模式识别第二次上机实验报告
模式识别实验报告

模式识别实验报告————————————————————————————————作者:————————————————————————————————日期:实验报告实验课程名称:模式识别姓名:王宇班级: 20110813 学号: 2011081325实验名称规范程度原理叙述实验过程实验结果实验成绩图像的贝叶斯分类K均值聚类算法神经网络模式识别平均成绩折合成绩注:1、每个实验中各项成绩按照5分制评定,实验成绩为各项总和2、平均成绩取各项实验平均成绩3、折合成绩按照教学大纲要求的百分比进行折合2014年 6月实验一、 图像的贝叶斯分类一、实验目的将模式识别方法与图像处理技术相结合,掌握利用最小错分概率贝叶斯分类器进行图像分类的基本方法,通过实验加深对基本概念的理解。
二、实验仪器设备及软件 HP D538、MATLAB 三、实验原理 概念:阈值化分割算法是计算机视觉中的常用算法,对灰度图象的阈值分割就是先确定一个处于图像灰度取值范围内的灰度阈值,然后将图像中每个像素的灰度值与这个阈值相比较。
并根据比较的结果将对应的像素划分为两类,灰度值大于阈值的像素划分为一类,小于阈值的划分为另一类,等于阈值的可任意划分到两类中的任何一类。
最常用的模型可描述如下:假设图像由具有单峰灰度分布的目标和背景组成,处于目标和背景内部相邻像素间的灰度值是高度相关的,但处于目标和背景交界处两边的像素灰度值有较大差别,此时,图像的灰度直方图基本上可看作是由分别对应于目标和背景的两个单峰直方图混合构成。
而且这两个分布应大小接近,且均值足够远,方差足够小,这种情况下直方图呈现较明显的双峰。
类似地,如果图像中包含多个单峰灰度目标,则直方图可能呈现较明显的多峰。
上述图像模型只是理想情况,有时图像中目标和背景的灰度值有部分交错。
这时如用全局阈值进行分割必然会产生一定的误差。
分割误差包括将目标分为背景和将背景分为目标两大类。
实际应用中应尽量减小错误分割的概率,常用的一种方法为选取最优阈值。
模式识别关于男女生身高和体重的神经网络算法

模式识别实验报告(二)学院:专业:学号:姓名:XXXX教师:目录1实验目的 (1)2实验内容 (1)3实验平台 (1)4实验过程与结果分析 (1)4.1基于BP神经网络的分类器设计 .. 1 4.2基于SVM的分类器设计 (4)4.3基于决策树的分类器设计 (7)4.4三种分类器对比 (8)5.总结 (8)1)1实验目的通过实际编程操作,实现对课堂上所学习的BP神经网络、SVM支持向量机和决策树这三种方法的应用,加深理解,同时锻炼自己的动手实践能力。
2)2实验内容本次实验提供的样本数据有149个,每个数据提取5个特征,即身高、体重、是否喜欢数学、是否喜欢文学及是否喜欢运动,分别将样本数据用于对BP神经网络分类器、SVM支持向量机和决策树训练,用测试数据测试分类器的效果,采用交叉验证的方式实现对于性能指标的评判。
具体要求如下:BP神经网络--自行编写代码完成后向传播算法,采用交叉验证的方式实现对于性能指标的评判(包含SE,SP,ACC和AUC,AUC的计算可以基于平台的软件包);SVM支持向量机--采用平台提供的软件包进行分类器的设计以及测试,尝试不同的核函数设计分类器,采用交叉验证的方式实现对于性能指标的评判;决策树--采用平台提供的软件包进行分类器的设计以及测试,采用交叉验证的方式实现对于性能指标的评判(包含SE,SP,ACC和AUC,AUC的计算基于平台的软件包)。
3)3实验平台专业研究方向为图像处理,用的较多的编程语言为C++,因此此次程序编写用的平台是VisualStudio及opencv,其中的BP神经网络为自己独立编写, SVM 支持向量机和决策树通过调用Opencv3.0库中相应的库函数并进行相应的配置进行实现。
将Excel中的119个数据作为样本数据,其余30个作为分类器性能的测试数据。
4)4实验过程与结果分析4.1基于BP神经网络的分类器设计BP神经网络能学习和存贮大量的输入-输出模式映射关系,而无需事前揭示描述这种映射关系的数学方程。
模式识别与智能信息处理实践实验报告

模式识别与智能信息处理实践实验报告
一、实验目的
本次实验的目的是:实现基于Matlab的模式识别与智能信息处理。
二、实验内容
1.对实验图片进行处理
根据实验要求,我们选取了两张图片,一张是原始图片,一张是锐化处理后的图片。
使用Matlab的imtool命令进行处理,实现对图片锐化、模糊处理、边缘检测、图像增强等功能。
2.基于模式识别算法进行图像分类
通过Matlab的k-means算法和PCA算法对实验图片进行图像分类,实现对图像数据特征提取,并将图像分类结果可视化。
3.使用智能信息处理技术处理实验数据
使用Matlab的BP网络算法,对实验图片进行处理,并实现实验数据的智能信息处理,以获得准确的分类结果。
三、实验结果
1.图片处理结果
2.图像分类结果
3.智能信息处理结果
四、总结
本次实验中,我们利用Matlab进行模式识别与智能信息处理的实践,实现了对图片的处理,图像分类,以及智能信息处理,从而获得准确的分
类结果。
模式识别实验报告

河海大学物联网工程学院《模式识别》课程实验报告学号 _______________专业 ____计算机科学与技术_____ 授课班号 _________________________ 学生姓名 ___________________指导教师 ___________________完成时间 _______________实验报告格式如下(必要任务必须写上,可选的课后实验任务是加分项,不是必要任务,可不写):实验一、Fisher分类器实验1.实验原理如果在二维空间中一条直线能将两类样本分开,或者错分类很少,则同一类别样本数据在该直线的单位法向量上的投影的绝大多数都应该超过某一值。
而另一类数据的投影都应该小于(或绝大多数都小于)该值,则这条直线就有可能将两类分开。
准则:向量W的方向选择应能使两类样本投影的均值之差尽可能大些,而使类內样本的离散程度尽可能小。
2.实验任务(1)两类各有多少组训练数据?(易)(2)试着用MATLAB画出分类线,用红色点划线表示(中)(3)画出在投影轴线上的投影点(较难)3.实验结果(1)第一类数据有200组训练数据,第二类数据有100组训练数据。
(2)如图所示,先得出投影线的斜率,后求其投影线的垂直线的斜率,即分类线的斜率,再求分类线的过的中垂点,加上即可得出。
画出红线代码:m = (-40:0.1:80);kw = w(2)/w(1);b = classify(w1, w2, w, 0);disp(b);n = (-1/kw).* m + b;plot(m,n,'r-', 'LineWidth', 3);(3)画出投影上的投影点如图,点用X表示。
代码:u = w/sqrt(sum(w.^2));p1 = w1*u*u';plot(p1(:,1),p1(:,2),'r+')p2 = w2*u*u';plot(p2(:,1),p2(:,2),'b+')实验二、感知器实验1.实验原理(1)训练数据必须是线性可分的(2)最小化能量,惩罚函数法-错分样本的分类函数值之和(小于零)作为惩罚值(3)方法:梯度下降法,对权值向量的修正值-错分样本的特征向量2.实验任务(1)训练样本不线性可分时,分类结果如何?(2)程序33-35行完成什么功能?用MATLAB输出x1、x2、x的值,进行观察(中)(3)修改程序,输出梯度下降法迭代的次数(易);3.实验结果(1)在创建样本时,故意将两组数据靠近,实现训练样本非线性。
《模式识别》实验报告-贝叶斯分类

《模式识别》实验报告-贝叶斯分类一、实验目的通过使用贝叶斯分类算法,实现对数据集中的样本进行分类的准确率评估,熟悉并掌握贝叶斯分类算法的实现过程,以及对结果的解释。
二、实验原理1.先验概率先验概率指在不考虑其他变量的情况下,某个事件的概率分布。
在贝叶斯分类中,需要先知道每个类别的先验概率,例如:A类占总样本的40%,B类占总样本的60%。
2.条件概率后验概率指在已知先验概率和条件概率下,某个事件发生的概率分布。
在贝叶斯分类中,需要计算每个样本在各特征值下的后验概率,即属于某个类别的概率。
4.贝叶斯公式贝叶斯公式就是计算后验概率的公式,它是由条件概率和先验概率推导而来的。
5.贝叶斯分类器贝叶斯分类器是一种基于贝叶斯定理实现的分类器,可以用于在多个类别的情况下分类,是一种常用的分类方法。
具体实现过程为:首先,使用训练数据计算各个类别的先验概率和各特征值下的条件概率。
然后,将测试数据的各特征值代入条件概率公式中,计算出各个类别的后验概率。
最后,取后验概率最大的类别作为测试数据的分类结果。
三、实验步骤1.数据集准备本次实验使用的是Iris数据集,数据包含150个Iris鸢尾花的样本,分为三个类别:Setosa、Versicolour和Virginica,每个样本有四个特征值:花萼长度、花萼宽度、花瓣长度、花瓣宽度。
2.数据集划分将数据集按7:3的比例分为训练集和测试集,其中训练集共105个样本,测试集共45个样本。
计算三个类别的先验概率,即Setosa、Versicolour和Virginica类别在训练集中出现的频率。
对于每个特征值,根据训练集中每个类别所占的样本数量,计算每个类别在该特征值下出现的频率,作为条件概率。
5.测试数据分类将测试集中的每个样本的四个特征值代入条件概率公式中,计算出各个类别的后验概率,最后将后验概率最大的类别作为该测试样本的分类结果。
6.分类结果评估将测试集分类结果与实际类别进行比较,计算分类准确率和混淆矩阵。
哈工大模式识别实验报告
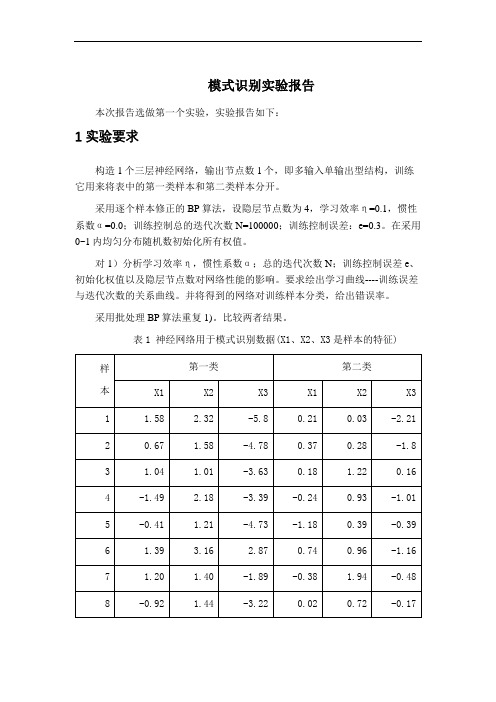
模式识别实验报告本次报告选做第一个实验,实验报告如下:1 实验要求构造1个三层神经网络,输出节点数1个,即多输入单输出型结构,训练它用来将表中的第一类样本和第二类样本分开。
采用逐个样本修正的BP算法,设隐层节点数为4,学习效率η=0.1,惯性系数α=0.0;训练控制总的迭代次数N=100000;训练控制误差:e=0.3。
在采用0~1内均匀分布随机数初始化所有权值。
对1)分析学习效率η,惯性系数α;总的迭代次数N;训练控制误差e、初始化权值以及隐层节点数对网络性能的影响。
要求绘出学习曲线----训练误差与迭代次数的关系曲线。
并将得到的网络对训练样本分类,给出错误率。
采用批处理BP算法重复1)。
比较两者结果。
表1 神经网络用于模式识别数据(X1、X2、X3是样本的特征)2 BP 网络的构建三层前馈神经网络示意图,见图1.图1三层前馈神经网络①网络初始化,用一组随机数对网络赋初始权值,设置学习步长η、允许误差ε、网络结构(即网络层数L 和每层节点数n l );②为网络提供一组学习样本; ③对每个学习样本p 循环a .逐层正向计算网络各节点的输入和输出;b .计算第p 个样本的输出的误差Ep 和网络的总误差E ;c .当E 小于允许误差ε或者达到指定的迭代次数时,学习过程结束,否则,进行误差反向传播。
d .反向逐层计算网络各节点误差)(l jp δ如果l f 取为S 型函数,即xl e x f -+=11)(,则 对于输出层))(1()()()()(l jp jdp l jp l jp l jp O y O O --=δ 对于隐含层∑+-=)1()()()()()1(l kj l jp l jp l jp l jp w O O δδe .修正网络连接权值)1()()()1(-+=+l ip l jp ij ij O k W k W ηδ式中,k 为学习次数,η为学习因子。
η取值越大,每次权值的改变越剧烈,可能导致学习过程振荡,因此,为了使学习因子的取值足够大,又不至产生振荡,通常在权值修正公式中加入一个附加动量法。
模式识别方法二实验报告

《模式识别》大作业人脸识别方法二---- 基于PCA 和FLD 的人脸识别的几何分类器(修改稿)一、 理论知识1、fisher 概念引出在应用统计方法解决模式识别问题时,为了解决“维数灾难”的问题,压缩特征空间的维数非常必要。
fisher 方法实际上涉及到维数压缩的问题。
fisher 分类器是一种几何分类器, 包括线性分类器和非线性分类器。
线性分类器有:感知器算法、增量校正算法、LMSE 分类算法、Fisher 分类。
若把多维特征空间的点投影到一条直线上,就能把特征空间压缩成一维。
那么关键就是找到这条直线的方向,找得好,分得好,找不好,就混在一起。
因此fisher 方法目标就是找到这个最好的直线方向以及如何实现向最好方向投影的变换。
这个投影变换恰是我们所寻求的解向量*W ,这是fisher 算法的基本问题。
样品训练集以及待测样品的特征数目为n 。
为了找到最佳投影方向,需要计算出各类均值、样品类内离散度矩阵i S 和总类间离散度矩阵w S 、样品类间离散度矩阵b S ,根据Fisher 准则,找到最佳投影准则,将训练集内所有样品进行投影,投影到一维Y 空间,由于Y 空间是一维的,则需要求出Y 空间的划分边界点,找到边界点后,就可以对待测样品进行进行一维Y 空间的投影,判断它的投影点与分界点的关系,将其归类。
Fisher 法的核心为二字:投影。
二、 实现方法1、 一维实现方法(1) 计算给类样品均值向量i m ,i m 是各个类的均值,i N 是i ω类的样品个数。
11,2,...,ii X im X i nN ω∈==∑(2) 计算样品类内离散度矩阵iS 和总类间离散度矩阵wS1()()1,2,...,i Ti i i X w ii S X m X m i nS Sω∈==--==∑∑(3) 计算样品类间离散度矩阵b S1212()()Tb S m m m m =--(4) 求向量*W我们希望投影后,在一维Y 空间各类样品尽可能地分开,也就是说我们希望两类样品均值之差(12m m -)越大越好,同时希望各类样品内部尽量密集,即希望类内离散度越小越好,因此,我们可以定义Fisher 准则函数:()Tb F Tw W S W J W W S W=使得()F J W 取得最大值的*W 为 *112()w WS m m -=-(5) 将训练集内所有样品进行投影*()Ty W X =(6) 计算在投影空间上的分割阈值0y在一维Y 空间,各类样品均值i m为 11,2,...,ii y imy i n N ω∈==∑样品类内离散度矩阵2i s和总类间离散度矩阵w s 22()ii iy sy mω∈=-∑21w ii ss==∑【注】【阈值0y 的选取可以由不同的方案: 较常见的一种是1122012N m N m y N N +=+另一种是121201ln(()/())22m m P P y N N ωω+=++- 】(7) 对于给定的X ,计算出它在*W 上的投影y (8) 根据决策规则分类0102y y X y y X ωω>⇒∈⎧⎨<⇒∈⎩2、程序中算法的应用Fisher 线性判别方法(FLD )是在Fisher 鉴别准则函数取极值的情况下,求得一个最佳判别方向,然后从高位特征向量投影到该最佳鉴别方向,构成一个一维的判别特征空间将Fisher 线性判别推广到C-1个判决函数下,即从N 维空间向C-1维空间作相应的投影。
模式识别实验【范本模板】

《模式识别》实验报告班级:电子信息科学与技术13级02 班姓名:学号:指导老师:成绩:通信与信息工程学院二〇一六年实验一 最大最小距离算法一、实验内容1. 熟悉最大最小距离算法,并能够用程序写出。
2. 利用最大最小距离算法寻找到聚类中心,并将模式样本划分到各聚类中心对应的类别中.二、实验原理N 个待分类的模式样本{}N X X X , 21,,分别分类到聚类中心{}N Z Z Z , 21,对应的类别之中.最大最小距离算法描述:(1)任选一个模式样本作为第一聚类中心1Z 。
(2)选择离1Z 距离最远的模式样本作为第二聚类中心2Z 。
(3)逐个计算每个模式样本与已确定的所有聚类中心之间的距离,并选出其中的最小距离.(4)在所有最小距离中选出一个最大的距离,如果该最大值达到了21Z Z -的一定分数比值以上,则将产生最大距离的那个模式样本定义为新增的聚类中心,并返回上一步.否则,聚类中心的计算步骤结束。
这里的21Z Z -的一定分数比值就是阈值T ,即有:1021<<-=θθZ Z T(5)重复步骤(3)和步骤(4),直到没有新的聚类中心出现为止。
在这个过程中,当有k 个聚类中心{}N Z Z Z , 21,时,分别计算每个模式样本与所有聚类中心距离中的最小距离值,寻找到N 个最小距离中的最大距离并进行判别,结果大于阈值T 是,1+k Z 存在,并取为产生最大值的相应模式向量;否则,停止寻找聚类中心。
(6)寻找聚类中心的运算结束后,将模式样本{}N i X i ,2,1, =按最近距离划分到相应的聚类中心所代表的类别之中。
三、实验结果及分析该实验的问题是书上课后习题2。
1,以下利用的matlab 中的元胞存储10个二维模式样本X {1}=[0;0];X{2}=[1;1];X {3}=[2;2];X{4}=[3;7];X{5}=[3;6]; X{6}=[4;6];X{7}=[5;7];X{8}=[6;3];X{9}=[7;3];X{10}=[7;4];利用最大最小距离算法,matlab 运行可以求得从matlab 运行结果可以看出,聚类中心为971,,X X X ,以1X 为聚类中心的点有321,,X X X ,以7X 为聚类中心的点有7654,,,X X X X ,以9X 为聚类中心的有1098,,X X X 。
统计模式识别上机实习报告

《统计模式识别》实习报告姓名:学号:专业:地球信息科学与技术教师:2017年11月data=load("C:\Users\siyuan\Desktop\统计模式识别实习内容\实习数据及读入程序\data.txt");%统计方法和函数set1={min(data)';max(data)';sort(data)';mean(data)';median(data)';std(data)';va r(data)';sum(data)';prod(data)';cumsum(data)';cumprod(data)'};%概率密度函数x=(-6:0.05:6);n1=pdf('Normal',x,0,0.5);n2=pdf('Normal',x,0,1);n3=pdf('Normal',x,0,2);n4=pdf('Normal',x,0,4);figureplot(x,n1,'s',x,n2,'.',x,n3,'*',x,n4,'+')%距离x = rand(4,3);y = rand(1,3);[pdist(x),pdist(x,'cityblock'),pdist(x,'minkowski'),pdist(x,'mahal')];pdist2(x,y);[linkage(x),linkage(x,'complete'),linkage(x,'centroid'),linkage(x,'average'),li nkage(x,'ward')];Warning: Non-monotonic cluster tree -- the centroid linkage is probably not appropriate. %简单聚类clusterdata(x,0.9);%谱系图tree = linkage(x,'average');figure()dendrogram(tree)%动态聚类load fisheririsX = meas(:,3:4);figure;plot(X(:,1),X(:,2),'k*','MarkerSize',5); title 'Fisher''s Iris Data';xlabel'Petal Lengths (cm)';ylabel'Petal Widths (cm)';rng(1); % For reproducibility[idx,C] = kmeans(X,3);x1 = min(X(:,1)):0.01:max(X(:,1));x2 = min(X(:,2)):0.01:max(X(:,2));[x1G,x2G] = meshgrid(x1,x2);XGrid = [x1G(:),x2G(:)]; % Defines a fine grid on the plotidx2Region = kmeans(XGrid,3,'MaxIter',1,'Start',C);Warning: Failed to converge in 1 iterations.% Assigns each node in the grid to the closest centroidfigure;gscatter(XGrid(:,1),XGrid(:,2),idx2Region,...[0,0.75,0.75;0.75,0,0.75;0.75,0.75,0],'..');hold on;plot(X(:,1),X(:,2),'k*','MarkerSize',5);title 'Fisher''s Iris Data';xlabel'Petal Lengths (cm)';ylabel'Petal Widths (cm)';legend('Region 1','Region 2','Region 3','Data','Location','SouthEast'); hold off;%贝叶斯load fisheririsO1 = fitcnb(meas,species);C1 = O1.predict(meas);cMat1 = confusionmat(species,C1)cMat1 =50 0 00 47 30 3 47O2 = fitcnb(meas,species,'dist',...{'normal','kernel','normal','kernel'}); C2 = O2.predict(meas);cMat2 = confusionmat(species,C2)cMat2 =50 0 00 47 30 3 47%参数估计data = normrnd(10,2,100,2);[mu,sigma,muci,sigmaci] = normfit(data) mu =9.8687 9.9183sigma =1.9954 1.9729muci =9.4728 9.526910.2647 10.3098sigmaci =1.7520 1.73222.3180 2.2918%mleload carbighistogram(MPG)phat = mle(MPG,'distribution','burr') phat =34.6447 3.7898 3.5722。
模式识别实验报告

二、实验步骤 前提条件: 只考虑第三种情况:如果 di(x) >dj(x) 任意 j≠ i ,则判 x∈ωi 。
○1 、赋初值,分别给 c 个权矢量 wi(1)(i=1,2,…c)赋任意的初
值,选择正常数ρ ,置步数 k=1;
○2 、输入符号未规范化的增广训练模式 xk, xk∈{x1, x2… xN} ,
二、实验步骤
○1 、给出 n 个混合样本,令 I=1,表示迭代运算次数,选取 c
个初始聚合中心 ,j=1,2,…,c;
○2 、 计 算 每 个 样 本 与 聚 合 中 心 的 距 离
,
。
若
, ,则
。
○3 、 计 算 c 个 新 的 聚 合 中 心 :
,
。
○4 、判断:若
,
,则 I=I+1,返回
第二步 b 处,否则结束。 三、程序设计
聚类没有影响。但当 C=2 时,该类别属于正确分类。 而类别数目大于 2 时,初始聚合中心对聚类的影响非常大,仿真
结果多样化,不能作为分类标准。 2、考虑类别数目对聚类的影响: 当类别数目变化时,结果也随之出现变化。 3、总结 综上可知,只有预先分析过样本,确定合适的类别数目,才能对
样本进行正确分类,而初始聚合中心对其没有影响。
8
7
6
5
4
3
2
1
0
0
1
2
3
4
5
6
7
8
9
初始聚合中心为(0,0),(2,2),(5,5),(7,7),(9,9)
K-均 值 聚 类 算 法 : 类 别 数 目 c=5 9
8
7
6
5
4
模式识别实验报告

模式识别实验报告班级:电信08-1班姓名:黄**学号:********课程名称:模式识别导论实验一安装并使用模式识别工具箱一、实验目的:1.掌握安装模式识别工具箱的技巧,能熟练使用工具箱中的各项功能;2.熟练使用最小错误率贝叶斯决策器对样本分类;3.熟练使用感知准则对样本分类;4.熟练使用最小平方误差准则对样本分类;5.了解近邻法的分类过程,了解参数K值对分类性能的影响(选做);6.了解不同的特征提取方法对分类性能的影响(选做)。
二、实验内容与原理:1.安装模式识别工具箱;2.用最小错误率贝叶斯决策器对呈正态分布的两类样本分类;3.用感知准则对两类可分样本进行分类,并观测迭代次数对分类性能的影响;4.用最小平方误差准则对云状样本分类,并与贝叶斯决策器的分类结果比较;5.用近邻法对双螺旋样本分类,并观测不同的K值对分类性能的影响(选做);6.观测不同的特征提取方法对分类性能的影响(选做)。
三、实验器材(设备、元器件、软件工具、平台):1.PC机-系统最低配置512M 内存、P4 CPU;2.Matlab 仿真软件-7.0 / 7.1 / 2006a等版本的Matlab 软件。
四、实验步骤:1.安装模式识别工具箱。
并调出Classifier主界面。
2.调用XOR.mat文件,用最小错误率贝叶斯决策器对呈正态分布的两类样本分类。
3.调用Seperable.mat文件,用感知准则对两类可分样本进行分类。
4.调用Clouds.mat文件,用最小平方误差准则对两类样本进行分类。
5.调用Spiral.mat文件,用近邻法对双螺旋样本进行分类。
6.调用XOR.mat文件,用特征提取方法对分类效果的影响。
五、实验数据及结果分析:(1)Classifier主界面如下(2)最小错误率贝叶斯决策器对呈正态分布的两类样本进行分类结果如下:(3)感知准则对两类可分样本进行分类当Num of iteration=300时的情况:当Num of iteration=1000时的分类如下:(4)最小平方误差准则对两类样本进行分类结果如下:(5)近邻法对双螺旋样本进行分类,结果如下当Num of nearest neighbor=3时的情况为:当Num of nearest neighbor=12时的分类如下:(6)特征提取方法对分类结果如下当New data dimension=2时,其结果如下当New data dimension=1时,其结果如下六、实验结论:本次实验使我掌握安装模式识别工具箱的技巧,能熟练使用工具箱中的各项功能;对模式识别有了初步的了解。
模式识别实习报告

一、贝叶斯估计做分类【问题描述】实习题目一:用贝叶斯估计做分类。
问题描述:给出试验区裸土加水田的tif图像,要求通过贝叶斯估计算法对房屋、水田及植被进行分类。
问题分析:首先通过目视解译法对图像进行分类,获取裸土、水田和植被的DN值,在此基础上,通过该部分各个类别的面积计算先验概率,然后带入公式进行计算,从而对整个图像进行分类。
【模型方法】与分布有关的统计分类方法主要有最大似然/ 贝叶斯分类。
最大似然分类是图像处理中最常用的一种监督分类方法,它利用了遥感数据的统计特征,假定各类的分布函数为正态分布,在多变量空间中形成椭圆或椭球分布,也就是和中个方向上散布情况不同,按正态分布规律用最大似然判别规则进行判决,得到较高准确率的分类结果。
否则,用平行六面体或最小距离分类效果会更好。
【方案设计】①确定需要分类的地区和使用的波段和特征分类数,检查所用各波段或特征分量是否相互已经位置配准;②根据已掌握的典型地区的地面情况,在图像上选择训练区;③计算参数,根据选出的各类训练区的图像数据,计算和确定先验概率;④分类,将训练区以外的图像像元逐个逐类代入公式,对于每个像元,分几类就计算几次,最后比较大小,选择最大值得出类别;⑤产生分类图,给每一类别规定一个值,如果分10 类,就定每一类分别为1 ,2 ……10 ,分类后的像元值便用类别值代替,最后得到的分类图像就是专题图像. 由于最大灰阶值等于类别数,在监视器上显示时需要给各类加上不同的彩色;⑥检验结果,如果分类中错误较多,需要重新选择训练区再作以上各步,直到结果满意为止。
【结果讨论】如图所示,通过贝叶斯算法,较好地对图像完成了分类,裸土、植被和水田三个类别清晰地判别出来。
在计算先验概率时,选择何种数据成为困扰我的一个问题。
既有ENVI自身提供的精确的先验概率值,也可以自己通过计算各个类别的面积,从而获取大致的先验概率值。
最后,在田老师的讲解下,我知道了虽然数据可能不太精确,但是,计算先验概率时,总体的倾向是一致的,所以在最后判别时,因此而引起的误差是微乎其微的,所以,一定要弄清楚算法原理,才能让自己的每一步工作都有理可循。
模式识别技术实验报告

模式识别技术实验报告本实验旨在探讨模式识别技术在计算机视觉领域的应用与效果。
模式识别技术是一种人工智能技术,通过对数据进行分析、学习和推理,识别其中的模式并进行分类、识别或预测。
在本实验中,我们将利用机器学习算法和图像处理技术,对图像数据进行模式识别实验,以验证该技术的准确度和可靠性。
实验一:图像分类首先,我们将使用卷积神经网络(CNN)模型对手写数字数据集进行分类实验。
该数据集包含大量手写数字图片,我们将训练CNN模型来识别并分类这些数字。
通过调整模型的参数和训练次数,我们可以得到不同准确度的模型,并通过混淆矩阵等评估指标来评估模型的性能和效果。
实验二:人脸识别其次,我们将利用人脸数据集进行人脸识别实验。
通过特征提取和比对算法,我们可以识别不同人脸之间的相似性和差异性。
在实验过程中,我们将测试不同算法在人脸识别任务上的表现,比较它们的准确度和速度,探讨模式识别技术在人脸识别领域的应用潜力。
实验三:异常检测最后,我们将进行异常检测实验,使用模式识别技术来识别图像数据中的异常点或异常模式。
通过训练异常检测模型,我们可以发现数据中的异常情况,从而做出相应的处理和调整。
本实验将验证模式识别技术在异常检测领域的有效性和实用性。
结论通过以上实验,我们对模式识别技术在计算机视觉领域的应用进行了初步探索和验证。
模式识别技术在图像分类、人脸识别和异常检测等任务中展现出了良好的性能和准确度,具有广泛的应用前景和发展空间。
未来,我们将进一步深入研究和实践,探索模式识别技术在更多领域的应用,推动人工智能技术的发展和创新。
【字数:414】。
模式识别实验报告哈工程

一、实验背景随着计算机科学和信息技术的飞速发展,模式识别技术在各个领域得到了广泛应用。
模式识别是指通过对数据的分析、处理和分类,从大量数据中提取有用信息,从而实现对未知模式的识别。
本实验旨在通过实践操作,加深对模式识别基本概念、算法和方法的理解,并掌握其应用。
二、实验目的1. 理解模式识别的基本概念、算法和方法;2. 掌握常用的模式识别算法,如K-均值聚类、决策树、支持向量机等;3. 熟悉模式识别在实际问题中的应用,提高解决实际问题的能力。
三、实验内容本次实验共分为三个部分:K-均值聚类算法、决策树和神经网络。
1. K-均值聚类算法(1)实验目的通过实验加深对K-均值聚类算法的理解,掌握其基本原理和实现方法。
(2)实验步骤① 准备实验数据:选取一组二维数据,包括100个样本,每个样本包含两个特征值;② 初始化聚类中心:随机选择K个样本作为初始聚类中心;③ 计算每个样本到聚类中心的距离,并将其分配到最近的聚类中心;④ 更新聚类中心:计算每个聚类中所有样本的均值,作为新的聚类中心;⑤ 重复步骤③和④,直到聚类中心不再变化。
(3)实验结果通过实验,可以得到K个聚类中心,每个样本被分配到最近的聚类中心。
通过可视化聚类结果,可以直观地看到数据被分成了K个类别。
2. 决策树(1)实验目的通过实验加深对决策树的理解,掌握其基本原理和实现方法。
(2)实验步骤① 准备实验数据:选取一组具有分类标签的二维数据,包括100个样本,每个样本包含两个特征值;② 选择最优分割特征:根据信息增益或基尼指数等指标,选择最优分割特征;③ 划分数据集:根据最优分割特征,将数据集划分为两个子集;④ 递归地执行步骤②和③,直到满足停止条件(如达到最大深度、叶节点中样本数小于阈值等);⑤ 构建决策树:根据递归分割的结果,构建决策树。
(3)实验结果通过实验,可以得到一棵决策树,可以用于对新样本进行分类。
3. 神经网络(1)实验目的通过实验加深对神经网络的理解,掌握其基本原理和实现方法。
模式识别实验报告2_贝叶斯分类实验_实验报告(例)

end
plot(1:23,t2,'b','LineWidth',3);
%下面是bayesian_fun函数
functionf=bayesian_fun(t2,t1,W1,W2,w1,w2,w10,w20)
x=[t1,t2]';
f=x'*W1*x+w1'*x+w10- (x'*W2*x+w2'*x+w20);
%f=bayesian_fun.m
function f=bayesian_fun(t2,t1,W1,W2,w1,w2,w10,w20)
x=[t1,t2]';
f=x'*W1*x+w1'*x+w10 - (x'*W2*x+w2'*x+w20);
w10=-1/2 * u1'*S1tinv*u1 - 1/2 *log(det(S1t)) + log(pw1);
w20=-1/2 * u2'*S2tinv*u2 - 1/2 *log(det(S2t)) + log(pw2);
t2=[]
fort1=1:23
tt2 = fsolve('bayesian_fun',5,[],t1,W1,W2,w1,w2,w10,w20);
'LineWidth',2,...
'MarkerEdgeColor','k',...
'MarkerFaceColor',[0 1 0],...
'MarkerSize',10)
模式识别实验报告

模式识别实验报告实验一、线性分类器的设计与实现1. 实验目的:掌握模式识别的基本概念,理解线性分类器的算法原理。
2. 实验要求:(1)学习和掌握线性分类器的算法原理;(2)在MATLAB 环境下编程实现三种线性分类器并能对提供的数据进行分类;(3)对实现的线性分类器性能进行简单的评估(例如算法适用条件,算法效率及复杂度等)。
注:三种线性分类器为,单样本感知器算法、批处理感知器算法、最小均方差算法批处理感知器算法算法原理:感知器准则函数为J p a=(−a t y)y∈Y,这里的Y(a)是被a错分的样本集,如果没有样本被分错,Y就是空的,这时我们定义J p a为0.因为当a t y≤0时,J p a是非负的,只有当a是解向量时才为0,也即a在判决边界上。
从几何上可知,J p a是与错分样本到判决边界距离之和成正比的。
由于J p梯度上的第j个分量为∂J p/ða j,也即∇J p=(−y)y∈Y。
梯度下降的迭代公式为a k+1=a k+η(k)yy∈Y k,这里Y k为被a k错分的样本集。
算法伪代码如下:begin initialize a,η(∙),准则θ,k=0do k=k+1a=a+η(k)yy∈Y k|<θuntil | ηk yy∈Y kreturn aend因此寻找解向量的批处理感知器算法可以简单地叙述为:下一个权向量等于被前一个权向量错分的样本的和乘以一个系数。
每次修正权值向量时都需要计算成批的样本。
算法源代码:unction [solution iter] = BatchPerceptron(Y,tau)%% solution = BatchPerceptron(Y,tau) 固定增量批处理感知器算法实现%% 输入:规范化样本矩阵Y,裕量tau% 输出:解向量solution,迭代次数iter[y_k d] = size(Y);a = zeros(1,d);k_max = 10000; %%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%% k=0;y_temp=zeros(d,1);while k<k_maxc=0;for i=1:1:y_kif Y(i,:)*a'<=tauy_temp=y_temp+Y(i,:)';c=c+1;endendif c==0break;enda=a+y_temp';k=k+1;end %%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%% %k = k_max;solution = a;iter = k-1;运行结果及分析:数据1的分类结果如下由以上运行结果可以知道,迭代17次之后,算法得到收敛,解出的权向量序列将样本很好的划分。
模式识别实验报告_3

模式识别实验报告_3第⼀次实验实验⽬的:1.学习使⽤ENVI2.会⽤MATLAB读⼊遥感数据并进⾏处理实验内容:⼀学习使⽤ENVI1.使⽤ENVI打开遥感图像(任选3个波段合成假彩⾊图像,保存写⼊报告)2.会查看图像的头⽂件(保存或者copy⾄报告)3.会看地物的光谱曲线(保存或者copy⾄报告)4.进⾏数据信息统计(保存或者copy⾄报告)5.设置ROI,对每类地物⾃⼰添加标记数据,并保存为ROI⽂件和图像⽂件(CMap贴到报告中)。
6.使⽤⾃⼰设置的ROI进⾏图像分类(ENVI中的两种有监督分类算法)(分类算法名称和分类结果写⼊报告)⼆MATLAB处理遥感数据(提交代码和结果)7.⽤MATLAB读⼊遥感数据(zy3和DC两个数据)8.⽤MATLAB读⼊遥感图像中ROI中的数据(包括数据和标签)9.把图像数据m*n*L(其中m表⽰⾏数,n表⽰列数,L表⽰波段数),重新排列为N*L的⼆维矩阵(其中N=m*n),其中N表⽰所有的数据点数量m*n。
(提⽰,⽤reshape函数,可以help查看这个函数的⽤法)10.计算每⼀类数据的均值(平均光谱),并把所有类别的平均光谱画出来(plot)(类似下⾯的效果)。
11.画出zy3数据中“农作物类别”的数据点(⾃⼰ROI标记的这个类别的点)在每个波段的直⽅图(matlab函数:nbins=50;hist(Xi,nbins),其中Xi表⽰这类数据在第i波段的数值)。
计算出这个类别数据的协⽅差矩阵,并画出(figure,imagesc(C),colorbar)。
1.打开遥感图像如下:2.查看图像头⽂件过程如下:3.地物的光谱曲线如下:4.数据信息统计如下:(注:由于保存的txt⽂件中的数据信息过长,所以采⽤截图的⽅式只显⽰了出⼀部分数据信息)5.设置ROI,对每类地物⾃⼰添加标记数据,CMap如下:6.使⽤⾃⼰设置的ROI进⾏图像分类(使⽤⽀持向量机算法和最⼩距离算法),⽀持向量机算法分类结果如下:最⼩距离算法分类结果如下:对⽐两种算法的分类结果可以看出⽀持分量机算法分类结果⽐最⼩距离算法分类结果好⼀些。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
北京科技大学计算机与通信工程学院模式分类第二次上机实验报告姓名:XXXXXX学号:00000000班级:电信11时间:2014-04-16一、实验目的1.掌握支持向量机(SVM)的原理、核函数类型选择以及核参数选择原则等;二、实验内容2.准备好数据,首先要把数据转换成Libsvm软件包要求的数据格式为:label index1:value1 index2:value2 ...其中对于分类来说label为类标识,指定数据的种类;对于回归来说label为目标值。
(我主要要用到回归)Index是从1开始的自然数,value是每一维的特征值。
该过程可以自己使用excel或者编写程序来完成,也可以使用网络上的FormatDataLibsvm.xls来完成。
FormatDataLibsvm.xls使用说明:先将数据按照下列格式存放(注意label放最后面):value1 value2 labelvalue1 value2 label然后将以上数据粘贴到FormatDataLibsvm.xls中的最左上角单元格,接着工具->宏执行行FormatDataToLibsvm宏。
就可以得到libsvm要求的数据格式。
将该数据存放到文本文件中进行下一步的处理。
3.对数据进行归一化。
该过程要用到libsvm软件包中的svm-scale.exeSvm-scale用法:用法:svmscale [-l lower] [-u upper] [-y y_lower y_upper] [-s save_filename] [-r restore_filename] filename (缺省值:lower = -1,upper = 1,没有对y进行缩放)其中,-l:数据下限标记;lower:缩放后数据下限;-u:数据上限标记;upper:缩放后数据上限;-y:是否对目标值同时进行缩放;y_lower为下限值,y_upper为上限值;(回归需要对目标进行缩放,因此该参数可以设定为–y -1 1 )-s save_filename:表示将缩放的规则保存为文件save_filename;-r restore_filename:表示将缩放规则文件restore_filename载入后按此缩放;filename:待缩放的数据文件(要求满足前面所述的格式)。
缩放规则文件可以用文本浏览器打开,看到其格式为:ylower upper min max xlower upperindex1 min1 max1index2 min2 max2其中的lower 与upper 与使用时所设置的lower 与upper 含义相同;index 表示特征序号;min 转换前该特征的最小值;max 转换前该特征的最大值。
数据集的缩放结果在此情况下通过DOS窗口输出,当然也可以通过DOS的文件重定向符号“>”将结果另存为指定的文件。
该文件中的参数可用于最后面对目标值的反归一化。
反归一化的公式为:(Value-lower)*(max-min)/(upper - lower)+lower其中value为归一化后的值,其他参数与前面介绍的相同。
建议将训练数据集与测试数据集放在同一个文本文件中一起归一化,然后再将归一化结果分成训练集和测试集。
4.训练数据,生成模型。
用法:svmtrain [options] training_set_file [model_file]其中,options(操作参数):可用的选项即表示的涵义如下所示-s svm类型:设置SVM 类型,默认值为0,可选类型有(对于回归只能选3或4):0 -- C- SVC 1 -- n - SVC 2 -- one-class-SVM 3 -- e - SVR 4 -- n - SVR -t核函数类型:设置核函数类型,默认值为2,可选类型有:0 -- 线性核:u'*v 1 -- 多项式核:(g*u'*v+ coef 0)deg ree 2 -- RBF 核:e( u v 2) g - 3 -- sigmoid 核:tanh(g*u'*v+ coef 0) -d degree:核函数中的degree设置,默认值为3;-g g :设置核函数中的g ,默认值为1/ k ;-r coef 0:设置核函数中的coef 0,默认值为0;-c cost:设置C- SVC、e - SVR、n6- SVR中从惩罚系数C,默认值为1;-n n :设置n - SVC、one-class-SVM 与n - SVR 中参数n ,默认值0.5;-p e :设置n - SVR的损失函数中的e ,默认值为0.1;-m cachesize:设置cache内存大小,以MB为单位,默认值为40;-e e :设置终止准则中的可容忍偏差,默认值为0.001;-h shrinking:是否使用启发式,可选值为0 或1,默认值为1;-b 概率估计:是否计算SVC或SVR的概率估计,可选值0 或1,默认0;-wi weight:对各类样本的惩罚系数C加权,默认值为1;-v n:n折交叉验证模式。
其中-g选项中的k是指输入数据中的属性数。
操作参数-v 随机地将数据剖分为n 部分并计算交叉检验准确度和均方根误差。
以上这些参数设置可以按照SVM 的类型和核函数所支持的参数进行任意组合,如果设置的参数在函数或SVM 类型中没有也不会产生影响,程序不会接受该参数;如果应有的参数设置不正确,参数将采用默认值。
training_set_file是要进行训练的数据集;model_file 是训练结束后产生的模型文件,该参数如果不设置将采用默认的文件名,也可以设置成自己惯用的文件名。
本实验中的参数-s取3,-t取2(默认)还需确定的参数是-c,-g,-p另,实验中所需调整的重要参数是-c 和–g,-c和-g的调整除了自己根据经验试之外,还可以使用gridregression.py对这两个参数进行优化。
(需要补充)该优化过程需要用到Python(2.5),Gnuplot(4.2),gridregression.py(该文件需要修改路径)。
然后在命令行下面运行:python.exe gridregression.py -log2c -10,10,1 -log2g -10,10,1 -log2p -10,10,1 -s 3 –t 2 -v 5 -svmtrainE:\libsvm\libsvm-2.86\windows\svm-train.exe-gnuplot E:\libsvm\libsvm-2.86\gnuplot\bin\pgnuplot.exe E:\libsvm\libsvm-2.86\windows\train.txt > gridregression_feature.parameter以上三个路径根据实际安装情况进行修改。
-log2c是给出参数c的范围和步长-log2g是给出参数g的范围和步长-log2p是给出参数p的范围和步长上面三个参数可以用默认范围和步长-s选择SVM类型,也是只能选3或者4 -t是选择核函数-v 10 将训练数据分成10份做交叉验证。
默认为5为了方便将gridregression.py是存放在python.exe安装目录下trian.txt为训练数据,参数存放在gridregression_feature.parameter中,可以自己命名。
搜索结束后可以在gridregression_feature.parameter中最后一行看到最优参数。
其中,最后一行的第一个参数即为-c,第二个为-g,第三个为-p,最后一个参数为均方误差。
前三个参数可以直接用于模型的训练。
然后,根据搜索得到的参数,重新训练,得到模型。
5.测试用法:svmpredict [options] test_file model_file output_file options(操作参数):-b probability_estimates:是否需要进行概率估计预测,可选值为0 或者1,默认值为0。
model_file 是由svmtrain 产生的模型文件;test_file 是要进行预测的数据文件;output_file 是svmpredict 的输出文件,表示预测的结果值。
输出结果包括均方误差(Mean squared error)和相关系数(Squared correlation coefficient)。
三、实验仪器、设备1.PC机-系统最低配置512M 内存、P4 CPU;2.Matlab 仿真软件-7.0 / 7.1 / 2006a 等版本的Matlab 软件。
3.Coil20数据库;四、实验原理使用svm-scale 对数据进行缩放是必要的。
因为适当的scale有助于参数的选取和建svm模型的速度。
svm-scale 会对value 做scale。
范围用-l, -u 指定,通常是[0,1],或是[-1,1]。
(文本分类一般选[0,1])。
輸出在stdout。
另外要注意的是testing data 和training data要一起scale。
而svm-scale 最难用的地方就是沒办法指定testing data/training data为同一文档,然后一起scale。
因此为了后面测试,还要对测试集进行scale。
五、实验数据及结果分析:训练样本识别率1(%) 测试样本识别$/(%)72.9 6279.3 6781 69.7Svmtoy输出图形Svm分类器matlab代码clear;%清屏clc;X =load('data.txt');n = length(X);%总样本数量y = X(:,4);%类别标志X = X(:,1:3);TOL = 0.0001;%精度要求C = 1;%参数,对损失函数的权重b = 0;%初始设置截距bWold = 0;%未更新a时的W(a)Wnew = 0;%更新a后的W(a)for i = 1 : 50%设置类别标志为1或者-1y(i) = -1;enda = zeros(n,1);%参数afor i = 1 : n%随机初始化a,a属于[0,C]a(i) = 0.2;end%为简化计算,减少重复计算进行的计算K = ones(n,n);for i = 1 :n%求出K矩阵,便于之后的计算for j = 1 : nK(i,j) = k(X(i,:),X(j,:));endendsum = zeros(n,1);%中间变量,便于之后的计算,sum(k)=sigma a(i)*y(i)*K(k,i); for k = 1 : nfor i = 1 : nsum(k) = sum(k) + a(i) * y(i) * K(i,k);endendwhile 1%迭代过程%启发式选点n1 = 1;%初始化,n1,n2代表选择的2个点n2 = 2;%n1按照第一个违反KKT条件的点选择while n1 <= nif y(n1) * (sum(n1) + b) == 1 && a(n1) >= C && a(n1) <= 0break;endif y(n1) * (sum(n1) + b) > 1 && a(n1) ~= 0break;endif y(n1) * (sum(n1) + b) < 1 && a(n1) ~=Cbreak;endn1 = n1 + 1;end%n2按照最大化|E1-E2|的原则选取E1 = 0;E2 = 0;maxDiff = 0;%假设的最大误差E1 = sum(n1) + b - y(n1);%n1的误差for i = 1 : ntempSum = sum(i) + b - y(i);if abs(E1 - tempSum)> maxDiffmaxDiff = abs(E1 - tempSum);n2 = i;E2 = tempSum;endend%以下进行更新a1old = a(n1);a2old = a(n2);KK = K(n1,n1) + K(n2,n2) - 2*K(n1,n2);a2new = a2old + y(n2) *(E1 - E2) / KK;%计算新的a2 %a2必须满足约束条件S = y(n1) * y(n2);if S == -1U = max(0,a2old - a1old);V = min(C,C - a1old + a2old);elseU = max(0,a1old + a2old - C);V = min(C,a1old + a2old);endif a2new > Va2new = V;endif a2new < Ua2new = U;enda1new = a1old + S * (a2old - a2new);%计算新的a1 a(n1) = a1new;%更新aa(n2) = a2new;%更新部分值sum = zeros(n,1);for k = 1 : nfor i = 1 : nsum(k) = sum(k) + a(i) * y(i) * K(i,k);endendWold = Wnew;Wnew = 0;%更新a后的W(a)tempSum = 0;%临时变量for i = 1 : nfor j = 1 : ntempSum= tempSum + y(i )*y(j)*a(i)*a(j)*K(i,j);endWnew= Wnew+ a(i);endWnew= Wnew - 0.5 * tempSum;%以下更新b:通过找到某一个支持向量来计算support = 1;%支持向量坐标初始化while abs(a(support))< 1e-4 && support <= nsupport = support + 1;endb = 1 / y(support) - sum(support);%判断停止条件if abs(Wnew/ Wold - 1 ) <= TOLbreak;endend%输出结果:包括原分类,辨别函数计算结果,svm分类结果for i = 1 : nfprintf('第%d点:原标号',i);if i <= 50fprintf('-1');elsefprintf(' 1');endfprintf(' 判别函数值%f 分类结果',sum(i) + b);if abs(sum(i) + b - 1) < 0.5fprintf('1\n');else if abs(sum(i) + b + 1) < 0.5fprintf('-1\n');elsefprintf('归类错误\n');endendend2.名为f的功能函数部分: function y = k(x1,x2)y = exp(-0.5*norm(x1 - x2).^2); end。