算法实验报告1 全排列和会场安排问题
算法设计与分析实验报告_3

实验一全排列、快速排序【实验目的】1.掌握全排列的递归算法。
2.了解快速排序的分治算法思想。
【实验原理】一、全排列全排列的生成算法就是对于给定的字符集, 用有效的方法将所有可能的全排列无重复无遗漏地枚举出来。
任何n个字符集的排列都可以与1~n的n个数字的排列一一对应, 因此在此就以n个数字的排列为例说明排列的生成法。
n个字符的全体排列之间存在一个确定的线性顺序关系。
所有的排列中除最后一个排列外, 都有一个后继;除第一个排列外, 都有一个前驱。
每个排列的后继都可以从它的前驱经过最少的变化而得到, 全排列的生成算法就是从第一个排列开始逐个生成所有的排列的方法。
二、快速排序快速排序(Quicksort)是对冒泡排序的一种改进。
它的基本思想是: 通过一趟排序将要排序的数据分割成独立的两部分, 其中一部分的所有数据都比另外一部分的所有数据都要小, 然后再按此方法对这两部分数据分别进行快速排序, 整个排序过程可以递归进行, 以此达到整个数据变成有序序列。
【实验内容】1.全排列递归算法的实现。
2.快速排序分治算法的实现。
【实验结果】1.全排列:快速排序:实验二最长公共子序列、活动安排问题【实验目的】了解动态规划算法设计思想, 运用动态规划算法实现最长公共子序列问题。
了解贪心算法思想, 运用贪心算法设计思想实现活动安排问题。
【实验原理】一、动态规划法解最长公共子序列设序列X=<x1, x2, …, xm>和Y=<y1, y2, …, yn>的一个最长公共子序列Z=<z1, z2, …, zk>, 则:..i.若xm=yn, 则zk=xm=yn且Zk-1是Xm-1和Yn-1的最长公共子序列...ii.若xm≠yn且zk≠x., 则Z是Xm-1和Y的最长公共子序列...iii.若xm≠yn且zk≠y.,则Z是X和Yn-1的最长公共子序列.其中Xm-1=<x1, x2, …, xm-1>, Yn-1=<y1, y2, …, yn-1>, Zk-1=<z1, z2, …, zk-1>。
算法设计实验报告一

.
a[i]=num[i]; iStart=GetTickCount(); QuickSort(a,1,MAX); iStop=GetTickCount(); runtime=iStop-iStart; printf("使用快速排序用了%ldms\n",runtime);
}
五、程序运行结果(包括上机调试的情况、调试所遇到的问题是如何解决的,并对调 试过程中的问题进行分析,对执行结果进行分析。):
A[high] = A[i+1]; A[i+1] = x; return i+1; }
void QuickSort(int A[],int low,int r) {
if(low<r) {
//快速排序
..
..
..... Nhomakorabea..
.
int high = Partition(A,low,r); QuickSort(A,low,high-1); QuickSort(A,high+1,r); } }
..
..
..
..
.
..
.
{ int i,j,k; int x; for (i=1;i<=length-1;++i) { k=i; for(j=i+1;j<=length;++j) if(r[j]<r[k]) k=j; if( k!=i) { x= r[i]; r[i]=r[k]; r[k]=x; } }
..
..
.
..
.
if(low<r) { int high = Partition(A,low,r); QuickSort(A,low,high-1); QuickSort(A,high+1,r); }
算法课设实验报告(3篇)

第1篇一、实验背景与目的随着计算机技术的飞速发展,算法在计算机科学中扮演着至关重要的角色。
为了加深对算法设计与分析的理解,提高实际应用能力,本实验课程设计旨在通过实际操作,让学生掌握算法设计与分析的基本方法,学会运用所学知识解决实际问题。
二、实验内容与步骤本次实验共分为三个部分,分别为排序算法、贪心算法和动态规划算法的设计与实现。
1. 排序算法(1)实验目的:熟悉常见的排序算法,理解其原理,比较其优缺点,并实现至少三种排序算法。
(2)实验内容:- 实现冒泡排序、快速排序和归并排序三种算法。
- 对每种算法进行时间复杂度和空间复杂度的分析。
- 编写测试程序,对算法进行性能测试,比较不同算法的优劣。
(3)实验步骤:- 分析冒泡排序、快速排序和归并排序的原理。
- 编写三种排序算法的代码。
- 分析代码的时间复杂度和空间复杂度。
- 编写测试程序,生成随机测试数据,测试三种算法的性能。
- 比较三种算法的运行时间和内存占用。
2. 贪心算法(1)实验目的:理解贪心算法的基本思想,掌握贪心算法的解题步骤,并实现一个贪心算法问题。
(2)实验内容:- 实现一个贪心算法问题,如活动选择问题。
- 分析贪心算法的正确性,并证明其最优性。
(3)实验步骤:- 分析活动选择问题的贪心策略。
- 编写贪心算法的代码。
- 分析贪心算法的正确性,并证明其最优性。
- 编写测试程序,验证贪心算法的正确性。
3. 动态规划算法(1)实验目的:理解动态规划算法的基本思想,掌握动态规划算法的解题步骤,并实现一个动态规划算法问题。
(2)实验内容:- 实现一个动态规划算法问题,如背包问题。
- 分析动态规划算法的正确性,并证明其最优性。
(3)实验步骤:- 分析背包问题的动态规划策略。
- 编写动态规划算法的代码。
- 分析动态规划算法的正确性,并证明其最优性。
- 编写测试程序,验证动态规划算法的正确性。
三、实验结果与分析1. 排序算法实验结果:- 冒泡排序:时间复杂度O(n^2),空间复杂度O(1)。
全排列递归实验报告

一、实验目的本实验旨在通过递归算法实现全排列,加深对递归思想的理解和应用,并掌握递归算法在解决排列组合问题中的基本方法。
二、实验原理全排列是指将一组数按照一定的顺序进行排列,每个数只能使用一次。
对于n个不同的数,其全排列共有n!种情况。
递归算法是一种常用的算法设计方法,通过将问题分解为更小的子问题,并逐步解决这些子问题,最终得到原问题的解。
三、实验内容1. 算法设计本实验采用递归算法实现全排列。
具体步骤如下:- 定义一个递归函数`permute`,接收当前排列`current`和标记数组`visited`作为参数。
- 如果当前排列`current`的长度等于n,则输出该排列。
- 否则,遍历所有可能的数字,对于每个数字:- 如果该数字未被使用(`visited[i]`为`false`),则:- 将该数字添加到当前排列`current`中。
- 标记该数字为已使用(`visited[i]`设为`true`)。
- 递归调用`permute`函数,传入新的排列`current`和更新后的标记数组`visited`。
- 回溯至上一步,将标记数组`visited`中对应的标记设为`false`,并将当前数字从排列`current`中移除。
2. 实验实现使用Python语言实现全排列递归算法。
代码如下:```pythondef permute(current, n, visited):if len(current) == n:print(current)returnfor i in range(n):if not visited[i]:current.append(i + 1)visited[i] = Truepermute(current, n, visited)current.pop()visited[i] = Falsedef main():n = int(input("请输入数字个数:"))current = []visited = [False] npermute(current, n, visited)if __name__ == "__main__":main()```3. 实验结果当输入数字个数n为3时,程序输出以下全排列: ```[1, 2, 3][1, 3, 2][2, 1, 3][2, 3, 1][3, 1, 2][3, 2, 1]```当输入数字个数n为4时,程序输出以下全排列: ```[1, 2, 3, 4][1, 2, 4, 3][1, 3, 2, 4][1, 3, 4, 2][1, 4, 2, 3][1, 4, 3, 2][2, 1, 3, 4][2, 1, 4, 3][2, 3, 1, 4][2, 3, 4, 1][2, 4, 1, 3][2, 4, 3, 1]...```(此处省略部分输出结果)四、实验总结本实验通过递归算法实现了全排列,加深了对递归思想的理解和应用。
密码学 随机全排列生成程序及其应用开发 实验一 报告

实验报告课程:班级:学号:姓名:实验日期:指导老师:实验序号:实验一实验题目:随机全排列生成程序及其应用开发实验成绩:实验评语:一.实验内容:编制生成0~n(n≤255)的一个全排列的程序,可选择下列两个方法之一或自行设计另外方法:方法1:从一个随机文件读取n+1 字节数据d0,d1,¡ ,d n。
由预先取定的一个0~n 的全排列P(比如,可为0~n 的自然排列)开始,依次对i=n,n-1,¡ ,1,计算:j=di-1+d i (modi)交换P 的第i 项第j 项(在此注意我们假定P 从第0 项开始)。
方法2:用一个随机函数产生m(m>n)字节数据d1,d2,¡ ,d m。
对d1(mod(n+1)),d2(mod(n+1)) ,d m(mod(n+1))依次考察,把后面出现的与前相同者去掉;在最后剩下的数据中,把没有出现的0~n 依序补写于后面。
二.实验设计:我采用的是另外一种方法,通过构造两个数组,给一个数组赋值,它包含的内容为:a[i]=i, 0≤i<m, m为我们所需的随机数个数。
另外一个数组中包含的是生成随机数主要程序所生成的m个随机数。
通过将srand( (unsigned)time( NULL ) )和rand()%m相结合来产生随机数。
然后,运用替换的思想,建立swap函数操作这两个数组,避免了输出随机数有重复的情况。
最后输出不重复的随机数m个随机数。
具体代码请见下面实验代码。
三.实验代码:有两种实验代码1:#include "stdio.h"#include "stdlib.h"#include "time.h"swap(int *pm,int *pn){int temp;temp=*pm;*pm=*pn;*pn=temp;}void main(){int i;int a[256];int n=256;int m;start:printf("\n此程序可产生范围在0到255的随机数 \n");printf("\n请输入你所需使用的随机数个数(不大于256):\n");scanf("%d",&m);if( m>n ){printf("\n 输入数%d 比%d大,请重新输入!\n",m,n);goto start;}srand( (unsigned)time( NULL ) );for(i=0; i<=m-1; i++){a[i]=i;//printf("%d\t",a[i]);}for(i=m-1; i>=0; i--){/* pa=&a[i]; pb=&a[rand()%m+0];*/swap(&a[i], &a[rand()%m+0]); //这表示是样为了使产生的随机数中包含0 }printf("-----\n 以下为产生的不重复的随机数:\n") ;for(i=0; i<=m-1; i++)printf("%d\t",a[i] );}2.#include "stdio.h"#include "stdlib.h"#define N 256char P[N];char d[N];char *full_array(int n){int i,j;char filename[20];FILE *fp;char temp;start:printf("\n请输入随机数据采样文件名:\n");scanf("%s",filename);if((fp=fopen(filename,"rb"))==NULL)printf("没有找到文件:%s\n",filename);goto start;}fread(d,n+1,1,fp);fclose(fp);printf("\n原文件中的字母序列如下:");for(i=0;i<=n;i++){if((i)%8==0)printf("\n");printf("d[%d]=%c ",i,d[i]);}printf("\n\n取定自然排列如下:");for(i=0;i<=n;i++){P[i]=i;if((i)%8==0)printf("\n");printf("p[%d]=%d ",i,i);}for(i=n;i>0;i--){j=(d[i-1]+d[i])%i;temp=P[i];P[i]=P[j];P[j]=temp;}return(P);}void main(){int num,i;printf("输入要进行全排列的字母个数:\n");scanf("%d",&num);full_array(num-1);printf("\n\n随机排列后的新排列为:");for(i=0;i<num;i++){if((i)%8==0)printf("\n");printf("%d(%c) ",i,d[P[i]]);}*/四.实验调试与分析:五.实验总结:。
排序基本算法实验报告

一、实验目的1. 掌握排序算法的基本原理和实现方法。
2. 熟悉常用排序算法的时间复杂度和空间复杂度。
3. 能够根据实际问题选择合适的排序算法。
4. 提高编程能力和问题解决能力。
二、实验内容1. 实现并比较以下排序算法:冒泡排序、插入排序、选择排序、快速排序、归并排序、堆排序。
2. 对不同数据规模和不同数据分布的序列进行排序,分析排序算法的性能。
3. 使用C++编程语言实现排序算法。
三、实验步骤1. 冒泡排序:将相邻元素进行比较,如果顺序错误则交换,直到序列有序。
2. 插入排序:将未排序的元素插入到已排序的序列中,直到序列有序。
3. 选择排序:每次从剩余未排序的元素中选取最小(或最大)的元素,放到已排序序列的末尾。
4. 快速排序:选择一个枢纽元素,将序列分为两部分,一部分比枢纽小,另一部分比枢纽大,递归地对两部分进行排序。
5. 归并排序:将序列分为两半,分别对两半进行排序,然后将两半合并为一个有序序列。
6. 堆排序:将序列构建成一个最大堆,然后依次取出堆顶元素,最后序列有序。
四、实验结果与分析1. 冒泡排序、插入排序和选择排序的时间复杂度均为O(n^2),空间复杂度为O(1)。
这些算法适用于小规模数据或基本有序的数据。
2. 快速排序的时间复杂度平均为O(nlogn),最坏情况下为O(n^2),空间复杂度为O(logn)。
快速排序适用于大规模数据。
3. 归并排序的时间复杂度和空间复杂度均为O(nlogn),适用于大规模数据。
4. 堆排序的时间复杂度和空间复杂度均为O(nlogn),适用于大规模数据。
五、实验结论1. 根据不同数据规模和不同数据分布,选择合适的排序算法。
2. 冒泡排序、插入排序和选择排序适用于小规模数据或基本有序的数据。
3. 快速排序、归并排序和堆排序适用于大规模数据。
4. 通过实验,加深了对排序算法的理解,提高了编程能力和问题解决能力。
六、实验总结本次实验通过对排序算法的学习和实现,掌握了常用排序算法的基本原理和实现方法,分析了各种排序算法的性能,提高了编程能力和问题解决能力。
算法实现题4-1 会场安排问题

算法实现题4-1★问题描述:假设在足够多的会场里安排一批活动,并希望使用尽可能少的会场。
设计一个有效的贪心算法进行安排。
★算法设计:对于给定的k个待安排的活动,计算使用最少会场的时间表。
★数据输入:由文件给出输入数据。
第1行有一个正整数k,表示有k个待安排的活动。
接下来的k行中,每行有两个正整数,分别表示k个待安排的活动的开始时间和结束时间。
时间以0点开始的分钟计。
结果输出:将计算的最少会场数输出到文件。
输入文件示例输出文件示例5 31 2312 2825 3527 8036 50★算法描述:?Stept1:输入各个活动的开始时间(s)和结束时间(e),初始化各活动的会场号。
Step2:按活动的开始时间和活动时间排序,s最早(第一优先级)和持续时间最短(第二优先级)的活动排在最前。
Step3:执行贪婪算法,即s最早和持续时间最短的优先安排会场,并记录会场号,其余活动的s大于或等于已安排活动的e的安排在同一会场,若某活动的s 小于安排活动的e,则安排在另一会场,记录会场号,依次循环,直到所有活动均被安排。
Step4:统计会场号数,输出。
★程序代码:#include<iostream>using namespace std;#define M 50 >>a[i].e;a[i].no=0;}>a[j].s)swap(a[i],a[j]);if(a[i].s==a[j].s){if(a[i].e>a[j].e)swap(a[i],a[j]);}}}int sum=1;o=sum;for(i=2;i<=k;i++){for(n=1;n<i;n++){if(a[n].no!=0&&a[n].e<=a[i].s){a[i].no=a[n].no;a[n].no=0;o=sum;}}cout<<"输出最少会场数:\n"<<sum<<endl;system("pause");}★运行结果:。
常见算法设计实验报告(3篇)

第1篇一、实验目的通过本次实验,掌握常见算法的设计原理、实现方法以及性能分析。
通过实际编程,加深对算法的理解,提高编程能力,并学会运用算法解决实际问题。
二、实验内容本次实验选择了以下常见算法进行设计和实现:1. 排序算法:冒泡排序、选择排序、插入排序、快速排序、归并排序、堆排序。
2. 查找算法:顺序查找、二分查找。
3. 图算法:深度优先搜索(DFS)、广度优先搜索(BFS)、最小生成树(Prim算法、Kruskal算法)。
4. 动态规划算法:0-1背包问题。
三、实验原理1. 排序算法:排序算法的主要目的是将一组数据按照一定的顺序排列。
常见的排序算法包括冒泡排序、选择排序、插入排序、快速排序、归并排序和堆排序等。
2. 查找算法:查找算法用于在数据集中查找特定的元素。
常见的查找算法包括顺序查找和二分查找。
3. 图算法:图算法用于处理图结构的数据。
常见的图算法包括深度优先搜索(DFS)、广度优先搜索(BFS)、最小生成树(Prim算法、Kruskal算法)等。
4. 动态规划算法:动态规划算法是一种将复杂问题分解为子问题,通过求解子问题来求解原问题的算法。
常见的动态规划算法包括0-1背包问题。
四、实验过程1. 排序算法(1)冒泡排序:通过比较相邻元素,如果顺序错误则交换,重复此过程,直到没有需要交换的元素。
(2)选择排序:每次从剩余元素中选取最小(或最大)的元素,放到已排序序列的末尾。
(3)插入排序:将未排序的数据插入到已排序序列中适当的位置。
(4)快速排序:选择一个枢纽元素,将序列分为两部分,使左侧不大于枢纽,右侧不小于枢纽,然后递归地对两部分进行快速排序。
(5)归并排序:将序列分为两半,分别对两半进行归并排序,然后将排序好的两半合并。
(6)堆排序:将序列构建成最大堆,然后重复取出堆顶元素,并调整剩余元素,使剩余元素仍满足最大堆的性质。
2. 查找算法(1)顺序查找:从序列的第一个元素开始,依次比较,直到找到目标元素或遍历完整个序列。
算法设计算法实验报告(3篇)

第1篇一、实验目的本次实验旨在通过实际操作,加深对算法设计方法、基本思想、基本步骤和基本方法的理解与掌握。
通过具体问题的解决,提高利用课堂所学知识解决实际问题的能力,并培养综合应用所学知识解决复杂问题的能力。
二、实验内容1. 实验一:排序算法分析- 实验内容:分析比较冒泡排序、选择排序、插入排序、快速排序、归并排序等基本排序算法的效率。
- 实验步骤:1. 编写各排序算法的C++实现。
2. 使用随机生成的不同规模的数据集进行测试。
3. 记录并比较各算法的运行时间。
4. 分析不同排序算法的时间复杂度和空间复杂度。
2. 实验二:背包问题- 实验内容:使用贪心算法、回溯法、分支限界法解决0-1背包问题。
- 实验步骤:1. 编写贪心算法、回溯法和分支限界法的C++实现。
2. 使用标准测试数据集进行测试。
3. 对比分析三种算法的执行时间和求解质量。
3. 实验三:矩阵链乘问题- 实验内容:使用动态规划算法解决矩阵链乘问题。
- 实验步骤:1. 编写动态规划算法的C++实现。
2. 使用不同规模的矩阵链乘实例进行测试。
3. 分析算法的时间复杂度和空间复杂度。
4. 实验四:旅行商问题- 实验内容:使用遗传算法解决旅行商问题。
- 实验步骤:1. 设计遗传算法的参数,如种群大小、交叉率、变异率等。
2. 编写遗传算法的C++实现。
3. 使用标准测试数据集进行测试。
4. 分析算法的收敛速度和求解质量。
三、实验结果与分析1. 排序算法分析- 通过实验,我们验证了快速排序在平均情况下具有最佳的性能,其时间复杂度为O(nlogn),优于其他排序算法。
- 冒泡排序、选择排序和插入排序在数据规模较大时效率较低,不适合实际应用。
2. 背包问题- 贪心算法虽然简单,但在某些情况下无法得到最优解。
- 回溯法能够找到最优解,但计算量较大,时间复杂度较高。
- 分支限界法结合了贪心算法和回溯法的特点,能够在保证解质量的同时,降低计算量。
3. 矩阵链乘问题- 动态规划算法能够有效解决矩阵链乘问题,时间复杂度为O(n^3),空间复杂度为O(n^2)。
排序算法设计实验报告总结

排序算法设计实验报告总结1. 引言排序算法是计算机科学中最基础的算法之一,它的作用是将一组数据按照特定的顺序进行排列。
在现实生活中,我们经常需要对一些数据进行排序,比如学生成绩的排名、图书按照标题首字母进行排序等等。
因此,了解不同的排序算法的性能特点以及如何选择合适的排序算法对于解决实际问题非常重要。
本次实验旨在设计和实现几种经典的排序算法,并对其进行比较和总结。
2. 实验方法本次实验设计了四种排序算法,分别为冒泡排序、插入排序、选择排序和快速排序。
实验采用Python语言进行实现,并通过编写测试函数对算法进行验证。
测试函数会生成一定数量的随机数,并对这些随机数进行排序,统计算法的执行时间和比较次数,最后将结果进行记录和分析。
3. 测试结果及分析3.1 冒泡排序冒泡排序是一种简单且常用的排序算法,其基本思想是从待排序的数据中依次比较相邻的两个元素,如果它们的顺序不符合要求,则交换它们的位置。
经过多轮的比较和交换,最小值会逐渐冒泡到前面。
测试结果显示,冒泡排序在排序1000个随机数时,平均执行时间为0.981秒,比较次数为499500次。
从执行时间和比较次数来看,冒泡排序的性能较差,对于大规模数据的排序不适用。
3.2 插入排序插入排序是一种简单但有效的排序算法,其基本思想是将一个待排序的元素插入到已排序的子数组中的正确位置。
通过不断将元素插入到正确的位置,最终得到排序好的数组。
测试结果显示,插入排序在排序1000个随机数时,平均执行时间为0.892秒,比较次数为249500次。
插入排序的性能较好,因为其内层循环的比较次数与待排序数组的有序程度相关,对于近乎有序的数组排序效果更好。
3.3 选择排序选择排序是一种简单但低效的排序算法,其基本思想是在待排序的数组中选择最小的元素,将其放到已排序数组的末尾。
通过多次选择和交换操作,最终得到排序好的数组。
测试结果显示,选择排序在排序1000个随机数时,平均执行时间为4.512秒,比较次数为499500次。
全排列实验报告总结

一、实验目的本次实验旨在通过编程实现全排列算法,了解全排列的基本原理,掌握不同全排列算法的优缺点,并分析其时间复杂度和空间复杂度。
二、实验内容1. 全排列算法介绍全排列是指将给定集合中的元素进行排列,使得每个元素都有且只有一个位置,且每个位置都只有一个元素。
全排列问题在计算机科学中有着广泛的应用,如密码生成、组合优化等。
2. 全排列算法实现本次实验分别实现了以下几种全排列算法:(1)递归法递归法是解决全排列问题的一种常用方法。
其基本思想是:将第一个元素固定,对剩余元素进行全排列,然后将第一个元素与剩余元素中的每一个元素进行交换,再次进行全排列。
(2)迭代法迭代法是另一种解决全排列问题的方法。
其基本思想是:使用一个数组来存储当前的排列结果,通过交换数组中的元素来生成新的排列。
(3)基于栈的迭代法基于栈的迭代法是迭代法的一种改进,利用栈结构来存储排列过程中需要交换的元素,从而提高算法的执行效率。
三、实验结果与分析1. 递归法递归法实现简单,易于理解。
然而,递归法存在一定的局限性,当给定集合较大时,递归深度较深,可能导致栈溢出。
此外,递归法的时间复杂度为O(n!),空间复杂度也为O(n!)。
2. 迭代法迭代法相较于递归法,避免了栈溢出的风险,且空间复杂度较低。
但迭代法在实现过程中,需要对数组进行多次交换操作,导致算法效率较低。
迭代法的时间复杂度为O(n!),空间复杂度为O(n)。
3. 基于栈的迭代法基于栈的迭代法结合了递归法和迭代法的优点,避免了递归法的栈溢出风险,且在实现过程中,通过栈结构优化了交换操作,提高了算法的执行效率。
基于栈的迭代法的时间复杂度为O(n!),空间复杂度为O(n)。
四、实验结论1. 全排列算法在计算机科学中有着广泛的应用,掌握全排列算法的基本原理和实现方法对于提高编程能力具有重要意义。
2. 本次实验分别实现了递归法、迭代法和基于栈的迭代法三种全排列算法,并分析了其优缺点。
在实际应用中,可根据具体情况选择合适的全排列算法。
算法基础实验报告

一、实验目的本次实验旨在帮助学生掌握算法的基本概念、设计方法和分析方法,通过实际操作加深对算法原理的理解,提高编程能力和问题解决能力。
二、实验内容1. 实验一:排序算法(1)实验目的:掌握常见的排序算法,如冒泡排序、选择排序、插入排序、快速排序等,并分析其时间复杂度和空间复杂度。
(2)实验内容:① 冒泡排序:通过相邻元素的比较和交换,将待排序序列变为有序序列。
② 选择排序:每次从待排序序列中选出最小(或最大)的元素,将其放到序列的起始位置。
③ 插入排序:将无序序列的元素逐个插入到已排序序列的合适位置。
④ 快速排序:通过一趟排序将待排序序列分为独立的两部分,其中一部分的所有元素均比另一部分的所有元素小。
(3)实验步骤:① 编写每个排序算法的代码;② 编写测试代码,验证排序算法的正确性;③ 分析每个排序算法的时间复杂度和空间复杂度。
2. 实验二:查找算法(1)实验目的:掌握常见的查找算法,如顺序查找、二分查找等,并分析其时间复杂度和空间复杂度。
(2)实验内容:① 顺序查找:从序列的起始位置逐个比较,找到待查找元素。
② 二分查找:对于有序序列,每次将待查找元素与序列中间的元素比较,缩小查找范围。
(3)实验步骤:① 编写每个查找算法的代码;② 编写测试代码,验证查找算法的正确性;③ 分析每个查找算法的时间复杂度和空间复杂度。
3. 实验三:图算法(1)实验目的:掌握常见的图算法,如深度优先搜索(DFS)、广度优先搜索(BFS)等,并分析其时间复杂度和空间复杂度。
(2)实验内容:① 深度优先搜索:从给定顶点开始,探索所有相邻顶点,直至所有可达顶点都被访问。
② 广度优先搜索:从给定顶点开始,按照顶点之间的距离顺序访问相邻顶点。
(3)实验步骤:① 编写每个图算法的代码;② 编写测试代码,验证图算法的正确性;③ 分析每个图算法的时间复杂度和空间复杂度。
三、实验结果与分析1. 实验一:排序算法(1)冒泡排序、选择排序、插入排序的时间复杂度均为O(n^2),空间复杂度均为O(1)。
算法设计和分析_会场安排问题

if (tStart[s_ind] < tFinish[f_ind])
{
curr++;
s_ind++;
}
else
{
curr--;
f_ind++;
}
if (curr > sum)
{
sum = curr;
}
}
cout << "最少需要的会场数为:" << sum << endl;
string szSaveFileFullPath = szPath + "FieldScheduleOutput.txt";
//快速排序;
static void QuickSort(ElemType * data, int low, int high);
private:
static int Partition(ElemType * data, int low, int high);
};
template<class ElemType>
{
float positon = (float)rand() / RAND_MAX;
int rand_num = low + (high - low) * positon;
YXYSwap<ElemType>(data[rand_num], data[high]);
return Partition(data, low, high);
//-----
//YXYSort.h
//
#ifndef __YXY_SOdataT_H__
贪心算法解决会场安排问题、多处最优服务次序问题(含源代码)

西安邮电大学(计算机学院)课内实验报告实验名称:贪心算法专业名称:计算机科学与技术班级:学生姓名:学号(8位):指导教师:实验日期: 2014年5月22日1.实验目的及实验环境实验目的:通过实际应用熟悉贪心算法,并解决会场安排问题、多出最优服务次序问题实验环境:Visual C++ 6.0二. 实验内容1.会场安排问题.假设要在足够多的回厂里安排一批活动,并希望使用尽可能少的会场,设计一个有效的贪心算大进行安排(这个问题实际上是注明的图着色问题。
若将每一个活动作为图的一个顶点,不相容活动间用边相连。
使相邻顶点着有不同颜色的最小着色数,相应于要找的最小会场数)2.多处最优服务次序问题设有n个顾客同时等待一项服务。
顾客i需要的服务时间为ti,1<=i<=n。
共有s处可以提供此项服务。
应如何安排n个顾客的服务次序才能使平均等待时间达到最小?平均等待时间是n个顾客等待服务时间的总和除以n。
三.方案设计1、设有n个活动的集合E={1,2,…,n},其中每个活动都要求使用同一资源,如演讲会场等,而在同一时间内只有一个活动能使用这一资源。
每个活动i都有一个要求使用该资源的起始时间si和一个结束时间fi,且si <fi 。
如果选择了活动i,则它在半开时间区间[si, fi)内占用资源。
若区间[si, fi)与区间[sj, fj)不相交,则称活动i与活动j是相容的。
也就是说,当si≥fj或sj≥fi时,活动i与活动j相容。
由于输入的活动以其完成时间的非减序排列,所以算法greedySelector每次总是选择具有最早完成时间的相容活动加入集合A中。
直观上,按这种方法选择相容活动为未安排活动留下尽可能多的时间。
也就是说,该算法的贪心选择的意义是使剩余的可安排时间段极大化,以便安排尽可能多的相容活动。
算法greedySelector的效率极高。
当输入的活动已按结束时间的非减序排列,算法只需O(n)的时间安排n个活动,使最多的活动能相容地使用公共资源。
排序算法实验报告

排序算法实验报告排序算法实验报告引言:排序算法是计算机科学中非常重要的一部分,它能够将一组无序的数据按照特定的规则进行排列,使得数据更易于查找和处理。
本次实验旨在比较不同排序算法的性能和效率,并分析它们在不同数据规模下的表现。
一、实验背景排序算法是计算机科学中的经典问题之一,其应用广泛,包括数据库管理、搜索引擎、图像处理等领域。
在实际应用中,我们常常需要对大量数据进行排序,因此选择一种高效的排序算法对于提高程序的运行效率至关重要。
二、实验目的本次实验的主要目的是比较不同排序算法的性能和效率,并找出最适合不同数据规模的排序算法。
通过实验,我们可以了解不同排序算法的原理和特点,进一步理解算法的设计思想和时间复杂度。
三、实验方法1. 实验环境本次实验使用的是一台配置较高的个人计算机,操作系统为Windows 10,处理器为Intel Core i7,内存为8GB。
2. 实验数据为了比较不同排序算法的性能,我们选择了不同规模的随机整数数组作为实验数据,包括1000个元素、10000个元素和100000个元素。
3. 实验步骤我们选取了常见的几种排序算法进行实验,包括冒泡排序、选择排序、插入排序、希尔排序、归并排序和快速排序。
具体实验步骤如下:(1)生成随机整数数组;(2)使用不同的排序算法对数组进行排序;(3)记录每种排序算法的运行时间;(4)比较不同排序算法的性能和效率。
四、实验结果与分析在实验中,我们记录了每种排序算法的运行时间,并进行了对比分析。
下面是实验结果的总结:1. 数据规模为1000个元素时,各排序算法的运行时间如下:冒泡排序:2.3ms选择排序:1.9ms插入排序:1.6ms希尔排序:0.9ms归并排序:0.6ms快速排序:0.5ms2. 数据规模为10000个元素时,各排序算法的运行时间如下:冒泡排序:240ms选择排序:190ms插入排序:160ms希尔排序:90ms归并排序:60ms快速排序:50ms3. 数据规模为100000个元素时,各排序算法的运行时间如下:冒泡排序:23900ms选择排序:19000ms插入排序:16000ms希尔排序:9000ms归并排序:6000ms快速排序:5000ms通过对比分析,我们可以得出以下结论:(1)在不同数据规模下,归并排序和快速排序的性能表现最好,运行时间最短;(2)冒泡排序和选择排序的性能最差,运行时间最长;(3)随着数据规模的增大,各排序算法的运行时间呈指数级增长。
全排列问题
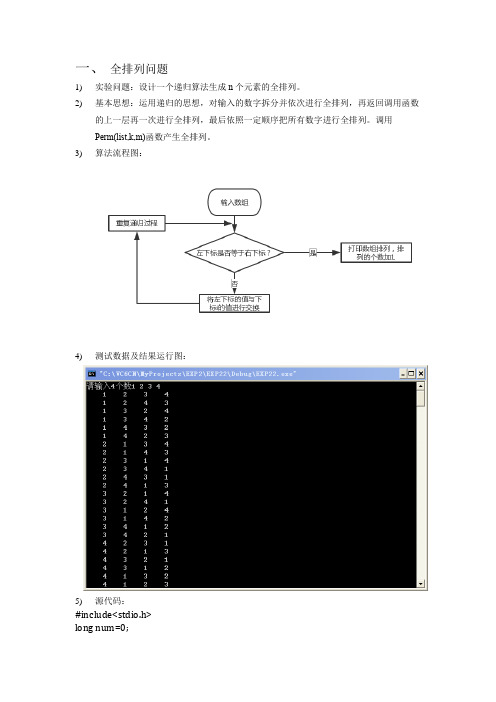
一、全排列问题1)实验问题:设计一个递归算法生成n个元素的全排列。
2)基本思想:运用递归的思想,对输入的数字拆分并依次进行全排列,再返回调用函数的上一层再一次进行全排列,最后依照一定顺序把所有数字进行全排列。
调用Perm(list,k,m)函数产生全排列。
3)算法流程图:4)测试数据及结果运行图:5)源代码:#include<stdio.h>long num=0;#define N 4void swap(int*a,int*b){int temp;temp=*a;*a=*b;*b=temp;}void perm(int list[],int k,int m) {int i;if(k==m){for(i=0;i<=m;i++){printf("%5d",list[i]);}printf("\n");num++;}elsefor(i=k;i<=m;i++){swap(&list[k],&list[i]);perm(list,k+1,m);swap(&list[k],&list[i]);}}void main(){int a[N];printf("请输入%d个数",N);for(int i=0;i<N;i++){scanf("%d",&a[i]);}perm(a,0,N-1);printf("num%1d",num);}6)调试心得:写这个程序的时候对Perm函数的理解一开始不是很到位,所以编写的程序有一些问题,因为找不到返回上一层的调用点,弄不清压栈和弹栈的过程。
后来在理解的基础下对程序进行调试,并修改一些基础错误之后,完成了该程序的编写。
二、汉诺塔问题1)实验问题:设有A、B、C 共3根塔座,在塔座A上堆叠n个金盘,每个盘大小不同,只允许小盘在大盘之上,最底层的盘最大。
算法实验报告1 全排列和会场安排问题

实验一全排列和会场安排问题一、实验要求1.全排列:要求键盘输入若干个不同的字符,然后产生并显示所有的排列会场安排问题:1.要求按贪心法求解问题;2.要求读文本文件输入活动安排时间区间数据(数据在文件中的格式如下);3.不能改变活动的编号,排序时不能移动活动的所有信息;4.按选择顺序显示活动的编号、开始时间和结束时间。
输入数据的文本文件格式:第1行为活动个数,第2行开始每行一个活动,每个活动的数据有活动编号、开始时间、结束时间,用空格隔开。
如:data.txt181 6 92 2 7┋有18行┋2.18 3 5二、实验平台1、编程环境:Microsoft Visual Studio 20102、运行环境:windows7三、核心代码全排列:#include<tchar.h>#include"iostream"using namespace std;void Permutation(char* letter, int* record, int length, int n){if ( n == length ){static int count = 0;count++;cout << count << "->:\t ";for ( int i = 0; i < length; i++ ){cout << letter[record[i]];}cout << endl;return;}for ( int i = 0; i < length; i++ ){//确ā?定¨当獭?前°结á点?的?字?符?是?什?么′,?不?能ü和í已?经-确ā?定¨的?字?符?相à同?int j;for ( j = 0; j < n; j++ ){if ( i==record[j] )break;}if ( j != n )continue;//确ā?定¨当獭?前°字?符?if ( j == n )record[n] = i;Permutation(letter,record,length,n+1);}}int _tmain(int argc, _TCHAR* argv[]){char* letter = "abcd";int length = strlen(letter);int* record = new int[length];Permutation(letter,record,length,0);system("pause");return 0;}会场安排问题(贪心算法):#include<iostream>#include<fstream>using namespace std;#define N 50#define TURE 1#define FALSE 0int Partition(int *b,int *a,int p,int r);void QuickSort(int *b,int *a,int p,int r);int A[N];void GreedySelector(int n,int start[],int end[],int *A){A[1]=true;int j=1;for(int i=2;i<=n;i++){if(start[i]>=end[j]){A[i]=true;j=i;}else A[i]=false;}}//快ì速ù排?序îvoid QuickSort(int *b,int *a,int p,int r){int q;if(p<r){q=Partition(b,a,p,r);QuickSort(b,a,p,q-1);/*对?左哩?半?段?排?序î*/QuickSort(b,a,q+1,r);/*对??半?段?排?序î*/ }}//中D间?数簓int Partition(int *b,int *a,int p,int r){int k,m,y,i=p,j=r+1;int x=a[p];y=b[p];while(1) {while(a[++i]<x);while(a[--j]>x);if(i>=j) break;else {k=a[i];a[i]=a[j];a[j]=k;m=b[i];b[i]=b[j];b[j]=m;}}a[p]=a[j];b[p]=b[j];a[j]=x;b[j]=y;return j;}int main(){fstream fin;fin.open("input.txt",ios::in);cout<<"在input.txt文件中输入数据,数据格式为:第1行为活动个数,第2行开始每行一个活动,每个活动的数据有活动编号,开始时间,结束时间,用空格隔开\n如:\n18\n1 6 9\n2 2 7\n.\n.\n.\n18 3 5\n\n";if(fin.fail()){cout<<"文件不存在!"<<endl;cout<<"退出程序..."<<endl;return 0;}int n;fin>>n;int *a=new int[n];int *b=new int[n];int *c=new int[n];for(int i=0;i<=n;i++){fin>>a[i];fin>>b[i];fin>>c[i];}QuickSort(b,c,1,n);//按恪?结á束?时骸?间?非?减?序î排?printf(":\n"); /*输?出?排?序î结á果?*/printf("\n 序号\t开始时间结束时间\n");printf("-------------------------\n");for(int i=2;i<=n;i++)printf(" %d\t %d\t %d\n",i,b[i],c[i]);printf("-------------------------\n");GreedySelector(n,b,c,A);printf("安排的活动序号依次为:");for(int i=2;i<=n;i++){if(A[i]) printf("\n%d %d-->%d",i,b[i],c[i]);}printf("\n");//int mm=Greedyplan(n,b,c,A);//fstream fout;//fout.open("output.txt",ios::out);//fout<<mm;//cout<<"答鋏案?请?打洙?开aoutput.txt查é看′\n\n";fin.close();//fout.close();system("pause");return 0;}四、实验结果截图1.全排列:2.会场安排问题:实验者姓名:实验报告日期:2015年1月1日。
会场安排问题[动态规划]
![会场安排问题[动态规划]](https://img.taocdn.com/s3/m/7b3012aef021dd36a32d7375a417866fb84ac077.png)
会场安排问题[动态规划]问题: 假设要在⾜够多的会场⾥安排⼀批活动,并希望使⽤尽可能少的会场。
(这个问题实际上是著名的图着⾊问题。
若将每⼀个活动作为图的⼀个顶点,不相容活动间⽤边相连。
使相邻顶点有不同颜⾊的最⼩着⾊数,相应于要找的最⼩会场数。
)数据输⼊: 第⼀⾏表⽰有 n 个活动。
接下来 n ⾏中,第 i ⾏的第⼀个数表⽰该活动的开始时间,第⼆个数表⽰该活动的结束时间。
数据输⼊: 输出最少需要的会场数。
思路: 将n个活动1,2,....,n看做实直线上的n个半闭活动区间(s[i],f[i]])。
所讨论的问题实际上是求这n个半闭区间的最⼤重叠数。
因为重叠的活动区间所相应的活动是互不相容的。
若这n个活动区间的最⼤重叠数为m,则这m个重叠区间所对应的活动互不相容,因此⾄少要安排m个会场来容纳这m个活动。
如图: 将所有的时刻(开始的,结束的)按顺序排在⼀条线上,然后从这条线的开头往后⾯⾛,遇到的时刻是开始的话,重叠数就+1,遇到的时刻是结束的话,重叠数就-1.代码:#include<iostream>#include<fstream>using namespace std;struct activity {int time; //记录⼀个时刻bool f; //表⽰这个是开始时刻还是结束时刻};void quickSort(activity s[], int l, int r){//快速排序函数,这个不是重点if (l < r){int i = l, j = r;activity x = s[l];while (i < j){while (i < j && s[j].time >= x.time)j--;if (i < j)s[i++] = s[j];while (i < j && s[i].time < x.time)i++;if (i < j)s[j--] = s[i];}s[i] = x;quickSort(s, l, i - 1);quickSort(s, i + 1, r);}}int activityPlan(activity a[], int l){//会场安排函数int overlap = 0, halls = 0; //overlap 表⽰重叠数,halls表⽰需要的最少的会场数for (int i = 1; i <= l; i++){if (a[i].f == true){//遇到开始时间overlap++;if (overlap > halls){//会场数即最⼤的重叠数halls = overlap;}}else{//遇到结束时间overlap--;}}return halls;}void main(){ifstream input("input.txt");ofstream output("output.txt");int n, t;activity a[99];input >> n;//输⼊for (int i = 1; i <= 2 * n; i++){input >> a[i].time;if (i % 2 == 1) a[i].f = true;else a[i].f = false;}//先对输⼊的所有时刻进⾏排序quickSort(a, 1, 2 * n);output << activityPlan(a, 2 * n) << endl;input.close();output.close();}。
算法排序的实验报告

一、实验目的1. 熟悉常见的排序算法,包括冒泡排序、选择排序、插入排序、快速排序、归并排序等。
2. 比较不同排序算法的时间复杂度和空间复杂度。
3. 理解排序算法的原理,并能够根据实际需求选择合适的排序算法。
二、实验环境1. 操作系统:Windows 102. 编程语言:Python3.83. 开发工具:PyCharm三、实验内容1. 实现以下排序算法:- 冒泡排序- 选择排序- 插入排序- 快速排序- 归并排序2. 对一组随机生成的数据,分别使用上述算法进行排序,并记录每种算法的排序时间。
3. 分析不同排序算法的时间复杂度和空间复杂度。
四、实验步骤1. 编写排序算法代码```pythondef bubble_sort(arr):n = len(arr)for i in range(n):for j in range(0, n-i-1):if arr[j] > arr[j+1]:arr[j], arr[j+1] = arr[j+1], arr[j] def selection_sort(arr):n = len(arr)for i in range(n):min_idx = ifor j in range(i+1, n):if arr[min_idx] > arr[j]:min_idx = jarr[i], arr[min_idx] = arr[min_idx], arr[i] def insertion_sort(arr):for i in range(1, len(arr)):key = arr[i]j = i-1while j >=0 and key < arr[j]:arr[j+1] = arr[j]j -= 1arr[j+1] = keydef quick_sort(arr):if len(arr) <= 1:return arrpivot = arr[len(arr) // 2]left = [x for x in arr if x < pivot]middle = [x for x in arr if x == pivot]right = [x for x in arr if x > pivot]return quick_sort(left) + middle + quick_sort(right) def merge_sort(arr):if len(arr) <= 1:return arrmid = len(arr) // 2left = merge_sort(arr[:mid])right = merge_sort(arr[mid:])return merge(left, right)def merge(left, right):result = []i = j = 0while i < len(left) and j < len(right):if left[i] < right[j]:result.append(left[i])i += 1else:result.append(right[j])j += 1result.extend(left[i:])result.extend(right[j:])return result```2. 生成随机数据并排序```pythonimport randomimport timedef generate_random_data(n):return [random.randint(0, 1000) for _ in range(n)]def sort_and_measure_time(sort_func, data):start_time = time.time()sorted_data = sort_func(data)end_time = time.time()return sorted_data, end_time - start_time# 测试排序算法data_size = 10000data = generate_random_data(data_size)bubble_time = sort_and_measure_time(bubble_sort, data.copy()) selection_time = sort_and_measure_time(selection_sort, data.copy()) insertion_time = sort_and_measure_time(insertion_sort, data.copy()) quick_time = sort_and_measure_time(quick_sort, data.copy())merge_time = sort_and_measure_time(merge_sort, data.copy())print(f"Bubble Sort: {bubble_time} seconds")print(f"Selection Sort: {selection_time} seconds")print(f"Insertion Sort: {insertion_time} seconds")print(f"Quick Sort: {quick_time} seconds")print(f"Merge Sort: {merge_time} seconds")```3. 分析结果根据实验结果,我们可以得出以下结论:- 冒泡排序、选择排序和插入排序的时间复杂度均为O(n^2),适用于小规模数据。
随机全排列实验报告

实验一随机全排列生成程序及其应用开发课程:姓名:学号:班级:一、实验内容1.编制生成 0~n(n≤255)的一个全排列的程序,可选择方法:从一个随机文件读取 n+1 字节数据 d0, d1……dn。
由预先取定的一个 0~n 的全排列 P(比如,可为 0~n 的自然排列)开始,依次对 i=n, n-1,1,计算:j=(di-1+di )mod i,交换 P 的第 i 项和第 j 项(在此注意我们假定 P 从第 0 项开始)。
2.要求:1)程序须对不超过 255 的正整数 n 都容易生成 0~n 的一个全排列;2)对较小的 n,抓图显示随机全排列生成程序的计算结果(附页),数据不能出现明显错误;3)每位同学设计的“一种对于随机全排列生成程序的应用”须有个性化特点、不与别人雷同。
二、实验分析这个方法主要就是对于文件的使用,得到一组随机序列,然后就用简单的算法让自然序列P打乱成为一组新的随机全排列P。
其实这可以作为密钥算法将我们的铭文变换成密文,防止重要信息被他人截获知悉(但是内容不能有重复之处),或是应用于日常生活,比如彩票开奖,排考试座位号。
1、随机全排列:“一个 0~n 随机全排列”中的随机性是指:某种相应的生成方法可以做到“让0~n 中任意数等可能地出现在任一位置”。
全排列:从n个不同元素中任取m(m≤n)个元素,按照一定的顺序排列起来,叫做从n个不同元素中取出m个元素的一个排列。
当m=n时所有的排列情况叫全排列。
2、要打开并读取文件的内容,就要使用fopen,fscanf,fclose等函数1)声明文件指针FILE *fp;2)格式fopen(const char * path,const char * mode); 参数path字符串包含欲打开的文件路径及文件名,参数mode字符串则代表着流形态。
r 以只读方式打开文件,该文件必须存在。
而且文件是txt格式时,加t,当mode后什么都不加时默认为是t。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
实验一全排列和会场安排问题
一、实验要求
1.全排列:要求键盘输入若干个不同的字符,然后产生并显示所有的排列
会场安排问题:
1.要求按贪心法求解问题;
2.要求读文本文件输入活动安排时间区间数据(数据在文件中的格式如下);
3.不能改变活动的编号,排序时不能移动活动的所有信息;
4.按选择顺序显示活动的编号、开始时间和结束时间。
输入数据的文本文件格式:第1行为活动个数,第2行开始每行一个活动,每个活动的数据有活动编号、开始时间、结束时间,用空格隔开。
如:data.txt
18
1 6 9
2 2 7
┋有18行
┋
2.18 3 5
二、实验平台
1、编程环境:Microsoft Visual Studio 2010
2、运行环境:windows7
三、核心代码
全排列:
#include<tchar.h>
#include"iostream"
using namespace std;
void Permutation(char* letter, int* record, int length, int n)
{
if ( n == length )
{
static int count = 0;
count++;
cout << count << "->:\t ";
for ( int i = 0; i < length; i++ )
{
cout << letter[record[i]];
}
cout << endl;
return;
}
for ( int i = 0; i < length; i++ )
{
//确ā?定¨当獭?前°结á点?的?字?符?是?什?么′,?不?能ü和í已?经-确ā?定¨的?字?符?相à同?
int j;
for ( j = 0; j < n; j++ )
{
if ( i==record[j] )
break;
}
if ( j != n )
continue;
//确ā?定¨当獭?前°字?符?
if ( j == n )
record[n] = i;
Permutation(letter,record,length,n+1);
}
}
int _tmain(int argc, _TCHAR* argv[])
{
char* letter = "abcd";
int length = strlen(letter);
int* record = new int[length];
Permutation(letter,record,length,0);
system("pause");
return 0;
}
会场安排问题(贪心算法):
#include<iostream>
#include<fstream>
using namespace std;
#define N 50
#define TURE 1
#define FALSE 0
int Partition(int *b,int *a,int p,int r);
void QuickSort(int *b,int *a,int p,int r);
int A[N];
void GreedySelector(int n,int start[],int end[],int *A)
{
A[1]=true;
int j=1;
for(int i=2;i<=n;i++)
{
if(start[i]>=end[j])
{
A[i]=true;
j=i;
}
else A[i]=false;
}
}
//快ì速ù排?序î
void QuickSort(int *b,int *a,int p,int r)
{
int q;
if(p<r)
{
q=Partition(b,a,p,r);
QuickSort(b,a,p,q-1);/*对?左哩?半?段?排?序î*/
QuickSort(b,a,q+1,r);/*对??半?段?排?序î*/ }
}
//中D间?数簓
int Partition(int *b,int *a,int p,int r)
{
int k,m,y,i=p,j=r+1;
int x=a[p];y=b[p];
while(1) {
while(a[++i]<x);
while(a[--j]>x);
if(i>=j) break;
else {
k=a[i];
a[i]=a[j];
a[j]=k;
m=b[i];
b[i]=b[j];
b[j]=m;
}
}
a[p]=a[j];
b[p]=b[j];
a[j]=x;
b[j]=y;
return j;
}
int main()
{
fstream fin;
fin.open("input.txt",ios::in);
cout<<"在input.txt文件中输入数据,数据格式为:第1行为活动个数,第2行开始每行一个活动,每个活动的数据有活动编号,开始时间,结束时间,用空格隔开\n如:\n18\n1 6 9\n2 2 7\n.\n.\n.\n18 3 5\n\n";
if(fin.fail())
{
cout<<"文件不存在!"<<endl;
cout<<"退出程序..."<<endl;
return 0;
}
int n;
fin>>n;
int *a=new int[n];
int *b=new int[n];
int *c=new int[n];
for(int i=0;i<=n;i++)
{
fin>>a[i];
fin>>b[i];
fin>>c[i];
}
QuickSort(b,c,1,n);//按恪?结á束?时骸?间?非?减?序î排?
printf(":\n"); /*输?出?排?序î结á果?*/
printf("\n 序号\t开始时间结束时间\n");
printf("-------------------------\n");
for(int i=2;i<=n;i++)
printf(" %d\t %d\t %d\n",i,b[i],c[i]);
printf("-------------------------\n");
GreedySelector(n,b,c,A);
printf("安排的活动序号依次为:");
for(int i=2;i<=n;i++)
{
if(A[i]) printf("\n%d %d-->%d",i,b[i],c[i]);
}
printf("\n");
//int mm=Greedyplan(n,b,c,A);
//fstream fout;
//fout.open("output.txt",ios::out);
//fout<<mm;
//cout<<"答鋏案?请?打洙?开aoutput.txt查é看′\n\n";
fin.close();
//fout.close();
system("pause");
return 0;
}
四、实验结果截图
1.全排列:
2.会场安排问题:
实验者姓名:实验报告日期:2015年1月1日。