海量数据挖掘技术研究刘君强
厦门大学信息检索大作业
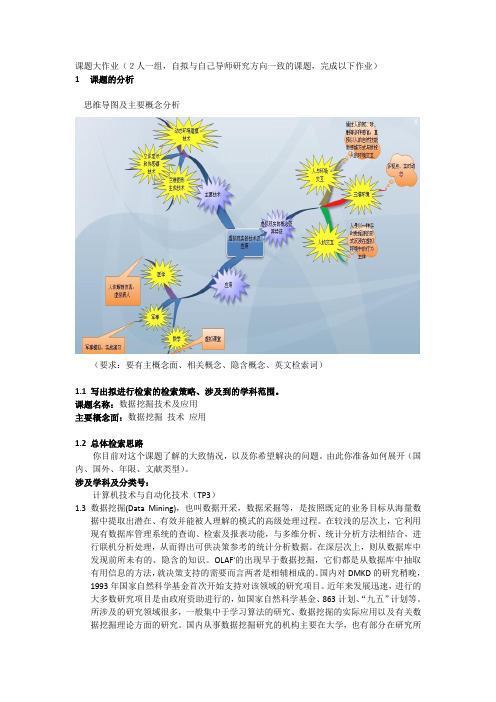
课题大作业(2人一组,自拟与自己导师研究方向一致的课题,完成以下作业)1课题的分析思维导图及主要概念分析(要求:要有主概念面、相关概念、隐含概念、英文检索词)1.1写出拟进行检索的检索策略、涉及到的学科范围。
课题名称:数据挖掘技术及应用主要概念面:数据挖掘技术应用1.2总体检索思路你目前对这个课题了解的大致情况,以及你希望解决的问题。
由此你准备如何展开(国内、国外、年限、文献类型)。
涉及学科及分类号:计算机技术与自动化技术(TP3)1.3数据挖掘(Data Mining),也叫数据开采,数据采掘等,是按照既定的业务目标从海量数据中提取出潜在、有效并能被人理解的模式的高级处理过程。
在较浅的层次上,它利用现有数据库管理系统的查询、检索及报表功能,与多维分析、统计分析方法相结合,进行联机分析处理,从而得出可供决策参考的统计分析数据。
在深层次上,则从数据库中发现前所未有的、隐含的知识。
OLAF'的出现早于数据挖掘,它们都是从数据库中抽取有用信息的方法,就决策支持的需要而言两者是相辅相成的。
国内对DMKD的研究稍晚,1993年国家自然科学基金首次开始支持对该领域的研究项目。
近年来发展迅速,进行的大多数研究项目是由政府资助进行的,如国家自然科学基金、863计划、“九五”计划等。
所涉及的研究领域很多,一般集中于学习算法的研究、数据挖掘的实际应用以及有关数据挖掘理论方面的研究。
国内从事数据挖掘研究的机构主要在大学,也有部分在研究所或公司。
这些单位包括清华大学、中科院计算技术研究所、空军第三研究所、海军装备论证中心等。
2搜索引擎(百度、谷歌、scirus):选择百度作为搜引擎2.1检索策略:如下图所示2.2找到的结果(截图第一页)2.3你选定的最相关的结果(要求必须可直接看原文)2.4 说明选择该文的原因,从中你是否有新的想法(线索)选择本文的原因是既涉及到数据挖掘这方面相关知识的研究与应用其次是与要检索的应用领域,也就是数据挖掘在航天或者军事方面的领域相吻合,并且在时间上也相对比较近。
基于三层过滤的评价对象抽取

基于三层过滤的评价对象抽取
牛振东;刘沙
【期刊名称】《北京理工大学学报》
【年(卷),期】2016(36)11
【摘要】针对互联网中的产品评论信息,提出一种三层过滤的评价对象抽取方法.该方法采用一个自举式的抽取算法在评论文本中得到候选的评价对象和情感词;利用评价对象与情感词之间的关联度对候选词进行关联置信度计算,提取关联置信度高的评价对象以提高识别的准确率;引入一个不相关的平行领域对剩余的候选词进行领域置信度计算,挖掘低频的评价对象.3个公开数据集中的实验结果表明该方法能够显著地提高评价对象的识别效果.
【总页数】6页(P1154-1159)
【关键词】评价对象抽取;情感词;关联置信度;领域置信度
【作者】牛振东;刘沙
【作者单位】北京理工大学计算机科学技术学院;北京市海量语言信息处理与云计算应用工程技术研究中心
【正文语种】中文
【中图分类】TP391
【相关文献】
1.基于LSTM网络的评价对象和评价词抽取 [J], 李盛秋;赵妍妍;秦兵;刘挺
2.基于LSTM网络的评价对象和评价词抽取 [J], 李盛秋;赵妍妍;秦兵;刘挺;
3.基于多层关系图模型的中文评价对象与评价词抽取方法 [J], 廖祥文;陈兴俊;魏晶晶;陈国龙;程学旗
4.基于胶囊特征聚合的评价词和评价对象抽取 [J], 康刚;吴四九;方睿
5.基于胶囊特征聚合的评价词和评价对象抽取 [J], 康刚;吴四九;方睿
因版权原因,仅展示原文概要,查看原文内容请购买。
云计算下的一种数据挖掘算法的研究

云计算下的一种数据挖掘算法的研究刘继华1,强彦2(1.吕梁学院,山西吕梁033000;2太原理工大学,太原030024)摘要:如何进行云计算下的数据挖掘一直以来都是研究的重点,本文针对传统挖掘算法K-meas 的不足,提出基于数据采样和分布密度的改进方法来获取算法的中心点,在聚类中构造函数提高了聚类效果,并对云计算下的Map/Reduce 模型进行了函数改进,仿真实验通过对不同的数据集进行实验,从聚类分析比较,系统运行时间,加速比等方面说明了本文的算法适合在云计算下的数据挖掘具有一定的优越性。
关键词:云计算;K-meas ;Map/Reduce 模型;中心点;聚类中图分类号:TP301.6文献标识码:A文章编号:1001-7119(2016)12-0133-05Research into a Data Mining Algorithm in Cloud ComputingLiu Jihua 1,Qiang Yan 2(1.Luliang Unvierstiy ,Shanxi Luliang 033000,China ;2.Taiyuan University of Technology ,Shanxi Taiyuan 030024,China )Abstract :How to conduct data mining in cloud computing has always been the focus of research.Aiming at the deficiency of traditional mining algorithm ,this paper proposes the data sampling and distribution density improvement method to obtain the center point of algorithm,constructs the function in the clusterto improve the effect of cluster,and improves the function of Map/Reduce model in cloud computing.Simulation experiments shows that algorithm in this paper is suitable for data mining in cloud computing and has certain superiority.Keywords :cloud computing ;Map/Reduce model ;center point ;cluster收稿日期:2016-02-15基金项目:吕梁学院自然基金(zrxn201507);山西省教育厅教改项目(J2014120)。
《人力资源数据分析师:HR数据化分析思维与数据建模》随笔

《人力资源数据分析师:HR数据化分析思维与数据建模》阅读札记目录一、内容概括 (2)1.1 背景与意义 (3)1.2 研究目的与内容 (4)二、人力资源数据化分析概述 (5)2.1 数据化分析的定义与优势 (7)2.2 数据化分析的流程与关键环节 (8)2.3 数据化分析与传统分析的区别与联系 (9)三、数据挖掘与预处理 (10)3.1 数据挖掘的概念与方法 (11)3.2 数据清洗与预处理的技巧 (13)3.3 数据转换与特征工程 (14)四、人力资源数据建模 (16)4.1 模型构建的重要性 (17)4.2 常用数据建模方法介绍 (19)4.3 模型评估与优化策略 (20)五、案例分析 (21)5.1 案例一 (23)5.2 案例二 (24)5.3 案例三 (26)六、数据安全与隐私保护 (28)6.1 数据安全性的重要性 (29)6.2 数据隐私保护法规与标准 (30)6.3 数据安全技术应用 (32)七、未来趋势与挑战 (33)7.1 人工智能在人力资源数据分析中的应用 (34)7.2 数据驱动的人力资源管理变革 (36)7.3 隐私保护与合规性挑战 (38)八、结语 (39)8.1 主要内容回顾 (40)8.2 研究体会与展望 (42)一、内容概括《人力资源数据分析师:HR数据化分析思维与数据建模》一书主要探讨了人力资源领域中的数据分析思维与数据建模方法。
本书内容分为几个主要部分,全面介绍了人力资源数据分析师所需的知识与技能。
书籍介绍了人力资源数据分析的基本概念及其重要性,阐述了在人力资源管理过程中,如何通过数据分析来优化人力资源配置,提高组织效率。
书籍深入讲解了数据化分析思维的培养,包括如何收集、整理、分析和解读人力资源数据,如何将数据分析融入日常工作中,如何通过数据驱动决策,以及如何利用数据分析解决实际问题。
书籍详细介绍了数据建模在人力资源领域的应用,包括数据建模的基本概念、原理和方法,如何构建适合组织的人力资源数据模型,以及如何利用数据模型进行预测和优化。
基于XGBoost算法的电商用户重复购买行为预测

㊀收稿日期:2022-09-07基金项目:中央高校基本科研业务费专项资金资助项目(19JNQM25)ꎻ广州市哲学社会科学发展 十四五 规划课题(2021GZYB18)ꎻ深圳市哲学社会科学规划课题(SZ2022B014)作者简介:景秀丽(1979-)ꎬ女ꎬ辽宁营口人ꎬ博士ꎬ硕士生导师ꎬ副教授ꎬ研究方向:大数据ꎬ文本处理ꎬ电子商务等.㊀㊀辽宁大学学报㊀㊀㊀自然科学版第50卷㊀第2期㊀2023年JOURNALOFLIAONINGUNIVERSITYNaturalSciencesEditionVol.50㊀No.2㊀2023基于XGBoost算法的电商用户重复购买行为预测景秀丽1ꎬ史明曦2(1.暨南大学深圳旅游学院ꎬ广东深圳518052ꎻ2.圣路易斯华盛顿大学奥林商学院ꎬ美国密苏里州圣路易斯63130)摘㊀要:机器学习算法广泛应用于电商用户行为数据分析及商业预测.其中ꎬXGBoost算法作为一种常用的有监督机器学习算法ꎬ能够实现电商用户行为特征最优选择与行为模型构建㊁评估消费价值㊁预测重复购买行为概率㊁提高商业决策的精准性与可行性.本研究采用阿里云天池大数据竞赛 天猫复购预测 所提供的 双十一 电商购物节关联数据集中约42万电商平台用户产生的5500万条行为数据ꎬ基于促销活动情境完成特征构造ꎬ实现有监督分类学习.本研究实现了XGBoost算法的参数优化与数据特征值处理过程优化ꎬ完成了促销活动后6个月内电商用户重复购买行为的预测模型演算.结果表明:优化后的XGBoost算法能够比较精准地预测电商用户重复购买行为㊁评估在线用户潜在购买价值㊁实现精准营销以及真正促进促销活动的长期投资回报率提高.关键词:XGBoost算法ꎻ集成学习ꎻ特征工程ꎻ重购预测ꎻ精准营销中图分类号:TP391㊀㊀㊀文献标志码:A㊀㊀㊀文章编号:1000-5846(2023)02-0134-12RepurchasePredictionofE ̄CommerceUserBasedonXGBoostJINGXiu ̄li1ꎬSHIMing ̄xi2(1.ShenzhenTourismCollegeꎬJinanUniversityꎬShenzhen518053ꎬChinaꎻ2.OlinBusinessSchoolꎬWashingtonUniversityinSt.LouisꎬSt.Louis63130ꎬU.S.A)Abstract:㊀MachinelearningiswidelyusedinE ̄commerceuserbehavioranalysisandE ̄commerceplatformbusinessforecasts.XGBoostisacommonlyusedsupervisedensemblelearningalgorithm.Itcanbeusedtoconstructpreciseusersᶄbehaviormodelsꎬthusevaluatingcustomervalueꎬandpredictingtheirrepurchaseprobabilityꎬaswellasimprovingbusinessdecisionsᶄprecisionandfeasibility.Thisresearchadoptstheuserrepurchasedatasetrelatedtothe DoubleEleven shoppingeventofferedbyAlibabaTianchiꎬwhichcollectsupto55millionbehavioraldatageneratedby420thousandusersꎬconstructsfeaturesbasedonthepromotionbackgroundandconductssupervisedlearning.ThisresearchoptimizestheXGBoostparametertuningandfeature㊀㊀processingꎬandconstructsarepurchaseforecastmodelforspecificuser ̄sellerpairsonasix ̄monthperiodafterthepromotion.TheresultindicatesthattheoptimizedalgorithmXGBoostcanpreciselypredictE ̄commerceuserrepurchasebehaviorandbeusedinevaluatingusersᶄpotentialinrepurchaseꎬimprovingE ̄commerceplatformsᶄprecisionmarketingandtrulyimprovingthelong ̄termROI(ReturnonInvestment)ofpromotionevents.Keywords:㊀XGBoostꎻensemblelearningꎻfeatureengineeringꎻrepurchasepredictionꎻprecisionmarketing0㊀引言我国电子商务行业的发展历经二十多年ꎬ在线零售市场不断创新和扩展ꎬ推动了新经济业态的成长与进步.Statista全球统计数据库的«2021年电子商务报告»显示ꎬ中国是目前世界最大和渗透率最高的电子商务市场.国内各大在线零售平台发展迅速ꎬ在激烈竞争中为了吸引用户源和争夺市场份额ꎬ积极探索促销活动形式与种类ꎬ例如天猫淘宝的 双十一购物狂欢节 ㊁京东的 618 购物节等.多样化高频率的购物节给平台引流了大量新用户(促销活动中出现首次购买行为的用户)和短期高成交额.陈可旺[1]分析促销作为一种短期刺激性工具ꎬ虽然能够有效激发用户对特定商品服务进行立即购买的欲望ꎬ但是电商平台更需要锁定长期持续的有效收益.Rosenberg等[2]提出企业重视客户留存并且开发一个新客户所需的成本是维护一个老客户所需成本的6倍.陈龙[3]研究表明电商平台及商家有必要确定哪些用户有可能转化为重复购买者ꎬ并对这些潜在忠诚用户进行精准营销ꎬ降低促销成本ꎬ提高投资回报率.蔡一凡[4]做了用户聚类和特征选择的在线购买行为研究.张李义等[5]聚焦新消费者重复购买意向的预测研究.当前对用户重复购买行为预测方法主要有两类方法ꎬ一是以Pareto/NBD(Negativebinomialdistribution)㊁MBG(Modifiedbetageometric)/NBD为代表的概率模型ꎬ二是以决策树㊁逻辑回归㊁SVM(Supporvectormachine)为代表的机器学习模型[6].基于海量数据的机器学习算法为电商平台精准地把握消费者偏好需求㊁预测消费者行为㊁评估客户价值提供了有效分析方法ꎬ采用数据挖掘技术能够运用多维变量进行预测ꎬ结果更加客观真实[7].电商平台用户数据对象涵盖用户信息㊁商品信息㊁商家信息ꎬ用户在网站上浏览商品时产生的一系列在线行为数据(如登录㊁点击㊁收藏㊁购买㊁评论㊁咨询客服等)ꎬ并且实时在网站日志中进行同步ꎬ构成了海量丰富的大数据集.通过对大数据集进行分析ꎬ电商平台可以提取出用户的需求㊁偏好㊁购买能力等价值信息ꎬ完成重复购买行为预测模型设计[8].消费者重复购买的预测问题转化为消费者是否将重复购买的分类问题ꎬ运用机器学习中的分类算法进行有监督训练.例如Rahim等[9]基于RFM(Recencyꎬfrequencyꎬmonetaryvalue)模型研究客户重复购买行为ꎬ运用SVM算法和决策树算法对客户进行分类ꎬ准确率超过了97%.相比单种算法构建的预测模型ꎬ集成学习方法通过串行或并行的方式将多个弱监督模型进行组合ꎬ可以进一步提高模型预测的准确性ꎬ代表算法有随机森林算法和GBDT(Gradient ̄boosteddecisiontrees)算法等ꎻ或运用多模型融合策略ꎬ将不同类型算法训练出的模型以Stacking㊁Voting㊁Blending㊁Ranking等方法进行531㊀第2期㊀㊀㊀㊀㊀㊀景秀丽ꎬ等:基于XGBoost算法的电商用户重复购买行为预测㊀㊀融合ꎬ提高模型的准确率和泛化能力[10].胡晓丽等[11]基于集成学习对用户重购行为进行预测ꎬ引入 分段下采样 的方法解决类别不平衡问题ꎬ并用Stacking融合了RandomForest㊁XGBoost㊁LightGBM构建预测模型ꎬ结果表明ꎬStacking方法能够带来0.4%至2%的AUC(Areaunderthereceiveroperatingcharacteristiccurve)提升.吕泽宇等[12]使用了LightGBM和XGBoost两种方法构建模型ꎬ并用Hyperopt进行参数搜索ꎬ证明该方法只需少量特征即可达到较好的预测效果.基于先进的机器学习算法ꎬ引入特征工程设计ꎬ也是数据挖掘的关键技术之一.机器学习算法用于解决多个领域多个方向问题ꎬ学习效果如何很大程度上依赖于特征工程中提取的特征是否真正贴合业务需要ꎬ这一过程需要结合许多研究领域的专家知识.文献研究发现ꎬ针对电商购物节后消费者重复购买行为预测研究不多ꎬ通过提取特征值ꎬ结合促销活动变量对消费者行为产生的特殊影响ꎬ可构建更精准的重复购买预测模型.此外ꎬ运用天猫大数据平台提供的公开数据集ꎬ针对促销前和促销中的用户短期行为等数据维度提取更加详细的特征值ꎬ运用XGBoost集成学习算法构建电商购物节后新用户重复购买行为预测模型ꎬ提高预测能力.1㊀算法背景决策树算法在机器学习中常用于预测和分类ꎬ是一种有监督的机器学习方法.在数据复杂的情况下ꎬ使用单一决策树进行预测有时无法取得较好的效果.Kearns等[13]认为可通过集成学习将弱学习算法提升为强学习算法.集成算法主要有Bagging和Boosting两类.其中Boosting提升算法由Schapire[14]通过构造多项式级算法ꎬ率先提出验证Kearns弱学习算法提升的思路ꎬ其各个相互依赖的分类器串行ꎬ根据预测能力的不同ꎬ预测函数的权重也不同.陈凯等[15]研究表明ꎬ在训练的过程中增加对分类错误样本的学习权重ꎬ在迭代中能够不断调整和持续提高准确度ꎬ将各个基学习器进行加权集成输出最终结果.XGBoost算法全称eXtremeGradientBoostꎬ由Chen等[16]在经典Boosting算法GBDT的基础上改进提出ꎬ在计算速度上表现优秀.XGBoost的核心思想是采用向前分布算法ꎬ每轮迭代产生的弱分类器都在上一轮迭代的残差基础上继续训练ꎬ通过不断减小残差来实现回归和分类ꎬ并将CART(Classficationandregressiontree)分类回归树作为基学习器.XGBoost算法的目标函数由损失函数和复杂度函数相加而成ꎬ模型误差小ꎬ更加简单ꎬ可防止过拟合ꎬ使用梯度提升法可使目标函数最小化.其目标函数在经过泰勒二次展开后可以简化为Obj=-12ðTj=1Gj2Hj+λ+γT(1)式中:T为叶子节点数ꎻγ为学习率限制叶子节点个数ꎻλ为正则化参数限制叶子节点分数ꎻGj为一阶导数ꎻHj为二阶导数.在每棵树选择特征进行分裂时ꎬXGBoost使用的是贪心法ꎬ遍历特征计算每个节点的分裂收益ꎬ选择增益最大的特征进行分裂:Gain=12GL2HL+λ+GR2HR+λ-(GL+GR)2HL+HR+λ[]-γ(2)即用分割后的目标函数值减去分割前的目标函数值ꎬ当增益大于γ阈值时ꎬ树才分裂ꎬ这样目标函数在优化的同时也实现了预剪枝.当数据量极大时贪心算法十分耗费内存ꎬ对此XGBoost算法还提出了一种近似搜索方法ꎬ在难以精确搜索情况下运用全局近似或者局部近似选取候选分裂点ꎬ再从中选择最佳分裂点ꎬ结果同样具有准确性.通过调用Python开发环境的XGBoost工具包进行重复631㊀㊀㊀辽宁大学学报㊀㊀自然科学版2023年㊀㊀㊀㊀购买行为的预测.2㊀数据采集与分析2.1㊀数据集数据集来源于阿里云天池大数据平台 天猫复购预测大赛 的公开数据集.该数据集包含了424170名匿名用户的基本信息以及他们在 双十一购物狂欢节 前6个月以及 双十一购物狂欢节 当天的交互行为记录和购物记录ꎬ同时标记了这些用户在购物节后6个月是否有重复购买行为.数据集一共包括 用户信息表 用户行为日志表 用户-商家消费行为表 3张数据表ꎬ提供了 用户编号 用户年龄范围 用户性别 商品编号 商品类别编号 商品品牌编号 商家编号 行为时间 行为类型 9个属性.数据初筛发现ꎬ数据集的样本用户皆有过一次以上的购买记录ꎬ且 双十一购物狂欢节 期间都有首次进行消费的商家.用户信息表和用户行为表包含了所有样本用户的相关数据.为满足模型训练及测试的需求ꎬ天池大数据平台提供的数据集将样本用户分为数量相当的两部分ꎬ并分别归入电商用户行为模型的训练集和测试集之中.其中训练集中的label字段已经完成对用户的标签化ꎬ即标明用户在 双十一购物狂欢节 后是否会重复购买ꎬ用于有监督学习对模型进行分类训练ꎻ而测试集中的prob字段表示预测用户是否在促销活动后重复购买ꎬ在模型训练后对无标签对象进行预测.2.2㊀数据清洗2.2.1㊀缺失值处理原数据集用户信息表中的age_range(用户年龄范围)字段有92914条缺失值㊁gender(用户性别)字段有10426条缺失值ꎬ缺失值在属性中占比较大ꎬ使用均值替换法在已有数据中寻找缺失数据的最可能值.购买同一产品的用户群体往往具有相似的年龄和性别.对应数据处理流程包括:首先ꎬ在用户信息表中获取缺失年龄或性别属性用户对应的user_id(用户编号)ꎬ通过这些user_id在用户行为日志表中寻找属性值缺失用户购买过的所有商品的item_id(商品编号)ꎻ其次ꎬ在用户行为表中寻找购买过这些商品的其他用户的编号ꎬ通过用户信息表得到这些用户的年龄范围或性别属性ꎬ以此计算商品用户群的平均年龄范围或性别属性ꎻ最后ꎬ以所有已购商品的平均用户年龄和性别的平均值填补该用户缺失的年龄或性别属性.用户行为日志表中的brand_id(商品品牌编号)字段有91015个缺失值ꎬ但由于同一商家售卖同一类别的同一商品ꎬ其品牌应当是相同的ꎬ其中大部分的缺失值可以通过与item_id(商品编号)ꎬcat_id(商品类别编号)ꎬseller_id(商家编号)进行匹配找回.2.2.2㊀数据转换在特征构造过程中需要按照时间进行数据提取ꎬ而原字段 time_stamp 时间戳以mmdd标识ꎬ如5月11日记为 0511 的string类型数据ꎬ来记录用户在线行为发生时间ꎬ无法进行数学运算ꎬ因此在数据集成时对 time_stamp 时间戳进行转换并添加一个int类型的新字段 day ꎬ用来表示用户在线行为发生时间在从5月11日至11月11日这185d的时间周期内所处的位置ꎬ如将 0511 转化为 1 ꎬ将 1111 转化为 185 ꎬ这样就不必考虑每月天数之间的差异并可以按时间进行数据提取.3㊀特征工程特征工程即对原始数据进行一系列处理的工程ꎬ最大限度地提炼出特征ꎬ作为输入供模型和算731㊀第2期㊀㊀㊀㊀㊀㊀景秀丽ꎬ等:基于XGBoost算法的电商用户重复购买行为预测㊀㊀法使用.特征工程是对数据进行理解㊁表示和展示的过程ꎬ其在实际过程中要求尽可能地去除原始数据里的噪声ꎬ提炼出更加高效的特征以供预测模型调用解决问题.高质量特征对于提高模型的性能和精准度有很大意义.特征工程需要结合多学科知识ꎬ首先对电商用户重复购买行为的影响因素模型进行分析.用户自身属性方面ꎬ徐鹏鹏[17]构建结构方程模型研究用户重复购买电商品牌的影响因素ꎬ认为客户的个人特征㊁质量关注㊁感知价值㊁网购依赖及购物满意度会造成影响.商品属性方面ꎬ李海霞[18]根据环境心理学理论和社会交换理论ꎬ认为客户面对与商家在口碑㊁技术㊁人员㊁产品等服务接触时产生的刺激ꎬ会对社会关系及经济关系进行是否满意和信任的考量ꎬ从而决定是否重复购买.在用户与商家间的交互关系上ꎬ经典的RFM模型通过客户最近一次的消费时间㊁消费频度和消费金额对客户价值进行衡量.针对电商行业特点ꎬ李敏等[19]在RFM模型的基础上加入客户对商品满意度和关注度的考量ꎬ构建RFMSA(Recencyꎬfrequencyꎬmonetaryꎬstatisfactionꎬattention)模型对用户忠诚度进行分类.薛红松等[20]验证了电商客户重购行为和商家商品销量和排名符合幂律分布ꎬ重购行为倾向于在一定时期内集中发生ꎬ且随着购买次数增加ꎬ重购周期将缩短ꎬ状态趋向稳定.由此可见ꎬ当前针对电商用户重复购买行为影响因素的研究ꎬ很多学者尚未将商家推广促销和电商平台购物节活动等纳入具体分析.促销刺激可以加速新用户与商家产生交互关系ꎬ也增加了对新用户价值判断的难度.对新老客户重复购买意愿的不同特点ꎬ卢美丽等[21]考虑了购买强化效应ꎬ并验证受此影响顾客购买次数可呈幂律分布或广延指数分布ꎬ即可将客户分为易受促销影响的提升区顾客和已形成购物惯性的稳定区顾客.结合上述研究以及数据集提供的有限信息ꎬ本研究将在特征提取时构建4大类特征ꎬ即用户特征㊁商家特征㊁关系特征㊁促销特征.原数据集的可用特征维度较低ꎬ因此在提取原特征之外还需要通过对原属性进行分割和结合ꎬ构造出新的特征.商家特征考虑商家热度㊁口碑㊁产品对重复购买的影响ꎻ用户特征考虑其人口特征㊁网购依赖度㊁网购信任度㊁稳定忠诚度ꎻ交互特征考虑用户对商家的交互时间㊁交互频次ꎻ促销特征考虑商家的促销力度以及用户的价格敏感度.如图1所示.图1㊀特征工程设计3.1㊀用户特征用户特征是对用户个人属性和购物偏好的描述ꎬ包括人口特征㊁网购依赖度㊁网购信任度㊁稳定度ꎬ会对其是否重复购买造成影响.多数研究者会从原始数据集的用户信息表中提取用户人口特征数据ꎬ参照此方法ꎬ本研究基于所用数据集中的用户信息表提取用户年龄和性别数据ꎬ探究其对消费831㊀㊀㊀辽宁大学学报㊀㊀自然科学版2023年㊀㊀㊀㊀者的购买行为和购买偏好的影响作用ꎬ即将上述两类数据属性作为原特征进行提取[14].网购依赖度则体现用户是否为电商平台的重度使用者ꎬ主要考虑其活跃度和使用深度.用户行为日志表中记录了用户在促销活动前和促销活动中的6个月内在平台内点击㊁加入购物车㊁购买收藏的行为.用户各类行为频次越高ꎬ登录天数越多ꎬ说明其对平台越忠实ꎬ具有更高的维护价值.因此可以从行为日志表统计出用户的点击总次数㊁加入购物车总次数㊁购买总次数㊁收藏总次数㊁登录总天数㊁购买总天数作为特征.另一方面ꎬ相较于只在平台购买小部分类别产品的用户ꎬ部分用户对平台使用程度更深ꎬ运用平台满足其大部分购物需求ꎬ有更高的重复购买可能性.可以据此统计用户购买类别总数㊁购买品牌总数㊁购买不同商品总数这几个特征.网购信任度代表用户对电商产品可靠性的认知以及对性价比的敏感度.一些用户属于冲动型消费者ꎬ在电商平台上查询到喜欢的商品之后无需多做了解就能提交订单ꎻ一些用户属于理智型消费者ꎬ在选购商品时习惯货比三家ꎬ争取最大可能以更优惠的价格买到性价比高的商品.通过用户行为日志表可以计算用户购买行为和非购买行为所有操作的比例ꎬ即购买行为占比和非购买行为占比ꎬ以及非购买行为的购买转化率ꎬ计算公式为用户操作行为占比=用户某种操作行为总次数用户所有操作行为总次数(3)非购买行为转化率=购买行为次数各种非购买行为总次数(4)用户稳定度说明用户转移购买的难易程度.电商平台产品质量相对难以直接判断ꎬ一些高稳定度用户在积攒购物经验ꎬ找到自己满意的商家后ꎬ会倾向于在该商家进行持续的购买以节省搜寻试错成本ꎬ有更高的重复购买可能性.此处重复购买者指的是在某商家购买天数超过两天的用户ꎬ可以对用户购买商家总数㊁用户重复购买次数㊁用户重复购买商家总数㊁重复购买率进行统计计算ꎬ公式如下:用户重复购买率=所有重复购买过的商家所有购买过的商家(5)3.2㊀商家特征商家特征描述的是商家的形象和吸引力ꎬ商家的热度㊁口碑以及产品特征会对重复购买决策造成影响.商家热度反映商家的客户及潜在客户数量ꎬ商家的热度越高说明其吸引顾客完成订单的能力越强.可以构建出商家被点击总次数㊁被加入购物车总次数㊁被购买总次数㊁被收藏总次数等特征.商家口碑及其客户满意度是用户决定是否重复购买的关键因素.如果有更多用户在查看㊁加购㊁收藏商家商品ꎬ进行多重信息搜集和产品比较后ꎬ最终能够完成转化进行购买ꎬ说明商家在信誉㊁价格等方面能够让顾客信任ꎬ有较好的口碑ꎬ这也将增加再次购买的可能性.据此构造商家的点击购买转化率㊁加购购买转化率㊁收藏购买转化率.此外购买者总数和重复购买者总数也是商家口碑的一个重要考量因素ꎬ重复购买率越大ꎬ说明其客户满意度越高.可构建的特征有商家购买者总数㊁重复购买者总数㊁重复购买率.重复购买率的计算公式是重复购买率=重复购买者总数购买者总数(6)商家产品类型和特点也会影响用户在店内重复购买的意向ꎬ商家的产品种类越丰富ꎬ越能吸引931㊀第2期㊀㊀㊀㊀㊀㊀景秀丽ꎬ等:基于XGBoost算法的电商用户重复购买行为预测㊀㊀用户进行搜索.因此统计出商家种类总数㊁品牌总数㊁商品总数的特征ꎬ将商家对用户吸引力进一步量化.3.3㊀交互特征交互特征描述的是每条记录中指定用户和商家之间存在的关系ꎬ关系越强ꎬ再次购买的可能性越大.关系强度可以通过最近一次交互行为的时间㊁交互频次体现.最近一次行为发生的时间越相近ꎬ说明用户近期对商家越关注ꎬ因此要计算用户最近一次与商家发生交互行为距离 双十一狂欢购物节 促销活动的天数.而用户对商品进行点击㊁加入购物车㊁收藏等操作的频次越高ꎬ说明用户对商品和商家越关注ꎬ可以构造出特定用户在特定商户中的点击总次数㊁点击总天数㊁加购商家总次数㊁收藏商家总次数等相关特征.用户单次在商家内部购买的商品数量会影响消费者与商家之间的关系深度ꎬ用户对商家内的多种不同商品有购买意向会影响未来重购行为的发生概率.从用户行为日志表中可以构造出用户在商家的购买总件数㊁购买不同商品数㊁购买品牌数㊁购买类别数等特征.3.4㊀促销特征促销帮助商家吸引了更多新用户ꎬ所以有必要针对促销构建特征帮助判断新客户重复购买的可能性ꎬ主要观察商家的促销力度及用户的价格敏感度.当商家活动力度大时ꎬ可能会导致短期购买量大涨ꎬ但在活动后一段时间内客户由于反差过大而不愿再次购买.可以通过比较商家近期关注度与长期关注度进行观察ꎬ构造商家促销月被点击次数㊁被加购次数㊁被购买次数㊁被收藏次数ꎬ促销月被点击占比㊁被加购占比㊁被购买占比㊁被收藏占比特征.当用户价格敏感度高时ꎬ在促销的驱动下可能会在短期内活跃度提高ꎬ产生更多交互记录ꎬ而促销结束后可能受价格影响不选择重复购买.对此可以在用户行为日志表中构造一些趋势特征来对用户的促销敏感度进行衡量ꎬ如促销月用户点击㊁加入购物车㊁购买㊁收藏行为的次数ꎬ以及这4种行为的次数在所有对应行为次数中的占比ꎬ即用户促销月点击占比㊁加购占比㊁购买占比㊁收藏占比.最终一共提取了3类55个特征.促销月某行为占比=促销月(商家受到或用户进行)某行为次数(商家受到或用户进行)某行为总次数(7)通过对数据集直接分析ꎬ构造出来的特征往往在取值范围上存在着较大的落差.如果某一特征的量级过大㊁方差过大ꎬ很有可能导致该特征在模型训练时发挥主导作用ꎬ从而使得其他特征失效.为了避免这一情况发生ꎬ在模型训练之前对特征值进行均值归一化处理ꎬ使所有特征值呈服从均值为0㊁标准差为1的标准正态分布.运用Python中sklearn包的StandardScaler完成这一操作.4㊀模型构建训练与预测4.1㊀模型构建4.1.1㊀样本划分与比例调整通过Python程序中的XGBoost包和sklearn包对预测模型进行构建与训练.运用XGBoost算法进行有监督训练.阿里云天池大数据平台 天猫复购预测大赛 数据集提供了带有用户分类标签的训练表一共包含260864条数据ꎬ数据量较为充足ꎬ可以按照标准形式将样本划分为训练集和测试集ꎬ比例为7ʒ3.样本数据中的正样本ꎬ即重复购买用户样本为15952条ꎬ负样本ꎬ即非重复购买用户样041㊀㊀㊀辽宁大学学报㊀㊀自然科学版2023年㊀㊀㊀㊀本为244912条.样本数量正负样本比例约为1ʒ15ꎬ数量差距较大ꎬ存在类别不平衡的问题.严重的类别不均衡在机器学习的过程中可能会导致模型倾向样本数量多的类别ꎬ引起过拟合问题ꎬ影响模型预测结果的准确性ꎬ因此通过一定的采样策略ꎬ保证模型训练时正负样本比例协调.Python的XGBoost包为解决数据类别不均衡的问题提供了方法.如果只考虑模型的ROC(Receiveropertatingcharacteristiccurve)㊁AUC㊁召回率指标ꎬ而不关心样本为某一类别的概率大小ꎬ可以通过将Booster参数中的 scale_pos_weight 设置为数据负样本数量/正样本数量ꎬ为比例小的样本赋予更大的权重ꎬ改变样本在训练中的贡献ꎬ减弱类别数量不平衡的影响ꎬ即将 scale_pos_weight 的参数值设置为15.4.1.2㊀参数设置Python程序中的XGBoost包对学习目标参数eval_metric设置指定分类器训练情况的输出指标ꎬ再调用sklearn包中的metrics选择整个模型需要输出的评估指标.XGBoost一共有通用参数㊁Booster参数㊁学习目标参数3类.1)通用参数对模型宏观功能进行控制.Booster决定的是迭代所用的模型ꎬ有树模型和线性模型ꎬ本实验使用的是树模型gbtree.silent决定运行时是否输出信息ꎬ默认值0输出.nthread决定运行时使用的线程数ꎬ默认值为-1ꎬ代表自动获取最大值.2)Booster参数用于控制每一步Booster(树或回归)的生成ꎬ如表1所示.eta即学习率ꎬ决定每次迭代的收缩步长ꎬ参数值越大越难以收敛ꎬ因此将参数值设置为偏小值0.1ꎬ提升学习过程的精细化.min_child_weight为最小叶子节点样本权重和ꎬ当一个叶子节点的样本权重总和小于该参数值时则停止分裂ꎬ取值范围为[0ꎬ+ɕ)ꎬ取值越大越保守ꎬ可以防止过拟合ꎬ默认值为1.max_depth为树的最大深度ꎬ该值越大模型则越复杂ꎬ越容易导致过拟合ꎬ默认值为6.sub_sample控制构建每棵树时采用的样本比例ꎬ可以防止过拟合ꎬ取值于(0ꎬ1]之间ꎬ此处设为值0.8.colsample_bytree控制构建每棵树时随机抽取的特征占比ꎬ取值于(0ꎬ1]之间ꎬ此处设为值0.8.gamma指的是节点分裂要求的最小损失函数减少值ꎬ参数越大越能避免过拟合ꎬ默认值为0.alpha为控制复杂度的权重的L1正则化项ꎬ参数值越大越能避免过拟合ꎬ可以加快高维度数据的运算速度ꎬ此处设为值1.scale_pos_weight可在类别样本数不平衡时加快算法收敛速度ꎬ此处设为值15.表1㊀Booster参数初始值设置参数名参数值eta0.1min_child_weight1gamma0max_depth6sub_sample0.8colsample_bytree0.8alpha1scale_pos_weight153)学习目标参数ꎬ确定模型学习目标.objective确定需要被最小化的损失函数ꎬ由于研究的问题是二分类问题ꎬ并要求以概率的形式输出结果ꎬ因此将此参数设定为binary:logisticꎬ即二分类回归.eval_metric定义的是分类器的评估指标ꎬ可以同时添加多种指标ꎬ此处添加常用的auc㊁logloss(负对数似然函数值)㊁error(二分类错误率).seed为随机数种子ꎬ该参数值能使随机数据复现ꎬ此处设置为100.4.2㊀模型训练4.2.1㊀初始参数训练XGBoost包中的XGBoost.train()用于对分类器进行训练ꎬ参数主要包括params㊁dtrain㊁num_boost_round㊁evals=()㊁early_stopping_rounds.dtrain指的是被训练的数据.num_boost_round指的是141㊀第2期㊀㊀㊀㊀㊀㊀景秀丽ꎬ等:基于XGBoost算法的电商用户重复购买行为预测。
大数据中效用挖掘的快速单阶段算法

大数据中效用挖掘的快速单阶段算法刘君强;周青峰;王文慧;时磊【摘要】现有数据挖掘算法的缺点是在挖掘大数据时会出现大量候选模式,从而造成可伸缩性瓶颈,个别算法虽然不生成候选模式,但是计算代价高昂,缺乏有效剪裁,运行效率存在瓶颈.为此,提出一个全新的单阶段不生成候选模式的数据挖掘算法,其创新性有3点:一是基于前缀生长的模式枚举和基于效用上限值评估的剪裁策略;二是基于稀疏矩阵和虚拟投影的效用信息表达;三是节省存储空间的深度优先搜索方法.大量实验表明,新算法的时间效率比现有算法高5倍以上,并且内存使用量比现有算法少20%~60%,可伸缩性高.【期刊名称】《电信科学》【年(卷),期】2015(031)004【总页数】9页(P77-85)【关键词】大数据;效用挖掘;高效用模式;频繁模式【作者】刘君强;周青峰;王文慧;时磊【作者单位】浙江工商大学杭州310018;浙江工商大学杭州310018;浙江水利水电学院杭州310018;浙江工商大学杭州310018【正文语种】中文1 引言效用模式挖掘[1~6]是近年来发展起来的大数据分析技术,不仅考虑数据统计显著性,而且也考虑用户兴趣和目标[7]。
例如,传统频繁模式挖掘技术[8~11]只能从销售数据中挖掘出购买频率较高的产品组合,而效用模式挖掘技术可以从中发现利润回报较高的产品组合。
效用模式挖掘不仅是各种挖掘问题的基础[12~14],也可以直接应用于各种大数据分析。
例如,网络传媒的点击率和转化率分析、价值链分析、网购的消费者行为理解和预测等。
然而,效用模式挖掘技术还不成熟,只有很少量成果。
由于效用模式不具有反单调性,即一个低效用模式的超集可能是高效用的,挖掘高效用模式要比挖掘频繁模式困难得多,因为很难剪裁搜索空间。
现有挖掘算法大多数采用两阶段法,即先在第1阶段从原始数据中挖掘出候选模式,再在第2阶段从候选模式中进一步挖掘出效用模式。
其缺点是挖掘大数据时会产生大量候选模式,造成存储空间开销过大,形成可伸缩性瓶颈,并最终导致运行的时间效率低下。
常用于信息检索和数据挖掘的加权技术

随着信息时代的到来,数据量的爆炸性增长使得信息检索和数据挖掘成为了重要的研究方向。
在这个过程中,加权技术作为一种常用的方法,被广泛应用于信息检索和数据挖掘的实践中。
本文将介绍常用于信息检索和数据挖掘的加权技术。
一、加权技术的概念加权技术是信息检索和数据挖掘中常用的一种技术手段,其基本思想是通过对不同数据或信息进行加权处理,从而得到更合理、更准确的结果。
在信息检索中,加权技术被用于对检索结果进行排序和过滤;在数据挖掘中,加权技术则被用于对数据进行特征提取和模式识别。
加权技术可以帮助我们更好地处理和利用海量的信息和数据,提高信息检索和数据挖掘的效率和准确性。
二、加权技术的常见方法1.TF-IDF方法TF-IDF(Term Frequency-Inverse Document Frequency)是一种常用的加权技术,它通过统计每个词在文档中的出现频率和在整个语料库中的出现频率来进行加权处理。
具体来说,TF-IDF方法先计算每个词的TF值(词频)和IDF值(逆文档频率),然后将它们相乘得到最终的加权值。
TF-IDF方法在信息检索中被广泛应用,能够有效地反映出每个词在文档中的重要程度,从而提高检索结果的准确性。
2.权重向量模型权重向量模型是另一种常见的加权技术,它通过构建特征向量并对每个特征进行加权处理来实现信息检索和数据挖掘的目的。
在权重向量模型中,我们可以根据具体的需求和场景选择不同的加权方法,比如使用余弦相似度进行加权,或者使用基于概率统计的方法进行加权。
权重向量模型在实际应用中具有较高的灵活性和可定制性,能够更好地适应不同的信息检索和数据挖掘任务。
3.基于机器学习的加权方法随着机器学习技术的不断发展,基于机器学习的加权方法也逐渐成为了信息检索和数据挖掘领域的热门话题。
这类方法通过构建模型并对训练数据进行学习,从而得到能够自动适应不同情况的加权规则。
在信息检索中,我们可以使用基于机器学习的排序模型来对检索结果进行加权和排序;在数据挖掘中,我们也可以使用基于机器学习的分类器来对数据进行加权和分类。
智能型数据挖掘工具的设计与实现

3, 1,<D=/?24 ) <F1;.D09A<?24
: 19-;.+-<D82 : >3+=BB<;95,<?FA8.?,.5?<A+.5
框架 、 数据抽取和处理规则, 是创建、 更新、 维护数据仓库的依 据。 其语法如下, 1 2内的文字表示语法概念, 3 4表示可选, 5 表 示多选一, 6 7表示重复出现 " 次至多次。 : 18090 :0;.-<=+. +,-./02 : >18090 :0;.-<=+. ?0/.2 618090 +<=;,.27618090 ,=@.2718.+,;AB9A<?2 : 18090 +<=;,.2 : >18090 +<=;,. ?0/.21+.;C.;2 1D<,09A<?21+.,=;A9E21C.?8<;2 : 18090 ,=@.2 : >1,=@. ?0/.2618A/.?+A<?27 61/.0+=;.271+90; /<8.D2 : 18.+,;AB9A<?2 : >1+.;C.;21D<,09A<?21+.,=;A9E2 1C.?8<;21=+.;+21,;.09. 9A/.21,E,D.2 : 18A/.?+A<?2 : >18A/.?+A<? ?0/.261D.C.D27 : 1D.C.D2 : >1D.C.D ?0/.2 1+<=;,. ,<D=/?2 : >1/.0+=;. ?0/.231+<=;,. ,<D=/?2 1/.0+=;.2 : 51,0D,=D09A<? F<;/=D024 : 1+90; /<8.D2 : >1F0,9 90@D.2618A/.?+A<? 90@D.27 1G<A? ,<?8A9A<?2 主要内容包括: (% ) 数据仓库主题名、 存储位置、 安全控制、 用户权限、 创建时间、 更新周期等; (! ) 外部数据源存储位置、 安 全控制、 供应者等; (# ) 星型模型的事实表、 维表; (H ) 数据立方 体的维和度量、 数据抽取和转换规则等。
云环境下基于全同态加密的全域匿名化算法

LIUJunQiang1) CHENFangHui1) XUCongFu2) GUOHong3) LITing1)
1)(犛犮犺狅狅犾狅犳犐狀犳狅狉犿犪狋犻狅狀犪狀犱犈犾犲犮狋狉犻犮犈狀犵犻狀犲犲狉犻狀犵,犣犺犲犼犻犪狀犵犌狅狀犵狊犺犪狀犵犝狀犻狏犲狉狊犻狋狔,犎犪狀犵狕犺狅狌 310018) 2)(犛犮犺狅狅犾狅犳犆狅犿狆狌狋犻狀犵犛犮犻犲狀犮犲犪狀犱犜犲犮犺狀狅犾狅犵狔,犣犺犲犼犻犪狀犵犝狀犻狏犲狉狊犻狋狔,犎犪狀犵狕犺狅狌 310027) 3)(犛犽狔犮犾狅狌犱犛狅犳狋狑犪狉犲犆狅.,犅犲犻犼犻狀犵 100193)
犃犫狊狋狉犪犮狋 Withthedevelopmentofthecloudcomputingtechnologyandtheexponentialgrowth ofdatavolume,peopleareoutsourcingtheirdatastorageandcomputationtaskstocloudservice providers,whichresultsinnewchallengestoprivacypreservation.Oneofsuchchallengesisthat thecomputationprocesstosanitizedataforprivacypreservationoverthecloudmayalsosuffer fromattacks,whichincursadditionalprivacyrisksandmakesithardtopreserveprivacywiththe cloudcomputingparadigm.Toaddressthechallenge,thispaperproposesafulldomaingenerali zationbasedanonymizationalgorithmthatissecuredbyfullyhomomorphicencryption.While fullyhomomorphicencryptionisdeemedasthemostpromisingtechnologytoaddressthesecurity andprivacyissueswiththecloudcomputingparadigm,thisworkisthefirstonethatintegrates thefullyhomomorphicencryptionwithdataanonymizationtoaddressprivacyissuesoverthe cloud,tothebestofourknowledge.Thenoveltyofthisworkcomeswiththreecontributions.
实现动态数据流分布式挖掘的网格平台模型

效 率与 空间的矛盾 , 高微观效率 ; 用网格技 术有 效地利 用计算资源进行分布式挖 掘 , 高宏观效率 。 提 应 提
关 键 词 :数 据 流 ;网格 ;数 据 挖 掘 ; 分布 式 系统
O 引言
动态数据流与静态数据集相 比 , 更能够刻划实 际应 用的要 求 。由于动态数据流具有数据 量大 、 变化快 、 随机存取代价 高 、 能力要求非常高 。尽管在挖掘静态数据 集方面有很多成果 , 挖
了新思路 。
融合 到 we ev e框架 中 , b Sri c 把计算 资源 、 存储资 源 、 网络 、 程
序、 数据 等都表示 成网格服 务 , 通过标 准的接 口和协议 支持 透 明服务的创建 、 终止 、 管理和开发 , 结合 We e i 技术 , b Sr c v e 支持 目前大多数 网格都建立在 Gl u 提供的协议和服务之上 o s b 。 功能之上。 o u 提出了资源管理安全 、 Glb s 信息服务及数据管理等关
格数据挖掘成果 。
网格数据挖掘研 究刚刚兴起 ,网格环境下数据挖掘应用的标准 挖掘 。 今, 至 尚未见系统性的研 究成果 , 尤其未见基于 OG A网 S 目前 , 有影 响的工作 是 , 共体 的网格环境 下数据 挖掘 较 欧
0 5年尚处在工具 与接 口的 本文围绕挖掘动态数据流 所隐藏频 繁模 式的问题 , 出具 工具与服 务的研 究项 目,但截止 2 0 提 也有 一些 关于非 OG A标 准的知识 网 S 有开放体 系结构 、 能处 理分布复杂 异构 的海量数据 、 支持多 种 描述与论证阶段 。此外 , 2 1 。 挖掘策略 、 与网格基础结构兼容 、 能集成新算法与工具 、 网格位 格 的工作还在进行 中【
数据挖掘在智能化企业竞争情报系统的应用研究_曹宇

现, 是指从大型数据库或数据仓库中提取隐含的、 未知的、 非平 凡的及有潜在应用价值的信息或模式 , 它是数据库研究中的一 个很有应用 价值的 新领域 , 融合 了数 据库、 人工 智能、 机器 学 习、 统计学等多个领域的理论和技术。这些信息的表现形式为 规则、 概念、 规律及模式等。数据挖 掘是一种新 的信息处 理技 术, 其主要特点是对数据库中的大量数据进行抽取、 转换、 分析 和其他模型化处 理, 并从 中提取辅助 决策的 关键性 数据 , 图 1 是数据挖掘的过程示意图。
作者简介 : 曹
宇 , 男 , 1973 年生 , 博士研究生 , 研究方向为工程项目投融资 ; 刘晓君 , 女 , 1961 年生 , 教授 , 研究方向为投资经济。
22
情报杂志 2006 年第 3 期
业竞争情报系统作为辅助工具。 随着电力体制市场化改革的不断深入 , 使建立适应市场需 要的电力市场面临着 迫切要求。电力市场智能 化企业竞 争情 报系统主要是通过深入分析用电市场的内部和外部环境 , 得到 电力市场需求变化的规律 , 并依据规律 做出相应 的经营决策。 智能化企业竞争情报系统主要内容有市场细分、 市场消费行为 分析、 市场潜力预测和营销策略制定等方面。本文的基本思想 就是将电力市场依据不 同的环境因素而细 分 ( 如 地域、 售 电对 象、 时间、 气象和经济因素等 ) , 利 用数据挖掘的 方法寻找 并研 究其具有的特征性规律 , 即电量水平的变化与各环境因素之间 的规律 , 根据规 律对电力 市场在 不同环 境下进 行电 量水平 预 测, 从而制定相应的经营策略。 为了更好地对 电力市场不同的 环境下发生 的售电行 为进 行描述 , 本文建立了 电力市场售电事务 的数学模型 , 将营 销历 史数据和其它的影响因素 数据通过引入数学中 空间的概 念而 有机灵活地组织起来 , 将电力市场营销分析问题转换为分析空 间中点的分布规律 , 更有利于利用数据 挖掘的工 具进行分析 , 并在此基础上进行 了智能 化企业 竞争情 报系统 环境 的开发。 系统构架采用 Web 的 B/ S 结构 , 利用 ASP 和 SQL 技术使得数 据维护、 用户查询、 决策分析 等功能 结合在同 一 Web 页面中。 在核心算法方面 , 采用了 COM 组件技术 , 提高了算法部分的可 重用性和扩展、 维护的功能。 2. 1 智能化企业竞争情报系统的技术体系 智能化企业竞 争情报系统的技术体系主要由数据仓库、 OL AP 以及数 据挖掘 三部分组成( 见图 2) 。
一种挖掘海量数据的高空间可伸性和高时间效率的多层频繁模式发现

专利名称:一种挖掘海量数据的高空间可伸性和高时间效率的多层频繁模式发现算法
专利类型:发明专利
发明人:刘君强
申请号:CN201110207427.5
申请日:20110722
公开号:CN102214248A
公开日:
20111012
专利内容由知识产权出版社提供
摘要:本发明“一种挖掘海量数据的高空间可伸性和高时间效率的多层频繁模式发现算法”涉及智能化信息处理领域,在海量数据挖掘特别是网络信息搜索与知识发现中有广泛应用前景。
针对现有多层算法只是简单地扩展单层算法因而在挖掘海量数据时存在时间与空间开销瓶颈的问题,本发明提出了三项全新的技术。
一是层次标签技术,能以最少的额外开销将层次结构信息集成到多种数据表示方式中,解决空间开销瓶颈。
二是扩展型虚拟投影方法,避免模式支持集的反复生成,空间利用率更高。
三是用于组织多层模式的倒置集合枚举树及其剪裁技术,大大减少了频繁模式的搜索空间,从而解决运行时间瓶颈。
本发明算法的时间效率比两个参照算法分别高近5倍和高1~3个数量级,并且空间开销最小。
本发明算法所具有的高性能使得海量Web挖掘、多媒体挖掘、文本挖掘等各种应用成为可能。
申请人:浙江工商大学
地址:310018 浙江省杭州市下沙高教园区学正街18号
国籍:CN
更多信息请下载全文后查看。
基于云计算的海量数据挖掘算法

基于云计算的海量数据挖掘算法
赵慧;王晓燕
【期刊名称】《产业与科技论坛》
【年(卷),期】2015(014)016
【摘要】随着大数据时代的到来,数据挖掘领域中海量数据处理和海量数据计算成为一个极为重要的问题.基于云计算的海量数据挖掘能够超越传统的数据挖掘所不适应的问题,并且能够不断增长高效、可靠、可信的数据信息.本文在介绍了云计算的含义、特点及分类的基础上,分析了海量数据挖掘的现状与发展,并分析了云计算支持下的数据挖掘算法.
【总页数】2页(P57-58)
【作者】赵慧;王晓燕
【作者单位】山东协和学院计算机学院;山东协和学院计算机学院
【正文语种】中文
【相关文献】
1.基于粗糙集的海量数据挖掘算法研究 [J], 牛咏梅
2.基于粗糙集的海量数据挖掘算法研究 [J], 张贵红;李中华
3.基于Hadoop平台的海量数据挖掘算法的研究分析 [J], 罗钊航;车宇;杨泽威
4.基于云计算的海量数据挖掘算法分析研究 [J], 邢国军;王保勇
5.试论一种基于粗糙集的海量数据挖掘算法 [J], 蔡丛豫
因版权原因,仅展示原文概要,查看原文内容请购买。
多维多层关联规则有效挖掘的新算法

多维多层关联规则有效挖掘的新算法
刘君强;王勋;孙晓莹
【期刊名称】《南京大学学报:自然科学版》
【年(卷),期】2003(39)2
【摘要】提出根据信息熵划分属性值区间或集合、自动生成与人机交互相结合确定层次结构的方法,将多维多层多数据类型问题转化为受约束的一维单层布尔型问题.在此基础上,对直接生成频繁模式的FPT Gen算法进行了扩展,实现了有效挖掘多维多层关联规则的新算法MDML FPT Gen,其效率与可伸缩性均优于经典方法.【总页数】6页(P205-210)
【关键词】数据挖掘;频繁模式;多维多层关联规则;知识发现;FPT-Gen算法;信息熵【作者】刘君强;王勋;孙晓莹
【作者单位】浙江大学计算机科学与技术学院;杭州商学院
【正文语种】中文
【中图分类】TP311.13;TP18
【相关文献】
1.遗传算法在多维多层关联规则挖掘中的应用 [J], 许学军
2.基于免疫遗传算法的多维多层关联规则挖掘 [J], 朱玉;张虹;孔令东
3.一种高效的多维多层关联规则挖掘算法 [J], 沈国强;覃征;沈云斐
4.基于商空间理论多维多层次关联规则挖掘算法研究 [J], 王文军;张天刚;杨泽民;
郭显娥
5.一种多层多维的关联规则挖掘算法在推荐系统中的应用 [J], 黎丹雨;陈怕华因版权原因,仅展示原文概要,查看原文内容请购买。
数据挖掘专利综述

数据挖掘专利综述
刘晓东;刘大有
【期刊名称】《电子学报》
【年(卷),期】2003(031)0z1
【摘要】尽管科学研究专利是反映科学研究成果的一个重要方面,专利申请本身是一项重要的科学研究工作,但是长期以来,专利所包含的科学研究成果在文献中却没有得到充分的反映.由此,对著名的美国专利和商标委员会数据库(US PATENT & TRADEMARK OFFICE DATABASE)中数据挖掘专利的授权情况进行了分析.对于专利授权比较集中的领域-关联规则、互联网挖掘、聚类算法和并行数据挖掘等方面中的代表性专利进行了总结和分析.最后,指出了当前数据挖掘专利的一些空白领域.【总页数】5页(P1989-1993)
【作者】刘晓东;刘大有
【作者单位】吉林大学计算机科学与技术学院,吉林,长春,130012;吉林大学符号计算与知识工程教育部重点实验室,吉林,长春,130012;吉林大学计算机科学与技术学院,吉林,长春,130012;吉林大学符号计算与知识工程教育部重点实验室,吉林,长春,130012
【正文语种】中文
【中图分类】TP311;TP18
【相关文献】
1.发展需要专利专利推动发展--上海轻工专利工作综述 [J], 耿言
2.基于专利文献的专利内在价值评估指标数据挖掘 [J], 付占海;杨扬
3.数据挖掘专利综述 [J], 刘晓东;刘大有
4.数据挖掘与应用统计现状及趋势研究r——第八届国际数据挖掘与应用统计研究会年会学术综述 [J], 李勇;张敏;刘浩;李禹锋;朱建平
5.浅谈专利技术综述对专利实质审查的裨益 [J], 孟凡娜;徐玉祥
因版权原因,仅展示原文概要,查看原文内容请购买。
云计算环境下海量数据中入侵检测挖掘模型

云计算环境下海量数据中入侵检测挖掘模型
刘增锁
【期刊名称】《计算机仿真》
【年(卷),期】2015(032)006
【摘要】云计算中的数据数量巨大,以数据挖掘模型和模式识别理论为基础的入侵检测方法,由于主要是对海量数据中入侵样本本身进行比较分析,没有考虑每一个海量数据中入侵特征挖掘样本所包含属性的重要性和差异性虑,没有充分考虑每一个属性对入侵分类的不同影响,所以存在不相关规则和尖锐边界等问题,降低了入侵检测的精度.提出引入模糊规则挖掘算法的云计算环境下海量数据中入侵检测方法,以模糊集理论为基础,在入侵关联规则挖掘中将特征属性模糊集作为单一属性来处理,有效地解决入侵规则中出现不相关规则和尖锐边界等问题.实验结果表明,利用改进算法进行云计算环境下海量数据中入侵检测的挖掘,能够有效提高挖掘的效率.【总页数】4页(P289-291,393)
【作者】刘增锁
【作者单位】河北师范大学信息技术学院,河北石家庄050024
【正文语种】中文
【中图分类】TP181
【相关文献】
1.大数据环境下的云计算网络安全入侵检测模型仿真 [J], 宋文超;王烨;黄勇;柳增寿
2.云计算环境下海量数据挖掘的优化方法研究 [J], 张捷;封俊红;朱晓姝
3.云计算环境下的海量数据特定特征挖掘技术 [J], 蹇旭
4.云计算环境下海量数据挖掘的研究 [J], 谢志明
5.云计算环境下海量数据挖掘分类算法研究 [J], 高文强;张晓梅
因版权原因,仅展示原文概要,查看原文内容请购买。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
【分类号】:TPDMD:1.2003.114001
【目录】: 前言4-6摘要6-8ABSTRACT8-14第1章 概论14-201.1 数据挖掘技术的兴起14-151.2 数据挖掘的主要问题15-171.2.1 数据挖掘任务与知识类型15-161.2.2 数据挖掘的过程161.2.3 数据挖掘的对象161.2.4 数据挖掘的应用16-171.2.5 面临的挑战171.3 本文的工作17-181.4 本文的结构18-20第2章 数据挖掘技术综述20-342.1 频繁模式与关联规则挖掘20-242.1.1 单层单维布尔型关联规则挖掘与Apriori算法20-222.1.2 对Apriori算法的改进22-232.1.3 频繁模式与关联规则挖掘研究的新发展23-242.2 闭合模式挖掘与A-Close算法24-272.2.1 闭合模式挖掘与A-Close算法24-262.2.2 其它闭合模式挖掘算法26-272.3 最大模式挖掘与Pincer-Search算法27-302.3.1 最大模式挖掘与Pincer-Search算法27-282.3.2 其它最大模式挖掘算法28-302.4 多层多维关联规则挖掘30-312.5 对关联规则挖掘的其它扩展31-322.6 数据挖掘软件的发展32-34第3章 伺机投影策略的挖掘算法34-503.1 引言34-353.2 问题的描述35-373.3 频繁模式树的构造37-383.4 模式支持集的表示与投影38-423.4.1 稀疏型PTS的基于数组表示及其投影38-403.4.2 密集型PTS的基于树表示及虚拟投影40-423.5 伺机投影策略与OpportuneProject算法42-453.5.1 伺机投影的启发式原则42-433.5.2 OpportuneProject算法43-453.6 性能评价45-493.6.1 数据集及其特性45-463.6.2 基本实验结果46-483.6.3 可伸缩性试验48-493.7 小结49-50第4章 闭合模式与最大模式挖掘50-664.1 引言50-514.2 问题的描述51-524.3 复合型频繁模式树及其生成52-544.3.1 复合型频繁模式树CFIST52-534.3.2 CFIST结点的合并53-544.3.3 CFIST的生成算法544.4 CFIST的剪裁与包含关系的检查54-564.4.1 高效的CFIST局部剪裁54-554.4.2 分枝包容关系的快速检查554.4.3 快速杂凑法55-564.5 CROP:挖掘闭合模式的高性能算法56-584.5.1 平衡CFIST生成与剪裁效率56-574.5.2 CROP算法57-584.6 CROP性能测评58-624.6.1 CROP与CHARM效率对比58-604.6.2 CROP与CLOSET效率对比604.6.3 CROP与MAFIA效率对比。60-614.6.4 可伸缩性实验61-624.7 挖掘最大频繁模式的新算法MOP62-644.7.1 最大频繁模式集及其剪裁624.7.2 MOP算法62-634.7.3 MOP的性能评价63-644.8 小结64-66第5章 多维多层关联规则与分类规则66-785.1 关联规则与无冗余关联规则66-685.2 多维多层多数据类型关联规则挖掘68-725.2.1 多维多层多数据类型关联规则挖掘问题69-705.2.2 MDML-PP算法70-715.2.3 性能测评71-725.3 挖掘多支持率分类规则72-765.3.1 分类规则挖掘与TTF扩展72-735.3.2 多支持率剪裁73-745.3.3 分类规则及其单阶段挖掘算法74-755.3.4 对比实验75-765.4 小结76-78第6章 智能型数据挖掘工具设计与实现78-926.1 引言78-796.2 数据仓库及其管理79-816.2.1 数据仓库模型与OLAP79-806.2.2 数据仓库的框架描述806.2.3 数据仓库管理器80-816.3 数据挖掘任务的描述、管理及执行机制81-846.3.1 数据挖掘作业Job的描述81-826.3.2 挖掘任务模型Scenario的定义82-836.3.3 挖掘任务模型的管理与执行83-846.4 智能型数据挖掘引擎84-876.4.1 算法描述库与算法模块84-866.4.2 知识库与引擎管理器86-876.5 SmartMiner体系结构87-886.6 关键技术与SmartMiner原型实现88-916.7 小结91-92第7章 网络海量数据协同挖掘92-1127.1 引言92-937.2 分布式黑板控制93-947.2.1 问题求解的黑板系统937.2.2 分布式问题求解与黑板控制93-947.3 形式化描述语言94-967.3.1 黑板的描述947.3.2 知识源的描述94-957.3.3 知识交换格式95-967.4 实现分布式黑板控制的一般智能代理96-987.4.1 一般智能代理GA的结构设计96-977.4.2 智能代理软件DBC-MA的实现97-987.5 分布式数据挖掘系统DistributedMiner98-1017.5.1 分布式知识发现功能997.5.2 DistributedMiner的黑板设计997.5.3 挖掘平台体系结构99-1007.5.4 DistributedMiner的实现与应用100-1017.6 从分布计算到移动计算101-1077.6.1 什么是智能代理1027.6.2 智能代理的特征102-1037.6.3 移动型智能代理103-1047.6.4 典型mobile agent系统104-1077.7 移动式数据挖掘系统模型107-1097.7.1 移动型智能代理服务器107-1087.7.2 DBC-MA变型108-1097.7.3 MobileMiner工作流程1097.8 小结109-112第8章 结论和展望112-114参考文献114-130公开发表的论文、主持和参加的科研项目130-132致谢132-133
海量数据挖掘技术研究刘君强
【摘要】: 随着信息技术特别是网络技术飞速发展,人们收集、存贮、传输数据能力小断提高。数据出现了爆炸性增长,与此形成鲜明对比的是,对决策有价值的知识却非常匮乏。知识发现与数据挖掘技术正是在这一背景下诞生的一门新学科。数据挖掘要在实际应用中发挥作用,高性能挖掘算法和数据挖掘软件平台是重要的技术基础。本文以数据挖掘最基本问题,频繁模式与关联规则挖掘为切入点,研究高时间效率、高空间可伸缩性的挖掘算法和分布、异质、海量数据的协同挖掘软件模型。 本文首先发现了基于树表示形式的虚拟投影方法,用于按深度优先挖掘密集型数据集;提出了稀疏型数据集表示形式及非过滤投影方法;进一步提出了基于伺机投影的思想,设计并实现了基于伺机投影的全新算法OpportuneProject,对比实验表明该算法挖掘各种规模与特性数据库的效率与可伸缩性都是最佳的。 由于其内在的计算复杂性,挖掘密集型数据的频繁模式完全集非常困难,解决办法是挖掘频繁模式的闭合集或最大集。本文提出了一种组织闭合模式集的复合型频繁模式树,支持搜索空间的高效剪裁,有效地平衡了树生成与树剪裁的代价,实现了闭合模式集挖掘算法CROP,其效率与可伸缩性大大优于CHARM等算法。在此基础上,本文提出了闭合性剪裁和一般性剪裁相结合,并能适时前窥的最大模式挖掘算法MOP,大大优于MaxMiner和MAFIA等算法。 本文进一步提出了根据信息熵自动生成与人机交互相结合来确定数值型与类别型属性概念层次的新方法,不仅支持逐层挖掘而且能进行跨层挖掘,并实现了多支持率剪裁,将所提出的挖掘频繁模式完全集、闭合集的新算法推广到无冗余关联规则、多维多层多数据类型关联规则、多支持率分类规则的挖掘问题。 本文在所取得的数据挖掘算法研究成果基础上,对数据挖掘软件模型作了深入研究。首先提出了数据挖掘作业描述语言MDL和挖掘任务模型脚本语言,设计并实现了一个集成数据仓库管理功能、挖掘引擎具有一定智能、体系结构可扩展的数据挖掘工具,并已经集成到一个大型商业连锁企业的经营决策系统中。 本文在研究分布式问题求解技术和分析移动型智能代理技术的基础上,提出了从网络海量数据中发现有用知识的协同挖掘模型。首先定义了黑板和知识源的描述语言以及知识交换格式,设计和实现了支持互联网上分布式问题求解的黑饭系统,提出了分布式网络海量数据挖掘系统DistributedMiner。接着在分析移动式 摘要 智能代理技术的基础上,设计了一种移动式智能代理服务器,通过重构基础结构 提出了移动式网络海量数据挖掘系统模型MobifeMiner。
【关键词】:知识发现 数据挖掘 关联规则 分类规则 多维多层多数据类型关联规则 频繁模式 闭合频繁模式 最大频繁模式 黑板系统 分布式问题求解 智能代理 移动型智能代理 协同数据挖掘 分布式数据挖掘 移动式数据挖掘 智能型数据挖掘工具 算法 软件 海量数据库
【学位授予单位】:浙江大学
【学位级别】:博士