Storm实时流处理框架PPT演讲
storm 处理流数据的工作机制

Storm 处理流数据的工作机制Storm 是一个开源的分布式实时计算系统,被广泛应用于处理实时流数据。
它具有高容错性、高吞吐量和低延迟的特点,适用于各种实时数据处理场景。
本文将详细介绍 Storm 处理流数据的工作机制。
1. Storm 概述Storm 是由 Apache 开源的,用于处理实时流数据的分布式计算系统,它能够在集群中处理连续不断的数据流,并实时地进行分析和计算。
它具有可伸缩性、容错性和高性能的特点,广泛应用于大规模数据处理领域。
2. Storm 架构Storm 运行在分布式集群中,通常由主节点(Master Node)和工作节点(Worker Node)组成。
Storm 采用主从架构,主节点负责任务分配和协调,而工作节点负责实际的数据处理。
2.1 Spout 组件在 Storm 中,Spout 组件用于从数据源中读取流数据,并将其发送给后续的数据处理组件。
Spout 组件可以读取各种类型的数据源,例如消息队列、文件系统或网络流。
2.2 Bolt 组件Bolt 组件是 Storm 中的数据处理单元,负责对传入的数据流进行处理和转换。
Bolt 组件可以执行各种计算、过滤、聚合和输出等操作,可以单独使用或者通过拓扑结构串连多个 Bolt 组件形成任务流水线。
2.3 Topology 拓扑Storm 中的任务被称为拓扑(Topology),它由一组 Spout 组件和一组 Bolt 组件构成。
通过定义这些组件之间的连接关系,可以形成一个完整的数据处理流程。
3. Storm 的工作流程Storm 的工作流程可以概括为以下几个步骤:1.主节点将任务拓扑提交给 Storm 集群。
2.Storm 集群将任务拓扑分发给工作节点。
3.每个工作节点负责执行一部分任务,并创建对应的任务线程。
4.Spout 组件从数据源中读取流数据,并将其发送给后续的 Bolt 组件。
5.Bolt 组件对接收到的数据流进行处理和转换,并将结果发送给下一个 Bolt组件或最终输出。
JStorm—实时流式计算框架入门介绍
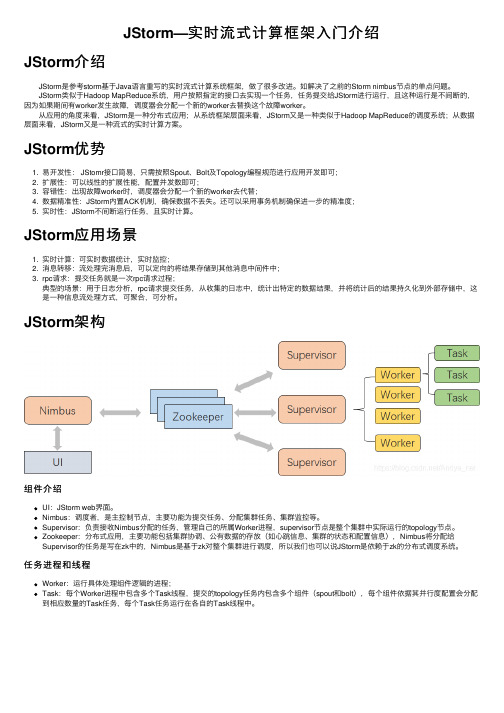
JStorm—实时流式计算框架⼊门介绍JStorm介绍 JStorm是参考storm基于Java语⾔重写的实时流式计算系统框架,做了很多改进。
如解决了之前的Storm nimbus节点的单点问题。
JStorm类似于Hadoop MapReduce系统,⽤户按照指定的接⼝去实现⼀个任务,任务提交给JStorm进⾏运⾏,且这种运⾏是不间断的,因为如果期间有worker发⽣故障,调度器会分配⼀个新的worker去替换这个故障worker。
从应⽤的⾓度来看,JStorm是⼀种分布式应⽤;从系统框架层⾯来看,JStorm⼜是⼀种类似于Hadoop MapReduce的调度系统;从数据层⾯来看,JStorm⼜是⼀种流式的实时计算⽅案。
JStorm优势1. 易开发性: JStomr接⼝简易,只需按照Spout、Bolt及Topology编程规范进⾏应⽤开发即可;2. 扩展性:可以线性的扩展性能,配置并发数即可;3. 容错性:出现故障worker时,调度器会分配⼀个新的worker去代替;4. 数据精准性:JStorm内置ACK机制,确保数据不丢失。
还可以采⽤事务机制确保进⼀步的精准度;5. 实时性:JStorm不间断运⾏任务,且实时计算。
JStorm应⽤场景1. 实时计算:可实时数据统计,实时监控;2. 消息转移:流处理完消息后,可以定向的将结果存储到其他消息中间件中;3. rpc请求:提交任务就是⼀次rpc请求过程;典型的场景:⽤于⽇志分析,rpc请求提交任务,从收集的⽇志中,统计出特定的数据结果,并将统计后的结果持久化到外部存储中,这是⼀种信息流处理⽅式,可聚合,可分析。
JStorm架构组件介绍UI:JStorm web界⾯。
Nimbus:调度者,是主控制节点,主要功能为提交任务、分配集群任务、集群监控等。
Supervisor:负责接收Nimbus分配的任务,管理⾃⼰的所属Worker进程,supervisor节点是整个集群中实际运⾏的topology节点。
《Storm框架分享》课件

对Storm框架的未来展望
我们预计Storm框架将与大数据生态系统更深入 地整合,在支持更多编程语言和数据源目标的 同时,提供更强大的实时计算能力。
《Storm框架分享》PPT 课件
欢迎大家参加今天的分享会!在本次课程中,我们将深入探讨Storm框架的各 个方面,包括其特点、基本概念、核心原理、具体应用、优缺点以及未来发 展趋势。
Storm框架简介
什么是Storm框架?
Storm是一个开源的实时计算系统,可用于处理大规模的流数据,提供高并发性和可靠性。
数据的可靠性保障
Storm框架通过在拓扑结构中引入消息可靠性机制,确保数据的传输和处理过程具有高可靠 性。
Storm框架的具体应用
1 实时数据处理
Storm框架适用于对实时流数据进行实时计算和分析,如实时推荐系统、广告投放分析等。
2 流量控制
通过Storm框架,可以对大规模的数据流进行控制和调度,确保数据的顺畅传输和负载均 衡。
Topology
消息处理的拓扑结构,由 多个Spout和Bolt组成,形 成一条处理流水线。
Storm框架的核心原理
数据的流式处理
Storm框架以流的方式进行数据处理,能够实时地对输入数据进行计算和分析。
数据的并行处理
通过将拓扑结构分解为多个任务,Storm框架能够并行处理大规模数据,提高处理效率。
传统数据处理 vs Storm框架
相比传统的批量处理方式,Storm框架能够实现实时流式处理,处理速度更快,反应更及时。
Storm框架的基本概念
Spout
消息的来源,负责从数据 源获取输入数据并发送给 下游的Bolt。
Bolt
消息的处理者,接收Spout 发送的数据并进行计算、 过滤等操作,然后将结果 发送给下一个Bolt。
Storm - 大数据Big Data实时处理架构

Storm - 大数据Big Data实时处理架构什么是Storm?Storm是:• 快速且可扩展伸缩• 容错• 确保消息能够被处理• 易于设置和操作• 开源的分布式实时计算系统- 最初由Nathan Marz开发- 使用Java 和 Clojure 编写Storm和Hadoop主要区别是实时和批处理的区别:Storm概念组成:Spout 和Bolt组成Topology。
Tuple是Storm的数据模型,如['jdon',12346]多个Tuple组成事件流:Spout是读取需要分析处理的数据源,然后转为Tuples,这些数据源可以是Web日志、 API调用、数据库等等。
Spout相当于事件流的生产者。
Bolt 处理Tuples然后再创建新的Tuples流,Bolt相当于事件流的消费者。
Bolt 作为真正业务处理者,主要实现大数据处理的核心功能,比如转换数据,应用相应过滤器,计算和聚合数据(比如统计总和等等) 。
以Twitter的某个Tweet为案例,看看Storm如何处理:这些tweett贴内容是:“No Small Cell Lung #Cancer(没有小细胞肺癌#癌症)” "An #OnCology Consult...."这些贴被Spout读取以后,产生Tuple,字段名是tweet,内容是"No Small Cell Lung #Cancer",格式类似:['No Small Cell Lung #Cancer',133221]。
然后进入被流消费者Bolt进行处理,第一个Bolt是SplitSentence,将tuple内容进行分离,结果成为:一个个单词:"No" "Small" "Cell" "Lung" "#Cancer" ;然后经过第二个Bolt进行过滤HashTagFilter处理,Hash标签是单词中用#标注的,也就是Cancer;再经过HasTagCount计数,可以本地内存缓存这个计数结果,最后通过PrinterBolt打印出标签单词统计结果。
基于storm的实时计算架构

应用场景@阿里巴巴
业务监控
效果监控中心
实时GMV 效果监控 实时流量 效果监控
推荐
网站实时推荐
首页实时推荐
店铺实时推荐
卖家360
买家实时活动
404页面实时推荐
Top likes/trends
实时访问动态 实时搜索动态
实时活动 效果监控
实时营销 效果监控
实时反馈动态 实时订阅动态
异常监控中心
日志异常实时报警 恶意点击 实时报警
配置服务 • 任务管理中心,直观反应当前任 务执行状态,能够中止、暂时、 重设任务 • 监控:系统(内存,cpu,网络, io等),功能(redis,meta, storm等),任务,数据质量 • storm集群管理
5.1 storm topology开发效率
简单统计场景(中文站UV,PV统计):
1.1 业务背景 • • • • • Big data数据量膨胀 业务快速变化,商业模式的创新 SNS,移动互联网 用户体验个性化,实时化 …
1.2 离线计算 vs. 流计算
From <IBM InfoSphere Streams: Harnessing Data in Motion>
1.3 数据分析演进趋势
message connector message adaptor
meta
MSC manager
supervisor bolt spout
nimbus
Data output service
file …
zookeper
DB
Engine state storage
Local buffer cache
Persistence storage
实时计算平台STORM流式数据核心技术与报文系统

实时计算平台STORM流式数据核心技术与报文系统摘要1随着应用创新的层出不穷和数据类型的不断丰富,企业面对的数据量急剧增长,随之而来的实时处理需求给管理者和开发人员带来了多方面的困难。
一方面,源源不断的数据流带来了硬件成本增加、难以有效管控等诸多问题;另一方面,传统的数据批处理系统无法满足实时数据处理需求,服务延迟及业务连续性不佳等问题比较严重。
为解决上述问题,作为一个优秀的实时计算框架,Storm 迅速在业界得到广泛应用与认可。
本文对Storm 平台特点及其背后的核心技术进行了深入剖析,并结合实时服务现状,特别是现有的报文系统需求,得到了一个基于Storm 的、满足高并发及业务隔离要求的原型系统,以期对下一代报文系统的设计与实现提供帮助。
1目录1. Storm及报文系统概述 (1)1.1 流式数据与Storm的诞生 (1)1.2 我司实时服务现状 (2)1.3 报文系统概述 (2)2. Storm关键技术 (3)2.1 系统架构 (3)2.1.1 调度系统 (3)2.1.2 通信模型 (5)2.2 拓扑与数据流 (6)2.2.1 Topology、Spout及Bolt (6)2.2.2 数据流Grouping策略 (9)2.3 Ack机制 (10)3. Storm中的高层机制 (11)3.1 事务处理 (11)3.2 Trident API (13)3.3 DRPC (14)4. 基于Storm的报文系统初探 (14)4.1 报文系统需求分析 (14)4.2 原型系统设计 (15)4.3 原型系统实现 (17)5. 总结与展望 (20)1. Storm 及报文系统概述1.1 流式数据与Storm 的诞生随着互联网的高速发展,各类数据应用层出不穷,而数据除了规模的爆炸性增长之外,新的形态也不断涌现。
流式数据便是这些新型大数据中的一类典型。
与传统数据的静态、批处理和持久化不同,流式数据是连续、无边界且瞬间性的。
Storm框架分享共20页

3 6 、 如 果 我 们 国 家 的 法 律 中 只 有 某 种 神 灵 , 而 不 是 殚 精 竭 虑 将 神 灵 揉 进 宪 法 , 总 体 上 来 说 , 法 律 就 会 更 好 。 — — 马 克 ·吐 温 3 7 、 纲 纪 废 弃 之 日 , 便 是 暴 政 兴 起 之 时 。 — — 威 ·皮 物 特
4 Storm集群角色
5 Storm中进程和线程关系
Worker :被Supervisor守护进程创建的用来干活的进程。每个Worker对应于一 个给定topology的全部执行任务的一个子集。反过来说,一个Worker 里面不会运行属于不同的topology的执行任务
Executor:可以理解成一个Worker进程中的工作线程。一个Executor中只能运行 隶属于同一个component(spout/bolt)的task。一个Worker进程中 可以有一个或多个Executor线程。在默认情况下,一个Executor运行一 个task
38、若是 没 有 公 众 舆 论 的 支 持 , 法 律 是 丝 毫 没 有 力 量 的 。 — — 菲 力 普 斯 39、一个 判 例 造 出 另 一 个 判 例 , 它 们 迅 速 累 聚 , 进 而 变 成 法 律 。 — — 朱 尼 厄 斯
40、人类 法 律 , 事 物 有 规 律 , 这 是 不 容 忽 视 的 。 — — 爱 献 生
Bolt:
在一个topology中接受数据然后执行处理的组件。Bolt可以执行过滤、 函数操作、合并、写数据库等任何操作。Bolt是一个被动的角色,其 接口中 有个execute(Tuple input)函数,在接受到消息后会调用此函数, 用户可以在其中执行自己想要的操作
基于案例讲解Storm实时流计算课件

实时监控超速车辆
在高速上,速度 是否>120
Spout 数据源
是否在高速 上
不在高速上,速 度是否>80
➢ 字段分组(Fields grouping):根据指定字段分割数据流,并分组。例如,根据“userid”字段,相同“user-id”的元组总是分发到同一个任务,不同“user-id”的元组可能分发 到不同的任务。
➢ 全部分组(All grouping):tuple被复制到bolt的所有任务。这种类型需要谨慎使用。 ➢ 全局分组(Global grouping):全部流都分配到bolt的同一个任务。明确地说,是分配
zookeeper
协调,存放集群的公共数据 (心跳,集群状态,配置信 息),Nimbus分配给Supervisor
的任务
Supervisor Supervisor
Worker Worker Worker
具体的处理 逻辑组件
接受Nimbus分配的任务,管 理自己的Worker进程
Storm组件
Topology
• 3.水平扩展。计算是在多个线程、进程和服务器之间并行进行的。 • 4.可靠的消息处理。Storm保证每个消息至少能得到一次完整处理。任
务失败时,它会负责从消息源重试消息。 • 5.快速。系统的设计保证了消息能得到快速的处理,使用ZeroMQ作为
其底层消息队列。 • 6.本地模式。Storm有一个“本地模式”,可以在处理过程中完全模拟
CountBolt计算 金额
云计算技术与应用专业《T3-Storm架构与流处理01Storm架构1》

– Nimbus是主节点, Supervisor是从节点
– Storm执行的是Topology
– Topology ———— Nimbus ———— Supervisor,运行具体处理组件逻辑的进程是Worker – Topology运行时,分为Spout阶段和Bolt阶段,每个阶段中传递的数据单位是Tuple
第三页,共三页。
Storm架构与流处理
第一页,共三页。Storm架 Nhomakorabea(1)• 与Hadoop MapReduce相似 • MapReduce是由JobTracker和TaskTracker组成
– JobTracker是主节点,TaskTracker是从节点
– MapReduce执行的是Job
– Job ———— JobTracker ———— TaskTracker,运行具体处理组件逻辑的进程是Child – Job运行时,分为map阶段和reduce阶段,每个阶段中传递的数据单位是kv对
第二页,共三页。
内容总结
Storm架构与流处理。JobTracker是主节点,TaskTracker是从节点。Job运行时,分为map阶段和reduce阶段,每个阶段中传递的数据单位是 kv对。Nimbus是主节点, Supervisor是从节点。Storm执行的是Topology。Topology ———— Nimbus ———— Supervisor,运行具体处理组件逻辑 的进程是Worker
流处理storm

流处理框架Storm简介EMC中国研究院向东提起Big Data,人们往往会提起大数据的4个V: Volume,Velocity , Variety 以及Value。
这四个V从各个侧面说明了大数据并不是新瓶装旧酒: 面对数据产生来源,产生方式,处理方式等等一系列质变,原来适用的数据挖掘/BI工具已经不再满足实际需要,人们迫切需要新的计算模式,基础架构以及开箱即用的工具集来使自己的业务运行的更好。
这也是当前大数据如此火热的原因。
流处理(Stream Processing)或者复杂事件处理(CEP,complex event processing)也不是一个新概念,对此相关的研究和相应的产品已经有很多了,其中最有名的应该算开源CEP引擎Esper(/)。
相对于原有的产品,现在的流处理新贵,比如来自Yahoo!的S4和来自Twitter的Storm,到底有哪些独到的长处,让人们趋之若鹜?本文试图在Storm的基础上对此解读。
Storm简介任何关注大数据的有心人想必对Storm 都不会陌生:Storm是由来自BackType的NathanMarz开发,后来BackType 被Twitter收购并开源(https:///nathanmarz/storm),随之也闻名天下。
Storm核心代码是由Clojure (/)这门极具潜力的函数式编程语言开发的,这也使得Storm格外引人注目。
Storm可以用于3种不同场景:事件流(stream processing),持续计算(continuous computation)以及分布式RPC (DistributedRPC)。
针对这些场景,Storm设计了自己独特的计算模型:图一:Storm Topology1. 如图一所示,Storm计算模型以Topology为单位。
一个Topology是由一系列Spout和Bolt构成的图。
Events stream 会在构成Topology的Spout和Bolt之间流动。
Storm及交通实时数据处理 ppt课件

PPT课件
7
Storm发展现状
• 最新版本:0.9.1 • 在GitHub上超过4000个项目负责人,全球共有29
名代码贡献者。(12年) • 很多公司在使用Storm,这些公司中不乏淘宝,百
度,Twitter,Groupon,雅虎等重量级公司。
PPT课件
8
目录
绪论知识 Storm架构 一个简单的Storm例子 Storm在交通数据处理中的应用
• 主要的处理模式可以分为流处理(stream process ing)和批处理(batch processing)两种。批处 理是先存储后处理(store-process),而流处理则 是直接处理(straight-through process)。(有 时也分为在线、离线、近线三种)
batch processing
ppt精选版28绪论知识storm架构一个简单的storm例子storm在交通数据处理中的应用目录ppt精选版29stormstorm在交通数据处理中的应用在交通数据处理中的应用大数据处理技术在智能交通中的应用周为钢选自第八届中国智能交通年会优秀论文集基于storm的实时gps数据客流特征分析系统来自新浪博客
• 为了实现这个topology,我们将使用一个spout来 负责读取单词,第一个bolt来标准化单词,第二个b olt来为单词计数,如下图所示:
PPT课件
22
项目结构
该实例的项目结构如下,其中TopologyMain.j ava是整个项目的入口。
PPT课件
23
Spout:WordReader
public class WordReader implements IRichSpout { ……………… public void open(Map conf, TopologyContext context, SpoutOutputCollector collector) { try { this.context = context; this.fileReader = new FileReader(conf.get("wordsFile").toSt ring()); } catch (FileNotFoundException e) { throw new RuntimeException("Error reading file ["+conf.g et("wordFile")+"]"); } this.collector = collector; } …………
storm的用法和搭配

storm的用法和搭配Storm 是一个开源的、分布式的实时计算系统,具有高容错性、可伸缩性和低延迟的特点。
它在处理大规模数据流的实时计算任务中得到了广泛应用。
本文将介绍 Storm 的用法和搭配,包括 Storm 的基本概念、组件及其相互关系,并阐述Storm 与其他相关技术的结合。
一、Storm 简介与基本概念1.1 Storm 简介Storm 是一个开源分布式实时大数据处理框架,由 Twitter 公司开发并于 2011年开源发布。
它是一种高度可靠且可伸缩的实时流处理系统,可以在大规模数据集上执行复杂计算任务。
1.2 Storm 组成部分Storm 主要由以下几个组件组成:- Nimbus:负责资源分配和任务调度,是整个 Storm 集群的主节点。
- Supervisor:运行在集群工作节点上,负责启动和监控工作进程(Worker),并向 Nimbus 汇报状态信息。
- ZooKeeper:提供协调服务,用于管理Nimbus 和Supervisor 节点之间的通信。
- Topology:描述 Storm 的计算任务模型,包含多个 Spout 和 Bolt 组件构成的有向无环图。
二、Storm 的使用方法2.1 创建 Topology创建一个 Storm Topology 需要以下步骤:- 定义 Spout:Spout 是数据源,可以从消息队列、日志文件等地方获取实时数据流并发送给下游的 Bolt。
通常,你需要实现一个自定义的 Spout 类来满足应用的需求。
- 定义 Bolt:Bolt 是对接收到的数据流进行处理和转换的组件。
在 Bolt 中,你可以执行计算、过滤和聚合等操作,并将处理后的结果发送给其他 Bolt 或外部存储系统。
- 连接 Spout 和 Bolt:通过指定 Spout 和 Bolt 之间的连接关系,形成有向无环图。
2.2 配置 Topology在创建 Topology 时,还需要进行相关配置。
大数据技术与应用基础第9、10章流实时处理系统Storm、企业级、大数据流处理Apex

当提示BUILD SUCCESS则代表命令执行成功。
此时执行下面命令运行主类中的main方法,命令如下: mvn exec:java "-Dstorm.topology=storm.starter.WordCountTopology"
第10章
企业级、大数据流处理Apex
21世纪高等院校“云计算和大数据”人才培养规划教材 《大数据技术与应用基础》 人民邮电出版社
没有报错后打包解压至其他节点。 进入Web界面进行查看:http://IP:8080, 看到节点都正常即安装成功。
二、Storm安装与配置
测试Storm
Maven是现在Java社区中最强大的项目管理和项目构建工具,这里我们使用借助Maven工具。 (1)首先我们下载maven。 sudo apt-get install maven (2)Storm安装目录自带的测试案例,所以进入Storm当前目录下的examples/storm-starter。 cd /usr/local/apache-storm-0.10.0/examples/storm-starter (3)storm-starter下有一个test文件夹,接着执行如下命令。 mvn test
Apex的特点: • Apache Apex是真正的stream,消息来一个做一 个; • 更java向,让开发人员可以编写或重复使用一般 的JAVA代码; • 自动化。
内容 导航
CONTENTS
Apache Apex简介 Apache Apex开发环境配置
运行Top N Words应用
二、Apache Apex开发环境配置
二、Apache Apex开发环境配置
创建Top N words应用
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
RPC。
RPC(RemoteProcedureCallProtocol)远程过程调用协议 参考: 1. /2012/12/storm入门教程-第一章-前言?spm=0.0.0.0.BuyqS9 《storm入门教程 第一章 前言》 2./tj/88ca09aa33002dsh.html?qq-pf-to=pcqq.c2c 《流处理框架Storm简介》
《Storm集群安装部署步骤【详细版】》
火龙果整理
SSH免密码配置
为使各台计算机间Zookeeper同步数据、应配置SSH免密码登录 1 确认本机sshd的配置文件(root) $ vi /etc/ssh/sshd_config 找到以下内容,并去掉注释符"#" RSAAuthentication yes PubkeyAuthentication yes AuthorizedKeysFile .ssh/authorized_keys 2 如果修改了配置文件需要重启sshd服务(root) $ vi /sbin/service sshd restart 3 ssh登陆系统 后执行测试命令 $ ssh localhost 回车会提示你输入密码,因为此时我们还没有生成证书。 4 生成证书公私钥 $ ssh-keygen -t dsa -P '' -f ~/.ssh/id_dsa $ cat ~/.ssh/id_dsa.pub >> ~/.ssh/authorized_keys
火龙果整理
安装Zeromq
jzmq的安装是依赖zeromq的,所以应该先装zeromq,再装jzmq。 # wget /zeromq-2.1.7.tar.gz # tar zxf zeromq-2.1.7.tar.gz # cd zeromq-2.1.7 # ./configure # make # make install # sudo ldconfig 2)安装jzmq
参考: 1. /xia520pi/archive/2012/05/16/2504132.html
《Hadoop集群(第5期副刊)_JDK和SSH无密码配置》
火龙果整理
安装Zookeeper及单机配置
# wget http://ftp.meisei-u.ac.jp/mirror/apache/dist/zookeeper/zookeeper3.4.5/zookeeper-3.4.5.tar.gz
追加:
export ZOOKEEPER_HOME="/path/to/zookeeper" export PATH=$PATH:$ZOOKEEPER_HOME/bin # cd /usr/local/zookeeper/conf/ # cp zoo_sample.cfg zoo.cfg (用zoo_sample.cfg制作$ZOOKEEPER_HOME/conf/zoo.cfg) zookeeper的单机安装完成。 启动服务 bin/zkServer.sh start 用bin/zkServer.sh status 查看会显示"standalone" 启动客户端测试bin/zkCli.sh -server 127.0.0.1:2181
在过程中很可能会遇到依赖库相关问题,详见参考1
参考: 1. /post/a8c5e_136579 《Twitter Storm 安装实战》 2./panfeng412/archive/2012/11/30/how-to-install-and-deploy-storm-cluster.html
火龙果整理 umlHale Waihona Puke
实时流计算背景
随着互联网的更进一步发展,信息浏览、搜索、关系交互传递型 ,以及电子商务、互联网旅游生活产品等将生活中的流通环节在线化 。对于实时性的要求进一步提升,而信息的交互和沟通正在从点对点 往信息链甚至信息网的方向发展,这样必然带来数据在各个维度的交 叉关联,数据爆炸已不可避免。因此流式处理和NoSQL产品应运而生 ,分别解决实时框架和数据大规模存储计算的问题。 流式处理可以用于3种不同场景: 事件流、持续计算以及分布式
参考: 1. /post/a8c5e_136579 《Twitter Storm 安装实战》 2./techdoc/system/2009/11/25/1146071.shtml 《linux ld.so.conf 和 pkgconf》 3./kindlucy/article/details/7320920 《linux下python安装》
。
参考: 1. /post/a8c5e_136579 《Twitter Storm 安装实战》 2. /hand51me/item/f738bdfb0b7e01d46325d28f 《centos 怎么安装 g++》
《storm入门教程 第一章 前言》
火龙果整理
目录
Storm介绍 Storm环境配置
Storm程序实例
Storm总结及问题
火龙果整理
依赖软件
Storm的依赖软件有Python、Zeromq、Jzmq、
Zookeeper。此外,系统应安装有Java、GCC、G++编译环境
火龙果整理
Storm组件
参考: 1. /yutianzuijin/article/details/8712690 《Storm入门教程 第二章 构建Topology》
火龙果整理
Storm特点
可扩展
计算任务可在多个线程、进程和服务器之间并行进行,支持灵活的水平扩展
参考: 1. /xia520pi/archive/2012/05/16/2504132.html
《Hadoop集群(第5期副刊)_JDK和SSH无密码配置》·
火龙果整理
SSH免密码配置
5 拷贝本地生产的key到远程服务器端 $cat ~/.ssh/id_rsa.pub | ssh 远程用户名@远程服务器ip 'cat - >> ~/.ssh/authorized_keys' 6 测试登陆 ssh user@远程ip 7 如果登陆不成功,需要修改远程服务器上的authorized_keys文件权限 $ chmod 600 ~/.ssh/authorized_keys
# yum install git(CentOS) & apt-get install git(Ubuntu)
# # # # # # git clone git:///nathanmarz/jzmq.git cd jzmq ./autogen.sh 可到https:///nathanmarz/jzmq直接下载压缩包 ./configure make make install
是数据一次写入,多次查询使用。Storm系统运行起来后是持续不断
的,而 hadoop往往只是在业务需要时调用数据。
参考: 1. 《实时处理方案架构(作者-落枫).pdf》
火龙果整理
Storm和Hadoop角色对比
参考: 1. /cnbird2008/article/details/8745156 《流式计算系统》
火龙果整理
实时流处理框架——Storm
演讲:李乾文
2013年11月5日
火龙果整理
目录
Storm介绍 Storm环境配置
Storm程序流程
Storm总结及问题
火龙果整理
目录
Storm介绍 Storm环境配置
Storm程序流程
Storm总结及问题
Tuple:一次消息传递的基本单元.
Stream grouping:消息的分组方法
参考: 1. /cnbird2008/article/details/8745156 《storm简介》
火龙果整理
Storm组件参考: 1. 图片搜索高可靠保证每条消息都能被完全处理
高容错性 nimbus、supervisor都是无状态的,可以用kill -9来杀死Nimbus和Supervisor进程 ,然后再重启它们,任务照常进行.当worker失败后,supervisor会尝试在本机重启它 支持多种编程语言 除了用java实现spout和bolt,还可用其他语言 支持本地模式 可在本地模拟一个Storm集群功能、进行本地测试
火龙果整理
Storm组件
Topology:storm中运行的一个实时应用程序. Nimbus:负责资源分配和任务调度. Supervisor:负责接受nimbus分配的任务,启动和停止属于自己管理的worker进程.
Worker:运行具体处理组件逻辑的进程.
Task:worker中每一个spout/bolt的线程称为一个task. Spout:在一个topology中产生源数据流的组件. Bolt:在一个topology中接受数据然后执行处理的组件.
火龙果整理
安装Python
# wget /ftp/python/2.7.2/Python-2.7.2.tgz # tar zxvf Python-2.7.2.tgz # cd Python-2.7.2 # ./configure # make # make install # vi /etc/ld.so.conf 追加/usr/local/lib/ # sudo ldconfig 这样的话,Python2.7.2就安装完毕了。
火龙果整理
数据分析系统组成
如HDFS
数据分析系统整体组成示意图
参考: 1. /guoery/article/details/8504257 《流式计算系统》
火龙果整理
流处理与批处理
Storm 关注的是数据多次处理一次写入,而 hadoop 关注的
高效
用ZeroMQ作为底层消息队列, 保入门教程-第一章-前言?spm=0.0.0.0.BuyqS9 3. /wanghai__/article/details/8834273 《Storm安装部署步骤》