Keil复制中文注释出现乱码的解决办法
keil软件编译常见错误解释总结和中文翻译

keil软件编译常见错误解释总结和中文翻译Keil编译时出现错误和警告的总结和C 编译器错误信息中文翻译(1)L15重复调用***WARNING L15: MULTIPLE CALL TO SEGMENTSEGMENT: ?PR?SPI_RECEIVE_WORD?D_SPICALLER1: ?PR?VSYNC_INTERRUPT?MAINCALLER2: ?C_C51STARTUP该警告表示连接器发现有一个函数可能会被主函数和一个中断服务程序(或者调用中断服务程序的函数)同时调用,或者同时被多个中断服务程序调用。
出现这种问题的原因之一是这个函数是不可重入性函数,当该函数运行时它可能会被一个中断打断,从而使得结果发生变化并可能会引起一些变量形式的冲突(即引起函数内一些数据的丢失,可重入性函数在任何时候都可以被ISR打断,一段时间后又可以运行,但是相应数据不会丢失)。
原因之二是用于局部变量和变量(暂且这样翻译,arguments,[自变量,变元一数值,用于确定程序或子程序的值])的内存区被其他函数的内存区所覆盖,如果该函数被中断,则它的内存区就会被使用,这将导致其他函数的内存冲突。
例如,第一个警告中函数WRITE_GMVLX1_REG 在D_GMVLX1.C 或者D_GMVLX1.A51被定义,它被一个中断服务程序或者一个调用了中断服务程序的函数调用了,调用它的函数是VSYNC_INTERRUPT,在MAIN.C中。
解决方法:如果你确定两个函数决不会在同一时间执行(该函数被主程序调用并且中断被禁止),并且该函数不占用内存(假设只使用寄存器),则你可以完全忽略这种警告。
如果该函数占用了内存,则应该使用连接器(linker)OVERLAY指令将函数从覆盖分析(overlay analysis)中除去,例如:OVERLAY (?PR?_WRITE_GMVLX1_REG?D_GMVLX1 ! *)上面的指令防止了该函数使用的内存区被其他函数覆盖。
在Matlab 里复制代码到word产生中文乱码的恢复方法
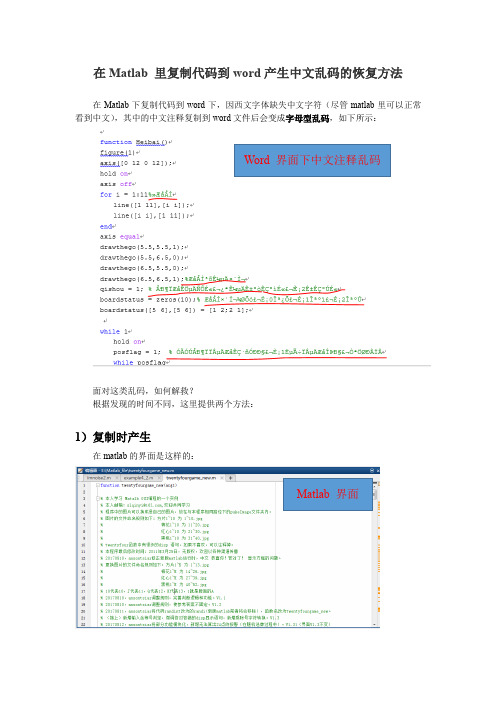
在Matlab 里复制代码到word产生中文乱码的恢复方法在Matlab下复制代码到word下,因西文字体缺失中文字符(尽管matlab里可以正常看到中文),其中的中文注释复制到word文件后会变成字母型乱码,如下所示:Word 界面下中文注释乱码面对这类乱码,如何解救?根据发现的时间不同,这里提供两个方法:1)复制时产生在matlab的界面是这样的:Matlab 界面复制到word后,是这样的Word 界面在复制的文字最后,有一个这样的图标:,用鼠标点击它,或者按Ctrl键,便弹出:,选择,中文便不会再乱码,如下图所示:这样虽失去了原有格式,但中文不再乱码了。
如果你不嫌麻烦,可以在乱码的基础上,对乱码一个一个手动更改,这样就不会变更格式,但太麻烦了,不是么?2)已经保存的word不小心保存了乱码文件,或者网上下载的word就包含前面所说的乱码。
在找不到原代码(m文件等)的情况下,对于word下已经形成的中文乱码,如何修复成中文?这里有一个办法:安装Ultra-Edit ANSI和简体中文,如下图所示。
(此编码是windows下matlab命令框和m文件使用的编码;若是linux 下的matlab,则是UTF-8。
这里只针对windows下的matlab。
)txt格式文件,编码选择ANSI/ASCII,然后保存它。
然后在word 将含乱码的m 文件代码复制到上图空的sample.txt (或你设定的名字),保存它,这时在Ultra-Edit 内看到的乱码和word 上看到的是一样的,表明乱码对应的编码信息没有被破坏。
这时,就可以关闭Ultra-Edit ,以windows 默认的记事本(简体中文状态或支持简体中文的条件下),看到的就不是乱码而是中文注释了。
如果要保留word 里原来含乱码的matlab 代码的格式,可将里面的注释乱码一个一个换成相应记事本txt 里的中文注释就可以了。
如果觉得这样麻烦,可以将全部代码替换成记事本txt 中的字符,这样可能不再保留原有格式。
国产乱码的解决方法

国产乱码的解决方法
如果在程序中遇到国产乱码问题,可以尝试以下几种解决方法:
1. 检查编码:首先确保你的程序和数据源文件(例如文本文件、数据库)是使用相同的字符编码。
常用的字符编码包括UTF-8、GBK等。
在程序中,可以使用相应的函数或指令来指定编码,例如在C++中可以使用`setlocale`函数来设置编码。
2. 转换编码:如果你的程序和数据源使用不同的编码,可以尝试将数据源文件的编码转换为程序所需的编码。
可以使用各种工具或库进行编码转换,例如iconv等。
3. 设置环境变量:在一些操作系统中,设置环境变量可以解决一些国产乱码问题。
例如,在Windows操作系统中,可以设置系统区域设置为适当的语言。
4. 使用特定的输入/输出库:某些编程语言和库提供了特定的输入/输出库,用于处理国产乱码问题。
例如,在C++中,可以使用`wifstream`和`wofstream`等宽字符输入/输出流,以支持Unicode字符。
5. 使用Unicode编码:Unicode是一种字符编码标准,可以表示世界上几乎所有的字符。
使用Unicode编码可以确保正确处理各种字符。
在程序中,可以使用相应的库或函数来支持Unicode编码,例如在C++中可以使用`wchar_t`类型和相关函数。
6. 避免使用特殊字符:如果可能的话,避免使用特殊字符,例如一些特殊符号或语言特定的字符。
这样可以减少国产乱码问题的发生。
以上是一些常见的解决国产乱码问题的方法,具体的解决方法可能因编程语言、操作系统和具体情况而有所不同。
在处理国产乱码问题时,建议先确定乱码的原因,然后针对性地采取适当的解决方法。
国产乱码的解决方法(一)

国产乱码的解决方法(一)国产乱码的解决方法问题背景在使用国产软件或操作系统时,经常会遇到乱码的问题。
国产软件或操作系统默认使用国内的字符编码,与国际标准的字符编码存在差异,因此在与国际用户交互时容易出现乱码情况。
本文将介绍几种常见的解决国产乱码问题的方法。
方法一:更改字符编码1.打开国产软件或操作系统的设置菜单。
2.在设置菜单中找到“语言”或“国际化”选项。
3.在语言或国际化选项中,找到字符编码相关的设置选项。
4.将字符编码设置为国际标准的UTF-8或Unicode。
5.保存设置并重启软件或操作系统。
方法二:使用专门的乱码修复工具1.在互联网上搜索并下载专门的乱码修复工具。
2.安装并运行乱码修复工具。
3.根据乱码修复工具的提示,选择需要修复的文件或目录。
4.等待修复工具完成乱码修复的过程。
方法三:转换文件编码格式1.打开国产软件或操作系统中出现乱码的文件。
2.将文件另存为其他格式,如UTF-8、ANSI等。
3.尝试打开另存为后的文件,查看是否乱码问题得到解决。
方法四:使用第三方软件代替国产软件1.在互联网上搜索并下载国际标准的软件。
2.安装并运行国际标准软件。
3.将需要处理的文件导入国际标准软件中进行操作,避免乱码问题。
方法五:联系软件或操作系统厂商寻求支持1.找到国产软件或操作系统的官方网站或客服联系方式。
2.联系厂商并向其反馈乱码问题的详细情况。
3.根据厂商提供的解决方案或建议进行操作,寻求问题的解决。
总结国产乱码问题在使用国产软件或操作系统时经常出现,但通过更改字符编码、使用乱码修复工具、转换文件编码格式、使用国际标准软件或联系厂商等方法,可以有效解决乱码问题。
希望本文介绍的方法对大家有所帮助,使使用国产软件或操作系统变得更加愉快和顺畅。
以上是针对“国产乱码的解决”的相关方法介绍,希望对您有所帮助!。
复制网页内容出现乱码时的快速去除方法,100%有效

复制网页内容出现乱码时的快速去除方法,100%有效
复制网页内容出现乱码是我最近在逛一个论坛的时候遇到的。
当时看到有一篇文章不错,就顺手把网页内容复制下来贴到记事本中,然而这一贴却发现出现了很多乱码,想必是网站做了防复制设置。
查看源文件,果然有此类代码。
在网上搜索到了几个去除复制网页内容出现的方法,原理是一样的,但是都不够全面。
尤其是用word替换字体的方法,个人认为基本上可行度很小了。
现在的防复制代码早已不仅仅是把乱码字体颜色设置成白色,而是进化得更巧妙。
就我遇见的情况,网页源文件中的防复制代码有两类,一个是<span style="display:none">,另一个是<font style="font-size:0px;color:#FDFFF2">。
很显然用word替换字体的方法基本上是无效的。
其实去除网页复制出现的乱码有一种即简单又有效的方法,步骤如下:
1、在要复制内容的页面上点击右键选择“查看源文件”,将需要复制的那部分内容源文件复制粘帖到记事本中(写字板也可,以个人所好)。
2、确定乱码源文件所在的html标签。
这一步很重要,因为现在的防复制代码做得都比较高级,像我遇见的就有span和font两种,所以一定要找全面了。
3、利用记事本的“替换”功能,将乱码的html标签全部替换成title。
再比如我这种情况,就是将 span 和 font 均替换为title。
4、将替换后的文本另存为htm或html文件,打开这个文件,然后将内容复制到记事本或者word中,这次原来内容中所有的代码就都没有了。
乱码形成原因及消除方法大全

乱码形成原因及消除方法大全.txt生活,是用来经营的,而不是用来计较的。
感情,是用来维系的,而不是用来考验的。
爱人,是用来疼爱的,而不是用来伤害的。
金钱,是用来享受的,而不是用来衡量的。
谎言,是用来击破的,而不是用来装饰的。
信任,是用来沉淀的,而不是用来挑战的。
乱码形成原因及消除方法大全2008-01-18 14:08乱码形成原因及消除方法大全当我们浏览网页、打开文档或邮件,运行软件时,经常会看到乱码,通常是由于源文件编码,Windows不能正确识别造成的的,也可能是其他原因。
乱码给我们带来了太多的烦恼,为了帮助大家彻底摆脱乱码,下面我们就来探讨一下乱码的形成原因及其消除方法。
一、乱码有五种类型常见的乱码,一般可以分成五种类型:第一类是文本/文档文件乱码,这一般是由于源文件编码,与Windows使用的编码不通用造成的;第二类是网页乱码,形成原因与第一类乱码类似;第三类是Windows系统界面乱码,即中文Windows的菜单、桌面、提示框等显示乱码,主要是Windows注册表中有关字体的部分设置不当引起的;第四类是应用程序的界面乱码,即各种应用程序(包括游戏)本来显示中文的地方出现乱码,形成原因比较复杂,有第二类的乱码原因,也可能是软件用到的中文链接库,被英文链接库覆盖造成的;第五类是邮件乱码,形成原因也极其复杂。
二、如何消除应用程序的界面乱码?目前有些软件发行了Unicode版本,这是一种通用的字符编码标准,涵盖了全球多种语言及古文和专业符号,这种版本的软件运行在任何系统和语言上都不会乱码,如果是非Unicode编码的程序,就会有乱码现象。
【形成原因】:原因有三种。
如果是由于Windows注册表中关于字体设置的信息不正确造成的,你可以用下面“如何消除Windows系统界面乱码”介绍的办法去解决;如果用上法解决不了,那就可能是由于软件的中文链接库,被英文链接库覆盖而引起的。
这种现象经常发生在用微软开发工具例如VB、VC开发的中文软件上,这类软件中,菜单等显示界面上的汉字都是受一个动态链接库(DLL文件)控制,而软件的这个动态链接库一般安装在WindowsSystem目录下,如果以后安装了某个英文软件也使用同名的动态链接库,则英文软件的动态链接库就会覆盖中文链接库,这样,运行中文软件时就会调用英文的动态链接库,因此出现乱码。
keil软件编译常见错误解释总结和中文翻译

Keil编译时出现错误和警告的总结和C 编译器错误信息中文翻译(1)L15重复调用***WARNING L15: MULTIPLE CALL TO SEGMENTSEGMENT: ?PR?SPI_RECEIVE_WORD?D_SPICALLER1: ?PR?VSYNC_INTERRUPT?MAINCALLER2: ?C_C51STARTUP该警告表示连接器发现有一个函数可能会被主函数和一个中断服务程序(或者调用中断服务程序的函数)同时调用,或者同时被多个中断服务程序调用。
出现这种问题的原因之一是这个函数是不可重入性函数,当该函数运行时它可能会被一个中断打断,从而使得结果发生变化并可能会引起一些变量形式的冲突(即引起函数内一些数据的丢失,可重入性函数在任何时候都可以被ISR打断,一段时间后又可以运行,但是相应数据不会丢失)。
原因之二是用于局部变量和变量(暂且这样翻译,arguments,[自变量,变元一数值,用于确定程序或子程序的值])的内存区被其他函数的内存区所覆盖,如果该函数被中断,则它的内存区就会被使用,这将导致其他函数的内存冲突。
例如,第一个警告中函数WRITE_GMVLX1_REG 在D_GMVLX1.C 或者D_GMVLX1.A51被定义,它被一个中断服务程序或者一个调用了中断服务程序的函数调用了,调用它的函数是VSYNC_INTERRUPT,在MAIN.C中。
解决方法:如果你确定两个函数决不会在同一时间执行(该函数被主程序调用并且中断被禁止),并且该函数不占用内存(假设只使用寄存器),则你可以完全忽略这种警告。
如果该函数占用了内存,则应该使用连接器(linker)OVERLAY指令将函数从覆盖分析(overlay analysis)中除去,例如:OVERLAY (?PR?_WRITE_GMVLX1_REG?D_GMVLX1 ! *)上面的指令防止了该函数使用的内存区被其他函数覆盖。
如果该函数中调用了其他函数,而这些被调用在程序中其他地方也被调用,你可能会需要也将这些函数排除在覆盖分析(overlay analysis)之外。
keil4 常见问题处理办法

keil 4 中的一些常见问题处理办法keil 软件对于一个单片机编程者来说已经再熟悉不过了,我们都用得很多,但往往我们应用时总会遇到这样那样的问题,但又苦于无法解决,最终只能凑合着用。
下面我就个人经验对部分问题的解决方法给大家分享一下,也为初学者打点keil的应用基础。
不管他是哪个版本的,其处理办法基本都差不多,甚至可以说是完全一样的,下面我们就谈点实际的问题。
1、keil 4 中注释时,为什么不能打进汉字,都是方框?其处理方法:Edit -> Configuration,点击Colors & Fonts选项卡,在Window列表中选择Editor C Files,在右侧选择字体Courier,Use color in Comments 不能打钩.在做完上面的操作后,我来进行一下前后比较:显示效果如下:1、操作前:如果后面注释的黑线是方框,操作一样,但要适当改变字体(eg:宋体、新宋体都行)。
2、操作后显示效果:通过显示我们可以很直观的看到,注释中的文字已经清楚的显示了出来。
2、改变关键字颜色:方法:Edit -> Configuration->Colors & Fonts->Editor C Files->keyword->选择foreground为任意你想要的颜色(蓝色)。
显示效果如下:通过这一系列操作后,你可以将不同类型的数据改成你想要的颜色,方便你的编程和查错。
3、当前操作行底纹颜色和选中文字颜色设置:(1)当前工作行底纹和选中其文字设置:显示效果:(2)当前选中文字颜色和底纹显示:显示效果:通过该项操作后,你可以快速的找到你所编辑的区域,行数,甚至行段。
4、程序中空格显示为一点,如下图:解决办法:修改后显示效果:该项操作可以让页面更漂亮,更能满足我们的视觉习惯,提高变成效率。
5、没有程序行数框架显示,如下图:操作方法:操作后显示结果:其它操作方式基本类似,均可进行相应操作,达到自己想要的结果。
keil软件编译常见错误解释总结和中文翻译
Keil编译时出现错误和警告的总结和C 编译器错误信息中文翻译(1)L15重复调用***WARNING L15: MULTIPLE CALL TO SEGMENTSEGMENT: ?PR?SPI_RECEIVE_WORD?D_SPICALLER1: ?PR?VSYNC_INTERRUPT?MAINCALLER2: ?C_C51STARTUP该警告表示连接器发现有一个函数可能会被主函数和一个中断服务程序(或者调用中断服务程序的函数)同时调用,或者同时被多个中断服务程序调用。
出现这种问题的原因之一是这个函数是不可重入性函数,当该函数运行时它可能会被一个中断打断,从而使得结果发生变化并可能会引起一些变量形式的冲突(即引起函数内一些数据的丢失,可重入性函数在任何时候都可以被ISR打断,一段时间后又可以运行,但是相应数据不会丢失)。
原因之二是用于局部变量和变量(暂且这样翻译,arguments,[自变量,变元一数值,用于确定程序或子程序的值])的内存区被其他函数的内存区所覆盖,如果该函数被中断,则它的内存区就会被使用,这将导致其他函数的内存冲突。
例如,第一个警告中函数WRITE_GMVLX1_REG 在D_GMVLX1.C 或者D_GMVLX1.A51被定义,它被一个中断服务程序或者一个调用了中断服务程序的函数调用了,调用它的函数是VSYNC_INTERRUPT,在MAIN.C中。
解决方法:如果你确定两个函数决不会在同一时间执行(该函数被主程序调用并且中断被禁止),并且该函数不占用内存(假设只使用寄存器),则你可以完全忽略这种警告。
如果该函数占用了内存,则应该使用连接器(linker)OVERLAY指令将函数从覆盖分析(overlay analysis)中除去,例如:OVERLAY (?PR?_WRITE_GMVLX1_REG?D_GMVLX1 ! *)上面的指令防止了该函数使用的内存区被其他函数覆盖。
如果该函数中调用了其他函数,而这些被调用在程序中其他地方也被调用,你可能会需要也将这些函数排除在覆盖分析(overlay analysis)之外。
keil程序注释乱码的解决方法

keil程序注释乱码的解决方法Keil程序注释乱码可能是由于编码格式不一致或者软件版本不兼容等原因引起的。
如果不及时解决,会给程序员带来很大的困扰和时间浪费。
下面就为大家介绍一些解决方法,希望对大家有所帮助。
1. 确认编码格式注释乱码与编码格式有关,因此首先要确认程序源码和注释的编码格式是否一致。
如果不一致,就会导致注释乱码的问题。
一般情况下,程序员常用的编码格式是UTF-8或者ANSI,因此需要将注释的编码格式设置为与程序源码一致,才能避免乱码。
2. 修改软件设置有些情况下,程序员可能会遇到Keil版本不兼容的问题,导致注释乱码。
这时候可以考虑修改软件设置,使用其他兼容的版本。
具体方法是在Keil软件中打开“工具-选项”,找到“编辑器”,然后将“字符集”设置为程序源码所使用的编码格式,最后重新打开程序文件即可。
3. 调整字体如果程序源码和注释的编码格式已经一致,而且Keil软件版本也正确,但是注释还是显示乱码,那就需要考虑调整字体。
可能是因为当前字体不支持所使用的字符集,需要更换其他字体。
具体方法是在Keil软件中打开“工具-选项”,找到“编辑器”,然后在“字体”选项中选择支持当前编码格式的字体即可。
总结在Keil程序中遇到注释乱码问题是比较常见的情况,但是只要正确的解决方法,就能轻松应对。
需要注意的是,在编写程序的过程中,要始终保持编码格式的一致性,这样才能有效避免注释乱码的问题的发生。
同时,在软件设置和字体调整方面也要仔细处理,以保证注释能够正确的呈现出来。
希望这些方法能够帮助到大家,让大家在编程中更加得心应手。
MDK(keil)4.7中文注释乱码解决

MDK(keil)4.7中⽂注释乱码解决
由于编码使⽤不统⼀导致别的开发环境下的⽂件在MDK(keil)下打开中⽂显⽰乱码,解决这⼀问题需要进⾏码制转换,
可以先将欲打开的⽂件转换成UTF-8格式(如在notepad中进⾏转换),也可以在打开⽂件前将MDK的编码设置为
chinese2312(Edit>Configuration>Editor>Encoding),
这样就能够正确显⽰中⽂了,然后再把编码格式改为Encode in ANSI,这样就完成了编码格式的转换。
keil MDK中默认编码为Encode in ANSI,中⽂占两个字符,在注释中输⼊汉字时光标需要移动两次才能后移⼀个汉字,
在插⼊汉字时很容易出现乱码,解决办法是把编码设置为chinese2312,这样每个汉字就能像英⽂字符⼀样被看做⼀个整体,不过仍占两个字符。
Keil C51汉字显示的bug问题

Keil C51汉字显示的bug问题(0xFD问题)Keil C51汉字显示的bug问题一、缘起这两天改进MCU的液晶显示方法,采用“即编即显”的思路,编写了一个可以直接显示字符串的程序。
如程序调用disstr("我是你老爸");液晶屏上就会显示“我是你老爸”。
二、问题但是,花了1天多时间辛辛苦苦改好的程序后,却发现有些汉字显示有问题。
比如:P1:在第一行显示“实时参数”,第二行显示“工作状态”,实际上“工作状态”却重复显示了,除了在正确的地方显示外,还在“实时参数”后显示了。
P2:"正"字后若有":",则都显示成乱码。
如果后面没有":",则"正"字可正确显示,但是后面却显示了后面的一行字。
P3:"过"字总显示乱码;三、求索通过调试发现,上述汉字显示不正常的时候,是因为在字库中找不到匹配的汉字。
可是,自建的字库中明明有这些汉字,而且"数","正"字在后面无字符的时候是显示正确的啊!问题找了好久,怀疑传参类型不对,汉字查找可能溢出等,反复修改,总是无法解决问题,而且从现象来思考,都不应该是这些问题。
今日灵光一现:为什么不在传递字符串后显示该字符串的变量值呢?经过详细研究,西文字符在传递时应该是ACSII值,一个字节,数值小于128;而汉字传递的是其机内码,分高低2个字节,2个字节都大于127,当然并小于256。
字符串传递参数值一显示,可不得了。
其惊人之处有:1."数","正","过"正确显示时其传参值为:0xca00,0xd500,0xb900;而其正确的机内码应该是:0xca fd,0xd5fd,0xb9fd。
看来其低位字节被无情忽视。
2."数","正","过"单独显示正确,但是后面带一个字符或汉字就显示乱码了。
PLC程序日文注释乱码怎么显示中文

PLC程序日文注释乱码怎么显示中文
日文乱码在中文系统中正确显示的方法技巧分享
工作中经常遇到日本发来资料(如:PLC程序注释)在中文系统或中文软件中显示成乱码,无法阅读,下面分享一个简单的日文乱码翻译技巧。
该方法是利用网页浏览器通常支持多国语言和字符编码的特性完成显示和转换的,当然,此方法也可以解决中文在日文系统中显示乱码的问题。
下面以欧姆龙PLC程序注释翻译举例:
1、打开注释文件,显示如下乱码:
2、将乱码复制到excel表格中(也可以复制到记事本或word等程序中):
3、保存excel文件,保存时选择其他格式(记事本和word同理,不再介绍):
4、保存格式选网页(即htm或html格式,直接修改excel、记事本或word文件格式后缀为htm也可以):
5、选中保存后的网页格式文件,右键使用google浏览器打开(其他浏览器也可以,但没有google浏览器支持的编码格式丰富):
6、在浏览器菜单中依次选择【工具】【编码】【日文Shift_JIS】,如下所示:
7、选择编码格式后,乱码被转换成正确显示,效果如下:
8、在网页中复制以上内容回到excel中,最后转换效果如下:转转后
技术部提供技术支持。
keil编译常见报错和解决方法

keil编译常见报错和解决方法Keil是一款常用的嵌入式开发工具,用于编写和调试嵌入式系统的程序。
在使用Keil编译时,我们常常会遇到一些报错信息。
本文将介绍一些常见的Keil编译报错及解决方法,帮助读者快速解决问题。
1. "Error: L6218E: Undefined symbol"错误这个错误通常是由于使用了未定义的变量或函数导致的。
解决方法是检查代码中使用的符号是否正确定义或是否包含了正确的头文件。
如果符号确实未定义,需要在代码中进行定义或者引入相关的头文件。
2. "Error: L6002U: Could not open file"错误这个错误表示编译器无法打开指定的文件。
解决方法是检查文件路径是否正确,文件是否存在,并且是否具有读取权限。
如果文件路径正确但是依然无法打开,可能是文件被其他程序占用或者权限设置不正确,需要解决这些问题后重新编译。
3. "Error: C2513: 'function' : no variable declared before '=' "错误这个错误表示在赋值语句中使用了未声明的变量。
解决方法是检查变量是否正确声明,并确保在赋值之前进行了声明。
如果变量确实未声明,需要在代码中添加相应的变量声明。
4. "Error: C2065: 'variable' : undeclared identifier"错误这个错误表示使用了未声明的变量。
解决方法是检查变量是否正确声明,并确保在使用之前进行了声明。
如果变量确实未声明,需要在代码中添加相应的变量声明。
5. "Error: C1083: Cannot open include file: 'header.h': No such file or directory"错误这个错误表示编译器无法找到指定的头文件。
source insight中文注释为乱码的解决办法

source insight中文注释为乱码的解决办法
今天在公司用source insight看代码,发现代码的中文注释为乱码,查网上资料尝试解决如下:
1)改字体格式。
options->preferences->Syntax Formatting->Styles;
在Style Name 选择 Comment,再对其Font Name 选择Pick,然后再选择“新宋体”或
“courier new”。
发现不行。
2)改编码。
用记事本打开源文件,中文可以显示,另存为,在保存选项中,编码一栏发现是:UTF-8。
选在ANSI一项,保存。
还是不行。
最后,在同事的帮助下,终于解决了,方法是:
开始->控制面板->时钟、语言和区域->更改显示时间
在弹出窗口中“位置”选项下的“当前位置”改为“中国”;在“管理”选项下点击“更改系统
区域设置”,在弹出窗口的“当前系统区域设置”改为“中文(简体,中国)”。
点击“应用”,“确定”,重启电脑,搞定!。
复制粘贴的时候为什么出现文字乱码

复制粘贴的时候为什么出现文字乱码
导读:问:最近遇到一个很奇怪的问题,就是在Windows XP中复制、粘贴文字时会出现乱码,而且不但在窗口界面中,即便在“记事本”程序里也会出现这个问题,而在同机安装的Windows 98系统中就没有类似现象。
请问如何解决这个问题?
答:导致该问题的原因是输入法设置不当。
Windows XP默认的输入法为英语,键盘模式为美式键盘,这个选项一直也用于Windows 98中,同时提供的还有中文键盘的模式,由于Windows 98中使用美式键盘没有任何问题,所以大家在设置的时候,也就习惯性的把中文键盘删除,只保留英文键盘。
就是因为这个原因才导致复制时出现乱码的问题。
解决的办法是删除英文的美式键盘模式,添加中文键盘模式并且设置为默认值。
具体操作步骤是:在系统桌面任务栏上的语言栏单击鼠标右键,在弹出的菜单中选择“设置”命令,进入到“文字服务和输入语言”对话框,切换至“设置”选项卡,在“已安装的服务”列表中找到键盘模式为美国英语键盘布局的英语输入法,将其删除,然后将默认的输入语言设定为“中文(中国)-简体中文-美式键盘”,最后保存退出即可。
若不能解决问题,建议您在剪切和粘贴时都启动中文输入法,这样也可以消除乱码现象。
keil程序注释乱码的解决方法

keil程序注释乱码的解决方法Keil是一款非常流行的嵌入式开发工具,它可以帮助开发者快速地编写、调试和测试嵌入式系统的程序。
然而,在使用Keil进行程序开发的过程中,有时会遇到注释乱码的问题,这会给开发者带来很大的困扰。
本文将介绍Keil程序注释乱码的解决方法,帮助开发者更好地使用Keil进行程序开发。
一、Keil程序注释乱码的原因在Keil中,程序注释通常使用ASCII码进行编码。
然而,有时候在编写注释时,可能会使用一些非ASCII字符,比如中文、日文、韩文等。
这些非ASCII字符在Keil中可能会出现乱码的情况,这是因为Keil默认使用的是ASCII编码,而非ASCII字符无法被正确地解析。
二、解决方法1. 修改Keil的编码方式Keil默认使用的是ASCII编码,如果需要支持非ASCII字符,可以将编码方式修改为UTF-8或者Unicode。
具体操作如下:打开Keil软件,点击“Options for Target”菜单,选择“Output”选项卡,在“Text Encoding”中选择“UTF-8”或者“Unicode”,然后点击“OK”按钮保存设置。
2. 修改注释的编码方式如果修改Keil的编码方式无法解决注释乱码的问题,可以尝试修改注释的编码方式。
具体操作如下:打开Keil软件,找到需要修改编码方式的注释,将其复制到记事本中,然后将记事本的编码方式修改为UTF-8或者Unicode,再将修改后的注释复制回Keil中即可。
3. 使用ASCII码表示非ASCII字符如果以上两种方法都无法解决注释乱码的问题,可以尝试使用ASCII码表示非ASCII字符。
具体操作如下:打开Keil软件,找到需要修改的注释,将其中的非ASCII字符替换为对应的ASCII码即可。
比如,中文“你好”可以用“\u4f60\u597d”表示。
4. 使用注释工具如果以上方法都无法解决注释乱码的问题,可以尝试使用注释工具。
程序中的汉字变乱码的解决方法

程序中的汉字变乱码的解决方法汉字出现乱码有好几种情况,大致可分成四类:网页、文本、文档和文件乱码。
第一类是由于港台的繁体中文大五码(BIG5)与大陆简体中文(GB2312)不通用造成的;第二类是系统(菜单、桌面、提示框)显示乱码,这是注册表中有关字体的部分设置不当引起的;第三类是各种应用程序(包括游戏)本来显示中文的地方出现乱码,形成原因比较复杂,有第二类的乱码原因,也可能是软件用到的中文动态链接库被英文动态链接库覆盖造成的;最后一类是邮件乱码。
(一)、网页、文本和文档文件乱码的消除网页乱码是浏览器(如IE等)对HTML网页解释时形成的。
如果在网页的代码中有形如:〈HTML〉〈HEAD〉〈META CONTENT=“text/html;charset=ISO-8859-1”〉〈/HEAD〉……〈/HTML〉的语句,浏览器在显示此页时,就会出现乱码。
因为浏览器会将此页语种辨认为“欧洲语系”。
解决的办法是将语种“ISO-8859-1”改为GB2312,如果是繁体网页则改为BIG5。
另一种解决办法是不修改网页代码,事先为浏览器安装多语言支持包(例如在安装IE时要安装多语言支持包),这样在浏览网页出现乱码时,就可以在浏览器中选择菜单栏下的“查看”/“编码”/“自动选择”/简体中文(GB2312),如为繁体中文则选择“查看”/“编码”/“自动选择”/繁体中文(BIG5),其它语言依此类推选择相应的语系,这样可消除网页乱码现象。
还有一种解决办法是利用多内码显示平台来转换内码。
常用多内码显示平台有:“南极星”、“四通利方”、“MagicWin 98等等。
网页无乱码保存的方法是:用浏览器打开网页时,在“查看”/“编码”中选择“自动选择”,存盘时保存类型选“web页”,编码选择“UNICOD”,这样保存过的网页再次打开时,在浏览器菜单“查看”、“编码”中不管选择简体中文(GB2312)、简体中文(HZ)还是UNICODE(UTF-8)或繁体中文(BIG5),最终显示都不会出现乱码。
程序中的汉字变乱码的解决方法

程序中的汉字变乱码的解决方法汉字出现乱码有好几种情况,大致可分成四类:网页、文本、文档和文件乱码。
第一类是由于港台的繁体中文大五码(BIG5)与大陆简体中文(GB2312)不通用造成的;第二类是系统(菜单、桌面、提示框)显示乱码,这是注册表中有关字体的部分设置不当引起的;第三类是各种应用程序(包括游戏)本来显示中文的地方出现乱码,形成原因比较复杂,有第二类的乱码原因,也可能是软件用到的中文动态链接库被英文动态链接库覆盖造成的;最后一类是邮件乱码。
(一)、网页、文本和文档文件乱码的消除网页乱码是浏览器(如IE等)对HTML网页解释时形成的。
如果在网页的代码中有形如:〈HTML〉〈HEAD〉〈META CONTENT=“text/html;charset=ISO-8859-1”〉〈/HEAD〉……〈/HTML〉的语句,浏览器在显示此页时,就会出现乱码。
因为浏览器会将此页语种辨认为“欧洲语系”。
解决的办法是将语种“ISO-8859-1”改为GB2312,如果是繁体网页则改为BIG5。
另一种解决办法是不修改网页代码,事先为浏览器安装多语言支持包(例如在安装IE时要安装多语言支持包),这样在浏览网页出现乱码时,就可以在浏览器中选择菜单栏下的“查看”/“编码”/“自动选择”/简体中文(GB2312),如为繁体中文则选择“查看”/“编码”/“自动选择”/繁体中文(BIG5),其它语言依此类推选择相应的语系,这样可消除网页乱码现象。
还有一种解决办法是利用多内码显示平台来转换内码。
常用多内码显示平台有:“南极星”、“四通利方”、“MagicWin 98等等。
网页无乱码保存的方法是:用浏览器打开网页时,在“查看”/“编码”中选择“自动选择”,存盘时保存类型选“web页”,编码选择“UNICOD”,这样保存过的网页再次打开时,在浏览器菜单“查看”、“编码”中不管选择简体中文(GB2312)、简体中文(HZ)还是UNICODE(UTF-8)或繁体中文(BIG5),最终显示都不会出现乱码。