MySQL高级教程 笔记
mysql 笔记_02_2013_05_24

mysql笔记更新至2012-6-151.如何查看数据表先要选择数据库:use judge然后查看该数据库中有哪些表:show tables查看表的结构:desc student说明:judge是数据库;student是表名。
2.表2.1.查询表mysql中如何查询rownum呢?mysql>set@mycnt=0;Query OK,0rows affected(0.00sec)mysql>select(@mycnt:=@mycnt+1)as ROWNUM,description from question;2.1.1.获取记录的条数st();connections=rs.getRow();2.2.创建表2.2.1.创建自增列:create table student(id int primary key auto_increment,name char(20));注意:自增列必须被定义成一个键(主键或者外键)2.3.删除表drop table student;2.4.修改表2.4.1.增加列alter table pass add column issuperpwd bit(1);2.4.2.删除列alter table student drop column name;2.4.3.修改列的类型alter table student change column name name bit(1);alter table student modify column name bit(2);注意:以上两种方法都可以。
2.4.4.修改列名称修改列的名称alter table student change column name name33char(5);2.4.5.修改表名alter table A rename to B;mysql>alter table A rename to B;Query OK,0rows affected(0.00sec)2.5.约束2.5.1.增加主键alter table student add primary key(id);2.5.2.删除主键alter table student drop primary key;2.5.3.设置自增列alter table student modify column id int auto_increment; mysql>alter table student modify column id int auto_increment; Query OK,0rows affected(0.00sec)Records:0Duplicates:0Warnings:0mysql>desc student;+-------+----------+------+-----+---------+----------------+|Field|Type|Null|Key|Default|Extra|+-------+----------+------+-----+---------+----------------+|id|int(11)|NO|PRI|NULL|auto_increment||name|char(20)|YES||NULL||+-------+----------+------+-----+---------+----------------+2rows in set(0.00sec)2.5.4.去掉自增列alter table student modify column id int;3.备份与还原3.1.备份恢复数据mysqldump-uroot-proot-w"id=2"books book>d:12.sql数据库books中有一个表bookmysqldump-uroot-proot huangwei pass>e:/test/pass.sql说明:huangwei是数据库名,数据库huangwei中有一个表pass mysqldump-uroot-proot-w id=2or id=3books book>d:12.sql备份整个数据库:mysqldump-uroot--password=root--database huangwei>e:/test/huangwei.sql仅备份数据:mysqldump-uroot-proot-t huangwei Question>e:/smb/question.sql说明:-n:不包含数据库的创建语句-t:不包含数据表的创建语句-d:不包含数据3.2.还原执行脚本\./home/whuang/pass.sqlsource d:123\12.sqlsource d:\download\pass_02.sqlmysql-uroot-proot<e:/test/huangwei.sql说明:执行上述命令时,不需要登录数据库4.数据库编码4.1.查看编码show variables like'character\_set\_%';正确的编码是+--------------------------+--------+|Variable_name|Value|+--------------------------+--------+|character_set_client|gbk||character_set_connection|gbk||character_set_database|utf8||character_set_filesystem|binary||character_set_results|gbk||character_set_server|utf8||character_set_system|utf8|+--------------------------+--------+错误的编码是:+--------------------------+--------+|Variable_name|Value|+--------------------------+--------+|character_set_client|gbk||character_set_connection|gbk||character_set_database|latin1||character_set_filesystem|binary||character_set_results|gbk||character_set_server|latin1||character_set_system|utf8|+--------------------------+--------+4.2.设置编码正确default-character-set=utf8错误default-character-set=utf-85.配置5.1.配置文件windows中的配置文件名称是my.inilinux中的配置文件名称是/etc/f配置文件如下:(vim/etc/f)[mysqld]datadir=/var/lib/mysqlsocket=/var/lib/mysql/mysql.sockuser=mysql#Default to using old password format for compatibility with mysql3.x#clients(those using the mysqlclient10compatibility package).old_passwords=1#added by huangweidefault-character-set=utf8#Disabling symbolic-links is recommended to prevent assorted security risks; #to do so,uncomment this line:#symbolic-links=0[mysqld_safe]log-error=/var/log/mysqld.logpid-file=/var/run/mysqld/mysqld.pid#added by huangwei[mysql]default-character-set=gbkwindows下的配置文件C:\Program Files\MySQL\MySQL Server5.1\my.ini5.1.1.设置自动提交set autocommit=1或set autocommit=on开启自动提交set autocommit=0或set autocommit=off禁止自动提交5.1.2.查看是否是自动提交查看自动提交show variables like'autocommit';select@@autocommit;执行set autocommit=0;完之后再查看:在mysql中设置set autocommit=0后,执行完SQL语句之后,并没有自动提交。
mysql高级教程笔记

mysql⾼级教程笔记MySQL⾼级教程1、存储引擎1.1、MyISAM和InnoDB对⽐项MyISAM InnoDB 主外键不⽀持⽀持事务不⽀持⽀持⾏表锁表锁,即使操作⼀条记录也会锁住整个表,不适合⾼并发的操作⾏锁,操作时只锁某⼀⾏,不对其他⾏有影响。
适合⾼并发的操作缓存只缓存索引,不缓存真实数据不仅缓存索引还要缓存真实数据,对内存要求较⾼,⽽且内存⼤⼩对性能有决定性的影响表空间⼩⼤关注点性能事务默认安装Y Y2、索引优化2.1、SQL执⾏顺序from -> on -> left/where -> group by -> having -> select -> order by -> limit2.2、索引简介2.2.1、索引是什么MySQL官⽅对索引的定义为:索引是帮助MySQL⾼效获取数据的数据结构。
可以得到索引的本质:索引是数据结构。
数据本⾝之外,数据库还维护着⼀个满⾜特定查找算法的数据结构,这些数据结构以某种⽅式指向数据,这样就可以在这些数据结构的基础上实现⾼级查找算法,这种数据结构就是索引。
⼀般来说索引本⾝也很⼤,不可能全部存储在内存中,因此索引往往以索引⽂件的形式存储在磁盘上我们平时所说的索引,如果没有特别指明,都是指B树(多路搜索树,并不⼀定是⼆叉的)结构组织的索引。
2.2.2、SQL索引分类1. 单值索引:即⼀个索引只包含单个列,⼀个表可以有很多个单列索引(最好不超过5个)2. 唯⼀索引:索引列的值必须唯⼀,但允许有空值3. 复合索引:⼀个索引包含包含多个列4. 基本语法创建:create [UNIQUE] index 索引名 on 表名(字段)alter 表名 add [UNIQUE] index 索引名 on (字段)删除:drop index [索引名] on 表名查看:show index from 表名5. 哪些情况下需要创建索引:主键⾃动建⽴唯⼀索引频繁作为查询条件的字段应该创建索引查询中与其他表关联的字段,外键关系建⽴索引频繁更新的字段不适合创建索引where条件⾥⽤不到的字段不建⽴索引单键/组合索引的选择问题(在⾼并发下倾向创建组合索引)查询中排序的字段,排序字段若通过索引去访问将⼤⼤提⾼排序速度查询中统计或者分组字段6. 哪些情况不要建索引:表记录太少经常增删改的表:不仅要维护数据,还要维护索引结构数据重复且平均分布的表字段,应该只为最经常查询和最经常排序的数据列建⽴索引。
宋红康mysql高级篇笔记

宋红康mysql高级篇笔记MySQL 是一款广泛应用于互联网领域的关系型数据库管理系统。
它的高级功能和优势使得它成为互联网开发者的首选。
本文将分享一些关于 MySQL 高级篇的笔记,涵盖了一些互联网技术介绍、互联网商业和技术应用方面的内容。
一、索引优化索引是提高数据库查询效率的重要手段之一。
在 MySQL 中,使用合适的索引可以显著提升查询性能。
首先,我们需要了解不同类型的索引,如主键索引、唯一索引和普通索引等。
其次,根据具体应用场景,我们可以使用覆盖索引、前缀索引、联合索引等技术进行索引优化。
此外,我们还要注意索引的维护和管理,及时进行索引的重建和优化。
二、查询优化在互联网应用中,查询是最常见的数据库操作之一。
如何编写高效的查询语句,能够快速地获取所需的数据,是每个开发者都应该关注的问题。
本节将介绍一些查询优化的技巧,例如避免使用通配符查询、合理使用 LIMIT 关键字、使用 EXPLAIN 分析查询执行计划等。
三、事务管理事务是保证数据库操作一致性和完整性的重要手段。
MySQL 支持事务的 ACID 特性,可以确保多个操作的原子性、一致性、隔离性和持久性。
本节将详细介绍如何使用事务管理,包括事务的开启、提交和回滚,以及事务并发控制的方法。
四、高级数据操作除了基本的增删改查操作,MySQL 还提供了一些高级数据操作功能,方便开发者完成复杂的数据处理任务。
本节将介绍如何使用子查询、联合查询、分组查询和多表操作等技术,实现更灵活和高效的数据操作。
五、存储引擎选择MySQL 支持多种存储引擎,如 InnoDB、MyISAM、Memory 等。
不同的存储引擎具有不同的特点和适用场景。
本节将比较各种存储引擎的优缺点,并给出存储引擎选择的建议。
六、高可用性和容灾备份在互联网应用中,数据库的高可用性和容灾备份是非常重要的。
本节将介绍如何使用主从复制、读写分离、故障转移和数据备份等技术,提高数据库的稳定性和可用性。
MySQL实战45讲学习笔记:第一讲
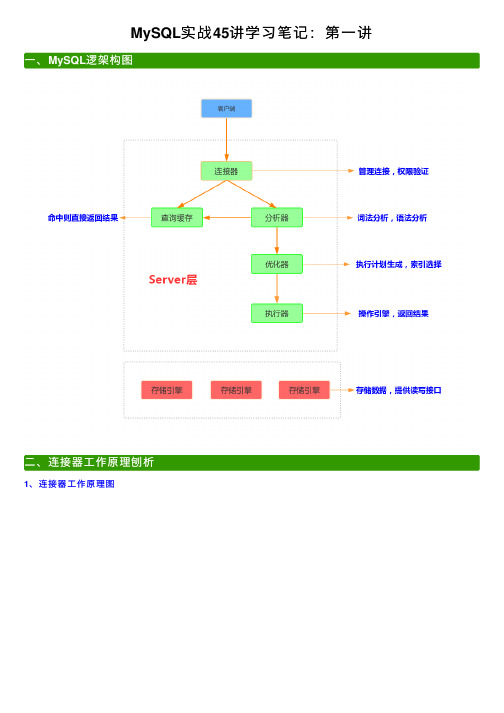
MySQL实战45讲学习笔记:第⼀讲⼀、MySQL逻架构图⼆、连接器⼯作原理刨析1、连接器⼯作原理图2、原理图说明1、连接命令mysql -h$ip -P$port -u$user -p2、查询链接状态3、长连接端连接1、什么是长链接?数据库⾥⾯,长连接是连接成功后,如果客户端持续有请求,则⼀直使⽤同⼀个链接。
2、什么是短连接?短连接则是指每次执⾏完很少的⼏次查询就断开连接,下次查询重新建⽴⼀个3、尽量使⽤长链接建⽴连接的过程通常是⽐较复杂的,所以我建议你在使⽤中尽量减少建⽴的动作,也就是使⽤长连接三、使⽤长链接困惑及解决⽅案1、为什么MySQL占⽤内存涨得特别快但是全部是⽤长连接后,你可能会发现,有些时候MySQL占⽤内存涨得特别快,这是因为MySQL在执⾏过程中临时使⽤的内存管理在连接对象⾥⾯的,这些资源会在连接断开的时候才释放,所以如果长链接积累下来,可能导致内存占⽤⼤,被系统强⾏杀掉,从现象看就是MySQL异常重启了2、如何解决MySQL占⽤内存涨得特别快1、定期断开长链接,使⽤⼀段时间,或者程序⾥⾯判断执⾏过⼀个占⽤内存的⼤查询后,断开连接,之后要查询再连接2、如果你⽤的是MySQL5.7或更新版本,可以在每次执⾏⼀个⽐较⼤的操作后,通过执⾏mysql_reset_connection来重新初始化连接资源,这个过程不需要重连或重新做权限验证,但是会将连接回复到刚刚创建完时的状态四、查询缓存1、⼯作流程刨析图解1. MySQL拿到⼀个查询请求后,会先到查询缓存看看,之前是不是执⾏过这条语句,如果有,就直接返回给客户端2. 如果语句不在查询缓存中,就会继续后⾯的执⾏阶段。
3. 执⾏完成后,执⾏结果会被存⼊查询缓存中,4. 如果查询命中缓存MySQL不需要执⾏后⾯的复杂操作,就可以直接返回结果,这个效率会很⾼2、为什么⼤多数情况下⽐建议使⽤查询缓存?1、查询缓存的失效⾮常频繁,只要有⼀个表更新,这个表上所有的查询缓存都被清空2、对于更新压⼒⼤的数据库来说,查询缓存的命中率会⾮常低,3、除⾮你的业务就是有⼀张静态表,很长时间才会更新⼀次(⽐如⼀个系统配置表)1、默认语句不实⽤查询缓存MySQL提供的按需使⽤的⽅式query_cache_type 设置成 DEMAND2、确定需要查询缓存的语句mysql> select SQL_CACHE * from T where ID=10;MySQL 8.0 版本直接将查询缓存的整块功能删掉了,也就是说 8.0 开始彻底没有这个功能了。
MySQL数据库学习笔记

MySQL数据库学习笔记数据库 DDL: 数据定义语⾔, 包含数据库和表相关的操作(MySQL中保存数据需要先建库再建表,最后把数据保存到表中) DML: 数据操作语⾔, 包含增删改查相关的SQL DQL: 数据查询语⾔, 只包含查询相关的SQL TCL: 事务控制语⾔, 包括和事务相关的SQL DCL: 数据控制语⾔, 包括⽤户管理及权限分配相关的SQLDDL数据定义语⾔ 数据库相关SQL 1. 查询所有数据库 show databases; 2. 创建数据库 格式: create database 数据库名; 指定字符集格式: create database 数据库名 character set utf8/gbk; 举例: create database db1; create database db2 character set utf8; create database db3 character set gbk; show databases; 3. 查询数据库详情 格式: show create database 数据库名; 举例: show create database db1; show create database db2; show create database db3; 4. 删除数据库 格式: drop database 数据库名; drop database db3; 5. 使⽤数据库必须使⽤了某个数据库之后才能执⾏表和数据相关的SQL 格式: use 数据库名; use db1; 表相关SQL 操作表相关的SQL 必须使⽤了某个数据库之后再操作use db1; 1. 创建表 格式: create table 表名(字段1名类型,字段2名类型); 指定字符集格式: create table 表名(字段1名类型,字段2名类型) charset=utf8/gbk; 举例: create table person (name varchar(20),age int); create table student(name varchar(20),score int) charset=utf8; create table car(name varchar(20),price int) charset=gbk; 2. 查询所有表 格式: show tables; 3. 查询表详情 格式: show create table 表名 举例: show create table person; 4. 查看表字段 格式: desc 表名; 举例: desc student; 5. 删除表 格式: drop table 表名 举例: drop table car; 表相关SQL(续) use db1; 1. 修改表名格式: rename table 原名 to 新名; rename table student to stu; 2. 添加表字段 最后添加格式: alter table 表名 add 字段名类型; 最前⾯添加个格式: alter table 表名 add 字段名类型 fifirst; xxx字段后⾯添加格式: alter table 表名 add 字段名类型 after xxx; 举例: alter table person add gender varchar(5); //最后⾯ alter table person add id int fifirst; //最前⾯ alter table person add salary int after name;//name后⾯ 3. 删除表字段 格式: alter table 表名 drop 字段名; alter table person drop salary; 4. 修改表字段 格式: alter table 表名 change 原名新名新类型; alter table person change gender salary int;DML数据操作语⾔(数据相关SQL语句) 1. 插⼊数据 全表插⼊格式: insert into 表名 values(值1,值2); 值的数量和表字段⼀致 批量插⼊格式: insert into 表名 values(值1,值2),(值1,值2),(值1,值2); 举例: insert into person values("Tom",18); //全表插⼊ insert into person(name) values("Jerry"); //指定字段插⼊ insert into person values("AAA",10),("BBB",20), ("CCC",30); 中⽂问题: insert into person values("刘德华",30); 如果执⾏上⾯包含中⽂的SQL 报以下错误执⾏ set names gbk; 2. 查询数据 格式: select 字段信息 from 表名 where 条件; 举例: select name from person; //查询表中所有的名字 select name,age from person; //查询表中所有名字和年龄 select * from person; //查询表中所有数据的所有字段信息 select * from person where age>20; //查询年龄⼤于20岁的信息 select * from person where name='Tom'; //查询Tom的信息 3. 修改数据 格式: update 表名 set xxx=xxx,xxx=xxx where 条件; 举例: update person set age=8 where name='Jerry'; update person set name="张学友",age=50 where name="刘德华"; update person set age=15 where age<20; 4. 删除数据 格式: delete from 表名 where 条件; 举例: delete from person where name='Tom'; delete from person where age<20; delete from person; 约束* 概念:对表中的数据进⾏限定,保证数据的正确性、有效性和完整性。
MySQL学习笔记:timediff、timestampdiff、datediff

MySQL学习笔记:timediff、timestampdiff、datediff⼀、时间差函数:timestampdiff 语法:timestampdiff(interval, datetime1,datetime2) 结果:返回(时间2-时间1)的时间差,结果单位由interval参数给出。
frac_second 毫秒(低版本不⽀持,⽤second,再除于1000)second 秒minute 分钟hour ⼩时day 天week 周month ⽉quarter 季度year 年 注意:MySQL 5.6之后才⽀持毫秒的记录和计算,如果是之前的版本,最好是在数据库除datetime类型之外的字段,再建⽴⽤于存储毫秒的int字段,然后⾃⼰进⾏转换计算。
# 所有格式SELECT TIMESTAMPDIFF(FRAC_SECOND,'2012-10-01','2013-01-13'); # 暂不⽀持SELECT TIMESTAMPDIFF(SECOND,'2012-10-01','2013-01-13'); # 8985600SELECT TIMESTAMPDIFF(MINUTE,'2012-10-01','2013-01-13'); # 149760SELECT TIMESTAMPDIFF(HOUR,'2012-10-01','2013-01-13'); # 2496SELECT TIMESTAMPDIFF(DAY,'2012-10-01','2013-01-13'); # 104SELECT TIMESTAMPDIFF(WEEK,'2012-10-01','2013-01-13'); # 14SELECT TIMESTAMPDIFF(MONTH,'2012-10-01','2013-01-13'); # 3SELECT TIMESTAMPDIFF(QUARTER,'2012-10-01','2013-01-13'); # 1SELECT TIMESTAMPDIFF(YEAR,'2012-10-01','2013-01-13'); # 0⼆、时间差函数:datediff 语法:传⼊两个⽇期参数,⽐较DAY天数,第⼀个参数减去第⼆个参数的天数值。
mysql学习笔记(一)之mysqlparameter

mysql学习笔记(⼀)之mysqlparameter基础琐碎总结-----参数化查询参数化查询(Parameterized Query )是指在设计与数据库链接并访问数据时,在需要填⼊数值或数据的地⽅,使⽤参数 (Parameter) 来给值,这个⽅法⽬前已被视为最有效可预防SQL注⼊攻击 (SQL Injection) 的攻击⼿法的防御⽅式。
下⾯将重点总结下Parameter构建的⼏种常⽤⽅法。
说起参数化查询当然最主要的就是如何构造所谓的参数:⽐如,我们登陆时需要密码和⽤户名,⼀般我们会这样写sql语句,Select * from Login where username= @Username and password = @Password,为了防⽌sql注⼊,我们该如何构建@Username和@Password两个参数呢,下⾯提供六种(其实⼤部分原理都是⼀样,只不过代码表现形式不⼀样,以此仅作对⽐,⽅便使⽤)构建参数的⽅法,根据不同的情况选⽤合适的⽅法即可:说明:以下loginId和loginPwd是户登陆时输⼊登陆⽤户名和密码,DB.conn是数据库连接,⽤时引⼊using System.Data.SqlClient命名空间⽅法⼀:SqlCommand command = new SqlCommand(sqlStr, DB.conn);command.Parameters.Add("@Username", SqlDbType.VarChar);command.Parameters.Add("@Pasword", SqlDbType.VarChar);command.Parameters["@Username"].Value = loginId;command.Parameters["@Pasword"].Value = loginPwd;⽅法⼆:SqlCommand command = new SqlCommand();command.Connection = DB.conn;mandText = sqlStr;command.Parameters.Add(new SqlParameter("@Username", loginId));command.Parameters.Add(new SqlParameter("@Pasword", loginPwd));⽅法三:Sqlcommand cmd=new Sqlcommand(sqlStr, DB.conn);cmd.parameters.add("@Username",DbType.varchar).value=loginId;cmd.parameters.add("@Pasword",DbType.varchar).value=loginPwd;⽅法四:Sqlcommand cmd=new Sqlcommand(sqlStr, DB.conn);cmd.parameters.addwithvalue("@Username",loginId);cmd.parameters.addwithvalue("@Pasword",loginPwd);⽅法五:Sqlcommand cmd=new Sqlcommand(sqlStr, DB.conn);SqlParameter para1=new SqlParameter("@Username",SqlDbType.VarChar,16);para1.Value=loginId;cmd.Parameters.Add(para1);SqlParameter para2=new SqlParameter("@Pasword",SqlDbType.VarChar,16);para2.Value=loginPwd;cmd.Parameters.Add(para2);⽅法六:SqlParameter[] parms = new SqlParameter[]{new SqlParameter("@Username", SqlDbType.NVarChar,20),new SqlParameter("@Pasword", SqlDbType.NVarChar,20),};SqlCommand cmd = new SqlCommand(sqlStr, DB.conn);// 依次给参数赋值parms[0].Value = loginId;parms[1].Value = loginPwd;//将参数添加到SqlCommand命令中foreach (SqlParameter parm in parms){cmd.Parameters.Add(parm);}法和实现⽅法的不同,也可以说是语法糖,但后记:鉴于园友对dedeyi,⿁⽕飘荡,guihwu的疑问,我在写⼀个说明。
Mysql笔记(附Mysql基础书pdf版)

Mysql笔记(附Mysql基础书pdf版)资料数据库篇SHOW DATABASES; //显⽰数据库系统中已经存在的数据库CREATE DATABASE 数据库名; //创建数据库DROP DATABASE 数据库名; //删除数据库表篇注:在使⽤操作表语句前,⾸先要使⽤USE语句选择数据库。
选择数据库语句的基本格式为“USE 数据库名”。
否则会报错,1046;CREATE TABLE 表名 ( 属性名数据类型 [完整性约束条件],属性名数据类型 [完整性约束条件],属性名数据类型);表名不能为SQL语句的关键字,⼀个表可以有多个属性。
定义时,字母⼤⼩写均可,各属性之间⽤逗号隔开,最后⼀个属性不需要加逗号。
主键主键有唯⼀值单字段主键属性名数据类型 primary key //创建主键,写在属性名数据类型后⾯;多字段主键primary key(属性名 1,属性名2,属性名n)两者的组合可以确定唯⼀的⼀条记录;外键外键不⼀定必须为⽗表的主键,但必须是唯⼀性索引,主键约束和唯⼀性约束都是唯⼀性索引;外键可以为空值;设置外键的基本语法规则如下:CONSTRAINT 外键别名 FOREIGN KEY(属性 1.1,属性1.2,属性1.n)REFERENCES 表名(属性2.1,属性2.2,属性2.n)其中,“外键别名”参数是为外键的代号;“属性1”参数列表是⼦表中设置的外键;“表名”参数是指⽗表的名称;“属性2”参数列表是⽗表的主键。
设置表的⾮空约束设置表的唯⼀性约束设置表的属性值⾃动增加查看表结构DESCRIBE 表名; // 查看表基本结构语句,可缩写为desc 表名SHOW CREATE TABLE 表名; //查看表详细结构语句(包含存储引擎、字符编码)删除表DROP TABLE 表名;//删除没有被关联的普通表删除⽗表需要先将外键删除,然后才能去删除⽗表。
字段篇//通过ALTER TABLE语句ALTER TABLE 旧表名 RENAME [TO] 新表名;//修改表名 TO参数是可选参数,是否在语句中出现不会影响语句的执⾏。
最全mysql笔记整理

最全mysql笔记整理mysql笔记整理作者:python技术⼈博客:Windows服务-- 启动MySQLnet start mysql-- 创建Windows服务sc create mysql binPath= mysqld_bin_path(注意:等号与值之间有空格)连接与断开服务器mysql -h 地址 -P 端⼝ -u ⽤户名 -p 密码show processlist -- 显⽰哪些线程正在运⾏show variables -- 显⽰系统变量信息数据库操作-- 查看当前数据库select database();-- 显⽰当前时间、⽤户名、数据库版本select now(), user(), version();-- 创建库create database[ if not exists] 数据库名数据库选项数据库选项:character set charset_namecollate collation_name-- 查看已有库show databases[ like pattern ]-- 查看当前库信息show create database 数据库名-- 修改库的选项信息alter database 库名选项信息-- 删除库drop database[ if exists] 数据库名同时删除该数据库相关的⽬录及其⽬录内容表的操作-- 创建表create [temporary] table[ if not exists] [库名.]表名 ( 表的结构定义 )[ 表选项]每个字段必须有数据类型最后⼀个字段后不能有逗号temporary 临时表,会话结束时表⾃动消失对于字段的定义:字段名数据类型 [not null | null] [default default_value] [auto_increment] [unique [key] | [primary] key] [comment string ]-- 表选项-- 字符集charset = charset_name如果表没有设定,则使⽤数据库字符集-- 存储引擎engine = engine_name表在管理数据时采⽤的不同的数据结构,结构不同会导致处理⽅式、提供的特性操作等不同常见的引擎:InnoDB MyISAM Memory/Heap BDB Merge Example CSV MaxDB Archive不同的引擎在保存表的结构和数据时采⽤不同的⽅式MyISAM表⽂件含义:.frm表定义,.MYD表数据,.MYI表索引InnoDB表⽂件含义:.frm表定义,表空间数据和⽇志⽂件show engines -- 显⽰存储引擎的状态信息show engine 引擎名 {logs|status} -- 显⽰存储引擎的⽇志或状态信息-- ⾃增起始数auto_increment = ⾏数-- 数据⽂件⽬录data directory = ⽬录-- 索引⽂件⽬录index directory = ⽬录-- 表注释comment = string-- 分区选项PARTITION BY ... (详细见⼿册)-- 查看所有表show tables[ like pattern ]show tables from 表名-- 查看表机构show create table 表名(信息更详细)desc 表名 / DESCRIBE 表名 / EXPLAIN 表名 / SHOW COLUMNS FROM 表名 [LIKE PATTERN ]show table status [from db_name] [like pattern ]-- 修改表-- 修改表本⾝的选项alter table 表名表的选项eg: alter table 表名 engine=MYISAM;-- 对表进⾏重命名rename table 原表名 to 新表名rename table 原表名 to 库名.表名(可将表移动到另⼀个数据库)-- rename可以交换两个表名-- 修改表的字段机构(13.1.2. ALTER TABLE语法)alter table 表名操作名-- 操作名add[ column] 字段定义 -- 增加字段after 字段名 -- 表⽰增加在该字段名后⾯first -- 表⽰增加在第⼀个add primary key(字段名) -- 创建主键add unique [索引名] (字段名)-- 创建唯⼀索引add index [索引名] (字段名) -- 创建普通索引drop [ column] 字段名 -- 删除字段modify[ column] 字段名字段属性 -- ⽀持对字段属性进⾏修改,不能修改字段名(所有原有属性也需写上)change[ columns] 原字段名新字段名字段属性 -- ⽀持对字段名修改drop primary key -- 删除主键(删除主键前需删除其AUTO_INCREMENT属性)drop index 索引名 -- 删除索引drop foreign key 外键 -- 删除外键-- 删除表drop table[ if exists] 表名 ...-- 清空表数据truncate [table] 表名-- 复制表结构-- 复制表结构和数据create table 表名 [as] select * from 要复制的表名-- 检查表是否有错误check table tbl_name [, tbl_name] ... [option] ...-- 优化表optimize [local | no_write_to_binlog] table tbl_name [, tbl_name] ...-- 修复表repair [local | no_write_to_binlog] table tbl_name [, tbl_name] ... [quick] [extended] [user_frm]-- 分析表analyze [local | no_write_to_binlog] table tbl_name [, tbl_name] ...数据操作-- 增insert [into] 表名 [(字段列表)] values (值列表)[, (值列表), ...]-- 如果要插⼊的值列表包含所有字段并且顺序⼀致,则可以省略字段列表。
MySQL高级教程笔记

M y S Q L高级教程笔记集团标准化办公室:[VV986T-J682P28-JP266L8-68PNN]MySQL-高级MySQL中的SQL编程的话题.触发器, 存储函数, 存储过程以上的是三个名词, 在SQL编程中, 地位是: 程序的载体, 程序的结果.编程所涉及的要素:变量, 数据类型, 流程控制, 函数, 运算符, 表达式.2.1内置函数MySQL自动提供的函数!例如: database(), now(), md5()2.2自定义函数–存储函数用户定义定义的, 存储在MySQL中的函数. 2.2.1create function, 创建函数适用语法:来创建函数2.2.2调用函数2.2.3drop function , 删除函数drop function [if exists] function-name;3变量–编程要素程序处理数据.数据在程序中的容器, 就是变量.强类型3.1全局变量函数外定义的变量变量不需要声明, 直接去设置即可!PS, 内置的变量: set autocommit = off, 不以 @开头3.2局部变量函数内定义的变量使用declare来声明.不需要使用@, 表示是用户自定义变量.强类型, 定义的局部变量, 必须定义为某种类型, 类型的表述与字段的类型一致!3.3重叠(嵌套)作用域局部内, 可访问到全局变量PS: 与JS保持一致13.4变量的赋值3.4.1set 变量 = 值3.4.2select into 变量当需要为变量赋值的数据, 来源于SQL中select语句的查询结果时, 可以使用select into完成变量的赋值.一次性, 赋值多个变量:函数内, 也可以使用4流程控制–编程要素循环和分支4.1分支- IF测试结果4.1.1内置分支函数: if()不是分支, 是典型的三元运算, 的函数封装语法MySQL不支持三元运算符 :.4.2分支-CASE测试结果4.3循环– while条件满足, 则循环继续其中标签, 用于在循环终止时, 一次性的终止多层循环! 类似于JS的语法.例如:4.4循环–终止终止当前循环:(continue), iterate终止全部:(break), leave终止, 都需要配合循环语句的标签使用! ierate:leave:如果需要终止多层:需要在后边跟随不同的标签即可5过程–存储过程– procedure与函数类似, 都是一段功能代码的集合, 称之为过程.与函数不一样的是, 函数由于完成某个特定的操作点, 例如, md5(), 获取md5摘要信息, 不是用来实现某中也无路基操作, 而是就是实现特定的操作. 过程是, 某个特定的业务逻辑.当我们需要使用SQL完成某件事时候, 使用过程, 而在过程的完成中, 需要一些特殊的操作, 就是函数.例如:需要插入, 1000条记录到某测试表中, 此时就应该创建过程.而在插入的时候, 需要随机的获取学生的姓名, 就可以定义一个函数, 完成获取随机的学生姓名工作.映射到PHP程序:浏览器所请求的一个URL, 对应的PHP代码, 就是一段过程. (例如, 商品添加, 用户注册), 就是过程.而在完成这个过程中, 需要将用户的密码做md5处理, md5就是函数.因此, 函数在意的是处理结果,函数具有返回值.而过程是一段执行, 不具有返回值.语法5.1创建过程: create procedure注意: 没有返回值参数有输入方式之分.过程内的写法, 与函数是一致的.5.2调用过程, call 过程()过程的调用不能出现在表达式中, 需要使用独立的语法进行独立调用.in: 由外向内传递out: 由内向外传递inout: 双向传递, 即可内向外, 也可外向内内, 外, 指的是, 过程外和过程内.创建过程外的三个变量:以三个变量作为实参, 调用过程:在获取过程外三个变量的值:inout 双向传递, 类似于 PHP中的引用传递!由于过程没有返回值, 需要在过程处理后, 得到过程的处理结果数据, 就因该, 使用带有out类型的参数.一个数据时被多个过程连续处理, 典型的需要 inout类型的参数.6练习一个纯粹的MySQL管理员需要完成某些操作, 需要使用过程, MySQL自带的编程方式.例如, 需要创建大量的测试数据, 可以过程完成:确定测试表的结构确定需要插入的数据格式要求:学号要从1开始递增.班级ID, 从1-100 随机姓名, 随机得来说明: 任意编程实现:编写, 需要的函数:获取班级ID生成名字:生成信息生成学号从1开始递增it-0000001it-0000002取得已有的最大学号.调用过程即可:测试数据7触发器– trigger事件驱动程序: 监听元素某些事件, 当事件被触发时, 事件处理器被调用. (PS: 类似于JS的事件驱动)触发器的事件:insert, delete, update扩展开共六种:before insert, after insertbefore delete, after deletebefore update, after update事件都是记录对象的事件, row的before insert, row after insert.语法7.1创建触发器, create trigger绑定事件处理器, 到 row 元素上.测试, 在学生表的添加事件上增加触发器程序:一旦学生表添加, 则在学生日志表中, 加入一条记录检测学生日志表:触发程序被自动调用触发器, 只是调用方式不同于存储过程而已, 都是功能的集合.7.2删除触发器drop trigger tigger-name7.3new, old预定义的变量, 表示触发该事件的行对象.就是事件源记录.使用 new, old 来引用这个事件源记录.new 和 old的区别:new, 新纪录old, 旧记录.只有在update事件时, 才会出现新旧记录同时存在的情况.更新: 将旧记录更改成新纪录.在 insert事件中, 只有new可用. before insert, after insert , 都可以使用new.在delete事件中, 只有 old可用. before delete after delete 都可以使用 old 无论是 before还是insert 都一样.7.4事件的触发可能会出现执行一条语句 , 触发多个事件的情况.有些语句, 带有逻辑判定功能:replace into, 尝试插入, 如果冲突, 则替换(删除旧的,插入新的)类似的:insert into on duplicate key update冲突时更新一个表, 的一个事件, 仅仅可以绑定一个事件处理器.一个表最多可以有6个触发器.8架构读写分离, 负载均衡.8.1读, 写服务器分离设计:, MySQL 充当写服务器.再添加2台linux 充当读服务器:初始化mac地址完全复制复制后, 启动复制的服务器:删除, 之前所保留的虚拟化网卡的文件, 使新生成的网卡生效.修改 eth0的配置文件:修改mac地址参数:修改为, virtualbox生成的mac地址:保持一致init 6 重启8.2读从写服务器复制数据在主服务器上开一个复制账号, 从服务器利用这个复制账号, 从主服务器进行复制.配置过程如下:8.2.1主服务器8.2.1.1开启二进制日志8.2.1.2指定唯一的服务器ID保证唯一即可!需要重启 mysqld(可以与步骤一一起完成)8.2.1.3增加复制账号登录主MySQL, 增加账号, 刷新权限.8.2.1.4记录当前状态位置show master status8.2.2从服务器8.2.2.1指定服务器的唯一IDmysqld 重启8.2.2.2开启复制从服务器的MySQL中执行:使用 change master 来指定;此时已经建立的主从复制联系8.2.2.3开启复制在从服务器上执行:start slave8.2.2.4查看复制状态。
【超详细】MySQL学习笔记汇总(三)之进阶1、2测试

【超详细】MySQL学习笔记汇总(三)之进阶1、2测试MySQL学习笔记汇总(三)四、进阶1、2测试题1、查询⼯资⼤于12000 的员⼯姓名和⼯资selectlast_name,salaryfromemployeeswheresalary > 12000;2、查询员⼯号为176 的员⼯的姓名和部门号和年薪selectemployee_id,last_name,department_id,salary * 12*(1+IFNULL(commission_pct,0)) as 年薪FROMemployeeswhereemployee_id = 176;3、选择⼯资不在5000 到12000 的员⼯的姓名和⼯资selectlast_name,salary,fromemployeeswherenot (salary between 5000 and 1200);4、选择在20 或50 号部门⼯作的员⼯姓名和部门号selectlast_name,department_idfromemployeeswhere#department_id in (20,50);department_id = 20 or department_id= 50;5、选择公司中没有管理者的员⼯姓名及 job_idselectlast_name,job_idfromemployeesWHEREmanager_id is null;6、选择公司中有奖⾦的员⼯姓名,⼯资和奖⾦级别selectlast_name,salary,commission_pctfromemployeeswherecommission_pct is not null;7、选择员⼯姓名的第三个字母是 a 的员⼯姓名select*from(selectCONCAT(first_name,last_name) as 姓名fromemployees) TwhereT.姓名 like '__a%';8、选择姓名中有字母 a 和 e 的员⼯姓名SELECTlast_namefromemployeeswherelast_name like '%a%' and last_name like '%e%' ;9、显⽰出表employees 表中 first_name 以 'e'结尾的员⼯信息SELECTfirst_namefromemployeeswherefirst_name like '%e';10、显⽰出表employees 部门编号在80-100 之间的姓名、职位selectlast_name,job_id,department_idfromemployeeswheredepartment_id between 80 and 100;11、显⽰出表employees 的manager_id 是 100,101,110 的员⼯姓名、职位selectlast_name,job_id,manager_idfromemployeeswheremanager_id in(100,101,110);12、查询没有奖⾦,且⼯资⼩于18000的salary,last_nameselectsalary,last_namefromemployeeswherecommission_pct is null and salary < 18000;13、查询job_id不为'IT' 或者⼯资为12000的员⼯信息;select*fromemployeeswherejob_id <> 'IT' or salary = 12000;。
MySql学习笔记

MySql学习笔记MySql学习笔记MySql概述:MySql是一个种关联数据库管理系统,所谓关联数据库就是将数据保存在不同的表中,而不是将所有数据放在一个大的仓库中。
这样就增加了速度与提高了灵活性。
并且MySql软件是一个开放源码软件。
注意,MySql所支持的TimeStamp的最大范围的问题,在32位机器上,支持的取值范围是年份最好不要超过2030年,然后如果在64位的机器上,年份可以达到2106年,而对于date、与datetime这两种类型,则没有关系,都可以表示到9999-12-31,所以这一点得注意下;还有,在安装MySql的时候,我们一般都选择Typical(典型安装)就可以了,当然,如果还有其它用途的话,那最好选择Complete(完全安装);在安装过程中,一般的还会让你进行服务器类型的选择,分别有三种服务器类型的选择,(Developer(开发机)、Server Machine(服务器)、Dedicated MySql Server Machine(专用MYSQL服务器)),选择哪种类型的服务器,只会对配置向导对内存等有影响,不然其它方面是没有什么影响的;所以,我们如果是开发者,选择开发机就可以啦;然后接下来,还会有数据库使用情况对话框的选择,我们只要按照默认就可以啦;连接与断开服务器:连接:在windows命令提示符下输入类似如下命令集:mysql –h host –u user –p 例如,我在用的时候输入的是:mysql –h localhost –u root –p 然后会提示要你输入用户密码,这个时候,如果你有密码的话,就输入密码敲回车,如果没有密码,直接敲回车,就可以进入到数据库客户端;连接远程主机上的mysql,可以用下面的命令:mysql –h 159.0.45.1 –u root –p 123 断开服务器:在进入客户端后,你可以直接输入quit然后回车就可以了;下面就数据库相关命令进行相关说明Alter table test add(address varchar(50) not null default …xm?,email varchar(20) not null);将表中某个字段的名字修改或者修改其对应的相关属性的时候,要用change对其进行操作; Alter table test change email email varchar(20) not null default …zz?;//不修改字段名Alter table test change email Email varchar(30) not null;//修改字段名称删除表中字段:Alter table test drop email;//删除单个字段Alter table test drop address,drop email;//删除多列可以用Drop来取消主键与外键等,例如:Alter table test drop foreign key fk_symbol; 删除索引:Drop index index_name on table_name; 例如:drop index t on test;向表中插入记录:注意,当插入表中的记录并不是所有的字段的时候,应该要在前面列出字段名称才行,不然会报错;Insert into test(name) values(…ltx?);Insert into test values(1,?ltx?);也可以向表中同时插入多列值,如:Insert into test(name) va lues(…ltx?),(…hhy?),(…xf?);删除表中记录:Delete from test;//删除表中所有记录;Delete from test where id=1;//删除表中特定条件下的记录;当要从一个表或者多个表当中查询出一些字段然后把这些字段又要插入到另一个表当中的时候,可以用insert …..select语法;Insert into testt(name) (select name from test where id=4);从文件中读取行插入数据表中,可以用Load data infile语句;Load data infile …test.txt? into table test;可以用Describe语法进行获取有关列的信息;Describe test;//可以查看test表的所有信息,包括对应列字段的数据类型等;MySql事务处理相关语法;开始一项新的事务:start transaction或者begin transaction 提交事务:commit事务回滚:rollbackset autocommit true|false 语句可以禁用或启用默认的autocommit模式,只可用于当前连接; 例子:Start transaction;Update person set name=?LJB? where id=1;Commit | rollback;数据库管理语句修改用户密码:以root用户为例,则可以写成下面的;mysql –u root –p 旧密码–password 新密码Mysql –u root –password 123;//将root用户的密码修改成123,由于root 用户开始的时候,是没有密码的,所以-p旧密码就省略了;例如修改一个有密码的用户密码:mysql –u ltx –p 123 –password 456;增加一个用户test1,密码为abc,让他可以在任何时候主机上登陆,并对所有数据库有查询、插入、修改、删除的权限。
mysql数据库学习笔记

2、查看 describe table_name desc table_name 查看表的定义
show create table table_name \G 注意:\G显示的更加人性化,美观(语句结束符 ;,\g,\G) 3、修改(add modify change rename drop)
格式:alter table tablename [rename/modify/add/change/drop]
desc t_test 添加到第三列
alter table tablename add three bigint after id
desc t_test 5、调整某些列的位置
alter table table_name modify column1 datatype first|alfter
column2
alter table t_test add first1 bigint first; 注意:没有long型,只有bigint
tinyint smallint mediumint int/Integer bigint
4、指定新列的位置
alter table tablename add columnname datatype after column
NOT NULL(NK)
DEFAULT
mysql数据库.txt[+]
Page 3
UNIQUE KEY(UK)
约束字段的值是唯一的
PRIMATYKEY(PK)
AUTO_INCREMENT
FOREIGN KEY(FK) 不支持check约束,即可以使用check约束,但是没有效果 约束:
单列约束
多列约束
属性名1和属性名2都必须存在
MySQL知识点总结(完整版)

MySQL知识点总结(完整版)MySQL学习笔记登录和退出MySQL服务器# 登录MySQL$ mysql -u root -p1*******# 退出MySQL数据库服务器exit;基本语法-- 显⽰所有数据库show databases;-- 创建数据库CREATE DATABASE test;-- 切换数据库use test;-- 显⽰数据库中的所有表show tables;-- 创建数据表CREATE TABLE pet (name VARCHAR(20),owner VARCHAR(20),species VARCHAR(20),sex CHAR(1),birth DATE,death DATE);-- 查看数据表结构-- describe pet;desc pet;-- 查询表SELECT * from pet;-- 插⼊数据INSERT INTO pet VALUES ('puffball', 'Diane', 'hamster', 'f', '1990-03-30', NULL);-- 修改数据UPDATE pet SET name = 'squirrel' where owner = 'Diane';-- 删除数据DELETE FROM pet where name = 'squirrel';-- 删除表DROP TABLE myorder;建表约束主键约束-- 主键约束-- 使某个字段不重复且不得为空,确保表内所有数据的唯⼀性。
CREATE TABLE user (id INT PRIMARY KEY,name VARCHAR(20));-- 联合主键-- 联合主键中的每个字段都不能为空,并且加起来不能和已设置的联合主键重复。
CREATE TABLE user (id INT,name VARCHAR(20),password VARCHAR(20),PRIMARY KEY(id, name));-- ⾃增约束-- ⾃增约束的主键由系统⾃动递增分配。
mysql数据库管理系统笔记

mysql数据库管理系统笔记MySQL数据库管理系统是一种流行的关系型数据库管理系统,广泛应用于各种应用程序和网站。
下面是一些关于MySQL的笔记:1. 安装和配置:MySQL可以通过不同的方式进行安装,包括二进制包、源代码和包管理器。
安装完成后,需要配置MySQL服务器,包括设置用户和权限、配置网络连接等。
2. 数据库和表:MySQL数据库由多个表组成,每个表包含一系列的行和列。
使用`CREATE DATABASE`和`CREATE TABLE`语句可以创建数据库和表。
3. 数据类型:MySQL支持多种数据类型,包括整数、浮点数、字符串、日期和时间等。
不同的数据类型适用于不同的数据存储需求。
4. 查询语言:MySQL使用结构化查询语言(SQL)进行数据操作和管理。
使用SELECT语句可以从表中检索数据,使用INSERT、UPDATE和DELETE语句可以插入、更新和删除数据。
5. 索引:索引用于加快查询速度,通过索引可以快速定位到表中的数据。
MySQL支持多种索引类型,包括B-tree索引、哈希索引等。
6. 视图:视图是一个虚拟表,它是基于SQL查询的结果集。
通过视图可以简化复杂的查询操作,同时提供数据安全性。
7. 存储过程和函数:存储过程是一组为了完成特定功能的SQL语句集合。
函数类似于存储过程,但函数可以返回值。
8. 触发器:触发器是与表相关联的特殊类型的存储过程,它会在指定事件(如INSERT、UPDATE或DELETE)发生时自动执行。
9. 事务处理:事务是一系列的操作,这些操作要么全部成功执行,要么全部失败回滚。
MySQL支持事务处理,确保数据的完整性和一致性。
10. 安全性和权限:MySQL提供了用户管理和权限控制机制,可以设置不同用户对数据库的访问权限。
通过设置用户名、密码和权限,可以控制用户对数据库的访问和操作。
mysql 数据库进阶笔记

mysql 数据库进阶笔记MySQL数据库进阶笔记1. 数据表优化- 使用适当的数据类型:选择正确的数据类型可以减少磁盘空间的使用和提高查询性能。
- 添加索引:索引可以加快查询速度,但同时会增加插入、更新和删除操作的时间。
因此,需要权衡查询速度和数据修改操作的频率。
- 分区表:将大表分成多个较小的分区,可以提高查询速度和数据的管理。
- 垂直拆分和水平拆分:根据数据访问模式,将表拆分为多个表,可以提高查询速度和减少数据冗余。
2. 查询优化- 使用合适的索引:为经常被查询的字段添加索引,可以提高查询速度。
注意避免过多的或不必要的索引,因为它们会增加写操作的开销。
- 编写有效的查询语句:避免使用不必要的连接、子查询以及使用全表扫描的情况。
使用合适的查询语句可以减少数据库的负载。
- 优化查询计划:通过分析查询计划和使用Explain命令,可以找出查询中的性能瓶颈,并对其进行调整。
3. 数据库安全- 权限管理:为数据库用户分配最小必要的权限,限制对敏感数据的访问。
- 防止SQL注入攻击:使用预处理语句或存储过程等方法来过滤用户输入的数据,避免恶意代码的注入。
- 密码安全:加密存储用户密码,并定期更换密码。
4. 数据备份和恢复- 定期备份数据:根据业务需求和数据增长情况,制定合适的备份策略,定期将数据库数据备份到可靠的存储介质中。
- 恢复测试:测试备份数据的完整性和可用性,并定期恢复测试,确保数据可以正常恢复。
5. 性能监控和调优- 监控数据库性能:使用性能监控工具,实时收集数据库的性能指标,并根据指标的变化进行性能调优。
- 查询性能调优:通过分析慢查询日志和优化查询计划,对查询进行优化,提高查询速度。
6. 高可用和容灾- 主从复制:通过设置主从复制,将数据从主数据库同步到一个或多个从数据库,实现数据冗余和故障转移。
- 数据库集群:使用数据库集群来实现高可用和负载均衡,多个数据库节点共同处理请求,并实现故障转移和故障恢复。
MySQL学习笔记:repeat、loop循环

END 2018-05-22 13:15:09
DECLARE a INT DEFAULT 10; REPEAT
SET a = a - 1; UNTIL a < 5 END REPEAT;
SELECT a; END $$ DELIMITER ;
# 调用 CALL test_repeat();
# 删除 DROP PROCEDURE test_repeat;
SET t = t + 1; IF t > 10 THEN LEAVE label; END IF; END LOOP label;
SELECT t; END $$ DELIMITER ;
# 调用 CALL test_loop();
# 删除 DROP PROCEDURE test_loop;
注意 loop 一般要和一个标签(此处为label,名称可以自定义,不过要保证前后一致)一起使用,且在 loop 循环中一定要有一个判断条 件,能够满足在一定的条件下跳出 loop 循环(即 leave )!
注意loop一般要和一个标签此处为label名称可以自定义不过要保证前后一致一起使用且在looБайду номын сангаас循环中一定要有一个判断条件能够满足在一定的条件下跳出loop循环即leave
MySQL学习笔记: repeat、 loop循环
一 、 repeat循 环
# ---- repeat ---DELIMITER $$ CREATE PROCEDURE test_repeat() BEGIN
注意使用repeat的时候,在判断条件(until条件)的那一行句末不加分号,这个很容易出错!
二 、 loop循 环
# ---- loop ---DELIMITER $$ CREATE PROCEDURE test_loop() BEGIN
mysql课堂笔记

1.show databases; 查看当前mysql软件中有哪些数据库e [数据库名称]选择要操作的数据库3. show tables; 查看当前某个数据库下有哪些表4.create database [数据库的名称] -0987654建数据库drop database [数据库名称]删除数据库5.建表:mysql中的数据类型数字定义数字的字段我们用这种类型int(9) 数字(最长n位) 0-999999999double(9,2) 浮点数 0-9999999.99定义字符串的类型注意:我们在数据库中使用''来表示字符串char(n)表示定长的字符串(方便查询) 最多放入n个字符放入的数据如果不够n个字符则补空无论放入几个字符都占n位varchar(n)表示变长的字符串(节省空间) 最多放入n个字符放入的数据是几个长度就占几个空间日期类型 :data日期年月日timestamp时间戳年月日时分秒=============================================建表语句 create table [表名](字段名字段类型,字段名字段类型,字段名字段类型,.... .......字段名字段类型 (最后一个千万不要加,));drop table [表名] 删除表create table t_user(id int(12),name char(12),phone varchar(12),email varchar(12));desc [表名]查询表的结构====================================================================插入数据:insert into t_user values (每个字段所要对应的值);insert into t_user values ('1001','tom','13244321',''); 下面插入数据的语句方式咱们比较推崇可能不需要某个字段insert into [表名] ([字段名称]) values ([字段值]);insert into t_user (name,phone) values ('mingming','1234@');注意: 数据库中的字符串我们要使用单引号,每条语句完事后都要加;Insert into t_user (id,name,phone,email) values (1001,'jerry','18383893','1234@');insert into t_user (id,name,phone,email) values (1001,'lucy','183838932','123@');insert into t_user (id,name,phone,email) values (1002,'jim','183d83893','12d34@');insert into t_user (id,name,phone,email) values (1003,'jerry','18383893','1234@');insert into t_user (id,name,phone,email) values (1004,'jerry','18383893','1234@');==================================================================== 查询: select * from [表名]查询某个表的全部数据查询: t_user中所有的名字和邮箱select [字段1,字段2,...] from [表名]select name,email from t_user;条件查询;where 条件查询使用 and来连接条件语句查找id = 1001 而且邮箱是 123@的用户名字select name from t_user where id=1001 and EMAIL = '123@'; ================================================================t_dept部门表 deptno (部门编号) dname(部门名称) loction(部门所在地) 10 财务部上海20 研发部北京30 销售部广州40 公关部东莞t_emp员工表编号姓名职位薪水奖金入职时间经理所在部门1001 张无忌 Manager 10000 2000 ‘2014-08-08’1003 10员工表create table t_dept(deptno int(12),danem varchar(20),location varchar(20));insert into t_dept values (10,'cwubu','sh');insert into t_dept values (20,'yfabu','bj');insert into t_dept values (30,'xiabu','gz');insert into t_dept values (40,'gongbu','dg');create table t_emp(empno int(12),ename varchar(20),job varchar(20),salary double(9,2),bonus double(9,2),hiredate date,mgr int(12),deptno int(12));insert into t_emp values (1001,'tom','Manager',10000,2000,'2014-05-10',1005,10);insert into t_emp values (1002,'slw','Analyst',8000,1000,'2013-05-10',1001,10);insert into t_emp values (1003,'ywh','Analyst',9000,1000,'2014-06-10',1001,10);insert into t_emp values (1004,'bhq','Programmer',5000,null,'2013-06-10',1001,10);insert into t_emp values (1005,'wg','Boss',30000,null,'2012-05-10',null,20);insert into t_emp values (1006,'ljd','Manager',5000,200,'2011-05-10',1005,10);insert into t_emp values (1007,'zfh','CLERK',3000,500,'2011-05-10',1006,20);insert into t_emp values (1008,'sh','Manager',5000,500,'2014-09-10',1005,30);insert into t_emp values (1009,'ztt','Salesman',4000,null,'2014-01-10',1008,30);insert into t_emp values (1010,'xqm','Salesman',4500,500,'2013-08-10',1008,30);insert into t_emp values (1010,'t_jdfkjd',null,null,null,'2013-08-10',null,null);=================================================================== 列的别名:查询出员工的名字月薪和年薪?select ename,salary,salary*12 year_sal from t_emp;==================================================================== mysql中空值的处理1.任何数据类型都可以为null2.null和任何数据进行算术运算结果都为null3.null和字符串做连接操作结果相当于空值不存在查询每个员工的月收入?ifnull(bonus,0) 如果bonus为null 那么按照0算select ename,salary+ifnull(bonus,0) sal from t_emp;==================================================================== 部门中有多少种职位? distinct关键字注意: distinct关键字一定要放在select后面select job from t_emp;查询每个部门不重复的职位?distinct放在所有字段的前面表名所有字段的组合必须唯一select distinct deptno,job from t_emp;===================================================================where条件查询查出薪水高于10000的员工的数据select ename from t_emp where salary >10000;==================================================================== 大小写的问题查询职位是Analyst的员工、SELECT ENAME FROM T_EMP WHERE JOB = 'ANALYST';select ename from t_emp where job = 'analyst';Oracel中大小写SQL语句不敏感数据敏感所以不管mysql怎么样我们全按照这个规则走==================================================================== 查找职位为Analyst的员工lower() uppper()函数select upper(ename) from t_emp;select ename from t_emp where upper(job) = 'ANALYST';==================================================================== between .....and ..... 关键字在区间 between 低值 and 高值闭区间 [低值,高值]薪水大于5000 并且薪水小于10000的员工的数据select * from t_emp where salary <=10000 and salary >=5000;select * from t_emp where salary between 5000 and 10000;查询在2014年入职的员工有哪些?select * from t_emp where hiredate between '2014-01-01' and '2014-12-31';==============================================================列出职位是Manager或者Analyst的员工 or是或者的意思select * from t_emp where job = 'Manager' or job = 'Analyst';in(列表)select * from t_emp where job in('Manager','Analyst');=================================================================模糊匹配 like %1 “%”表示0到多个字符跟like配合使用2 "_"表示一个字符列出职位中包含'na'字符的员工的数据?select * from t_emp where lower(job) like '%na%';列出职位中第二个字符是'a'的数据?select * from t_emp where lower(job) like '_a%';查询名字中以 "t_"开头的名字##########select * from t_emp where ename like 't\_%' escape '\';(Oracle中专用的)====================================================================查询哪些员工没有奖金?select * from t_emp where bonus = null;(X)is nullselect * from t_emp where bonus is null;哪些员工有奖金?is not nullselect * from t_emp where bonus is not null;哪些员工的薪水不在5000-8000之间select * from t_emp where salary not between 5000 and 8000;哪些员工不是20号和30号部门的====================================================================select * from t_emp where deptno not in(20,30);==================================================================== mysqlDDL (data definition language) 数据定义语言create 创建数据库表alter 修改数据库drop 删除操作DML (数据操纵语言)insertupdatedeleteDQL (数据查询语言)select==================================================================== DQL (数据查询语言)====================================================查询结果进行排序将所有人的薪水进行由高到低排序 order byasc 升序desc 降序select * from t_emp order by salary desc;默认情况下按升序走select * from t_emp order by salary;按照入职日期进行排序时间早越排在前面select * from t_emp order by hiredate desc;按照部门进行排序同一部门的薪水按照由高到低进行排序select * from t_emp order by deptno,salary desc;================================================组函数: 注意:count()里面的参数算的是非null的情况员工的总记录数 count()计算数量select count(*) from t_emp;select count(empno) from t_emp;select count(bonus) from t_emp;===============================================avg() 平均数 sum() 求和 max()最大值 min()最小值计算部门员工的人数总和薪水总和平均薪水 ?select count(empno) num,sum(salary) sum_sal,avg(salary) avg_sal from t_emp;就算员工的最高薪水和最低薪水、select max(salary) maxSalary,min(salary) minSalaryfrom t_emp;==================================================分组查询:group by 列名表示按某指定列进行分组按部门进行计算每个部门的最高薪水和最低薪水分别是多少?select ename,min(salary) from t_emp group by deptno;(X)注意:在分组函数中 select查询的字段只能出现两样东西一个是组函数一个是group by后面出现的字段名称如果按照deptno分组应该讲deptno出现在select查询的字段中如果不出现不会出错只是信息不够全求每个部门的平均薪水和平均薪水总和?求每个职位的最高和平均薪水和人数 ?====================================================================1.having字句用于对的分组后的数据进行过滤where 是对表中的数据进行过滤 having是对分组后得到的结果数据进行进一步过滤 .平均薪水大于5000的部门数据没有部门的不算在内select deptno,avg(ifnull(salary,0)) avg_s from t_emp where deptno is not null group by deptno havingavg(ifnull(salary,0)) >5000;薪水总和大于20000元的部门数据没有部门的不算在内按照工资降序来?select deptno,sum(ifnull(salary,0)) s_salary from t_emp where deptno is not nullgroup by deptno having sum(ifnull(salary,0)) >20000 order by sum(ifnull(salary,0)) asc;哪些职位的人数超过2人?select job,count(empno) from t_emp where job is not null group by job having count(empno) >2;注意:order by一定要放在最后====================================================================子查询;查询最高薪水的人是谁?分两步:select max(salary) from t_emp;select ename from t_emp where salary = 30000;子查询:select ename from t_emp where salary = (select max(salary) from t_emp);====================================================================查询语句的基本结构:select 字段1,字段2,字段3,表达式,函数from 表名where 条件group by 列名放在where 后面 having 前面 where ... groupby ... having ...having 带组函数的条件order by 列名==================================================================== 子查询二:单行比较符 > < >= <= <>不等于号 a > {3,8}1. 谁的薪水比tom高?select ename from t_emp where salary > (select salary from t_emp where ename = 'tom');2.yanfabu有哪些职位?select distinct job from t_emp where deptno = (select deptno from t_dept where dname = 'yanfabu');!!!!!!!!!!!!!!!!!!!!!!!!!!!!谁的薪水比tom高?准备数据:insert into t_emp (empno,ename,salary) values (1012,'tom',12000);现在这个查询的是谁的薪水比所有叫tom的人都高select ename from t_emp where salary >ALL(select salary from t_emp where ename = 'tom');这个查询的是比任意叫tom的人的薪水高的人select ename from t_emp where salary >Any(select salary from t_emp where ename = 'tom') and ename <> 'tom';谁和slw在同一个部门列出除去slw之外的员工名字select ename from t_emp where deptno = (select deptno from t_emp where ename ='slw') and ename <>'slw';准备数据:insert into t_emp (empno,ename,deptno)values (1013,'slw',20);select ename from t_emp where deptno in (select deptno from t_emp where ename ='slw') and ename <>'slw';谁是tom的下属 ?select ename from t_emp where mgr in (select empno from t_emp where ename = 'tom');根据子查询返回的结果的行数选择不同的比较运算符;返回一行 > >= = <= < <>返回多行 All Any In==================================================================== 每个部门拿最高薪水的人是谁?请注意: 子查询的条件是单列还是多列没有关系关键是看要返回的数据是单行还是多行。
mysql笔记

目录1、什么是sql (3)1)数据定义语言(Data Definition Language,DDL) (3)2)数据操作语言(Date Manipulation Language,DML) (3)3)数据查询语言(Date Query Language,DQL) (3)4)数据控制语言(Data Control Language,DCL) (4)2、用户操作 (4)3、mysql 对数据库的操作 (5)4、mysql数据类型 (5)5、mysql中的注释 (6)6、mysql对表的操作 (6)6.1 创建表 (6)6.2 修改表名 (7)6.3 查看表的字符集(编码方式) (7)6.4 修改表的字符集 (7)6.5 查看表结构 (7)6.6 修改字段名及类型 (7)6.7 修改字段名 (8)6.8 修改字段类型 (8)6.9 删除字段 (8)6.10 添加字段 (8)6.11 删除表 (8)7、对数据的操作 (8)7.1 插入数据 (9)7.2 修改数据 (9)7.3 删除数据 (9)7.4 查询数据 (10)7.5 where 语句 (10)7.6 like模糊查询 (10)7.7 order by 排序 (10)7.8 group by 分组语句 (13)7.9 having 关键词 (13)7.10 空值查询 (14)7.11 between and 范围查询 (14)7.12 limit 分页查询 (14)7.13 设置别名 (15)7.14 distinct 去重 (15)8、运算符及函数 (15)8.1 算数运算符 (15)8.2 逻辑运算符 0假 1真 (16)8.3 比较运算符 (16)8.4 位运算符(二进制运算) (16)8.5 in 和 not in (16)8.6 常用函数 (17)9、MySql约束 (18)9.1 主键约束 (18)9.2 外键约束 (19)9.3 唯一约束 (19)9.4 检查约束 (19)9.5 非空约束 (19)9.6 默认值约束 (19)10、表连接 (20)10.1 内连接 (20)10.2 外连接 (21)10.3 自然连接 (21)10.4 交叉连接 (22)11、子查询 (22)12、索引 (23)12.1 创建索引 (23)12.1 删除索引 (24)13、视图 (24)13.1 创建视图 (24)13.2 修改视图 (25)13.3 删除视图 (25)14、存储过程 (25)14.1 创建存储过程 (25)14.2 调用存储过程 (26)14.3 删除存储过程 (27)15、存储函数 (28)15.2删除存储函数 (29)16、流程控制 (29)17、循环 (31)20、事件 (37)20.1 事件的格式 (37)20.3 修改事件(和创建事件格式基本相同) (40)21、事务 (41)22、 mysql日志管理 (44)23、数据库备份于恢复 (46)24、JDBC (46)1、什么是sql•sql(structured Query Language,结构化查询语言)–是一种数据库查询和程序设计语言,用于存取数据以及查询更新和管理关系数据库系统sql包含四部分:数据定义语言(DDL)create、alter、drop数据操作语言(DML)insert、update、delete数据查询语言(DQL)select数据控制语言(DCL)grant、revoke、commit、rollback1)数据定义语言(Data Definition Language,DDL)•用来创建或删除数据库以及表等对象,主要包含以下几种命令:–drop:删除数据库和表等对象;–create:创建数据库和表等对象;–alter:修改数据库和表等对象的结构;2)数据操作语言(Date Manipulation Language,DML)•用来变更表中的记录,主要包含以下几种命令:–insert:向表中插入数据–update:更新表中数据–delete:删除表中数据3)数据查询语言(Date Query Language,DQL)•用来查询表中记录,主要包含了select命令;–select:查询4)数据控制语言(Data Control Language,DCL)•用来确认或者取消数据库中的数据进行的变更,除此之外,还可以对数据库中的用户设定权限,主要包含以下命令:–grant:赋予用户操作权限–revoke:取消用户的操作权限–commit:确认对数据库中的数据进行的变更–rollback:取消对数据库中数据进行的变更2、用户操作1. 查看用户及作用域select user,host from er;2. 查看用户权限show grants for 'root'@'localhost';3. 创建用户create user '用户名'@'作用域' identified by '密码';4. 刷新权限表flush privileges;5. 给用户授权grant 权限 on 数据库名.表名 to '用户名'@'作用域';权限all privileges 或 all 所有权限单个权限 select,update,insert,delete等,单个权限之间用逗号隔开6. 修改用户密码alter user '用户名'@'作用域' identified by '新密码';7. 撤销用户权限revoke 权限 on 数据库.表名 form '用户名'@'作用域';8. 删除用户drop user '用户名'@'作用域';3、mysql 对数据库的操作1.查看所有数据库show databases;2.创建数据库第一种:create database 数据库名;第二种:create database if not exists 数据库名 default character set 字符集;3.查看数据库定义声明show create database 数据库名;4.修改数据库alter database 数据库名 default character set 字符集;5.选择跳转数据库use 数据库名;6.查看当前使用的数据库select database();7.删除数据库drop database 数据库名;4、mysql数据类型整数类型int浮点数类型float、double日期时间类型字符串类型var 、 varcharMySQL数据类型大致可分为:数值类型(整数,浮点数),日期时间,字符串,二进制等;1.整数类型int 整数 4字节 -2147483648-2147483647 21亿2.浮点数类型float 单精度浮点型 4double 双精度浮点型 83.日期时间类型time HH:MM:DDdata YYYY-MM-DDdatatime YYYY-MM-DD HH:MM:DD4.字符串类型char(num) 定长字符串varchar(num) 变长字符串5、mysql中的注释# 【单行注释】只能注释掉#以后的当前行-- 【空格】也可做单行注释/* */ 【多行注释】需要注释的内容要写在斜杠星开头星斜杠里面解释说明的意思用来做笔记用的6、mysql对表的操作6.1 创建表create talbe 表名(字段名类型,字段名类型...字段名类型);#判断是否存在,如果存在就删除drop table if exists day01;#创建表create table day01(id int,name varchar(20),age int,phone varchar(15),address varchar(50));#查看所有表show tables;6.2 修改表名alter talbe 表名 rename to 新表名;#修改表名alter table day01 rename to test01;6.3 查看表的字符集(编码方式)show table status from 数据库名 like '表名';#查看表的字符集show table status from sjkkf01 like 'test01';6.4 修改表的字符集alter table 表名 character set 字符集;#修改表的字符集alter table test01 character set gbk;6.5 查看表结构desc 表名;desc test01;6.6 修改字段名及类型alter table 表名 change 旧字段名新字段名新数据类型;#修改test01表中的name为names;alter table test01 change name names varchar(15);6.7 修改字段名alter table 表名 rename column 就列名 to 新列名;alter table test01 rename column id to ids; 6.8 修改字段类型alter table 表名 modify 字段名字段类型;alter table test01 modify names varchar(20); 6.9 删除字段alter table 表名 drop 字段名;alter table test01 drop age;6.10 添加字段alter table 表名 add column(列名数据类型);alter table test01 add column (age int(3)); 6.11 删除表drop table 表名;drop table test01;desc test01;7、对数据的操作#创建表drop table if exists test01;create table test01(id int,name varchar(20),age int,phone varchar(15),address varchar(50));#查看表中所有数据select * from test01;7.1 插入数据•全字段插入insert into 表名 values (对应字段的值,对应字段的值...对应字段的值);insert into test01 values(1,'小小',20,'110','甘肃兰州');•选定字段插入insert into 表名(字段名,字段名..) values (对应字段的值,对应字段的值....);insert into test01 (id,name,phone) values (2,'嘟嘟','120');7.2 修改数据update 表名 set 字段=值,字段=值... where 条件;update test01 set age=30;update test01 set age=20 where id = 1;insert into test01 values(3,'小小',40,'119','甘肃酒泉');select * from test01;update test01 set address='甘肃武威' where id = 1 or id = 2;7.3 删除数据delete from 表名 where 条件;delete from test01;delete from test01 where name = '小小' and age = 40;7.4 查询数据查询表中所有数据select * from 表名;查询表中指定字段数据select id,name,age from test01;7.5 where 语句•同时满足多个条件用and、或者 or、还可以使用关系运算符 > < >= <= != insert into test01 values(3,'小小',40,'119','甘肃酒泉');select * from test01;select * from test01 where id <= 2;7.6 like模糊查询•like 用于模糊查询,查询条件中可以使用like代替=号,•通常和%任意多个 _单个一起连用(通配符)#查询姓小的用户信息select * from test01 where name like '小_';7.7 order by 排序•order by 子句用于数据的排序默认为升序asc 降序desc、【注意】:要跟在where的后面select * from test01 where name='小小' order by age desc;#雇员表drop table if exists emp;create table emp(empno int(4) primary key comment '雇员编号',ename varchar(10) comment '官员姓名',job varchar(9) comment '雇员职位',mgr int(4) comment '领导编号',hiredate datetime comment '入职日期',sal double(7,2) comment '薪资',comm double(7,2) comment '奖金',deptno int(2) comment '部门编号');#插入数据insert into emp values(7369,'SMITH','CLERK',7902,'1980-12-1 7',800,null,20);insert into emp values(7499,'ALLEN','SALESMAN',7698,'1981-0 1-20',1600,300,30);insert into emp values(7521,'WARD','SALESMAN',7698,'1981-02 -22',1250,500,30);insert into emp values(7566,'JONES','MANAGER',7839,'1981-04 -02',2975,null,20);insert into emp values(7654,'MARTIN','SALESMAN',7698,'1981-09-28',1250,1400,30);insert into emp values(7698,'BLAKE','MANAGER',7839,'1981-05 -01',2850,null,30);insert into emp values(7782,'CLARK','MANAGER',7839,'1981-06 -09',2450,null,10);insert into emp values(7788,'SCOTT','ANALYST',7566,'1987-04 -19',3000,null,20);insert into emp values(7839,'KING','PRESIDENT',null,'1981-1 1-17',5000,null,10);insert into emp values(7844,'TURNER','SALESMAN',7698,'1981-09-08',1500,0,30);insert into emp values(7876,'ADAMS','CLERK',7788,'1987-05-2 3',1100,null,20);insert into emp values(7900,'JAMES','CLERK',7698,'1981-12-0 3',950,null,30);insert into emp values(7902,'FORD','ANALYST',7566,'1981-12-03',3000,null,20);insert into emp values(7934,'MILLER','CLERK',7782,'1982-12-03',1300,null,10);commit;select * from emp;#部门表drop table if exists dept;create table dept(deptno int(2) primary key comment '部门编号',dname varchar(14) comment '部门名称',loc varchar(13) comment '部门位置');#插入数据insert into dept values (10,'ACCOUNTING','NEW YORK'); #财务部insert into dept values (20,'RESEARCH','DALLAS');#研究部insert into dept values (30,'SALES','CHICAGO');#销售部insert into dept values (40,'OPERATIONS','BOSTON');#运营部#工资表drop table if exists bonus;create table bonus(ename varchar(20) comment '雇员姓名',job varchar(20) comment '雇员职位',sal int(6) comment '雇员薪资',comm int(6) comment '雇员奖金');#工资等级表drop table if exists salgrade;create table salgrade(grade int comment '工资等级',losal int comment '该等级最低工资',hisal int comment '该等级最高工资');#插入数据insert into salgrade values (1,700,1200);insert into salgrade values (2,1201,1400);insert into salgrade values (3,1401,2000);insert into salgrade values (4,2001,3000);insert into salgrade values (5,3001,9999);commit;7.8 group by 分组语句#使用emp表根据部门分组,并查出部门编号及每个部门的人数select deptno,count(*) from emp group by deptno;#利用group_concat()函数显示出每组需要显示的数据select deptno,group_concat(ename) from emp group by deptno;#利用with rollup 统计显示内容的记录总和select deptno,group_concat(ename) from emp group by deptno with rollup;7.9 having 关键词•使用having关键字对分组后的数据进行过滤,having关键字和where关键字都可以用来过滤数据•where 和 having关键字的不同之处:–where作用于表和试图,having作用与组;–where查询条件中不可以使用聚合函数,having查询条件中可以使用聚合函数–where在数据分组前进行过滤,having在数据分组后进行过滤#根据sal字段进行分组,并使用having查询分组后平均薪资在2000以上的员工部门编号,名字和薪资select deptno,group_concat(ename),sal from emp group by sal having avg(sal)>2000;7.10 空值查询•is null 为空•is not null 不为空select * from emp;#查询emp表中没有奖金的员工信息select * from emp where comm is null;7.11 between and 范围查询在多少到多少之间between 开始 and 结束#查询emp表中薪资在2000 到 3000 之间的员工信息select * from emp where sal between 2000 and 3000;7.12 limit 分页查询limit 起始位置,记录数limit 记录数#从第三条数据开始显示5条select * from emp limit 2,5;#显示前5条select * from emp limit 5;#limit 可以和offset组合使用limit 记录数 offset 起始位置#从第一条记录开始显示5条select * from emp limit 5 offset 0;7.13 设置别名表名或字段名 as 别名#给emp表起别名通过别名查询名字为king的雇员信息select * from emp as e where e.ename = 'king';#查询emp表中的ename和sal字段并跟别起别名为姓名和工资select ename as 姓名,sal as 工资 from emp;7.14 distinct 去重•select distinct 字段名,字段名... from 表名;•distinct 关键字只能在select 语句中使用•在对一个或多个字段去重时,distinct关键字必须在所有字段的最前面•如果distinct关键字后有多个字段,则会对多个字段进行组合去重,也就是说,只有多个字段组合起来完全是一样的情况下才会被去重#通过去重找到所有的职位select distinct job from emp;8、运算符及函数8.1 算数运算符算数运算符:+-*/算数运算符:%8.2 逻辑运算符 0假 1真and和&& 与 (都为1时结果为1)or和 || 或 (只要有一个为1结果为1) not和! 非 (取反)xor 异或 (相同为0 不同为1) select 1 and 1;8.3 比较运算符> < >= <= != =is null 为空is not null 不为空between and 两者之间8.4 位运算符(二进制运算)& 相对应的位都为1时结果为1| 相对应的位只要有一个为1结果为1 ^ 相对应的位相同为0 不同为1~ 相对应的位取反<< 二进制位整体左移>> 二进制位整体右移1024 512 256 128 64 32 16 8 4 2 18.5 in 和 not inin 包含在里面not in 包含子里面select 1 in (1,2,3,4,5);8.6 常用函数数值型函数:abs 求绝对值sqrt 求二次方根mod 求余数ceil 和 ceiling 两个函数功能相同,都是返回不小于参数的最小整数,向上取整floor 向下取整,返回值转化位一个bigintrand 生成一个0-1之间的随机数,传入整数参数是用来产生重复序列round 对所传参数进行四舍五入sign 返回参数的符号pow 和 power 两个函数的功能相同,都是所传参数的次方的结果值sin 求正弦值asin 反正弦值cos 求余弦值acos 求反余弦值tan 求正切atan 求反正切cot 求余切值字符串函数:length 计算字符串长度函数,返回字符串的字节长度concat 合并字符串函数,返回结果位链接参数产生的字符串,参数可以是一个或者多个insert 替换字符串函数lower 将字符串的字母转换位小写数:upper 将字符串的字母转换位大写left 从左侧截取字符串返回字符串左边的若干个字符right 从右侧截取字符串返回字符串右边的若干个字符trim 删除字符串左右两测空格replace 字符串替换函数,返回替换后的新字符串substring 截取字符串,返回从指定位置开始的指定长度的字符串revese 字符串反转java avaj ,返回与原始字符串顺序相反的字符串聚合函数:max 查询指定列的最大值min 查询指定列的最小值count 统计查询结果的行数sum 求和,返回指定列的总和avg 求平均,返回指定列数据的平均值9、MySql约束•在mysql中,约束是指对表中数据的一种约束,能够帮助数据库管理员更好的管理数据库,并且能够确保数据库中数据的正确性和有效性;9.1 主键约束•表示表中某条数据的值是唯一的,一个表中只能有一个字段为主键•可以在后面加上auto_increment 实现主键自动增长9.2 外键约束•用来确保两个表中的字段数据一致9.3 唯一约束•用来确保字段中数据的值是唯一的和主键类似,唯一约束可以有多个9.4 检查约束•用来检查字段中的值是否有效,列如性别只能是男或女,避免无效数据输入9.5 非空约束•用来约束字段值不能为空9.6 默认值约束•用来约束当数据表中某个字段不输入值时,自动为其添加一个设置好的值create table t1(id int primary key auto_increment,#设置主键并自动增长name varchar(20) unique,#设置唯一约束保证名字不重复age int check(age>0 and age<=100), #设置检查约束保证年龄在0~100之间sex varchar(2) default('男'),#设置默认值约束如果不指定默认为phone varchar(12) not null#设置非空约束保证电话字段不为空);insert into t1 values (null,'小小',30,'女','110');insert into t1 values (null,'莹莹',18,'','120');insert into t1 values (null,'洋洋',18,default,'');insert into t1 values (null,'英英',18,default,null);select * from t1;create table t2(id int primary key auto_increment,t1id int not null,name varchar(20),#设置外键关联t1表主键constraint fk_t1_t2 foreign key(t1id) reference s t1(id));后期添加外键alter table 表名 add constraint 外键名 foreign key(列名) references 主表名(列名);删除外键alter table 表名 drop foreign key 外键名;查看表中的约束show create table 表名;10、表连接10.1 内连接•取每个表都能够匹配的值,如果对应的列值不存在,则被抛弃表1 inner join 表2 on 连接条件#内连接查询员工姓名及部门名称select e.ename,d.dname from emp e inner join de pt d on e.deptno = d.deptno;10.2 外连接•左外连接–以左表为基表(左表为主)–可以查询出左表中的所有记录和右表中匹配连接条件的记录;–如果左表的某行在右表中没有匹配行,那么在返回结果中,右表的字段值均为为空值(null)左表 left join 右表 on 连接条件;select * from emp e left join dept d on e. deptno = d.deptno;•右外连接–以右表为基表(右表为主)–可以查询出右表中的所有记录和左表中匹配连接条件的记录;–如果右表的某行在左表红没有匹配行,那么在返回结果中,左表的字段值均为空值(null)左表 right join 右表 on 连接条件;select * from emp e right join dept d one.deptno = d.deptno;10.3 自然连接•会根据表中相同名称的字段进行自动匹配表1 natural join 表2;select * from emp natural join dept;10.4 交叉连接返回连接表的笛卡尔积(两个集合的乘积)A = {1,2}B = {3,4,5}A *B = {(1,3),(1,4),(1,5),(2,3),(2,4),(2,5)}B * A = {(3,1),(3,2),(4,1),(4,2),(5,1),(5,2)}以上A B 和 B A的结果就叫做两个集合的笛卡尔积;容易导致查询结果重复,混乱,效率慢,不建议使用表1 cross join 表2; 可以加where条件select * from emp cross join dept;11、子查询•相当于十查询语句嵌套,在一个查询结果中继续查询想要的数据,•子查询经常出现在where 子句中#查询工资最低的雇员姓名职位及薪资select ename,job,sal from emp where sal = (sele ct min(sal) from emp);#查询平均薪资最低的部门名称select dname from dept where deptno =(select deptno from emp group by deptno o rder by avg(sal) limit 1);#查询薪资高于clark的所有员工的姓名部门名称工作和薪资select e.ename,d.dname,e.job,e.sal from emp e l eft join dept d on e.deptno = d.deptnowhere sal > (select sal from emp where ename = 'clark');12、索引•类似于书中的目录,索引可以大大提高mysql的检索速度,依旧是查询性能, •但是索引也不是越多越好,过多的索引会降低更新(插入,修改,删除)速度, •因为索引是更具表中的一列或若干列按照一定顺序建立的列值与记录行之间的对应关系表,•索引越多关系表越多(浪费磁盘空间),同时更新操作不但要更新内容而且要更新索引文件(降低了数据维护速度)12.1 创建索引create index 索引名 on 表名(字段);#普通索引create unique index 索引名 on 表名(字段);#唯一索引•普通索引和唯一索引:–查询操作(影响微乎其微几乎没有影响)•普通:检索到第一个匹配项后会继续往后检索,知道检索到第一个不匹配项停止检索;•唯一:检索到第一个匹配项后停止检索;–更新操作(如果数据不在内存中唯一索引涉及磁盘读取会降低性能) •普通:检索到位置后直接更新•唯一:检索到位置后判断是否是唯一再更新•性能总和考虑建议使用普通索引12.1 删除索引drop index 索引名 on 表名;13、视图•视图就是一张虚拟的表,我们可以将我们需要的表中的数据查出来定义为视图去查看,•视图中的数据随着真实表中的数改变而改变,对试图的操作和对表的操作是一样的;•视图的优点:1. 安全:用户只能查询和修改他们所能看到的数据,数据库中的其他数据则既看不到,也取不到,保证了数据的安全性;2. 聚焦特定数据:多个表中数据可能有很多,可是用户想要看的数据可能只是其中的部分,这样就可以使用视图将用户想要显示的数据进行显示;13.1 创建视图create view 视图名 as 查询语句create view ed_view asselect e.ename,e.sal,e.deptno,d.dname fro m emp e left join dept d on e.deptno = d.deptno;#查看视图select * from ed_view;13.2 修改视图alter view 视图名 as 查询语句;alter view ed_view asselect e.ename,d.dname from e mp e left join dept d on e.deptno = d.deptno;13.3 删除视图drop view 视图名;drop view ed_view;14、存储过程•平时我们都是对表进行单条sql语句的操作,可往往有时候要完成一个操作可能会需要多条sql语句来处理,这时我们就能使用存储过程将一组为了完成特定功能sql语句打包起来进行操作;14.1 创建存储过程mysql以分号作为结束符而存储过程中包含多条语句所以会有问题所以一般在存储过程前用delimiter修改结束符delimiter // #修改结束符为两个斜杠create procedure 过程名(过程参数)begin过程体end // #用两个斜杠结束14.2 调用存储过程call 过程名#如果这个存储过程存在就删除drop procedure if exists show_emp;#利用存储过程查询emp表中所有信息delimiter //create procedure show_emp()beginselect * from emp;end //#调用存储过程call show_emp();drop procedure if exists show_emps;#利用存储过程查询emp表中前n条信息delimiter //create procedure show_emps(in num int) #in 代表输入参数 num参数名字后面时类型beginselect * from emp limit num;end//#调用存储过程并传入参数call show_emps(5);drop procedure if exists show_empCount;#利用存储过程查询员工人数delimiter //create procedure show_empCount(out sum int) #ou t 代表输出参数beginselect count(*) from emp;end//#调用时要参数匹配call show_empCount(@sum);drop procedure if exists show_empSal;#利用存储过程通过员工编号查询员工薪资delimiter //create procedure show_empSal(inout num int) #in out 代表输入输出参数beginselect sal from emp where empno = num;end //#设置参数值set @num = 7369#传入参数调用过程call show_empSal(@num);14.3 删除存储过程drop procedure 过程名;15、存储函数•存储函数和存储过程一样,都是在数据库中定义一些sql语句的集合;•存储函数可以通过return 语句返回值,用于计算返回一个值;•而存储过程没有直接返回值,用于执行操作;•存错过程的参数可以时in,out,inout类型,而函数的参数只能时in类型#如果创建时遇到这个报错This function has none of DETERMINISTIC,#NO SQL,or READS SQL DATA in its declaration an d binary#loggin is enables#在mysql数据库中执行以下语句(临时生效,重启后失效)set global log_bin_trust_function_creators=TRUE;drop function if exists getEnameByEmpno;#通过员工编号查询员工姓名delimiter//create function getEnameByEmpno(id int)returns varchar(20) #返回类型beginreturn (select ename from emp where empno =id);end //#执行函数并传入参数select getEnameByEmpno(7369);drop function if exists addNum;#实现两个数字相加delimiter //create function addNum(n1 int,n2 int)returns intbegindeclare sum int; #定义变量set sum = n1 + n2; #设置值return sum;end //#执行函数并传入参数select addNum(10,20);15.2删除存储函数drop function 函数名;16、流程控制1- if else thenif elseif elsedrop procedure if exists maxNum;#存储过程实现求两个数最大值delimiter //create procedure maxNum(in n1 int,in n2 i nt)beginset @mnum = 0;if n1 > n2 thenset @mnum = n1;elseif n1 < n2 thenset @mnum = n2;elseset @mnum = 0;end if;end //#调用过程call maxNum(1,2);#查看结果select @mnum;drop function if exists selectMax;#存储函数实现求两个数的最大值delimiter //create function selectMax(n1 int,n2 int)returns intbeginif n1 > n2 thenreturn n1;elsereturn n2;end if;end //#执行函数select selectMax(3,4);2- case when thendrop procedure if exists nums;delimiter //create procedure nums(in n1 int,in n2 int, out res varchar(20))begincasewhen n1>n2 then set res='n1>n 2';when n1<n2 then set res='n1<n 2';else set res='n1==n2';end case;end //#执行call nums(3,6,@res);#查看结果select @res;17、循环drop table if exists num;create table num(num int);select * from num;1- while dodrop procedure if exists ins1;#利用循环添加数据delimiter //create procedure ins1()begindeclare i int; #定义变量set i = 1; #给变量赋值while i <= 5 doinsert into num values(i);set i=i+1;end while;end //#执行,call ins1();2- repeat untildrop procedure if exists ins2;delimiter //create procedure ins2()begindeclare i int default 6; #定义变量并给默认值repeatinsert into num values(i);set i = i+1;until i>10end repeat;end //#执行call ins2();3- loopdrop procedure if exists ins3;delimiter //create procedure ins3()begindeclare i int default 11;loop_i:loopinsert into num values(i);set i=i+1;if i>=15 thenleave loop_i;end if;end loop;end //#执行call ins3();十八.游标游标相当于一个用来指定一条单一数据的标识,类似于索引值也就是下标值一. 定义游标declare 游标名 cursor for 查询语句;二. 打开游标open 游标名;三. 取值fetch 游标名 into 值1,值2....四. 关闭游标close 游标名;drp procedure if exists getMes;delimiter //create procedure getMes()begin#定义变量declare en varchar(20);declare jb varchar(20);declare sa int;#创建游标declare getM cursor for select ename,job,sal from emp; open getM; #打开游标fetch getM into en,jb,sa; #赋值close getM; #关闭游标select en,jb,sa; #游标默认取出第一条数据end //#执行call getMes();drop table if exists users;create table users(id int,name varchar(20),sex varchar(2));select * from users;insert into users values(1,'宝宝','男');insert into users values(2,'贝贝','男');insert into users values(3,'亲亲','男');drop procedure if exists up_users;#利用游标及存储过程修改所有性别为女delimiter //create procedure up_users()begindeclare names varchar(20);declare no int;declare up_sex cursor for select name from users;declare continue handler for not found set no=1; #找不到时将no改为1 set no = 0;open up_sex; #打开游标while no=0 dofetch up_sex into names; #取值update users set sex = '女' where name=names; #通过姓名更改性别end while;close up_sex;end //#执行call up_users();触发器和存储过程一样,都是嵌入到mysql中的一段程序,存储过程需要call来执行,而触发器是在执行某个操作的时候自动执行的当有多个表具有一定的相互联系的时候,触发器能够让不同的表保持数据的一致性, 只有执行insert,update,delete操作的才能激活触发器,其他sql不会激活触发器;1.创建触发器create trigger 触发器名称触发时机(before之前 after之后) 触发事件 on 哪个表上建for each row 要执行的操作drop table if exists users;create table users(id int primary key auto_increment,name varchar(20),age int);drop table if exists log;create table log(id int primary key auto_increment,logtime timestamp,mes varchar(100));select * from users;select * from log;drop trigger 触发器名drop trigger if exists user_log;delimiter //create trigger user_log after insert on users for each rowbegininsert into log values(null,now(),'users执行了插入操作');end //insert into users values(null,'张三',20);insert into users values(null,'李四',30);20、事件mysql5.1版本开始引进的 event(时间触发器)概念,mysql中的事件是用于执行定时或周期性的任务的,有时候也可被称为临时触发器,事件由一个特定的线程来管理的,也就是所谓的事件调度器,但是事件不能直接调用,事件是基于特定事件周期触发来执行,触发器是基于某几个表所产生的事件而触发,这也是他们之间的区别;20.1 事件的格式create#可选,用于定义事件执行时检查权限definer#可选,用于判断要创建的事件是否存在if not exists#必选,用于指定事件名event 事件名#必须,用于定义执行的时间和间隔on schedule 执行计划#可选,用于定义时间是否循环执行#at 时间戳,用于完成单次计划任务#every 单位,用于完成重复的计划任务on completion [not] preserve#可选,用于指定事件的一种属性#关键字enable表示该事件是活动的#关键子disable表示该事件是关闭的#关键字disable on slave表示事件是关闭的,如果不指定这三个选择中的任意一个, #则一个事件创建之后,它立即变为活动的;enable | disable | disable on slave#可选,用于定义注释comment '注释内容'#必选,用于指定事件启动时要执行的内容#可以是任何有效的sql语句,存储过程或者一个计划执行的事件#如果包含多条,可以使用begin end复合结构do 内容2. 创建事件注意:使用事件前必须确保event_scheduler已开启如果未开启执行set global event_scheduler=1;drop table if exists users;create table users(id int primary key auto_increment,name varchar(20),age int);select * from users;2.1创建立即启动事件create event insertUsersEvent1on schedule at now()do insert into users values(null,'小白',20);2.2 创建一个10秒后启动事件create event insertUserEvent2on schedule at current_timestamp+interval 10 second do insert into users values(null,'小红',30);2.3 创建重复执行事件create event isnertUserEvent3on schedule every 15 secondon completion preserve disabledobegininsert into users values(null,'事件1',20);insert into users values(null,'事件2',30);end20.3 修改事件(和创建事件格式基本相同)alter#必选,用于指定事件名event 事件名#必须,用于定义执行的时间和间隔on schedule 执行计划#可选,用于定义时间是否循环执行#at 时间戳,用于完成单次计划任务#every 单位,用于完成重复的计划任务on completion [not] preserve#可选,用于指定事件的一种属性#关键字enable表示该事件是活动的关键子disable表示该事件是关闭的#关键字disable on slave表示事件是关闭的,如果不指定这三个选择中的任意一个, #则一个事件创建之后,它立即变为活动的;enable | disable | disable on slave#可选,用于定义注释comment '注释内容'#必选,用于指定事件启动时要执行的内容#可以是任何有效的sql语句,存储过程或者一个计划执行的事件#如果包含多条,可以使用begin end复合结构do 内容通过修改事件将一个事件临时关闭或再次活动alter event 事件名 disable; --关闭事件alter event 事件名 on completion preserve enable; #开启定时任务alter event 事件名 on completion preserve disable; #关闭定时任务alter event isnertUserEvent3 on completion preserve enable;alter event isnertUserEvent3 on completion preserve disable;select * from users;21、事务一.什么时事务数据库的事务(Transaction)一种机制,一个操作序列,包含了一组数据库操作命令. 即这一组数据库命令要么都执行,要么都不执行,因此事务是一个不饿分割的工作逻辑单元,执行dml操作的时候(insert delete update)并没有真正的影响到我们表里面的内容,直到提交当前事务;一个事务的结束就是下一个事务的开始二.事务的特性原子性(Actomicty): 一个事务要么全部提交,要么全部回滚一致性(Consistent): 事务回滚/提交前后数据库的属性不会发生改变隔离性(Isolation):多个事物之间不会相互影响。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
MySQL-高级1标题1................................................................................................... 错误!未定义书签。
1.1标题2 ...............................................................................................错误!未定义书签。
1.1.1标题3 ............................................................................................错误!未定义书签。
MySQL中的SQL编程的话题.触发器, 存储函数, 存储过程以上的是三个名词, 在SQL编程中, 地位是: 程序的载体, 程序的结果.编程所涉及的要素:变量, 数据类型, 流程控制, 函数, 运算符, 表达式.2.1 内置函数MySQL自动提供的函数!例如: database(), now(), md5()2.2 自定义函数– 存储函数用户定义定义的, 存储在MySQL中的函数.2.2.1create function, 创建函数适用语法:来创建函数2.2.2调用函数2.2.3drop function , 删除函数drop function [if exists] function-name;3 变量–编程要素程序处理数据.数据在程序中的容器, 就是变量.强类型3.1 全局变量函数外定义的变量变量不需要声明, 直接去设置即可!PS, 内置的变量: set autocommit = off, 不以@开头3.2 局部变量函数内定义的变量使用declare来声明.不需要使用@, 表示是用户自定义变量.强类型, 定义的局部变量, 必须定义为某种类型, 类型的表述与字段的类型一致!3.3 重叠(嵌套)作用域局部内, 可访问到全局变量PS: 与JS保持一致13.4 变量的赋值3.4.1set 变量= 值3.4.2select into 变量当需要为变量赋值的数据, 来源于SQL中select语句的查询结果时, 可以使用select into 完成变量的赋值.一次性, 赋值多个变量:函数内, 也可以使用4 流程控制–编程要素循环和分支4.1 分支- IF测试结果4.1.1内置分支函数: if()不是分支, 是典型的三元运算, 的函数封装语法MySQL不支持三元运算符? :.4.2 分支-CASE测试结果4.3 循环– while条件满足, 则循环继续其中标签, 用于在循环终止时, 一次性的终止多层循环! 类似于JS的语法.例如:4.4 循环– 终止终止当前循环:(continue), iterate终止全部:(break), leave终止, 都需要配合循环语句的标签使用! ierate:leave:如果需要终止多层:需要在后边跟随不同的标签即可5 过程–存储过程– procedure与函数类似, 都是一段功能代码的集合, 称之为过程.与函数不一样的是, 函数由于完成某个特定的操作点, 例如, md5(), 获取md5摘要信息, 不是用来实现某中也无路基操作, 而是就是实现特定的操作. 过程是, 某个特定的业务逻辑.当我们需要使用SQL完成某件事时候, 使用过程, 而在过程的完成中, 需要一些特殊的操作, 就是函数.例如:需要插入, 1000条记录到某测试表中, 此时就应该创建过程.而在插入的时候, 需要随机的获取学生的姓名, 就可以定义一个函数, 完成获取随机的学生姓名工作.映射到PHP程序:浏览器所请求的一个URL, 对应的PHP代码, 就是一段过程. (例如, 商品添加, 用户注册), 就是过程.而在完成这个过程中, 需要将用户的密码做md5处理, md5就是函数.因此, 函数在意的是处理结果,函数具有返回值.而过程是一段执行, 不具有返回值.语法注意: 没有返回值参数有输入方式之分.过程内的写法, 与函数是一致的.5.2 调用过程, call 过程()过程的调用不能出现在表达式中, 需要使用独立的语法进行独立调用.// 表达式中max(class_id) + 10;需要用call5.4 参数的输入类型, in, out, inoutin, out, inout, 表示, 过程的参数的数据的传递方向.in: 由外向内传递out: 由内向外传递inout: 双向传递, 即可内向外, 也可外向内内, 外, 指的是, 过程外和过程内.创建过程外的三个变量:以三个变量作为实参, 调用过程:在获取过程外三个变量的值:inout 双向传递, 类似于PHP中的引用传递!由于过程没有返回值, 需要在过程处理后, 得到过程的处理结果数据, 就因该, 使用带有out类型的参数.一个数据时被多个过程连续处理, 典型的需要inout类型的参数.6 练习一个纯粹的MySQL管理员需要完成某些操作, 需要使用过程, MySQL自带的编程方式.例如, 需要创建大量的测试数据, 可以过程完成:确定测试表的结构确定需要插入的数据格式要求:学号要从1开始递增.班级ID, 从1-100 随机姓名, 随机得来说明: 任意编程实现:编写, 需要的函数:获取班级ID生成名字:生成信息生成学号从1开始递增it-0000001it-0000002取得已有的最大学号.调用过程即可:测试数据7 触发器– trigger事件驱动程序: 监听元素某些事件, 当事件被触发时, 事件处理器被调用. (PS: 类似于JS的事件驱动)触发器的事件:insert, delete, update扩展开共六种:before insert, after insertbefore delete, after deletebefore update, after update事件都是记录对象的事件, row的before insert, row after insert.语法7.1 创建触发器, create trigger绑定事件处理器, 到row 元素上.测试, 在学生表的添加事件上增加触发器程序:一旦学生表添加, 则在学生日志表中, 加入一条记录检测学生日志表:触发程序被自动调用触发器, 只是调用方式不同于存储过程而已, 都是功能的集合.7.2 删除触发器drop trigger tigger-name7.3 new, old预定义的变量, 表示触发该事件的行对象.就是事件源记录.使用new, old 来引用这个事件源记录.new 和old的区别:new, 新纪录old, 旧记录.只有在update事件时, 才会出现新旧记录同时存在的情况.更新: 将旧记录更改成新纪录.在insert事件中, 只有new可用. before insert, after insert , 都可以使用new.在delete事件中, 只有old可用. before delete after delete 都可以使用old 无论是before还是insert 都一样.7.4 事件的触发可能会出现执行一条语句, 触发多个事件的情况.有些语句, 带有逻辑判定功能:replace into, 尝试插入, 如果冲突, 则替换(删除旧的,插入新的)类似的:insert into on duplicate key update冲突时更新一个表, 的一个事件, 仅仅可以绑定一个事件处理器.一个表最多可以有6个触发器.8 架构读写分离, 负载均衡.8.1 读, 写服务器分离设计:56.101, MySQL 充当写服务器.再添加2台linux 充当读服务器:初始化mac地址完全复制复制后, 启动复制的服务器:删除, 之前所保留的虚拟化网卡的文件, 使新生成的网卡生效.修改eth0的配置文件:修改mac地址参数:修改为, virtualbox生成的mac地址:保持一致init 6 重启8.2 读从写服务器复制数据在主服务器上开一个复制账号, 从服务器利用这个复制账号, 从主服务器进行复制.配置过程如下:8.2.1主服务器8.2.1.1 开启二进制日志8.2.1.2 指定唯一的服务器ID保证唯一即可!需要重启mysqld(可以与步骤一一起完成)8.2.1.3 增加复制账号登录主MySQL, 增加账号, 刷新权限.8.2.1.4 记录当前状态位置show master status8.2.2从服务器8.2.2.1 指定服务器的唯一IDmysqld 重启8.2.2.2 开启复制从服务器的MySQL中执行:使用change master 来指定;此时已经建立的主从复制联系8.2.2.3 开启复制在从服务器上执行:start slave8.2.2.4 查看复制状态。