利用Python进行数据分析之 数据加载
使用Python进行大数据分析和处理

使用Python进行大数据分析和处理一、引言随着大数据时代的到来,数据分析和处理技术愈发重要。
Python作为一种简单易学、功能强大的编程语言,被广泛应用于数据科学领域。
本文将介绍如何使用Python进行大数据分析和处理,并分为以下几个部分:数据获取、数据清洗、数据分析、数据可视化和模型建立。
二、数据获取在进行大数据分析和处理之前,我们需要从各种数据源中获取数据。
Python提供了丰富的库和工具,可以轻松地从数据库、API、Web页面以及本地文件中获取数据。
比如,我们可以使用pandas库中的read_sql()函数从数据库中读取数据,使用requests库从API获取数据,使用beautifulsoup库从Web页面获取数据,使用csv库从本地CSV文件中获取数据。
三、数据清洗获取到原始数据之后,通常需要进行数据清洗。
数据清洗是指对数据进行预处理,包括处理缺失值、处理异常值、处理重复值、数据格式转换等。
Python提供了丰富的库和函数来帮助我们进行数据清洗,如pandas库中的dropna()函数用于处理缺失值,使用numpy库中的where()函数用于处理异常值,使用pandas库中的duplicated()函数用于处理重复值。
四、数据分析数据分析是大数据处理的核心环节之一。
Python提供了强大的库和工具来进行数据分析,如pandas库和numpy库。
使用这些库,我们可以进行数据聚合、数据筛选、数据排序、数据计算等。
例如,我们可以使用pandas库中的groupby()函数进行数据聚合,使用pandas库中的query()函数进行数据筛选,使用pandas库中的sort_values()函数进行数据排序,使用numpy库中的mean()函数进行数据计算。
五、数据可视化数据可视化是将数据以图形化的方式展现出来,帮助我们更好地理解数据的分布和趋势。
Python提供了多种库和工具来进行数据可视化,如matplotlib库和seaborn库。
如何使用Python进行网络数据分析和网络安全监测

如何使用Python进行网络数据分析和网络安全监测Python是一种功能强大的编程语言,它提供了许多库和工具,可以用于网络数据分析和网络安全监测。
在本文中,我将介绍如何使用Python来进行这两项任务。
首先,让我们来看一下如何使用Python进行网络数据分析。
网络数据分析可以帮助我们理解网络流量、网络性能和网络用户行为。
以下是一些Python库和工具,可以用于网络数据分析:1. Scapy:Scapy是一个功能强大的Python库,可以用于创建、发送和解析网络数据包。
它提供了一种灵活的方式来捕获和分析网络流量。
使用Scapy,您可以编写Python脚本来捕获网络流量并提取关键信息,如源IP地址、目的IP地址、传输协议等。
2. PyShark:PyShark是一个用于Wireshark的Python封装器。
它可以帮助我们从Wireshark捕获的网络数据包中提取关键信息。
使用PyShark,您可以编写Python脚本来分析网络数据包,并进行诸如流量统计、协议分析和用户行为分析等任务。
3. Pandas:Pandas是一个功能强大的数据处理和分析库。
它提供了各种数据结构和函数,用于处理和分析大型数据集。
使用Pandas,您可以轻松地加载和处理网络数据,进行统计分析、数据可视化等任务。
4. Matplotlib:Matplotlib是一个用于绘制图表和可视化数据的库。
使用Matplotlib,您可以轻松地绘制网络数据的图表、图形和图像,以便进行更深入的数据分析。
5. NetworkX:NetworkX是一个用于构建、操作和分析复杂网络的库。
它提供了各种函数和算法,用于分析网络拓扑结构、节点关系和网络效能。
使用NetworkX,您可以进行网络拓扑分析、节点中心性分析和社交网络分析等任务。
现在,让我们来看一下如何使用Python进行网络安全监测。
网络安全监测可以帮助我们及时发现和应对网络攻击、漏洞和其他安全威胁。
如何利用Python进行数据分析

如何利用Python进行数据分析在当今信息化的时代,数据分析在各行各业中愈发重要,特别是业务和决策层在做出决策时需要大量的数据支持。
Python作为一种高级编程语言,加上它强大的数据处理及可视化库,Python 已成为最流行的数据分析和科学计算语言之一。
在本篇文章中,将从以下维度探讨如何利用Python进行数据分析。
1. 数据处理数据处理是数据分析的首要环节,也是数据分析中最繁琐的环节。
在Python中,Numpy、Pandas、Scipy、matplotlib等库都能为数据处理提供有效的帮助。
Numpy是Python数据处理的核心库,提供大量的数学函数和矩阵运算,使处理和计算数据变得十分方便快捷。
例如,可使用Numpy进行数组操作,如下所示:```pythonimport numpy as np# 创建一个数据数组data = np.array([1, 2, 3, 4, 5])# 进行运算mean = np.mean(data)variance = np.var(data)std_dev = np.std(data)# 打印结果print("Mean: ", mean)print("Variance: ", variance)print("Standard deviation: ", std_dev)```Pandas库同样是十分重要的数据处理库,它提供了灵活的数据结构和数据集操作的工具。
Pandas的DataFrame可以看做是一个二维表格数据结构,支持SQL,Excel等风格的操作语法。
```pythonimport pandas as pd# 将数据读入到dataframedf = pd.read_csv("filename.csv")# 输出前几行print(df.head())# 获取列数据data = df['column_name']# 计算平均数mean = data.mean()```除此以外,Pandas还具有强大的数据合并、数据统计、数据重塑等操作功能。
论文写作中如何利用Python进行数据分析

论文写作中如何利用Python进行数据分析随着科技的发展,数据分析在各个领域中扮演着越来越重要的角色。
在论文写作中,利用Python进行数据分析可以帮助研究者更好地理解和解释数据,从而提升研究的可信度和深度。
本文将介绍如何利用Python进行数据分析,并分享一些实用的技巧和工具。
一、数据准备在开始数据分析之前,首先需要准备好相关的数据。
可以通过各种途径获取数据,例如实验、调查、采集等。
在获取到数据后,可以使用Python的pandas库进行数据的导入和处理。
pandas是一个强大的数据分析工具,可以对数据进行清洗、转换、合并等操作,使数据更加规范和易于分析。
二、数据可视化数据可视化是数据分析的重要环节之一,它可以帮助我们更直观地理解数据。
Python中的matplotlib和seaborn库提供了丰富的绘图功能,可以绘制各种类型的图表,如折线图、柱状图、散点图等。
通过可视化数据,我们可以发现数据中的规律和趋势,为后续的分析提供指导。
三、统计分析在数据分析中,统计分析是不可或缺的一环。
Python中的NumPy和SciPy库提供了丰富的统计函数和方法,可以进行各种统计分析,如均值、方差、相关性等。
此外,还可以使用pandas库中的describe()函数生成数据的描述性统计信息,快速了解数据的分布和特征。
四、机器学习机器学习是当前热门的研究方向之一,它可以帮助我们从数据中发现隐藏的模式和规律。
Python中的scikit-learn库是一个强大的机器学习工具,提供了各种机器学习算法的实现。
可以利用scikit-learn库进行数据的分类、回归、聚类等任务,从而深入挖掘数据的内在规律。
五、文本分析在一些研究领域中,文本数据是非常重要的资源。
Python中的nltk和gensim库提供了丰富的文本分析功能,可以进行文本的预处理、关键词提取、情感分析等。
通过文本分析,我们可以对大量的文本数据进行深入挖掘,发现其中的信息和洞察。
python数据分析案例

python数据分析案例在数据分析领域,Python 凭借其强大的库和简洁的语法,成为了最受欢迎的编程语言之一。
本文将通过一个案例来展示如何使用 Python进行数据分析。
首先,我们需要安装 Python 以及一些数据分析相关的库,如 Pandas、NumPy、Matplotlib 和 Seaborn。
这些库可以帮助我们读取、处理、分析和可视化数据。
接下来,我们以一个实际的数据分析案例来展开。
假设我们有一个包含用户购物数据的 CSV 文件,我们的目标是分析用户的购买行为。
1. 数据加载与初步查看使用 Pandas 库,我们可以轻松地读取 CSV 文件中的数据。
首先,我们导入必要的库并加载数据:```pythonimport pandas as pd# 加载数据data = pd.read_csv('shopping_data.csv')```然后,我们可以使用 `head()` 方法来查看数据的前几行,以确保数据加载正确。
```pythonprint(data.head())```2. 数据清洗在数据分析之前,数据清洗是一个必不可少的步骤。
我们需要处理缺失值、重复数据以及异常值。
例如,我们可以使用以下代码来处理缺失值:```python# 检查缺失值print(data.isnull().sum())# 填充或删除缺失值data.fillna(method='ffill', inplace=True)```3. 数据探索在数据清洗之后,我们进行数据探索,以了解数据的分布和特征。
我们可以使用 Pandas 的描述性统计方法来获取数据的概览:```pythonprint(data.describe())```此外,我们还可以绘制一些图表来可视化数据,例如使用Matplotlib 和 Seaborn 绘制直方图和箱线图:```pythonimport matplotlib.pyplot as pltimport seaborn as sns# 绘制直方图plt.figure(figsize=(10, 6))sns.histplot(data['purchase_amount'], bins=20, kde=True) plt.title('Purchase Amount Distribution')plt.xlabel('Purchase Amount')plt.ylabel('Frequency')plt.show()# 绘制箱线图plt.figure(figsize=(10, 6))sns.boxplot(x='category', y='purchase_amount', data=data) plt.title('Purchase Amount by Category')plt.xlabel('Category')plt.ylabel('Purchase Amount')plt.show()```4. 数据分析在数据探索的基础上,我们可以进行更深入的数据分析。
如何用Python实现数据分析?一篇文章搞定!
如何用Python实现数据分析?一篇文章搞定!如何用Python实现数据分析?一篇文章搞定!Python已经成为了数据分析领域中非常流行的编程语言之一。
通过使用Python的各种数据分析库,我们可以方便地处理、分析和可视化数据。
本文将介绍Python的基本数据分析工具,以及如何在Python中进行数据分析。
1.Python数据分析基础Python是一种非常流行的编程语言,因为它易读易写、可扩展性强、可移植性好等特点,因此在数据分析领域中被广泛使用。
在Python中进行数据分析的基本工具包括NumPy、Pandas、Matplotlib、Seaborn和Scikit-learn。
1.1 NumPyNumPy是Python中用于数值计算的基本库,它支持高效的多维数组运算。
在NumPy 中,最基本的数据结构是数组。
NumPy数组是由同类型元素的集合组成的,可以是一维数组或多维数组。
NumPy的一维数组类似于Python的列表,而多维数组则类似于矩阵。
1.1.1 安装NumPy在使用NumPy之前,需要先安装它。
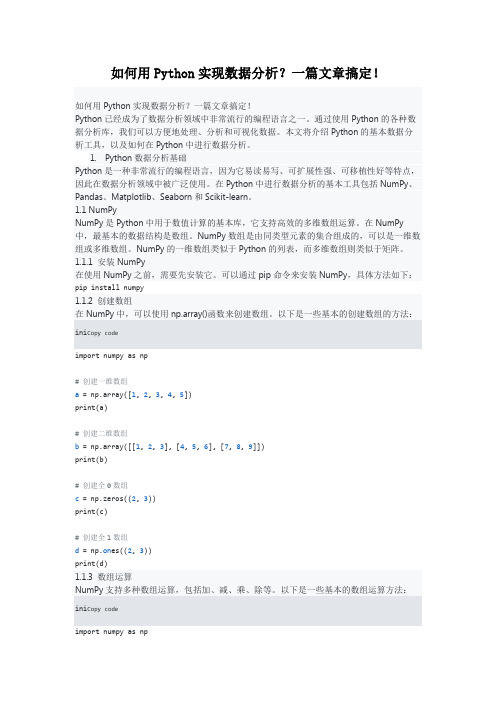
可以通过pip命令来安装NumPy,具体方法如下:pip install numpy1.1.2 创建数组在NumPy中,可以使用np.array()函数来创建数组。
以下是一些基本的创建数组的方法:ini Copy codeimport numpy as np# 创建一维数组a = np.array([1, 2, 3, 4, 5])print(a)# 创建二维数组b = np.array([[1, 2, 3], [4, 5, 6], [7, 8, 9]])print(b)# 创建全0数组c = np.zeros((2, 3))print(c)# 创建全1数组d = np.on es((2, 3))print(d)1.1.3 数组运算NumPy支持多种数组运算,包括加、减、乘、除等。
以下是一些基本的数组运算方法:ini Copy codeimport numpy as npa = np.array([1, 2, 3])b = np.array([4, 5, 6])# 数组加法c = a + bprint(c)# 数组减法d = a - bprint(d)# 数组乘法e = a * bprint(e)# 数组除法f = a / bprint(f)1.2 PandasPandas是基于NumPy的数据处理库,提供了快速便捷的数据结构和数据分析工具。
软件开发知识:如何利用Python进行商业数据分析

软件开发知识:如何利用Python进行商业数据分析Python是一门广泛应用于计算机科学、数据科学等领域的编程语言。
近年来,Python在商业数据分析领域的应用愈发广泛。
Python可以帮助我们将海量数据进行清洗、整理和分析,为商业决策提供有力的支持。
本文将从基础知识出发,介绍如何利用Python进行商业数据分析。
1.数据清洗与整理商业数据往往是从不同来源、格式和系统中获取的,因此需要进行数据清洗和整理。
Python可以帮助我们对数据进行预处理、清洗和处理。
首先,我们需要将数据读入Python中,可以使用pandas库进行读取和处理。
pandas是Python中常用的数据分析和处理库,可以读取多种格式的数据,如CSV、Excel等。
pandas提供了DataFrame数据结构,可以将数据以表格的形式展示,方便我们进行数据分析和处理。
例如,我们可以使用以下代码读取CSV格式的数据:```import pandas as pddf = pd.read_csv('data.csv')```其中,df是一个DataFrame对象,表示读入的数据。
我们可以使用head()方法查看前五行数据:```df.head()```数据清洗和处理的过程包括去除缺失值、异常值、重复值等。
可使用isnull()方法查看缺失值,并可以使用fillna()方法对缺失值进行填充:```df.isnull().sum() #查看缺失值df['col'].fillna(mean_val, inplace=True) #平均值填充缺失值```我们可以使用drop_duplicates()方法去除重复值:```df.drop_duplicates(subset=['col1', 'col2'], inplace=True) #去除col1和col2重复的记录```2.数据分析和可视化数据清洗和整理完成后,接下来可以进行数据分析和可视化。
python读取数据的方法

python读取数据的方法
Python是一种流行的编程语言,广泛用于数据分析和科学计算。
在数据分析方面,读取数据是非常基础和重要的一步。
下面介绍几种Python读取数据的方法:
1. 使用pandas库读取数据:pandas是一个强大的数据处理库,可以轻松读取各种格式的数据文件,例如csv、excel、json 等。
使用pandas读取数据非常简单,只需要使用read_csv、
read_excel等函数即可。
2. 使用numpy库读取数据:numpy是Python中用于科学计算的一个库,其中包含了读取和处理各种数据的函数。
使用numpy读取数据需要使用loadtxt、genfromtxt等函数。
3. 使用标准库csv读取数据:Python标准库中包含了csv模块,可以用于读取csv文件。
使用csv模块读取数据需要打开文件、读取文件内容等步骤。
4. 使用第三方库xlrd读取excel数据:如果需要读取excel 文件,可以使用第三方库xlrd。
使用xlrd需要先安装库,然后使用open_workbook函数打开excel文件,并使用sheet_by_index、sheet_by_name等函数读取数据。
以上是几种Python读取数据的方法,具体使用方法可以查看相应的文档。
掌握这些方法可以帮助你更好地进行数据分析和处理。
- 1 -。
Python中的数据分析实战案例

Python中的数据分析实战案例数据分析是一项重要的技能,而Python作为一种流行的编程语言,提供了丰富的工具和库来支持数据分析。
本文将介绍一些Python中的实际数据分析案例,帮助读者更好地理解和运用数据分析的方法和技巧。
一、销售数据分析假设我们是一家电商公司,我们有一份销售数据的表格,包含了产品名称、销售数量、销售额等信息。
我们可以利用Python的数据分析库,如Pandas和NumPy,对销售数据进行统计和分析。
首先,我们可以使用Pandas库加载销售数据表格,并进行数据清洗和预处理。
我们可以去除重复的数据、处理缺失值,并转换数据类型。
然后,我们可以使用Pandas提供的函数和方法对数据进行统计分析,如求和、平均值、最大值、最小值等。
接下来,我们可以使用Matplotlib库创建可视化图表,比如柱状图、折线图、饼图等,以便更直观地展示销售数据的情况。
我们可以通过图表来观察销售额随时间的变化趋势,以及不同产品的销售数量对比情况。
此外,我们还可以使用Python的机器学习库,如Scikit-learn,进行销售趋势预测和销售量预测。
我们可以利用历史销售数据训练模型,然后使用模型对未来的销售情况进行预测,帮助我们做出合理的经营决策。
二、用户行为分析在互联网时代,用户行为数据对于企业的经营和发展非常重要。
Python可以帮助我们分析和挖掘用户行为数据,帮助企业了解用户需求和行为习惯,以便更好地进行市场营销和用户体验优化。
假设我们是一家电商平台,我们有用户的点击记录、购买记录、评论记录等数据。
我们可以使用Python的数据分析库,如Pandas和NumPy,对用户行为数据进行处理和分析。
首先,我们可以使用Pandas库加载用户行为数据,并进行数据清洗和预处理。
我们可以去除异常值、处理缺失值,并转换数据类型。
然后,我们可以使用Pandas提供的函数和方法对数据进行统计分析,如计算用户的平均购买次数、平均评论数量等。
利用Python进行数据分析

O'Reilly精品图书系列利用Python进行数据分析Python for Data Analysis(美)麦金尼(McKinney,W.) 著唐学韬 译ISBN:978-7-111-43673-7本书纸版由机械工业出版社于2014年出版,电子版由华章分社(北京华章图文信息有限公司)全球范围内制作与发行。
版权所有,侵权必究客服热线:+ 86-10-68995265客服信箱:service@官方网址:新浪微博 @研发书局腾讯微博 @yanfabookO'Reilly Media,Inc.O'Reilly Media通过图书、杂志、在线服务、调查研究和会议等方式传播创新知识。
自1978年开始,O'Reilly一直都是前沿发展的见证者和推动者。
超级极客们正在开创着未来,而我们关注真正重要的技术趋势——通过放大那些“细微的信号”来刺激社会对新科技的应用。
作为技术社区中活跃的参与者,O'Reilly的发展充满了对创新的倡导、创造和发扬光大。
O'Reilly为软件开发人员带来革命性的“动物书”;创建第一个商业网站(GNN);组织了影响深远的开放源代码峰会,以至于开源软件运动以此命名;创立了Make杂志,从而成为DIY革命的主要先锋;公司一如既往地通过多种形式缔结信息与人的纽带。
O'Reilly的会议和峰会集聚了众多超级极客和高瞻远瞩的商业领袖,共同描绘出开创新产业的革命性思想。
作为技术人士获取信息的选择,O'Reilly现在还将先锋专家的知识传递给普通的计算机用户。
无论是通过书籍出版,在线服务或者面授课程,每一项O'Reilly的产品都反映了公司不可动摇的理念——信息是激发创新的力量。
“O'Reilly Radar博客有口皆碑。
” ——Wired“O'Reilly凭借一系列(真希望当初我也想到了)非凡想法建立了数百万美元的业务。
如何利用Python进行大数据处理和分析

如何利用Python进行大数据处理和分析在当今数字化的时代,数据量呈爆炸式增长,大数据已经成为了各个领域的重要资产。
而 Python 作为一种强大而灵活的编程语言,在大数据处理和分析领域发挥着至关重要的作用。
接下来,让我们一起深入探讨如何利用 Python 进行大数据处理和分析。
一、Python 在大数据处理中的优势Python 之所以在大数据处理中备受青睐,主要归因于以下几个方面:1、丰富的库和工具Python 拥有众多强大的库,如 Pandas、NumPy 和 SciPy 等,这些库为数据处理和分析提供了高效的函数和方法。
2、简洁易读的语法Python 的语法简洁明了,使得代码易于理解和维护,降低了开发成本和出错率。
3、跨平台性Python 可以在不同的操作系统上运行,包括 Windows、Linux 和macOS,这为开发者提供了极大的便利。
4、活跃的社区支持Python 拥有庞大而活跃的社区,开发者可以在社区中获取丰富的资源和帮助,解决遇到的问题。
二、大数据处理的基本概念在深入了解如何使用 Python 进行大数据处理之前,我们先来了解一些基本概念。
1、数据采集这是获取数据的过程,数据来源可能包括数据库、文件、网络爬虫等。
2、数据清洗对采集到的数据进行清理和预处理,去除噪声、缺失值和异常值等。
3、数据分析运用各种统计和机器学习方法,对数据进行探索和分析,以提取有价值的信息。
4、数据可视化将分析结果以直观的图表形式展示出来,帮助人们更好地理解数据。
三、Python 中的数据处理库1、 PandasPandas 是 Python 的核心数据分析支持库,提供了快速、灵活、明确的数据结构,旨在简单、直观地处理关系型、标记型数据。
它的主要数据结构是 Series(一维数据)和 DataFrame(二维数据)。
通过Pandas,我们可以轻松地读取、写入各种格式的数据文件,如 CSV、Excel 等,并进行数据选择、过滤、排序、聚合等操作。
学习Python实现数据处理与分析

学习Python实现数据处理与分析Python是一种开源的编程语言,具备简洁、高效的特点,并且在数据处理与分析领域有着广泛的应用。
本文将从数据清洗、数据分析和数据可视化三个方面,介绍如何使用Python进行数据处理与分析。
一、数据清洗数据清洗是数据处理的第一步,也是非常重要的一步。
下面介绍几个常用的数据清洗方法。
1. 去除重复值在处理大量数据时,常常会遇到重复的数据。
可以使用Python 的pandas库中的drop_duplicates()函数去除重复值。
例如,我们可以使用以下代码去除data中的重复值:data = data.drop_duplicates()2. 缺失值处理在数据中,经常会遇到缺失值的情况。
可以使用Python的pandas库中的fillna()函数对缺失值进行处理。
例如,我们可以使用以下代码将data中的所有缺失值替换为0:data = data.fillna(0)3. 数据类型转换数据在导入时,可能会出现数据类型不一致的情况,影响后续的数据分析。
可以使用Python的pandas库中的astype()函数将数据类型进行转换。
例如,我们可以使用以下代码将data中的数据转换为整数类型:data = data.astype(int)二、数据分析Python具备强大的数据分析能力,下面介绍几个常用的数据分析方法。
1. 描述性统计描述性统计是对数据进行初步分析的一种方法,可以使用Python的pandas库中的describe()函数来得到数据的基本统计量,如均值、中位数、标准差等。
例如,我们可以使用以下代码计算data的描述性统计量:data.describe()2. 相关性分析相关性分析用来研究两个变量之间的相关关系,可以使用Python的pandas库中的corr()函数来计算变量之间的相关系数。
例如,我们可以使用以下代码计算data中各个变量之间的相关系数:data.corr()3. 数据建模数据建模是数据分析的重要环节,可以使用Python的scikit-learn库进行数据建模。
Python大数据分析与挖掘方法

Python大数据分析与挖掘方法在当前信息时代,数据已经成为了一种重要的资源,各个行业大量产生的数据也让数据分析和挖掘变得越来越重要。
Python作为一种开放源代码的高级编程语言,具有易学易用、功能强大、生态丰富等优点,成为了数据分析和挖掘的热门语言之一。
本文介绍Python大数据分析与挖掘方法,包括数据获取、数据预处理、数据分析和数据可视化等方面。
一、数据获取数据获取是数据分析和挖掘的前提,Python有丰富的获取数据的方法,包括文件读取、网页爬虫、API接口等。
其中,网页爬虫是一种常见的数据获取方法。
Python中有多个强大的爬虫工具,如BeautifulSoup、Scrapy等,可以用于从网页中获取数据。
使用爬虫获取数据的核心在于定位并解析网页中的数据。
通过分析HTML结构和规律,可以使用BeautifulSoup等工具提取所需数据。
二、数据预处理数据预处理是数据分析和挖掘的一个重要步骤。
Python中有多个工具和库可以用于数据预处理,如NumPy、Pandas等。
Pandas是一个专门用于数据处理和分析的库,支持各种格式的数据读取和处理,包括CSV、Excel、SQL数据库等。
在进行数据处理之前,需要对数据进行清洗和预处理。
例如,去除缺失数据、去除重复数据、数据规范化等。
三、数据分析Python是一种功能强大的编程语言,可以用于数据分析和挖掘的多个方面。
数据分析是通过对数据进行各种统计分析和计算,来发现数据中的规律和趋势。
Python中常用的数据分析库和工具有NumPy、SciPy、Pandas、Matplotlib等。
其中,Matplotlib是一个专门用于数据可视化的库,可以用于绘制各种图表和可视化。
四、数据可视化数据可视化是数据分析和挖掘的重要环节,在可视化过程中可以将数据更加直观地呈现给用户。
Python中常用的数据可视化工具有Matplotlib、Seaborn、Plotly等。
python dataload用法

python dataload用法Python中的数据加载(dataload)是指从不同的数据源加载数据,并进行适当的处理和转换,以便进行后续分析和处理。
Python提供了各种用于数据加载的库和工具,其中最常用的是Pandas库和NumPy库。
使用Python的Pandas库进行数据加载非常简单。
首先,我们需要导入Pandas 库:import pandas as pd然后,我们可以使用Pandas的read_csv()函数从CSV文件中加载数据:data = pd.read_csv('data.csv')在上面的代码中,'data.csv'是我们要加载的CSV文件的文件名。
read_csv()函数将该文件加载为一个Pandas的DataFrame对象,并将其存储在data变量中。
DataFrame是Pandas库中最常用的数据结构,类似于Excel表格,可以方便地进行数据分析和处理。
除了CSV文件,Pandas还支持从其他常见数据源加载数据,如Excel文件、SQL数据库、JSON文件等。
例如,我们可以使用read_excel()函数从Excel文件中加载数据:data = pd.read_excel('data.xlsx')类似地,我们可以使用read_sql()函数从SQL数据库中加载数据:data = pd.read_sql('SELECT * FROM customers', 'sqlite:///data.db')在上面的代码中,'SELECT * FROM customers'是要执行的SQL查询语句,'sqlite:///data.db'是SQLite数据库的连接字符串。
除了Pandas库,NumPy库也提供了用于数据加载的函数。
我们可以使用numpy.load()函数从NumPy的二进制文件(.npy)中加载数据:import numpy as npdata = np.load('data.npy')在上面的代码中,'data.npy'是我们要加载的NumPy二进制文件的文件名。
python数据分析代码

python数据分析代码
Python数据分析代码一般由五大步骤组成:
1.载入数据
在进行数据分析之前,首先要将数据载入到python环境中。
我们
可以使用标准的Python I/O函数将数据文件从本地读取到python环
境中。
如果数据来源是数据库,可以使用相关的数据库接口把数据导
入到Python环境。
2. 数据清洗
数据清洗是指对原始数据进行处理,以便于后续分析的过程。
通
常会涉及到去重、填补缺失值、数据转换等工作。
Python有许多内置
的数据清洗功能,可以使得我们的数据处理过程变得更加简单高效。
3.字段分析
字段分析包括对数据集中各个字段的统计分析,例如统计每个字
段的最大值、最小值、均值、标准差等。
Python 也有内置的统计函数,可以帮助我们更快更方便的完成字段分析。
4. 数据可视化
数据可视化可以帮我们更好的理解数据。
Python有大量的可视化库,可以帮助我们把数据可视化成更加直观的图表。
5.数据建模
数据建模是指对数据集进行机器学习和深度学习操作,以便对数
据进行预测或分类。
Python有大量的机器学习库,可以帮助我们更快
更简单的完成数据建模。
总的来说,Python作为一种强大的脚本语言,可以为我们分析海
量的数据提供便利,把数据分析的各个环节自动化,并且能够进行实
时分析,使我们有效的利用数据,推动决策。
使用Python进行网络数据分析的基本步骤

使用Python进行网络数据分析的基本步骤随着互联网的飞速发展,海量的网络数据成为了我们获取信息和洞察用户行为的重要来源。
而Python作为一种强大的编程语言,在网络数据分析领域也有着广泛的应用。
本文将介绍使用Python进行网络数据分析的基本步骤。
第一步:数据收集网络数据分析的第一步是收集数据。
在互联网上,我们可以通过各种方式获取数据,例如爬取网页数据、API接口调用、抓取社交媒体数据等。
Python提供了丰富的库和工具,如BeautifulSoup、Scrapy、Requests等,可以帮助我们方便地进行数据收集。
第二步:数据清洗与预处理收集到的网络数据往往存在着各种噪声和不规范之处,需要进行数据清洗和预处理。
Python中的pandas库提供了强大的数据处理工具,可以帮助我们对数据进行清洗、去重、缺失值处理等操作。
此外,还可以使用正则表达式等方法对数据进行规范化和格式化。
第三步:数据分析与可视化清洗和预处理后的数据可以用于进一步的数据分析和可视化。
Python中的numpy和scipy库提供了丰富的数学和统计函数,可以进行数据的统计分析和建模。
而matplotlib和seaborn等库可以帮助我们生成各种图表和可视化效果,直观地展示数据的特征和趋势。
第四步:模型建立与预测在数据分析的过程中,我们常常需要建立模型来预测未来的趋势或者进行分类等任务。
Python中的scikit-learn库提供了各种机器学习算法的实现,可以帮助我们进行模型的建立和训练。
同时,还可以使用tensorflow和pytorch等深度学习库进行更加复杂的模型建立和训练。
第五步:结果评估与优化建立模型后,我们需要对模型进行评估和优化。
Python中的sklearn.metrics模块提供了各种评估指标,可以帮助我们评估模型的性能。
此外,还可以使用交叉验证和网格搜索等方法来优化模型的参数和超参数。
第六步:结果展示与报告最后,我们需要将分析结果进行展示和报告。
python load data infile的方法

python load data infile的方法摘要:1.Python读取文件简介2.load()函数解析3.infile参数详解4.实践案例与代码展示5.总结与建议正文:随着大数据时代的到来,数据处理和分析成为了各行各业的必备技能。
Python作为一门简洁易学的编程语言,其强大的数据处理能力备受推崇。
在本篇文章中,我们将介绍Python中load data using infile的方法,帮助大家更好地应对实际工作中的数据处理任务。
1.Python读取文件简介在Python中,读取文件主要有两种方式:使用内置的open()函数和使用专门的文件读取库。
本篇文章将主要介绍使用内置的open()函数读取文件的方法。
2.load()函数解析在Python中,load()函数是用于从文件中读取数据的一种方法。
该函数属于pandas库中的DataFrame对象,可以在创建DataFrame时直接使用。
load()函数的主要参数为文件路径和文件格式。
3.infile参数详解infile参数是load()函数的一个关键参数,用于指定要读取的文件路径。
其可以是相对路径、绝对路径,也可以是网络路径。
此外,infile参数还可以指定文件格式,如".csv"、".xls"、".txt"等。
以下是使用infile参数读取文件的示例代码:```pythonimport pandas as pd# 指定文件路径和格式file_path = " relative/path/to/your/file.csv"file_format = ".csv"# 读取文件df = pd.read_csv(file_path, engine="python")```4.实践案例与代码展示接下来,我们将通过一个简单的案例来演示如何使用load()函数和infile 参数读取文件。
python数据处理与分析报告(附代码数据)

python数据处理与分析报告(附代码数据)Python数据处理与分析报告1. 引言数据处理与分析在当今社会中扮演着越来越重要的角色。
Python作为一种功能强大、易于学习的编程语言,已经成为数据处理与分析的首选工具。
本报告将介绍如何使用Python进行数据处理与分析,并提供相应的代码和数据。
2. 环境配置在进行Python数据处理与分析之前,需要首先安装Python环境以及相关的库。
本报告将使用Python 3.x版本,并安装以下库:- NumPy:用于数值计算和矩阵操作- pandas:用于数据处理和分析- Matplotlib:用于数据可视化- Seaborn:用于统计图形和数据可视化可以使用pip命令安装以上库:pip install numpy pandas matplotlib seaborn3. 数据处理数据处理是数据分析和挖掘的重要步骤,主要包括数据清洗、数据转换、数据整合等。
在本节中,我们将使用pandas库进行数据处理。
3.1 数据清洗数据清洗是数据处理的第一步,主要包括处理缺失值、异常值和重复值。
以下是一个简单的示例:import pandas as pd创建一个包含缺失值、异常值和重复值的数据框data = pd.DataFrame({'A': [1, 2, 3, 4, 5, 6, 7, 8, 9, 10],'B': [10, 20, np.nan, 40, 50, 60, 70, 80, 90, 100],'C': [100, 200, 300, 400, 500, 600, 700, 800, 900, 1000]})删除缺失值data_cleaned = data.dropna()删除异常值data_cleaned = data[(data['A'] >= 1) & (data['A'] <= 10)]删除重复值data_cleaned = data.drop_duplicates()3.2 数据转换数据转换是指将数据转换成适合分析和挖掘的形式。
Python数据分析数据检查

数据加载和检查本章主要内容数据获取数据加载属性检查内容查看数据获取•数据产生主体:如各类管理机构、公司、研究所等。
•数据中心社区:如Kaggle、和鲸社区、CSDN等•个人收集:如私人博客、私人网站、私人收藏等•无论哪一种方式,都需要注意合法合规以及数据隐私问题教学数据集介绍•记录了1995-2020年世界上主要城市的日均气温读数。
•数据包括8列:Region、Country、State、City、Month、Day、Year、AvgTemperature•记录条数:2906327数据加载•常见的数据集格式:文本文件、Excel文件、CSV文件•CSV文件通常采取分号(;)作为字段分隔符,简单易用•有些CSV文件会采用其他分隔符,如空格、逗号、制表符等•Pandas提供read_csv()方法加载CSV文件数据加载•read_csv()在加载数据集时,可能会报错或者给出警告信息•下面代码的警告信息是因为第4列(State)数据包括空值•解决方法:data = pd.read_csv('d:/dataset/city_temperature.csv', dtype={'State':object})数据加载•常见加载异常及解决方法异常解决方法(修改对应的read_csv()参数)分隔符非默认的分号通过sep或delimiter参数指定分隔符,如sep=';’读入内容显示乱码通过encoding参数指定文件编码,中文常用编码包括utf-8、gbk(Windows系统常见)、gb2312等无标题行设定参数header=None 数据解析出错设定参数engine='Python'属性检查•查看数据集大小:data.shape•查看列名:data.columns•查看索引:data.index•查看各列数据类型:data.dtypes•查看头(尾)数据内容:data.head()、data.tail()Pandas核心数据结构介绍Series和DataFramePandas核心数据结构•DataFrame = Series1 + Series2 + Series3 + …•Series:带索引的一维数组•DataFrame:带索引的二维数组Pandas核心数据结构索引与下标•索引:行、列的别名•行索引:每一行的别名,如右图中的’A’、‘B’、‘C’、‘D’•列索引:每一列的别名,如右图中的’C1’、’C2’•索引可以随意指定,允许重复的索引•下标:行、列的位置•通俗的说:第几行,第几列•下标为从0开始的连续自然数,如右图中0、1、2、3•不存在重复的下标查看数据内容查询•基于索引的方式•基于单值或者一维列表:选择列•查询某一列:data[‘City’]•查询多列:data[ [‘Country’,’City’] ]•基于切片索引的方式:选择行(基于下标)•下标从5到14:data[5:15]•基于.loc和.iloc的方式•以索引为基础的行、列查询:data.loc[ 行索引,列索引]•以下标为基础的行、列查询:data.iloc[ 行位置,列位置]•以布尔型数组为基础的查询:data•以条件为基础的查询:data.query(“查询条件”)内容查询使用方法参数作用索引方式: DataFrame[参数]单个字符串显示对应的列字符串列表显示列表里面的所有列整数切片显示满足切片的行布尔型数组显示数组元素为True对应的行表达式查询方式:DataFrame.query(参数)查询条件显示满足查询条件的所有行.iloc方式:DataFrame.iloc[行参数, 列参数]单个整数显示对应的行(或列)整数切片显示满足切片要求的行(或列)整数列表显示列表里面出现的行(或列)布尔型列表显示True值对应的行或列callable方法依据方法返回值选择行或列.loc方式:DataFrame loc[行参数,列参数]单值、字符切片、字符列表参考.iloc对于不同类型参数的处理。
学习如何使用Python进行数据分析

学习如何使用Python进行数据分析第一章:Python数据分析介绍Python作为一种高级编程语言,广泛应用于数据分析领域。
数据分析是通过对大量数据进行处理、统计、分析和可视化,以发现数据背后的规律和趋势,提供决策支持和洞察业务问题的方法和过程。
Python作为一种灵活、易用和功能强大的编程语言,被数据分析师广泛采用。
在使用Python进行数据分析之前,首先需要了解Python的基本概念和语法。
Python具有简洁明了的语法结构,适合初学者快速上手,并且有丰富的第三方库和工具,提供了许多用于数据分析的函数和方法。
第二章:Python数据处理库介绍在进行数据分析时,数据处理是非常重要的一步。
Python提供了多个数据处理库,用于快速处理和清洗数据。
其中最常用的包括NumPy、Pandas和SciPy。
NumPy是Python科学计算的基础包,提供了高性能的多维数组对象,以及处理这些数组的函数和工具。
Pandas则是建立在NumPy之上的库,提供了数据结构和数据分析工具,具有灵活高效的数据处理能力。
SciPy是用于科学计算和数据分析的Python 库,包含了许多数学、科学和工程计算中常用的函数和工具。
第三章:Python数据可视化库介绍数据可视化是数据分析中重要的环节,通过图表、图像和动画等形式,将复杂的数据转化为直观且易于理解的可视化形式,帮助人们更好地理解和分析数据。
在Python中,有多个数据可视化库可供选择。
其中最常用的包括Matplotlib、Seaborn和Plotly。
Matplotlib是Python中最著名的绘图库之一,它提供了丰富的绘图功能,包括散点图、线图、柱状图和饼图等。
Seaborn是基于Matplotlib的高级数据可视化库,专注于统计图表和信息可视化。
Plotly则是一个交互式可视化库,可以生成交互式图表和仪表盘,支持在线共享和协作编辑。
第四章:Python数据分析案例为了更好地理解和应用Python进行数据分析,下面以某电商平台销售数据为例,进行数据分析过程的展示。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
不添加后缀的话默认是一个 file文件
sys.stdout就相当于print,使用之前要import
data.to_csv(sys.stdout, sep='|') # 打印到屏幕 data.to_csv(sys.stdout, na_rep='NULL') # 空字符处显示为NULL data.to_csv(sys.stdout, index=False, header=False) # 禁用行和列的标签 data.to_csv(sys.stdout, cols=['a', 'b', 'c']) # 按照指定的顺序显示列
使用数据库,将excel的数据导入DB中
python支持多种关系型数据库:SQL Server, MySQL,DB2等, 我是直接使用Python自带的SQLite数据库
创建了一个test1表,用来存储数据
使用数据库,将excel的数据导入DB中
python支持多种关系型数据库:SQL Server, MySQL,DB2等, 我是直接使用Python自带的SQLite数据库
4,二进制数据格式(pickle函数,短期存储格式)
5,使用HTML和WEB API(requests包)
6,使用数据库
读取文本格式数据
read_csv
read_table read_fwf read_clipboard
从文件,url,文件型对象中加载带分隔符的数据,默认分隔符为逗号。
从文件,url,文件型对象中加载带分隔符的数据,默认分隔符为制表符('\t')。 读取定宽格Байду номын сангаас的数据,无分隔符 读取剪贴板中数据
调用函数分别打印th和一行td
XML和HTML:WEB信息收集
Python有许多可以读写HTML和XML格式数据的库,lxml就是其中之一。
直接用Dataframe把行和表头拼起来也行 这里TextParser类可以自动转换数据类型 最后用to_excel比to_csv好用,to_csv保存的时候中文不好用
数据加载,存储与文件格式
目录
1,读写文本格式数据: (read_csv,read_table,read_fwf,read_clipboard,open() to_csv,to_excel,write()) 2, JSON数据: (两个方法:json.loads() json.dumps()) 3,XML和HTML:WEB信息收集(两个接口lxml.html, lxml.objectify)
找到这个连接下面的所有table元素
table=tables[0] print(‘---------calls-----------’) print (calls)
rows =table.findall(‘.//tr’) print('---------rows-----------') print (rows)
读取文本格式数据
pandas读取文件会自动推断数据类型,不用指定。
以read_csv为例,下面是常用的几个参数:
用 names重新规定列名,用index_col指定索引,也可以将多个列组合作为层次化索引。 可以编写正则表达式规定分隔符。 用skiprows跳过某些行。
缺失数据要么没有,要么用某个标记值表示,pandas常用NA、-1.#IND、NULL等进行标记。
找到想要的table
找到table下面所有的行
XML和HTML:WEB信息收集
Python有许多可以读写HTML和XML格式数据的库,lxml就是其中之一。
def _unpack(row,kind='td'): elts=row.findall('.//%s' % kind) return [val.text_content().strip() for val in elts]
text_content()取到每一个td下面的内容 strip() 删除前后的空格
print(‘---------th-----------’) print(_unpack(rows[0],kind='th')) print() print('---------td1-----------') print(_unpack(rows[1],kind='td'))
使用了for循环每次读取一条数据然后插入 到test1表中
Thank you
XML和HTML:WEB信息收集
Python有许多可以读写HTML和XML格式数据的库,lxml就是其中之一。
from lxml.html import parse from urllib.request import urlopen urllib2在python中是urllib.request from pandas.io.parsers import TextParser import pandas as pd parsed=parse(urlopen(‘/rank/capitalforsale.html’)) doc=parsed.getroot() 可以得到url里面所有的element print('---------doc-----------') print (doc) links=doc.findall(‘.//a’) lnk=links[3] print('---------lnk-----------') print(links[3]) tables=doc.findall(‘.//table’) print('---------table-----------') print (tables) 获取所有为 的超链接 找到其中的一个连接下面的内容 打开url
json.dumps()
JSON格式
Html基本信息
• • • •
HTML 使用标记标签来描述网页 HTML 文档描述网页 保存为后缀名带.html打开就是一个网页 a href 超链接
XML和HTML:WEB信息收集
Python有许多可以读写HTML和XML格式数据的库,lxml就是其中之一。
使用数据库,将excel的数据导入DB中
python支持多种关系型数据库:SQL Server, MySQL,DB2等, 我是直接使用Python自带的SQLite数据库
1.导入Python SQLITE数据库模块
import sqlites
2. 创建/打开数据库 在调用connect函数的时候,会指定库名称,如果指定的数据库存在就直接打开这个数据库,如果不存在就 新创建一个再打开。 con=splites.connect(‘:memory:’) 3.使用游标查询数据库 我们需要使用游标对象SQL语句查询数据库,获得查询对象。 通过以下方法来定义一个游标 cursor=con.cursor() cursor.execute() #执行sql语句 cursor.executemany #执行多条sql语句 cursor.close() #关闭游标 cursor.fetchone() #从结果中取一条记录,并将游标指向下一条记录 cursor.fetchmany() #从结果中取多条记录 cursor.fetchall() #从结果中取出所有记录 cursor.scroll() #游标滚动
JSON数据
JSON数据已经成为通过http请求在wed浏览器和其他应用程序之间发送数据的标准格式之一, 它是一种比表格型文本格式更灵活的数据格式。JSON非常接近于有效的python代码,基本类 型都有对象,数组,字符串,数值,布尔型以及null。
JSON格式
json.loads()
Python形式
用na_values用来不同的NA标记值。 Nrows 只读取几行 Chunksize:逐块读取文件
跳过第3行 定义一个字典为各个列指 定NA标记值,直接=null 的就是把df中所有为空值 的都标为null
将数据写出到文本格式
1、利用data_frame的to_csv方法,可以将数据写到一个以逗号分隔的文件中,也可用sep参数指 定分隔符,如 data.to_csv() 2、缺失值写入输出时会被表示为空字符串,可使用na_rep表示为别的标记值。