基于栅格数据的空间聚类
栅格数据空间分析

栅格数据空间分析
栅格数据空间分析是一种地理信息系统(GIS)分析方法,用于对栅
格数据进行处理和分析。
栅格数据由等尺度的正方形单元组成,在地理空
间上形成一个网格。
每个栅格单元代表一个特定的地理区域,例如一块土地、一座建筑物或一个气象站。
接下来是数据变换,包括栅格数据融合、相似性度量和特征提取等。
栅格数据融合是将多个栅格数据集合并到一个单一的栅格数据中,以获取
更全面和准确的信息。
相似性度量用于比较不同栅格数据之间的相似性和
差异性,以支持空间分析和决策制定。
特征提取是从栅格数据中提取具有
特定意义和价值的特征,例如提取建筑物、道路或河流等。
最后是空间分析,包括空间统计、遥感应用和模拟建模等。
空间统计
用于分析和研究栅格数据中的空间分布和空间关联性,例如热点分析、空
间插值和时空分析等。
遥感应用利用栅格数据进行地物分类、土地利用变
化检测和资源管理等。
模拟建模是利用栅格数据构建地理模型,进行模拟
和预测,例如气候模拟、城市扩张和生态模拟等。
栅格数据空间分析的主要优势在于能够处理大量的空间数据和复杂的
空间关系,同时还能够考虑地球表面的不规则性和异质性。
然而,栅格数
据空间分析也存在一些限制,例如空间分辨率和数据量的限制,以及对数
据获取和预处理的要求较高。
总之,栅格数据空间分析是一种重要的GIS分析方法,能够有效地提取、分析和模拟栅格数据中的空间信息,为决策制定和问题解决提供支持。
在不同的应用领域中,栅格数据空间分析具有广泛的应用前景和发展潜力。
空间分析——栅格数据的空间分析(一)

重分类娱乐场所直线距离数据集
娱乐场所近~远 对应于 适宜度10~1
重分类现有学校直线距离数据集
新学校距离现有学校比较远时适宜性好,仍分 为10级,距离学校最远的单元赋值为10,距离学校 最近的单元赋值为1。得到重分类学校距离图。
重分类土地利用数据集
土地利用对新建学校的适宜性有一定的影响。 如在有湿地、水体分布区建学校的适宜性极差,于 是在重分类时删除这两类,然后对剩下的其它土地 利用类型重新赋值。 赋值如下:
(一)背景
合理的学校空间位置布局,有利于学生的上课
与生活。学校的选址问题需要考虑地理位置、学生
娱乐场所配套、与现有学校的距离间隔等因素,从
总体上把握这些因素能够确定出适宜性比较好的学 校选址区。
(二)目的
通过练习,熟悉ArcGIS栅格数据距离制图、
成本距离加权、数据重分类、多层面合并等空间 分析功能;熟练掌握利用ArcGIS空间分析功能, 分析类似学校选址等实际应用问题。
密度制图
密度制图根据输入的要素数据集计算整 个区域的数据聚集状况,从而产生一个连续 的密度表面。密度制图主要是基于点数据生 成的,以每个待计算格网点为中心,进行圆 形区域的搜寻,进而来计算每个格网点的密 度值。
表面分析
表面分析主要生成新的数据集,诸如等 值线、坡度、坡向、山体阴影等派生数据, 获得更多的反映原始数据集所暗含的空间特 征、空间格局等信息。
表面分析的功能有:查询表面值、从表 面获取坡度和坡向信息、创建等值线、面积 和体积、数据重分类、将表面转化为矢量数 据等。
统计分析
是基于栅格数据的一种空间统计分析,包括
基于单元的统计(cell statistics)、邻域统计、 分类区统计等内容。
栅格数据分析的基本模式

算术运算 指两层以上的对应网格值经加、减运算,而得到新的栅格 数据系统的方法。这种复合分析法具有很大的应用范围。图 6-4给出了该方法在栅格数据编辑中的应用例证。
基于栅格数据结构的叠加分析
B A
标号 A B 地貌 阳坡 阴坡
1
3
2
标号 1 2 3 标号 A1 A2 A3 B1 B2
植被 林地 农地 牧地 综合属性 阳坡 林地 阳坡 农地 阳坡 牧地 阴坡 林地 阴坡 农地
A1 A2
B1 A3
B2
复合运算方法
数学运算复合法 指不同层面的栅格数据逐网格按一定的数学法则进行 运算,从而得到新的栅格数据系统的方法。其主要类型有以 下几种:
1耕地 2园地 3林地 4居民点 5独立工矿 6水域 7未利用地
图
某镇土地利用现状图
4
4
6
4 4 6 4
图 空间聚类分析输出图形
4.1.2聚合分析
概念 聚合分析是根据预先设定的聚合条件,在同一 图层上进行数据类别的合并或转换,以实现空间地 域的兼并,从而将复杂的空间数据合并成预定的类 别 空间聚合的结果往往是将复杂的类别转换为较简单 的类别,大多数以小比例尺图形输出。当从大比例 尺图形向小比例尺图形转换时,常使用这种方法。
题图或地形图进行视觉复合,就可以直觉地解决某些“异物同
谱”分类问题,从而大大提高遥感分类精度。
遥感影像与专题地图的复合
C 专题图和数字高程图视觉复合
专题图通常用平面图来表示,而数字高程模型( DEM )
的立体彩色显示是具有高度真实感的,如果把各种专题图和数
字高程图复合生成立体专题图,可以大大增强视觉效果,便于 人们认识和研究自然资源。例如,把旅游图和数字高程图结合 生成立体旅游景观图,有利于人们观察景点分布和旅游路线选 择;再如将野生动物分布图与数字高程图结合,生成立体野生
栅格数据的空间分析报告
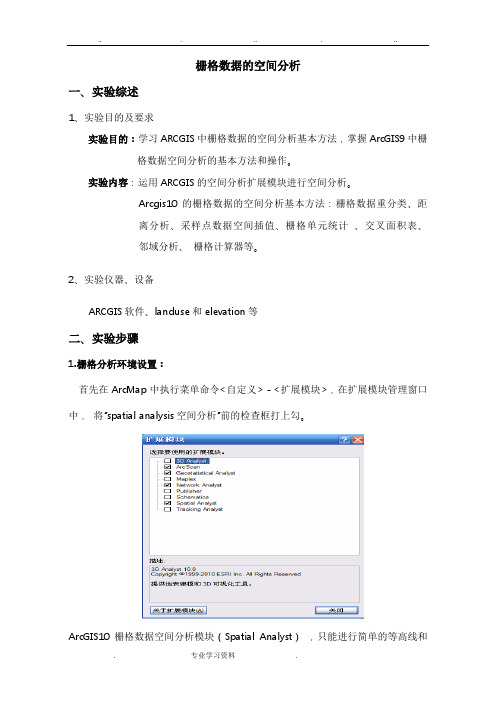
栅格数据的空间分析一、实验综述1、实验目的及要求实验目的:学习ARCGIS中栅格数据的空间分析基本方法,掌握ArcGIS9中栅格数据空间分析的基本方法和操作。
实验内容:运用ARCGIS的空间分析扩展模块进行空间分析。
Arcgis10的栅格数据的空间分析基本方法:栅格数据重分类、距离分析、采样点数据空间插值、栅格单元统计、交叉面积表、邻域分析、栅格计算器等。
2、实验仪器、设备ARCGIS软件、landuse和elevation等二、实验步骤1.栅格分析环境设置:首先在ArcMap中执行菜单命令<自定义>-<扩展模块>,在扩展模块管理窗口中,将“spatial analysis空间分析”前的检查框打上勾。
ArcGIS10栅格数据空间分析模块(Spatial Analyst),只能进行简单的等高线和直方图分析。
其它的分析工具要在Arctools工具中进行。
点击工具栏“”打开Arctools。
2. 高程数据生成坡度数据在Arctools-Spatial Analyst-表面分析中双击打开“坡度”。
按如下设置。
点击“确定”,生成坡度图。
3、高程数据生成坡向图在“Arctools-Spatial Analyst-表面分析”中双击打开“坡向”。
按如下设置。
点击“确定”,生成坡向图。
4、高程数据生成等高线图在“Arctools-Spatial Analyst-表面分析中”双击打开“等值线”。
按如下设置。
点击“确定”,生成等值线图。
5、视域分析在“Arctools-Spatial Analyst-表面分析”中双击打开“视域”。
按如下设置。
点击“确定”,生成视域分析图。
6、栅格数据重分类(Reclassify)重分类:将栅格图层的数值进行重新分类组织或者重新解释。
重分类的关键是确定原数据到新数据之间的对应关系。
在“Arctools-Spatial Analyst-重分类”中双击打开“重分类”。
空间分析与应用-复习题

《空间分析与应用》复习题一、名词解释1、空间分析:是以地理事物的空间位置和形态特征为基础,以空间数据运算、空间数据与属性数据的综合运算为特征,提取与产生新的空间信息的技术和过程。
2、空间聚类分析:是将地理空间实体或地理单元集合依照某种相似性度量原则划分为若干个类似地理空间实体或地理单元组成的多个类或簇的过程。
类中实体或单元彼此间具有较高相似性,类间实体或单元具有较大差异性。
3、坡长:是指在地面上一点沿水流方向到其流向起点间的最大地面距离在水平面上的投影长度,是水土保持的重要因子,水力侵蚀的强度依据坡长来决定,坡面越长,汇集的流量越大,侵蚀力就越强。
4、平面曲率:是过地面上某点的水平面沿水平方向切地形表面所得到曲线在该点的曲率值,它描述的是地表曲面沿水平方向的弯曲、变化情况。
5、地表粗糙度:反映地表的起伏变化和侵蚀程度的指标,一般定义为地表单元的曲面面积与其在水平面上的投影面积之比,公式:R = S 曲面/S水平,实际应用中,当分析窗口为3*3时,可采用近似公式求解:R = 1/cos(S),其中S- 坡度。
6、地理空间分析:是以地理事物的空间位置和形态特征为基础,以空间数据运算、空间数据与属性数据的综合运算为特征,提取与产生新的空间信息的技术和过程。
7、地理空间认知:是指在在日常生活中,人类如何逐步理解地理空间,进行地理分析和决策,主要包括地理信息的知觉、编码、存储、以及和解码等一系列心理过程。
8图论中的路径:一个图的路径是顶点vi和边ei的交替序列卩=v0e1v1e2 , vn-1envn如果v0 = vn ,称路径是闭合的,否则称为开的;路径中边的数据称为路径的长;若路径卩的边e1,e2, en均不同,则卩称为链;若它的所有顶点都不同,称为路;一条闭合的路称为回路。
9、增广链:设f是一个可行流,卩是从vs到vt的一条链,若卩满足前向弧都是非饱和弧,反向弧都是都是非零流弧,则称卩是(可行流f的)一条增广链。
地理栅格数据的插值与空间分析方法研究与比较

地理栅格数据的插值与空间分析方法研究与比较地理栅格数据在地理信息系统(GIS)中得到广泛应用,但由于各种原因(如传感器分布不均、采样间隔不同等),地理数据常常存在缺失或不完整的情况。
为了填补这些缺失值,插值方法成为一种重要的工具。
同时,在地理数据的空间分析中,如何选择合适的方法也是值得研究的问题。
一、地理栅格数据的插值方法研究1. 数字高程模型(DEM)数据的插值DEM数据是描述地表高程的栅格数据,在地质勘探、水文模拟等领域中广泛应用。
常用的DEM插值方法有最邻近法、反距离权重法、克里金插值法等。
最邻近法是一种简单的插值方法,即根据缺失值点周围最近的已知值来填补缺失值。
该方法计算简单,但存在着整体偏差的缺点。
反距离权重法是一种基于距离权重的插值方法,通过已知值的权重来计算缺失值。
这种方法能更好地反映空间距离的影响,但对于离散的点数据效果较差。
克里金插值法是基于样本点间距离和方差的插值方法,可以较好地拟合空间数据的变异性。
但该方法需要进行半方差函数的拟合,增加了计算复杂度。
2. 气候数据的插值气候数据插值主要用于补全不同气象站点间的气象数据以及空间上局地降水、温度等气象要素的估算。
插值方法常用的有插值法、空间统计法和基于物理模型的插值法。
经验插值法是一种简单直观的插值方法,通过实现不同站点数据的平均或加权平均,来得出缺失值。
空间统计法则考虑了空间自相关性,如变量的空间平稳性和半变异函数等。
3. 土壤属性的插值土壤属性插值用于补全土壤丰度、质地等数据以及土壤污染评估等。
根据实际情况选择的插值方法多种多样,如反距离权重插值、泛克里金插值或者克里金插值等。
二、地理栅格数据的空间分析方法比较1. 栅格数据的空间统计分析空间统计分析是指在地理栅格数据上进行的各种统计分析,如空间聚类、空间关联等。
常用的空间统计方法有点密度分析、空间自相关分析等。
点密度分析是用于确定地理栅格数据中某一特征在空间上的分布情况,以及空间上的密度变化。
如何进行栅格地图制作和空间数据分析

如何进行栅格地图制作和空间数据分析栅格地图制作和空间数据分析是地理信息系统中非常重要的环节,它们为我们提供了对地理空间信息的深入了解和分析。
本文将探讨如何进行栅格地图制作和空间数据分析的相关技术和方法。
一、栅格地图制作在进行栅格地图制作之前,我们首先需要了解栅格地图的概念。
栅格地图是将地理空间信息离散化表示的一种方法,通常被表示为由多个像元组成的矩阵,每个像元代表一个地理区域的属性值。
制作栅格地图的关键步骤如下:1. 数据采集:首先需要采集所需要的地理空间数据。
这些数据可以来自卫星遥感、测量仪器、民众调查等多种途径。
在数据采集过程中,需要注意数据的准确性和可靠性。
2. 数据预处理:采集到的地理空间数据并不能直接用于栅格地图制作,需要进行一些预处理工作。
这包括数据清洗、数据融合、坐标转换等操作,以保证数据的一致性和可用性。
3. 数据插值:在栅格地图中,不同地理位置的像元通常是通过插值方法来获得属性值的。
插值可以采用各种方法,如反距离权重插值、三角网插值等。
插值方法的选择应根据数据特点和需求进行。
4. 栅格化:将插值后的数据转化为栅格地图的形式。
栅格化是将连续的地理空间信息划分为离散的像元,每个像元代表一个区域的属性值。
栅格化过程中需要考虑像元的大小和分辨率。
5. 栅格地图设计:栅格地图的设计通常包括选择合适的颜色方案、标注和符号等。
设计应根据地图的用途和受众群体来进行,以提高地图的可读性和有效性。
二、空间数据分析空间数据分析是地理信息系统中的重要组成部分,它通过对地理空间数据的统计和分析,揭示地理现象的内在联系和规律。
空间数据分析的一般步骤如下:1. 数据准备:进行空间数据分析之前,首先需要准备好相应的数据。
这些数据可以是栅格地图、矢量数据或其他形式的地理信息。
数据准备包括数据的收集、整理、清洗和转换等。
2. 空间统计:空间统计是通过对地理空间数据的分析和计算来揭示其空间分布特征和相关性。
常见的空间统计方法包括聚类分析、空间自相关分析、热点分析等。
栅格数据分析

•提取分析
•信息复合分析
•追踪分析
•窗口分析
1.聚类分析
根据设定的聚类条件对原有数据系统进行有选择 的信息提取而建立新的栅格数据系统的方法。
在四种类型要素中提取其中要素2的聚类
2.聚合分析
根据空间分辨力和 分类表,进行数据 类型的合并或转换 以实现空间地域的 兼并。
1、 2 类合 并为b, 3、 4 类合 并为a 2、3 类合 并为c, 1、4 类合 并为d
9
32 30 25
33
9 32 21
32
3 24 15
29
25 3 12
20
14 11 3
16
19
20
25
10
对栅格数据开辟一个有固定分析半径的分析窗口, 并在该窗口内进行诸如极值、均值等一系列统计 计算,或与其它层面的信息进行必要的复合分析。 窗口类型如下: •矩形窗口 •圆形窗口 •环形窗口 •扇形窗口
3.信息复合分析
1)视觉信息复合分析 将不同侧面的信息内容叠加显示在结果图件或屏幕上, 以便研究者判断其相互空间关系,获得更为丰富的 空间信息。视觉信息叠加包括以下几类: 点状图,线状图和面状图之间的叠加显示。 面状图区域边界之间或一个面状图与其他专题区域 边界之间的叠加。 遥感影像与专题地图的叠加(融合)。 专题地图与数字高程模型(DEM)叠加显示立体专 题图。 遥感影像与DEM复合生成三维地物景观。
4.追踪分析
对于特定的栅格数据系 统,由某一个或多个 起点,按照一定的追 踪线索进行追踪目标 或者追踪轨迹信息提 取的空间分析方法。
3 4 4 2 9 13 9 9 9 8 12 20 12 18 25 17 23 28 18 23 26 17 20 20
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
基于栅格数据的空间聚类
作者:李敏
来源:《信息安全与技术》2013年第06期
【摘要】空间聚类是GIS空间分析的主要内容之一,传统矢量空间聚类算法存在数据冗余、结果不直观等弊端,介绍了基于栅格数据的空间聚类,并且针对现下主流的网格和密度方法的聚类算法存在效率和质量问题,提出了与栅格相结合的聚类挖掘算法,以期得到时间效率和聚类质量上的提高。
【关键词】栅格;空间聚类;地图代数;距离变换
1 引言
空间聚类是GIS空间分析的主要内容之一,近几年来,随着空间数据挖掘研究的发展,空间聚类对于海量数据处理、大型空间数据库中有用信息和知识的提取等方面具有十分重要的意义。
传统观念上,由于矢量数据模型对于现实世界中的抽象描述与表达更符合人的思维习惯,其分析方法自然采用了矢量途径,而对于栅格途径相应的研究及成果却少见;所见的国外文献中,大多限于栅格途径“ 可行性” 的研究,没有对其进行系统、深入的探讨。
传统的空间聚类算法都是基于矢量数据的,矢量空间分析方法具有简单、易操作的特点,但同时存在数据冗余、难以向高维和全形态扩展的缺点,为此本文着重于介绍基于栅格距离变换的空间聚类算法及其在各个领域的应用。
2 基于栅格的空间聚类算法
从空间聚类的算法过程来看,可以分为系统聚类、逐步分解和判别聚类。
系统聚类由各点自成一类开始,逐步合并至一个适当的分类数目。
与此相反,则为逐步分解。
判别聚类是先确定若干聚类中心,然后逐点比较以确定各离散点的归属。
从一般聚类的算法特征上看,目前主要有划分法(如K-means、K-medoids等)、层次法(如AGNES、BIRCH_l等)、基于密度的方法(如DBSCAN、DENCLUE等)和基于网格的方法(如STING等)。
常用的空间聚类分析统计量有分布密度、相关系数、夹角余弦、指数相似系数、欧氏距离、绝对值距离、切比雪夫距离、兰氏距离、马氏距离、斜交空间距离、非参数方法等l0余种,尤以最短欧氏距离最为常用。
本文就简单介绍基于最短欧式聚类的空间聚类栅格算法。
地图代数以栅格点集严密的量度作为其理论和方法论述的起点,来度量空间距离。
其距离变换的核心是建立栅格平方平面,坐标值在栅格平面上均为整数,距离值与横纵坐标的平方和为一一映射关系,由于欧式距离需要开平方,为了增加计算精度,用距离平方值代替距离值参与运算。
设距离平方值记为SqD,每个栅格单元的SqD值需要根据周同的8领域栅格单元的SqD来判断。
这8个栅格单元的SqD值按图3依次标记为SqD1,SqD:,…, SqD8。
据此其变换的步骤为:
①赋所有实体点为0值,并赋所有非实体空间点为一足够大的正数M;②顺序访问,即行号由0,l,2,…递增,列号由0,l,2,…递增,按下式改写各点平方值:SqD(0,0)=0,SqD(i,j) =MIN(SqDl(i,J),SqD2(i,j),SqD3(i,j),SqD4(i,j),SqD (i,j));③逆序访问并改写各点平方值:SqD(i,j) =MIN(Sqi)5(i,j),SqD6(i,j),SqD7(i,j),SqD8(i,j),SqD(i,j));④改写各点距离平方值为距离值:c(i,j) =INT{[SqD(i,j)] +0.5}。
经过地图代数栅格距离变换后的整个栅格空间被颜色不同的象素所填充,我们将其称为距离波,用黑线将那些色度值相同的栅格连接起来就构成了等距线。
这些等距线与空间点集之间的关系就可以揭示空间聚类过程。
经计算过后,各计算点被从最小距离到最大距离之间的间隔为1的等距线包围,然后就可以根据不同的条件(等距线数值)聚类。
3 与其他算法的结合
空间聚类(Spatial Clustering)是空间数据挖掘的重要组成部分,是聚类研究在空间数据分析中的应用.空间聚类应用广泛,如地理信息系统、生态环境、军事、市场分析等领域。
通过空间聚类可以从空间数据集中发现隐含的信息或知识,包括空间实体聚集趋势、分布规律和发展变化趋势等。
3.1 研究现状
目前国内外对聚类挖掘算法的研究众多,其中基于网格的聚类算法和基于密度的聚类算法成为聚类算法中最重要的两种方法。
基于网格的聚类方法主要采用网格技术对空间进行划分,以单一的网格对象作为聚类处理目标,忽略其内部的所有数据属性。
这样处理的一个突出优点就是速度快、聚类效率高。
但是利用网格技术存在的最大问题是没有涉及聚类边界点的处理,可能造成聚类边界对象的丢失,导致聚类精度的降低。
而基于密度的聚类方法是将簇视为对象空间中被低密度区域分割开的高密度对象区域。
此方法主要的优点就是可以发现任意形状的类簇,但是对主存要求较高,主要由于在密度聚类过程中对每一个对象必须与其他对象求解其距离。
因此,合理地设计出质量精确和时间效率高的聚类算法,成为数据挖掘领域迫切需要解决的问题,也是一个难点问题。
3.2 算法结合
虽然基于栅格的本身隐含了拓扑关系这种特性,避免了很多情况下矢量数据初始化大量的工作,但是现在处理数据还是以矢量较多。
我们可以将栅格聚类融于网格聚类和密度聚类中,进一步简化算法。
以密度聚类为例,栅格单元进行局部密度聚类后,生成的局部聚簇,需将原本属于一类的两个不同分区局部聚簇进行聚簇合并。
该算法将对每一个栅格单位进行密度聚类,这样对栅格单元中的小数据集进行聚类,大大提高了聚类效率。
如果每个栅格单元都进行密度聚类,那么将大大增加聚类时间。
因此,引入概念密度阈值DT来计算栅格空间中的密度大小,并衡量是否需要进一步DBSCAN 密度聚类。
设d 维空间的点集P ={p1 ,p2 ,…,pn },当数据对象pi 划分到栅格单元G 时,设置一个阈值minpts,若划分到某一栅格单元中的数据量大于或等于minpts,则是高密度栅格单元;反之,则是低密度栅格单元。
这个minpts称为密度阈值DT。
如果栅格单元中的数据量小于密度阈值时,那么将不进行DBSCAN 聚类分析,并将数据对象标记为全局噪声点,这样无须对小数据集进行密度聚类,大大减少了聚类时间,从而降低时间复杂度;反之,若栅格单元中的数据量大于密度阈值时,那么将用DBSCAN 对栅格空间进行聚类分析。
而实验结果也表明融入栅格技术可以使密度聚类算法获得更高的聚类效率,保留DBSCAN密度聚类算法,可以保证聚类结果的一致性。
4 结束语
空间聚类分析是从总体、全局的角度来描述空间变量和空间物体的特性,在空间数据量日益海量化的现代GIS中,简单、直观进行空间聚类分析具有重要的意义。
地图代数以点集变换与运算的代数观念来全面而本质地阐述图形符号的可视化及空间分析。
本文只是对栅格数据的空间聚类算法进行初步的介绍,提出将栅格聚类与其他聚类方法融合的思路,寻求优势互补,提高计算的精确度和成功率。
密度聚类的网格聚类的基本单元都可视为点,这为算法互补提供了基础,而栅格距离变换后的特征点、线蕴藏着更深的空间关系,有待进一步地发掘。
参考文献
[1] 耿协鹏,胡鹏.基于最短欧式距离的空间点集聚类的栅格算法 [J].测绘科学,2008,33(3):35-37.
[2] 柳盛,吉根林.空间聚类技术研究综述[J].南京师范大学学报(工程技术版),2010,10(2):57-62.
[3] 郭金来,胡鹏.网络最短路径的地图代数栅格算法[J].测绘科学,2007,32(1):109-111.
[4] 熊仕勇.一种新型的基于密度和栅格的聚类算法[J].计算机应用研究,2011,28(5):1721-1724.
[5] 胡鹏,游涟,杨传勇.地图代数[M].武汉:武汉大学出版社,2001:117—136.
[6] 杨帆,米红.一种基于网格的空间聚类方法在区域划分中的应用[J].测绘科学,2007,suppl:66-69.
[4] 丁丽萍.Android 操作系统的安全性分析[J].信息网络安全,2012,(03):23-26.
[5] 吴轩亮.三网融合下城域网DDoS攻击的监测及防范技术研究[J].信息网络安全,2012,(03):45-48.
作者简介:
李敏(1986-),女,汉族,河北河间人,硕士研究生,助理工程师;
研究方向:地图制图及地理信息数据应用。