HIVE结构解析_第二章阅读
Hive入门

Hive⼊门第⼀章 Hive 基本概念1.1 什么是 HiveApache Hive是⼀款建⽴在Hadoop之上的开源数据仓库系统,可以将存储在Hadoop⽂件中的结构化、半结构化数据⽂件映射为⼀张数据库表,基于表提供了⼀种类似SQL的查询模型,称为Hive查询语⾔(HQL),⽤于访问和分析存储在Hadoop⽂件中的⼤型数据集。
Hive核⼼是将HQL转换为MapReduce程序,然后将程序提交到Hadoop群集执⾏。
Hive由Facebook实现并开源。
1.2 为什么使⽤Hive使⽤Hadoop MapReduce直接处理数据所⾯临的问题⼈员学习成本太⾼需要掌握java语⾔MapReduce实现复杂查询逻辑开发难度太⼤使⽤Hive处理数据的好处操作接⼝采⽤类SQL语法,提供快速开发的能⼒(简单、容易上⼿)避免直接写MapReduce,减少开发⼈员的学习成本⽀持⾃定义函数,功能扩展很⽅便背靠Hadoop,擅长存储分析海量数据集1.3 Hive与Hadoop的关系从功能来说,数据仓库软件,⾄少需要具备下述两种能⼒:存储数据的能⼒分析数据的能⼒Apache Hive作为⼀款⼤数据时代的数据仓库软件,当然也具备上述两种能⼒。
只不过Hive并不是⾃⼰实现了上述两种能⼒,⽽是借助Hadoop。
Hive利⽤HDFS存储数据,利⽤MapReduce查询分析数据。
这样突然发现Hive没啥⽤,不过是套壳Hadoop罢了。
其实不然,Hive的最⼤的魅⼒在于⽤户专注于编写HQL,Hive帮您转换成为MapReduce程序完成对数据的分析。
1.4 Hive与MysqlHive虽然具有RDBMS数据库的外表,包括数据模型、SQL语法都⼗分相似,但应⽤场景却完全不同。
Hive只适合⽤来做海量数据的离线分析。
Hive的定位是数据仓库,⾯向分析的OLAP系统。
因此时刻告诉⾃⼰,Hive不是⼤型数据库,也不是要取代Mysql承担业务数据处理。
Hive基础ppt课件

Sets the value of a particular configuration variable (key). Note: If you misspell the variable name, the CLI will not show an error.
group:进行聚合 order by:全局排序,一个reduce
sort by:单机排序,多个reduce DISTRIBUTE BY:按照指定的字段对数据进行划分到不
同的输出reduce / 文件中。与sort by配合使用,避免数 据的重叠和丢失 CLUSTER BY:等于Distribute By + Sort By,倒序排序
解析用户提交hive语句,对其进行 解析,分解为表、字段、分区等 hive对象
根据解析到的信息构建对应的表、 字段、分区等对象,从 SEQUENCE_TABLE中获取构建对 象的最新ID,与构建对象信息(名称 ,类型等)一同写入到元数据表中去 ,成功后将SEQUENCE_TABLE中 对应的最新ID+5。
语句 转换
解析器:生成抽象语法树 语法分析器:验证查询语句 逻辑计划生成器(包括优化器):生成操作符树 查询计划生成器:转换为map-reduce任务
数据 存储
Hive数据以文件形式存储在HDFS的指定目录下 Hive语句生成查询计划,由MapReduce调用执行
Page 2
Hive元数据
Hive VS RDBMS
Hive 的内容是读多写少的因此 ,不支持对数据的改写和删除 ,数据都是在加载的时候中确 定好的
Hive(二)hive的基本操作

Hive(⼆)hive的基本操作⼀、DDL操作(定义操作)1、创建表(1)建表语法结构CREATE [EXTERNAL] TABLE [IF NOT EXISTS] table_name[(col_name data_type [COMMENT col_comment], ...)] //字段注释[COMMENT table_comment] //表的注释[PARTITIONED BY (col_name data_type [COMMENT col_comment], ...)] //分区,前⾯没有出现的字段[CLUSTERED BY (col_name, col_name, ...) //分桶,前⾯出现的字段[SORTED BY (col_name [ASC|DESC], ...)] INTO num_buckets BUCKETS][ROW FORMAT row_format][STORED AS file_format][LOCATION hdfs_path]分区:不⽤关注数据的具体类型,放⼊每⼀个分区⾥;分桶:调⽤哈希函数取模的⽅式进⾏分桶(2)建表语句相关解释create table:创建⼀个指定名字的表。
如果相同名字的表已经存在,则抛出异常;⽤户可以⽤ IF NOT EXISTS 选项来忽略这个异常。
external :关键字可以让⽤户创建⼀个外部表,在建表的同时指定⼀个指向实际数据的路径( LOCATION), Hive 创建内部表时,会将数据移动到数据仓库指向的路径;若创建外部表,仅记录数据所在的路径,不对数据的位置做任何改变。
在删除表的时候,内部表的元数据和数据会被⼀起删除,⽽外部表只删除元数据,不删除数据。
(经典⾯试问题)partitioned :在 Hive Select 查询中⼀般会扫描整个表内容,会消耗很多时间做没必要的⼯作。
有时候只需要扫描表中关⼼的⼀部分数据,因此建表时引⼊了 partition 概念。
(完整word版)HIVE说明文档

HIVE说明文档一、HIVE简介:1、HIVE介绍Hive是一个基于Hadoop的开源数据仓库工具,用于存储和处理海量结构化数据。
它是Facebook 2008年8月开源的一个数据仓库框架,提供了类似于SQL语法的HQL语句作为数据访问接口。
Hive 是基于Hadoop 构建的一套数据仓库分析系统,它提供了丰富的SQL查询方式来分析存储在Hadoop 分布式文件系统中的数据,可以将结构化的数据文件映射为一张数据库表,并提供完整的SQL查询功能,可以将SQL语句转换为MapReduce任务进行运行,通过自己的SQL 去查询分析需要的内容,这套SQL 简称Hive SQL,使不熟悉mapreduce 的用户很方便的利用SQL 语言查询,汇总,分析数据.2、HIVE适用性:它与关系型数据库的SQL 略有不同,但支持了绝大多数的语句如DDL、DML 以及常见的聚合函数、连接查询、条件查询。
HIVE不适合用于联机(online)事务处理,也不提供实时查询功能。
它最适合应用在基于大量不可变数据的批处理作业。
HIVE的特点:可伸缩(在Hadoop的集群上动态的添加设备),可扩展,容错,输入格式的松散耦合.hive不支持用insert语句一条一条的进行插入操作,也不支持update操作。
数据是以load的方式加载到建立好的表中。
数据一旦导入就不可以修改。
DML包括:INSERT插入、UPDATE更新、DELETE删除。
3、HIVE结构Hive 是建立在Hadoop上的数据基础架构,它提供了一系列的工具,可以用来进行数据提取转化加载(ETL),这是一种可以存储、查询和分析存储在Hadoop中的大规模数据的机制,Hive定义了简单的累SQL 查询语言,称为HQL,它允许熟悉SQL的用户查询数据,同时,这个语言也允许熟悉MapReduce开发者的开发自定义的mapper和reducer来处理內建的mapper和reducer无法完成的复杂的分析工作。
Hive入门基础知识

HDFS下对 应存储目 录:
第21页,共55页。
Hive开发使用-Hive的数据模型
外部表
外部表指向已经在HDFS中存在的数据,可以创建Partition。它和内部表在元 数据的组织上是相同的,而实际数据的存储则有较大的差异。内部表的创建过程 和数据加载过程这两个过程可以分别独立完成,也可以在同一个语句中完成,在 加载数据的过程中,实际数据会被移动到数据仓库目录中;之后对数据访问将会 直接在数据仓库目录中完成。删除表时,表中的数据和元数据将会被同时删除。 而外部表只有一个过程,加载数据和创建表同时完成(CREATE EXTERNAL TABLE ……LOCATION),实际数据是存储在LOCATION后面指定的 HDFS 路径 中,并不会移动到数据仓库目录中。当删除一个External Table时,仅删除该链 接。
第22页,共55页。
Hive开发使用-Hive的数据模型
如何选择使用内部表或外部表?
如果所有处理都由hive来完成,则使用内部表
如果需要用hive和外部其他工具处理同一组数据集,则使用外部表。
第23页,共55页。
Hive开发使用-Hive的数据模型
分区
Partition对应于关系数据库中的Partition列的密集索引,但是Hive中 Partition的组织方式和数据库中的很不相同。在Hive中,表中的一个 Partition对应于表下的一个目录,所有的Partition的数据都存储在对应的目 录中。例如pvs表中包含ds和city两个Partition,则
序,可以通过指定的主机和端口连接 到在另一个进程中运行的hive服务 器
ODBC客户端:ODBC驱动允许支持
ODBC协议的应用程序连接到Hive
hive之基本架构
hive之基本架构什么是Hive hive是建⽴在Hadoop体系架构上的⼀层SQL抽象,使得数据相关⼈员是⽤他们最为熟悉的SQL语⾔就可以进⾏海量的数据的处理、分析和统计⼯作,⽽不是必须掌握JAVA等变成语⾔和具备开发MapReduce程序的能⼒。
Hive SQL实际上是先被SQL解析器进⾏解析然后被Hive框架解析成⼀个MapReduce可执⾏的计划,并且按照该计划⽣成MapReduce任务后交给Hadoop集群处理。
由于Hive SQL 是翻译为MapReduce任务后在Hadoop集群执⾏的,⽽Hadoop是⼀个批处理系统,所以Hive SQL是⾼延迟的,不但翻译成的MapReduce任务执⾏延迟⾼,⽽且任务的提交和处理过程也是⾮常的耗时。
因此,Hive即使处理的数据量⾮常的⼩,在执⾏的过程中也会有⼀定的延迟现象。
同时,Hive不能提供数据排序和查询缓存功能,也不提供在线事务处理,更不提供实时查询和记录的更新,因为HIVE本⾝被定义为处理⼤规模的离线数据集。
如果需要实现实时查询或记录的更新,HBASE是⼀个不错的选择。
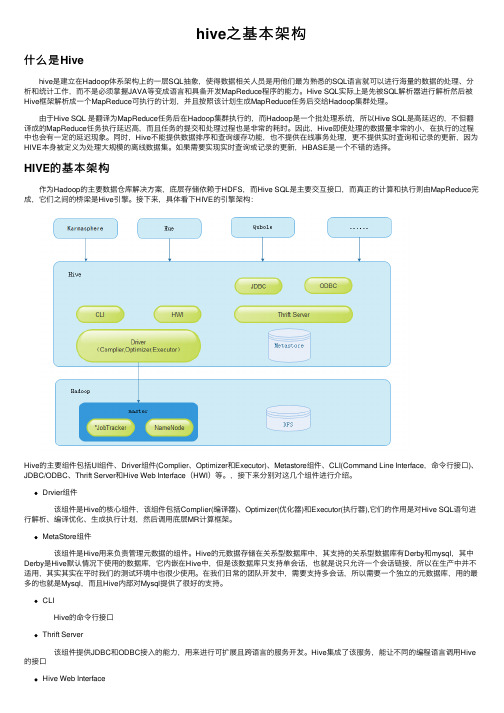
HIVE的基本架构 作为Hadoop的主要数据仓库解决⽅案,底层存储依赖于HDFS,⽽Hive SQL是主要交互接⼝,⽽真正的计算和执⾏则由MapReduce完成,它们之间的桥梁是Hive引擎。
接下来,具体看下HIVE的引擎架构:Hive的主要组件包括UI组件、Driver组件(Complier、Optimizer和Executor)、Metastore组件、CLI(Command Line Interface,命令⾏接⼝)、JDBC/ODBC、Thrift Server和Hive Web Interface(HWI)等。
,接下来分别对这⼏个组件进⾏介绍。
Drvier组件 该组件是Hive的核⼼组件,该组件包括Complier(编译器)、Optimizer(优化器)和Executor(执⾏器),它们的作⽤是对Hive SQL语句进⾏解析、编译优化、⽣成执⾏计划,然后调⽤底层MR计算框架。
【八斗学院】8.2Hive数据模型详解

Hive数据模型详解来源:八斗学院1)Hive数据库类似传统数据库的DataBase,例如 hive >create database test_database;2)内部表Hive的内部表与数据库中的表在概念上是类似。
每一个Table在Hive中都有一个相应的目录存储数据。
例如一个表hive_test,它在HDFS中的路径为/home/hdp_lbg_ectech/warehouse/hdp_lbg_ectech_bdw.db/hive_test,其中/home/hdp_lbg_ectech/warehouse是在hive-site.xml中由${hive.metastore.warehouse.dir}指定的数据仓库的目录,所有的Table数据(不包括外部表)都保存在这个目录中。
删除表时,元数据与数据都会被删除。
建表语句示例:CREATE EXTERNAL TABLE hdp_lbg_ectech_bdw.hive_test(`userid` string COMMENT'')ROW FORMAT DELIMITED FIELDS TERMINATED BY'\001';load data inpath ‘/home/hdp_lbg_ectech/resultdata/test.txt’overwrite into table hive_test;3)外部表外部表指向已经在HDFS中存在的数据,可以创建分区。
它和内部表在元数据的组织上是相同的,而实际数据的存储则有较大的差异。
内部表在加载数据的过程中,实际数据会被移动到数据仓库目录中。
删除表时,表中的数据和元数据将会被同时删除。
而外部表只有一个过程,加载数据和创建表同时完成(CREATE EXTERNAL TABLE ……LOCATION),实际数据是存储在LOCATION后面指定的 HDFS 路径中,并不会移动到数据仓库目录中。
hive 逻辑语法树解析

hive 逻辑语法树解析Hive是一个基于Hadoop的数据仓库基础架构。
它提供了类似于SQL的查询语言,称为Hive Query Language(HQL),用于处理结构化数据。
在Hive中,逻辑语法树是执行HQL查询的重要步骤之一。
本文将介绍Hive逻辑语法树的解析过程,以帮助读者更好地理解和使用Hive。
1. Hive的逻辑语法树概述Hive的逻辑语法树是将HQL查询转换为逻辑查询计划的过程。
逻辑查询计划是一个抽象的、与具体执行引擎无关的中间表示形式。
通过构建逻辑语法树,Hive可以对查询进行优化,并生成可执行的物理查询计划。
因此,了解Hive逻辑语法树的解析过程对于理解Hive的查询执行过程至关重要。
Hive的逻辑语法树解析可以分为以下几个步骤:2.1 解析和词法分析在Hive中,查询语句首先会经过解析器和词法分析器的处理。
解析器负责解析HQL查询语句,将其转换为一系列的词法单元。
词法分析器则负责将这些词法单元进行识别和分类,为后续的语法分析做准备。
2.2 语法分析语法分析的主要目标是验证查询语句的语法正确性,并将其转换为逻辑语法树。
语法分析器会根据Hive查询语言的语法规则,生成一棵由不同节点组成的树形结构。
每个节点代表查询语句中的一个语法要素,如SELECT、FROM、WHERE等。
这些节点之间的关系描述了查询语句的结构和层次关系。
2.3 语义分析语义分析的目标是验证查询语句的语义正确性,并对其进行一些语义的补全和优化。
在语义分析阶段,Hive会检查表的引用、列的引用、数据类型的一致性等方面的语义问题,并进行必要的预处理。
例如,如果查询语句中引用了不存在的表或列名,Hive会报错并提示用户进行修正。
2.4 逻辑优化在完成语义分析之后,Hive会进行一系列的逻辑优化操作,以提高查询的执行效率。
逻辑优化的具体内容包括冗余列消除、谓词下推、连接顺序的优化等。
这些优化操作主要针对逻辑语法树进行,是为了生成更加高效的物理查询计划。
hive concatenate底层原理

hive concatenate底层原理Hive Concatenate的底层原理一、引言Hive是一个基于Hadoop的数据仓库基础设施,它提供了一种将结构化数据映射到Hadoop分布式文件系统的方式。
在Hive中,我们可以使用HiveQL进行数据查询和分析。
在Hive中,Concatenate 是一种常用的操作,可以将多个小文件合并为一个大文件,以提高查询性能和数据处理效率。
本文将探讨Hive Concatenate的底层原理。
二、Hive Concatenate的作用在Hive中,当数据量较大时,文件数量也会相应增加,这可能会导致查询性能下降。
而使用Concatenate操作可以将多个小文件合并为一个大文件,从而减少了文件数量,提高了查询性能和数据处理效率。
三、Hive Concatenate的底层实现原理1. 文件合并策略在Hive中,Concatenate操作是由Merge File操作来实现的。
Merge File操作是一种合并文件的策略,它将多个小文件合并为一个大文件。
在执行Concatenate操作时,Hive会将需要合并的文件按照一定的规则进行分组,然后对每个分组内的文件进行合并,最终生成一个大文件。
2. 文件分组规则Hive将文件分组的规则是基于Hive表的分区信息。
在Hive中,一个表可以按照某个或多个列进行分区,这些分区将数据按照不同的值存储在不同的目录中。
当执行Concatenate操作时,Hive会根据表的分区信息将需要合并的文件分组,每个分组内的文件将被合并为一个大文件。
3. 文件合并过程在文件合并过程中,Hive会启动一个MapReduce任务来执行Merge File操作。
在Map阶段,Hive会将每个分组内的文件作为输入,将它们读取到内存中,并按照一定的规则进行合并。
在Reduce阶段,Hive会将合并后的文件写入到HDFS中,并更新表的元数据信息。
四、Hive Concatenate的使用注意事项1. 数据备份在执行Concatenate操作之前,需要确保数据已经做好备份。
hive insert overwrite 动态分区原理-定义说明解析

hive insert overwrite 动态分区原理-概述说明以及解释1.引言概述部分的内容示例:1.1 概述在大数据技术领域,Hive是一种基于Hadoop的数据仓库工具,它提供了一个类似于SQL的查询语言来处理和分析大规模数据集。
而Hive 的动态分区功能是其重要的特性之一。
动态分区(Dynamic Partitioning)是指在将数据插入到Hive表中时,根据数据的某个字段自动生成分区。
相比于静态分区,动态分区更加灵活和方便,不需要提前对分区进行定义,可以根据数据的实际情况进行分区。
而Hive的Insert Overwrite命令是用来向表中插入新的数据的,当与动态分区功能结合使用时,能够实现根据数据自动生成和更新分区的能力。
本文将详细介绍Hive的Insert Overwrite动态分区的原理和工作机制,以帮助读者更好地理解并应用于实际的数据分析和处理任务中。
在接下来的章节中,我们将首先对Hive进行简要介绍,然后详细讲解Insert Overwrite动态分区的概念和原理,并在最后给出结论和应用场景,展望未来动态分区的发展趋势。
通过阅读本文,读者将能够掌握使用Hive的Insert Overwrite命令进行动态分区的方法,并了解其背后的原理和机制。
同时,还将能够运用这一功能解决实际的数据处理问题,并在今后的数据仓库建设和大数据分析中发挥重要的作用。
让我们开始深入探索Insert Overwrite动态分区的奥秘吧!文章结构部分的内容应该包括以下内容:1.2 文章结构本文将按照以下结构来介绍Hive中的Insert Overwrite动态分区原理:1. 引言:介绍本文要讨论的主题,并对文章进行概述,说明文章的结构和目的。
2. 正文:- 2.1 Hive简介:对Hive进行简要介绍,包括其定义、特点和主要应用场景,为后面动态分区的讨论提供背景信息。
- 2.2 Insert Overwrite动态分区概述:对Insert Overwrite动态分区进行基本概述,解释其作用和使用场景,引出后续原理的讨论。
Hadoop数据仓库工具--hive介绍
HIVE介绍1简介1.1是什么hive是一个基于hadoop的数据仓库。
使用hadoop-hdfs作为数据存储层;提供类似SQL的语言(HQL),通过hadoop-mapreduce完成数据计算;通过HQL语言提供使用者部分传统RDBMS一样的表格查询特性和分布式存储计算特性。
类似的系统有yahoo的pig[1] ,google的sawzall[2],microsoft的DryadLINQ[3]。
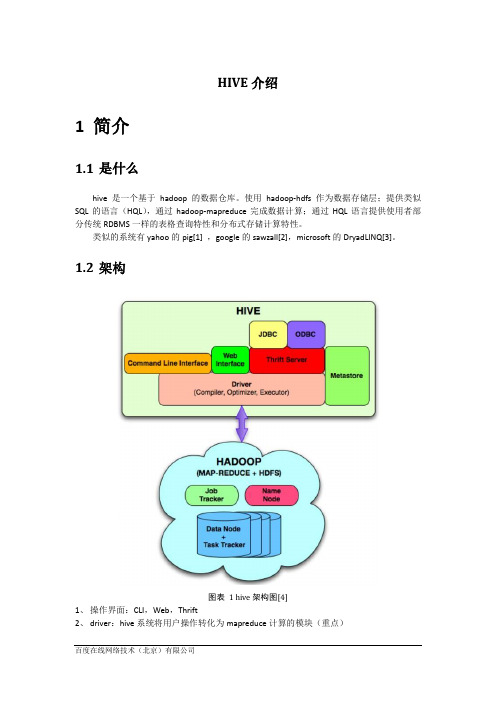
1.2架构图表 1 hive架构图[4]1、操作界面:CLI,Web,Thrift2、driver:hive系统将用户操作转化为mapreduce计算的模块(重点)3、hadoop:hdfs+mapreduce4、metastore:存储元数据1.3语言一般有DDL和DML两种:hive采用DDL方式和少量DML方式,类似sql;pig使用DML方式。
DDL:data definition language(只讲definition,不讲实现){create/alter/drop}{table/view/partition}create table as selectDML:data manipulation language(有关于实现操作)insert overwrite1.4其他一些功能1、能够ALERT一个table,主要是add一个column。
2、分区(partition):a)建表的时候指定分区方式:CREATE TABLE invites (foo INT, bar STRING) PARTITIONED BY (ds STRING);b)导入的时候指定分区依据:LOAD DATA LOCAL INPATH './examples/files/kv2.txt' OVERWRITE INTO TABLE invites PARTITION (ds='2008-08-15');LOAD DATA LOCAL INPATH './examples/files/kv3.txt' OVERWRITE INTO TABLE invites PARTITION (ds='2008-08-08');3、类似select * from tbl 的查询不需要MapReduce。
Hive基础ppt课件
Sets the value of a particular configuration variable (key). Note: If you misspell the variable name, the CLI will not show an error.
Page 3
Hive 和普通关系数据库的异同
Hive 是建立在 Hadoop 之上数据存储
的,所有 Hive 的数据都是存 储在 HDFS 中的。 数据库则可以将数据保存在块 设备或者本地文件系统中
Hive 中没有定义专门的数据格
数据格式 式,由用户指定,需要指定三
个属性:列分隔符,行分隔符 ,以及读取文件数据的方法 数据库中,存储引擎定义了自 己的数据格式。所有数据都会 按照一定的组织存储
Page 4
目录
1 Hive结构 2 Hive基础操作 33 Hive的MAP/RED 4 山东现场实际应用
Page 5
Hive客户端
CLI
usage: hive -d,--define <key=value> -e <quoted-query-string> -f <filename> -h <hostname> --hiveconf <property=value>
delete FILE[S] <filepath>* delete JAR[S] <filepath>*
! <command>
dfs <dfs command>
hive知识点总结

hive知识点总结Hive是一个基于Hadoop的数据仓库工具,它提供了一个类似于SQL的查询语言(HiveQL),用于在大规模数据集上执行分析和处理任务。
Hive的主要目标是提供一个简单易用的接口,使非技术人员也能够使用Hadoop进行数据分析。
以下是关于Hive的一些重要知识点总结:1. 数据模型:Hive使用一种类似于关系型数据库的表结构来组织数据。
表可以包含多个列和行,并且可以分区和分桶。
它支持各种数据类型,如字符串、数值、日期等。
2. HiveQL:Hive的查询语言HiveQL是基于SQL的,它允许用户使用SQL类似的语法来查询和处理数据。
HiveQL支持常见的SQL操作,如SELECT、INSERT、JOIN、GROUP BY等。
它还提供了一些Hive特有的功能,如自定义函数、窗口函数等。
3. 数据存储:Hive使用Hadoop的分布式文件系统(HDFS)来存储数据。
数据以文件的形式存储在HDFS上,并且可以被压缩和分块。
Hive还支持不同的数据存储格式,如文本、序列文件、Avro、Parquet 等。
4. 数据转换与ETL:Hive提供了一些内置函数和操作符,用于对数据进行转换和提取。
用户可以使用这些函数来处理和清洗数据,将数据从一种格式转换为另一种格式,执行数据分析和聚合等操作。
5. 执行计划和优化器:Hive使用查询优化器来优化查询执行计划。
它会尝试选择最有效的执行方式,如使用索引、过滤不必要的数据等。
用户可以使用EXPLAIN命令来查看查询的执行计划,并根据需要进行调整和优化。
6. 扩展功能:Hive提供了一些扩展功能,如UDF(用户自定义函数)、UDAF(用户自定义聚合函数)、UDTF(用户自定义表函数)等。
这些功能允许用户编写自定义逻辑来处理数据,以满足特定的需求。
7. 集成和扩展性:Hive可以与其他Hadoop生态系统中的工具集成,如HBase、Spark、Pig等。
hive中动态分区的用法

hive中动态分区的用法1.引言1.1 概述概述部分的内容如下:引言是一篇文章的开端,它介绍了文章所要讨论的主题,并提供了读者对即将阐述的内容的整体概念。
本文将探讨Hive中动态分区的用法。
Hive是基于Hadoop的数据仓库基础架构,旨在提供方便的数据查询和分析能力。
在大数据时代,数据的规模不断增长,因此高效地组织和查询数据变得至关重要。
动态分区是一种灵活的数据管理技术,它使得在处理数据时可以根据数据的特征自动创建和维护分区。
相比于静态分区,动态分区可以让数据的组织和查询更加灵活和高效。
传统上,Hive在处理分区数据时需要手动创建和维护分区,这对于大规模数据集变得非常繁琐和低效。
而动态分区的引入,能够自动识别和处理分区属性,极大地简化了数据分区的管理过程。
本文将首先介绍动态分区的概念,解释动态分区是如何根据数据的特征自动创建和维护分区的。
然后,我们将深入探讨Hive中动态分区的用法,包括动态分区的创建、加载和查询等方面。
通过学习这些用法,读者将能够更好地理解如何在Hive中使用动态分区来优化数据的管理和查询效率。
总之,本文将详细介绍Hive中动态分区的用法,以及动态分区相对于静态分区的优势。
通过阅读本文,读者将能够充分了解动态分区的概念和用法,并在实际应用中灵活运用动态分区来提升数据处理的效率和灵活性。
接下来,我们将开始探索动态分区的概念和Hive中的具体用法。
1.2 文章结构文章结构部分的内容可以包括以下内容:文章结构部分旨在为读者提供对整篇文章结构的概览,使读者对文章的内容有一个清晰的了解。
本文将按照以下结构组织内容:1. 引言:介绍本文的主题和背景,说明为什么动态分区在Hive中是一个重要的话题。
2. 正文:分为两个部分,分别是动态分区的概念和Hive中动态分区的用法。
2.1 动态分区的概念:详细介绍了动态分区的含义以及其在数据处理中的作用。
讲解动态分区的定义、特点和优势,引导读者理解动态分区的基本概念。
HIVE架构介绍(繁体)

HIVE架構介紹1簡介1.1是什麼hive是一個基於hadoop的資料倉庫。
使用hadoop-hdfs作為資料存儲層;提供類似SQL 的語言(HQL),通過hadoop-mapreduce完成資料計算;通過HQL語言提供使用者部分傳統RDBMS一樣的表格查詢特性和分散式存儲計算特性。
類似的系統有yahoo的pig[1] ,google的sawzall[2],microsoft的DryadLINQ[3]。
1.2架構圖表1 hive架構圖[4]1、操作介面:CLI,Web,Thrift2、driver:hive系統將使用者操作轉化為mapreduce計算的模組(重點)3、hadoop:hdfs+mapreduce4、metastore:存儲中繼資料1.3語言一般有DDL和DML兩種:hive採用DDL方式和少量DML方式,類似sql;pig使用DML 方式。
DDL:data definition language(只講definition,不講實現){create/alter/drop}{table/view/partition}create table as selectDML:data manipulation language(有關於實現操作)insert overwrite1.4其他一些功能1、能夠ALERT一個table,主要是add一個column。
2、分區(partition):a)建表的時候指定分區方式:CREATE TABLE invites (foo INT, bar STRING) PARTITIONED BY (ds STRING);b)導入的時候指定分區依據:LOAD DATA LOCAL INPATH './examples/files/kv2.txt' OVERWRITE INTO TABLE invites PARTITION (ds='2008-08-15');LOAD DATA LOCAL INPATH './examples/files/kv3.txt' OVERWRITE INTO TABLE invites PARTITION (ds='2008-08-08');3、類似select * from tbl 的查詢不需要MapReduce。
hive解析数组

hive解析数组Hive解析数组是一项非常有用的数据处理技术,它可以有效地处理多维数组表示的数据。
它的实现非常简单,可以在不消耗多少计算资源的情况下处理大规模多维数组。
它也可以根据特定规则对数组进行排序,并可以利用查询语句来快速提取所需的数据。
Hive解析数组也是一项分布式系统技术,它可以充分利用集群计算机的优势,将大量的多维数组分发到不同的机器中去处理,从而大大缩短处理时间。
它可以极大地提高数据处理的效率和准确性,是一种非常有用的数据处理技术。
原理Hive解析数组的原理非常简单,它的实现步骤如下:1.先,Hive将要被处理的数组表示的数据进行分割,以确定数组的大小和维数;2.后,Hive将数据进行排序,以便可以更快地提取所需的数据;3.着,对每个维度上的数据进行排序,以帮助确定数组中包含的每个数据项;4.后,Hive将分割、排序以及确定所有数据项之后的数组表示的数据,利用查询语句进行检索,以获取最终的结果数据。
优势Hive解析数组的优势非常明显,它可以有效地处理大规模数据,而对于多维度的数据处理,它可以极大地提高数据检索的效率和准确性。
此外,Hive解析数组也是一项分布式系统技术,它可以有效地将大规模的多维数组分发到不同的机器中,从而大大提高了数据处理的速度。
应用Hive解析数组在实际应用中有很多,它可以用于处理机器学习任务中的大量多维数据,也可以处理医学影像分析和技术分析等任务中用到的多维数组。
它也可以用于处理气象学、空间数据分析和金融等领域的多维数据。
总结Hive解析数组是一项非常有用的数据处理技术,它可以有效地处理大规模的多维数组,从而大大提高数据检索的效率和准确性,也可以有效地将大规模的多维数组分发到不同的机器中,从而大幅度缩短数据处理的时间。
Hive解析数组在机器学习、医学影像分析、技术分析以及气象学、空间数据分析、金融领域的应用也非常普遍,是一种十分有用的数据处理技术。
hive string array类型 匹配规则-概述说明以及解释

hive string array类型匹配规则-概述说明以及解释1. 引言1.1 概述概述部分应主要介绍Hive String Array类型和本文将要探讨的匹配规则。
你可以按照以下方式撰写该部分内容:概述:Hive是一种基于Hadoop的数据仓库基础架构,用于处理大规模数据集。
Hive提供了一种称为String Array的数据类型,它允许我们存储和操作字符串类型的数组。
Hive String Array类型在数据分析和处理过程中发挥着重要作用,特别是在需要处理复杂结构数据时。
本文将重点探讨Hive String Array类型的匹配规则。
匹配规则是指如何在Hive中对String Array类型进行匹配和查找操作。
本文将介绍两种常见的匹配方式:精确匹配和模糊匹配。
精确匹配要求进行完全匹配,而模糊匹配则可以在一定程度上进行模糊匹配,以提供更灵活的查询方式。
通过本文的学习,读者将了解Hive String Array类型的定义和特点,以及其在实际场景中的使用。
同时,读者还将深入了解不同的匹配规则,并学会如何在Hive中应用这些规则进行数据查询和分析。
接下来,本文将会详细讨论Hive String Array类型和匹配规则的相关内容,以帮助读者更好地理解和应用这些知识。
1.2 文章结构在文章结构部分,我们将详细介绍本篇文章的组织结构。
通过此部分,读者可以清晰了解文章的整体布局和内容安排。
本文主要包含三个主要部分:引言、正文和结论。
下面将对每个部分进行详细说明:1. 引言:- 概述:在本部分,我们将简要介绍Hive String Array类型的背景和基本概念。
- 文章结构:本小节将介绍文章的整体结构,以帮助读者更好地理解文章的内容安排。
- 目的:我们将明确本篇文章的写作目的,以确保读者能够明确文章的主题和意义。
2. 正文:- Hive String Array类型:- 定义和特点:在这一小节中,我们将详细介绍Hive String Array类型的定义和其特点,包括该类型的结构和用途等。
Hive原理总结(完整版)

Hive原理总结(完整版)⽬录课程⼤纲(HIVE增强) 31. Hive基本概念 41.1 Hive简介 41.1.1 什么是Hive 41.1.2 为什么使⽤Hive 41.1.3 Hive的特点 41.2 Hive架构 51.2.1 架构图 51.2.2 基本组成 51.2.3 各组件的基本功能 51.3 Hive与Hadoop的关系 61.4 Hive与传统数据库对⽐ 61.5 Hive的数据存储 62. Hive基本操作 72.1 DDL操作 72.1.1 创建表 72.1.2 修改表 92.1.3 显⽰命令 112.2 DML操作 112.2.1 Load 112.2.2 Insert 132.2.3 SELECT 152.3 Hive Join 182.5 Hive Shell使⽤进阶 212.5.1 Hive命令⾏ 212.5.2. Hive参数配置⽅式 234. Hive函数 244.1 内置运算符 244.2 内置函数 244.3 Hive⾃定义函数和Transform 244.3.1 ⾃定义函数类别 244.3.2 UDF开发实例 244.3.3 Transform实现 255. Hive执⾏过程实例分析 265.3 DISTINCT 276. Hive使⽤注意点(各种⼩细节) 27 6.1 字符集 276.2 压缩 286.3 count(distinct) 286.4 ⼦查询 286.5 Join中处理null值的语义区别 286.6 分号字符 296.7 Insert 296.7.1新增数据 296.7.2 插⼊次序 306.7.3 初始值 307. Hive优化技巧 317.1 HADOOP计算框架特性 317.2 优化的常⽤⼿段概述 317.3 全排序 327.3.1 例1 327.3.2 例2 347.4 怎样写exist/in⼦句 367.5 怎样决定reducer个数 367.6 合并MapReduce操作 367.7 Bucket 与 Sampling 377.8 Partition优化 387.9 JOIN优化 397.9.1 JOIN原则 397.9.2 Map Join 397.10 数据倾斜 407.10.1 空值数据倾斜 407.10.2 不同数据类型关联产⽣数据倾斜 41 7.10.3 ⼤表Join的数据偏斜 417.11 合并⼩⽂件 427.12 Group By 优化 437.12.1 Map端部分聚合: 437.12.2 有数据倾斜的时候进⾏负载均衡 438. Hive实战 44Hive 实战案例1——数据ETL 44需求: 44Hive 实战案例2——访问时长统计 47需求: 47实现步骤: 47Hive实战案例3——级联求和 48需求: 48实现步骤 48课程⼤纲(HIVE增强)Hive增强HIVE基本概念HIVE架构及运⾏机制HQL-DDL基本语法HQL-DML基本语法HIVE的joinHIVE UDF函数HIVE shell基本操作HIVE 参数配置HIVE ⾃定义函数和TransformHIVE 执⾏HQL的实例分析HIVE最佳实践注意点HIVE优化策略HIVE实战案例1HIVE实战案例2HIVE实战案例3学习⽬标:1、熟练掌握hive的使⽤2、熟练掌握hql的编写3、理解hive的⼯作原理4、具备hive应⽤实战能⼒1. Hive基本概念1.1 Hive简介1.1.1 什么是HiveHive是基于Hadoop的⼀个数据仓库⼯具,可以将结构化的数据⽂件映射为⼀张数据库表,并提供类SQL查询功能。
hive数据结构与查询

hive数据结构与查询hive 常见数据结构:1,struct ⼤约 c语⾔之中的结构体,都可以使⽤'.'来进⾏访问元素的内容2,map 键值对3,array 数组创建⽂件xiaoming,lili_bingbing,xiao xiao:18_xiaoqiang song :19 tong luo wan针对以上数据创建表:根据⾏来进⾏创建 ,指定每⼀⾏的数据类型与分隔符create table test(name string,friends array<string>,address struct<street:string, city:string>) row format delimitedfields terminated by','/*每⾏以,分割*/collection items terminated by'_'map keys terminated by':'/* 查询*/select friends[1],address.city from test;使⽤ jdbc 连接 hive, 需要开启 hiveserver2# 需要 bin/hiveserver2./beeline -u jdbc:hive2://master:10000# 或者 !connect jdbc:hive2://master:10000内部表与外部表:1,内部表数据由Hive⾃⾝管理,外部表数据由HDFS管理2,删除内部表会直接删除元数据(metadata)及存储数据;删除外部表仅仅会删除元数据,HDFS上的⽂件并不会被删除;表分区:1,在 hive 之中表是以⽂件夹(最⼤值为block ⼤⼩)的形式展⽰的,以⽂件的⾓度来说,分区是表⽂件增加⼦⽬录,⼦⽬录存储⽂件 2,hive 没有索引,因此使⽤分区(指定⽂件夹)来避免全局扫描/*数据库增加表字段类型*/alter database sga set dbproperties("ctime"="1990-28-18");/*查看数据库(包括隐藏字段)*/desc database extended sga;drop database sga cascade; /*级联删除也会将 hdfs 之中的⽂件进⾏删除!*//*修改表名称但是不⽀持数据库重命名*/alter table test rename to FPGA;/*表增减字段*/alter table stu add columns(gg string,address struct <street:string, city:string >)/* 执⾏的 mr 任务,不仅创建表结构,还会将数据加载进去 */create table students as select*from stu;/* 只有表结构的数据*/create table student1 like stu;/* 查看表详细信息 */desc formatted student;/*默认创建的是管理表(内部表),使⽤ external关键字创建外部表*/create external table dept(dept int ,dname string, loc int) row format delimited fields terminated by'\t';/* 外部表删除会将原始数据不会删除!可以重新建表*/drop table dept/*内部表转化成外部表(区分⼤⼩写,单双引号,不然会加属性) Table Type: EXTERNAL_TABLE */alter table student set tblproperties('EXTERNAL'='TRUE');/*内部表转化成外部表 Table Type: MANAGED_TABLE*/alter table student set tblproperties('EXTERNAL'='FALSE');/*创建分区表*/create table stu_partition(id int,name string) partitioned by(month string) row format delimited fields terminated by'\t';/*分区表插⼊数据 ,也就是指定表⽂件下的⼦⽂件夹 /user/hive/warehouse/stu_partition/month=19960712*/load data local inpath '/home/hadoop/hive/bin/stu.txt'into table stu_partition partition(month=19960712);/*按照表分区进⾏查询,表分区是加了⼀个表字段*/select*from stu_partition where month=19960712or month=19960711;/*为表增加两个分区*/alter table stu_partition add partition(month=19960721) partition(month=19960722);/*为表删除⼀个分区,多个使⽤ ',' */alter table stu_partition drop partition(month=19960721),partition(month=19960722);hive 序列化操作针对⽂件为192.168.57.4--[29/Feb/2016:18:14:35 +0800] "GET /bg-upper.png HTTP/1.1" 304-192.168.57.4--[29/Feb/2016:18:14:35 +0800] "GET /bg-nav.png HTTP/1.1" 304-192.168.57.4--[29/Feb/2016:18:14:35 +0800] "GET /asf-logo.png HTTP/1.1" 304-192.168.57.4--[29/Feb/2016:18:14:35 +0800] "GET /bg-button.png HTTP/1.1" 304-192.168.57.4--[29/Feb/2016:18:14:3192.168.57.4 -创建 sql 语句CREATE TABLE logtbl1 (host STRING,identity STRING,t_user STRING,time STRING,request STRING,referer STRING,agent STRING)ROW FORMAT SERDE 'org.apache.hadoop.hive.serde2.RegexSerDe' WITH SERDEPROPERTIES ("input.regex" = "([^ ]*) ([^ ]*) ([^ ]*) \\[(.*)\\] \"(.*)\" (-|[0-9]*) (-|[0-9]*)")STORED AS TEXTFILE;查询结果(hive 读时检查数据格式,如果不正确,那么久会显⽰ null)hive 动态分区:# 修改权限开启动态分区set hive.exec.dynamic.partiton=true#修改默认状态默认strict。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
HIVE结构解析在认识真正的HIVE文件之前,先列举HIVE文件的几个主要特征。
先入为主的将它们呈现出来将有助于我们对其文件组织和数据结构的理解。
注册表由多个HIVE文件组成。
一个HIVE文件由多个巢箱(BIN)组成HIVE文件的首部有一个文件头(基本块、base block),用于描述这个HIVE文件的一些全局信息一个BIN由多个巢室(CELL)组成,CELL可以分为具体的5种(后面介绍),用于存储不同的注册表数据。
本文中,我们并不统一使用HIVE、BIN和CELL的英文单词,而是和对应的中文词汇交替出现。
在中文里,它们分别对应储巢、巢箱和巢室三个名词。
一个储巢被看成是一些称为块(block)的分配单元,类似于将磁盘分为簇的形式。
根据定义,每一个注册表块的大小为4096字节(4KB),当新的数据要加入到一个储巢中来时,该储巢总是按照块的粒度来增加。
一个储巢的第一个块是基本块(base block),包含了有关该储巢的全局信息,包括一个特征签名“regf”,更新序列号,储巢上一次写操作发生的时间戳,储巢格式版本号、检验和,以及该储巢文件的内部文件名等等。
下面的_HBASE_BLOCK就是一个基本块的数据结构还原。
typedef struct _HBASE_BLOCK{ULONG Signature; /* 签名ASCII-"regf" = 0x66676572 (小端序)*/ULONG Sequence1;ULONG Sequence2;LARGE_INTEGER TimeStamp; /* 最后一次写操作的时间戳 */ULONG Major; /* 主版本号 */ULONG Minor; /* 次版本号 */ULONG Type;ULONG Format;ULONG RootCell; /* 第一个键记录的偏移 */ULONG Length; /* 数据块长度*/ULONG Cluster;UCHAR name[64]; /* 储巢文件名*/ULONG Reserved1[99];ULONG CheckSum; /* 校验和*/ULONG Reserved2[894];ULONG BootType;ULONG BootRecover;} HBASE_BLOCK, *PHBASE_BLOCK;Windows将一个储巢所存储的注册表条目组织在一种称为巢室的容器中,当一个巢室加入到一个储巢中,而且该巢室必须经过扩展才能容纳该巢室时,系统将创建一个巢箱的分配单元。
巢箱是新巢室正好扩展到下一个块的边界的大小,系统将巢室的尾部和巢箱的尾部之间的任何空间都看作是空闲空间,因而可以分配其他的巢室。
巢箱也有头部的标识,包含了一个特殊的签名“hbin”,一个记录了该巢箱在储巢文件中偏移量的域,以及该巢箱的大小。
下面是巢箱的数据结构。
typedef struct _HBIN{ULONG Signature; /* 签名 ASCII-"hbin" = 0x6E696268 (小端序)*/ULONG FileOffset; /* 本巢箱相对第一个巢箱起始的偏移*/ULONG Size; /* 本巢箱的大小*/ULONG Reserved1[2];LARGE_INTEGER TimeStamp;ULONG Spare;} HBIN, *PHBIN;一个巢室可以容纳一个键、一个值、一个安全描述符、一列子键或者一列键值,分别有对应的巢室来存储数据。
在巢室数据的开始之处,有一个数据域描述了该巢室数据的类型,具体的数据结构如下:键巢室,包含了一个注册表键(也称为键节点)的巢室,一个键巢室包含一个特征签名(对于一个键是kn,一个符号链接是kl)、该键最近一次更新的时间戳、该键父键巢室的巢室索引、代表该键的子键的子键列表巢室的索引、该键的安全描述符巢室索引、一个代表该键类名的字符串键巢室索引,以及该键的名称。
typedef struct _CM_KEY_NODE{USHORT Signature; /* 签名ASCII-"kn" = 0x6B6E (小端序)*/ USHORT Flags; /* 根键标识: 0x2C, 其他为0x20 */LARGE_INTEGER LastWriteTime;ULONG Spare;ULONG Parent; /* 父键的偏移*/ULONG SubKeyCounts[2]; /* SubKeyCounts[0]为子键的个数 */union /* 偏移为0x001C 联合体 */{struct{ULONG SubKeyLists[2]; /* SubKeyLists[0]为子键列表相差本BIN的偏移*/CHILD_LIST ValueList; /* ValueList结构体*/};ULONG ChildHiveReference[4];};ULONG Security; /* 安全描述符记录的偏移 */ULONG Class; /* 类名的偏移 */ULONG MaxNameLen: 16;ULONG UserFlags: 4;ULONG VirtControlFlags: 4;ULONG Debug: 8;ULONG MaxClassLen;ULONG MaxValueNameLen;ULONG MaxValueDataLen;ULONG WorkVar;USHORT NameLength; /* 键名长度 */USHORT ClassLength; /* 类名长度*/PBYTE Name; /* 键名称*/}CM_KEY_NODE, *PCM_KEY_NODE;值巢室,一个巢室,包含了关于一个键的值的信息,该巢室包含一个签名kv,该值的类型,如REG_DWORD或REG_BINARY,以及该值的名称。
一个值巢室也包含了另一个值巢室的索引,后者包含了对前者的数据。
typedef struct _CM_KEY_VALUE{WORD Signature; /* 签名ASCII-"kv" = 0x6B76(小端序)*/WORD NameLength; /* 名称长度 */ULONG DataLength; /* 数据长度*/ULONG Data; /*数据偏移或数据, 如果DataLength最高位为1,那么它就是数据,且DataLenth&0x7FFFFFFF为数据长度;否则*/ULONG Type; /* 值类型*/WORD Flags;WORD Spare;PWCHAR Name; /* 值名称 */} CM_KEY_VALUE, *PCM_KEY_VALUE;子键列表巢室,有一系列的键巢室的巢室索引构成的巢室,这些键巢室是同一个父键下面的所有子键。
typedef struct _CM_KEY_INDEX{WORD Signature;WORD Count;ULONG List[1];} CM_KEY_INDEX, *PCM_KEY_INDEX;如果Signature==CM_KEY_FAST_LEAF,签名为“fl”,或者Signature==CM_KEY_HASH_LEAF,签名为“hl”,那么List后是一个结构体:struct{ULONG offset;ULONG HashKey;}否则为:ULONG offset;值列表巢室,有一系列的值巢室的巢室索引构成的巢室,这些值巢室是同一个父键下面的所有值。
其数据结构即上文说到的结构。
即上面_CM_KEY_NODE的联合体中ValueList数据域。
typedef struct _CHILD_LIST{ULONG Count; /* ValueList.Count值的个数*/ULONG List; /* ValueList.List值列表相差本BIN的偏移 */} CHILD_LIST, *PCHILD_LIST;安全描述符巢室,包含了一个安全描述符巢室,其首部的特征签名为ks,以及一个引用计数,该引用计数值记录了所有共享安全描述符的键节点数目,多个键巢室可以共享同样的安全描述符巢室。
typedef struct _CM_KEY_SECURITY{WORD Signature; /* 签名ASCII-"sk" = 0x6B73 (小端序)*/WORD Reserved;ULONG Flink; /*上一个"sk"记录的偏移*/ULONG Blink; /*下一个"sk"记录的偏移*/ULONG ReferenceCount; /* 引用计数*/ULONG DescriptorLength; /* 数据大小 */SECURITY_DESCRIPTOR_RELATIVE Descriptor; /* 数据 */} CM_KEY_SECURITY, *PCM_KEY_SECURITY;储巢的结构是通过一些链接建立起来的,这些链接称为巢室索引(cell index)。
每个巢室索引是一个巢室在储巢文件中的偏移。
因此,巢室索引就像是一个指针,从一个巢室指向另一个巢室,配置管理器将巢室索引解释为相对于储巢起始处的偏移。
因此,假如你想找到子键A的键巢室,并且A的父键是B,那么就必须先利用B的巢室中的子键列表巢室索引,找到包含B的所有子键列表的那个巢室,然后再利用该子键列表巢室中的巢室索引列表,找到B的每个子键的巢室,随即找到A。
巢室,巢箱和块之间的区别很容易让人混淆,所以我们来看一个简单的注册表储巢的布局示例,如图5。
该示例中包含了一个基本块和两个巢箱,第一个巢箱是空的,第二个巢箱包含了几个巢室。
该巢室有两个键,一个是根键Root,另一个是Root的子键——SubKey。
Root有两个值,Val1和Val2,通过一个子键列表巢室,可以定位到根键的子键,通过一个值列表巢室,可以定位到根键的值。
第二个巢箱中,空闲的空间属于空的巢室。
编辑本段获得HIVE文件知道了HIVE们的存放位置,自然就想到要把它们抓过来,逐个解剖。
抓捕工作看似棘手,但解决起来也很简单。
HIVE是Windows的重要资源,自启动以来就只能被系统独占访问。
我们换一种思路,在另外一个系统中启动,如同一台机器上的Linux,那目前系统的HIVE文件不是就可以访问了吗?但是这里如果你非要在当前系统访问这个HIVE文件,就只有求助于文件系统驱动了。
后者已经超出了本文的讨论范围,故我们不作考虑。
不过,为了示例学习的需要,我们总希望HIVE文件能相对简单一些,让我们把它的结构看个清楚明白。
系统内部的HIVE文件一般都不太适合,从其文件尺寸已经达到MB级别,就可看出其数据量的巨大。