数据挖掘作业完整版
数据挖掘作业1

数据挖掘技术选修课大作业学院:计算机学院专业:软件工程姓名:王小妮班级:软工1201学号:12080101071.1数据挖掘技术的定义1.2数据挖掘的含义1.3数据挖掘商业角度的定义1.4数据挖掘和数据仓库1.5数据挖掘和在线分析处理1.6软硬件发展对数据挖掘的影响2数据挖掘的典型技术2.1聚类分析2.1关联规则2.3回归分析2.4其他技术3数据挖掘技术的应用3.1在intnet的应用3.2在金融的应用4学习收获参考文献:1.1数据挖掘技术的定义数据挖掘(Data Mining)就是从大量的、不完全的、有噪声的、模糊的、随机的实际应用数据中,提取隐含在其中的、人们事先不知道的、但又是潜在有用的信息和知识的过程。
1.2数据挖掘技术的含义与数据挖掘相近的同义词有数据融合、数据分析和决策支持等。
这个定义包括好几层含义:数据源必须是真实的、大量的、含噪声的;发现的是用户感兴趣的知识;发现的知识要可接受、可理解、可运用;并不要求发现放之四海皆准的知识,仅支持特定的发现问题。
----何为知识?从广义上理解,数据、信息也是知识的表现形式,但是人们更把概念、规则、模式、规律和约束等看作知识。
人们把数据看作是形成知识的源泉,好像从矿石中采矿或淘金一样。
原始数据可以是结构化的,如关系数据库中的数据;也可以是半结构化的,如文本、图形和图像数据;甚至是分布在网络上的异构型数据。
发现知识的方法可以是数学的,也可以是非数学的;可以是演绎的,也可以是归纳的。
发现的知识可以被用于信息管理,查询优化,决策支持和过程控制等,还可以用于数据自身的维护。
因此,数据挖掘是一门交叉学科,它把人们对数据的应用从低层次的简单查询,提升到从数据中挖掘知识,提供决策支持。
在这种需求牵引下,汇聚了不同领域的研究者,尤其是数据库技术、人工智能技术、数理统计、可视化技术、并行计算等方面的学者和工程技术人员,投身到数据挖掘这一新兴的研究领域,形成新的技术热点。
数据挖掘作业

数据挖掘作业作业⼀:1. 给出⼀个例⼦,其中数据挖掘对于商务的成功是⾄关重要的。
该商务需要什么数据挖掘功能?它们能够由数据查询处理或简单的统计分析来实现吗?答:1)Yahoo!通过对⽤户使⽤⾏为的意外模式分析,发现在每次会话中,⼈们阅读邮件和阅读新闻的⾏为之间存在很强的相关关系。
Yahoo!电⼦邮箱产品⼩组验证了这种关系的影响:在⼀组测试⽤户的邮箱⾸页上显⽰⼀个新闻模块,其中的新闻标题被醒⽬显⽰。
⽤户的流失率显著下降,实际上,在这次试验中,最弱的⼀组流失率下降了40%!于是Yahoo!⽴刻开发并完善了新闻模块,并嵌⼊Yahoo!电⼦邮箱的⾸页,到现在,上亿的消费者都可以看到并使⽤这种产品。
可见,数据挖掘对商务的成功是⾄关重要的。
2)该商务应⽤了关联规则数据挖掘功能。
3)⽤于数据或信息检索的数据查询处理不具有发现关联规则能⼒。
同样,简单的统计分析不能处理⼤量的数据。
2. 使⽤你熟悉的⽣活中的数据库,给出关联规则挖掘、序列模式分析、分类、聚类、孤⽴点分析等数据挖掘功能的例⼦。
答:关联规则挖掘的例⼦:如果顾客买了尿⽚与⽜奶,他很可能买啤酒。
把啤酒放在尿⽚的附近。
序列模式分析的例⼦:买了喷墨打印机的的顾客中,80%的⼈三个⽉后⼜买了墨盒。
分类数据挖掘功能的例⼦:信⽤卡发放聚类数据挖掘功能的分析:⼈脸识别孤⽴点分析的例⼦:信⽤卡公司需要检测⼤量的⽀付⾏为。
可以利⽤⽀付⾏为中的地点、⽀付类型以及⽀付频率等信息检测出孤⽴点。
3. 与挖掘少量数据相⽐,挖掘海量数据的挑战有哪些?答:1)规模⼤⾼效算法, 并⾏处理2)⾼维特性导致搜索空间指数级的增长,维度约减3)过拟合因过分强调对训练样本的效果导致过度拟合,使得对未知预测样本效果就会变差4)动态、缺失、噪⾳数据5)领域知识的运⽤6)模式的可理解性2.4 假设医院对18个随机挑选的成年⼈检查年龄和⾝体肥胖,得到如下结果:(a) 计算age 和%fat 的均值、中位数和标准差。
数据挖掘作业——林雪燕——2012E8018661082

数据挖掘Part I:手写作业:Part II: 上机作业:Recommendation Systems Hand-in: The list of association rules generated by the model.设置min-support=5%,min-confidence=50%,如图所示:结果如下图所示:关联规则如下:⇒biscuits m ilk yoghurt milk⇒⇒tom ato souse pastatomato souse milk⇒∧⇒pasta water milk⇒juices milk∧⇒biscuits pasta milk⇒rice pasta∧⇒tomato souse pasta milk∧⇒coffee pasta milk∧⇒tomato souse milk pasta∧⇒biscuits w ater m ilkbrioches pasta milk∧⇒∧⇒yoghurt pasta milkSort the rules by lift, support, and confidence, respectively to see the rules identified. Hand-in: For each case, choose top 5 rules (note: make sure no redundant rules in the 5 rules) and give 2-3 lines comments. Many of the rules will be logically redundant and therefore will have to be eliminated after you think carefully about them.按support排序:support最高的5个规则是:1.biscuits m ilk⇒2.yoghurt milk⇒3.tom ato souse pasta⇒4.tomato souse milk⇒5.pasta water milk∧⇒按support排序的前5个规则没有冗余规则。
数据挖掘作业

证明决策树生长的计算时间最多为 m D log( D ) 。
3.4 考虑表 3-23 所示二元分类问题的数据集。 表 3-23 习题 3.4 数据集
A
B
类标号
T
F
+
T
T
+
T
T
+
T
F
-
T
T
+
F
F
-
F
F
-
F
F
-
T
T
-
T
F
-
(1) 计算按照属性 A 和 B 划分时的信息增益。决策树归纳算法将会选择那个属性?
y ax 转换成可以用最小二乘法求解的线性回归方程。
表 3-25 习题 3.8 数据集
X 0.5 3.0 4.5 4.6 4.9 5.2 5.3 5.5 7.0 9.5
Y-
-
+++-
-
+-
-
根据 1-最近邻、 3-最近邻、 5-最近邻、 9-最近邻,对数据点 x=5.0 分类,使用多数表决。
3.9 表 3-26 的数据集包含两个属性 X 与 Y ,两个类标号“ +”和“ -”。每个属性取三个不同值策略: 0,1 或
记录号
A
B
C
类
1
0
0
0
+
2
0
0
1
-
3
0
1
1
-
4
0
1
1
-
5
0
0
1
+
6
1
0
1
+
7
1
SAS数据挖掘大作业最终版本
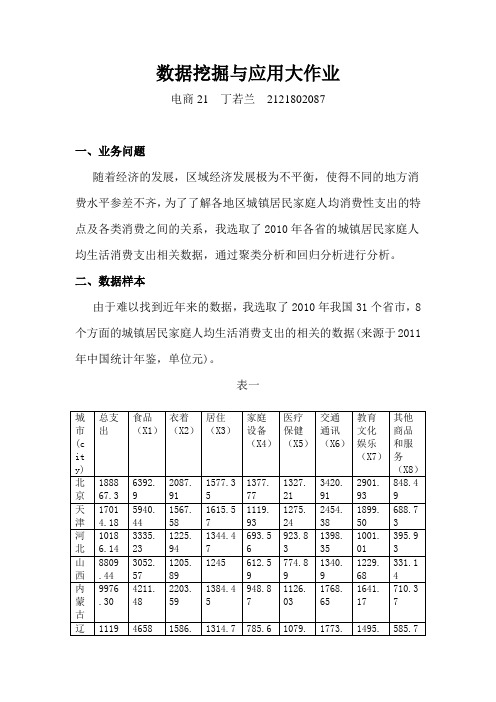
数据挖掘与应用大作业电商21 丁若兰2121802087一、业务问题随着经济的发展,区域经济发展极为不平衡,使得不同的地方消费水平参差不齐,为了了解各地区城镇居民家庭人均消费性支出的特点及各类消费之间的关系,我选取了2010年各省的城镇居民家庭人均生活消费支出相关数据,通过聚类分析和回归分析进行分析。
二、数据样本由于难以找到近年来的数据,我选取了2010年我国31个省市,8个方面的城镇居民家庭人均生活消费支出的相关的数据(来源于2011年中国统计年鉴,单位元)。
表一三、分析方法1、聚类分析首先是导入数据图一然后通过运行以下程序进行聚类分析proc tree horizontal;id v;run;运行结果如下图图二2、回归分析(1)进行回归分析的程序如下proc factor data=A;var X1-X8;run;结果如下图图三由上图可知X3(居住)和X5(医疗保健)外,其它的相关性都太高,要剔除掉,再进行一次相关性分析。
(2)程序如下proc reg data=A;model city=X3 X5;run;结果如下图图四四、分析结果由图二可知,31个城市的消费由聚类给分析大致可以分成5种类型。
由图三、图四可知食品消费(X1)、衣着消费(X2)、居住消费(X3)、家庭设备消费(X4)、医疗保健消费(X5)、交通通讯消费(X6)、教育文化娱乐消费(X7)、其他商品和服务的消费(X8)这八类消费的相关性太强了,剔除了X1、X2、X4、X6、X7、X8。
所以,总消费主要是由居住消费(X3)和医疗保健消费(X5)影响的。
数据挖掘大作业例子

数据挖掘大作业例子1. 超市购物数据挖掘呀!想想看,如果把超市里每个顾客的购买记录都分析一遍,那岂不是能发现很多有趣的事情?比如说,为啥周五晚上大家都爱买啤酒和薯片呢,是不是都打算周末在家看剧呀!2. 社交媒体情感分析这个大作业超有意思哦!就像你能从大家发的文字里看出他们今天是开心还是难过,那简直就像有了读心术一样神奇!比如看到一堆人突然都在发伤感的话,难道是发生了什么大事情?3. 电商用户行为挖掘也很棒呀!通过分析用户在网上的浏览、购买行为,就能知道他们喜欢什么、不喜欢什么,这难道不是很厉害吗?就像你知道了朋友的喜好,能给他推荐最适合的礼物一样!4. 交通流量数据分析呢!想象一下,了解每个路口的车流量变化,是不是就能更好地规划交通啦?难道这不像是给城市的交通装上了一双明亮的眼睛?5. 医疗数据挖掘更是不得了!能从大量的病例中找到疾病的规律,这简直是在拯救生命啊!难道这不是一件超级伟大的事情吗?比如说能发现某种疾病在特定人群中更容易出现。
6. 金融交易数据挖掘也超重要的呀!可以知道哪些交易有风险,哪些投资更靠谱,那不就像有个聪明的理财顾问在身边吗!就好比能及时发现异常的资金流动。
7. 天气数据与出行的结合挖掘也很有趣呀!根据天气情况来预测大家的出行选择,真是太神奇了吧!难道不是像有了天气预报和出行指南合二为一?8. 音乐喜好数据挖掘呢!搞清楚大家都喜欢听什么类型的音乐,从而能更好地推荐歌曲,这不是能让人更开心地享受音乐吗!好比为每个人定制了专属的音乐播放列表。
9. 电影票房数据挖掘呀!通过分析票房数据就能知道观众最爱看的电影类型,这不是超厉害的嘛!就像知道了大家心里最期待的电影是什么样的。
我觉得数据挖掘真的太有魅力了,可以从各种看似普通的数据中发现那么多有价值的东西,真是让人惊叹不已啊!。
数据挖掘作业2

数据挖掘作业2一、任务背景与目的数据挖掘作业2旨在通过应用数据挖掘技术,从给定的数据集中发现有价值的信息和模式,以帮助决策者做出准确的决策。
本次作业的任务是基于一个电子商务网站的用户行为数据,分析用户购买行为,并构建一个预测模型,以预测用户是否会购买某个特定的产品。
二、数据集介绍本次作业使用的数据集包含了一段时间内的用户行为数据,包括用户的浏览、加购物车、购买等行为。
数据集中的字段包括用户ID、时间戳、产品ID、行为类型等。
数据集共有100万条记录。
三、数据预处理1. 数据清洗:对数据集进行清洗,去除重复记录、缺失值等异常数据。
2. 特征选择:根据业务需求和特征的相关性,选择合适的特征进行分析和建模。
3. 特征编码:对类别型特征进行编码,如使用独热编码将类别型特征转换为数值型特征。
4. 数据划分:将清洗和编码后的数据集划分为训练集和测试集,一般采用70%的数据作为训练集,30%的数据作为测试集。
四、数据分析与建模1. 数据可视化:通过绘制柱状图、折线图等方式,对用户行为数据进行可视化分析,了解用户行为的分布和趋势。
2. 关联规则挖掘:使用关联规则算法(如Apriori算法)挖掘用户行为之间的关联关系,发现用户购买某个产品的规律。
3. 用户分类:根据用户的购买行为特征,使用聚类算法(如K-means算法)将用户划分为不同的类别,以便更好地理解用户的购买行为。
4. 预测模型构建:选择合适的机器学习算法(如决策树、随机森林等),构建用户购买行为的预测模型。
五、模型评估与优化1. 模型评估:使用准确率、召回率、F1值等指标对构建的预测模型进行评估,选择最优的模型。
2. 模型优化:根据评估结果,对模型进行调参和优化,以提高模型的准确性和泛化能力。
六、结果分析与报告撰写1. 结果分析:对模型预测结果进行分析,比较不同模型的性能差异,找出影响用户购买行为的主要因素。
2. 报告撰写:根据分析结果,撰写数据挖掘作业2的报告,包括任务背景、数据处理方法、模型构建过程、结果分析等内容。
电子科大数据挖掘作业

数据挖掘课后习题数据挖掘作业1——6第一章绪论1)数据挖掘处理的对象有哪些?请从实际生活中举出至少三种。
1、关系数据库2、数据仓库3、事务数据库4、高级数据库系统和数据库应用如空间数据库、时序数据库、文本数据库和多媒体数据库等,还可以是 Web 数据信息。
实际生活的例子:①电信行业中利用数据挖掘技术进行客户行为分析,包含客户通话记录、通话时间、所开通的服务等,据此进行客户群体划分以及客户流失性分析。
②天文领域中利用决策树等数据挖掘方法对上百万天体数据进行分类与分析,帮助天文学家发现其他未知星体。
③市场业中应用数据挖掘技术进行市场定位、消费者分析、辅助制定市场营销策略等。
2)给出一个例子,说明数据挖掘对商务的成功是至关重要的。
该商务需要什么样的数据挖掘功能?它们能够由数据查询处理或简单的统计分析来实现吗?以一个百货公司为例,它可以应用数据挖掘来帮助其进行目标市场营销。
运用数据挖掘功能例如关联规则挖掘,百货公司可以根据销售记录挖掘出强关联规则,来诀定哪一类商品是消费者在购买某一类商品的同时,很有可能去购买的,从而促使百货公司进行目标市场营销。
数据查询处理主要用于数据或信息检索,没有发现关联规则的方法。
同样地,简单的统计分析没有能力处理像百货公司销售记录这样的大规模数据。
第二章数据仓库和OLAP技术1)简述数据立方体的概念、多维数据模型上的OLAP操作。
●数据立方体数据立方体是二维表格的多维扩展,如同几何学中立方体是正方形的三维扩展一样,是一类多维矩阵,让用户从多个角度探索和分析数据集,通常是一次同时考虑三个维度。
数据立方体提供数据的多维视图,并允许预计算和快速访问汇总数据。
●多维数据模型上的OLAP操作a)上卷(roll-up):汇总数据通过一个维的概念分层向上攀升或者通过维规约b)下卷(drill-down):上卷的逆操作由不太详细的数据到更详细的数据,可以通过沿维的概念分层向下或引入新的维来实现c)切片和切块(slice and dice)投影和选择操作d)转轴(pivot)立方体的重定位,可视化,或将一个3维立方体转化为一个2维平面序列2)OLAP多维分析如何辅助决策?举例说明。
数据挖掘大作业(打印) 2

数据挖掘在客户关系管理中的应用一、数据挖掘技术在客户关系管理中的主要应用领域1、客户关系管理中常用的数据挖掘方法常用的数据挖掘方法主要包括:分类、聚类、关联规则、统计回归、偏差分析等等。
(1)分类:分类在数据挖掘中是一项非常重要的任务。
分类的目的是通过统计方法、机器学习方法(包括决策树法和规则归纳法)、神经网络方法等构造一个分类模型,然后把数据库中的数据映射到给定类别中的某一个。
(2)聚类:聚类是把一组个体按照相似性归成若干类别。
即“物以类聚”。
它的目的是使同一类别之内的相似性尽可能大,而类别之间的相似性尽可能小。
这种方法可以用来对客户进行细分,根据客户的特征和属性把客户分成不同客户群,根据其不同需求,制订针对不同客户群的营销策略。
(3)关联规则:它是描述数据库中数据项之间存在关联的规则,即根据一个事物中某些项的出现可导出另一项在同一事物中也出现,即隐藏在数据间的关联或相互关系。
在客户关系管理中,通过对企业客户数据库里大量数据进行挖掘,可以从中发现有趣的关联关系。
(4)回归分析:回归分析反映的是事务数据库中属性值在时间上的特征.主要用于预测,即利用历史数据自动推出对给定数据的推广描述.从而对未来数据进行预测。
它可应用于商品销售趋势预测、客户赢利能力分析和预测等。
(50偏差分析:偏差分析侧重于发现不规则和异常变化,即与通常不同的事件。
在相类似的客户中,对客户的异常变化要给予密切关注。
例如某客户购买行为发生较大变化,购买量较以前大大减少,就要对客户的这种原因进行调查,避免客户流失。
2、数据挖掘在客户关系管理中的具体运用由于零售业采用P O S机和C R M。
使得顾客的资料及购买信息得以贮存。
在这些海量的数据中存在着许多能对商品决策提供真正有价值的决策信息。
商家面临以下问题是:真正有价值的信息是哪些。
这些信息有哪些关联等等。
因此,需要从大量的数据中, 经过深层分析,从而获得有利商业运作提高企业争力的信息。
数据挖掘作业2

数据挖掘作业2一、任务背景数据挖掘是一项重要的技术,它可以匡助我们从大量的数据中发现有价值的信息和模式。
本次数据挖掘作业2的任务是基于给定的数据集,运用数据挖掘算法进行数据分析和模式发现。
二、数据集介绍本次任务使用的数据集是关于电子商务网站用户行为的数据集。
该数据集包含了用户在网站上的点击、浏览、购买等行为数据,以及用户的个人信息和购买记录。
数据集中的字段包括用户ID、会话ID、时间戳、页面类型、购买行为等。
三、数据预处理在进行数据挖掘之前,我们需要对数据进行预处理,以保证数据的质量和可用性。
预处理的步骤包括数据清洗、数据集成、数据变换和数据规约。
1. 数据清洗数据清洗是指对数据集中的噪声、缺失值和异常值进行处理。
我们可以使用各种方法来处理这些问题,如删除含有缺失值的样本、填补缺失值、删除异常值等。
2. 数据集成数据集成是指将来自不同数据源的数据进行整合,以便进行后续的数据挖掘分析。
在本次任务中,我们可以将用户行为数据和用户个人信息数据进行关联,以获取更全面的信息。
3. 数据变换数据变换是指将原始数据转换为适合进行数据挖掘分析的形式。
在本次任务中,我们可以进行数据标准化、数据离散化、数据归一化等操作,以便于后续的算法处理。
4. 数据规约数据规约是指将数据集进行简化,以便于挖掘出实用的模式。
在本次任务中,我们可以使用抽样、维度规约等方法来减少数据的复杂性和计算量。
四、数据挖掘算法选择根据任务的要求,我们需要选择合适的数据挖掘算法来进行分析和模式发现。
常用的数据挖掘算法包括关联规则挖掘、分类算法、聚类算法等。
1. 关联规则挖掘关联规则挖掘是一种用于发现数据集中的频繁项集和关联规则的方法。
通过分析用户的购买行为,我们可以挖掘出用户购买的商品之间的关联规则,从而为商家提供推荐策略。
2. 分类算法分类算法是一种用于将数据分为不同类别的方法。
通过分析用户的个人信息和购买行为,我们可以构建分类模型,预测用户的购买意向或者判断用户的忠诚度。
数据挖掘作业答案

数据挖掘作业答案第二章数据准备5.推出在[-1,1]区间上的数据的最小-最大标准化公式。
解:标准化相当于按比例缩放,假如将在[minA,maxA]间的属性A的值v映射到区间[new_minA,new_maxA],根据同比关系得:(v-minA)/(v’-new_minA)=(maxA-minA)/(new_maxA-new_minA)化简得:v’=(v-minA)* (new_maxA-new_minA)/ (maxA-minA)+ new_minA6.已知一维数据集X={-5.0 , 23.0 , 17.6 , 7.23 , 1.11},用下述方法对其进行标准化:a) 在[-1,1]区间进行小数缩放。
解:X’={-0.050 ,0.230 ,0.176 ,0.0723 ,0.0111}b) 在[0,1]区间进行最小-最大标准化。
解:X’={0 , 1 , 0.807 ,0.437 ,0.218 }c) 在[-1,1]区间进行最小-最大标准化。
解:X’={-1 , 1 , 0.614 , -0.126 , 0.564}d) 标准差标准化。
解:mean=8.788 sd=11.523X’={-1.197 , 1.233 , 0.765 , -0.135 , -0.666}e) 比较上述标准化的结果,并讨论不同技术的优缺点。
解:小数缩放标准化粒度过大(以10为倍数),但计算简单;最小-最大值标准化需要搜索整个数据集确定最小最大数值,而且最小最大值的专家估算可能会导致标准化值的无意识的集中。
标准差标准化对距离测量非常效,但会把初始值转化成了未被认可的形式。
8.已知一个带有丢失值的四维样本。
X1={0,1,1,2}X2={2,1,*,1}X3={1,*,*,-1}X4={*,2,1,*}如果所有属性的定义域是[0,1,2],在丢失值被认为是“无关紧要的值”并且都被所给的定义域的所有可行值替换的情况下,“人工”样本的数量是多少?解:X1 “人工”样本的数量为 1X2 “人工”样本的数量为 3X3 “人工”样本的数量为9X4 “人工”样本的数量为9所以“人工”样本的数量为1×3×9×9=24310.数据库中不同病人的子女数以矢量形式给出:C={3,1,0,2,7,3,6,4,-2,0,0,10,15,6}a)应用标准统计参数——均值和方差,找出C中的异常点:mean=3.9286 sd=4.4153在3个标准差下的阈值:阈值=均值±3*标准差=3.928±3*4.4153=[-9.318,17.174]根据实际情况子女数不可能为负数,所以其范围可缩减为:[0,17.174]C中的异常点有:-2b)在2个标准差下的阈值:阈值=均值±2*标准差=3.928±2*4.4153=[-4.903,12.758]根据实际情况子女数不可能为负数,所以其范围可缩减为:[0,12.758]C中的异常点有:-2, 1511.已知的三维样本数据集X:X=[{1,2,0},{3,1,4},{2,1,5},{0,1,6},{2,4,3},{4,4,2},{5,2,1},{7,7,7},{0,0,0},{3,3,3}]。
数据挖掘作业

作业作为平时成绩(占20%)的衡量标准:一共有24道题,希望大家认真做,不收打印版!1.什么是数据挖掘?在你的回答中,针对以下问题:(a)它又是一种广告宣传吗?(b)它是一种从数据库、统计学和机器学习发展的技术的简单转换吗?(c) 解释数据库技术发展如何导致数据挖掘。
(d)当把数据挖掘看做知识发现过程时,描述数据挖掘所涉及的步骤。
2.数据仓库和数据库有何不同?有哪些相似之处?3.简述以下高级数据库系统和应用:对象——关系数据库、空间数据库、文本数据库、多媒体数据库、流数据和万维网。
4.定义下列数据挖掘功能:特征化,区分、关联和相关分析、分类、预测、聚类和演变分析。
5.区分和分类的差别是什么?特征化和聚类的差别是什么?分类和预测呢?对于每一对任务,它们有何相似之处。
6.解释为什么概念分层在数据挖掘中是有用的。
7.描述以下数据挖掘系统与数据库或数据仓库集成方法的差别:不耦合、松散耦合、半紧密耦合和紧密耦合。
你认为哪种方法最流行,为什么?8.试描述关于数据挖掘方法和用户交互问题的三个数据挖掘挑战。
9.与挖掘少量数据相比,挖掘海量数据的主要挑战是什么?10.数据的质量可以用精确性、完整性和一致性来评估。
提出数据质量的两种其他尺度。
11.假设给定的数据集的值已经分组为区间。
区间和对应的频率如下:年龄频率年龄频率1~5 200 5~15 45015~20 300 20~50 150050~80 700 80~110 44计算数据的近似中位数值。
12.假定用于分析的数据包含属性age。
数据元组的age值以递增序为:13,15,16,16,19,20,20,21,22,22,25,25,25,25,30,33,33,35,35,35,35,36,40,45,46, 52,70(a)该数据的均值是什么?中位数是什么?(b) 该数据的众数是什么?讨论数据的峰。
(c) 数据的中列数是什么?(d)找出数据的第一个四分位数(Q1)和第三个四分位数(Q3)。
已经完成的数据挖掘作业

五、计算题
(1)假定基本立方体有三个维A,B,C,其单元数如下:|A|=100,000,|B|=10,000,|C|=1,000,假定分块将每维分成10部分
a.请指出方体中内存空间需求量最小的块计算次序和内存空间需求量最大的块计算次序;
b.分别求这两个次序下计算二维平面所需要的内存空间的大小。
(a)为数据仓库画出雪花模式图。
(b)由基本方体[student, course, semester, instructor]开始,为列出Big_University每个学生的CS课程的平均成绩,应当使用哪些OLAP操作(如,由学期上卷到学年)。
(c)如果每维有5层(包括all),如student < major < status < university <all,该数据方包含多少方体(包含基本方体和顶点方体)?
(4)请简述几种典型的多维数据的OLAP操作
答:典型的OLAP操作包括以下几种
上卷:通过一个维的概念分层向上攀升或者通过维归约,在数据立方体上进行聚集;
下钻:上卷的逆操作,由不太详细的数据得到更详细的数据;通常可以通过沿维的概念分层向下或引入新的维来实现;
切片:在给定的数据立方体的一个维上进行选择,导致一个子方;
(2)(6)关于数据仓库的设计,四种不同的视图必须考虑,分别是:自顶向下视图、数据源视图、数据仓库视图、商务查询视图
(3)(7)OLAP服务器的类型主要包括:关系OLAP服务器(ROLAP)、多维OLAP服务器(MOLAP)和混合OLAP服务器(HOLAP)
(4)(8)求和函数sum()是一个分布的
切块:通过对两个或多个维执行选择,定义子方;
数据挖掘作业(第七章)

第4章聚类分析4.1 什么是聚类?简单描述如下的聚类方法:划分方法,层次方法,基于密度的方法,基于模型的方法。
为每类方法给出例子。
4.2 假设数据挖掘的任务是将如下的8个点(用(x,y)代表位置)聚类为三个簇。
A1(2,10),A2(2,5),A3(8,4),B1(5,8),B2(7,5),B3(6,4),C1(1,2),C2(4,9)。
距离函数是Euclidean 函数。
假设初始我们选择A1,B1和C1为每个簇的中心,用k-means 算法来给出(a) 在第一次循环执行后的三个簇中心;(b) 最后的三个簇中心及簇包含的对象。
4.3 聚类被广泛地认为是一种重要的数据挖掘方法,有着广泛的应用。
对如下的每种情况给出一个应用例子:(a) 采用聚类作为主要的数据挖掘方法的应用;(b) 采用聚类作为预处理工具,为其它数据挖掘任务作数据准备的应用。
4.4 假设你将在一个给定的区域分配一些自动取款机以满足需求。
住宅区或工作区可以被聚类以便每个簇被分配一个ATM。
但是,这个聚类可能被一些因素所约束,包括可能影响A TM 可达性的桥梁,河流和公路的位置。
其它的约束可能包括对形成一个区域的每个地域的A TM 数目的限制。
给定这些约束,怎样修改聚类算法来实现基于约束的聚类?4.5 给出一个数据集的例子,它包含三个自然簇。
对于该数据集,k-means(几乎总是)能够发现正确的簇,但二分k-means不能。
4.6 总SSE是每个属性的SSE之和。
如果对于所有的簇,某变量的SSE都很低,这意味什么?如果只对一个簇很低呢?如果对所有的簇都很高?如果仅对一个簇高呢?如何使用每个变量的SSE信息改进聚类?4.7 使用基于中心、邻近性和密度的方法,识别图4-19中的簇。
对于每种情况指出簇个数,并简要给出你的理由。
注意,明暗度或点数指明密度。
如果有帮助的话,假定基于中心即K均值,基于邻近性即单链,而基于密度为DBSCAN。
图4-19 题4.7图4.8 传统的凝聚层次聚类过程每步合并两个簇。
数据挖掘技术平时作业

数据挖掘技术平时作业第一次:1.什么是数据挖掘?当把数据挖掘看作知识发现过程时,描述数据挖掘所涉及的步骤。
【参考答案】数据挖掘是指从大量数据中提取有趣的(有价值的、隐含的、先前未知的、潜在有用的)关系、模式或趋势,并用这些知识与规则建立用于决策支持的模型,提供预测性决策支持的方法。
很多学者把数据挖掘当作另一术语KDD的同义词,而另一些学者把数据挖掘看作KDD的一个步骤。
当把数据挖掘看作知识发现过程时,数据挖掘的过程大致有以下几步:!)数据清理与集成2)任务相关数据分析与选择3)数据挖掘实施4)模式评估5)知识理解与应用第二次:1.在现实世界中,元组在某些属性上缺少值是常有的。
描述处理该问题的各种方法。
【参考答案】处理空缺的属性值有以下几种方法:1)忽略元组2)人工填写空缺值3)自动填充(1)使用全局常量,如用Unknown 或-∞(2)使用属性的平均值(3)使用与给定元组属于同一类的所有样本的平均值(4)使用可能的值:这些值可以用回归、判定树、基于推导的贝叶斯形式化方法等确定2.假定用于分析的数据包含属性age,数据元组中age的值如下:13,15,16,16,19,20,20,21,22,22,25,25,25,25,30,33,33,35,35,35,35,36,40,45,46,52,70a)使用最小-最大规范化,将age值35转换到[0.0,1.0]区间。
【参考答案】根据公式min'(_max_min)_minmax minAA A AA AVV new new new-=-+-进行计算。
根据提供的数据,maxA=70,minA=13,将将age值35转换到[0.0,1.0]区间,有:V’=(35-13)/(70-13)*(1.0-0.0)+0.0=0.386所以,将值35映射到区间[0.0,1.0]后的值为0.386。
b)使用Z-Score规范化转换age值,其中age的标准差为12.94。
数据挖掘作业

第一章:简述数据挖掘技术及数据挖掘步骤一.数据挖掘技术1.数据挖掘的概念(1)数据挖掘 (从数据中发现知识)从大量的数据中挖掘哪些令人感兴趣的、有用的、隐含的、先前未知的和可能有用的模式或知识。
数据挖掘的替换词:数据库中的知识挖掘(KDD),知识提炼,数据/模式分析,数据考古,数据捕捞、信息收获等等。
(2)数据挖掘定义数据挖掘利用人工智能、机器学习、模式识别、统计学和数据库系统,从大量数据中提取人们感兴趣的知识过程,是一门学科知识融合的交叉学科。
数据挖掘是从大量的、不完全的、有噪声的、模糊的、随机的数据集中识别有效的、新颖的、潜在有用的,以及最终可理解的模式的过程。
它是一门涉及面很广的交叉学科,包括机器学习、数理统计、神经网络、数据库、模式识别、粗糙集、模糊数学等相关技术。
2. 数据挖掘的功能数据挖掘通过预测未来趋势及行为,做出前瞻的、基于知识的决策。
数据挖掘的目标是从数据库中发现隐含的、有意义的知识,主要有以下五类功能。
(1)自动预测趋势和行为(2)关联分析(3)聚类(4)概念描述(5)偏差检测3. 数据挖掘的分类(1)数据类型A:关系数据库B:面向对象数据库C:文本数据D:多媒体数据 E:异构数据 F:WWW数据(2)知识类型A:关联挖掘 B:序列模式挖掘 C:聚类挖掘 D:分类挖掘E:孤立点挖掘 F:概化挖掘 G:预测挖掘(3)挖掘方法A:机器学习:归纳学习、基于实例学习、逻辑推理;B:统计方法:回归分析、判别分析、聚类分析;C:公式发现器:寻找与发现连续属性之间的关系;D:可视化技术:对数据的分布规律进行可视化显示;E:仿生物技术:神经网络、遗传算法、支持向量机等等。
4.数据挖掘可发现的知识(1)广义型知识:事物共同性质的知识;(2)特征型知识:反映事物各方面的知识;(3)差异型知识:事物之间属性的差别;(4)关联性知识:事物之间的依赖关系;(5)预测型知识:由过去和现在预测未来;(6)偏离型知识:揭示事物偏离常规的异常现象。
数据挖掘作业

HW1Due Date: Nov. 8Submission requirements:Please submit your solutions to our class website.Part I: written part:1. Suppose that a data warehouse consists of four dimensions, date, spectator, location, and game, andtwo measures, count and charge, where charge is the fare that a spectator pays when watching a game on a given date. Spectators may be students, adults, or seniors, with each category having its owncharge rate.(a) Draw a star schema diagram for the data warehouse.(b)(b) Starting with the base cuboid [date, spectator, location, game],what specific OLAPoperations should one perform in order to list the total charge paid by student spectators in Los Angeles?(c)(c) Bitmap indexing is a very useful optimization technique. Please present the pros and cons ofusing bitmap indexing in this given data warehouse.2.某电子邮件数据库中存储了大量的电子邮件。
数据挖掘作业答案

数据挖掘作业答案数据挖掘作业题⽬+答案华理计算机专业选修课第⼆章:假定⽤于分析的数据包含属性age。
数据元组中age值如下(按递增序):13 ,15 ,16 ,16 ,19 ,20 ,20,21 ,22 ,22,25 ,25 ,25 ,25 ,30 ,33 ,33 ,35 ,35 ,35,35,36,40,45,46,52,70.分别⽤按箱平均值和边界值平滑对以上数据进⾏平滑,箱的深度为3.使⽤最⼩-最⼤规范化,将age值35转换到[0.0,1.0]区间使⽤z-Score规范化转换age值35 ,其中age的标准差为12.94年。
使⽤⼩数定标规范化转换age值35。
画⼀个宽度为10的等宽直斱图。
该数据的均值是什么?中位数是什么?该数据的众数是什么?讨论数据的峰(即双峰,三峰等)数据的中列数是什么?(粗略地)找出数据的第⼀个四分位数(Q1 )和第三个四分位数(Q3 )给出数据的五数概括画出数据的盒图第三章假定数据仓库包含三个维:time doctor和patient ;两个度量:count和charge;其中charge是医⽣对病⼈⼀次诊治的收费。
画出该数据仓库的星型模式图。
由基本⽅体[day, doctor, patient]开始,为列出2004年每位医⽣的收费总数,应当执⾏哪些OLAP操作。
如果每维有4层(包括all ),该⽴⽅体包含多少⽅体(包括基本⽅体和顶点⽅体)?第五章数据库有4个事务。
设min_sup=60%,min_conf=80%TID Itmes_boughtT100 {K,A,D,B}T200 {D,A,C,E,B}T300 {C,A,B,E}T400 {B,A,D}分别使⽤Apriori和FP-增长算法找出频繁项集。
列出所有的强关联规则(带⽀持度s和置信度c ),它们不下⾯的元规则匹配,其中,X是代表顼客的变量,itmei是表⽰项的变量(例如:A、B等)下⾯的相依表会中了超级市场的事务数据。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
数据挖掘作业HEN system office room 【HEN16H-HENS2AHENS8Q8-HENH1688】1、给出K D D的定义和处理过程。
KDD的定义是:从大量数据中提取出可信的、新颖的、有用的且可以被人理解的模式的高级处理过程。
因此,KDD是一个高级的处理过程,它从数据集中识别出以模式形式表示的知识。
这里的“模式”可以看成知识的雏形,经过验证、完善后形成知识:“高级的处理过程”是指一个多步骤的处理过程,多步骤之间相互影响反复调整,形成一种螺旋式上升的过程。
KDD的全过程有五个步骤:1、数据选择:确定发现任务的操作对象,即目标数据,它是根据用户的需要从原始数据库中抽取的一组数据;2、数据预处理:一般可能包括消除噪声、推到技术却只数据、消除重复记录、完成数据类型转换等;3、数据转换:其主要目的是消减数据维数或降维,即从初始特征中找出真正有用的特征以减少数据开采时要考虑的特征或变量个数;4、数据挖掘:这一阶段包括确定挖掘任务/目的、选择挖掘方法、实施数据挖掘;5、模式解释/评价:数据挖掘阶段发现出来的模式,经过用户或机器的评价,可能存在冗余或无关的模式,需要剔除;也有可能模式不满足用户的要求,需要退回到整个发现阶段之前,重新进行KDD过程。
2、阐述数据挖掘产生的背景和意义。
数据挖掘产生的背景:随着信息科技的进步以及电子化时代的到来,人们以更快捷、更容易、更廉价的方式获取和存储数据,使得数据及信息量以指数方式增长。
据粗略估计,一个中等规模企业每天要产生100MB以上的商业数据。
而电信、银行、大型零售业每天产生的数据量以TB来计算。
人们搜集的数据越来越多,剧增的数据背后隐藏着许多重要的信息,人们希望对其进行更高层次的分析,以便更好的利用这些数据。
先前的数据库系统可以高效的实现数据的录入、查询、统计等功能,但无法发现数据中存在的关系与规则,无法根据现有的数据来预测未来的发展趋势。
缺乏挖掘数据背后隐藏的知识的手段。
导致了“数据爆炸但知识贫乏”的现象。
于是人们开始提出“要学会选择、提取、抛弃信息”,并且开始考虑:如何才能不被信息淹没如何从中及时发现有用的知识、提高信息利用率如何从浩瀚如烟海的资料中选择性的搜集他们认为有用的信息这给我们带来了另一些头头疼的问题:第一是信息过量,难以消化;第二是信息真假难以辨别;第三是信息安全难以保证;第四是信息形式不一致,难以统一处理面对这一挑战,面对数量很大而有意义的信息很难得到的状况面对大量繁杂而分散的数据资源,随着计算机数据仓库技术的不断成熟,从数据中发现知识(KnowledgeDiscoveryinDatabase)及其核心技术——数据挖掘(DataMining)便应运而生,并得以蓬勃发展,越来越显示出其强大的生命力。
数据挖掘的意义:数据挖掘之所以被称为未来信息处理的骨干技术之一,主要在于它正以一种全新的概念改变着人类利用数据的方式。
在20世纪,数据库技术取得了重大的成果并且得到了广泛的应用。
但是,数据库技术作为一种基本的信息储存和管理方式,仍然是以联机事务处理为核心应用,缺少对决策、分析、预测等高级功能的支持机制。
众所周知,随着硬盘存储容量及的激增以及磁盘阵列的普及,数据库容量增长迅速,数据仓库以及Web等新型数据源出现,联机分析处理、决策支持以及分类、聚类等复杂应用成为必然。
面对这样的挑战,数据挖掘和知识发现技术应运而生,并显现出强大的生命力。
数据挖掘和知识发现使数据处理技术进入了一个更加高级的阶段。
它不仅能对过去的数据进行查询,而且能够找出过去数据之间的潜在联系,进行更高层次的分析,以便更好地作出决策、预测未来的发展趋势等等。
通过数据挖掘,有价值的知识、规则或更高层次的信息就能够从数据库的相关数据集合中抽取出来,从而使大型数据库作为一个丰富、可靠的资源为知识的提取服务。
3、给出一种关联规则的算法描述,并举例说明。
Apriori算法描述:Apriori算法由Agrawal等人于1993年提出,是最有影响的挖掘布尔关联规则频繁项集的算法,它通过使用递推的方法生成所有频繁项目集。
基本思想是将关联规则挖掘算法的设计分解为两步:(1)找到所有频繁项集,含有k个项的频繁项集称为k-项集。
Apriori使用一种称作逐层搜索的迭代方法,k-项集用于探索(k+1)-项集。
首先,出频繁1-项集的集合。
该集合记作L1。
L1用于找频繁2-项集的集合L2,而L2用于找L3,如下去,直到不能找到频繁k-项集。
找出每个Lk都需要一次数据库扫描。
为提高频繁项集层产生的效率,算法使用Apriori性质用于压缩搜索空间。
(2)使用第一步中找到的频繁项集产生关联规则。
从算法的基本思想可知,Apriori算法的核心和关键在第一步。
而第一步的关键是如何将Apriori性质用于算法,利用Lk-1找Lk。
这也是一个由连接和剪枝组成的两步过程:(1)连接步:为找Lk,通过Lk-1与自己连接产生候选k-项集的集合。
该候选项集的集合记作Ck。
设l1和l2是Lk-1中的项集。
记号li[j]表示li的第j项(例如,l1[k-2]表示l1的倒数第3项)。
为方便计,假定事务或项集中的项按字典次序排序。
执行连接Lk-1Lk-1;其中,Lk-1的元素是可连接的,如果它们前(k-2)项相同;即Lk-1的元素l1和l2是可连接的,如果(l1[1]=l2[1])∧(l1[2]=l2[2])∧...∧(l1[k-2]=l2[k-2])∧(l1[k-1]<l2[k-1])。
条件(l1[k-1]<l2[k-1])是简单地保证不产生重复。
连接l1和l2产生的结果项集是l1[1]l1[2]...l1[k-1]l2[k-1]。
(2)剪枝步:Ck是Lk的超集;即,它的成员可以是,也可以不是频繁的,但所有的频繁k-项集都包含在Ck中。
扫描数据库,确定Ck中每个候选的计数,从而确定Lk(即,根据定义,计数值不小于最小支持度计数的所有候选是频繁的,从而属于Lk)。
然而,Ck可能很大,这样所涉及的计算量就很大。
为压缩Ck,可以用以下办法使用Apriori性质:任何非频繁的(k-1)-项集都不可能是频繁k-项集的子集。
因此,如果一个候选k-项集的(k-1)-子集不在Lk-1中,则该候选也不可能是频繁的,从而可以由Ck中删除。
Apriori算法举例:如有如下数据每一行表示一条交易,共有9行,既9笔交易,左边表示交易ID,右边表示商品名称。
最小支持度是22%,那么每件商品至少要出现9*22%=2次才算频繁。
第一次扫描数据库,使得在每条交易中,按商品名称递增排序。
第二次扫描数据,找频繁项集为1的元素有:左边表示商品名称,右边表示出现的次数,都大于阈值2。
在此基础上找频繁项集是2的元素,方法是两两任意组合,第三次扫描数据得到它们出现的次数:此时就有规律性了,在频繁项集为K的元素上找频繁项集为K+1的元素的方法是:在频繁项集为K的项目(每行记录)中,假如共有N行,两两组合,满足两两中前K-1个元素相同,只后一个元素要求前一条记录的商品名称小于后一条记录的商品名称,这样是为了避免重复组合,求它们的并集得到长度为K+1的准频繁项集,那么最多共有Apriori算法种可能的组合,有:想想如果N很大的话,Apriori算法是一个多么庞大的数字,这时就要用到Apriori的核心了:如果K+1个元素构成频繁项集,那么它的任意K个元素的子集也是频繁项集。
然后将每组K+1个元素的所有长度为K的子集,有Apriori算法中组合,在频繁项集为K的项集中匹配,没有找到则删除,用第一条记录{I1,I2,I3}它的长度为2的频繁项集有:Apriori算法分别是:{I1,I2},{I1,I3},{I2,I3}种情况,幸好这三种情况在频繁项集为2的项集中都找到了。
通过这步过滤,得到的依旧是准频繁项集,它们是:此时第四次扫描数据库,得到真正长度为3的频繁项集是:因为{I1,I2,I4}只出现了1次,小于最小支持度2,删除。
就这个例子而言,它的最大频繁项集只有3,就是{I1,I2,I3}和{I1,I2,I5}。
4、给出一种聚类算法描述,并举例说明。
k-means 算法是一种属于划分方法的聚类算法,通常采用欧氏距离作为 2 个样本相似程度的评价指标,其基本思想是:随机选取数据集中的 k 个点作为初始聚类中心,根据数据集中的各个样本到k 个中心的距离将其归到距离最小的类中,然后计算所有归到各个类中的样本的平均值,更新每个类中心,直到平方误差准则函数稳定在最小值。
算法步骤:1.为每个聚类确定一个初始聚类中心,这样就有K 个初始聚类中心。
2.将样本集中的样本按照最小距离原则分配到最邻近聚类3.使用每个聚类中的样本均值作为新的聚类中心。
4.重复步骤步直到聚类中心不再变化。
k-means 算法举例:数据对象集合S 见下表,作为一个聚类分析的二维样本,要求的簇的数量k=2。
(1)选择 , 为初始的簇中心,即 , (2)对剩余的每个对象,根据其与各个簇中心的距离,将它赋给最近的簇。
对 : 显然,故将 分配给 对于 : 因为,所以将 分配给 对于: 因为,所以将 分配给 更新,得到新簇 和 计算平方误差准则,单个方差为总体平均方差是: (3)计算新的簇的中心。
重复(2)和(3),得到O 1分配给C 1;O 2分配给C 2,O 3分配给C 2 ,O 4分配给C 2,O 5分配给C 1。
更新,得到新簇 和 。
中心为, 。
单个方差分别为总体平均误差是: 由上可以看出,第一次迭代后,总体平均误差值~,显着减小。
由于在两次迭代中,簇中心不变,所以停止迭代过程,算法停止。
()10,2O 20,0O()110,2M O ==()220,0M O ==3O ()13, 2.5d M O ==()23, 1.5d M O ==()()2313,,d M O d M O ≤3O 2C 4O ()14,d M O ==()24,5M O ==()()2414,,d M O d M O ≤4O 5O ()15,5d M O ==()25,d M O ==()()1525,,d M O d M O ≤5O 1C {}115,C O O ={}2234,,C O O O =()())(()222210022052225E ⎡⎤⎤⎡=-+-+-+-=⎣⎣⎦⎦122527.2552.25E E E =+=+=()()()()2,5.2222,2501=++=M {}115,C O O ={}2234,,C O O O =()2,5.21=M ()2 2.17,0M =()())(()222210 2.522 2.552212.5E ⎡⎤⎤⎡=-+-+-+-=⎣⎣⎦⎦5、 给出一种分类的算法描述,并举例说明。