meta分析中固定效应模型、随机效应模型和混合OLS模型的选择
混合ols回归 固定效应 随机效应

混合ols回归固定效应随机效应嘿,朋友!咱今天来聊聊混合 OLS 回归、固定效应和随机效应,这可都是在统计学和经济学里常碰到的“硬骨头”。
你想想,咱们生活里,有时候得判断各种因素对结果的影响,就像炒菜的时候,得知道每种调料放多少能让菜更好吃,这时候这些效应模型就派上用场啦。
先说混合 OLS 回归,这就好比是一个大杂烩。
它把所有的数据都当成一个整体来处理,不管个体之间有啥差异,统统放在一起算。
这是不是有点像不管是大人小孩,都给一样的饭量,不太合理吧?
再说说固定效应。
这就像是给每个个体都量身定制了一套规则。
比如说,不同的班级,各自有自己的特点,这个特点不会变,这就是固定效应在起作用。
它能把那些个体特有的、不变的因素给考虑进去,让分析更准确。
随机效应呢,则像是一场“碰运气”的游戏。
它认为个体之间的差异是随机产生的,就好像抽奖,谁也不知道下一个抽到啥。
那怎么选呢?这可没有绝对的标准答案。
要是你研究的那些个体差异不明显,混合 OLS 回归或许能凑合用。
但要是个体差异大,像不同地区的经济发展水平,那固定效应可能更合适。
要是觉得个体差异有点随机,那随机效应也许能帮上忙。
举个例子,研究不同学校学生的成绩,学校之间的差异很明显,用固定效应能更好地找出影响成绩的因素。
要是研究不同消费者对某种商品的购买意愿,这里面的个体差异可能更随机,随机效应也许更能反映真实情况。
总之,混合 OLS 回归、固定效应和随机效应,各有各的特点和用处,就看你怎么根据实际情况去挑选啦。
别选错了,不然得出的结论可能就不靠谱咯!。
混合OLS、固定模型与随机模型的区别

方差分析(写成英文我就认识了。
analysi s of varianc e (ANOVA) )主要有三种模型:即固定效应模型(fixed effects model),随机效应模型(randomeffects model),混合效应模型(mixed effects model)。
所谓的固定、随机、混合,主要是针对分组变量而言的。
固定效应模型,表示你打算比较的就是你现在选中的这几组。
例如,我想比较3种药物的疗效,我的目的就是为了比较这三种药的差别,不想往外推广。
这三种药不是从很多种药中抽样出来的,不想推广到其他的药物,结论仅限于这三种药。
“固定”的含义正在于此,这三种药是固定的,不是随机选择的。
随机效应模型,表示你打算比较的不仅是你的设计中的这几组,而是想通过对这几组的比较,推广到他们所能代表的总体中去。
例如,你想知道是否名牌大学的就业率高于普通大学,你选择了北大、清华、北京工商大学、北京科技大学4所学校进行比较,你的目的不是为了比较这4所学校之间的就业率差异,而是为了说明他们所代表的名牌和普通大学之间的差异。
你的结论不会仅限于这4所大学,而是要推广到名牌和普通这样的一个更广泛的范围。
“随机”的含义就在于此,这4所学校是从名牌和普通大学中随机挑选出来的。
混合效应模型就比较好理解了,就是既有固定的因素,也有随机的因素。
一般来说,只有固定效应模型,才有必要进行两两比较,随机效应模型没有必要进行两两比较,因为研究的目的不是为了比较随机选中的这些组别。
固定效应和随机效应的选择是大家做面板数据常常要遇到的问题,一个常见的方法是做huas man检验,即先估计一个随机效应,然后做检验,如果拒绝零假设,则可以使用固定效应,反之如果接受零假设,则使用随机效应。
meta分析中固定效应模型、随机效应模型和混合OLS模型的选择教学教材

meta分析中固定效应模型、随机效应模型和混合OLS模型的选择在Meta分析中最常用的是固定效应模型、随机效应模型。
怎样理解这两种模型呢?举个简单的例子:让十个学生去测量操场中的同一根旗杆,旗杆长度的测量值可以看作是一个固定效应模型;然而如果让一个学生去测量操场上长度不同的十根旗杆,旗杆长度的测量值则是随机效应模型。
一般来说,随机效应模型得出的结论偏向于保守,置信区间较大,更难以发现差异,带给我们的信息是如果各个试验的结果差异很大的时候,是否需要把各个试验合并需要慎重考虑,作出结论的时候就要更加小心。
从另一个角度来说,Meta分析本来就是用来分析结论不一致甚至是相反的临床试验,通过Meta分析提供一个可靠的综合的答案,如果每个试验的结果都一模一样,根本就没有必要作Meta分析,因此要通过齐性检验来解决这对矛盾。
一般来说判断方法是根据I2来确定。
1.就是根据I2值来决定模型的使用,大部分认为>50%,存在异质性,使用随机效应模型,≤50%,用固定效应模型,有了异质性,通过敏感性分析,或者亚亚组分析,去探求异质性的来源,但是这两者都是定性的,不一定能找到,即使你做了,研究数目多的话,可以做个meta回归来找异质性的来源2.在任何情况下都使用随机效应模型,因为如果异质性很小,那么随即和固定效应模型最终合并结果不会有很大差别,当异质性很大时,就只能使用随机效应模型,所以可以说,在任何情况下都使用随机效应模型3.还有一种,看P值,一般推荐P的界值是0.1,但现在大部分使用0.05,就是说P >0.05,用固定,≤0.05用随机效应模型。
但是这些都没有统一的说法,存在争议,如果你的审稿人是其中一种,你和他相冲突了,你只能按照他说的去修改,因为没有谁对谁错,但是现在你的文章在人家手里,如果模型不影响你的结果,你就遵照他们的建议但是,也不必过度强调哪种方法,更重要的是找到异质性根源。
meta分析中,异质性是天然存在的。
固定效应,随机效应和混合模型

固定效应,随机效应和混合模型
# 固定效应
固定效应模型是指以能够捕捉因变量与自变量之间固定关系的方式,对一组数据进行分析的经济统计建模方法。
该模型假定自变量之间存在固定的线性关系,它把多变量因变量分析归结为求解一元线性方程的问题,从而迅速、方便得出满足实际需要的结果;而且,在实践中,该模型的参数通常极其稳定,具有较高的可靠性。
# 随机效应
随机效应模型是一种对研究对象进行总体研究时,以估计总体各类属性个体直接效应而不考虑个体之间的关系的方法。
随机效应模型假设要解释的变量的取值是一系列独立的随机变量,采用抽样的方法估计一定的参数,该模型能有效地缩小抽样误差和提高估计的精确度;这也是为什么众多学者,对于定量研究采用这一模型的原因之一。
# 混合模型
混合模型是指综合固定因素和随机因素方法,在概念上由按同一种统计方法分析混合型数据集。
它把成熟的固定效应和随机效应方法以识别单位级差异和模型存在的相关性的混合模型综合而成,已经被广泛的应用在道口里科学研究中,尤其在更复杂的研究对象上,可以考虑使用混合模型来进行分析,可以很好地把握更多的因素,获得更加准确的结果。
经典Meta分析统计模型的合理选择

经典M eta分析统计模型的合理选择张天嵩上海市静安区中心医院(上海200040)【摘要】M eta分析可定量、科学地整合研究结果,常用的两种统计模型为固定效应模型和随机效应模型,在实际运用中选择合适的M eta分析合并模型非常重要。
本文介绍经典M eta分析统计模型的新观点,及其假设、结果解释,探讨合理选择模型时应考虑的因素,并给出推荐建议。
【关键词】M eta分析;统计模型;共同效应;固定效应;随机效应•方法学*The selection of appropriate statistical models for traditional meta-analysisZHANG TiansongJing'an District Central Hospital, Shanghai 200040, P.R.ChinaCorrespondingauthor:ZHANGTiansong,Email:***********************.cn【Abstract】Meta-analysis is the quantitative,scientific synthesis of research results.Fixed-effect and random-effectmodels are two popular statistical models for meta-analysis.The selection of the appropriate model is crucial.In this paper,we introduce some noval views of models and explain key assumptions,hypothesis,and interpretation of each model.We conclude with a discussion of factors to consider in model selection,and provide a recommendation on selection of appropriate statistical models for traditional meta-analysis.【Key words】Meta-analysis;Statistical model;Common-effect;Fixed-effect;Random-effectMeta分析可定量、科学地整合研究结果,已在 许多科学领域取得显著成果在医学领域常可用于比较不同干预措施有益还是有害121。
混合OLS、固定模型与随机模型的区别甄选.

混合OLS、固定模型与随机模型的区别(优.选)方差分析(写成英文我就认识了。
analysis of variance (ANOVA) )主要有三种模型:即固定效应模型(fixed effects model),随机效应模型(random effects model),混合效应模型(mixed effects model)。
所谓的固定、随机、混合,主要是针对分组变量而言的。
固定效应模型,表示你打算比较的就是你现在选中的这几组。
例如,我想比较3种药物的疗效,我的目的就是为了比较这三种药的差别,不想往外推广。
这三种药不是从很多种药中抽样出来的,不想推广到其他的药物,结论仅限于这三种药。
“固定”的含义正在于此,这三种药是固定的,不是随机选择的。
随机效应模型,表示你打算比较的不仅是你的设计中的这几组,而是想通过对这几组的比较,推广到他们所能代表的总体中去。
例如,你想知道是否名牌大学的就业率高于普通大学,你选择了北大、清华、北京工商大学、北京科技大学4所学校进行比较,你的目的不是为了比较这4所学校之间的就业率差异,而是为了说明他们所代表的名牌和普通大学之间的差异。
你的结论不会仅限于这4所大学,而是要推广到名牌和普通这样的一个更广泛的范围。
“随机”的含义就在于此,这4所学校是从名牌和普通大学中随机挑选出来的。
混合效应模型就比较好理解了,就是既有固定的因素,也有随机的因素。
一般来说,只有固定效应模型,才有必要进行两两比较,随机效应模型没有必要进行两两比较,因为研究的目的不是为了比较随机选中的这些组别。
固定效应和随机效应的选择是大家做面板数据常常要遇到的问题,一个常见的方法是做huasman检验,即先估计一个随机效应,然后做检验,如果拒绝零假设,则可以使用固定效应,反之如果接受零假设,则使用随机效应。
但这种方法往往得到事与愿违的结果。
另一个想法是在建立模型前根据数据性质确定使用那种模型,比如数据是从总体中抽样得到的,则可以使用随机效应,比如从N个家庭中抽出了M个样本,则由于存在随机抽样,则建议使用随机效应,反之如果数据是总体数据,比如31个省市的Gdp,则不存在随机抽样问题,可以使用固定效应。
Meta分析系列之一Meta分析的类型

Meta分析系列之一Meta分析的类型一、本文概述在医学、社会科学及许多其他领域中,Meta分析已经成为了一种重要的研究工具。
通过整合多个独立研究的结果,Meta分析能够提供更为全面和准确的科学证据,帮助决策者、研究人员和公众更好地理解某一特定问题或现象。
然而,不同类型的Meta分析在方法、目的和结果解释上都有所不同。
因此,本文旨在详细阐述Meta分析的主要类型,包括固定效应Meta分析、随机效应Meta分析、累积Meta分析、元回归分析和剂量-反应Meta分析等,以帮助读者更好地理解和应用这一强大的研究工具。
本文首先将对Meta分析的基本概念进行简要介绍,以便读者了解其基本框架和原理。
然后,将逐一详细介绍各种类型的Meta分析,包括它们的基本假设、适用条件、实施步骤和结果解释等。
还将讨论这些不同类型的Meta分析在实际研究中的应用场景和优缺点,以便读者能够根据实际情况选择合适的Meta分析方法。
本文还将对Meta分析的未来发展趋势进行展望,以期为读者提供更为全面和深入的理解。
二、Meta分析类型概述Meta分析是一种统计方法,通过综合多个独立研究的结果来得出更全面、更准确的结论。
根据不同的分类标准,Meta分析可以分为多种类型。
以下是几种常见的Meta分析类型概述:连续型数据Meta分析:当多个研究的数据是连续型变量(如身高、体重、血压等)时,可以采用连续型数据的Meta分析。
这种分析方法主要关注各研究结果的均数和标准差,通过合并这些统计量来得出结论。
二分类数据Meta分析:当多个研究的数据是二分类变量(如疾病的发生与否、治疗的有效与否等)时,应采用二分类数据的Meta分析。
这种分析方法主要关注各研究结果的阳性率、阴性率或比值比(Odds Ratio, OR)等统计量。
均值差Meta分析:当多个研究关注的是某一干预措施对某一连续型指标的影响时,可以使用均值差(Mean Difference, MD)作为效应量度量。
各类效应模型的选择,遴选最优效应模型

各类效应模型的选择,遴选最优效应模型Meta分析中,随机效应模型和固定效应模型的区别Meta分析的统计方法包括固定效应模型(fixed effect model)和随机效应模型(random effect model)。
固定效应模型是假设各独立研究来自同一总体的样本,各研究的效应值只是总体参数的一次实现,各研究之间的差异只是有抽样误差引起的,不同研究之间的变异性很小。
随机效应模型是指各个研究来自不同的总体,各个研究的变异性很大,即包括了各个研究的内部的变异,每一个研究都有其相应的总体效应,meta分析的合并效应值是多个不同总体参数的加权平均。
这两种模型用到的具体的计算公式不一样,目的都是为了使meta分析结果更可信,更加准确的表示出实际的效应。
就像如果数据符合正态分布用均数±标准差,不符合正态分布,用中位数和四位分数间距表示一样的。
一般来说,随机效应模型得出的结论偏向于保守,置信区间较大,更难以发现差异,带给我们的信息是如果各个试验的结果差异很大,需要慎重考虑是否对数据进行meta分析,作出结论的时候也要更加小心。
随机效应模型和固定效应模型的选择依据1 Q统计量:Q服从于自由度为k-1的卡方分布,Q值越大,其对应的P值越小。
P<0.05,表明研究间存在异质性,选用随机效应模型;否则不存在异质性,选用固定效应模型。
2 I square (I2):反映非抽样误差引起的差异在总变异中所占的比重。
一般认为I2>50%,表示存在明显的异质性,使用随机效应模型;如果I2≤50%,采用固定效应模型。
3.H统计量型:一般情况下,若H>1.5 提示研究间存在异质性,H<1.2则提示可认为各研究同质;若H值在1.2 和1.5之间,当H值的95%CI包含1,认为不存在显著的异质性,若没包含1则可认为存在显著的异质性。
互助问答第119期:固定效应、随机效应、混合回归模型选择
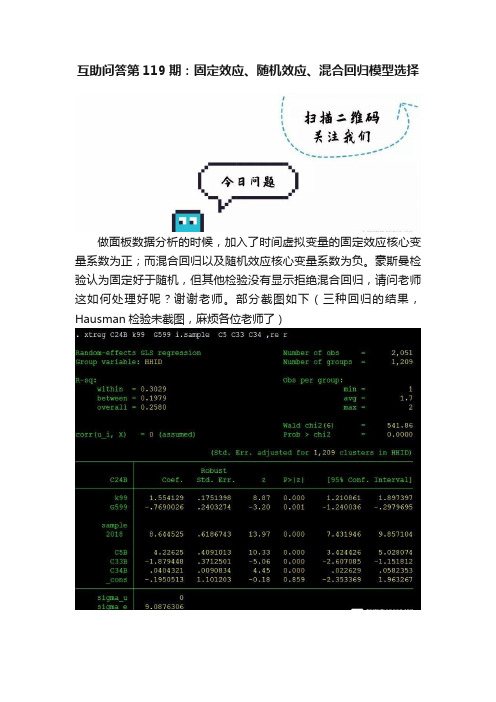
互助问答第119期:固定效应、随机效应、混合回归模型选择
做面板数据分析的时候,加入了时间虚拟变量的固定效应核心变量系数为正;而混合回归以及随机效应核心变量系数为负。
豪斯曼检验认为固定好于随机,但其他检验没有显示拒绝混合回归,请问老师这如何处理好呢?谢谢老师。
部分截图如下(三种回归的结果,Hausman检验未截图,麻烦各位老师了)
一般而言,BP检验随机效应和混合效应,原假设混合效应。
F检验选择固定效应和混合效应,原假设混合效应。
具体而言,模型固定效应回归的F检验显示Prob>F=0.0000,拒绝原假设,应该使用固定效应。
综合hausman检验结果,此处应该选择固定效应。
固定效应模型和混合效应模型的选择

固定效应模型和混合效应模型的选择固定效应模型分为三种:个体固定效应模型、时刻固定效应模型和个体时刻固定效应模型)。
如果我们是对个体固定,则应选择个体固定效用模型。
但是,我们还需作个体固定效应模型和混合估计模型的选择。
所以,就要作F值检验。
相对于混合估计模型来说,是否有必要建立个体固定效应模型可以通过F检验来完成。
H0:对于不同横截面模型截距项相同(建立混合估计模型)。
SSErH1:对于不同横截面模型的截距项不同(建立时刻固定效应模型)。
SSEuF统计量定义为:F=[( SSEr - SSEu)/(T+k-2)]/[ SSEu/(NT-T-k)]其中,SSEr,SSEu分别表示约束模型(混合估计模型的)和非约束模型(个体固定效应模型的)的残差平方和(Sum squared resid)。
非约束模型比约束模型多了T–1个被估参数。
需要指出的是:当模型中含有k个解释变量时,F统计量的分母自由度是NT-T- k。
通过对F 统计量我们将可选择准确、最佳的估计模型。
在作回归时也是四步:第一步,先作混合效应模型:在cross-section 一栏选择None ,Period也是None;Weights是cross-section Weights,然后把回归结果的Sum squared resid值复制出来,就是SSEr第二步:作个体固定效用模型:在cross-section 一栏选择Fixed ,Period也是None;Weights是cross-section Weights,然后把回归结果的Sum squared resid值复制出来,就是SSEu第三步:根据公式F=[( SSEr - SSEu)/(T+k-2)]/[ SSEu/(NT-T-k)]。
计算出结果。
其中,T为年数,不管我们的数据是unbalance还是balance看observations就行了,也即Total pool (balanced)observations:的值,但是如果是balance我们也可以计算,也即是每一年的企业数的总和。
混合OLS、固定模型与随机模型的区别(优.选)

方差分析(写成英文我就认识了。
analysis of variance (ANOVA) )主要有三种模型:即固定效应模型(fixed effects model),随机效应模型(random effects model),混合效应模型(mixed effects model)。
所谓的固定、随机、混合,主要是针对分组变量而言的。
固定效应模型,表示你打算比较的就是你现在选中的这几组。
例如,我想比较3种药物的疗效,我的目的就是为了比较这三种药的差别,不想往外推广。
这三种药不是从很多种药中抽样出来的,不想推广到其他的药物,结论仅限于这三种药。
“固定”的含义正在于此,这三种药是固定的,不是随机选择的。
随机效应模型,表示你打算比较的不仅是你的设计中的这几组,而是想通过对这几组的比较,推广到他们所能代表的总体中去。
例如,你想知道是否名牌大学的就业率高于普通大学,你选择了北大、清华、北京工商大学、北京科技大学4所学校进行比较,你的目的不是为了比较这4所学校之间的就业率差异,而是为了说明他们所代表的名牌和普通大学之间的差异。
你的结论不会仅限于这4所大学,而是要推广到名牌和普通这样的一个更广泛的范围。
“随机”的含义就在于此,这4所学校是从名牌和普通大学中随机挑选出来的。
混合效应模型就比较好理解了,就是既有固定的因素,也有随机的因素。
一般来说,只有固定效应模型,才有必要进行两两比较,随机效应模型没有必要进行两两比较,因为研究的目的不是为了比较随机选中的这些组别。
固定效应和随机效应的选择是大家做面板数据常常要遇到的问题,一个常见的方法是做huasman检验,即先估计一个随机效应,然后做检验,如果拒绝零假设,则可以使用固定效应,反之如果接受零假设,则使用随机效应。
但这种方法往往得到事与愿违的结果。
另一个想法是在建立模型前根据数据性质确定使用那种模型,比如数据是从总体中抽样得到的,则可以使用随机效应,比如从N个家庭中抽出了M个样本,则由于存在随机抽样,则建议使用随机效应,反之如果数据是总体数据,比如31个省市的Gdp,则不存在随机抽样问题,可以使用固定效应。
Meta分析思考与练习参考答案

第25章M e t a分析思考与练习参考答案一、最佳选择题1. Meta分析中,如果异质性检验不拒绝H0,一般采用(A)进行效应合并。
A.随机效应模型 B. 固定效应模型 C.混合效应模型D. 回归模型E. 贝叶斯模型2. 关于meta分析,以下(C)说法不正确。
A.meta分析本质上是一种观察性研究,因而可能存在各种偏倚B.meta分析是用定量的方法综合同类研究结果的一种系统评价C.采用随机效应模型能使meta分析的结果更加可靠D.meta分析时,如果研究间异质性很大,应认真考察异质性的来源,并考虑这些研究的可合并性E.亚组分析能使meta分析的结果更有针对性3. 对连续型变量资料的meta分析,如果各纳入研究的测量单位不同,应采用(A)作为效应合并指标。
A.标准化均数差 B. 加权均数差 C.均数差D. 标准化P值E. 危险度差值4. 异质性检验采用的统计量是(B)。
A.F统计量 B. Q统计量 C.t统计量D.H统计量 E. Z统计量5. 关于发表偏移,以下说法(C)不正确。
A.通过漏斗图可大致判断是否存在发表偏倚B.产生发表偏倚的主要原因是作者往往只把统计学上有意义的阳性研究结果拿来写文章并投稿C.若发表偏倚对meta分析的影响较大,则需要增加很多个研究,才能使meta分析的结果被逆转D.尽量搜集未发表的阴性研究结果,可减少发表偏倚E.漏斗图的基本思想是纳入研究效应的精度随着样本含量的增加而增加二、思考题1. Meta分析的基本步骤有哪些?答:Meta分析的基本步骤包括:提出问题,制定研究计划;检索相关文献;选择符合要求的纳入文献;提取纳入文献的数据信息;纳入研究的质量评价;资料的统计学处理;敏感性分析;结果的分析和讨论。
2. Meta分析的目的和意义是什么?答:通过meta分析能增加统计功效,评价研究结果的一致性,增强结论的可靠性和客观性,通过亚组分析,得出新结论,寻找新的假说和研究思路。
如何选择适当的面板数据回归模型固定效应还是随机效应

如何选择适当的面板数据回归模型固定效应还是随机效应如何选择适当的面板数据回归模型:固定效应还是随机效应在进行面板数据回归分析时,一个重要的问题是选择适当的模型来控制面板特征和个体间的异质性。
其中,固定效应模型(Fixed Effects Model)和随机效应模型(Random Effects Model)是常用的两种方法。
本文将重点讨论如何选择适当的面板数据回归模型,包括固定效应模型和随机效应模型的基本原理、适用条件以及实施步骤。
1. 固定效应模型固定效应模型是一种通过控制个体固定效应来解决面板数据回归中个体间异质性的方法。
也就是说,固定效应模型假设个体固定效应对因变量的解释存在差异,但是在解释变量上是常数。
固定效应模型的基本原理是加入个体固定效应项,在个体内部的观测值上利用时间序列变化进行估计。
固定效应模型的主要优点是对个体固定效应的控制,能够更准确地估计个体自身的影响因素。
固定效应模型的适用条件包括:个体固定效应存在,并且与解释变量无关;个体固定效应对因变量的解释具有显著差异;解释变量中不含个体间的变化。
如果以上条件满足,可以采用固定效应模型进行面板数据回归分析。
实施固定效应模型的步骤如下:(1)数据处理:根据面板数据的特点进行数据整理和转换,确保数据的准确性和一致性。
(2)检验个体固定效应:通过统计方法或绘制图表来判断个体固定效应是否存在,并且与解释变量无关。
(3)估计固定效应:引入虚拟变量或时间固定效应来表示不同个体或时间的差异,并将其纳入回归模型进行估计。
(4)模型评估:对固定效应模型进行统计推断和模型拟合度评估,确保模型的有效性和可靠性。
2. 随机效应模型随机效应模型是一种通过考虑个体随机效应来克服面板数据回归中个体异质性的方法。
该模型假设个体随机效应与解释变量相关,并且具有随机性。
随机效应模型的基本原理是引入个体随机效应项,并将其纳入回归模型进行估计。
随机效应模型的优点是能够控制个体间的时间不变影响,更关注个体与解释变量的相关性。
固定效应和随机效应模型选择依据

固定效应和随机效应模型选择依据
固定效应模型与随机效应模型选择依据需要根据不同的研究设计、研究问题,以及准备进行计算的数据来确定。
固定效应模型是当正在考虑所有在研究中参与者上的单一平均效应时所使用的方法。
而随机效应模型则是对平均效应的一般化,其中考虑到参与者之间存在的组内差异,可以指明组的性能。
固定效应模型适用于研究设计,其中只允许每个参与者参与一次,也就是说,没有重复测量。
如果参与者只进行一次测量,那么所有参与者都会具有相同的潜在效应,该效应就是固定的,因为每个参与者只在一次实验中发生一次效应。
因此,如果研究中没有重复测量,那么固定效应模型就很合适。
反之,如果需要在每个参与者身上进行多次测量,则应考虑使用随机效应模型。
随机效应模型是考虑到参与者之间的组内差异的更一般的效应,以确定组的性能。
它引入了两个新的变量,一个是“每个参与
者的差异”,另一个是“组间差异”。
每个参与者的差异是指个
体之间的差异,它反映了每个参与者在研究过程中出现的差异,而组间差异则是指组内样本之间的差异,它反映了每个组在研究过程中出现的差异。
总而言之,在选择固定效应模型或随机效应模型时,首先需要考虑研究设计、研究问题,以及参与者之间是否存在差异。
如果研究中没有重复测量,那么固定效应模型就很合适;而如果有重复测量,那么随机效应模型就更加合适,因为它可以考虑参与者之间存在的组内差异。
互助问答第23问 OlS模型、面板固定效应(FE)、面板随机效应(RE)模型估计的优缺点

问:关于三个模型比较的问题。
OlS模型、面板固定效应(FE)、面板随机效应(RE)模型估计的优缺点。
答:
给定一个面板数据,OLS模型可以作为基准模型,优点是简单,缺点是没纳入个体效应。
固定效应和随机效应模型的优点是纳入了个体效应。
当个体效应与自变量相关时,应使用固定效应模型,因为此时随机效应模型系数估计不一致。
当个体效应与自变量不相关时,教科书的传统说法是应该使用随机效应,因为更有效,并且有Hausman检验判断固定效应和随机效应模型哪个更好。
实际上,在线性面板模型中,目前大都默认使用固定效应,一来因为个体效应很难真正与自变量不相关,二来因为随着数据量的增大,有效性问题越来越不重要,大家更关注一致性问题。
但是,如果是非线性模型(比如Probit),控制大量个体哑变量(即固定效应)会造成系数估计偏差,随机效应模型可能会更好——计量中这依然是一个前沿领域。
混合OLS、固定模型与随机模型的区别

方差分析(写成英文我就认识了。
analys is of varian ce (ANOVA) )主要有三种模型:即固定效应模型(fixedeffect s model),随机效应模型(random effect s model),混合效应模型(mixedeffect s model)。
所谓的固定、随机、混合,主要是针对分组变量而言的。
固定效应模型,表示你打算比较的就是你现在选中的这几组。
例如,我想比较3种药物的疗效,我的目的就是为了比较这三种药的差别,不想往外推广。
这三种药不是从很多种药中抽样出来的,不想推广到其他的药物,结论仅限于这三种药。
“固定”的含义正在于此,这三种药是固定的,不是随机选择的。
随机效应模型,表示你打算比较的不仅是你的设计中的这几组,而是想通过对这几组的比较,推广到他们所能代表的总体中去。
例如,你想知道是否名牌大学的就业率高于普通大学,你选择了北大、清华、北京工商大学、北京科技大学4所学校进行比较,你的目的不是为了比较这4所学校之间的就业率差异,而是为了说明他们所代表的名牌和普通大学之间的差异。
你的结论不会仅限于这4所大学,而是要推广到名牌和普通这样的一个更广泛的范围。
“随机”的含义就在于此,这4所学校是从名牌和普通大学中随机挑选出来的。
混合效应模型就比较好理解了,就是既有固定的因素,也有随机的因素。
一般来说,只有固定效应模型,才有必要进行两两比较,随机效应模型没有必要进行两两比较,因为研究的目的不是为了比较随机选中的这些组别。
固定效应和随机效应的选择是大家做面板数据常常要遇到的问题,一个常见的方法是做hu asman检验,即先估计一个随机效应,然后做检验,如果拒绝零假设,则可以使用固定效应,反之如果接受零假设,则使用随机效应。
固定效应,随机效应和混合模型

固定效应,随机效应和混合模型
固定效应、随机效应和混合模型是统计学中常用的模型类型。
它们被广泛应用于各种领域,如经济学、生物学、心理学等等。
在这篇文章中,我们将讨论这三种模型的概念、应用和优缺点。
固定效应模型是一种最简单的模型类型。
它适用于研究中对所有个体都有相同数量的观测值的情况。
在这种情况下,我们将每个个体视为具有相同的参数,这些参数是我们想要估计的。
固定效应模型假设这些参数是固定的,不随时间或其他因素而变化。
这种模型通常用于研究某个疗法或干预措施的效果,或者研究某个特定群体的一些特征。
随机效应模型与固定效应模型相似,但它们假设每个个体具有不同的参数。
这些参数是从一个分布中随机抽取的,因此我们无法精确地估计它们。
随机效应模型通常用于研究不同个体之间的差异,或者研究某些因素对不同群体的影响。
混合模型是固定效应模型和随机效应模型的结合。
它们假设每个个体都具有固定的和随机的参数,这些参数可以同时影响个体的特征和差异。
混合模型通常用于解释不同个体之间的异质性,或者研究某些因素对不同群体的影响时考虑个体的特征和差异。
总之,固定效应、随机效应和混合模型都是重要的统计学模型。
它们可以应用于各种领域,用于解释不同个体之间的差异或相似性,并帮助我们更好地理解数据背后的规律。
- 1 -。
meta分析中固定效应模型、随机效应模型和混合OLS模型的选择

meta分析中固定效应模型、随机效应模型和混合OLS模型的选择在Meta分析中最常用的是固定效应模型、随机效应模型。
怎样理解这两种模型呢?举个简单的例子:让十个学生去测量操场中的同一根旗杆,旗杆长度的测量值可以看作是一个固定效应模型;然而如果让一个学生去测量操场上长度不同的十根旗杆,旗杆长度的测量值则是随机效应模型。
一般来说,随机效应模型得出的结论偏向于保守,置信区间较大,更难以发现差异,带给我们的信息是如果各个试验的结果差异很大的时候,是否需要把各个试验合并需要慎重考虑,作出结论的时候就要更加小心。
从另一个角度来说,Meta分析本来就是用来分析结论不一致甚至是相反的临床试验,通过Meta分析提供一个可靠的综合的答案,如果每个试验的结果都一模一样,根本就没有必要作Meta分析,因此要通过齐性检验来解决这对矛盾。
一般来说判断方法是根据I2来确定。
1.就是根据I2值来决定模型的使用,大部分认为>50%,存在异质性,使用随机效应模型,≤50%,用固定效应模型,有了异质性,通过敏感性分析,或者亚亚组分析,去探求异质性的来源,但是这两者都是定性的,不一定能找到,即使你做了,研究数目多的话,可以做个meta回归来找异质性的来源2.在任何情况下都使用随机效应模型,因为如果异质性很小,那么随即和固定效应模型最终合并结果不会有很大差别,当异质性很大时,就只能使用随机效应模型,所以可以说,在任何情况下都使用随机效应模型3.还有一种,看P值,一般推荐P的界值是0.1,但现在大部分使用0.05,就是说P >0.05,用固定,≤0.05用随机效应模型。
但是这些都没有统一的说法,存在争议,如果你的审稿人是其中一种,你和他相冲突了,你只能按照他说的去修改,因为没有谁对谁错,但是现在你的文章在人家手里,如果模型不影响你的结果,你就遵照他们的建议但是,也不必过度强调哪种方法,更重要的是找到异质性根源。
meta分析中,异质性是天然存在的。
孟德尔随机化联合meta随机效应模型和固定效应模型区别

孟德尔随机化联合meta随机效应模型和固定效应模型区别下载提示:该文档是本店铺精心编制而成的,希望大家下载后,能够帮助大家解决实际问题。
文档下载后可定制修改,请根据实际需要进行调整和使用,谢谢!本店铺为大家提供各种类型的实用资料,如教育随笔、日记赏析、句子摘抄、古诗大全、经典美文、话题作文、工作总结、词语解析、文案摘录、其他资料等等,想了解不同资料格式和写法,敬请关注!Download tips: This document is carefully compiled by this editor. I hope that after you download it, it can help you solve practical problems. The document can be customized and modified after downloading, please adjust and use it according to actual needs, thank you! In addition, this shop provides you with various types of practical materials, such as educational essays, diary appreciation, sentence excerpts, ancient poems, classic articles, topic composition, work summary, word parsing, copy excerpts, other materials and so on, want to know different data formats and writing methods, please pay attention!孟德尔随机化联合meta随机效应模型和固定效应模型区别1. 引言在统计学和数据分析中,meta分析是一种整合多个研究结果以得出总体结论的技术。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
meta分析中固定效应模型、随机效应模型和混合OLS模型的选择meta分析中固定效应模型、随机效应模型和混合OLS模型的选择在Meta分析中最常用的是固定效应模型、随机效应模型。
怎样理解这两种模型呢?举个简单的例子:让十个学生去测量操场中的同一根旗杆,旗杆长度的测量值可以看作是一个固定效应模型;然而如果让一个学生去测量操场上长度不同的十根旗杆,旗杆长度的测量值则是随机效应模型。
一般来说,随机效应模型得出的结论偏向于保守,置信区间较大,更难以发现差异,带给我们的信息是如果各个试验的结果差异很大的时候,是否需要把各个试验合并需要慎重考虑,作出结论的时候就要更加小心。
从另一个角度来说,Meta分析本来就是用来分析结论不一致甚至是相反的临床试验,通过Meta分析提供一个可靠的综合的答案,如果每个试验的结果都一模一样,根本就没有必要作Meta分析,因此要通过齐性检验来解决这对矛盾。
一般来说判断方法是根据I2来确定。
1.就是根据I2值来决定模型的使用,大部分认为>50%,存在异质性,使用随机效应模型,≤50%,用固定效应模型,有了异质性,通过敏感性分析,或者亚亚组分析,去探求异质性的来源,但是这两者都是定性的,不一定能找到,即使你做了,研究数目多的话,可以做个meta 回归来找异质性的来源2.在任何情况下都使用随机效应模型,因为如果异质性很小,那么随即和固定效应模型最终合并结果不会有很大差别,当异质性很大时,就只能使用随机效应模型,所以可以说,在任何情况下都使用随机效应模型3.还有一种,看P值,一般推荐P的界值是0.1,但现在大部分使用0.05,就是说P>0.05,用固定,≤0.05用随机效应模型。
但是这些都没有统一的说法,存在争议,如果你的审稿人是其中一种,你和他相冲突了,你只能按照他说的去修改,因为没有谁对谁错,但是现在你的文章在人家手里,如果模型不影响你的结果,你就遵照他们的建议但是,也不必过度强调哪种方法,更重要的是找到异质性根源。
meta分析中,异质性是天然存在的。
如果异质性较小,选择固定效应模型更可靠;如果异质性较大,则建议选择随机效应模型,但仍然需要通过敏感性分析,寻找到异质性根据,以消除其影响。
有关异质性,齐性,下面再有一个例子进行说明:Meta分析是汇总众多研究结果的一种定量分析方法,主要目的是为了得到比单一研究更精确的结果估计,以及分析影响研究结果间差异的因素。
目前,Meta 分析主要根据研究的“效应尺度”(effect magnitude)的齐性检验结果,决定采用固定效应或随机效应模型合并每项研究的“效应尺度”,但一般未考虑到研究具有不同的特征以及相应的平均“效应尺度”的差异[2]。
多水平模型是国外教育学界80年代中后期发展起来的一门多元统计分析新技术,是当前国际上统计学研究中一个新兴而重要的领域[1]。
本文拟通过对“效应尺度”的选择以及具有协变量的两水平混合效应模型建模方法的探讨,估计总平均“效应尺度”以及具有不同研究特征的平均“效应尺度”及其可信区间。
Meta分析的数据具有两个水平的层次结构(two-level hierarchy),水平2为研究水平,水平1为个体水平。
对于具有这种特征的数据,两个水平模型可将传统模型中单一的随机误差项分解到与数据层次结构相对应的水平上,即分解出研究水平的变异。
模型基本结构为:Y ij=β0+u0j+e ijj=1,2,…,m,代表研究项目数;i=1,2,…,n,代表研究个体数;Y ij为各项研究的“效应尺度”;β0为总平均“效应尺度”的估计;u0j和e ij分别为研究水平和个体水平残差。
Meta分析一般只能得到各项研究的结果即“效应尺度”及其标准误以及样本含量等数据,研究个体的数据一般是不可得的,因此,这里拟合的两水平模型为聚集水平(水平2)模型,可表达为:Y*j=β0+u.j+e*jVar(u.j)=σ2uVar(e.j)=σ2e/n j总方差为σ2u+σ2e/n j,可通过对随机部分定义一个设计变量来拟合模型,即z.j=1/n j,相应的随机系数为e.j,n j为每项研究中的研究个体数。
本文首先拟合的无任何解释变量的“无效模型”(null model)为:Y.j=β0+u.j+e.j z.j在收集到的文献中,多数研究的“效应尺度”为OR值,有的为ln(OR)值,即通过logistic 回归模型获得的β值,两者可相互转换。
分别将OR值和ln(OR)值作为反应变量拟合两个“无效模型”,因此,式中Y.j分别表示两个模型中第j项研究的OR j值和ln(OR j)值,β0分别表示合并全部OR j和ln(OR j)的平均估计值,u.j 为第j项研究的随机效应,e.j为与第j项研究有关的随机误差,结果见表1。
然后ln(OR)为反应变量,在模型中引入研究水平协变量国别x.j(国内研究取0,国外研究取1),将其效应β1拟合为固定效应,用一个随机成份拟合剩余的部分,结果见表2。
混合效应模型为:Y.j=β0+β1x.j+u.j+e.j z.j另一种建模方式,即不拟合截距项,将国别转换为x1.j和x2.j两个哑变量引入模型,它们分别对应于国内与国外研究,仍将其效应β1和β2拟合为固定效应,同时用一个共同的随机成份u.j拟合剩余部分,结果见表3与表4。
模型可表达为:Y.j=β1x1.j+β2x2.j+u.j+e.j z.j表1分别以OR和ln(OR)为“效应尺度”的拟合结果以OR为“效应尺度”以ln(OR)为“效应尺度”估计值标准误估计值标准误固定参数β05.1640 0.6086 1.40600.1050随机参数研究水平σ2u个体水平σ2e17.790013.63200.539210.10940 以OR为“效应尺度”,模型所估计的总平均“效应尺度”为 5.1640,95%可信区间为3.9711~6.3569;以ln(OR)为“效应尺度”,根据ln(O)±uαS ln(OR),可计算总平均“效应尺度”OR的估计为eβ0=4.0796,95%可信区间为4.0796×e±1.96×0.1050,即3.3208~5.0118。
可见,总平均“效应尺度”下降了 1.0844,可信区间亦变窄。
此外,研究水平的方差估计从17.7900下降到0.5392,估计精度亦增加,标准误从3.6320下降到0.1094。
表2引入研究水平协变量的拟合结果估计值标准误固定参数β0β11.03700.62380.14960.1943随机参数σ2u(研究水平)σ2u(个体水平)0.445310.0904结果表明,“效应尺度”与国别有关,其参数估计为正,表明国外研究的OR值较大,经转换得国内研究的OR估计为e1.0370=2.8207,国外研究的OR值计为e1.6608=5.2635,相差甚大。
研究间方差及其标准误估计分别从0.5392和0.1094下降为0.4453和0.0904,亦表明国别这一研究水平协变量解释了部分研究结果间变异。
但从参数估计难以计算国外平均“效应尺度”的可信区间。
表3引入研究水平协变量的拟合结果(不拟合截距项)估计值标准误固定参数β0β11.03701.66000.14960.1241随机参数σ2u(水平2)σ2u(水平1) 0.445310.0904根据,可直接得到国内与国外研究的平均“效应尺度”及其可信区间,见表4。
表4根据表3的转换结果研究数目OR 95%可信区间国内研究20 2.8207 2.1039~3.7818国外研究29 5.2593 4.1237~6.7076与表2转换结果比较,国内、外研究的OR 估计基本一致,研究间方差及其标准误估计完全一致,但拟合国内外两个哑变量的固定效应,可直接得到其标准误的估计,国外略小。
在流行病学横断面调查和病例对照研究中,常采用比值比OR反映暴露与疾病的联系强度,即患者暴露比与非患者暴露比的比值,但其常不服从正态分布,而其对数转换值ln(OR)近似服从正态分布。
多水平模型的基本假定是反应变量遵从正态分布,水平2和水平1残差遵从N(0,σ2u)和N(0,σ2e/n j)[1],故在两水平混合效应模型中应以ln(OR)为分析的“效应尺度”,然后再将分析结果转换为OR值,否则平均“效应尺度”及其可信区间均不可靠。
通过采用的固定效应或随机效应模型可得到平均“效应尺度”及其可信区间的估计,但这些模型一般不能分析影响研究结果间差异的因素[2]。
两水平混合效应模型将研究水平协变量拟合为固定效应,用以解释研究结果间的差别,以一个随机成份拟合其剩余部分,从而正确评价研究水平的因素对研究结果的影响。
在Meta 分析中,各面研究结果常具有很大的不同一性,如本文国内外研究结果的估计分别为2.8207和5.2593,相差达2.4386,如不考虑研究水平协变量的影响而直接合并的结果为4.0796,可见,固定或随机效应模型的合并是不适宜的。
“无效模型”中研究水平的方差估计σ2u为0.5392,亦提示研究结果之间存在较大的不同一性。
混合效应模型表明,国别这一研究水平协变量解释了部分研究结果间的变异,研究水平方差下降为0.4453,但仍遗留了较大的变异,提示尚存在其它因素导致研究结果间的差异,如果可得到这些研究水平的因素,则可通过两水平混合效应模型进一步评价其对研究结果的影响。