ONEStor分布式存储系统介绍
ONEStor分布式存储系统介绍
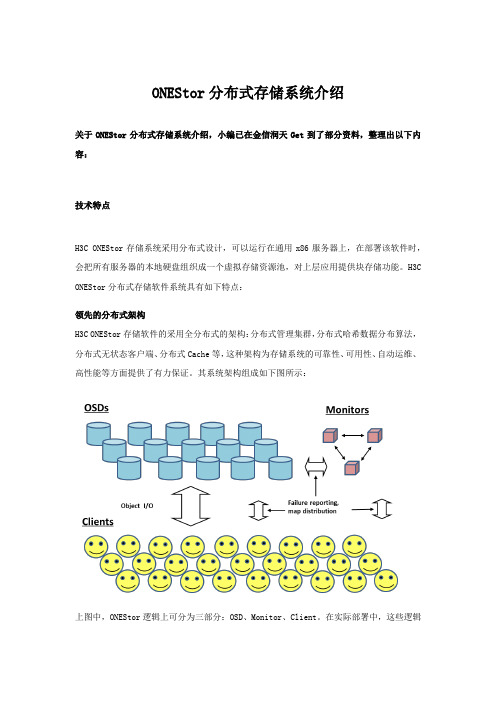
ONEStor分布式存储系统介绍关于ONEStor分布式存储系统介绍,小编已在金信润天Get到了部分资料,整理出以下内容:技术特点H3C ONEStor存储系统采用分布式设计,可以运行在通用x86服务器上,在部署该软件时,会把所有服务器的本地硬盘组织成一个虚拟存储资源池,对上层应用提供块存储功能。
H3C ONEStor分布式存储软件系统具有如下特点:领先的分布式架构H3C ONEStor存储软件的采用全分布式的架构:分布式管理集群,分布式哈希数据分布算法,分布式无状态客户端、分布式Cache等,这种架构为存储系统的可靠性、可用性、自动运维、高性能等方面提供了有力保证。
其系统架构组成如下图所示:上图中,ONEStor逻辑上可分为三部分:OSD、Monitor、Client。
在实际部署中,这些逻辑组件可灵活部署,也就是说既可以部署在相同的物理服务器上,也可以根据性能和可靠性等方面的考虑,部署在不同的硬件设备上。
下面对每一部分作一简要说明。
OSD:Object-based Storage DeviceOSD由系统部分和守护进程(OSD deamon)两部分组成。
OSD系统部分可看作安装了操作系统和文件系统的计算机,其硬件部分包括处理器、内存、硬盘以及网卡等。
守护进程即运行在内存中的程序。
在实际应用中,通常将每块硬盘(SSD或HDD)对应一个OSD,并将其视为OSD的硬盘部分,其余处理器、内存、网卡等在多个OSD之间进行复用。
ONEStor存储集群中的用户都保存在这些OSD中。
OSD deamon负责完成OSD的所有逻辑功能,包括与monitor 和其他OSD(事实上是其他OSD的deamon)通信以维护更新系统状态,与其他OSD共同完成数据的存储和维护,与client通信完成各种数据对象操作等等。
Monitor:Monitor是集群监控节点。
Monitor持有cluster map信息。
所谓Cluster Map,粗略的说就是关于集群本身的逻辑状态和存储策略的数据表示。
分布式存储解决方案

分布式存储解决方案目录一、内容概览 (2)1. 背景介绍 (3)2. 目标与意义 (3)二、分布式存储技术概述 (5)1. 分布式存储定义 (6)2. 分布式存储技术分类 (7)3. 分布式存储原理及特点 (8)三、分布式存储解决方案架构 (9)1. 整体架构设计 (10)1.1 硬件层 (12)1.2 软件层 (13)1.3 网络层 (14)2. 关键组件介绍 (15)2.1 数据节点 (16)2.2 控制节点 (18)2.3 存储节点 (19)2.4 其他辅助组件 (20)四、分布式存储解决方案核心技术 (22)1. 数据分片技术 (23)1.1 数据分片原理 (25)1.2 数据分片策略 (26)1.3 数据分片实例分析 (28)2. 数据复制与容错技术 (29)2.1 数据复制原理及策略 (31)2.2 容错机制与实现方法 (32)2.3 错误恢复过程 (34)3. 数据一致性技术 (35)3.1 数据一致性概念及重要性 (36)3.2 数据一致性协议与算法 (37)3.3 数据一致性维护与保障措施 (38)4. 负载均衡与性能优化技术 (39)4.1 负载均衡原理及策略 (41)4.2 性能优化方法与手段 (43)4.3 实例分析与展示 (43)五、分布式存储解决方案应用场景及案例分析 (44)1. 场景应用分类 (46)2. 具体案例分析报告展示 (47)一、内容概览分布式存储解决方案是一种旨在解决大规模数据存储和管理挑战的技术架构,它通过将数据分散存储在多个独立的节点上,提高数据的可用性、扩展性和容错能力。
本文档将全面介绍分布式存储系统的核心原理、架构设计、应用场景以及优势与挑战。
我们将从分布式存储的基本概念出发,阐述其相较于集中式存储的优势,如数据分布的均匀性、高可用性和可扩展性。
深入探讨分布式存储系统的关键组件,包括元数据管理、数据分布策略、负载均衡和容错机制等,并分析这些组件如何协同工作以保障数据的可靠存储和高效访问。
深信服分布式存储 参数

深信服分布式存储参数1. 介绍深信服分布式存储是一种高可靠、高性能和可扩展的存储解决方案。
它采用分布式架构,将数据分散存储在多个节点上,通过数据冗余和负载均衡来提高系统的可靠性和性能。
在这篇文章中,我们将详细介绍深信服分布式存储的参数及其相关概念。
2. 参数说明2.1 存储容量存储容量是指深信服分布式存储系统能够存储的数据量大小。
它通常以字节(B)、千字节(KB)、兆字节(MB)、吉字节(GB)或太字节(TB)为单位进行表示。
在设计和规划深信服分布式存储系统时,需要根据实际需求来确定所需的存储容量。
2.2 可扩展性可扩展性是指深信服分布式存储系统能够根据需要进行水平或垂直扩展的能力。
水平扩展是指通过增加更多的节点来增加系统的容量和性能,而不影响现有节点的工作负载。
垂直扩展是指通过增加单个节点的处理能力来提高系统的性能。
2.3 数据冗余数据冗余是指在深信服分布式存储系统中将数据复制到多个节点上的过程。
通过数据冗余,即使某个节点发生故障,系统仍然可以继续提供服务,而不会丢失任何数据。
常见的数据冗余策略包括副本复制和纠删码。
•副本复制是指将数据复制到多个节点上,并保持多个副本之间的一致性。
当一个节点发生故障时,系统可以从其他副本中恢复数据。
•纠删码是一种更高效的数据冗余策略,它通过对数据进行编码和解码来实现容错能力。
与副本复制相比,纠删码可以节省存储空间,并提供更好的容错性能。
2.4 数据一致性数据一致性是指在深信服分布式存储系统中,多个节点之间保持数据的一致性。
当一个节点更新了某个数据项时,其他节点也应该能够看到该更新。
为了实现数据一致性,通常采用强一致性或最终一致性模型。
•强一致性要求在任何时间点上都有且只有一个正确的副本。
当一个节点更新了数据后,其他节点必须立即看到该更新。
然而,强一致性模型可能会影响系统的性能和可用性。
•最终一致性要求在一段时间后,所有的节点最终达到一致的状态。
最终一致性模型可以提高系统的性能和可用性,但在某些情况下可能会导致数据不一致。
Oceanstor_T3000_G3_产品彩页V1.1

CB、CE、UL、FCC、CCC、ROHS、GOST
SUSE Linux、Windows Server、RedHat Linux、SUN Solaris 提供 ISM 管理软件 支持 IPMI2.0 支持 KVM over LAN,支持 Virtual Media over LAN 支持整机 S3 待机休眠和自动唤醒,唤醒时间小于 30 秒 硬盘缓启动设计,控制启动电流,降低了系统整体功耗需求 指定硬盘休眠技术和自动唤醒功能 智能风扇调速功能,监测环境温度和系统实时温度,自动调节风扇转速
机柜,节省空间,通用性更高;
整机休眠:业界率先支持 S3 待机休眠模式,
可支持整机的待机休眠和自动唤醒;
硬盘缓启动:硬盘缓启动设计,控制启动电流,
降低了系统整体功耗需求;
健康监测:针对关键器件进行健康监测,保 证系统健康绿色;
易维护:主板易维护.、关键部件热插拔,降低
维护成本;
友好:提供 Web 界面的 ISM 管理软件;
10GE,性能大幅提升;
高性能
高性能:采用英特尔 Sandybridge EN 2400 系
列处理器,12 个 DDR3 内存插槽,满足不同应 用对处理能力的需求;
大容量:可支持 3.5’或者 2.5’硬盘规格,提供多
达 25 个 2.5’盘位或 36 个 3.5’盘位,满足大容量 存储的应用需求;
AC,200V~240V 工作模式(平均功耗):<400W S3 待机模式:<50W 4U,175mm(H)*446mm(W)*585mm(D) ≤68kg
。
适用于 NSP、政府、教育、能源、金融等客 户,承担 Web 服务器、文件服务器、Mail 服务器、 数据库服务器等各种应用角色。
ONEStor分布式存储系统介绍
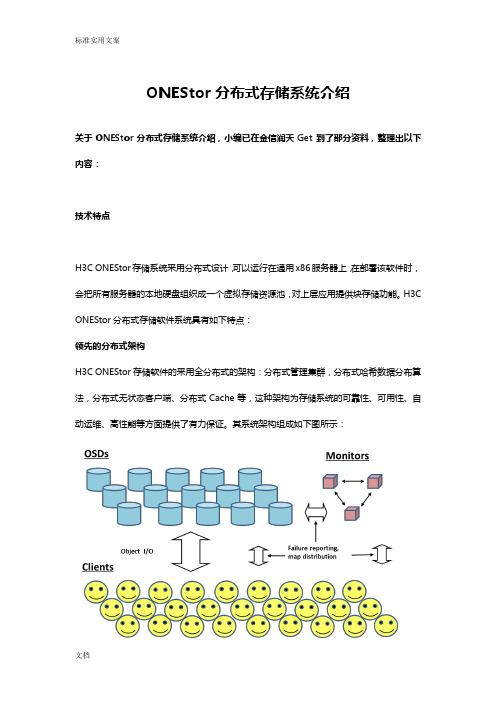
ONEStor分布式存储系统介绍关于ONEStor分布式存储系统介绍,小编已在金信润天Get到了部分资料,整理出以下内容:技术特点H3C ONEStor存储系统采用分布式设计,可以运行在通用x86服务器上,在部署该软件时,会把所有服务器的本地硬盘组织成一个虚拟存储资源池,对上层应用提供块存储功能。
H3C ONEStor分布式存储软件系统具有如下特点:领先的分布式架构H3C ONEStor存储软件的采用全分布式的架构:分布式管理集群,分布式哈希数据分布算法,分布式无状态客户端、分布式Cache等,这种架构为存储系统的可靠性、可用性、自动运维、高性能等方面提供了有力保证。
其系统架构组成如下图所示:上图中,ONEStor逻辑上可分为三部分:OSD、Monitor、Client。
在实际部署中,这些逻辑组件可灵活部署,也就是说既可以部署在相同的物理服务器上,也可以根据性能和可靠性等方面的考虑,部署在不同的硬件设备上。
下面对每一部分作一简要说明。
OSD:Object-based Storage DeviceOSD由系统部分和守护进程(OSD deamon)两部分组成。
OSD系统部分可看作安装了操作系统和文件系统的计算机,其硬件部分包括处理器、内存、硬盘以及网卡等。
守护进程即运行在内存中的程序。
在实际应用中,通常将每块硬盘(SSD或HDD)对应一个OSD,并将其视为OSD的硬盘部分,其余处理器、内存、网卡等在多个OSD之间进行复用。
ONEStor存储集群中的用户都保存在这些OSD中。
OSD deamon负责完成OSD的所有逻辑功能,包括与monitor和其他OSD(事实上是其他OSD的deamon)通信以维护更新系统状态,与其他OSD共同完成数据的存储和维护,与client通信完成各种数据对象操作等等。
Monitor:Monitor是集群监控节点。
Monitor持有cluster map信息。
所谓Cluster Map,粗略的说就是关于集群本身的逻辑状态和存储策略的数据表示。
H3C ONEStor存储技术白皮书

H3C ONEStor存储技术白皮书目录1 ONEStor概述 (1)2 ONEStor存储系统介绍 (2)2.1 技术特点 (2)2.1.1 领先的分布式架构 (2)2.1.2 线性扩展能力 (6)2.1.3 高可靠性 (7)2.1.4 良好的性能 (10)2.1.5 统一的存储业务 (11)2.2 典型应用场景 (12)2.2.1 使用场景 (12)2.2.2 典型组网架构 (15)2.3 ONEStor对硬件设备要求 (16)2.3.1 硬件要求 (16)3 ONEStor管理系统 (18)3.1 管理系统的特点 (18)3.1.1 无中心管理架构设计 (18)3.1.2 场景化设计 (19)3.2 管理系统的主要功能 (20)4 规格参数 (22)5 缩略语表 (22)i1 ONEStor概述云计算、移动计算、社交媒体以及大数据的发展,使得数据爆炸式增长。
一方面,企业要存储这些数据,以便对数据进行利用;另一方面,相比于数据中心的计算模块和网络模块,存储模块在近三十年虽然一直发展,但发展缓慢,并未出现技术革命带来存储领域的翻天覆地的变化。
现实的情况是:传统的存储系统已经很难满足爆炸增长的数据需求,急需要新的存储技术进行变革。
数据的激增对存储的需求主要体现在:(1)可扩展性:存储集群可以根据用户需求线性扩展,并且数据会自动均衡,无需人工干预。
(2)低成本:和传统的SAN/NAS相比,在性价比上具有明显的优势。
(3)高性能:存储集群架构具有灵活的扩展能力,集群性能随着规模的增长线性增长。
(4)高可靠性:集群中的每个数据至少保存两份副本,且集群会自动将数据分布在不同的存储单元上,硬件损坏的情况下依然可以获取一份完整的数据,并且丢失的数据会自动重构。
(5)高可用性:存储集群提供多副本机制,当某个故障单元发生故障后,整个集群依然可以对外提供服务。
(6)易用性:提供方便易用的管理界面,实现存储集群的灵活部署和监控运维。
新华三UIS超融合方案介绍

四川省国家税务局
UIS 超融合承载四川省国家税务生产系 统,分担了传统存储的数据容量压力, 提供了成本更优、扩容更灵活的软件定 义存储,降低了业务扩展的平台要求。
涉及15台UIS 节点,共计ONEStor软件 定义存储720TB
云计算——分布式存储

THANKS
感谢观看
云计算——分布式存储
汇报人: 2023-12-14
目录
• 分布式存储概述 • 分布式存储技术原理 • 分布式存储系统架构 • 分布式存储应用场景 • 分布式存储性能优化策略 • 分布式存储安全问题及解决方案
01
分布式存储概述
定义与特点
定义
分布式存储是一种数据存储技术,它通过将数据分散到多个独立的节点上,以 实现数据的分布式存储和访问。
云计算平台建设
01
02
03
云存储服务
分布式存储作为云计算平 台的核心组件,提供高效 、可扩展的存储服务。
云服务集成
与其他云服务(如计算、 网络、安全等)紧密集成 ,形成完整的云计算解决 方案。
自动化运维与管理
通过自动化工具实现分布 式存储系统的运维和管理 ,提高效率。
物联网数据存储与处理
实时数据采集
现状
目前,分布式存储技术已经成为了云计算领域的重要组成部 分,各大云服务提供商都提供了基于分布式存储的云存储服 务。同时,随着技术的不断发展,分布式存储的性能和稳定 性也在不断提高。
优势与挑战
优势
分布式存储具有高性能、高可用性、安全性、容错性和可维护性等优势,它可以 提供更加高效、灵活和可靠的数据存储服务,同时还可以提供更加灵活的扩展能 力,以满足不断增长的数据存储需求。
支持物联网设备实时采集 数据,并存储在分布式存 储系统中。
数据处理与分析
对物联网数据进行处理和 分析,提取有价值的信息 。
智能决策与控制
基于物联网数据分析结果 ,实现智能决策和控制, 提高生产效率。
05
分布式存储性能优化策略
数据压缩与解压缩技术
主流超融合厂商技术优劣对比

主流超融合厂商技术对比超融合基础架构(HCI)是继服务器虚拟化技术之后的一次重大IT技术革新,其特点是通过分布式存储技术将各个计算节点(Hypervisor)的存储资源整合为一个统一的存储资源池,给虚拟化平台提供存储服务,实现计算、存储、网络、虚拟化的统一管理和资源的横向扩展,保障用户业务的高可用。
在超融合基础架构中,虚拟化是基础,而分布式存储则是超融合的技术核心。
从架构而言,HCI的分布式存储通常有两种方式来支持虚拟化,一种是以Nutanix NGFS为代表的采用控制虚拟机方式支持Hypervisor,如图一;另一种是直接在Hypervisor中集成分布式存储功能,如VSAN。
业界除了VSAN外,其它HCI全部采用控制虚拟机方案支持VMware虚拟化,而对于KVM虚拟化,各厂家采用在物理主机中实现分布式存储功能。
图一主流的超融合厂商有Nutanix(NGFS),VMware(VSAN),以及国内新兴代表力量如华为(FusionCube),H3C(OneStor),SMARTX(ZBS),深信服(aSAN),和道熵(Titlis)。
其中Nutanix的NGFS和SMARTX 的ZBS 脱胎于Google的GFS分布式文件系统;华为的FusionCube和H3C的OneStor是基于Ceph的定制化开发;而深信服的aSAN则是基于GlusterFS;VSAN在很大程度上和Ceph架构类似;而道熵的Titlis分布式存储在接口层兼容了标准Ceph接口,底层采用了磁盘阵列中常见的存储虚拟化技术。
根据对超融合产品的重要程度,我们选择了几方面的技术功能进行了相关考察:1、抗静默错误2副本或3副本机制可以保证在硬盘损坏甚至节点宕机的恶劣环境下,仍然保持高可用。
但是面对“静默错误”的情况,分布式块存储的副本机制则无能为力,腾讯云在不久前的“静默错误”风波证明了这一点,后果也是相当严重,用户的所有数据全部丢失,无法修复。
Thin LUN磁盘空间回收问题

ONEStor 构成。
O N E S t o r 存储系统基于Ceph,可运行在多台通用的x86服务器。
ONEStor 通过把多台不同服务器的本地硬盘组织成一个统一的存储资源池,对上层应用提供存储服务。
分布式存储磁盘空间报警每台服务器2块600GB 的SAS 盘安装CVK笔者单位在IDC 机房的服务器实施了虚拟化与云计算。
整个云平台由6台惠普ProLiant DL580 Gen9高配服务器,单台配置为512G 内存、4棵12核心CPU、2块600G 的SAS 盘、3块2T 的SATA 盘、2块480G 的固态盘,安装部署了新华三公司的云计算管理平台和分布式存储系统,由CAS(Cloud Automation System)和Thin LUN 磁盘空间回收问题■ 四川 赖文书编者按: 笔者单位在启动业务上云后,对原有提系统及设备进行了更新部署,其中采用的H3C ONEStor 存储系统出现磁盘空间报警问题,笔者联合厂商工程师专家进行了排查。
图1 OSD 磁盘使用率detection”命令,出现“Followingp o r t (s ) h a s (h a v e ) l o o p b a c k l i n k : GigabitEthernet1/0/9”字样,说明GigabitEthernet1/0/9有环回。
通过查看GigabitEthernet1/0/9端口的线标,发现该端口对应着二层的某间办公室。
顺藤摸瓜,解决问题笔者前往网线上标注的房间查明故障原因,发现该房间的墙插上连接了4口普通小交换机,小交换机的四个口都插满网线,办公室只有三台电脑,电脑走明线连接小交换机。
在经过一番排查后,笔者发现一根网线的两端都连在交换机上,形成了线路环回,同在一个VLAN 的队长办公室电脑和其他一些办公室电脑都受到影响,将其移除,经过测试网络立刻畅通,一切如初。
经验总结1.加强管理引起环路是因为管理不善,对各部门的控制力不足,需制定相应的管理制度,完善联网准入制度,不准私自购买小交换机、无线路由器等设备。
分布式存储系统详解

传统SAN架构
FC/IP
孤立的存储资源:存储通过 专用网络连接到有限数量的 服务器。
存储设备通过添加硬盘框 增加容量,控制器性能成 为瓶颈。
第3页
分布式Server SAN架构
虚拟化/操作系统 InfiniBand /10GE Network
InfiniBand /10GE Network
Server 3
Disk3 P9 P10 P11 P12
P2’ P6’ P14’ P18’
Disk4 P13 P14’ P15 P16’ P7’ P11’ P19’ P23’
Disk5 P17 P18’ P19 P20’ P3’ P12’ P15’ P24’
Disk6 P21 P22 P23 P24 P4’ P8’ P16’ P20’
第10页
FusionStorage部署方式
融合部署
指的是将VBS和OSD部署在同一台服务器中。 虚拟化应用推荐采用融合部署的方式部署。
分离部署
指的是将VBS和OSD分别部署在不同的服务器中。 高性能数据库应用则推荐采用分离部署的方式。
第11页
基础概念 (1/2)
资源池:FusionStorage中一组硬盘构成的存储池。
第二层为SSD cache,SSD cache采用热点读机制,系统会统计每个读取的数据,并统计热点访问因 子,当达到阈值时,系统会自动缓存数据到SSD中,同时会将长时间未被访问的数据移出SSD。
FusionStorage预读机制,统计读数据的相关性,读取某块数据时自动将相关性高的块读出并缓存
到SSD中。
数据可靠是第一位的, FusionStorage建议3副本配 置部署。
如果两副本故障,仍可保障 数据不丢失。
大规模分布式存储系统概念及分类

大规模分布式存储系统概念及分类一、大规模分布式存储系统概念大规模分布式存储系统,是指将大量存储设备通过网络连接起来,形成一个统一的存储资源池,实现对海量数据的存储、管理和访问。
这种系统具有高可用性、高扩展性、高性能和低成本等特点,广泛应用于云计算、大数据、互联网等领域。
大规模分布式存储系统的主要特点如下:1. 数据规模大:系统可存储的数据量达到PB级别甚至更高。
2. 高并发访问:系统支持大量用户同时访问,满足高并发需求。
3. 高可用性:通过冗余存储、故障转移等技术,确保数据安全可靠。
4. 易扩展:系统可根据业务需求,动态添加或减少存储设备,实现无缝扩展。
5. 低成本:采用通用硬件,降低存储成本。
二、大规模分布式存储系统分类1. 块存储系统(1)分布式文件系统:如HDFS、Ceph等,适用于大数据存储和处理。
(2)分布式块存储:如Sheepdog、Lustre等,适用于高性能计算场景。
2. 文件存储系统文件存储系统以文件为单位进行存储,支持丰富的文件操作接口。
常见的文件存储系统有:(1)网络附加存储(NAS):如NFS、SMB等,适用于文件共享和备份。
(2)分布式文件存储:如FastDFS、MooseFS等,适用于大规模文件存储。
3. 对象存储系统对象存储系统以对象为单位进行存储,具有高可用性和可扩展性。
常见的对象存储系统有:(1)Amazon S3:适用于云存储场景。
(2)OpenStack Swift:适用于私有云和混合云场景。
4. 键值存储系统键值存储系统以键值对为单位进行存储,具有简单的数据模型和高速访问性能。
常见的键值存储系统有:(1)Redis:适用于高速缓存和消息队列场景。
(2)Memcached:适用于分布式缓存场景。
5. 列存储系统列存储系统以列为单位进行存储,适用于大数据分析和查询。
常见的列存储系统有:(1)HBase:基于Hadoop的分布式列存储数据库。
(2)Cassandra:适用于大规模分布式系统的高可用性存储。
H3C ONEStor 分布式存储系统 兼容性列表

H3C ONEStor 3.0分布式存储系统兼容性列表目录1硬件兼容性············································································································································ 1-11.1 硬件兼容性判断流程·························································································································· 1-11.2 块存储服务 ········································································································································ 1-11.2.1 RAID卡··································································································································· 1-11.2.2 网卡 ········································································································································ 1-21.2.3 主存盘····································································································································· 1-41.2.4 缓存盘····································································································································· 1-11.3 文件存储服务····································································································································· 1-31.3.1 RAID卡··································································································································· 1-31.3.2 网卡 ········································································································································ 1-31.3.3 主存盘····································································································································· 1-41.3.4 缓存盘····································································································································· 1-41.4 对象存储服务····································································································································· 1-51.4.1 RAID卡··································································································································· 1-51.4.2 网卡 ········································································································································ 1-61.4.3 主存盘····································································································································· 1-71.4.4 缓存盘····································································································································· 1-1 2生态兼容性············································································································································ 2-12.1 块存储服务 ········································································································································ 2-12.1.1 操作系统 ································································································································· 2-12.1.2 集群软件 ································································································································· 2-12.1.3 数据库软件······························································································································ 2-21 硬件兼容性1.1 硬件兼容性判断流程如图1-1所示,分别对服务器、RAID卡、网卡、主存盘、缓存盘等几个部分硬件的兼容性进行判断。
H3C ONEStor存储产品技术概述

9
ONEStor高扩展性的基础
基于算法的数据放置策略
1. 将文件分割成若干对象 单元。 2. 将每个对象单元映射到 一个确定的PG(放置组)。 3. 利用CRUSH算法,将每 个PG映射到一组OSD集
合。
10
ONEStor分布式算法的基本流程
ONEStor 中在对象和设备之间有两个概念: Pool和P G (Placement Group) ,每个对象要先计算对应的Pool,然后计算对应的P G , 通过 P G 可得到该对象对应的多个副本的位置,这些副本中第一个是 Primary,其余被称为replica。假设一个对象foo,其所在的pool 是 bar ,计算device 的方式如下: 1. 计算foo (object)的hash 值得到0x3F4AE323 2. 计算bar (pool)的pool id得到3 3. p o o lb a r 中的P G 数量为256 ,0x3F4AE323 m o d 256 = 23 , 所以P G 的id为3.23 ( P G 的数量需要达到满足在P G 中均衡的目的)
UIS-Cell超融合一体机方案介绍

因此对于UIS-Cell 设备,只需要对一台设备进行初始化(后续胶片有详细的初始化过程),之后该设备即可作为管
理设备,其余的设备只需要接入到同一个管理网络中,即可自动发现,从而完成IP地址配置,集群建立。
UIS-Cell 组网要求(网络无冗余要求)
管理网 ONEStor 数据网 ONEStor 业务网 业务网
业务网
UIS-Cell 组网要求(网络有冗余要求)--- 2
交换机1 组网介绍:
交换机2
UIS-Cell 3000设备,如果需要冗余的网络组网,建议配置多张网卡解决。 UIS-Cell 4000设备,如果需要冗余的网络组网,需要将两个XGE端口捆绑城聚合,将两个GE 也捆绑城聚合。 两个XGE捆绑的聚合运行的CAS 的管理网,ONEStor 的管理网,ONEStor 的业务网,ONEStor的数据网 连个GE 捆绑城的聚合,运行服务器的对外访问业务,包括CVM对外访问,包括ONEStor Handy 对外访问,UIS-Cell 对外访问,以及虚拟机提供的业务访问
英特尔至强E5-2600v3/v4系列 CPU,最大支持22核
英特尔C610 Series Chipset 24个DDR4 RDIMM/LRDIMM,最高2400MHz 前端:8个2.5寸小盘(UIS-Cell 3010);12个3.5寸大盘(UIS-Cell 3030);25个2.5寸小盘(UIS-Cell 3020)
MAC MAC MAC MAC MAC MAC
S
S
S
S
S
S
一小时内完成UIS-Cell超融合首次安装部署
首次部署 存储部署
创建虚机
资源扩展
首先部署存储网络,支持存储的网 络合并部署或者是分开部署 需要设置存储网络的 IP网段,和 其他的网段不冲突即可。
OneStor SP-3584扩展可存储平台(ESP)说明书

Regulatory Model No. SP-2584Data SheetOneStor TMSP-3584Extensible Storage Platform (ESP)Features5U rack-mount enclosure stores up to 5 petabytes of data per rack, saving space in the data center •Certified 80 PLUS Platinum efficient power conversion and adaptive cooling technologyreduces power and cooling costs •Data center space savings + power and cooling cost savings = exceptionally low total cost of ownership•Ultra-dense, with up to 84 3.5” SAS hard disk drives or solid state drives per 5U enclosure •Unique drawer design provides extremely high density per rack unit, and provides easy access to hot swap drives•Capacity of 840Tb in 5U using 10Tb enterprise HDDs•Expansion capability up to 336 drives Dual 12Gb SAS I/O modules with integral data path redundancy•Maximum of 28.8 GB/s in a dual controller configurationThe proliferation of digital content in the enterprise has created increasingly complex and costly storage systems. These systems consume large amounts of energy and prevent companies from easily adapting their IT infrastructure as needs change. As the pace of change continues to accelerate, the evolution of storage technologies has become essential. OEMs and solution integrators need an extensible storage infrastructure that provides flexibility, reliability and energy efficiency to meet diverse application requirements. These include applications in digital media, in compliance retention and in data archival.The OneStor SP-3584 evolves the mature SP-2584 platform to 12G SAS while maintaining the prior architecture utilizing significant hardware reuse, a common management API and SBB 2.0 compatibility. This enables OEMs to accelerate market introduction of new technologies and also significantly simplifies development and testing of storage implementations while reducing overhead.Seagate Advancing 12Gb/s SASSeagate Advancing 12Gb/s SAS The Seagate implementation of 12Gb/s SAS offers a number of significant improvements to 6Gb/s SAS over and above the doubling of the data transfer rate from 6 Gb/s to 12 Gb/s. These include support and capabilities for managed cables, active and optical cables, universal ports, self configuration, and standardized zoning. Seagate supports 12Gb/s SAS in end-to-end configurations providing an effective maximum throughput of 14.4 GB/s per I/O module or 28.8 GB/s in a dual controller configuration, enough to support the highest performing solid state storage devices.Delivering a Versatile & Scalable ArchitectureAs a member of the OneStor family, the SP-3584 leverages the reuse of interchangeable I/O modules, a common enclosure management and SBB 2.0 compatibility. This enables OEMs to accelerate market introduction of new technologies and also significantly simplifies development and testing of storage implementations while reducing overhead.Assuring Robust Data AvailabilityThrough its intelligent Unified System Management (USM), OneStor safeguards data and ensures maximum availability. Users are able to leverage fault diagnosis and resolution capabilities, persistent error logging and monitoring. In addition, OneStor provides high availability features such as dual redundant PSUs, N+1 cooling modules, dual I/O modules and dual data paths to all drives.Customizing to Meet OEM Specific RequirementsOEMs can easily tailor each OneStor platform to meet end product requirements, including colored plastics, custom moldings, labeling, logo printing and product packaging.AMERICAS Seagate Technology LLC 10200 South De Anza Boulevard, Cupertino, California 95014, United States, 408-658-1000 ASIA/PACIFIC Seagate Singapore International Headquarters Pte. Ltd. 7000 Ang Mo Kio Avenue 5, Singapore 569877, 65-6485-3888EUROPE, MIDDLE EAST AND AFRICA Seagate Technology SAS 16–18, rue du Dôme, 92100 Boulogne-Billancourt, France, 33 1-4186 10 00© 2016 Seagate Technology LLC. All rights reserved. Printed in USA. Seagate, Seagate Technology and the Wave logo are registered trademarks of Seagate Technology LLC in the United States and/or other countries. Seagate OneStor is either trademarks or registered trademarks of Seagate Technology LLC or one of its affiliated companies in the United States and/or other countries. All other trademarks or registered trademarks are the property of their respective owners. When referring to drive capacity, one gigabyte, or GB, equals one billion bytes. Your computer’s operating system may use a different standard of measurement and report a lower capacity. In addition, some of the listed capacity is used for formatting and other functions, and thus will not be available for data storage. Actual data rates may vary depending on operating environment and other factors. The export or re-export of hardware or software containing encryption may be regulated by the U.S. Department of Commerce, Bureau of Industry and Security (for more information, visit ), andcontrolled for import and use outside of the U.S. Seagate reserves the right to change, without notice, product offerings or specifications. Issue 1.0 | 2017Take the next step: to learn more about Seagate ®Cloud Systems and Solutions visit /oem。
智慧校园云解决方案范文

智慧校园云解决方案范文-融合创新助校园数字化转型在教育信息化2.0阶段,校园数字化建设蓬勃发展,信息技术深度融合教育应用创新,校园信息化深度融合教学、科研、管理和服务,成为高校全面创新变革重要推力。
与此同时,云计算技术逐步走向成熟应用阶段,内涵不断丰富,充分融合网络、安全、大数据、存储、人工智能等领域的前沿技术,可以更好服务和促进新型智慧校园建设。
云实现了IT资源集中共享,但云上业务系统还是各自独立,云内数据不能集成挖掘,因此,校园云只是实现了IT服务,对于促进教学、科研、管理创新不足。
传统校园云建设存在的典型问题校园云建设缺乏针对高校场景化适配,如:师生使用流程和习惯匹配度不足、云租户差异化安全存在不足、应用系统IPv6支持不足等问题。
不同云组件之间缺乏融合联动,资源服务智能性不足,同时存在运维管理复杂的问题。
基于校园信息化和技术发展趋势,新华三推出全融合校园云中心解决方案,新华三全融合校园云除了提供全面IT资源服务外,还可以全面针对教学、科研、管理等提供智慧应用服务,如:实现面向社会需求的学科优化,在大数据技术支撑下,针对不同学生,可以实现因材施教;随着新技术飞速发展,校园云还可以提供AI、HPC等创新服务。
全融合校园云中心通过技术创新促进海量智慧应用创新,海量智慧应用创新促进智慧校园创新。
新华三全融合校园云秉承标准化、开放化技术路线,整体架构如下:校园云中心技术架构应用层/SaaSH3C+云生态合作联盟PaaS服务层科研环境仿真服务开发平台服务应用层/SaaSH3C+云生态合作联盟PaaS服务层科研环境仿真服务开发平台服务Docker服务应用中间件服务消息中间件服务高性能计算服务IaaS服务层IT硬件层安全资源池(vFW、vLB)网络资源池(vNET)存储资源池(SAN、分布式存储)HPC资源池计算资源池(虚拟机、物理机)资源池控制层……云杀毒服务云负载均衡服务云防火墙服务对象存储服务块存储服务物理云主机服务虚拟云主机服务非结构化数据服务结构化数据服务……大数据平台服务专业领域数据平台服务面向社会公众服务类应用智慧校园创新类应用教学、科研、管理类应用统一运营管理门户统一云中心服务门户门户层校园云运维模块云管理层云安全服务模块基于业界主流OpenStack架构,整体云平台包括:门户层、云管理层、资源池控制层、IT硬件层,还有贯穿各个层面的云安全服务模块和云运维模块。
联想分布式存储系统解决方案

联想分布式存储系统解决方案目录一、内容综述 (2)1.1 背景与挑战 (3)1.2 目的与意义 (3)二、联想分布式存储系统概述 (4)2.1 系统定义 (5)2.2 架构特点 (6)三、联想分布式存储系统架构 (7)3.1 存储节点 (9)3.2 网络架构 (10)3.3 数据分布与冗余 (11)四、联想分布式存储系统功能 (12)4.1 数据冗余与备份 (13)4.2 数据安全与隐私保护 (14)4.3 数据访问与共享 (15)4.4 自动化与智能化管理 (16)五、联想分布式存储系统优势 (17)5.1 高可用性 (19)5.2 高性能 (20)5.3 高扩展性 (21)5.4 简化管理 (23)六、联想分布式存储系统应用场景 (24)6.1 云计算平台 (25)6.2 大数据分析 (26)6.3 企业级存储需求 (28)七、安装与部署 (29)7.1 系统要求 (30)7.2 安装步骤 (31)7.3 部署策略 (32)八、维护与升级 (34)8.1 日常维护 (35)8.2 定期检查 (36)8.3 版本升级 (37)九、方案总结 (39)9.1 联想分布式存储系统价值 (40)9.2 未来发展趋势 (41)一、内容综述随着信息技术的快速发展和大数据时代的到来,数据规模的不断增长和复杂性的提升对存储系统提出了更高的要求。
在这样的背景下,联想分布式存储系统解决方案应运而生,旨在为企业提供高效、可靠、可扩展的存储服务。
本解决方案基于分布式存储技术,结合联想在硬件、软件及云计算领域的优势,为企业提供全方位的存储服务,满足其日益增长的数据存储需求。
高效的数据存储和管理:通过分布式存储架构,将数据存储在网络中的多个节点上,实现数据的分布式存储和管理。
这种架构可以大大提高数据的可靠性和可用性,同时提高数据的读写性能。
可扩展的存储能力:随着企业数据规模的不断增长,存储系统的可扩展性显得尤为重要。
联想分布式存储系统可以随着企业需求的增长而扩展,轻松应对大规模数据的挑战。
OceanStor 9000存储产品方案介绍

①主机E向Node C的客户端发出数据读请求
②Node C的客户端向分布式锁服务器申请 分条资源读锁
LOCK
CPU
CPU
3.返回数据在Node A缓存中
CPU Memory storage
Node C
③系统检查所读数据的缓存是否在全局缓存 中以及缓存在哪个节点上,左图显示该文件 分条资源在Node A节点上的缓存中 ④ Node C从Node A节点上的全局缓存中 获数据并返回(如果不在全局缓存中,则直 接从各个节点上读取该分条数据的所有条带 数据后构造出分条数据后再返回)
Social Network
Business Intelligence
传统NAS
NFS CIFS FTP
HDFS API OceanStor 9000
S3
Swift
keystone
全分布式架构,高可靠数据保护
N+1~N+4的数据保护,
最大允许4块硬盘/节点故障
磁盘利用率最高达95%
+1
+3
+2
P36
C72
4U,3.5寸盘,36盘位 面向高清编辑,新闻制作,高端HPC
4U,3.5寸盘,72盘位 面向近线存储,视频监控
OceanStor 9000整体视图一
P25
前视图 后视图 2U 25盘(2.5寸数据盘)设备 标配:双路Intel IvyBridge CPU,48G内存, 2GB NVDIMM, 1*400GB SSD+24*900GB/1.2TB SAS盘
• 无需人工干预,无需更改配置
• 负载过程对应用透明
node
192.168.0.20 192.168.0.21
联想LeoStor分布式存储系统

300PB
大文件
大小文件
跨节点的Raid 5 奇偶校验任何磁盘或机箱故 障会导致昂贵的再分配和再平衡的数据在所 有参与的节点
多副本机制或者跨节点校验模式,可根据需 求动态设置快速恢复时间,1T磁盘半小时 内恢复完成
基于IP地址池的后端负载均衡
透明的客户端和存储服务器之间的负载平衡 请求
数据在存储到数据服务器上之后进行切片分 发,如果此时服务器出现损坏则会出现数据 丢失
存储系统只对大文件读写做了优化, 分别对大文件和小文件读写做了双重
无小文件优化策略
优化
刀片服务器,每台刀片带2块存储磁 盘,硬件要求非常高,硬件要求较 高
通用机架式服务器,每台服务器可带 1-36块磁盘 ,硬件要求较低
单卷容量
PB级(官方网站给出)
300PB
数据保护
数据丢失重建 成本
分层校验,通过动态复制数据段进 行数据块损坏时数据保护,单点故 障与整个磁盘损坏则完全通过RAID 机制加以实现 500G数据重建时间在90分钟左右, 且需要借助所有刀片同时参与数据 恢复,影响整体性能。
LeoStor 智能前端切片技术
切片4K~64M
AP1
AP2
AP3
OSS1
OSS2
OSS3
存储节点(OSS)
OSS4
数据写入模式
Servers 客户端算法计算元数据
Servers Servers
交换机
MDS元数据节点
元数据服务器通过负 载均衡算法进行负载 均衡运算
存储服务器
OSS数据节点
数据读取模式
元数据信息存放在每台数据服务器上,且每 台数据服务器要存储所有的元数据信息,在 通过后台进行复杂的数据交换,保证数据的 一致性
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
ONEStor分布式存储系统介绍关于ONEStor分布式存储系统介绍,小编已在金信润天Get到了部分资料,整理出以下内容:技术特点H3C ONEStor存储系统采用分布式设计,可以运行在通用x86服务器上,在部署该软件时,会把所有服务器的本地硬盘组织成一个虚拟存储资源池,对上层应用提供块存储功能。
H3C ONEStor分布式存储软件系统具有如下特点:领先的分布式架构H3C ONEStor存储软件的采用全分布式的架构:分布式管理集群,分布式哈希数据分布算法,分布式无状态客户端、分布式Cache等,这种架构为存储系统的可靠性、可用性、自动运维、高性能等方面提供了有力保证。
其系统架构组成如下图所示:上图中,ONEStor逻辑上可分为三部分:OSD、Monitor、Client。
在实际部署中,这些逻辑组件可灵活部署,也就是说既可以部署在相同的物理服务器上,也可以根据性能和可靠性等方面的考虑,部署在不同的硬件设备上。
下面对每一部分作一简要说明。
OSD:Object-based Storage DeviceOSD由系统部分和守护进程(OSD deamon)两部分组成。
OSD系统部分可看作安装了操作系统和文件系统的计算机,其硬件部分包括处理器、内存、硬盘以及网卡等。
守护进程即运行在内存中的程序。
在实际应用中,通常将每块硬盘(SSD或HDD)对应一个OSD,并将其视为OSD的硬盘部分,其余处理器、内存、网卡等在多个OSD之间进行复用。
ONEStor存储集群中的用户都保存在这些OSD中。
OSD deamon负责完成OSD的所有逻辑功能,包括与monitor 和其他OSD(事实上是其他OSD的deamon)通信以维护更新系统状态,与其他OSD共同完成数据的存储和维护,与client通信完成各种数据对象操作等等。
Monitor:Monitor是集群监控节点。
Monitor持有cluster map信息。
所谓Cluster Map,粗略的说就是关于集群本身的逻辑状态和存储策略的数据表示。
ONEStor Cluster Map包括Monitor map、osd map、pg map、crush map等,这些map构成了集群的元数据。
总之,可以认为Monitor 持有存储集群的一些控制信息,并且这些map信息是轻量级的,只有在集群的物理设备(如主机、硬盘)和存储策略发生变化时map信息才发生改变。
Client:这里的Client可以看出外部系统获取存储服务的网关设备。
client通过与OSD或者Monitor 的交互获取cluster map,然后直接在本地进行计算,得出数据的存储位置后,便直接与对应的OSD通信,完成数据的各种操作。
在此过程中,客户端可以不依赖于任何元数据服务器,不进行任何查表操作,便完成数据访问流程。
这一点正是ONEStor分布式存储系统可以实现扩展性的重要保证。
客户的数据到达Client后,如何存储到OSD上,其过程大致如下图所示:首先对上图中的一些名词进行简要描述:File:此处的file是对用户或者应用而言的,指用户或者应用需要存储或者访问的文件。
如果将ONEStor作为对象存储的后端,这个file也就对应于应用中的“对象”,也就是用户直接操作的“对象”。
Object:此处的object是ONEStor内部定义的“对象”。
object的大小用户可以自行配置(在配置文件中设置,通常为2MB或4MB)。
当上层应用向ONEStor集群存入size较大的file时,需要将file切分成统一大小的一系列 object(最后一个的大小可以不同)进行存储。
为避免混淆,在本文中将尽量避免使用中文的“对象”这一名词,而直接使用file 或object进行说明。
PG:(Placement Group)PG是一个逻辑概念,其作用是对object的存储进行组织和位置映射。
这样便在object和osd之间提供一个中间映射层,即object->pg->osd。
某个object 通过算法映射到某个确定的pg,这个pg再通过某种算法映射到一组确定的osd(其个数和副本或纠删码配置有关,具体见后面章节描述)。
从数量上看,一般object数量远大与pg 数量,pg数量(一般比osd大两个数量级)远大于osd数量。
PG的概念类似于一致性哈希算法中的虚拟节点,引入PG后,可以在总体上大大减少每个osd相关的元数据的数量。
下面对上图中的寻址流程进行简要说明。
1, File->Object映射:(ino,ono)->oid这个映射比较简单,就是将用户要操作的file,映射为ONEStor能够处理的object。
其本质就是按照配置文件定义的object大小对file进行切分,相当于RAID中的条带化过程。
这种切分的好处有二:一是让大小不限的file变成size一致、可以被存储集群高效管理的object;二是让对单一file实施的串行处理变为对多个object实施的并行化处理,以提高读写性能。
对于要操作的File,Client将会从Monitor获得全局唯一的inode number,即ino。
File 切分后产生的object将获得唯一(在File的范围内)的object number,即ono。
Ono的编号从0开始,依次累加。
oid就是将ono连缀在ino之后得到的。
容易看出,由于ino的全局唯一性(通过Monitor获得),oid同样具备全局唯一性。
2, Object -> PG映射在file被映射为一个或多个object之后,就需要将每个object独立地映射到一个PG中去。
这个映射过程也很简单,其计算公式是:hash(oid) & mask -> pgid或者更加明显的表示成:hash(oid) mod (pgno) -> pgid上式中,pgno表示配置的pg数量,一般为2的整数次幂。
整个计算由两步组成。
首先是使用ONEStor系统指定的一个特定的哈希函数计算oid的哈希值(这个值将具备近似均匀分布的特性)。
然后,将这个伪随机值对pgno取模,就得到了pgid。
这样,pgid的取值范围是从0到pgno-1。
由哈希函数的伪随机特性,容易想见,大量的oid将近似均匀地映射到不同的pgid上。
3, PG -> OSD映射第三次映射就是将作为object的逻辑组织单元的PG通过CRUSH算法映射到一组OSD集合。
集合中具体的OSD个数一般为数据副本的个数。
比如,用户配置了3副本,那么每个pg将映射到3个osd。
多副本可以大大提高数据的可靠性(具体可见后面相关章节的说明)。
相比于“object -> PG”映射过程,CRUSH算法要复杂的多。
通常情况下,一个好的分布式算法至少满足如下的要求:1,数据的放置位置是Client计算出来的,而不是向Server查出来的2,数据在存储体上满足概率均匀分布3,存储体动态变化时数据重分布时引入的数据迁移量达到最优或者次优除了这3点基本要求外,一个好的算法还应该满足:4,可以基于指定的策略放置副本: 用于故障域隔离或其它要求5,在存储体引入权“weight”的概念,以便对磁盘容量/速度等进行区分CRUSH算法是ONEStor的核心算法,完全满足上面提到的5点要求,限于篇幅,此处不对算法本身进行描述。
当系统中的OSD状态、数量发生变化时,cluster map亦随之变化,而这种变化将会影响到PG与OSD之间的映射,从而使数据重新再OSD之间分布。
由此可见,任何组件,只要拥有cluster map,都可以独立计算出每个object所在的位置(去中心化)。
而对于cluster map,只有当删除添加设备或设备故障时,这些元数据才需要更新,更新的cluster map会及时更新给client和OSD,以便client和OSD重新计算数据的存储位置。
1.自动化运维自动化运维主要体现在如下几个方面:(1)存储集群快速部署,包括批量部署、单节点增减、单磁盘增减等。
(2)设置监控报警系统,发生故障时能快速界定问题、排查故障。
(3)根据硬件能力,灵活地对集群中的节点进行灵活配置。
(4)允许用户定制数据分布策略,方便地进行故障域隔离,以及对数据存储位置进行灵活选择。
(5)在增删存储介质,或存储介质发生故障时,自动进行数据均衡。
保证集群数据的高可用性。
(6)在系统平衡数据(例如系统扩容或者存储节点、磁盘发生故障)的过程中,为保证用户IO,ONEStor存储系统支持IO优先级控制和Qos保证能力。
对于(1)(2)两点,详见“ONEStor管理系统”章节,在此不再赘述。
对于(3),ONEStor系统可以根据用户需求灵活地部署Monitor节点和Client节点。
一方面,这些节点既可以部署在单独的物理服务器上,也可以部署在和OSD相同的物理节点上。
另一方面,Monitor和Client的节点可以根据用户的需求灵活地调整。
比如为了可靠性保证,至少需要部署3个Monitor节点;为了保证对象存储网关的性能,需要部署过个RGW (Client)节点。
对于(4),用户的需求主要体现在存储策略上,比如在选用副本策略时,用户可能希望不同数据副本存储在不同机架上面的主机上;或者主副本存储在某个机架的主机上,其它副本存储在另外机架的主机上;或者主副本存储在SSD上,其它副本存储在HDD上。
诸如此类等等。
这些需要都可以通过配置cluster map中的rule set进行灵活地配置。
对于(5),在增删存储介质,或存储介质发生故障时,系统会及时进行检测。
比如,在磁盘发生故障时,ONEStor会利用损坏数据在其他存储体上的副本进行复制,并将复制的数据保存在健康的存储体上;在增加磁盘时,同样会把其他存储体的数据安排容量比例重新分布到新磁盘,使集群的数据达到均衡。
在上述过程中,完全不需要人工干预。
对于(6),我们知道,在系统扩容或者存储节点、磁盘故障过程中,为保证数据的可靠性,系统会自动进行数据平衡。
为了尽快完成数据平衡,往往会沾满每个存储节点的带宽和IO 能力,这样做的好处是会使平衡时间最短,坏处是此时前端用户的IO请求会得不到满足。
在某些业务场景下,这时用户无法接受的。
为此,ONEStor存储系统实现了IO优先级和Qos 控制机制,可以对前端用户网络流量和后端存储网络流量进行控制,保证一定比例的用户IO得到满足。
2.线性扩展能力所谓线性扩展能力,主要体现在两个方面:一个是集群部署规模可以线性扩展,另一个方面,随集群规模的扩展,其性能要能够线性或近似线性扩展。
在规模上,传统存储之所以在扩展能力上受限,一个很重要的原因就是一般其采用集中式控制,并且在控制节点存储大量的元数据信息,从而使控制节点容易成为系统的瓶颈。