id3决策树算法例题
机器学习--决策树算法(ID3C4.5)

机器学习--决策树算法(ID3C4.5)在⽣活中,“树”这⼀模型有很⼴泛的应⽤,事实证明,它在机器学习分类和回归领域也有着深刻⽽⼴泛的影响。
在决策分析中,决策树可以明确直观的展现出决策结果和决策过程。
如名所⽰,它使⽤树状决策模型。
它不仅仅是在数据挖掘中⽤户获取特定⽬标解的策略,同时也被⼴泛的应⽤于机器学习。
如何使⽤树来表⽰算法为此,我们考虑使⽤泰坦尼克号数据集的⽰例,以预测乘客是否会⽣存。
下⾯的模型使⽤数据集中的3个特征/属性/列,即性别,年龄和SIBSP(配偶或⼉童的数量)。
这是⼀棵体现了⼈性光辉的决策树。
树的形状是⼀棵上下颠倒的决策树,叶⼦节点在下,根节点在上。
在图像中,⿊⾊中的粗体⽂本表⽰条件/内部节点,基于树分成分⽀/边缘。
不再分裂的分⽀结束是决策/叶⼦,在这种情况下,乘客是否被死亡或幸存,分别表⽰为红⾊和绿⾊⽂本。
虽然,⼀个真实的数据集将有很多功能,这只是⼀个更⼤的树中的部分分⽀,但你不能忽略这种算法的简单性。
该特征重要性是明确的,可以轻易查看决策关系。
该⽅法更常见于来⾃数据的学习决策树,并且在树上被称为分类树,因为⽬标是将乘客分类为幸存或死亡,上⾯所展⽰的决策树就是分类树。
回归树以相同的⽅式表⽰,例如⽤于预测房⼦价格的连续价值。
通常,决策树算法被称为CART或分类和回归树。
那么,算法⽣成的背后发⽣了什么呢?如何⽣成⼀个决策树取决于选择什么特征和在何种情况下进⾏分裂,以及在什么时候停⽌。
因为⼀棵树通常是随意⽣长的,你需要修剪它,让它看起来漂亮(研究如何⽣成决策树)。
ID3算法ID3算法⽣成决策树ID3算法(Iterative Dichotomiser 3)是决策树⽣成算法的⼀种,基于奥卡姆剃⼑原理(简约原则) 1。
是Ross Quinlan发明的⼀种决策树算法,这个算法的基础就是上⾯提到的奥卡姆剃⼑原理,越是⼩型的决策树越优于⼤的决策树,尽管如此,也不总是⽣成最⼩的树型结构,⽽是⼀个启发式算法。
决策树ID3例题经典案例

决策树ID3例题经典案例
决策树ID3例题是探究决策树原理的经典案例。
它的主要内容是利用决策树对一组状态变量输入,按照规则变化,最终得出一组结论。
决策树ID3例题的经典案例如下:
假设有一组客户,他们的信息如下:
客户年龄收入是否有孩子是否有信用卡
A 35 150 有有
B 25 100 有无
C 60 150 无有
D 35 200 无有
这个案例中,状态变量为年龄、收入、是否有孩子、是否有信用卡,如果想要利用决策树分析得出最终结论,可以根据如下规则进行对比:
(1)根据年龄,将客户分为年轻客户和中老年客户;
(2)根据收入,将客户分为低收入和高收入;
(3)根据是否有孩子,将客户分为家庭客户和非家庭客户;
(4)根据是否有信用卡,将客户分为信用良好客户和信用较差客户。
以上就是用决策树ID3例题的经典案例,通过综合分析多个状态变量,最终得出一组划分客户的结论,以便采取相应的策略。
- 1 -。
仿照例题,使用id3算法生成决策树

标题:使用ID3算法生成决策树一、概述在机器学习领域,决策树是一种常见的分类和回归算法。
它基于一系列属性对数据进行划分,最终生成一棵树状图来表示数据的分类规则。
在本文中,我们将介绍ID3算法,一种经典的决策树生成算法,并演示如何使用ID3算法生成决策树。
二、ID3算法概述ID3算法是一种基于信息论的决策树生成算法,其全称为Iterative Dichotomiser 3。
它由Ross Quinlan于1986年提出,是C4.5算法的前身。
ID3算法的核心思想是在每个节点选择最佳的属性进行划分,使得各个子节点的纯度提高,从而最终生成一棵有效的决策树。
ID3算法的主要步骤包括计算信息增益、选择最佳属性、递归划分数据集等。
在这一过程中,算法会根据属性的信息增益来确定最佳的划分属性,直到满足停止条件为止。
三、使用ID3算法生成决策树的步骤使用ID3算法生成决策树的步骤如下:1. 收集数据集:需要收集一个包含多个样本的数据集,每个样本包含多个属性和一个类别标签。
2. 计算信息增益:对每个属性计算信息增益,信息增益越大表示该属性对分类的贡献越大。
3. 选择最佳属性:选择信息增益最大的属性作为当前节点的划分属性。
4. 划分数据集:根据选择的属性值将数据集划分成若干子集,每个子集对应属性的一个取值。
5. 递归生成子节点:对每个子集递归调用ID3算法,生成子节点,直到满足停止条件。
6. 生成决策树:将所有节点连接起来,生成一棵完整的决策树。
四、使用ID3算法生成决策树的示例为了更好地理解ID3算法的生成过程,我们以一个简单的示例来说明。
假设有一个包含天气、温度和湿度三个属性的数据集,我们希望使用ID3算法生成一个决策树来预测是否适合外出活动。
我们需要计算每个属性的信息增益。
然后选择信息增益最大的属性进行划分,将数据集划分成若干子集。
接着递归调用ID3算法,直到满足停止条件为止。
经过计算和递归划分,最终我们得到一棵决策树,可以根据天气、温度和湿度来预测是否适合外出活动。
决策树系列(三)——ID3

决策树系列(三)——ID3预备知识:初识ID3回顾决策树的基本知识,其构建过程主要有下述三个重要的问题:(1)数据是怎么分裂的(2)如何选择分类的属性(3)什么时候停⽌分裂从上述三个问题出发,以实际的例⼦对ID3算法进⾏阐述。
例:通过当天的天⽓、温度、湿度和季节预测明天的天⽓ 表1 原始数据当天天⽓温度湿度季节明天天⽓晴2550春天晴阴2148春天阴阴1870春天⾬晴2841夏天晴⾬865冬天阴晴1843夏天晴阴2456秋天晴⾬1876秋天阴⾬3161夏天晴阴643冬天⾬晴1555秋天阴⾬458冬天⾬1.数据分割对于离散型数据,直接按照离散数据的取值进⾏分裂,每⼀个取值对应⼀个⼦节点,以“当前天⽓”为例对数据进⾏分割,如图1所⽰。
对于连续型数据,ID3原本是没有处理能⼒的,只有通过离散化将连续性数据转化成离散型数据再进⾏处理。
连续数据离散化是另外⼀个课题,本⽂不深⼊阐述,这⾥直接采⽤等距离数据划分的李算话⽅法。
该⽅法先对数据进⾏排序,然后将连续型数据划分为多个区间,并使每⼀个区间的数据量基本相同,以温度为例对数据进⾏分割,如图2所⽰。
2. 选择最优分裂属性ID3采⽤信息增益作为选择最优的分裂属性的⽅法,选择熵作为衡量节点纯度的标准,信息增益的计算公式如下:其中,表⽰⽗节点的熵;表⽰节点i的熵,熵越⼤,节点的信息量越多,越不纯;表⽰⼦节点i的数据量与⽗节点数据量之⽐。
越⼤,表⽰分裂后的熵越⼩,⼦节点变得越纯,分类的效果越好,因此选择最⼤的属性作为分裂属性。
对上述的例⼦的跟节点进⾏分裂,分别计算每⼀个属性的信息增益,选择信息增益最⼤的属性进⾏分裂。
天⽓属性:(数据分割如上图1所⽰)温度:(数据分割如上图2所⽰)湿度:季节:由于最⼤,所以选择属性“季节”作为根节点的分裂属性。
3.停⽌分裂的条件停⽌分裂的条件已经在决策树中阐述,这⾥不再进⾏阐述。
(1)最⼩节点数 当节点的数据量⼩于⼀个指定的数量时,不继续分裂。
决策树id3算法例题

决策树id3算法例题决策树ID3算法是一种常用的分类算法,用于根据已知的一组特征和标签数据,构建一个决策树模型来进行分类预测。
下面我将以一个示例来介绍决策树ID3算法的基本步骤和过程。
假设我们想要构建一个决策树模型来帮助我们判断一个人是否会购买一款新的智能手机。
我们已经收集了一些关于个体的特征数据和对应的购买结果数据,包括性别、年龄、收入和是否购买。
首先,我们需要计算每个特征对于分类结果的信息增益。
信息增益是指通过使用某个特征来对数据进行分类,所能获得的关于数据的新的信息量。
计算信息增益的公式如下:信息增益 = 熵(D) - ∑(Dv/D) * 熵(Dv)其中,熵(D)表示数据集D的混乱程度,熵的计算公式为:熵(D) = - ∑(pi * log2(pi))Dv表示特征A的某个取值,D表示数据集D的标签集合,pi表示标签i在数据集D中的比例。
我们首先计算整个数据集的熵D,然后计算每个特征的条件熵,最后将它们相加得到信息增益。
选择信息增益最大的特征作为当前节点的划分特征。
接下来,我们根据选择的特征将数据集划分成不同的子集。
每个子集都对应一个特征值的取值,例如性别特征可能有男和女两个取值。
我们对每个子集重复上述过程,以递归的方式构建子树。
在每个子树中,我们需要选择一个特征进行划分。
如果所有的特征都已经使用完毕,或者剩余的数据集已经完全属于同一类别,那么我们停止划分,将当前节点标记为叶节点,并将最常见的类别作为该节点的预测结果。
否则,我们选择信息增益最大的特征作为当前节点的划分特征,并继续递归构建子树。
最终,我们得到了一个完整的决策树模型。
我们可以使用该模型来对新的个体进行分类预测。
从根节点开始,根据个体的特征值选择相应的子节点,直到到达叶节点,将叶节点的预测结果作为最终的分类结果。
在本示例中,决策树模型可能会根据最佳特征先根据性别划分,接着根据年龄划分,最后根据收入划分。
我们可以根据决策树模型将一个新的个体划分到某个叶节点,并预测其是否会购买手机。
决策树ID3算法的实例解析

根据票数排名筛选出10大算法 (如果票数相同,则按字母顺序进行排名)
数据挖掘10大算法产生过程
1 2 3 4
三步鉴定流程 18种通过审核的候选算法 算法陈述 数据挖掘10大算法:一览
5
开放式讨论
18种通过审核的候选算法
§分类(Classification)
1. C4.5: Quinlan, J. R. 1993. C4.5: Programs for Machine Learning. Morgan Kaufmann Publishers Inc. 2. CART: L. Breiman, J. Friedman, R. Olshen, and C. Stone. Classification and Regression Trees. Wadsworth, Belmont, CA, 1984. 3. K Nearest Neighbours (kNN): Hastie, T. and Tibshirani, R. 1996. Discriminant Adaptive Nearest Neighbor Classification. IEEE Trans. Pattern Anal. Mach. Intell. (TPAMI). 18, 6 (Jun. 1996), 607-616. 4. Naive Bayes Hand, D.J., Yu, K., 2001. Idiot's Bayes: Not So Stupid After All? Internat. Statist. Rev. 69, 385-398.
共有145人参加了ICDM 2006 Panel (会议的专题讨论),并对18种 候选算法进行投票,选出了数据挖掘10大算法
排名 挖掘主题
1实验1-ID3算法填空及决策树构建

1实验1-ID3算法填空及决策树构建姓名:蔡菲菲学号:22015045填空,将答案直接填写在横线上。
1. ID3 算法是⼀个众所周之的决策树算法,该算法是澳⼤利亚悉尼⼤学的Ross Quinlan 于1986年提出,也是国际上最早、最有影响⼒的决策树算法。
2. 信息量的单位是位。
3. 熵是系统混乱程度的统计量。
熵越⼤,表⽰系统混乱程度越⼤。
4. 熵的计算公式为:∑=-=mi i i p p D Info 12)(log )(,那么投掷硬币这⼀⾏为的信息含量就是多少? 15. 决策树算法的关键在于如何选择⼀个分裂属性形成决策树的决策节点,并从当前节点⽣成决策分枝。
在选择某⼀分裂属性作为决策节点时,通常希望该属性能够最⼤程度地反映训练样本集的分类特征。
在ID3算法中,决策节点属性的选择运⽤了信息论中的熵概念作为启发式函数。
在这种属性选择⽅法中,选择具有最⼤信息增益的属性作为当前划分节点。
6. 设数据划分D 为类标记的元组的训练集。
假定类标号属性具有M 个不同值,定义m 个不同的类C i (I =1,2,…,m ),C i,D 是C i 类的元组的集合。
D 和D Ci ,分别表⽰D 和C i,D 中元组的个数。
对D 中的元组分类所需的期望信息由下式给出:∑=-=mi i i p p D Info 12)(log )(假设属性A 具有v 个不同的离散属性值,可使⽤属性A 把数据集D 划分成v 个⼦集{D 1, D 2,…D v }。
设⼦集D j 中全部的记录数在A 上具有相同的值a j 。
基于按A划分对D 的元组分类所需要的期望信息由下式给出: )( Dj )(1j v j A D Info D D Info ∑=?-=信息增益定义:原来的信息需求(基于类⽐例)与新的信息需求(对A 划分之后得到的)之间的差,即Gain(A)=Info (D )-Info A (D )根据以上提⽰计算的:(要求写出计算过程)数据:⼼⾎管病住院患者信息表(D )类标号属性:住院天数少于两周则Info (D )= 0.94029分别计算基于性别、主要诊断、⼊院病情、⾼⾎压病史和平时⾝体状况作为划分属性来对D 分类所需要的期望信息值:Info 性别(D )= 0.69523Info 主要诊断(D )= 0.836125Info ⼊院病情(D )= 0.479088Info⾼⾎压病史(D)= 0.894225Info平时⾝体状况(D)= 0.936728根据信息增益定义,我们可以计算出Gain(性别)= 0.245056Gain(主要诊断)=0.106141Gain(⼊院病情)=0.461198Gain(⾼⾎压病史)=0.046061Gain(平时⾝体状况)=0.003558决策树构建1)将你电脑上⼼⾎管病住院患者信息表.xls 的数据导⼊到SQL server 2005 数据库中以备后期数据挖掘⽤,数据库命名为⼼⾎管病住院患者信息。
分类决策树ID3算法-理论加实例

第6章 决策树
决策树基本概念
关于归纳学习(3)
归纳学习由于依赖于检验数据,因此又称为检验学习。 归纳学习存在一个基本的假设:
任一假设如果能够在足够大的训练样本集中很好的逼 近目标函数,则它也能在未见样本中很好地逼近目标函数。 该假定是归纳学习的有效性的前提条件。
第6章 决策树
决策树基本概念
关于归纳学习(4)
第 6 章 决策树
决策树基本概念 决策树算法 决策树研究问题
主要内容
决策树基本概念 决策树算法 决策树研究问题
第6章 决策树
关于分类问题
决策树基本概念
分类(Classification)任务就是通过学习获得一个目标函数 (Target Function)f, 将每个属性集x映射到一个预先定义好的类 标号y。
买
不买
买
在沿着决策树从上到下的遍历过程中,在每个结点都有一个 测试。对每个结点上问题的不同测试输出导致不同的分枝,最后 会达到一个叶子结点。这一过程就是利用决策树进行分类的过程, 利用若干个变量来判断属性的类别
第6章 决策树
决策树算法
CLS(Concept Learning System)算法
CLS算法是早期的决策树学习算法。它是许多决策树学习算法 的基础。
归类:买计算机?
不买 不买 买 买 买 不买 买 不买 买 买 买 买 买 不买 买
假定公司收集了左表数据,那么对 于任意给定的客人(测试样例), 你能帮助公司将这位客人归类吗?
即:你能预测这位客人是属于“买” 计算机的那一类,还是属于“不买” 计算机的那一类?
又:你需要多少有关这位客人的信 息才能回答这个问题?
3、可自动忽略目标变量没有贡献的属性变量,也为判断属性 变量的重要性,减少变量的数目提供参考。
数据挖掘ID3算法决策树

问题描述:人对舒适度的感觉是通过穿衣指数和气候的温度、湿度、风力决定的。
请用ID3算法构建决策树.原始数据库:表1根节点的选择:根节点的选择标准就是看哪一个属性的增益最大,下面计算四个属性的增益:第一步:计算决策属性的熵表2根据感觉舒适度的类别属性划分D为相互独立的类,决策属性感觉舒适度有20个记录,其中9个记录是舒适,11个记录是不舒适,分别为p1,p2.其概率分布为p={9/20,11/20},使用公式计算熵得:Info(感觉舒适度)= -(9/20)*log2(9/20)-(11/20)*log2(11/20)=0.993位第二步:计算条件属性的熵样本集共有4个条件属性,分别为:穿衣指数,温度,湿度,风力,使用公式计算各条件属性的熵。
1.穿衣指数的熵:按穿衣指数将D划分为D1(正常),D2(较多),D3(很多)三个集合D=D1∪D2∪D3,P的概率分布为:P={6/20,3/20,11/20}表3(1)用公式计算属性值的熵对于集合D1(正常)有舒适一个类别,其概率分布为P={6/6},Info(D1)= -(6/6)*log2(6/6)=0.0;对于集合D2(较多)有不舒适一个类别,其概率分布为P={ 3/3 },Info(D2)= -(3/3)*log2(3/3) =0.0;对于集合D3(很多)有舒适和不舒适两个类别,其概率分布为P={3/11,8/11},Info(D3)= -(3/11)*log2(3/11)-(8/11)*log2(8/11)=0.772位(2)用公式计算属性的熵(三个子集的加权平均值)Info(穿衣指数) =6/20*Info(D1)+3/20*Info(D2)+11/20*Info(D3)=6/20*0.0+3/20*0.0+11/20*0.772 =0.42462,温度的熵:按温度将D划分为D1(适中),D2(很高)两个集合D=D1∪D2,P的概率分布为:P={11/20,9/20}表4(1)用公式计算属性值的熵对于集合D1(适中)有两个类别舒适,不舒适,其概率分布为P={4/11,7/11}, Info(D1)= -(4/11)log2(4/11)-(7/11)log2(7/11)=0.9457;对于集合D2(很高)有两个类别舒适,不舒适,其概率分布为P={5/9,4/9}, Info(D2)= -(5/9)log2(5/9)-(4/9)log2(4/9)=0.9911;(2)用公式计算属性的熵(两个子集的加权平均值)Info(D,温度)=11/20*Info(D1)+9/20*Info(D2) =11/20*0.9457+9/20*0.9911 =0.9661位3.湿度的熵:按湿度将D划分为D1(正常),D2(很大)两个集合D=D1∪D2,P的概率分布为:P={8/20,12/20}表5(1)用公式计算属性值的熵对于集合D1(高)有两个类别舒适,不舒适,其概率分布为P={5/8,3/8},Info(D1)= -(5/8)log2(5/8)-(3/8)log2(3/8)=0.9544对于集合D2(正常)有两个类别舒适,不舒适,其概率分布为P={4/12,8/12}, Info(D2)= -(4/12)log2(4/12)-(8/12)log2(8/12)=0.9183(2)用公式计算属性的熵(两个子集的加权平均值)Info(D,湿度)=8/20*Info(D1)+12/20*Info(D2)=8/20*0.9544+12/20*0.9183 =0.93274.3.风力的熵:按风力将D划分为D1(中等),D2(没有),D3(很大)三个集合D=D1∪D2∪D3,P的概率分布为:P={8/20,7/20,5/20}表6(1)用公式计算属性值的熵对于集合D1(中等)有两个类别舒适,不舒适,其概率分布为P={4/8,4/8},Info(D1)=-(4/8)log2(4/8)-(4/8)log2(4/8)=1;对于集合D2(没有)有一个类别舒适,不舒适,其概率分布为P={3/7,4/7},Info(D2)=-(3/7)log2(3/7)-(4/7)log2(4/7)=0.9848;对于集合D3(很大)有一个类别舒适,不舒适,其概率分布为P={2/5,3/5},Info(D3)=-(2/5)log2(2/5)-(3/5)log2(3/5)=0.9710;(2)用公式计算属性的熵(三个子集的加权平均值)Info(D,风力)=8/20*Info(D1)+7/20*Info(D2) +5/20*Info(D3)=8/20*1+7/20*0.9848+5/20*0.9710 =0.9874第三步:计算条件属性的增益使用公式计算条件属性的增益为:Gain(穿衣指数)=Info(感觉舒适度)-Info(D,穿衣指数)= 0.993-0.4246=0.5684Gain(温度)=Info(感觉舒适度)-Info(D,温度)= 0.993-0.9661=0.0269Gain(湿度)=Info感觉舒适度)-Info(D,湿度)= 0.993-0.9327=0.0603Gain(风力)=Info感觉舒适度)-Info(D,风力)= 0.993-0.9874=0.0056结论:条件属性穿衣指数有最大的增益,所以它用于决策树的根节点正常很多 较多表7穿衣指数(正常)的分支根节点的选择:第一步:计算决策属性的熵根据感觉舒适度类别属性划分D 为相互独立的类,决策属性感觉舒适度有6个记录,全部为舒适.其概率分布为p={1},使用公式计算熵得: Info(感觉舒适度)= -(6/6)log2(6/6) =0第二步:计算条件属性的熵样本集共有3个条件属性,分别为:温度,湿度,风力,使用公式计算各条件属性的熵。
机器学习--决策树(ID3)算法及案例

机器学习--决策树(ID3)算法及案例1基本原理决策树是一个预测模型。
它代表的是对象属性与对象值之间的一种映射关系。
树中每个节点表示某个对象,每个分支路径代表某个可能的属性值,每个叶结点则对应从根节点到该叶节点所经历的路径所表示的对象的值。
一般情况下,决策树由决策结点、分支路径和叶结点组成。
在选择哪个属性作为结点的时候,采用信息论原理,计算信息增益,获得最大信息增益的属性就是最好的选择。
信息增益是指原有数据集的熵减去按某个属性分类后数据集的熵所得的差值。
然后采用递归的原则处理数据集,并得到了我们需要的决策树。
2算法流程检测数据集中的每个子项是否属于同一分类:If 是,则返回类别标签;Else计算信息增益,寻找划分数据集的最好特征划分数据数据集创建分支节点(叶结点或决策结点)for 每个划分的子集递归调用,并增加返回结果到分支节点中return 分支结点算法的基本思想可以概括为:1)树以代表训练样本的根结点开始。
2)如果样本都在同一个类.则该结点成为树叶,并记录该类。
3)否则,算法选择最有分类能力的属性作为决策树的当前结点.4 )根据当前决策结点属性取值的不同,将训练样本根据该属性的值分为若干子集,每个取值形成一个分枝,有几个取值形成几个分枝。
匀针对上一步得到的一个子集,重复进行先前步骤,递归形成每个划分样本上的决策树。
一旦一个属性只出现在一个结点上,就不必在该结点的任何后代考虑它,直接标记类别。
5)递归划分步骤仅当下列条件之一成立时停止:①给定结点的所有样本属于同一类。
②没有剩余属性可以用来进一步划分样本.在这种情况下.使用多数表决,将给定的结点转换成树叶,并以样本中元组个数最多的类别作为类别标记,同时也可以存放该结点样本的类别分布[这个主要可以用来剪枝]。
③如果某一分枝tc,没有满足该分支中已有分类的样本,则以样本的多数类生成叶子节点。
算法中2)步所指的最优分类能力的属性。
这个属性的选择是本算法种的关键点,分裂属性的选择直接关系到此算法的优劣。
决策树id3算法例题经典

决策树id3算法例题经典一、决策树ID3算法例题经典之基础概念决策树ID3算法就像是一个超级聪明的小侦探,在数据的世界里寻找线索。
它是一种用来分类的算法哦。
比如说,我们要把一群小动物分成哺乳动物和非哺乳动物,就可以用这个算法。
它的基本思想呢,就是通过计算信息增益来选择特征。
就好比是在一堆乱糟糟的东西里,先找到那个最能区分开不同类别的特征。
比如说在判断小动物的时候,有没有毛发这个特征可能就很关键。
如果有毛发,那很可能就是哺乳动物啦。
二、经典例题解析假设我们有这样一个数据集,是关于一些水果的。
这些水果有颜色、形状、是否有籽等特征,我们要根据这些特征来判断这个水果是苹果、香蕉还是橙子。
首先看颜色这个特征。
如果颜色是红色的,那可能是苹果的概率就比较大。
但是仅仅靠颜色可不够准确呢。
这时候就需要计算信息增益啦。
通过计算发现,形状这个特征对于区分这三种水果的信息增益更大。
比如说圆形的可能是苹果或者橙子,弯弯的可能就是香蕉啦。
再考虑是否有籽这个特征。
苹果和橙子有籽,香蕉没有籽。
把这个特征也加入到决策树的构建当中,就可以更准确地判断出到底是哪种水果了。
三、决策树ID3算法的优缺点1. 优点这个算法很容易理解,就像我们平常做选择一样,一步一步来。
它的结果也很容易解释,不像有些复杂的算法,结果出来了都不知道怎么回事。
它不需要太多的计算资源,对于小数据集来说,速度很快。
就像小马拉小车,轻松就能搞定。
2. 缺点它很容易过拟合。
就是在训练数据上表现很好,但是一到新的数据就不行了。
比如说我们只根据训练数据里的几个苹果的特征构建了决策树,新的苹果稍微有点不一样,就可能判断错了。
它只能处理离散型的数据。
如果是连续型的数据,就需要先进行离散化处理,这就多了一道工序,比较麻烦。
四、实际应用场景1. 在医疗领域,可以用来判断病人是否患有某种疾病。
比如说根据病人的症状、年龄、性别等特征来判断是否得了感冒或者其他疾病。
就像医生的小助手一样。
ID3决策树算法应用
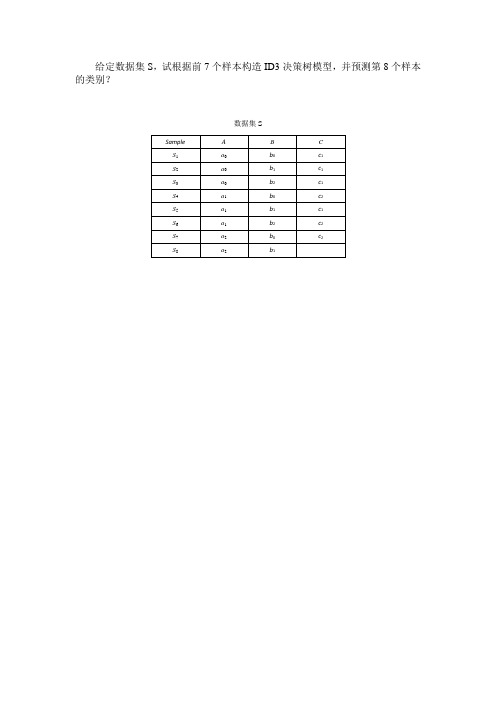
给定数据集S,试根据前7个样本构造ID3决策树模型,并预测第8个样本的类别?数据集S格式要求ID3决策树算法的计算题示例(蓝色字体部分属于分析过程,在提交时可以不写):下列信息表包含5个属性: Warm_blooded ,Feathers,Fur,Swims,Lay_eggs,其中类标号属性为Lay_eggs,请根据该信息表通过计算建立一棵决策树。
解:类标号属性Lay_eggs有2个不同的取值0和1,其中1有4个样本,0有2个样本,故对给定样本分类所需的期望信息为:I(s1,s2)=I(4,2)=-(4/6)log2(4/6) -(2/6)log2(2/6)=0.918接下来计算每个训练属性的信息增益:(先考虑Warm_blooded属性,显然,Warm_blooded=1有3个Lay_eggs=1的样本,2个Lay_eggs=0的样本;,Warm_blooded=0有1个Lay_eggs=1的样本,0个Lay_eggs=0的样本)对于Warm_blooded=1,s11=3,s21=2,I(s11,s21)=0.971。
对于Warm_blooded=0,s12=1,s22=0,I(s12,s22)=0。
所以E(Warm_blooded)=(5/6) I(s11,s21)+(1/6) I(s12,s22)=0.809Gain(Warm_blooded)= I(s1,s2)- E(Warm_blooded)=0.109对于Feathers =1,s11=3,s21=0,I(s11,s21)=0。
对于Feathers =0,s12=1,s22=2,I(s12,s22)=0.918。
所以E(Feathers)=(3/6) I(s11,s21)+(3/6) I(s12,s22)=0.459Gain(Feathers)= I(s1,s2)- E(Feathers)=0.459对于Fur =1,s11=0,s21=1,I(s11,s21)=0。
决策树ID3算法的java实现(基本适用所有的ID3)

决策树ID3算法的java实现(基本适⽤所有的ID3)已知:流感训练数据集,预定义两个类别;求:⽤ID3算法建⽴流感的属性描述决策树流感训练数据集No.头痛肌⾁痛体温患流感1是(1)是(1)正常(0)否(0)2是(1)是(1)⾼(1)是(1)3是(1)是(1)很⾼(2)是(1)4否(0)是(1)正常(0)否(0)5否(0)否(0)⾼(1)否(0)6否(0)是(1)很⾼(2)是(1)7是(1)否(0)⾼(1)是(1)原理分析:在决策树的每⼀个⾮叶⼦结点划分之前,先计算每⼀个属性所带来的信息增益,选择最⼤信息增益的属性来划分,因为信息增益越⼤,区分样本的能⼒就越强,越具有代表性其中。
信息熵计算:信息增益:计算的结果(草稿上的字丑别喷):--------------------------------------------------------------------------------------------------------------------------------------------*************************************************************************************************************************************实现*********************************************package ID3Tree;import parator;;@SuppressWarnings("rawtypes")public class Comparisons implements Comparator{String str1 = (String)a;String str2 = (String)b;return pareTo(str2);}}package ID3Tree;public class Entropy {//信息熵public static double getEntropy(int x, int total) {if (x == 0){return 0;}double x_pi = getShang(x,total);return -(x_pi*Logs(x_pi));}public static double Logs(double y){return Math.log(y) / Math.log(2);}public static double getShang(int x, int total) {return x * Double.parseDouble("1.0") / total; }}package ID3Tree;public class TreeNode {//⽗节点TreeNode parent;//指向⽗节点的属性String parentAttribute;String nodeName;String[] attributes;TreeNode[] childNodes;}package ID3Tree;import java.util.*;public class UtilID3 {TreeNode root;private boolean[] flag;//训练集private Object[] trainArrays;//节点索引private int nodeIndex;public static void main(String[] args){//初始化训练集数组Object[] arrays = new Object[]{new String[]{"是","是","正常","否"},new String[]{"是","是","⾼","是"},new String[]{"否","是","正常","否"},new String[]{"否","否","⾼","否"},new String[]{"否","是","很⾼","是"},new String[]{"是","否","⾼","是"}};UtilID3 ID3Tree = new UtilID3();ID3Tree.create(arrays, 3);}//创建public void create(Object[] arrays, int index){this.trainArrays = arrays;initial(arrays, index);createDTree(arrays);printDTree(root);}//初始化public void initial(Object[] dataArray, int index){this.nodeIndex = index;//数据初始化this.flag = new boolean[((String[])dataArray[0]).length];for (int i = 0; i<this.flag.length; i++){if (i == index){this.flag[i] = true;}else{this.flag[i] = false;}}}//创建决策树public void createDTree(Object[] arrays){Object[] ob = getMaxGain(arrays);if (this.root == null){this.root = new TreeNode();root.parent = null;root.parentAttribute = null;root.attributes = getAttributes(((Integer)ob[1]).intValue());root.nodeName = getNodeName(((Integer)ob[1]).intValue());root.childNodes = new TreeNode[root.attributes.length];insert(arrays, root);}}//插⼊决策树public void insert(Object[] arrays, TreeNode parentNode){String[] attributes = parentNode.attributes;for (int i = 0; i < attributes.length; i++){Object[] Arrays = pickUpAndCreateArray(arrays, attributes[i],getNodeIndex(parentNode.nodeName)); Object[] info = getMaxGain(Arrays);double gain = ((Double)info[0]).doubleValue();if (gain != 0){TreeNode currentNode = new TreeNode();currentNode.parent = parentNode;currentNode.parentAttribute = attributes[i];currentNode.attributes = getAttributes(index);currentNode.nodeName = getNodeName(index);currentNode.childNodes = new TreeNode[currentNode.attributes.length]; parentNode.childNodes[i] = currentNode;insert(Arrays, currentNode);}else{TreeNode leafNode = new TreeNode();leafNode.parent = parentNode;leafNode.parentAttribute = attributes[i];leafNode.attributes = new String[0];leafNode.nodeName = getLeafNodeName(Arrays);leafNode.childNodes = new TreeNode[0];parentNode.childNodes[i] = leafNode;}}}//输出public void printDTree(TreeNode node){System.out.println(node.nodeName);TreeNode[] childs = node.childNodes;for (int i = 0; i < childs.length; i++){if (childs[i] != null){System.out.println("如果:"+childs[i].parentAttribute);printDTree(childs[i]);}}}//剪取数组public Object[] pickUpAndCreateArray(Object[] arrays, String attribute, int index) {List<String[]> list = new ArrayList<String[]>();for (int i = 0; i < arrays.length; i++){String[] strs = (String[])arrays[i];if (strs[index].equals(attribute)){list.add(strs);}}return list.toArray();}//取得节点名public String getNodeName(int index){String[] strs = new String[]{"头痛","肌⾁痛","体温","患流感"};for (int i = 0; i < strs.length; i++){if (i == index){return strs[i];}}return null;//取得叶⼦节点名public String getLeafNodeName(Object[] arrays){if (arrays != null && arrays.length > 0){String[] strs = (String[])arrays[0];return strs[nodeIndex];}return null;}//取得节点索引public int getNodeIndex(String name){String[] strs = new String[]{"头痛","肌⾁痛","体温","患流感"};for (int i = 0; i < strs.length; i++){if (name.equals(strs[i])){return i;}}return -1;}//得到最⼤信息增益public Object[] getMaxGain(Object[] arrays){Object[] result = new Object[2];double gain = 0;int index = -1;for (int i = 0; i<this.flag.length; i++){if (!this.flag[i]){double value = gain(arrays, i);if (gain < value){gain = value;index = i;}}}result[0] = gain;result[1] = index;if (index != -1){this.flag[index] = true;}return result;}//取得属性数组public String[] getAttributes(int index){@SuppressWarnings("unchecked")TreeSet<String> set = new TreeSet<String>(new Comparisons());for (int i = 0; i<this.trainArrays.length; i++){String[] strs = (String[])this.trainArrays[i];set.add(strs[index]);String[] result = new String[set.size()];return set.toArray(result);}//计算信息增益public double gain(Object[] arrays, int index){String[] playBalls = getAttributes(this.nodeIndex);int[] counts = new int[playBalls.length];for (int i = 0; i<counts.length; i++){counts[i] = 0;}for (int i = 0; i<arrays.length; i++){String[] strs = (String[])arrays[i];for (int j = 0; j<playBalls.length; j++){if (strs[this.nodeIndex].equals(playBalls[j])){counts[j]++;}}}double entropyS = 0;for (int i = 0;i <counts.length; i++){entropyS = entropyS + Entropy.getEntropy(counts[i], arrays.length); }String[] attributes = getAttributes(index);double total = 0;for (int i = 0; i<attributes.length; i++){total = total + entropy(arrays, index, attributes[i], arrays.length);}return entropyS - total;}public double entropy(Object[] arrays, int index, String attribute, int totals) {String[] playBalls = getAttributes(this.nodeIndex);int[] counts = new int[playBalls.length];for (int i = 0; i < counts.length; i++){counts[i] = 0;}for (int i = 0; i < arrays.length; i++){String[] strs = (String[])arrays[i];if (strs[index].equals(attribute)){for (int k = 0; k<playBalls.length; k++){if (strs[this.nodeIndex].equals(playBalls[k])){counts[k]++;}}}int total = 0;double entropy = 0;for (int i = 0; i < counts.length; i++){total = total +counts[i];}for (int i = 0; i < counts.length; i++){entropy = entropy + Entropy.getEntropy(counts[i], total); }return Entropy.getShang(total, totals)*entropy;}}。
id3算法案例

id3算法案例那咱就来个简单又有趣的“猜动物”的ID3算法案例。
一、游戏设定。
假设我们有一堆动物的特征,要通过ID3算法来猜出你心里想的那个动物。
我们先确定一些动物的特征,比如说:有没有四条腿、是不是会飞、是不是吃肉、是不是生活在水里。
我们有这么几个动物:猫、狗、鱼、鸟。
二、构建决策树的过程。
1. 先看第一个特征“有没有四条腿”如果有四条腿,那这个动物可能是猫或者狗。
这时候我们再看第二个特征“是不是吃肉”。
如果是吃肉的,那这个动物可能是猫(猫是肉食性的,狗虽然也吃肉,但我们先这么分)。
如果不是吃肉的,那这个动物就是狗(假设是吃狗粮之类的非纯肉食物)。
如果没有四条腿,那这个动物可能是鱼或者鸟。
然后我们看第二个特征“是不是会飞”。
如果会飞,那这个动物就是鸟。
如果不会飞,那这个动物就是鱼。
2. 假设我要猜你心里想的动物,我就开始问你问题啦。
我先问:“你想的这个动物有四条腿吗?”如果你说“有”,我就接着问:“这个动物吃肉吗?”如果你说“吃”,我就猜这个动物是猫。
如果你说“不吃”,我就猜这个动物是狗。
如果你说“没有”,我就接着问:“这个动物会飞吗?”如果你说“会”,我就猜这个动物是鸟。
如果你说“不会”,我就猜这个动物是鱼。
你看,这就有点像简单的ID3算法啦。
我们从一个大的特征开始(有没有四条腿),把动物分成不同的组,然后针对每个组再用其他特征继续细分,就像顺着树杈一样,最后找到我们要猜的那个动物。
就好像走迷宫,先根据大方向走,走到一个小区域了再根据小方向走,最后就能到达目的地(猜出动物)。
id3算法例题构建三层决策树

标题:深入理解ID3算法:通过例题构建三层决策树在机器学习领域,ID3算法是一种经典的分类算法,它可以通过构建决策树来对数据进行分类。
本文将深入解析ID3算法,并通过一个例题,一步步构建三层决策树,让读者更加深入地理解这一算法的原理和应用。
1. ID3算法的基本原理ID3算法是一种基于信息论的分类算法,它以信息增益作为分裂属性的选择标准,希望通过选择能够使得信息增益最大的属性来进行数据的划分。
其基本原理可以用以下几个步骤来概括:- 步骤一:计算数据集的信息熵,以及每个特征属性的信息增益。
- 步骤二:选择信息增益最大的特征作为节点,对数据集进行划分。
- 步骤三:对每个划分后的子数据集递归地应用ID3算法,构建决策树。
2. 例题背景描述假设我们有一个数据集,包含了以下几个属性:芳龄、收入、学历和是否购买电子产品。
我们希望通过这个数据集构建一个决策树模型,来预测一个人是否会购买电子产品。
3. 数据集的信息熵计算我们需要计算整个数据集的信息熵。
在这个过程中,我们需要对每个属性进行划分,并计算每个属性的信息增益,以便选择最佳的划分属性。
我们按照信息增益最大的属性进行数据集的划分,并对子数据集进行递归处理。
4. 构建决策树通过以上步骤,我们逐渐构建出了一个三层决策树。
在这个决策树中,根节点是选择信息增益最大的属性,中间节点是根据不同属性值进行划分,叶节点则表示最终的分类结果。
5. 个人观点和总结通过这个例题的分析,我们可以更深入地理解ID3算法的原理和应用。
ID3算法以信息增益作为属性选择的标准,通过构建决策树来进行分类预测。
在实际应用中,我们可以根据ID3算法构建的决策树模型,对未知数据进行分类预测,从而实现自动化决策。
ID3算法作为一种经典的分类算法,具有较好的解释性和可解释性,在实际应用中具有广泛的应用前景。
希望通过本文的介绍,读者能够更加深入地理解ID3算法,并能够灵活运用于实际问题的解决中。
本文总字数超过3000字,详细探讨了ID3算法的基本原理和应用,通过例题构建了三层决策树,并共享了个人观点和总结。
id3决策树算法例题

id3决策树算法例题
以下是一个使用ID3决策树算法的例题:
假设我们有一个关于公司销售数据的集,包含每个公司的销售记录,每个公司销售的年份和每个年份的销售额。
我们可以用这些记录创建ID3决策树。
1. 选择基础特征:每个公司的销售记录中的年份。
2. 选择特征:每个公司的销售记录中的每个年份的销售额。
3. 选择操作:将销售额设置为0,表示这个公司从来没有销售过产品。
将销售额设置为1,表示这个公司最近一年没有销售过产品。
将销售额设置为2,表示这个公司在过去两年中销售过产品。
4. 选择操作:将销售额除以平均销售额,得到每个类别的平均销售额和变异系数。
5. 选择操作:将变异系数设置为-1,表示所有公司的销售额都是0。
6. 建立ID3决策树:输入年份特征,按顺序输出每个类别的销售额特征,再输出类别对应的变异系数。
例如,当输入年份为2018年时,ID3决策树的输出如下:
- 类别1:2018年销售过产品,平均销售额3,变异系数-0.25;
- 类别2:2019年销售过产品,平均销售额2,变异系数-0.12;
- 类别3:2020年销售过产品,平均销售额1,变异系数0.18;
- 类别4:2019年没有销售过产品,平均销售额3,变异系数-0.3; - 类别5:2020年没有销售过产品,平均销售额2,变异系数-0.2。
输出结果即为每个类别的销售额特征和对应的变异系数,这可以帮助我们更好地理解公司的销售额分布和趋势。
ID3算法例题

14
14
14
基于天气决定是否打网球的信息增益为:
gain(天气) = inf o([9,5]) − inf o([2,3],[4,0],[3,2]) = 0.25
gain(气温) = 0.03
gain(风)= 0.05
gain(湿度)= 0.15
天 气 湿 风 打网
气温度
球
gain (天气) = 0.25
inf o([0,2],[1,1],[1,0]) = 0.40
gain(气温) = 0.57
天气 气温 湿度 风 打网球
gain(风) = 0.02
gain(湿度) = 0.97
gain(气温) = 0.57
gain(风) = 0.02
ID3
在生成决策树 后,可以方便地提 取决策树描述的知 识,并表示成ifthen形式的分类规 则。沿着根节点到 叶节点的每一条路 径对应一条决策规 则。
inf o([9,5]) = − 9 log 9 − 5 log 5 = 0.94 14 14 14 14
序天 打 号气 网
球
序天 打 号气 网
球
1晴 N 8 晴 N
2晴 N 9 晴 Y
3 多云 Y 10 雨 Y
4 雨 Y 11 晴 Y
5 雨 Y 12 多云 Y
6 雨 N 13 多云 Y
晴
inf
o([27,3])多=ain(风)= 0.05
gain(湿度)= 0.15
天气晴的条件下打网球的期望增益:
gain(气温) = inf o([2,3]) − inf o([0,2],[1,1],[1,0]) = 0.57
天 气 湿 风 打网
气温度
球
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
ID3决策树算法例题
简介
决策树是一种常见的机器学习算法,用于解决分类和回归问题。
其中,ID3(Iterative Dichotomiser 3)决策树算法是最早被提出的决策树算法之一。
本文将以一个例题为例,深入探讨ID3决策树算法的原理和应用。
例题描述
假设我们要根据以下特征来判断一个水果是苹果还是橘子: 1. 颜色:红、橙 2. 直径:大、中等、小 3. 纹理:平滑、凹凸
我们已经收集到了一些水果的样本数据,如下所示:
编号颜色直径纹理类别
1 红大平滑苹果
2 红大凹凸苹果
3 橙大平滑橘子
4 橙小平滑橘子
5 红中等平滑苹果
我们希望构建一个决策树模型,通过输入颜色、直径和纹理这3个特征,能够预测水果的类别。
ID3决策树算法原理
ID3决策树算法的核心思想是选择每次划分时信息增益最大的特征作为决策节点。
它采用自顶向下的贪心策略,递归地构建决策树。
下面详细介绍ID3算法的原理。
1. 计算信息熵
首先,我们需要计算每个特征的信息熵,以此来衡量特征对分类结果的纯度影响。
信息熵的计算公式如下:
H (D )=−∑p i N
i=1
log 2p i
其中,H (D )表示数据集D 的信息熵,N 表示类别的个数,p i 表示类别i 在数据集D 中的比例。
2. 计算信息增益
接下来,对于每个特征A ,我们需要计算其信息增益Gain (D,A )。
信息增益是指特征A 对于数据集D 的纯度提升程度,计算公式如下:
Gain (D,A )=H (D )−∑
|D v ||D |
V
v=1H (D v ) 其中,V 表示特征A 的取值个数,D v 表示特征A 取值为v 的样本子集。
3. 选择最佳划分特征
根据计算得到的信息增益,选择信息增益最大的特征作为决策节点。
4. 递归构建决策树
将选择的特征作为决策节点,以该特征的不同取值作为分支,递归地构建决策树。
计算步骤
根据上面的原理,我们来逐步计算示例中的决策树。
1. 计算初始数据集的信息熵H (D )
根据表格中的数据,我们可以计算出初始数据集的信息熵H (D ),其中苹果出现的
概率为35,橘子出现的概率为25。
根据信息熵的计算公式,可以得到H (D )=
−(35log 235+25log 225)。
2. 计算每个特征的信息增益
接下来,我们需要计算每个特征的信息增益。
颜色特征
颜色特征有2个取值:红和橙。
根据这两个取值分割数据集,我们计算出红色的水
果出现的概率为35,橙色的水果出现的概率为25,再根据信息熵的计算公式,可以得
到红色特征的信息熵H (D 红)=−(35log 235+25log 225)。
同样地,我们计算出橙色特征的信息熵H(D 橙)=−(15log 215+45log 245)。
根据信息增益的计算公式,我们可以得到颜色特征的信息增益Gain (D,颜色)=
H (D )−510H (D 红)−510H(D 橙)。
直径特征
直径特征有3个取值:大、中等、小。
根据这3个取值分割数据集,我们可以计算
出大直径的水果出现的概率为25,中等直径的水果出现的概率为15,小直径的水果出
现的概率为25,再根据信息熵的计算公式,可以得到直径特征的信息熵H (D 大)=−(15log 215+45log 245)。
同样地,我们可以得到中等直径特征的信息熵H(D 中等)=−(15log 215+45log 245),小直径特征的信息熵H (D 小)=−(15log 215+45log 245)。
根据信息增益的计算公式,我们可以得到直径特征的信息增益Gain (D,直径)=
H (D )−510H (D 大)−210H(D 中等)−310H (D 小)。
纹理特征
纹理特征有2个取值:平滑和凹凸。
根据这2个取值分割数据集,我们可以计算出
平滑纹理的水果出现的概率为45,凹凸纹理的水果出现的概率为15,再根据信息熵的
计算公式,可以得到纹理特征的信息熵H (D 平滑)=−(35log 235+25log 225)。
同样地,我们可以得到凹凸纹理特征的信息熵H (D 凹凸)=−(15log 215+45log 245)。
根据信息增益的计算公式,我们可以得到纹理特征的信息增益Gain (D,纹理)=
H (D )−510H (D 平滑)−510H (D 凹凸)。
3. 选择最佳划分特征
根据上面计算得到的信息增益,我们可以比较三个特征的信息增益大小,选择信息增益最大的特征作为决策节点。
在这个例题中,直径特征的信息增益最大,因此我们选择直径作为决策节点。
4. 递归构建决策树
在选择了直径特征作为决策节点后,我们根据直径特征的不同取值(大、中等、小)划分数据集,得到三个子集。
对于每个子集,我们可以再次计算特征的信息增益,并选择信息增益最大的特征作为该子集的决策节点。
我们继续递归地进行这个过程,直到所有数据子集都属于同一类别或没有更多特征可供划分。
最终构建得到的决策树如下所示:
决策节点:直径
- 大
- 类别:苹果
- 中等
- 类别:苹果
- 小
- 纹理
- 平滑
- 类别:苹果
- 凹凸
- 类别:橘子
总结
本文以一个例题为例,详细介绍了ID3决策树算法的原理和应用过程。
ID3算法是
一种自顶向下的贪心策略,通过计算信息增益来选择最佳划分特征,并根据划分特征递归构建决策树。
通过这个例题,我们可以更加深入地理解ID3决策树算法的计算过程和决策树构建的原理。