泛微ecology常用数据库语句
泛微OA-ecology-二次开发实例-开发完整说明学习资料

泛微OA-ecology-二次开发实例-开发完整说明学习资料二次开发培训文档一、ECOLOGY系统框架结构1、主要的程序结构EcologyClassbean 存放编译后的CLASS文件js 系统中使用的JA V ASCRIPT和VBSCRIPT脚本Css 系统中JSP页面使用的样式ImagesImages_faceImages_frame 系统中使用的图片的存放目录CrmWorkflow 该功能分文件夹存放每个功能的文件WEB-INFProp 系统配置文件存放Service 系统的接口配置文件的存放二、说明一个JSP页面,一个JA V A程序的基本组成,如何阅读JSP页面1、一个jsp页面通常需要包含什么内容2、如何阅读一个JSP页面由于ECOLOGY系统支持多语言,因此在JSP页面上一般不出现中文,全部使用标签的形式来显示中文:比如:在IE上显示“姓名”那么在JSP页面中将通过<%=SystemEnv.getHtmlLabelName(413,user.getLanguage() )%>这样的形式来表示,其中的数字413就是表示姓名,同时可以通过“select labelname from htmllabelinfo where indexid=413 and languageid=7”来获取到“姓名”这个显示名称,其中languageid=7表示中文显示名称,languageid=8表示英文显示名称.delete from HtmlLabelIndex where id=81249delete from HtmlLabelInfo where indexid=81249INSERT INTO HtmlLabelIndex values(81249,'选择范围')INSERT INTO HtmlLabelInfo VALUES(81249,'选择范围',7)INSERT INTO HtmlLabelInfo VALUES(81249,'Range of choice',8)INSERT INTO HtmlLabelInfo VALUES(81249,'選擇範圍',9)3、JA V A程序的基本组成在ECOLOGY中开发JA V A程序建议继承weaver.general. BaseBean,在BaseBean 中主要封装了两个方法:写日志文件,获取配置文件中的参数值。
泛微OA 数据库维护笔记(e-cology)

泛微OA数据库维护笔记本文介绍泛微OA系统流程相关表结构,以及常用的查询、修改流程数据、导出流程数据的操作:这里主要介绍流程的数据存放结构及如果通过流程类型获取到流程的字段信息,流程的载体分为表单和单据两类,表单和单据的区别在于:所有使用表单的流程数据存放在同一个表中,而单据每个单据对应着一张独立的数据表1.表单一、对于表单而言流程的数据信息存放在三个数据表中Workflow_requestbase:该表存放了流程的基本信息:标题,创建人,创建时间,流程类型等等Workflow_form:该表存储了流程的具体信息通过REQUESTID字段和Workflow_requestbase表关联Workflow_formdetail:该表存放了流程的明细信息,同样通过REQUESTID字段和Workflow_requestbase表关联二、通过流程的类型如何获取该流程使用了Workflow_form和Workflow_formdetail表中哪些字段在Workflow_form和Workflow_formdetail表中存放了大量字段,所有使用表单的流程的字段都在这两个表中,如何获取每个流程使用了那些字段呢?A、找到流程的类型ID,假定为wfidB、找到流程用了哪个表单select formid from workflow_base whereid=wfid and isbill=’0’C、获得该表单用到了哪些主字段:select(select fieldlable from workflow_fieldlable whereworkflow_fieldlable.fieldid=workflow_formfield.fieldid and langurageid=7andworkflow_fieldlable.formid=workflow_formfield.formid)as name,(select fieldname from workflow_formdictwhere id=fieldid)from workflow_formfield whereformid=上面获取的FORMID and (isdetail is null orisdetail=’’)哪些明细字段:select(select fieldname fromworkflow_formdictdetail where id=fieldid)fromworkflow_formfield where formid=上面获取的FORMID andisdetail=’1’➢下面是查询出差申请流程“表单”数据的步骤:2.单据对于表单而言流程的数据信息存放在三个数据表中Workflow_requestbase:该表存放了流程的基本信息:标题,创建人,创建时间,流程类型等等Workflow_form:该表只存放Workflow_requestbase和单据表之间的关系信息各单据主表:该表存储了流程的具体信息通过REQUESTID字段和Workflow_requestbase表关联,如何获取该表呢:A、找到流程的类型ID,假定为wfidB、找到流程用了哪个单据select formid form workflow_basewhere id=wfid and isbill=’1’C、通过单据ID可以获取到该单据使用的字段Select * from workflow_billfield where billid= formidD、通过单据ID找到其用了那个表存储流程主信息,那个表存储流程明细信息select tablename from workflow_bill where id= formidselect tablename from workflow_billdetailtablewhere id= formid各单据主明细表:该表存放了流程的明细信息,同样通过REQUESTID字段和Workflow_requestbase表关联➢下面是查询名片申请流程“单据”数据的步骤:1、流程的其他信息表结构流程处理人情况表Workflow_currentoperator:此表存储了流程当前未操作者,已操作者等信息workflow_requestlog 流程处理意见表:此表存储了流程处理人处理过的审批意见workflow_requestviewlog 流程的查看日志workflow_requestbase.doc workflow_bill.doc workflow_base.doc workflow_currentoperator.docworkflow_requestLog.doc➢如何查询浏览按钮的数据列表(以医药信息为例)➢如何查询下拉框选项列表数据(以省份信息为例)➢例子:导出表单流程数据select*from workflow_base where workflowname like'经销协议申请%'得到表单ID Formid=-41和WorkFlowID=ID=959Select*from workflow_billfield where billid=-41and fieldname='wtcp'得到表单字段select tablename from workflow_bill where id=-41得到主表名称 formtable_main_41select tablename from workflow_billdetailtable where id=-41得到明细表名称select*from Workflow_requestbase where WORKFLOWID=959得到所有申请记录以及具体的RequestID=26710select xsmbb,xsmb2 from formtable_main_41 where requestid=31245得到表单内容select xsmb2 from formtable_main_41_dt1 where mainid=1181如何查字段名称Select b.fieldname, belnamefrom workflow_billfield bleft join HtmlLabelInfo lon b.fieldlabel = l.indexid and nguageid=7where billid =-41and belname='销售目标2'如何查“浏览按钮”的明细信息select*from MODEINFO where modename='省份信息'找到FormID =-85select*from workflow_bill where id=-58找到表名 formtable_main_85select*from formtable_main_58 where id=2此表即为数据查下拉列表select*from workflow_SelectItem where fieldid=6288➢查询某人有哪些流程➢批量设置超时。
泛微 ecology 流程存储数据说明
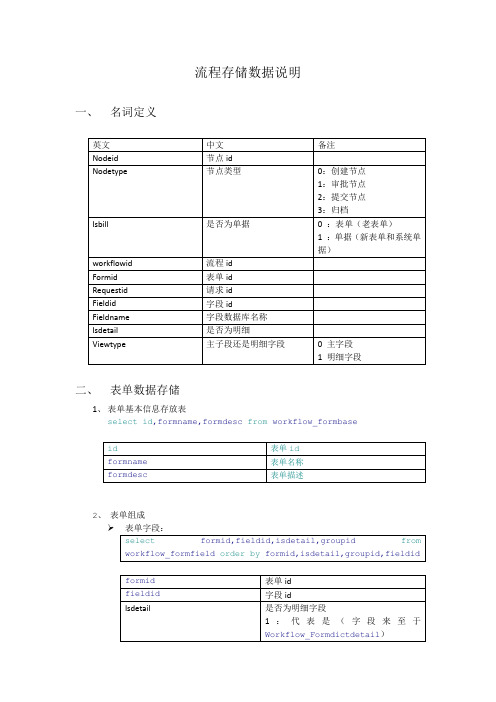
流程存储数据说明一、名词定义二、表单数据存储1、表单基本信息存放表select id,formname,formdesc from workflow_formbase2、表单组成3、字段信息主字段:select * from Workflow_formdict明细字段:select * from Workflow_Formdictdetail4、数据表主字段数据select * from workflow_form明细字段数据select * from workflow_formdetail通过groupid区分不同明细表数据主字段数据和明细字段数据的关联关系workflow_form.requestid = workflow_formdetail.requestid三、单据1、单据的基本信息select b.indexdesc,a.* from workflow_bill a,htmllabelindex b where label = b.id表单id < 0 自定义表单表单id > 0 系统单据23、数据表四、示例1、通过workflowid查找当前请求数据存储的位置以workflowid = 5 为例,该流程为内部留言流程查询结果如下:Formid = 3,Isbill=0 参照第一部分的名词定义我们可以得知,留言流程使用的是formid=3的老表单。
第二步,查询流程所在的表和字段信息参照第二部分的表单数据存储。
表单字段数据存储主表明细2、通过requestid查找当前流程数据存储的位置假设requestid = 249查询结果第二步查找流程的基本信息第一步里面找到了workflowid = 52Formid = -13,Isbill=1 参照第一部分的名词定义我们可以得知,出差申请流程使用的是formid=-13的新表单第三步查询流程所在的表和字段信息参照第二部分的表单数据存储。
(泛微e-cology7.0)数据库表结构设计文档

泛微网络有限公司
Table Name HrmRoleMembers HrmRoles HrmSalaryChange HrmSalaryHistory HrmSalaryItem HrmSalaryPay HrmSalaryPaydetail HrmSalaryPersonality HrmSalaryRank HrmSalaryTaxbench HrmSalaryTaxrate HrmSalaryWelfarerate HrmSchedule HrmScheduleDiff HrmScheduleMaintance HrmSearchMould hrmshare HrmSpeciality HrmStatusHistory HrmSubCompany HrmTrain HrmTrainActor HrmTrainAssess HrmTrainBeforeWork HrmTrainDay HrmTrainLayout HrmTrainLayoutAssess HrmTrainPlan HrmTrainPlanDay HrmTrainPlanRange HrmTrainRecord HrmTrainResource HrmTrainTest HrmTrainType HrmUseDemand HrmUseKind HrmUserDefine
Comment 人力资源总部表 人力资源技能表 人力资源工资统计表 人力资源合同表 人力资源合同模板表 人力资源合同种类表 国家表 人力资源部门表 人力资源教育情况表 人力资源外文级别表 人力资源家庭情况表 入职维护项目表 入职维护项目状态表 人力资源招聘考试通知 人力资源招聘考试评价 人力资源招聘考试结果 人力资源职责表 人力资源职称表 人力资源职务类型表 人力资源岗位表 人力资源职务表 人力资源语言能力表 人力资源功能项目管理表 人力资源办公地点表 人力资源其它信息种类表 人力资源结束周期 人力资源计划色块设置表 人力资源省份表 人力资源公众假日表 人力资源表 人力资源能力表 人力资源工资表 人力资源其他信息表 人力资源技能表 人力资源奖惩信息表(入职前) 人力资源奖惩信息表(入职后) 人力资源奖惩类型 7
泛微 ecology workflow_currentoperator
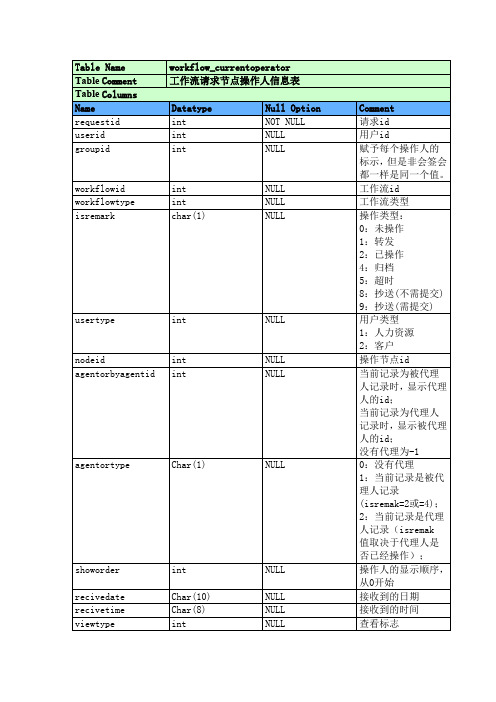
workflow_currentoperator 工作流请求节点操作人信息表 Datatype int int int Null Option NOT NULL NULL NULL Comment 请求id 用户id 赋予每个操作人的 标示, 但是非会签会 都一样是同一个值。 工作流id 工作流类型 操作类型: 0:未操作 1:转发 2:已操作 4:归档 5:超时 8:抄送(不需提交) 9:抄送(需提交) 用户类型 1:人力资源 2:客户 操作节点id 当前记录为被代理 人记录时, 显示代理 人的id; 当前记录为代理人 记录时, 显示被代理 人的id; 没有代理为-1 0:没有代理 1:当前记录是被代 理人记录 (isremak=2或=4); 2:当前记录是代理 人记录(isremak 值取决于代理人是 否已经操作); 操作人的显示顺序, 从0开始 接收到的日期 接收到的时间 查看标志
workflow_currentoperator 工作流请求节点操作人信息表 Datatype Char(1) Null Option NULL Comment 1:已经超时提醒 是否已经超时处理 过 1:自动流转 2:流转到指定对象 3:超时并未启用超 时处理或自动流转 失败 工作流超时提醒人 工作流超时提醒人 类型 改变前的isremark 是否为退回前的节 点操作人 (用于分叉 流转日志显示) 1:是 0或其它:否
workflowid workflowtype isremark
int int char(1)
NULL NULL NULL
usertype
int
NULL
泛微e9 文档操作 数据库语句

泛微e9 文档操作数据库语句泛微e9是一款功能强大的企业协同办公平台,可以帮助企业实现文档管理、流程管理、知识管理等多项业务需求。
在使用泛微e9进行文档操作时,需要掌握一些基本的数据库语句,以便更好地管理和操作文档数据。
下面列举了一些常用的数据库语句,供参考:1. 创建数据库表:CREATE TABLE tablename (column1 datatype,column2 datatype,...);2. 删除数据库表:DROP TABLE tablename;3. 插入数据:INSERT INTO tablename (column1, column2, ...) VALUES (value1, value2, ...);4. 更新数据:UPDATE tablename SET column1 = value1, column2 = value2, ... WHERE condition;5. 删除数据:DELETE FROM tablename WHERE condition;6. 查询数据:SELECT column1, column2, ... FROM tablename WHERE condition;7. 查询数据并排序:SELECT column1, column2, ... FROM tablename WHERE condition ORDER BY column ASC/DESC;8. 查询数据并限制结果集:SELECT column1, column2, ... FROM tablename WHERE condition LIMIT n;9. 查询数据并计算结果:SELECT COUNT(column) FROM tablename;10. 连接多个表查询数据:SELECT column1, column2, ... FROM tablename1 INNER JOIN tablename2 ON condition;这些数据库语句可以帮助我们对泛微e9中的文档数据进行增删改查等操作。
泛微协同商务系统Ecology系统底层包开发指南

泛微协同商务系统E c o l o g y系统底层包开发指南文档编制序号:[KKIDT-LLE0828-LLETD298-POI08]底层包开发指南目录1. 引言1.1 概述本文档为泛微协同商务系统(Ecology)程序员开发指导文档,讲述了开发底层工具包的应用,常用功能的开发。
2. 底层包应用及范例本章对ecology系统的底层工具包进行讲解,开发人员可以从这里学到怎样利用底层的工具包进行开发2.1 最基本的继承类继承的例子如下:java bean 的继承public class ResourceComInfo extends BaseBean {public void doSomething() { 2003年8月12日2004-01-102004-03-10String debugInfo = "This is test" ;roperties。
比如:系统的运行目录为 d:\ecology\,那么属性文件必须放在d:\ecology\WEB-INF\prop\ 目录下,取名为,其中thefilename是任意的。
在属性文件中某一个键值的值用等号来赋值,等号后面的值必须放在一行,如果一行不够写(或者为了查看的方便),可以用 \ 来链接多行。
否则其它行的值不能被键值取得。
等号左右都可以有空格,对键值和键值的值没有影响。
比如:thekeyname = thevalue将键值的值放到多行:thekeyname = thevalue1 \thevalue2 \thevalue3thevalue4这时候thekeyname 的值为thevalue1thevalue2thevalue3 ,thevalue4 取不到,因为thevalue3后面没有 \在程序中要取得上述属性文件中键值thekeyname的值,使用方法:getPropValue(“thefilename” , “thekeyname”) ;获取属性文件的值的例子如下:public class ResourceComInfo extends BaseBean {private void setResourceInfo() throws Exception{业务处理过程……….String keyValue = getPropValue(“thefilename” , “thekeyname”) ; getConfigFile() 来获取,当主属性文件名称因为需要改变得时候,不必改变所有用到这个属性文件的类,只需要改变GCONST类中常量的值2.2 怎样获取系统的运行目录类提供了一个静态方法getRootPath() ,返回系统的运行目录,比如系统的运行目录为d 盘的ecology目录,将返回d:\ecology\获取系统的运行目录的例子如下:public class TestBean extends BaseBean {import ;public void getSysRunPath(){String sysRunPath = GCONST. GetRootPath() ;..……}2、使用指定的链接池ecologytest执行SQL语句RecordSet rs = new RecordSet() ;(" update TB_Example set name = 'the new value' " , "ecologytest" ) ;3、使用指定的链接池ecologytest执行存储过程 PD_Example_UpdateById存储过程PD_Example_UpdateById 如下:CREATE PROCEDURE [PD_Example_UpdateById](@name varchar(100),@id int,@flag integer output,@msg varchar(80) output)ASupdate TB_Example set name = @name where id = @idGORecordSet rs = new RecordSet() ;String newname = ....... ;String id = ...... ;String procpara = newname + () + id ;( "PD_Example_UpdateById" , procpara , "ecologytest" ) ;4、在一个客户程序多个执行之间,查询结果可以保留到下一次查询RecordSet rs = new RecordSet() ;(" select * from TB_Example ") ;(" update TB_Example set name = 'the new value '") ;while( () ) {String thename = ("name") ; ..…….}(" select * from TB_Example ") ;while( () ) {String thename = ("name") ; ..……}访问和运行数据库脚本的例子:public class ResourceComInfo extends BaseBean {private void setResourceInfo() throws Exception{业务处理过程……….String sqlStr = “select * from Hrmresorce” ;RecordSet rt = new RecordSet() ;(sqlStr) ;while()){String id = ("id"));String loginid = ("loginid"));String lastname = ("lastname"));持对一个或多个由属性文件定义的数据库连接池的访问.客户程序可以调用getInstance()方法访问本类的唯一实例。
泛微e8常用sql语句

泛微e8的数据库结构和具体的SQL语句会因系统版本、设置等因素而有所不同。
但是,以下是一些常用的SQL语句,可能适用于泛微e8系统:1. 查询某个表中所有数据:```sqlSELECT * FROM table_name;```2. 根据某个字段查询数据:```sqlSELECT * FROM table_name WHERE field_name = 'value';```3. 排序查询结果:```sqlSELECT * FROM table_name ORDER BY field_name ASC/DESC;```4. 查询满足多个条件的数据:```sqlSELECT * FROM table_name WHERE condition1 AND condition2;```5. 插入数据:```sqlINSERT INTO table_name (field1, field2, field3) VALUES (value1, value2, value3);```6. 更新数据:```sqlUPDATE table_name SET field1 = value1, field2 = value2 WHERE condition;```7. 删除数据:```sqlDELETE FROM table_name WHERE condition;```8. 查询某个表中满足某个条件的记录数:```sqlSELECT COUNT(*) FROM table_name WHERE condition;```9. 分页查询:```sqlSELECT * FROM table_name LIMIT offset, limit;```这些语句是一些常见的SQL操作,但是具体的语法和用法可能会根据泛微e8系统的数据库类型和版本有所不同。
请注意,在进行数据库操作时,建议遵循系统管理员或相关规范,以保护系统的安全性和完整性。
泛微e-cology知识管理示例

企业知识管理平台“个人知识首页”
企业知识管理平台“资讯中心”
企业知识管理平台员工工作blog
企业知识管理平台“知识地图总纲”
企业知识管理平台“知识专家网络”
企业知识管理平台“公司成长历程图”
企业知识管理平台“产品知识地图”
企业知识管理平台“岗位知识地图”
企业知识管理平台“岗位工作历程图”
Weaver Software----A Pioneer of Collaborative Commerce system!
2理平台关键业务流程协助地图企业知识管理平台内部刊物企业知识管理平台企业文化展现企业知识管理平台企业文化展现企业知识管理平台人才发展知识地图企业知识管理平台制度和流程知识地图企业知识管理平台企业内部培训院企业知识管理平台会议知识共享企业知识管理平台知识树展现企业知识管理平台互动创意企业知识管理平台外部情报企业知识管理平台情报分类企业知识管理平台知识图片展现企业知识管理平台知识图片分享企业知识管理平台销售工具集企业知识管理平台知识协助中心企业知识管理平台知识报表企业知识管理平台知识订阅管理企业知识管理平台企业模板中心企业知识管理平台知识树平面展现企业知识管理平台知识搜索中心企业知识管理平台知识转移和复制企业知识管理平台制度和流程知识地图企业知识管理平台知识推送企业知识管理平台知识库中心企业知识管理平台单篇知识展现结束语脑力联网知识创新希望有机会参与企业内部知识管理建设weaversoftwareapioneerofcollaborativecommercesystem
企业知识管理平台“关键业务流程协助地图”
企业知识管理平台“内部刊物”
企业知识管理平台“企业文化展现”
企业知识管理平台“企业文化展现”
企业知识管理平台“人才发展知识地图”
泛微e8常用sql语句

泛微e8常用sql语句泛微E8常用SQL语句主要用于对泛微E8系统中的数据库进行操作和查询,可以帮助用户更好地管理和维护系统数据。
以下是一些常用的SQL语句及其用法:1. 查询数据:使用SELECT语句可以从数据库中检索数据。
语法如下:SELECT 列名 FROM 表名 WHERE 条件;2. 更新数据:使用UPDATE语句可以更新数据库中的数据。
语法如下:UPDATE 表名 SET 列名 = 新值 WHERE 条件;3. 插入数据:使用INSERT语句可以向数据库中插入新的数据。
语法如下:INSERT INTO 表名 (列1, 列2, 列3,...) VALUES (值1, 值2, 值3,...);4. 删除数据:使用DELETE语句可以从数据库中删除数据。
语法如下:DELETE FROM 表名 WHERE 条件;5. 连接查询:使用JOIN语句可以连接两个或多个表,并一起检索数据。
常见的JOIN类型包括INNER JOIN、LEFT JOIN、RIGHT JOIN等。
6. 排序数据:使用ORDER BY语句可以按照指定的列对数据进行排序。
语法如下:SELECT 列名 FROM 表名 ORDER BY 列名 ASC|DESC;7. 分组数据:使用GROUP BY语句可以将数据按照指定的列进行分组。
语法如下:SELECT 列名, 聚合函数 FROM 表名 GROUP BY 列名;8. 聚合函数:常用的聚合函数包括COUNT、SUM、AVG、MIN、MAX等,可以对数据进行统计计算。
9. 条件查询:使用WHERE语句可以添加条件来筛选数据。
常见的操作符包括等号(=)、大于(>)、小于(<)、LIKE等。
10. 子查询:可以在SELECT语句中嵌套使用子查询来实现更复杂的数据操作。
以上是一些泛微E8常用的SQL语句及其用法,通过灵活运用这些语句可以实现对系统数据的高效管理和查询。
在使用SQL语句时,需要谨慎操作,避免对数据产生不良影响。
泛微协同商务系统Ecology系统底层包开发指南

泛微协同商务系统E c o l o g y系统底层包开发指南Company number【1089WT-1898YT-1W8CB-9UUT-92108】目录1.引言1.1概述本文档为泛微协同商务系统(Ecology)程序员开发指导文档,讲述了开发底层工具包的应用,常用功能的开发。
2.底层包应用及范例本章对ecology系统的底层工具包进行讲解,开发人员可以从这里学到怎样利用底层的工具包进行开发2.1最基本的继承类继承的例子如下:java bean 的继承public class ResourceComInfo extends BaseBean {public void doSomething() { 2003年8月12日2004-01-102004-03-10String debugInfo = "This is test" ; roperties。
比如:系统的运行目录为 d:\ecology\,那么属性文件必须放在d:\ecology\WEB-INF\prop\ 目录下,取名为,其中thefilename是任意的。
在属性文件中某一个键值的值用等号来赋值,等号后面的值必须放在一行,如果一行不够写(或者为了查看的方便),可以用 \ 来链接多行。
否则其它行的值不能被键值取得。
等号左右都可以有空格,对键值和键值的值没有影响。
比如:thekeyname = thevalue将键值的值放到多行:thekeyname = thevalue1 \thevalue2 \thevalue3thevalue4这时候thekeyname 的值为thevalue1thevalue2thevalue3 ,thevalue4 取不到,因为thevalue3后面没有 \在程序中要取得上述属性文件中键值thekeyname的值,使用方法:getPropValue(“thefilename” , “thekeyname”) ;获取属性文件的值的例子如下:public class ResourceComInfo extends BaseBean {private void setResourceInfo() throws Exception{业务处理过程……….String keyValue = getPropValue(“thefilename” , “thekeyname”) ;getConfigFile() 来获取,当主属性文件名称因为需要改变得时候,不必改变所有用到这个属性文件的类,只需要改变GCONST类中常量的值2.2怎样获取系统的运行目录类提供了一个静态方法getRootPath() ,返回系统的运行目录,比如系统的运行目录为d 盘的ecology目录,将返回d:\ecology\获取系统的运行目录的例子如下:public class TestBean extends BaseBean {import ;public void getSysRunPath(){String sysRunPath = GCONST. GetRootPath() ;..……}2、使用指定的链接池ecologytest执行SQL语句RecordSet rs = new RecordSet() ;(" update TB_Example set name = 'the new value' " , "ecologytest" ) ;3、使用指定的链接池ecologytest执行存储过程 PD_Example_UpdateById存储过程PD_Example_UpdateById 如下:CREATE PROCEDURE [PD_Example_UpdateById](@name varchar(100),@id int,@flag integer output,@msg varchar(80) output)ASupdate TB_Example set name = @name where id = @idGORecordSet rs = new RecordSet() ;String newname = ....... ;String id = ...... ;String procpara = newname + () + id ;( "PD_Example_UpdateById" , procpara , "ecologytest" ) ;4、在一个客户程序多个执行之间,查询结果可以保留到下一次查询RecordSet rs = new RecordSet() ;(" select * from TB_Example ") ;(" update TB_Example set name = 'the new value '") ;while( () ) {String thename = ("name") ; ..…….}(" select * from TB_Example ") ;while( () ) {String thename = ("name") ; ..……}访问和运行数据库脚本的例子:public class ResourceComInfo extends BaseBean {private void setResourceInfo() throws Exception{业务处理过程……….String sqlStr = “select * from Hrmresorce” ;RecordSet rt = new RecordSet() ;(sqlStr) ;while()){String id = ("id"));String loginid = ("loginid"));String lastname = ("lastname"));持对一个或多个由属性文件定义的数据库连接池的访问.客户程序可以调用getInstance()方法访问本类的唯一实例。
泛微OA 数据库维护笔记(e-cology)

泛微OA数据库维护笔记本文介绍泛微OA系统流程相关表结构,以及常用的查询、修改流程数据、导出流程数据的操作:这里主要介绍流程的数据存放结构及如果通过流程类型获取到流程的字段信息,流程的载体分为表单和单据两类,表单和单据的区别在于:所有使用表单的流程数据存放在同一个表中,而单据每个单据对应着一张独立的数据表1.表单一、对于表单而言流程的数据信息存放在三个数据表中Workflow_requestbase:该表存放了流程的基本信息:标题,创建人,创建时间,流程类型等等Workflow_form:该表存储了流程的具体信息通过REQUESTID字段和Workflow_requestbase表关联Workflow_formdetail:该表存放了流程的明细信息,同样通过REQUESTID字段和Workflow_requestbase表关联二、通过流程的类型如何获取该流程使用了Workflow_form和Workflow_formdetail表中哪些字段在Workflow_form和Workflow_formdetail表中存放了大量字段,所有使用表单的流程的字段都在这两个表中,如何获取每个流程使用了那些字段呢?A、找到流程的类型ID,假定为wfidB、找到流程用了哪个表单select formid from workflow_basewhere id=wfid and isbill=’0’C、获得该表单用到了哪些主字段:select (select fieldlable from workflow_fieldlable whereworkflow_fieldlable.fieldid=workflow_formfield.fieldid andlangurageid=7 andworkflow_fieldlable.formid=workflow_formfield.formid) asname, (select fieldname from workflow_formdict whereid=fieldid) from workflow_formfield where formid=上面获取的FORMID and (isdetail is null or isdetail=’’)哪些明细字段:select (select fieldname from workflow_formdictdetailwhere id=fieldid) from workflow_formfield where formid=上面获取的FORMID and isdetail=’1’➢下面是查询出差申请流程“表单”数据的步骤:2.单据对于表单而言流程的数据信息存放在三个数据表中Workflow_requestbase:该表存放了流程的基本信息:标题,创建人,创建时间,流程类型等等Workflow_form:该表只存放Workflow_requestbase和单据表之间的关系信息各单据主表:该表存储了流程的具体信息通过REQUESTID字段和Workflow_requestbase表关联,如何获取该表呢:A、找到流程的类型ID,假定为wfidB、找到流程用了哪个单据select formid formworkflow_base where id=wfid and isbill=’1’C、通过单据ID可以获取到该单据使用的字段Select * from workflow_billfield where billid= formidD、通过单据ID找到其用了那个表存储流程主信息,那个表存储流程明细信息select tablename from workflow_bill where id= formidselect tablename from workflow_billdetailtable where id=formid各单据主明细表:该表存放了流程的明细信息,同样通过REQUESTID字段和Workflow_requestbase表关联➢下面是查询名片申请流程“单据”数据的步骤:1、流程的其他信息表结构流程处理人情况表Workflow_currentoperator:此表存储了流程当前未操作者,已操作者等信息workflow_requestlog 流程处理意见表:此表存储了流程处理人处理过的审批意见workflow_requestviewlog 流程的查看日志workflow_requestbase.doc workflow_bill.doc workflow_base.doc workflow_currentoperator.docworkflow_requestLog.doc➢如何查询浏览按钮的数据列表(以医药信息为例)➢如何查询下拉框选项列表数据(以省份信息为例)➢例子:导出表单流程数据➢查询某人有哪些流程本例子是通过查询流程的当前处理人表来实现的,如果某人没有处理过一条流程,则查不出此人有哪些流程➢批量设置超时感谢下载!欢迎您的下载,资料仅供参考。
泛微e-cology客户期刊2012年第45期:数据库查询和处理语句(八)

上海泛微网络科技股份有限公司
2
上海市浦东新区耀华支路 39 弄 9 号 泛微软件大厦 200126 电话:021-68869298 传真:021-50942278
泛微 ecology 客户应用期刊 Weaver Network Co., LTD.
数据库查询和处理语句(八)
2、查询某个时间段某个人处理过的流程 id,流程名称以及创建人
select requestid,(select requestname from workflow_requestbase where requestid = a.requestid) as requestname,(select lastname from hrmresource where id =(select creater from workflow_requestbase where requestid = a.requestid)) as name from workflow_currentoperator a where a.operatedate = '2011-11-12' and a.operatetime >='09:00:00' and a.operatetime <='15:00:00' and userid = 1
checkDate("7241","7242"); }); jQuery("#field7242").bind("propertychange",function(){
checkDate("7241","7242"); });
function check(startfieldid,endfieldid){ var startdate = jQuery('#field'+startfieldid).val(); var end = jQuery('#field'+endfieldid).val(); if(end !='' && startdate != ''){ if(end < startdate){ if(startfieldid =='7243'){ alert("实际开巟时间丌能大于填写日期!"); jQuery("#field"+startfieldid).val(""); jQuery("#field"+startfieldid+"span").html(""); }else if(startfieldid =='7244'){ alert("填写日期丌能大于竣巟时间!"); jQuery("#field"+startfieldid).val(""); jQuery("#field"+startfieldid+"span").html(""); } } }
泛微e-cology常见_问题解决及性能调优

常见问题之安装问题
5. Resin无法启动问题
问题原因: 1) 配置原因 2) 数据库无法连接
解决方法: 1) Windows下可检查Resin/log/stdout.log及stderr.log日志文件。 配置错误原因在stderr.log中一般会有详细描述。如配置文件中<http port=’80’/>写成<http port=’80’>的错误 提示如下:
regsvr32 jscript.dll regsvr32 vbscript.dll
本方法可解决问题: 1) 右键菜单无法使用 2) 点击人力资源浏览按钮等报JS错误 3) IE客户端图形化无法加载 4) 确定IE客户端的其他JS问题
常见问题及解决方法
性能调优
常见问题之性能调优
1. Resin 优化
2.调整内存最 大值活动阀至
最高处
常见问题之性能调优
2) SQL Server提升处理优先级(非必须)
1.选择处理 器选项卡
2.将提升SQL Server的优先 级选项打上钩
操作系统将分派较 多资源给SQL
Server,Resin与 数据库装在同一台 上时,建议不要使
用此项
常见问题之性能调优
3. SQL Server 2005 优化
com.caucho.xml.XmlParseException: /D:/WEAVER_SERVER/Resin/conf/resin.conf:59: expected `</http>' at `</http-server> ‘ 类似以上错误其实告诉你http标签缺少结束标签。
Ecology9.0常用Sql场景培训资料

Sql几个概念:表、列、字段类型查询-select1.查询某表所有数据:select * from 表名例:查询人力资源表中所有信息Select * from hrmresource2.精确查询和模糊查询-where/like:select * from 表名where 字段=123 //*表示查询出此表中满足字段=12的所有数据,*改为具体字段则表示具体数据列,此条件为完全匹配(where 字段Like’%1%’ //模糊匹配,%位置表示模糊匹配位置,例如,%1则会查出test01)例:●条件查询:在workflow_base表中查询id小于50的流程路径Select * from workflow_base where id<50●多条件精确查询:在workflow_base表中查询id小于50并且id大于10的流程路径Select * from workflow_base where id<50 and id>10●条件之间是‘或’的关系:在workflow_base表中查询id 等于1或者3的流程路径Select * from workflow_base where id in (1,3)Select * from workflow_base where id =1 or id = 3●模糊查询:查询出人力资源表中所有姓'张'的人员信息select * from hrmresource where lastname like ‘张%’3.定义列名-as:select A as XX,B as XX from 表名//as 将搜出的这两列信息表头重新命名定义别名,不影响数据,as可不加,A、B表示数据库字段名例:查询workflow_base表中workflowtype的值,并设置别名叫流程类型Select workflowtype as 流程类型from workflow_base4.查询-数据排序-order byselect A,B,C from 表名order by 字段desc //desc降序、asc升序,不写默认asc 例:查询workflow_base表中的所有流程路径,按照id降序排序Select * from workflow_base order by id desc5.查询前十条-top:select top 10 * from 表名order by A desc , B asc //根据多个进行排序例:查询workflow_base表中的前5条流程路径Select top 5 * from workflow_base6.数据去重:过滤掉重复的值-distinctselect distinct X,Y from 表名例:查询workflow_base表中workflowtype 的值,并排除重复的值Select distinct workflowtype from workflow_base7.查询-计数-count:对一些重复性数据进行分类计数,不统计null值select count(*/字段)as 计数列命名from 表名where XXX group by 分组字段注意使用Group By规则:(1)不能Group By非标量基元类型的列,如不能Group By text或image类型的列;(2)不能将表中不存在的列进行排序;例:统计workflow_base表中每个流程类型下面的流程路径数量,并按照workflowtype 进行升序排序Select count(*) from workflow_base group by workflowtype order by workflowtype asc8.查询-求平均值avg、最大值Max、最小值MinSELECT AVG(字段) ,MAX(字段) ,Min(字段) FROM 表名例:查询出合同信息表中的平均金额、最大金额和最小金额select avg(htje) 平均合同额,MAX(htje) 最高合同金额,Min(htje) 最少合同金额from formtable_main_219.多表查询:例:查询出各个路径的路径类型名称select workflowname,workflowtype, (select typename from workflow_type where id=workflowtype)as 类型from workflow_base新增/插入-insertinsert into 表名(字段A,字段B)values(’插入值’,’插入值’)//文本要加单引号(不加文本进不去),数字不用加,值与字段顺序对应,否则无法插入例:往workflow_base 表中插入一条路径名为test的数据Insert into workflow_base(workflowname,workflowtype,formid,isvalid) values('test',1,1,1)更新/修改-update:update 表名set A=’123’ where 条件//更改表单中满足条件的数据的字段A的值为123,没有条件即为所有,为避免操作失误,建议先进行查询,以验证条件是否正确,尤其是数据较复杂时。
泛微协同商务系统(Ecology)_系统底层包开发指南

泛微协同商务系统(Ecology) 底层包开发指南目录1.引言 (3)1.1概述 (3)1.2定义................................................................................ 错误!未定义书签。
2.底层包应用及范例 (3)2.1最基本的继承类 (3)2.2怎样记录日志 (3)2.3怎样获取属性文件的值 (6)2.4怎样获取系统的运行目录 (7)2.5怎样访问和运行数据库脚本 (8)2.6如何上传一个文件 (11)2.7如何访问已经上传的文件 (15)2.8如何使用缓存提高系统效率 (15)2.9其它底层类基本方法 (26)1. 引言1.1 概述本文档为泛微协同商务系统(Ecology)程序员开发指导文档,讲述了开发底层工具包的应用,常用功能的开发。
2. 底层包应用及范例本章对ecology系统的底层工具包进行讲解,开发人员可以从这里学到怎样利用底层的工具包进行开发2.1 最基本的继承类系统中每一个java bean 都需要继承weaver.general.BaseBean 类。
这个类实现了记录日志和获取属性文件值的方法。
继承这两个类的其它类可直接应用这些方法来记录日志,获取属性文件某一个属性的值。
方法的实现见后面的例子。
继承的例子如下:java bean 的继承public class ResourceComInfo extends BaseBean {public void doSomething() { //某一个方法方法的处理………writeLog(s) ;// 写日志}}2.2 怎样记录日志继承了weaver.general.BaseBean ,可以直接使用writeLog方法记录日志信息。
注意这里是使用,而不是调用,因为这个方法是这两个被继承类中的方法。
注意writeLog 方法的使用:/*** 将某个对象写入Log文件* @param obj 被写入的对象*/public void writeLog(Object obj)我们看到,可以被记入日志的是任意一个java对象。
泛微ecology开发实例

泛微ecology开发实例
泛微ecology的开发实例能够帮助你更好地了解泛微ecology的功能和使用方法。
下面是一个简单的开发实例:
系统框架结构:
- ecology Classbean:存放编译后的CLASS文件。
- js:系统中使用的JAVASCRIPT和VBSCRIPT脚本。
- css:系统中JSP页面使用的样式。
- images:系统中使用的图片的存放目录。
- crm Workflow:该功能分文件夹存放每个功能的文件。
- WEB-INF Prop:系统配置文件存放。
通过上述开发实例,你可以了解到泛微ecology的基本程序结构和文件目录。
在实际的开发过程中,你可以根据具体的需求和情况,对泛微ecology进行进一步的开发和扩展。
如果你需要了解更多关于泛微ecology开发的信息,可以继续向我提问。
泛微ecology常用数据库语句

一、查询三个月未登陆系统的人员的语句select lastname,lastlogindate from hrmresource where lastlogindate not between CONVERT(varchar(100), GETDATE()-90, 23) and CONVERT(varchar(100), GETDATE(), 23)二、通过流程ID,查询当前未操作者及当前节点当前节点:select currentnodeid from workflow_requestbase where requestid = ?当前未操作者:select userid from workflow_currentoperator where requestid = ? and isremark = '0'三、将2009年12月31日之前创建的、未归档的流程全部列出来,并作归档处理update workflow_currentoperator set iscomplete=1 where requestid in (select requestid from workflow_requestbase where createdate<='2009-12-31')/update workflow_currentoperator set iscomplete=1, isremark='2' where isremark='0' and requestid in (select requestid from workflow_requestbase where createdate<='2009-12-31')/update workflow_requestbase set currentnodetype='3', currentnodeid=(select nodetype from workflow_flownode where workflow_requestbase.workflowid=workflow_flownode.workflowid and workflow_flownode.nodetype='3') where createdate<='2009-12-31'/四、系统人员的所在分部ID和信息--查询登录用户所在分部信息,以登录用户名为查询条件select hrc.* from HrmResource hr,HrmSubcompany hrc where hr.subcompanyid1=hrc.id and loginid='登录用户名'--查询登录用户所在分部id,以登录用户名为查询条件select hrc.id from HrmResource hr,HrmSubcompany hrc where hr.subcompanyid1=hrc.id and loginid='登录用户名'五、查询人员的所有的角色与角色级别--(1)人力资源表,以登录名为查询条件,取id作为(2)的条件@idselect * from HrmResource where loginid='登录用户名'--(2)以人力资源@id为查询条件select hrm.*,hr.rolesname from HrmRoleMembers hrm,HrmRoles hr where hrm.roleid=hr.id and resourceid=@id---roleid:为角色ID---rolelevel:角色级别0=部门,1=分部,2=总部---rolesname:角色名称六、把某几个目录下面的文档全都共享给某一个人--(1)获得需要修改的主目录id号,以主目录名称为条件select id as maincateid,categoryname from DocMainCategory where categoryname='主目录名称'--(2)获得需要修改的分目录id号,以(1)中获得的maincateid为条件@maincateidselect id as subcateid,categoryname from DocSubCategory where maincategoryid=@maincateid--(3)获得需要修改的子目录id号,以(2)中获得的subcateid为条件@subcateid,并且以子目录名称为条件select id as docid,categoryname from DocSecCategory where subcategoryid=@subcateid and categoryname='子目录名称'--(4)以登录名为条件,获得需要获得文档权限的用户的useridselect t.id as userid from HrmResource t where t.loginid='liur'--(5)将某个目录下面的以前的所有文档的查看权限赋予某个系统用户,-----以(3)获得的docid为条件@docid,替换下面语句中的@docid,-----以(4)获得的userid替换下面语句中的@userid,-----执行下面两个insert语句。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
一、查询三个月未登陆系统的人员的语句
select lastname,lastlogindate from hrmresource where lastlogindate not between CONVERT(varchar(100), GETDATE()-90, 23) and CONVERT(varchar(100), GETDATE(), 23)
二、通过流程ID,查询当前未操作者及当前节点
当前节点:
select currentnodeid from workflow_requestbase where requestid = ?
当前未操作者:
select userid from workflow_currentoperator where requestid = ? and isremark = '0'
三、将2009年12月31日之前创建的、未归档的流程全部列出来,并作归档处理
update workflow_currentoperator set iscomplete=1 where requestid in (select requestid from workflow_requestbase where createdate<='2009-12-31')
/
update workflow_currentoperator set iscomplete=1, isremark='2' where isremark='0' and requestid in (select requestid from workflow_requestbase where createdate<='2009-12-31')
/
update workflow_requestbase set currentnodetype='3', currentnodeid=(select nodetype from workflow_flownode where workflow_requestbase.workflowid=workflow_flownode.workflowid and workflow_flownode.nodetype='3') where createdate<='2009-12-31'
/
四、系统人员的所在分部ID和信息
--查询登录用户所在分部信息,以登录用户名为查询条件
select hrc.* from HrmResource hr,HrmSubcompany hrc where hr.subcompanyid1=hrc.id and loginid='登录用户名'
--查询登录用户所在分部id,以登录用户名为查询条件
select hrc.id from HrmResource hr,HrmSubcompany hrc where hr.subcompanyid1=hrc.id and loginid='登录用户名'
五、查询人员的所有的角色与角色级别
--(1)人力资源表,以登录名为查询条件,取id作为(2)的条件@id
select * from HrmResource where loginid='登录用户名'
--(2)以人力资源@id为查询条件
select hrm.*,hr.rolesname from HrmRoleMembers hrm,HrmRoles hr where hrm.roleid=hr.id and resourceid=@id
---roleid:为角色ID
---rolelevel:角色级别0=部门,1=分部,2=总部
---rolesname:角色名称
六、把某几个目录下面的文档全都共享给某一个人
--(1)获得需要修改的主目录id号,以主目录名称为条件
select id as maincateid,categoryname from DocMainCategory where categoryname='主目录名称'
--(2)获得需要修改的分目录id号,以(1)中获得的maincateid为条件@maincateid
select id as subcateid,categoryname from DocSubCategory where maincategoryid=@maincateid
--(3)获得需要修改的子目录id号,以(2)中获得的subcateid为条件@subcateid,并且以子目录名称为条件
select id as docid,categoryname from DocSecCategory where subcategoryid=@subcateid and categoryname='子目录名称'
--(4)以登录名为条件,获得需要获得文档权限的用户的userid
select t.id as userid from HrmResource t where t.loginid='liur'
--(5)将某个目录下面的以前的所有文档的查看权限赋予某个系统用户,
-----以(3)获得的docid为条件@docid,替换下面语句中的@docid,
-----以(4)获得的userid替换下面语句中的@userid,
-----执行下面两个insert语句。
--注:(1)下面的insert语句执行一次就可以了。
------(2)默认的安全级别SECLEVEL为1,若不是可以手动调整。
------(3)sharelevel:共享级别,1=查看,2=编辑,3完全控制。
------(4)需要替换以下语句中的参数@userid,@docid。
--docshare:权限表
INSERT INTO docshare(DOCID,SHARETYPE,SECLEVEL,ROLELEVEL,SHARELEVEL,USERID,SUBCOMPANYID,DEPART MENTID,ROLEID,FORALLUSER,CRMID,SHARESOURCE,ISSECDEFAULTSHARE,ORGGROUPID,DOWNL OADLEVEL)
select id,1,1,0,1,@userid,0,0,0,0,0,NULL,'1',0,NULL
from docdetail
where seccategory=@docid
-- shareinnerdoc:权限明细表
INSERT INTO shareinnerdoc(SOURCEID,TYPE,CONTENT,SECLEVEL,SHARELEVEL,SRCFROM,OPUSER,SHARESOUR CE,DOWNLOADLEVEL)
select id,1,@userid,1,1,1,0,0,NULL
from docdetail
where seccategory=@docid
本文来自:阳光网驿_企业信息化专家详细出处请参考:/thread-122938-1-1.html。