973当代汉语文本语料库分词、词性标注加工规范
对外汉语教学中的词类划分

对外汉语教学中的词类划分作者:朱芸来源:《现代语文(语言研究)》2008年第05期摘要:本文运用语料库的研究方法,对对外汉语教材《博雅汉语》中级冲刺篇中动词、名词、形容词的使用情况进行了调查研究,通过统计数据我们发现,其中部分动词和形容词具有名词用法。
但是,在词典和教材生词表上并未将这些动词和形容词归入兼类词,也未标明其具有名词用法。
本文试图通过描述这些动词、形容词的分布状态概括出其共性。
关键词:语料库词类活用词的兼类引言语料库是指存放在计算机里的原始语料文本或经过加工后带有语言学信息标注的文本。
语料库语言学是基于语料库提供的语言材料展开的语言研究。
近年来,随着计算机语言学和语料库语言学的发展,越来越多的人通过语料库所提供的语料进行汉语研究。
本文通过建立一个小型的对外汉语教材语料库,对其中的动词、名词、形容词的使用进行分类统计,从而为对外汉语中的词汇教学提供一些切实可行的建议。
一、语料库建设语料库素材:北大出版社《博雅汉语》中级上下两册,适用于已经基本掌握了基础语言知识和交际功能的学习者。
其中上册12课,下册10课,不包括标点在内共有53504字次,2044字;共有34530词次,4829词。
平均每篇课文2432字,1569词。
该语料库从2006年3月开始录入文本到6月完成词性标注及校对,历时三个月,实际总共耗时60小时左右。
词类标记:本语料库采取“973当代汉语文本语料库分词、词性标注加工规范”“北京大学现代汉语语料库基本加工规范”在实际操作中以前者为主,并采用后者中动词和形容词的特殊用法标记。
将这些特殊用法标注出来可以为词的兼类研究提供计量依据,主要词类标记如下:注:碍于语料和精力有限,本文集中考察动词和形容词的名词用法在语料库中的分布情况。
二、标注标准计算机对语料进行自动分词和标注词性后,人工校对的过程中发现了部分动词和形容词的词性标注存在问题。
即部分词性并不符合其在具体句子中的语法功能。
当汉语语料库文本分词规范草案

973当代汉语文本语料库分词、词性标注加工规范(草案)山西大学从1988年开始进行汉语语料库的深加工研究,首先是对原始语料进行切分和词性标注,1992年制定了《信息处理用现代汉语文本分词规范》。
经过多年研究和修改,2000年又制定出《现代汉语语料库文本分词规范》和《现代汉语语料库文本词性体系》。
这次承担973任务后制定出本规范。
本规范主要吸收了语言学家的研究成果,并兼顾各家的词性分类体系,是一套从信息处理的实际要求出发的当代汉语文本加工规范。
本加工规范适用于汉语信息处理领域,具有开放性和灵活性,以便适用于不同的中文信息处理系统。
《973当代汉语文本语料库分词、词性标注加工规范》是根据以下资料提出的。
1.《信息处理用现代汉语分词规范》,中国国家标准GB13715,1992年2.《信息处理用现代汉语词类标记规范》,中华人民共和国教育部、国家语言文字工作委员会2003年发布3.《现代汉语语料库文本分词规范》(Ver 3.0),1998年北京语言文化大学语言信息处理研究所清华大学计算机科学与技术系4.《现代汉语语料库加工规范——词语切分与词性标注》,1999年北京大学计算语言学研究所5.《信息处理用现代汉语词类标记规范》,2002年,教育部语言文字应用研究所计算语言学研究室6.《现代汉语语料库文本分词规范说明》,2000年山西大学计算机科学系山西大学计算机应用研究所7.《資讯处理用中文分词标准》,1996年,台湾计算语言学学会一、分词总则1.词语的切分规范尽可能同中国国家标准GB13715《信息处理用现代汉语分词规范》(以下简称为“分词规范”)保持一致。
本规范规定了对现代汉语真实文本(语料库)进行分词的原则及规则。
追求分词后语料的一致性(consistency)是本规范的目标之一。
2.本规范中的“分词单位”主要是词,也包括了一部分结合紧密、使用稳定的词组以及在某些特殊情况下可能出现在切分序列中的孤立的语素或非语素字。
汉语文本词性标注标记集的规范

汉语文本词性标注标记集的规范汉语文本词性标注标记集的规范代码名称帮助记忆的诠释 Ag 形语素形容词性语素。
形容词代码为a,语素代码g前面置以A。
a 形容词取英语形容词adjective的第1个字母。
ad 副形词直接作状语的形容词。
形容词代码a和副词代码d并在一起。
an 名形词具有名词功能的形容词。
形容词代码a和名词代码n并在一起。
b 区别词取汉字“别”的声母。
c 连词取英语连词conjunction的第1个字母。
Dg 副语素副词性语素。
副词代码为d,语素代码g前面置以D。
d 副词取adverb的第2个字母,因其第1个字母已用于形容词。
e 叹词取英语叹词exclamation的第1个字母。
f 方位词取汉字“方” g 语素绝大多数语素都能作为合成词的“词根”,取汉字“根”的声母。
h 前接成分取英语head的第1个字母。
i 成语取英语成语idiom的第1个字母。
j 简称略语取汉字“简”的声母。
k 后接成分 l 习用语习用语尚未成为成语,有点“临时性”,取“临”的声母。
m 数词取英语numeral的第3个字母,n,u已有他用。
Ng 名语素名词性语素。
名词代码为n,语素代码g前面置以N。
n 名词取英语名词noun的第1个字母。
nr 人名名词代码n和“人(ren)”的声母并在一起。
ns 地名名词代码n和处所词代码s 并在一起。
nt 机构团体“团”的声母为t,名词代码n和t并在一起。
nz 其他专名“专”的声母的第1个字母为z,名词代码n和z并在一起。
o 拟声词取英语拟声词onomatopoeia的第1个字母。
p 介词取英语介词prepositional的第1个字母。
q 量词取英语quantity的.第1个字母。
r 代词取英语代词pronoun的第2个字母,因p已用于介词。
s 处所词取英语space的第1个字母。
Tg 时语素时间词性语素。
时间词代码为t,在语素的代码g前面置以T。
现代汉语语料库加工规范词语切分和词性标注词...
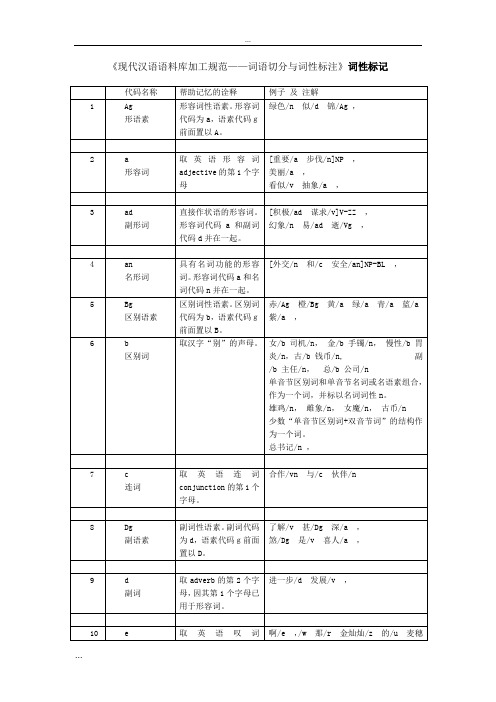
[芜湖/ns专区/n] NS,
[宣城/ns地区/n]ns,
[内蒙古/ns自治区/n]NS,
[深圳/ns特区/n]NS,
[厦门/ns经济/n特区/n]NS,
[香港/ns特别/a行政区/n]NS,
甲/Mg减下/v的/u人/n让/v乙/Mg背上/v ,
凡/d“/w寅/Mg年/n”/w中/f出生/v的/u人/n生肖/n都/d属/v虎/n ,
18
m数词
取英语numeral的第3个字母,n,u已有他用。
1.数量词组应切分为数词和量词。三/m个/q, 10/m公斤/q,一/m盒/q点心/n ,
但少数数量词已是词典的登录单位,则不再切分。
合作/vn与/c伙伴/n
8
Dg
副语素
副词性语素。副词代码为d,语素代码g前面置以D。
了解/v甚/Dg深/a,
煞/Dg是/v喜人/a,
9
d
副词
取adverb的第2个字母,因其第1个字母已用于形容词。
进一步/d发展/v,
10
e
叹词
取英语叹词exclamation的第1个字母。
啊/e,/w那/r金灿灿/z的/u麦穗/n,
约/d一百/m多/m万/m,仅/d一百/m个/q,四十/m来/m个/q,二十/m余/m只/q,十几/m个/q,三十/m左右/m,
两个数词相连的及“成百”、“上千”等则不予切分。
五六/m年/q,七八/m天/q,十七八/m岁/q,成百/m学生/n,上千/m人/n,
4.表序关系的“数+名”结构,应予切分。
[宝山/ns钢铁/n总/b公司/n]NT,(/w宝钢/j)/w
973当代汉语文本语料库分词、词性标注加工规范

973当代汉语文本语料库分词、词性标注加工规范(草案)山西大学从1988年开始进行汉语语料库的深加工研究,首先是对原始语料进行切分和词性标注,1992年制定了《信息处理用现代汉语文本分词规范》。
经过多年研究和修改,2000年又制定出《现代汉语语料库文本分词规范》和《现代汉语语料库文本词性体系》。
这次承担973任务后制定出本规范。
本规范主要吸收了语言学家的研究成果,并兼顾各家的词性分类体系,是一套从信息处理的实际要求出发的当代汉语文本加工规范。
本加工规范适用于汉语信息处理领域,具有开放性和灵活性,以便适用于不同的中文信息处理系统。
《973当代汉语文本语料库分词、词性标注加工规范》是根据以下资料提出的。
1.《信息处理用现代汉语分词规范》,中国国家标准GB13715,1992年2.《信息处理用现代汉语词类标记规范》,中华人民共和国教育部、国家语言文字工作委员会2003年发布3.《现代汉语语料库文本分词规范》(Ver 3.0),1998年北京语言文化大学语言信息处理研究所清华大学计算机科学与技术系4.《现代汉语语料库加工规范——词语切分与词性标注》,1999年北京大学计算语言学研究所5.《信息处理用现代汉语词类标记规范》,2002年,教育部语言文字应用研究所计算语言学研究室6.《现代汉语语料库文本分词规范说明》,2000年山西大学计算机科学系山西大学计算机应用研究所7.《資讯处理用中文分词标准》,1996年,台湾计算语言学学会一、分词总则1.词语的切分规范尽可能同中国国家标准GB13715《信息处理用现代汉语分词规范》(以下简称为“分词规范”)保持一致。
本规范规定了对现代汉语真实文本(语料库)进行分词的原则及规则。
追求分词后语料的一致性(consistency)是本规范的目标之一。
2.本规范中的“分词单位”主要是词,也包括了一部分结合紧密、使用稳定的词组以及在某些特殊情况下可能出现在切分序列中的孤立的语素或非语素字。
国家语委现代汉语语料库介绍

应用文 难于归类的语料
人文与社会科学类
人文与社会科学类划分为8个大类和30个小类:
政法:哲学、政治、宗教、法律; 历史:历史、考古、民族; 社会:社会学、心理、语言文字、教育、文艺理论、新闻、
民俗; 经济:工业经济、农业经济、政治经济、财贸经济; 艺术:音乐、美术、舞蹈、戏剧; 文学:小说、散文、传记、报告文学、科幻、口语; 军体:军事、体育; 生活。
章程法规:章程、条例、细则、制度、公约、办法、法律条 文等;
司法文书:诉讼、辩护词、控告信、委托书等; 商业文告:说明、广告、调查报告、经济合同等; 礼仪辞令:欢迎词、贺电、讣告、唁电、慰问信、祝酒词等; 实用文书:请假条、检讨、申请书、请愿书等。
综合类约占语料总量的20%
样例 语料分类
信息处理用现代汉语词类标记集规范
基本词类体系 基本词类体系的标记代码 《规范》的制定
在国家社科基金“九五”重大项目《信息处理用现代汉语词汇研 究》的子项目“信息处理用现代汉语词类标记集规范的基础上完 成
得到国家语委“九五”重大项目《现代汉语语料库建设》子课题 “国家语委核心语料分词及词性标注加工”的支持。
样例 语料库查询统计工具
样例 句法树库的信息检索
样例 基于互联网的语料库例句检索
样例 语料库全文检索
语料库的管理
国家语委语料库由国家语委委托语言文字应用 研究所负责建设和管理
国家语委语料库可以提供的服务
语料库使用权许可 检索、查询、统计等数据服务 软件开发等其他服务
语料库提供服务的方式
语料库选材
人文与社会科学类
以1919年为上限,选取五四以来的语言材料。 对五四以来各个历史时期的语料采取不等密度选用的方式。
汉语文本短语结构的人工标注语料库的加工与应用

語料的加工
對”北大加工規範”做的介紹及調整 人名:nr 姓與名都分開 nrx nrm
不易或不知道姓與名就記作nr 王/nr建民/nr 王/nrx 建民/nrm 大衛‧歐提茲/nr 大衛/nrm‧/w歐提茲/nrx
地名:nd 長的國名要考慮切割 中華人民共和國/nd ﹛中華/ab 人民/ng 共和國/ng﹜nd 只有在行政區名稱是單音節且前面成分也是單音節為一切分 單位:{台北/nd市/n}nd 台州/nd 長江/nd etc
語料的加工
與”北大加工規範”不同之處︰
1.
2.
3.
4. 5.
時間詞(nt)、處所詞(ns)放在名詞大類下面,如果 要單一查某類,可用小類標記符號查尋 區別詞(ab)放在形容詞大類中 五種語素標記法,顛倒字母次序,方便找查 Ng Vg Ag Dg Tg gN gV gA gD gT 去掉名動詞vn、名形詞an、副動詞vd、副形詞 ad 在10個大類中設立了10個其他的小類,記做~g
單音節動詞的重疊式加“看”
語料的加工 短語標注源自 前人的短語標注與樹庫建立
Lancaster-Leeds Penn
英語樹庫加工目的
提供一些具體服務(翻譯 檢索 索引等)
方法及特點
人機互助(人注-機注-人校) 朝機器自動化發展
語料的加工
現有漢語短語句法標
記集描述
語料的加工
詞性標記
現有詞性標注集
27大類 有些分類細
有些分類粗
語料的加工
自定標注集
標注細一點,因
沒詞典做支撐 適當吸收現代漢 語研究結果來做 分類
語料的加工
23個大類,用英文字母表示,有11個大類下面有
现代汉语语料库加工-词语切分与词性标注规范与手册

现代汉语语料库加工——词语切分与词性标注规范与手册俞士汶主编北京大学计算语言学研究所1999年4月目录●现代汉语语料库加工规范——词语切分与词性标注⒈前言 (1)⒉切分规范 (3)⒊切分和标注相结合的规范 (10)⒋标注规范 (14)⒌后记 (19)●现代汉语语料库加工手册——词语切分与词性标注⒈语料库加工的标记集及其说明 (20)⒉加工好的样例 (20)⒊若干个常用多类词的处理 (24)⒋词语切分和词性标注中的典型错例及分析 (28)⒌准谓宾动词示例 (41)⒍机器自动加工的样例及后校正注意事项 (42)⒎后记 (46)●附录:⒈按代码的字母顺序排列的标记集 (47)⒉按名称的汉语拼音顺序排列的标记集 (48)⒊参考文献 (49)现代汉语语料库加工规范——词语切分与词性标注1999年3月版北京大学计算语言学研究所1999年3月14日⒈前言北大计算语言学研究所从1992年开始进行汉语语料库的多级加工研究。
第一步是对原始语料进行切分和词性标注。
1994年制订了《现代汉语文本切分与词性标注规范V1.0》。
几年来已完成了约60万字语料的切分与标注,并在短语自动识别、树库构建等方向上进行了探索。
在积累了长期的实践经验之后,最近又进行了《人民日报》语料加工的实验。
为了保证大规模语料加工这一项重要的语言工程的顺利进行,北大计算语言学研究所于1998年10月制订了《现代汉语文本切分与词性标注规范V2.0》(征求意见稿)。
因这次加工的任务超出词语切分与词性标注的范围,故将新版的规范改名为《现代汉语语料库加工规范》。
制订《现代汉语语料库加工规范》的基本思路如下:⑴词语的切分规范尽可能同中国国家标准GB13715“信息处理用现代汉语分词规范”(以下简称为“分词规范”)保持一致。
由于现在词语切分与词性标注是结合起来进行的,而且又有了一部《现代汉语语法信息词典》(以下有时简称“语法信息词典”或“语法词典”)可作为词语切分与词性标注的基本参照,这就有必要对“分词规范”作必要的调整和补充。
(整理)现代汉语语料库加工规范词语切分与词性标注词
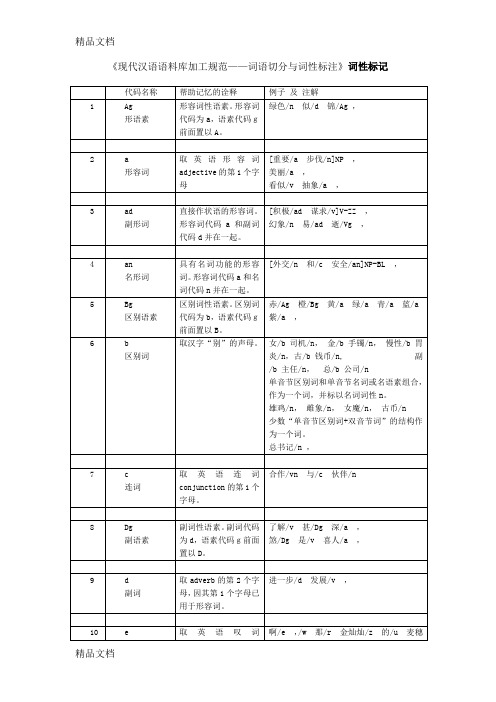
出/v过/u两/m天/q差/Ng,
疾病成本法和人力资本法将环境污染引起人体健康的经济损失分为直接经济损失和间接经济损失两部分。直接经济损失有:预防和医疗费用、死亡丧葬费;间接经济损失有:影响劳动工时造成的损失(包括病人和非医务人员护理、陪住费)。这种方法一般通常用在对环境有明显毒害作用的特大型项目。理/v了/u一/m次/q发/Ng,
一个/m ,一些/m ,
2.基数、序数、小数、分数、百分数一律不予切分,为一个切分单位,标注为m。
一百二十三/m,20万/m,123.54/m,一个/m,第一/m,第三十五/m,20%/m,三分之二/m,千分之三十/m,几十/m人/n,十几万/m元/q,第一百零一/m个/q ,
3.约数,前加副词、形容词或后加“来、多、左右”等助数词的应予分开。
岗位/n ,城市/n ,机会/n ,
[例题-2006年真题]下列关于建设项目环境影响评价实行分类管理的表述,正确的是( )她/r是/v责任/n编辑/n ,
(编辑/v科技/n文献/n )
21
nr人名
名词代码n和“人(ren)”的声母并在一起。
1.汉族人及与汉族起名方式相同的非汉族人的姓和名单独切分,并分别标注为nr。
张/nr仁伟/nr,欧阳/nr修/nr,阮/nr志雄/nr,朴/nr贞爱/nr
汉族人除有单姓和复姓外,还有双姓,即有的女子出嫁后,在原来的姓上加上丈夫的姓。如:陈方安生。这种情况切分、标注为:陈/nr方/nr安生/nr;唐姜氏,切分、标注为:唐/nr姜氏/nr。
2.姓名后的职务、职称或称呼要分开。
江/nr主席/n,小平/nr同志/n,江/nr总书记/n,张/nr教授/n,王/nr部长/n,陈/nr老总/n,李/nr大娘/n,刘/nr阿姨/n,龙/nr姑姑/n
现代汉语语料库加工规范词语切分与词性标注词

代码名称
帮助记忆的诠释
例子及注解
1
Ag
形语素
形容词性语素。形容词代码为a,语素代码g前面置以A。
绿色/n似/d锦/Ag,
2
a
形容词
取英语形容词adjective的第1个字母
[重要/a步伐/n]NP,
美丽/a,
看似/v抽象/a,
3
ad
副形词
直接作状语的形容词。形容词代码a和副词代码d并在一起。
3.专有名称后接多音节的名词,如“语言”、“文学”、“文化”、“方式”、“精神”等,失去专指性,则应分开。
欧洲/ns语言/n,法国/ns文学/n,西方/ns文化/n,贝多芬/nr交响乐/n,雷锋/nr精神/n,美国/ns方式/n,日本/ns料理/n,宋朝/t古董/n
4.商标(包括专名及后接的“牌”、“型”等)是专指的,标以nz,但其后所接的商品仍标以普通名词n。
二/m连/n, 三/m部/n ,
19
Ng名语素
名词性语素。名词代码为n,语素代码g前面置以N。
出/v过/u两/m天/q差/Ng,
理/v了/u一/m次/q发/Ng,
20
n名词
取英语名词noun的第1个字母。
(参见动词--v)
岗位/n ,城市/n ,机会/n ,
她/r是/v责任/n编辑/n ,(编辑/v科技/n文献/n )
克林顿/nr,叶利钦/nr,才旦卓玛/nr,小林多喜二/nr,北研二/nr,
华盛顿/nr,爱因斯坦/nr
有些西方人的姓名中有小圆点,也不分开。
卡尔·马克思/nr
22
ns地名
名词代码n和处所词代码s并在一起。
中文文本分词及词性标注自动校对方法研究

中文文本分词及词性标注自动校对方法研究【摘要】:语料库建设是中文信息处理研究的基础性工程。
汉语语料的基本加工过程,包括自动分词和词性标注两个阶段。
自动分词和词性标注在很多现实应用(中文文本的自动检索、过滤、分类及摘要,中文文本的自动校对,汉外机器翻译,汉字识别与汉语语音识别的后处理,汉语语音合成,以句子为单位的汉字键盘输入,汉字简繁体转换等)中都扮演着关键角色,为众多基于语料库的研究提供重要的资源和有力的支持。
语料库的有效利用在很大程度上依赖于语料库切分和标注的层次和质量。
当前对汉语语料的加工结果,虽已取得了一定的成绩,但国家的评测结果表明,其离实际需要的差距还是很大的,还有待于进一步的提高。
本文以进一步提高汉语语料库分词和词性标注的正确率,提高汉语语料的整体加工质量为目标,分别针对语料加工中的分词和词性标注两个阶段进行了研究和探讨:1.讨论和分析了自动分词的现状,并针对分词问题,提出了一种基于规则的中文文本分词自动校对方法。
该方法通过对机器分词语料和人工校对语料的学习,自动获取中文文本的分词校对规则,并应用规则对机器分词结果进行自动校对。
2.讨论和分析了词性标注的现状,并针对词性标注问题,提出了一种基于粗糙集的兼类词词性标注校对规则的自动获取方法。
该方法以大规模汉语语料为基础,利用粗糙集理论及方法为工具,挖掘兼类词词性标注校对规则,并应用规则对机器标注结果进行自动校对。
3.设计和实现了一个中文文本分词及词性标注自动校对实验系统,并分别做了封闭测试、开放测试及结果分析。
根据实验,分词校对封闭测试和开放测试的正确率分别为93.75%和81.05%;词性标注校对封闭测试和开放测试的正确率分别为90.40%和84.85%。
【关键词】:分词自动校对词性标注自动校对粗糙集中文信息处理语料库加工质量保证【学位授予单位】:山西大学【学位级别】:硕士【学位授予年份】:2003【分类号】:TP391.12【目录】:1引言8-141.1语料库加工及其意义81.2语料库加工现状及分析8-121.2.1机器自动加工现状8-101.2.2分词及词性标注校对现状10-121.3本论文的主要工作12-142基于规则的分词自动校对14-222.1问题提出142.2分词校对规则的自动获取14-182.2.1分词校对知识的获取及表示15-162.2.2分词校对规则的生成16-182.3分词自动校对18-212.3.1自动校对算法18-192.3.2机器学习19-212.4规则的评价及规则集维护21-223基于粗糙集的兼类词词性自动校对22-313.1问题提出223.2相关理论简介22-243.2.1知识表达系统及决策表22-233.2.2决策表的约简23-243.3构建词性校对决策表24-273.3.1词性校对决策表的建立24-253.3.2词性校对决策表属性的约简25-273.4词性校对规则集的生成27-293.4.1规则一致化27-283.4.2规则集的评价及优化28-293.5词性自动校对29-314中文文本分词及词性标注自动校对实验系统31-404.1中文文本分词自动校对系统31-344.1.1中文文本分词自动校对系统结构31-324.1.2各模块主要功能32-334.1.3测试结果及分析33-344.2中文文本词性标注自动校对系统34-404.2.1中文文本词性标注自动校对系统结构34-354.2.2各模块主要功能35-364.2.3测试结果及分析36-405结束语40-41致谢41-42参考文献42-44 本论文购买请联系页眉网站。
对外汉语教学中的词类划分

对外汉语教学中的词类划分本文运用语料库的研究方法,对对外汉语教材《博雅汉语》中级冲刺篇中动词、名词、形容词的使用情况进行了调查研究,通过统计数据我们发现,其中部分动词和形容词具有名词用法。
但是,在词典和教材生词表上并未将这些动词和形容词归入兼类词,也未标明其具有名词用法。
本文试图通过描述这些动词、形容词的分布状态概括出其共性。
标签:语料库词类活用词的兼类引言语料库是指存放在计算机里的原始语料文本或经过加工后带有语言学信息标注的文本。
语料库语言学是基于语料库提供的语言材料展开的语言研究。
近年来,随着计算机语言学和语料库语言学的发展,越来越多的人通过语料库所提供的语料进行汉语研究。
本文通过建立一个小型的对外汉语教材语料库,对其中的动词、名词、形容词的使用进行分类统计,从而为对外汉语中的词汇教学提供一些切实可行的建议。
一、语料库建设语料库素材:北大出版社《博雅汉语》中级上下两册,适用于已经基本掌握了基础语言知识和交际功能的学习者。
其中上册12课,下册10课,不包括标点在内共有53504字次,2044字;共有34530词次,4829词。
平均每篇课文2432字,1569词。
该语料库从2006年3月开始录入文本到6月完成词性标注及校对,历时三个月,实际总共耗时60小时左右。
词类标记:本语料库采取“973当代汉语文本语料库分词、词性标注加工规范”“北京大学现代汉语语料库基本加工规范”在实际操作中以前者为主,并采用后者中动词和形容词的特殊用法标记。
将这些特殊用法标注出来可以为词的兼类研究提供计量依据,主要词类标记如下:注:碍于语料和精力有限,本文集中考察动词和形容词的名词用法在语料库中的分布情况。
二、标注标准计算机对语料进行自动分词和标注词性后,人工校对的过程中发现了部分动词和形容词的词性标注存在问题。
即部分词性并不符合其在具体句子中的语法功能。
所以,作者在校对中根据实际情况增加了动词的名词用法(vn)和形容词的名词用法(an)两类。
大规模中文文本语料库分词与词性标注一致性检验技术研究-山西大学

大规模中文文本语料库分词与词性标注一致性检验技术研究基本信息批准号60473139项目名称大规模中文文本语料库分词与词性标注一致性检验技术研究项目类别面上项目申请代码F020603项目负责人郑家恒负责人职称教授依托单位山西大学研究期限2005-01-01 到 2007-12-31资助经费23(万元)项目摘要中文摘要目前,在机器翻译、语音识别、信息检索等应用系统的开发中,广泛地使用语料库。
建设高质量的大规模语料库是中文信息处理领域的基础性工程。
由于自动分词和词性标注的正确率达不到百分之百;人工校对语料时,校对者对分词单位和词性标注认识上存在着差异,造成语料加工结果不一致现象的存在。
因此,研究语料库一致性检验技术是十分必要的,它不仅可以保证语料库加工的质量,也可以提高语料库加工的自动化程度,减轻人工校对的工作量。
课题研究的内容有:研究语料库加工规范的分词模式、词性标注模式的形式和生成;一致性检验模式库的构建、维护、优化策略,模式的选择,模式匹配条件的确定;建立组合型歧义字段语言环境和兼类词语言环境模型;应用基于范例推理、粗糙集、分类、聚类和模式识别技术,获取分词与词性标注一致性检验知识库,研究一致性检验算法;开发分词与词性标注一致性检验软件,为建设高质量的大规模语料库提供有力的保证。
中文主题词分词一致性;词性标注一致性;语言环境模型;语料加工规范模式英文摘要英文主题词consistency of segmentation;co结题摘要建设高质量的大规模语料库是中文信息处理领域的基础性工程,也是很多相关应用领域进行更深层次研究的根本保证。
由于自动分词和词性标注的正确率达不到百分之百;人工校对语料时,校对者对分词单位和词性标注认识上存在着差异,造成语料加工结果不一致现象的存在。
因此,研究语料库一致性检验技术是十分必要的,它不仅可以保证语料库加工的质量,也可以提高语料库加工的自动化程度,减轻人工校对的工作量。
试析中文分词国家规范

试析中文分词国家规范许顺吕强(苏州大学计算机科学与技术学院,江苏省计算机信息处理技术重点实验室,江苏苏州215006)摘要:中文自动分词是计算机中文信息处理的基础难题,而分词标准又是中文自动分词的首要问题。
中文分词规范提出了切分单位的概念,定义了中文信息处理的一系列分词规则。
而目前的分词研究对分词规范的作用重视不够。
本文首先强调了分词规范应该成为分词问题本身的标准描述。
然后本文详细分析了中文分词国家分词规范的完备性和一致性,论述了相应的不够完善的地方。
最后总结了应用国家分词规范的重要意义,提出分词规范还需要进一步研究。
关键词:中文分词规范,中文自动分词,完备性,一致性中图法分类号:TP391Towards Chinese Word Segmentation SpecificationXu Shun Lv Qiang(School of Computer Science and Technology, Suzhou University)( Jiangsu Key Laboratory of Information Processing Technology)Suzhou, 215006, ChinaAbstract:Chinese automatic segmentation is a fundamental hard problem in Chinese information processing (CIP). And segmentation standard is the principal problem in Chinese automatic segmentation. Chinese word segmentation specification has proposed the definition of segmentation unit and some rules for Chinese segmentation, while the current research has a little bit underestimated the importance of this specification. Firstly this paper emphasizes that the segmentation specification should be the only answer of the question what is the segmentation problem. Secondly this paper analyzes the completeness and consistency of the National Chinese Language Word Segmentation Specification for Information Processing, and points out the related flaw. Finally the authors summarize the importance of application of the segmentation specification, and strongly propose that the research on the segmentation specification should be investigated furthermore.Keywords: Chinese segmentation specification, automatic segmentation, completeness, consistency1问题的提出随着计算机技术日新月异的发展,中文信息处理的应用更加广泛,例如语音识别,信息检索,文本分类,自然语言的理解和机器翻译等。
国家语委现代汉语通用平衡语料库 标注语料库数据及使用说明

国家语委现代汉语通用平衡语料库标注语料库数据及使用说明肖航教育部语言文字应用研究所1. 国家语委现代汉语通用平衡语料库1.1 语料库全库国家语委现代汉语通用平衡语料库全库约为1亿字符,其中1997年以前的语料约7000万字符,均为手工录入印刷版语料;1997之后的语料约为3000万字符,手工录入和取自电子文本各半。
语料库的通用性和平衡性通过语料样本的广泛分布和比例控制实现。
语料库类别分布如下所示:1.2 标注语料库标注语料库为国家语委现代汉语通用平衡语料库全库的子集,约5000万字符。
标注是指分词和词类标注,已经经过3次人工校对,准确率大于>98%。
语料库全库按照预先设计的选材原则进行平衡抽样,以期达到更好的代表性。
标注语料库在样本分布方面近似于全库,不破坏语料选材的平衡原则。
标注语料库类别分布如下所示:标注语料库与全库的样本分布比较如下所示:(蓝色曲线为语料库全库;红色曲线为标注语料库)2. 国家语委现代汉语通用平衡语料库语料选材与样本分布2.1 选材原则依据材料内容,选材大体作如下分类:(下文字数为建库时数据)2.1.1 教材大中小学教材单作一类,约2000万字。
2.1.2 人文与社会科学的语言材料约占全库的60%,共3000万字,包括:·政法(含哲学、政治、宗教、法律等);·历史(含民族等)·社会(含社会学、心理、语言、教育、文艺理论、新闻学、民俗学等);·经济;·艺术(含音乐、美术、舞蹈、戏剧等);·文学(含口语);·军体;·生活(含衣食住行等方面的普及读物)。
2.1.3 自然科学(含农业、医学、工程与技术)的语言材料,应涉及其发展的各个领域。
拟从大、中、小学教材和科普读物中选取。
其中,科普读物约占6%,共300万字。
教材字数另计。
2.1.4 报刊。
以1949年以后正式出版的由国家、省、市及各个部委主办的报纸和综合性刊物为主,兼顾1949年以前的报纸和综合性刊物。
现代汉语语料库加工中的切词与词性标注处理

现代汉语语料库加工中的切词与词性标注处理周强, 段惠明北京大学计算语言学研究所北京,100871目前,大规模真实文本处理已成为计算语言学界的一个热门话题。
一个重要的原因是因为它给我们提供了一种新的研究思路,即从大规模的语料库中提取所需要的知识。
而汉语语料库的加工和处理,又涉及到汉语语法研究的许多问题,如:词的定义,词类的划分,短语的确定等等。
在这方面,我们进行了一些探索,积累了一些经验。
本文只讨论切词与词性标注问题。
1. 汉语语料库的多级加工总结国内外语料库建设的经验,可以看到:一个计算机语料库的功能主要和下面三种因素密切相关,即库的规模、语料分布和语料的加工深度。
因为库容量的大小直接影响到统计结果的可靠性,语料分布的考虑则关系到统计结果的适用范围,而加工深度则决定了该语料库能为自然语言处理提供什么样的知识。
对于汉语语料库的处理,可以设想有以下几个阶段,如图1所示[5]。
这样,经过不同阶段的处理,语料库所携带的各类消息也不断增加,最终将成为一个名副其实的语言知识库。
这样的知识库可以为汉语统计分析、汉语理解和机器翻译提供重要的资源和有力的支持。
┌────┐┌────┐┌────┐┌────┐│"生图 1 库存语料的加工顺序2. 关于切词和标注结合处理的规范从92年初开始, 北大计算语言学研究所开始进行汉语语料库的多级加工处理的研究,其第一步工作是对原始语料进行切分和词性标注, 并且我们是将切词和标注结合起来进行的。
通过使用一个带词类标记的切词词典, 在自动切词的同时, 给每个切分单位标上初始词性标记, 然后通过规则与统计相结合的方法排歧, 实现词类的自动标注, 再利用构词规则, 发现一些符合汉语构词规律的未定义词并确定其词类。
[6]以上工作的基础是“信息处理用现代汉语分词规范”[1](下简称为“分词规范”)、现代汉语词语分类体系[2]、汉语构词法理论[3]和现代汉语语法电子词典[4]。
在对约40万字语料的切分与标注的实践基础上, 我们发现了一些新的处理规律, 积累了许多有益的经验。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
973当代汉语文本语料库分词、词性标注加工规范(草案)山西大学从1988年开始进行汉语语料库的深加工研究,首先是对原始语料进行切分和词性标注,1992年制定了《信息处理用现代汉语文本分词规范》。
经过多年研究和修改,2000年又制定出《现代汉语语料库文本分词规范》和《现代汉语语料库文本词性体系》。
这次承担973任务后制定出本规范。
本规范主要吸收了语言学家的研究成果,并兼顾各家的词性分类体系,是一套从信息处理的实际要求出发的当代汉语文本加工规范。
本加工规范适用于汉语信息处理领域,具有开放性和灵活性,以便适用于不同的中文信息处理系统。
《973当代汉语文本语料库分词、词性标注加工规范》是根据以下资料提出的。
1.《信息处理用现代汉语分词规范》,中国国家标准GB13715,1992年2.《信息处理用现代汉语词类标记规范》,中华人民共和国教育部、国家语言文字工作委员会2003年发布3.《现代汉语语料库文本分词规范》(Ver 3.0),1998年北京语言文化大学语言信息处理研究所清华大学计算机科学与技术系4.《现代汉语语料库加工规范——词语切分与词性标注》,1999年北京大学计算语言学研究所5.《信息处理用现代汉语词类标记规范》,2002年,教育部语言文字应用研究所计算语言学研究室6.《现代汉语语料库文本分词规范说明》,2000年山西大学计算机科学系山西大学计算机应用研究所7.《資讯处理用中文分词标准》,1996年,台湾计算语言学学会一、分词总则1.词语的切分规范尽可能同中国国家标准GB13715《信息处理用现代汉语分词规范》(以下简称为“分词规范”)保持一致。
本规范规定了对现代汉语真实文本(语料库)进行分词的原则及规则。
追求分词后语料的一致性(consistency)是本规范的目标之一。
2.本规范中的“分词单位”主要是词,也包括了一部分结合紧密、使用稳定的词组以及在某些特殊情况下可能出现在切分序列中的孤立的语素或非语素字。
本文中仍用“词”来称谓“分词单位”。
3.分词中充分考虑形式与意义的统一。
形式上要看一个结构体的组成成分能否单用,结构体能否扩展,组成成分的结构关系,以及结构体的音节结构;意义上要看结构体的整体意义是否具有组合性。
4. 本规范规定的分词原则及规则,既要适应语言信息处理与语料库语言学研究的需要,又力求与传统的语言学研究成果保持一致;既要适合计算机自动处理,又要便于人工校对。
5.分词时遵循从大到小的原则逐层顺序切分。
一时难以判定是否切分的结构体,暂不切分。
二、词性标注总则信息处理用现代汉语词性标注主要原则有三个:(1)语法功能原则。
语法功能是词类划分的主要依据。
词的意义不作为划分词类的主要依据,但有时也起着某些参考作用。
(2)允许有兼类。
根据各种统计研究,现代汉语的某些词具有多种语法功能,但这多种功能的分布概率不同。
在信息处理用现代汉语词类体系中,各词类的确立要根据词的主要语法功能。
(3)词类加工规范的标记集中的大类应能覆盖现代汉语的全部词。
为满足计算机处理真实文本词类标注的需要,本规范所定义的标记集,覆盖了比词小的单位,如前接成分(前缀)、后接成分(后缀)、语素字、非语素字等;比词更大的单位,如习用语、简称和略语,以及标点符号、非汉字符号等。
三、词类标记集本规范的词类标记集采用《信息处理用现代汉语词类标记规范》的大类,只增加了部分细类。
本规范的词类标记集规定,每个分词单位的标记由英文字母串构成。
标记的第一位代码,表示信息处理用现代汉语词类的基本词类,共20类,标记的第二、三位代码,表示信息处理用现代汉语基本词类下的细类。
词类分别为:(1)名词n:普通名词(n)时间名词(nt)方位名词(nd)处所名词(nl)人名(nh)汉族或类汉族人名(人名 nhh:姓nhf, 名nhg)音译名或类音译名(nhy)日本人名(nhr)其他(nhw):如绰号,笔名,尊称等。
地名(ns)族名(nn)团体机构名(ni)其他专有名词(nz)(2)动词v:普通动词(v)能愿动词(vu)趋向动词(vd)系动词(vl)(3)形容词:性质形容词(aq)状态形容词(as)(4)区别词f(5)数词m(6)量词q(7)副词d(8)代词r(9)介词p(10)连词c(11)助词u(12)叹词e(13)拟声词o(14)习用语i名词性习用语(in)动词性习用语(iv)形容词性习用语 (ia)连词性习用语(ic)(15)简称和略语j名词性简称和略语 jn动词性简称和略语 jv形容词性简称和略语 ja(16)前接成分h(17)后接成分k(18)语素字g(19)非语素字x(20)其它w:标点符号 (wp)非汉字字符串(ws)其他未知的符号(wu)四、细则1.本规范参照 GB/T 13715-92的做法,以词类为纲对各类单位作具体切分与词性标注规定。
2.本次加工规定,凡是收入词表中的词语,不再遵循本规范进行切分。
所使用词表的收词原则遵从清华大学《信息处理用现代汉语分词词表》规范。
3.独立性较强的语素字均标注词类,减少语素字标记的比例。
4.大类与细类可兼类。
五、分词与词性标注的详细说明1.名词(n)表示人和事物的名称或时间、处所等,在句中主要充当主语和宾语。
1.l 普通名词(n)表示人和事物的名称1.1.l 合成式[1] 并列关系凡是使用稳定、结合紧密的二字并列关系名词一律为分词单位。
如:省市/n 房屋/n 资金/n其余双音节的只要能扩展,则可切分。
三音节以上的结构体能扩展的应切分。
例如:省/n市/n县/n[2] 定中关系A.[名十名]对2至4音节组合,如其中一部分音节长度为1,一般来说,整体不切分。
例如:阵营/n 风波/n 法人/n 饭店/n大气层/n 火车站/n 州政府/n凤仙花汁/n 芭蕾舞裙/n对两部分音节长度都大于或等于2的组合,如中间能加“的”且意义不变的切开,否则不切分。
例如:中国/ns 公民/n 软件/n 程序/n 文件/n精神/n知识产权/n 技术人员/n 航空母舰/n 绿色食品/n 集团公司/n5音节以上的组合原则上切开。
例如:律师/n 资格/n 获得者/n 超线程/n 技术/nB.[动十名]对2至4音节组合,构成动宾式合成词时,如其中一部分音节长度为1,则整体不切分。
例如:编号/n 贷款/n 报表/n代名词/n 承包商/n 负责人/n 影响力/n说明:“动+名”如为述宾结构的短语,应切分开。
如:看/v 电影/n 洗/v 衣服/n 买/v 东西/n但有些结合紧密或使用稳定的述宾结构已在词典中登录,则处理成一个切分单位,标注为动词v,如:吃饭/v 跳舞/v 唱歌/v。
对两部分音节长度都大于或等于2的组合,如中间能加“的”且意义不变的切开,否则不切分。
如:等待/v时间/n 设计/v方案/n 生产关系/nC.[形十名]以下几种情况不切分,整体标注名词,其余情况切分。
a.形容词反映的是名词所指事物的典型属性,如:咸盐/n 白雪/n 蓝天/n 绿叶/n 白兔/n 红花/n 绿草/n 冷水/n 低价/nb.形容词具有分类作用而不是临时指别作用,如:体细胞/n 小桥/n 矮个子/nc.形容词与名词的组合有一定象征意义。
如:红旗/nd.形容词与名词的切分意义发生了变化。
如:黑市/n 软盘/n 白菜/n 冷门/n 小金库/n 多媒体/nD.[量十名]双音节的不切分,整体标注为n。
如:度数/n 天数/n 个数/n 页数/n 种数/n 次数/n三音节以上的切分,量词与名词分别标注。
例如:亩/q 产量/n 公里/q数/nE. [数十名]a.表序数的一般要切分,数词与名词分别标注。
例如:五/m楼/n 三/m厂/nb.省略量词的组合,整体不作为分词单位,分别标注。
如:两/m 脚/n 都/d 是/v 泥/nc.其余的组合,不切分,标注为n。
例如:半岛/n 半球/n 二心/n 六指儿/n 两头/n[3] 主谓关系结构体在上下文中呈体词性时,无论音节多少,均不切分, 标注为n。
例如:癌变/n 海啸/n 脑溢血/n1.1.2 附加式附加式包括如下几部分构词形式[1] 前接成分十语素或词[2] 语素或词+后接成分[3] 前接成分+语素或词+后接成分这类名词的切分和标注规则见前后接成分。
1.1.3 重叠式。
不切分。
例如:人人/n 家家/n 山山水水/n 方方面面/n1.1.4明显带排行的亲属称谓不切开。
三哥/n 大婶/n 大女儿/n 大哥/n 小弟/n 老爸/n1.1.5专业术语[1] 专业术语四音节以下(含四音节)的一般不切分,标注n,四音节以上的按词切分。
例如:不定积分/n 氯胺酮/n 汇编语言/n 生物化学/n 多/a弹头/n导弹/n[2] 食谱上的菜名一般不切分,标注n。
八宝粥/n 霉干菜/n 松鼠鳜鱼/n 红烧肉/n,鸡蛋汤/n 芝麻饼/n 鸡丝面/n1.2 时间名词 (nt)表示时间。
[1] 一周的七天,农历的初一到初十,“(大)年初一”到“(大)年初十”不切分。
例:星期一/nt 初三/nt 年初二/nt 大年初一/nt[2] 年月日时分秒,按年、月、日、时、分、秒切分,标注为nt 。
1997/m 年/nt 3/m 月/nt 19/m 日/nt,下午/nt 2/m 时/nt 18/m 分/nt 35/m 秒/nt[3] 朝代名不切分,标注为nt。
例如:唐朝/nt 南北朝/nt 清代 /nt[4] 著名的节日名,不切分, 标注为nt。
例如:春节/nt 圣诞节/nt 国庆节/nt 复活节/nt 三八妇女节/nt “六一”儿童节/nt[5]“前、后、上、下、大前、大后、头”加“天”或“上/下”加“月/周/星期”时,不切分,标注为nt。
例如:前天/nt 大前天/nt 头天/nt 上周/nt 上月/nt 下星期/nt 但是中间加数词或量词时切开。
例如:前/nd几/m天/nt 上/nd半/m年/nt 上/nd 个/q月/nt 下/nd个/q 星期/nt[6] “点钟、分钟、秒钟、刻钟”不切分, 标注为nt:一/m点钟/nt 十/m秒钟/nt[7] “年间”不切分。
例如:乾隆/nhh 年间/nt 战乱/j 年间/nt[8] “年终、此间、公元前、前不久”均不切分,标注为nt。
[9] 十二生宵表示的年不切分,标注为nt。
例如:牛年/nt 虎年/nt[10] 以天干、地支表示的年不切分,标注为nt。
例如:甲午年/nt、庚子/nt、戊戌/nt[11] 二十四节气不切分,标注nt。
例如:春分/nt 惊蛰/nt[12] 数字与“:”或“-”结合在一起的表示具体时间的串,整体标注nt。
如:08:35:28/nt 2003-03-29/nt1.3 方位名词(nd)表示位置、时间、数的相对方向或范围的词语。
方位词分为单纯方位词和合成方位词两种,一般来说,方位词和名词组合后(方位结构),构成处所词或时间词。