RabbitMQ集群使用说明
rabbimq prometheus 指标说明

rabbimq prometheus 指标说明RabbitMQ是一个开源的消息中间件,它提供了强大的消息队列功能来协调分布式应用程序之间的通信。
Prometheus是一个流行的监控系统,用于收集和存储系统的各种指标数据。
本文将介绍如何使用RabbitMQ提供的Prometheus插件来获取RabbitMQ的各项指标数据。
1. 连接数指标:RabbitMQ提供了多个与连接相关的指标,包括当前连接数、连接建立数、连接关闭数等。
这些指标可以让你了解到系统中的连接活动情况,以便进行适当的调优和监控。
2. 队列指标:RabbitMQ的队列指标可以告诉你当前队列中未处理的消息数量、已消费的消息数量和队列的长度等信息。
这些指标能帮助你判断系统的消息处理能力,为后续的工作负载规划提供依据。
3. 交换机指标:交换机是RabbitMQ中消息的路由节点,它负责将消息发送到对应的队列。
交换机指标可以告诉你当前交换机的状态、消息发布数量和消息确认数量等。
通过对交换机指标的监控,可以了解到系统中消息的流动情况,为系统设计提供参考。
4. 消费者指标:消费者是指在RabbitMQ中消费消息的应用程序。
RabbitMQ提供了消费者的指标,包括消费者数量、消费速率、消费者取消数量等。
通过监控消费者指标,可以追踪消费者的活动情况,及时发现消费者的问题。
5. 堆积指标:堆积是指在RabbitMQ中积压的消息数量。
堆积指标可以让你了解到系统当前的消息积压情况,以及处理消息的速度是否能够跟上消息的产生速度。
这对于系统的稳定性和可靠性至关重要。
总结:以上是RabbitMQ Prometheus指标的一些常见示例。
通过监控和分析这些指标,可以帮助你了解RabbitMQ的运行情况、系统的负载情况以及潜在的问题。
有了这些信息,你可以及时做出调整和优化,提高RabbitMQ的性能和可靠性。
Rabbitmq基本API使用

Rabbitmq基本API使⽤⼀、⽣产者1. 创建ConnectionFactory⼯⼚(地址、⽤户名、密码、vhost)2. 创建Connection3. 创建信道(Channel)4. 创建 exchange(指定名称、类型-DIRECT("direct"), FANOUT("fanout"), TOPIC("topic"), HEADERS("headers");、是否持久化)5. 发送消息(指定:exchange、发送的routingKey ,发送到的消息)基础的⽣产者:public class TestProducer {public final static String EXCHANGE_NAME = "direct_logs";public static void main(String[] args)throws IOException, TimeoutException {/* 创建连接,连接到RabbitMQ*/ConnectionFactory connectionFactory = new ConnectionFactory();connectionFactory.setHost("192.168.112.131");connectionFactory.setVirtualHost("my_vhost");connectionFactory.setUsername("admin");connectionFactory.setPassword("admin");Connection connection = connectionFactory.newConnection();/*创建信道*/Channel channel = connection.createChannel();/*创建交换器*/channel.exchangeDeclare(EXCHANGE_NAME,"direct");//channel.exchangeDeclare(EXCHANGE_NAME,BuiltinExchangeType.DIRECT);/*⽇志消息级别,作为路由键使⽤*/String[] routekeys = {"king","queue","prince"};for(int i=0;i<3;i++){String routekey = routekeys[i%3];String msg = "Hellol,RabbitMq"+(i+1);/*发布消息,需要参数:交换器,路由键,其中以⽇志消息级别为路由键*/channel.basicPublish(EXCHANGE_NAME,routekey,null,msg.getBytes());System.out.println("Sent "+routekey+":"+msg);}channel.close();connection.close();}}View Code⼆、消费者1. 创建ConnectionFactory⼯⼚(地址、⽤户名、密码、vhost)2. 创建Connection3. 创建信道(Channel)4. 声明⼀个 exchange(指定名称、类型、是否持久化)5. 创建⼀个队列(指定:名称,是否持久化,是否独占,是否⾃动删除,其他参数)6. 队列、exchange通过routeKey进⾏绑定7. 消费者接收消息(队列名称,是否⾃动ACK)基本的消费者:public class TestConsumer {public static void main(String[] argv)throws IOException, TimeoutException {ConnectionFactory factory = new ConnectionFactory();factory.setHost("192.168.112.131");factory.setVirtualHost("my_vhost");factory.setUsername("admin");factory.setPassword("admin");// 打开连接和创建频道,与发送端⼀样Connection connection = factory.newConnection();final Channel channel = connection.createChannel();channel.exchangeDeclare(TestProducer.EXCHANGE_NAME,"direct");/*声明⼀个队列*/String queueName = "focuserror";channel.queueDeclare(queueName,false,false,false,null);/*绑定,将队列和交换器通过路由键进⾏绑定*/String routekey = "king";/*表⽰只关注error级别的⽇志消息*/channel.queueBind(queueName,TestProducer.EXCHANGE_NAME,routekey);System.out.println("waiting for message........");/*声明了⼀个消费者*/final Consumer consumer = new DefaultConsumer(channel){@Overridepublic void handleDelivery(String consumerTag,Envelope envelope,AMQP.BasicProperties properties,byte[] body) throws IOException {String message = new String(body, "UTF-8");System.out.println("Received["+envelope.getRoutingKey()+"]"+message);}};/*消费者正式开始在指定队列上消费消息*/channel.basicConsume(queueName,true,consumer);}}View Code三、消息持久化1. exchange 需要持久化2. 发送消息设置参数为 MessageProperties.PERSISTENT_TEXT_PLAIN3. 队列需要设置参数为持久化1、//TODO 创建持久化交换器 durable=truechannel.exchangeDeclare(EXCHANGE_NAME,"direct",true);2、//TODO 发布持久化的消息(delivery-mode=2)channel.basicPublish(EXCHANGE_NAME,routekey,MessageProperties.PERSISTENT_TEXT_PLAIN,msg.getBytes());3、//TODO 声明⼀个持久化队列(durable=true)// autoDelete=true 消费者停⽌了,则队列会⾃动删除//exclusive=true独占队列,只能有⼀个消费者消费String queueName = "msgdurable";channel.queueDeclare(queueName,true,false,false,null);四、如何⽀持事务(防⽌投递消息的时候消息丢失-效率特别低,不建议使⽤,可以使⽤⽣产者ACK机制)1. 启动事务2. 成功提交3. 失败则回滚//TODO//加⼊事务channel.txSelect();try {for(int i=0;i<3;i++){String routekey = routekeys[i%3];// 发送的消息String message = "Hello World_"+(i+1)+("_"+System.currentTimeMillis());channel.basicPublish(EXCHANGE_NAME, routekey, true,null, message.getBytes());System.out.println("----------------------------------");System.out.println(" Sent Message: [" + routekey +"]:'"+ message + "'");Thread.sleep(200);}//TODO//事务提交channel.txCommit();} catch (IOException e) {e.printStackTrace();//TODO//事务回滚channel.txRollback();} catch (InterruptedException e) {e.printStackTrace();}View Code五、消费消息⼿动ACK,如果异常则使⽤拒绝的⽅式,然后异常消息推送到-死信队列批量ack的时候如果其中有⼀个消息出现异常,则会导致消息丢失(⽇志处理的时候可以使⽤批量)1 /*消费者正式开始在指定队列上消费消息,第⼆个参数false为⼿动应答*/channel.basicConsume(queueName,false,consumer);2 收到消息以后,⼿动应答数据接收成功channel.basicAck(envelope.getDeliveryTag(),false);3 收到消息,如果处理失败则拒绝消息:DeliveryTag是消息在队列中的标识channel.basicReject(envelope.getDeliveryTag(),false);4 决绝的参数说明//TODO Reject⽅式拒绝(这⾥第2个参数决定是否重新投递),不要重复投递,因为消息重复投递后处理可能依然异常//channel.basicReject(envelope.getDeliveryTag(),false);//TODO Nack⽅式的拒绝(第2个参数决定是否批量,第3个参数是否重新投递)channel.basicNack(envelope.getDeliveryTag(), false, true);View Code六、创建队列的参数解析:场景,延迟队列,保存带有时效性的订单,⼀旦订单过期,则信息会转移到死信队列//TODO /*⾃动过期队列--参数需要Map传递*/String queueName = "setQueue";Map<String, Object> arguments = new HashMap<String, Object>();arguments.put("x-expires",10*1000);//消息在队列中保存10秒后被删除//TODO 队列的各种参数/*加⼊队列的各种参数*/// autoDelete=true 消费者停⽌了,则队列会⾃动删除//exclusive=true独占队列,只能有⼀个消费者消费channel.queueDeclare(queueName,true,true, false,arguments);七、发送消息以后带有应答的队列1. 声明⼀个回应队列2. 声明⼀个回应消息的消费者3. 声明⼀个属性对象(指定队列,会唯⼀的id)4. ⽣产者发送消息给消费者(带着回应队列)5. 消费者接收到消息以后根据对应的信息,给予回应⽣产者端:1、//TODO 响应QueueName ,消费者将会把要返回的信息发送到该QueueString responseQueue = channel.queueDeclare().getQueue();//TODO 消息的唯⼀idString msgId = UUID.randomUUID().toString();2、/*声明了⼀个消费者*/final Consumer consumer = new DefaultConsumer(channel){@Overridepublic void handleDelivery(String consumerTag,Envelope envelope,AMQP.BasicProperties properties,byte[] body) throws IOException {String message = new String(body, "UTF-8");System.out.println("Received["+envelope.getRoutingKey()+"]"+message);}};//TODO 消费者应答队列上的消息channel.basicConsume(responseQueue,true,consumer);3、//TODO 设置消息中的应答属性AMQP.BasicProperties properties = new AMQP.BasicProperties.Builder().replyTo(responseQueue).messageId(msgId).build();4、String msg = "Hello,RabbitMq";//TODO 发送消息时,把响应相关属性设置进去channel.basicPublish(EXCHANGE_NAME,"error",properties,msg.getBytes());View Code消费者端:String message = new String(body, "UTF-8");System.out.println("Received["+envelope.getRoutingKey()+"]"+message);//TODO 从消息中拿到相关属性(确定要应答的消息ID,)AMQP.BasicProperties respProp= new AMQP.BasicProperties.Builder().replyTo(properties.getReplyTo()).correlationId(properties.getMessageId()).build();//TODO 消息消费时,同时需要⽣作为⽣产者⽣产消息(以OK为标识)channel.basicPublish("", respProp.getReplyTo() ,respProp ,("OK,"+message).getBytes("UTF-8"));⼋、死信队列 - 下列消息会放到死信队列1. 消息被否定确认,使⽤ channel.basicNack 或 channel.basicReject ,并且此时requeue 属性被设置为false。
rabbitmq集群节点 测试方法

rabbitmq集群节点测试方法为了确保rabbitmq集群的稳定运行,需要进行节点的测试。
下面是测试rabbitmq集群节点的方法:1. 检查集群状态:使用命令`rabbitmqctl cluster_status`来检查集群的状态。
确保所有节点都处于正常运行的状态,并且节点间的连接正常。
2. 发送消息测试:使用命令`rabbitmqctl eval'rabbit_amqqueue:info(rabbit_misc:rabbit_var(running_queue),properties)'`来测试消息的发送和接收。
通过查看队列的属性信息,可以确认消息是否被成功发送和接收。
3. 节点故障模拟:通过关闭某个节点来模拟节点故障。
使用命令`rabbitmqctl stop_app`关闭节点,然后使用`rabbitmqctl start_app`重新启动节点。
通过观察集群状态,确认故障节点是否成功重新加入集群。
4. 节点重启测试:在正常运行的状态下,尝试重启一个节点。
使用命令`rabbitmqctl stop`停止节点,然后使用`rabbitmqctl start`重新启动节点。
观察集群状态,确认节点是否成功重新加入集群。
5. 集群容量测试:通过发送大量消息来测试集群的容量。
使用命令`rabbitmq-perf-test`发送大量消息到集群中,并通过观察各个节点的资源占用情况来评估集群的容量。
6. 网络分区测试:模拟网络分区情况,将一个节点与其他节点隔离开来。
通过断开节点间的网络连接,观察集群的行为。
确认集群在网络分区情况下是否能够正常运行,并在网络连接恢复时能够自动合并。
7. 自动恢复测试:模拟节点故障后的自动恢复过程。
关闭一个节点,并观察集群状态。
系统应该能够自动检测到节点的故障,并进行自动恢复。
8. 压力测试:使用压力测试工具,如JMeter,模拟高并发情况下的消息发送和接收。
通过观察集群的性能指标,如吞吐量和响应时间,评估集群的性能。
rabbitmq new queue参数

rabbitmq new queue参数========一、简介----RabbitMQ是一种流行的消息队列服务,它允许应用程序之间进行异步通信,提高系统的可扩展性和可靠性。
在RabbitMQ中,队列(Queue)是消息的存储容器,用于接收和存储消息。
为了更好地管理和使用队列,我们需要了解一些关于新队列的参数。
二、新队列参数详解---------### 1. 名称新队列的名称是由你指定的唯一标识符。
建议为队列选择有意义的名称,以方便管理和调试。
### 2. 参数队列(arguments queue)参数队列允许你为队列设置一些额外的属性。
你可以设置一些与队列相关的参数,如消息确认模式、消息持久化、死信交换等。
### 3. 持久化RabbitMQ支持消息的持久化,这意味着即使在节点故障或重启后,消息也不会丢失。
你可以通过在参数队列中设置`x-message-ttl`和`x-dead-letter-exchange`来启用消息持久化和死信交换。
### 4. 确认模式消息确认模式决定了消费者如何处理接收到的消息。
在RabbitMQ中,有三种常见的确认模式:* `one-way`: 消费者只接收并确认单条消息,不需要发送任何回馈给生产者。
* `request-reply`: 消费者会向生产者发送确认或拒绝信号,并在确认或拒绝时发送一条回馈消息。
这适用于需要请求-回复类型通信的应用程序。
* `stream`: 这种模式用于消费者逐条接收并消费消息流,不进行确认或拒绝操作。
### 5. 交换器类型交换器是RabbitMQ中的核心概念之一,用于匹配发送到队列的消息。
你可以选择不同类型的交换器,如direct、fanout、topic、headers等。
这些交换器类型会影响消息如何在队列之间路由。
### 6. 绑定规则队列和交换器之间的绑定规则决定了消息如何在队列和交换器之间路由。
常见的绑定规则包括direct、fanout、x-publish-x-consume等。
rabbitmq 集群迁移方案

rabbitmq 集群迁移方案RabbitMQ是一种基于AMQP协议的开源消息队列中间件,常用于构建分布式系统或实现异步消息处理。
当现有的RabbitMQ集群需要迁移到新的环境时,需要一套可靠的迁移方案来确保数据的完整性和业务的连续性。
一、备份现有集群数据在进行迁移之前,首先需要备份现有集群的数据。
可以通过RabbitMQ提供的命令行工具或者管理界面进行备份操作。
备份的数据包括消息队列、交换机、绑定关系以及其他配置信息。
二、搭建新的集群环境在迁移过程中,需要先搭建一个新的RabbitMQ集群环境。
新的环境可以是一台或多台服务器,根据实际需求进行部署。
在部署时需要注意以下几点:1. 确保新的服务器环境与原有环境相同或兼容,包括操作系统、网络配置等。
2. 安装相同版本的RabbitMQ软件,并保证配置文件的一致性。
3. 配置集群节点间的通信,可以使用RabbitMQ提供的集群插件或者手动配置。
三、数据迁移1. 将备份的数据导入新的集群环境。
可以使用RabbitMQ提供的命令行工具或者管理界面导入备份数据。
2. 确保数据导入的完整性和准确性。
可以通过监控工具或者手动检查数据是否正确导入。
3. 在数据导入完成后,可以进行一些简单的验证测试,确保新的集群环境正常工作。
四、切换生产环境1. 在进行切换之前,需要确保新的集群环境已经稳定运行,没有任何故障或异常。
2. 将生产环境的消息生产者和消费者指向新的集群环境。
可以通过修改相关配置文件或者代码来实现。
3. 确保消息的正常传递和处理。
可以通过监控工具或者手动检查消息的发送和接收情况。
五、监控和优化1. 监控新的集群环境的性能和稳定性。
可以使用RabbitMQ提供的监控工具或者第三方工具来进行监控。
2. 根据监控数据进行优化和调整。
可以调整集群节点的数量、队列的大小等参数来提高性能和稳定性。
3. 及时处理异常和故障。
如果发现有异常或者故障,需要及时进行排查和修复,确保集群环境的稳定运行。
rabbitmq 集群的工作原理

rabbitmq 集群的工作原理
RabbitMQ是一个开源的消息代理软件,它实现了高级消息队列协议(AMQP),用于在应用程序之间传递数据。
RabbitMQ集群是多个RabbitMQ节点组成的集合,它们共同协作以提供高可用性和可伸缩性。
RabbitMQ集群的工作原理涉及以下几个方面:
1. 数据复制和同步,RabbitMQ集群中的每个节点都存储相同的交换机、队列和绑定信息。
当消息到达一个节点时,它会被复制到其他节点,以确保消息的高可用性和可靠性。
节点之间会进行数据同步,以保持数据一致性。
2. 负载均衡,RabbitMQ集群可以通过负载均衡来分发消息,以确保每个节点的负载相对均衡。
当一个节点负载过重时,集群可以将消息路由到负载较轻的节点上,从而提高整个集群的性能。
3. 高可用性,RabbitMQ集群可以提供高可用性,即使一个节点出现故障,集群仍然可以继续工作。
当一个节点不可用时,集群会自动将消息路由到其他可用的节点上,确保消息的可靠传递。
4. 故障转移,当一个节点出现故障时,RabbitMQ集群可以自动进行故障转移,将受影响的节点从集群中移除,并将其角色转移给其他节点,从而保持整个集群的稳定运行。
总的来说,RabbitMQ集群通过数据复制、负载均衡、高可用性和故障转移等机制,实现了高性能、高可靠性和可扩展性,从而能够满足大规模应用程序的消息传递需求。
希望这些信息能够全面回答你关于RabbitMQ集群工作原理的问题。
2021-04-25RabbitMQ七种队列模式应用场景案例分析(通俗易懂)

RabbitMQ 七种队列模式应用场景案例分析(通俗易懂)七种模式介绍与应用场景简单模式(Hello World)做最简单的事情,一个生产者对应一个消费者,RabbitMQ相当于一个消息代理,负责将A的消息转发给B应用场景:将发送的电子邮件放到消息队列,然后邮件服务在队列中获取邮件并发送给收件人工作队列模式(Work queues)在多个消费者之间分配任务(竞争的消费者模式),一个生产者对应多个消费者,一般适用于执行资源密集型任务,单个消费者处理不过来,需要多个消费者进行处理应用场景:一个订单的处理需要10s,有多个订单可以同时放到消息队列,然后让多个消费者同时处理,这样就是并行了,而不是单个消费者的串行情况订阅模式(Publish/Subscribe)一次向许多消费者发送消息,一个生产者发送的消息会被多个消费者获取,也就是将消息将广播到所有的消费者中。
应用场景:更新商品库存后需要通知多个缓存和多个数据库,这里的结构应该是:•一个fanout类型交换机扇出两个个消息队列,分别为缓存消息队列、数据库消息队列•一个缓存消息队列对应着多个缓存消费者•一个数据库消息队列对应着多个数据库消费者路由模式(Routing)有选择地(Routing key)接收消息,发送消息到交换机并且要指定路由key ,消费者将队列绑定到交换机时需要指定路由key,仅消费指定路由key的消息应用场景:如在商品库存中增加了1台iphone12,iphone12促销活动消费者指定routing key为iphone12,只有此促销活动会接收到消息,其它促销活动不关心也不会消费此routing key的消息主题模式(Topics)根据主题(Topics)来接收消息,将路由key和某模式进行匹配,此时队列需要绑定在一个模式上,#匹配一个词或多个词,*只匹配一个词。
应用场景:同上,iphone促销活动可以接收主题为iphone的消息,如iphone12、iphone13等远程过程调用(RPC)如果我们需要在远程计算机上运行功能并等待结果就可以使用RPC,具体流程可以看图。
rabbitmq的使用方法

rabbitmq的使用方法RabbitMQ是一个开源的消息代理软件,用于实现异步消息传递。
以下是使用RabbitMQ的一些基本方法:1. 安装和配置:首先,你需要从RabbitMQ的官网下载并安装RabbitMQ 服务器。
安装完成后,你可以通过浏览器访问RabbitMQ的管理界面,进行基本的配置。
2. 创建队列:在RabbitMQ中,消息被存储在队列中。
你可以使用RabbitMQ的管理界面或者通过编程的方式创建队列。
例如,使用Python 的pika库,你可以这样创建一个队列:```pythonimport pikaconnection = (('localhost'))channel = ()_declare(queue='hello')()```3. 发送消息:一旦你创建了队列,你就可以开始发送消息到这个队列。
同样使用pika库,你可以这样发送消息:```pythonimport pikaconnection = (('localhost'))channel = ()_publish(exchange='', routing_key='hello', body='Hello World!') ()```4. 接收消息:要接收消息,你需要创建一个消费者来从队列中获取消息。
消费者可以是任何能够处理RabbitMQ消息的应用程序。
例如,你可以创建一个Python消费者来接收消息:```pythonimport pikaconnection = (('localhost'))channel = ()_declare(queue='hello')def callback(ch, method, properties, body):print(f" [x] Received {body}")_consume(queue='hello', on_message_callback=callback,auto_ack=True)print(' [] Waiting for messages. To exit press CTRL+C')_consuming()```5. 确认消息处理:在RabbitMQ中,你可以选择自动确认(auto_ack)或手动确认(manual_ack)消息处理。
mysql-canal-rabbitmq安装部署超详细教程
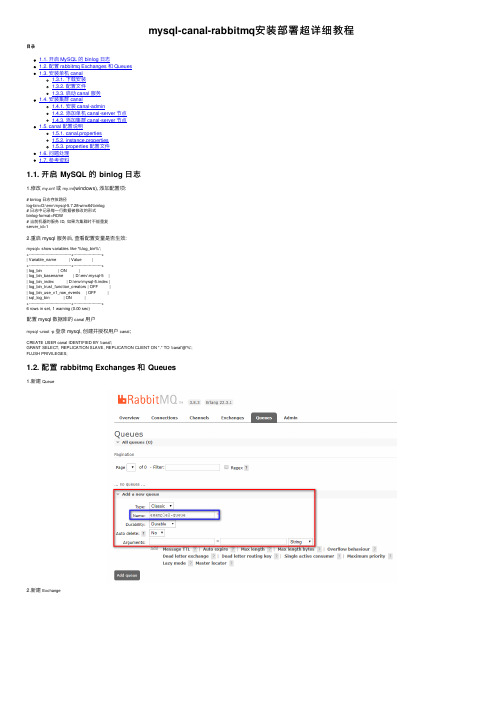
mysql-canal-rabbitmq安装部署超详细教程⽬录1.1. 开启 MySQL 的 binlog ⽇志1.2. 配置 rabbitmq Exchanges 和 Queues1.3. 安装单机 canal1.3.1. 下载安装1.3.2. 配置⽂件1.3.3. 启动 canal 服务1.4. 安装集群 canal1.4.1. 安装 canal-admin1.4.2. 添加单机 canal-server 节点1.4.3. 添加集群 canal-server 节点1.5. canal 配置说明1.5.1. canal.properties1.5.2. instance.properties1.5.3. properties 配置⽂件1.6. 问题处理1.7. 参考资料1.1. 开启 MySQL 的 binlog ⽇志1.修改f或my.ini(windows), 添加配置项:# binlog ⽇志存放路径log-bin=D:\env\mysql-5.7.28-winx64\binlog# ⽇志中记录每⼀⾏数据被修改的形式binlog-format=ROW# 当前机器的服务 ID, 如果为集群时不能重复server_id=12.重启 mysql 服务后, 查看配置变量是否⽣效:mysql> show variables like '%log_bin%';+---------------------------------+----------------------+| Variable_name | Value |+---------------------------------+----------------------+| log_bin | ON || log_bin_basename | D:\env\mysql-5 || log_bin_index | D:\env\mysql-5.index || log_bin_trust_function_creators | OFF || log_bin_use_v1_row_events | OFF || sql_log_bin | ON |+---------------------------------+----------------------+6 rows in set, 1 warning (0.00 sec)配置 mysql 数据库的canal⽤户mysql -uroot -p登录 mysql, 创建并授权⽤户canal;CREATE USER canal IDENTIFIED BY 'canal';GRANT SELECT, REPLICATION SLAVE, REPLICATION CLIENT ON *.* TO 'canal'@'%';FLUSH PRIVILEGES;1.2. 配置 rabbitmq Exchanges 和 Queues1.新建Queue2.新建Exchange3.设置 Queue ⾥的 Bindings, 填写Exchange名称, 以及路由Routing key;1.3. 安装单机 canal1.3.1. 下载安装并解压缩;sudo wget https:///alibaba/canal/releases/download/canal-1.1.4/canal.deployer-1.1.4.tar.gzsudo tar -zxvf canal.deployer-1.1.4.tar.gz最新版本1.1.5的安装sudo wget https:///alibaba/canal/releases/download/canal-1.1.5-alpha-1/canal.deployer-1.1.5-SNAPSHOT.tar.gz sudo tar -zxvf canal.deployer-1.1.5-SNAPSHOT.tar.gz1.3.2. 配置⽂件1.3.2.1. 节点配置⽂件 canal.properties# tcp bind ip, 当前节点的 IP 地址canal.ip = 192.168.2.108# register ip to zookeeper, 注册到 ZK 的 IP 地址, 如下图1.canal.register.ip = 192.168.2.108canal.zkServers = zk集群# tcp, kafka, RocketMQ, 最新版本 1.1.5 可以直接连接 rabbitmqcanal.serverMode = rabbitmq# destinations, 当前 server 上部署的 instance 列表, 对应各个实例⽂件夹(../conf/<instance_name>)名称canal.destinations = example2# 设置 mq 服务器地址, 此处为 rabbitmq 的服务器地址# !! 此处下载后默认的配置是有配置IP:端⼝的# rabbitmq 此处则不需要配置端⼝canal.mq.servers = 192.168.208.100# ⼀下⼏项均为 1.1.5 新版本新增⽀持 rabbitmq 的配置canal.mq.vhost=/canal.mq.exchange=example2-ex # 指定 rabbitmq 上的 exchange 名称, "新建 `Exchange`" 步骤新建的名称ername=admin # 连接 rabbitmq 的⽤户名canal.mq.password=**** # 连接 rabbitmq 的密码canal.mq.aliyunuid=1.3.2.2. 实例配置⽂件 instance.properties# position info, 数据库的连接信息canal.instance.master.address=192.168.2.108:3306# 以下两个配置, 需要在上⾯配置的 address 的数据库中执⾏ `SHOW MASTER STATUS` 获取的 `File` 和 `Position` 两个字段值=mysql-5.7canal.instance.master.position=674996# table meta tsdb info, 禁⽤ tsdb 记录 table meta 的时间序列版本canal.instance.tsdb.enable=false# username/password, 实例连接数据的⽤户名和密码canal.instance.dbUsername=canalcanal.instance.dbPassword=canal# table regex, 正则匹配需要监听的数据库表canal.instance.filter.regex=ysb\\.useropcosttimes_prod# mq config, 指定 rabbitmq 设置绑定的路由, 详见"配置rabbitmq"步骤⾥的第三步配置的`Routing key`canal.mq.topic=example2-routingkey1.3.3. 启动 canal 服务Linux 对应的启动脚本./bin/startup.sh, Windows 对应的启动脚本./bin/startup.bat; 以 Windows 为例:λ .\startup.batstart cmd : java -Xms128m -Xmx512m -XX:PermSize=128m -Djava.awt.headless=true .preferIPv4Stack=true -Dapplication.codeset=UTF-8 -Dfile.encoding=UTF-8 -server -Xdebug -Xnoagent piler=NONE -Xrunjdwp:transport=dt_socket,add Java HotSpot(TM) Server VM warning: ignoring option PermSize=128m; support was removed in 8.0Listening for transport dt_socket at address: 9099最后⼿动修改数据库数据, 或者等待其他的修改, 再查看⼀下 rabbitmq 上的监控即可知道流程是否⾛通了.1.4. 安装集群 canal1.4.1. 安装 canal-admin1.4.1.1. 下载安装并解压缩sudo wget https:///alibaba/canal/releases/download/canal-1.1.5-alpha-1/canal.admin-1.1.5-SNAPSHOT.tar.gzsudo tar -zxvf canal.admin-1.1.5-SNAPSHOT.tar.gz1.4.1.2. 配置⽂件application.ymlserver:port: 8089spring:jackson:date-format: yyyy-MM-dd HH:mm:sstime-zone: GMT+8spring.datasource:address: 192.168.2.108:3306database: canal_managerusername: canalpassword: canaldriver-class-name: com.mysql.jdbc.Driver# 数据库连接字符串末尾需添加`serverTimezone=UTC`, 否则启动时会报时区异常;url: jdbc:mysql://${spring.datasource.address}/${spring.datasource.database}?useUnicode=true&characterEncoding=UTF-8&useSSL=false&serverTimezone=UTChikari:maximum-pool-size: 30minimum-idle: 1canal:# 配置 canal-admin 的管理员账号和密码adminUser: adminadminPasswd: 123456canal_manager.sql在管理canal-admin数据的数据库中执⾏该 sql 脚本, 初始化⼀些表;1.4.1.3. 启动 canal-admin 服务Linux 对应的启动脚本./bin/startup.sh, Windows 对应的启动脚本./bin/startup.bat; 以 Windows 为例:λ .\startup.batstart cmd : java -Xms128m -Xmx512m -Djava.awt.headless=true .preferIPv4Stack=true -Dapplication.codeset=UTF-8 -Dfile.encoding=UTF-8 -DappName=canal-admin -classpath "D:\env\green\canal-1.1.5-admin\bin\\..\conf\..\lib\*;D:\env\green\canal-2020-04-13 20:01:39.495 [main] INFO com.alibaba.otter.canal.admin.CanalAdminApplication - Starting CanalAdminApplication on Memento-PC with PID 50696 (D:\env\green\canal-1.1.5-admin\lib\canal-admin-server-1.1.5-SNAPSHOT.jar started by Memento in 2020-04-13 20:01:39.527 [main] INFO com.alibaba.otter.canal.admin.CanalAdminApplication - No active profile set, falling back to default profiles: default2020-04-13 20:01:39.566 [main] INFO o.s.b.w.s.c.AnnotationConfigServletWebServerApplicationContext - Refreshing org.springframework.boot.web.servlet.context.AnnotationConfigServletWebServerApplicationContext@13a5bf6: startup date [Mon Apr 13 20:01 2020-04-13 20:01:41.149 [main] INFO o.s.boot.web.embedded.tomcat.TomcatWebServer - Tomcat initialized with port(s): 8089 (http)2020-04-13 20:01:41.166 [main] INFO org.apache.coyote.http11.Http11NioProtocol - Initializing ProtocolHandler ["http-nio-8089"]2020-04-13 20:01:41.176 [main] INFO org.apache.catalina.core.StandardService - Starting service [Tomcat]2020-04-13 20:01:41.177 [main] INFO org.apache.catalina.core.StandardEngine - Starting Servlet Engine: Apache Tomcat/8.5.29...2020-04-13 20:01:42.996 [main] INFO org.apache.coyote.http11.Http11NioProtocol - Starting ProtocolHandler ["http-nio-8089"]2020-04-13 20:01:43.007 [main] INFO .NioSelectorPool - Using a shared selector for servlet write/read2020-04-13 20:01:43.019 [main] INFO o.s.boot.web.embedded.tomcat.TomcatWebServer - Tomcat started on port(s): 8089 (http) with context path ''2020-04-13 20:01:43.024 [main] INFO com.alibaba.otter.canal.admin.CanalAdminApplication - Started CanalAdminApplication in 3.919 seconds (JVM running for 5.241)1.4.1.4. 注意事项canal-admin连接数据库的账号, 必须有建表, 读写数据的权限, 如果还是采⽤上⽂中创建的canal账号, 需要另外扩展⼀下权限:GRANT ALL PRIVILEGES ON *.* TO 'canal'@'%' ;1.4.2. 添加单机 canal-server 节点1.4.2.1. 启动 canal-server 节点服务单机 canal-server 照常启动, 此时, canal-server 默认加载的../conf/canal.properties⾥的配置信息, 可以从../bin/startup.bat[startup.sh]脚本中获悉, 获取从执⾏的脚本命令提⽰⾥获悉;1.4.2.2. 新建单机 server在canal-admin中新建⼀个单机server该server会⾃动识别已启动的canal-server节点, 但是此时由admin接管后, 不会⾃动加载../conf/canal.properties的配置⽂件, 点击最右侧的操作-配置查看, 该 server 加载的是默认的配置信息需要⼿动将1.3.2中配置好的../conf/canal.properties⾥的配置信息拷贝到该配置⾥进⾏覆盖!1.4.2.3. 新建实例 instance⼿动在canal-admin中新建⼀个instance, 对应单机canal-server配置下的实例example2; 同样, 需要⼿动将./conf/<实例名称>/instance.properies配置⽂件⼿动拷贝到 admin 中!!注意在新建或启动instance实例时, 先删除实例⽂件夹下的meta.dat⽂件, 并更新=..., canal.instance.master.position=...两个配置项;1.4.3. 添加集群 canal-server 节点1.4.3.1. 新建集群需要指定集群名称, 以及配置集群绑定的zookeeper集群地址;新建成功后, 在最右侧的操作-主配置中配置集群的通⽤ server 配置信息此处也可以将之前配置的../conf/canal.properties配置直接拷贝过来, 稍微修改⼀下就可以⽤了# canal admin configcanal.admin.manager = 192.168.2.108:8089canal.instance.global.mode = manager1.4.3.2. 新建 server指定所属集群, 为1.4.3.1中设定的集群名称;如果先前已经启动了canal-server节点服务, 则新建的 server 会⾃动识别为启动状态, 否则为断开状态;这⾥有⼀点需要⼗分注意的地⽅细⼼的⼈可能会发现, 除了canal.properties配置⽂件, 还有⼀个canal_local.properties的配置⽂件, 后者⽐前者的内容少了很多, 因为这个⽂件就是⽤于搭建canal集群时, 本地节点的配置⽂件, ⽽前者配置⽂件⾥的其他信息都是交由canal-admin集中配置管理的;在./bin/startup.bat[startup.sh]启动脚本⾥, 默认是加载canal.properties配置⽂件, 即以单机形式启动的服务;windows 在搭建canal集群时, 需要⼿动修改startup.bat, 蓝⾊标注处是加载%canal_conf%变量的配置⽂件路径, 所以需要将红⾊框内的变量调整为:@rem set canal_conf=...set canal_conf=%conf_dir%\canal_local.properties使启动时加载canal_local.properties的配置⽂件1.4.3.3. 新建 instance此处配置也可以基于单机 server 中的实例1.4.2.3配置进⾏调整使⽤;# 2. position info, 指定 mysql 开始同步的 binlog 位置信息canal.instance.master.address=192.168.0.25:63306=mysql-bin.001349canal.instance.master.position=198213313# 3. username/password, 设置同步 mysql 的数据库⽤户名和密码canal.instance.dbUsername=xxxxcanal.instance.dbPassword=xxx# 4. table regex, 正则匹配需要同步的数据表canal.instance.filter.regex=xxxx# 5. mq config, 指定 mysql 上的路由绑定, 见 `1.2.3`canal.mq.topic=example2-routingkey保存后即可在操作中启动该实例后话如果此处的 instance ⽆法启动, 按⼀下⼏个步骤检查操作⼀下试试:检查集群⾥的主配置⾥的canal.destinations是否包含新建的实例instance名称;检查canal-server节点是否加载的canal_local.properties配置⽂件;删除实例⽂件夹下的.db, .bat⽂件, 更新实例配置⽂件中的canal.instance.master.position的binglog位置后, 启动instance;1.5. canal 配置说明1.5.1. canal.properties1. canal.ip, 该节点 IP2. canal.register.ip, 注册到 zookeeper 上的 IP3. canal.zkServers, zk 集群4. 是否启⽤ tsdb, 开启 table meta 的时间序列版本记录功能5. // 5. canal.serverMode, 设置为 rabbitmq, 默认为 tcpcanal.instance.tsdb.enable = truecanal.instance.tsdb.dir = ${canal.file.data.dir:../conf}/${canal.instance.destination:}canal.instance.tsdb.url = jdbc:h2:${canal.instance.tsdb.dir}/h2;CACHE_SIZE=1000;MODE=MYSQL;canal.instance.tsdb.dbUsername = canalcanal.instance.tsdb.dbPassword = canal5.canal.destinations, 当前集群上部署的 instance 列表6.canal.mq.servers, 设置 Rabbitmq 集群地址, !! 此处不可以加上端⼝1.5.2. instance.properties1. canal.instance.master.address, master 数据库地址2. , 在数据库中执⾏show master status的File值3. canal.instance.master.position, 在数据库中执⾏show master status的Position值4. canal.instance.tsdb.enable=false, 禁⽤ tsdb5. canal.instance.dbUsername, 实例数据库⽤户名6. canal.instance.dbPassword, 实例数据库密码7. canal.instance.filter.regex, 匹配需要同步的表8. canal.mq.topic, canal 注册 mq 的 topic 名称1.5.3. properties 配置⽂件properties配置分为两部分canal.properties (系统根配置⽂件)instance.properties (instance 级别的配置⽂件, 每个实例⼀份)1.canal.propertiescanal.destinations # 当前 server 上部署的 instance 列表canal.conf.dir # conf ⽬录所在路径canal.auto.scan # 开启 instance ⾃动扫描# 如果配置为 true, canal.conf.dir ⽬录下的 instance 配置变化会⾃动触发# 1. instance ⽬录新增: 触发 instance 配置载⼊, lazy 为 true 时则⾃动启动;# 2. instance ⽬录删除: 卸载对应 instance 配置, 如已启动则进⾏关闭;# 3. instance.properties ⽂件变化: reload instance 配置, 如已启动则⾃动进⾏重启操作;canal.auto.scan.interval # instance ⾃动扫描间隔时间, 单位 scanal.instance.global.mode # 全局配置加载⽅式zy # 全局 lazy 模式canal.instance.global.manager.address # 全局的 manager 配置⽅式的链接信息canal.instance.global.spring.xml # 全局的 spring 配置⽅式的组件⽂件canal.instance.example.modezycanal.instance.example.spring.xml# instance 级别的配置定义, 如有配置, 会⾃动覆盖全局配置定义模式canal.instance.tsdb.enable # 是否开启 table meta 的时间序列版本记录功能canal.instance.tsdb.dir # 时间序列版本的本地存储路径, 默认为 instance ⽬录canal.instance.tsdb.url # 时间序列版本的数据库连接地址, 默认为本地嵌⼊式数据库canal.instance.tsdb.dbUsername # 时间序列版本的数据库连接账号canal.instance.tsdb.dbPassword # 时间序列版本的数据库连接密码2.instance.propertiescanal.id # 每个 canal server 实例的唯⼀标识canal.ip # canal server 绑定的本地 IP 信息, 如果不配置, 默认选择⼀个本机 IP 进⾏启动服务canal.port # canal server 提供 socket 服务的端⼝canal.zkServers # canal server 连接 zookeeper 集群的连接地址, 例如: 10.20.144.22:2181,10.20.144.23:2181canal.zookeeper.flush.period # canal 持久化数据到 zookeeper 上的更新频率, 单位 mscanal.instance.memory.batch.mode # canal 内存 store 中数据缓存模式# 1. ITEMSIZE: 根据 buffer.size 进⾏限制, 只限制记录的数量# 2. MEMSIZE: 根据 buffer.size * buffer.memunit 的⼤⼩, 限制缓存记录的⼤⼩;canal.instance.memory.buffer.size # canal 内存 store 中可缓存 buffer 记录数, 需要为 2 的指数canal.instance.memory.buffer.memunit # 内存记录的单位⼤⼩, 默认为 1KB, 和 buffer.size 组合决定最终的内存使⽤⼤⼩canal.instance.transactions.size # 最⼤事务完整解析的长度⽀持, 超过该长度后, ⼀个事务可能会被拆分成多次提交到 canal store 中, ⽆法保证事务的完整可见性canal.instance.fallbackIntervalInSeconds # canal 发⽣ mysql 切换时, 在新的 mysql 库上查找 binlog 时需要往前查找的时间, 单位 s# 说明: mysql 主备库可能存在解析延迟或者时钟不⼀致, 需要回退⼀段时间, 保证数据不丢canal.instance.detecting.enable # 是否开启⼼跳检查canal.instance.detecting.sql # ⼼跳检查 sql, insert into retl.xdual values(1,now()) on duplicate key update x=now()canal.instance.detecting.interval.time # ⼼跳检查频率, 单位 scanal.instance.detecting.retry.threshold # ⼼跳检查失败重试次数canal.instance.detecting.heatbeatHaEnable # ⼼跳检查失败后, 是否开启 mysql ⾃动切换# 说明: ⽐如⼼跳检查失败超过阈值后, 如果该配置为 true, canal 会⾃动连到 mysql 备库获取 binlog 数据work.receiveBufferSize # ⽹络连接参数, SocketOptions.SO_RCVBUFwork.sendBufferSize # ⽹络连接参数, SocketOptions.SO_SNDBUFwork.soTimeout # ⽹络连接参数, SocketOptions.SO_TIMEOUT1.5.4. canal.mq.dynamicTopic1.6. 问题处理1.windows 下执⾏startup.bat启动 canal 时, 出现如下异常Failed to instantiate [ch.qos.logback.classic.LoggerContext]Reported exception:ch.qos.logback.core.LogbackException: Unexpected filename extension of file [file:/D:/env/green/canal/conf/]. Should be either .groovy or .xmlat ch.qos.logback.classic.util.ContextInitializer.configureByResource(ContextInitializer.java:79)at ch.qos.logback.classic.util.ContextInitializer.autoConfig(ContextInitializer.java:152)at org.slf4j.impl.StaticLoggerBinder.init(StaticLoggerBinder.java:85)at org.slf4j.impl.StaticLoggerBinder.<clinit>(StaticLoggerBinder.java:55)at org.slf4j.LoggerFactory.bind(LoggerFactory.java:141)at org.slf4j.LoggerFactory.performInitialization(LoggerFactory.java:120)at org.slf4j.LoggerFactory.getILoggerFactory(LoggerFactory.java:331)at org.slf4j.LoggerFactory.getLogger(LoggerFactory.java:283)at org.slf4j.LoggerFactory.getLogger(LoggerFactory.java:304)at com.alibaba.otter.canal.deployer.CanalLauncher.<clinit>(CanalLauncher.java:29)解决⽅法:将startup.bat⾥的⼀下这⾏代码注释打开@rem set logback_configurationFile=%conf_dir%\logback.xml注, 新版1.1.5不存在该问题, 1.1.5这个⽂件中的这⼀⾏是没有注释掉的.1.1.5新版本canal-admin启动时出现如下异常:2020-04-10 18:55:40.406 [main] ERROR com.zaxxer.hikari.pool.HikariPool - HikariPool-1 - Exception during pool initialization.java.sql.SQLException: The server time zone value '�й��� ʱ��' is unrecognized or represents more than one time zone. You must configure either the server or JDBC driver (via the serverTimezone configuration property) to use a more specifc time zone value if you want to utilize time zone support.解决⽅法spring.datasource.url配置的 mysql 连接地址后⾯加上参数&serverTimezone=UTCInstance⽇志⾥出现异常errno = 1236, sqlstate = HY000 errmsg = log event entry exceeded max_allowed_packet;2020-04-13 13:06:09.507 [destination = example3 , address = /192.168.2.108:3306 , EventParser] ERROR mon.alarm.LogAlarmHandler -destination:example3[java.io.IOException: Received error packet: errno = 1236, sqlstate = HY000 errmsg = log event entry exceeded max_allowed_packet; Increase max_allowed_packet on master; the first event 'mysql-5.7' at 671745, the last event read from 'D:\env\mysql-5.7' at 673181, the last byte read from 'D:\env\mysql-5.7' at 673200.at com.alibaba.otter.canal.parse.inbound.mysql.dbsync.DirectLogFetcher.fetch(DirectLogFetcher.java:102)at com.alibaba.otter.canal.parse.inbound.mysql.MysqlConnection.dump(MysqlConnection.java:235)at com.alibaba.otter.canal.parse.inbound.AbstractEventParser$3.run(AbstractEventParser.java:265)at ng.Thread.run(Unknown Source)]解决⽅法删除canal/conf下对应实例⾥的meta.dat⽂件, 让canal-admin⾃动再⽣成即可;1.7. 参考资料到此这篇关于mysql-canal-rabbitmq 安装部署超详细教程的⽂章就介绍到这了,更多相关mysql-canal-rabbitmq 安装部署内容请搜索以前的⽂章或继续浏览下⾯的相关⽂章希望⼤家以后多多⽀持!。
rabbitmq使用手册

rabbitmq使用手册RabbitMQ是一种开源的消息队列中间件,采用AMQP协议,被广泛应用于构建可靠、高效的分布式系统。
本手册将详细介绍RabbitMQ 的安装、配置、使用和常见问题解决方案,帮助读者快速上手使用RabbitMQ。
第一章安装与配置1.1 环境准备在开始安装RabbitMQ之前,需要确保系统满足以下要求:操作系统(例如Linux、Windows)、Erlang运行时环境以及RabbitMQ软件包。
1.2 安装RabbitMQ按照文档提供的方式,在所选的操作系统上安装RabbitMQ。
安装过程中需注意版本兼容性和安全配置。
1.3 配置RabbitMQ在安装完成后,需要对RabbitMQ进行适当的配置。
主要包括网络配置、认证与授权、虚拟主机、交换机和队列的创建等。
第二章消息发布与订阅2.1 消息生产者通过使用RabbitMQ的API,开发者可以编写生产者代码将消息发布到RabbitMQ的交换机上。
这里需要注意消息的序列化和指定交换机名称。
2.2 消息消费者RabbitMQ的消费者通过订阅交换机的队列来接收消息,可以使用RabbitMQ的API编写消费者代码,并实现消息的处理逻辑。
2.3 消息确认机制RabbitMQ提供了消息的确认机制,确保消息在传输过程中的可靠性。
开发者可以选择隐式确认或显式确认来保证消息的消费状态。
第三章消息路由与过滤3.1 路由模式RabbitMQ支持多种路由模式,如直接路由、主题路由和广播路由。
开发者可以根据实际需求选择最适合的路由模式。
3.2 消息过滤通过使用RabbitMQ的消息过滤功能,可以根据消息的属性进行过滤,只有满足条件的消息才会被消费者接收。
第四章高级特性与扩展4.1 持久化使用RabbitMQ的持久化机制,可以确保消息在服务器重启后依然存在,防止消息丢失。
4.2 集群与高可用通过搭建RabbitMQ集群,可以提高系统的可用性和扩展性。
在集群中,消息将自动在节点之间进行复制。
RabbitMQ从零到集群高可用.NetCore(.NET5)-RabbitMQ简介和六种。。。

RabbitMQ从零到集群⾼可⽤.NetCore(.NET5)-RabbitMQ简介和六种。
系列⽂章:⼀、RabbitMQ简介是⼀个开源的消息代理和队列服务器,⽤来通过普通协议在完全不同的应⽤之间共享数据,RabbitMQ是使⽤Erlang(⾼并发语⾔)语⾔来编写的,并且RabbitMQ是基于AMQP协议的。
1.1 AMQP协议Advanced Message Queuing Protocol(⾼级消息队列协议)1.2 AMQP专业术语:(多路复⽤->在同⼀个线程中开启多个通道进⾏操作)Server:⼜称broker,接受客户端的链接,实现AMQP实体服务Connection:连接,应⽤程序与broker的⽹络连接Channel:⽹络信道,⼏乎所有的操作都在channel中进⾏,Channel是进⾏消息读写的通道。
客户端可以建⽴多个channel,每个channel代表⼀个会话任务。
Message:消息,服务器与应⽤程序之间传送的数据,由Properties和Body组成.Properties可以对消息进⾏修饰,必须消息的优先级、延迟等⾼级特性;Body则是消息体内容。
virtualhost: 虚拟地址,⽤于进⾏逻辑隔离,最上层的消息路由。
⼀个virtual host⾥⾯可以有若⼲个Exchange和Queue,同⼀个Virtual Host ⾥⾯不能有相同名称的Exchange 或 Queue。
Exchange:交换机,接收消息,根据路由键转单消息到绑定队列Binding: Exchange和Queue之间的虚拟链接,binding中可以包换routing keyRouting key: ⼀个路由规则,虚拟机可⽤它来确定如何路由⼀个特定消息。
(如负载均衡)1.3 RabbitMQ整体架构ClientA(⽣产者)发送消息到Exchange1(交换机),同时带上RouteKey(路由Key),Exchange1找到绑定交换机为它和绑定传⼊的RouteKey的队列,把消息转发到对应的队列,消费者Client1,Client2,Client3只需要指定对应的队列名即可以消费队列数据。
rabbitmq的用法

rabbitmq的用法
RabbitMQ是一种开源的消息队列中间件,用于在分布式系统中传递和存储消息。
以下是两种常见的rabbitmq用法:
1. 用作消息传递中间件:
RabbitMQ通过将消息发送到队列中并使用异步方式将其传递给接收者,实现了
松耦合的系统间通信。
发送者将消息发布到交换机,然后交换机将消息路由到一个或多个队列,接收者可以订阅一个或多个队列以接收消息。
这种模式非常适合异步处理、解耦和系统扩展。
2. 用作任务队列:
RabbitMQ还可以用作任务队列,将任务从一个应用程序分发给多个工作进程。
发送者将任务作为消息发布到队列,多个工作进程消费队列中的消息并执行相应的任务。
这种模式通常用于在高并发的情况下平衡任务负载和提高系统的可靠性。
无论是作为消息传递中间件还是任务队列,RabbitMQ的使用步骤大致相同:首先需要安装和配置RabbitMQ服务器,然后使用相关的客户端库在应用程序中进
行消息的发送和接收。
在发送消息时,可以指定消息的目标队列或交换机,也可以设置其他的消息属性。
在接收消息时,可以按照特定的策略进行消息的消费和处理。
需要注意的是,RabbitMQ还提供了许多高级特性,比如消息持久化、消息确认机制、消息优先级等,根据具体的需求和场景,可以选择合适的配置和使用方式。
Linux系统RabbitMQ高可用集群安装部署文档

Linux系统RabbitMQ⾼可⽤集群安装部署⽂档RabbitMQ⾼可⽤集群安装部署⽂档架构图1)RabbitMQ集群元数据的同步RabbitMQ集群会始终同步四种类型的内部元数据(类似索引):a.队列元数据:队列名称和它的属性;b.交换器元数据:交换器名称、类型和属性;c.绑定元数据:⼀张简单的表格展⽰了如何将消息路由到队列;d.vhost元数据:为vhost内的队列、交换器和绑定提供命名空间和安全属性;2)集群配置⽅式cluster:不⽀持跨⽹段,⽤于同⼀个⽹段内的局域⽹;可以随意的动态增加或者减少;节点之间需要运⾏相同版本的 RabbitMQ 和 Erlang。
节点类型RAM node:内存节点将所有的队列、交换机、绑定、⽤户、权限和 vhost 的元数据定义存储在内存中,好处是可以使得像交换机和队列声明等操作更加的快速。
Disk node:将元数据存储在磁盘中,单节点系统只允许磁盘类型的节点,防⽌重启 RabbitMQ 的时候,丢失系统的配置信息。
解决⽅案:设置两个磁盘节点,⾄少有⼀个是可⽤的,可以保存元数据的更改。
Erlang Cookieerlang Cookie 是保证不同节点可以相互通信的密钥,要保证集群中的不同节点相互通信必须共享相同的 Erlang Cookie3)搭建RabbitMQ集群所需要安装的组件a.Jdk 1.8b.Erlang运⾏时环境c.RabbitMq的Server组件1、安装yum源⽂件2、安装Erlang# yum -y install erlang3、配置java环境 /etc/profileJAVA_HOME=/usr/local/java/jdk1.8.0_151PATH=$JAVA_HOME/bin:$PATHCLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar4、安装配置rabbitmq# tar -xf rabbitmq-server-generic-unix-3.6.15.tar -C /usr/local/# mv /usr/local/rabbitmq_server-3.6.15/ /usr/local/rabbitmq5、配置RabbitMQ环境变量/etc/profileRABBITMQ_HOME=/usr/local/rabbitmqPATH=$PATH:$ERL_HOME/bin:/usr/local/rabbitmq/sbin# source /etc/profile6、修改主机配置⽂件/etc/hosts192.168.2.208 rabbitmq-node1192.168.2.41 rabbitmq-node2192.168.2.40 rabbitmq-node3各个主机修改配置⽂件保持⼀致# /root/.erlang.cookie7、后台启动rabbitmq# /usr/local/rabbitmq/sbin/rabbitmq-server -detached添加⽤户# rabbitmqctl add_user admin admin给⽤户授权# rabbitmqctl set_user_tags admin administrator# rabbitmqctl set_permissions -p / admin ".*" ".*" ".*"启⽤插件,可以使⽤rabbitmq管理界⾯# rabbitmq-plugins enable rabbitmq_management查看⽤户列表# rabbitmqctl list_users查看节点状态# rabbitmqctl status查看集群状态# rabbitmqctl cluster_status查看插件# rabbitmq-plugins list添加防⽕墙规则/etc/sysconfig/iptables-A INPUT -m state --state NEW -m tcp -p tcp --dport 27017 -j ACCEPT -A INPUT -m state --state NEW -m tcp -p tcp --dport 28017 -j ACCEPT -A INPUT -m state --state NEW -m tcp -p tcp --dport 15672 -j ACCEPT -A INPUT -m state --state NEW -m tcp -p tcp --dport 5672 -j ACCEPT -A INPUT -m state --state NEW -m tcp -p tcp --dport 25672 -j ACCEPT8、添加集群node节点,从节点执⾏(⽬前配置2个节点)# rabbitmqctl stop_app# rabbitmqctl join_cluster --ram rabbit@rabbitmq-node2或者# rabbitmqctl join_cluster rabbit@rabbitmq-node2# rabbitmqctl change_cluster_node_type ram启动节点#rabbitmqctl start_app9、删除集群node 节点删除1. rabbitmq-server -detached2. rabbitmqctl stop_app3. rabbitmqctl reset4. rabbitmqctl start_app设置镜像队列策略在web界⾯,登陆后,点击“Admin--Virtual Hosts(页⾯右侧)”,在打开的页⾯上的下⽅的“Add a new virtual host”处增加⼀个虚拟主机,同时给⽤户“admin”和“guest”均加上权限1、2、# rabbitmqctl set_policy -p hasystem ha-allqueue "^" '{"ha-mode":"all"}' -n rabbit"hasystem" vhost名称, "^"匹配所有的队列, ha-allqueue 策略名称为ha-all, '{"ha-mode":"all"}' 策略模式为 all 即复制到所有节点,包含新增节点,则此时镜像队列设置成功.rabbitmqctl set_policy [-p Vhost] Name Pattern Definition [Priority]-p Vhost:可选参数,针对指定vhost下的queue进⾏设置Name: policy的名称Pattern: queue的匹配模式(正则表达式)Definition:镜像定义,包括三个部分ha-mode, ha-params, ha-sync-modeha-mode:指明镜像队列的模式,有效值为 all/exactly/nodesall:表⽰在集群中所有的节点上进⾏镜像exactly:表⽰在指定个数的节点上进⾏镜像,节点的个数由ha-params指定nodes:表⽰在指定的节点上进⾏镜像,节点名称通过ha-params指定ha-params:ha-mode模式需要⽤到的参数ha-sync-mode:进⾏队列中消息的同步⽅式,有效值为automatic和manualpriority:可选参数,policy的优先级注以上集群配置完成⾼可⽤HA配置Haproxy 负载均衡,keepalived实现健康检查HA服务安装配置解压⽂件# tar -zxf haproxy-1.8.17.tar.gz查看内核版本# uname –r# yum -y install gcc gcc-c++ make切换到解压⽬录执⾏安装# make TARGET=3100 PREFIX=/usr/local/haproxy # make install PREFIX=/usr/local/haproxy创建配置⽂件相关⽬录# mkdir /usr/local/haproxy/conf# mkdir /var/lib/haproxy/# touch /usr/local/haproxy/haproxy.cfg# groupadd haproxy# useradd haproxy -g haproxy# chown -R haproxy.haproxy /usr/local/haproxy# chown -R haproxy.haproxy /var/lib/haproxy配置⽂件globallog 127.0.0.1 local2chroot /var/lib/haproxypidfile /var/run/haproxy.pidmaxconn 4000user haproxygroup haproxydaemon# turn on stats unix socketstats socket /var/lib/haproxy/stats#---------------------------------------------------------------------defaultsmode httplog globaloption httplogoption dontlognulloption http-server-closeoption redispatchretries 3timeout http-request 10stimeout queue 1mtimeout connect 10stimeout client 1mtimeout server 1mtimeout http-keep-alive 10stimeout check 10smaxconn 3000#监控MQ管理平台listen rabbitmq_adminbind 0.0.0.0:8300 server rabbitmq-node1 192.168.2.208:15672 server rabbitmq-node2 192.168.2.41:15672 server rabbitmq-node3 192.168.2.40:15672#rabbitmq_cluster监控代理listen rabbitmq_local_clusterbind 0.0.0.0:8200#配置TCP模式mode tcpoption tcplog#简单的轮询balance roundrobin#rabbitmq集群节点配置 server rabbitmq-node1 192.168.2.208:5672 check inter 5000 rise 2 fall 2 server rabbitmq-node2 192.168.2.41:5672 check inter 5000 rise 2 fall 2 server rabbitmq-node3 192.168.2.40:5672 check inter 5000 rise 2 fall 2 #配置haproxy web监控,查看统计信息listen private_monitoringbind 0.0.0.0:8100mode httpoption httplogstats enablestats uri /statsstats refresh 30s#添加⽤户名密码认证stats auth admin:admin启动haproxy服务# /usr/local/haproxy/sbin/haproxy -f /usr/local/haproxy/conf/haproxy.cfg#Keepalived 源码安装软件包路径 /usr/local/src安装路径 /usr/local/keepalived配置⽂件/etc/keepalived/keeplived.conf# tar -zxf keepalived-2.0.10.tar.gz#安装依赖包# yum -y install openssl-devel libnl libnl-devel libnfnetlink-devel# ./configure --prefix=/usr/local/keepalived && make && make install创建keepalived配置⽂件⽬录#mkdir /etc/keepalived拷贝配置⽂件到/etc/keepalived⽬录下# cp /usr/local/keepalived/etc/keepalived/keepalived.conf /etc/keepalived/复制keepalived脚本到/etc/init.d/ ⽬录# cp /usr/local/src/keepalived-2.0.10/keepalived/etc/init.d/keepalived /etc/init.d/拷贝keepalived脚本到/etc/sysconfig/ ⽬录# cp /usr/local/keepalived/etc/sysconfig/keepalived /etc/sysconfig/建⽴软连接# ln -s /usr/local/keepalived/sbin/keepalived /sbin/添加到开机启动# chkconfig keepalived on查看服务状况# systemctl status keepalivedKeepalived启动# systemctl start keepalivedmaster 配置⽂件#Master :global_defs {notification_email {134********m@}notification_email_from 134********m@smtp_server 127.0.0.1smtp_connect_timeout 30router_id NGINX_DEVEL}vrrp_script chk_haproxy {script "/usr/local/keepalived/check_haproxy.sh"interval 2weight 2fall 3rise 2}vrrp_instance haproxy_1 {state MASTERinterface ens33virtual_router_id 104priority 150advert_int 1mcast_src_ip 192.168.2.41authentication {auth_type PASSauth_pass 1111}track_interface {ens33}track_script {check_haproxy.sh}virtual_ipaddress {192.168.33.110}}#virtual_server 192.168.2.110 80 {# delay_loop 6 # 设置健康检查时间,单位是秒# lb_algo wrr # 设置负载调度的算法为wlc# lb_kind DR # 设置LVS实现负载的机制,有NAT、TUN、DR三个模式# nat_mask 255.255.255.0# persistence_timeout 0# protocol TCP# real_server 192.168.220.128 80 { # 指定real server1的IP地址# weight 3 # 配置节点权值,数字越⼤权重越⾼#TCP_CHECK {# connect_timeout 10# nb_get_retry 3# delay_before_retry 3# connect_port 80# }# }# }}#Slave :global_defs {notification_email {134********m@}notification_email_from 134********m@smtp_server 127.0.0.1smtp_connect_timeout 30router_id NGINX_DEVEL}vrrp_script chk_haproxy {script "/usr/local/keepalived/check_haproxy.sh"interval 2weight 2fall 3rise 2}vrrp_instance haproxy_2 {state SLAVEinterface ens33virtual_router_id 104priority 150advert_int 1mcast_src_ip 192.168.2.208authentication {auth_type PASSauth_pass 1111}track_interface {ens33}track_script {check_haproxy.sh}virtual_ipaddress {192.168.2.246}}#virtual_server 192.168.2.110 80 {# delay_loop 6 # 设置健康检查时间,单位是秒# lb_algo wrr # 设置负载调度的算法为wlc# lb_kind DR # 设置LVS实现负载的机制,有NAT、TUN、DR三个模式# nat_mask 255.255.255.0# persistence_timeout 0# protocol TCP# real_server 192.168.220.128 80 { # 指定real server1的IP地址# weight 3 # 配置节点权值,数字越⼤权重越⾼#TCP_CHECK {# connect_timeout 10# nb_get_retry 3# delay_before_retry 3# connect_port 80# }# }# }}haproxy检测#!/bin/bashHaproxyStatus=`ps -C haproxy --no-header | wc -l`if [ $HaproxyStatus-eq 0 ];then/etc/init.d/haproxy startsleep 3if [ `ps -C haproxy --no-header | wc -l ` -eq 0 ];then/etc/init.d/keepalived stopfifi。
RabbitMQ集群搭建-镜像模式

RabbitMQ集群搭建-镜像模式可以参考https:///wexiaoword/article/details/81352045服务器介绍node1:192.168.174.10node2:192.168.174.11node3:192.168.174.12node4:192.168.174.13node5:192.168.174.14其中,node1、node2、node3三台服务器安装RabbitMQ服务,node4和node5安装HA-proxy和Keepalived。
服务集群架构HA-proxyHaproxy 介绍以常见的TCP应⽤为例,负载均衡器在接收到第⼀个来⾃客户端的SYN请求时,会通过设定的负载均衡算法选择⼀个最佳的后端服务器,同时将报⽂中⽬标IP地址修改为后端服务器IP,然后直接转发给该后端服务器,这样⼀个负载均衡请求就完成了。
从这个过程来看,⼀个TCP 连接是客户端和服务器直接建⽴的,⽽负载均衡器只不过完成了⼀个类似路由器的转发动作。
在某些负载均衡策略中,为保证后端服务器返回的报⽂可以正确传递给负载均衡器,在转发报⽂的同时可能还会对报⽂原来的源地址进⾏修改。
整个过程下图所⽰Haproxy 的特点是:⾼可⽤,负载均衡。
KeepAlivedKeepAlived 介绍KeepAlived 的特点:通过VRRP协议(虚拟ip)实现⾼可⽤功能(主备切换)。
KeepAlived ⾼可⽤原理注意:master节点恢复时,是否重新接管master⾓⾊,看我们⾃⼰的配置,后⾯配置KeepAlived会讲。
镜像模式镜像模式,是中⼩型企业常⽤的rabbitmq集群架构:镜像模式架构图消息的发布(除了Basic.Publish之外)与消费都是通过master节点完成。
master节点对消息进⾏处理的同时将消息的处理动作通过GM(Guarenteed Multicast)⼴播给所有的slave节点,slave节点的GM收到消息后,通过回调交由mirror_queue_slave进⾏实际的处理。
使用Prometheus和Grafana监控RabbitMQ集群(使用RabbitMQ自带插件)

RabbitMQ 在专用 TCP 端口(默认为15692)上公开指标。
因此rabbitmq集群需要开放15692端口才行
配置 prometheus
- job_name: 'rabbitmq' static_configs: - targets: ['172.16.0.207:15692','172.16.0.84:15692','172.16.0.7:15692']
# 启用插件 rabbitmq-plugins enable rabbitmq_prometheus
# 启用插件后的效果显示 rrometheus
Enabling plugins on node rabbit@ed9618ea17c9: rabbitmq_prometheus The following plugins have been configured:
rabbitmq_management_agent rabbitmq_prometheus rabbitmq_web_dispatch Applying plugin configuration to rabbit@ed9618ea17c9... The following plugins have been enabled: rabbitmq_management_agent rabbitmq_prometheus rabbitmq_web_dispatch
RabbitMQ知识体系梳理PPT

RabbitMQ
演讲人 2022-07-21
目录
01. 工作模式
02.
RabbitMQ不允许您使用不同的参数 重新定义现有队列,
03. 消息持久性标记
04. 集群方式
01 工作模式
工作模式
一个生产者一 个消费者
Work Queues
Publish/Su bscribe
RPC
Topics
消息队列是一个例外,消息队列默
B
认情况下位于一个节点上,尽管它 们在所有节点上都是可见且可访问
的
C
主节点宕机后,集群不可用,无法 自动转移故障节点
存在两个节点之间 数据落差大
集群方式
镜像集群
发布到队列的消息 将复制到所有镜像
队列镜像可提高可用性, 但不会在节点之间分配 负载(所有参与节点均
完成所有工作)
由一个主服务器和 多个镜像组成
镜像都会丢弃已在 主服务器上确认的
消息
主服务器的节点发 生故障,则最早的 镜像将被同步到新
的主服务器
3.8新出
集群方式
仲裁集群
202X
感谢聆听
能者多劳调度 一次不要给一个worker发送一条以上的消息,在worker处理并确认前一个
消息之前,不要向它发送新消息。
一个生产者对应多个消费者
默认情况下,手动消息确认处于打开状态
确认必须在接收传递的同一通道上发送。尝试使用不同的通道进行确认将导 致通道级协议异常。
工作模式
Publish/Subscribe
02
如果您需要更强有力的保证,则 可以使用发布者确认。
尽管告诉RabbitMQ将消息保存到 磁盘,但是RabbitMQ接受消息但 尚未将其保存时,仍有很保 证不会丢失消息
rabbitmq集群同步原理

rabbitmq集群同步原理RabbitMQ是一种流行的开源消息队列软件,它支持多种消息协议和消息传输方式。
为了提高可靠性和可伸缩性,RabbitMQ可以部署为集群,即多个RabbitMQ节点组成的集合。
在RabbitMQ集群中,节点之间需要进行同步,以确保消息的正确传递和处理。
本文将介绍RabbitMQ集群同步的原理。
1. 集群搭建在RabbitMQ集群中,所有节点都是对等的,没有主节点和从节点之分。
集群中每个节点都需要安装RabbitMQ软件,并且节点之间需要网络互通。
2. 集群节点之间的通信在RabbitMQ集群中,节点之间通过AMQP协议进行通信,节点之间可以互相发送消息。
当一个节点收到消息后,它可以选择将消息发送到其他节点,使得集群中的其他节点也能够处理该消息。
3. 集群节点之间的同步为了保证集群中的所有节点都具有相同的队列和交换机信息,RabbitMQ集群使用了一种称为“镜像队列”的机制。
在镜像队列中,队列中的所有消息都会被复制到集群中的其他节点。
这样,即使某个节点宕机,集群中的其他节点仍然能够接收并处理该节点上的消息。
4. 镜像队列的实现RabbitMQ使用了Erlang语言的分布式特性来实现镜像队列。
在RabbitMQ集群中,每个节点都可以充当队列的“镜像节点”。
当一个队列被创建时,RabbitMQ会将该队列的元数据信息(比如队列名称、队列参数等)同步到集群中的所有节点。
当一个节点接收到一个队列中的消息时,它会将该消息复制到该队列的所有镜像节点。
这样,该队列的所有镜像节点都可以接收到该消息,并进行处理。
5. 镜像队列的优缺点镜像队列机制可以提高RabbitMQ集群的可靠性和可伸缩性。
它可以确保集群中的每个节点都拥有相同的队列和交换机信息,从而避免了单点故障。
同时,镜像队列还可以提高集群中的消息吞吐量,因为消息可以在多个节点之间并行处理。
但是,镜像队列也有一些缺点。
由于每个节点都需要复制所有消息,这会占用大量的网络带宽和存储空间。
RabbitMQ入门讲义

生产者流转过程示意图
消费者流转过程示意图
RABBITMQ组成部分
• Broker: 消息队列服务进程,包含两个部分Exchange和Queue; • Exchange: 消息队列交换机,按一定的规则将消息路由转发到某个队列,对消息进行过滤; • Queue: 存储消息的队列,消息到达队列并转发给指定的消费方; • Producer: 消息生产者发送消息到MQ; • Consumer: 消息消费者接收MQ转发的消息。。
消息队列的适用场景
任务异步处理 • 把不需要同步处理并且耗时较长的操作由消息队列通知消 息接收方进行异步处理,提高了应用程序的响应时间。
应用程序解耦合 • MQ相当于一个代理,生产者通过MQ与消费者交互,它将 应用程序进行解耦合。
削峰填谷
• 如订单系统。
AMQP-高级消息队列协议
• AMQP是一个提供统一消息服务的应用层标准高级消息队列协议,是应用层协议的一个开放标准, 为面向消息的中间件设计。
为什么使用RABBITMQ
• 消息队列是应用程序与应用程序之间的通信方法。 • 在项目中, 可以将一些无需即时返回并且耗时的操作提取出来, 进行异步处理, 节省服务器的请求
响应时间, 从而提高了系统的吞吐量。 • 使用简单, 功能强大; • 基于AMQP 0-9-1协议; • 社区活跃, 文档丰富; • 高并发性能好, 这主要得益于erlang语言; • SpringBoot默认已集成RabbitMQ。
• 每个消费者监听自己的队列, 并且可以设置多个路由键; • 生产者将消息发给交换机, 发送消息时需要指定路由键, 由交换机根据路由键来转发消息到指定的
队列。。
通配符模式
• 每个消费者监听自己的队列,并且设置带通配符的路由键。 • 符号#: 匹配一个或多个词; • 符号*: 只能匹配一个词。 • 案例: 根据用户的通知设置去通知用户。。
rabbitmq的memory_details详细解读_概述说明

rabbitmq的memory details详细解读概述说明1. 引言1.1 概述在当今高并发、大规模数据处理的背景下,消息队列作为一种重要的通信机制,被广泛应用于各种系统中。
RabbitMQ作为最流行的开源消息中间件之一,具有可靠、高性能和可扩展性等特点,在分布式系统架构中起到了至关重要的作用。
本文将详细讨论RabbitMQ内存使用的细节,并探讨如何对其进行调优,以提高其性能和稳定性。
同时也会介绍在集群环境下如何管理和同步内存,以实现高可用性和平衡内存容量。
1.2 文章结构本文共分为五个部分:引言、RabbitMQ内存细节详解、RabbitMQ内存调优、RabbitMQ集群中的内存管理以及结论与展望。
- 第一部分是引言部分,主要对文章的背景和内容进行简要介绍。
- 第二部分将详细介绍RabbitMQ的基本概念与原理,并深入研究其内存管理机制。
- 第三部分将重点讨论如何通过设置和管理队列的内存限制来调优RabbitMQ,同时还会探讨消息持久化与内存使用之间的权衡。
- 第四部分将介绍在RabbitMQ集群中的内存管理策略,包括集群模式下的内存分配机制以及集群节点间的内存同步策略,并探讨高可用性和内存容量之间的平衡考虑。
- 最后一部分是总结本文重点要点,并对未来发展进行展望。
1.3 目的本文旨在深入了解RabbitMQ的内存使用细节,帮助读者全面理解RabbitMQ 在消息传递过程中所涉及到的内存管理机制。
同时,通过探讨调优方法和集群环境下的内存管理策略,读者将能够更好地使用和配置RabbitMQ,以提高系统性能并保证其稳定运行。
通过阅读本文,读者将获得以下收益:- 对RabbitMQ的基本原理和概念有深刻理解;- 掌握RabbitMQ内存调优方法和技巧;- 在集群环境中有效管理和同步内存的能力;- 对未来RabbitMQ发展趋势有一定洞察力。
通过这样的研究与实践,可以使读者更好地应用RabbitMQ来构建可靠、高性能和可扩展的系统。
rabbit高级用法

RabbitMQ是一个流行的消息队列中间件,提供了灵活的消息传递模型、可靠的消息传递、路由控制等功能。
以下是一
些RabbitMQ的高级用法:
1. 消息持久化:通过将消息和队列持久化到磁盘上,确保消息在重启或故障情况下不会丢失。
2. 消息确认机制:消费者可以向RabbitMQ发送确认消息,告知消息已被成功处理。
这有助于确保消息被正确处理,并在出现问题时进行重试或进行其他操作。
3. 死信队列:当消息无法被正常处理或消费者意外失败时,可以将消息发送到一个特殊的死信队列中。
这样可以方便地查看和处理未处理的消息。
4. 优先级队列:RabbitMQ支持基于优先级的队列,可以根据业务需求设置不同消息的优先级。
5. 延迟队列:通过延迟队列,可以将消息延迟一段时间后发送给消费者,实现延迟处理的功能。
6. 主题交换器:使用主题交换器,可以根据消息的主题将消息路由到不同的队列中,从而实现更灵活的消息路由控制。
7. 泛化消费者:泛化消费者可以同时监听多个队列,接收来自不同队列的消息。
这样可以实现更高效的资源利用和并发处理。
8. 插件扩展:RabbitMQ提供了丰富的插件扩展机制,
可以扩展其功能,例如与Kafka集成、与数据库集成等。
9. 集群部署:通过集群部署,可以实现高可用性和高性能的RabbitMQ服务,确保消息传递的可靠性和稳定性。
10. 权限控制:RabbitMQ提供了用户角色和权限控制机制,可以设置不同的用户角色和权限,控制对队列、交换器和路由的管理和访问。
以上是RabbitMQ的一些高级用法,通过这些高级特性,可以更好地满足复杂的应用场景和业务需求。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
文件编号:
版本号:V1.0 RabbitMQ集群使用说明
编写:
审核:
批准:
文档修改记录
1.Maven配置pom
在pom.xml中加入rabbitmq和spring rabbitmq依赖包。
2.使用Java API 直接连接RabbitMQ集群
使用官方的Java API(amqp-client-3.5.4.jar)来直接连接RabbitMQ集群。
2.1RabbitMQ发送
直接连接RabbitMQ集群,然后发送消息。
2.2RabbitMQ接收
直接连接RabbitMQ集群,然后接收消息,注意需要手动打开应答机制,并手动提交确认消息,保证公平调度和消息持久化。
3.使用Spring Xml托管连接RabbitMQ集群
使用xml配置,采用amqp-client-3.5.4.jar、spring-rabbit-1.4.5.RELEASE.jar 和spring-amqp-1.4.5.RELEASE.jar手动配置bean,然后采用Spring加载xml文件连接RabbitMQ集群,从而发送和接收消息。
3.1RabbitMQ生产者
RabbitMQ生产者的xml配置文件如下。
3.2RabbitMQ消费者
RabbitMQ生产者的xml配置文件如下。