分布式数据库实验指导
构建高可用性的分布式数据库系统的实践指南

构建高可用性的分布式数据库系统的实践指南构建高可用性的分布式数据库系统是现代企业中极为重要的一项技术任务。
随着数据量和业务需求的不断增长,传统的单机数据库系统已经无法满足高并发、大规模数据处理和容错等要求。
本文将为您提供一些实践指南,帮助您构建高可用性的分布式数据库系统。
1.分布式数据库架构设计构建高可用性的分布式数据库系统首先需要设计合适的架构。
一般而言,分布式数据库系统采用主从复制、分片和数据一致性等技术来提高性能和可靠性。
在设计时需要考虑以下几个方面:-数据分片:将数据分割成多个片段,存储在不同的节点上。
通过数据分片可以提高并发处理能力和水平扩展性。
-主从复制:使用主节点和多个从节点的架构来提高数据的可用性。
主节点负责写入和更新数据,从节点负责读取数据,从而分担主节点的负载。
-数据备份和恢复:定期备份数据,通过备份文件或者增量备份来恢复数据。
备份和恢复策略需要根据业务需求来选择。
2.负载均衡和故障转移在分布式数据库架构中,负载均衡和故障转移是至关重要的。
通过合理的负载均衡可以充分利用系统资源,提高整体性能。
而故障转移则保证了系统的高可用性。
以下是一些实践指南:-负载均衡:可以通过使用负载均衡器,将请求均匀地分发到不同的数据库节点上,以减轻单个节点的负载压力。
-故障检测和恢复:使用心跳机制或监控系统来监测节点的健康状态。
一旦检测到故障,及时进行节点的替换或修复。
-数据冗余:在分布式系统中,可以通过数据冗余的方式来提高系统的可用性。
将数据备份存储在多个节点上,当一个节点故障时,可以从其他节点中读取数据。
3.数据一致性和容错性在分布式数据库系统中,保持数据的一致性和容错性是非常重要的。
以下是一些实践指南:-事务支持:分布式数据库系统需要支持事务管理,确保数据的一致性。
通过使用分布式事务管理器,可以协调多个节点之间的事务操作。
-数据一致性协议:使用一致性哈希算法或拜占庭容错算法来保证数据的一致性和容错性。
福建农林大学分布式数据库实验三

福建农林大学实验指导书(2014 —2015学年第2学期)软件工程系软件工程专业2012 年级 2 班课程名称分布式数据库实验教材名称分布式数据库实验指导书主要参考书分布式数据库系统原理与应用教材大纲类型2012大纲任课教师颜吉强实验三分布式分片技术实现实验目的1.了解俄掌握oracle上不同站点间的数据链接2.了解和掌握依据站点的特性对数据库进行分片实验学时4学时实验内容创建两个数据库lin1和lin2在lin1中创建myorcl1表,在myorcl2中创建myorcl2表1 创建到另一个数据库的链接数据库链接用于建立与远程数据的联系,它为远程数据库指定了数据库、用户帐户和口令。
数据库链接可以是公共的,也可以是私有的。
数据库链接存放在“本地”计算机的数据字典内,当使用时,它作为远程数据库的用户帐户连接到指定的数据库。
当操作完成后,数据库链接退出远程的据库。
如远程数据库正在运行分布式选件,数据库链接可用于远程数据修改,如果远程数据库没有运行分布式选件,则只能用于远程数据查询。
数据库键接的建立语句为:CREATE [PUBLIC] DATABASE LINK Linkname[CONNECT TO username IDENTIFIED By password][USING…connectstring']其中:Linkname 数据库链接的名称Username 用户帐户password 口令connectstring 远程数据库的连接串连接串在SQL*NET 2.X版中,为远程数据库的别名。
在SQL*NET 1.X版中包括用冒号隔开的三个部分,分别为网络接口驱动程序、服务器名称和数据库实例。
在myorcl中连接myorcl2,Create public database link myorcl1_2Connect to system identified by linchaoUsing …(description=(address_list=(address=(protocol=tcp)(host=localhost)(port=1521)))(connect_data=(service_name=myorcl2)))‟;2 访问远程数据库的数据数据库链接建立好后,即可访问远程数据库的数据,使用数据链接的方式为:SELECT col1, col2,…… FROM tablename@ dbLink在该查询语句中,符号@指示该基表为数据库链接dbLink所指定的存放在远程数据库中的基表select * from myorcl2@ myorcl1_2;3 分片数据库及表的建立•按myorcl1, myorcl2的属性导出Define fragment zu1 asSelect lin1.snumber , myorcl1.sname , myorcl2.sgroudFrom myorcl1, myorcl2@lin1_2Where myorcl1.snumber =lin2.snumber ;按myorcl1, myorcl2的水平分片导出Define fragment zu2 asSelect * From myorcl2@lin1_2 Where snumber in (Select snumber from lin1);这个实验做得有点儿赶,但是最后还是完成了,算是结束了对oracle的课程了吧,但是学习还远远没有结束,以后的日子我会再接再厉的。
分布式数据库性能测试实验报告

分布式数据库性能测试实验报告引言:分布式数据库是由多个节点构成的数据库系统,每个节点都可以独立地处理查询和事务操作。
为了评估分布式数据库的性能表现,本实验进行了一系列的性能测试并得出了相应的结果和结论。
本报告旨在对分布式数据库性能进行全面的评估和分析。
实验目的:1. 通过性能测试评估分布式数据库的处理能力和并发性能。
2. 分析分布式数据库对于不同规模数据和负载的响应情况。
3. 探讨分布式数据库在扩展性和容错性方面的表现。
实验环境:- 数据库系统:分布式数据库系统XYZ- 硬件:主机配置为X GHz处理器、XGB内存、XGB磁盘空间- 软件:操作系统为X,数据库管理系统为XYZ- 数据集:使用XGB规模的数据集进行测试实验方法:1. 测试负载:使用不同类型的查询和事务操作构建测试负载,包括读操作、写操作和复杂查询操作。
2. 并发用户数:逐步增加并发用户数,从10个用户逐渐增加到100个用户。
3. 测量指标:记录每个操作的执行时间、吞吐量和响应时间。
实验结果与分析:1. 响应时间:随着并发用户数的增加,响应时间逐渐增加,但整体呈现出较好的线性扩展性。
2. 吞吐量:在低并发用户数时,吞吐量随并发用户数的增加而逐渐提高。
然而,当并发用户数达到一定阈值后,吞吐量的增加速度减缓。
3. 数据一致性:由于分布式数据库的数据分布在多个节点上,数据一致性成为一个重要的考虑因素。
实验结果表明,在正常情况下,分布式数据库能够保持数据一致性。
4. 容错性:通过模拟节点故障,实验发现分布式数据库具有较好的容错性能,能够在某些节点故障的情况下继续正常运行。
结论:1. 分布式数据库在处理大规模数据和并发操作方面表现出良好的性能。
2. 分布式数据库的吞吐量随并发用户数的增加呈现出递增趋势,但在一定阈值后增速减缓。
3. 数据一致性和容错性是分布式数据库设计和管理的重要考虑因素。
4. 开发人员和系统管理员应根据实际需求选择合适的分布式数据库,并且注意数据库的配置和优化。
分布式数据库管理实验报告

分布式数据库管理实验报告一、引言随着互联网和大数据技术的迅速发展,传统的集中式数据库管理系统已经无法满足日益增长的数据处理需求。
分布式数据库管理系统应运而生,能够将数据分散存储在不同的节点上,并实现数据的有效管理和处理。
本实验旨在通过对分布式数据库管理系统的实验操作,深入了解其工作原理和应用场景。
二、实验目的1. 了解分布式数据库管理系统的基本概念和特点;2. 掌握分布式数据库管理系统的架构和工作原理;3. 能够使用实际案例进行分布式数据库管理系统的操作。
三、实验内容1. 搭建分布式数据库管理系统的实验环境;2. 创建分布式数据库并进行数据导入;3. 进行跨节点的数据查询和更新操作;4. 测试分布式数据库管理系统的性能和扩展性。
四、实验步骤1. 搭建实验环境在实验室服务器上安装分布式数据库管理系统软件,并配置节点信息,确保各节点之间可以正常通信。
2. 创建分布式数据库使用SQL语句在不同节点上创建分布式数据库,并将数据导入到对应的表中。
3. 数据查询和更新编写SQL查询语句,可以跨节点进行数据查询操作,并测试分布式数据库系统的读写性能。
4. 性能测试模拟大量的数据操作,测试分布式数据库管理系统在高负载情况下的性能表现,并观察系统的负载均衡能力。
五、实验结果分析通过实验操作,我们成功搭建了分布式数据库管理系统的实验环境,并能够灵活操作数据库中的数据。
在性能测试中,我们发现分布式数据库系统能够有效分担数据处理压力,提高系统的稳定性和可靠性。
六、结论分布式数据库管理系统是当前大数据时代的重要组成部分,能够满足高并发、大规模数据处理的要求。
通过本次实验,我们对分布式数据库管理系统有了更深入的了解,可以更好地应用于实际的数据处理工作中。
七、参考文献1. 《分布式数据库管理系统原理与技术》2. 《大规模分布式存储系统设计与实现》3. 《分布式数据库管理系统性能优化与调优》以上是本次分布式数据库管理实验报告的具体内容,希朓能对您有所帮助。
《分布式数据库》实验报告_研究生BACKUP11

安徽工业大学
《分布式数据库》实验报告
课题名称***
学院计算机
专业计算机应用
专业班级2010班
组长刘乾
成员周松成金祥胡锦
赵起姚佳岷
指导教师戴小平
二Ο一一年月日
课程名称:《分布式数据库》课程号码:XXXXXX
实验学时:学分:
实验地点:校内实验时间:2011.3.10~2011.5.10
连锁百货商店通常由一个中心,多个远程连锁店组成。
为此我们设计了一个数据库作为主数据库,用来模拟百货商店总店数据库,同时利用另一数据库作为从数据库,用来模拟连锁百货商店分店数据库。
并分别为主数据库和从数据库设计了GUI.
我们将百货商店的数据通过分片与分配的方式,分布式的存储在主从两个不同的数据库中,并有区别的给与主从数据库不同的权限。
同时基于SQL Server 2005 数据库之间的通讯,我们设计了数据通讯模块,实现了数据库之间的相互通信,并通过发布与订阅的方式保持了数据一致性。
另外在基本数据库添加删除操作的基础上,我们添加了品牌管理的功能模。
分布式数据库实验指导

福建农林大学实验指导书(2014 —2015学年第2学期)软件工程系软件工程专业2012 年级 2 班课程名称分布式数据库实验教材名称分布式数据库实验指导书主要参考书分布式数据库系统原理与应用教材大纲类型2012大纲任课教师颜吉强实验一Oracle安装与卸载实验目的和要求☐掌握Oracle10g数据库服务器的安装与配置☐掌握Oracle10g数据库服务器安装过程中问题的解决☐掌握Oracle10g数据库服务器卸载方法实验学时2学时实验内容1、安装Oracle10g数据库服务器的安装1)首先点击安装软件进入安装界面图如下2)选择安装类型单击“下一步”按钮。
3)进入指定主目录界面,默认“下一步”4)进入先决条件检查界面,等检查成功后,单击“下一步”按钮5)进入配置选项,可以配置数据库。
先选择数据库用途,然后给数据库命名,执行默认操作创建好数据库6)设置数据库备份和恢复选项。
7)创建数据库密码。
8)进入安装数据库操作。
找到下路这个目录E:\app\Administrator\product\11.2.0\dbhome_1\jdk\bin\java.exe安装完成后请记住:Enterprise Manager Database Control URL - (orcl) :http://192.168.0.3:1158/em数据库配置文件已经安装到D:\oracle\product\10.2.0,同时其他选定的安装组件也已经安装到D:\oracle\product\10.2.0\db_2。
iSQL*Plus URL 为:http://192.168.0.3:5560/isqlplusSQL*Plus DBA URL 为:http://192.168.0.3:5560/isqlplus/dba2、Oracle10g数据库服务器卸载1)停止所有Oracle相关的服务2)卸载Oracle 10g数据库服务器组件在开始菜单中,找到Universal Installer,运行Oracle Universal Installer,单击卸载产品3)手动删除注册表中与Oracle相关的内容。
分布式数据库实验

1.运行环境
操作系统 Solaris VM or Windows or Linux (Unix)
开发语言 JAVA JDK1.2.2以上版本 (Windows下需要Make工具)
1.运行环境
JAVA环境变量设置 Set path = …………;C:\j2sdk1.4.0_01\bin\ CLASSPATH
transaction提供了一些基本的类以帮助你完成工作, 它包含了ResourceManager的接口。请注意,你不要 修改此文件,你的RM实现要基于名为 ResourceManagerImpl的类(以及一些自己定义的新 类),这个类提供了ResourceManager的接口。你必 须自己编写接口实现代码,以替代目前提供的这个 ResourceManagerImpl.java文件中的接口实现代码。
= .;C:\j2sdk1.4.0_01\lib\tools.jar;C:\j2 sdk1.4.0_01\lib\dt.jar;C:\j2sdk1.4.0_01\ jre\lib\rt.jar;D:\project\
1.运行环境
怎样运行
javac *.java
生成 *.class 文件
make runreg
提交截止日期:2007年1月20日
参考文献
《分布式数据库系统及其应用》 《数据库系统导论》 《Java2 API 大全》 《Java编程思想》
谢 谢!
Windows下需用我们提供的makefile文件 替换part1.tar中的makefile文件。而 Linux下则不用。
基本框架结构(Part I) :C/S
Client 1
Client 2
Clie
Flights, Hotels, Cars, Customers
分布式数据库实训报告

一、实训背景随着互联网技术的飞速发展,数据量呈爆炸式增长,传统的集中式数据库已无法满足日益增长的数据存储和处理的性能需求。
分布式数据库作为一种新型的数据库架构,通过将数据分散存储在多个节点上,提高了数据库的可扩展性、可用性和容错性。
为了更好地理解和掌握分布式数据库的原理和应用,我们开展了分布式数据库实训。
二、实训目标1. 理解分布式数据库的基本概念、架构和原理;2. 掌握分布式数据库的安装、配置和管理;3. 学会使用分布式数据库进行数据存储、查询和事务处理;4. 分析分布式数据库的优缺点,了解其在实际应用中的挑战和解决方案。
三、实训内容1. 分布式数据库基本概念分布式数据库是由多个节点组成的系统,这些节点通过网络连接在一起,共同存储和管理数据。
分布式数据库具有以下特点:(1)数据分散存储:数据分布在多个节点上,降低了单节点存储的负担;(2)高可用性:通过冗余设计,提高系统的可用性;(3)可扩展性:系统可根据需求动态增加节点,提高性能;(4)容错性:系统在部分节点故障的情况下仍能正常运行。
2. 分布式数据库架构分布式数据库架构主要包括以下几种:(1)主从复制架构:主节点负责处理数据更新,从节点负责读取数据;(2)对等复制架构:所有节点都具有读写权限,数据在节点间同步;(3)分片架构:将数据按照一定的规则划分到不同的节点上;(4)多活架构:所有节点都可以同时处理读写请求。
3. 分布式数据库安装与配置以分布式数据库HBase为例,介绍其安装与配置过程:(1)安装Java环境:HBase基于Java开发,需要安装Java环境;(2)下载HBase安装包:从Apache官网下载HBase安装包;(3)解压安装包:将安装包解压到指定目录;(4)配置HBase环境变量:在系统环境变量中添加HBase的bin目录;(5)启动HBase服务:运行hbase.sh start命令启动HBase服务;(6)创建HBase表:使用hbase shell命令创建表。
分布式数据库的最佳实践与经验总结(系列二)

分布式数据库的最佳实践与经验总结一、引言在当前大数据时代,分布式数据库成为了处理海量数据的关键技术。
而分布式数据库的设计和实践则是一个具有挑战性的任务。
本文将总结一些分布式数据库的最佳实践和经验,帮助读者更好地理解和应用分布式数据库技术。
二、理解分布式数据库分布式数据库是将数据存储和处理分布在多个节点上的数据库系统。
相比于传统的集中式数据库,分布式数据库具有更强大的横向扩展能力和高可用性。
然而,分布式数据库的设计与管理复杂度更高,需要考虑数据的一致性、容错性以及数据分片等因素。
三、数据分片与负载均衡在设计分布式数据库时,合理的数据分片策略和负载均衡机制是至关重要的。
一方面,数据分片可以将数据分布在不同的节点上,避免单点故障和性能瓶颈;另一方面,负载均衡机制能够平衡各个节点的压力,提高整体性能。
根据应用场景和数据特点,选择合适的分片键和负载均衡算法非常重要。
四、一致性与并发控制在分布式环境下,保证数据的一致性是一项具有挑战性的任务。
分布式数据库需要选择合适的一致性模型,例如强一致性、弱一致性或最终一致性。
同时,针对并发控制,可以采用乐观锁或悲观锁等机制来实现事务的隔离性和一致性。
五、容错与故障恢复分布式数据库需要具备良好的容错性,能够应对节点故障和网络中断等异常情况。
采用数据冗余和备份机制可以保证数据的可靠性和可恢复性。
此外,及时的故障检测和自动恢复机制也是分布式数据库设计的重要方面。
六、性能监控与优化为了保证分布式数据库的高性能,需要进行实时的性能监控和优化。
通过监控系统指标,例如请求响应时间,吞吐量等,可以及时发现并解决潜在的性能瓶颈。
此外,优化查询语句、索引设计和数据模型等方面也是提高性能的关键。
七、数据安全与隐私保护分布式数据库中的数据安全和隐私保护是至关重要的。
采用合适的身份认证和访问控制机制可以防止未经授权的访问和数据泄露。
另外,数据加密和数据脱敏等技术也能有效保护数据隐私。
八、云原生与容器化在云计算时代,云原生和容器化的技术越来越受到关注。
分布式数据库原理及应用实验1-windows下的软件安装测试卸载
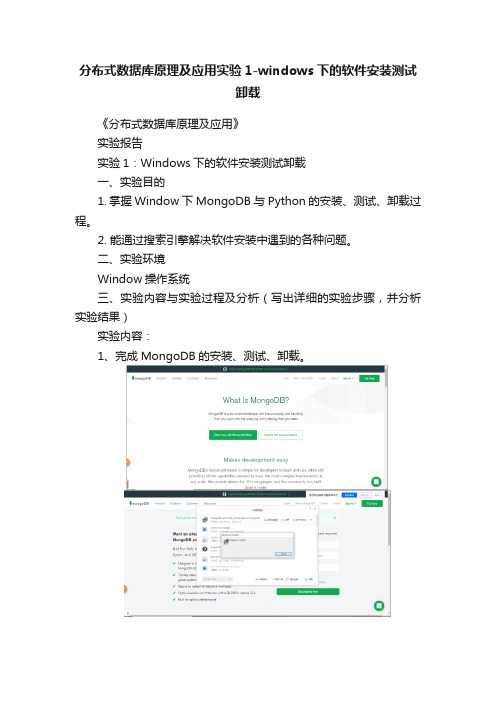
分布式数据库原理及应用实验1-windows下的软件安装测试
卸载
《分布式数据库原理及应用》
实验报告
实验1:Windows下的软件安装测试卸载
一、实验目的
1. 掌握Window下MongoDB与Python的安装、测试、卸载过程。
2. 能通过搜索引擎解决软件安装中遇到的各种问题。
二、实验环境
Window操作系统
三、实验内容与实验过程及分析(写出详细的实验步骤,并分析实验结果)
实验内容:
1、完成MongoDB的安装、测试、卸载。
启动客户端:
2. 完成Python的安装、测试、卸载。
配置环境变量:
测试环境:
3. Windows的几种安装包的区别
.msi
.msi文件是Windows Installer的数据包,它实际上是一个数据库,包含安装一种产品所需要的信息和在很多安装情形下安装(和卸载)程序所需的指令和数据,只要系统中包含windows installer支持就能够使用。
.msi是Windows installer开发出来的程序安装文件,它可以让你安装,修改,卸载你所安装的程序。
说白了.msi就是Windows installer的数据包,把所有和安装文件相关的内容封装在一个包里。
四、实验总结(每项不少于20字)
存在问题:对具体细节掌握不是很清楚,容易出错,需要花费大量时间才能纠正错误。
解决方法:多尝试通过命令行对文件进行操作,网络百度搜索。
收获:长时间配置不成功,有很大的收获,能让自己真正学会如何使用软件,提高动手能力。
五、教师批语。
分布式数据库系统的实验与性能评估

分布式数据库系统的实验与性能评估分布式数据库系统是一种将数据存储在不同地理位置上的多个数据库管理系统中,并通过网络进行连接和通信的系统。
相较于传统的集中式数据库系统,分布式数据库系统更加灵活和可伸缩,并且能够提供更好的数据可用性和容错性。
然而,在实际应用中,分布式数据库系统面临着很多挑战,如数据一致性、性能与效率等问题。
本文将对分布式数据库系统的实验和性能评估进行探讨。
一、分布式数据库系统的实验1. 实验设计在进行分布式数据库系统的实验之前,我们需要首先设计实验方案。
实验设计应该包括实验目标、实验环境和实验步骤等内容。
例如,我们可以通过搭建多个数据库节点、模拟分布式场景,来测试分布式数据库系统在不同数据负载和并发访问下的性能表现。
2. 数据准备实验的数据准备是非常重要的一步。
我们可以选择合适的数据集,并将其导入到各个数据库节点中。
数据集的选择应该充分考虑到实验的需求,包括数据规模、数据类型和数据分布等。
3. 实验指标在进行实验时,我们需要选择合适的实验指标来评估分布式数据库系统的性能。
常用的实验指标包括吞吐量、延迟、并发性能等。
通过对这些指标的评估,我们可以判断分布式数据库系统的性能是否符合要求。
二、分布式数据库系统的性能评估1. 性能测试性能测试是评估分布式数据库系统性能的重要方法之一。
我们可以通过模拟真实的应用场景、设置不同的负载和并发访问情况,来测试系统的性能极限和稳定性。
通过性能测试,我们可以获得系统的吞吐量、响应时间等性能指标,并对系统的瓶颈进行分析和优化。
2. 数据一致性评估在分布式数据库系统中,数据一致性是一个重要的问题。
我们需要评估分布式数据库系统在数据复制、数据同步和数据更新等方面的数据一致性能力。
常用的评估方法包括数据一致性检查、数据冲突处理和数据恢复等。
3. 容错性评估容错性是衡量分布式数据库系统可靠性的一个重要指标。
我们需要评估系统在节点故障、网络断连和数据丢失等异常情况下的容错能力。
《分布式数据库原理与应用》课程教案

《分布式数据库原理与应用》课程教案一、课程简介1.1 课程名称:分布式数据库原理与应用1.2 课程性质:专业核心课1.3 学时安排:总共32学时,包括16次授课,每课时45分钟。
1.4 先修课程:数据库原理、计算机网络、操作系统1.5 课程目标:使学生了解分布式数据库的基本概念、原理和设计方法,掌握分布式数据库系统的构建、维护和优化技术,培养学生解决分布式数据库相关问题的能力。
二、教学内容2.1 分布式数据库基本概念分布式数据库的定义与特点分布式数据库系统的结构与分类分布式数据库的体系结构2.2 分布式数据库的数据模型与查询语言分布式数据库的数据模型分布式数据库的查询语言(分布式SQL)2.3 分布式数据库的实现技术分布式数据库的复制与分片分布式数据库的数据一致性与事务管理分布式数据库的备份与恢复2.4 分布式数据库的安全性与隐私保护分布式数据库的安全性威胁与防护措施分布式数据库的隐私保护技术2.5 分布式数据库的应用案例分布式数据库在云计算中的应用分布式数据库在大数据处理中的应用分布式数据库在物联网中的应用三、教学方法3.1 讲授法:通过讲解、案例分析等方式,使学生掌握分布式数据库的基本概念、原理和设计方法。
3.2 实践法:安排实验课程,让学生亲手操作,巩固所学知识,提高解决实际问题的能力。
3.3 讨论法:组织学生分组讨论,分享学习心得,互相提问,激发学生的学习兴趣和主动性。
四、教学资源4.1 教材:选用国内外优秀教材《分布式数据库原理与应用》。
4.2 课件:制作精美、清晰的课件,辅助学生理解课堂内容。
4.3 实验环境:配备计算机实验室,提供分布式数据库实验所需的软硬件资源。
4.4 网络资源:引导学生利用网络资源,了解分布式数据库的最新发展动态。
五、教学评价5.1 平时成绩:包括课堂表现、作业完成情况、实验报告等,占总评的30%。
5.2 考试成绩:包括期末笔试和案例分析,占总评的70%。
5.3 评价标准:要求学生掌握分布式数据库的基本概念、原理和设计方法,能够运用所学知识解决实际问题。
《分布式数据库》实验报告_研究生

1)用户设置模块:客户、分店负责人、营业员以及管理人员的权限问题等。
2)图书信息模块:图书的类别、图书的基本相关的信息,以及相关的操作等。
3)员工信息模块:是对员工的信息的基本简单增删改的操作。
4)会员信息模块:包括会员的基本信息,还有订单,优惠消费等状况。
5)进货信息模块:主要是供应商的管理,记录各个分库状态,以及各个分库的销售状态以及图书的供求信息等。
任务分配:
对于前期的系统的需求分析、数据库设计包括概念设计、逻辑设计、分片和分布等都需要我们参与其中讨论合适的方案。但是对系统的开发具体的任务做如下分配:
高汉:员工和会员的模块开发以及主要的分片发布的方案。
魏宗斌:用户设置和图书信息的模块设置。
龚海晏:进货信息模块以及系统的代码测试的工作。
三、实验总结:
高汉:
魏宗斌:通过这次的课程设计让我对分布式数据库有了重新的认识,分布式数据库不是我原来所认为的那么简单。分布式数据库系统(DDBS)包含分布式数据库管理系统(DDBMS)和分布式数据库(DDB)。在分布式数据库系统中,一个应用程序可以对数据库进行透明操作,数据库中的数据分别在不同的局部数据库中存储、由不同的DBMS进行管理、在不同的机器上运行、由不同的操作系统支持、被不同的通信网络连接在一起。数据分片最常见的就是水平分片和垂直分片两种。对于数据库管理信息系统,首要要做好需求分析的工作,设计各个模块的功能以及功能之间的相互关联。因为做的是分布式数据库系统,所以系统主要是体现“分布”二字,因此使我对分布式数据库有了更深的认识。该系统前台界面的编写主要是用的vs进行开发的,后台数据库使用的是SQLServer。当在一个大企业或大部门中已建成了若干个数据库之后,为了利用相互的资源,为了开发全局应用,就要研制分布式数据库系统.分布式数据库系统虽然也要对各现存的局部数据库系统做某些改动、重构,但比起把这些数据库集中起来重建一个集中式数据库,则无论从经济上还是从组织上考虑,分布式数据库均是较好的选择.这就是分布式数据库系统的优势所在。
分布式数据库性能评估与优化实验报告

分布式数据库性能评估与优化实验报告引言:分布式数据库是一种能够将数据存储在多个节点上,实现高可用性和高性能的数据库系统。
在大数据时代,分布式数据库得到了广泛的应用和研究。
本实验旨在评估分布式数据库系统的性能,并针对性能瓶颈进行优化,从而提高数据库的整体运行效率。
一、实验目标本实验的目标是对分布式数据库系统进行性能评估,并针对性能瓶颈进行优化。
通过实验,可以更好地理解分布式数据库的工作原理,尝试解决分布式数据库中的性能问题,并提高数据库的整体性能。
二、实验环境本实验的实验环境如下:硬件:4台普通PC,每台配置为:8核CPU、16GB内存、1TB硬盘软件:分布式数据库系统DDBS v2.0实验数据:100GB大小的模拟数据三、实验步骤1. 数据准备为了模拟真实的数据情况,我们使用了100GB大小的数据集,并通过分布式方式将数据存储到4台PC的硬盘上。
这样可以保证每个节点上都有一部分数据,从而实现数据的均衡存储和访问。
2. 性能评估我们对分布式数据库进行了性能评估,测试了以下几个方面的指标:- 响应时间:测试数据库系统的读取和写入操作的响应时间。
- 吞吐量:测试数据库系统在单位时间内能处理的请求数量。
- 并发性能:测试数据库系统在并发情况下的处理能力和稳定性。
3. 优化策略根据性能评估的结果,我们确定了分布式数据库系统的性能瓶颈,并提出了以下的优化策略:- 索引优化:通过分析查询语句和数据访问模式,对数据库中的索引进行优化,提升查询性能。
- 数据分区优化:重新划分数据的分布,使得每个节点上的数据量相对均衡,减少数据访问的频率和延迟。
- 并发控制优化:采用更高效的并发控制机制,如乐观锁和MVCC,提高数据库的并发性能和事务处理能力。
四、实验结果与分析经过性能评估和优化策略的实施,我们得到了以下的实验结果和分析:1. 响应时间:优化后的分布式数据库系统的读取和写入操作的响应时间均明显降低,提高了用户的使用体验。
分布式数据库的最佳实践与经验总结(系列一)

分布式数据库的最佳实践与经验总结近年来,随着云计算和物联网技术的快速发展,大数据量、高并发和高可靠性的挑战也逐渐显现出来。
为了应对这些挑战,分布式数据库成为了当今互联网领域的一个热门话题。
分布式数据库通过将数据分散存储于多个节点上,并利用一系列复制、分片、负载均衡等技术,实现数据的高可用性、高并发和高性能。
在实践过程中,我们积累了一些分布式数据库的最佳实践和经验,现在就来总结一下。
一、定义合适的数据分片策略在分布式数据库中,数据的分片是非常重要的一个环节,直接影响到系统的可扩展性和性能。
在设计分片策略时,我们应该充分考虑数据的访问模式、负载均衡和分片负担等因素。
一种常用的策略是按照数据的哈希值进行分片,确保数据能够均匀地分布在各个节点上。
另一种策略是按照数据的某个属性进行分片,比如按照用户ID进行分片,可以将属于同一用户的数据存储在同一个节点上,提高查询效率。
二、实现数据的一致性与可用性在分布式系统中,一致性和可用性是互相矛盾的。
为了保证系统的高可用性,我们通常会采用 CAP 原则,即在网络分区时优先保证系统的可用性,而在无网络分区时追求一致性。
为了实现这一目标,可以引入副本机制,在多个节点上保存数据的副本,保证数据的冗余性和容错性。
此外,还可以采用基于时间戳或向量时钟的版本控制机制,解决并发操作引起的冲突问题。
三、优化查询性能和负载均衡在高并发的场景下,优化查询性能是一个关键问题。
首先,我们可以采用横向扩展的方式,将查询请求分发到多个节点上,提高系统的并发处理能力。
其次,可以使用缓存机制,将频繁查询的结果缓存在内存中,减少对数据库的访问。
此外,还可以对查询语句进行优化,合理设计索引,避免全表扫描和耗时的操作。
四、确保数据的安全性和一致性在分布式数据库中,数据的安全性和一致性是非常重要的,尤其对于金融、电商等对数据完整性要求较高的行业。
为了保证数据的安全性,我们可以采用密码学技术,对数据进行加密存储和传输。
分布式数据库的最佳实践与经验总结(系列七)

分布式数据库的最佳实践与经验总结引言:随着互联网的快速发展和数据规模的不断增长,传统的单机数据库已经不能满足大规模应用的需求。
分布式数据库的出现为解决数据存储和处理的问题提供了新的方案。
本文将针对分布式数据库的最佳实践与经验进行总结,旨在为开发者提供一些指导和借鉴。
一、架构设计:在设计分布式数据库的架构时,需要考虑数据的分片和存储方式、读写操作的负载均衡,以及可扩展性和高可用性等关键因素。
分片是指将数据水平拆分为多个片段,每个片段独立存储在不同的节点上,避免单一节点成为性能瓶颈。
存储方式可以选择主从复制或者多主复制,根据具体的业务需求和数据访问模式进行选择。
负载均衡可以采用哈希算法或者一致性哈希算法,将读写操作均匀分布到各个节点上,提高整体系统的吞吐量。
同时,为了保证系统的可扩展性和高可用性,需要引入自动化的故障检测和恢复机制,以及数据备份和灾备方案。
二、数据一致性与可靠性:在分布式数据库中,保证数据的一致性和可靠性是至关重要的。
一致性可以通过引入分布式事务机制来解决,常见的有两阶段提交和基于消息队列的分布式事务。
两阶段提交是一种同步的分布式事务协议,通过协调者和参与者节点的通信来保证所有节点的数据状态一致。
而基于消息队列的分布式事务则是一种异步的处理方式,将事务操作及其依赖的消息放入消息队列,由消费者节点负责处理和更新数据。
可靠性方面,可以通过引入数据冗余和备份,以及数据同步和数据恢复机制来保证数据的安全性和可靠性。
三、性能优化与调优:在分布式数据库的实际应用中,为了提高系统的性能和响应速度,需要进行性能优化和调优工作。
首先,可以通过合理的索引设计和查询优化来提高读取操作的性能。
合理选择索引字段,并根据查询需求调整索引类型和索引覆盖范围,可以有效缩小查询范围和减少IO操作。
同时,利用缓存技术和分布式内存数据库来加速热点数据的访问和计算,可以大幅降低读取延迟和提高并发处理能力。
其次,对于写入操作,可以采用批量写入和异步写入策略,减少锁竞争和磁盘IO,提高写入吞吐量。
解析和设计分布式数据库的最佳实践

解析和设计分布式数据库的最佳实践随着大数据时代的到来,数据量的增长和数据处理的需求变得越来越庞大,传统的数据库已经无法满足这些需求,因此分布式数据库成为了新的解决方案。
分布式数据库是指将数据存储和管理分布在多台计算机或服务器上,通过网络连接进行协同工作的数据库系统。
在分布式数据库的架构下,数据可以被统一管理和访问,并且可以实现高可用性、高性能和可拓展性。
本文将探讨分布式数据库的最佳实践,包括架构设计、数据分片、数据一致性、故障处理等方面,希望能够为分布式数据库的实践和应用提供一些有益的指导和建议。
一、架构设计1.1数据库类型选择在选择分布式数据库的时候,需要根据实际的业务需求和场景来选择适合的数据库类型。
常见的分布式数据库类型包括关系型数据库、NoSQL数据库和新型数据库。
对于需要保证数据一致性和完整性的场景,可以选择关系型数据库,如MySQL Cluster、PostgreSQL等;对于需要处理大规模结构化和半结构化数据的场景,可以选择分布式NoSQL数据库,如MongoDB、Cassandra等;而对于需要处理实时数据的场景,可以选择新型数据库,如TiDB、CockroachDB等。
1.2数据库架构设计在进行分布式数据库的架构设计时,需要考虑数据的分片、负载均衡、数据一致性和故障处理等因素。
合理的架构设计可以提高数据库系统的稳定性和性能,为业务提供更好的支持。
分布式数据库的架构设计需要考虑以下几个方面:(1)数据分片:将数据按照一定的规则进行分片,分布在不同的节点上,以实现数据的均衡存储和访问。
(2)负载均衡:通过负载均衡机制将查询请求和写入请求分发到不同的节点上,以均衡数据库的负载。
(3)数据一致性:确保分布式数据库的数据一致性,即所有节点上的数据保持同步和一致。
(4)故障处理:尽可能地预防和处理数据库节点的故障,以保证数据库系统的高可用性。
1.3高可用性和容灾设计在分布式数据库的架构设计中,高可用性和容灾是非常重要的因素。
分布式数据库实验报告

南华大学计算机科学与技术学院实验报告(2011 ~2012 学年度第一学期)课程名称软件设计模式实验名称设计模式UML建模姓名肖喜武学号20094350225专业软件工程班级本09软件02班地点8-212 教师余颖一、实验目的(1)学会如何根据站点的特点对数据库进行分片(2)学会如何实验amoeba软件对数据库实现分片二、实验内容⏹某个公司有三个计算机站点,站点B和站点C分别属于部门2和部门3现在希望在站点B和C上分别频繁访问EMPLOYEE和PROJECT表中有关工作在该部门的雇员和该部门管辖的项目信息。
⏹雇员信息主要是指EMPLOYEE表的NAME,ESSN,SALARY和SUPERSSN属性。
⏹站点A供公司总部(部门1)使用,经常存取为保险目的而记录的DEPENDENT信息外,还定期地存取所有雇员和项目的信息。
请根据这些要求,对该公司关系数据库中的关系进行分片和分布EMPLOYEEFNAME MINIT LNAME ESSN BDATE ADDRESS SEX SALARY SUPRESSN DNO DEPARTEMNTDNAME DNO MGRSSN MGRSTARTDA TEDEPT_LOCATIONDNO DLOCA TIONPROJECTPNAME PNUMER PLOCATION DNOWORKS_ONESSN PNO HOURSDEPENDENTESSN DEPENDENT SEX BDATE RELATIONSHIP三、实验步骤(1)理论分析先根据DEPARTMENT表的主码DNO的值进行水平分片,然后基于外码部门号(DNO)将导出的片段应用到关系EMPLOYEE、PROJECT和DEPPTLOCATIONS上,再在刚才得到的EMPLOYEE片段上进行垂直分片,得到只含熟悉你给{NAME,ESSN,SALARY,SUPERSSN,DNO}的片段。
图2.13给出了EMPD2和EMPD3的混合分片,它包括了分别满足条件DNO=2和DNO=3的EMPLOYEE元组。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
福建农林大学
实验指导书
(2014 —2015学年第2学期)
软件工程系软件工程专业2012 年级 2 班
课程名称分布式数据库实验
教材名称分布式数据库实验指导书
主要参考书分布式数据库系统原理与应用
教材大纲类型2012大纲
任课教师颜吉强
实验一Oracle安装与卸载
实验目的和要求
☐掌握Oracle10g数据库服务器的安装与配置
☐掌握Oracle10g数据库服务器安装过程中问题的解决
☐掌握Oracle10g数据库服务器卸载方法
实验学时
2学时
实验内容
1、安装Oracle10g数据库服务器的安装
1)首先点击安装软件进入安装界面图如下
2)选择安装类型单击“下一步”按钮。
3)进入指定主目录界面,默认“下一步”
4)进入先决条件检查界面,等检查成功后,单击“下一步”按钮
5)进入配置选项,可以配置数据库。
先选择数据库用途,然后给数据库命名,执行默认操作创建好数据库
6)设置数据库备份和恢复选项。
7)创建数据库密码。
8)进入安装数据库操作。
找到下路这个目录
E:\app\Administrator\product\11.2.0\dbhome_1\jdk\bin\java.exe
安装完成后请记住:
Enterprise Manager Database Control URL - (orcl) :http://192.168.0.3:1158/em
数据库配置文件已经安装到D:\oracle\product\10.2.0,同时其他选定的安装组件也已经安装到D:\oracle\product\10.2.0\db_2。
iSQL*Plus URL 为:http://192.168.0.3:5560/isqlplus
SQL*Plus DBA URL 为:http://192.168.0.3:5560/isqlplus/dba
2、Oracle10g数据库服务器卸载
1)停止所有Oracle相关的服务
2)卸载Oracle 10g数据库服务器组件
在开始菜单中,找到Universal Installer,运行Oracle Universal Installer,单击卸载产品
3)手动删除注册表中与Oracle相关的内容。
4)删除Oracle环境变量
5)删除TEMP目录下Oracle相关的文件夹
6)检查“开始”菜单中是否还有Oracle程序组,如果有,则将其删除
7)重新启动计算机
8)删除Windows系统安装磁盘中的Program Files\Oracle 目录
实验分析
在安装Oracle10g的过程中,在进行“产品特定的先决条件检查”时,“正在进行网络配置检查”
的状态为“未执行” .
原因:当前系统的IP地址采用的是DHCP动态分配的IP地址。
虽然Oracle 10g支持动态IP,但要求在安装之前必须将Microsoft LoopBack Adapter配置为系统的主网络适配器。
通常,Oracle 10g将最后配置的网络适配器作为默认的网络适配器。
解决方法:将Microsoft LoopBack Adapter配置为系统的主网络适配器。
打开“控制面板”,双击“添加硬件”,在“添加硬件向导”中单击“下一步”按钮;
然后选择“是,我已经连接了此硬件”,单击“下一步”按钮;在“已安装的硬件”
列表中选择“添加新的硬件设备”,单击“下一步”按钮;选择“安装我手动从列表
选择的硬件”,单击“下一步”按钮;从“常见硬件类型”中选择“网络适配器”,
单击“下一步”按钮;在“厂商”列表中选择“Microsoft”,在“网卡”列表中选择
“Microsoft Loopback Adapter”,单击“下一步”按钮;进行Microsoft Loopback
Adapter的添加。
添加完成后,打开“控制面板”中的“网络连接”,会发现新添加
的“Microsoft LoopBack Adapter”网络适配器。
将该网络适配器的IP地址设置为一
个静态IP地址,如192.168.0.1。
实验二Oracle数据库的创建
实验目的:
1.掌握使用数据库配置助手创建数据库方法
2.了解手动创建数据库的方法
实验学时
4学时
实验内容:
●数据库配置助手创建数据库方法:就是使用DBCA创建数据库
●手动创建数据库的方法如下:
1.确定数据库名称与实例名称
a)在“命令提示符”界面中执行下列命令设置操作系统环境变量ORACLE_SID:C:\>SET
ORACLE_SID=MYNEWDB
2.确定数据库管理员的认证方式
a)采用操作系统认证方式。
保证当前操作系统用户必须是ORA_DBA操作系统用户组的成
员
3.创建初始化参数文件
a)将Oracle提供的文本初始化参数文件的样本复制一份,然后在此基础上进行修改,以创
建自己的文本初始化参数文件。
b)Oracle 10g提供的文本初始化参数样本文件是位于
<ORACLE_HOME>\admin\sample\pfile目录中的initsmpl.ora文件。
4.连接Oracle实例
a)C:\>SQLPLUS /NOLOG
b)SQL>CONNECT sys/tiger AS SYSDBA
5.启动实例
a)SQL>STARTUP NOMOUNT
6.使用CREATE DATABASE语句创建数据库
7.创建附加的表空间
a)用CREATE DATABASE语句创建的数据库中,只有SYSTEM,SYSAUX,UNDOTBS,USERS
和TEMP这5个表空间,还需要创建其他一些额外的表空间。
应该根据实际应用需要,为数据库创建附加表空间。
8.运行脚本创建数据字典视图
a)SQL>@D:\oracle\product\10.2.0\db_1\rdbms\admin\catalog.sql;
b)SQL>@D:\oracle\product\10.2.0\db_1\rdbms\admin\catproc.sql;
9.创建服务器初始化参数文件
a)SQL>CREATE SPFILE FROM PFILE;
实验分析
实验三分布式分片技术实现
实验目的
1.了解俄掌握oracle上不同站点间的数据链接
2.了解和掌握依据站点的特性对数据库进行分片
实验学时
4学时
实验内容
1 创建到另一个数据库的链接
数据库链接用于建立与远程数据的联系,它为远程数据库指定了数据库、用户帐户和口令。
数据库链接可以是公共的,也可以是私有的。
数据库链接存放在“本地”计算机的数据字典内,当使用时,它作为远程数据库的用户帐户连接到指定的数据库。
当操作完成后,数据库链接退出远程的据库。
如远程数据库正在运行分布式选件,数据库链接可用于远程数据修改,如果远程数据库没有运行分布式选件,则只能用于远程数据查询。
数据库键接的建立语句为:CREATE [PUBLIC] DATABASE LINK Linkname [CONNECT TO username IDENTIFIED By password]
[USING‘connectstring']其中:Linkname 数据库链接的名称
Username 用户帐户
password 口令connectstring 远程数据库的连接串连接串在SQL*NET 2.X版中,为远程数据库的别名。
在SQL*NET 1.X版中包括用冒号隔开的三个部分,分别为网络接口驱动程序、服务器名称和数据库实例。
2 访问远程数据库的数据
数据库链接建立好后,即可访问远程数据库的数据,使用数据链接的方式为:SELECT col1, col2,…… FROM tablename@ dbLink 在该查询语句中,符号@指示该基表为数据库链接dbLink所指定的存放在远程数据库中的基表
3 分片数据库及表的建立
实验分析。