聚类分析SPSS习题作业答案
spss期末试题及答案

spss期末试题及答案一、选择题(每题2分,共20分)1. SPSS中,用于描述数据集中的变量分布情况的统计量是()。
A. 平均值B. 中位数C. 众数D. 标准差答案:ABC2. 在SPSS中,进行数据录入时,如果需要输入缺失值,应该使用以下哪个符号表示?()A. 0B. 9C. -D. *答案:C3. 以下哪个选项不是SPSS中的数据类型?()A. 数值型B. 字符串C. 逻辑型D. 图像型答案:D4. 在SPSS中,进行相关性分析时,通常使用哪种统计方法?()A. t检验B. 方差分析C. 卡方检验D. 皮尔逊相关系数答案:D5. SPSS中,用于创建数据文件的命令是()。
A. GET FILEB. SAVEC. OPEN DATAD. NEW DATA答案:A6. 在SPSS中,如果要对数据进行分组处理,应该使用以下哪个功能?()A. 分类汇总B. 数据筛选C. 数据排序D. 数据转换答案:A7. SPSS中,用于绘制数据分布直方图的命令是()。
A. GRAPHB. CHARTC. PLOTD. HISTOGRAM答案:B8. 在SPSS中,如果要进行回归分析,应该使用以下哪个菜单选项?()A. 分析B. 描述统计C. 预测D. 回归答案:D9. SPSS中,用于计算数据集中变量的方差的命令是()。
A. DESCRIPTIVESB. FREQUENCIESC. MEANSD. CORRELATIONS答案:A10. 在SPSS中,如果要对数据进行因子分析,应该使用以下哪个菜单选项?()A. 因子B. 聚类C. 多变量D. 描述统计答案:A二、填空题(每题3分,共15分)1. 在SPSS中,数据视图的窗口分为三个部分:________、变量视图和数据视图。
答案:数据结构视图2. SPSS中,用于计算数据集中变量的均值的命令是________。
答案:MEANS3. 在SPSS中,进行独立样本t检验的命令是________。
用SPSS进行聚类分析

实习六、用SPSS进行聚类分析SPSS中进行聚类分析统计分析过程,是由菜单“Analyze”-“Classify”导出的。
选择后显示三个过程命令。
1.K-means Cluster means Cluster过程•进行快速聚类过程,属于非系统聚类法的一种。
方法原理:选择(或人为指定)某些观测作为凝聚点,按就近原则将其余观测向凝聚点凝集,计算出各个初始分类的中心位置(均值),用计算出的中心位置重新进行聚类如此反复循环,直到凝聚点位置收敛为止。
思想:基于使聚类性能指标最小化,所用的聚类准则函数是聚类集中每一个样本点到该类中心的距离平方之和,并使其最小化。
2.Hierarchical Cluster Hierarchical Cluster过程分层聚类方法,进行样本聚类和变量聚类过程,属于系统聚类法的一种。
方法原理:先将所有n个变量/观测看成不同的n类,然后将性质最接近(距离最近)的两类合并为一类,再从这n-1类中找到最接近的两类加以合并。
依此类推,直到所有的变量/观测被合为一类,使用者再根据具体的问题和聚类结果来决定应当分几类。
调用此过程可完成系统聚类分析。
在系统聚类分析中,用户事先无法确定类别数,系统将所有例数均调入内存,且可执行不同的聚类算法。
系统聚类分析有两种形式,一是对研究对象本身进行分类,称为Q型举类;另一是对研究对象的观察指标进行分分层聚类方法类,称为R型聚类。
分层聚类方法是最常用的分类方法。
3.Discriminant过程判别分析过程。
例如:下表是1999年中国省、自治区的城市规模结构特征的一些数据,可通过聚类分析将这些省、自治区进行分类,具体过程如下:省、自治区首位城市规模(万人)城市首位度四城市指数基尼系数城市规模中位值(万人)京津冀699.70 1.4371 0.9364 0.7804 10.880山西179.46 1.8982 1.0006 0.5870 11.780内蒙古111.13 1.4180 0.6772 0.5158 17.775辽宁389.60 1.9182 0.8541 0.5762 26.320吉林211.34 1.7880 1.0798 0.4569 19.705黑龙江259.00 2.3059 0.3417 0.5076 23.480苏沪923.19 3.7350 2.0572 0.6208 22.160浙江139.29 1.8712 0.8858 0.4536 12.670安徽102.78 1.2333 0.5326 0.3798 27.375福建108.50 1.7291 0.9325 0.4687 11.120江西129.20 3.2454 1.1935 0.4519 17.080山东173.35 1.0018 0.4296 0.4503 21.215河南151.54 1.4927 0.6775 0.4738 13.940湖北434.46 7.1328 2.4413 0.5282 19.190湖南139.29 2.3501 0.8360 0.4890 14.250广东336.54 3.5407 1.3863 0.4020 22.195广西96.12 1.2288 0.6382 0.5000 14.340海南45.43 2.1915 0.8648 0.4136 8.730川渝365.01 1.6801 1.1486 0.5720 18.615云南146.00 6.6333 2.3785 0.5359 12.250贵州136.22 2.8279 1.2918 0.5984 10.470西藏11.79 4.1514 1.1798 0.6118 7.315陕西244.04 5.1194 1.9682 0.6287 17.800甘肃145.49 4.7515 1.9366 0.5806 11.650青海61.36 8.2695 0.8598 0.8098 7.420宁夏47.60 1.5078 0.9587 0.4843 9.730新疆128.67 3.8535 1.6216 0.4901 14.470(1)打开数据文件,在spss中可以打开多种类型的文件,如*.xls、*.dbf、*.txt、*.sav等,FILE→OPEN→DATA;(2)进行聚类分析:ANALYZE→CLASSIFY→HIERARCHICAL CLUSTER(此例子中用层次聚类法);进入如下对话框,设置聚类变量,以及采用的聚类方法,是否显示聚类谱系图等(因为采用不同的聚类方法,分类结果不同)。
北语2024春季《SPSS统计分析与应用》完美答案文档

北语2024春季《SPSS统计分析与应用》完美答案文档一、引言本文档旨在提供北语2024春季《SPSS统计分析与应用》完美答案。
以下是各章节的详细内容。
二、章节一:SPSS统计分析基础本章介绍SPSS统计分析的基础知识和技巧。
包括SPSS软件的安装和基本操作,数据导入和清洗,以及常用的统计分析方法。
三、章节二:描述性统计分析本章介绍描述性统计分析的原理和方法。
包括数据的中心趋势和离散程度的测量,频数分布和直方图的绘制,以及描述性统计图表的解读。
四、章节三:参数检验本章介绍参数检验的原理和应用。
包括独立样本t检验、配对样本t检验、单因素方差分析和多因素方差分析等常用的参数检验方法。
五、章节四:非参数检验本章介绍非参数检验的原理和应用。
包括Wilcoxon符号秩检验、Mann-Whitney U检验、Kruskal-Wallis H检验和Friedman检验等常用的非参数检验方法。
六、章节五:相关分析本章介绍相关分析的原理和应用。
包括皮尔逊相关系数、斯皮尔曼相关系数和判定系数等常用的相关分析方法。
七、章节六:回归分析本章介绍回归分析的原理和应用。
包括简单线性回归分析和多元线性回归分析等常用的回归分析方法。
八、章节七:因子分析本章介绍因子分析的原理和应用。
包括主成分分析和因子旋转等常用的因子分析方法。
九、章节八:聚类分析本章介绍聚类分析的原理和应用。
包括层次聚类和K均值聚类等常用的聚类分析方法。
十、章节九:判别分析本章介绍判别分析的原理和应用。
包括线性判别分析和二次判别分析等常用的判别分析方法。
十一、结论本文档总结了北语2024春季《SPSS统计分析与应用》的完美答案。
通过学习本课程,学生能够掌握SPSS软件的使用和各种统计分析方法的应用,为实际问题提供科学的数据分析支持。
以上是《SPSS统计分析与应用》完美答案文档的内容概要。
希望能对您有所帮助。
SPSS_16_实用教程习题答案

SPSS_16_实⽤教程习题答案第⼀章1-1答:SPSS的运⾏⽅式有三种,分别是批处理⽅式、完全窗⼝菜单运⾏⽅式、程序运⾏⽅式。
1-2 答:与⼀般电⼦表格处理软件相⽐,SPSS的“Data V iew”窗⼝还有以下⼀些特性:(1)⼀个列对应⼀个变量,即每⼀列代表⼀个变量(V ariable)或⼀个被观测量的特征;(2)⾏是观测,即每⼀⾏代表⼀个个体、⼀个观测、⼀个样品,在SPSS中称为事件(Case);(3)单元包含值,即每个单元包括⼀个观测中的单个变量值;(4)数据⽂件是⼀张长⽅形的⼆维表。
第⼆章2-1 答:SPSS中输⼊数据⼀般有以下三种⽅式:(1)通过⼿⼯录⼊数据;(2)可以将其他电⼦表格软件中的数据整列(⾏)的复制,然后粘贴到SPSS中;(3)通过读⼊其他格式⽂件数据的⽅式输⼊数据。
2-2 答:选择“Transform”菜单的Replace Missing V alues命令,弹出Replace Missing V alues 对话框。
先在变量名列中选择1个或多个存在缺失值的变量,使之添加到“New V ariable(s)”框中,这时系统⾃动产⽣⽤于替代缺失值的新变量。
最后选择合适的替代⽅式即可。
2-3 答:选择“Data”菜单中的Weight Cases命令,出现如图2-22所⽰的Weight Cases对话框。
其中,Do not weight cases项表⽰不做加权,这可⽤于取消加权;Weight cases by 项表⽰选择1个变量做加权。
2-4 答:变量的⾃动赋值可以将字符型、数字型数值转变成连续的整数,并将结果保存在⼀个新的变量中。
具体操作的过程如下:选择“Transform”菜单中的Automatic Recode命令,在出现的对话框中,从左边的变量列表中选择需要⾃动赋值的变量,将它添加到V ariable -> New Name框中,然后在下⾯New Name右边的⽂本框中输⼊新的变量名称,单击New Name按钮,将新的变量名添加到上⾯的框中。
聚类分析SPSS习题作业答案共37页

谢谢!
聚类分析SPSS习题作业答案
6
、
露
凝
无
游
氛
,
天
高
风
景
澈
。
7、翩翩新 来燕,双双入我庐 ,先巢故尚在,相 将还旧居。
8
、
吁
嗟
身
后
名
,
于
我
若
浮
烟
。
9、 陶渊 明( 约 365年 —427年 ),字 元亮, (又 一说名 潜,字 渊明 )号五 柳先生 ,私 谥“靖 节”, 东晋 末期南 朝宋初 期诗 人、文 学家、 辞赋 家、散1 Nhomakorabea0
、
倚
南
窗
以
寄
傲
,
审
容
膝
之
易
安
。
21、要知道对好事的称颂过于夸大,也会招来人们的反感轻蔑和嫉妒。——培根 22、业精于勤,荒于嬉;行成于思,毁于随。——韩愈
23、一切节省,归根到底都归结为时间的节省。——马克思 24、意志命运往往背道而驰,决心到最后会全部推倒。——莎士比亚
文 家 。汉 族 ,东 晋 浔阳 柴桑 人 (今 江西 九江 ) 。曾 做过 几 年小 官, 后辞 官 回家 ,从 此 隐居 ,田 园生 活 是陶 渊明 诗 的主 要题 材, 相 关作 品有 《饮 酒 》 、 《 归 园 田 居 》 、 《 桃花 源 记 》 、 《 五 柳先 生 传 》 、 《 归 去来 兮 辞 》 等 。
《统计分析与SPSS的应用第五版》课后练习答案第10章.doc

《统计分析与S P S S的应用(第五版)》(薛薇)课后练习答案第10章SPSS的聚类分析1、根据“高校科研研究.sav”数据,利用层次聚类分析对各省市的高校科研情况进行层次聚类分析。
要求:1)根据凝聚状态表利用碎石图对聚类类数进行研究。
2)绘制聚类树形图,说明哪些省市聚在一起。
3)绘制各类的科研指标的均值对比图。
4)利用方差分析方法分析各类在哪些科研指标上存在显著差异。
采用欧氏距离,组间平均链锁法利用凝聚状态表中的组间距离和对应的组数,回归散点图,得到碎石图。
大约聚成4类。
步骤:分析→分类→系统聚类→按如下方式设置……结果:凝聚计划阶段组合的集群系数首次出现阶段集群下一个阶段集群 1 集群 2 集群 1 集群 21 26 30 328.189 0 0 22 26 29 638.295 1 0 73 20 25 1053.423 0 0 54 4 12 1209.922 0 0 155 8 20 1505.035 0 3 66 8 16 1760.170 5 0 97 24 26 1831.926 0 2 108 7 11 1929.891 0 0 119 5 8 2302.024 0 6 2210 24 31 2487.209 7 0 2211 2 7 2709.887 0 8 1612 22 28 2897.106 0 0 1913 6 23 2916.551 0 0 1714 10 19 3280.752 0 0 2515 4 21 3491.585 4 0 2116 2 3 4229.375 11 0 2117 6 13 4612.423 13 0 2018 9 18 5377.253 0 0 2519 14 22 5622.415 0 12 2420 6 15 5933.518 17 0 2321 2 4 6827.276 16 15 2622 5 24 7930.765 9 10 2423 6 27 9475.498 20 0 2624 5 14 14959.704 22 19 2825 9 10 19623.050 18 14 2726 2 6 24042.669 21 23 2827 9 17 32829.466 25 0 2928 2 5 48360.854 26 24 2929 2 9 91313.530 28 27 3030 1 2 293834.503 0 29 0将系数复制下来后,在EXCEL中建立工作表。
spss习题及其答案

spss习题及其答案
SPSS习题及其答案
SPSS(Statistical Package for the Social Sciences)是一种统计分析软件,广泛应用于社会科学和商业研究。
它可以帮助研究人员对数据进行分析、建模和预测。
在学习和使用SPSS的过程中,习题和答案是非常重要的,可以帮助我们更好地理解和掌握SPSS的使用方法和技巧。
下面是一些常见的SPSS习题及其答案,供大家参考:
1. 问题:如何在SPSS中导入数据?
答案:在SPSS中,可以通过“文件”菜单中的“打开”选项来导入数据,也可以直接拖拽数据文件到SPSS的工作区。
2. 问题:如何计算变量的描述性统计量?
答案:在SPSS中,可以使用“分析”菜单中的“描述统计”选项来计算变量的描述性统计量,包括均值、标准差、最大值、最小值等。
3. 问题:如何进行相关性分析?
答案:在SPSS中,可以使用“分析”菜单中的“相关”选项来进行相关性分析,可以计算变量之间的皮尔逊相关系数或斯皮尔曼相关系数。
4. 问题:如何进行回归分析?
答案:在SPSS中,可以使用“回归”选项来进行回归分析,可以进行简单线性回归、多元线性回归等不同类型的回归分析。
5. 问题:如何进行因子分析?
答案:在SPSS中,可以使用“因子”选项来进行因子分析,可以帮助研究人员发现变量之间的潜在结构和关联。
通过以上习题及其答案的学习和实践,我们可以更好地掌握SPSS的使用方法,提高数据分析的效率和准确性。
希望大家在学习SPSS的过程中能够多多练习,不断提升自己的数据分析能力。
SPSS习题及其答案是我们学习的好帮手,也是我们进步的动力。
第3章聚类分析答案

第3章聚类分析答案第三章聚类分析⼀、填空题1.在进⾏聚类分析时,根据变量取值的不同,变量特性的测量尺度有以下三种类型:间隔尺度、顺序尺度和名义尺度。
2.Q 型聚类法是按___样品___进⾏聚类,R 型聚类法是按_变量___进⾏聚类。
3.Q 型聚类统计量是____距离_,⽽R 型聚类统计量通常采⽤_相似系数____。
4.在聚类分析中,为了使不同量纲、不同取值范围的数据能够放在⼀起进⾏⽐较,通常需要对原始数据进⾏变换处理。
常⽤的变换⽅法有以下⼏种:__中⼼化变换_____、__标准化变换____、____规格化变换__、__ 对数变换 _。
5.距离ij d ⼀般应满⾜以下四个条件:对于⼀切的i,j ,有0≥ij d 、 j i =时,有0=ij d 、对于⼀切的i,j ,有ji ij d d =、对于⼀切的i,j,k ,有kj ik ij d d d +≤。
6.相似系数⼀般应满⾜的条件为:若变量i x 与 j x 成⽐例,则1±=ij C 、对⼀切的i,j ,有1≤ij 和对⼀切的i,j ,有ji ij C C =。
7.常⽤的相似系数有夹⾓余弦和相关系数两种。
8.常⽤的系统聚类⽅法主要有以下⼋种:最短距离法、最长距离法、中间距离法、重⼼法、类平均法、可变类平均法、可变法、离差平⽅和法。
9.快速聚类在SPSS 中由__K-mean_____________过程实现。
10.常⽤的明⽒距离公式为:()qp k q jk ik ij x x q d 11??-=∑=,当1=q 时,它表⽰绝对距离;当2=q 时,它表⽰欧⽒距离;当q 趋于⽆穷时,它表⽰切⽐雪夫距离。
11.聚类分析是将⼀批样品或变量,按照它们在性质上的亲疏、相似程度进⾏分类。
12.明⽒距离的缺点主要表现在两个⽅⾯:第⼀明⽒距离的值与各指标的量纲有关,第⼆明⽒距离没有考虑到各个指标(变量)之间的相关性。
13.马⽒距离⼜称为⼴义的欧⽒距离。
2020年spss期末考试题和答案

2020年spss期末考试题和答案一、单项选择题(每题2分,共20分)1. 在SPSS中,数据文件的扩展名是()。
A. .txtB. .csvC. .savD. .xls2. 在SPSS中,数据视图和变量视图分别对应于()。
A. 数据编辑和数据浏览B. 数据浏览和数据编辑C. 数据输入和数据输出D. 数据输出和数据输入3. 在SPSS中,执行描述性统计分析的菜单路径是()。
A. 分析 > 描述统计 > 频率B. 分析 > 描述统计 > 描述C. 分析 > 描述统计 > 探索D. 分析 > 描述统计 > 交叉表4. 在SPSS中,执行相关分析的菜单路径是()。
A. 分析 > 相关 > 双变量B. 分析 > 相关 > 偏相关C. 分析 > 相关 > 距离相关D. 分析 > 相关 > 聚类相关5. 在SPSS中,执行回归分析的菜单路径是()。
A. 分析 > 回归 > 线性B. 分析 > 回归 > 逻辑斯蒂C. 分析 > 回归 > 非线性D. 分析 > 回归 > 多项式6. 在SPSS中,执行因子分析的菜单路径是()。
A. 分析 > 降维 > 因子B. 分析 > 降维 > 聚类C. 分析 > 降维 > 对应分析D. 分析 > 降维 > 多维尺度分析7. 在SPSS中,执行聚类分析的菜单路径是()。
A. 分析 > 分类 > 聚类B. 分析 > 分类 > 系统聚类C. 分析 > 分类 > K均值聚类D. 分析 > 分类 > 层次聚类8. 在SPSS中,执行判别分析的菜单路径是()。
A. 分析 > 判别 > 线性判别B. 分析 > 判别 > 二次判别C. 分析 > 判别 > 逐步判别D. 分析 > 判别 > 非线性判别9. 在SPSS中,执行生存分析的菜单路径是()。
北语2024春《SPSS统计与分析应用》作业满分答案文档

北语2024春《SPSS统计与分析应用》作业满分答案文档问题一: 描述性统计分析数据收集首先,我们需要收集一组数据以进行描述性统计分析。
在此作业中,我们收集了100个学生的数学成绩数据。
描述性统计分析使用SPSS软件进行描述性统计分析,我们得到了以下结果:- 平均数:78.5- 标准差:9.2- 最小值:60- 最大值:95- 中位数:80- 四分位数:- 第一四分位数:72.5- 第二四分位数:80- 第三四分位数:85结论根据描述性统计分析结果,我们可以得出以下结论:- 这组学生的平均数成绩为78.5,说明整体水平中等偏上。
- 标准差为9.2,说明学生的成绩相对分散。
- 最低分为60,最高分为95,成绩分布较为广泛。
- 中位数为80,说明成绩的中等水平集中在80左右。
- 第一四分位数为72.5,第三四分位数为85,说明成绩的大部分集中在72.5到85之间。
问题二: 相关性分析数据收集我们收集了100个学生的数学成绩和英语成绩数据。
相关性分析使用SPSS软件进行相关性分析,我们得到了以下结果:- 相关系数:0.75- p值:0.001结论根据相关性分析结果,我们可以得出以下结论:- 数学成绩和英语成绩之间存在较强的正相关关系。
- 相关系数为0.75,接近于1,说明两个变量之间的关联程度较高。
- p值为0.001,小于显著性水平0.05,因此可以得出该相关关系是显著的。
问题三: T检验数据收集我们收集了两组学生的数学成绩数据:男生组和女生组。
T检验使用SPSS软件进行T检验,我们得到了以下结果:- T值:2.16- 自由度:98- p值:0.034结论根据T检验结果,我们可以得出以下结论:- 男生组和女生组的数学成绩之间存在显著差异。
- T值为2.16,自由度为98,p值为0.034,小于显著性水平0.05,因此可以得出这种差异是显著的。
问题四: 方差分析数据收集我们收集了三个不同班级的学生的数学成绩数据。
《统计分析与SPSS的应用(第五版)》课后练习答案(第10章)word版本

《统计分析与SPSS的应用(第五版)》(薛薇)课后练习答案第10章SPSS的聚类分析1、根据“高校科研研究.sav”数据,利用层次聚类分析对各省市的高校科研情况进行层次聚类分析。
要求:1)根据凝聚状态表利用碎石图对聚类类数进行研究。
2)绘制聚类树形图,说明哪些省市聚在一起。
3)绘制各类的科研指标的均值对比图。
4)利用方差分析方法分析各类在哪些科研指标上存在显著差异。
采用欧氏距离,组间平均链锁法利用凝聚状态表中的组间距离和对应的组数,回归散点图,得到碎石图。
大约聚成4类。
步骤:分析→分类→系统聚类→按如下方式设置……结果:凝聚计划阶段组合的集群系数首次出现阶段集群下一个阶段集群 1 集群 2 集群 1 集群 21 26 30 328.189 0 0 22 26 29 638.295 1 0 7 320251053.4235 44 121209.922155 8201505.035 03 66 8 16 1760.170 5 0 97 24 26 1831.926 0 2 108 7 11 1929.891 0 0 119 5 8 2302.024 0 6 2210 24 31 2487.209 7 0 2211 2 7 2709.887 0 8 1612 22 28 2897.106 0 0 1913 6 23 2916.551 0 0 1714 10 19 3280.752 0 0 2515 4 21 3491.585 4 0 2116 2 3 4229.375 11 0 2117 6 13 4612.423 13 0 2018 9 18 5377.253 0 0 2519 14 22 5622.415 0 12 2420 6 15 5933.518 17 0 2321 2 4 6827.276 16 15 2622 5 24 7930.765 9 10 2423 6 27 9475.498 20 0 2624 5 14 14959.704 22 19 2825 9 10 19623.050 18 14 2726 2 6 24042.669 21 23 2827 9 17 32829.466 25 0 2928 2 5 48360.854 26 24 2929 2 9 91313.530 28 27 3030 1 2 293834.503 0 29 0选中数据列,点击“插入”菜单 拆线图……碎石图:由图可知,北京自成一类,江苏、广东、上海、湖南、湖北聚成一类。
数据分析与SPSS软件应用试题及答案

数据分析与SPSS软件应用试题及答案一、填空题(每空2分,共20分)1.SPSS软件包含的运行方式有批处理方式、和。
2.Data菜单中,Insert variable的意义是。
3.SPSS中对变量进行加权操作的菜单是。
4.根据两组样本的关系,可将均值比较分为和。
5.单因素方差分析要求资料满足的基本条件是随机性、独立性、正态分布和。
6.两独立样本的曼-惠特尼U检验的原假设为。
7.简单相关分析包括定距变量的相关分析和变量的相关分析。
8.线性回归模型y=bx+a+e(a和b均为位置参数)中,e被称为。
二、选择题(每小题2分,共20分)1.SPSS输出文件的扩展名是()A spvB savC sasD sps2.下列不是SPSS对变量名称的制定规则的是()A 变量最后一个字符不能是句号。
B 不能使用空白字符或其他特殊字符(如“!”、“?”等)。
C变量命名可以有两个相同的变量名。
D 变量名称不区分大小写。
3.下列不属于测度数据集中趋势的统计量有()A 方差B 平均值C 中位数 D众数4.对于两配对样本T检验,其相关前提条件不正确的是?()A 样本是配对的B 总体服从正态分布C 样本观察数目相同D 观察值顺序可以随意改变5.下列关于方差分析说法错误的是( )A 判断因素的水平是否对因变量有影响,实际上就是比较组间方差与组内方差之间差异的大小B 组间方差包含系统误差和随机误差C 组间方差和组内方差的大小均与观测量大小有关D 在原假设成立的情况下,可以根据组间方差和组内方差的比值构造一个服从卡方分布的统计量6.与参数检验相比,非参数检验的主要特点是?()A 对总体的分布没有任何要求B 不依赖于总体的分布C 只考虑总体的位置参数D 只考虑总体的分布7.测定变量之间相关密切程度的指标是()A 均值 B协方差 C 相关系数 D标准差8.关于拟合优度的说法,下面表述正确的是()A 拟合优度越小,残差平方和小B 拟合优度越大,残差平方和大C 拟合优度与残差平方和无关D 拟合优度越小,残差平方和大9.聚类分析中,不属于小类与小类、样本与小类间聚类方法的是()A 最近邻元素法 B组间链接法 C质心聚类法 D 快速聚类法10.设A是载荷矩阵,则衡量(公共)因子重要性的一个量是()A A的列元素平方和B A的行元素平方和C A的元素平方和D A的元素三、判断题(每小题2分,共20分)1.SPSS可以用于多种格式数据之间的转换。
spss聚类分析例题

1.打开数据文件后,在数据编辑窗口中,从菜单栏中选择“分析”—“分类”—“k-均值
聚类”命令。
2.在该对话框中选择变量城市进入“个案标记依据”文本框,作为标签变量。
把聚类数标
记为4次。
3.选择变量一至十二月份的日照时数进入“变量”列表框作为观测变量。
4.单击“迭代”按钮,迭代次数为10次,收敛性标准为0.
5.单击“保存”按钮,选择“聚类成员”。
6.单击“选项”按钮,选择“初始聚类中心”和“ANOVA表”,要求输出方差分析表,单
击“继续”。
7.单击“确定”按钮,执行快速聚类分析。
[数据集1] C:\Documents and Settings\Administrator\桌面\ch9\主要城市日照时数.sav
每个聚类中的案例数。
聚类分析SPSS习题作业答案

-0.413 -0.467 -0.574
12
-0.962
0.072
0.536
-0.243 -0.763 -1.366 -0.596 -0.460 -0.679
13
-0.689
-0.400
0.435
-0.271 -0.636 -0.814 -0.502 -0.466 -0.625
14
-0.557
-0.891
8 8.762 5.928 4.456 4.226 6.675 1.480 2.817 .000 2.549 2.585 4.167 2.602 2.660 4.106 1.804 3.011 2.921 3.622 3.610 2.631 3.188
9 7.178 6.134 4.255 3.987 6.741 3.363 1.395 2.549 .000 .457 2.255 1.622 .972 2.721 1.319 1.760 1.440 1.671 1.918 1.407 2.108
7 95.416Biblioteka 0.801 71.106926.35
291.52 8.135 4.063 0.012
8 62.901
1.652 73.307 1 501.24
225.25 18.352 2.645 0.034
9 86.624
0.841 68.904
897.36
196.37 16.861 5.176 0.055
4 5.679 2.674 4.565 .000 3.827 4.440 4.068 4.226 3.987 3.861 4.664 4.337 4.059 4.151 4.073 3.943 3.371 3.386 3.090 3.400 2.885
华师15春《SPSS 统计软件》在线作业100分答案

华师《SPSS 统计软件》在线作业
一、单选题(共20 道试题,共40 分。
)
1. 频数分析中常用的统计图包括()
A. 直方图
B. 柱形图
C. 饼图
D. 树形图
正确答案:C
2. ()的功能是定义SPSS 数据的结构、录入编辑和管理待分析的数据。
A. 数据编辑窗口
B. 结果输出窗口
C. 数据视图
D. 变量视图
正确答案:A
3. SPSS 中进行参数检验应选择()主窗口菜单。
A. 视图
B. 编辑
C. 文件
D. 分析
正确答案:D
4. 下面偏度系数的值表明数据分布形态是正态分布的是()
A. 1.429
B. 0
C. -3.412
D. 1
正确答案:B
5. SPSS 的()就是将数据编辑窗口中数据的行列互换
A. 数据转置
B. 加权处理
C. 数据才分
D. 以上不都是
正确答案:A。
IBM SPSS数据统计分析练习题参考答案

IBM SPSS数据统计分析练习题参考答案1. 简介IBM SPSS(即Statistical Package for the Social Sciences)是一款功能强大的数据统计分析软件。
它提供了各种统计分析工具和技术,用于解释数据、预测趋势、进行模式识别和构建预测模型。
本文将提供一些IBM SPSS数据统计分析练习题的参考答案。
2. 描述性统计描述性统计是对数据进行初步分析的一种方法,通过计算数据的中心趋势、离散程度和分布形状等指标,帮助我们了解数据的特征和总体分布情况。
在IBM SPSS中,可以使用Descriptive Statistics命令进行描述性统计分析。
3. 相关性分析相关性分析用于研究两个或多个变量之间的关系。
在IBM SPSS中,可以使用Correlations命令计算变量之间的相关系数。
相关系数的取值范围为-1到1,其中-1表示完全负相关,1表示完全正相关,0表示无相关。
4. 回归分析回归分析用于研究自变量和因变量之间的关系,并构建预测模型。
在IBM SPSS中,可以使用Regression命令进行回归分析。
通过分析回归系数、显著性水平和方差解释比等指标,我们可以了解自变量对因变量的影响程度和预测能力。
5. 方差分析方差分析用于比较两个或多个样本的均值是否存在显著差异。
在IBM SPSS中,可以使用ANOVA(Analysis of Variance)命令进行方差分析。
通过分析组间方差和组内方差的比较,我们可以判断不同样本均值之间是否存在显著差异。
6. 非参数检验非参数检验是一种不依赖于总体分布形态的统计方法,用于比较样本之间的差异或关系的显著性。
在IBM SPSS中,可以使用Nonparametric Tests命令进行非参数检验,如Wilcoxon符号秩和检验、Mann-Whitney U检验、Kruskal-Wallis单因素方差分析等。
7. 因子分析因子分析是一种数据降维方法,用于识别和解释观测变量之间的潜在构念或因子。
spss作业,聚类分析
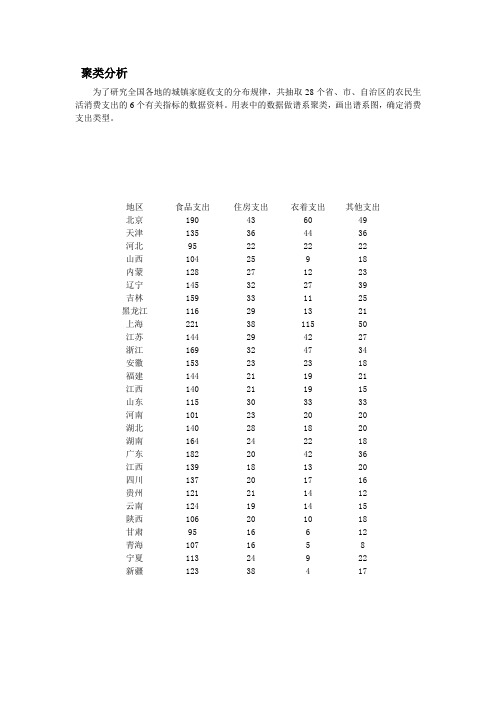
聚类分析为了研究全国各地的城镇家庭收支的分布规律,共抽取28个省、市、自治区的农民生活消费支出的6个有关指标的数据资料。
用表中的数据做谱系聚类,画出谱系图,确定消费支出类型。
地区食品支出住房支出衣着支出其他支出北京190 43 60 49天津135 36 44 36河北95 22 22 22山西104 25 9 18内蒙128 27 12 23辽宁145 32 27 39吉林159 33 11 25黑龙江116 29 13 21上海221 38 115 50江苏144 29 42 27浙江169 32 47 34安徽153 23 23 18福建144 21 19 21江西140 21 19 15山东115 30 33 33河南101 23 20 20湖北140 28 18 20湖南164 24 22 18广东182 20 42 36江西139 18 13 20四川137 20 17 16贵州121 21 14 12云南124 19 14 15陕西106 20 10 18甘肃95 16 6 12青海107 16 5 8宁夏113 24 9 22新疆123 38 4 17【结果与分析】一、欧氏距离平方、组间平均距离连接法Case Processing Summary(a)CasesValid Missing Total N Percent N Percent N Percent28 100.0 0 .0 28 100.0a Average Linkage (Between Groups)上表表示进行聚类分析的有效样品是28个,无缺失值。
Agglomeration ScheduleStageCluster CombinedCoefficientsStage Cluster FirstAppearsNext Stage Cluster 1 Cluster 2 Cluster 1 Cluster 21 14 21 15.000 0 0 62 22 23 22.000 0 0 123 4 24 30.000 0 0 104 3 16 45.000 0 0 155 8 27 51.000 0 0 106 14 20 55.500 1 0 87 13 17 67.000 0 0 88 13 14 82.167 7 6 169 12 18 123.000 0 0 1410 4 8 141.000 3 5 1511 25 26 161.000 0 0 1812 5 22 179.000 0 2 1613 2 10 215.000 0 0 1914 7 12 302.500 0 9 2215 3 4 310.750 4 10 1816 5 13 333.600 12 8 2017 11 19 342.000 0 0 2318 3 25 386.000 15 11 2519 2 6 396.500 13 0 2120 5 28 617.250 16 0 2221 2 15 833.667 19 0 2422 5 7 915.222 20 14 2423 1 11 1021.000 0 17 2624 2 5 1225.875 21 22 2525 2 3 1757.844 24 18 2626 1 2 5112.264 23 25 2727 1 9 18396.630 26 0 0上表表示聚类过程,从中可知,聚类共进行27步;第一步首先合并距离最近的14号和21号样品,形成类G1;因为next stage=6,所以在第6步G1和20号进行复聚类,因此,在Stage Cluster First Appears里列的Cluster 1=1,Cluster 2=0;第二步,合并22号和23号样品,形成类G2;因为next stage=12,所以在第12步,G2和第5号样品进行复聚类,且Cluster 1=0,Cluster 2=2;第一次出现类类的合并在第8步,Cluster 1=7,Cluster 2=6,表示第7步和第6步合并形成的类在第8步合并;其余的类似,不再详细叙述。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
对比检验:EXCEL处理后的结果
(2)欧氏距离测度21个单元距离
操作:菜单栏→分析→相关→距离
(2)欧氏距离测度21个单元距离
(2)欧氏距离测度21个单元距离
1 2 1 .000 6.343 2 6.343 .000 3 7.862 6.272 4 5.679 2.674 5 6.595 2.069 6 9.139 6.193 7 7.463 6.352 8 8.762 5.928 9 7.178 6.134 10 7.068 5.997 11 6.665 6.639 12 8.032 6.676 13 7.513 6.378 14 6.846 6.248 15 8.010 6.279 16 7.477 6.352 17 6.843 5.679 18 5.950 5.684 19 6.102 5.432 20 6.594 5.512 21 6.232 4.655 这是非相似性矩阵 3 7.862 6.272 .000 4.565 7.186 4.952 4.338 4.456 4.255 4.279 5.023 4.538 4.369 2.484 4.241 4.500 4.248 4.492 4.528 4.358 4.442 4 5.679 2.674 4.565 .000 3.827 4.440 4.068 4.226 3.987 3.861 4.664 4.337 4.059 4.151 4.073 3.943 3.371 3.386 3.090 3.400 2.885 5 6.595 2.069 7.186 3.827 .000 7.130 6.877 6.675 6.741 6.510 6.814 7.430 7.060 7.006 7.002 7.131 6.460 6.438 6.272 6.182 5.293 6 9.139 6.193 4.952 4.440 7.130 .000 3.340 1.480 3.363 3.474 4.861 2.831 3.210 4.817 2.514 3.429 3.500 4.074 4.041 3.218 4.169 7 7.463 6.352 4.338 4.068 6.877 3.340 .000 2.817 1.395 1.353 2.790 1.533 1.181 3.227 1.364 1.338 1.361 2.028 1.978 2.244 2.824 8 8.762 5.928 4.456 4.226 6.675 1.480 2.817 .000 2.549 2.585 4.167 2.602 2.660 4.106 1.804 3.011 2.921 3.622 3.610 2.631 3.188 9 7.178 6.134 4.255 3.987 6.741 3.363 1.395 2.549 .000 .457 2.255 1.622 .972 2.721 1.319 1.760 1.440 1.671 1.918 1.407 2.108 近似值矩阵 欧氏距离 10 11 12 7.068 6.665 8.032 5.997 6.639 6.676 4.279 5.023 4.538 3.861 4.664 4.337 6.510 6.814 7.430 3.474 4.861 2.831 1.353 2.790 1.533 2.585 4.167 2.602 .457 2.255 1.622 .000 2.229 1.852 2.229 .000 2.934 1.852 2.934 .000 1.172 2.517 .801 2.734 3.283 3.337 1.405 3.220 1.223 1.814 3.387 1.436 1.433 3.212 1.909 1.791 2.463 2.225 1.948 3.190 2.353 1.498 2.144 2.102 1.936 3.262 3.233 13 7.513 6.378 4.369 4.059 7.060 3.210 1.181 2.660 .972 1.172 2.517 .801 .000 2.940 1.048 1.129 1.350 1.703 1.832 1.738 2.576 14 6.846 6.248 2.484 4.151 7.006 4.817 3.227 4.106 2.721 2.734 3.283 3.337 2.940 .000 3.259 3.312 3.021 3.019 3.162 3.044 3.159 15 8.010 6.279 4.241 4.073 7.002 2.514 1.364 1.804 1.319 1.405 3.220 1.223 1.048 3.259 .000 1.319 1.494 2.346 2.281 2.000 2.580 16 7.477 6.352 4.500 3.943 7.131 3.429 1.338 3.011 1.760 1.814 3.387 1.436 1.129 3.312 1.319 .000 .957 1.896 1.527 2.428 2.678 17 6.843 5.679 4.248 3.371 6.460 3.500 1.361 2.921 1.440 1.433 3.212 1.909 1.350 3.021 1.494 .957 .000 1.466 .934 2.082 1.947 18 5.950 5.684 4.492 3.386 6.438 4.074 2.028 3.622 1.671 1.791 2.463 2.225 1.703 3.019 2.346 1.896 1.466 .000 .985 1.569 2.187 19 6.102 5.432 4.528 3.090 6.272 4.041 1.978 3.610 1.918 1.948 3.190 2.353 1.832 3.162 2.281 1.527 .934 .985 .000 2.154 2.031 20 6.594 5.512 4.358 3.400 6.182 3.218 2.244 2.631 1.407 1.498 2.144 2.102 1.738 3.044 2.000 2.428 2.082 1.569 2.154 .000 2.110 21 6.232 4.655 4.442 2.885 5.293 4.169 2.824 3.188 2.108 1.936 3.262 3.233 2.576 3.159 2.580 2.678 1.947 2.187 2.031 2.110 .000
5.402 5.79 8.413 3.425 5.593 8.701 12.945 12.654 8.461 10.078
spss聚类分析
数据导入
(1)标准差标准化
操作:菜单栏→分析→描述
标准差标准化结果
标准差标准化结果
标准差标准化后的数据表
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 3.904 0.442 -0.193 0.477 0.285 -0.696 -0.275 -0.781 -0.412 -0.337 -0.563 -0.962 -0.689 -0.557 -0.562 -0.215 0.084 0.442 0.384 0.071 0.151 -1.515 1.553 0.132 0.751 1.412 2.354 -0.481 1.479 -0.389 -0.456 -0.350 0.072 -0.400 -0.891 0.028 -0.819 -0.803 -0.628 -0.948 0.542 -0.642 -2.176 -1.718 0.592 -1.220 -2.148 1.185 0.900 1.023 0.777 0.642 -0.264 0.536 0.435 0.284 0.726 0.318 0.463 -0.045 0.049 -0.029 -0.331 -2.157 1.690 0.282 0.910 0.833 1.167 -0.347 1.071 -0.418 -0.384 -2.375 -0.243 -0.271 -0.598 0.465 0.454 0.442 -0.623 0.141 -0.644 0.607 0.382 1.960 0.129 0.975 3.310 -0.411 0.344 -0.322 -0.613 -0.310 -0.404 -0.763 -0.636 -0.696 -0.460 -0.366 -0.152 -0.642 -0.290 -0.825 -0.211 1.090 1.694 0.175 0.091 2.599 -0.921 -0.920 0.185 0.024 0.177 0.341 -1.366 -0.814 0.299 -0.599 -1.325 -0.642 -0.565 -0.770 0.158 1.090 2.641 1.737 -1.472 1.141 1.723 -0.596 -0.596 -0.915 -0.347 -0.242 -0.413 -0.596 -0.502 -0.224 -0.805 -0.473 -0.150 -0.063 0.260 -0.209 0.099 0.684 0.284 3.392 0.509 -0.311 -0.462 -0.461 -0.450 -0.439 -0.428 -0.467 -0.460 -0.466 2.143 -0.462 -0.462 -0.388 -0.461 -0.432 -0.443 -0.420 2.179 2.289 0.292 0.983 1.723 -0.753 -0.753 -0.980 -0.574 -0.805 -0.574 -0.679 -0.625 -0.266 -0.949 -0.652 -0.227 0.355 0.315 各个区域单元的有关数据, 下面请运用系统聚类法,对该农业生态经济系统进行聚类 分析, (1)用标准差标准化方法,对9项指标的原始数据进行 处理; (2)采用欧氏距离测度21个区域单元之间的距离;