哈尔滨工程大学模式识别实验报告
哈工大系统辨识实验三

zl=[z(3:16)]'
hl1=-z(2:15)'
hl2=-z(1:14)'
hl3=u(2:15)'
hl4=u(1:14)'
Hl=[hl1,hl2,hl3,hl4];
theta=((Hl'*Hl)^-1)*Hl'*zl;
disp('辨识后得到的参数:')
disp(theta)
end
function m=m_xulie(n,k)%n为M序列的阶数k为序列的长度
………………………………………………………………………………………….....(2)
设
,
则式(2)可写为
…………………………………………………………………………….(3)
式中:y为N维输出向量; 为N维噪声向量; 为 维参数向量; 为 测量矩阵。为了尽量减小噪声 对 估值的影响,应取 ,即方程数目大于未知数数目。
通过本次上机实验课程,我体会到了最小二乘法辨识是一种近代的系统辨识方法,其优点是只需要考虑系统的输入输出特性,而不强调系统的内部机理。适用于单输入单输出系统的差分方程模型中的参数估计。
最后感谢老师在指导我们上机实验当中所付出的努力。
当系统中没有白噪声时,理论上应该得到准确的参数,我们把模型中的v(k)项剔除,得到以下的辨识结果:
这说明当不存在白噪声时,可以精确获得精确的估计值 ,估计值 的均方差随着噪声的均方差的增大而增大。
8
在这次上机实验当中,我们跟着老师学会了运用最小二乘法实现对系统的参数的估计,估计结果与系统的实际参数存在一定的偏差,原因是白噪声对系统的干扰造成的。
x(j)=X(n);
end
x=-2*x+ones(1,k);
模式识别实验报告(一二)

信息与通信工程学院模式识别实验报告班级:姓名:学号:日期:2011年12月实验一、Bayes 分类器设计一、实验目的:1.对模式识别有一个初步的理解2.能够根据自己的设计对贝叶斯决策理论算法有一个深刻地认识3.理解二类分类器的设计原理二、实验条件:matlab 软件三、实验原理:最小风险贝叶斯决策可按下列步骤进行: 1)在已知)(i P ω,)(i X P ω,i=1,…,c 及给出待识别的X 的情况下,根据贝叶斯公式计算出后验概率:∑==cj iii i i P X P P X P X P 1)()()()()(ωωωωω j=1,…,x2)利用计算出的后验概率及决策表,按下面的公式计算出采取ia ,i=1,…,a 的条件风险∑==cj j jii X P a X a R 1)(),()(ωωλ,i=1,2,…,a3)对(2)中得到的a 个条件风险值)(X a R i ,i=1,…,a 进行比较,找出使其条件风险最小的决策ka ,即()()1,min k i i aR a x R a x ==则ka 就是最小风险贝叶斯决策。
四、实验内容假定某个局部区域细胞识别中正常(1ω)和非正常(2ω)两类先验概率分别为 正常状态:P (1ω)=; 异常状态:P (2ω)=。
现有一系列待观察的细胞,其观察值为x :已知先验概率是的曲线如下图:)|(1ωx p )|(2ωx p 类条件概率分布正态分布分别为(-2,)(2,4)试对观察的结果进行分类。
五、实验步骤:1.用matlab 完成分类器的设计,说明文字程序相应语句,子程序有调用过程。
2.根据例子画出后验概率的分布曲线以及分类的结果示意图。
3.最小风险贝叶斯决策,决策表如下:结果,并比较两个结果。
六、实验代码1.最小错误率贝叶斯决策 x=[] pw1=; pw2=; e1=-2; a1=; e2=2;a2=2;m=numel(x); %得到待测细胞个数pw1_x=zeros(1,m); %存放对w1的后验概率矩阵 pw2_x=zeros(1,m); %存放对w2的后验概率矩阵results=zeros(1,m); %存放比较结果矩阵for i = 1:m%计算在w1下的后验概率pw1_x(i)=(pw1*normpdf(x(i),e1,a1))/(pw1*normpdf(x(i),e1,a1)+pw2*normp df(x(i),e2,a2)) ;%计算在w2下的后验概率pw2_x(i)=(pw2*normpdf(x(i),e2,a2))/(pw1*normpdf(x(i),e1,a1)+pw2*normp df(x(i),e2,a2)) ;endfor i = 1:mif pw1_x(i)>pw2_x(i) %比较两类后验概率result(i)=0; %正常细胞elseresult(i)=1; %异常细胞endenda=[-5::5]; %取样本点以画图n=numel(a);pw1_plot=zeros(1,n);pw2_plot=zeros(1,n);for j=1:npw1_plot(j)=(pw1*normpdf(a(j),e1,a1))/(pw1*normpdf(a(j),e1,a1)+pw2*no rmpdf(a(j),e2,a2));%计算每个样本点对w1的后验概率以画图pw2_plot(j)=(pw2*normpdf(a(j),e2,a2))/(pw1*normpdf(a(j),e1,a1)+pw2*no rmpdf(a(j),e2,a2));endfigure(1);hold onplot(a,pw1_plot,'co',a,pw2_plot,'r-.');for k=1:mif result(k)==0plot(x(k),,'cp'); %正常细胞用五角星表示elseplot(x(k),,'r*'); %异常细胞用*表示end;end;legend('正常细胞后验概率曲线','异常细胞后验概率曲线','正常细胞','异常细胞');xlabel('样本细胞的观察值');ylabel('后验概率');title('后验概率分布曲线');grid onreturn%实验内容仿真:x = [, ,,, , ,, , , ,,,,,,, ,,,,,,, ]disp(x);pw1=;pw2=;[result]=bayes(x,pw1,pw2);2.最小风险贝叶斯决策x=[]pw1=; pw2=;m=numel(x); %得到待测细胞个数R1_x=zeros(1,m); %存放把样本X判为正常细胞所造成的整体损失R2_x=zeros(1,m); %存放把样本X判为异常细胞所造成的整体损失result=zeros(1,m); %存放比较结果e1=-2;a1=;e2=2;a2=2;%类条件概率分布px_w1:(-2,) px_w2(2,4)r11=0;r12=2;r21=4;r22=0;%风险决策表for i=1:m%计算两类风险值R1_x(i)=r11*pw1*normpdf(x(i),e1,a1)/(pw1*normpdf(x(i),e1,a1)+pw2*norm pdf(x(i),e2,a2))+r21*pw2*normpdf(x(i),e2,a2)/(pw1*normpdf(x(i),e1,a1) +pw2*normpdf(x(i),e2,a2));R2_x(i)=r12*pw1*normpdf(x(i),e1,a1)/(pw1*normpdf(x(i),e1,a1)+pw2*norm pdf(x(i),e2,a2))+r22*pw2*normpdf(x(i),e2,a2)/(pw1*normpdf(x(i),e1,a1) +pw2*normpdf(x(i),e2,a2));endfor i=1:mif R2_x(i)>R1_x(i) %第二类比第一类风险大result(i)=0; %判为正常细胞(损失较小),用0表示elseresult(i)=1; %判为异常细胞,用1表示endenda=[-5::5] ; %取样本点以画图n=numel(a);R1_plot=zeros(1,n);R2_plot=zeros(1,n);for j=1:nR1_plot(j)=r11*pw1*normpdf(a(j),e1,a1)/(pw1*normpdf(a(j),e1,a1)+pw2*n ormpdf(a(j),e2,a2))+r21*pw2*normpdf(a(j),e2,a2)/(pw1*normpdf(a(j),e1, a1)+pw2*normpdf(a(j),e2,a2))R2_plot(j)=r12*pw1*normpdf(a(j),e1,a1)/(pw1*normpdf(a(j),e1,a1)+pw2*n ormpdf(a(j),e2,a2))+r22*pw2*normpdf(a(j),e2,a2)/(pw1*normpdf(a(j),e1, a1)+pw2*normpdf(a(j),e2,a2))%计算各样本点的风险以画图endfigure(1);hold onplot(a,R1_plot,'co',a,R2_plot,'r-.');for k=1:mif result(k)==0plot(x(k),,'cp');%正常细胞用五角星表示elseplot(x(k),,'r*');%异常细胞用*表示end;end;legend('正常细胞','异常细胞','Location','Best');xlabel('细胞分类结果');ylabel('条件风险');title('风险判决曲线');grid onreturn%实验内容仿真:x = [, ,,, , ,, , , ,,,,,,, ,,,,,,, ]disp(x);pw1=;pw2=;[result]=bayes(x,pw1,pw2);七、实验结果1.最小错误率贝叶斯决策后验概率曲线与判决显示在上图中后验概率曲线:带红色虚线曲线是判决为异常细胞的后验概率曲线青色实线曲线是为判为正常细胞的后验概率曲线根据最小错误概率准则,判决结果显示在曲线下方:五角星代表判决为正常细胞,*号代表异常细胞各细胞分类结果(0为判成正常细胞,1为判成异常细胞):0 0 0 0 0 0 0 0 0 0 0 0 0 1 0 1 1 1 0 0 0 1 0 12. 最小风险贝叶斯决策风险判决曲线如上图所示:带红色虚线曲线是异常细胞的条件风险曲线;青色圆圈曲线是正常细胞的条件风险曲线根据贝叶斯最小风险判决准则,判决结果显示在曲线下方:五角星代表判决为正常细胞,*号代表异常细胞各细胞分类结果(0为判成正常细胞,1为判成异常细胞):1 0 0 0 0 0 0 0 0 0 0 0 1 1 0 1 1 1 0 0 0 1 0 1八、实验分析由最小错误率的贝叶斯判决和基于最小风险的贝叶斯判决得出的图形中的分类结果可看出,样本、在前者中被分为“正常细胞”,在后者中被分为“异常细胞”,分类结果完全相反。
哈工大 模式识别总结

非监督学习方法
与监督学习 方法的区别
主要任务:数据分析 数据分析的典型类型:聚类分析 直接方法:按概率密度划分 投影法 基 于 对 称性 质 的 单 峰 子集 分 离方法 间接方法:按数据相似度划分 动态聚类 方法 C-均值 算法 ISODATA 算法 分级聚类 算法
第三章 判别函数及分类器的设计
(1)非参数分类决策方法的定义;与贝叶斯决策方法进行比 较,分析非参数分类方法的基本特点。 (2)线性分类器。说明这种分类器的定义及其数学表达式, 进一步分析数学表达式的各种表示方法,从而导出典型的线 性分类器设计原理:Fisher准则函数、感知准则函数。 (3)非线性判别函数。从样本的线性不可分例子说明线性判 别函数的局限性,从而引入分段线性判别函数概念及相应计 算方法。 (4)近邻法的定义及性能分析。从近邻法的优缺点导入改进 的近邻法;
非参数判别分类方法原理----有监督学习方法
线性分类器
近邻法: 最近邻法,K近邻法
Fisher 准则
扩展:分段 线性分类器 方法实现非 线性分类器
感知准则 函数
多层感知器 (神经网络)
支持向量机
SVM
改进的近邻法: --剪辑近邻法 --压缩近邻法
特征映射方法实 现非线性分类器
错误修正算法 可实现最小分段数的局部训练算法
特征空间优化:概念、目的及意义
两种优化方法:特征选择、特征提取 评判标准:判据 ------基于距离的可分性判据 -----基于概率的可分性判据 特征提取 特征选择 KL变换 产生矩阵 包含在类平 均信息中判 别信息的最 优压缩 最优方法 分支 定界 算法 次优方法 顺序前 进法, 广义顺 序前进 法 顺序后 退法, 广义顺 序后退 法
哈工大模式识别课程8主成分分析

主讲人: 主讲人:邱剑彬 李君宝
jbqiu@ lijunbao@
哈尔滨工业大学
1
1.引言 1.引言 主成分分析(PCA) 2 主成分分析(PCA) 3 基于K-L展开式的特征提取 基于K 4.应用举例 4.应用举例
一般来说, 一般来说 , 我们希望能用一个或少数几个综合指 分数)来代替原来分数表做统计分析, 标 ( 分数 ) 来代替原来分数表做统计分析 , 而且 希望新的综合指标能够尽可能地保留原有信息, 希望新的综合指标能够尽可能地保留原有信息 , 并具有最大的方差。 并具有最大的方差。
8
【问题的提出】
主成分分析的目的
17
ቤተ መጻሕፍቲ ባይዱ
二、主成分分析的计算步骤
(一)计算相关系数矩阵
r11 r 21 R = ⋮ r p1 r12 r22 ⋮ rp 2 ⋯ ⋯ ⋯ r1 p r2 p ⋮ r pp
rij (i,j=1,2,…,p)为原变量xi 与xj的相关系数, rij=rji,其计算公式为
⑤ 各主成分的得分
z11 z Z = 21 ⋮ z n1 z12 z 22 ⋮ zn2 z1m ⋯ z2m ⋮ ⋯ z nm ⋯
21
关于特征值
对于一个N × N的矩阵A,有N 个标量λk,k = 1, N,满足 ⋯ A − λk I = 0
λk 称为矩阵的一组特征值。
情形II下总分的方差为 , 情形 下总分的方差为0, 显然不能反映三个学生各科成 下总分的方差为 绩各有所长的实际情形, 绩各有所长的实际情形,而红色标记的变量对应的方差最 可反映原始数据的大部分信息。 大,可反映原始数据的大部分信息。 7
《模式识别》实验报告-贝叶斯分类

《模式识别》实验报告-贝叶斯分类一、实验目的通过使用贝叶斯分类算法,实现对数据集中的样本进行分类的准确率评估,熟悉并掌握贝叶斯分类算法的实现过程,以及对结果的解释。
二、实验原理1.先验概率先验概率指在不考虑其他变量的情况下,某个事件的概率分布。
在贝叶斯分类中,需要先知道每个类别的先验概率,例如:A类占总样本的40%,B类占总样本的60%。
2.条件概率后验概率指在已知先验概率和条件概率下,某个事件发生的概率分布。
在贝叶斯分类中,需要计算每个样本在各特征值下的后验概率,即属于某个类别的概率。
4.贝叶斯公式贝叶斯公式就是计算后验概率的公式,它是由条件概率和先验概率推导而来的。
5.贝叶斯分类器贝叶斯分类器是一种基于贝叶斯定理实现的分类器,可以用于在多个类别的情况下分类,是一种常用的分类方法。
具体实现过程为:首先,使用训练数据计算各个类别的先验概率和各特征值下的条件概率。
然后,将测试数据的各特征值代入条件概率公式中,计算出各个类别的后验概率。
最后,取后验概率最大的类别作为测试数据的分类结果。
三、实验步骤1.数据集准备本次实验使用的是Iris数据集,数据包含150个Iris鸢尾花的样本,分为三个类别:Setosa、Versicolour和Virginica,每个样本有四个特征值:花萼长度、花萼宽度、花瓣长度、花瓣宽度。
2.数据集划分将数据集按7:3的比例分为训练集和测试集,其中训练集共105个样本,测试集共45个样本。
计算三个类别的先验概率,即Setosa、Versicolour和Virginica类别在训练集中出现的频率。
对于每个特征值,根据训练集中每个类别所占的样本数量,计算每个类别在该特征值下出现的频率,作为条件概率。
5.测试数据分类将测试集中的每个样本的四个特征值代入条件概率公式中,计算出各个类别的后验概率,最后将后验概率最大的类别作为该测试样本的分类结果。
6.分类结果评估将测试集分类结果与实际类别进行比较,计算分类准确率和混淆矩阵。
哈工大模式识别实验报告
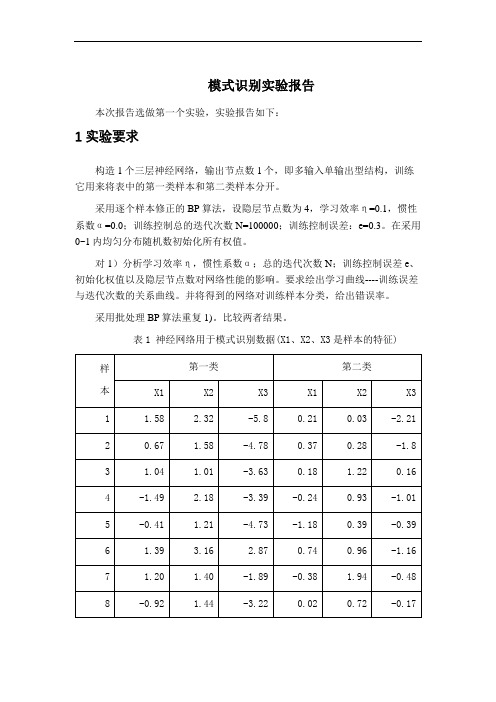
模式识别实验报告本次报告选做第一个实验,实验报告如下:1 实验要求构造1个三层神经网络,输出节点数1个,即多输入单输出型结构,训练它用来将表中的第一类样本和第二类样本分开。
采用逐个样本修正的BP算法,设隐层节点数为4,学习效率η=0.1,惯性系数α=0.0;训练控制总的迭代次数N=100000;训练控制误差:e=0.3。
在采用0~1内均匀分布随机数初始化所有权值。
对1)分析学习效率η,惯性系数α;总的迭代次数N;训练控制误差e、初始化权值以及隐层节点数对网络性能的影响。
要求绘出学习曲线----训练误差与迭代次数的关系曲线。
并将得到的网络对训练样本分类,给出错误率。
采用批处理BP算法重复1)。
比较两者结果。
表1 神经网络用于模式识别数据(X1、X2、X3是样本的特征)2 BP 网络的构建三层前馈神经网络示意图,见图1.图1三层前馈神经网络①网络初始化,用一组随机数对网络赋初始权值,设置学习步长η、允许误差ε、网络结构(即网络层数L 和每层节点数n l );②为网络提供一组学习样本; ③对每个学习样本p 循环a .逐层正向计算网络各节点的输入和输出;b .计算第p 个样本的输出的误差Ep 和网络的总误差E ;c .当E 小于允许误差ε或者达到指定的迭代次数时,学习过程结束,否则,进行误差反向传播。
d .反向逐层计算网络各节点误差)(l jp δ如果l f 取为S 型函数,即xl e x f -+=11)(,则 对于输出层))(1()()()()(l jp jdp l jp l jp l jp O y O O --=δ 对于隐含层∑+-=)1()()()()()1(l kj l jp l jp l jp l jp w O O δδe .修正网络连接权值)1()()()1(-+=+l ip l jp ij ij O k W k W ηδ式中,k 为学习次数,η为学习因子。
η取值越大,每次权值的改变越剧烈,可能导致学习过程振荡,因此,为了使学习因子的取值足够大,又不至产生振荡,通常在权值修正公式中加入一个附加动量法。
模式识别基础实验报告资料

2015年12月实验一 Bayes 分类器的设计一、 实验目的:1. 对模式识别有一个初步的理解,能够根据自己的设计对贝叶斯决策理论算法有一个深刻地认识;2. 理解二类分类器的设计原理。
二、 实验条件:1. PC 微机一台和MATLAB 软件。
三、 实验原理:最小风险贝叶斯决策可按下列步骤进行:1. 在已知)(i P ω,)|(i X P ω,c i ,,1 =及给出待识别的X 的情况下,根据贝叶斯公式计算出后验概率:∑==c j jj i i i P X P P X P X P 1)()|()()|()|(ωωωωω c j ,,1 =2. 利用计算出的后验概率及决策表,按下式计算出采取i α决策的条件风险: ∑==c j j j i i X P X R 1)|(),()|(ωωαλα a i ,,1 =3. 对2中得到的a 个条件风险值)|(X R i α(a i ,,1 =)进行比较,找出使条件风险最小的决策k α,即:)|(min )|(,,1X R X R k c i k αα ==, 则k α就是最小风险贝叶斯决策。
四、 实验内容:假定某个局部区域细胞识别中正常(1ω)和非正常(2ω)两类先验概率分别为: 正常状态:)(1ωP =0.9;异常状态:)(2ωP =0.1。
现有一系列待观察的细胞,其观察值为x :-3.9847 -3.5549 -1.2401 -0.9780 -0.7932 -2.8531-2.7605 -3.7287 -3.5414 -2.2692 -3.4549 -3.0752-3.9934 2.8792 -0.9780 0.7932 1.1882 3.0682-1.5799 -1.4885 -0.7431 -0.4221 -1.1186 4.2532)|(1ωx P )|(2ωx P 类条件概率分布正态分布分别为(-2,0.25)(2,4)。
决策表为011=λ(11λ表示),(j i ωαλ的简写),12λ=6, 21λ=1,22λ=0。
模式识别实验【范本模板】

《模式识别》实验报告班级:电子信息科学与技术13级02 班姓名:学号:指导老师:成绩:通信与信息工程学院二〇一六年实验一 最大最小距离算法一、实验内容1. 熟悉最大最小距离算法,并能够用程序写出。
2. 利用最大最小距离算法寻找到聚类中心,并将模式样本划分到各聚类中心对应的类别中.二、实验原理N 个待分类的模式样本{}N X X X , 21,,分别分类到聚类中心{}N Z Z Z , 21,对应的类别之中.最大最小距离算法描述:(1)任选一个模式样本作为第一聚类中心1Z 。
(2)选择离1Z 距离最远的模式样本作为第二聚类中心2Z 。
(3)逐个计算每个模式样本与已确定的所有聚类中心之间的距离,并选出其中的最小距离.(4)在所有最小距离中选出一个最大的距离,如果该最大值达到了21Z Z -的一定分数比值以上,则将产生最大距离的那个模式样本定义为新增的聚类中心,并返回上一步.否则,聚类中心的计算步骤结束。
这里的21Z Z -的一定分数比值就是阈值T ,即有:1021<<-=θθZ Z T(5)重复步骤(3)和步骤(4),直到没有新的聚类中心出现为止。
在这个过程中,当有k 个聚类中心{}N Z Z Z , 21,时,分别计算每个模式样本与所有聚类中心距离中的最小距离值,寻找到N 个最小距离中的最大距离并进行判别,结果大于阈值T 是,1+k Z 存在,并取为产生最大值的相应模式向量;否则,停止寻找聚类中心。
(6)寻找聚类中心的运算结束后,将模式样本{}N i X i ,2,1, =按最近距离划分到相应的聚类中心所代表的类别之中。
三、实验结果及分析该实验的问题是书上课后习题2。
1,以下利用的matlab 中的元胞存储10个二维模式样本X {1}=[0;0];X{2}=[1;1];X {3}=[2;2];X{4}=[3;7];X{5}=[3;6]; X{6}=[4;6];X{7}=[5;7];X{8}=[6;3];X{9}=[7;3];X{10}=[7;4];利用最大最小距离算法,matlab 运行可以求得从matlab 运行结果可以看出,聚类中心为971,,X X X ,以1X 为聚类中心的点有321,,X X X ,以7X 为聚类中心的点有7654,,,X X X X ,以9X 为聚类中心的有1098,,X X X 。
模式识别实验报告

二、实验步骤 前提条件: 只考虑第三种情况:如果 di(x) >dj(x) 任意 j≠ i ,则判 x∈ωi 。
○1 、赋初值,分别给 c 个权矢量 wi(1)(i=1,2,…c)赋任意的初
值,选择正常数ρ ,置步数 k=1;
○2 、输入符号未规范化的增广训练模式 xk, xk∈{x1, x2… xN} ,
二、实验步骤
○1 、给出 n 个混合样本,令 I=1,表示迭代运算次数,选取 c
个初始聚合中心 ,j=1,2,…,c;
○2 、 计 算 每 个 样 本 与 聚 合 中 心 的 距 离
,
。
若
, ,则
。
○3 、 计 算 c 个 新 的 聚 合 中 心 :
,
。
○4 、判断:若
,
,则 I=I+1,返回
第二步 b 处,否则结束。 三、程序设计
聚类没有影响。但当 C=2 时,该类别属于正确分类。 而类别数目大于 2 时,初始聚合中心对聚类的影响非常大,仿真
结果多样化,不能作为分类标准。 2、考虑类别数目对聚类的影响: 当类别数目变化时,结果也随之出现变化。 3、总结 综上可知,只有预先分析过样本,确定合适的类别数目,才能对
样本进行正确分类,而初始聚合中心对其没有影响。
8
7
6
5
4
3
2
1
0
0
1
2
3
4
5
6
7
8
9
初始聚合中心为(0,0),(2,2),(5,5),(7,7),(9,9)
K-均 值 聚 类 算 法 : 类 别 数 目 c=5 9
8
7
6
5
4
模式识别实验报告

模式识别实验报告班级:电信08-1班姓名:黄**学号:********课程名称:模式识别导论实验一安装并使用模式识别工具箱一、实验目的:1.掌握安装模式识别工具箱的技巧,能熟练使用工具箱中的各项功能;2.熟练使用最小错误率贝叶斯决策器对样本分类;3.熟练使用感知准则对样本分类;4.熟练使用最小平方误差准则对样本分类;5.了解近邻法的分类过程,了解参数K值对分类性能的影响(选做);6.了解不同的特征提取方法对分类性能的影响(选做)。
二、实验内容与原理:1.安装模式识别工具箱;2.用最小错误率贝叶斯决策器对呈正态分布的两类样本分类;3.用感知准则对两类可分样本进行分类,并观测迭代次数对分类性能的影响;4.用最小平方误差准则对云状样本分类,并与贝叶斯决策器的分类结果比较;5.用近邻法对双螺旋样本分类,并观测不同的K值对分类性能的影响(选做);6.观测不同的特征提取方法对分类性能的影响(选做)。
三、实验器材(设备、元器件、软件工具、平台):1.PC机-系统最低配置512M 内存、P4 CPU;2.Matlab 仿真软件-7.0 / 7.1 / 2006a等版本的Matlab 软件。
四、实验步骤:1.安装模式识别工具箱。
并调出Classifier主界面。
2.调用XOR.mat文件,用最小错误率贝叶斯决策器对呈正态分布的两类样本分类。
3.调用Seperable.mat文件,用感知准则对两类可分样本进行分类。
4.调用Clouds.mat文件,用最小平方误差准则对两类样本进行分类。
5.调用Spiral.mat文件,用近邻法对双螺旋样本进行分类。
6.调用XOR.mat文件,用特征提取方法对分类效果的影响。
五、实验数据及结果分析:(1)Classifier主界面如下(2)最小错误率贝叶斯决策器对呈正态分布的两类样本进行分类结果如下:(3)感知准则对两类可分样本进行分类当Num of iteration=300时的情况:当Num of iteration=1000时的分类如下:(4)最小平方误差准则对两类样本进行分类结果如下:(5)近邻法对双螺旋样本进行分类,结果如下当Num of nearest neighbor=3时的情况为:当Num of nearest neighbor=12时的分类如下:(6)特征提取方法对分类结果如下当New data dimension=2时,其结果如下当New data dimension=1时,其结果如下六、实验结论:本次实验使我掌握安装模式识别工具箱的技巧,能熟练使用工具箱中的各项功能;对模式识别有了初步的了解。
模式识别实验报告哈工程

一、实验背景随着计算机科学和信息技术的飞速发展,模式识别技术在各个领域得到了广泛应用。
模式识别是指通过对数据的分析、处理和分类,从大量数据中提取有用信息,从而实现对未知模式的识别。
本实验旨在通过实践操作,加深对模式识别基本概念、算法和方法的理解,并掌握其应用。
二、实验目的1. 理解模式识别的基本概念、算法和方法;2. 掌握常用的模式识别算法,如K-均值聚类、决策树、支持向量机等;3. 熟悉模式识别在实际问题中的应用,提高解决实际问题的能力。
三、实验内容本次实验共分为三个部分:K-均值聚类算法、决策树和神经网络。
1. K-均值聚类算法(1)实验目的通过实验加深对K-均值聚类算法的理解,掌握其基本原理和实现方法。
(2)实验步骤① 准备实验数据:选取一组二维数据,包括100个样本,每个样本包含两个特征值;② 初始化聚类中心:随机选择K个样本作为初始聚类中心;③ 计算每个样本到聚类中心的距离,并将其分配到最近的聚类中心;④ 更新聚类中心:计算每个聚类中所有样本的均值,作为新的聚类中心;⑤ 重复步骤③和④,直到聚类中心不再变化。
(3)实验结果通过实验,可以得到K个聚类中心,每个样本被分配到最近的聚类中心。
通过可视化聚类结果,可以直观地看到数据被分成了K个类别。
2. 决策树(1)实验目的通过实验加深对决策树的理解,掌握其基本原理和实现方法。
(2)实验步骤① 准备实验数据:选取一组具有分类标签的二维数据,包括100个样本,每个样本包含两个特征值;② 选择最优分割特征:根据信息增益或基尼指数等指标,选择最优分割特征;③ 划分数据集:根据最优分割特征,将数据集划分为两个子集;④ 递归地执行步骤②和③,直到满足停止条件(如达到最大深度、叶节点中样本数小于阈值等);⑤ 构建决策树:根据递归分割的结果,构建决策树。
(3)实验结果通过实验,可以得到一棵决策树,可以用于对新样本进行分类。
3. 神经网络(1)实验目的通过实验加深对神经网络的理解,掌握其基本原理和实现方法。
模式识别实验报告2_贝叶斯分类实验_实验报告(例)

end
plot(1:23,t2,'b','LineWidth',3);
%下面是bayesian_fun函数
functionf=bayesian_fun(t2,t1,W1,W2,w1,w2,w10,w20)
x=[t1,t2]';
f=x'*W1*x+w1'*x+w10- (x'*W2*x+w2'*x+w20);
%f=bayesian_fun.m
function f=bayesian_fun(t2,t1,W1,W2,w1,w2,w10,w20)
x=[t1,t2]';
f=x'*W1*x+w1'*x+w10 - (x'*W2*x+w2'*x+w20);
w10=-1/2 * u1'*S1tinv*u1 - 1/2 *log(det(S1t)) + log(pw1);
w20=-1/2 * u2'*S2tinv*u2 - 1/2 *log(det(S2t)) + log(pw2);
t2=[]
fort1=1:23
tt2 = fsolve('bayesian_fun',5,[],t1,W1,W2,w1,w2,w10,w20);
'LineWidth',2,...
'MarkerEdgeColor','k',...
'MarkerFaceColor',[0 1 0],...
'MarkerSize',10)
模式识别实验

《模式识别》实验报告班电子信息科学与技术13级02 班级:姓名:学号:指导老师:成绩:通信与信息工程学院二〇一六年实验一 最大最小距离算法一、实验内容1. 熟悉最大最小距离算法,并能够用程序写出。
2. 利用最大最小距离算法寻找到聚类中心,并将模式样本划分到各聚类中心对应的类别中。
二、实验原理N 个待分类的模式样本{}N X X X , 21,,分别分类到聚类中心{}N Z Z Z , 21,对应的类别之中。
最大最小距离算法描述:(1)任选一个模式样本作为第一聚类中心1Z 。
(2)选择离1Z 距离最远的模式样本作为第二聚类中心2Z 。
(3)逐个计算每个模式样本与已确定的所有聚类中心之间的距离,并选出其中的最小距离。
(4)在所有最小距离中选出一个最大的距离,如果该最大值达到了21Z Z -的一定分数比值以上,则将产生最大距离的那个模式样本定义为新增的聚类中心,并返回上一步。
否则,聚类中心的计算步骤结束。
这里的21Z Z -的一定分数比值就是阈值T ,即有:1021<<-=θθZ Z T(5)重复步骤(3)和步骤(4),直到没有新的聚类中心出现为止。
在这个过程中,当有k 个聚类中心{}N Z Z Z , 21,时,分别计算每个模式样本与所有聚类中心距离中的最小距离值,寻找到N 个最小距离中的最大距离并进行判别,结果大于阈值T 是,1+k Z 存在,并取为产生最大值的相应模式向量;否则,停止寻找聚类中心。
(6)寻找聚类中心的运算结束后,将模式样本{}N i X i ,2,1, =按最近距离划分到相应的聚类中心所代表的类别之中。
三、实验结果及分析该实验的问题是书上课后习题2.1,以下利用的matlab 中的元胞存储10个二维模式样本X{1}=[0;0];X{2}=[1;1];X{3}=[2;2];X{4}=[3;7];X{5}=[3;6]; X{6}=[4;6];X{7}=[5;7];X{8}=[6;3];X{9}=[7;3];X{10}=[7;4]; 利用最大最小距离算法,matlab 运行可以求得从matlab 运行结果可以看出,聚类中心为971,,X X X ,以1X 为聚类中心的点有321,,X X X ,以7X 为聚类中心的点有7654,,,X X X X ,以9X 为聚类中心的有1098,,X X X 。
模式识别实验报告

模式识别实验报告实验一、线性分类器的设计与实现1. 实验目的:掌握模式识别的基本概念,理解线性分类器的算法原理。
2. 实验要求:(1)学习和掌握线性分类器的算法原理;(2)在MATLAB 环境下编程实现三种线性分类器并能对提供的数据进行分类;(3)对实现的线性分类器性能进行简单的评估(例如算法适用条件,算法效率及复杂度等)。
注:三种线性分类器为,单样本感知器算法、批处理感知器算法、最小均方差算法批处理感知器算法算法原理:感知器准则函数为J p a=(−a t y)y∈Y,这里的Y(a)是被a错分的样本集,如果没有样本被分错,Y就是空的,这时我们定义J p a为0.因为当a t y≤0时,J p a是非负的,只有当a是解向量时才为0,也即a在判决边界上。
从几何上可知,J p a是与错分样本到判决边界距离之和成正比的。
由于J p梯度上的第j个分量为∂J p/ða j,也即∇J p=(−y)y∈Y。
梯度下降的迭代公式为a k+1=a k+η(k)yy∈Y k,这里Y k为被a k错分的样本集。
算法伪代码如下:begin initialize a,η(∙),准则θ,k=0do k=k+1a=a+η(k)yy∈Y k|<θuntil | ηk yy∈Y kreturn aend因此寻找解向量的批处理感知器算法可以简单地叙述为:下一个权向量等于被前一个权向量错分的样本的和乘以一个系数。
每次修正权值向量时都需要计算成批的样本。
算法源代码:unction [solution iter] = BatchPerceptron(Y,tau)%% solution = BatchPerceptron(Y,tau) 固定增量批处理感知器算法实现%% 输入:规范化样本矩阵Y,裕量tau% 输出:解向量solution,迭代次数iter[y_k d] = size(Y);a = zeros(1,d);k_max = 10000; %%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%% k=0;y_temp=zeros(d,1);while k<k_maxc=0;for i=1:1:y_kif Y(i,:)*a'<=tauy_temp=y_temp+Y(i,:)';c=c+1;endendif c==0break;enda=a+y_temp';k=k+1;end %%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%% %k = k_max;solution = a;iter = k-1;运行结果及分析:数据1的分类结果如下由以上运行结果可以知道,迭代17次之后,算法得到收敛,解出的权向量序列将样本很好的划分。
模式识别实验报告_3

模式识别实验报告_3第⼀次实验实验⽬的:1.学习使⽤ENVI2.会⽤MATLAB读⼊遥感数据并进⾏处理实验内容:⼀学习使⽤ENVI1.使⽤ENVI打开遥感图像(任选3个波段合成假彩⾊图像,保存写⼊报告)2.会查看图像的头⽂件(保存或者copy⾄报告)3.会看地物的光谱曲线(保存或者copy⾄报告)4.进⾏数据信息统计(保存或者copy⾄报告)5.设置ROI,对每类地物⾃⼰添加标记数据,并保存为ROI⽂件和图像⽂件(CMap贴到报告中)。
6.使⽤⾃⼰设置的ROI进⾏图像分类(ENVI中的两种有监督分类算法)(分类算法名称和分类结果写⼊报告)⼆MATLAB处理遥感数据(提交代码和结果)7.⽤MATLAB读⼊遥感数据(zy3和DC两个数据)8.⽤MATLAB读⼊遥感图像中ROI中的数据(包括数据和标签)9.把图像数据m*n*L(其中m表⽰⾏数,n表⽰列数,L表⽰波段数),重新排列为N*L的⼆维矩阵(其中N=m*n),其中N表⽰所有的数据点数量m*n。
(提⽰,⽤reshape函数,可以help查看这个函数的⽤法)10.计算每⼀类数据的均值(平均光谱),并把所有类别的平均光谱画出来(plot)(类似下⾯的效果)。
11.画出zy3数据中“农作物类别”的数据点(⾃⼰ROI标记的这个类别的点)在每个波段的直⽅图(matlab函数:nbins=50;hist(Xi,nbins),其中Xi表⽰这类数据在第i波段的数值)。
计算出这个类别数据的协⽅差矩阵,并画出(figure,imagesc(C),colorbar)。
1.打开遥感图像如下:2.查看图像头⽂件过程如下:3.地物的光谱曲线如下:4.数据信息统计如下:(注:由于保存的txt⽂件中的数据信息过长,所以采⽤截图的⽅式只显⽰了出⼀部分数据信息)5.设置ROI,对每类地物⾃⼰添加标记数据,CMap如下:6.使⽤⾃⼰设置的ROI进⾏图像分类(使⽤⽀持向量机算法和最⼩距离算法),⽀持向量机算法分类结果如下:最⼩距离算法分类结果如下:对⽐两种算法的分类结果可以看出⽀持分量机算法分类结果⽐最⼩距离算法分类结果好⼀些。
哈尔滨工程大学模式识别实验报告

实验报告实验课程名称:模式识别:班级: 20120811 学号:注:1、每个实验中各项成绩按照5分制评定,实验成绩为各项总和2、平均成绩取各项实验平均成绩3、折合成绩按照教学大纲要求的百分比进行折合2015年 4月实验1 图像的贝叶斯分类1.1 实验目的将模式识别方法与图像处理技术相结合,掌握利用最小错分概率贝叶斯分类器进行图像分类的基本方法,通过实验加深对基本概念的理解。
1.2 实验仪器设备及软件HP D538、MATLAB1.3 实验原理1.3.1基本原理阈值化分割算法是计算机视觉中的常用算法,对灰度图象的阈值分割就是先确定一个处于图像灰度取值围的灰度阈值,然后将图像中每个像素的灰度值与这个阈值相比较。
并根据比较的结果将对应的像素划分为两类,灰度值大于阈值的像素划分为一类,小于阈值的划分为另一类,等于阈值的可任意划分到两类中的任何一类。
此过程中,确定阈值是分割的关键。
对一般的图像进行分割处理通常对图像的灰度分布有一定的假设,或者说是基于一定的图像模型。
最常用的模型可描述如下:假设图像由具有单峰灰度分布的目标和背景组成,处于目标和背景部相邻像素间的灰度值是高度相关的,但处于目标和背景交界处两边的像素灰度值有较大差别,此时,图像的灰度直方图基本上可看作是由分别对应于目标和背景的两个单峰直方图混合构成。
而且这两个分布应大小接近,且均值足够远,方差足够小,这种情况下直方图呈现较明显的双峰。
类似地,如果图像中包含多个单峰灰度目标,则直方图可能呈现较明显的多峰。
上述图像模型只是理想情况,有时图像中目标和背景的灰度值有部分交错。
这时如用全局阈值进行分割必然会产生一定的误差。
分割误差包括将目标分为背景和将背景分为目标两大类。
实际应用中应尽量减小错误分割的概率,常用的一种方法为选取最优阈值。
这里所谓的最优阈值,就是指能使误分割概率最小的分割阈值。
图像的直方图可以看成是对灰度值概率分布密度函数的一种近似。
如一幅图像中只包含目标和背景两类灰度区域,那么直方图所代表的灰度值概率密度函数可以表示为目标和背景两类灰度值概率密度函数的加权和。
哈工大 模式识别

模式识别模式识别及其应用摘要:模式还可分成抽象的和具体的两种形式。
前者如意识、思想、议论等,属于概念识别研究的范畴,是人工智能的另一研究分支。
我们所指的模式识别主要是对语音波形、地震波、心电图、脑电图、图片、照片、文字、符号、生物的传感器等对象进行测量的具体模式进行分类和辨识。
关键词:模式识别应用模式识别(Pattern Recognition)是人类的一项基本智能,在日常生活中,人们经常在进行“模式识别”。
随着20世纪40年代计算机的出现以及50年代人工智能的兴起,人们当然也希望能用计算机来代替或扩展人类的部分脑力劳动。
(计算机)模式识别在20世纪60年代初迅速发展并成为一门新学科。
一,模式识别基本概念模式识别(Pattern Recognition)是指对表征事物或现象的各种形式的(数值的、文字的和逻辑关系的)信息进行处理和分析,以对事物或现象进行描述、辨认、分类和解释的过程,是信息科学和人工智能的重要组成部分。
什么是模式呢?广义地说,存在于时间和空间中可观察的事物,如果我们可以区别它们是否相同或是否相似,都可以称之为模式。
但模式所指的不是事物本身,而是我们从事物获得的信息。
因此,模式往往表现为具有时间或空间分布的信息。
模式还可分成抽象的和具体的两种形式。
前者如意识、思想、议论等,属于概念识别研究的范畴,是人工智能的另一研究分支。
我们所指的模式识别主要是对语音波形、地震波、心电图、脑电图、图片、照片、文字、符号、生物的传感器等对象进行测量的具体模式进行分类和辨识。
模式识别研究主要集中在两方面,一是研究生物体(包括人)是如何感知对象的,属于认识科学的范畴,二是在给定的任务下,如何用计算机实现模式识别的理论和方法。
前者是生理学家、心理学家、生物学家和神经生理学家的研究内容,后者通过数学家、信息学专家和计算机科学工作者近几十年来的努力,已经取得了系统的研究成果。
应用计算机对一组事件或过程进行鉴别和分类。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
实验报告实验课程名称:模式识别姓名:班级:学号:注:1、每个实验中各项成绩按照5分制评定,实验成绩为各项总和2、平均成绩取各项实验平均成绩3、折合成绩按照教学大纲要求的百分比进行折合;2015年4月实验1 图像的贝叶斯分类实验目的将模式识别方法与图像处理技术相结合,掌握利用最小错分概率贝叶斯分类器进行图像分类的基本方法,通过实验加深对基本概念的理解。
实验仪器设备及软件HP D538、MATLAB(实验原理基本原理阈值化分割算法是计算机视觉中的常用算法,对灰度图象的阈值分割就是先确定一个处于图像灰度取值范围内的灰度阈值,然后将图像中每个像素的灰度值与这个阈值相比较。
并根据比较的结果将对应的像素划分为两类,灰度值大于阈值的像素划分为一类,小于阈值的划分为另一类,等于阈值的可任意划分到两类中的任何一类。
此过程中,确定阈值是分割的关键。
对一般的图像进行分割处理通常对图像的灰度分布有一定的假设,或者说是基于一定的图像模型。
最常用的模型可描述如下:假设图像由具有单峰灰度分布的目标和背景组成,处于目标和背景内部相邻像素间的灰度值是高度相关的,但处于目标和背景交界处两边的像素灰度值有较大差别,此时,图像的灰度直方图基本上可看作是由分别对应于目标和背景的两个单峰直方图混合构成。
而且这两个分布应大小接近,且均值足够远,方差足够小,这种情况下直方图呈现较明显的双峰。
类似地,如果图像中包含多个单峰灰度目标,则直方图可能呈现较明显的多峰。
上述图像模型只是理想情况,有时图像中目标和背景的灰度值有部分交错。
这时如用全局阈值进行分割必然会产生一定的误差。
分割误差包括将目标分为背景和将背景分为目标两大类。
实际应用中应尽量减小错误分割的概率,常用的一种方法为选取最优阈值。
这里所谓的最优阈值,就是指能使误分割概率最小的分割阈值。
图像的直方图可以看成是对灰度值概率分布密度函数的一种近似。
如一幅图像中只包含目标和背景两类灰度区域,那么直方图所代表的灰度值概率密度函数可以表示为目标和背景两类灰度值概率密度函数的加权和。
如果概率密度函数形式已知,就有可能计算出使目标和背景两类误分割概率最小的最优阈值。
假设目标与背景两类像素值均服从正态分布且混有加性高斯噪声,上述分类问题可用模式识别中的最小错分概率贝叶斯分类器来解决。
以1p 与2p 分别表示目标与背景的灰度分布概率密度函数,1P 与2P 分别表示两类的先验概率,则图像的混合概率密度函数用下式表示1122()()()p x P p x P p x =+式中1p 和2p 分别为…2121()21()x p x μσ--=2222()22()x p x μσ--=121P P +=1σ、2σ是针对背景和目标两类区域灰度均值1μ与2μ的标准差。
若假定目标的灰度较亮,其灰度均值为2μ,背景的灰度较暗,其灰度均值为1μ,因此有12μμ<现若规定一门限值T 对图像进行分割,势必会产生将目标划分为背景和将背景划分为目标这两类错误。
通过适当选择阈值T ,可令这两类错误概率为最小,则该阈值T 即为最佳阈值。
把目标错分为背景的概率可表示为12()()TE T p x dx -∞=⎰…把背景错分为目标的概率可表示为21()()TE T p x dx +∞=⎰总的误差概率为2112()()()E T P E T PE T =+为求得使误差概率最小的阈值T ,可将()E T 对T 求导并令导数为零,可得1122()()P p T P p T =代换后,可得221212222111()()ln 22P T T P σμμσσσ---=-、此时,若设12σσσ==,则有2122121ln 2P T P μμσμμ⎛⎫+=+ ⎪-⎝⎭若还有12P P =的条件,则122T μμ+=这时的最优阈值就是两类区域灰度均值1μ与2μ的平均值。
上面的推导是针对图像灰度值服从正态分布时的情况,如果灰度值服从其它分布,依理也可求出最优阈值来。
一般情况下,在不清楚灰度值分布时,通常可假定灰度值服从正态分布。
因此,本课题中亦可使用此方法来求得最优阈值,来对实验图像进行分割。
最优阈值的迭代算法在实际使用最优阈值进行分割的过程中,需要利用迭代算法来求得最优阈值。
设有一幅数字图像(,)f x y ,混有加性高斯噪声,可表示为`(,)(,)(,)g x y f x y n x y =+此处假设图像上各点的噪声相互独立,且具有零均值,如果通过阈值分割将图像分为目标与背景两部分,则每一部分仍然有噪声点随机作用于其上,于是,目标1(,)g x y 和2(,)g x y 可表示为11(,)(,)(,)g x y f x y n x y =+ 22(,)(,)(,)g x y f x y n x y =+迭代过程中,会多次地对1(,)g x y 和2(,)g x y 求均值,则111{(,)}{(,)(,)}{(,)}E g x y E f x y n x y E f x y =+= 222{(,)}{(,)(,)}{(,)}E g x y E f x y n x y E f x y =+=可见,随着迭代次数的增加,目标和背景的平均灰度都趋向于真实值。
因此,用迭代算法求得的最佳阈值不受噪声干扰的影响。
$利用最优阈值对实验图像进行分割的迭代步骤为: (1)确定一个初始阈值0T ,0T 可取为min max02S S T +=式中,min S 和max S 为图像灰度的最小值和最大值。
(2)利用第k 次迭代得到的阈值将图像分为目标1R 和背景2R 两大区域,其中1{(,)|(,)}k R f x y f x y T =≥ 2{(,)|0(,)}k R f x y f x y T =<<(3)计算区域1R 和2R 的灰度均值1S 和2S 。
)(4)计算新的阈值1k T +,其中1212k S S T ++=(5)如果1||k k T T +-小于允许的误差,则结束,否则1k k =+,转步骤(2)。
利用迭代法求得最优阈值后,仍需进行一些人工调整才能将此阈值用于实验图像的分割,这是因为,这种最优阈值仍然属于全局阈值,它利用了图像中所有像素点的信息,但当光照不均匀时,图像中部分区域的灰度值可能差距较大,造成计算出的最优阈值分割效果不理想,此时,可设一人工经验因子进行校正。
、实验步骤及程序实验步骤:1、读取指定图像,取矩阵的最大值和最小值,并以最大值、最小值的平均值为初始阈值A 。
2、比较所有的矩阵因子和初始阈值的大小,若某矩阵因子较大,则有效区域的像素点数增加1,该点灰度值需计入有效区域的灰度总值。
反之,背景的像素点增加1,该点灰度值需计入背景的灰度值。
·3、所有的矩阵因子都比较完以后,计算有效区域的像素平均灰度值和背景的平均灰度值。
取这两个平均值的平均,记为B ,若A=B,则循环结束,该值为最优阈值。
否则,令A=B , 重复步骤2、3。
图程序流程图实验程序:I=imread('');Picgray = rgb2gray(I);imhist(Picgray);figureSMax=max(max(I));SMin=min(min(I));&TK=(SMax+SMin)/2;bCal=1;iSize=size(I);while(bCal)iForeground=0;iBackground=0;ForegroundSum=0;BackgroundSum=0;!for i=1:iSize(1)for j=1:iSize(2)tmp=I(i,j);if(tmp>=TK)iForeground=iForeground+1;ForegroundSum=ForegroundSum+double(tmp);elseiBackground=iBackground+1;~BackgroundSum=BackgroundSum+double(tmp);endendendZO=ForegroundSum/iForeground;ZB=BackgroundSum/iBackground;TKTmp=double((ZO+ZB)/2);if(TKTmp==TK)(bCal=0;elseTK=TKTmp;endenddisp(strcat('diedaihoudeyuzhi£º',num2str(TK)));newI=im2bw(I,double(TK)/255);imshow(I)%figureimshow(newI)、实验结果与分析实验得到的迭代后的分割阈值:分割效果图如下所示。
图原始图像;图分割后的图像050100150200250图原始图像的灰度直方图实验分析:对灰度图象的阈值分割就是先确定一个处于图像灰度取值范围内的灰度阈值,然后将图像中每个像素的灰度值与这个阈值相比较。
并根据比较的结果将对应的像素划分为两类,灰度值大于阈值的像素划分为一类,小于阈值的划分为另一类,等于阈值的可任意划分到两类中的任何一类。
其中确定阈值是分割的关键。
最优阈值的求得需要使用迭代算法。
它将会影响到迭代的次数和结果精度。
~.]实验2 K均值聚类算法实验目的将模式识别方法与图像处理技术相结合,掌握利用K均值聚类算法进行图像分类的基本方法,通过实验加深对基本概念的理解。
实验仪器设备及软件HP D538、MATLAB、WIT实验原理K均值聚类法分为如下几个步骤:一、初始化聚类中心1、;2、根据具体问题,凭经验从样本集中选出C个比较合适的样本作为初始聚类中心。
3、用前C个样本作为初始聚类中心。
4、将全部样本随机地分成C类,计算每类的样本均值,将样本均值作为初始聚类中心。
二、初始聚类1、按就近原则将样本归入各聚类中心所代表的类中。
2、取一样本,将其归入与其最近的聚类中心的那一类中,重新计算样本均值,更新聚类中心。
然后取下一样本,重复操作,直至所有样本归入相应类中。
三、判断聚类是否合理采用误差平方和准则函数判断聚类是否合理,不合理则修改分类。
循环进行判断、修改直至达到算法终止条件。
\实验步骤及程序实验步骤:1、读取原始图像,确定四个初始聚类中心。
2、计算各点与聚类中心的距离,以及各点到不同聚类中心的距离之差,选取距离最近的聚类中心作为该点的聚类中心,依据此原理将属于不同聚类中心的元素聚类。
3、求各类的平均值作为新的聚类中心,检验是否满足精度条件。
4、输出的四个聚类中心值,将图像分成四类输出。
图实验程序流程图实验程序:clcclear¥tic% A=imread('');A=imread('N:模式识别实验资料\实验图片\');figure,imshow(A)figure,imhist(A)A=double(A);for i=1:200c1(1)=25;^c2(1)=75;c3(1)=120;c4(1)=200;r=abs(A-c1(i));g=abs(A-c2(i));b=abs(A-c3(i));y=abs(A-c4(i));r_g=r-g;'g_b=g-b;r_b=r-b;b_y=b-y;r_y=r-y;g_y=g-y;n_r=find(r_g<=0&r_b<=0&r_y<=0);n_g=find(r_g>0&g_b<=0&g_y<=0);n_b=find(g_b>0&r_b>0&b_y<=0);:n_y=find(r_y>0&g_y>0&b_y>0);i=i+1;c1(i)=sum(A(n_r))/length(n_r);c2(i)=sum(A(n_g))/length(n_g);c3(i)=sum(A(n_b))/length(n_b);c4(i)=sum(A(n_y))/length(n_y); d1(i)=sqrt(abs(c1(i)-c1(i-1)));d2(i)=sqrt(abs(c2(i)-c2(i-1)));d3(i)=sqrt(abs(c3(i)-c3(i-1)));-d4(i)=sqrt(abs(c4(i)-c4(i-1)));if d1(i)<=&&d2(i)<=&&d3(i)<=&&d4(i)<=R=c1(i);G=c2(i);B=c3(i);Y=c4(i);k=i;break;~endendRGBYA=uint8(A);A(find(A<(R+G)/2))=0;*A(find(A>(R+G)/2&A<(G+B)/2))=75;A(find(A>(G+B)/2&A<(Y+B)/2))=150;A(find(A>(B+Y)/2))=255;tocfigure,imshow(A)figure,imhist(A)实验结果与分析使用MATLAB所得结果:聚类类别数为4类,聚类中心R = ,G =,B = ,Y =,迭代次数9次、运行时间。