《数据结构实用教程(C语言版)》第7章 查找
实用数据结构(C++描述)(第二版)第7章

/*函数返回被查找元素x在线性表中的序号, 如果在线性表中不存在元素值x,则返回-1 */ int serch(v,n,x) int n; ET v[],x; /*ET为线性表数据类型*/ { int k; k=0; while ((k<n)&&(v[k]≠x)) k=k+1; if (k==n) k=-1; return(k); }
第7章 查找技术
7.1 7.2 7.3 7.4 7.5
顺序查找 有序表的对分查找 分块查找 二叉排序树查找 多层索引树查找
查找(Searching)又称检索,就是从一个数据 元素集合中找出某个特定的数据元素。它是数据 处理中经常使用的一种重要操作,尤其是当所涉 及的数据量较大时,查找算法的优劣对整个软件 系统的效率影响是很大的。好的查找方法可以极 大地提高程序的运行速度。
struct node { ET d; struct node *next; }; /*函数返回被查找元素x所在结点的存储地址, 如果在线性链表中不存在元素值为x的结点,则返回NULL*/ struct node *lserch(head,x) struct node *head; ET x; /*ET为线性链表中值域的数据类型*/ { struct node k; k=head; while ((k≠NULL)&&(k->d≠x)) k=k->next; return(k); }
int bserch(v,n,x) /*函数返回被查找元素x在线性表中的序号 如果在线性表中不存在元素值x,则返回-1 */ int n; ET x,v[]; { int i,j,k; i=1; j=n; while (i<=j) { k=(i+j)/2; if (v[k-1]==x) return(k-1); if (v[k-1]>x) j=k-1; else i=k+1; } return(-1); }
数据结构-第7章 查找
}
北京林业大学信息学院
2020年12月16日
顺序查找的性能分析
• 空间复杂度:一个辅助空间。 • 时间复杂度: 1) 查找成功时的平均查找长度
-1 2 3-4 5 6-7 8 9-10 11 h
1-2 2-3
4-5 5-6
7-8 8-9 10-11 11-
外结点
查找成功时比较次数:为该结点在判定树上的层次数,不超过树 的深度 d = log2 n + 1
查找不成功的过程就是走了一条从根结点到外部结点的路径d或 d-1。
北京林业大学信息学院
顺序查找
应用范围: 顺序表或线性链表表示的静态查找表 表内元素之间无序
顺序表的表示
typedef struct { ElemType *R; //表基址 int length; //表长
}SSTable;
北京林业大学信息学院
2020年12月16日
第2章在顺序表L中查找值为e的数据元素
int LocateELem(SqList L,ElemType e) { for (i=0;i< L.length;i++)
2020年12月16日
折半查找
123456 5 13 19 21 37 56
若k==R[mid].key,查找成功 若k<R[mid].key,则high=mid-1 若k>R[mid].key,则low=mid+1
找21
数据结构实用教程(C语言版)

02
03
树的定义
树是一种非线性数据结构, 由节点和边组成,具有层 次结构。
树的基本操作
包括创建树、插入节点、 删除节点、查找节点等。
树的表示方法
常用表示方法包括孩子表 示法、孩子兄弟表示法等。
二叉树的定义和基本性质
二叉树的定义
二叉树是一种特殊的树,每个节点最多有两个子节点,分 别称为左子节点和右子节点。
数据结构实用教程(c语言版)
目 录
• 引言 • 线性表 • 栈和队列 • 树和二叉树 • 图和网络 • 查找和排序 • 数据结构应用实例分析
01 引言
数据结构的重要性
01
数据结构是计算机科学的基础
数据结构是计算机科学的核心内容之一,它研究如何有效地组织、存储
和处理数据,为算法设计和程序实现提供基础支持。
Dijkstra算法和Floyd算法是常用的最短路径算法,用于求解图中两个顶点之间的最短 路径。
最小生成树算法
Prim算法和Kruskal算法是常用的最小生成树算法,用于求解连通图的最小生成树,即 连接所有顶点的边的权值和最小的子图。
网络流算法和应用
网络流算法
Ford-Fulkerson算法和Edmonds-Karp算 法是常用的网络流算法,用于求解最大流和 最小割等问题。
实例四:图的着色问题
• 问题描述:图的着色问题是一个著名的NP完全问题,它要求给图中的每个顶点 着色,使得相邻的顶点颜色不同,并且使用的颜色数量最少。
• 数据结构应用:图的着色问题可以使用邻接矩阵或邻接表来表示图的结构。邻 接矩阵是一个二维数组,用于表示顶点之间的连接关系;邻接表则使用链表来 表示每个顶点的邻居节点。在图的着色过程中,我们可以使用数组来保存每个 顶点的颜色。
《数据结构(C语言版 第2版)》(严蔚敏 著)第七章练习题答案

《数据结构(C语言版第2版)》(严蔚敏著)第七章练习题答案第7章查找1.选择题(1)对n个元素的表做顺序查找时,若查找每个元素的概率相同,则平均查找长度为()。
A.(n-1)/2B.n/2C.(n+1)/2D.n答案:C解释:总查找次数N=1+2+3+…+n=n(n+1)/2,则平均查找长度为N/n=(n+1)/2。
(2)适用于折半查找的表的存储方式及元素排列要求为()。
A.链接方式存储,元素无序B.链接方式存储,元素有序C.顺序方式存储,元素无序D.顺序方式存储,元素有序答案:D解释:折半查找要求线性表必须采用顺序存储结构,而且表中元素按关键字有序排列。
(3)如果要求一个线性表既能较快的查找,又能适应动态变化的要求,最好采用()查找法。
A.顺序查找B.折半查找C.分块查找D.哈希查找答案:C解释:分块查找的优点是:在表中插入和删除数据元素时,只要找到该元素对应的块,就可以在该块内进行插入和删除运算。
由于块内是无序的,故插入和删除比较容易,无需进行大量移动。
如果线性表既要快速查找又经常动态变化,则可采用分块查找。
(4)折半查找有序表(4,6,10,12,20,30,50,70,88,100)。
若查找表中元素58,则它将依次与表中()比较大小,查找结果是失败。
A.20,70,30,50B.30,88,70,50C.20,50D.30,88,50答案:A解释:表中共10个元素,第一次取⎣(1+10)/2⎦=5,与第五个元素20比较,58大于20,再取⎣(6+10)/2⎦=8,与第八个元素70比较,依次类推再与30、50比较,最终查找失败。
(5)对22个记录的有序表作折半查找,当查找失败时,至少需要比较()次关键字。
A.3B.4C.5D.6答案:B解释:22个记录的有序表,其折半查找的判定树深度为⎣log222⎦+1=5,且该判定树不是满二叉树,即查找失败时至多比较5次,至少比较4次。
(6)折半搜索与二叉排序树的时间性能()。
数据结构:第七章 查找

索引表
22 48 86 1 7 13
查38
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 22 12 13 8 9 20 33 42 44 38 24 48 60 58 74 57 86 53
查找方法比较
ASL 表结构 存储结构
顺序查找 最大
折半查找 最小
关键字输入顺序:45,24,53,12,28,90
45
24
53
12
28
90
9.4 哈希查找
基本思想:在记录的存储地址和它的关键字之间建立一 个确定的对应关系(函数关系);这样,不经过比较, 直接通过计算就能得到所查元素。
一、定义
❖哈希函数——在记录的关键字与记录的存储地址之间 建立的一种对应关系叫哈希函数。
high low
1 2 3 4 5 6 7 8 9 10 11 5 13 19 21 37 56 64 75 80 88 92
6
56
3
9
19
80
1
4
7
10
5 21 64 88
比较1次 比较2次 比较3次
2
13
5
8
37 75
11
92
比较4次
判定树(二叉排序树):描 述查找过程的二叉树
把当前查找区间的中间位 置上的结点作为根,左子表 和右子表中的结点分别作 为根的左子树和右子树
适用条件:采用顺序存储结构的有序表。 算法实现
❖设表长为n,low、high 和 mid分别指向待查元素所 在区间的上界、下界和中点,k为给定值
❖初始时,令low=1, high=n, mid=(low+high)/2 ❖让k与mid指向的记录比较
《数据结构(C语言)》第7章 查找

教学要求
❖ 建议学时:6学时 ❖ 总体要求
掌握顺序查找、折半查找的实现方法; 掌握动态查找表(二叉排序树、二叉平衡树)的构造
和查找方法; 掌握哈希表、哈希函数a structures
教学要求
❖ 相关知识点
顺序查找、折半查找的基本思想、算法实现和查找效 率分析
Data structures
静态查找表
❖ 顺序查找
❖1. 一般线性表的顺序查找
(2) 静态查找表的顺序存储结构
静态查找表采用顺序存储结构,其类型定义如下:
typedef struct
{ ElemType *elem; 建表时按实际长度分配*/
/*元素存储空间基址,
int TableLen;
/*表的长度*/
Data structures
静态查找表
❖ 分块查找
索引表的类型定义如下:
typedef struct{
Elemtype key;
/*块内最大关键字值*/
int stadr; 的位置*/
/*块中第一个记录
}indexItem;
typedef struct{
indexItem elem[n];
int length;
Data structures
静态查找表
❖ 折半查找
4.折半查找算法 算法7.2 折半查找算法
else if(L.elem[mid].key>key)high=mid-1; 前半部分继续查找*/
else low=mid+1; /*从后半部分继续查找*/
}
return -1; /*顺序表中不存在待查元素*/
(1) 基本思想 从线性表的一端开始,逐个检查关键字是否满足给定
数据结构》第七章查找

(最坏情况)
可编辑ppt
11
7.2 顺序查找
成功查找的平均查找长度为(n+1)/2。显然不成功 查找次数为n+1,其时间复杂度均为 O(n)。
顺序查找的优点是:算法简单且适用面广,它对表的 结构无任何要求。无论记录是否按关键字的大小有序,其 算法均可应用,而且上述讨论对线性链表也同样适用。
顺序查找的缺点是:查找效率低,当 n 较大时,不宜 采用顺序查找。
中
5 13 19 21 37 56 64 75 80 88 92
low>high 查找失败
123456
low high
mid 7 8 9 10 11
5 13 19 21 37 56 64 75 80 88 92
可编辑ppt
16
high low
7.3 二分法查找
从二分法查找的执行情况分析,每做一次比较,查找的 范围都缩小一半。因此二分法查找的平均查找长度为
【答案】
查找成功时,最少比较1次,最多比较5次。
2、已知如下11个数据元素的有序表(6,14,19, 21,36,57,63,76,81,89,93),请画出 查找键值为21和85的查找过程。
可编辑ppt
18
7.4 分块查找
可编辑ppt
10
01 64 5
23456 13 19 21 37 56
找64 7 8 9 10 11 64 75 80 88 92
监视哨
比较次数:
查找第n个元素: 1
查找第n-1个元素:2
……….
查找第1个元素: n
查找第i个元素: n+1-i
查找失败:
n+1
iiiii
数据结构 C语言版(严蔚敏版)第7章 图

1
2
4
1
e6 2 4
2016/11/7
29
7.3 图的遍历
从已给的连通图中某一顶点出发,沿着一 些边访遍图中所有的顶点,且使每个顶点 仅被访问一次,就叫做图的遍历 ( Graph Traversal )。 图中可能存在回路,且图的任一顶点都可 能与其它顶点相通,在访问完某个顶点之 后可能会沿着某些边又回到了曾经访问过 的顶点。 为了避免重复访问,可设置一个标志顶点 是否被访问过的辅助数组 visited [ ]。
2
1 2
V2
V4
17
结论:
无向图的邻接矩阵是对称的; 有向图的邻接矩阵可能是不对称的。 在有向图中, 统计第 i 行 1 的个数可得顶点 i 的出度,统计第 j 行 1 的个数可得顶点 j 的入度。 在无向图中, 统计第 i 行 (列) 1 的个数可得 顶点i 的度。
2016/11/7
18
2
邻接表 (出度表)
adjvex nextarc
data firstarc
0 A 1 B 2 C
2016/11/7
1 0 1
逆邻接表 (入度表)
21
网络 (带权图) 的邻接表
6 9 0 2 1 C 2 8 3 D
data firstarc Adjvex info nextarc
2016/11/7
9
路径长度 非带权图的路径长度是指此路径 上边的条数。带权图的路径长度是指路径 上各边的权之和。 简单路径 若路径上各顶点 v1,v2,...,vm 均不 互相重复, 则称这样的路径为简单路径。 回路 若路径上第一个顶点 v1 与最后一个 顶点vm 重合, 则称这样的路径为回路或环。
数据结构C语言版(第2版)严蔚敏人民邮电出版社课后习题答案

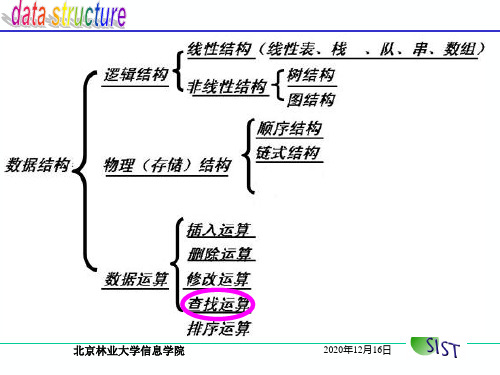
数据结构( C语言版)(第 2版)课后习题答案李冬梅2015.3目录第 1 章绪论 (1)第 2 章线性表 (5)第 3 章栈和队列 (13)第 4 章串、数组和广义表 (26)第 5 章树和二叉树 (33)第 6 章图 (43)第 7 章查找 (54)第 8 章排序 (65)第1章绪论1.简述下列概念:数据、数据元素、数据项、数据对象、数据结构、逻辑结构、存储结构、抽象数据类型。
答案:数据:是客观事物的符号表示,指所有能输入到计算机中并被计算机程序处理的符号的总称。
如数学计算中用到的整数和实数,文本编辑所用到的字符串,多媒体程序处理的图形、图像、声音、动画等通过特殊编码定义后的数据。
数据元素:是数据的基本单位,在计算机中通常作为一个整体进行考虑和处理。
在有些情况下,数据元素也称为元素、结点、记录等。
数据元素用于完整地描述一个对象,如一个学生记录,树中棋盘的一个格局(状态)、图中的一个顶点等。
数据项:是组成数据元素的、有独立含义的、不可分割的最小单位。
例如,学生基本信息表中的学号、姓名、性别等都是数据项。
数据对象:是性质相同的数据元素的集合,是数据的一个子集。
例如:整数数据对象是集合N={0 ,± 1,± 2,, } ,字母字符数据对象是集合C={‘A’,‘B’, , ,‘Z’,‘ a’,‘ b’, , ,‘z ’} ,学生基本信息表也可是一个数据对象。
数据结构:是相互之间存在一种或多种特定关系的数据元素的集合。
换句话说,数据结构是带“结构”的数据元素的集合,“结构”就是指数据元素之间存在的关系。
逻辑结构:从逻辑关系上描述数据,它与数据的存储无关,是独立于计算机的。
因此,数据的逻辑结构可以看作是从具体问题抽象出来的数学模型。
存储结构:数据对象在计算机中的存储表示,也称为物理结构。
抽象数据类型:由用户定义的,表示应用问题的数学模型,以及定义在这个模型上的一组操作的总称。
具体包括三部分:数据对象、数据对象上关系的集合和对数据对象的基本操作的集合。
数据结构实用教程(C语言版)下ppt

4
4.排序的稳定性 排序码相同的两个记录经过排序之后,其相对次序 保持不变,称该排序方法是稳定的;反之,称该 排序方法是不稳定的。
5.内部排序与外部排序
整个排序过程全部在内存中进行,这种排序称为内 部排序。涉及内外存之间数据交换的排序称为外 部排序。外部排序的速度比内部排序的速度要慢 得多。
6.排序两种基本操作: 1)比较两个记录排序码的大小;2)将记录从一个 位置移动到另一个位置。
22
起泡排序的性能分析
• 时间效率:起泡排序的最好时间复杂度为 O(n),最坏时间复杂度为O(n2),可以证明 它的平均时间复杂度也为O(n2)。
• 空间效率:在整个算法中,需要一个用于 交换记录的辅助空间,所以起泡排序的空 间复杂度为O(1)。
• 稳定性:起泡排序是稳定的。
2021/8/24
23
直接插入排序过程图示
2021/8/24
9
直接插入排序算法的C函数如下:
void insertSort (RecType R[]) /*对数组R中的记录进行直接插 入排序*/
{ int i,j;
for(i=2;i<=N;i++)
/*待插入记录为R[2],…,R[N]*/
{ R[0]=R[i];
/*将待插入的记录R[i]放入R[0]中*/
R[5] 25 25 25 25 48 48 48 48
R[6] 65 65 65 65 65 65 43 43
R[7] 43 43 43 43 43 43 65 57
R[8] 57 57 57 57 57 57 57 65
2021/8/24
一趟排序的过程图示
20
R[1] R[ 2] R[ 3] R[4] R[5] R[6] R[7] R[ 8]
数据结构(c语言版)课后习题答案完整版

第1章 绪论5.选择题:CCBDCA6.试分析下面各程序段的时间复杂度。
.试分析下面各程序段的时间复杂度。
(1)O (1) (2)O (m*n ) (3)O (n 2) (4)O (log 3n )(5)因为x++共执行了n-1+n-2+……+1= n(n-1)/2,所以执行时间为O (n 2) (6)O(n )第2章 线性表1.选择题.选择题babadbcabdcddac 2.算法设计题.算法设计题(6)设计一个算法,通过一趟遍历在单链表中确定值最大的结点。
)设计一个算法,通过一趟遍历在单链表中确定值最大的结点。
ElemType Max (LinkList L ){if(L->next==NULL) return NULL; pmax=L->next; //假定第一个结点中数据具有最大值假定第一个结点中数据具有最大值 p=L->next->next;while(p != NULL ){//如果下一个结点存在if(p->data > pmax->data) pmax=p; p=p->next; }return pmax->data;(7)设计一个算法,通过遍历一趟,将链表中所有结点的链接方向逆转,仍利用原表的存储空间。
的存储空间。
void inverse(LinkList &L) { // 逆置带头结点的单链表 Lp=L->next; L->next=NULL; while ( p) {q=p->next; // q 指向*p 的后继 p->next=L->next;L->next=p; // *p 插入在头结点之后 p = q; }}、空间(n)、空间(10)已知长度为n的线性表A采用顺序存储结构,请写一时间复杂度为O(n)的数据元素。
复杂度为O(1)的算法,该算法删除线性表中所有值为item的数据元素。
《数据结构实用教程(C语言版)》第7章查找.

返回到本节首页
返回到本节首页
2.折半查找的算法
(1)折半查找的算法如算法7.3所示。 算法7.3 int BinSearch(LineList r[], int n, KeyType k) { int low,high,mid; low=1; high=n; /*置区间初值 */ while(low<=high) /*查找区间 不为空时*/ { mid=(low+high)/2;
数据结构实用教程(C语言版)
中国水利水电出版社
第7章 查找
本章主要介绍以下内容: 静态查找方法,主要介绍顺序查找、折半查找和 分块查找 动态查找方法,主要介绍二叉排序树查找 哈希表查找
本章目录
1 2 3 4 5
7.1 基本概念
7.2 静态查找
7.3 二叉排序树查找
7.4 哈希表查找
7.5 小结
结束
7.1 基本概念
1.查找表 用于查找的数据元素集合称为查找表。查找表 由同一类型的数据元素构成。 2.静态查找表 在查找过程中查找表本身不发生变化,称为静 态查找表。对静态表的查找称为静态查找。 3.动态查找表 若在查找过程中可以将查找表中不存在的数据 元素插入,或者从查找表中删除某个数据元 素,则称这类查找表为动态查找表。对动态 查找表进行的查找称为动态查找。
返回到本节首页
7.2 静态查找
静态查找主要有顺序查找、折半查找、分块 查找三种。 7.2.1顺序查找
7.2.2 折半查找
7.2.3 分块查找
返回到总目录
7.2.1顺序查找
1.顺序查找的主要思想 顺序查找是一种最简单的查找方法,它的基本 思路是:从表的一端开始,用所给定的关键 字依次与顺序表中各记录的关键字逐个比较, 若找到相同的,查找成功;否则查找失败。
数据结构 (C语言版)课件:第7章_图

2020/9/30
3
7.1 图的逻辑结构
7.1.1 图的定义
● 相关概念 无向图和有向图
● 无向图:如果图中顶点 vi 和 vj 之间的边无方向,则称这条边为无向边, 用无序偶对 (vi, vj) 表示,称该图为无向图。
● 有向图:如果图中顶点 vi 和 vj 之间的边有方向,则称这条边为有向边, 用有序偶对 <vi, vj> 表示,称该图为有向图。
无论有向图还是无向图,顶点数 n、边 数 e 和度数之间满足:
2020/9/30
8
7.1 图的逻辑结构
7.1.1 图的定义
● 相关概念 权和网
● 权:权通常是指对图中边赋予的有意义的数值量。在实际应用中,权 可以有具体的含义。
● 网:如果将图中的每条边上都赋上一个权值,则称这种图为网,或称 为有权图 。
2020/9/30
6
7.1 图的逻辑结构
7.1.1 图的定义
● 相关概念 稀疏图和稠密图
● 稀疏图:边数很少的图称为稀疏图,如果 e 表示图中的边数,n 表示 图中的顶点数,则 e<nlogn。
● 稠密图:边数很多的图称为稠密图,如果 e 表示图中的边数,n 表示 图中的顶点数,则 e≥nlogn。
2020/9/30
无向完全图
有向完全图
5
7.1 图的逻辑结构
7.1.1 图的定义
● 相关概念 邻接和依附
● 邻接:对图 G=(V, VR),如果边 (vi, vj)∈VR,则称顶点 vi 和 vj 互为邻 接点;如果弧<vi, vj>∈VR,则称顶点 vi 邻接到 vj,vj 邻接自 vi。
● 依附:对图 G=(V, VR),如果边 (vi, vj)∈VR 或弧 <vi, vj>∈VR,则称 边 (vi, vj) 或弧 <vi, vj> 依附于顶点 vi 和 vj。
《数据结构与算法(C语言版)》教学参考模块7

模块7 查找教学要求:(1)了解查找的基本概念。
(2)掌握静态查找表的使用方法,包括顺序查找、二分查找和分块查找。
(3)掌握动态查找表的使用方法啊,包括二叉排序树和平衡二叉树。
(4)掌握哈希表的使用方法。
教学重点:几种典型静态查找方法;二叉排序树的定义及有关操作;哈希查找技术。
教学难点:哈希查找。
课时安排:本章安排6课时。
其中,理论讲授4课时,上机实验2课时。
教学大纲:模块7 查找案例导入案例分析相关知识7.1 查找的基本概念7.2 静态查找表7.2.1 顺序查找7.2.2 二分查找7.2.3 分块查找7.3 动态查找表7.3.1 二叉排序树7.3.2 平衡二叉树7.4 哈希表7.4.1 哈希表与哈希方法7.4.2 哈希函数的构造方法7.4.3 处理冲突的方法案例实施案例总结思考与练习主要概念:1.关键字2.主关键字3.次关键字4.查找5.静态查找6.动态查找7.顺序查找8.折半查找(二分查找)9.斐波那契查找10.分块查找11.平均查找长度(ASL)12.二叉排序树13.二叉排序树的查找14.哈希表15.哈希查找16.哈希函数17.冲突18.除留余数法19.直接定址法20.数字分析法21.开放定址法22.链地址法23.哈希表的装填因子实验:实验折半查找算法的实现(2学时)本书附录上机实验8。
清华版数据结构C版07章

设在数据表 dataList 中顺序搜索时,数据元素 的序号从 1 开始计数,到 CurrentSize 为止;而 实际存储位置则是从数组下标 0 开始存放,直 到 CurrentSize-1。因此,元素序号 i (i≥1)与 元素实际存储位置下标 (i≥0) 差 1.
搜索算法中把序号为CurrentSize+1的数据元素 作为控制搜索过程自动结束的“监视哨”使用。
i = 3 10 20 30 40 50 60
22
顺序搜索的递归算法
template <class T, class E>
int dataList<T, E>::SeqSearch (T x, int loc) const {
//在数据表 Element[1..n] 中搜索其关键码与给定值
//匹配的对象, 函数返回其表中位置。参数 loc(≥1)
int x; int Loc; cin >> L1; cout << L1;
//输入L1 //输出L1
cout << “Search for a integer : ”;
cin >> x;
//输入要搜索的数据
if ( (Loc = L1.Seqsearch(x)) != L1.Length() ) cout << “找到元素位置在:” << Loc+1 << endl; else cout << “ 没有找到待查元素\n”;
5
数据表的类定义
#include <iostream.h>
#include <assert.h>
const int defaultSize = 100;
数据结构与算法课件第7章查找

1.二叉排序树的定义 二叉排序树(Binary Sort Tree),或者是一棵
空树;或者是具有下列性质的二叉树: (1)若左子树不空,则左子树上所有结点的值
均小于根结点的值; (2)若右子树不空,则右子树上所有结点的值
均大于根结点的值; (3)左、右子树本身又各都是一棵二叉排序树。
二叉排 序树
第一步以 X 为轴心,将 B 从 X 的左上方转到 X 的左下 侧,使 B 成为 X 的左孩子, X 成为 A 的左孩子。第二 步跟 LL 型一样处理 ( 应以 X 为轴心 ) 。
(4)右左(RL)型 新结点 X 插在 A 的右孩子的左子树里。分为两步进行:
第一步以 X 为轴心,将 B 从 X 的右上方转到 X 的右下 侧,使 B 成为 X 的右孩子, X 成为 A 的右孩子。第二 步跟 RR 型一样处理 ( 应以 X 为轴心 ) 。
二叉排序树 生成过程
4.二叉排序树的删除
如图三颗二叉排序树由值相同的关键字构成,但 是它们的输入顺序不ห้องสมุดไป่ตู้样:
图 (a)是按一月到十二月的自然月份序列输入所 生成的;
图 (b)的输入序列为(July, Feb, May, Mar, Aug, Jan, Apr, Jun, Oct, Sept, Nov, Dec)
比较的次数的期望值,通常记作ASL。
对于一个含有n个元素的表,查找成功时的平均查找长度 可表示为
其中,Pi为表中查找第i个记录的概率,Ci为查找第i个 记录所用到的比较次数。显然,对于不同的查找方法Ci 可能不一同。Pi很难通过分析给出,一般情形下我们认 为查找每个记录的概率相等。
顺序查找的基本思想是:从表的一端开始,顺序扫描 线性表,依次将扫描到的结点关键字和待查找值key相 比较,若相等,则查找成功,若整个表扫描完毕,仍 末找到关键字等于key的元素,则查找失败。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
返回到本节首页
返回到本节首页
2.折半查找的算法 .
所示。 (1)折半查找的算法如算法 )折半查找的算法如算法7.3所示。 所示 算法7.3 算法 int BinSearch(LineList r[], int n, KeyType k) { int low,high,mid; low=1; high=n; /*置区间初值 置区间初值 */ while(low<=high) /*查找区间 查找区间 不为空时*/ 不为空时 { mid=(low+high)/2;
【例7.1】有关键字序列 ,4,6,9,10, 】有关键字序列{2, , , , , 13,15,27,29},采用折半查找法查找 , , , , 6和17的具体过程。 的具体过程。 和 的具体过程 为低位指针, 为高位指针, 解:设low为低位指针,high为高位指针, 为低位指针 为高位指针 mid为中间位置指针。其中 为中间位置指针。 为中间位置指针 其中mid= ,若 mid所指元素大于关键字 时,这时令 所指元素大于关键字k时 所指元素大于关键字 high=mid-1,向mid前一半的表中继续 , 前一半的表中继续 查找。 所指元素小于关键字k时 查找。若mid所指元素小于关键字 时,这 所指元素小于关键字 时令low=mid+1,向mid后一半的表中 时令 , 后一半的表中 继续查找。 继续查找。当high<low时,表示不存在这 时 样的查找子表空间,查找失败。 样的查找子表空间,查找失败。
返回到本节首页
算法7.2 算法 int SeqSearch1(LineList r[],int n,KeyType k) { int i=n; r[0]=k; while(r[i].key!=k) /*若k不等于所比 若 不等于所比 较关键字时*/ 较关键字时 i--; return(i); }
返回到本节首页
顺序查找的线性表定义如下: 顺序查找的线性表定义如下: #define MaxSize 1000 大存储容量*/ 大存储容量 typedef int KeyType; 域为整型*/ 域为整型 typedef int ElemType; 类型为整型,可为其它类型*/ 类型为整型,可为其它类型 /*顺序表的最 顺序表的最 /*重定义关键字 重定义关键字 /*重定义数据域 重定义数据域
返回到本节首页
if(k==r[mid].key) return(mid); /*找到待查元素 找到待查元素 */ else if(k<r[mid].key) high=mid-1; /*未找到,继续 未找到, 未找到 在前半区间进行查找*/ 在前半区间进行查找 else low=mid+1; /*未找到,继续 未找到, 未找到 在后半区间进行查找*/ 在后半区间进行查找 } return (0); }
(a)以数组的下标作为二叉判定树结点的关键字(b)以序列中的值作为二叉判定树结点的关键字 以数组的下标作为二叉判定树结点的关键字( 图7 - 4 9个结点的二叉判定树 9个结点的二叉判定树
返回到本节首页
7.2.3 分块查找
分块查找又称为索引顺序查找,是顺序查找的一种改 分块查找又称为索引顺序查找, 进,其性能介于顺序查找和折半查找之间。 其性能介于顺序查找和折半查找之间。 分块查找把查找表分成若干块, 分块查找把查找表分成若干块,每块中的元素存储顺 序是任意的,但块与块之间必须按关键字大小有序 序是任意的, 排列。即前一块中的最大关键字小于(或大于) 排列。即前一块中的最大关键字小于(或大于)后 一块中的最小(最大)关键字值。 一块中的最小(最大)关键字值。另外还需要建立 一个索引表,索引表中的一项对应线性表的一块, 一个索引表,索引表中的一项对应线性表的一块, 索引项由关键字域和指针域组成, 索引项由关键字域和指针域组成,关键字域存放相 应块的块内最大关键字,指针域存放指向本块第一 应块的块内最大关键字, 个和最后一个元素的指针(即数组下标值)。 )。索引 个和最后一个元素的指针(即数组下标值)。索引 表按关键字值递增(或递减)顺序排列。 表按关键字值递增(或递减)顺序排列。
2.顺序查找的算法 .
(2)顺序查找的改进算法 ) 我们可以使用监视哨来改进算法。 我们可以使用监视哨来改进算法。主要思路 顺序表中数据元素存放在数组下标为1 是:顺序表中数据元素存放在数组下标为 的位置, 到n的位置,而下标为 的位置空出来作为监 的位置 而下标为0的位置空出来作为监 视哨。在查找之前, 视哨。在查找之前,先将要查找的关键字存 放到数组下标为0的位置 的位置, 放到数组下标为 的位置,从顺序表的最后 一个记录开始, 一个记录开始,从后至前依次进行给定值与 记录关键字的比较, 记录关键字的比较,若某记录的关键字与给 定值k相同 则查找成功, 相同, 定值 相同,则查找成功,返回该记录在表 中的存储位置;若查找不成功,返回0。 中的存储位置;若查找不成功,返回 。相 应的算法如算法7.2。 应的算法如算法 。
2.顺序查找的算法 .
(1)顺序查找的基本算法如下: )顺序查找的基本算法如下: 算法7.1 算法 int SeqSearch(LineList r[],int n,KeyType k) { int i=1;/*为与其改进算法匹配,方便在主函数 为与其改进算法匹配, 为与其改进算法匹配 调用,查找表存储范围为下标1..n*/ 调用,查找表存储范围为下标 while(i<=n &&r[i].key!=k) i++; if(i>n) return(0); else return(i); } 返回到本节首页
7.2.2 折半查找
折半查找又称为二分查找。这种查找方法的前 折半查找又称为二分查找。 提条件是要求待查找的查找表必须是按关键 字大小有序排列的顺序表。 字大小有序排列的顺序表。 1.折半查找的主要步骤为: .折半查找的主要步骤为: (1)置初始查找范围:low=1,high=n; )置初始查找范围: , (2)求查找范围中间项:mid= (low + high)/2 )求查找范围中间项: (3)将指定的关键字值 与中间项的关键字比 )将指定的关键字值k与中间项的关键字比 较: 若相等,查找成功, 若相等,查找成功,找到的数据元素为此时 mid 指向的位置; 指向的位置;
结束
2
3 4
5
7.1 基本概念
1.查找表 . 用于查找的数据元素集合称为查找表。 用于查找的数据元素集合称为查找表。查找表 由同一类型的数据元素构成。 由同一类型的数据元素构成。 2.静态查找表 . 在查找过程中查找表本身不发生变化, 在查找过程中查找表本身不发生变化,称为静 态查找表。对静态表的查找称为静态查找。 态查找表。对静态表的查找称为静态查找。 3.动态查找表 . 若在查找过程中可以将查找表中不存在的数据 元素插入, 元素插入,或者从查找表中删除某个数据元 则称这类查找表为动态查找表。 素,则称这类查找表为动态查找表。对动态 查找表进行的查找称为动态查找。 查找表进行的查找称为动态查找。
返回到本节首页
7.2 静态查找
静态查找主要有顺序查找、折半查找、分块 静态查找主要有顺序查找、折半查找、 查找三种。 查找三种。 7.2.1顺序查找 顺序查找 7.2.2 折半查找 7.2.3 分块查找
返回到总目录
7.2.1顺序查找 顺序查找
1.顺序查找的主要思想 . 顺序查找是一种最简单的查找方法, 顺序查找是一种最简单的查找方法,它的基本 思路是:从表的一端开始, 思路是:从表的一端开始,用所给定的关键 字依次与顺序表中各记录的关键字逐个比较, 字依次与顺序表中各记录的关键字逐个比较, 若找到相同的,查找成功;否则查找失败。 若找到相同的,查找成功;否则查找失败。
返回到本节首页
折半查找过程可用一个二叉树来描述,把当前 折半查找过程可用一个二叉树来描述, 查找区间的中间位置上的记录作为根, 查找区间的中间位置上的记录作为根,左子 表和右子表中的记录分别作根的左子树和右 子树。树中每个结点表示一个记录, 子树。树中每个结点表示一个记录,结点中 的值为该记录在表中的位置, 的值为该记录在表中的位置,则称该二叉树 为折半查找的判定树。例如例7.1关键字序 为折半查找的判定树。例如例7.1关键字序 列有9个 列有 个,关键字与数据下标的关系对应表 如图7-3所示。若用数组下标作为判定树中 所示。 如图 所示 结点的值,所对应的判定树如图7-4(a) 结点的值,所对应的判定树如图 ( ) 所示, 所示,若用查找表中的关键字作为判定树中 的结点的值,所对应的判定树如图7-4(b) 的结点的值,所对应的判定树如图 ( ) 所示。 所示。 返回到本节首页
数据结构实用教程(C语言版)
Байду номын сангаас
中国水利水电出版社
第7章 查找
本章主要介绍以下内容: 本章主要介绍以下内容: 静态查找方法,主要介绍顺序查找、折半查找和 静态查找方法,主要介绍顺序查找、 分块查找 动态查找方法, 动态查找方法,主要介绍二叉排序树查找 哈希表查找
本章目录
1
7.1 基本概念 7.2 静态查找 7.3 二叉排序树查找 7.4 哈希表查找 7.5 小结
返回到本节首页
小于中间项关键字, 若k小于中间项关键字,查找范围的低端数 小于中间项关键字 据元素指针low不变,高端数据元素指针 不变, 据元素指针 不变 high更新为 更新为mid-1; 更新为 大于中间项关键字, 若k大于中间项关键字,查找范围的高端数 大于中间项关键字 据元素指针high不变,低端数据元素指针 不变, 据元素指针 不变 low更新为 更新为mid+1; 更新为 )、(3) (4)重复步骤(2)、( )直到查找成功或 )重复步骤( )、( 查找范围为空( ),即查找失败 查找范围为空(low>high),即查找失败 ), 为止。 为止。 (5)如果查找成功,返回找到元素的存放位 )如果查找成功, 即当前的中间项位置指针mid;否则返 置,即当前的中间项位置指针 ; 返回到本节首页 回查找失败标志。 回查找失败标志。