火车采集器采集结果保存为本地word,excel,html,txt文件
城市规划与研究中的开放数据(大数据)获取方法及应用分析技术

1.了解大众点评网(西安美食板块)的网页结构
一级网址
二级网址 ……
/search/category/17/10/r124p5?aid= 40d5143611213e8d872390ff0d058388d22d7cbfc50973aebd00 86c3c60a0cb4ed30cee2e7fc1523f25f39a106cc8b81b8072fdcdf fd93a4bdda34e688ffaa9fa90fbc174acb62adc050f0d33e50b45a 830f15ddcbab34d35b4aff11e4d5ad43943ac53cfc788520e4da8 91862daf6a543aeb01508e3792237264aeac95a706c0c5ca7b35 1b3a3d42c271281f4930e05
大众点评网(,始于2003年4月)是我国最早建立的第三方点评 平台,注册会员可以通过网站自由发表对餐馆的评论和消费心得,通过一定的信息聚 合和组织以后,为潜在的消费者提供客观准确的点评信息。网站包括美食、休闲娱乐、 购物等诸多领域的生活服务信息,可以在一定程度上借助其海量点评信息对城市相关 服务业的空间分布、密度、热度等进行分析,从而对规划决策提供一定的数据基础支 撑。
分页网址 信息网址 /shop/19677471
1.了解大众点评网(西安美食板块)的网页结构
明确采集数据的内容及类型
标题; 点评数量; 人均消费; 口味;
环境; 服务; 经纬度(坐标);
其他……
2.运用火车采集器采集网页数据信息
餐饮业在各公共中心的“热度值”分布
餐饮业主中 心:餐饮业 高“热度” 区 餐饮业 副中心: 餐饮业 中“热 度”区
火车头采集使用方法

什么是火车头?我们打开一个网站,看到有一篇文章很不错,于是我们就将文章的标题和内容复制了一下,将这篇文章转到我们的网站上.我们的这个过程,就可以称作一个采集,将别人网站上对自己有用的信息转到自己网站上;互联网上的内容,大多数都是通过复制-修改-黏贴的过程产生的,所以信息采集很重要,也很普遍,我们平台发到网站上的文章,多数也是这样的一个过程;为什么很多人感觉新闻更新很麻烦,因为这个工作是重复的,枯燥乏味的,浪费时间的;火车头是目前国内使用人数最多、功能最完善、网站程序支持最全面、数据库支持最丰富的软件产品;现在是大数据时代,它可以快速、批量、海量的获取到互联网上的数据,并按照我们需要的格式存储起来;说的简单一点,对我们来说有什么用?我们需要更新新闻,需要发商机,如果让你准备1000篇文章,你要用多久?5个小时?在有规则的情况下,火车头只需要5分钟!前提是有规则,所以我们要先学写规则,写规则如果数量的话,一个规则几分钟就好了,但刚开始学的时候会比较慢;名称解释与规则编写流程n以火车头8.6版本为准第1步:打开—登录第2步:新建分组第3步:右击分组,新建任务,填写任务名;第4步:写采集网址规则(起始网址和多级网址获取)第5步:写采集内容规则(如标题、内容)第6步:发布内容设置勾选启用方式二(1)保存格式:一条记录保存为一个txt;(2)保存位置自定义;(3)文件模板不用动;(4)文件名格式:点右边的倒立笔型选[标签:标题];(5)文件编码可以先选utf-8,如果测试时数据正常,但保存下来的数据有乱码则选gb2312;第7步:采集设置,都选100;a.单任务采集内容线程个数:同时可以采集几个网址;b.采集内容间隔时间毫秒数:两个任务的间隔时间;c.单任务发布内容线程个数:一次保存多少条数据;d.发布内容间隔时间毫秒数:两次保存数据的时间间隔;附注:如果网站有防屏蔽采集机制(如数据很多但只能采集一部分下来,或提示多久才能打开一次页面),则适当调小a值和调大b的值;第8步:保存、勾选并开始任务(如果是同一分组的,可以在分组上批量选中)以前的方式:比如我要准备n篇文章,要先找到这个文章是在哪个网站上的(如是采集同行A还是同行B),是在其哪个栏目下的(如是产品信息还是新闻信息),在这个栏目下有n 条信息,我要选哪一条,然后进去后把标题复制下来,把内容复制下来再进到另一个页面把标题内容复制下来,以此类推,然后同样的流程我要执行n遍;怎么转换:怎么把这个流程转化为软件操作呢?我要准备n篇新闻,这就表明要n个标题+对应的内容,要n个新闻链接,这n个新闻链接是从一个网站的新闻栏目上找的,而这个网站的新闻栏目有可能是很多页,比如10页,这个时候再从同行A的网站—栏目—内页;即先找到要采集的网站,打开这个网站的栏目页(确定好是采集新闻还是产品),写网址规则采集栏目下的所有新闻链接,然后写内容规则采集所有新闻链接中的标题和内容,最后保存下来;采网址详解-具体操作找到要采集网址的栏目页,如新闻栏目复制栏目的第一页链接url,起始网址右侧中点添加,在单条网址中黏贴栏目的第一页链接后点添加,如用右边的(*)代替,因为第1页已经添加了,还剩9页,这时在等差数列那一行把项数改成9,首项是2(因为第2页的链接是,然后点添加-完成;1、点对应右侧的添加,然后如下图所示是示例,右侧大图是说明;2、点击保存后点右下角的看看是否能采集到新闻网址,如果能采集到则正确,双击一个新闻网址进到下一步;如果采集到的不正确,返回修改直到成功;网址过滤可以自己观察其对应的规律;1、到采集内容规则这里后,把作者、时间、出处都选中后删掉,如右面第一张图,因为这些标签正常情况下都用不到;2、选中标题标签点修改,或直接双击该标签,进入编辑界面;3、进入后标签名的“标题”别改,改过后是要改对应的模板的;4、下面的数据提取方式:前后截取和开始结束字符串,也尽量用默认的,在不熟练的情况下不要改;5、点击下面数据处理的添加—内容替换,如右图;6、内容替换将标题后面的都替换为空,如果不替换的话采集的是页面title,这时需要打开两个新闻页面,看看这两个新闻页面的公共部分是什么,把公共部分替换掉例:如下面两个标题,“-”是公共部分,即把其替换为“空”;【图文】你知道螺旋加料机的加工方法吗螺旋加料机原理你了解吗【图文】气动式加料机的优点是什么你知道粉末加料机工作原理吗例:如下面的则需要把“-健康网”替换成“空”;例:如下面的则需要把“-健康网”替换成“空”;我喜欢吃西瓜-健康网苹果好吃吗?-健康网1、选中内容点编辑,或直接双击进入到内容标签编辑界面,标签名千万别改;2、写开始和结束字符串,就是找能把所有新闻都包裹起来的,在所有新在所有新闻页面中都是闻页面中都有的,且是唯一的一段字符串;即这个页面模板中的唯一代码串;举例:采集内容的时候,需要选择内容区域,因为要采集的可能是n篇,如100篇,这个时候就需要想法怎么能写一个采集到全部的,方法就是打开两个新闻链接如,查看第一篇新闻的源文件,找到新闻正文,然后向上找离新闻第一句话最近的,在这个页面中是唯一的一段代码(如果不唯一,软件能知道从第几个开始吗?),但又不是新闻中的内容,如<div id=“zoom”>,复制后在第二篇新闻页面源文件中搜一下看看有没有,如果有,则可采用;同理找到新闻最后一句话,向下找离其最近的页面中唯一的一段代码,复制后在第二篇新闻页面源文件中搜一下看看有没有,如果有,则可采用;数据处理:因为采集的是其他网站的信息,里面有可能有其他网站的资料,如公司名、联系方式、品牌等信息,也可能有其他网站的超链接等信息,这个时候就需要对信息进行过滤处理;数据处理—添加—下面对应的参数HTML标签过滤:滚动轴横向拉到最后,在所有标签前面打钩后点确定;内容替换:将这个网站的信息替换成自己的,原则是先整后拆,有公司名、电话号(拆分)、手机号(拆分)、邮箱、公司地址(拆分)、品牌名、网址(拆分);其中拆分的意思是对这个数据进行拆解替换,这个时候就需要做如下替换:因为在新闻中,,这是时候就需要对其拆解替换才能替换干净,可以多看一下他的新闻中,可能会用什么样的格式;注:数据处理还有很多技巧,需要自己在使用的过程中琢磨,更是采集的核心,如果处理不好,有可能是为他人做嫁衣,所以一定要仔细观察,考虑全面,如果处理好了,采集下来的文章甚至可以直接就发布(非自己企业站)注意事项1、右击分组:会出现如下图菜单,正常都能用到;新建任务:在此分组上新建任务;运行该分组下所有任务:顾名思义;新建任务:在该分组下再建分组;编辑/删除分组:编辑/删除当前分组;导入/导出分组规则:可以导出当前分组下的所有任务,并导入到同版本火车头上;导入任务至该分组:将导出的单个任务导入到该分组下面;黏贴任务到该分组下:要复制过任务后此项才出现,可以黏贴多个同样的任务,然后再黏贴后的任务上进行编辑即可;开始任务:和菜单栏上的开始一样;编辑任务:编辑已经写好的任务;导出任务:可以将当前规则导出,在其他同版本工具上导入,但导入数据时需重复上面的第6步-发布内容设置,必须要重新选/填一遍;复制任务到黏贴板:复制后,选择一个任务分组并右击,可以黏贴不同数量的任务到那个分组中,这样就避免同一个任务多次编写了;清空任务所有采集数据:新如果之前采集过任务想重新采集的,则需求先清空;3、其他设置:顶部菜单栏中点击工具—选项,配置全局选项和默认选项;全局选项:可以调整下同时运行任务最大个数,正常是5即可,可不调;默认选项:是否忽略大小写点是;。
火车头采集教程
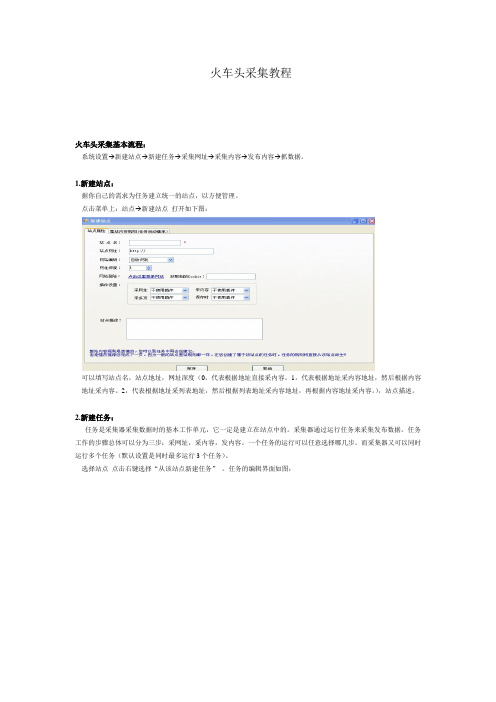
火车头采集教程火车头采集基本流程:系统设置→新建站点→新建任务→采集网址→采集内容→发布内容→抓数据。
1.新建站点:据你自己的需求为任务建立统一的站点,以方便管理。
点击菜单上:站点→新建站点打开如下图:可以填写站点名,站点地址,网址深度(0,代表根据地址直接采内容。
1,代表根据地址采内容地址,然后根据内容地址采内容。
2,代表根据地址采列表地址,然后根据列表地址采内容地址,再根据内容地址采内容。
),站点描述。
2.新建任务:任务是采集器采集数据时的基本工作单元,它一定是建立在站点中的。
采集器通过运行任务来采集发布数据。
任务工作的步骤总体可以分为三步:采网址,采内容,发内容。
一个任务的运行可以任意选择哪几步。
而采集器又可以同时运行多个任务(默认设置是同时最多运行3个任务)。
选择站点点击右键选择“从该站点新建任务”。
任务的编辑界面如图:采集器的使用最主要的就是对任务的设置。
而采集数据可以分为两步,第一步是:采网址,第二步:采内容。
3.采集网址:采网址,就是从列表页中提取出内容页的地址。
从页面自动分析得到地址连接:以/sbzhz/index_2.html页面为例。
我们来采集这个网址上的书信息。
这个页面中有很多书信息的链接,要采集每个链接中书内容.首先需要将每个书信息的链接地址抓取到也就是抓取内容页的地址。
先将该列表页地址添加到采集器里。
点击“<<向导添加”后弹出“添加开始采集地址”对话框。
我们选择“单条网址”如图:如果我们选择“批量/多页”,如图:可用通配符:(*)可以代替页码变化时的地址之间的差异。
数字变化可以设置你要爬取该列表页多少页。
间隔倍数可以数字页码变化的倍数。
你也可以设置字母变化。
设置完之后点击添加按钮把列表地址添加到下框中,点击完成即可完成列表地址设置。
你也可以选择文本导入和正则提取在这里就不一一讲了,因为这二种基本用的很少。
手动填写连接地址规则是将需要的网址用参数来获得并组合成我们需要的网址。
火车头采集器介绍与使用流程说明

五、字段处理
• 网页编码设定: • 每个网站都有一个相对应的编码:如UTF-8。如果选错编码,则采集
出来的数据就会呈现一种乱码格式。 • 大多数的网页编码火车头都可以自动识别,如不能则需要手动指定一
二、创建任务
• 1.新建分组
填写分组名称
二、创建任务
• 2网址
三、采集网址
• 点击“添加”按钮出现如下界面
三、采集网址
• 切换至“批量/多页”选项卡,可以批量添加网址
网址通用序号用通 配符(*)替换
这添加方式主要用来处理分页网址
三、采集网址
• 切换至“其他网址格式”选项卡,也可以批量添加网址
日期格式
网址通用序号用通 配符(*)替换
这添加方式主要用来处理含有日期的网址
三、采集网址
• 多级网址采集
点击‘添加’按钮
网址过滤条件
三、采集网址
• 手动采集配置链接地址规则:
• 手动连接格式是将需要的网址用参数来获得并组合成我们需要的网址。 这个好处是处理网址那块有规律的网址很好处理。而且可以用这方法 采集需要的字段,如:公告新闻类的标题、日期等。
火车采集器是目前信息采集与信息挖掘处理类软件中最流行、性价比 最高、使用人数最多、市场占有率最大、使用周期最长的智能采集程 序。
一、软件介绍
• 火车采集器数据发布原理:
• 在我们将数据采集下来后数据默认是保存在本地的,我们可以使用以 下几种方式对种据进行处理。
• 1.不做任何处理。因为数据本身是保存在数据库的(access或是 db3),您如果只是想看一下,直接用相关软件查看就可以了。
火车头使用说明
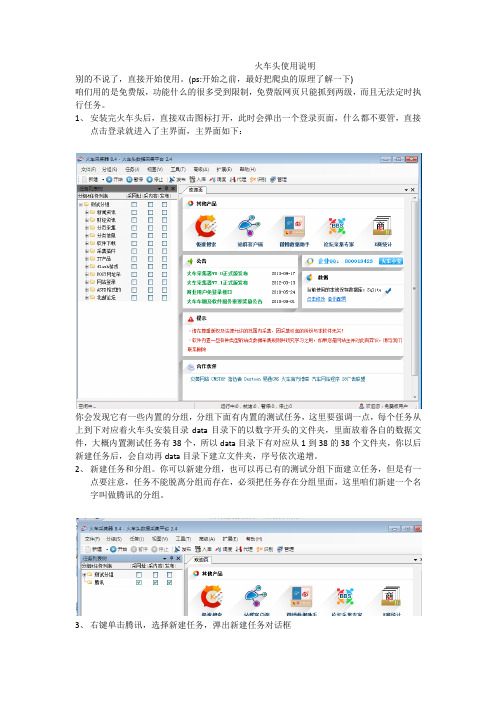
火车头使用说明别的不说了,直接开始使用。
(ps:开始之前,最好把爬虫的原理了解一下)咱们用的是免费版,功能什么的很多受到限制,免费版网页只能抓到两级,而且无法定时执行任务。
1、安装完火车头后,直接双击图标打开,此时会弹出一个登录页面,什么都不要管,直接点击登录就进入了主界面,主界面如下:你会发现它有一些内置的分组,分组下面有内置的测试任务,这里要强调一点,每个任务从上到下对应着火车头安装目录data目录下的以数字开头的文件夹,里面放着各自的数据文件,大概内置测试任务有38个,所以data目录下有对应从1到38的38个文件夹,你以后新建任务后,会自动再data目录下建立文件夹,序号依次递增。
2、新建任务和分组。
你可以新建分组,也可以再已有的测试分组下面建立任务,但是有一点要注意,任务不能脱离分组而存在,必须把任务存在分组里面,这里咱们新建一个名字叫做腾讯的分组。
3、右键单击腾讯,选择新建任务,弹出新建任务对话框4、下面我们以腾讯新闻采集为例说一下如何去配置,任务名叫做腾讯新闻可以看到,这里分为四步,第一部就是采集网址规则(这一步就相当于爬虫里面设置种子url 并且入队的过程),在出现的起始网址,添加单条网址,并点击”添加“按钮。
我们在网页中,通过分析,发现国内新闻的第二页及以后都是以数字递增的方式显示的,我们现在添加等差数列形式的网址最后点击完成,查看效果起始网址的添加就是种子URL的设置过程,这里可以添加多个种子URL,我这里设置了六页下面就是多级网址获取,点击添加按钮,出现如下画面(这一步相当于提取网页所有连接的过程)如果直接点击保存,相当于提取网页中所有链接,但真实情况下我们并不需要所有的链接,所以需要对链接进行过滤,可以从该选定区域提取网址,也可以对结果网址过滤,这里我们设置结果网址必须包含/a,然后点击保存。
你可以看到有一个检测重复网址,这个选项的目的就是告诉你,在多次抓取的过程中是否抓取相同网址的页面,这里默认是选中的。
火车头采集器使用手册
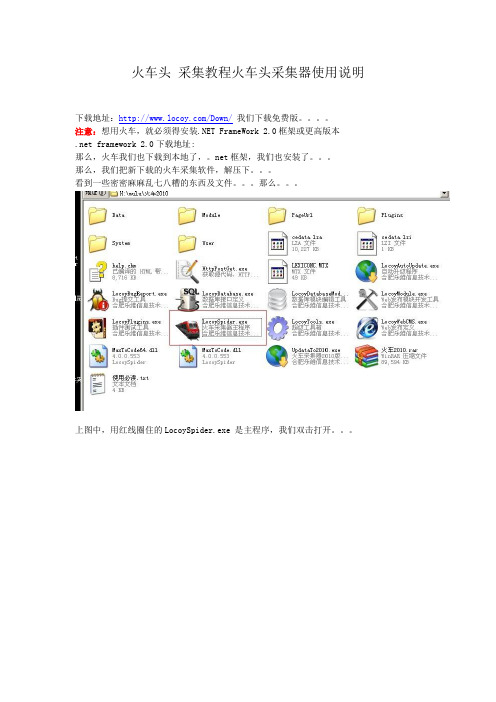
火车头采集教程火车头采集器使用说明下载地址:/Down/我们下载免费版。
注意:想用火车,就必须得安装.NET FrameWork 2.0框架或更高版本.net framework 2.0下载地址:那么,火车我们也下载到本地了,。
net框架,我们也安装了。
那么,我们把新下载的火车采集软件,解压下。
看到一些密密麻麻乱七八糟的东西及文件。
那么。
上图中,用红线圈住的LocoySpider.exe 是主程序,我们双击打开。
ps:这里说下,上图中,有好多任务是我自己用的。
新程序,并没有那么多。
我们会看到火车的界面,看起来非常复杂,是吧?呵呵,其实并没有那么复杂,对于新手,有好多东西是用不到的。
下边会一一的讲解。
我们先补习一下,火车头采集软件的工作原理。
因为我们浏览到的网页,最后都是通过html输出的,那么意味着,我们可以查看到html的源码,那么火车头为什么会采集到内容呢?我们看下网站的基本结构。
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN""/TR/xhtml1/DTD/xhtml1-transitional.dtd"><html xmlns="/1999/xhtml"><head><meta http-equiv="Content-Type" content="text/html; charset=utf-8" /> -------这些蓝色的东西,对于新手,我们不需要知道!<title>网页的标题</title> ----红色的是网页的标题。
如下图(1)</head><body>内容在这个<body>和</body>之间的,是网站的内容部分。
火车采集器采集说明

火车采集器采集说明1 首先,如果你的电脑没有Microsoft_DotNetFXCHS这个软件,先安装文件夹里,然后打开2、打开软件,进入采集页面3 、在站点任务列表空白处右击“新建站点”,进入任务栏,站点名随便写,其他的不用填,点确定就可以了4 、单击选中站点,右击“从该站点新建任务”,进入任务栏,如任务名“优美散文”5、单击“向导添加”,进入采集地址6、地址栏,从采集页面第二页,网址复制,可能图看不清,网址,记住把数字标记为同样,选中数字,然后点(*),变成(*).html,如果想采集多的数字变化从1到你采集的页面,然后点击“添加”按钮,出现这个页面,点击完成就可以了。
7、在输入随便一篇采集文章的网址,选中数字,点击(*)按钮,变成8、这个页面的需要文章列表源代码,右击选择产看“网页源代码”9、最重要的,代码不能出错,再次强调文章列表的源代码,进入到源代码,找到文章列表开始处的靠近的源代码,如选中一段代码,复制,然后按Ctrl+f 键,输入框粘贴,看选中的源代码是否是第1条,记住,所选源代码必须是第一条(我用的是谷歌浏览器,显示的是0,其他的浏览器只要是第一条即可),确定所选是第一条源代码,就输入,结束代码和开始代码一样,文章列表结束处找代码10、上述第一步,结束之后,第二步采集内容规则所选标签随自己选择,不需要的可以删。
11、单击打开“内容”标签,随便打开文章页,右击“查看源代码”,和上述文章列表开始和结束的源代码一样,必须是第一条12、自定义数据里面除了段落、换行<br>、换行Tab\r\n\t三个不要,如图,单击确定。
13、单击第三步:发布内容设置在方式二:保存为本地文件,启用前打钩,保存格式为.Txt,保存位置自定义,保存位置设置好以后,单击保存按钮14、打开站点,选中任务,右击开始任务采集,这样就可以了。
火车头采集步骤和数据导出详解

3.1 打开火车头工具,单击左侧空白处,根据需要新建分组
3.2 右击刚才建立好的分组,新建采集任务,并填写好任务名称
3.3 填写批量采集网址规则,注意先分析目标列表页url规则
3.4 设置“多级网址获取”规则
3.4 设置“多级网址获取”规则,并测试设置好的规则是否生效
1、采集的目标页面,不需要登录 即可访问; 2、采集的内容列表页面url跟随一 定的规律改变; 3、该网站不屏蔽不干扰采集器的 工作。
2、认识火车头采集工具
火车采集器,是目前使用人数最 多的互联网数据抓取、处理、分 析,挖掘软件。 软件凭借其灵活 的配置与强大的 性能领先国内数据采集类产品。 使用火车采集器,你可以建立一 个拥有庞大内容的网站。
3.5 校验设置好的规则是否生效,如果生效,则返回修改设置;如 果得到的结果不正确,也需要返回修改设置(重新分析采集范围是 否正确,一直校验到是我们需要的结果)
3.6 返回修改采集的项数,并且记得点击“添加”和“完成”
3.7 进入到第二步“采集内容规则” 采集文章的标题,选中“标题”,点击左侧的修改,选择“前后截取”,将文章标 题的html区域填写完整,右侧“典型页面”填写一条内容页url,以供随时测试。
选中Excel表格的“内容”列,用查找功能,将图片路径 “10_12/xxxxx.jpg”替换为/10_12/xxxxx.jpg” 同时,将采集到的图片文件夹“10_12”上传到你的空间根目录,发布 文章的时候,图片就能显示出来。
使用方法如此简单,赶紧去试一试吧~
4.4、已经能用Excel打开采集到的文章内容之后, 就可以利用Excel对数据进行批量处理,比如批 量添加文章的发布时间、批量替换文字、批量修 改图片路径等等。 比如:在Excel表格里,按Ctrl+F,出现的对话框 中选择“替换”,填写好需要替换的文字,即可 对采集到的内容进行批量替换文字。
火车头采集器应该如何使用

关于火车头使用方法目录目录 (2)一、原理描述 (3)1.火车采集器数据抓取原理: (3)2.火车采集器数据发布原理: (3)3.火车采集器工作流程: (3)二、术语解释 (4)三、下载地址 (5)四、安装升级与卸载 (6)五、操作步骤 (7)一、原理描述1.火车采集器数据抓取原理:火车采集器如何去抓取数据,取决于您的规则。
您要获取一个栏目的网页里的所有内容,需要先将这个网页的网址采下来,这就是采网址。
程序按您的规则抓取列表页面,从中分析出网址,然后再去抓取获得网址的网页里的内容。
再根据您的采集规则,对下载到的网页分析,将标题内容等信息分离开来并保存下来。
如果您选择了下载图片等网络资源,程序会对采集到的数据进行分析,找出图片,资源等的下载地址并下载到本地。
2.火车采集器数据发布原理:在我们将数据采集下来后数据默认是保存在本地的,我们可以使用以下几种方式对数据进行处理。
1、不做任何处理。
因为数据本身是保存在数据库的(access、db3、mysql、sqlserver),您如果只是查看数据,直接用相关软件打开查看即可。
2、Web发布到网站。
程序会模仿浏览器向您的网站发送数据,可以实现您手工发布的效果。
3、直接入数据库。
您只需写几个SQL语句,程序会将数据按您的SQL语句导入到数据库中。
4、保存为本地文件。
程序会读取数据库里的数据,按一定格式保存为本地sql或是文本文件。
3.火车采集器工作流程:火车采集器采集数据是分成两个步骤的,一是采集数据,二是发布数据。
这两个过程是可以分开的。
1、采集数据,这个包括采集网址,采集内容。
这个过程是获得数据的过程。
我们做规则,在采的过程中也算是对内容做了处理。
2、发布内容就是将数据发布到自己的论坛,CMS的过程,也是实现数据为已有的过程。
可以用WEB在线发布,数据库入库或存为本地文件。
具体的使用其实是很灵活的,可以根据实际来决定。
比如我可以采集时先采集不发布,有时间了再发布,或是同时采集发布,或是先做发布配置,也可以在采集完了再添加发布配置。
火车头采集器采集文章使用教程实例
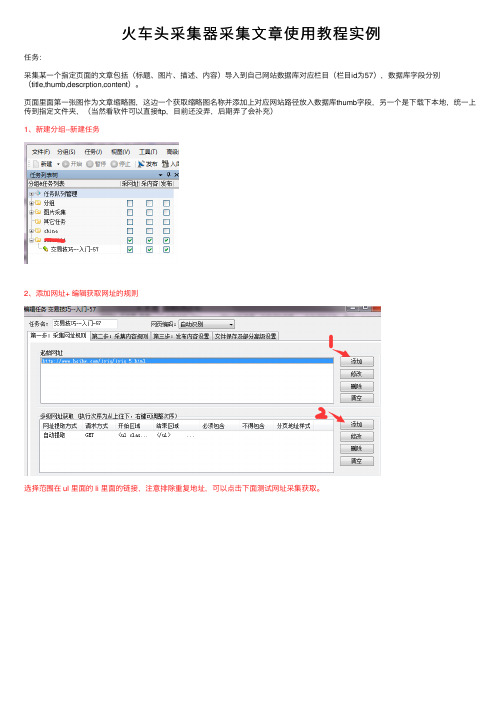
⽕车头采集器采集⽂章使⽤教程实例任务:采集某⼀个指定页⾯的⽂章包括(标题、图⽚、描述、内容)导⼊到⾃⼰⽹站数据库对应栏⽬(栏⽬id为57),数据库字段分别(title,thumb,descrption,content)。
页⾯⾥⾯第⼀张图作为⽂章缩略图,这边⼀个获取缩略图名称并添加上对应⽹站路径放⼊数据库thumb字段,另⼀个是下载下本地,统⼀上传到指定⽂件夹,(当然看软件可以直接ftp,⽬前还没弄,后期弄了会补充)1、新建分组--新建任务2、添加⽹址+ 编辑获取⽹址的规则选择范围在 ul ⾥⾯的 li ⾥⾯的链接,注意排除重复地址,可以点击下⾯测试⽹址采集获取。
可以看到有采集到的⽂章链接了。
3、采集内容规则我这边需要采集下⾯图上展⽰数据(catid是栏⽬id,可以将采集到的数据放⼊对应栏⽬,设置固定值就好)着重说下内容和图⽚的采集,标题和描述同理内容采集内容采集:打开⼀个采集的⽂章页⾯,查看源代码(禁了右键的f11 或者在⽹址前⾯加上 view-source: ⼀样可以查看):选中⽂章开头⼀个位置,截取⼀段在ctrl+f 搜下是否唯⼀⼀段,若是就可以放在位置下图1处,结尾同开头⼀样。
我截取内容不想⾥⾯还带有链接图⽚可以数据处理,添加--html标签排除--选好确定--确定还有需要下载页⾯图⽚,勾选和填写下⾯选项图⽚采集:(1)选中范围和内容⼀样(⽂章内图⽚)(2)数据处理选提取第⼀张图⽚内容是:/2017/33/aa.jpg(3)只要aa.jpg,正则过滤 ,获取内容:aa.jpg (4)数据库存储有前缀,添加上, upload/xxxxx/找⼀个页⾯测试⼀下,可以看到对应项⽬都获取到了。
4、发布内容设置,这⾥以⽅式三发布到数据库为例⼦,编辑后回到这边勾选刚定义的模块就好:5、我需要保存图⽚到本地,要设置下保存⽂件的路径(ftp后续会试着使⽤)。
6、保存,查看刚新建的任务,右键开始任务运⾏,这边就可以看到⽂字和图⽚都下载下来了,数据库⾥⾯也可以看到了。
火车头采集工具使用指南V5.7
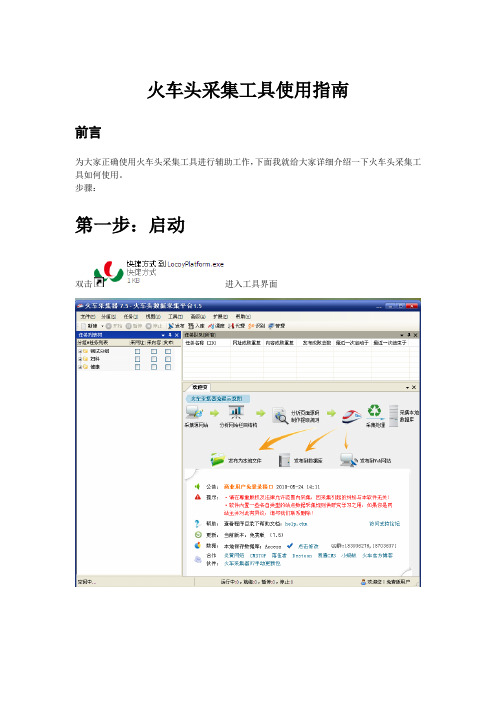
火车头采集工具使用指南前言为大家正确使用火车头采集工具进行辅助工作,下面我就给大家详细介绍一下火车头采集工具如何使用。
步骤:第一步:启动双击进入工具界面第二步:新建任务在分组列表处“右击”,新建分组输入你要采集的分组名称,如:男性保健第三步:新建任务选中你新建的分组,右击,新建任务:下面,我们开始进行采集工作。
首先,我们要先给任务一个名称,如:男性保健。
这个系统本身就给我们定了四步走,我们现在做的是第一步,点击一下起始网址规则右边的“添加”按钮,添加开始采集地址:量/多页”标签。
以:/gjml/list_28_2.html为例。
该列表只有2页,所以在设置的时候应如下设置:设置时要注意用(*)号将会变动的那个数字(页数)(如/gjml/list_28_2.html就可以替换为“/gjml/list_28_(*).html”)替换下,以便在采集的时候自己跳转页:,在基数设置的时候要注意,有几页就设置几项。
然后点击:“添加”,最好点击“完成”,添加采集网址的步骤就完成了。
然后就要进行下一步:侧的“使用Xpath浏览器”按钮,选择完以后会出现一个条件,而后点击测试,测试后有文章链接出来,则表示采集文章地址成功,可以确定进行下一步。
切记,上一步完成文章地址采集后,要在这里点击一下“保存”是上面的保存,而非下面的。
第四步:采集内容规则双击标题位置:设置标题的开始字符和结束字符步骤是点开一篇你要采集站的文章,找到他的标题位置,看是以什么唯一的标志开始,以什么标志结束。
以“长期憋尿可致前列腺增生”/gjml/2012-283.html 为例:正文部分:找一个离正文开始位置最近的div标记,在上下文搜索保证没有重复的,就可以做为文章的开始标记,结尾部分一样的方法。
结尾的也是一样:正文中有要替换的文字可以用:替换-> 内容替换来完成但要记得添加一个格式替换:替换-> Html标签过滤->点击全选全选后,要注意以下圈住的是要不选的,共四列,第一列第5个不选,第二列第2上不选,第三列前4个不选,第四列前3个不选。
火车头采集器教程演示文稿

火车头采集器教程演示文稿一、介绍你好,大家好!今天我非常荣幸给大家介绍一个非常实用的工具,火车头采集器。
它是一款强大的网络数据采集工具,可以帮助我们快速获取互联网上的各种信息。
二、功能1.数据采集:可以采集各种网站上的数据,如商品信息、新闻、评论等。
2.数据筛选:可以根据指定的条件对采集到的数据进行筛选和整理,提高数据的质量。
3. 数据导出:可以将采集到的数据导出为Excel、CSV等格式,方便进行后续分析和处理。
4.定时采集:可以设置定时任务,实现自动采集数据功能。
5.模拟登录:可以模拟用户的登录操作,以获得更多的数据。
6.反爬虫模式:可以通过一系列的反爬虫策略,规避网站的反爬虫机制,提高数据采集的成功率。
三、操作步骤下面我将为大家演示如何使用火车头采集器进行数据采集。
1.打开火车头采集器软件,点击左上角的“新建任务”按钮。
2.在弹出的窗口中,输入任务名称和要采集的网站URL,点击确定。
5.等待采集完成后,点击“导出数据”按钮,选择导出格式和保存路径,并点击确定。
6.打开导出的文件,即可查看采集到的数据。
四、常见问题及解决方法1.采集速度较慢:可以尝试调整线程数和延时时间,以提高采集速度。
2.采集到的数据不完整:可以检查采集器的配置是否正确,并尝试使用正则表达式提取所需数据。
3.被网站反爬虫封IP:可以使用代理IP或者设置访问频率来规避网站的反爬虫机制。
4.无法模拟登录:可以检查登录账号和密码是否正确,并确保网站的登录接口没有变动。
5.无法启动采集器:可以检查网络连接是否正常,并尝试重新安装软件。
五、总结火车头采集器是一款功能强大、易于操作的网络数据采集工具,可以帮助我们快速获取互联网上的各种信息。
通过本次演示,我相信大家已经对火车头采集器的使用有了初步的了解。
希望大家能够通过学习和实践,更好地应用这个工具,在数据采集和处理方面取得更好的成果。
谢谢大家!。
抓取网页数据工具火车采集器插件说明

抓取网页数据工具火车采集器插件说明抓取网页数据工具火车采集器插件说明在使用火车采集器抓取网页数据时,也会用到插件,火车采集器把采集到的数据传递给的外部程序,我们称之为插件,随后插件对数据进行处理,然后再把数据返回给采集器。
火车采集器V9支持PHP和C#两种语言的插件编写,且V9支持插件的源码编辑。
抓取网页数据工具火车采集器的插件可应用至采集结果的处理,HTTP 请求,文件下载三处。
大家可以在插件设置时从下拉框中选择插件管理器中已有的某个插件来实现具体的应用。
下面以58手机号码识别插件和百度翻译插件给大家讲解下用法。
58插件演示:(1)首先我们需要把插件58验证码V9.dll放入到采集器的Plugins目录中(2)然后在“其他设置——插件——采集结果处理插件”中选择这个插件。
(3)最后我们需要建立个名字为“手机号码”的标签,采集到58手机号码的图片地址,这样运行的时候,采集器就会自动调用插件来将图片转义成数字文本的形式输出了。
翻译插件演示:(1)首先我们需要把插件百度翻译.dll放入到采集器的Plugins目录中(2)然后在“其他设置——插件——采集结果处理插件”中选择这个插件。
(3)最后我们需要建立个名字为“翻译标签”的标签,将需要翻译的字段名字以固定字符串的形式写入。
再建立个名字为“翻译反向”的标签,将翻译语言以固定字符串的形式写入,如中文翻译成英文,代码:zh>en(zh表示中文,en 表示英文,这类语言代码在使用前查询一下)。
经过这样的操作,在运行的时候,火车采集器V9就会自动调用插件来翻译了。
在插件的帮助下我们可以使用火车采集器来完成更加复杂的任务,采集器中,除了使用已有的插件之外,我们也可以自行编写所需插件来使用,非技术人员可联系官方定制所需插件。
火车头采集规则

火车头采集规则是一个使用火车头定制抓取规则的重要步骤。
火车头
采集规则是指在使用火车头软件进行信息抓取时,需要为抓取的任务
制定的规则,它用于定义抓取任务的来源、要抓取的内容类型以及抓
取时间等。
首先,火车头采集规则需要定义抓取的目标网页。
火车头的抓取范围
可以从一个简单的网站,甚至是一个更大的网站组成的网络整体。
火
车头还允许用户设定自定义URL和正则表达式,进一步定义抓取目标,以便更加精准地抓取信息。
其次,在火车头采集规则中,还需要定义抓取时间,以便更好地抓取
到想要采集的最新信息。
火车头提供了一系列抓取时间设置,包括实
时抓取、定时抓取、间隔抓取等,用户可以根据实际需求为抓取任务
指定时间。
此外,在火车头采集规则中,还需要定义解析规则。
这是抓取任务的
关键步骤,通过这些解析规则,火车头能够正确识别抓取到的信息,
并将其按照指定格式存储到数据库中。
而根据抓取的目标网页不同,
火车头采集规则中的解析规则也不同,用户可以按照和目标网页的结
构类似的方式来编写解析规则。
总的来说,火车头采集规则是使用火车头软件抓取信息的必要步骤,
它能够准确抓取想要获取的内容,为软件的抓取操作提供必要的指导。
在使用火车头抓取信息时,采集规则的正确定义对保证抓取数据的准
确性、完整性和及时性至关重要。
火车头采集说明

ITool网站综合查询系统火车头采集说明
1.火车头下载
下载地址:/
2.后台配置
后台站点设置,配置火车头入库KEY
3.如何采集
请先完成第4步,火车头配置部分
网址采集可以按自己需要的,自己组合,格式必须要求是/ 必须是http://www.开头,用/结尾
此处介绍一种比较方便的方法
使用百度高级搜索,/gaoji/advanced.html
每页100条,将网址复制过来
设置正则
完成后,点提取地址
选择“IT ool采集”点“开始”,即可开始采集
4.火车头配置
将IT ool网站综合查询系统.cwr文件,放置到火车头Module目录里
打开火车头软件
新建一个站点
导入任务,选择IT ool采集.ljob文件
双击IT ool采集
启用“WEB在线发布到网站”
点击“定义web在线发布全局设置”
点“添加”
配置WEB发布信息
关闭配置管理
添加发布配置
选择刚才添加的配置,添加
配置入库KEY
配置完成!。
火车采集器采集结果保存为本地word,excel,html,txt文件
火车采集器采集结果保存为本地word,excel,html,txt文件
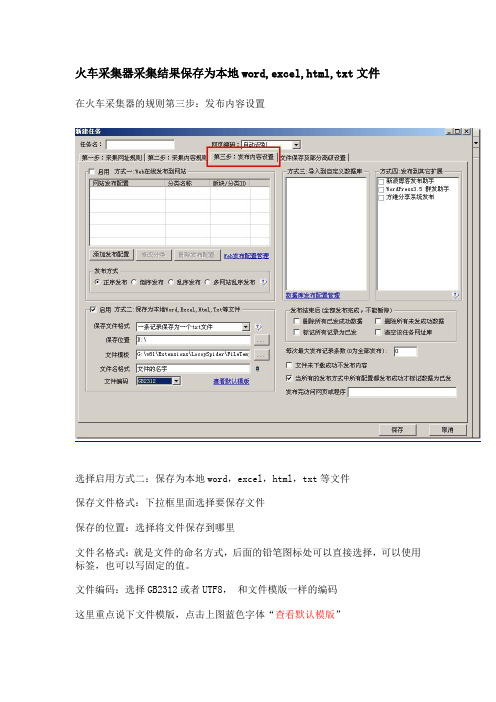
在火车采集器的规则第三步:发布内容设置
选择启用方式二:保存为本地word,excel,html,txt等文件
保存文件格式:下拉框里面选择要保存文件
保存的位置:选择将文件保存到哪里
文件名格式:就是文件的命名方式,后面的铅笔图标处可以直接选择,可以使用标签,也可以写固定的值。
文件编码:选择GB2312或者UTF8,和文件模版一样的编码
这里重点说下文件模版,点击上图蓝色字体“查看默认模版”
模版就是要以何种方式保存采集到的文章,默认模版已经做了例子
根据自己的需要修改使用
模版里面的标签名一定要和规则里面的标签名一一对应,不能写错名字,否则标签采集到的值是不能保存的文件里面的
比如下图:
上面模版里面只写了标题内容,但是规则里面还有作者时间出处等标签,这样保存的文件是不包含作者时间出处等信息的,也就是说用户可以随意选择需要保存的标签内容。
火车采集器使用教程
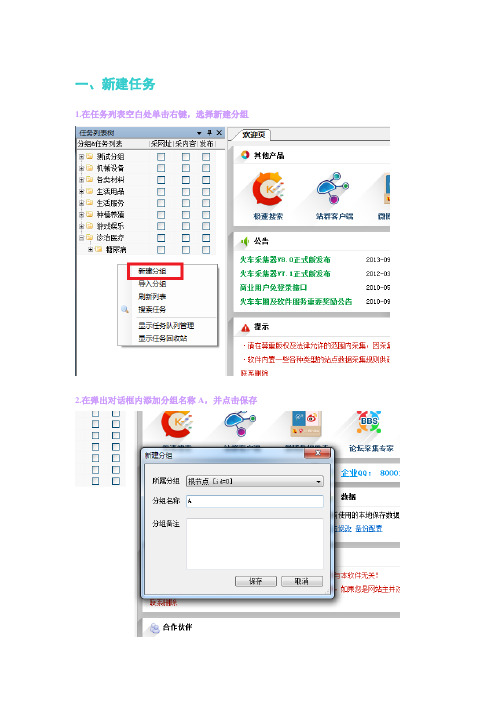
一、新建任务1.在任务列表空白处单击右键,选择新建分组2.在弹出对话框内添加分组名称A,并点击保存3.左键单击新建分组A,选择之后右键单击,选择新建任务4.在弹出对话框内添加任务名B二、添加采集网址规则1.在起始网址右侧单击“添加”按钮2.在弹出对话框内添加采集列表页规则:(1)单页面网址添加在“单条网址”分页内:直接把URL复制到文本框内,依次点击“添加”、“完成”即可;(2)有规则的批量网页可以在“批量/多页”分页内添加:将地址格式(如:/list/?204_1.html和/list/?204_2.html的规则是/list/?204_(*).html)3.在多级网址获取右侧单击“添加”按钮4.在弹出对话框内添加采集脚本规则附录:脚本规则填写方法找到新闻列表页要采集的内容,并在源码中找到文章所对应的链接,观察代码规则,发现他们的共同点是:<td style="border-bottom:dashed 1px #ccc;" align="left"><a href="[参数]">(*)</a></td>[参数]是你要采集文章的链接,(*)为变量。
注意:一定要确保[参数]两端的规则完整,不能光填写<a href="[参数]">,因为通篇只要带链接的都会是这样的代码。
如这样填写会造成抓取错误。
注:填写完采集规则后,可以点击“测试网址采集”按钮,来验证你填写的规则是否能让程序采集到文章页URL。
三、添加采集内容规则1.删除不需采集的内容在“采集内容规则”分页中将不需要采集的几个选项删除掉,双击需要采集的内容相应的框框,并在弹出的对话框内填写相应的规则。
(1)在页面中找到你想要采集的标题(2)在源码中找到你想采集的标题对应的位置(3)填写标题规则(正则提取)。
如上面代码中的规则为:<h3 style="text-align:center;">[参数]</h3>其中[参数]是想要采集的标题注:[参数]的前后必须唯一,确保整个源码页面中只出现一次,否则会影响程序采集基本与标题规则填写方式相同1.寻找正文前面唯一的代码规则2.寻找正文后面唯一的代码规则3.填写正文规则(正则提取)。
火车头采集器介绍与使用流程说明
五、字段处理
• 文件下载功能 • 火车头采集还提供了一个下载附件的功能, • 同样以为例:配置完采集规则之后,需将网址补全,因为大多网页源
代码中都是相对路径。操作如下: • 点击添加,选中“补全单网址”,之后点击文件下载,勾选“探测文
件并下载”即可。
附件下载情况
五、字段处理
• 附件下载配置好之后,还需给个文件存放路径及文件保存格式。
处理之后的效果
四、采集内容
• 备注:
• 前后字符串截取与正则提取是火车头最基本、最常用的两种采集方式,其原 理就是通过网页源代码中的前后关键字来获取所要采集的内容,通常这类前 后的关键字在网页源代码中具有一定的唯一性。
五、字段处理
• 火车头采集器除了有最基本的采集截取之外,还有大量的对数据自动 作特殊处理的功能。Fra bibliotek日期格式
网址通用序号用通 配符(*)替换
这添加方式主要用来处理含有日期的网址
三、采集网址
• 多级网址采集
点击‘添加’按钮
网址过滤条件
三、采集网址
• 手动采集配置链接地址规则:
• 手动连接格式是将需要的网址用参数来获得并组合成我们需要的网址。 这个好处是处理网址那块有规律的网址很好处理。而且可以用这方法 采集需要的字段,如:公告新闻类的标题、日期等。
二、创建任务
• 1.新建分组
填写分组名称
二、创建任务
• 2.新建任务
填写任务名称
添加采集网址
三、采集网址
• 点击“添加”按钮出现如下界面
三、采集网址
• 切换至“批量/多页”选项卡,可以批量添加网址
网址通用序号用通 配符(*)替换
这添加方式主要用来处理分页网址
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
火车采集器采集结果保存为本地word,excel,html,txt文件
在火车采集器的规则第三步:发布内容设置
选择启用方式二:保存为本地word,excel,html,txt等文件
保存文件格式:下拉框里面选择要保存文件
保存的位置:选择将文件保存到哪里
文件名格式:就是文件的命名方式,后面的铅笔图标处可以直接选择,可以使用标签,也可以写固定的值。
文件编码:选择GB2312或者UTF8,和文件模版一样的编码
这里重点说下文件模版,点击上图蓝色字体“查看默认模版”
模版就是要以何种方式保存采集到的文章,默认模版已经做了例子
根据自己的需要修改使用
模版里面的标签名一定要和规则里面的标签名一一对应,不能写错名字,否则标签采集到的值是不能保存的文件里面的
比如下图:
上面模版里面只写了标题内容,但是规则里面还有作者时间出处等标签,这样保存的文件是不包含作者时间出处等信息的,也就是说用户可以随意选择需要保存的标签内容。