中文分词实验
基于统计学习的中文分词算法研究与实现

基于统计学习的中文分词算法研究与实现1. 研究背景与意义中文自然语言处理一直是计算机科学领域研究热点之一,而中文分词作为中文自然语言处理的基础,对于中文信息处理的准确性和效率至关重要。
因此,如何实现中文分词算法成为了研究的重要方向之一。
而基于统计学习的中文分词算法由于其高效和准确的特点,近年来受到了学术界和工业界的广泛关注。
2. 统计学习原理统计学习是一种主要通过样本数据学习统计规律,进而进行模型预测和决策的机器学习方法。
在中文分词领域,统计学习方法主要包括条件随机场(Conditional Random Fields, CRF)算法和隐马尔可夫模型(Hidden Markov Model, HMM)算法。
2.1 CRF算法CRF算法是一种基于给定观测序列预测标签序列的判别式模型,相较于传统的隐马尔可夫模型,CRF算法不需要对序列进行假设,因此能更加准确地建立标签之间的依赖关系。
在中文分词中,CRF算法可以通过学习一系列特征函数和标签序列之间的联系来识别分词位置。
同时,CRF算法还可以应用于词性标注、命名实体识别等中文自然语言处理问题中。
2.2 HMM算法HMM算法是一种基于一定数目隐藏状态序列的概率模型,其主要思想是对一个观测序列建立一个与之对应的隐藏状态序列,再通过对两个序列之间的概率分布进行建模,从而得到概率最大的标签序列。
在中文分词领域,HMM算法通常基于字或者词的频率统计建立模型,并通过对模型参数的不断优化来提高分词准确率。
3. 中文分词算法实现3.1 数据预处理在进行中文分词算法实现前,首先需要进行数据预处理。
该步骤主要包括数据清洗、分词、标注等处理,以得到处理后的具有代表性的中文数据集。
3.2 特征选择特征选择是建立中文分词模型的关键步骤。
基于统计学习的中文分词算法主要通过选取能够有效区分不同中文词汇的特征来建立模型。
常用的特征选择方法包括:互信息、信息增益比、卡方检验、TF-IDF等。
词法分析实验报告

词法分析实验报告词法分析实验报告引言词法分析是自然语言处理中的一个重要环节,它负责将输入的文本分割成一个个的词语,并确定每个词语的词性。
本次实验旨在通过实现一个简单的词法分析器,来探索词法分析的原理和实践。
实验内容本次实验中,我们使用Python编程语言来实现词法分析器。
我们选取了一段简单的英文文本作为输入,以便更好地理解和演示词法分析的过程。
1. 文本预处理在进行词法分析之前,我们首先需要对输入文本进行预处理。
预处理的目的是去除文本中的标点符号、空格和其他无关的字符,以便更好地进行后续的分词操作。
2. 分词分词是词法分析的核心步骤之一。
在这个步骤中,我们将文本分割成一个个的词语。
常见的分词方法包括基于规则的分词和基于统计的分词。
在本次实验中,我们选择了基于规则的分词方法。
基于规则的分词方法通过事先定义一系列的分词规则来进行分词。
这些规则可以是基于语法的,也可以是基于词典的。
在实验中,我们使用了一个简单的基于词典的分词规则,即根据英文单词的常见前缀和后缀来进行分词。
3. 词性标注词性标注是词法分析的另一个重要步骤。
在这个步骤中,我们为每个词语确定其词性。
词性标注可以通过事先定义的规则和模型来进行。
在本次实验中,我们使用了一个简单的基于规则的词性标注方法。
基于规则的词性标注方法通过定义一系列的词性标注规则来进行词性标注。
这些规则可以是基于词法的,也可以是基于语法的。
在实验中,我们使用了一个简单的基于词法的词性标注规则,即根据英文单词的后缀来确定其词性。
实验结果经过实验,我们得到了输入文本的分词结果和词性标注结果。
分词结果如下:- I- love- natural- language- processing词性标注结果如下:- I (代词)- love (动词)- natural (形容词)- language (名词)- processing (名词)讨论与总结通过本次实验,我们深入了解了词法分析的原理和实践。
PHP简易中文分词系统对闽菜名的分词实验与结果分析

【 莱考夫 ・ 2 】 约翰逊. 我们赖 以生存 的隐喻 [】 芝加哥:芝加哥大学 M.
出版 社 ,2 0 . 03
宁波万科 集团: “ 万科城 ” “ 万科 云鹭湾” “ 科金 万
域华府” “ 万科金 色水岸” “ 万科金 色城市”等 。
( ) 以历 史 典故 转 喻 小 区名 四 以与 该地 区相 关 的历 史典 故来指代居 民小 区的专名 。如 :
( )宁波华泰 股份有 限公 司: “ 7 华泰银座” “ 华泰剑 桥” “ 华泰 星城”等。
宁波雅 戈 尔置业有 限公 司: “ 戈 尔 ・ 雅 钱湖 比华 利” “ 戈 尔都市丽湾” “ 戈尔世 纪花 园” “ 戈 尔锦绣 东 雅 雅 雅
转喻 的思维 方法 ,通过小 区与客观物理世界 的相关关系来 命名 。本 文通过对宁波市 居民小区命名 中的转 喻的探究发
断 为 动 词 ,导 致 了切 分 错 误 或 是 词 性 判 断 错 误 。 例 如 “ 肉 语 言单位 。只有 少数菜名是直 接 由语言学 上的 “ ”构成 词 烧 白菜 ”这 个 菜 名 ,若 分 词 系 统 将 “ ” 判 定 为 动 词 , 本 的 ,更 多的菜名是 由两个或 者 以上语 言学上 的 “ ”组合 烧 词 为 名 词 性 短 语 的菜 名 就 被 切 分 为 “ 主语 + 语 + 语 ” 的成 构 成 的 名 词 性 短 语 。 所 谓 “ 词 性 短 语 ” , 也 叫 体 词 性 短 谓 宾 名 分 。又 如 福 建 名 菜 “ 跳 墙 ” , 若 分 词 系 统 未 能 识 别 这 是 语 。性质上是名 词性的 ,功 能上跟名词相 当 ,经常充 当主 佛
【 赵艳芳. 知语言学概论 . 3 】 认 上海:上海外语教育出版杜 ,2 0. 01
自然语言理解课程实验报告

实验一、中文分词一、实验内容用正向最大匹配法对文档进行中文分词,其中:(1)wordlist.txt 词表文件(2)pku_test.txt 未经过分词的文档文件(3)pku_test_gold.txt 经过分词的文档文件二、实验所采用的开发平台及语言工具Visual C++ 6.0三、实验的核心思想和算法描述本实验的核心思想为正向最大匹配法,其算法描述如下假设句子: , 某一词 ,m 为词典中最长词的字数。
(1) 令 i=0,当前指针 pi 指向输入字串的初始位置,执行下面的操作:(2) 计算当前指针 pi 到字串末端的字数(即未被切分字串的长度)n,如果n=1,转(4),结束算法。
否则,令 m=词典中最长单词的字数,如果n<m, 令 m=n;(3) 从当前 pi 起取m 个汉字作为词 wi,判断:(a) 如果 wi 确实是词典中的词,则在wi 后添加一个切分标志,转(c);(b) 如果 wi 不是词典中的词且 wi 的长度大于1,将wi 从右端去掉一个字,转(a)步;否则(wi 的长度等于1),则在wi 后添加一个切分标志,将wi 作为单字词添加到词典中,执行 (c)步;(c) 根据 wi 的长度修改指针 pi 的位置,如果 pi 指向字串末端,转(4),否则, i=i+1,返回 (2);(4) 输出切分结果,结束分词程序。
四、系统主要模块流程、源代码(1) 正向最大匹配算法12n S c c c 12i mw c c c(2) 原代码如下// Dictionary.h#include <iostream>#include <string>#include <fstream>using namespace std;class CDictionary{public:CDictionary(); //将词典文件读入并构造为一个哈希词典 ~CDictionary();int FindWord(string w); //在哈希词典中查找词private:string strtmp; //读取词典的每一行string word; //保存每个词string strword[55400];};//将词典文件读入并CDictionary::CDictionary(){ifstream infile("wordlist.txt"); // 打开词典if (!infile.is_open()) // 打开词典失败则退出程序{cerr << "Unable to open input file: " << "wordlist.txt"<< " -- bailing out!" << endl;exit(-1);}int i=0;while (getline(infile, strtmp)) // 读入词典的每一行并将其添加入哈 希中{strword[i++]=strtmp;}infile.close();}CDictionary::~CDictionary(){}//在哈希词典中查找词,若找到,则返回,否则返回int CDictionary::FindWord(string w){int i=0;while ((strword[i]!=w) && (i<55400))i++;if(i<55400)return 1;elsereturn 0;}// 主程序main.cpp#include "Dictionary.h"#define MaxWordLength 14 // 最大词长为个字节(即个汉字)# define Separator " " // 词界标记CDictionary WordDic; //初始化一个词典//对字符串用最大匹配法(正向)处理string SegmentSentence(string s1){string s2 = ""; //用s2存放分词结果string s3 = s1;int l = (int) s1.length(); // 取输入串长度int m=0;while(!s3.empty()){int len =(int) s3.length(); // 取输入串长度if (len > MaxWordLength) // 如果输入串长度大于最大词长 {len = MaxWordLength; // 只在最大词长范围内进行处理 }string w = s3.substr(0, len); //(正向用)将输入串左边等于最大词长长度串取出作为候选词int n = WordDic.FindWord(w); // 在词典中查找相应的词while(len > 1 && n == 0) // 如果不是词{int j=len-1;while(j>=0 && (unsigned char)w[j]<128){j--;}if(j<1){break;}len -= 1; // 从候选词右边减掉一个英文字符,将剩下的部分作为候选词 w = w.substr(0, len); //正向用n = WordDic.FindWord(w);}s2 += w + Separator; // (正向用)将匹配得到的词连同词界标记加到输出串末尾s3 = s1.substr(m=m+w.length(), s1.length()); //(正向用)从s1-w处开始}return s2;}int main(int argc, char *argv[]){string strtmp; //用于保存从语料库中读入的每一行string line; //用于输出每一行的结果ifstream infile("pku_test.txt"); // 打开输入文件if (!infile.is_open()) // 打开输入文件失败则退出程序{cerr << "Unable to open input file: " << "pku_test.txt"<< " -- bailing out!" << endl;exit(-1);}ofstream outfile1("SegmentResult.txt"); //确定输出文件if (!outfile1.is_open()){cerr << "Unable to open file:SegmentResult.txt"<< "--bailing out!" << endl;exit(-1);}while (getline(infile, strtmp)) //读入语料库中的每一行并用最大匹配法处理{line = strtmp;line = SegmentSentence(line); // 调用分词函数进行分词处理outfile1 << line << endl; // 将分词结果写入目标文件cout<<line<<endl;}infile.close();outfile1.close();return 0;}五、实验结果及分析(1)、实验运行结果(2) 实验结果分析在基于字符串匹配的分词算法中,词典的设计往往对分词算法的效率有很大的影响。
实验报告-中文分词参考模板

实验报告1 双向匹配中文分词•小组信息目录摘要--------------------------------------------------------------------------------------- 1理论描述--------------------------------------------------------------------------------- 1算法描述--------------------------------------------------------------------------------- 2详例描述--------------------------------------------------------------------------------- 3软件演示--------------------------------------------------------------------------------- 4总结--------------------------------------------------------------------------------------- 6•摘要这次实验的内容是中文分词,现有的分词算法可分为三大类:基于字符串匹配的分词方法、基于理解的分词方法和基于统计的分词方法。
按照是否与词性标注过程相结合,又可以分为单纯分词方法和分词与标注相结合的一体化方法。
而我们用到的分词算法是基于字符串的分词方法(又称机械分词方法)中的正向最大匹配算法和逆向匹配算法。
一般说来,逆向匹配的切分精度略高于正向匹配,遇到的歧义现象也较少。
统计结果表明,单纯使用正向最大匹配的错误率为1/169,单纯使用逆向最大匹配的错误率为1/245。
•理论描述中文分词指的是将一个汉字序列切分成一个一个单独的词。
experiment翻译

experiment翻译
experiment
英/ɪkˈsperɪmənt
美/[ɪkˈsperɪmənt]
n.
实验;试验;尝试;实践
vi.
做试验;进行实验;尝试;试用
第三人称单数:experiments
复数:experiments
现在分词:experimenting
过去式:experimented
过去分词:experimented
派生词:
experimenter n.
记忆技巧:ex 出+ peri 通过;尝试+ ment 表结果→不断尝试→实验
双语例句
全部实验试验尝试实践做试验进行实验试用
1.The results of the experiment are not statistically significant.
从统计学的观点看,实验结果意义不明显。
2.The experiment had the reverse effect to what was intended.
实验的结果与原来的意图相反。
3.Many people do not like the idea of experiments on animals.
许多人不赞成在动物身上做试验。
4.The experiments were carried out under simulated examination conditions.
试验是在模拟的情况下进行的。
5.The temperature remained constant while pressure was a variable in the experiment.
做这实验时温度保持不变,但压力可变。
中文分词案例

中文分词案例中文分词是自然语言处理中的一个重要任务,其目的是将连续的中文文本切分成单个的词语。
中文分词在很多应用中都起到了关键作用,例如机器翻译、信息检索、文本分类等。
本文将以中文分词案例为题,介绍一些常用的中文分词方法和工具。
一、基于规则的中文分词方法1. 正向最大匹配法(Maximum Matching, MM):该方法从左到右扫描文本,从词典中找出最长的词进行匹配,然后将该词从文本中删除。
重复这个过程,直到文本被切分完毕。
2. 逆向最大匹配法(Reverse Maximum Matching, RMM):与正向最大匹配法相反,该方法从右到左扫描文本,从词典中找出最长的词进行匹配,然后将该词从文本中删除。
重复这个过程,直到文本被切分完毕。
3. 双向最大匹配法(Bidirectional Maximum Matching, BMM):该方法同时使用正向最大匹配和逆向最大匹配两种方法,然后选择切分结果最少的作为最终结果。
二、基于统计的中文分词方法1. 隐马尔可夫模型(Hidden Markov Model, HMM):该方法将中文分词问题转化为一个序列标注问题,通过训练一个隐马尔可夫模型来预测每个字的标签,进而切分文本。
2. 条件随机场(Conditional Random Fields, CRF):与隐马尔可夫模型类似,该方法也是通过训练一个条件随机场模型来预测每个字的标签,进而切分文本。
三、基于深度学习的中文分词方法1. 卷积神经网络(Convolutional Neural Network, CNN):该方法通过使用卷积层和池化层来提取文本特征,然后使用全连接层进行分类,从而实现中文分词。
2. 循环神经网络(Recurrent Neural Network, RNN):该方法通过使用循环层来捕捉文本的时序信息,从而实现中文分词。
四、中文分词工具1. 结巴分词:结巴分词是一个基于Python的中文分词工具,它采用了一种综合了基于规则和基于统计的分词方法,具有较高的准确性和速度。
中文bpe分词

中文bpe分词
BPE(Byte Pair Encoding)是一种子词切分算法,将稀有和未知的单词编码为子词单元的序列。
其主要步骤如下:
1. 准备足够大的训练语料。
2. 确定期望的subword词表大小。
3. 将单词拆分为字符序列并在末尾添加后缀“</w>”,统计单词频率。
本阶段的subword 的粒度是字符。
例如,“low”的频率为5,那么我们将其改写为“l o w </w>”:5。
4. 统计每一个连续字节对的出现频率,选择最高频者合并成新的subword。
5. 重复第4步直到达到第2步设定的subword词表大小或下一个最高频的字节对出现频率为1。
BPE 算法可以将不同词类通过拆分为比单词更小的单元进行组合,从而实现对文本的分析和处理。
在实际应用中,BPE 算法可以与其他自然语言处理技术相结合,以提高文本分析的准确性和效率。
experiment的用法总结大全

experiment的用法总结大全(学习版)编制人:__________________审核人:__________________审批人:__________________编制学校:__________________编制时间:____年____月____日序言下载提示:该文档是本店铺精心编制而成的,希望大家下载后,能够帮助大家解决实际问题。
文档下载后可定制修改,请根据实际需要进行调整和使用,谢谢!并且,本店铺为大家提供各种类型的经典范文,如英语单词、英语语法、英语听力、英语知识点、语文知识点、文言文、数学公式、数学知识点、作文大全、其他资料等等,想了解不同范文格式和写法,敬请关注!Download tips: This document is carefully compiled by this editor.I hope that after you download it, it can help you solve practical problems. The document can be customized and modified after downloading, please adjust and use it according to actual needs, thank you!In addition, this shop provides various types of classic sample essays, such as English words, English grammar, English listening, English knowledge points, Chinese knowledge points, classical Chinese, mathematical formulas, mathematics knowledge points, composition books, other materials, etc. Learn about the different formats and writing styles of sample essays, so stay tuned!experiment的用法总结大全experiment的意思experiment的简明意思n. 试验;实验;尝试vi. 尝试;做实验英式发音 [ɪk'sperɪmənt] 美式发音 [ɪk'sperɪmənt]experiment的词态变化为:名词: experimenter 过去式: experimented 过去分词: experimented 现在分词: experimenting 第三人称单数: experimentsexperiment的详细意思在英语中,experiment不仅具有上述意思,还有更详尽的用法,experiment作名词 n. 时具有试验;实验;尝试;考验;会晤;科研设备,仪器,实验用的仪器;实践;实验的进行;实验法等意思,experiment作动词 v. 时具有进行实验,做实验;试验,进行试验,做试验;尝试;试用等意思,experiment的具体用法用作名词 n.experiment用作名词的意思是“实验,试验”“尝试”,既可作可数名词,又可作不可数名词。
中文文本相似度分析实验报告

中文文本相似度分析一、实验目的1、了解中文文本如何分词;2.了解如何对中文进行解码;3、掌握python的规则及用法;4、掌握求文本相似度的方法。
二、设备与环境普通PC机、XP操作系统、Python2.7三、实验方案实验内容是先对中文文本进行分词,然后求文本相似度放到一个矩阵中,最后把结果输出到一个.txt文件里,画出图像。
具体方案如下:1、对中文文本进行预处理,即网上在线分词。
2、构建空间向量模型,即求出词的频数。
3、构建文本相似度矩阵,即用余弦函数求出文本相似度。
4、结果存到.txt文件中,画出文本相似度图像。
四、核心技术及具体实现1、技术介绍在此次项目设计中用到的编程工具有Python,下面就对Python进行简单的介绍:Python是一种解释型、面向对象、动态数据类型的高级程序设计语言。
它由Guido van Rossum于1989年底发明,第一个公开发行版发行于1991年。
Python 语法简捷而清晰,具有丰富和强大的类库。
它常被昵称为胶水语言,它能够很轻松的把用其他语言制作的各种模块(尤其是C/C++)轻松地联结在一起。
Python是完全面向对象的语言。
函数、模块、数字、字符串都是对象。
并且完全支持继承、重载、派生、多继承,有益于增强源代码的复用性。
Python 支持重载运算符和动态类型。
相对于Lisp这种传统的函数式编程语言,Python 对函数式设计只提供了有限的支持。
有两个标准库(functools,itertools)提供了Haskell和Standard ML中久经考验的函数式程序设计工具。
2、具体实现及代码。
1)把部分政府报告组建成自己的文本语料库,并在NLTK中的PlaintextCorpusReader帮助下载入它们。
代码如下:import nltkfrom nltk.corpus import PlaintextCorpusReadercorpus_root="D:\\nltk_data\\corpora\\mycorpus"wordlists=PlaintextCorpusReader(corpus_root,".*",encoding="UTF-8")2)对语料库中的中文文本进行预处理。
experiment是什么意思,experiment的解释

experiment是什么意思,experiment的解释汉语翻译n. 实验, 试验, 实验仪器vi. 实验, 尝试【化】实验【医】实验词型变化:名词:experimenter动词过去式:experimented 过去分词:experimented 现在分词:experimenting 第三人称单数:experiments词意辨析:trial, experiment, test, try这些名词均有“试验”之意。
trial: 指为观察、研究某事物以区别其真伪、优劣或效果等而进行较长时间的试验或试用过程。
experiment: 多指用科学方法在实验室内进行较系统的操作实验以验证、解释或说明某一理论、定理或某一观点等。
test: 普通用词,含义广,指用科学方法对某物质进行测试以估价其性质或效能等。
try: 普通用词,多用于口语或非正式场合,指试一试。
英语解释:名词 experiment:1.the act of conducting a controlled test or investigation同义词:experimentation2.the testing of an idea同义词:experimentation3.a venture at something new or different动词 experiment:1.to conduct a test or investigation2.try something new, as in order to gain experience同义词:try out例句:1.The teacher gave each of us a piece of filter paper before doing the experiment.做试验前,老师给我们每个人发了一张滤纸。
2.We are doing a chemical experiment.我们正在做化学实验。
基于云计算的中文分词研究

基于云计算的中文分词研究摘要:计算机科学技术的发展,催生了云计算概念,在各个领域的得到广泛应用。
中文分词作为进行中文信息检索、查询以及数据挖掘的基础技术,与云计算技术的结合能够实现更好的数据存储与挖掘效果,实现对中文信息的高效处理,提高信息资源的使用率,更好地为决策提供依据。
关键词:中文分词;云计算;Hadoop;MapReduce1系统架构在2台Dell R410服务器上部署Vmware vSphere Hypervisor,安装4个安装了Hadoop 0.2的FreeBSD操作系统,在Hadoop平台进行中文分词,服务器架构见图1。
图1 系统架构图在分布式系统内,使用具有8个节点组成的运行FreeBSD UNIX系统的HDFS架构进行平台环境的配置。
HDFS采用主从架构,一个集群由一个Master与多个Slave构成,主架构成为名字节点(NameNode),从架构为数据节点(DataNode)。
在Hadoop平台下,一个文件被分割,成为若干Block存储于数据节点之上,而名字节点则负责进行文件的打开、关闭等基本操作,数据节点与Block之间映射关系的建立,方便进行文件的读写与删减等。
MapReduce编程理念主要用于大量数据集的并行运算处理,将中文分词与MapReduce编程理念相结合,可以实现运行速度的提高。
Hadoop平台中使用IKAnalyzer,基于Java语言环境的中文分词工具包,使得该工具包在各个节点顺利工作,该工具包经过了一系列发展已推出了多个版本,其发展之初是为了实现Luence项目,后来借助于词典分词与文法分析算法的中文分词组件,实现了基于Java语言的公用分词组件的发展。
2关键技术关键技术包含了中文分词的MapReduce流程与中文分词组件的分发。
2.1中文分词的MapReduce流程如图2所示:图2 中文分词的MapReduce流程图主要涉及了6个步骤,首先,JobClient向Hadoop平台与HDFS文件系统传输job.jar,job.split,job.xml三种类型的文件,job.jar文件中涉及了此次目标任务中的各种类,如Mapper,Reducer等,job.split主要是文件的分块信息,包括块的数目与大小,job.xml文件则是对目标配置的表达,包括Mapper,Combiner等的类型、输入输出格式等内容,这些文件实现了中文分词任务上传到JobTracker中,并有效实现了文件的分块与设置。
《自然语言处理》教学上机实验报告
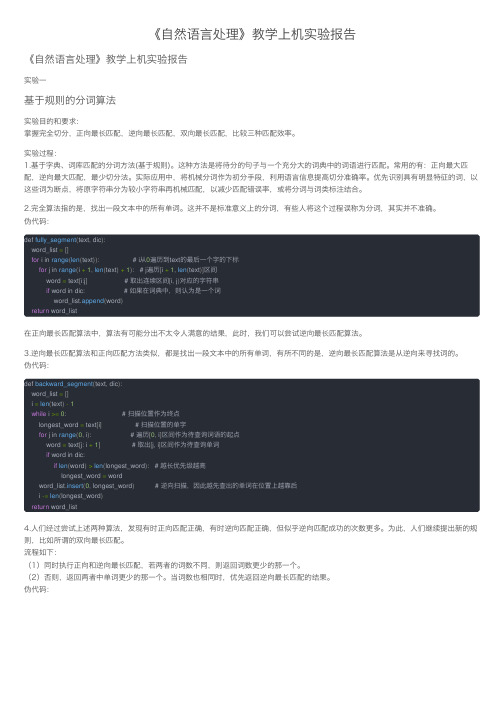
《⾃然语⾔处理》教学上机实验报告《⾃然语⾔处理》教学上机实验报告实验⼀基于规则的分词算法实验⽬的和要求:掌握完全切分,正向最长匹配,逆向最长匹配,双向最长匹配,⽐较三种匹配效率。
实验过程:1.基于字典、词库匹配的分词⽅法(基于规则)。
这种⽅法是将待分的句⼦与⼀个充分⼤的词典中的词语进⾏匹配。
常⽤的有:正向最⼤匹配,逆向最⼤匹配,最少切分法。
实际应⽤中,将机械分词作为初分⼿段,利⽤语⾔信息提⾼切分准确率。
优先识别具有明显特征的词,以这些词为断点,将原字符串分为较⼩字符串再机械匹配,以减少匹配错误率,或将分词与词类标注结合。
2.完全算法指的是,找出⼀段⽂本中的所有单词。
这并不是标准意义上的分词,有些⼈将这个过程误称为分词,其实并不准确。
伪代码:def fully_segment(text, dic):word_list =[]for i in range(len(text)): # i从0遍历到text的最后⼀个字的下标for j in range(i +1,len(text)+1): # j遍历[i +1,len(text)]区间word = text[i:j] # 取出连续区间[i, j)对应的字符串if word in dic: # 如果在词典中,则认为是⼀个词word_list.append(word)return word_list在正向最长匹配算法中,算法有可能分出不太令⼈满意的结果,此时,我们可以尝试逆向最长匹配算法。
3.逆向最长匹配算法和正向匹配⽅法类似,都是找出⼀段⽂本中的所有单词,有所不同的是,逆向最长匹配算法是从逆向来寻找词的。
伪代码:def backward_segment(text, dic):word_list =[]i =len(text)-1while i >=0: # 扫描位置作为终点longest_word = text[i] # 扫描位置的单字for j in range(0, i): # 遍历[0, i]区间作为待查询词语的起点word = text[j: i +1] # 取出[j, i]区间作为待查询单词if word in dic:if len(word)>len(longest_word): # 越长优先级越⾼longest_word = wordword_list.insert(0, longest_word) # 逆向扫描,因此越先查出的单词在位置上越靠后i -=len(longest_word)return word_list4.⼈们经过尝试上述两种算法,发现有时正向匹配正确,有时逆向匹配正确,但似乎逆向匹配成功的次数更多。
中文分词的三种方法

中文分词的三种方法
中文分词是对汉字序列进行切分和标注的过程,是许多中文文本处理任务的基础。
目前常用的中文分词方法主要有基于词典的方法、基于统计的方法和基于深度学习的方法。
基于词典的方法是根据预先构建的词典对文本进行分词。
该方法将文本与词典中的词进行匹配,从而得到分词结果。
优点是准确率较高,但缺点是对新词或专业术语的处理效果不佳。
基于统计的方法是通过建立语言模型来实现分词。
该方法使用大量的标注语料训练模型,通过统计词语之间的频率和概率来确定分词结果。
优点是对新词的处理有一定的鲁棒性,但缺点是对歧义性词语的处理效果有限。
基于深度学习的方法是利用神经网络模型进行分词。
该方法通过训练模型学习词语与其上下文之间的依赖关系,从而实现分词。
优点是对新词的处理效果较好,且具有较强的泛化能力,但缺点是需要大量的训练数据和计算资源。
综上所述,中文分词的三种方法各自具有不同的优缺点。
在实际应用中,可以根据任务需求和资源条件选择合适的方法进行处理。
例如,在自然语言处理领域,基于深度学习的方法在大规模数据集的训练下可以取得较好的效果,可以应用于机器翻译、文本分类等任务。
而基于词典的方法可以适用于某些特定领域的文本,如医药领
域或法律领域,因为这些领域往往有丰富的专业词汇和术语。
基于统计的方法则可以在较为通用的文本处理任务中使用,如情感分析、信息抽取等。
总之,中文分词方法的选择应根据具体任务和数据特点进行灵活调整,以期获得更好的处理效果。
中文分词的三种方法(一)

中文分词的三种方法(一)中文分词的三种中文分词是指将一段中文文本划分为一个个有实际意义的词语的过程,是自然语言处理领域中的一项基本技术。
中文分词技术对于机器翻译、信息检索等任务非常重要。
本文介绍中文分词的三种方法。
基于词典的分词方法基于词典的分词方法是将一段文本中的每个字按照词典中的词语进行匹配,将匹配到的词作为分词结果。
这种方法的优点是分词速度快,但缺点是无法解决新词和歧义词的问题。
常见的基于词典的分词器有哈工大的LTP、清华大学的THULAC等。
基于统计的分词方法基于统计的分词方法是通过对大规模语料库的训练,学习每个字在不同位置上出现的概率来判断一个字是否为词语的一部分。
这种方法能够较好地解决新词和歧义词的问题,但对于生僻词和低频词表现不够理想。
常见的基于统计的分词器有结巴分词、斯坦福分词器等。
基于深度学习的分词方法基于深度学习的分词方法是通过神经网络对中文分词模型进行训练,来获取词语的内部表示。
这种方法的优点是对于生僻词和低频词的表现较好,但需要大量的标注数据和计算资源。
常见的基于深度学习的分词器有哈工大的BERT分词器、清华大学的BERT-wwm分词器等。
以上是中文分词的三种方法,选择哪种方法需要根据实际应用场景和需求进行评估。
接下来,我们将对三种方法进行进一步的详细说明。
基于词典的分词方法基于词典的分词方法是最简单的一种方法。
它主要针对的是已经存在于词典中的单词进行分词。
这种方法需要一个词典,并且在分词时将文本与词典进行匹配。
若匹配上,则将其作为一个完整的单词,否则就将该文本认为是单字成词。
由于它只需要匹配词典,所以速度也是比较快的。
在中文分词中,“哈工大LTP分词器”是基于词典的分词工具之一。
基于统计的分词方法基于统计的分词方法是一种基于自然语言处理技术的分词方法。
其主要思路是统计每个字在不同位置出现的概率以及不同字的组合出现的概率。
可以通过训练一个模型来预测哪些字符可以拼接成一个词语。
实验1 中文分词实验

• 语பைடு நூலகம்可以任意:
• 作业以程序软件+报告的格式,要求:
• 作业提交格式:
作业内容放置一个文件夹中,并压缩交给我 文件夹命名:实验一+班级+姓名.rar
实验报告1 双向匹配中文分词 • 理论描述:
中文分词是。。。。,
• 算法描述:
本文实现双向匹配算法,具体算法描述如下: MM: RMM:
• 详例描述:
以“一把青菜”为例,详细描述算法如下
将程序实现的截图粘贴过来
• 软件演示:
另外,请每个小组将每次的作业实现在同一个软件平台中,班级及 成员不要变化,这样学期结束,就实现了一个NLP的工具集,最后 添加一个应用就是你的大作业了。
2.请使用概率最大方法及给定语料库对以下句子分词:
• “对外经济技术合作与交流不断扩大。” • 要求:利用人民日报语料库来计算每个候选词的概率值及 最佳左邻词,及分词结果。并计算分词的P,R,F值和分词 时间。
注意作业提交要求:看后一个PPT
作业提交要求
• 作业完成时间:
2周,请在第4周上课前提交,4人以内小组提交。 最好是C++或JAVA 报告标题、理论描述、算法描述、详例描述、软件演 示图, 请看样板
实验一 中文分词
实验内容
• 请分别使用正向最大匹配算法和逆向最大匹配 算法及给定的字典对以下句子进行分词,并分 别显示结果:
一把青菜 幼儿园地节目
实验一作业
• 请选择以下任意一个完成:
1.请使用双向匹配算法对给定测试文本进行分词:
• 给定测试文本为:实验1作业测试文本.txt • 词典为:chineseDic.txt • 要求:编程实现,并计算分词的P, R,F值和分词时间。
一种基于Lucene的中文分词的设计与测试

( ol eo Ifr t nSc r y S a g M ioo gU iesy S a g a 00 0 C ia C lg f noma o eu i ,b n h Jatn nvri ,h n h i 0 3 , hn ) e i t t 2
s ac i g s se . e h n y tm r
Ke r s: Ch n s r e e t t n; s a c n i y wo d i e e wo d sห้องสมุดไป่ตู้g n a i m o e r h e gne; L c n u e e;f r a d x mu mac g rtm o w r sma i m t h a o i l h
和 效率上 的差异。对 于如何构 建一 个高效 的 中文检 索 系统 ,提 出了一种 实现 方案 。 关键词 :中文分词 ;搜索 引擎 ;Lcn ;正 向最大匹 配算法 uee
A e i n a d t s f Ch n s r e m e t to a e n Lu e e d sg n e to i e e wo d s g n a i n b s d o c n
wiey u e r h tcu e L c n n d c mb n st e ma i m th n l o tm n p i z d C i e e d l s d a c i tr u e e,a o ie x mu mac ig a g r h a d o t e h n s e h i mi w r s d cin r oa h e e ah g f ce c n c u a y o h n s o d e e t t n h ep p ras o d it ay t c i v ih e iin y a d a c r c fC i e e w r ss g na i .T a e lo o m o c mp r s h mo u e i t S a d r An y e n C K a y e i f n t n n e iin y y l o ae t e d l w h t a d a z a d J An lz r n u c i a d f ce c b t e n l o 1
自然语言处理-中文分词程序实验报告(含源代码)

9
infile.open("dict/number.txt.utf8"); if (!infile.is_open()) { cerr << "Unable to open input file: " << "wordlexicon" << " -- bailing out!" << endl; exit(-1); } while (getline(infile, strtmp)) // 读入词典的每一行并将其添加入哈希中 { istringstream istr(strtmp); istr >> word; //读入每行第一个词 numberhash.insert(sipair(word, 1)); //插入到哈希中 } infile.close(); infile.open("dict/unit.txt.utf8"); if (!infile.is_open()) { cerr << "Unable to open input file: " << "wordlexicon" << " -- bailing out!" << endl; exit(-1); } while (getline(infile, strtmp)) // 读入词典的每一行并将其添加入哈希中 { istringstream istr(strtmp); istr >> word; //读入每行第一个词 unithash.insert(sipair(word, 1)); //插入到哈希中 } infile.close(); } //删除语料库中已有的分词空格,由本程序重新分词 string eat_space(string s1) { int p1=0,p2=0; int count; string s2; while(p2 < s1.length()){ //删除全角空格 // if((s1[p2]-0xffffffe3)==0 && // s1[p2+1]-0xffffff80==0 && // s1[p2+2]-0xffffff80==0){//空格
experiment短语

experiment短语【释义】experimentn.实验,试验;尝试,实践v.进行实验,做试验;试,尝试复数experiments第三人称单数experiments现在分词experimenting过去式experimented过去分词experimented【短语】1thought experiment思想实验;思考实验;思维实验2Milgram experiment米尔格拉姆实验;米尔格伦实验;名的米尔格拉姆试验3Stanford prison experiment斯坦福监狱实验;史丹福监狱实验;斯坦福监狱试验4The Experiment死亡实验;未知实验5Das Experiment死亡实验;实验监狱;死亡试验;实验6design of experiment实验设计;试验试验设计;实验计划法;实验设计法7Griffith's experiment格里菲斯实验8afshar experiment阿弗沙尔实验9Computer experiment计算机试验;上机实验【例句】1I decided to conduct an experiment.我决定做一项实验。
2The experiment went horribly wrong.实验弄得一塌糊涂。
3As an experiment,we bought Ted a watch.作为尝试,我们给特德买了块手表。
4This experiment was harmless to the animals.这个实验对动物无害。
5I've never cooked this before so it's an experiment.我以前从未做过这种菜,所以这是一个尝试。
6The results of the experiment confirmed our predictions.实验结果证实了我们的预测。
7This was demonstrated in a laboratory experiment with rats.这点通过在实验室中用老鼠做试验得到证明。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
中文分词实验
一、实验目的:
目的:了解并掌握基于匹配的分词方法,以及分词效果的评价方法。
实验要求:
1、从互联网上查找并构建不低于10万词的词典,构建词典的存储结构;
2、选择实现一种机械分词方法(双向最大匹配、双向最小匹配、正向减字最大匹配法等)。
3、在不低于1000个文本文件,每个文件大于1000字的文档中进行中文分词测试,记录并分析所选分词算法的准确率、分词速度。
预期效果:
1、平均准确率达到85%以上
二、实验方案:
1.实验平台
系统:win10
软件平台:spyder
语言:python
2.算法选择
选择正向减字最大匹配法,参照《搜索引擎-原理、技术与系统》教材第62页的描述,使用python语言在spyder软件环境下完成代码的编辑。
算法流程图:
Figure 错误!未指定顺序。
. 正向减字最大匹配算法流程
Figure 错误!未指定顺序。
. 切词算法流程算法伪代码描述:
3.实验步骤
1)在网上查找语料和词典文本文件;
2)思考并编写代码构建词典存储结构;
3)编写代码将语料分割为1500个文本文件,每个文件的字数大于1000字;
4)编写分词代码;
5)思考并编写代码将语料标注为可计算准确率的文本;
6)对测试集和分词结果集进行合并;
7)对分词结果进行统计,计算准确率,召回率及F值(正确率和召回率的
调和平均值);
8)思考总结,分析结论。
4.实验实施
我进行了两轮实验,第一轮实验效果比较差,于是仔细思考了原因,进行了第二轮实验,修改参数,代码,重新分词以及计算准确率,效果一下子提升了很多。
实验过程:
(1)语料来源:语料来自SIGHAN的官方主页
(/),SIGHAN是国际计算语言学会(ACL)
中文语言处理小组的简称,其英文全称为“Special Interest Group for
Chinese Language Processing of the Association for Computational
Linguistics”,又可以理解为“SIG汉“或“SIG漢“。
SIGHAN为我们提供了一
个非商业使用(non-commercial)的免费分词语料库获取途径。
我下载
的是Bakeoff 2005的中文语料。
有86925行,2368390个词语。
语料形
式:“没有孩子的世界是寂寞的,没有老人的世界是寒冷的。
”
Figure 错误!未指定顺序。
. notepad++对语料文本的统计结果
(2)词典:词典用的是来自网络的有373万多个词语的词典,采用的数据结
构为python的一种数据结构——集合。
Figure 错误!未指定顺序。
. notepad++对词典文本的统计结果
(3)分割测试数据集:将原数据分割成1500个文本文件,每个文件的词数大于
1000。
Figure 错误!未指定顺序。
. 测试数据集分解截图
Figure 错误!未指定顺序。
. 其中某文件的形式
Figure 错误!未指定顺序。
. notepad++对其中一个测试文本的统计结果
(4)编写分词代码:采用python语言和教材上介绍的算法思路,进行编程。
(5)编写代码将语料标注为可计算准确率的文本:用B代表单词的开始字,
E代表结尾的字,BE代表中间的字,如果只有一个字,用E表示。
例如:原数据是:“人们常说生活是一部教科书”
而我将它转化为了如下格式:
人 B
们 E
常 E
说 E
生 B
活 E
是 E
一 E
部 E
教 B
科 BE
书 E
(6)进行分词:使用之前编写的分词函数,载入文本,进行分词,将每个文
本结果输出到txt文本。
Figure 错误!未指定顺序。
. 分词结果文件
Figure 9. 测试数据的形式(文本截图)
Figure 10. 分词结果(文本截图)
用时17秒左右:
Figure 11. 运行时间
(7)对测试集和分词结果集进行合并:将测试集和分词结果集合并是为了进
行准确率,召回率等的计算。
测试集和训练集都是下面的格式:人 B
们 E
常 E
说 E
生 B
活 E
是 E
一 E
部 E
教 B
科 BE
书 E
我将他们合并为下面的格式,第二列为测试集的标注,第三列为训练集的结果:
人 B B
们 E E
常 E E
说 E E
生 B B
活 E E
是 E E
一 E BE
部 E E
教 B B
科 BE BE
书 E E
(8)对分词结果进行统计,计算准确率P,召回率R及F值(正确率和召回
率的调和平均值),设提取出的信息条数为C,提取出的正确信息条数为CR, 样本中的信息条数O:
P=CR C
R=CR O
F=2×P×R P+R
计算结果如下:
(9)反思:平均准确率只有75.79%,为何分词效果这么差,没有达到我的预期效果
85%,经过思考和多次尝试才发现,原来是因为我的词典太大了,最大匹配分词效果对词典依赖很大,不是词典越大越好,还有就是我的词典和我的测试数据的相关性不大,于是我修改了词典,进行了第二轮测试。
(10)修改词典:将词典大小裁剪,但是不能只取局部,例如前面10万词或后面10万
词,于是我的做法是在373万词的词典中随机取3万词,再用之前没用完的语料
制作7万词,组成10万词的词典:
Figure 12. notepad++对重新制作的词典文本的统计结果
(11)
此时分词的平均准确率提高到了87.13%,还是很不错的,说明我的反思是有道理的。
三、实验结果及分析:
实验结果:
第一轮分词结果只有75.79%,而我的预期效果或者说目标是85%以上,我先是思考是不是这个算法只能达到这么多,于是通过网络和询问同学的分词准确率知道,这个结果是可以继续提升的。
于是,我仔细思考了每一个环节,发现问题主要出在词典上面,因为词典中的词越多,利用做大匹配分出来的词的平均长度就越长,分得的词数也越少,错误率反而增大,而那些分法可能并不是我
们想要的,而且我的词典和我的语料相关性很小,分词效果是依赖于这个词典的相关性的。
然后我尝试减少词典的大小,见减小到150万词,发现效果确实好了点,于是干脆只在原词典中取出3万词,自己再用语料库没用过的同类型的语料做一份词典,再把它们合起来,结果分词准确率一下子提高到了87.13%,说明我的想法是有道理。
简言之:
影响中文分词效果的因素:词典的大小,数据集的规范性,算法的优越程度
如何提高中文分词的准确率:规范的数据集,合理大小的词典,好的算法
四、实验总结:
本次实验大概总耗时50个小时,代码量为300余行,期间遇到过很多问题,幸好都一一解决了,比如在合并测试集和分词结果集时,合并测试集和分词结果集时中词语的位置有错位,想了好几个办法才解决,其实在实验之前多思考思考是可以避免这种情况的。
本次实验中,分词是实验的重点,但难点不在分词上面,而在数据的处理和计算准确率。
我们还应多练习,多运用,多思考才能真正提升自己的能力。
五、参考文献:
数据集:SIGHAN bakeoff2005 数据集中的简体中文部分
链接:/bakeoff2005/
文献:1. 知乎:如何解释召回率与准确率?
链接:https:///question/19645541
2. 《搜索引擎--原理、技术与系统》。