_input;int p_token;char ch;char* KEY_WORDS[]={"main","int","char","if","else","for","while",_KEY_WORD_END}; WORD* scaner();void main(){FILE *fin;char buffer[100];int size;int over=1;WORD* oneword=new WORD;if((fin=fopen("test.txt","r"))==NULL){printf("Cannot open the file!\n");exit(-1);}fin=fopen("test.txt","r");while(fgets(buffer,100,fin)!=NULL){strcat(input,buffer);}while(over<1000&&over!=-1){oneword=scaner();if(oneword->typenum<1000)printf("(%d,%s)",oneword->typenum,oneword->word);over=oneword->typenum;}printf("\npress # to exit:\n");scanf("%[^#]",input);fclose(fin);}char m_getch(){ch=input[p_input];p_input=p_input+1;return (ch);}void getbc(){while(ch==' '||ch==10){ch=input[p_input];p_input=p_input+1;}}void concat(){token[p_token]=ch;p_token=p_token+1;token[p_token]='\0';}int letter(){if(ch>='a'&&ch<='z'||ch>='A'&&ch<='Z')return 1;else return 0;}int digit(){if(ch>='0'&&ch<='9')return 1;else return 0;}int reserve(){int i=0;while(strcmp(KEY_WORDS[i],_KEY_WORD_END)){ if(!strcmp(KEY_WORDS[i],token)){return i+1;}i=i+1;}return 10;}void retract(){p_input=p_input-1;}char* dtb(){return NULL;}WORD* scaner(){WORD* myword=new WORD;myword->typenum=10;myword->word="";p_token=0;m_getch();getbc();if(letter()){while(letter()||digit()){concat();m_getch();}retract();myword->typenum=reserve();myword->word=token;return(myword);}else if(digit()){while(digit()){concat();m_getch();}retract();myword->typenum=20;myword->word=token;return(myword);}else switch(ch){case '=': m_getch();if (ch=='='){myword->typenum=39;myword->word="==";return(myword);}retract();myword->typenum=21;myword->word="=";return(myword);break;case '+': myword->typenum=22;myword->word="+";return(myword);break;case '-': myword->typenum=23;myword->word="-";return(myword);break;case '*': myword->typenum=24;myword->word="*";return(myword);break;case '/': myword->typenum=25;myword->word="/";return(myword);break;case '(': myword->typenum=26;myword->word="(";return(myword);break;case ')': myword->typenum=27;myword->word=")";return(myword);break;case '[': myword->typenum=28;myword->word="[";return(myword);break;case ']': myword->typenum=29;myword->word="]";return(myword);break;case '{': myword->typenum=30;myword->word="{";return(myword);break;case '}': myword->typenum=31;myword->word="}";return(myword);break;case ',': myword->typenum=32;myword->word=",";return(myword);break;case ':': myword->typenum=33;myword->word=":";return(myword);break;case ';': myword->typenum=34;myword->word=";";return(myword);break;case '>': m_getch();if (ch=='='){myword->typenum=37;myword->word=">=";return(myword);}retract();myword->typenum=35;myword->word=">";return(myword);break;case '<': m_getch();if (ch=='='){myword->typenum=38;myword->word="<=";return(myword);}retract();myword->typenum=36;myword->word="<";return(myword);break;case '!': m_getch();if (ch=='='){myword->typenum=40;myword->word="!=";return(myword);}retract();myword->typenum=-1;myword->word="ERROR";return(myword);break;case '\0': myword->typenum=1000;myword->word="OVER";return(myword);break;default: myword->typenum=-1;myword->word="ERROR";return(myword);}}。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
#include <iostream>
#include <fstream> #include <string> #include <math.h> #include <ctype.h> #include <cstdlib>
using namespace std;
#define Max 655 //最大代码长度 #define WordMaxNum 256 //变量最大个数 #define DigitNum 256 //常量最大个数 #define MaxKeyWord 32 //关键字数量 #define MaxOptANum 8 //运算符最大个数 #define MaxOptBNum 4 //运算符最大个数 #define MaxEndNum 11 //界符最大个数
typedef struct DisplayTable {
int Index; //标识符所在表的下标 int type; //标识符的类型 int line; //标识符所在表的行数 char symbol[20]; //标识符所在表的名称 }Table;
int TableNum = 0; //display 表的下标 char Word[WordMaxNum][20]; //标识符表 char Digit[WordMaxNum][20]; //数字表 int WordNum = 0; //变量表的下标 int DigNum = 0; //常量表的下标 bool errorFlag = 0; //错误标志
遇到的问题:(a)、判别标识符超过规定长度(20)时,未输出处理结果;(b)、整数 长度过长输出结果仍为整数类型 3;(c)、对于小数如﹒045,被解释为界符和整数;(d)、 对以数字开头的一般标识符的处理,如 100nuts 被解释为整数类型和标识符,未给出错误提 示。
如上测试,出现前两个问题时已报错并输出所在行,而后两个问题待解决。
六、总结:
词法分析是构造编译器的起始阶段,也是相应比较简单的一个环节。词法分析的主要任 务是:根据构造的状态转换图,从左到右逐个字符地対源程序进行扫描,识别开源程序中具 有独立含义的最小语法单位——符号或单词,如变量标识符,关键字,常量,运算符,界符 等。
然后将提取出的标识符以内码的形式表示,即用 int 类型的数字来表示其类型和在 display 表中的位置,而无须保留原来标识符本身的字符串,这不仅节省了内存空间,也有 利于下一阶段的分析工作。
词法分析实验报告
一、实验目的与要求:
1、了解字符串编码组成的词的内涵,感觉一下字符串编码的方法和解读 2、了解和掌握自动机理论和正规式理论在词法分析程序和控制理论中的应用
二、实验内容:
构造一个自己设计的小语言的词法分析器: 1、这个小语言能说明一些简单的变量 识别诸如 begin,end,if,while 等保留字;识别非保留字的一般标识符(有下划线、 字符、数字,且第一个字符不能是数字)。识别数字序列(整数和小数);识别:=,<=,>= 之类的特殊符号以及;,(,)等界符。 2、相关过程(函数): Scanner()词法扫描程序,提取标识符并填入 display 表中 3、这个小语言有顺序结构的语句 4、这个小语言能表达分支结构的语句 5、这个小语言能够输出结果
部分结果如下:
其他测试ห้องสมุดไป่ตู้结果如下:
③、出错处理; 注:若有错误,则只指出错误,不输出各个表;
(5)、评价: 这个小语言程序基本上能完成词法分析阶段的工作,识别诸如 begin,if 等保留字;识
别非保留字的一般标识符(有下划线、字符、数字,且第一个字符不能是数字)。识别数字 序列(整数和小数);识别:=,<=,>=之类的特殊符号以及;,(,)等界符。在扫描源程序 串的同时,能进行一些简单的处理,如删除空格、tab、换行等无效字符,也进行了一些基 本的错误处理,如变量长度的判别等。
begin z:=y*y-x; z:=z+x*x;
end else
z:=x+y;
prn z; end. (4)、结果: ①、从键盘读入;
部分结果如下:
(类型:该标识符所属的类型,如关键字,变量等;下标:该标识符所对应表(如变量标 识符表,常量标识符表等)中其相应的位置,下同)
②、从文件读入,输出到文件;
总之这个小语言词法分析器能提供以上所说明到的语法描述的功能……
三、实验步骤:
1、测试评价
(1)、测试 1:能说明一些简单的变量,如关键字、一般标识符、界符等; (2)、测试 2:能输出结果:单词符号(内码形式)、各种信息表(如符号表、常量表等); (3)、测试程序:
var x,y,z; begin
x:=2; y:=3; if (x+5>=y*y) then
经过分析,我们在现有局限性的基础上,设计出一种折中的表结构,即在表结构中只添 加标识符在其相应表中的对应下表,标记符类型码等关键的几处,这样既能 唯一确定一标 识符,达到该实验的要求,同时又为表保留了很好的扩充性,以达到后续实验的要求。表结 构设计好后,其余的工作就是提取字符串和写入 display 表,在提取单字符还是双字符组成 的运算符时有些麻烦,不过利用数据结构的相关知识也是容易做到。
2、对小语言的词法规则(正规式)画出一个确定的有限自动机(见附录 2、3)
四、实验的源代码:(见附录 1)
五、实验中发现的问题和遇到的困难及解决方法:
由于以前未曾接触过编译原理,在该实验的设计中,的确遇到一定的困难。主要是 display 表结构的设计,由于语法分析和语义分析还未学习,无法站在全局的角度统筹兼顾, 在表结构设计时,不知该往表结构体中添加哪些内容,可以为后续的工作做铺垫,这是刚开 始就遇到的最大的困难,也是最难的。
当然,在扫描源程序串的同时,进行一些简单的处理,如删除空格、tab、换行等无效 字符,也进行了一些基本的错误处理,如变量长度的判别,有些不合词法规则的标识符判别 等。总之,严格说来,词法分析程序只进行和词法分析相关的工作。
七、实验感想:
通过此次实验,让我了解到如何设计、编制并调试词法分析程序,加深对词法分析原理 的理解;熟悉了构造词法分析程序的手工方式的相关原理,使用某种高级语言(例如 C++语 言)直接编写此法分析程序。另外,也让我重新熟悉了 C++语言的相关内容,加深了对 C++ 语言的用途的理解。