走下神坛的内存调试器--定位多线程内存越界问题实践总结
java多线程编程实验总结与体会

java多线程编程实验总结与体会[Java多线程编程实验总结与体会]本次实验锻炼了我的Java多线程编程能力,让我更深入地了解了多线程编程的实现原理和技巧,同时也让我意识到在多线程环境下需要考虑的问题和注意事项。
下面我将结合具体实验内容,分享我在实践中的体会和思考。
1. 实验环境搭建在进行本次实验之前,我首先进行了实验环境的搭建。
我选择了Java SE Development Kit 8和Eclipse作为开发工具,同时也安装了JDK8的API 文档作为参考资料。
在搭建环境的过程中,我认识到Java的生态系统非常强大,附带的工具和资源也非常充足,这为我们开发和调试带来了很大的便利。
2. 多线程原理在研究多线程编程之前,我们需要对Java语言中的线程概念有一个清晰的认识。
线程是指操作系统能够进行运算调度的最小单位,是执行线程代码的路径。
在Java中,线程是一种轻量级的进程,可以同时运行多个线程。
每个线程都有自己的堆栈和局部变量,线程之间可以共享全局变量。
Java的多线程编程是通过Thread类和Runnable接口来实现的。
在实践中,我发现多线程编程最基本的原理是线程的并发执行。
多个线程可以在同一时间内执行不同的代码,提高CPU利用率,加快程序运行速度。
但是,在多线程并发执行的过程中,我们需要注意线程之间的同步问题,避免出现数据竞争和并发安全等问题。
3. 多线程的实现在Java中,我们可以通过继承Thread类或者实现Runnable接口来创建线程。
对于简单的线程,我们可以采用继承Thread类的方式来实现。
例如,在实验一中,我们在Main线程内创建了两个子线程,分别用来执行奇数和偶数的累加操作。
我们可以分别定义两个类OddThread和EvenThread继承Thread类,分别实现run()方法,用来执行具体的奇数和偶数累加操作。
然后在Main线程内创建OddThread和EvenThread 对象,并调用start()方法来启动两个线程,并等待两个线程完成操作。
多线程程序实验报告(3篇)

第1篇一、实验目的1. 理解多线程的概念和作用。
2. 掌握多线程的创建、同步和通信方法。
3. 熟悉Java中多线程的实现方式。
4. 提高程序设计能力和实际应用能力。
二、实验环境1. 操作系统:Windows 102. 开发工具:IntelliJ IDEA3. 编程语言:Java三、实验内容本次实验主要完成以下任务:1. 创建多线程程序,实现两个线程分别执行不同的任务。
2. 使用同步方法实现线程间的同步。
3. 使用线程通信机制实现线程间的协作。
四、实验步骤1. 创建两个线程类,分别为Thread1和Thread2。
```javapublic class Thread1 extends Thread {@Overridepublic void run() {// 执行Thread1的任务for (int i = 0; i < 10; i++) {System.out.println("Thread1: " + i);}}}public class Thread2 extends Thread {@Overridepublic void run() {// 执行Thread2的任务for (int i = 0; i < 10; i++) {System.out.println("Thread2: " + i);}}}```2. 创建一个主类,在主类中创建两个线程对象,并启动它们。
```javapublic class Main {public static void main(String[] args) {Thread thread1 = new Thread1();Thread thread2 = new Thread2();thread1.start();thread2.start();}```3. 使用同步方法实现线程间的同步。
```javapublic class SynchronizedThread extends Thread {private static int count = 0;@Overridepublic void run() {for (int i = 0; i < 10; i++) {synchronized (SynchronizedThread.class) {count++;System.out.println(Thread.currentThread().getName() + ": " + count);}}}}public class Main {public static void main(String[] args) {Thread thread1 = new SynchronizedThread();Thread thread2 = new SynchronizedThread();thread1.start();thread2.start();}```4. 使用线程通信机制实现线程间的协作。
多线程编程心得体会.doc

多线程编程心得体会篇一:多线程实验报告宁波工程学院电信学院计算机教研室实验报告课程名称:Java2姓名:***实验项目:多线程实验学号:****指导教师:****班级:****实验位置:电信楼机房日期:一、实验目的1、掌握多线程编程的特点和工作原理;2、掌握编写线程程序的方法3、了解线程的调度和执行过程4、掌握线程同步机理二、实验环境windows记事本,javajdk1.60版本,cmd命令运行窗口三、实验内容实验一:应用Java中线程的概念写一个Java程序(包括一个测试线程程序类TestThread,一个Thread类的子类PrintThread)。
在测试程序中用子类PrintThread创建2个线程,使得其中一个线程运行时打印10次“线程1正在运行”,另一个线程运行时打印5次“线程2正在运行源程序:publicclassA{publicstaticvoidmain(Stringargs[]){Test1A1;Test2A2;A1=newTest1();A2=newTest2();A1.start();A2.start();}} classPrintThreadextendsThread{}classTest1extendsPrintThread{publicvoidrun(){for(inti=1;i<=10;i++){System.out.println("线程1正在运行!"); }}}classTest2extendsPrintThread{publicvoidrun(){for(inti=1;i<=5;i++){System.out.println("线程2正在运行!");}}}运行结果:实验二:将上述程序用Runnable接口改写,并上机验证源程序publicclassd{publicstaticvoidmain(Stringargs[]){movemove=newmove();move.test1.start();move.test2.start();}}classmoveimplementsRunnable{Threadtest1,test2;move(){test1=newThread(this);test1.setName("线程1正在运行!");test2=newThread(this);test2.setName("线程2正在运行!");}publicvoidrun(){if(Thread.currentThread()==test1){for(inti=1;i<=10;i++){System.out.println(test1.getName());}}}else{for(inti=1;i<=5;i++){System.out.println(test2.getName());}} 运行结果:实验三:importjava.awt.*;importjava.awt.event.*;publicclassE{publicstaticvoidmain(Stringargs[]){newframemoney();}} classframemoneyextendsframe implementsRunnable,ActionListener {intmoney=100;TextAreatext1,text2;Thread会计,出纳;intweekday;buttonstart=newbutton("开始演示"); framemoney(){会计=newThread(this);出纳=newThread(this);text1=newTextArea(12,15);text2=newTextArea(12,15); setLayout(newflowLayout());add(start);add(text1);add(text2);setVisible(true);setSize(360,300);validate();addwindowListener(newwindowAdapter(){publicvoidwindowclosing(windowEvente){System.exit(0);}});start.addActionListener(this);}publicvoidactionPerformed(ActionEvente){if(!(出纳.isAlive())){会计=newThread(this);出纳=newThread(this);}try{会计.start();出纳.start();}catch(Exceptionexp){}}publicsynchronizedvoid存取(intnumber)//存取方法{if(Thread.currentThread()==会计){text1.append("今天是星期"+weekday+"\n");for(inti=1;i<=3;i++)//会计使用存取方法存入90元,存入30元,稍歇一下{money=money+number;//这时出纳仍不能使用存取篇二:实验七——线程同步与多线程编程实验七线程同步与多线程编程一.实验目的:1.了解系统中线程同步的基本原理。
关于内存越界

关于内存越界1. 原理分析经常有些新C++程序员问:C++的类的成员个数是不是有限制,为什么我加⼀个变量后程序就死了?或者说:是不是成员变量的顺序很重要,为什么我两个成员变量顺序换⼀换程序就不⾏了?凡此种种之怪现象,往往都是内存访问越界所致。
何谓内存访问越界,简单的说,你向系统申请了⼀块内存,在使⽤这块内存的时候,超出了你申请的范围。
例如,你明明申请的是100字节的空间,但是你由于某种原因写⼊了120字节,这就是内存访问越界。
内存访问越界的后果是:你的写⼊破坏了本不属于你的空间。
下⾯是⼀个简单的例⼦:int a;char b[16]="abcd";int c;a = 1;c = 2;printf("a=%d,c=%d\n", a,c);memset(b, 0,32); //注意这⾥访问越界了,你只有16字节空间,却修改了32字节printf("a=%d,c=%d\n", a,c);你可以看出,在memset前后,两个printf语句打印出来的值并不⼀样,因为memset越界后修改了a或者c的值(由于不同编译器对变量在空间中顺序的安排可能有不同策略,因此我⽤两个变量,希望能抓到越界信息。
对于VC,debug模式下系统添加了很多填充字节,你可能需要增加越界的数量才能看到效果)2. 为什么增加⼀个变量后程序就崩溃了?增加⼀个变量后,内存中变量的布局也发⽣了变化。
如果⼀个内存越界破坏了⼀个不含指针的结构,程序虽然逻辑不对,但是不⾄于崩溃。
但是如果增加变量后,内存访问越界破坏了⼀个指针,则会导致程序崩溃。
例如:int a;char b[128];//bool c;char* d=new char[128];int e;b[136] = '\0';b[137] = '\0';b[138] = '\0';b[139] = '\0';strcpy(d, "haha");注意, b访问越界了8个字节位置处的4个字节。
线程实例实验报告总结

一、实验目的本次实验旨在通过实例操作,深入了解线程的概念、创建、同步与通信机制,以及线程在实际编程中的应用。
通过实验,提高对线程的理解和运用能力,为以后开发多线程程序打下坚实基础。
二、实验环境1. 操作系统:Windows 102. 开发工具:Visual Studio 20193. 编程语言:C#三、实验内容1. 线程的基本概念线程是程序执行的最小单位,是操作系统进行资源分配和调度的基本单位。
线程具有以下特点:(1)线程是轻量级的,创建、销毁线程的开销较小。
(2)线程共享进程的资源,如内存、文件等。
(3)线程之间可以并发执行。
2. 线程的创建在C#中,可以使用以下方式创建线程:(1)使用Thread类```csharpThread thread = new Thread(new ThreadStart(MethodName));thread.Start();```(2)使用lambda表达式```csharpThread thread = new Thread(() => MethodName());thread.Start();```(3)使用匿名方法```csharpThread thread = new Thread(delegate () { MethodName(); });thread.Start();```3. 线程的同步线程同步是指多个线程在执行过程中,为了防止资源冲突而采取的协调机制。
C#提供了以下同步机制:(1)互斥锁(Mutex)```csharpMutex mutex = new Mutex();mutex.WaitOne();// 线程同步代码mutex.ReleaseMutex();```(2)信号量(Semaphore)```csharpSemaphore semaphore = new Semaphore(1, 1);semaphore.WaitOne();// 线程同步代码semaphore.Release();```(3)读写锁(ReaderWriterLock)```csharpReaderWriterLock rwlock = new ReaderWriterLock();rwlock.AcquireReaderLock();// 读取操作rwlock.ReleaseReaderLock();```4. 线程的通信线程通信是指线程之间传递消息、共享数据的过程。
内存泄漏的检测定位和解决经验总结

内存泄漏的检测定位和解决经验总结内存泄漏是指程序在运行过程中,分配的内存没有被正确释放,导致内存资源无法被再次利用的情况。
由于没有及时释放内存,内存泄漏会导致系统的内存消耗不断增加,最终可能造成程序崩溃或者系统运行缓慢。
解决内存泄漏问题需要进行检测、定位和解决。
一、内存泄漏的检测1. 使用内存分析工具:可以使用一些专门的内存分析工具来检测内存泄漏问题,例如Valgrind、Memcheck等。
这些工具可以跟踪程序运行过程中的内存分配和释放,帮助定位内存泄漏的位置。
2.编写测试用例:通过编写一些针对性的测试用例,模拟程序运行过程中常见的内存分配和释放场景,观察内存的使用情况。
如果发现内存占用持续增长或者没有被及时释放,就可以判断存在内存泄漏问题。
3.监控系统资源:通过监控系统的资源使用情况,如内存占用、CPU使用率等,可以观察系统是否存在内存泄漏的迹象。
如果发现系统的内存占用不断增加,并且没有明显的释放情况,就需要进一步检查是否存在内存泄漏。
二、内存泄漏的定位1.使用日志输出:通过在程序中添加日志输出语句,记录程序运行过程中的重要信息,特别是涉及内存分配和释放的地方。
通过观察日志输出,可以发现是否有内存没有被正确释放的情况。
2.代码分析:通过代码分析,找出可能导致内存泄漏的地方。
常见的内存泄漏问题包括:不恰当的内存分配和释放顺序、不正确的内存释放方式、内存分配大小不匹配等。
对于涉及动态分配内存的地方,要特别关注是否有被遗漏的释放操作。
3.堆栈跟踪:当发现内存泄漏问题比较复杂或者难以定位时,可以使用堆栈跟踪来追踪内存分配和释放的调用路径,找出内存泄漏的具体位置。
在调试过程中,可以通过打印调用栈来获取函数调用的过程,进而确定哪个函数没有正确释放内存。
三、内存泄漏的解决1.及时释放内存:在程序中,所有动态分配的内存都需要及时释放。
对于每个内存分配操作,都要确保相应的释放操作存在,并且在适当的时候进行调用。
多线程调试技巧及其实现

多线程调试技巧及其实现多线程调试技巧及其实现多线程是在计算机中运用多个线程(线程是操作系统能够进行运算调度的最小单位)来完成多个子任务,从而达到加快程序运行速度的效果。
而在实现多线程过程中,经常会遇到调试难度较大的问题。
本文将介绍多线程调试的一些常用技巧及其实现方法。
一、多线程调试技巧1.使用断点调试多线程程序的首选工具是调试器,其中使用断点是很重要的一种调试技巧。
将断点用在程序的关键位置上,可以在程序执行到这个位置时自动停止程序。
通过在停止位置上检查变量、栈和线程状态等来判断程序是否运行正确。
如果需要进一步调试,可以通过调试器提供的单步执行功能来逐步调试程序执行过程。
2.查看线程信息在多线程程序中,每个线程都拥有自己的执行上下文,包括程序计数器、寄存器值、堆栈等。
调试器可以通过查看线程信息来跟踪线程的执行状态。
在调试器中,可以切换到不同的线程并查看线程的当前状态,如线程ID、线程状态、线程优先级等。
3.使用条件断点条件断点是一种在程序执行到特定条件时自动停止程序的断点。
在多线程调试中,使用条件断点可以让程序在满足特定条件时自动停止,以便检查程序状态。
例如,在并发程序中,在其他线程修改一个变量的值之前,需要确保当前线程已经完成该变量的读取操作。
可以通过设置条件断点来检查当前线程是否完成读取,以便查找程序中的并发问题。
4.使用日志记录日志记录是一种很方便的调试技巧。
通过在程序中添加日志记录语句,可以在程序执行过程中记录程序状态。
在多线程程序中,可以在每个线程的关键位置上添加日志记录,以便跟踪线程状态。
同时,可以将日志信息输出到文件或控制台中,以便后续分析和调试。
5.使用调试工具调试工具是一种很有用的多线程调试技巧。
调试工具是一种功能强大的工具,可以提供线程跟踪、内存分析和性能分析等功能。
例如,在Linux系统中,使用gdb调试器可以轻松跟踪多线程程序的执行过程。
在Windows系统中,使用Visual Studio调试器可以进行线程跟踪和性能分析等操作。
内存泄漏的检测定位和解决经验总结

内存泄漏的检测定位和解决经验总结内存泄漏是指在程序运行过程中,分配的内存一直没有被释放,导致内存的使用量越来越大,最终耗尽系统资源,造成程序崩溃。
内存泄漏是一种常见的程序缺陷,需要及时发现和解决。
一、检测内存泄漏的方法有以下几种:1. 静态代码检查:通过静态代码分析工具进行检查,工具可以扫描代码中的内存分配和释放情况,并发现潜在的内存泄漏问题。
常用的静态代码检查工具包括Coverity、PMD等。
2. 动态代码检查:通过运行时检查工具对程序进行监控,记录内存分配和释放的情况,检查是否有未释放的内存。
常用的动态代码检查工具包括Valgrind、Dr.Memory等。
3. 内存使用分析工具:通过监控程序的内存使用情况,包括内存的分配与释放,内存占用量等信息,来判断是否存在内存泄漏。
常用的内存使用分析工具有Google Performance Tools、Eclipse Memory Analyzer 等。
二、定位内存泄漏的方法有以下几种:1.添加日志:在程序中添加日志跟踪内存的分配与释放情况,当发现内存没有被释放时,通过日志定位问题的位置。
可以通过添加打印语句或者使用专门的日志工具来完成日志记录。
2. 使用内存调试工具:内存调试工具可以跟踪程序中的内存分配和释放情况,并将未被释放的内存标记出来。
通过分析工具提供的报告,可以定位内存泄漏的位置。
常用的内存调试工具有Valgrind、Dr.Memory等。
3. 内存堆栈分析:当程序出现内存泄漏时,通过分析内存堆栈可以得到导致内存泄漏的代码路径。
可以使用工具来进行内存堆栈分析,例如Eclipse Memory Analyzer。
三、解决内存泄漏的方法有以下几种:1. 显式释放内存:在程序中显式地调用释放内存的函数,确保内存被正确地释放。
例如,在使用动态内存分配函数malloc或new分配内存后,必须使用free或delete释放内存。
2. 自动垃圾回收:使用编程语言或框架提供的垃圾回收机制,自动释放不再使用的内存。
多线程编程实验总结与体会 -回复

多线程编程实验总结与体会-回复[多线程编程实验总结与体会]作为一名计算机科学专业的学生,在学习多线程编程时,我们不仅需要理论知识,还需要通过实践来深入理解多线程的编写和应用。
在完成多线程编程的实验过程中,我吸取了许多经验和教训,形成了深刻的体会和总结。
以下是我在完成多线程编程实验后所得到的心得体会,希望对于有需求的学生有所帮助。
一、了解多线程编程的基础知识在进行多线程编程之前,必须要先掌握多线程的基础知识,包括线程的概念、线程的生命周期、线程的状态、线程同步和线程互斥等概念。
对于多线程编程的初学者来说,这是一个非常重要的基础,只有通过这些基础知识的学习,才能够更好地编写程序,解决实际的多线程应用问题。
二、了解并掌握多线程编程语言的特点在进行多线程编程时,我们需要使用支持多线程的编程语言,如Java、Python等。
对于不同的编程语言,其多线程操作的实现方式也有所不同。
因此,在进行多线程编程前,需要先掌握所用编程语言特有的多线程操作方式,并对其有所了解。
三、考虑问题全面,深入分析多线程编程的逻辑在设计多线程程序时,需要全面考虑程序的逻辑,注重多线程之间的协同工作和互相制约的因素。
多线程程序中需要解决的问题可能会很复杂,会牵扯到线程之间的通信、共享数据、同步/互斥和线程调度等问题。
因此,在编写多线程程序时,要仔细分析每个线程的作用和实现,考虑线程的优先级和时间片等有关因素,以便更好地实现程序的协同工作。
四、如何调试多线程程序多线程编程常常会带来一些难以预测的问题,使得程序的调试变得困难。
在调试多线程程序时,可以使用一些常见的调试方法,如使用输出语句来查看程序运行过程中的变量值和状态,使用调试器来单步调试程序,并在开发初期就引入测试用例,在程序开发与质量保证过程中使用到测试方法、性能调优和代码静态分析等工具,在不断地测试迭代中逐步减少bug 和其他难以预测的问题。
五、常见的多线程编程问题及解决方法在多线程编程中,常常会出现一些问题,这些问题可能会导致程序的运行出现异常,甚至会导致数据丢失和程序崩溃。
内存越界

/* In an actual memory block in the debug heap,
* this structure is followed by:
* unsigned char data[nDataSize];
* unsigned char anotherGap[nNoMansLandSize];
*/
szFileName是存储的发起分配操作的那行代码所在的文件的路径和名称,而nLine则是行号。nDataSize是请求分配的大小,我们的例子里当然就是10了,nBlockUse是类型,而lRequest是请求号。最后一项gap,又称NoMansLand,是 4byte(nNoMansLandSize=4)大小的一段区域,注意看最后几行注释就明白了,在这个结构后面跟的是用户真正需要的10byte数据区域,而其后还跟了一个4byte的Gap,那么也就是说用户申请分配的区域是被一个头结构,和一个4byte的gap包起来的。在释放这10byte空间的时候,会检查这些信息。Gap被分配之后会被以0xFD填充。检查中如果gap中的值变化了,就会以Assert fail的方式报错。不过vc6中提示的比较难懂,DAMAGE :after Normal block(#dd) at 0xhhhhhhhh,而vs2005里面会提示Heap Corruption Detected!而如果你是release版本,那么这个错误就会潜伏直到它的破坏力发生作用。
struct _CrtMemBlockHeader *pBlockHeaderNext;
// Pointer to the block allocated just after this one:
struct _CrtMemBlockHeader *pBlockHeaderPrev;
谈谈C++内存越界问题及解决方法

谈谈C++内存越界问题及解决方法与内存泄露相比,C++最令人头痛的问题是内存越界,而内存越界很多情况下是由于悬挂指针引起的。
假设一个指针变量:Object * ptr;使用ptr时,我们除了要判断ptr是否为0以外,还要怀疑它指向的对象是否有效,是不是已经在别的地方被销毁了。
我们希望当它指向的对象被销毁时,ptr被自动置为0。
显然,C++没有这种机制,但是,可以借助于boost::weak_ptr做到这一点。
inline void null_deleter(void const *){}class X{private:shared_ptr this_;int i_;public:explicit X(int i): this_(this, &null_deleter), i_(i){}X(X const & rhs): this_(this, &null_deleter), i_(rhs.i_){}X & operator=(X const & rhs){i_ = rhs.i_;}weak_ptr weak_this() const { return this_; }};定义变量:weak_ptr ptr = x.weak_this(); // x为一个X 对象则当 x 被销毁时,ptr 被自动置为无效。
使用方法如下:if ( shard_ptr safePtr = ptr.lock() ) safePtr->do_something();这种办法用于单线程中,因为 x 对象可能是基于栈分配的。
如果需要在多线程中访问X对象,那么的办法还是使用shared_ptr 来管理对象的生命期。
这样的话,对于safePtr, 可以保证在 safePtr 的生命期内,它所指向的对象不会被其它线程删除。
1 2。
多线程编程实验总结与体会

多线程编程实验总结与体会《多线程编程实验总结与体会》2000字以上通过本次多线程编程实验,我对多线程编程的原理、实现方式以及应用场景有了更加深入的理解,并且学会了使用Java语言进行多线程编程。
在整个实验过程中,我遇到了许多困难和挑战,但最终通过不断学习和探索,我成功地完成了实验任务。
在此过程中,我从中收获了许多宝贵的经验和教训。
首先,在实验过程中我学会了如何创建线程以及线程的基本操作。
在Java 中,使用Thread类可以创建一个新的线程,通过重写run()方法可以定义线程的执行任务。
通过调用start()方法可以启动线程,并且多个线程可以并发执行。
而在实验中,我了解到了使用Runnable接口也可以实现线程的创建,并且相比于直接使用Thread类,使用Runnable接口可以更好的实现线程的共享和资源的线程安全性。
其次,在多线程编程中,线程之间的协调和通信是非常重要的。
通过学习实验,我了解到了使用synchronized关键字可以实现线程的互斥操作,保证同一时刻只有一个线程可以访问某个共享资源。
此外,实验还引入了Lock对象以及Condition条件变量,这些类提供了更加灵活和高级的线程同步机制,如可以实现线程的中断、超时等功能。
同时,在实验中我还了解到了线程的调度和优先级的概念。
在Java中,线程调度是由操作系统负责的,通过使用yield()方法可以让出一段时间的CPU执行时间,从而让其他优先级较高的线程有机会执行。
而在实验中,我也了解到了线程优先级的设置,通过使用setPriority()方法可以设置线程的优先级,优先级较高的线程获取CPU时间片的几率更大。
此外,在多线程编程中,线程安全是一个非常重要的问题。
在实验中,我学习到了一些线程安全的编程技巧。
比如,使用volatile关键字可以保证变量的可见性,多个线程对该变量的修改能够在其他线程中立即得到通知。
另外,使用synchronized关键字可以保证共享资源的一致性,通过对关键代码块或方法进行加锁,可以防止多个线程同时修改共享资源导致的错误。
linux多线程编程实验心得

linux多线程编程实验心得在进行Linux多线程编程实验后,我得出了一些心得体会。
首先,多线程编程是一种高效利用计算机资源的方式,能够提高程序的并发性和响应性。
然而,它也带来了一些挑战和注意事项。
首先,线程同步是多线程编程中需要特别关注的问题。
由于多个线程同时访问共享资源,可能会引发竞态条件和数据不一致的问题。
为了避免这些问题,我学会了使用互斥锁、条件变量和信号量等同步机制来保护共享数据的访问。
其次,线程间通信也是一个重要的方面。
在实验中,我学会了使用线程间的消息队列、管道和共享内存等方式来实现线程间的数据传递和协作。
这些机制可以帮助不同线程之间进行有效的信息交换和协调工作。
此外,线程的创建和销毁也需要注意。
在实验中,我学会了使用pthread库提供的函数来创建和管理线程。
同时,我也了解到线程的创建和销毁是需要谨慎处理的,过多或过少的线程都可能导致系统资源的浪费或者性能下降。
在编写多线程程序时,我还学会了合理地划分任务和资源,以充分发挥多线程的优势。
通过将大任务拆分成多个小任务,并将其分配给不同的线程来并行执行,可以提高程序的效率和响应速度。
此外,我还学会了使用调试工具来分析和解决多线程程序中的问题。
通过使用gdb等调试器,我可以观察线程的执行情况,查找潜在的错误和死锁情况,并进行相应的修复和优化。
总结起来,通过实验我深刻认识到了多线程编程的重要性和挑战性。
合理地设计和管理线程,正确处理线程同步和通信,以及使用调试工具进行分析和修复问题,都是编写高效稳定的多线程程序的关键。
通过不断实践和学习,我相信我能够更好地应用多线程编程技术,提升程序的性能和可靠性。
freertos 内存越界的定位方法

freertos 内存越界的定位方法【原创版4篇】目录(篇1)一、引言二、FreeRTOS 简介三、内存越界原因及影响四、内存越界定位方法1.使用 mprotect 设置只读地址2.使用 backtrace 拦截信号打印堆栈3.使用 addr2line 解析出符号地址五、总结正文(篇1)一、引言在嵌入式系统中,FreeRTOS 作为一款开源实时操作系统,因其稳定性、可靠性以及可扩展性,被广泛应用于各种场景。
然而,在使用过程中,可能会遇到内存越界的问题,导致程序运行不正常。
本文将介绍 FreeRTOS 内存越界的定位方法。
二、FreeRTOS 简介FreeRTOS 是一款基于任务调度的实时操作系统,其核心功能包括任务管理、时间管理、队列、信号量、互斥量等。
在 FreeRTOS 中,任务分为优先级任务和普通任务,优先级任务具有更高的优先级,普通任务则按照先进先出的原则执行。
三、内存越界原因及影响内存越界是指程序在访问内存时,超出了其分配的内存空间范围,可能会导致程序崩溃、数据错误等问题。
在 FreeRTOS 中,内存越界问题可能源于如下原因:1.错误的指针操作,例如使用未初始化的指针或者访问不存在的内存地址。
2.缓冲区溢出,当程序向缓冲区写入数据时,超过了缓冲区的容量,导致数据覆盖到相邻的内存区域。
3.数组越界,当程序访问数组元素时,超出了数组的范围。
四、内存越界定位方法在 FreeRTOS 中,内存越界问题的定位可以采用以下方法:1.使用 mprotect 设置只读地址mprotect 是 Linux 内核中的一个命令,用于设置内存区域的保护属性。
通过将相关内存区域设置为只读,可以防止程序误写操作,从而定位内存越界问题。
2.使用 backtrace 拦截信号打印堆栈backtrace 是 Linux 系统中的一个信号处理程序,当接收到SIGRTMIN 信号时,会打印当前堆栈信息。
通过在程序中添加信号处理函数,并使用 kill 命令向程序发送 SIGRTMIN 信号,可以获取堆栈信息,从而定位内存越界问题。
踩内存问题定位

踩内存问题定位这⼏天在做总结,把三年前写的⼀个定位案例,翻了出来。
回想起定位这个问题时的场景,领导催得紧,⾃⼰对很多东西⼜不熟悉,所以当时⾯临的压⼒还是很⼤的。
现在回想起来感慨还是很多的,我们在遇到任何⼀个问题,⼀定不要放弃。
还记得在产品线做开发时,学到的⼀些项⽬知识,任何⼀个bug,他总有⼀天会爆发出来。
任何⼀个问题,总有⼀天找到好的解决⽅案。
当我们尝尽了所有可以尝试的⽅案,定位办法,解决思路后,往往这个问题也就迎刃⽽解了。
把⼯程上的事情放⼤看,其实⽣活中很多事情都是⼀样的,任何⼀个问题都有解决办法,但是这个办法不是摆在那⾥给我们⽤,他是藏在某个地⽅,等着我们去挖掘的。
所以勤奋,努⼒,不⽓馁,找对⽅向都是很重要的。
好了,我们⾔归正传,说下我这个踩内存的问题。
⾸先我们来看⼀下,公司常讲的编程规范:有⼀条是说,结构体指针在使⽤前需要赋初值。
这是很简单的⼀条规则,很多时候,我们会觉着⿇烦,或者我们在后⾯具体⽤到这个结构体时,我们再对结构体的成员赋值也可以,或者我们在使⽤时,仅对我们感兴趣的成员赋值就好了,其他的我们就不关⼼了。
但是下⾯我来告诉⼤家,这是不⾏的,下⾯这个问题会告诉⼤家,编程规范都是⽤⾎的教训写出来的。
遵守它,我们就可以避免很多不必要的debuging。
我们下⾯看下这种写法是否正确:struct msghdr msg;msg.msg_iov = &iov;msg.msg_iovlen = iovlen;ret = recvmsg(sockfd, &msg, int flags);在函数中,我们定义了⼀个msg结构体,但是没有给这个结构体赋初值,仅对其中的两个我们关⼼的变量做了赋值。
那么这样是否会带来问题呢?在项⽬交付前,A同学需要完成对S系统的压⼒测试,上⾯会反复的重启虚拟机,反复的杀死⼤量服务进程,做cpu,内存加压。
这样的压⼒测试⼤概执⾏⼀天到两天,就会出现异常,C服务出现了⼤量的coredump。
内存越界的定位方法

内存越界的定位方法内存越界是指程序试图访问已经超出了其所拥有的内存范围之外的内存地址。
这种错误可能会导致程序崩溃、逻辑错误等问题,因此及时定位内存越界问题非常重要。
本文将介绍几种常用的定位内存越界问题的方法。
1. 使用调试工具调试工具是开发人员定位内存越界问题的重要辅助工具。
例如Visual Studio、GDB等工具都提供了内存越界检测功能,可以通过断点调试或者内存监视等方式快速定位问题代码。
此外,也可以使用工具自带的内存检测插件,例如DUMA、Valgrind等工具,这些插件可以帮助开发人员检查内存泄漏、非法内存操作等问题,从而帮助更快地定位到内存越界问题。
2. 代码审查代码审查是开发人员定位内存越界问题的另一种常用方式。
通过代码审查,可以识别代码中存在的潜在问题,包括内存越界问题。
具体来说,可以在代码中查找语句,看是否存在数组下标访问越界的情况,如果有,将其进行修复即可。
此外,还可以检查内存分配和释放的情况,是否存在内存泄漏问题。
3. 使用静态分析工具静态分析工具是对代码进行静态分析,以识别代码中的问题。
在开发过程中,可以使用静态分析工具对代码进行分析,以帮助开发人员快速发现内存越界问题。
有些静态分析工具的精度非常高,可以对复杂的程序结构进行分析,并且可以为开发人员提供相关的提示和建议,从而帮助开发人员更快地定位内存越界问题。
4. 使用代码注释在开发代码的过程中,为了更好地理解代码的目的和实现方式,可以添加一些代码注释。
这种方式虽然不能直接帮助开发人员定位内存越界问题,但是通过注释的方式,可以更加准确地描述程序的逻辑,从而帮助其他开发人员理解代码的含义,也有助于更快地发现内存越界等错误问题。
总之,定位内存越界问题需要采用多种方法,包括调试工具、代码审查、静态分析工具和代码注释等。
通过这些方式,可以更加准确、快速地定位到内存越界问题,并对其进行修复。
开发人员在实际开发过程中,应该注重代码质量,避免内存越界等问题的出现。
软件编程低级错误:内存越界

• 本胶片收集了常见的内存越界案例,给出了相应的纠正措施。对应的编程规范:防 本胶片收集了常见的内存越界案例,给出了相应的纠正措施。对应的编程规范: 止内存操作越界
HUAWEI TECHNOLOGIES CO., LTD. Huawei Confidential Page 2
常见的内存越界问题和解决措施建议
问 题 措 施 数组分配未考虑最大情况,导致空间不够 数组的大小要考虑最大情况,避免数组分配空间不够 使用危险函数printf /vsprintf/strcpy 使用相对安全的字符串库函数snprintf/strncpy/ /strcat/gets操作字符串 strncat/fgets操作字符串 使用memcpy/memset没有判断长度 使用memcpy/memset时一定要确保长度不要越界;注意 memcpy/strncpy的区别 计算长度时+1 将指针作为无结构的内存块进行操作,先将其转化为char *类型 调用函数来计算,不要手工计算 调用sizeof计算,不要手工计算 调用sizeof计算,不要手工计算 对于外部输入的数组下标要作检查 注意相似的宏定义/结构,copy/paste特别小心 总是初始化变量:在首次使用前声明、定义、初始化变量 在外部接口处,校验所有的输入数据 头文件的声明应该统一规划,一个文件里面不要有多种字节 对齐方式 应尽量减少或合并编译开关 在函数原型定义时,就应写作正确的指针类型
字符串没有考虑最后的’\0’ 指针加减操作时,没有考虑指针类型
魔鬼数字:人工计算字符串长度出错 魔鬼数字:人工计算结构长度出错 未考虑结构类型,内存分配不够 数组下标未检查导致越界 使用了相似名字的宏定义/结构名称 变量没有初始化 没有校验外部输入参数 字节对齐出错
编译开关不一致 错误使用sizeof
学会使用调试器和内存分析工具来解决程序编辑中的问题

学会使用调试器和内存分析工具来解决程序编辑中的问题在软件开发的过程中,程序员经常会遇到各种各样的问题。
这些问题可能是语法错误、逻辑错误或者内存管理问题等等。
为了定位和解决这些问题,学会使用调试器和内存分析工具是非常重要的。
本文将介绍如何使用调试器和内存分析工具来解决程序编辑中的问题。
一、调试器的使用调试器是一种可以帮助程序员找出程序中的错误的工具。
不同的编程语言和开发环境可能有不同的调试器,但它们的基本功能都是相似的。
调试器可以让程序员逐行执行程序并观察程序的运行情况,同时还能够提供一些特殊的功能帮助定位和解决问题。
1. 设置断点断点是调试器中的一个重要功能,它可以让程序在执行到指定的代码行时停下来,以便程序员可以观察程序的状态和变量的值。
在调试器中设置断点的方法通常很简单,只需要在目标代码行的左侧点击一下即可。
2. 单步执行调试器可以让程序一步一步地执行,同时提供各种观察和调试信息。
在程序执行过程中,程序员可以观察变量的值、函数的返回结果以及程序跳转的路径等等,以此来定位问题所在。
3. 查看变量的值在调试器中,程序员可以查看变量的当前值和历史值。
通过观察变量的值的变化,可以帮助程序员发现问题的根源并进行修复。
二、内存分析工具的使用内存分析工具是一种可以帮助程序员分析程序内存使用情况的工具。
它可以帮助程序员找出内存泄漏、内存溢出等问题,并提供相应的建议和解决方案。
1. 内存泄漏检测内存泄漏是指在程序运行过程中未及时释放不再使用的内存,导致内存占用不断增加的现象。
内存分析工具可以帮助程序员检测和分析内存泄漏问题,并提供相应的调试信息和建议。
2. 内存溢出检测内存溢出是指程序在申请内存时无法找到足够的内存空间的现象。
这种问题可能导致程序崩溃或运行缓慢。
内存分析工具可以帮助程序员检测和分析内存溢出问题,并提供相应的解决方案。
3. 内存优化建议内存分析工具可以帮助程序员找出内存使用效率低下的地方,并提供相应的优化建议。
Linux C语言 内存越界问题总结
Linux C语言内存越界问题总结内存越界问题是项目开发中比较难解决的问题,下面就简单的描述下内存越界的种类、现象及引起的原因。
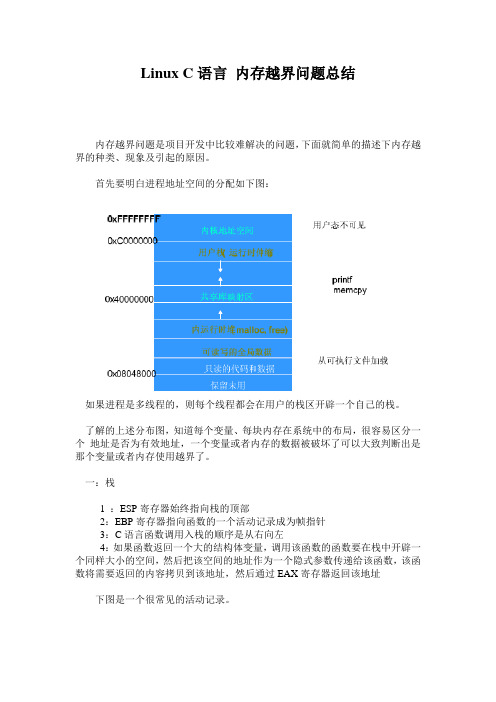
首先要明白进程地址空间的分配如下图:如果进程是多线程的,则每个线程都会在用户的栈区开辟一个自己的栈。
了解的上述分布图,知道每个变量、每块内存在系统中的布局,很容易区分一个地址是否为有效地址,一个变量或者内存的数据被破坏了可以大致判断出是那个变量或者内存使用越界了。
一:栈1 :ESP寄存器始终指向栈的顶部2:EBP寄存器指向函数的一个活动记录成为帧指针3:C语言函数调用入栈的顺序是从右向左4:如果函数返回一个大的结构体变量,调用该函数的函数要在栈中开辟一个同样大小的空间,然后把该空间的地址作为一个隐式参数传递给该函数,该函数将需要返回的内容拷贝到该地址,然后通过EAX寄存器返回该地址下图是一个很常见的活动记录。
二:堆1:malloc 分配小块内存时是在小于0x4000 0000的内存中分配的,通过brk/sbrk不断向上扩展。
分配大块内存是是通过mmap分配在大于0x4000 0000的文件映射区。
2:malloc分配的内存前面存放该内存的大小,后面是空闲内存块(可能会被malloc调用分配出去)三:内存越界的种类1:栈溢出:主要现象:(1):某些全局变量被修改(2):某些任务不能正常工作函数调用不正常(3):某些局部变量被修改主要原因:(1):线程堆栈开辟的太小(2):定义的太大的局部变量(3):函数调用太深2:堆栈内部越界主要现象:(1):某些局部变量被修改(2):函数返回的时候死机主要原因:(1):临时变量或者数组越界3:全局变量或者动态分配的内存越界主要现象:(1):全局变量被修改(2):内存泄漏(如果动态分配的内存越界,有可能导致被越界的内存无法释放或者不能全部释放)主要原因:全局或者动态分配的内存越界。
一些容易引起内存越界的操作:1:注意strcpy sprintf memcpy 函数目的缓冲区的大小2:strncpy strcpy 目的缓冲区的大小及源缓冲区是否以\0结尾3:还要注意数组的大小、循环的次数4:链表的头部和尾部在处理插入和删除节点时的操作注:如果是全局变量被越界,可以用readelf工具读出可执行文件的符号表,看下该全局变量前面的变量是哪个,然后看下相关代码是否有越界的情况。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
定位多线程内存越界问题实践总结2013/2/4杨志丰***********************关键字多线程,内存越界,valgrind,electric-fence,mprotect,libsigsegv,glibc最近定位了在一个多线程服务器程序(OceanBase MergeServer)中,一个线程非法篡改另一个线程的内存而导致程序core掉的问题。
定位这个问题花了整整一周的时间,期间历经曲折,尝试了各种内存调试的办法。
往往感觉就要柳暗花明了,却发现又进入了另一个死胡同。
最后,使用强大的mprotect+backtrace+libsigsegv等工具成功定位了问题。
整个定位过程遇到的问题和解决办法对于多线程内存越界问题都很典型,简单总结一下和大家分享。
只对终极组合秘技感兴趣的同学,请直接阅读最后一节,其他的章节写到这里是为了科普。
现象core是在系统集成测试过程中发现的。
服务器程序MergeServer有一个50个工作线程组成的线程池,当使用8个线程的测试程序通过MergeServer读取数据时,后者偶尔会core 掉。
用gdb查看core文件,发现core的原因是一个指针的地址非法,当进程访问指针指向的地址时引起了段错误(segment fault)。
见下图。
发生越界的指针ptr_位于一个叫做cname_的对象中,而这个对象是一个动态数组field_columns_的第10个元素的成员。
如下图。
复现问题之后,花了2天的时间,终于找到了重现问题的方法。
重现多次,可以观察到如下一些现象:1.随着客户端并发数的加大(从8个线程到16个线程),出core的概率加大;2.减少服务器端线程池中的线程数(从50个到2个),就不能复现core了。
3.被篡改的那个指针,总是有一半(高4字节)被改为了0,而另一半看起来似乎是正确的。
4.请看前一节,重现多次,每次出core,都是因为field_columns_这个动态数组的第10个元素data_[9]的cname_成员的ptr_成员被篡改。
这是一个不好解释的奇怪现象。
5.在代码中插入检查点,从field_columns_中内容最初产生到读取导致越界的这段代码序列中“埋点”,既使用二分查找法定位篡改cname_的代码位置。
结果发现,程序有时core到检查点前,有时又core到检查点后。
综合以上现象,初步判断这是一个多线程程序中内存越界的问题。
使用glibc的MALLOC_CHECK_因为是一个内存问题,考虑使用一些内存调试工具来定位问题。
因为OB内部对于内存块有自己的缓存,需要去除它的影响。
修改OB内存分配器,让它每次都直接调用c库的malloc和free等,不做缓存。
然后,可以使用glibc内置的内存块完整性检查功能。
使用这一特性,程序无需重新编译,只需要在运行的时候设置环境变量MALLOC_CHECK_(注意结尾的下划线)。
每当在程序运行过程free内存给glibc时,glibc会检查其隐藏的元数据的完整性,如果发现错误就会立即abort。
用类似下面的命令行启动server程序:export MALLOC_CHECK_=2bin/mergeserver -z 45447 -r 10.232.36.183:45401 -p45441使用MALLOC_CHECK_以后,程序core到了不同的位置,是在调用free时,glibc检查内存块前面的校验头错误而abort掉了。
如下图。
但这个core能带给我们想信息也很少。
我们只是找到了另外一种稍高效地重现问题的方法而已。
或许最初看到的core的现象是延后显现而已,其实“更早”的时刻内存就被破坏掉了。
valgrindglibc提供的MALLOC_CHECK_功能太简单了,有没有更高级点的工具不光能够报告错误,还能分析出问题原因来?我们自然想到了大名鼎鼎的valgrind。
用valgrind来检查内存问题,程序也不需要重新编译,只需要使用valgrind来启动:nohup valgrind --error-limit=no --suppressions=suppress bin/mergeserver -z 45447 -r 10.232.36.183:45401 -p45441 >nohup.out &默认情况下,当valgrind发现了1000中不同的错误,或者总数超过1000万次错误后,会停止报告错误。
加了--error-limit=no以后可以禁止这一特性。
--suppressions用来屏蔽掉一些不关心的误报的问题。
经过一翻折腾,用valgrind复现不了core的问题。
valgrind报出的错误也都是一些与问题无关的误报。
大概是因为valgrind运行程序大约会使程序性能慢10倍以上,这会影响多线程程序运行时的时序,导致core不能复现。
此路不通。
magic number既然MALLOC_CHECK_可以检测到程序的内存问题,我们其实想知道的是谁(哪段代码)越了界。
此时,我们想到了使用magic number填充来标示数据结构的方法。
如果我们在被越界的内存中看到了某个magic number,就知道是哪段代码的问题了。
首先,修改对于malloc的封装函数,把返回给用户的内存块填充为特殊的值(这里为0xEF),并且在开始和结束部分各多申请24字节,也填充为特殊值(起始0xBA,结尾0xDC)。
另外,我们把预留内存块头部的第二个8字节用来存储当前线程的ID,这样一旦观察到被越界,我们可以据此判定是哪个线程越的界。
代码示例如下。
然后,在用户程序通过我们的free入口释放内存时,对我们填充到边界的magic number 进行检查。
同时调用mprobe强制glibc对内存块进行完整性检查。
最后,给程序中所有被怀疑的关键数据结构加上magic number,以便在调试器中检查内存时能识别出来。
例如好了,都加好了。
用MALLOC_CHECK_的方式重新运行。
程序如我们所愿又core掉了,检查被越界位置的内存:如上图,红色部分是我们自己填充的越界检查头部,可以看到它没有被破坏。
其中第二行存储的线程号经过确认确实等于我们当前线程的线程号。
蓝色部分为前一个动态内存分配的结尾,也是完整的(24个字节0xdc)。
0x44afb60和0x44afb68两行所示的内存为glibc malloc 存储自身元数据的地方,程序core掉的原因是它检查这两行内容的完整性时发现了错误。
由此推断,被非法篡改的内容小于16个字节。
仔细观察这16字节的内容,我们没有看到熟悉的magic number,也就无法推知有bug的代码是哪块。
这和我们最初发现的core的现象相互印证,很可能被非法修改的内容仅为4个字节(int32_t大小)。
另外,虽然我们加宽了检查边界,程序还是会core到glibc malloc的元数据处,而不是我们添加的边界里。
而且,我们总可以观察到前一块内存(图中蓝色所示)的结尾时完整的,没被破坏。
这说明,这不是简单的内存访问超出边界导致的越界。
我们可以大胆的做一下猜测:要么是一块已经释放的内存被非法重用了;要么这是通过野指针“空投”过来的一次内存修改。
如果我们的猜测是正确的,那么我们用这种添加内存边界的方式检查内存问题的方法几乎必然是无效的。
打怪利器electric-fence至此,我们知道某个时间段内某个变量的内存被其他线程非法修改了,但是却无法定位到是哪个线程哪段代码。
这就好比你明明知道未来某个时间段在某个地点会发生凶案,却没办法看到凶手。
无比郁闷。
有没有办法能检测到一个内存地址被非法写入呢?有。
又一个大名鼎鼎的内存调试库electric-fence(简称efence)就华丽登场了。
使用MALLOC_CHECK_或者magic number的方式检测的最大问题是,这种检查是“事后”的。
在多线程的复杂环境中,如果不能发生破坏的第一时间检查现场,往往已经不能发现罪魁祸首的蛛丝马迹了。
electric-fence利用底层硬件(CPU提供的虚拟内存管理)提供的机制,对内存区域进行保护。
实际上它就是使用了下一节我们要自己编码使用的mprotect系统调用。
当被保护的内存被修改时,程序会立即core掉,通过检查core文件的backtrace,就容易定位到问题代码。
这个库的版本有点混乱,容易弄错。
搜索和下载这个库时,我才发现,electric-fence的作者也是大名鼎鼎的busybox的作者,牛人一枚。
原作者的官网上的下载地址为/FreeSoftware/ElectricFence/。
但是,这个版本在linux上编译连接到我的程序的时候会报WARNING,而且后面执行的时候也会出错。
后来,找到了debian提供的一个更高版本的库,估计是社区针对linux做了改进。
我最后用的是这个 2.2.4版本:/sid/electric-fence。
使用efence需要重新编译程序。
efence编译后提供了一个静态库libefence.a,它包含了能够替代glibc的malloc, free等库函数的一组实现。
编译时需要一些技巧。
首先,要把-lefence 放到编译命令行其他库之前;其次,用-umalloc强制g++从libefence中查找malloc等本来在glibc中包含的库函数:g++ -umalloc –lefence …用strings来检查产生的程序是否真的使用了efence:和很多工具类似,efence也通过设置环境变量来修改它运行时的行为。
通常,efence在每个内存块的结尾放置一个不可访问的页,当程序越界访问内存块后面的内存时,就会被检测到。
如果设置EF_PROTECT_BELOW=1,则是在内存块前插入一个不可访问的页。
通常情况下,efence只检测被分配出去的内存块,一个块被分配出去后free以后会缓存下来,直到一下次分配出去才会再次被检测。
而如果设置了EF_PROTECT_FREE=1,所有被free的内存都不会被再次分配出去,efence会检测这些被释放的内存是否被非法使用(这正是我们目前怀疑的地方)。
但因为不重用内存,内存可能会膨胀地很厉害。
我使用上面2个标记的4种组合运行我们的程序,遗憾的是,问题无法复现,efence 没有报错。
另外,当EF_PROTECT_FREE=1时,运行一段时间后,MergeServer的虚拟内存很快膨胀到140多G,导致无法继续测试下去。
又进入了一个死胡同。
终极神器mprotect + backtrace + libsigsegv electric-fence 的神奇能力实际上是使用系统调用mprotect 实现的。