生物信息学_高通量测序技术及数据分析
高通量测序技术的生物信息学分析

高通量测序技术的生物信息学分析引言:高通量测序技术作为一种新型基因测序技术,已经被广泛应用于现代生物研究中。
利用高通量测序技术,科学家们可以快速解码基因组序列、转录组序列以及蛋白质组序列。
然而,高通量测序技术不仅仅是一种实验技术,它也需要强大的生物信息学工具来支持数据分析和解读。
本文将介绍高通量测序技术的生物信息学分析,包括原始数据质量控制、序列比对和注释、基因表达分析、基因变异分析等等。
一、原始数据质量控制原始数据质量控制是高通量测序数据分析的第一步,其目的是剔除低质量序列以及包含污染序列的读段,确保下游的数据分析结果准确可靠。
利用FASTQC等软件对原始的FASTQ格式数据进行质量评估,可以得到关于以下几个质量指标的信息:1. GC含量2. Q20和Q30的比例3. 碱基分布的均匀性4. 过度重叠序列的比例基于以上质量指标,可以对数据进行质量控制处理,包括碱基修剪、低质量序列过滤、去除污染序列等等。
二、序列比对和注释序列比对指的是将高通量测序数据基因组参考序列进行比对,得到参考序列上的SNP、InDel的信息,从而对样品进行全面的基因变异检测、注释和分析。
在序列比对和注释的过程中,需要正确选择合适的比对软件和参考序列。
目前较为流行的比对软件包括BWA、Bowtie、STAR等等。
针对RNA-seq数据的注释工具包括Cufflinks、StringTie、Transcriptome Assembly等等。
基于参考序列的比对结果,还可以利用Variant Effect Predictor (VEP)等工具对候选变异位点进行注释。
注释信息包括dbSNP、ClinVar、ExAC等公共数据库的信息,帮助生物学家了解该变异的生物学特性,并识别其潜在的影响。
三、基因表达分析高通量测序技术还可以用于RNA表达谱的分析,以揭示不同组织和不同发育阶段的基因表达差异。
在基因表达分析中,首先将RNA-seq数据进行质量控制和过滤,然后对序列进行比对和注释,获得基因的计数信息。
高通量基因表达数据分析与生物信息学方法综述

高通量基因表达数据分析与生物信息学方法综述概述随着高通量测序技术的不断发展,基因表达数据的产生速度和规模大幅增加。
这些数据的分析对于深入理解生物体内基因调控网络和相关疾病的发生机制具有重要意义。
生物信息学方法的应用为高通量基因表达数据的解读提供了强大的工具。
本文将综述高通量基因表达数据分析的方法,包括预处理、差异表达分析、功能注释以及数据可视化方法。
1. 高通量测序数据的预处理高通量测序数据包括了RNA测序、小RNA测序、DNA甲基化测序等。
在进行数据分析之前,需要进行一系列的预处理步骤以确保数据的质量和准确性。
预处理包括了去除低质量序列、去除接头污染、去除PCR扩增产物、去除宿主污染等。
一般使用的预处理工具包括Trim Galore、Fastx-toolkit、Cutadapt等。
2. 差异表达分析差异表达分析是高通量基因表达数据分析的重要步骤,通过对实验组和对照组进行比较,筛选出在不同生物条件下显著表达变化的基因。
在差异表达分析中,常使用的方法包括DESeq、edgeR、limma等。
这些方法可以考虑到数据的离散性和复现性,并对差异表达结果进行统计显著性检验。
3. 功能注释功能注释是对差异表达基因的功能进行解读和理解的过程。
通过将差异表达基因与公共数据库进行比对,可以确定基因的功能和相关代谢通路。
常用的功能注释工具包括DAVID、KOBAS、GOseq、KEGG等。
这些工具可以对差异表达基因进行富集分析、通路分析和功能注释。
4. 数据可视化方法数据可视化是高通量基因表达数据分析的重要环节,能够直观地展示数据分布、差异表达基因的表达模式和特征。
常用的数据可视化工具包括ggplot2、heatmap、PCA、Venn图等。
这些工具可以绘制柱状图、热图、散点图、气泡图等多种图形,帮助研究人员深入理解基因表达数据。
结论高通量基因表达数据分析需要经过预处理、差异表达分析、功能注释和数据可视化等多个步骤。
生物信息学中的高通量测序数据分析研究

生物信息学中的高通量测序数据分析研究在生物学领域中,随着人们对生物系统的研究日益深入,高通量测序技术的出现为基因和蛋白质序列的鉴定和分析提供了非常有效的手段。
高通量测序数据分析研究作为生物信息学领域中的一个重要分支,以其高效、快速、准确的特性,不断地吸引着研究者的关注。
高通量测序技术是指一种能够同时测定大量DNA序列的方法,它不仅能够用于基因组组装和注释,还可以通过RNA测序技术来分析基因表达。
这种技术极大地加快了生物学研究的速度和效率,为生物学家提供了大量的测序数据。
然而,这些数据的处理和分析却是非常复杂的。
首先,高通量测序数据的预处理是数据分析的第一步。
当测序数据被生成后,必须对其进行质量控制、过滤低质量序列、去除接头序列等处理,才能得到较为准确的数据。
此外,还有一些其他的预处理过程,例如去重、去序列污染等。
接着,对于各类高通量测序数据进行生物信息学分析非常关键。
生物信息学分析的主要目的是确定基因或蛋白质序列,并了解它们在不同生理状态下的表达和功能。
对于RNA测序数据,其主要方法是将原始数据经过拼接或比对成转录本,然后对得到的转录本进行表达量分析,从而确定不同表达和差异表达基因的信息。
而对于DNA测序数据,则可通过基因组拼装、变异分析、基因预测和功能注释等方法进行深入研究。
近年来,生物信息学领域发展迅速,高通量测序数据分析也成为了该领域中的一个热门研究方向。
许多学者正在研究开发更加准确、更加高效、更加专业的分析工具和方法。
例如,结合机器学习技术的表达量分析方法和差异表达基因分析,能够更加准确地发现差异表达的基因;metagenomics(环境微生物组学)领域,则还需要研究多样性分析、代谢通路分析等更为复杂的问题。
总之,高通量测序数据分析是一个关键的研究领域,它为更深入、全面的生物学研究提供了非常重要的工具和方法。
未来,生物信息学领域需要进一步发展,带来更多的高精度、高效率的数据处理和分析技术,以满足更严格的生物学研究需求。
生物信息学中的高通量基因测序数据处理与分析

生物信息学中的高通量基因测序数据处理与分析随着高通量基因测序技术的发展,大量的基因测序数据得以产生。
这些数据对于生物信息学的研究和应用具有重要意义,因此高通量基因测序数据的处理与分析成为了生物信息学领域的重点之一。
高通量基因测序数据处理是指对原始的测序数据进行加工、清洗和预处理的过程。
首先,需要将测序数据从测序仪中读取出来,得到序列文件。
接着,需要对序列文件进行质量控制,去除低质量序列,过滤掉可能的污染和重复序列。
其次,对于RNA测序数据,需要对序列进行去除adaptor序列、多态性核苷酸等预处理步骤。
最后,对于基因组测序数据,还需要进行比对到参考基因组的工作。
高通量基因测序数据的处理过程中,还需要注意到错误和偏倚的存在。
测序错误可以来源于测序仪的误差,也可以来源于PCR扩增的偏差。
针对这些问题,研究人员可以利用错误纠正算法和统计模型来识别和修复错误的测序数据。
同时,也可以通过样本间和实验间的重复测序来评估和控制测序的偏差。
处理完高通量基因测序数据之后,研究人员就可以进一步进行数据分析。
高通量基因测序数据的分析主要包括基因定量和差异表达分析、基因组注释和变异分析、及关联分析和机器学习等。
基因定量分析可以通过计算读数或转录本的丰度来研究基因的表达模式;差异表达分析可以用于比较不同条件或组织中基因的表达差异,从而找出与特定生物过程或疾病相关的基因。
基因组注释分析可以将基因定位到基因组中的特定位置,并评估基因功能和调控元件的存在。
变异分析可以用于检测和注释基因组中的突变和多态性,研究其与疾病相关性,以及对个体差异的贡献。
关联分析和机器学习可以挖掘大规模测序数据中的相关性和模式,为生物学研究提供新的理解和预测。
为了更好地处理和分析高通量基因测序数据,研究人员还需要掌握一些常用的生物信息学工具和算法。
例如,常用的序列比对算法包括BLAST、Bowtie、BWA等;基因定量和差异表达分析可使用DESeq2、edgeR、limma 等;基因组注释可利用Ensembl、NCBI、UCSC等数据库和工具。
高通量测序的生物信息学分析
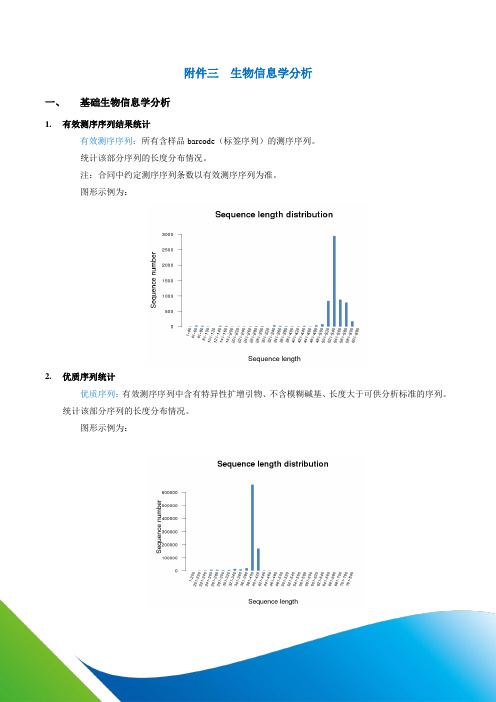
附件三生物信息学分析一、基础生物信息学分析1.有效测序序列结果统计有效测序序列:所有含样品barcode(标签序列)的测序序列。
统计该部分序列的长度分布情况。
注:合同中约定测序序列条数以有效测序序列为准。
图形示例为:2.优质序列统计优质序列:有效测序序列中含有特异性扩增引物、不含模糊碱基、长度大于可供分析标准的序列。
统计该部分序列的长度分布情况。
图形示例为:3.各样本序列数目统计:统计各个样本所含有效测序序列和优质序列数目。
结果示例为:样品有效序列优质序列AB4.OTU生成:根据序列的相似性,将序列归为多个OTU(操作分类单元),以便后续分析。
OTU name A B C D E F G HOTU1 149 410 27 252 45 124 136 101OTU2 0 0 0 0 0 0 0 0OTU3 2 3 14 23 1 5 17 29OTU4 0 47 0 11 0 5 1 7OTU5 19 28 82 9 57 45 303 9OTU6 0 0 0 0 0 0 0 0OTU7 0 182 94 24 14 5 12 60OTU8 0 0 0 0 0 0 0 0...... …………………………………………5.稀释曲线(rarefaction 分析)根据第4条中获得的OTU数据,做出每个样品的Rarefaction曲线。
本合同默认生成OTU相似水平为0.03的rarefaction曲线。
rarefaction曲线结果示例:6.指数分析计算各个样品的相关分析指数,包括:•丰度指数:ace\chao•多样性指数:shannon\simpson•本合同默认生成OTU相似水平为0.03的上述指数值。
多样性指数分析结果示例:注:默认分析以上所列指数,如有特殊需要请说明。
7.Shannon-Wiener曲线利用各样品的测序量在不同测序深度时的微生物多样性指数构建曲线,反映各样本在不同测序数量时的微生物多样性。
生物信息学与高通量数据分析

生物信息学与高通量数据分析生物信息学是一门综合性学科,通过计算机科学和统计学的原理与方法,来研究生物学中的基因组学、转录组学、蛋白质组学等领域。
而高通量数据分析则是生物信息学中的一个重要分支,其涉及大规模的数据收集、处理和解析,以揭示生物系统的运作方式以及恶性疾病的形成机制。
本文将简要介绍生物信息学和高通量数据分析的基本概念、方法和应用。
一、生物信息学的基本概念与研究方法生物信息学是将计算机科学和生物学相结合的学科,旨在利用计算机和统计学的方法来解析与理解生物学中的大量数据。
它包括生物数据库的构建与管理、序列比对与注释、基因表达数据的挖掘与分析等内容。
生物信息学通过整合和分析这些数据,揭示宏观和微观层面上的生物学规律,为科学家们提供深入研究生物系统的便捷工具。
在生物信息学中,常用的研究方法包括序列比对、蛋白质结构预测、进化分析和基因表达分析等。
序列比对是通过将待研究的序列与已知序列进行比对,以找出其相似性和功能区域。
蛋白质结构预测则是根据已知的蛋白质结构,通过计算机模拟和算法预测待研究蛋白质的二级、三级结构。
进化分析通过比较不同生物种群的基因组、蛋白质或DNA序列,推断它们的亲缘关系和进化历程。
基因表达分析则是通过测定不同条件下基因的表达水平,来研究基因调控与功能。
二、高通量数据分析的意义与挑战高通量数据分析是生物信息学中的重要组成部分,其包括了基因组学、转录组学、蛋白质组学等大规模数据的采集、处理和解析过程。
高通量数据来源于一系列高效的实验技术,如基因芯片、测序技术和质谱技术等。
这些技术的发展使得大量生物数据的快速获取成为可能,提供了解析生物系统和研究疾病机制的宝贵资源。
然而,高通量数据分析也面临着许多挑战。
首先,数据量庞大,需要进行高效的存储和处理;其次,数据质量不稳定,可能存在实验误差和测量偏差,需要进行数据清洗和预处理;此外,数据分析方法和工具多样,选择合适的分析策略对于结果的准确性和可靠性至关重要。
高通量基因测序数据分析及生物信息学算法评估

高通量基因测序数据分析及生物信息学算法评估近年来,随着测序技术的发展和普及,高通量基因测序已成为研究生物学和医学领域的重要工具。
高通量基因测序技术能够迅速、准确地获得大量的DNA或RNA序列数据,为研究人员提供了大量的数据资源,但同时也带来了数据分析和算法评估的挑战。
高通量基因测序数据分析是对产生的海量序列进行处理和解析的过程,其目的是从混合的DNA或RNA样本中准确地识别和描述基因组中的序列变异和表达变化。
这一过程通常包括质量控制、序列比对、变异检测、基因表达分析等步骤。
质量控制是高通量基因测序数据分析的起点,它主要用于检测和过滤掉低质量的序列数据。
低质量的序列数据可能由于测序仪器或实验操作等原因导致错误或偏倚,因此需要通过质量控制筛选出高质量的数据,以保证后续的分析结果准确可靠。
序列比对是高通量基因测序数据分析中的核心步骤之一,它将测序得到的短序列与已知的参考基因组或转录组序列进行比对。
目前常用的比对算法包括BWA、Bowtie等。
比对的目的是确定每个测序片段与参考序列的匹配位置,从而获得关于基因组中变异和表达的信息。
变异检测是高通量基因测序数据分析的重要任务之一。
通过比对结果,可以识别出基因组中的SNP(单核苷酸多态性)、Indel(插入缺失)等变异。
变异检测的方法包括基于规则的变异挖掘、基于统计学的变异检验等,这些方法能够帮助研究人员分析和理解基因组的个体差异。
基因表达分析是高通量基因测序数据分析的另一个重要任务。
通过比对并计算每个基因的表达水平,可以研究基因的功能和调控机制。
常用的基因表达分析方法包括RPKM(Reads Per Kilobase of transcript per Million mapped reads)、DESeq2(Differential Expression analysis based on the Negative Binomial Distribution)等。
生物信息学中的高通量数据处理与分析

生物信息学中的高通量数据处理与分析随着生物技术的不断发展,生物研究过程中产生的数据量越来越大,从基因测序到蛋白质组学,都需要处理和分析海量的数据。
这些数据需要高效地存储、管理、分析和可视化,这就需要生物信息学中的高通量数据处理与分析。
I. 生物信息学中的高通量数据高通量数据是指能够同时分析多个样品或者检测多个分子的数据。
在生物实验中,高通量数据主要来自基因测序、轮廓芯片、蛋白质组学等领域。
这些数据的产生量及其复杂性已经远远超过了传统的实验方法。
1. 基因测序数据基因测序是现代遗传学和生物学的基础工具。
通过对基因组、转录组或者蛋白质组的测序,可以帮助我们深入理解生物体的结构和功能。
基因测序数据量巨大,每一次基因测序都会产生几百万到几十亿条碱基序列。
这些数据需要经过预处理、比对、拼接、注释等复杂的处理之后才能生成可靠的结果。
2. 蛋白质组学数据蛋白质组学是研究生物体内蛋白质的种类、数量、结构和功能的学科。
蛋白质组学数据包括蛋白质组的鉴定、定量和结构分析。
鉴定蛋白质需要将复杂的混合物分离出来,通过蛋白质质谱技术进行鉴定。
这个过程中需要对大量的数据进行分析和解释,通过与数据库的比对,找到与之匹配的蛋白质。
II. 高通量数据处理与分析的挑战处理和分析高通量数据需要面对许多挑战。
首先,这些数据量非常庞大,处理过程需要大量的计算资源和存储空间。
其次,处理的过程非常复杂,需要运用许多不同的算法和工具。
最后,数据的质量也是一个重要的因素。
高通量数据中存在许多误差和噪声,因此需要有效的数据预处理和质量控制方法。
1. 数据预处理数据预处理是数据分析的第一步。
基因测序数据需要进行序列质量评估、序列去重、序列比对、序列拼接等处理,才能得到有效的结果。
蛋白质组学数据需要进行数据清洗、信噪比估计、谱酶定量、定量值筛选、差异分析等处理。
2. 数据分析对于高通量数据的分析一般分为两种:有监督的分析和无监督的分析。
有监督的分析是基于已有的信息对数据进行分析和解释,例如对基因测序数据进行差异分析、基因富集分析等。
高通量测序技术的数据分析方法教程

高通量测序技术的数据分析方法教程随着生物技术的发展,高通量测序技术(high-throughput sequencing technology)已成为生物学、医学和生物信息学研究中的重要工具。
高通量测序技术可以快速而准确地测定DNA或RNA序列,透过大量的数据来揭示生物体的基因组、转录组以及其他生物学过程中的变化。
然而,正确且高效地分析测序数据是高通量测序技术应用的关键一步。
本文将介绍高通量测序技术的数据分析方法教程。
首先,分析高通量测序数据前,我们需要了解常见的测序平台和数据格式。
当前常用的高通量测序平台包括Illumina、ABI SOLiD、Ion Torrent等,而测序数据通常以FASTQ、SAM/BAM和VCF等格式存储。
FASTQ格式用于存储原始测序数据,其中包含了每个测序读段的序列信息及其对应的质量分数。
而SAM/BAM格式则是将测序读段比对到参考基因组之后的结果,其中SAM是比对结果的文本格式,而BAM则是对应的二进制格式。
VCF(Variant Call Format)格式则用于存储基因型变异信息。
接下来,我们将介绍高通量测序数据的基本分析流程。
通常,测序数据分析可以分为质控、比对、变异检测和功能注释几个主要步骤。
在质控步骤中,我们需要对测序数据进行质量评估和过滤。
质量评估可以通过查看测序数据的质量分数、GC含量、碱基分布和测序错误率等指标来判断测序数据的质量。
使用质量评估工具如FastQC和NGS QC Toolkit可以帮助我们快速准确地评估测序数据的质量,并进行相应的过滤工作,去除低质量的测序读段。
接下来,我们需要将测序读段比对到参考基因组上。
比对工作可以通过软件如Bowtie、BWA和HISAT等进行。
比对结果通常以SAM格式存储,然后可以进行排序、去重和索引等处理,生成最终的BAM格式文件。
在变异检测步骤中,我们需要从比对后的BAM文件中检测样本中存在的变异信息。
变异检测可以通过多种工具来实现,如GATK、Samtools和VarScan等。
高通量测序数据分析的方法与技术

高通量测序数据分析的方法与技术高通量测序是一种快速、准确、高通量的基因组学工具,随着测序技术的不断发展,可以获取到越来越多的基因组数据。
这些大量的基因组数据需要经过分析才能发挥作用。
在过去的二十年中,生物信息学发生了巨大的变化,这种变化归功于高通量测序技术的到来。
高通量测序数据的分析需要结合多种技术和方法,才能更好地对基因组信息进行解读。
本文将介绍高通量测序数据分析的方法和技术。
一、测序质量控制对于典型的高通量测序数据,数据的可靠性和准确性是非常重要的。
这就需要对测序数据进行质控,以确保数据的可用性。
测序数据的质量检查有两个方面,首先是对原始数据进行检查,其次是对数据进行后处理的检查。
1.1 原始序列数据质量检测原始序列数据包括核苷酸序列的碱基质量和流量图信息。
DNA测序技术测序是通过测序仪交付大量的序列数据然后进行过滤和切割,核苷酸序列的碱基质量和流量图信息的质量将直接影响序列的可靠性。
测序数据质量预处理的主要任务是检查数据的质量。
1.2 数据后处理的质量检测数据处理主要包括去除接头,过滤低质量的碱基,截取序列等。
这些数据的处理可以避免错误的数据和噪声干扰。
因此,经过后处理的数据需要再次进行质量检测。
二、测序数据预处理测序数据预处理是通过处理原始序列数据来减少序列错误、去除噪声和过滤低质量序列的过程。
由于DNA测序技术涉及到大量的碱基读数、低频率和高变异等问题,因此,在数据处理时需要引入一系列技术和算法,以确保我们获得高质量数据。
预处理包括以下几个方面。
2.1 质量过滤质量过滤是在后续分析之前标准化序列数据的过程。
该过程包括破解接头序列、对低质量的序列进行过滤,其中低质量的序列是通过查找AMDF(自适应中值滤波器)确定出来的。
2.2 清除重复序列重复序列也是影响结果的因素之一,这些序列可能来自于PCR反应,或与基因组重复序列类似。
由于重复序列(也称为缺失复合物,CD)有助于分子生物学操纵的误解和解释,因此,将其从数据集中清除是非常必要的。
高通量测序技术及实用数据分析ppt课件

第三代测序:单分子测序
不同于第二代测序依赖于DNA模板与固体表面相结合然后边合成边测序,第三代 分子测序,不需要进行PCR扩增。
早在2008年,HelicoBio Science 公司的Harris等在Science上报道了他们开发的 TIRM(total internal reflection microscopy)测序技术。
;.
18
Ion Torrent测序技术:
使用半导体技术将生化反应与电流强度直接联系。在聚合酶反应时,每聚合 一个碱基会释放出相应的质子,引起周围环境PH的变化,将PH变化转化为 电流的变化,最终记录电流信号,获得测序序列。读长约200bp,根据芯片 不同可以一次产生10M-20G的数据。
;.
19
物上每一个dNTP的聚合与一次荧光信号的释放偶联起来,通过检测荧光的释放和强度,达到
实时测定DNA序列的目的。
;.
14
;.
15
Hiseq2000/Hiseq1000(HIseq2500/Hiseq1500)平台简介: 原理:基于DNA单分子簇边合成 ➢ 将基因组DNA的随机片段附着到光学透明的玻璃表面(即Flow cell),这些DNA片段经过延伸
;.
7
常见的高通量测序测序平台
;.
8
;.
9
;.
10
;.
11
;.
12
;.
13
焦磷酸测序技术:引物与模板DNA退火后,在dna聚合酶(DNA polymerase)、ATP硫酸化酶(ATP
sulfurytase)、荧光素酶(1uciferase)和三磷酸腺苷双磷酸酶(Apyrase)4种酶的协同作用下,将引
• 每一个k-mer作为图中一个节点,两 个k-mer如果在同一read中相邻,则 形成一个边。
基于高通量测序的生物信息学分析方法研究

基于高通量测序的生物信息学分析方法研究随着高通量测序技术的发展,生物学研究的重心已经从单个基因序列的研究转向了大规模基因组和转录组的研究。
高通量测序技术的出现不仅大大降低了生物学研究的成本和时间,而且为生物学领域的研究提供了更加深入、全面的信息。
生物信息学分析作为高通量测序技术的重要组成部分,为研究者提供了多种分析工具和方法,为生物学领域的研究提供了强大的支持。
一、高通量测序技术概述在高通量测序技术中,数据量非常大,需要进行大量的数据处理和分析。
因此,生物信息学分析在高通量测序技术中至关重要。
高通量测序技术包括Illumina、Roche/454、ABI/SOLiD等多种技术,其中Illumina是最常用的测序技术。
Illumina的测序原理是通过选取不同长度的DNA片段来进行序列的测定,将这些片段拼接在一起形成完整的序列。
这种方法具有高产量、高精度、高效率、适用于大规模测序等优点。
二、生物信息学分析方法高通量测序技术所产生的海量数据需要进行深入的分析,生物信息学分析方法正是为这些分析工作提供有效手段的重要组成部分。
生物信息学分析方法可分为基本分析、预测分析和差异分析等几个方面。
1. 基本分析生物信息学基本分析主要分为数据预处理和序列的比对两个部分。
在数据预处理方面,主要包括质控、去除低质量序列、去除适配器、去除含有未知碱基序列的数据、序列长度筛选和低频序列处理等步骤。
在序列比对方面,主要包括基于参考序列和基于无参考序列的两种比对方式。
基于参考序列的比对方式可以使用Bowtie、BWA等较为常用的软件;基于无序参考序列的比对方式,可以使用SOAP、TopHat等软件。
2. 预测分析预测分析是通过基因结构预测、蛋白质结构和功能预测等手段进行分析。
基因结构预测的方法主要有基于比对和基于组装两种方法,通过分析基因转录模式、隐含马尔科夫模型、比对到参考序列的拼接方向等方面进行预测。
蛋白质结构和功能预测则可以通过使用大量的基因组序列和蛋白质数据库,结合计算机预测和实验验证等方法进行预测。
生物信息学中的高通量基因测序数据分析与挖掘技术研究

生物信息学中的高通量基因测序数据分析与挖掘技术研究随着基因测序技术的发展,大规模的高通量基因测序数据正在迅速增加。
这些海量数据提供了一个宝贵的资源,可以用于了解生物的基因组结构、功能和演化等方面的信息。
为了从这些数据中获取有效的信息,生物信息学中的高通量基因测序数据分析和挖掘技术起到了关键的作用。
高通量基因测序技术是一种高效、高通量的测序方法,可以在较短的时间内获得大量的DNA或RNA序列信息。
这种技术的出现大大加速了生物学研究的进展,也为生物信息学研究提供了大量的数据。
高通量基因测序数据分析的主要目标是从原始的测序数据中提取出有用的信息,包括基因组的组装、基因功能注释、SNP(Single Nucleotide Polymorphism)的检测等。
基于高通量测序技术的数据,研究人员可以更好地理解生物体的基因组结构和功能。
高通量基因测序数据分析的第一步是质量控制。
由于测序过程中存在一定的误差,需要对测序数据进行质量评估和处理。
常用的质量控制方法包括去除低质量的测序数据、去除测序接头和引物等。
在数据质量控制后,研究人员可以进行下一步的数据分析。
第二步是基因组的组装。
基因组组装是将测序数据拼接成较长的连续序列,以还原生物的基因组结构。
对于无参考基因组的组装,采用de novo序列组装方法,通过对大量的短读长序列进行拼接,得到较长的序列。
对于已有参考基因组的组装,采用基于参考序列的对齐方法,通过将测序数据与参考序列进行比对,填充空缺以获得更完整的序列。
基因组组装的主要挑战是解决序列重复和大规模基因组的组装难题。
第三步是基因功能注释。
基因功能注释是将基因组序列和基因之间的功能关联进行分析和注释的过程。
常见的功能注释包括基因的功能类型、基因的表达水平和调控因子等。
通过对测序数据进行基因功能注释,可以帮助研究人员理解基因的功能和相互关系。
第四步是SNP(Single Nucleotide Polymorphism)的检测。
高通量生物实验技术与生物数据分析

高通量生物实验技术与生物数据分析随着科技的不断发展,越来越多的新技术被应用于生物学研究中,其中高通量生物实验技术和生物数据分析技术尤为重要。
本文将从这两个方面入手,对它们进行介绍和探讨。
高通量生物实验技术高通量生物实验技术是指一种能够同时对大量生物标本进行实验的技术。
其特点是高速度,大规模和高灵敏度,能够在很短的时间内完成大量实验,同时保证实验结果的准确性和可靠性。
通常,高通量生物实验技术包括基因序列分析,蛋白质分析,细胞分析等。
下面将以基因序列分析为例,介绍常用的高通量生物实验技术。
1. 基因芯片技术基因芯片技术是一种将大量的DNA分子固定到芯片表面上,利用金属电极读取每一个点的蛋白质信号的技术。
基本原理是,将一系列DNA片段固定在芯片表面上,利用杂交技术,将目标DNA序列与芯片上的DNA片段结合。
然后,用荧光染料等方法,测定每个点的光信号。
通过分析光信号的大小和强度,可以确定每个点所代表的DNA序列。
2. 比较基因组学比较基因组学是一种对不同生物种群的基因组进行比较和分析的技术。
通过将两个不同物种的基因组进行比较,可以找到共同的特征和差异,进而推动科学家研究这些物种间的遗传关系、演化过程等。
3. 单细胞测序技术单细胞测序技术是一种能够分离出单个细胞并对其进行基因组测序的技术。
与传统的基因组测序技术不同的是,单细胞测序技术在样品预处理和分离细胞的过程中具有更高的技术要求和更高的精度。
目前,单细胞测序技术被广泛应用于病毒学、肿瘤学和生物发育等方面的研究中。
生物数据分析技术生物数据分析技术是指一种将高通量测序后得到的原始数据进行分析,抽取有用的信息并进行处理的技术。
在高通量生物实验技术的基础上,生物数据分析技术始终被认为是决定实验结果的关键之一。
下面将介绍常用的生物数据分析技术。
1. 基因组学基因组学是对基因组进行全面的分析和描述的学科。
通过比较两个不同物种的基因组中的基因组成,科学家可以发现两个物种之间存在的基因演化关系、差异的来源以及可能对生物表型的影响等。
高通量测序技术在生物信息学中的应用研究

高通量测序技术在生物信息学中的应用研究标题:高通量测序技术在生物信息学中的应用研究摘要:随着高通量测序技术的迅速发展,越来越多的研究已经将其应用于生物信息学领域。
本文旨在探讨高通量测序技术在生物信息学中的应用,包括研究问题及背景、研究方案方法、数据分析和结果呈现以及结论与讨论。
通过文献综述和实例分析,本文旨在揭示高通量测序技术在生物信息学中的潜力以及未来发展的趋势。
一、研究问题及背景随着生物领域研究的深入,科学家们面临着越来越复杂的生物信息学问题。
传统的测序方法无法满足高通量测序大规模数据的需求,因此高通量测序技术的出现为生物信息学研究提供了有效的解决方案。
本段介绍了高通量测序技术在生物信息学研究中的应用背景,并阐述了该研究的重要性和意义。
二、研究方案方法本节详细介绍了高通量测序技术在生物信息学研究中的应用方案和方法。
首先,介绍了高通量测序技术的基本原理和常用的测序方法,如Illumina测序、Ion Torrent测序等。
然后,探讨了高通量测序技术在生物信息学研究中的样本准备、测序过程以及数据质控等关键步骤。
最后,介绍了实验设计和数据分析的策略,包括差异表达分析、多组学数据整合以及功能注释等方法。
三、数据分析和结果呈现本节详细介绍了高通量测序技术在生物信息学研究中的数据分析和结果呈现。
首先,介绍了常用的数据分析工具和软件,如Bowtie、TopHat、Cufflinks等。
然后,介绍了数据质量控制和预处理的方法,包括去除低质量序列、过滤噪声和去除冗余等。
接着,详细阐述了差异表达基因的鉴定和功能注释的方法。
最后,通过实际案例展示了高通量测序技术在生物信息学研究中的数据分析流程和结果呈现方法。
四、结论与讨论本节总结了高通量测序技术在生物信息学研究中的应用,并提出了结论和讨论。
首先,总结了高通量测序技术在生物信息学领域的重要性和应用潜力。
然后,讨论了高通量测序技术在解析基因组结构、揭示基因调控机制、发现新的功能基因以及研究复杂疾病等方面的应用前景。
高通量测序数据的生物信息学分析方法研究

高通量测序数据的生物信息学分析方法研究随着科技的进步,高通量测序技术成为了现代生物学研究中的关键工具之一。
高通量测序技术可以快速地产生大量的DNA或RNA序列信息,为研究者提供了更详尽的基因组、转录组和蛋白质组数据,进而揭示生物体内基因的组成和功能。
然而,高通量测序数据的处理和分析是一个复杂的过程,涉及到大量的生物信息学方法和工具。
本文将介绍常用于高通量测序数据分析的生物信息学方法研究。
1. 数据预处理高通量测序数据的分析首先需要进行数据预处理,以保证数据的质量和准确性。
数据预处理的主要步骤包括:①将原始测序数据进行清洗,去除低质量的序列和污染物。
②对清洗后的数据进行质量控制,包括检查测序错误率、测序深度等指标。
③进行数据格式转换,将原始测序数据转化为常用的FASTQ格式。
2. 序列比对与基因组注释在对高通量测序数据进行分析前,需要将测序读段与参考序列进行比对。
比对工具的选择取决于测序数据的类型和实验目的。
常用的比对工具包括Bowtie、BWA和HISAT等。
比对完成后,需要对比对结果进行基因组注释。
基因组注释是将比对结果与已知的基因组信息进行对应,以确定测序数据中的基因、外显子和转录本的位置和功能。
常用的基因组注释工具包括ANNOVAR、Ensembl和NCBI等数据库。
3. 差异表达分析差异表达分析在研究中起着重要的作用,可以帮助我们找到在不同实验条件下显著表达差异的基因。
差异表达分析的主要步骤包括:①基因表达定量:利用比对结果和已知的基因组信息,对样本中的基因表达进行定量。
②样本分组:将样本分为研究组和对照组,根据研究目的和实验设计确定。
③差异表达分析方法:常用的差异表达分析方法包括DESeq、edgeR和limma。
④基因功能富集分析:为了理解差异表达基因的功能和途径,可以进行基因功能富集分析,寻找共同富集的功能和途径。
4. RNA结构预测与编码区鉴定高通量测序数据还可以用于RNA结构预测和编码区鉴定。
生物信息学在高通量测序数据分析中的应用

HiSeq 2000
Genome Analyzer II
MiSeq
高通量测序技术
了解物种的起源和演化历程 CATGGAAGGCAATCCCACATA Sanger结合NGS
AB/SOLiD
CATGCTAGAAAACATTTAATA
对未知基因组序列的物种
生物信息学在RNA omics方面的应用
PE, paired-end sequencing; SE, single-end sequencing; O, yes; X, no
454
SolexaSOLiD制备乳滴PCR桥式PCR
乳滴PCR
测序反应
聚合反应
聚合反应
连接反应
原理
焦磷酸
反向终止合成 可剪切探针连接
光学检测
是
是
是
最大读长
~1 kb
250 bp
75 bp
最大数据产出* 700 Mb
600 Gb
300 Gb
运行时间
较短
长
最长
主要错误
Indel
替换
替换
准确率
低
高
最高
5500 Series Genetic Analysis Systems
GS FLX+ System
缺点:错误率高 (单次反应错误率~15%。
组装软件:SoapDenovo
Amborella植物测序基因组解决了“达尔文难解之谜”——为什么几百万年前花在地球上突然激增的问题。
单链DNA两端加上非对称的通用接头(包括测序引物),接头与事先固定在固相芯片表面的序列互补
常用基因组拼接软件
• Velvet • Ray • ABySS • SOAPdenovo • SSAKE • SHARCGS • MIRA • Edena
生物信息学_高通量测序技术及数据分析_陈润生院士 ppt课件

背景介绍
• 高通量测序数据格式
– fastq
Q =-10 log10(p) OR Q =-10 log10[p/(1-p)] (p:碱基错误率) 字符的ASCII值 - 64 = 质量值 OR 字符的ASCII值 - 33 = 质量值
NCBI/Sanger or Illumina 1.8 and later. Using a Phred scale encoded using ASCII 33 to 93. This is the standard for fastq formats except for the early Illumina data formats (this changed with version 1.8 of the Illumina Pipeline). Illumina Pipeline 1.2 and earlier. Using a Solexa/Illumina scale (-5 to 40) using ASCII 59 to 104. The Workbench automatically converts these quality scores to the Phred scale on import in order to ensure a common scale for analyses across data sets from different platforms (see details on the conversion next to the sample below). Illumina Pipeline 1.3 and 1.4. Using a Phred scale using ASCII 64 to 104. Illumina Pipeline 1.5 to 1.7. Using a Phred scale using ASCII 64 to 104. Values 0 (@) and 1 (A) are not used anymore. Value 2 (B) has special meaning and is used as a trim clipping. This means that when selecting Illumina Pipeline 1.5 and later, the reads are trimmed when a B is encountered in the input the Trim reads option is checked. 36 39 39 39 39 39 39 39 39 39 38 39 39 生36物36信3息4 3学4 _2高9 3通1 量2 2测0 序20技19术1及9 1数9 据38分38析38 36 36 36 36 36 36 30 32 35 35
生物信息学研究中的高通量测序数据分析

生物信息学研究中的高通量测序数据分析随着科技的发展,高通量测序技术已经成为生物学和医学研究中最重要的方法之一。
通过高通量测序,我们可以获得大量的DNA或RNA测序数据,从而深入了解生物体的基因组或转录组信息。
然而,这些海量数据的分析和解读却是一个繁琐且复杂的过程。
首先,高通量测序数据的处理是数据分析的关键步骤之一。
测序仪输出的原始图像数据需要经过一系列的处理步骤,包括图像重建、碱基识别和测序质量评估等。
通过这些处理步骤,我们可以得到测序数据的质量评估报告,根据报告可以判断数据的可靠性和准确性。
在获得可靠的测序数据后,下一步就是对数据进行基本的分析和处理。
首先是数据的清洗和去噪,即去除低质量的碱基和测序错误等。
这个步骤对于后续的数据分析和解读非常重要,因为错误的数据会导致后续分析的偏差和误解。
清洗和去噪后,我们就可以对数据进行进一步的分析了。
其中最重要的是基因组或转录组的拼接和组装。
通过将测序片段按照一定的规则进行拼接和组装,我们可以获得一个完整的基因组或转录组序列。
这个步骤的关键在于算法的选择和优化,因为不同的算法会对结果产生不同的影响。
一旦获得了基因组或转录组的序列,接下来就是对基因组结构和功能的研究。
在基因组结构的研究中,我们可以通过比对已知基因组序列来寻找新基因或进行基因家族的分析。
同时,也可以通过注释来确定基因的结构和功能,例如编码蛋白质的序列、启动子和转录因子结合位点等。
在转录组研究中,我们可以通过比对已知转录组序列来鉴定新的转录本或进行差异表达分析。
差异表达分析可以帮助我们了解不同生物体在基因表达水平上的差异,并找出对这些差异负责的关键基因。
这对于研究生物体的发育、适应性和疾病等方面非常重要。
除了基因组和转录组的研究,高通量测序数据还可以应用于其他方面的生物信息学研究。
例如,我们可以利用测序数据进行种群遗传学和进化生物学研究,通过比较不同个体间的遗传差异来推测物种的进化历程和亲缘关系。
高通量基因测序和组学数据分析技术

高通量基因测序和组学数据分析技术随着人类基因组计划、HapMap计划以及1000基因组计划的实现,生物信息学与生命科学已成为一种新的交叉学科,高通量基因测序和组学数据分析技术也已成为当前生物学研究的热点。
高通量基因测序技术是一种高效的新型测序技术,与Sanger测序技术相比,其速度更快、成本更低、产量更高、误差率更低。
目前常见的高通量基因测序技术主要包括Illumina、454、Ion Torrent和PacBio等。
其中Illumina是目前最常用的高通量测序技术,其依据的是“桥式扩增”技术,可同时测序数百万个DNA片段。
高通量基因测序技术的应用范围非常广泛,包括基因组测序、转录组测序、表观组测序和以单细胞为单位的测序等。
高通量基因测序技术所得到的大量大规模数据需要依靠组学数据分析技术进行解析和分析。
组学数据分析技术包括生物信息学方法和统计学方法等多种方法,其目的在于从海量数据中提取出有生物学意义和研究价值的信息。
常用的分析方法包括序列比对、功能注释、差异表达分析、蛋白质组学等。
其中,序列比对是基因组和转录组分析的关键步骤,其主要目的是将测序数据与参考基因组序列进行比对,从而获得序列特征和序列变异等信息。
除此之外,对于转录组测序和表观组测序等功能注释也是非常重要的一步。
随着高通量基因测序技术的发展和组学数据分析技术的不断创新,我们已经可以通过这些技术更好地了解生命现象的发生和机制,发现新的致病基因,并进一步探索药物研发过程。
例如在人类基因组计划中,利用高通量基因测序技术已经测定了人类的基因组序列,并发现了大量的人类基因,从而为人类疾病的分子机制研究提供了基础。
在研究肿瘤的发病机制时,高通量基因测序和组学数据分析技术可以帮助我们发现致病基因和分析肿瘤的转录组水平、表观组学水平等多个维度的信息。
在新药研发中,高通量基因测序和组学数据分析技术可以快速筛选出具有活性、特异性和可控性等特征的靶标分子,从而为后续药物研发提供了重要的基础数据。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
– 参考文献
• Metzker, M.L. (2010). Sequencing technologies - the next generation. Nat Rev Genet 11, 31-46.
/nrg/journal/v11/n1/full/nrg2626.html
背景介绍
背景介绍
• 第一代测序技术
– Sanger测序法
• 链终止法 • 双脱氧终止法 • 1975年
Frederick Sanger 弗雷德里克· 桑格 1918年8月13日-2013年11月19日 1958年 诺贝尔化学奖 1980年 诺贝尔化学奖
Transcription
/s/blog_7110867f0100zi09.html
基因芯片与高通量 测序的比较
芯片与测序比较
• 基因芯片
– 约20年的历史,技术比较成熟,成本相对较低 – 原理
• 探针,互补配对的原则 • 靶序列用荧光标记 • 通过荧光强度间接反映靶序列的数量
生物信息学
高通量测序技术及数据分析介绍
高通量测序技术及数据分析介绍
• 背景介绍
– 第一代测序技术 – 第二代(高通量)测序技术
• 基因芯片与高通量测序的比较 • 高通量测序技术的应用
– – – – – – 高通量测序数据分析概览 高通量测序数据质量评估与过滤 基因组测序 RNA-seq ChIP-seq UCSC Genome Bioinformatics
背景介绍
• 以Illumina为例简单介绍测序原理
cBot
Illumina HiSeq 2500
背景介绍
• 高通量测序数据格式
– fasta
• 序列文件的第一行是由大于符号(>)打头的任意文 字说明,主要为标记序列用。从第二行开始是序列 本身,标准核苷酸符号,通常核苷酸符号大小写均 可
– fastq
背景介绍
• 第二代测序技术
– 边合成边测序
• 2005年左右 • Sequencing by synthesis
Illumina HiSeq 2500
– 代表性测序技术
• • • • • Illumina/Solexa Roche/454 ABI/SOLiD Polonator HeliScope
NCBI/Sanger or Illumina 1.8 and later. Using a Phred scale encoded using ASCII 33 to 93. This is the standard for fastq formats except for the early Illumina data formats (this changed with version 1.8 of the Illumina Pipeline). Illumina Pipeline 1.2 and earlier. Using a Solexa/Illumina scale (-5 to 40) using ASCII 59 to 104. The Workbench automatically converts these quality scores to the Phred scale on import in order to ensure a common scale for analyses across data sets from different platforms (see details on the conversion next to the sample below). Illumina Pipeline 1.3 and 1.4. Using a Phred scale using ASCII 64 to 104. Illumina Pipeline 1.5 to 1.7. Using a Phred scale using ASCII 64 to 104. Values 0 (@) and 1 (A) are not used anymore. Value 2 (B) has special meaning and is used as a trim clipping. This means that when selecting Illumina Pipeline 1.5 and later, the reads are trimmed when a B is encountered in the input file if the Trim reads option is checked. 36 39 39 39 39 39 39 39 39 39 38 39 39 36 36 34 34 29 31 2 20 20 19 19 19 38 38 38 36 36 36 36 36 36 30 32 35 3-end
• 首先将DNA样本进行片段化处理形成200-500bp的片 段,引物序列连接到DNA片段的一端,然后末端加 上接头,将片段固定在flow cell上生成DNA簇,上机 测序单端读取序列。
– 双末端测序,pair,在第一轮测序完成后,去除第一轮 测序的模板链,引导互补链在原位置再生和扩增, 以达到第二轮测序所用的模板量,进行第二轮互补 链的合成测序。
• 第一行由‘@’开始,后面跟着序列的描述信息,这点 跟fasta格式是一样的;第二行是序列;第三行由‘+’ 开始,后面也可以跟着序列的描述信息;第四行是 第二行序列的质量评价(quality values),字符数跟 第二行的序列是相等的。背介绍• 高通量测序数据格式
– fastq
Q =-10 log10(p) OR Q =-10 log10[p/(1-p)] (p:碱基错误率) 字符的ASCII值 - 64 = 质量值 OR 字符的ASCII值 - 33 = 质量值