hadoop的运行环境配置
Hadoop的配置及运行WordCount

Hadoop的配置及运行WordCount目录Hadoop的配置及运行WordCount (1)一、环境: (1)二、步骤: (1)1 JDK及SSH安装配置: (1)1.1 卸载Fedora自带的OpenJDK,安装Oracle的JDK (1)1.2 配置SSH (2)2 Hadoop安装配置: (4)2.1 下载并配置Hadoop的JDK环境 (4)2.2 为系统配置Hadoop环境变量 (5)2.3 修改Hadoop的配置文件 (6)2.4 初始化HDFS文件系统,和启动Hadoop (8)2.5 关闭HDFS (11)3 运行WordCount: (11)3.1 下载和编译WordCount示例 (11)3.2 建立文本文件并上传至DFS (13)3.3 MapReduce执行过程显示信息 (14)结尾: (15)一、环境:计算机Fedora 20、jdk1.7.0_60、Hadoop-2.2.0二、步骤:1 JDK及SSH安装配置:1.1 卸载Fedora自带的OpenJDK,安装Oracle的JDK*由于Hadoop,无法使用OpenJDK,所以的下载安装Oracle的JDK。
1.1.1、以下为卸载再带的OpenJDK:然后到/technetwork/java/javase/downloads/index.html下载jdk,可以下载rpm格式的安装包或解压版的。
rpm版本的下载完毕后可以运行安装,一般会自动安装在/usr/java/的路径下面。
接下来就配置jdk的环境变量了。
1.1.2、进入到系统的环境变量配置文件,加入以下内容:(按i进行编辑,编辑完毕按ESC,输入:wq,回车即保存退出)截图如下:Java环境变量配置输入这个回车即可保存退出java –version,检测配置是否成功。
如下结果则Java 配置安装成功。
1.2 配置SSH搭建hadoop分布式集群平台,为了实现通讯之间的可靠,防止远程管理过程中的信息泄露问题。
Hadoop环境配置与实验报告
李富豪
Байду номын сангаас
学号
131440
计算机新技术综合实践
2014 年 4 月 至 2014 年 6 月 周学时 1 学分 2
简
(1) 小组答辩过程表述很清晰;
要
(2) 实验结果的演示表明搭建的系统以及编写的程序很好地满
评
足功能要求;
(3) 报告内容很好地符合要求。
语
考核论题 总评成绩 (含平时成绩)
备注
任课教师签名:
3 Java 环境安装 ...................................................................................................................... 9 3.1 安装 JDK ...................................................................................................................... 10 3.2 配置环境变量 ............................................................................................................. 10 3.2.1 编辑"/etc/profile"文件 ........................................................................................ 10 3.2.2 添加 Java 环境变量 ............................................................................................. 10 3.2.3 使配置生效.......................................................................................................... 10 3.3 验证安装成功 ............................................................................................................. 10 3.4 安装剩余机器 ............................................................................................................. 11
Hadoop环境搭建及wordcount实例运行
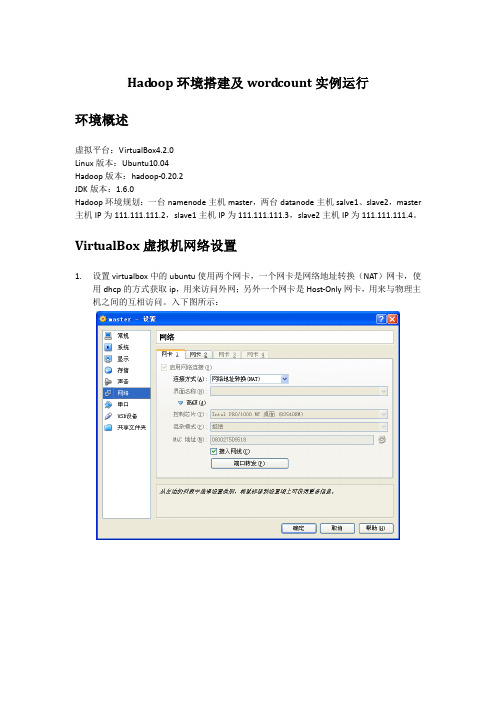
环境概述
虚拟平台:VirtualBox4.2.0
Linux版本:Ubuntu10.04
Hadoop版本:hadoop-0.20.2
JDK版本:1.6.0
Hadoop环境规划:一台namenode主机master,两台datanode主机salve1、slave2,master主机IP为111.111.111.2,slave1主机IP为111.111.111.3,slave2主机IP为111.111.111.4。
ssh_5.3p1-3ubuntu3_all.deb
依次安装即可
dpkg -i openssh-client_5.3p1-3ubuntu3_i386.deb
dpkg -i openssh-server_5.3p1-3ubuntu3_i386.deb
dpkg -i ssh_5.3p1-3ubuntu3_all.deb
14/02/20 15:59:58 INFO mapred.JobClient: Running job: job_201402201551_0003
14/02/20 15:59:59 INFO mapred.JobClient: map 0% reduce 0%
14/02/20 16:00:07 INFO mapred.JobClient: map 100% reduce 0%
111.111.111.2 master
111.111.111.3 slave1
111.111.111.4 slave2
然后按以下步骤配置master到slave1之间的ssh信任关系
用户@主机:/执行目录
操作命令
说明
hadoop@master:/home/hadoop
hadoop环境配置以及hadoop伪分布式安装实训目的

Hadoop环境配置以及Hadoop伪分布式安装是用于学习和实践大数据处理和分析的重要步骤。
下面将详细解释配置Hadoop环境以及安装Hadoop伪分布式的目的。
一、Hadoop环境配置配置Hadoop环境是为了在实际的硬件或虚拟机环境中搭建Hadoop集群,包括安装和配置Hadoop的各个组件,如HDFS(Hadoop分布式文件系统)、MapReduce(一种编程模型和运行环境)等。
这个过程涉及到网络设置、操作系统配置、软件安装和配置等步骤。
通过这个过程,用户可以了解Hadoop的基本架构和工作原理,为后续的学习和实践打下基础。
二、Hadoop伪分布式安装Hadoop伪分布式安装是一种模拟分布式环境的方法,它可以在一台或多台机器上模拟多个节点,从而在单机上测试Hadoop的各个组件。
通过这种方式,用户可以更好地理解Hadoop 如何在多台机器上协同工作,以及如何处理大规模数据。
安装Hadoop伪分布式的主要目的如下:1. 理解Hadoop的工作原理:通过在单机上模拟多个节点,用户可以更好地理解Hadoop如何在多台机器上处理数据,以及如何使用MapReduce模型进行数据处理。
2. 练习Hadoop编程:通过在单机上模拟多个节点,用户可以编写和测试Hadoop的MapReduce程序,并理解这些程序如何在单机上运行,从而更好地理解和学习Hadoop编程模型。
3. 开发和调试Hadoop应用程序:通过在单机上模拟分布式环境,用户可以在没有真实数据的情况下开发和调试Hadoop应用程序,从而提高开发和调试效率。
4. 为真实环境做准备:一旦熟悉了Hadoop的伪分布式环境,用户就可以逐渐将知识应用到真实环境中,例如添加更多的实际节点,并开始处理实际的大规模数据。
总的来说,学习和实践Hadoop环境配置以及Hadoop伪分布式安装,对于学习和实践大数据处理和分析具有重要意义。
它可以帮助用户更好地理解和学习Hadoop的工作原理和编程模型,为将来在实际环境中应用和优化Hadoop打下坚实的基础。
Hadoop的安装与配置

Hadoop的安装与配置建立一个三台电脑的群组,操作系统均为Ubuntu,三个主机名分别为wjs1、wjs2、wjs3。
1、环境准备:所需要的软件及我使用的版本分别为:Hadoop版本为0.19.2,JDK版本为jdk-6u13-linux-i586.bin。
由于Hadoop要求所有机器上hadoop的部署目录结构要相同,并且都有一个相同的用户名的帐户。
所以在三台主机上都设置一个用户名为“wjs”的账户,主目录为/home/wjs。
a、配置三台机器的网络文件分别在三台机器上执行:sudo gedit /etc/network/interfaceswjs1机器上执行:在文件尾添加:auto eth0iface eth0 inet staticaddress 192.168.137.2gateway 192.168.137.1netmask 255.255.255.0wjs2和wjs3机器上分别执行:在文件尾添加:auto eth1iface eth1 inet staticaddress 192.168.137.3(wjs3上是address 192.168.137.4)gateway 192.168.137.1netmask 255.255.255.0b、重启网络:sudo /etc/init.d/networking restart查看ip是否配置成功:ifconfig{注:为了便于“wjs”用户能够修改系统设置访问系统文件,最好把“wjs”用户设为sudoers(有root权限的用户),具体做法:用已有的sudoer登录系统,执行sudo visudo -f /etc/sudoers,并在此文件中添加以下一行:wjsALL=(ALL)ALL,保存并退出。
}c、修改三台机器的/etc/hosts,让彼此的主机名称和ip都能顺利解析,在/etc/hosts中添加:192.168.137.2 wjs1192.168.137.3 wjs2192.168.137.4 wjs3d、由于Hadoop需要通过ssh服务在各个节点之间登陆并运行服务,因此必须确保安装Hadoop的各个节点之间网络的畅通,网络畅通的标准是每台机器的主机名和IP地址能够被所有机器正确解析(包括它自己)。
hadoop环境搭建
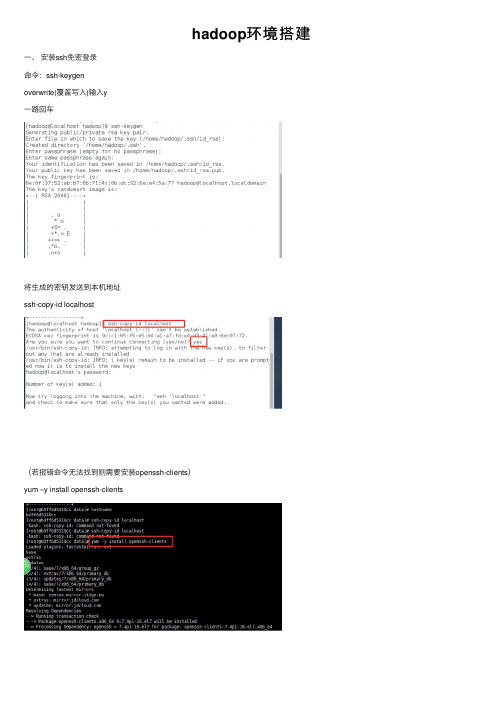
hadoop环境搭建⼀、安装ssh免密登录命令:ssh-keygenoverwrite(覆盖写⼊)输⼊y⼀路回车将⽣成的密钥发送到本机地址ssh-copy-id localhost(若报错命令⽆法找到则需要安装openssh-clients)yum –y install openssh-clients测试免密设置是否成功ssh localhost⼆、卸载已有java确定JDK版本rpm –qa | grep jdkrpm –qa | grep gcj切换到root⽤户,根据结果卸载javayum -y remove java-1.8.0-openjdk-headless.x86_64 yum -y remove java-1.7.0-openjdk-headless.x86_64卸载后输⼊java –version查看三、安装java切换回hadoop⽤户,命令:su hadoop查看下当前⽬标⽂件,命令:ls将桌⾯的hadoop⽂件夹中的java及hadoop安装包移动到app⽂件夹中命令:mv /home/hadoop/Desktop/hadoop/jdk-8u141-linux-x64.gz /home/hadoop/app mv /home/hadoop/Desktop/hadoop/hadoop-2.7.0.tar.gz /home/hadoop/app解压java程序包,命令:tar –zxvf jdk-7u79-linux-x64.tar.gz创建软连接ln –s jdk1.8.0_141 jdk配置jdk环境变量切换到root⽤户再输⼊vi /etc/profile输⼊export JAVA_HOME=/home/hadoop/app/jdk1.8.0_141export JAVA_JRE=JAVA_HOME/jreexport CLASSPATH=.:$JAVA_HOME/lib:$JAVA_JRE/lib export PATH=$PATH:$JAVA_HOME/bin保存退出,并使/etc/profile⽂件⽣效source /etc/profile能查询jdk版本号,说明jdk安装成功java -version四、安装hadoop切换回hadoop⽤户,解压缩hadoop-2.6.0.tar.gz安装包创建软连接,命令:ln -s hadoop-2.7.0 hadoop验证单机模式的Hadoop是否安装成功,命令:hadoop/bin/hadoop version此时可以查看到Hadoop安装版本为Hadoop2.7.0,说明单机版安装成功。
Hadoop 搭建

(与程序设计有关)
课程名称:云计算技术提高
实验题目:Hadoop搭建
Xx xx:0000000000
x x:xx
x x:
xxxx
2021年5月21日
实验目的及要求:
开源分布式计算架构Hadoop的搭建
软硬件环境:
Vmware一台计算机
算法或原理分析(实验内容):
Hadoop是Apache基金会旗下一个开源的分布式存储和分析计算平台,使用Java语言开发,具有很好的跨平台性,可以运行在商用(廉价)硬件上,用户无需了解分布式底层细节,就可以开发分布式程序,充分使用集群的高速计算和存储。
三.Hadoop的安装
1.安装并配置环境变量
进入官网进行下载hadoop-2.7.5, 将压缩包在/usr目录下解压利用tar -zxvf Hadoop-2.7.5.tar.gz命令。同样进入 vi /etc/profile 文件,设置相应的HADOOP_HOME、PATH在hadoop相应的绝对路径。
4.建立ssh无密码访问
二.JDK安装
1.下载JDK
利用yum list java-1.8*查看镜像列表;并利用yum install java-1.8.0-openjdk* -y安装
2.配置环境变量
利用vi /etc/profile文件配置环境,设置相应的JAVA_HOME、JRE_HOME、PATH、CLASSPATH的绝对路径。退出后,使用source /etc/profile使环境变量生效。利用java -version可以测试安装是否成功。
3.关闭防火墙并设置时间同步
通过命令firewall-cmd–state查看防火墙运行状态;利用systemctl stop firewalld.service关闭防火墙;最后使用systemctl disable firewalld.service禁止自启。利用yum install ntp下载相关组件,利用date命令测试
Hadoop集群配置心得(低配置集群+自动同步配置)

Hadoop集群配置⼼得(低配置集群+⾃动同步配置)本⽂为本⼈原创,⾸发到炼数成⾦。
情况是这样的,我没有⼀个⾮常强劲的电脑来搞出⼀个性能⾮常NB的服务器集群,相信很多⼈也跟我差不多,所以现在把我的低配置集群经验拿出来写⼀下好了。
我的配备:1)五六年前的赛扬单核处理器2G内存笔记本 2)公司给配的ThinkpadT420,i5双核处理器4G内存(可⽤内存只有3.4G,是因为装的是32位系统的缘故吧。
)就算是⽤公司配置的电脑,做出来三台1G内存的虚拟机也显然是不现实的。
企业笔记本运⾏的软件多啊,什么都不做空余内存也才不到3G。
所以呢,我的想法就是:⽤我⾃⼰的笔记本(简称PC1)做Master节点,⽤来跑Jobtracker,Namenode 和SecondaryNamenode;⽤公司的笔记本跑两个虚拟机(简称VM1和VM2),⽤来做Slave节点,跑Tasktracker和Datanode。
这么做的话,就需要让PC1,VM1和VM2处于同⼀个⽹段⾥,保证他们之间可以互相连通。
⽹络环境:我的两台电脑都是通过⼀个⽆线路由上⽹。
构建跟外部的电脑同⼀⽹段的虚拟机配置过程:准备⼯作:构建⼀个集群,⾸先前提条件是每台服务器都要有⼀个固定的IP地址,然后才可能进⾏后续的操作。
所以呢,先把我的两台笔记本电脑全部设置成固定IP(注意,如果像我⼀样使⽤⽆线路由上⽹,那就要把⽆线⽹卡的IP设置成固定IP)。
⽤来做Master节点的PC1:192.168.33.150,⽤来跑虚拟机的宿主笔记本:192.168.33.157。
⽬标:VM1和VM2的IP地址分别设置成192.168.33.151和152。
步骤:1)新建VM1虚拟机。
2)打开VM1的⽹卡设置界⾯,连接⽅式选Bridge。
(桥接)关于桥接的具体信息,可以百度⼀下。
我们需要知道的,就是⽤桥接的⽅式,可以让虚拟机通过本机的⽹关来上⽹,所以就可以跟本机处于同⼀个⽹段,互相之间可以进⾏通信。
《hadoop基础》课件——第三章 Hadoop集群的搭建及配置

19
Hadoop集群—文件监控
http://master:50070
20
Hadoop集群—文件监控
http://master:50070
21
Hadoop集群—文件监控
http://master:50070
22
Hadoop集群—任务监控
http://master:8088
23
Hadoop集群—日志监控
http://master:19888
24
Hadoop集群—问题 1.集群节点相关服务没有启动?
1. 检查对应机器防火墙状态; 2. 检查对应机器的时间是否与主节点同步;
25
Hadoop集群—问题
2.集群状态不一致,clusterID不一致? 1. 删除/data.dir配置的目录; 2. 重新执行hadoop格式化;
准备工作:
1.Linux操作系统搭建完好。 2.PC机、服务器、环境正常。 3.搭建Hadoop需要的软件包(hadoop-2.7.6、jdk1.8.0_171)。 4.搭建三台虚拟机。(master、node1、node2)
存储采用分布式文件系统 HDFS,而且,HDFS的名称 节点和数据节点位于不同机 器上。
2、vim编辑core-site.xml,修改以下配置: <property>
<name>fs.defaultFS</name> <value>hdfs://master:9000</value> </property> <property> <name>hadoop.tmp.dir</name> <value>/opt/soft/hadoop-2.7.6/tmp</value> </property> <property> <name>fs.trash.interval</name> <value>1440</value> </property>
云计算Hadoop运行环境的配置实验报告

以上操作的目的,是确保每台机器除了都能够使用ip地址访问到对方外,还可以通过主
注意:另外2台也要运行此命令。
)查看证书
hadooptest身份,进入hadooptest家目录的 .ssh文件夹。
(3)新建“认证文件”,在3台机器中运行如下命令,给每台机器新建“认证文件”注意:另外2台也要运行此命令。
其次,虚拟机之间交换证书,有三种拷贝并设置证书方法:
hadoops1机器里的authorized_keys也有三份证书,内容如下:hadoops2机器里的authorized_keys也有三份证书,内容如下:
) Java环境变量配置
继续以root操作,命令行中执行命令”vi m /etc/profile”,在最下面加入以下内容,
.实验体会
通过这次的实验熟悉并了Hadoop运行环境,并学会了如何使用它。
这次实验成功完成了Hadoop 集群,3个节点之间相互ping通,并可以免密码相互登陆,完成了运行环境java安装和配置。
大数据--Hadoop集群环境搭建

⼤数据--Hadoop集群环境搭建⾸先我们来认识⼀下HDFS, HDFS(Hadoop Distributed File System )Hadoop分布式⽂件系统。
它其实是将⼀个⼤⽂件分成若⼲块保存在不同服务器的多个节点中。
通过联⽹让⽤户感觉像是在本地⼀样查看⽂件,为了降低⽂件丢失造成的错误,它会为每个⼩⽂件复制多个副本(默认为三个),以此来实现多机器上的多⽤户分享⽂件和存储空间。
Hadoop主要包含三个模块:HDFS模块:HDFS负责⼤数据的存储,通过将⼤⽂件分块后进⾏分布式存储⽅式,突破了服务器硬盘⼤⼩的限制,解决了单台机器⽆法存储⼤⽂件的问题,HDFS是个相对独⽴的模块,可以为YARN提供服务,也可以为HBase等其他模块提供服务。
YARN模块:YARN是⼀个通⽤的资源协同和任务调度框架,是为了解决Hadoop中MapReduce⾥NameNode负载太⼤和其他问题⽽创建的⼀个框架。
YARN是个通⽤框架,不⽌可以运⾏MapReduce,还可以运⾏Spark、Storm等其他计算框架。
MapReduce模块:MapReduce是⼀个计算框架,它给出了⼀种数据处理的⽅式,即通过Map阶段、Reduce阶段来分布式地流式处理数据。
它只适⽤于⼤数据的离线处理,对实时性要求很⾼的应⽤不适⽤。
多相关信息可以参考博客:。
本节将会介绍Hadoop集群的配置,⽬标主机我们可以选择虚拟机中的多台主机或者多台阿⾥云服务器。
注意:以下所有操作都是在root⽤户下执⾏的,因此基本不会出现权限错误问题。
⼀、Vmware安装VMware虚拟机有三种⽹络模式,分别是Bridged(桥接模式)、NAT(⽹络地址转换模式)、Host-only(主机模式):桥接:选择桥接模式的话虚拟机和宿主机在⽹络上就是平级的关系,相当于连接在同⼀交换机上;NAT:NAT模式就是虚拟机要联⽹得先通过宿主机才能和外⾯进⾏通信;仅主机:虚拟机与宿主机直接连起来。
hadoop搭建与eclipse开发环境设置

hadoop搭建与eclipse开发环境设置――罗利辉1.前言1.1 目标目的很简单,为进行研究与学习,部署一个hadoop运行环境,并搭建一个hadoop开发与测试环境。
具体目标是:✓在ubuntu系统上部署hadoop✓在windows 上能够使用eclipse连接ubuntu系统上部署的hadoop进行开发与测试1.2 软硬件要求注意:Hadoop版本和Eclipse版本请严格按照要求。
现在的hadoop最新版本是hadoop-0.20.203,我在windows上使用eclipse(包括3.6版本和3.3.2版本)连接ubuntu上的hadoop-0.20.203环境一直没有成功。
但是开发测试程序是没有问题的,不过需要注意权限问题。
如果要减少权限问题的发生,可以这样做:ubuntu上运行hadoop的用户与windows 上的用户一样。
1.3 环境拓扑图ubuntu 192.168.69.231ubuntu2192.168.69.233 ubuntu1192.168.69.2322.Ubuntu 安装安装ubuntu11.04 server系统,具体略。
我是先在虚拟机上安装一个操作系统,然后把hadoop也安装配置好了,再克隆二份,然后把主机名与IP修改,再进行主机之间的SSH配置。
如果仅作为hadoop的运行与开发环境,不需要安装太多的系统与网络服务,或者在需要的时候通过apt-get install进行安装。
不过SSH服务是必须的。
3.Hadoop 安装以下的hadoop安装以主机ubuntu下进行安装为例。
3.1 下载安装jdk1.6安装版本是:jdk-6u26-linux-i586.bin,我把它安装拷贝到:/opt/jdk1.6.0_263.2 下载解压hadoop安装包是:hadoop-0.20.2.tar.gz。
3.3 修改系统环境配置文件切换为根用户。
●修改地址解析文件/etc/hosts,加入3.4 修改hadoop的配置文件切换为hadoop用户。
Hadoop环境搭建

Hadoop环境搭建啥是⼤数据?问啥要学⼤数据?在我看来⼤数据就很多的数据,超级多,咱们⽇常⽣活中的数据会和历史⼀样,越来越多⼤数据有四个特点(4V):⼤多样快价值学完⼤数据我们可以做很多事,⽐如可以对许多单词进⾏次数查询(本节最后的实验),可以对股市进⾏分析,所有的学习都是为了赚⼤钱!(因为是在Linux下操作,所以⽤到的全是Linux命令,不懂可以百度,这篇⽂章有⼀些简单命令。
常⽤)第⼀步安装虚拟机配置环境1.下载虚拟机,可以⽤⾃⼰的,没有的可以下载这个 passowrd:u8lt2.导⼊镜像,可以⽤这个 password:iqww (不会创建虚拟机的可以看看,不过没有这个复杂,因为导⼊就能⽤)3.更换主机名,vi /etc/sysconfig/network 改HOSTNAME=hadoop01 (你这想改啥改啥,主要是为了清晰,否则后⾯容易懵)注:在这⾥打开终端4.查看⽹段,从编辑-虚拟⽹络编辑器查看,改虚拟机⽹段,我的是192.168.189.128-254(这个你根据⾃⼰的虚拟机配置就⾏,不⽤和我⼀样,只要记住189.128这个段就⾏)5.添加映射关系,输⼊:vim /etc/hosts打开⽂件后下⾯添加 192.168.189.128 hadoop01(红⾊部分就是你们上⾯知道的IP)(这⾥必须是hadoop01,为了⽅便后⾯直接映射不⽤敲IP)6.在配置⽂件中将IP配置成静态IP 输⼊: vim /etc/sysconfig/network-scripts/ifcfg-eth0 (物理地址也要⼀样哦!不知道IP的可以输⼊:ifconfig 查看⼀下)7.重启虚拟机输⼊:reboot (重启后输⼊ ping 能通就说明没问题)第⼆步克隆第⼀台虚拟机,完成第⼆第三虚拟机的配置1.⾸先把第⼀台虚拟机关闭,在右击虚拟机选项卡,管理-克隆即可(克隆两台⼀台hadoop02 ⼀台hadoop03)2.克隆完事后,操作和第⼀部基本相同唯⼀不同的地⽅是克隆完的虚拟机有两块⽹卡,我们把其中⼀个⽹卡注释就好(⼀定牢记!通过这⾥的物理地址⼀定要和配置⽂件中的物理地址相同)输⼊:vi /etc/udev/rules.d/70-persistent-net.rules 在第⼀块⽹卡前加# 将第⼆块⽹卡改为eth03.当三台机器全部配置完之后,再次在hosts⽂件中加⼊映射达到能够通过名称互相访问的⽬的输⼊:vim /etc/hosts (三台都要如此设置)(改完之后记得reboot重启)第三步使三台虚拟机能够通过SHELL免密登录1.查看SSH是否安装 rmp -qa | grep ssh (如果没有安装,输⼊sudo apt-get install openssh-server)2.查看SSH是否启动 ps -e | grep sshd (如果没有启动,输⼊sudo /etc/init.d/ssh start)3.该虚拟机⽣成密钥 ssh-keygen -t rsa(连续按下四次回车就可以了)4.将密钥复制到另外⼀台虚拟机⽂件夹中并完成免密登录输⼊:ssh-copy-id -i ~/.ssh/id_rsa.pub 2 (同样把秘钥给hadoop03和⾃⼰)(输⼊完后直接下⼀步,如果下⼀步失败再来试试改这个修改/etc/ssh/ssh_config中的StrictHostKeyCheck ask )5.之后输⼊ ssh hadoop02就可以正常访问第⼆台虚拟机啦注:可能你不太理解这是怎么回事,我这样解释⼀下,免密登录是为了后⾯进⾏集群操作时⽅便,⽣成秘钥就像是⽣成⼀个钥匙,这个钥匙是公钥,公钥可以打开所有门,之后把这个钥匙配两把,⼀把放在hadoop02的那⾥,⼀把放在hadoop03的那⾥,这样hadoop01可以对hadoop02和hadoop03进⾏访问。
Hadoop环境搭建--Docker完全分布式部署Hadoop环境(菜鸟采坑吐血整理)

Hadoop环境搭建--Docker完全分布式部署Hadoop环境(菜鸟采坑吐⾎整理)系统:Centos 7,内核版本3.10本⽂介绍如何从0利⽤Docker搭建Hadoop环境,制作的镜像⽂件已经分享,也可以直接使⽤制作好的镜像⽂件。
⼀、宿主机准备⼯作0、宿主机(Centos7)安装Java(⾮必须,这⾥是为了⽅便搭建⽤于调试的伪分布式环境)1、宿主机安装Docker并启动Docker服务安装:yum install -y docker启动:service docker start⼆、制作Hadoop镜像(本⽂制作的镜像⽂件已经上传,如果直接使⽤制作好的镜像,可以忽略本步,直接跳转⾄步骤三)1、从官⽅下载Centos镜像docker pull centos下载后查看镜像 docker images 可以看到刚刚拉取的Centos镜像2、为镜像安装Hadoop1)启动centos容器docker run -it centos2)容器内安装java下载java,根据需要选择合适版本,如果下载历史版本拉到页⾯底端,这⾥我安装了java8/usr下创建java⽂件夹,并将java安装包在java⽂件下解压tar -zxvf jdk-8u192-linux-x64.tar.gz解压后⽂件夹改名(⾮必需)mv jdk1.8.0_192 jdk1.8配置java环境变量vi ~/.bashrc ,添加内容,保存后退出export JAVA_HOME=/usr/java/jdk1.8export JRE_HOME=${JAVA_HOME}/jreexport CLASSPATH=.:${JAVA_HOME}/libexport PATH=$PATH:${JAVA_HOME}/bin使环境变量⽣效 source ~/.bashrc验证安装结果 java -version这⾥注意,因为是在容器中安装,修改的是~/.bashrc⽽⾮我们使⽤更多的/etc/profile,否则再次启动容器的时候会环境变量会失效。
Hadoop开发环境搭建(Win8 + Eclipse + Linux)

Hadoop开发环境搭建(Win8+Linux)常见的Hadoop开发环境架构有以下三种:1、Eclipse与Hadoop集群在同一台Windows机器上。
2、Eclipse与Hadoop集群在同一台Linux机器上。
3、Eclipse在Windows上,Hadoop集群在远程Linux机器上。
点评:第一种架构:必须安装cygwin,Hadoop对Windows的支持有限,在Windows 上部署hadoop会出现相当多诡异的问题。
第二种架构:Hadoop机器运行在Linux上完全没有问题,但是有大部分的开发者不习惯在Linux上做开发。
这种架构适合习惯使用Linux的开发者。
第三种架构:Hadoop集群部署在Linux上,保证了稳定性,Eclipse在Windows 上,符合大部分开发者的习惯。
本文主要介绍第三种Hadoop开发环境架构的搭建方法。
Hadoop开发环境的搭建分为两大块:Hadoop集群搭建、Eclipse环境搭建。
其中Hadoop集群搭建可参考官方文档,本文主要讲解Eclipse环境搭建(如何在Eclipse 中查看和操作HDFS、如何在Eclipse中执行MapReduce作业)。
搭建步骤:1、搭建Hadoop集群(Linux、JDK6、Hadoop-1.1.2)2、在Windows上安装JDK6+3、在Windows上安装Eclipse3.3+4、在Eclipse上安装hadoop-eclipse-plugin-1.1.2.jar插件(如果没有,则需自行编译源码)5、在Eclipse上配置Map/Reduce Location搭建Hadoop集群此步骤可参考Hadoop官方文档在Windows上安装JDK此步骤可参考官方文档在Window上安装Eclipse此步骤可参考官方文档在Eclipse上安装hadoop-eclipse-plugin-1.1.2.jar插件Hadoop-1.1.2的发布包里面没有hadoop-eclipse-plugin-1.1.2.jar,开发者必须根据所在的环境自行编译hadoop-eclipse-plugin-1.1.2.jar插件。
centos环境下hadoop的安装与配置实验总结

centos环境下hadoop的安装与配置实验总结实验总结:CentOS环境下Hadoop的安装与配置一、实验目标本次实验的主要目标是学习在CentOS环境下安装和配置Hadoop,了解其基本原理和工作机制,并能够运行简单的MapReduce程序。
二、实验步骤1. 准备CentOS环境:首先,我们需要在CentOS上安装和配置好必要的基础环境,包括Java、SSH等。
2. 下载Hadoop:从Hadoop官方网站下载Hadoop的稳定版本,或者使用CentOS的软件仓库进行安装。
3. 配置Hadoop:解压Hadoop安装包后,需要进行一系列的配置。
这包括设置环境变量、配置文件修改等步骤。
4. 格式化HDFS:使用Hadoop的命令行工具,对HDFS进行格式化,创建其存储空间。
5. 启动Hadoop:启动Hadoop集群,包括NameNode、DataNode等。
6. 测试Hadoop:运行一些简单的MapReduce程序,检查Hadoop是否正常工作。
三、遇到的问题和解决方案1. 环境变量配置问题:在配置Hadoop的环境变量时,有时会出现一些问题。
我们需要检查JAVA_HOME是否设置正确,并确保HADOOP_HOME 在PATH中。
2. SSH连接问题:在启动Hadoop集群时,需要确保各个节点之间可以通过SSH进行通信。
如果出现问题,需要检查防火墙设置和SSH配置。
3. MapReduce程序运行问题:在运行MapReduce程序时,可能会遇到一些错误。
这通常是由于程序本身的问题,或者是由于HDFS的权限问题。
我们需要仔细检查程序代码,并确保运行程序的用户有足够的权限访问HDFS。
四、实验总结通过本次实验,我们深入了解了Hadoop的安装和配置过程,以及如何解决在安装和运行过程中遇到的问题。
这对于我们今后在实际应用中部署和使用Hadoop非常重要。
同时,也提高了我们的实践能力和解决问题的能力。
标准hadoop集群配置

标准hadoop集群配置Hadoop是一个开源的分布式存储和计算框架,由Apache基金会开发。
它提供了一个可靠的、高性能的数据处理平台,可以在大规模的集群上进行数据存储和处理。
在实际应用中,搭建一个标准的Hadoop集群是非常重要的,本文将介绍如何进行标准的Hadoop集群配置。
1. 硬件要求。
在搭建Hadoop集群之前,首先需要考虑集群的硬件配置。
通常情况下,Hadoop集群包括主节点(NameNode、JobTracker)和从节点(DataNode、TaskTracker)。
对于主节点,建议配置至少16GB的内存和4核以上的CPU;对于从节点,建议配置至少8GB的内存和2核以上的CPU。
此外,建议使用至少3台服务器来搭建Hadoop集群,以确保高可用性和容错性。
2. 操作系统要求。
Hadoop可以在各种操作系统上运行,包括Linux、Windows和Mac OS。
然而,由于Hadoop是基于Java开发的,因此建议选择Linux作为Hadoop集群的操作系统。
在实际应用中,通常选择CentOS或者Ubuntu作为操作系统。
3. 网络配置。
在搭建Hadoop集群时,网络配置非常重要。
首先需要确保集群中的所有节点能够相互通信,建议使用静态IP地址来配置集群节点。
此外,还需要配置每台服务器的主机名和域名解析,以确保节点之间的通信畅通。
4. Hadoop安装和配置。
在硬件、操作系统和网络配置完成之后,接下来就是安装和配置Hadoop。
首先需要下载Hadoop的安装包,并解压到指定的目录。
然后,根据官方文档的指导,配置Hadoop的各项参数,包括HDFS、MapReduce、YARN等。
在配置完成后,需要对Hadoop集群进行测试,确保各项功能正常运行。
5. 高可用性和容错性配置。
为了确保Hadoop集群的高可用性和容错性,需要对Hadoop集群进行一些额外的配置。
例如,可以配置NameNode的热备份(Secondary NameNode)来确保NameNode的高可用性;可以配置JobTracker的热备份(JobTracker HA)来确保JobTracker的高可用性;可以配置DataNode和TaskTracker的故障转移(Failover)来确保从节点的容错性。
Hadoop环境配置之hive环境配置详解

<value>/opt/module/apache-hive-3.1.2-bin/tmp/${hive.session.id}_resources</value> <description>Temporary local directory for added resources in the remote file system.</description>
<configuration> <property>
<name>javax.jdo.option.ConnectionDriverName</name> <value>com.mysql.cj.jdbc.Driver</value> <description>Driver class name for a JDBC metastore</description> </property> <property> <name>javax.jdo.option.ConnectionUserName</name> <value>root</value> <description>Username to use against metastore database</description> </property> <property> <name>javax.jdo.option.ConnectionPassword</name> <value>123456</value> # 自定义密码 <description>password to use against metastore database</description> </property> <property> <name>javax.jdo.option.ConnectionURL</name> <value>jdbc:mysql://192.168.1.100:3306/hive?useUnicode=true&characterEncoding=utf8&useSSL=false&serverTimezone=GMT</value> <description>
hadoop配置环境变量

hadoop配置环境变量hadoop安装包解压tar -xvf hadoop-2.7.7.tar.gz解压成功ll查看⽂件配置环境变量1.vi /home/wj/hadoop-2.7.7/etc/hadoop/hadoop-env.sh修改export JAVA_HOME={$JAVA_HOME}为 export JAVA_HOME=/usr/java/jdk1.8.0_162/2.vi yarn-env.sh找到#export JAVA_HOME=/home/y/libexec/jdk.1.6.0/去掉#,改为export JAVA_HOME=/usr/java/jdk1.8.0_1623.vi core-site.xml<configuration> <property> <name>fs.defaultFS</name> <value>hdfs://master:9000</value> </property> <property> <name>hadoop.tmp.dir</name> <value>/home/wj/hadoopdata</value> </property></configuration>4.vi hdfs-site.xml<configuration><property><name>dfs.replication</name><value>1</value></property></configuration>5.vi yarn-site.xml<configuration><!-- Site specific YARN configuration properties --> <property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> #洗牌,类似排序 </property> <property> <name>yarn.resourcemanager.address</name> <value>master:18040</value>#主机端⼝ </property> <property> <name>yarn.resourcemanager.scheduler.address</name> <value>master:18030</value>#调度端⼝ </property> <property> <name>yarn.resourcemanager.resource-tracker.address</name> <value>master:18025</value>#跟踪端⼝ </property>⾸次运⾏格式化[wj@master hadoop]$ hdfs namenode -format <property> <name>yarn.resourcemanager.admin.address</name> <value>master:18141</value>#管理操作端⼝ </property> <property> <name>yarn.resourcemanager.webapp.address</name>#监控页⾯ <value>master:18088</value> </property></configuration>6.复制 mapred-site-template.xmlcp etc/hadoop/mapred-site-template.xml etc/hadoop/mapred-site.xmlvi mapred-site.xml<configuration> <property> <name></name> <value>yarn</value> </property></configuration>7.wj@master ~]$ pwd/home/wj[wj@master ~]$ vi ~/.bash_profile 或者vi /etc/profile#JAVAexport JAVA_HOME=/usr/java/jdk1.8.0_162export PATH=$JAVA_HOME/bin:$PATH#hadoopexport HADOOP_HOME=/home/wj/hadoop2.7.7export PATH=$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$PATH使配置⽣效[wj@master ~]$ source .bash_profile 或者source /etc/profile。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
4.2配置Slave机器上的Hadoop
现在在Master机器上的Hadoop配置就结束 了,剩下的就是配置Slave机器上的Hadoop。
一种方式 是按照上面的步骤,把Hadoop的安装包在用普通用户 hadoop通过"scp"复制到其他机器的"/home/hadoop"目 录下,然后根据实际情况进行安装配置 另一种方式 是将 Master上配置好的hadoop所在文件夹 "/usr/hadoop"复制到所有的Slave的"/usr"目录下
4.4网页查看集群
用"hadoop dfsadmin -report"查看Hadoop集群的状态。
网页查看集群 访问"http:192.168.1.120:50030“ mapreduce的web页面 访问"http:192.168.1.120:50070" hdfs的web页面
5运行程序步骤
首先启动hadoop,把jar包放到指定位置 通过hadoop的命令在HDFS上创建/tmp/work 目录(本次所需) 通过copyFromLocal命令把本地的word.txt复 制到HDFS上 通过命令运行例子,主要是指定jar程序包, 需要统计的数据文件和结果存放的文件 查看运行结果
4.3Hadoop启动及验证
格式化HDFS文件系统
只需一次,下次启动不再需要格式化
启动hadoop(启动前关闭所有机器的防火墙)
可以一次全部启动所有的节点
service iptables stop start-all.sh
或是分别启动namenode、 datanode、 tasktracker 、secondarynamenode 、 jobtracker 验证hadoop
127.0.0.1 localhost 192.168.1.120 ubuntu1 192.168.1.121 ubuntu2 192.168.1.122 ubuntu3 192.168.1.123 ubuntu4
1.3hadoop的主从节点结构分解
2环境说明和安装配置SSH
2.1在所有的机器上建立相同的用户 对每个系统进行系统名和ip地址的配置
4.1配置文件
配置masters文件 第一种:修改localhost为Master.Hadoop 第二种:去掉"localhost",加入Master机器的IP: 192.168.1.121 配置slaves文件(Master主机特有)
第一种:去掉"localhost",每行只添加一个主机名, 把剩余的Slave主机名都填上。 第二种:去掉"localhost",加入集群中所有Slave 机器的IP,也是每行一个。
SSH配置
这就必须在节点之间执行指令的时候是不需要输 入密码的形式,故我们需要配置SSH运用无密码公 钥认证的形式,这样NameNode使用SSH无密码登录 并启动DataName进程,同样原理,DataNode上也 能使用SSH无密码登录到NameNode。
在用户目录下建立ssh的安装目录,之后设置权限 Master机器上生成无密码密码对,追加权限
SSH安装配置
2 .2安装配置SSH 安装和启动SSH协议
yum install ssh 安装SSH协议 yum install rsync service sshd restart 启动服务
配置Master无密码登录所有Salve Hadoop运行过程中需要管理远端Hadoop守护 进程,在Hadoop启动以后,NameNode是通的。
和Master无密码登录所有Slave原理一样,就是把 Slave的公钥追加到Master的".ssh"文件夹下的 "authorized_keys"中 这样就建立了Master和Slave之间的无密码验证相 互登录
3 jdk安装配置
安装jdk1.6.45 环境变量配置
编辑"/etc/profile"文件,在后面添加Java的"JAVA_HOME"、 "CLASSPATH"以及"PATH"内容。
注意:目录要设成700 有执行权限 authorized_keys要设成600 否则会出错 还有ssh 登陆要加入用户名的
SSH配置
用root用户登录服务器修改SSH配置文件 /etc/ssh/sshd_config,无密码登录本级已经设 置完毕,接下来的事儿是把公钥复制所有的Slave 机器上
配置所有Slave无密码登录Master
export JAVA_HOME=/usr/java/jdk1.6.0_31 export CLASSPATH=.:$CLASSPATH:$JAVA_HOME/lib:$JAVA_HOME/jre/lib export PATH=$PATH:$JAVA_HOME/bin:$JAVA_HOME/jre/bin
必须在所有的机器上建立相同的用户,设置每个系统 的ip地址。
2.2配置NameNode和DataNode 配置hosts文件
修改每台机器的/etc/hosts(包括namenode和datanode) ) 127.0.0.1 localhost 192.168.1.120 ubuntu1 192.168.1.121 ubuntu2 192.168.1.122 ubuntu3 192.168.1.123 ubuntu4
使配置生效 (重要) source /etc/profile 验证 Slave安装jdk: Master下的JDK复制到其他Slave的/home/hadoop/下面剩下 的事儿就是在其余的Slave服务器上按照步骤安装JDK。
4 Hadoop集群安装配置
首先在namenode上配置,配置后在分发到datanode上 在“/usr/hadoop”下面创建tmp文件夹
安装
把"/usr/hadoop"读权限分配给hadoop用户
配置hadoop
配置hadoop-env.sh 使得能够找到java的路径 export HADOOP_HOME=/usr/hadoop export JAVA_HOME=/usr/java/jdk1.6.0_29
4.1配置文件
配置文件也被分成了三个core-site.xml、 hdfs-site.xml、mapred-site.xml。 修改Hadoop核心配置文件core-site.xml, 这里配置的是HDFS的地址和端口号。 修改Hadoop中HDFS的配置hdfs-site.xml。 (就是Slave的台数默认3个) 修改Hadoop中MapReduce的配置文件mapredsite.xml, 配置的是JobTracker的地址和端口。
基于Hadoop平台 的并行编程实践
李东秀
内容介绍
熟悉hadoop配置环境 搭建实验 平台 编写 (矩阵相乘)运算的 map, reduce函数 在hadoop实验 平台上实现 配置计算环境: 1个Master、3个Slave的 Hadoop集群
1.1 Hadoop简介
Apache软件基金会下的一个开源分布式计算平台 以Hadoop的HDFS和MapReduce为核心的Hadoop为用 户提供了系统底层细节透明的分布式基础架构。 对于Hadoop的集群来讲,可以分成两大类角色: Master和Salve。 一个HDFS集群是由一个NameNode和若干个 DataNode组成的。 MapReduce框架是由一个单独运行在主节点上的 JobTracker和运行在每个集群从节点的TaskTracker 共同组成的。
1.2环境说明
HDFS在MapReduce任务处理过程中提供了文件操作 和存储等支持,MapReduce在HDFS的基础上实现了任务 的分发、跟踪、执行等工作,并收集结果,二者相互 作用,完成了Hadoop分布式集群的主要任务。 集群中包括4个节点:1个Master,3个Salve,节点IP 地址分布如下: