es中英文分词
es 分词检索高亮显示 剔除html java案例

对于这个主题,我们需要对es 分词检索高亮显示进行深入的讨论。
ES (Elasticsearch)是一个开源的分布式搜索引擎,提供了全文搜索功能,可以对大规模数据进行快速的检索和分析。
而分词检索高亮显示则是ES在搜索过程中非常重要的一个功能,它能够将搜索结果中的关键词进行高亮显示,方便用户快速找到所需信息。
接下来,我们将从以下几个方面进行讨论。
1. ES 分词ES在进行检索时,会对文档内容先进行分词处理,将文本分割成一个个的词语,这些词语就是ES进行搜索的基本单位。
ES内置了一些常用的分词器,比如standard、simple、whitespace等,用户也可以根据自己的需求自定义分词器。
分词的好坏直接影响到搜索的准确性,因此选择合适的分词器非常重要。
2. 检索ES的检索功能非常强大,可以通过各种查询方式来实现不同的检索需求,比如term查询、match查询、bool查询等。
在进行检索时,ES 会使用之前提到的分词器对搜索关键词进行分词,然后再在分词后的词语中进行匹配,找到符合条件的文档。
3. 高亮显示高亮显示是ES在搜索结果中非常常用的一个功能,在搜索结果中将匹配的关键词进行特殊标记,让用户一眼就能看出哪些部分是与搜索条件匹配的。
通过高亮显示,用户可以更直观地了解搜索结果与搜索条件的关联程度,提高了搜索的可用性。
4. 剔除html在实际应用中,文档内容通常是包含有HTML标签的,而在搜索结果中我们通常不希望看到HTML标签,因此需要将搜索结果中的HTML 标签进行剔除,只显示纯文本内容。
ES提供了一些过滤器可以用来实现这个功能,比如HTML strip字符过滤器。
5. Java案例我们将以一个Java案例来演示如何在Java程序中使用ES进行分词检索和高亮显示。
首先需要引入ES的Java客户端库,然后通过编写相应的代码来实现搜索功能,包括构造查询条件、实现分词和高亮显示等。
这个案例将帮助大家更好地理解ES分词检索高亮显示的具体实现方法。
es基于match_phrasefuzzy的模糊匹配原理及使用

es基于match_phrasefuzzy的模糊匹配原理及使⽤ 在业务中经常会遇到类似数据库的"like"的模糊匹配需求,⽽es基于分词的全⽂检索也是有类似的功能,这个就是短语匹配match_phrase,但往往业务需求都不是那么简单,他想要有like的功能,⼜要允许有⼀定的容错(就是我搜索"东⽅宾馆"时,"⼴州花园宾馆酒店"也要出来,这个就不是单纯的"like"),下⾯就是我需要解析的问题(在此吐槽⼀下业务就是这么变态。
) 描述⼀个问题时⾸先需要描述业务场景:假设es中有⼀索引字段name存储有以下⽂本信息:doc[1]:{"name":"⼴州东⽅宾馆酒店"}doc[2]:{"name":"⼴州花园宾馆酒店"}doc[3]:{"name":"东⽅公园宾馆"}需求要求在输⼊:"东⽅宾馆"的时候doc[1]排最前⾯doc[3]排第⼆doc[2]排第三,对于这个需求从简单的全⽂检索match来说,doc[3]:{"name":"东⽅公园宾馆"}应该是第⼀位(注意:为了简化原理分析,分词我们使⽤standard即按单个字分词) 业务分析:显然对于上⾯的业务场景如果单独使⽤match的话,显然是不合适,因为按照standard分词,doc[3]的词条长度要⽐doc[1]的词条长度短,⽽词频⼜是都出现了[东][⽅][宾][馆]4个词,使⽤match匹配的话就会吧doc[3]排到最前⾯,显然业务希望把输⼊的⽂字顺序匹配度最⾼的数据排前⾯,因为我确实要找的是"⼴州东⽅宾馆酒店"⽽不是"东⽅公园宾馆"你不能把doc[3]给我排前⾯,OK业务逻辑好像是对的那么怎么解决问题; 解决问题前介绍⼀哈match_phrase原理(match的原理我就不说了⾃⼰回去看⽂档),简单点说match_phrase就是⾼级"like"。
es中英文分词

es中英文分词Elasticsearch(简称为es)是一种开源分布式搜索引擎,广泛用于各种应用场景中,如全文搜索、日志分析、实时推荐等。
在多语言环境下,es对中英文的分词处理尤为重要。
本文将介绍es中英文分词的原理和实现方式。
一、中文分词中文文本由一系列汉字组成,而汉字与字之间没有明确的分隔符。
因此,中文分词就是将连续的汉字切分成有意义的词语的过程。
es中的中文分词器使用了基于词典匹配和规则引擎的方式进行分词。
1. 词典匹配基于词典匹配的中文分词器会将待分析的文本与一个中文词典进行匹配。
词典中包含了中文的常用词汇。
当待分析的文本与词典中的词汇相匹配时,就将其作为一个词语进行标记。
这种方法简单高效,适用于大部分中文分词场景。
2. 规则引擎规则引擎是一种基于规则的匹配引擎,它可以根据事先定义好的规则来对文本进行处理。
es中的规则引擎分词器可以根据指定的规则对中文文本进行分词操作。
这种方式的优点是可以根据具体的分词需求编写灵活的规则,适应不同语料库的分词要求。
二、英文分词英文文本中的词语之间通常以空格或标点符号作为分隔符。
因此,英文分词的目标是将文本按照空格或标点符号进行分隔。
es中的英文分词器使用了基于空格和标点符号的切分方式。
它会将空格或标点符号之间的文本作为一个词语进行标记。
如果文本中包含连字符或点号等特殊符号,分词器会将其作为一个整体进行标记。
三、多语言分词es还支持多语言环境下的分词处理。
对于既包含中文又包含英文的文本,es可以同时使用中文分词器和英文分词器进行处理。
这样可以将中文和英文的词语分开,并分别进行索引,提高搜索的准确性和效率。
四、自定义分词器除了内置的中文分词器和英文分词器,es还提供了自定义分词器的功能。
用户可以根据自己的需求,编写自己的分词规则或使用第三方分词工具,然后将其配置到es中进行使用。
在es中,可以通过设置分词器的类型、配置分词规则和添加自定义词典等方式来实现自定义分词器。
es中英文分词

在Elasticsearch(简称ES)中,中英文分词是一个重要的功能,它可以帮助我们更准确地搜索和索引中英文文本。
下面是一些关于ES 中英文分词的基本知识和常用方法:1.内置分词器:Elasticsearch 内置了一些分词器,如Standard 分词器和Simple 分词器,它们都可以处理英文文本的分词。
但对于中文文本,它们可能不太适用,因为它们会将整个中文词语作为一个词项。
2.中文分词器:为了处理中文文本,我们需要使用专门的中文分词器,如IK 分词器、Jieba 分词器等。
这些分词器可以将中文文本分割成一个个有意义的词语,从而提高搜索的准确性。
3.安装插件:要在Elasticsearch 中使用中文分词器,通常需要安装相应的插件。
例如,对于IK 分词器,可以下载相应的插件包并安装到Elasticsearch 中。
4.配置分词器:安装插件后,需要在Elasticsearch 的配置文件中指定要使用的分词器。
这通常涉及到在索引设置中定义分析器(analyzer)和分词器(tokenizer)。
5.测试分词效果:配置好分词器后,可以使用Elasticsearch 的分析API 来测试分词效果。
这可以帮助我们了解分词器是如何处理中英文文本的,并根据需要进行调整。
6.优化分词策略:根据测试结果,我们可以调整分词策略以提高搜索效果。
例如,可以自定义词典来处理一些特殊的词汇或术语,或者调整分词器的参数来改变分词的行为。
7.注意事项:在使用中英文分词时,需要注意一些细节。
例如,要避免过度分词(将一个词分割成过多的词项)或分词不足(未能将长词或短语正确分割)。
此外,还需要考虑如何处理中英文混合文本以及如何处理标点符号等问题。
ES004-Elasticsearch高级查询及分词器
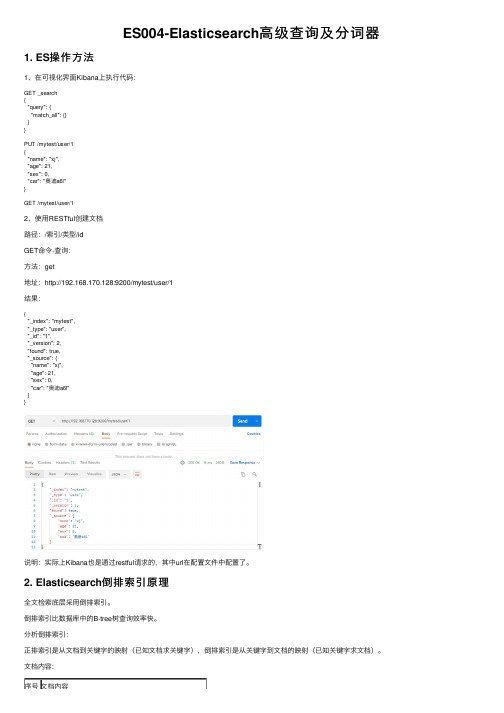
ES004-Elasticsearch⾼级查询及分词器1. ES操作⽅法1、在可视化界⾯Kibana上执⾏代码:GET _search{"query": {"match_all": {}}}PUT /mytest/user/1{"name": "xj","age": 21,"sex": 0,"car": "奥迪a6l"}GET /mytest/user/12、使⽤RESTful创建⽂档路径:/索引/类型/idGET命令-查询:⽅法:get地址:http://192.168.170.128:9200/mytest/user/1结果:{"_index": "mytest","_type": "user","_id": "1","_version": 2,"found": true,"_source": {"name": "xj","age": 21,"sex": 0,"car": "奥迪a6l"}}说明:实际上Kibana也是通过restful请求的,其中url在配置⽂件中配置了。
2. Elasticsearch倒排索引原理全⽂检索底层采⽤倒排索引。
倒排索引⽐数据库中的B-tree树查询效率快。
分析倒排索引:正排索引是从⽂档到关键字的映射(已知⽂档求关键字),倒排索引是从关键字到⽂档的映射(已知关键字求⽂档)。
⽂档内容:序号⽂档内容1⼩俊是⼀家科技公司创始⼈,开的汽车是奥迪a8l,加速爽。
[ES]elasticsearch章5 ES的分词(一)
![[ES]elasticsearch章5 ES的分词(一)](https://img.taocdn.com/s3/m/495dbcc377a20029bd64783e0912a21614797fbc.png)
[ES]elasticsearch章5 ES的分词(⼀)初次接触 Elasticsearch 的同学经常会遇到分词相关的难题,⽐如如下这些场景:1.为什么明明有包含搜索关键词的⽂档,但结果⾥⾯就没有相关⽂档呢?2.我存进去的⽂档到底被分成哪些词(term)了?3.我⾃定义分词规则,但感觉好⿇烦呢,⽆从下⼿1.从⼀个实例出发,如下创建⼀个⽂档:然后我们做⼀个查询,我们试图通过搜索 eat 这个关键词来搜索这个⽂档ES的返回结果为0。
这不太对啊,我们⽤最基本的字符串查找也应该能匹配到上⾯新建的⽂档才对啊!先来看看什么是分词。
2. 分词搜索引擎的核⼼是倒排索引,⽽倒排索引的基础就是分词。
所谓分词可以简单理解为将⼀个完整的句⼦切割为⼀个个单词的过程。
在 es 中单词对应英⽂为 term 。
我们简单看个例⼦:ES 的倒排索引即是根据分词后的单词创建,即我、爱、北京、天安门这4个单词。
这也意味着你在搜索的时候也只能搜索这4个单词才能命中该⽂档。
实际上 ES 的分词不仅仅发⽣在⽂档创建的时候,也发⽣在搜索的时候,如下图所⽰:读时分词发⽣在⽤户查询时,ES 会即时地对⽤户输⼊的关键词进⾏分词,分词结果只存在内存中,当查询结束时,分词结果也会随即消失。
⽽写时分词发⽣在⽂档写⼊时,ES 会对⽂档进⾏分词后,将结果存⼊倒排索引,该部分最终会以⽂件的形式存储于磁盘上,不会因查询结束或者 ES 重启⽽丢失。
ES 中处理分词的部分被称作分词器,英⽂是Analyzer,它决定了分词的规则。
ES ⾃带了很多默认的分词器,⽐如Standard、Keyword、Whitespace等等,默认是Standard。
当我们在读时或者写时分词时可以指定要使⽤的分词器。
3. 写时分词结果回到上⼿阶段,我们来看下写⼊的⽂档最终分词结果是什么。
通过如下 api 可以查看:其中test为索引名,_analyze为查看分词结果的endpoint,请求体中field为要查看的字段名,text为具体值。
Es学习第五课,分词器介绍和中文分词器配置

Es学习第五课,分词器介绍和中⽂分词器配置上课我们介绍了倒排索引,在⾥⾯提到了分词的概念,分词器就是⽤来分词的。
分词器是ES中专门处理分词的组件,英⽂为Analyzer,定义为:从⼀串⽂本中切分出⼀个⼀个的词条,并对每个词条进⾏标准化。
它由三部分组成,Character Filters:分词之前进⾏预处理,⽐如去除html标签Tokenizer:将原始⽂本按照⼀定规则切分为单词Token Filters:针对Tokenizer处理的单词进⾏再加⼯,⽐如转⼩写、删除或增新等处理,也就是标准化预定义的分词器ES⾃带的分词器有如下:Standard Analyzer默认分词器按词切分,⽀持多语⾔⼩写处理⽀持中⽂采⽤的⽅法为单字切分Simple Analyzer按照⾮字母切分⼩写处理Whitespace Analyzer空⽩字符作为分隔符Stop Analyzer相⽐Simple Analyzer多了去除请⽤词处理停⽤词指语⽓助词等修饰性词语,如the, an, 的,这等Keyword Analyzer不分词,直接将输⼊作为⼀个单词输出Pattern Analyzer通过正则表达式⾃定义分隔符默认是\W+,即⾮字词的符号作为分隔符ES默认对中⽂分词是⼀个⼀个字来解析,这种情况会导致解析过于复杂,效率低下,所以⽬前有⼏个开源的中⽂分词器,来专门解决中⽂分词,其中常⽤的叫IK中⽂分词难点中⽂分词指的是将⼀个汉字序列切分为⼀个⼀个的单独的词。
在英⽂中,单词之间以空格作为⾃然分界词,汉语中词没有⼀个形式上的分界符上下⽂不同,分词结果迥异,⽐如交叉歧义问题常见分词系统:实现中英⽂单词的切分,可⾃定义词库,⽀持热更新分词词典:⽀持分词和词性标注,⽀持繁体分词,⾃定义词典,并⾏分词等:由⼀系列模型与算法组成的Java⼯具包,⽬标是普及⾃然语⾔处理在⽣产环境中的应⽤:中⽂分词和词性标注安装配置ik中⽂分词插件# 在Elasticsearch安装⽬录下执⾏命令,然后重启esbin/elasticsearch-plugin install https:///medcl/elasticsearch-analysis-ik/releases/download/v6.3.0/elasticsearch-analysis-ik-6.3.0.zip # 如果由于⽹络慢,安装失败,可以先下载好zip压缩包,将下⾯命令改为实际的路径,执⾏,然后重启esbin/elasticsearch-plugin install file:///path/to/elasticsearch-analysis-ik-6.3.0.zipik两种分词模式ik_max_word 和 ik_smart 什么区别?ik_max_word: 会将⽂本做最细粒度的拆分,⽐如会将“中华⼈民共和国国歌”拆分为“中华⼈民共和国,中华⼈民,中华,华⼈,⼈民共和国,⼈民,⼈,民,共和国,共和,和,国国,国歌”,会穷尽各种可能的组合;ik_smart: 会做最粗粒度的拆分,⽐如会将“中华⼈民共和国国歌”拆分为“中华⼈民共和国,国歌”。
动词第三人称单数变化规则如下

动词第三人称单数变化规则1) 一般情况下,动词后面直接加-s. 例如:works gets says reads2) 以ch,sh,s,x 或o 结尾的动词,在后面加-es。
例如:go-goes teach-,teache wash-washes brush-brushes ,catch-catches ,do-does ,fix -fixes3) 以辅音字母+ y结尾的动词,把y变为i 再加-es. 例如:study- studies try-tries carry-carries ,fly-flies cry-cries现在分词变化规则1.直接+ ing(例:sleep+ing sleeping)2.去e+ing(例:bite-e+ing biting)3重读闭音节,且末尾只有1个辅音字母,双写辅音字母+ing(例:sit+t+ing sitting)4.特殊变化:die-dying,lie-lying,tie-tying5.不规则变化现在进行时的基本用法:A 表示现在( 指说话人说话时) 正在发生的事情。
例:We are waiting for you.B. 习惯进行:表示长期的或重复性的动作,说话时动作未必正在进行。
例:Mr. Green is writing another novel.(说话时并未在写,只处于写作的状态。
)例:She is learning piano under Mr. Smith.C.已经确定或安排好的将来活动I'm leaving for a trek in Nepal next week.(已经安排了)we're flying to Paris tomorrow.(票已经拿到了)D.有些动词(状态动词不用于进行时态)1.表示知道或了解的动词:believe,doubt,forget,imagine,know, remember,realize,suppose,understand2.表示“看起来”“看上去"appear,resemble,seem3表示喜爱或不喜爱hate,like.lover.prefer4表示构成或来源的动词be come from.contain,include5表示感官的动词hear see smell sound taste6表示拥有的动词belong to.need.own .possess.want wish1、现在进行时的构成现在进行时由"be+v-ing"构成。
elasticsearch英文分词

一、概述Elasticsearch是一个开源的分布式搜索引擎,其作为一个基于Lucene的搜索引擎,在处理中文搜索时面临很多挑战。
其中一个重要的挑战就是中文分词。
中文分词是将中文文本按照语义进行切分的过程,而在Elasticsearch中,英文分词是先决条件。
在本文中,我们将深入探讨Elasticsearch中的英文分词器。
二、英文分词器概述1. 什么是分词器?在Elasticsearch中,分词器(Tokenizer)是指将文本按照一定规则切分成一个个有意义的词条(Token)的工具。
而在英文中,分词通常是按照空格、标点符号等进行切分。
2. Elasticsearch中的英文分词器Elasticsearch中内置了多种用于英文分词的分词器,常见的包括standard、simple、whitespace等。
每个分词器都有不同的分词规则和性能特点,可以根据需求选择合适的分词器进行配置。
三、常见的英文分词器1. Standard分词器Standard分词器是Elasticsearch中默认的英文分词器,其基于Unicode文本分割算法进行分词,能够处理绝大部分英文文本。
然而,在处理专有名词、缩写词等方面可能存在一定的局限性。
2. Simple分词器Simple分词器是一种基本的英文分词器,它仅按照非字母字符进行切分。
由于其简单性,适用于一些特殊场景下的文本处理。
3. Whitespace分词器Whitespace分词器是根据空格进行切分的分词器,适用于处理英文文本中的词语。
然而,在现实场景中,往往需要更为复杂的分词规则来处理文本。
四、自定义英文分词器除了内置的英文分词器外,Elasticsearch还支持自定义分词器。
用户可以根据实际需求,自定义分词规则、添加停用词等,以适配特定的文本处理场景。
1. 自定义分词规则通过配置自定义的分词规则,用户可以根据具体的需求,实现更为精确的文本处理。
针对特定行业的术语、品牌名称等进行定制化分词处理。
es修改拼音分词器源码实现汉字拼音简拼混合搜索时同音字不匹配

es修改拼⾳分词器源码实现汉字拼⾳简拼混合搜索时同⾳字不匹配[版权声明]:本⽂章由danvid发布于,如需转载或部分使⽤请注明出处 在业务中经常会⽤到拼⾳匹配查询,⼤家都会⽤到拼⾳分词器,但是拼⾳分词器匹配的时候有个问题,就是会出现同⾳字匹配,有时候这种情况是业务不希望出现的。
业务场景:我输⼊"纯⽣pi酒"进⾏搜索,⽂档中有以下数据:doc[1]:{"name":"纯⽣啤酒"}doc[2]:{"name":"春⽣啤酒"}doc[3]:{"name":"纯⽣劈酒"}以上业务点是我输⼊"纯⽣pi酒"理论上业务希望只返回doc[1]:{"name":"纯⽣啤酒"}和doc[3]:{"name":"纯⽣劈酒"}其他的不是我要的数据,因为从业务⾓度来看,我已经输⼊"纯⽣"了,理论上只需要返回有"纯⽣"的数据(当然也有很多情况,会希望把"春⽣"也返回来),正常使⽤拼⾳分词器,会把doc[2]也会返回,原因是拼⾳分词器会把doc[2]变成:{"tokens": [{"token": "c","start_offset": 0,"end_offset": 1,"type": "word","position": 0},{"token": "chun","start_offset": 0,"end_offset": 1,"type": "word","position": 0},{"token": "s","start_offset": 1,"end_offset": 2,"type": "word","position": 1},{"token": "sheng","start_offset": 1,"end_offset": 2,"type": "word","position": 1},{"token": "p","start_offset": 2,"end_offset": 3,"type": "word","position": 2},{"token": "pi","start_offset": 2,"end_offset": 3,"type": "word","position": 2},{"token": "j","start_offset": 3,"end_offset": 4,"type": "word","position": 3},{"token": "jiu","start_offset": 3,"end_offset": 4,"type": "word","position": 3}]}由于"纯⽣"和"春⽣"是同⾳字,分词结果doc[1]和doc[2]是⼀样的,所以把doc[2]匹配上就是理所当然了,那么如何解决? 其实我们的需求是就当输⼊搜索⽂本时(搜索⽂本中可能同时存在中⽂/拼⾳),搜索⽂本中有[中⽂] 则按[中⽂]匹配,有[拼⾳]则按[拼⾳]匹配即可,这样就屏蔽掉了输⼊中⽂时匹配到同⾳字的问题。
ES-自然语言处理之中文分词器

ES-⾃然语⾔处理之中⽂分词器前⾔中⽂分词是中⽂⽂本处理的⼀个基础步骤,也是中⽂⼈机⾃然语⾔交互的基础模块。
不同于英⽂的是,中⽂句⼦中没有词的界限,因此在进⾏中⽂⾃然语⾔处理时,通常需要先进⾏分词,分词效果将直接影响词性、句法树等模块的效果。
当然分词只是⼀个⼯具,场景不同,要求也不同。
在⼈机⾃然语⾔交互中,成熟的中⽂分词算法能够达到更好的⾃然语⾔处理效果,帮助计算机理解复杂的中⽂语⾔。
根据中⽂分词实现的原理和特点,可以分为:基于词典分词算法基于理解的分词⽅法基于统计的机器学习算法基于词典分词算法基于词典分词算法,也称为字符串匹配分词算法。
该算法是按照⼀定的策略将待匹配的字符串和⼀个已经建⽴好的"充分⼤的"词典中的词进⾏匹配,若找到某个词条,则说明匹配成功,识别了该词。
常见的基于词典的分词算法为⼀下⼏种:正向最⼤匹配算法。
逆向最⼤匹配法。
最少切分法。
双向匹配分词法。
基于词典的分词算法是应⽤最⼴泛,分词速度最快的,很长⼀段时间内研究者在对对基于字符串匹配⽅法进⾏优化,⽐如最⼤长度设定,字符串存储和查找⽅法以及对于词表的组织结构,⽐如采⽤TRIE索引树,哈希索引等。
这类算法的优点:速度快,都是O(n)的时间复杂度,实现简单,效果尚可。
算法的缺点:对歧义和未登录的词处理不好。
基于理解的分词⽅法这种分词⽅法是通过让计算机模拟⼈对句⼦的理解,达到识别词的效果,其基本思想就是在分词的同时进⾏句法、语义分析,利⽤句法信息和语义信息来处理歧义现象,它通常包含三个部分:分词系统,句法语义⼦系统,总控部分,在总控部分的协调下,分词系统可以获得有关词,句⼦等的句法和语义信息来对分词歧义进⾏判断,它模拟来⼈对句⼦的理解过程,这种分词⽅法需要⼤量的语⾔知识和信息,由于汉语⾔知识的笼统、复杂性,难以将各种语⾔信息组成及其可以直接读取的形式,因此⽬前基于理解的分词系统还在试验阶段。
基于统计的机器学习算法这类⽬前常⽤的算法是HMM,CRF,SVM,深度学习等算法,⽐如stanford,Hanlp分词⼯具是基于CRF算法。
使用ES对中文文章进行分词,并进行词频统计排序

使⽤ES对中⽂⽂章进⾏分词,并进⾏词频统计排序前⾔:⾸先有这样⼀个需求,需要统计⼀篇10000字的⽂章,需要统计⾥⾯哪些词出现的频率⽐较⾼,这⾥⾯⽐较重要的是如何对⽂章中的⼀段话进⾏分词,例如“北京是×××的⾸都”,“北京”,“×××”,“中华”,“华⼈”,“⼈民”,“共和国”,“⾸都”这些是⼀个词,需要切分出来,⽽“京是”“民共”这些就不是有意义的词,所以不能分出来。
这些分词的规则如果⾃⼰去写,是⼀件很⿇烦的事,利⽤开源的IK分词,就可以很容易的做到。
并且可以根据分词的模式来决定分词的颗粒度。
ik_max_word: 会将⽂本做最细粒度的拆分,⽐如会将“×××国歌”拆分为“×××,中华⼈民,中华,华⼈,⼈民共和国,⼈民,⼈,民,共和国,共和,和,国国,国歌”,会穷尽各种可能的组合;ik_smart: 会做最粗粒度的拆分,⽐如会将“×××国歌”拆分为“×××,国歌”。
⼀:⾸先要准备环境如果有ES环境可以跳过前两步,这⾥我假设你只有⼀台刚装好的CentOS6.X系统,⽅便你跑通这个流程。
(1)安装jdk。
$ wget /otn-pub/java/jdk/8u111-b14/jdk-8u111-linux-x64.rpm$ rpm -ivh jdk-8u111-linux-x64.rpm(2)安装ES$ wget https://download.elastic.co/elasticsearch/release/org/elasticsearch/distribution/rpm/elasticsearch/2.4.2/elasticsearch-2.4.2.rpm$ rpm -iv elasticsearch-2.4.2.rpm(3)安装IK分词器在github上⾯下载1.10.2版本的ik分词,注意:es版本为2.4.2,兼容的版本为1.10.2。
es的分词器方法

es的分词器方法ES(Elasticsearch)是一个开源的分布式搜索和分析引擎,它提供了多种分词器方法用于处理文本数据。
分词器是将原始文本转化为有意义的词汇单元的工具,对于全文搜索和文本分析非常重要。
本文将介绍ES的几种常用的分词器方法及其应用。
一、标准分词器(Standard Analyzer)标准分词器是ES默认的分词器,它使用了Unicode文本分割算法,将文本按照空格、标点符号等进行分词。
该分词器适用于大多数场景,可以将文本切分为意义明确的单词。
例如,对于输入的句子“ES的分词器方法很强大”,标准分词器会将其分割为“ES”、“的”、“分词器”、“方法”、“很强大”等词汇单元。
二、简单分词器(Simple Analyzer)简单分词器是一种基本的分词器,它按照非字母字符对文本进行切分,将连续的字母作为单词。
这种分词器适用于一些特殊的场景,例如对于英文单词的分词。
例如,对于输入的句子“El asticsearch is a powerful search engine”,简单分词器会将其分割为“Elasticsearch”、“is”、“a”、“powerful”、“search”、“engine”等词汇单元。
三、语言分词器(Language Analyzer)ES提供了多种语言分词器,如中文分词器、日文分词器等。
这些分词器根据不同的语言特点进行了优化,可以更准确地进行分词。
例如,对于中文文本“Elasticsearch是一个强大的搜索引擎”,中文分词器会将其分割为“Elasticsearch”、“是”、“一个”、“强大”、“的”、“搜索引擎”等词汇单元。
四、较少使用的分词器除了以上常用的分词器,ES还提供了一些较少使用的分词器,如关键字分词器(Keyword Analyzer)、路径分词器(Path Analyzer)等。
关键字分词器将整个文本作为一个词汇单元,适用于需要精确匹配的场景。
ES优化中文分词器

ES优化中⽂分词器⽬录⼀、ES优化1.限制内存1.启动内存最⼤是32G2.服务器⼀半的内存全都给ES3.设置可以先给⼩⼀点,慢慢提⾼4.内存不⾜时1)让开发删除数据2)加节点3)提⾼配置5.关闭swap空间2.⽂件描述符1.配置⽂件描述符[root@db02 ~]# vim /etc/security/limits.conf* soft memlock unlimited* hard memlock unlimited* soft nofile 131072* hard nofile 1310722.普通⽤户[root@db02 ~]# vim /etc/security/limits.d/20-nproc.conf* soft nproc 65535root soft nproc unlimited[root@db02 ~]# vim /etc/security/limits.d/90-nproc.conf* soft nproc 65535root soft nproc unlimited3.语句优化1.条件查询时,使⽤term查询,减少range的查询2.建索引的时候,尽量使⽤命中率⾼的词⼆、中⽂分词器 ik0.引出# 为什么有中⽂分词器如下案例所⽰,在搜索“中国”时,会将⼀个整体拆分开进⾏搜索,变成“中”“国”,在搜索时并不是精确匹配,会将很多不相关搜索全部显⽰,同理,在百度搜索栏中,如果搜索中国这个词汇,结果显⽰很多只包含了这个字,⽽不是词,会将很多没⽤信息⼀同展⽰,所以就有了中⽂分词器,将需要组合成⼀个词的句⼦,存储成⼀个整体,在搜索时直接精确匹1.插⼊数据POST /index/_doc/1{"content":"美国留给伊拉克的是个烂摊⼦吗"}POST /index/_doc/2{"content":"公安部:各地校车将享最⾼路权"}POST /index/_doc/3{"content":"中韩渔警冲突调查:韩警平均每天扣1艘中国渔船"}POST /index/_doc/4{"content":"中国驻洛杉矶领事馆遭亚裔男⼦枪击嫌犯已⾃⾸"}2.查询数据POST /index/_search{"query" : { "match" : { "content" : "中国" }},"highlight" : {"pre_tags" : ["<tag1>", "<tag2>"],"post_tags" : ["</tag1>", "</tag2>"],"fields" : {"content" : {}}}}#查看结果,会获取到带中字和国字的数据,我们查询的词被分开了,所以我们要使⽤ik中⽂分词器3.配置中⽂分词器0)注意:1.集群内所有的机器需要全部安装插件2.创建模版之前要先单独创建索引1)创建模板⽅式1)安装插件# 1.配置中⽂分词器cd /usr/share/elasticsearch./bin/elasticsearch-plugin install https:///medcl/elasticsearch-analysis-ik/releases/download/v6.6.0/elasticsearch-analysis-ik-6.6.0.zip2)创建索引与mapping# 1.创建索引# 2.创建模板curl -XPOST http://localhost:9200/news/text/_mapping -H 'Content-Type:application/json' -d'{"properties": {"content": {"type": "text","analyzer": "ik_max_word","search_analyzer": "ik_smart"}}}'# 3.插⼊测试数据POST /news/text/1{"content":"美国留给伊拉克的是个烂摊⼦吗"}POST /news/text/2{"content":"公安部:各地校车将享最⾼路权"}POST /news/text/3{"content":"中韩渔警冲突调查:韩警平均每天扣1艘中国渔船"}POST /news/text/4{"content":"中国驻洛杉矶领事馆遭亚裔男⼦枪击嫌犯已⾃⾸"}# 4.再次查询数据发现已经能识别中⽂了POST /news/_search{"query" : { "match" : { "content" : "中国" }},"highlight" : {"pre_tags" : ["<tag1>", "<tag2>"],"post_tags" : ["</tag1>", "</tag2>"],"fields" : {"content" : {}}}}# 注意:ik_max_word: 会将⽂本做最细粒度的拆分,⽐如会将“中华⼈民共和国国歌”拆分为“中华⼈民共和国,中华⼈民,中华,华⼈,⼈民共和国,⼈民,⼈,民,共和国,共和,和,国国,国歌”,会穷尽各种可能的组合;ik_smart: 会做最粗粒度的拆分,⽐如会将“中华⼈民共和国国歌”拆分为“中华⼈民共和国,国歌”。
es英文分词

ES英文分词ES(Elasticsearch)是一个流行的分布式搜索和分析引擎,可以快速、准确地对大量文本进行搜索和分析。
在ES中,分词是一个关键的步骤,它将文本拆分成一个个有意义的词语,以便更好地进行搜索和分析。
本文将介绍ES英文分词的原理和常见的分词器。
正文1. ES英文分词的原理ES英文分词的原理是基于词典和规则的匹配。
首先,ES使用内置的英文词典,将文本按照空格、标点符号等进行分割,形成候选词语。
然后,根据一系列的规则,对候选词语进行进一步的细分,例如将复合词拆分成独立的单词。
最后,ES将分词结果返回给用户,用户可以根据需要进行搜索和分析。
2. 常见的ES英文分词器ES提供了多种英文分词器,可以根据不同的需求选择合适的分词器。
以下是几种常见的分词器:(1) Standard Analyzer:标准分词器是ES默认的英文分词器,它根据空格、标点符号等将文本分割成词语。
虽然简单,但在大多数情况下效果还是不错的。
(2) English Analyzer:英文分析器是基于Standard Analyzer 的改进版,它考虑到了英语的特殊性,可以更好地处理英文文本。
例如,它可以正确地将复数形式的单词转换为单数形式。
(3) Keyword Analyzer:关键词分析器是将整个文本作为一个词语进行处理,不进行分词。
适用于需要完整匹配的场景,例如搜索产品型号或者精确匹配的关键字。
(4) Custom Analyzer:自定义分析器是ES提供的一种灵活的分词器,可以根据自己的需求定义分词规则。
用户可以添加自己的词典、停用词等,以达到更准确的分词效果。
3. ES英文分词的应用ES英文分词在各种场景中都有广泛的应用。
例如,在电商网站中,可以使用ES英文分词对商品标题和描述进行分词,以便用户能够更快速地搜索到他们感兴趣的商品。
在新闻网站中,可以使用ES 英文分词对新闻标题和正文进行分词,以便用户能够更方便地找到相关的新闻。
es elasticsearch 中文分词

es elasticsearch 中文分词摘要:一、Elasticsearch 简介1.Elasticsearch 是什么2.Elasticsearch 的应用场景二、中文分词在Elasticsearch 中的重要性1.什么是中文分词2.中文分词在Elasticsearch 中的作用3.中文分词的难点三、Elasticsearch 中文分词的解决方案1.常用的中文分词工具2.Elasticsearch 内置中文分词器3.如何选择合适的中文分词工具四、Elasticsearch 中文分词的最佳实践1.选择合适的分词算法2.调整分词参数3.评估分词效果正文:Elasticsearch 是一款非常流行的开源搜索引擎,它可以帮助用户快速地存储、搜索和分析大量数据。
在实际应用中,Elasticsearch 经常用于构建全文搜索功能,因此中文分词在Elasticsearch 中显得尤为重要。
中文分词,顾名思义,就是将中文文本切分成一个个有意义的词汇。
由于中文没有明确的词语分隔标志(如英文中的空格),因此中文分词相对较为复杂。
在Elasticsearch 中,中文分词的作用是将文本转换为可以进行索引和搜索的关键词。
目前,常用的中文分词工具有jieba、THULAC、ICTCLAS 等。
其中,jieba 是一个基于前缀词典的分词工具,适合初学者和简单场景;THULAC 是一个基于深度学习的分词工具,准确率较高;ICTCLAS 是一款经典的中文分词工具,适合大规模文本处理。
Elasticsearch 内置了中文分词器,支持基于词典的分词和基于统计的分词。
用户可以根据需求选择合适的分词算法,并调整分词参数,以获得更好的分词效果。
在实际应用中,选择合适的中文分词工具和算法非常重要。
首先,要确保分词工具的准确率和召回率;其次,要考虑分词工具的性能,避免影响Elasticsearch 的搜索速度;最后,要根据具体场景调整分词参数,以达到最佳分词效果。
es全文检索字段类型

es全文检索字段类型
ES(Elasticsearch)是一种基于Lucene的分布式全文搜索引擎,它具有强大的搜索和分析能力。
在ES中,可以使用不同类型的字段来定义索引中的数据类型。
以下是ES常用的字段类型:
1、Text(文本类型):用于存储长文本数据,会分词并建立倒排索引,支持全文搜索和模糊匹配。
2、Keyword(关键词类型):用于存储短文本数据,不会分词,支持精确匹配和聚合操作。
3、Numeric(数值类型):包括整型(integer)、长整型(long)、短整型(short)、字节型(byte)、双精度浮点型(double)、单精度浮点型(float)等。
4、Date(日期类型):用于存储日期和时间数据,支持包括范围查询、日期格式化和日期计算等操作。
5、Boolean(布尔类型):用于存储布尔值(true/false)。
6、Object(对象类型):用于存储复杂结构的数据,可以嵌套其他字段。
7、Geo(地理位置类型):用于存储经纬度等地理位置信息,支持地理位置查询和距离计算。
8、Binary(二进制类型):用于存储二进制数据,如图片、音频或视频等。
这些是ES中常用的字段类型,根据实际需求,可以选择合适的字段类型来存储数据,并为搜索和聚合操作提供更好的支持。
ES分词器详解

ES分词器详解⼀、分词器1、作⽤:①切词 ②normalizaton(提升recall召回率:能搜索到的结果的⽐率)2、分析器①character filter:分词之前预处理(过滤⽆⽤字符、标签等,转换⼀些&=>and 《Elasticsearch》=> Elasticsearch A、HTML Strip Character Filter:html_strip escaped_tags 需要保留的html标签PUT my_index{"settings": {"analysis": {"char_filter": {"my_char_filter":{"type":"html_strip", "escaped_tags":["a"]}},"analyzer": {"my_analyzer":{"tokenizer":"keyword","char_filter":"my_char_filter"}}}}}测试分词 GET my_index/_analyze { "analyzer": "my_analyzer", "text": "liuyucheng <a><b>edu</b></a>" } B、Mapping Character Filter:type mappingPUT my_index{"settings": {"analysis": {"analyzer": {"my_analyzer": {"tokenizer": "keyword","char_filter": ["my_char_filter"]}},"char_filter": {"my_char_filter": {"type": "mapping","mappings": ["٠ => 0","١ => 1","٢ => 2","٣ => 3","٤ => 4","٥ => 5","٦ => 6","٧ => 7","٨ => 8","٩ => 9"]}}}}测试分词POST my_index/_analyze{"analyzer": "my_analyzer","text": "My license plate is ٢٥٠١٥"} C、Pattern Replace Character Filter:正则替换type pattern_replace PUT my_index{"settings": {"analysis": {"analyzer": {"my_analyzer": {"tokenizer": "standard","char_filter": ["my_char_filter"]}},"char_filter": {"my_char_filter": {"type": "pattern_replace","pattern": "(\\d+)-(?=\\d)","replacement": "$1_"}}}}}测试分词POST my_index/_analyze{"analyzer": "my_analyzer","text": "My credit card is 123-456-789"}②tokenizer:分词器③token filter:时态转换、⼤⼩写转换、同义词转换、语⽓词处理等 ⽐如:has=>have him=>he apples=>apple the/oh/a=>⼲掉 A、⼤⼩写 lowercase token filterGET _analyze{"tokenizer" : "standard","filter" : ["lowercase"],"text" : "THE Quick FoX JUMPs"}GET /_analyze{"tokenizer": "standard","filter": [{"type": "condition","filter": [ "lowercase" ],"script": {"source": "token.getTerm().length() < 5"}}],"text": "THE QUICK BROWN FOX"} B、停⽤词 stopwords token filterPUT /my_index{"settings": {"analysis": {"analyzer": {"my_analyzer":{"type":"standard","stopwords":"_english_"}}}}}GET my_index/_analyze"analyzer": "my_analyzer","text": "Teacher Ma is in the restroom"} C、分词器 tokenizer :standardGET /my_index/_analyze{"text": "江⼭如此多娇,⼩姐姐哪⾥可以撩","analyzer": "standard"} D、⾃定义 analysis,设置type为custom告诉Elasticsearch我们正在定义⼀个定制分析器。
es表中分词创建语法

es表中分词创建语法(原创版)目录1.es 表中分词的概述2.es 表中分词的创建语法3.es 表中分词的应用实例4.总结正文一、es 表中分词的概述es 表中分词是自然语言处理(NLP)中的一种分词方法,主要用于中文分词任务。
与传统的基于词典的分词方法不同,es 表中分词采用统计方法,通过训练数据来识别中文句子中的词汇边界。
这种方法具有较强的适应性,能够较好地处理新词和未登录词的分词问题。
二、es 表中分词的创建语法es 表中分词的创建语法主要包括以下三个步骤:1.词向量表示:将词汇表中的每个词映射为一个固定长度的向量,这一过程通常使用预训练的词向量模型(如 Word2Vec、GloVe 等)来实现。
2.隐马尔可夫模型(HMM):根据词向量表示,构建一个隐马尔可夫模型。
在该模型中,每个状态对应一个词,而状态之间的转移概率则表示句子中词汇之间的概率关系。
3.条件随机场(CRF):在隐马尔可夫模型的基础上,引入上下文信息,构建一个条件随机场。
这样,分词模型不仅能够考虑词汇之间的概率关系,还可以利用句子的结构信息来进行分词。
三、es 表中分词的应用实例以下是一个使用 es 表中分词方法对中文句子进行分词的实例:输入句子:小明去了上海迪士尼乐园游玩。
词向量表示:通过预训练的词向量模型,将句子中的每个词表示为一个向量。
隐马尔可夫模型:根据词向量表示,构建一个隐马尔可夫模型,并计算状态之间的转移概率。
条件随机场:在隐马尔可夫模型的基础上,引入上下文信息,构建一个条件随机场。
分词结果:通过条件随机场计算句子中每个词的概率,得到分词结果:“小明/去了/上海/迪士尼乐园/游玩”。
四、总结es 表中分词作为一种基于统计方法的中文分词方法,具有一定的优势。
它不仅能够较好地处理新词和未登录词的分词问题,还可以利用句子的结构信息来进行分词。
然而,这种方法也存在一定的局限性,例如计算复杂度较高、需要大量的训练数据等。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
es中英文分词
Elasticsearch(简称ES)是一个开源的分布式搜索引擎,拥有强大的全文检索功能。
在ES中,中文和英文的分词处理方式略有不同。
本文将介绍ES中文和英文分词的基本原理和常见的分词策略。
一、中文分词
中文分词是将连续的汉字序列切分为一个个独立的词语,是中文文本处理的基本步骤。
ES中文分词默认采用的是基于词表的正向最大匹配算法。
1. 正向最大匹配(Forward Maximum Matching,FMM)
正向最大匹配是一种简单而高效的分词方法。
它从文本的最左侧开始,找出匹配词典中最长的词,并将其切分出来。
然后从剩余部分继续匹配最长的词,直到整个文本被切分完毕。
2. 逆向最大匹配(Backward Maximum Matching,BMM)
逆向最大匹配与正向最大匹配相反,它从文本的最右侧开始,按照相同的规则进行词语切分。
逆向最大匹配的优点是可以较好地处理人名、地名等固有名词。
3. 双向最大匹配(Bi-directional Maximum Matching,BIMM)
双向最大匹配结合了正向最大匹配和逆向最大匹配的优点,它首先使用正向最大匹配和逆向最大匹配进行分词,然后将切分结果进行比对,选择合理的结果作为最终的分词结果。
二、英文分词
相比于中文,英文的分词规则相对简单。
ES中的英文分词器使用
的是标准分词器(Standard Analyzer),它基于空格和标点符号来进行
英文单词的切分。
1. 标准分词器(Standard Analyzer)
标准分词器将文本按空格和标点符号进行切分,将切分后的词语作
为单词,并进行小写转换。
例如,"Elasticsearch is a distributed search engine."会被切分为"elasticsearch","is","a","distributed","search"和"engine"。
2. 字母分词器(Letter Analyzer)
字母分词器将文本按照字母进行切分,忽略标点符号和空格。
例如,"Elasticsearch is a distributed search engine."会被切分为"Elasticsearch","is","a","distributed","search"和"engine"。
3. 单词分词器(Whitespace Analyzer)
单词分词器按照空格进行切分,不考虑标点符号和字母。
例如,"Elasticsearch is a distributed search engine."会被切分为"Elasticsearch","is","a","distributed","search"和"engine"。
以上是ES中英文分词的基本内容,ES还支持自定义分词器,使用
者可以根据实际需求选择合适的分词策略。
对于中文分词,可以结合
将词库和规则的方式进行扩展,提高准确性和效果。
对于英文分词,
也可以根据特定需要选择适合的分词策略。
ES作为一个强大的搜索引擎,分词是其中重要的一环。
合理地进行中英文分词,能够提高搜索的准确性和用户的搜索体验。
在实际应用中,根据不同的场景和需求选择合适的分词策略,将会对搜索结果的质量产生积极的影响。