hadoop集群eclipse安装配置
Hadoop搭建与Eclipse开发环境设置

hadoop搭建与eclipse开发环境设置――邵岩飞1.Ubuntu 安装安装ubuntu11.04 desktop系统。
如果是虚拟机的话,这个无所谓了,一般只需要配置两个分区就可以。
一个是\另一个是\HOME 文件格式就用ext4就行了。
如果是实机的话建议在分配出一个\SWAP分区。
如果嫌麻烦建议用wubi安装方式安装。
这个比较傻瓜一点。
2.Hadoop 安装hadoop下载到阿帕奇的官方网站下载就行,版本随意,不需要安装,只要解压到适当位置就行,我这里建议解压到$HOME\yourname里。
3.1 下载安装jdk1.6如果是Ubuntu10.10或以上版本是不需要装jdk的,因为这个系统内置openjdk63.2 下载解压hadoop不管是kubuntu还是ubuntu或者其他linux版本都可以通过图形化界面进行解压。
建议放到$HOME/youraccountname下并命名为hadoop.如果是刚从windows系统或者其它系统拷贝过来可能会遇到权限问题(不能写入)那么这就需要用以下命令来赋予权限。
sudo chown –R yourname:yourname [hadoop]例如我的就是:sudo chown –R dreamy:dreamy hadoop之后就要给它赋予修改权限,这就需要用到:sudo chmod +X hadoop3.3 修改系统环境配置文件切换为根用户。
●修改环境配置文件/etc/profile,加入:你的JAVA路径的说明:这里需要你找到JAVA的安装路径,如果是Ubuntu10.10或10.10以上版本,则应该在/usr/bin/java这个路径里,这个路径可能需要sudo加权限。
3.4 修改hadoop的配置文件●修改hadoop目录下的conf/hadoop-env.sh文件加入java的安装根路径:●把hadoop目录下的conf/core-site.xml文件修改成如下:<?xml version="1.0"?><?xml-stylesheet type="text/xsl" href="configuration.xsl"?><!-- Put site-specific property overrides in this file. --><configuration><property><name>hadoop.tmp.dir</name><value>/hadoop</value></property><property><name></name><value>hdfs://ubuntu:9000</value></property><property><name>dfs.hosts.exclude</name><value>excludes</value></property><property>●把hadoop目录下的conf/ hdfs-site.xml文件修改成如下:<?xml version="1.0"?><?xml-stylesheet type="text/xsl" href="configuration.xsl"?><!-- Put site-specific property overrides in this file. --><configuration><property><name>dfs.data.dir</name><value>/hadoop/data</value></property><property><name>dfs.replication</name><value>3</value></property></configuration>●把hadoop目录下的conf/ mapred-site.xml文件修改成如下:注意:别忘了hadoop.tmp.dir,.dir,dfs.data.dir参数,hadoop存放数据文件,名字空间等的目录,格式化分布式文件系统时会格式化这个目录。
eclipse hadoop开发环境配置

eclipse hadoop开发环境配置win7下安装hadoop完成后,接下来就是eclipse hadoop开发环境配置了。
具体的操作如下:一、在eclipse下安装开发hadoop程序的插件安装这个插件很简单,haoop-0.20.2自带一个eclipse的插件,在hadoop目录下的contrib\eclipse-plugin\hadoop-0.20.2-eclipse-plugin.jar,把这个文件copy到eclipse的eclipse\plugins目录下,然后启动eclipse就算完成安装了。
这里说明一下,haoop-0.20.2自带的eclipse的插件只能安装在eclipse 3.3上才有反应,而在eclipse 3.7上运行hadoop程序是没有反应的,所以要针对eclipse 3.7重新编译插件。
另外简单的解决办法是下载第三方编译的eclipse插件,下载地址为:/p/hadoop-eclipse-plugin/downloads/list由于我用的是Hadoop-0.20.2,所以下载hadoop-0.20.3-dev-eclipse-plugin.jar.然后将hadoop-0.20.3-dev-eclipse-plugin.jar重命名为hadoop-0.20.2-eclipse-plugin.jar,把它copy到eclipse的eclipse\plugins目录下,然后启动eclipse完成安装。
安装成功之后的标志如图:1、在左边的project explorer 上头会有一个DFS locations的标志2、在windows -> preferences里面会多一个hadoop map/reduce的选项,选中这个选项,然后右边,把下载的hadoop根目录选中如果能看到以上两点说明安装成功了。
二、插件安装后,配置连接参数插件装完了,启动hadoop,然后就可以建一个hadoop连接了,就相当于eclipse里配置一个weblogic的连接。
Eclipse配置hadoop开发环境
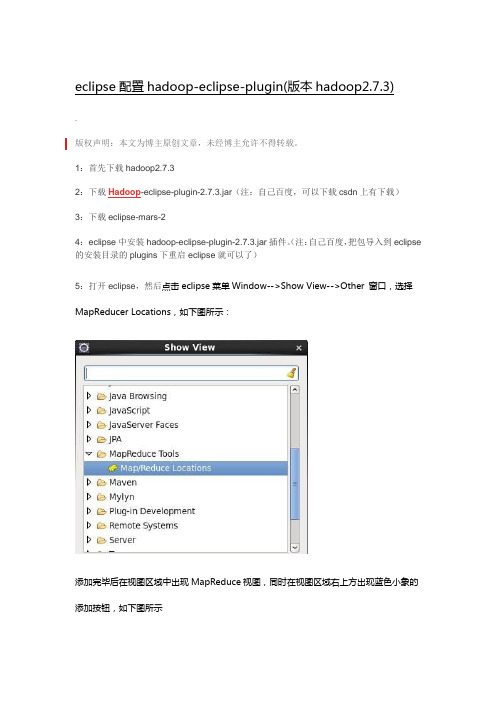
eclipse配置hadoop-eclipse-plugin(版本hadoop2.7.3)
.
版权声明:本文为博主原创文章,未经博主允许不得转载。
1:首先下载hadoop2.7.3
2:下载Hadoop-eclipse-plugin-2.7.3.jar(注:自己百度,可以下载csdn上有下载)
3:下载eclipse-mars-2
4:eclipse中安装hadoop-eclipse-plugin-2.7.3.jar插件。
(注:自己百度,把包导入到eclipse 的安装目录的plugins下重启eclipse就可以了)
5:打开eclipse,然后点击eclipse菜单Window-->Show View-->Other 窗口,选择MapReducer Locations,如下图所示:
添加完毕后在视图区域中出现MapReduce视图,同时在视图区域右上方出现蓝色小象的添加按钮,如下图所示
6:新建Hadoop Location
点击蓝色小象新增按钮,提示输入MapReduce和HDFS Master相关信息,其中:Lacation Name:为该位置命名,能够识别该,可以随意些;
MapReduce Master:与$HADOOP_DIRCONF/mapred-site.xml配置保持一致;
HDFS Master:与$HADOOP_DIRCONF/core-site.xml配置保持一致
User Name:登录hadoop用户名,可以随意填写
7:配置完毕后,在eclipse的左侧DFS Locations出现CentOS HDFS的目录树,该目录为HDFS文件系统中的目录信息:。
Hadoop安装及基于Eclipse的开发环境部署(限IT组内部使用)20150427

Had oop安装及基于Eclipse的开发环境部署1、Had oop-1.2.1安装1.1 Hadoop安装工具1、操作系统:Win7系统2、虚拟机软件:VMware Workstation 103、Linux系统安装包:ubuntukylin-14.04-desktop-i386.iso(32位)4、JDK包:jdk-8u45-linux-i586.gz5、Hadoop-1.2.1程序安装包(非源码):/apache/hadoop/common/hadoop-1.2.1/hadoop-1.2.1.tar.gz 1.2Hadoop安装步骤(部分详细内容可参见《Hadoop安装指南》)1、Ubuntu虚拟机安装(建议安装32位Ubuntu操作系统)2、Windows与linux之间的共享文件夹设置,实现windows与linux之间的文件共享;具体设置如下图:设置完成后,可以看到一个共享文件夹,通过该文件夹可以实现windows与linux之间的文件共享;该共享文件夹默认在linux系统的/mnt/hgfs目录下。
3、ssh安装(ubuntu默认没有安装ssh,需要通过apt-get install 进行安装,这里建议暂时不要生成公钥)4、网络连接配置;网络连接配置的主要目的是保证能够使用Xshell等工具链接虚拟机进行操作。
由于采用NAT模式没有连接成功,本文建议使用自定义的虚拟网络进行连接,具体步骤及设置如下:1)本地虚拟网络IP设置;具体设置如图(可以根据自己的情况设置IP(如192.168.160.1),该IP将作为虚拟机的网关):2)虚拟机网络适配器设置;建议采用自定义虚拟网络连接,设置如下:3)虚拟机网络IP设置;主要目的是设置自定义的IP、网关等;具体设置流程如下:4)当网络连接设置完成后,使用Ubuntu:service networking restart(centOS:service network restart)命令重启虚拟机网络服务;注意,重启网络服务后,建议在本机的DOS环境下ping一下刚刚在虚拟机中设置的IP地址,如果ping不通,可能是网卡启动失败,可以使用ifconfig eth0 up命令启动网卡(eh0是网卡名称,可以在网路连接设置中查看网卡名称)。
hadoop单机部署、集群部署及win7本地Eclipse远程配置管理

准备工作:Window版hadoop下载地址:/apache/hadoop/common/hadoop-1.2.1/hadoop-1.2.1-bin.tar.gz下载Eclipse hadoop的插件地址:hadoop-eclipse-plugin-1.2.1.jarLinux Hadoop下载地址:/apache/hadoop/common/hadoop-1.2.1/hadoop-1.2.1.tar.gz在linux服务器上创建用户名为hadoop的用户:[root@localhost ~]# useradd hadoop设置密码:[root@localhost ~]# passwd hadoop添加hadoop用户使用vim、vi等命令的权限:[root@localhost ~]# vim /etc/sudoersroot ALL=(ALL) ALLhadoop ALL=(ALL) ALL此处保存是可能需要使用:wq!强制保存。
以下文档如无特殊说明均使用hadoop账户进行操作1.Hadoop单机部署1.下载hadoop-1.2.1.tar.gz文件。
2.运行命令tar zxvf hadoop-1.2.1.tar.gz将hadoop解压到自己喜欢的目录下(我的解压在/usr/local/目录下)3.编辑hadoop-1.2.1目录下的conf/hadoop-env.sh文件,将其中的JA V A_HOME配置为自己的jdk目录(如我的为:JA V A_HOME=/usr/local/jdk1.7.0_60)4.到此出Hadoop单机部署基本完成。
5.单机模式的操作方法默认情况下,Hadoop被配置成以非分布式模式运行的一个独立Java进程。
这对调试非常有帮助。
下面的实例将已解压的 conf 目录拷贝作为输入,查找并显示匹配给定正则表达式的条目。
输出写入到指定的output目录。
[hadoop@localhost hadoop-1.2.1]$ mkdir input[hadoop@localhost hadoop-1.2.1]$ cp conf/*.xml input[hadoop@localhost hadoop-1.2.1]$ bin/hadoop jar hadoop-examples-1.2.1.jargrep input output 'dfs[a-z.]+' $ cat output/*注:语法不理解没关系看下面进一步说明显示结果 1 dfsadmin2.Hadoop伪分布式模式部署1.下载hadoop-1.2.1.tar.gz文件。
2.3.3 在Eclipse 中配置Hadoop[共2页]
![2.3.3 在Eclipse 中配置Hadoop[共2页]](https://img.taocdn.com/s3/m/f32952c56edb6f1aff001ff7.png)
Categories=Development;StartupNotify=true接下来,将此文件复制到桌面并添加可执行权限。
$ cp /usr/share/applications/eclipse.desktop ~/桌面$ chmod +x ~/桌面/eclipse.desktop之后,双击Ubuntu的桌面上的eclipse图标,即可自由地启动Eclipse。
2.3.2 下载hadoop-eclipse-plugin插件由于Hadoop和Eclipse的发行版本较多,不同版本之间往往存在兼容性问题,因此必须注意hadoop-eclipse-plugin的版本问题。
(1)访问以下链接,可下载hadoop-eclipse-plugin-2.7.2.jar包。
/detail/tondayong1981/9432425根据上传者“tondayong1981”介绍,该插件通过了Eclipse Java EE IDE for Web Developers. Version: Mars.1 Release (4.5.1)的测试。
在此,作者请求本书的读者首先对上传者的分享精神点赞,因为他们的努力方便了大家的学习。
【注意】当我们确实找不到一个合适的插件时,可通过以下操作方法来获得想要的插件。
①首先,下载一个包含插件源码的zip文件,例如通过https:///winghc/hadoop2x- eclipse-plugin下载hadoop2x.eclipse-plugin-master.zip。
解压之后,release文件夹中的hadoop. eclipse-kepler-plugin-2.2.0.jar就是编译好的插件,只是这个文件不是我们想要的插件。
$ unzip hadoop2x.eclipse-plugin-master.zip②进入hadoop2x-eclipse-plugin/src/contrib/eclipse-plugin目录。
课题_windows7+eclipse+hadoop2.5.2环境配置

windows7+eclipse+hadoop2.5.2环境配置一.hadoop集群环境配置参考我的前一篇文章(ubuntu + hadoop2.5.2分布式环境配置)但本人配置时还修改了如下内容(由于你的环境和我的可能不一致,可以在后面出现相关问题后再进行修改):a.在master节点上(ubuntu-V01)修改hdfs-site.xml加上以下内容<property><name>dfs.permissions</name><value>false</value></property>旨在取消权限检查,原因是为了解决我在windows机器上配置eclipse连接hadoop服务器时,配置map/reduce连接后报以下错误,org.apache.hadoop.security.AccessControlException: Permission denied:b.同样在master节点上(ubuntu-V01)修改hdfs-site.xml加上以下内容<property><name>dfs.web.ugi</name><value>jack,supergroup</value></property>原因是运行时,报如下错误WARN org.apache.hadoop.security.ShellBasedUnixGroupsMapping: got exception trying to get groups for user jack应该是我的windows的用户名为jack,无访问权限更多权限配置可参看官方说明文档:HDFS权限管理用户指南/docs/r1.0.4/cn/hdfs_permissions_guide.html配置修改完后重启hadoop集群:hadoop@ubuntu-V01:~/data$./sbin/stop-dfs.shhadoop@ubuntu-V01:~/data$./sbin/stop-yarn.shhadoop@ubuntu-V01:~/data$./sbin/start-dfs.shhadoop@ubuntu-V01:~/data$./sbin/start-yarn.sh二.windows基础环境准备windows7(x64),jdk,ant,eclipse,hadoop1.jdk环境配置jdk-6u26-windows-i586.exe安装后好后配置相关JAVA_HOME环境变量,并将bin目录配置到path2.eclipse环境配置eclipse-standard-luna-SR1-win32.zip解压到D:\eclipse\目录下并命名eclipse-hadoop3.ant环境配置apache-ant-1.9.4-bin.zip解压到D:\apache\目录下,配置环境变量ANT_HOME,并将bin目录配置到path4.下载hadoop-2.5.2.tar.gz5.下载hadoop-2.5.2-src.tar.gz6.下载hadoop2x-eclipse-plugin7.下载hadoop-common-2.2.0-bin分别将hadoop-2.5.2.tar.gz、hadoop-2.5.2-src.tar.gz、hadoop2x-eclipse-plugin、hadoop-common-2.2.0-bin下载解压到F:\hadoop\目录下8.修改本地hosts文件,加入如下内容:192.168.1.112 ubuntu-V01三、编译hadoop-eclipse-plugin-2.5.2.jar配置1.添加环境变量HADOOP_HOME=F:\hadoop\hadoop-2.5.2\追加环境变量path内容:%HADOOP_HOME%/bin2.修改编译包及依赖包版本信息修改F:\hadoop\hadoop2x-eclipse-plugin-master\ivy\libraries.propertieshadoop.version=2.5.2jackson.version=1.9.133.ant编译F:\hadoop\hadoop2x-eclipse-plugin-master\src\contrib\eclipse-plugin>ant jar -Dversion=2.5.2 -Declipse.home=D:\eclipse\eclipse-hadoop\eclipse -Dhadoop.home=F:\hadoop\hadoop-2.5.2编译好后hadoop-eclipse-plugin-2.5.2.jar会在F:\hadoop\hadoop2x-eclipse-plugin-master\build\contrib\eclipse-plugin目录下四、eclipse环境配置1.将编译好的hadoop-eclipse-plugin-2.5.2.jar拷贝至eclipse的plugins目录下,然后重启eclipse2.打开菜单Window--Preference--Hadoop Map/Reduce进行配置,如下图所示:3.显示Hadoop连接配置窗口:Window--Show View--Other-MapReduce Tools,如下图所示:4.配置连接Hadoop,如下图所示:查看是否连接成功,能看到如下信息,则表示连接成功:五、hadoop集群环境添加测试文件(如果已有则无需配置)a.dfs上创建input目录hadoop@ubuntu-V01:~/data/hadoop-2.5.2$bin/hadoop fs -mkdir -p inputb.把hadoop目录下的README.txt拷贝到dfs新建的input里hadoop@ubuntu-V01:~/data/hadoop-2.5.2$bin/hadoop fs -copyFromLocal README.txt input六、创建一个Map/Reduce Project1.新建项目File--New--Other--Map/Reduce Project 命名为MR1,然后创建类org.apache.hadoop.examples.WordCount,从hadoop-2.5.2-src中拷贝覆盖(F:\hadoop\hadoop-2.5.2-src\hadoop-mapreduce-project\hadoop-mapreduce-examples\src\main\java\org\apache\hadoop\examples\WordCount.java)2.创建log4j.properties文件在src目录下创建log4j.properties文件,内容如下:log4j.rootLogger=debug,stdout,Rlog4j.appender.stdout=org.apache.log4j.ConsoleAppenderyout=org.apache.log4j.PatternLayoutyout.ConversionPattern=%5p - %m%nlog4j.appender.R=org.apache.log4j.RollingFileAppenderlog4j.appender.R.File=mapreduce_test.loglog4j.appender.R.MaxFileSize=1MBlog4j.appender.R.MaxBackupIndex=1yout=org.apache.log4j.PatternLayoutyout.ConversionPattern=%p %t %c - %m%n.codefutures=DEBUG3.解决ng.UnsatisfiedLinkError: org.apache.hadoop.io.nativeio.NativeIO$Windows.access0(Ljava/lang/String;I)异常问题(由于你的环境和我的可能不一致,可以在后面出现相关问题后再进行修改)拷贝源码文件org.apache.hadoop.io.nativeio.NativeIO到项目中然后定位到570行,直接修改为return true;如下图所示:七、windows下运行环境配置(如果不生效,则需要重启机器)需要hadoop.dll,winutils.exe我是直接拷贝F:\hadoop\hadoop-common-2.2.0-bin-master\bin目录下内容覆盖F:\hadoop\hadoop-2.5.2\bin八、运行project在eclipse中点击WordCount.java,右键,点击Run As—>Run Configurations,配置运行参数,即输入和输出文件夹hdfs://ubuntu-V01:9000/user/hadoop/input hdfs://ubuntu-V01:9000/user/hadoop/output如下图所示:注意:如果output目录已经存在,则删掉或换个名字,如output01,output02 。
hadoop搭建与eclipse开发环境设置--已验证通过
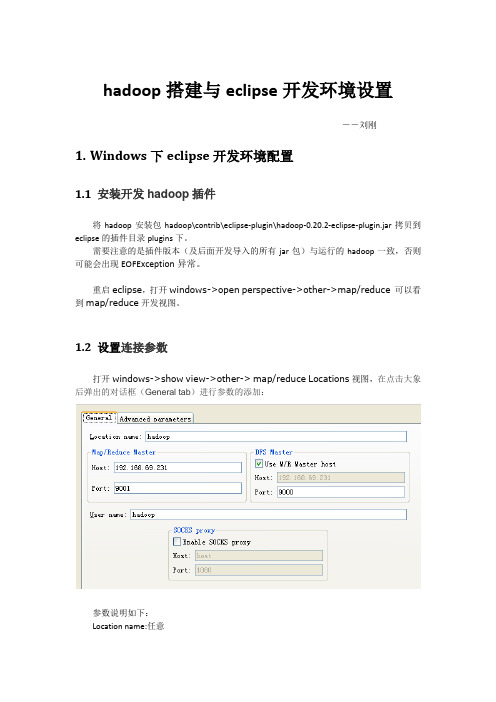
hadoop搭建与eclipse开发环境设置――刘刚1.Windows下eclipse开发环境配置1.1 安装开发hadoop插件将hadoop安装包hadoop\contrib\eclipse-plugin\hadoop-0.20.2-eclipse-plugin.jar拷贝到eclipse的插件目录plugins下。
需要注意的是插件版本(及后面开发导入的所有jar包)与运行的hadoop一致,否则可能会出现EOFException异常。
重启eclipse,打开windows->open perspective->other->map/reduce 可以看到map/reduce开发视图。
1.2 设置连接参数打开windows->show view->other-> map/reduce Locations视图,在点击大象后弹出的对话框(General tab)进行参数的添加:参数说明如下:Location name:任意map/reduce master:与mapred-site.xml里面mapred.job.tracker设置一致。
DFS master:与core-site.xml里设置一致。
User name: 服务器上运行hadoop服务的用户名。
然后是打开“Advanced parameters”设置面板,修改相应参数。
上面的参数填写以后,也会反映到这里相应的参数:主要关注下面几个参数::与core-site.xml里设置一致。
mapred.job.tracker:与mapred-site.xml里面mapred.job.tracker设置一致。
dfs.replication:与hdfs-site.xml里面的dfs.replication一致。
hadoop.tmp.dir:与core-site.xml里hadoop.tmp.dir设置一致。
hadoop.job.ugi:并不是设置用户名与密码。
Hadoop的eclipse的插件安装方法
Hadoop的eclipse的插件安装⽅法
1)⽹上下载hadoop-eclipse-plugin-2.7.4.jar,将该jar包拷贝到Eclipse安装⽬录下的dropins⽂件夹下,我的⽬录是
C:\Users\test\eclipse\jee-oxygen\eclipse\dropins,然后重启Eclipse就可以看到MapReduce选项了。
2)启动eclipse,点开Windows->preferences,弹出如下对话框,设置hadoop的安装⽬录。
3)点开Windows->ShowView->Other…,弹出如下对话框。
在其中选中Map/ReduceLocations,点击Open后将成功添加Map/ReduceLocations窗⼝,点击右侧的⼩象图标创建New Hadoop Location,如下图:
总结
以上所述是⼩编给⼤家介绍的Hadoop的eclipse的插件安装⽅法,希望对⼤家有所帮助,如果⼤家有任何疑问请给我留⾔,⼩编会及时回复⼤家的。
在此也⾮常感谢⼤家对⽹站的⽀持!
如果你觉得本⽂对你有帮助,欢迎转载,烦请注明出处,谢谢!。
hadoop-eclipse-plugin插件安装
Hadoop-eclipse-plugin插件安装学习Hadoop有一段时间了,以前每次的做法都是先在win下用eclipse写好Mapreduce程序,然后打成jar文件,上传到linux下用hadoop集群去运行jar文件。
然后这样的话调试起来极其麻烦。
所以想到安装hadoop的eclipse插件,直接在eclipse下调试Mapreduce程序,会节省很多时间。
下面介绍一下hadoop的eclipse插件安装:首先,下载hadoop-eclipse-plugin插件:我的集群环境是hadoop-1.0.3,所以我下载的插件式hadoop-1.0.3-eclipse-plugin将hadoop-1.0.3-eclipse-plugin.jar复制到eclipse\plugins下面重启eclipse会发现打开open perspective选项卡,点击other,弹出窗口下会多出Mapreduce选项配置本地Hadoop Install 目录如下图:新建一个Hadoop Location点击“New Hadoop Location”会出现以下对话框根据hadoop环境正确填写General和Advanced parameters内容,点击finish 生效后,就会在左侧导航栏看到以下情景。
如下图:至此,就可以hadoop-eclipse插件配置就已经完成,可以使用eclipse连接至hadoop集群,进行Mapreduce程序开发和调试了。
相关异常信心以及解决办法:1.ERROR erGroupInform ation: PriviledgedActionEx ception as: hadoopcause:java.io.IOEx ception Failed to set perm issions ofpath:\usr\hadoop\tm p\m apred\staging\hadoop753422487\.staging to 0700Exception in thread "m ain" java.io.IOException: Failed to set perm issions of path: \usr\hadoop\tm p \m apred\staging\hadoop753422487\.staging to 0700解决办法:修改主机名与集群用户名一致,或者重新编译.apache.fs.FileUtil类,修改hadoop源代码,去除权限认证,修改FileUtil.java的checkReturnValue 方法,如下:private static void checkReturnValue(boolean rv, File p, FsPermission permission) throws IOException {// if (!rv) {// throw new IOException("Failed to set permissions of path: " + p + // " to " +// String.format("%04o", permission.toShort()));// }}.apache.hadoop.security.AccessControlException:org.apache.hadoop.security.AccessControlException: Permissiondenied: user=Administrator, access=WRITE,inode="hadoop":hadoop:supergroup:rwxr-xr-xat sun.reflect.NativeConstructorAccessorImpl.newInstance0(Native Method)atsun.reflect.NativeConstructorAccessorImpl.newInstance(NativeConstr uctorAccessorImpl.java:39)开放hdfs权限 hadoop fs –chmod 777 /user/MDSS3. hadoop使用随记Mapreduce在w in dows eclipse开发环境提交job到远处linux hadoop集群,运行mapred 报错“IOException: Cannot run program "chmod": CreateProcess error=2”原因:安装cygwin,而且需要设置"cygwin\bin"到环境变量PATH中,使用eclipse-plugin提交mapreduce程序,必须在window端安装cygwin,并将cygwin\bin"到环境变量PATH中,否则不行。
Eclipse搭建hadoop开发环境
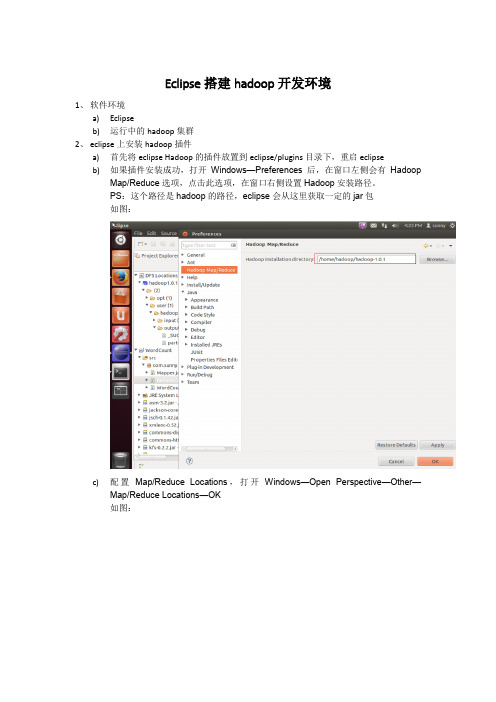
Eclipse搭建hadoop开发环境1、软件环境a)Eclipseb)运行中的hadoop集群2、eclipse上安装hadoop插件a)首先将eclipse Hadoop的插件放置到eclipse/plugins目录下,重启eclipseb)如果插件安装成功,打开Windows—Preferences后,在窗口左侧会有HadoopMap/Reduce选项,点击此选项,在窗口右侧设置Hadoop安装路径。
PS:这个路径是hadoop的路径,eclipse会从这里获取一定的jar包如图:c)配置Map/Reduce Locations,打开Windows—OpenPerspective—Other—Map/Reduce Locations—OK如图:d)点击新增hadoop如图:3、新建WordCount项目a)上传两个文件到hadoop集群里面b)分别写Mapper、Reducer、Main,如图所示:c)运行WordCountMain.java,Run As-----Run Configurations,然后配置如图:d)结果如图:4、碰到的错误a)Windows eclipse配置插件时候,碰到权限不够(org.apache.hadoop.security.AccessControlException),导致不能连接到hadoop,解决方案:1、将windows的账户名和用户组都设置成hadoop启动的账号一样的名字2、如果是自己的测试机器,可以关闭dfs的权限检测,在conf/hdfs-site.xml 将dfs.permissions修改成falseb)Exception in thread "main" java.io.IOException: Failed to set permissions of path:\tmp\hadoop-Administrator\mapred\staging\Administrator-519341271\.staging to0700这个是Windows下文件权限问题,在Linux下可以正常运行,不存在这样的问题。
hadoop搭建与eclipse开发环境设置

hadoop搭建与eclipse开发环境设置――罗利辉1.前言1.1 目标目的很简单,为进行研究与学习,部署一个hadoop运行环境,并搭建一个hadoop开发与测试环境。
具体目标是:✓在ubuntu系统上部署hadoop✓在windows 上能够使用eclipse连接ubuntu系统上部署的hadoop进行开发与测试1.2 软硬件要求注意:Hadoop版本和Eclipse版本请严格按照要求。
现在的hadoop最新版本是hadoop-0.20.203,我在windows上使用eclipse(包括3.6版本和3.3.2版本)连接ubuntu上的hadoop-0.20.203环境一直没有成功。
但是开发测试程序是没有问题的,不过需要注意权限问题。
如果要减少权限问题的发生,可以这样做:ubuntu上运行hadoop的用户与windows 上的用户一样。
1.3 环境拓扑图ubuntu 192.168.69.231ubuntu2192.168.69.233 ubuntu1192.168.69.2322.Ubuntu 安装安装ubuntu11.04 server系统,具体略。
我是先在虚拟机上安装一个操作系统,然后把hadoop也安装配置好了,再克隆二份,然后把主机名与IP修改,再进行主机之间的SSH配置。
如果仅作为hadoop的运行与开发环境,不需要安装太多的系统与网络服务,或者在需要的时候通过apt-get install进行安装。
不过SSH服务是必须的。
3.Hadoop 安装以下的hadoop安装以主机ubuntu下进行安装为例。
3.1 下载安装jdk1.6安装版本是:jdk-6u26-linux-i586.bin,我把它安装拷贝到:/opt/jdk1.6.0_263.2 下载解压hadoop安装包是:hadoop-0.20.2.tar.gz。
3.3 修改系统环境配置文件切换为根用户。
●修改地址解析文件/etc/hosts,加入3.4 修改hadoop的配置文件切换为hadoop用户。
基于Eclipse的Hadoop开发环境配置方法

基于Eclipse的Hadoop开发环境配置方法(1)启动hadoop守护进程在Terminal中输入如下命令:$ bin/hadoop namenode -format$ bin/start-all.sh(2)在Eclipse上安装Hadoop插件找到hadoop的安装路径,我的是hadoop-0.20.2,将/home/wenqisun/hadoop-0.20.2/contrib/eclipse-plugin/下的hadoop-0.20.2-eclipse-plugin.jar拷贝到eclipse安装目录下的plugins里,我的是在/home/wenqisun/eclipse /plugins/下。
然后重启eclipse,点击主菜单上的window-->preferences,在左边栏中找到Hadoop Map/Reduce,点击后在右边对话框里设置hadoop的安装路径即主目录,我的是/home/wenqisun/hadoop-0.20.2。
(3)配置Map/Reduce Locations在Window-->Show View中打开Map/Reduce Locations。
在Map/Reduce Locations中New一个Hadoop Location。
在打开的对话框中配置Location name(为任意的名字)。
配置Map/Reduce Master和DFS Master,这里的Host和Port要和已经配置的mapred-site.xml 和core-site.xml相一致。
一般情况下为Map/Reduce MasterHost:localhostPort:9001DFS MasterHost:localhostPort:9000配置完成后,点击Finish。
如配置成功,在DFS Locations中将显示出新配置的文件夹。
(4)新建项目创建一个MapReduce Project,点击eclipse主菜单上的File-->New-->Project,在弹出的对话框中选择Map/Reduce Project,之后输入Project的名,例如Q1,确定即可。
Hadoop开发环境eclipse搭建

1.1.文档说明本文档包含使用eclipse开发工具基于hadoop平台开发Map/Reduce的说明和示例。
2.开发前准备下面所述中除了MR要安装在服务器上之外,其他的都是需要在本地开发环境上安装。
2.1. 安装MR由于Map/Reduce的运行依赖于MR,所以要提前将MR安装在服务器上,并且保证MR的hdfs和mr进程运行正常。
同时复制MR到本地,解压到任意目录,供本地开发使用,服务器上MR的安装请参考MR相关安装手册。
2.2. 安装Cygwin如果本地开发环境的操作系统是Windows,需要先安装Cygwin,如果是Linux则不需要。
2.2.1.Cygwin的安装如果只是Dmp的本地开发可以不安装Cygwin;Cygwin可以在windows环境下安装一个linux模拟环境来进行调试。
在安装Cygwin之前,得先下载Cygwin安装程序setup-x86.exe。
Cygwin安装程序下载地址:/setup-x86.exe,本教程下载的是Cygwin2.819(32bit)版本。
Cygwin 安装程序的存放目录可随意无要求。
当下载成功后,运行setup-x86.exe,弹出如下图所示的对话框:在上图所示的对话框中,直接点击“下一步”,进入如下图所示的对话框:在上图所示的对话框中,选择“Install from Internet”,然后点击“下一步”,进入如下图所示对话框:在上图所示的对话框中,设置Cygwin 的安装目录,Install For 选择“All Users”,Default Text File Type 选择“Unix/binary”,然后点击“下一步”,进入如下图所示对话框:在上图所示的对话框中,设置Cygwin 安装包存放目录,然后点击“下一步”,进入如下图所示对话框:在上图所示的对话框中,根据实际网络情况选择连网方式,然后点击“下一步”,如果进入如下图所示对话框:在上图所示的对话框中,点击“下一步”,将进入如下图所示的对话框:进入“Select Packages”对话框后,必须保证“Net Category”下的“OpenSSL和openssh”被安装,如下图所示:如果还打算在eclipse 上编译Hadoop,则还必须安装“Base Category”下的“sed”,如下图所示:当完成上述操作后,点击“Select Packages”对话框中“下一步”,进入Cygwin 安装包下载过程,如下图所示:等待安装包下载完毕,当下载完后,会自动进入到如下图所示的对话框:在上图所示的对话框中,选中“Create icon on Desktop”,以方便直接从桌面上启动Cygwin,然后点击“完成”按钮。
Hadoop-Eclipse插件下载与安装

Hadoop-Eclipse插件下载与安装Eclipse插件下载与安装1.⾸先下载对应版本的hadoop插件 这⾥推荐下载hadoop-eclipse-plugin-2.7.3.jar。
下载 hadoop-eclipse-plugin-2.7.3.jar2.进⼊Eclipse的⽬录,找到Plugins⽂件夹,讲刚才下载的插件拷贝进去(注意,Eclipse最好要处于关闭状态)并重启Eclipse3.打开,Eclipse,使⽤Project Explorer 会发现左侧多了⼀个DFS Location,说明已经安装成功4.打开Window-->Preferens,可以看到Hadoop Map/Reduc选项。
⾼版本的eclipse可能看不到该选项,搜索hadoop即可。
然后点击,然后添加hadoop-2.6.0进来,如图所⽰: ⽬录选择hadoop解压⽬录即可5.打开Windows–Show View配置Map/ReduceLocations1)点击Window-->Show View -->MapReduce Tools 点击Map/ReduceLocation2)点击Map/ReduceLocation选项卡,点击右边⼩象图标,打开Hadoop Location配置窗⼝:输⼊Location Name,任意名称即可.配置Map/Reduce Master和DFS Mastrer,Host和Port配置成hdfs-site.xml与core-site.xml的设置⼀致即可。
3)打开后,下⽅会出现⼩黄象的选项卡,如果没有请尝试切换⼀下java视图4)在空⽩处点击右键,选择新建⼀个位置 New Hadoop Location如图进⾏修改5)在window系统需要下载Hadoop的window环境 下载⽹盘中的hadoopwindows-master.zip,解压并复制到hadoop的bin⽬录下,这⾥我⽤的是hadoop2.7.7 6)并配置环境变量HADOOP_HOME=D:\xl-download\hadoop-2.7.7\hadoop-2.7.7\bin (改为你⾃⼰hadoop的安装⽬录下的bin⽂件夹 6.可能出现的问题1. 如果出现null/bin/winutils.exe,则将hadoopbin_for_hadoop2.7.7.zip解压到hadoop安装⽬录的bin⽬录下,然后双击winutils.exe,如果出现窗⼝⼀闪⽽过则没有问题,如果不⾏,则需要将msvcr120.dll放到C:\Windows\System32⽬录下,然后重新执⾏winutils.exe。
eclipse中hadoop的插件安装

eclipse中hadoop的插件安装1.将jar导入到eclipse安装目录下的plugins文件夹下将hadoop-eclipse-plugin-2.7.0.jar放入eclipse的根目录下的plugins 2、重启eclipse3.在eclipse中的Window下的Preferences下的找到Hadoop Map/Reduce4.设置本地hadoop安装环境目录(比如D:\Program File\hadoop)5.打开插件,配置本地连接(配置主机名以及对应的用户)与mapred-site.xml中的配置相同Host:主机名Part:9001与core-site.xml中的配置相同Host:主机名Part:90006.在C:\Windows\System32\drivers\etc下的hosts文件配置一下主机名与ip的对应关系Ip主机名---例如:192.168.2.112 HadoopOne7、在hdfs-site.xml中配置关闭权限:<property><name>dfs.permissions.enabled</name><value>false</value></property>7.配置环境变量HADOOP_HOME以及pathHADOOP_HOME: hadoop根目录Path:%HADOOP_HOME %\bin8.hadoopbin.zip添加到本地hadoo环境(hadoop安装路径下bin)中: D:\Program File\hadoop-2.5.0-cdh5.3.3\bin9、hadoopbin.zip中的文件添加到系统文件中:C:\Windows\System3210、创建mavenproject:一、将repository.tar.gz中的内容添加到.m2中repository文件夹中。
搭建eclipse的hadoop开发环境知识点

搭建eclipse的hadoop开发环境知识点一、概述在大数据领域,Hadoop是一个非常重要的框架,它提供了分布式存储和处理海量数据的能力。
而Eclipse作为一款强大的集成开发环境,为我们提供了便利的开发工具和调试环境。
搭建Eclipse的Hadoop 开发环境对于开发人员来说是必不可少的。
本文将从安装Hadoop插件、配置Hadoop环境、创建Hadoop项目等方面来详细介绍搭建Eclipse的Hadoop开发环境的知识点。
二、安装Hadoop插件1. 下载并安装Eclipse我们需要在全球信息湾上下载最新版本的Eclipse,并按照提示进行安装。
2. 下载Hadoop插件在Eclipse安装完成后,我们需要下载Hadoop插件。
可以在Eclipse 的Marketplace中搜索Hadoop,并进行安装。
3. 配置Hadoop插件安装完成后,在Eclipse的偏好设置中找到Hadoop插件,并按照提示进行配置。
在配置过程中,需要指定Hadoop的安装目录,并设置一些基本的环境变量。
三、配置Hadoop环境1. 配置Hadoop安装目录在Eclipse中配置Hadoop的安装目录非常重要,因为Eclipse需要通过这个路径来找到Hadoop的相关文件和库。
2. 配置Hadoop环境变量除了配置安装目录,还需要在Eclipse中配置Hadoop的环境变量。
这些环境变量包括HADOOP_HOME、HADOOP_COMMON_HOME、HADOOP_HDFS_HOME等,它们指向了Hadoop的各个组件所在的目录。
3. 配置Hadoop项目在Eclipse中创建一个新的Java项目,然后在项目的属性中配置Hadoop库,以及其它一些必要的依赖。
四、创建Hadoop项目1. 导入Hadoop库在新建的Java项目中,我们需要导入Hadoop的相关库,比如hadoopmon、hadoop-hdfs、hadoop-mapreduce等。
Windows 下配置 Eclipse 连接 Hadoop 开发环境
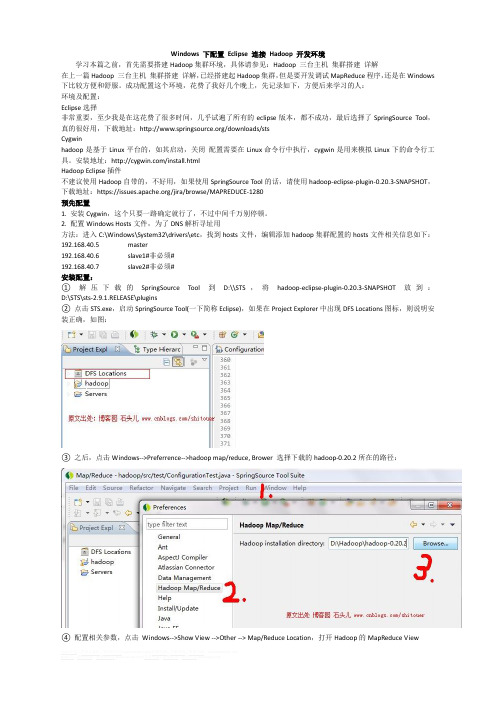
Windows 下配置Eclipse 连接Hadoop 开发环境学习本篇之前,首先需要搭建Hadoop集群环境,具体请参见:Hadoop 三台主机集群搭建详解在上一篇Hadoop 三台主机集群搭建详解,已经搭建起Hadoop集群,但是要开发调试MapReduce程序,还是在Windows 下比较方便和舒服。
成功配置这个环境,花费了我好几个晚上,先记录如下,方便后来学习的人:环境及配置:Eclipse选择非常重要,至少我是在这花费了很多时间,几乎试遍了所有的eclipse版本,都不成功,最后选择了SpringSource Tool,真的很好用,下载地址:/downloads/stsCygwinhadoop是基于Linux平台的,如其启动,关闭配置需要在Linux命令行中执行,cygwin是用来模拟Linux下的命令行工具。
安装地址:/install.htmlHadoop Eclipse插件不建议使用Hadoop自带的,不好用,如果使用SpringSource Tool的话,请使用hadoop-eclipse-plugin-0.20.3-SNAPSHOT,下载地址:https:///jira/browse/MAPREDUCE-1280预先配置1. 安装Cygwin,这个只要一路确定就行了,不过中间千万别停顿。
2. 配置Windows Hosts文件,为了DNS解析寻址用方法:进入C:\Windows\System32\drivers\etc,找到hosts文件,编辑添加hadoop集群配置的hosts文件相关信息如下:192.168.40.5master192.168.40.6slave1#非必须#192.168.40.7slave2#非必须#安装配置:①解压下载的SpringSource Tool到D:\\STS,将hadoop-eclipse-plugin-0.20.3-SNAPSHOT放到:D:\STS\sts-2.9.1.RELEASE\plugins②点击STS.exe,启动SpringSource Tool(一下简称Eclipse),如果在Project Explorer中出现DFS Locations图标,则说明安装正确,如图:③之后,点击Windows-->Preferrence-->hadoop map/reduce, Brower 选择下载的hadoop-0.20.2所在的路径:④配置相关参数,点击Windows-->Show View -->Other --> Map/Reduce Location,打开Hadoop的MapReduce View点击Ok之后,出现如下图⑤上一步你不应该看到hadoopLoc, 应该什么都没有,右键点击空白处-->New Hadoop Location, 你会看到一个填写MapReduce Location参数的一个界面:其中:Location Name:这个不用在意,就是对这个MapReduce的标示,只要能帮你记忆即可Map/Reduce Master 部分相关定义:Host:上一节搭建的集群中JobTracker所在的机器的IP地址port:JobTracker的端口两个参数就是mapred-site.xml中mapred.job.tracker的ip和端口DFS Master部分:Host:就是上一节集群搭建中Namenode所在机器IPPort:就是namenode的端口这两个参数是在core-site.xml里里面的ip和端口User Name:就是搭建Hadoop集群是所用的用户名,我这里用的是root⑥填写完以上信息以后,关闭Eclipse,然后重新启动。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
第二步: 选择"Window"菜单下的"Preference", 然后弹出一个窗体, 在窗体的左侧, 有一列选项, 里面会多出"Hadoop Map/Reduce"选项, 点击此选项, 选择 Hadoop 的安装目录 (如我的 Hadoop 目录: E:\HadoopWorkPlat\hadoop-1.0.0) 。 结果如下图:
"中的"
",点击"Other"选项,也可以弹出上图,从中选
7 / 30
第四步:建立与 Hadoop 集群的连接,在 Eclipse 软件下面的"Map/Reduce Locations"进行右击,弹出一个选项,选 择"New Hadoop Location",然后弹出一个窗体。
8 / 30
注意上图中的红色标注的地方,是需要我们关注的地方。
hadoop fs -ls
Байду номын сангаас
12 / 30
到此为止,我们的 Hadoop Eclipse 开发环境已经配置完毕,不尽兴的同学可以上传点本地文件到 HDFS 分布式文件上, 可以互相对比意见文件是否已经上传成功。 3、Eclipse 运行 WordCount 程序 配置 Eclipse 的 JDK 如果电脑上不仅仅安装的 JDK6.0,那么要确定一下 Eclipse 的平台的默认 JDK 是否 6.0。从"Window"菜单下选择 "Preference",弹出一个窗体,从窗体的左侧找见"Java",选择"Installed JREs",然后添加 JDK6.0。下面是我的默认选择 JRE。
右击"Win7ToHadoop user hadoop"可以尝试建立一个"文件夹--xiapi",然后右击刷新就能查看我们刚才建立的 文件夹。
11 / 30
创建完之后,并刷新,显示结果如下:
用 SecureCRT 远程登录"Master.Hadoop"服务器,用下面命令查看是否已经建立一个"xiapi"的文件夹。
17 / 30
接着,填写 MapReduce 工程的名字为"WordCountProject",点击"finish"完成。
18 / 30
目前为止我们已经成功创建了 MapReduce 项目,我们发现在 Eclipse 软件的左侧多了我们的刚才建立的项目。
19 / 30
创建 WordCount 类 选择"WordCountProject"工程,右击弹出菜单,然后选择"New",接着选择"Class",然后填写如下信息:
接着选择"本地用户和组",展开"用户",找到系统管理员"Administrator",修改其为"hadoop",操作结果如下图:
3 / 30
最后,把电脑进行"注销"或者"重启电脑",这样才能使管理员才能用这个名字。 Eclipse 插件开发配置 第一步:把我们的"hadoop-eclipse-plugin-1.0.0.jar"放到 Eclipse 的目录的"plugins"中,然后重新 Eclipse 即可生效。
User name:hadoop(默认为 Win 系统管理员名字,因为我们之前改了所以这里就变成了 hadoop。)
9 / 30
备注:这里面的 Host、Port 分别为你在 mapred-site.xml、core-site.xml 中配置的地址及端口。 接着点击"Advanced parameters"从中找见"hadoop.tmp.dir",修改成为我们 Hadoop 集群中设置的地址,我们的 Hadoop 集群是"/usr/hadoop/tmp",这个参数在"core-site.xml"进行了配置。
2 / 30
用的 Win7 系统管理员名字,默认一般为"Administrator",把它修改为"hadoop",此用户名与 Hadoop 集群普通用户一 致, 大家应该记得我们 Hadoop 集群中所有的机器都有一个普通用户——hadoop, 而且 Hadoop 运行也是用这个用户进行 的。为了不至于为权限苦恼,我们可以修改 Win7 上系统管理员的姓名,这样就避免出现该用户在 Hadoop 集群上没有权限 等都疼问题,会导致在 Eclipse 中对 Hadoop 集群的 HDFS 创建和删除文件受影响。 你可以做一下实验,查看 Master.Hadoop 机器上"/usr/hadoop/logs"下面的日志。发现权限不够,不能进行"Write" 操作,网上有几种解决方案,但是对 Hadoop1.0 不起作用,详情见"常见问题 FAQ_2"。下面我们进行修改管理员名字。 首先"右击"桌面上图标"我的电脑",选择"管理",弹出界面如下:
2、Hadoop Eclipse 简介和使用 Eclipse 插件介绍 Hadoop 是一个强大的并行框架, 它允许任务在其分布式集群上并行处理。 但是编写、 调试 Hadoop 程序都有很大难度。 正因为如此,Hadoop 的开发者开发出了 Hadoop Eclipse 插件,它在 Hadoop 的开发环境中嵌入了 Eclipse,从而实现了 开发环境的图形化,降低了编程难度。在安装插件,配置 Hadoop 的相关信息之后,如果用户创建 Hadoop 程序,插件会 自动导入 Hadoop 编程接口的 JAR 文件,这样用户就可以在 Eclipse 的图形化界面中编写、调试、运行 Hadoop 程序(包 括单机程序和分布式程序),也可以在其中查看自己程序的实时状态、错误信息和运行结果,还可以查看、管理 HDFS 以及 文件。总地来说,Hadoop Eclipse 插件安装简单,使用方便,功能强大,尤其是在 Hadoop 编程方面,是 Hadoop 入门和 1 / 30
Hadoop 编程必不可少的工具。 Hadoop 工作目录简介 为了以后方便开发,我们按照下面把开发中用到的软件安装在此目录中,JDK 安装除外,我这里把 JDK 安装在 C 盘的默 认安装路径下,下面是我的工作目录:
系统磁盘(E:) |---HadoopWorkPlat |--- eclipse |--- hadoop-1.0.0 |--- workplace |---……
5 / 30
第三步:切换"Map/Reduce"工作目录,有两种方法: 1)选择"Window"菜单下选择"Open Perspective",弹出一个窗体,从中选择"Map/Reduce"选项即可进行切换。
6 / 30
2)在 Eclipse 软件的右上角,点击图标" 择"Map/Reduce",然后点击"OK"即可确定。 切换到"Map/Reduce"工作目录下的界面如下图所示。
点击"finish"之后,会发现 Eclipse 软件下面的"Map/Reduce Locations"出现一条信息,就是我们刚才建立的 "Map/Reduce Location"。 10 / 30
第五步:查看 HDFS 文件系统,并尝试建立文件夹和上传文件。点击 Eclipse 软件左侧的"DFS Locations"下面的 "Win7ToHadoop",就会展示出 HDFS 上的文件结构。
21 / 30
从上面目录中找见"WordCount.java"文件,用记事本打开,然后把代码复制到刚才建立的 java 文件中。当然源码有些 变动,变动的红色已经标记出。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27
下面是没有添加之前的设置如下:
13 / 30
下面是添加完 JDK6.0 之后结果如下:
14 / 30
接着设置 Complier。
15 / 30
设置 Eclipse 的编码为 UTF-8
16 / 30
创建 MapReduce 项目 从"File"菜单,选择"Other",找到"Map/Reduce Project",然后选择它。
hadoop 集群 eclipse 安装配置
1、Hadoop 开发环境简介 Hadoop 集群简介 Java 版本:jdk-6u31-linux-i586.bin Linux 系统:CentOS6.0 Hadoop 版本:hadoop-1.0.0.tar.gz Windows 开发简介 Java 版本:jdk-6u31-windows-i586.exe Win 系统:Windows 7 旗舰版 Eclipse 软件:eclipse-jee-indigo-SR1-win32.zip | eclipse-jee-helios-SR2-win32.zip Hadoop 软件:hadoop-1.0.0.tar.gz Hadoop Eclipse 插件:hadoop-eclipse-plugin-1.0.0.jar 备注: 下面是网上收集的收集的"hadoop-eclipse-plugin-1.0.0.jar", 除"版本 2.0"是根据"V1.0"按照"常见问题 FAQ_1" 改的之外,剩余的"V3.0"、"V4.0"和"V5.0"和"V2.0"一样是别人已经弄好的,而且我已经都测试过,没有任何问题,可以放 心使用。我们这里选择第"V5.0"使用。记得在使用时重新命名为"hadoop-eclipse-plugin-1.0.0.jar"。