网页提取源代码
Python爬虫项目实战源代码集锦

Python爬虫项目实战源代码集锦为了满足标题描述的内容需求,下面是一些Python爬虫项目实战的源代码示例,供参考和学习。
1. 爬取网页数据import requests# 发送HTTP请求获取网页内容response = requests.get(url)content = response.text# 解析网页内容# ...# 提取所需信息# ...# 存储数据# ...2. 爬取图片import requests# 发送HTTP请求获取图片资源response = requests.get(image_url)# 保存图片到本地with open('image.jpg', 'wb') as f:f.write(response.content)3. 爬取动态网页from selenium import webdriver # 启动浏览器驱动driver = webdriver.Chrome()# 打开动态网页driver.get(url)# 等待动态内容加载完成# ...# 提取所需信息# ...# 存储数据# ...4. 登录网站并获取数据import requests# 登录网站login_data = {'username': 'your_username','password': 'your_password'}session = requests.Session() session.post(login_url, data=login_data) # 发送登录后的请求response = session.get(url)# 解析网页内容# ...# 提取所需信息# ...# 存储数据# ...5. 反爬虫处理import requestsfrom fake_useragent import UserAgent # 构造随机HTTP请求头user_agent = UserAgent().random# 发送带有伪装的HTTP请求headers = {'User-Agent': user_agent}response = requests.get(url, headers=headers)# 解析网页内容# ...# 提取所需信息# ...# 存储数据# ...以上是一些Python爬虫项目实战源代码的简单示例,可以根据具体项目的需求进行修改和扩展。
网页源码爬取
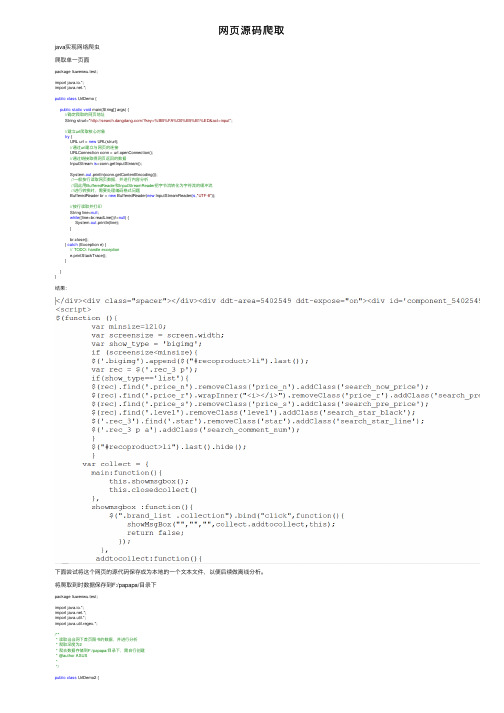
⽹页源码爬取java实现⽹络爬⾍爬取单⼀页⾯package liuwenwu.test;import java.io.*;import .*;public class UrlDemo {public static void main(String[] args) {//确定爬取的⽹页地址String strurl="/?key=%BB%FA%D0%B5%B1%ED&act=input";//建⽴url爬取核⼼对象try {URL url = new URL(strurl);//通过url建⽴与⽹页的连接URLConnection conn = url.openConnection();//通过链接取得⽹页返回的数据InputStream is=conn.getInputStream();System.out.println(conn.getContentEncoding());//⼀般按⾏读取⽹页数据,并进⾏内容分析//因此⽤BufferedReader和InputStreamReader把字节流转化为字符流的缓冲流//进⾏转换时,需要处理编码格式问题BufferedReader br = new BufferedReader(new InputStreamReader(is,"UTF-8"));//按⾏读取并打印String line=null;while((line=br.readLine())!=null) {System.out.println(line);}br.close();} catch (Exception e) {// TODO: handle exceptione.printStackTrace();}}}结果:下⾯尝试将这个⽹页的源代码保存成为本地的⼀个⽂本⽂件,以便后续做离线分析。
将爬取到时数据保存到F:/papapa/⽬录下package liuwenwu.test;import java.io.*;import .*;import java.util.*;import java.util.regex.*;/*** 读取当当⽹下⾸页图书的数据,并进⾏分析* 爬取深度为2* 爬去数据存储到F:/papapa/⽬录下,需⾃⾏创建* @author ASUS**/public class UrlDemo2 {//提取的数据存放到该⽬录下private static String savepath="F:/papapa/";//等待爬取的urlprivate static List<String> allwaiturl=new ArrayList<>();//爬取过得urlprivate static Set<String> alloverurl=new HashSet<>();//记录所有url的深度进⾏爬取判断private static Map<String, Integer> allurldepth=new HashMap<>();//爬取的深度private static int maxdepth=2;public static void main(String[] args) {//确定爬取的⽹址String strurl="/";workurl(strurl, 1);}public static void workurl(String strurl,int depth) {//判断当前url是否爬取过if(!(alloverurl.contains(strurl)||depth>maxdepth)) {//建⽴url爬取核⼼对象try {URL url = new URL(strurl);//通过url建⽴与⽹页的连接URLConnection conn = url.openConnection();//通过链接取得⽹页返回的数据InputStream is=conn.getInputStream();System.out.println(conn.getContentEncoding());//⼀般按⾏读取⽹页数据,并进⾏内容分析//因此⽤BufferedReader和InputStreamReader把字节流转化为字符流的缓冲流//进⾏转换时,需要处理编码格式问题BufferedReader br=new BufferedReader(new InputStreamReader(is,"GB2312"));//按⾏读取并打印String line=null;//正则表达式的匹配规则提取该⽹页的链接Pattern p=pile("<a .*href=.+</a>");//建⽴⼀个输出流,⽤于保存⽂件,⽂件名为执⾏时间,以防重复PrintWriter pw=new PrintWriter(new File(savepath+System.currentTimeMillis()+".txt"));while((line=br.readLine())!=null) {//编写正则,匹配超链接地址pw.println(line);Matcher m=p.matcher(line);while(m.find()) {String href=m.group();//找到超链接地址并截取字符串//有⽆引号href=href.substring(href.indexOf("href="));if(href.charAt(5)=='\"') {href=href.substring(6);}else {href=href.substring(5);}//截取到引号或者空格或者到">"结束try {href=href.substring(0,href.indexOf("\""));} catch (Exception e) {try {href=href.substring(0,href.indexOf(""));} catch (Exception e2) {href=href.substring(0,href.indexOf(">"));}}if(href.startsWith("http:")||href.startsWith("https:")){//将url地址放到队列中allwaiturl.add(href);allurldepth.put(href,depth+1);}}}pw.close();br.close();} catch (Exception e) {// TODO: handle exceptione.printStackTrace();}//将当前url归列到alloverurl中alloverurl.add(strurl);System.out.println(strurl+"⽹页爬取完成,以爬取数量:"+alloverurl.size()+",剩余爬取数量:"+allwaiturl.size()); }//⽤递归的⽅法继续爬取其他链接String nexturl=allwaiturl.get(0);allwaiturl.remove(0);workurl(nexturl, allurldepth.get(nexturl));}}控制台:本地⽬录如果想提⾼爬⾍性能,那么我们就需要使⽤多线程来处理,例如:准备好5个线程来同时进⾏爬⾍操作。
如何获取网页代码

如何获取网页代码网页源码,我们可以把它理解成源文代码。
任何一个网站页面,换成源码就是一堆按一定格式书写的文字和符号,通过浏览器(或服务器)翻译成平常我们看到的样子。
网站源码分为两种,一种是动态源码如:ASP,PHP,JSP,.NET,CGI等,一种是静态源码如:HTML 等。
获取网页源码有以下几种方式:一、通过浏览器获取下载并打开谷歌、搜狐等浏览器,在网页空白处,点击鼠标右键并选择“查看网页源码”,然后将显示出来的源码复制下来即可。
二、通过八爪鱼采集器采集八爪鱼采集器有自定义抓取方式的功能,可通过此功能抓取网页源码。
1、采集整个网页源码1)在八爪鱼中打开目标网页,点击网页空白处,在操作提示框中,先点击一下“HTML”,然后选择“采集该元素的Outer H Html”,如下图所示:如何获取网页代码图12)点击保存,然后启动本地采集,将采集后的数据导出,可以看到,网页的源码被采集下来了,如下图所示:如何获取网页代码图2注意:①以上只是一个提取网页源码的简单示例,其他操作步骤,请参考八爪鱼新手入门教程②网页源码导出过程中,可能出现因太长而被excel截断的情况,导出到数据库可避免被截断。
2、采集网页上某个元素的源码可通过“抓取这个元素的OuterHtml,InnerHtml”选项,抓取网页源码。
打开八爪鱼,找到提取数据步骤,选择:自定义抓取方式-从页面中提取数据-抓取这个元素的OuterHtml (包含当前元素的网页源代码,带格式的文本和图片)如何获取网页代码图3相关采集教程:京东商品信息采集新浪微博数据采集搜狗微信文章采集八爪鱼——70万用户选择的网页数据采集器。
1、操作简单,任何人都可以用:无需技术背景,会上网就能采集。
完全可视化流程,点击鼠标完成操作,2分钟即可快速入门。
2、功能强大,任何网站都可以采:对于点击、登陆、翻页、识别验证码、瀑布流、Ajax脚本异步加载数据的网页,均可经过简单设置进行采集。
批量下载网页图片源代码

$new_image_ext = 'xbm';
break;
default:
$image_create_func = 'ImageCreateFromJPEG';
$image_save_func = 'ImageJPEG';
$new_image_ext = 'jpg';
$image_save_func = 'ImageBMP';
$new_image_ext = 'bmp';
break;
case 'gif':
$image_create_func = 'ImageCreateFromGIF';
$image_save_func = 'ImageGIF';
$new_image_ext = 'gif';
}
//根据‘指定扩展名标志’set_extension属性来合成本地图片文件名
if(isSet($this->set_extension)){
$ext = strrchr($this->source, ".");
$strlen = strlen($ext);
$new_name = basename(substr($this->source, 0, -$strlen)).'.'.$new_image_ext;
2012-05-02 14:22 php批量下载网页图片源代码 有GetAllPic.php、DownImage.class.php两个文件和data放置下载图片的文件夹。GetAllPic.php为主文件,DownImage.class.php为类文件
如何复制通过查看网页源代码的方式快速复制网页上的文字方法技巧

如何复制通过查看网页源代码的方式快速复制网页上的文字方法技巧通过查看源代码的方式快速复制网页上的文字如何复制不给复制的网页文字网页源码复制编辑技巧针对现在网页上有些资料,想要复制提取其中一点信息,不用自己编辑打字,现在问题来了,有的网站开店不给复制粘贴功能。
现在教大家一个小方法和技巧,来使用:1、打开要复制的网页要复制出会现弹框付费关注公众号等一堆不想要的操作,而且还可能复制不了,这个时候又想要里面的内容,打字时间太长,怎么办?如图,随意取一网站上的为例子:复制这样。
2、在网页中,右键——查看源文件。
击右上角的查看菜单,查看源代码。
或者点击右键,查看源代码3、看到没有,找到一堆乱乱的,看到头昏眼花的东西,看起来很乱。
这个时候不要慌。
选择复制到word里面。
这个时候网页里有很多这些乱的字符。
如图4、这个时候就看我们的编辑技巧了。
主要用到word的查找和替换功能来还原,还有特殊的HTML编辑器可以,自行下载。
但对于日常来说,就自己简单手工编辑快。
下列技巧来了。
对文档进行替换三步。
把</p><p>替换成换行符(^p)对</strong>换成替换成换行符(^p)对<strong>换成替换成换行符(^p)看下列过程图:看效果:到这步就是很多换行符,最后一步,对换行符两个替换成一个,进行多次替换。
如图:当进行两三次替换后,就会还原出效果。
简单的几步:看效果:注:可能还会有其它的链接什么的,再手工处理一下就非常完全了。
自己动手,非常的方便。
这个技巧也实用。
易语言取网页指定内容

易语言取网页指定内容在易语言中,我们可以利用网络编程的相关函数来实现对网页指定内容的提取。
这在一些网络爬虫、数据采集等应用中非常常见。
本文将介绍如何使用易语言来取网页指定内容,以及一些注意事项和技巧。
首先,我们需要明确一点,即要取网页指定内容,我们需要先获取网页的源代码。
在易语言中,可以使用WinHttp.WinHttpRequest对象来实现网页的下载和源代码的获取。
通过调用该对象的相关方法和属性,我们可以轻松地获取到网页的源代码。
接着,我们需要对获取到的网页源代码进行分析,找到我们需要提取的内容所在的位置。
这一步通常需要借助一些字符串处理函数来实现,比如InStr、Mid等。
通过分析网页源代码的结构和特点,我们可以找到目标内容所在的位置,并将其提取出来。
在提取内容之前,我们还需要注意一些细节。
比如,网页的编码方式可能不同,需要根据实际情况来确定正确的编码方式;另外,网页的结构可能会有所变化,需要考虑到这些变化,以确保我们的提取方法的稳定性和可靠性。
在实际操作中,我们还可以借助一些正则表达式来实现对网页源代码的分析和内容的提取。
正则表达式是一种强大的字符串匹配工具,可以帮助我们更加灵活地进行内容的提取和处理。
除了以上介绍的方法外,我们还可以考虑使用一些第三方的库或工具来实现对网页内容的提取。
比如,一些专门用于网页解析和数据提取的库,可以帮助我们更加高效地实现对网页内容的提取。
总的来说,易语言可以很好地实现对网页指定内容的提取。
通过对网页源代码的获取和分析,以及一些字符串处理和正则表达式的运用,我们可以轻松地实现对网页指定内容的提取。
当然,在实际应用中,我们还需要考虑到一些细节和特殊情况,以确保我们的提取方法的稳定性和可靠性。
希望本文的介绍对大家有所帮助,谢谢阅读!。
浏览器开发者工具导出部分源码

浏览器开发者工具导出部分源码一、什么是浏览器开发者工具?浏览器开发者工具是一种内置于现代浏览器中的工具集,旨在帮助开发人员调试和分析网站。
它可以让开发人员通过检查网站的HTML、CSS和JavaScript代码,来诊断问题并修复错误。
二、如何打开浏览器开发者工具?不同的浏览器有不同的快捷键或菜单选项来打开它们的开发者工具。
以下是几种流行浏览器的打开方式:1. Google Chrome:按下Ctrl + Shift + I(Windows)或Command + Option + I(Mac)2. Mozilla Firefox:按下Ctrl + Shift + I(Windows)或Command + Option + I(Mac)3. Safari:按下Option + Command + C4. Microsoft Edge:按下F12键三、如何导出部分源码?在大多数浏览器中,都可以使用“检查元素”功能来查看和编辑网站源代码。
以下是如何导出部分源码:1. 在浏览器中打开要检查的网页,并使用快捷键或菜单选项打开浏览器开发者工具。
2. 在“Elements”选项卡中选择要导出代码的元素。
3. 右键单击所选元素,并选择“Copy” > “Copy element”.4. 将复制到剪贴板的代码粘贴到您选择的文本编辑器中,然后保存文件。
四、如何导出整个网页源码?如果您需要导出整个网页的源代码,而不仅仅是某个元素的代码,则可以使用以下步骤:1. 在浏览器中打开要检查的网页,并使用快捷键或菜单选项打开浏览器开发者工具。
2. 在“Sources”选项卡中找到并选择“Page”或“HTML”,以查看整个网页的源代码。
3. 右键单击页面上任意位置,并选择“Save as”(另存为)选项。
4. 输入保存文件的名称和位置,并选择保存文件类型为“Webpage, Complete”(完整网页)或“HTML Only”(仅HTML)。
查看源代码快捷键

查看源代码快捷键引言:在编程和网页开发过程中,查看源代码是一个常见的需求。
查看源代码可以帮助开发者了解网页的结构和布局,发现隐藏的功能以及学习其他的编程技巧。
然而,在大多数情况下,我们必须使用鼠标右键点击网页然后选择“查看源代码”来实现这一目标。
但是,许多开发者并不知道还有更快捷的方法来查看网页的源代码。
在本文中,我们将介绍一些常用的快捷键来帮助您快速查看网页的源代码。
快捷键是一种在键盘上的组合键,用于执行特定的功能或操作。
使用快捷键可以大大提高工作效率,减少不必要的鼠标操作。
查看源代码快捷键是一些被广泛接受和应用的快捷键组合,可以在不离开当前页面的情况下快速查看源代码。
一、常见的查看源代码快捷键1. Windows 系统快捷键在 Windows 系统中,常用的查看源代码快捷键是使用 Ctrl+U 组合键。
要查看当前网页的源代码,在打开的网页上按住 Ctrl 键,然后按 U 键。
这将立即打开网页的源代码,供您分析和学习。
2. macOS 系统快捷键在 macOS 系统中,可以使用 Command+Option+U 组合键快速查看源代码。
打开网页后,按住 Command 和 Option 键,然后按U 键即可打开源代码。
二、使用浏览器的开发者工具除了快捷键之外,现代浏览器通常提供了一种更强大的工具来查看和分析网页的源代码,即开发者工具。
几乎所有的主流浏览器,包括谷歌浏览器、火狐浏览器、Safari 等,都有内置的开发者工具。
要打开开发者工具,您只需要按下 F12 键。
一旦开发者工具打开,您可以在其中找到“Elements”(元素)或类似的选项卡,里面包含了网页的 HTML 结构和 CSS 样式。
您可以轻松地在开发者工具中导航和查看网页的源代码。
此外,开发者工具还提供了许多其他有用的功能,例如网络监控、调试器和性能分析工具等,这些工具可以帮助开发者更好地分析和优化网页。
三、通过命令行查看源代码对于一些高级用户和开发者来说,可以通过命令行实现快速查看网页源代码的目的。
三种获取网页源码的方法(使用MFCSocket实现)

三种获取⽹页源码的⽅法(使⽤MFCSocket实现)<afxinet.h>复制代码代码如下:CString GetHttpFileData(CString strUrl){CInternetSession Session("Internet Explorer", 0);CHttpFile *pHttpFile = NULL;CString strData;CString strClip;pHttpFile = (CHttpFile*)Session.OpenURL(strUrl);while ( pHttpFile->ReadString(strClip) ){strData += strClip;}return strData;}要讲⼀下,pHttpFile->ReadString() 每次可能只读⼀个数据⽚断,读多少次取决于⽹络状况,所以要把每次读到的数据加到总数据的尾部,⽤了CString 省去了缓冲区处理:)别忘了包含头⽂件#include <afxinet.h> 在⼯程设置,⾥⾯要选择 using MFC 要不然编译不了第⼆种是使⽤WinNet的纯API实现的复制代码代码如下:#define MAXBLOCKSIZE 1024#include <windows.h>#include <wininet.h>#pragma comment(lib, "wininet.lib")void GetWebSrcCode(const char *Url);int _tmain(int argc, _TCHAR* argv[]){GetWebSrcCode("https:///");return 0;}void GetWebSrcCode(const char *Url){HINTERNET hSession = InternetOpen("zwt", INTERNET_OPEN_TYPE_PRECONFIG, NULL, NULL, 0);if (hSession != NULL){HINTERNET hURL = InternetOpenUrl(hSession, Url, NULL, 0, INTERNET_FLAG_DONT_CACHE, 0);if (hURL != NULL){char Temp[MAXBLOCKSIZE] = {0};ULONG Number = 1;FILE *stream;if( (stream = fopen( "E:\\test.html", "wb" )) != NULL ){while (Number > 0){InternetReadFile(hURL, Temp, MAXBLOCKSIZE - 1, &Number);fwrite(Temp, sizeof (char), Number , stream);}fclose( stream );}InternetCloseHandle(hURL);hURL = NULL;}InternetCloseHandle(hSession);hSession = NULL;}}复制代码代码如下:int main(int argc, char* argv[]){SOCKET hsocket;SOCKADDR_IN saServer;WSADATA wsadata;LPHOSTENT lphostent;int nRet;char Dest[3000];char* host_name="";char* req="GET /s/blog_44acab2f01016gz3.html HTTP/1.1\r\n""User-Agent: Mozilla/4.0 (compatible; MSIE 8.0; Windows NT 5.1; Trident/4.0; .NET CLR 1.1.4322; .NET CLR 2.0.50727; .NET4.0C; .NET4.0E; .NET CLR 3.0.4506.2152; .NET CLR 3.5.30729)\r\n""Host:\r\n\r\n";// 初始化套接字if(WSAStartup(MAKEWORD(2,2),&wsadata))printf("初始化SOCKET出错!");lphostent=gethostbyname(host_name);if(lphostent==NULL)printf("lphostent为空!");hsocket = socket(AF_INET,SOCK_STREAM,IPPROTO_TCP);saServer.sin_family = AF_INET;saServer.sin_port = htons(80);saServer.sin_addr =*((LPIN_ADDR)*lphostent->h_addr_list);// 利⽤SOCKET连接nRet = connect(hsocket,(LPSOCKADDR)&saServer,sizeof(SOCKADDR_IN));if(nRet == SOCKET_ERROR){printf("建⽴连接时出错!");closesocket(hsocket);return 0;}// 利⽤SOCKET发送nRet = send(hsocket,req,strlen(req),0);if(nRet==SOCKET_ERROR){printf("发送数据包时出错!");closesocket(hsocket);}nRet=1;while(nRet>0){// 接收返回数据包nRet=recv(hsocket,(LPSTR)Dest,sizeof(Dest),0);if(nRet>0)Dest[nRet]=0;elseDest[0]=0;char sDest[3000] = {0};UTF8_2_GB2312(sDest,nRet,Dest,nRet);// 显⽰返回数据包的⼤⼩、内容//printf("\nReceived bytes:%d\n",nRet);printf("Result:\n%s",sDest);}}另外,以上我们获取⽹页的时候,获取到的可能是UTF8,似乎⽬前⼤多数⽹站都⽤的这种编码吧!下⾯是编码转换。
网页中内容如何下载方法

网页中内容如何下载方法在日常的网络使用中,我们经常会遇到一些有价值的网页内容想要下载保存下来。
然而,对于许多人来说,他们可能不清楚如何正确地下载网页中的内容。
本文将介绍几种常见的网页内容下载方法,以帮助您轻松获取所需的内容。
一、截屏保存对于简单的网页内容,如图片或文本,最简单的下载方法是使用截屏保存功能。
您可以按下键盘上的Print Screen键(可能需要与Fn键一同使用),然后将其粘贴到您选择的图像编辑工具中(如Paint、Photoshop等),再进行保存。
这种方法适用于不需高清晰度的简单内容。
二、右键另存为对于某些网页内容,如图片、音频或视频等,您可以通过右键点击鼠标来选择“另存为”选项。
在打开的菜单中,选择您希望保存的位置,点击保存即可将内容下载到本地。
这种方法适用于绝大多数网页内容的下载。
三、使用插件或扩展对于需要批量下载网页内容的情况,您可以考虑使用一些专门的插件或扩展来帮助您完成下载。
例如,对于Chrome浏览器用户,可以使用一些强大的下载扩展程序,如DownloadMaster、DownThemAll等。
这些工具可以提供更多高级的下载功能,如多线程下载、下载管理和下载加速等。
四、使用网页源代码对于一些需要提取文本或特定信息的网页内容,您可以查看该网页的源代码,并将相关内容复制保存到文本编辑器中。
首先,在浏览器上右键点击网页,选择“查看页面源代码”选项。
在弹出的源代码窗口中,您可以使用Ctrl+F(或Cmd+F)来查找并复制所需的内容。
然后将其粘贴到文本编辑器中,并进行保存。
这种方法适用于需要提取大量文本信息的情况。
五、使用专门的下载工具除了上述的方法之外,还有一些专门的下载工具可以帮助您下载网页中的内容。
这些工具通常具有更丰富的功能和更高的下载速度。
常见的下载工具包括IDM(Internet Download Manager)、Free Download Manager等。
您只需将工具安装到您的计算机上,然后在浏览器中启用它们的插件或扩展,便可快速、稳定地下载您需要的网页内容。
怎么获取网站源码

怎么获取网站源码一般网站都是由源代码编写而成,有的时候我们需要去批量获取网站源码,或者从网站源码中提取指定的数据,比如采集淘宝联盟时从网站源码中获取销量、佣金、比率等信息,那么应该如何做呢。
下面本文以采集淘宝联盟为例,为大家介绍怎么获取网站源码。
使用功能点:●创建循环翻页●商品URL采集提取●创建URL循环采集任务●修改Xpath步骤1:创建淘宝联盟采集任务1)进入主界面,选择“自定义采集”淘宝联盟源码提取数据步骤12)将要采集的网站URL复制粘贴到输入框中,点击“保存网址”淘宝联盟源码提取数据步骤23)保存网址后,鼠标点击输入框,在右侧操作提示框中,选择“输入文字”淘宝联盟源码提取数据步骤34)然后输入采集的商品,点击确定淘宝联盟源码提取数据步骤45)网络加载速度比较慢,所以需要设置执行前等待,为防止输入框没加载完毕操作失效还需要设置出现元素。
淘宝联盟源码提取数据步骤5然后点击搜索,并选择“点击该按钮”淘宝联盟源码提取数据步骤6由于网页涉及Ajax技术。
所以需要选中点击元素,打开“高级选项”,勾选“Ajax 加载数据”,设置时间为“5秒”。
因为页面打开后需要向下滑动才可以出现更多内容,所以还需要设置页面滚动,滚动次数选择30次,每次间隔2秒,选择向下滚动一屏完成后,点击“确定”。
淘宝联盟源码提取数据步骤7步骤2:创建翻页循环1)将页面下拉到底部,找到下一页按钮,鼠标点击,在右侧操作提示框中,选择“循环点击单个链接”淘宝联盟源码提取数据步骤82)同上,此步骤也需要设置高级选项,打开“高级选项”,勾选“Ajax加载数据”,设置时间为“3秒”。
因为页面打开后需要向下滑动才可以出现更多内容,所以还需要设置页面滚动,滚动次数选择30次,每次间隔1秒,选择向下滚动一屏完成后,点击“确定”淘宝联盟源码提取数据步骤9步骤3:采集阿里妈妈淘宝联盟商品信息1)移动鼠标,选中第一个商品图片,标题,店铺名,系统会自动识别出相似的元素,在提示框中选择“选中全部”,随后点击采集图片地址或者采集以下元素文本。
获取h5页面源码的方法

获取h5页面源码的方法H5页面凭借其出色的交互性和跨平台优势,在互联网时代成为了展示个人简历、企业宣传和产品介绍的重要手段。
获取H5页面源码,从而能够自定义和修改页面内容,是许多用户关注的问题。
以下将详细介绍获取H5页面源码的方法。
### 获取H5页面源码的方法#### 1.网络资源下载用户可以访问一些提供免费或付费H5模板的网站,根据个人需求选择合适的H5页面模板进行下载。
下载的文件通常为压缩包格式,包含HTML、CSS、JavaScript等源码文件。
以下是下载步骤:- 在搜索引擎中输入关键词,如“免费H5模板下载”;- 浏览相关网站,挑选喜欢的模板;- 注册账号,根据网站提示下载对应的H5页面源码压缩包;- 将下载的压缩包解压,即可获取H5页面的源码。
#### 2.开发工具创建如果用户具备一定的前端开发技能,可以使用HTML、CSS、JavaScript等编程语言,通过开发工具(如Visual Studio Code、Sublime Text等)手动编写H5页面源码。
以下是创建步骤:- 安装并启动开发工具;- 创建一个新的HTML文件,编写基本的HTML结构;- 在CSS文件中编写样式,对H5页面进行美化;- 在JavaScript文件中编写交互逻辑;- 通过本地服务器(如Apache、Nginx等)预览并调试H5页面;- 确认无误后,将源码文件保存并导出。
#### 3.在线H5制作平台市面上还有许多在线H5制作平台,如易企秀、百度H5等。
这些平台提供了丰富的模板和可视化编辑功能,用户可以在线编辑并生成H5页面。
以下是获取源码步骤:- 注册并登录在线H5制作平台;- 选择合适的模板,开始编辑H5页面;- 修改页面内容,添加所需的交互效果;- 在制作完成后,根据平台提示导出H5页面源码。
#### 4.注意事项- 获取H5页面源码时,请注意版权问题,避免侵犯他人的知识产权;- 在下载或使用模板时,务必确保模板的质量和安全性,避免潜在的安全风险;- 如果修改源码,请确保了解代码结构和逻辑,以免出现错误。
java用程序抓取网页的源代码

packagecom.yjf.util;importjava.io.BufferedReader;importjava.io.IOException;importjava.io.InputStream;importjava.io.InputStreamReader;.HttpURLConnection;import .URL;public class HttpWebUtil {/***网页抓取方法* @paramurlString要抓取的url地址* @param charset 网页编码方式* @param timeout 超时时间* @paramautor /* @return 抓取的网页内容* @throws IOException抓取异常*/public static String GetWebContent(String urlString, final String charset, int timeout) throws IOException {if (urlString == null || urlString.length() == 0) {return "";}urlString = (urlString.startsWith("http://") || urlString.startsWith("https://")) ? urlString : ("http://" + urlString).intern();URL url = new URL(urlString);HttpURLConnection conn = (HttpURLConnection) url.openConnection();conn.setDoOutput(true);conn.setRequestProperty("Pragma", "no-cache");conn.setRequestProperty("Cache-Control", "no-cache");int temp = Integer.parseInt(Math.round(Math.random()*(UserAgent.length-1))+"");conn.setRequestProperty("User-Agent",UserAgent[temp]); // 模拟手机系统conn.setRequestProperty("Accept","text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8");//只接受text/html类型,当然也可以接受图片,pdf,*/*任意,就是tomcat/conf/web里面定义那些conn.setConnectTimeout(timeout);try {if (conn.getResponseCode() != HttpURLConnection.HTTP_OK) {return "";}} catch (Exception e) {try {System.out.println(e.getMessage());} catch (Exception e2) {e2.printStackTrace();}return "";}InputStream input = conn.getInputStream();BufferedReader reader = new BufferedReader(new InputStreamReader(input,charset));String line = null;StringBuffersb = new StringBuffer("");while ((line = reader.readLine()) != null) {sb.append(line).append("\r\n");}if (reader != null) {reader.close();}if (conn != null) {conn.disconnect();}returnsb.toString();}public static String[] UserAgent = {转载注明来源:/"Mozilla/5.0 (Linux; U; Android 2.2; en-us; Nexus One Build/FRF91) AppleWebKit/533.1 (KHTML, like Gecko) Version/4.0 Mobile Safari/533.2","Mozilla/5.0 (iPad; U; CPU OS 3_2_2 like Mac OS X; en-us) AppleWebKit/531.21.10 (KHTML, like Gecko) Version/4.0.4 Mobile/7B500 Safari/531.21.11","Mozilla/5.0 (SymbianOS/9.4; Series60/5.0 NokiaN97-1/20.0.019; Profile/MIDP-2.1 Configuration/CLDC-1.1) AppleWebKit/525 (KHTML, like Gecko) BrowserNG/7.1.18121", "Nokia5700AP23.01/SymbianOS/9.1 Series60/3.0","UCWEB7.0.2.37/28/998","NOKIA5700/UCWEB7.0.2.37/28/977","Openwave/UCWEB7.0.2.37/28/978","Mozilla/4.0 (compatible; MSIE 6.0; ) Opera/UCWEB7.0.2.37/28/989"};}。
selenium 中常用的解析与提取数据的方法

Selenium是一个自动化测试工具,可以用于模拟用户在浏览器上的操作,如点击、输入、提交表单等。
在实际应用中,除了模拟用户行为,还需要对网页上的数据进行解析和提取,以便进一步的数据处理和分析。
下面将介绍一些Selenium中常用的解析和提取数据的方法。
1. 使用find_element方法定位元素在Selenium中,可以使用find_element方法来定位网页上的元素,如文本框、按钮、信息等。
定位到元素之后,就可以进一步提取其中的数据。
例如:```pythonfrom selenium import webdriverdriver = webdriver.Chrome()driver.get('element = driver.find_element_by_id('username')print(element.text)```2. 使用get方法获取页面源代码Selenium的get方法可以用来获取网页的源代码,然后可以使用正则表达式或BeautifulSoup等库对源代码进行解析和提取数据。
例如:```pythonfrom selenium import webdriverdriver = webdriver.Chrome()driver.get('page_source = driver.page_sourceprint(page_source)```3. 使用execute_script方法执行JavaScript有些网页上的数据是动态生成的,无法通过上述方法直接获取。
这时可以使用execute_script方法执行JavaScript代码。
可以使用document.querySelectorAll方法来获取多个元素的数据。
例如:```pythonfrom selenium import webdriverdriver = webdriver.Chrome()driver.get('elements = driver.execute_script("returndocument.querySelectorAll('p')")for element in elements:print(element.text)```4. 使用WebDriverWait方法等待元素加载有些网页上的数据需要等待一段时间才能加载出来。
网络爬虫的技术:如何使用代码自动提取网页数据

网络爬虫的技术:如何使用代码自动提取网页数据网络爬虫是一种自动化的程序工具,用于在互联网上抓取信息。
通过网络爬虫,我们可以快速、自动地从互联网上的网页中提取所需要的信息,而不需要人工手动去浏览、复制、粘贴这些数据。
在实际应用中,网络爬虫被广泛应用于搜索引擎、数据挖掘、网络监控等领域。
下面我将介绍一些网络爬虫的技术,以及如何使用代码自动提取网页数据:一、选择合适的爬虫框架在编写网络爬虫代码之前,首先需要选择一个合适的爬虫框架来帮助我们快速搭建爬虫程序。
目前比较流行的爬虫框架有Scrapy、BeautifulSoup、Requests等。
其中,Scrapy是一个功能强大的爬虫框架,提供了很多便捷的工具和方法来实现爬虫任务,并且具有良好的可扩展性。
二、编写爬虫程序1.准备工作:在编写爬虫程序之前,首先需要安装相应的爬虫框架。
以Scrapy为例,可以通过pip install scrapy命令来安装Scrapy框架。
2.创建项目:在命令行中输入scrapy startproject<project_name>来创建一个新的Scrapy项目。
3.编写爬虫程序:在项目中创建一个新的Spider,继承自scrapy.Spider,并重写start_requests和parse方法来定义爬取逻辑。
在parse方法中,可以使用XPath或CSS选择器来定位所需的数据,并提取出来。
4.启动爬虫:在命令行中输入scrapy crawl <spider_name>来启动爬虫程序,程序将开始抓取指定网站的数据。
三、数据提取技术1. XPath:XPath是一种在XML文档中定位节点的语言,也可以用于网页中的数据提取。
通过XPath表达式,可以精确地定位到所需的数据,并提取出来。
2. CSS选择器:CSS选择器是一种在网页中定位元素的方法,使用简单、灵活,适合于提取网页中的文本、链接等信息。
3.正则表达式:正则表达式是一种强大的文本匹配工具,可以用于从网页中提取特定格式的数据。
2C#获取网页源代码的5种方法

th Stream writer = request.GetRequestStream(); //获得请求流 writer.Write(payload,0,payload.Length); //将请求参数写入流 writer.Close(); //关闭请求流 HttpWebResponse response; response = (HttpWebResponse)request.GetResponse(); //获得响应
ASCIIEncoding encoding = new ASCIIEncoding(); byte[] data = encoding.GetBytes(postData); HttpWebRequest request = (HttpWebRequest)WebRequest.Create (strURL); request.Method = "POST"; request.ContentType = "application/x-www-form-urlencodeБайду номын сангаас"; request.ContentLength = data.Length; Stream newStream = request.GetRequestStream(); newStream.Write(data, 0, data.Length); newStream.Close();
wpe的原理及应用

WPE的原理及应用1. 什么是WPE?WPE(Web Page Extraction)是一种用于从网页中提取信息的技术,它能够自动地从网页中提取出所需的数据,并将其转化为结构化的格式。
WPE主要用于数据挖掘、机器学习和自然语言处理等领域,为这些领域的研究人员和开发者提供了强大的工具和技术支持。
2. WPE的原理WPE的原理是通过分析网页的HTML源代码,提取出其中的有用信息。
WPE使用一系列的规则和模式识别算法,来识别和抽取网页中的内容。
WPE首先要经过网页解析的过程,将网页的HTML源代码转换为DOM树的形式,然后通过分析DOM树来提取所需的内容。
WPE可以使用XPath、CSS选择器或正则表达式等不同的方法来定位和提取网页中的数据。
具体来说,WPE会遍历DOM树的每个节点,根据预定义的规则和模式进行匹配和提取。
WPE可以识别并提取出网页中的文本、链接、图片、表格等各种类型的内容。
WPE还可以处理动态生成的网页,如使用JavaScript动态加载数据的网页。
3. WPE的应用WPE在各个领域都有广泛的应用。
3.1 数据挖掘WPE可以帮助研究人员从大量的网页中提取出所需的数据,用于进行数据挖掘和分析。
例如,通过WPE可以从电商网站上抓取商品信息、用户评论等数据,用于市场研究和竞争分析。
WPE还可以从新闻网站上抓取新闻标题、摘要、发布时间等信息,用于新闻数据分析和舆情监测。
3.2 机器学习WPE可以为机器学习算法提供训练数据。
通过从网页中提取出结构化的数据,可以为机器学习算法构建数据集。
例如,可以使用WPE从房产网站上抓取房屋信息和价格,用于房价预测模型的训练。
WPE还可以从社交媒体上抓取用户信息和社交关系,用于社交网络分析和推荐系统的构建。
3.3 自然语言处理WPE可以用于从网页中抽取出文本数据,用于自然语言处理任务。
例如,可以使用WPE从维基百科上抓取词条的内容,用于构建知识图谱。
WPE还可以从论坛或博客上抓取用户评论和回复,用于情感分析和舆情监测。
python获取整个网页源码的方法
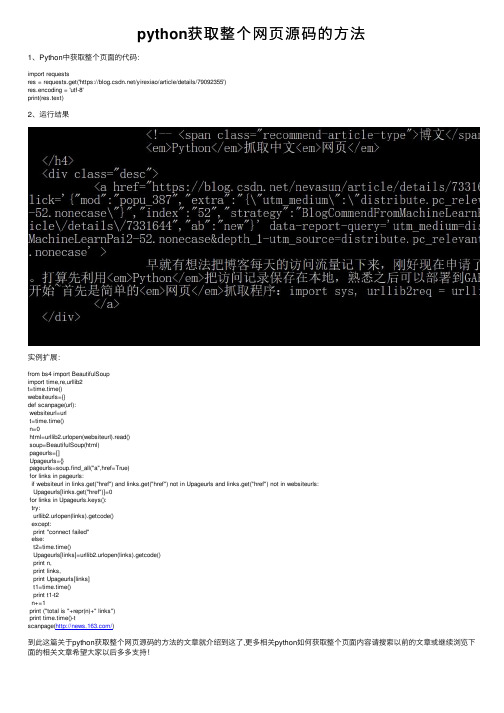
python获取整个⽹页源码的⽅法1、Python中获取整个页⾯的代码:import requestsres = requests.get('https:///yirexiao/article/details/79092355')res.encoding = 'utf-8'print(res.text)2、运⾏结果实例扩展:from bs4 import BeautifulSoupimport time,re,urllib2t=time.time()websiteurls={}def scanpage(url):websiteurl=urlt=time.time()n=0html=urllib2.urlopen(websiteurl).read()soup=BeautifulSoup(html)pageurls=[]Upageurls={}pageurls=soup.find_all("a",href=True)for links in pageurls:if websiteurl in links.get("href") and links.get("href") not in Upageurls and links.get("href") not in websiteurls:Upageurls[links.get("href")]=0for links in Upageurls.keys():try:urllib2.urlopen(links).getcode()except:print "connect failed"else:t2=time.time()Upageurls[links]=urllib2.urlopen(links).getcode()print n,print links,print Upageurls[links]t1=time.time()print t1-t2n+=1print ("total is "+repr(n)+" links")print time.time()-tscanpage(/)到此这篇关于python获取整个⽹页源码的⽅法的⽂章就介绍到这了,更多相关python如何获取整个页⾯内容请搜索以前的⽂章或继续浏览下⾯的相关⽂章希望⼤家以后多多⽀持!。
通过链接获取Html源码内容

通过链接获取Html源码内容/// <summary>/// 通过链接获取⽹页源码/// </summary>/// <param name="url"></param>/// <returns></returns>public static string GetContenFrommUrl(string url){string Content = string.Empty;Uri uri = new Uri(url);//WebRequest需要添加引⽤ ;WebRequest myReq = WebRequest.Create(uri);WebResponse result = myReq.GetResponse();Stream receviceStream = result.GetResponseStream();//Encoding.UTF8//StreamReader readerOfStream = new StreamReader(receviceStream, System.Text.Encoding.GetEncoding("gb2312"));StreamReader readerOfStream = new StreamReader(receviceStream, System.Text.Encoding.UTF8);Content = readerOfStream.ReadToEnd();readerOfStream.Close();receviceStream.Close();result.Close();return Content;}/// <summary>/// 获取指定DIV的内容/// </summary>/// <param name="strHTML">被筛选的字符串</param>/// <param name="name">ID名</param>/// <returns></returns>public static string GetDivFromStr(string strHTML){string Content = string.Empty;//Match,Regex需要添加引⽤ System.Text.RegularExpressions;Match m = Regex.Match(strHTML, @"<div[^>]*?id=""listLeft""[^>]*>((?>(?<o><div[^>]*>)|(?<-o></div>)|(?:(?!</?div)[\s\S]))*)(?(o)(?!))</div>", RegexOptions.IgnoreCase); if (m.Success){Content = m.Value;}return Content;}/// <summary>/// 下载图⽚,并将图⽚保存到本地/// </summary>/// <param name="URL">图⽚链接</param>/// <returns>本地图⽚地址</returns>public static string DowmLoadImage(string URL){string Image = string.Empty;string Path = "D:/MyJob/HtmlToData/Images/";//WebClient需要添加引⽤ ;WebClient myWebClient = new .WebClient();//URL 图⽚路径, Path + System.IO.Path.GetFileName(URL) 图⽚保存位置myWebClient.DownloadFile(URL, Path + System.IO.Path.GetFileName(URL));Image = "2016/12/22/" + System.IO.Path.GetFileName(URL);return Image;}/// <summary>/// 替换指定图⽚/// </summary>/// <param name="Content">Html代码</param>/// <returns>返回替换后的Html代码</returns>public static string ReplaceImage(string Content){//获取图⽚路径//Regex需要添加引⽤ System.Text.RegularExpressions;Regex regImg = new Regex(@"<img\b[^<>]*?\bsrc[\s\t\r\n]*=[\s\t\r\n]*[""']?[\s\t\r\n]*(?<imgUrl>[^\s\t\r\n""'<>]*)[^<>]*?/?[\s\t\r\n]*>", RegexOptions.IgnoreCase);//MatchCollection 需要添加引⽤ System.Text.RegularExpressions;MatchCollection matches = regImg.Matches(Content);//将某⼀特定图⽚(横杠杠)替换为<hr />foreach (Match match in matches){if (match.Groups["imgUrl"].Value == "/file/images/split-e5.gif"){Content = Content.Replace(match.Value, "<hr />"); //将图⽚/file/images/split-e5.gif替换为<hr />break;}}return Content;}/// <summary>/// 替换指定Div/// </summary>/// <param name="Content">Html代码</param>/// <param name="strHTML">被筛选的字符串</param>/// <returns>返回替换后的Html代码</returns>public static string ReplaceDiv(string Content,string strHTML){//将< div id = "pages" ></div>中的内容替换为<hr />//Match,Regex需要添加引⽤ System.Text.RegularExpressions;Match mm = Regex.Match(strHTML, @"<div[^>]*?id=""pages""[^>]*>((?>(?<o><div[^>]*>)|(?<-o></div>)|(?:(?!</?div)[\s\S]))*)(?(o)(?!))</div>", RegexOptions.IgnoreCase); Content = Content.Replace(mm.Value, "<hr />");return Content;}/// <summary>/// 获取指定imge标签的src/// </summary>/// <param name="strHTML"></param>/// <returns></returns>public static string GetImageSrc(string strHTML){string Titleimage = "";//Match,Regex需要添加引⽤ System.Text.RegularExpressions;Match maimage = Regex.Match(strHTML, @"<img\b[^<>]*?\bsrc[\s\t\r\n]*=[\s\t\r\n]*[""']?[\s\t\r\n]*(?<imgUrl>[^\s\t\r\n""'<>]*)[^<>]*?/?[\s\t\r\n]*>");//获取标题图⽚if (maimage.Success){Titleimage = DowmLoadImage(maimage.Groups["imgUrl"].Value);}return Titleimage;}/// <summary>///获取<a> 标签的href和内容/// </summary>/// <param name="AStr">Html代码</param>/// <returns></returns>public static string[] GetHref(string AStr){string[] ListStr = new string[2];//Match,Regex需要添加引⽤ System.Text.RegularExpressions;Match ma = Regex.Match(AStr, @"(?is)<a[^>]+?href=(['""])([^'""]*)\1[^>]*>(.+)</a>");if (ma.Success){ListStr[0] = ma.Groups[3].Value;//textListStr[1] = ma.Groups[2].Value;//超链接}return ListStr;}/// <summary>/// 获取指定p(<p class="auxiInfo">)标签的内容/// </summary>/// <param name="PStr">Html代码</param>/// <returns>返回P标签的内容</returns>public static string GetTargetPContent(string PStr){string content = "";//Match,Regex需要添加引⽤ System.Text.RegularExpressions;Match mtime = Regex.Match(PStr, @"<p[^>]*?class=""auxiInfo""[^>]*>((?>(?<o><p[^>]*>)|(?<-o></p>)|(?:(?!</?p)[\s\S]))*)(?(o)(?!))</p>", RegexOptions.IgnoreCase);if (mtime.Success){content = mtime.Groups[1].Value;}return content;}/// <summary>/// 获取P标签的内容/// </summary>/// <param name="PStr">Html代码</param>/// <returns>返回P标签的内容</returns>public static string GetPContent(string PStr){string content = "";//Match,Regex需要添加引⽤ System.Text.RegularExpressions;Match mp = Regex.Match(PStr, @"(?is)<p>(.*?)</p>");if (mp.Success){content = mp.Groups[1].Value;}return content;}。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
#pragma comment (lib, "wininet.lib")
void download(const char *Url)
{
HINTERNET hSession = InternetOpen("RookIE/1.0", INTERNET_OPEN_TYPE_PRECONFIG, NULL, NULL, 0);
{
i--;
}
return i;
}
bool TrimString(LPTSTR pszBuffer,UINT &w,UINT &k,bool chinese)
{
LPTSTR pszSource=pszBuffer;
LPTSTR pszDest=pszBuffer;
if(*pszSource=='{')
k++;
if(k==0) //如果未被包含在{}中
{
if(w!=0) //如果包含在<>中
LPTSTR pszTemp=pszBuffer;
bool ch=false;
bool mark=false;
while (*pszSource!='\0')
{
while(*pszSource=='&') //删除html文件中的空格标记:
{ *pszSource='\0';
pszSource+=6;
}
while(64<(*pszSource)&&(*pszSource)<123)
{
pszSource++; //删去文件中的英文,使得原来包含英文的语句成为一些标点符号聚集的地方;
{
download("");
/* if(argc > 1)
{
download((const char*)argv[1]);
}
else
{
cout<<"Usage: auto-Update url";
if(*pszSource=='<')
{
w++;
mark=true;
}
else
{
if(mark) //每段文字以空格分开
{
*pszDest=' ';
fread(duf,1,number,fh);
UINT w,h;
w=h=0;
TrimString(duf,w,h,1); //读取html文件到duf指针;
FILE *fp1=fopen("aa.txt","wb");
fwrite(duf,1,strlen(duf)-10,fp1); //将duf指针的内容写入txt文件中;
fclose(fh);
fclose(fp1);
return 0;
}
pszDest++;
mark=false;
}
*pszDest=*pszSource;
pszDest++;
}
}
}
if(*pszSource=='}')
k--;
pszSource++;
} //结束处理
{
while (Number > 0)
{
InternetReadFile(handle2, Temp, MAXBLOCKSIZE - 1, &Number);
ofs<<Temp;
}
ofs.close();
while(*pszSource=='&')
pszSource+=6;
}
if(!ch&&(*pszSource)<0) //本段字符中是否含有中文字符
ch=true;
if (hSession != NULL)
{
HINTERNET handle2 = InternetOpenUrl(hSession, Url, NULL, 0, INTERNET_FLAG_DONT_CACHE, 0);
if (handle2 != NULL)
{
int statistics(LPTSTR pszBuffer) //指针应该是多大的数组的函数;
{
LPTSTR pszSource=pszBuffer;
int i=100000;
while(*(pszSource+i-1)==*(pszSource+i-2))
{
if(*pszSource=='>')
w--;
else if(*pszSource=='<')
{
w++;
}
}
else
{ //未包含在<>中
cout<<Url<<endl;
byte Temp[MAXBLOCKSIZE];
ULONG Number = 1;
ofstream ofs("download.txt");
if(ofs)
}
InternetCloseHandle(handle2);
handle2 = NULL;
}
InternetCloseHandle(hSession);
hSession = NULL;
}
}
if(chinese)
{
if(ch)
{
*pszDest='\0';
}
else
{
*pszDest='\0';
}
}
else
{
*pszDest='\0';
}
return 1;
}
int main(int argc, char* argv[])
printf("%d\n",number); //输出文件所占的字符数;
fclose(fp);
FILE *fh=fopen("download.txt","rb");
char *duf=new char[number]; //定义字符所占的是适合数组;
}
*/
FILE *fp=fopen("download.txt","rb");
char *buf=new char[100000];
fread(buf,1,100000,fp);
int number;
number=statistics(buf); //统计html文件中的字符数;
#include <iostream.h>
#include <fstream.h>
#include <Windows.h>
#include <wininet.h>
#include"stdio.h"
#include"string.h"
typedef chaINT;