阿尔法围棋
阿尔法围棋的工作原理

阿尔法围棋的工作原理
阿尔法围棋是一种利用深度神经网络和强化学习算法相结合的人工智能系统。
它的工作原理可以概括为以下三个步骤:
1. 建立神经网络:阿尔法围棋系统通过学习人类棋手的下棋数据来建立神经网络。
这个网络可以处理棋盘上各个位置的信息,并在每一步棋后输出自己的最优决策。
这个过程需要大量计算资源和训练数据来支持。
2. 优化网络参数:在建立好的神经网络中,有很多参数需要优化。
这些参数可以影响系统的棋力和对弈策略。
阿尔法围棋采用强化学习算法,通过与自己下棋来不断训练和优化神经网络的参数,以提高自己的棋力和弈和策略。
3. 对弈:阿尔法围棋在经过训练后,可以与其他围棋棋手进行对弈。
它的决策是基于神经网络和训练后的强化学习算法。
在对弈中,它会不断地学习和优化自己的策略,以提高自己的棋力。
阿尔法围棋的主要工作原理

阿尔法围棋的主要工作原理
嘿,朋友们!今天咱就来讲讲阿尔法围棋那超厉害的主要工作原理。
阿尔法围棋啊,就像是一个超级聪明的棋坛大师!它可不是随随便便就下子的哦。
它是靠对大量棋局的学习和分析来工作的。
比如,它就像一个勤奋的学生,不断地学习各种棋谱,把那些高明的招法都记在心里头。
它在与人对弈的时候,首先会观察棋盘,就好像一个侦探在寻找线索一样。
然后,它会根据自己学到的知识和算法,快速地计算出各种可能的走法和后续变化。
这多牛啊!就好比它能一下子看到未来几步棋会是什么样子呢!
“哎呀,那它不就无敌啦?”你可能会这么问。
别急呀,虽然它厉害,但人类棋手也有自己的优势呀!阿尔法围棋虽然计算能力超强,但它可没有人类棋手的那种灵感和创造力。
有时候,人类棋手会突然灵光一闪,走出一步神来之笔,这是它学不来的呢!
在一场比赛中,阿尔法围棋和一位顶尖棋手对决。
棋手每下一步,阿尔法围棋都能快速做出反应,就像是随时准备出击的战士。
它不断地调整策略,寻找最佳的应对方法。
而棋手呢,也不甘示弱,凭借着自己的经验和直觉与它对抗。
“这不就是一场精彩的博弈吗!”
我觉得啊,阿尔法围棋的出现真的是让人又爱又恨。
爱的是它推动了围棋的发展,让我们看到了更多的可能;恨的是它也给人类棋手带来了巨大的压力。
但不管怎么说,它都是科技的杰作,值得我们去深入研究和思考。
所以呀,我们可不能小瞧了它的厉害,要好好去探讨它背后蕴含的智慧呢!。
深度坑|当谷歌“阿尔法狗”打败了欧洲围棋冠军

深度坑|当谷歌“阿尔法狗”打败了欧洲围棋冠军从世界首席国际象棋大师卡斯帕罗夫输给IBM公司的计算机“深蓝”至今已近二十年,最近,谷歌的AlphaGo击败了欧洲围棋冠军樊麾。
从国际象棋到围棋的突破,其背后的算法是有着怎样的飞跃?以及,这位“阿尔法狗”是否可能走上碾压人类智力的无敌之路?文 | LostAbaddon 编辑 | Agnes围棋,是一项中国先人所发明的古老对弈游戏。
相较于中国象棋或者国际象棋,围棋的最大特点在于它的每一个棋子都是相同的,没有不同的走法与规则,以及,更重要的一点,围棋中每个棋子的作用不是由其自身的“特殊功能”决定的,而是与它在整个棋局中与别的棋子之间的关系来决定的。
这种特殊的规则,既简单又复杂。
说简单,在于每个子都遵守相同的规则,规则本身并不冗长难懂;而说复杂,则在于在如此一目了然的规则之下,却能演化出几近无穷的可能性[1]。
因此,对人工智能持怀疑态度的人曾放言,人工智能永远不可能战胜人类;而对人工智能持乐观态度的人也觉得,大约十年后才能看到人工智能在围棋这一人类传统智力竞赛活动中战胜人类——当然这里说的是人类中的职业棋手,我这样的学龄前战五渣要战胜当然是分分钟的。
但就在上个星期,这一无论是永远还是十年的预期,被谷歌的AlphaGo打破了。
虽然它所战胜的是国际围棋排名在633位的欧洲围棋冠军,且这位欧洲冠军据闻现场发挥有点失常,但无论如何,战胜了一位人类的职业棋手,这样的事终于还是在人类最乐观的预期前好多年,发生在了现实生活中。
这无疑为人工智能界打了一剂强心针,使得这一正从低谷中一步步走出的领域名正言顺地踏进了快车道。
左为此次被AlphaGo打败的棋手樊麾,右为3月将迎战AlphaGo 的世界冠军李世石在AlphaGo战胜人类职业棋手之前,人工智能早就在人类的棋类游戏世界中战胜过人类中的职业棋手了。
对,这里所说的就是1997年5月的那场世界焦点之战:世界首席国际象棋大师卡斯帕罗夫对阵IBM公司的计算机“深蓝”,最后深蓝以2:1战胜了人类的世界冠军。
阿尔法围棋机器人

阿尔法围棋机器人引言随着人工智能技术的不断发展,阿尔法围棋机器人作为一项重要的创新成果,已经引起了广泛的关注和讨论。
阿尔法围棋机器人是基于深度学习算法的人工智能系统,通过学习和模拟人类的下棋思路和技巧,能够在围棋比赛中达到甚至超越人类棋手的水平。
深度学习算法在围棋中的应用深度学习算法在围棋中的应用是阿尔法围棋机器人能够实现非凡棋力的关键。
深度学习是一种基于人工神经网络的机器学习方法,其通过大量的数据训练模型,使其能够自动学习和提取特征,从而实现对复杂问题的解决。
在围棋中,阿尔法围棋机器人通过深度学习算法学习大量的围棋棋局数据,并构建神经网络模型。
这个模型能够通过输入一个围棋棋局的状态,输出每一步棋的最优选择。
而这个模型的训练是通过对大量棋局数据进行深度学习算法的训练,不断调整模型参数来优化网络的预测准确度。
阿尔法围棋机器人的核心技术强化学习强化学习是阿尔法围棋机器人实现优秀水平的核心技术之一。
在围棋中,每一步棋对于最终局势的影响是复杂且长期的,而强化学习则是通过不断试错和反馈来优化模型的决策能力。
阿尔法围棋机器人利用强化学习的方法不断与自己下棋,通过观察自己的胜负情况来调整模型的参数,从而改进自身的棋力。
蒙特卡洛树搜索蒙特卡洛树搜索是阿尔法围棋机器人实现快速搜索最优解的关键技术之一。
它通过模拟大量的围棋棋局来评估每一步棋的胜率,并根据胜率来选择最优的走棋策略。
蒙特卡洛树搜索能够在很短的时间内找到最优解,并将其用于实际的棋局中。
阿尔法围棋机器人的优势和应用前景优势阿尔法围棋机器人相较于人类棋手具有以下优势:•学习能力强:通过深度学习算法,阿尔法围棋机器人能够自动学习和提取围棋中的关键特征,从而实现对复杂棋局的准确判断和决策。
•无疲劳和情绪:与人类棋手不同,阿尔法围棋机器人不会受到疲劳和情绪的影响,能够持续保持高水平的棋力。
•高速搜索:阿尔法围棋机器人拥有高效的蒙特卡洛树搜索算法,能够在短时间内搜索到最优解。
阿尔法围棋程序的工作原理

阿尔法围棋程序的工作原理一、引言阿尔法围棋是一个基于人工智能技术的围棋程序,它可以与人类顶尖的围棋选手进行对弈,并且在某些情况下能够获胜。
本文将详细介绍阿尔法围棋程序的工作原理。
二、阿尔法围棋程序的架构阿尔法围棋程序由多个模块组成,主要包括搜索模块、策略模块和价值网络模块。
其中搜索模块负责搜索可能的走法,策略模块负责根据当前局面选择最佳走法,价值网络模块则用于评估当前局面的好坏程度。
三、搜索模块搜索模块是阿尔法围棋程序最核心的部分之一,它通过搜索所有可能的走法来找到最佳的下一步着法。
具体来说,搜索模块使用了蒙特卡罗树搜索算法,并结合了深度学习技术进行优化。
这个算法会从当前局面出发,不断尝试所有可能的着子,并对每个着子进行评估。
评估结果包括两部分:第一部分是价值网络给出的当前局面估值;第二部分是策略网络给出的当前着子的概率。
这两部分评估结果会被组合成一个综合评估值,用于判断当前着子是否是最优着法。
搜索模块会不断地进行这个过程,直到找到最优的下一步着法。
四、策略模块策略模块是阿尔法围棋程序中另一个重要的模块。
它主要负责根据当前局面选择最佳的下一步着法。
具体来说,策略模块使用了深度神经网络模型,通过学习大量围棋对弈数据来预测下一步最佳着法。
这个神经网络模型被称为策略网络,它将当前局面作为输入,并输出一个概率分布,表示每个可能的着子的概率大小。
在执行搜索时,搜索模块会利用策略网络给出的概率分布来指导搜索方向,并选择最有可能获胜的走法。
五、价值网络模块价值网络是阿尔法围棋程序中另一个重要的组成部分。
它主要负责评估当前局面的好坏程度,并为搜索和策略模块提供参考依据。
具体来说,价值网络也是一个深度神经网络模型,在训练时会学习围棋对弈数据中的胜负情况,并根据当前局面的特征预测当前局面的胜率。
在执行搜索时,搜索模块会利用价值网络给出的胜率来评估当前局面的好坏程度,并根据评估结果选择最优着法。
六、总结阿尔法围棋程序是一个基于人工智能技术的围棋程序,它通过搜索模块、策略模块和价值网络模块等多个组成部分实现了与人类顶尖围棋选手对弈并且获胜的能力。
高中材料作文:00字的文章。阿尔法围棋(AlphaGo)是一款围棋人工智能程序,由谷歌旗下De

高中材料作文 2019.111,阅读下面的材料,根据要求写一篇不少于800字的文章。
阿尔法围棋(AlphaGo)是一款围棋人工智能程序,由谷歌旗下DeepMind 公司开发。
其主要工作原理是“深度学习”。
2016年3月,该程序与围棋世界冠军、职业九段选手李世石进行人机大战,并以4:1总比分获胜。
016年末2017年初,该程序与中、日、韩数十位围棋手对决,连续60局无一败绩。
赛后,棋手们纷纷表示,“在人工智能面前,我们感到前所未有的自卑和无能”。
在人工智能面前,人类毫无机会吗?人工智能到底是脱缰的野马,还是人类手里高飞的风筝?无知者无畏,有未知才有探索;一知半解也有一知半解的快乐。
然而,面对人工智能,人类真的做好了准备吗?要求:自定立意,自拟标题,文体白定(诗歌除外);不少于800字;不要套作,不得抄袭。
1, 【答案】勇迎挑战,发现机遇机器人潮流势不可挡,它们既给我们带来惊喜,也给我们带来挑战,而我们能做的只有勇敢相迎,发现机遇。
机器人“入侵”职场,是时代发展的必然结果。
枯燥乏味的程序性工作在科技发展导一定条件下势必会被机器所替代,无需人更多耗费时间与精力,可以促进资源的更好配置。
从古以来,就纺织业而言,由手织单衣到织机的出现,再到蒸汽、电力的投入使用,再到现在的大数据线下直接生产,无不体现着机器的进步,其带来的结果是“织女”职业的消失。
而站在当今时代看,这带来的利是显而易见的:产品质量更好,女性也在社会中发挥着更大的作用。
由此类比今日机器人的“入侵”,体现出职场的“优胜劣汰”,其短时间内会带给我们“技术性失业”难题,可就长远看来,其会倒逼劳动者提升自我技能,将人类向更高的发展层面推进,这样的发展机遇是可遇而不可求的。
机器人对人类的挑战的确不小,可也无需畏惧。
在“人机大战”中,人工智能阿尔法完胜围棋冠军李世石,体现出的是人类智慧的强大,而非人工智能的胜利。
人工智能是人造产物,只是按照人类所制定的程序执行而产生的结果,其构成程序终不及人脑,其能力终敌不过人类。
探秘阿尔法围棋机器人

探秘阿尔法围棋机器人作者:来源:《科学导报》2016年第17期3月10日,“阿尔法围棋”再次战胜李世石。
无论执黑执白,李世石均无还手之力。
有人欣喜,有人哀叹,有人惊掉下巴。
机器杀伐决断,只凭三种武器:神经网络、蒙特卡洛算法和评估局面。
首先,“阿尔法围棋”是一团神经网络,不是一本大全棋谱。
它下棋不是翻谱,而是跟人一样靠计算和直觉,但它“少年老成”,直觉更准。
职业棋手有种“棋感”,那是下了上万盘棋后,大脑见多识广,感觉到某一手的优劣,尽管说不出道理。
画画、骑车、拿榔头敲钉子,都是凭感觉,“唯技熟耳”。
有个极端的例子,中国有种专业,可以辨认刚孵蛋出来的小鸡雄雌,他们说不出怎么辨认,凭感觉去选,基本没错。
临帖一万次,有了书法感觉;打谱一万遍就有了棋感。
为什么?大脑=神经细胞+神经突触,突触是大脑的电线,经常“过电”的突触会更强壮。
小孩子的大脑正是如此学习:伴随成功的快乐,刚用过的神经突触就会加强,习惯就养成了。
早在冯·诺依曼时代,科学家就想到用电脑模拟大脑:计算单元+通路,通路的强度可调节。
虚拟大脑一次次接受任务,每次调用不同的神经通路去做,如果任务成功,刚用过的通路强度会被提高,反之强度降低。
“阿尔法围棋”复制了小孩子的学习过程,成功调高相关通路强度,失败了就调低,使神经网络在自我对弈百万盘(用不同风格)后调整到最优。
“阿尔法围棋”的“肉身”是神经网络;在此基础上,它有两套心法:蒙特卡洛算法和评估局面。
蒙特卡洛算法很好理解,很多棋类软件都这么干。
你吩咐狗熊去玉米田里掰一个最大的棒子,但玉米田太大,累死了也走不完。
狗熊想了个主意:根据经验选十来个常出大棒子的地方,仔细找一遍。
最后掰的大棒子,就算不是整块田里最大的,也差不离。
这就是蒙特卡洛式的狗熊。
围棋盘有19乘19个位置,以前大家认为天文数字的可能性,电脑算不过来的。
但蒙特卡洛算法只选取一小部分有希望的点来考虑。
“阿尔法围棋”跟之前的“ZEN”等围棋软件都是如此,倒不出奇。
阿尔法围棋创始人德米什·哈萨比斯励志故事

阿尔法围棋创始人德米什哈萨比斯励志故事哈萨比斯说,此次阿尔法围棋的对弈选择了中国的规则。
因为对电脑来说,中国的规则更为简便易行。
而且他知道,中国也有许多高水平棋手,他们也希望阿尔法围棋能与高水平的棋手对弈,比如柯洁。
但是,此次人机大战是历史上第一次电脑挑战职业九段棋手,哈萨比斯表示,他们希望选择在顶尖水平已有十年甚至更久的李世石。
也许更年轻的选手,也能有这个水平,但现在还不确定,因为他们还需要有十年顶尖水平去证明自己。
我们也知道,还有很多实力很强的选手,所以这次比赛之后,也许我们也会去中国、日本,与那里的高手切磋棋艺,哈萨比斯说。
作为一位人工智能专家,哈萨比斯对围棋的浓厚兴趣促使他对阿尔法围棋进行研发。
他告诉记者,早在20年前上大学时,他曾在剑桥的一个高水平围棋社团里学习围棋,并很快沉迷其中。
但是因为忙于电脑方面的工作,他没有足够时间去练习,围棋技艺仅停留在业余一段水平。
不过,这并不妨碍他喜欢围棋。
励志人物上大学时,哈萨比斯教会了他的合伙人下围棋。
那时正值超级电脑深蓝战胜世界冠军卡斯帕罗夫。
从那时起,哈萨比斯就在想有一天能为围棋写一个程序,并赢得冠军。
两年前,哈萨比斯终于等到合适的时机。
他创建的深度思维公司开发了深度学习的程序。
他们想让这项技术得到更广泛的应用,于是,哈萨比斯选择了围棋。
他希望通过利用深度学习程序打造阿尔法围棋能战胜人类围棋大师。
哈萨比斯坦言,他没有与阿尔法围棋对弈过,因为它实在太强大了。
阿尔法围棋的学习能力很强,自己完全不是它的对手。
在哈萨比斯看来,他并不认为人工智能会让人类生活变得危险。
相反,他觉得人工智能很神奇。
他谈到了欧洲围棋冠军樊麾。
阿尔法围棋此前以5:0战胜了樊麾。
目前,樊麾在为阿尔法围棋这个项目提供咨询。
樊麾告诉他,在与阿尔法围棋对弈过程中,自己的排名在三四个月的时间里,从世界600名提升到了第300名。
哈萨比斯因此感到,这也许是今后阿尔法围棋能投入市场应用的一个目标,许多人可以通过这个程序提高自己的围棋水平。
阿尔法围棋观后感

来自未来的棋局2016年初,AlphaGO毫无征兆地横空出世,先是战胜了樊麾,然后又战胜了本世纪最伟大的围棋大师——李世石,随后又以master的身份在网上连胜60盘,一时间引起了全世界人民的广泛关注,最后在2017年以3:0战胜当时人类最强棋手——柯洁后便销声匿迹。
现在虽然有关AlphaGO的热度逐渐减退,但它与李世石就像是来自未来一般的那五盘棋仍然令我们着迷,吸引着无数对人工智能感兴趣的人们。
围棋,被称作是人类智慧的结晶,因为其复杂程度远远超过了宇宙中存在的粒子总数,而被视为人工智能难以逾越的障碍。
自从深蓝战胜了卡特帕罗夫后,人们一直在想办法攻克围棋这一阵地,然而普遍的观点是至少要二三十年人工智能才能做到与顶尖职业选手平起平坐。
但AlphaGO打破了人们的这一幻想,人们突然发现,人工智能离我们是那么的近。
作为一个围棋爱好者,我很有幸地目睹了AlphaGO打败李世石的历史性时刻,也见证了这一事件的全过程。
重新回顾当时这五场比赛,去看赛前,赛中,与赛后的一些言论与变化,会发现这是一个极其戏剧化的反高潮剧本。
就像之前所说,包括李世石在内的许多职业选手都认为,电脑下围棋的水平还没有达到可以战胜人类的程度,至少现在还不到时候。
我清楚记得当时在网上看直播的时候请了四位嘉宾,包括柯洁两位职业选手和一位业余爱好者,还有一位就是研究围棋AI的博士。
赛前站边,那三位自然选李世石,这位博士独站AlphaGo,看上去有些势单力薄,这也是当时普遍的大趋势,除了少数专业领域的工作者之外,全世界关注围棋的人们实现了大团结,期待人的智慧可以战胜电脑,好似全人类群情激昂,认为自己必将战胜外星侵略者。
在记录片中,我看到了许多李世石当时的面部表情与特写,确实感受到他的一些焦虑,如片中所说,李世石下意识看向对手,想了解的对手的心态,然而他什么也看不到,他眼前的这个人无法给出任何有效信息,他真正的对手不过是电脑里的一堆代码。
如果说第一局李世石的失败,围棋界大部分的感觉是震惊,但仍然认为人类还有赢得希望,那么在连输三局之后,整个围棋界,包括所有关注这场人机大战的人都陷入的一丝绝望与恐慌感,当时整个比赛大厅都陷入了一片沉寂。
关于围棋人工智能阿尔法的观后感作文

关于围棋人工智能阿尔法的观后感作文围棋,这项古老而充满智慧的游戏,在人类文明的长河中闪耀了数千年。
然而,当人工智能阿尔法(AlphaGo)横空出世,它以一种前所未有的方式挑战并改变了我们对围棋的认知。
第一次听闻阿尔法战胜人类顶尖围棋选手时,我的内心充满了震撼与疑惑。
围棋,那可是人类智慧的结晶,是无数棋手穷其一生钻研的艺术,怎么会被一个机器轻易超越?带着这样的疑问,我开始深入了解阿尔法以及它所代表的人工智能技术。
观看阿尔法与人类棋手的对弈过程,就像是在目睹一场跨越时空的智慧较量。
每一步棋,阿尔法都展现出了超乎寻常的计算能力和战略眼光。
它不会被情绪左右,不会因为压力而犯错,始终以一种冷静、精准的方式进行着思考和决策。
这让我不禁思考,人工智能的优势究竟在哪里?是强大的计算能力?还是能够快速处理海量数据的能力?或许两者兼而有之。
但更重要的是,它能够从无数次的自我对弈和学习中总结经验,不断优化自己的策略。
相比之下,人类棋手虽然有着丰富的经验和直觉,但在面对复杂的局面时,难免会受到情绪、疲劳等因素的影响。
而且,人类的思维模式往往存在一定的局限性,容易陷入固有的套路和偏见。
然而,这并不意味着人类在围棋领域就失去了价值。
阿尔法的出现,反而激发了更多人类棋手去探索围棋的奥秘。
它让我们看到了围棋更多的可能性,也促使我们重新审视自己对于围棋的理解和追求。
从更深层次的角度来看,阿尔法的成功不仅仅是在围棋领域的突破,更是对整个人类社会的一次冲击和启示。
它让我们意识到,科技的发展正在以惊人的速度改变着我们的生活和思维方式。
在过去,我们总是认为只有人类才能拥有智慧和创造力,但阿尔法的出现让我们开始重新定义这些概念。
它告诉我们,机器也可以通过学习和进化,展现出类似于人类的智慧行为。
但这是否意味着未来的世界将完全由人工智能主导?我认为并非如此。
人工智能固然强大,但它终究是人类智慧的产物。
它没有情感、没有价值观、没有道德观念,这些都是人类所独有的特质。
关于围棋人工智能阿尔法的观后感作文

关于围棋人工智能阿尔法的观后感作文I am deeply impressed by the documentary about the AlphaGo, an artificial intelligence program developed by DeepMind to play the board game Go. Watching the development of AlphaGo, from its initial struggles to its ultimate victory over the reigning world champion, has been a truly fascinating and inspiring experience.我深受关于AlphaGo的纪录片的触动,这是由DeepMind开发的一款人工智能程序,用于下围棋。
从AlphaGo最初的挣扎到最终战胜现任世界冠军,观看其发展过程是一次非常迷人和鼓舞人心的经历。
One of the most striking aspects of the documentary is the level of dedication and passion shown by the developers and researchers at DeepMind. The amount of time, effort, and sheer brainpower that went into creating and training AlphaGo is truly awe-inspiring. The team's unwavering commitment to pushing the boundaries of what was thought possible in the field of artificial intelligence is nothing short of incredible.纪录片最引人注目的一点是DeepMind的开发人员和研究人员所展现出的敬业和激情。
阿尔法狗围棋程序工作原理

阿尔法狗围棋程序工作原理
AlphaGo 被开发出来用于围棋,是通过自我学习算法(self-learning algorithm)而实现的。
这个算法能够根据玩家的棋局,自动学习并归纳出更优的棋手的棋局特征。
AlphaGo 的开发者还有使用了深度学习(deep learning)算法,这是一种通过多层神经网络(multilayer neural network)模拟人脑的学习方式。
这种方法可以让机器在很短的时间内学习复杂的外部状态。
围棋程序 AlphaGo 的成功,证明了深度学习在机器学习领域的重要性。
深度学习能够帮助机器通过多层神经网络模拟人脑的学习方式,从而更好地学习复杂的外部状态。
这种方法已经被证明是非常有效的,在围棋程序 AlphaGo 中就使用了这种方法。
AlphaGo 的开发者还有使用了深度学习(deep learning)算法,这是一种通过多层神经网络(multilayer neural network)模拟人脑的学习方式。
使用深度学习算法,机器可以更好地学习复杂的外部状态。
这种方法已经被证明是非常有效的,在 AlphaGo 程序中就使用了这种方法。
AlphaGo 的成功,证明了深度学习在机器学习领域的重要性。
深度学习能够帮助机器通过多层神经网络模拟人脑的学习方式,从而更好地学习复杂的外部状态。
这种方法已经被证明是非常有效的,在围棋程序AlphaGo 中就使用了这种方法。
阿尔法围棋

阿尔法围棋折叠编辑本段程序原理折叠深度学习阿尔法围棋阿尔法围棋(AlphaGo)的主要工作原理是“深度学习”。
“深度学习”是指多层的人工神经网络和训练它的方法。
一层神经网络会把大量矩阵数字作为输入,通过非线性激活方法取权重,再产生另一个数据集合作为输出。
这就像生物神经大脑的工作机理一样,通过合适的矩阵数量,多层组织链接一起,形成神经网络“大脑”进行精准复杂的处理,就像人们识别物体标注图片一样。
折叠两个大脑阿尔法围棋(AlphaGo)是通过两个不同神经网络“大脑”合作来改进下棋。
这些大脑是多层神经网络跟那些Google图片搜索引擎识别图片在结构上是相似的。
它们从多层启发式二维过滤器开始,去处理围棋棋盘的定位,就像图片分类器网络处理图片一样。
经过过滤,13 个完全连接的神经网络层产生对它们看到的局面判断。
这些层能够做分类和逻辑推理。
这些网络通过反复训练来检查结果,再去校对调整参数,去让下次执行更好。
这个处理器有大量的随机性元素,所以人们是不可能精确知道网络是如何“思考”的,但更多的训练后能让它进化到更好。
第一大脑:落子选择器(Move Picker)阿尔法围棋(AlphaGo)的第一个神经网络大脑是“监督学习的策略网络(Policy Network)” ,观察棋盘布局企图找到最佳的下一步。
事实上,它预测每一个合法下一步的最佳概率,那么最前面猜测的就是那个概率最高的。
这可以理解成“落子选择器”。
第二大脑:棋局评估器(Position Evaluator)阿尔法围棋(AlphaGo)的第二个大脑相对于落子选择器是回答另一个问题。
不是去猜测具体下一步,它预测每一个棋手赢棋的可能,在给定棋子位置情况下。
这“局面评估器”就是“价值网络(Value Network)”,通过整体局面判断来辅助落子选择器。
这个判断仅仅是大概的,但对于阅读速度提高很有帮助。
通过分类潜在的未来局面的“好”与“坏”,AlphaGo能够决定是否通过特殊变种去深入阅读。
阿尔法狗围棋十诀之一:没事点三三
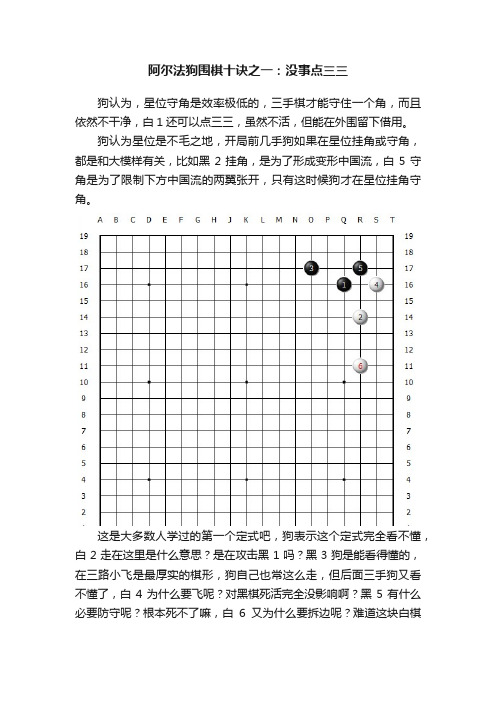
阿尔法狗围棋十诀之一:没事点三三狗认为,星位守角是效率极低的,三手棋才能守住一个角,而且依然不干净,白1还可以点三三,虽然不活,但能在外围留下借用。
狗认为星位是不毛之地,开局前几手狗如果在星位挂角或守角,都是和大模样有关,比如黑2挂角,是为了形成变形中国流,白5守角是为了限制下方中国流的两翼张开,只有这时候狗才在星位挂角守角。
这是大多数人学过的第一个定式吧,狗表示这个定式完全看不懂,白2走在这里是什么意思?是在攻击黑1吗?黑3狗是能看得懂的,在三路小飞是最厚实的棋形,狗自己也常这么走,但后面三手狗又看不懂了,白4为什么要飞呢?对黑棋死活完全没影响啊?黑5有什么必要防守呢?根本死不了嘛,白6又为什么要拆边呢?难道这块白棋的安全有问题吗?看狗疑惑不解,旁边有人类棋手过来对狗解释说:这几步棋不是什么死活问题,都是价值很大的棋,狗听了目瞪口呆:价值很大?白棋不过来挂角,让黑棋自己围,黑连花几手能围几目棋?白棋挂角的时候,黑棋小飞防守一下,后面都脱先,让白棋可着劲的在角上飞,尖三三,白连花几手能围几目棋?你告诉我这里价值很大?人类棋手说:那你说,当前四手占完四个空角之后,第五手走在哪儿价值最大?狗说:构筑大模样或者小目守角挂角,价值都很大,难分伯仲。
人类棋手说:嗯,我赞同,接下来什么价值最大?狗说:接下来是点三三。
狗咬狗50盘棋第三盘的实战图人类棋手:啊?为什么?狗说:因为布局走到这里,棋盘上没有可以攻杀的孤棋,也没有哪里可以马上能成大模样,此时最大的官子难道不是点三三吗?人类棋手:官子……好吧,单纯从目数上说,点三三确实是此时目数最大的,这个我确实无法反驳,可是…狗:那不就行了?围棋是比谁占的空更多,当然是哪里目数最大就下在哪里。
人类棋手:可是,点三三让对方成了一道外势,不怕影响全局吗?狗:缩在一个角上的外势能有什么全局影响?人类棋手:至少可以拆边成空啊。
狗:拆多大?拆小了是不是围空效率很低?拆大了我打入进去,你这道外势是不是自身不干净,没法攻击我?人类棋手:怎么没法攻击你?来,咱俩摆一盘试试。
阿尔法围棋战胜韩国九段李世石

• 最后用中科院计算所副所长陈熙 霖的一段话结个尾——千万不要 把人工智能和人的智能等同起来, 围棋人机大战是人工智能发展的 重要时刻,但是它只是人类历史 上连续发展的一个瞬间而已。
谢谢观赏
阿尔法围棋战胜 韩国九段李世石
“新物种”会让人类失业 吗
•但这些问题并不需 要我们过多的担心, 我们其实只关细节的 工作比如文物修复,这就无法 让机器人来做,而且这些贵重 的文物人也不会放心机器人去 做的,所以机器人并不是所有 工作都能干的
阿尔法狗打败围棋冠军作文素材

阿尔法狗打败围棋冠军作文素材When AlphaGo defeated the world champion in the game of Go, it not only marked a major milestone in the development of artificial intelligence, but also raised profound questions about the capabilities and limitations of machines.当阿尔法狗在围棋比赛中击败世界冠军时,这不仅标志着人工智能发展中的一个重要里程碑,也引发了对机器的能力和局限性的深刻思考。
From a technological perspective, the victory of AlphaGo demonstrated the immense progress that has been made in the field of artificial intelligence. The ability of a machine to outperform a human in a complex game like Go showcases the power of algorithms and machine learning.从技术角度来看,阿尔法狗的胜利展示了人工智能领域所取得的巨大进步。
机器在围棋等复杂游戏中胜过人类,彰显了算法和机器学习的强大力量。
However, the victory also raised concerns about the impact of artificial intelligence on human society. As machines becomeincreasingly capable of performing complex tasks, there is a fear that they may replace human workers and further exacerbate societal inequality.然而,这场胜利也引发了对人工智能对人类社会影响的担忧。
阿尔法围棋案例

阿尔法围棋案例
介绍
阿尔法围棋(AlphaGo)是Google旗下DeepMind公司研发的一款人工智
能围棋对弈程序,它是终极挑战人类智慧的绝佳例子。
该案例于2016年3月在韩国一场围棋锦标赛中,和李世石(Lee Sedol)的围棋比赛中大获全胜,引起围棋界的轰动及全球关注。
阿尔法围棋的背后技术原理主要是由强化学习、深度神经网络及博弈
论的荟萃而成。
它的网络结构包括一个搜索网络和一个估计网络,前
者用于模拟棋局,后者用于估计最终胜负情况。
在2016年,Google通
过AlphaGo获得了第三届国际计算机围棋大赛(CCC)冠军,使用1,920
个核心的CPU+1,024个核心的GPU云服务器。
阿尔法围棋以人工智能及机器学习的方式,与世界级的棋手一对一比赛,对人工智能的发展起到了里程碑性的推进作用,也是历史上人类
智慧和强大的机器智慧能力共识的完美示范。
阿尔法围棋程序原理

阿尔法围棋程序原理
近年来,随着人工智能技术的快速发展,阿尔法围棋程序成为人们关注的焦点。
阿尔法围棋程序通过深度学习和强化学习等技术,从大量的棋局数据中学习并提升自己的棋力,实现了在围棋对局中超越人类顶尖棋手的能力。
阿尔法围棋程序的原理可以分为以下几个关键步骤:
1. 数据准备:阿尔法围棋程序首先需要收集大量的围棋棋局数据,包括人类棋手对局和自我对局等。
这些数据作为训练样本,用于构建模型和优化算法。
2. 深度学习:阿尔法围棋程序采用深度神经网络模型,通过训练样本进行学习和优化。
深度神经网络模型可以对输入的围棋局面进行复杂的特征提取和分析,识别关键的棋局信息。
3. 蒙特卡洛树搜索:阿尔法围棋程序利用蒙特卡洛树搜索算法来选择合适的下棋步骤。
该算法通过模拟大量的围棋对局来评估每个棋步的价值,从而选择最优的下一步。
4. 强化学习:阿尔法围棋程序通过与自己不断对弈来进行自我训练和优化。
在每个对局结束后,程序会根据游戏的胜负情况来更新模型和算法,以提升自己的棋力和决策能力。
通过这些关键步骤,阿尔法围棋程序能够在对弈中不断学习和进步,最终达到甚至超越人类顶尖棋手的水平。
它的原理基于
深度学习和强化学习的组合,借助人工智能技术实现了在围棋领域的突破。
阿尔法围棋

幕后制作
格 雷 格 ·科 斯 是 美 国 资 深 纪 录 片 导 演 , 但 他 在 开 展 该 项 目 前 对 A I 一 无 所 知 。 一 天 , G o o g l e 公 司 中 专 门 负 责 音 频 和 视 频 类 工 作 的 创 意 实 验 室 邀 请 格 雷 格 ·科 斯 , 为 他 们 拍 摄 李 世 石 和 A l p h a G o 的 围 棋 比 赛 。 一 开 始 , G o o g l e 公 司 只 希 望 格 雷 格 ·科 斯 单 纯 记 录 , 并 没 有 发 展 成 一 部 电 影 的 计 划 。 但 格 雷 格 ·科 斯 拍 着 拍 着 , 发 现 这 是 一 个 很 棒 的 题材,背后有很多可以挖掘的故事,便主动向Google公司提出拍成电影的想法,于是便有了纪录片《阿尔法围 棋》 。
剧情简介
李世石作为世界一流的围棋选手,曾无比自信地认为自己可以战胜人工智能机器人“阿尔法狗”(Alpha Go)。 在世界另一端的谷歌办公楼里,李世石的对手很担心。他们的作品有一个缺陷,很可能令系统失控。再过几天, “阿尔法狗”就要与李世石对战,缺陷已经来不及修复。出人意料的是,“阿尔法狗”对李世石之战,获得了压 倒性的胜利。在5场比赛中,“阿尔法狗”获胜4场。随着比赛尘埃落定,双方都在新的世界里感到苦涩 。
《阿尔法围棋》不仅记录了科技成就,也记录了Deep Mind项目团队、樊麾等人对围棋倾注心血的故事,这 让纪录片充满着人性光芒 。该片的故事层层递进,把“人类”的心态变化,从高傲到自我怀疑到释怀到奋然一 搏到平静把握得很好。而AlphaGo这边,技术团队的每一个关键人物的出镜,坦陈自己复杂而矛盾的情绪,以及 对自己所创造出对程序对观感,也能够让观众更加理解人和机器对关系,而不是对着一个稻草人感到恐慌或者敬 畏。李世石在五盘对阵中对表现以及总结也非常棒,同时具有骄傲和脆弱,闪现着人类的高贵感 。(第一财经、 新浪综合评)
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
阿尔法围棋
阿尔法围棋(AlphaGo)是第一个击败人类职业围棋选手、第一个战胜围棋世界冠军的人工智能机器人,由谷歌(Google)旗下DeepMind公司戴密斯•哈萨比斯领衔的团队开发。
其主要
工作原理是“深度学习”。
2016年3月,阿尔法围棋与围棋世界冠军、职业九段棋手
李世石进行围棋人机大战,以4比1的总比分获胜;2016年末2017年初,该程序在中国棋类网站上
以“大师”(Master)为注册帐号与
中日韩数十位围棋高手进行快棋对决,
连续60局无一败绩;2017年5月,
在中国乌镇围棋峰会上,它与排名世
界第一的世界围棋冠军柯洁对战,以
3比0的总比分获胜。
围棋界公认阿
尔法围棋的棋力已经超过人类职业围
棋顶尖水平,在GoRatings网站公布
的世界职业围棋排名中,其等级分曾超过排名人类第一的棋手
柯洁。
2017年5月27日,在柯洁与阿尔法围棋的人机大战之后,阿尔法围棋团队宣布阿尔法围棋将不再参加围棋比赛。
2017年10月18日,DeepMind团队公布了最强版阿尔法围棋,代号AlphaGo Zero。