数据结构大作业
数据结构大作业题目

数据结构大作业专业:班级:题目:学生姓名:(课程设计报告撰写的基本要求)题目(三号,黑体,居中)(空一行)一、任务与目标(标题均为小三号,宋体)(正文均为小四号,宋体,行距1.5倍)(这一部分需简单介绍题目内容,即该题目到底要做什么。
如果涉及明确的算法,最好再简单介绍一下算法产生的背景,还要列出各项本设计要达到的具体的目标。
)二、方案设计与论证(对目标进行总体分析,说明要采用的基本思路,说明遇到的问题和解决方法。
说明完成本次课程设计的完整过程。
要描述程序的设计思想,重点描述你自己提出的与已有工作不同的程序设计思想。
)三、算法说明(这一部分需详细描述解决问题所需要用到的算法和重要的数据结构,即该课程设计到底应该怎么做。
基本要求:处理问题中所用到的关键算法都要描述清楚,而不是仅描述主函数。
算法和数据结构可用伪码和图示描述,不要只写源代码和注释。
这一部分的目的是让读者在短时间内清楚地理解作者解决问题的整体思路,表达方式必须比源代码更通俗易懂。
如果读者感觉还不如直接读源代码来得明白,这一部分内容就失去了意义。
)四、全部源程序清单(给出本次大作业所编写全部源程序已经调试好的可运行代码清单,字体可以用宋体五号,页数可增加,每个程序开头用注释文字说明此程序的用途和大体工作过程,,程序中必要部分也要加入足够多的注释行。
)五、程序运行的测试与分析(这一部分内容需要紧扣课程设计的题目类型和要求,设计提供相应的测试方法和结果。
这部分包括运行图。
对于需要比较不同算法性能优劣的题目,应设计并填写一张性能比较表格,列出不同算法在同一指标下的性能表现。
仅仅罗列出一堆数据是不够的,还应将数字转化为图形、曲线等方式,帮助读者更直观地理解测试结果。
对于需要利用某算法解决某问题的题目,应设计并填写一张测试用例表。
每个测试用例一般应包括下列内容:·测试输入:设计一组输入数据;·测试目的:设计该输入的目的在于测试程序在哪方面可能存在漏洞;·正确输出:对应该输入,若程序正确,应该输出的内容;·实际输出:该数据输入后,实际测试得到的输出内容;·错误原因:如果实际输出与正确输出不符,需分析产生错误的可能原因;·当前状态:分为“通过”(实际输出与正确输出相符)、“已改正’’(实际输出与正确输出不符,但现在已修改正确)、“待修改”(实际输出与正确输出不符,且尚未改正)三种状态。
湖北汽车工业学院数据结构期末大作业

数据结构大作业只收手工纸面版,统一用学院的实验稿纸。
自留底稿,不退。
(已更新单选错误地方)单选题复习用1、数据结构除了研究数据本身如何表示和存储外,还需要重点研究数据___________D_____。
(A)的数量(B)的质量(C)的属性(D)之间的关系2、以下哪种逻辑结构重点表示数据之间的层次关系。
B(A)线性结构(B)树形结构(C)图形结构(D)集合结构3、以下哪种存储结构主要是通过增加新的管理数据来同时保证读取数据的高速和动态修改数据的高速。
C(A)顺序存储(B)链接存储(C)索引结构(D)哈希存储4、遍历操作是对某个数据结构中所有数据需要做到__A____的访问。
(A)至少一次且至多一次(B)可以多次(C)大部分一次,部分可以重复(D)二次5、下面哪一句话是正确的。
C(A)算法就是可以运行的程序(B)算法是程序的总结,只能用中文表示(C)算法是表示一种解决问题的思路(D)算法最好用英语表示,这样可以很快切换成程序。
6、一个满二叉树共有三层,问有几个结点?C(A)5 (B)6 (C)7 (D)87、结点个数为4个的无向完全图的边数是多少条?B(A)5 (B)6 (C)7 (D)88、实现函数调用返回点管理应该用数据结构__C_____。
(A)二叉树(B)图(C)栈(D)队列1、二分查找法适合__C____。
(A)适合顺序表和链表等结构(B)数据不需要排序,但是必须顺序存储(C)仅仅把数据排序后的顺序表(D)二叉树和图2、在字符串结构中,哪一个是进行查找操作?D(A)求子串(B)串比较(C)串遍历(D)子串定位3、在字符串的索引结构中,哪一个操作没有对原始数据区进行处理?C(A)插入字符(B)删除字符串(C)删除行(D)修改字符4、一个m*n的矩阵,用列优先存储,元素A(i,j)存储在位置k上,在横向关系上的直接前驱在一维数组中一般地址为(约定每一个元素仅仅占一个单元):D(A)k+1 (B)k-1 (C)k+m (D)k-m5、用建立大根堆来进行排序,最后的结果是什么?A(A)升序(B)降序(C)逆序(D)不一定6、图结构的遍历操作中,一般采用什么机制可以最简单地避免再次访问已经被访问过的结点。
数据结构大作业

班级021051学号021050**数据结构大作业题目 Huffman的编码与译码学院电子工程学院专业智能科学与技术学生姓名****导师姓名朱虎明Huffman 编码与译码1.实验目的:在掌握相关基础知识的基础上,学会自己设计实验算法,熟练掌握Huffman 树的建立方法,Huffman 编码的方法,进而设计出Huffman 译码算法,并编程实现。
2.实验要求:制作出能够实现基于26个英文字母的任意字符串的编译码。
写出技术工作报告并附源程序。
3.实验内容及任务:3.1.设字符集为26个英文字母,其出现频度如下表所示。
3.2.建Huffman 树;3.3.利用所建Huffman 树对任一字符串文件进行编码——即设计一个Huffman 编码器;3.4.对任一字符串文件的编码进行译码——即设计一个Huffman 译码器。
实现步骤:(1)数据存储结构设计; (2)操作模块设计; (3)建树算法设计;51 48 1 15 63 57 20 32 5 1 频度z y x w v u t 字符11611882380频度p 21 f q15 g r 47 h s o n m l k j 字符 57 103 32 22 13 64 186 频度 i e d c b a 空格 字符(4)编码器设计;(5)译码器设计4.分析以及算法描述4.1.分析问题1)首先学习二叉树的知识,了解二叉树的路径、权数以及带权路径长度计算。
2)认识霍夫曼树,了解霍夫曼树的定义,构造霍夫曼树构造算法①又给定的n个权值{w1,w2,w3,……,w n}构造根节点的二叉树,从而得到一个二叉树森林F={T1,T2,T3,……T n}。
②在二叉树森里选取根节点全职最小和此最小的两棵二叉树作为左右节点构造新的二叉树,此时新的二叉树的根节点权值为左右子树权值之和。
③在二叉树森林中删除作为新二叉树的根节点左右子树的两棵二叉树,将新的二叉树加入到二叉树森林F中。
数据结构大作业3

数据结构大作业一、大作业的性质和目的数据结构大作业是对软件设计的综合训练,包括问题分析、总体设计、用户界面设计、程序设计基本技能和技巧,以至一套软件工作规范的训练和科学作风的培养。
在数据结构实验中,完成的只是单一而“小”的算法,而本课程设计是对学生的整体编程能力的锻炼。
数据结构大作业的目的是训练学生对问题的抽象能力和算法的运用能力。
二、大作业安排每位同学独立完成,可自选题目或根据选择后面的一个参考题目来完成。
开学第一周统一提交到教学在线。
提交的内容包括:(1)设计报告文档。
该文档是评分的重要依据之一,请认真对待。
该文档包括如下内容:●需求分析: (陈述要解决的问题,要实现的功能),●详细设计:包括设计算法流程图、算法分析、使用的数据结构(要求详细论证);●软件测试:包括测试数据和测试结果记录●总结:设计过程中遇到的问题及解决方法;尚未解决的问题及考虑应对的策略;收获和心得;(2)源代码。
要求注释清晰,编写规范,模块化。
(3)可运行的exe文件。
要求充分测试,在XP操作系统中能正常运行。
以上内容打包后提交到教学在线。
三、考核和成绩评定老师根据设计文档、源代码和可执行文件,进行判分。
对于出现以下情况的学生,要求统一进行答辩:●执行文件无法正常运行。
●源程序疑似抄袭。
如果有发现两个同学的代码相类似则需要共同出席答辩。
如果判定抄袭,则为不及格。
开发过程可以部分复用网上的开源代码,但必须体现自己的工作,如果没有自己工作的部分,同样判为抄袭。
五、题目(任选其中之一或自拟)1. 数字化校园(1)设计华南理工大学的校园平面图,至少包括10个以上的地点,每两个地点间可以有不同的路,且路长可能不同。
以图中顶点表示校内各地点,存放名称、代号、简介等信息;用边表示路径,存放路径长度等相关信息。
(2)提供图中任意地点相关信息的查询。
(3)提供图中任意地点的问路查询,即查询任意两个地点之间的一条最短路径。
(4)学校要新建一间超市,请为超市选址,实现总体最优。
数据结构大作业

数据结构作业(1)年级:2004级(2)班专业:计算机科学与技术专业学号:200431500066姓名:秦博纯病人看病模拟程序编写一个程序,反映病人到医院看病,排队看医生的情况。
在病人排队过程中,主要重复两件事:1.病人到达诊室,将病历本交给护士,排到等待队列中候诊。
2.护士从等待队列中取出下一们病人的病历,该病人进入人诊室就诊。
要求模拟病人等待这一过程,程序采用菜单方式,其选项及功能说明如下:a.排队——输入排队病人的病历号,加入病人排队队列中;b.就诊——病人排队队列中最前面的病人就诊,并将其从队列中删除;c.查看排队——从队首到队尾列出所有的排队病人的病历号;d.不再排队,余下依次就诊——从队首到队尾列出所有的排队病人的病历号,并退出运行;e.下班——退出运行。
解:本项目的组成结构如图1所示,本程序的模块结构图如图2所示,图中方框表示函数,方框中指出函数名,箭头方向表示函数间的调用关系,虚线方框表示文件的组成,即指出该虚线方框中的函数存放在哪个文件中。
文件包含如下函数:. SeeDoctor():模拟病人看病的过程。
病人排队看医生,所以要用到一个队列,这里设计了一个不带头结点的单链表作为队列。
源程序如下:图1 项目组成#include<stdio.h>#include<malloc.h>typedef struct qnode{int data;struct qnode *next;}QNode;typedef struct{QNode *front,*rear;}QuType; 图2 项目的程序结构图void SeeDoctor(){int sel,flag=1,find,no;QuType *qu;QNode *p;qu=(QuType *)malloc(sizeof(QuType)); /*创建空队*/qu->front=qu->rear=NULL;while(flag==1) /*循环执行*/{printf("1:排队2:就诊3:查看排队4:不再排队,余下依次就诊5:下班请选择");scanf("%d",&sel);switch(sel){case 1:printf(">>输入病历号:");do{scanf("%d",&no);find=0;p=qu->front;while(p!=NULL&&!find){if(p->data==no)find=1;elsep=p->next;}if(find)printf(">>输入的病历号重复,重新输入:");}while(find==1);p=(QNode *)malloc(sizeof(QNode)); /*创建结点*/p->data=no;p->next=NULL;if(qu->rear==NULL) /*第一个病人排队*/ {qu->front=qu->rear=p;}else{qu->rear->next=p; /*将*p结点入队*/qu->rear=p;}break;case 2: /*队空*/ if(qu->front==NULL)printf(">>没有排队的病人!\n");else /*队不空*/{p=qu->front;printf(">>病人%d就诊\n",p->data);if(qu->rear==p) /*只有一个病人排队*/{qu->front=qu->rear=NULL;}elsequ->front=p->next;free(p);}break;case 3: /*队空*/ if(qu->front==NULL)printf(">>没有排列的病人!\n");else /*队不空*/{p=qu->front;printf(">>排队病人: ");while(p!=NULL){printf("%d ",p->data);p=p->next;}printf("\n");}break;case 4: /*队空*/ if(qu->front==NULL)printf(">>没有排队的病人!\n");else /*队不空*/{p=qu->front;printf(">>病人按以下顺序就诊: ");while(p!=NULL){printf("%d ",p->data);p=p->next;}printf("\n");}flag=0; /*退出*/break;case 5: /*队不空*/ if(qu->front!=NULL)printf(">>请排队的病人明天就医!\n");flag=0; /*退出*/break;}}}void main(){SeeDoctor();}程序运行结果如下:。
数据结构大作业

数据结构大作业在计算机科学领域中,数据结构是非常重要的一个概念。
它是指组织和存储数据的方式,以及对数据进行操作的方法。
数据结构的选择与实现直接影响着算法的复杂度和程序的性能。
因此,在学习数据结构的过程中,一般都会有相应的大作业,以帮助学生更好地理解和应用所学的知识。
本篇文章将重点介绍数据结构大作业的一般要求和一种可能的实现方案,供读者参考。
一、数据结构大作业要求数据结构大作业一般旨在让学生将所学的数据结构知识应用于实际问题的解决。
作业要求通常包括以下几个方面:1. 题目选择:作业题目需要涵盖数据结构的各个方面,例如链表、栈、队列、树、图等等。
题目应具备一定的难度,能够考察学生对数据结构的理解和运用能力。
2. 实现方式:学生需要根据题目要求选择合适的数据结构和算法,并进行实现。
一般要求使用编程语言来完成实现,并给出相应的代码。
3. 功能要求:作业题目通常会要求实现某些特定的功能或解决某些问题。
学生需要确保所实现的程序能够满足这些功能需求,并能正确运行。
4. 性能评估:作业可能会要求对所实现的程序进行性能评估,比如时间复杂度、空间复杂度等。
学生需要能够分析和解释程序的性能,并对可能的改进方法进行讨论。
5. 报告撰写:作业一般要求学生完成一份报告,对所实现的程序进行详细的说明和分析。
报告需要包括程序设计思路、实现细节、运行结果以及遇到的问题和解决方法等。
二、数据结构大作业实现方案示例以下是一个可能的数据结构大作业实现方案示例,以一个简化的社交网络系统为题目:1. 题目描述:设计一个基于图的社交网络系统,能够实现用户的注册、好友关系的建立和查询、用户之间的消息传递等功能。
2. 数据结构选择:可以使用图的数据结构来存储用户和好友关系的信息,使用链表来存储用户的消息队列。
3. 算法实现:根据题目要求,需要实现用户注册、好友关系的建立和查询、消息传递等功能的算法。
可以使用深度优先搜索或广度优先搜索算法来查找用户的好友关系,使用链表来实现用户消息的发送和接收。
《数据结构》大作业

《数据结构》大作业
数据结构是计算机科学中构建可靠计算机系统所必需的基础知识。
它主要是用来处理
非常大的量级的数据,并为用户快速访问,高效的解决计算机问题。
由于中央处理机的特
点是高速而有效,起到了极大的性能提升。
数据结构有很多不同的结构,其中最重要的是线性结构和非线性结构。
线性结构又可
以分为数组、单向链表、双向链表和循环链表;非线性结构可以分为二叉树、二叉搜索树、B树、堆、红黑树和图。
在实际计算机程序中,数据结构一般被用来搜索和排序存储的数据,这些操作有助于
提高计算机的运行效率。
如果用户想要查找某一个数据,可以在合适的存储结构中找到它;如果用户希望把一系列数据按照某种顺序排列起来,也可以使用数据结构进行排序。
同时数据结构还可以用于实现数据结构间的转换,使得用户可以较为方便的获得数据。
它的运用,更加方便了计算机的工作,更加提高了计算机的性能。
总之,数据结构是计算机科学中重要的组成部分,它为计算机的工作提供了重要的基础,更加方便了用户的操作,也帮助用户更好地完成计算机系统中的各种工作和解决方案。
数据结构大作业实验报告要求范文

浙江工商大学计算机与信息工程学院数据结构实验大作业报告专业:班级:学号:姓名:指导教师:年月一、大作业报告内容包括以下几个部分⒈问题描述:(题目)⒉设计:⑴数据结构设计和核心算法设计描述;⑵主控及功能模块层次结构;⑶主要功能模块的输入、处理(算法框架描述)和输出;⑷功能模块之间的调用与被调用关系等。
⒊测试:测试范例,测试结果,测试结果的分析与讨论,测试过程中遇到的主要问题及所采用的解决措施。
⒋使用说明和作业小结:⑴使用说明主要描述如何使用你的程序以及使用时的主要事项;⑵在小结中说明程序的改进思想、经验和体会;⒌整理一份程序清单及运行示例的结果。
将以上各项文字材料及程序清单等装订成册,形成一个完整的报告。
题目从以下题目中任选一个,每人1个题目。
(一)试设计一个航空客运定票系统。
基本要求如下:1、每条航线所涉及的信息有:终点站名、航班号、飞机号、飞机周日(星期几)、乘员定额、余票量、订定票的客户名单(包括姓名、订票量、舱位等级1,2或3)以及等候替补的客户名单(包括姓名、所需数量)。
2、系统能实现的操作和功能如下:1)查询航线:根据客户提出的终点站名输出如下信息:航班号、飞机号、星期几飞行,最近一天航班的日期和余票额;2)承办订票业务:根据客户提出的要求(航班号、订票数额)查询该航班票额情况,若有余票,则为客户办理订票手续,输出座位号;若已满员或余票少余订票额,则需重新询问客户要求。
若需要,可登记排队候补;3)承办退票业务:根据客户提出的情况(日期、航班号),为客户办理退票手续,然后查询该航班是否有人排队候补,首先询问排在第一的客户,若所退票额能满足他的要求,则为他办理订票手续,否则依次询问其它排队候补的客户。
3、实现提示:两个客户名单可分别由线性表和队列实现。
为查找方便,已订票客户的线性表应按客户姓名有序,并且,为了插入和删除方便,应以链表作为存储结构。
由于预约人数无法预计,队列也应以链表作为存储结构。
数据结构实践作业

数据结构作业利用单向链表数据结构完成对链表的如下操作:1、创建一条含整数结点的无序链表2、链表结点的输出3、链表结点的升序排序4、分别计算链表中奇数和偶数结点之和并输出5、释放链表具体要求将程序功能做成菜单,形式如下:1、创建一条含整数结点的无序链表2、链表结点的输出3、链表结点的升序排序4、分别计算链表中奇数和偶数结点之和并输出5、释放链表0、退出《数据结构》大作业1 总体要求将程序功能做成菜单,形式如下:(1)创建一条含整数结点的无序链表(2)链表结点的输出(3)链表结点的升序排序(4)分别计算链表中奇数和偶数结点之和并输出(5)释放链表2 开发环境软件环境:Window10,Visual Studio 20173 系统运行效果截图(1)主菜单:(2)创建一条含整数结点的无序链表:3,6,2,5,9(3)链表结点的输出(4)链表结点的升序排序(5)分别计算链表中奇数和偶数结点之和并输出(6)释放链表4 源程序#include<iostream>//头文件using namespace std;//节点数据结构定义struct node{int data;node *next;};//创建一条含整数结点的无序链表node *CreateLinkList(){node *p1, *p2, *head;int n;p2 = NULL;head = NULL;cout <<"正在创建一个无序链表\n";cout <<"请输入一个整数,以-1结束:";cin >> n;//循环输入一个整数,直到数值为-1结束,创建一条无序链表while (n != -1){p1 = new node;p1->data = n;//采用尾插法,新建一个结点并连接到链表尾部if (head == 0){head = p1; p2 = p1; //首结点的建立}else{p2->next = p1; p2 = p1;}cout <<"请输入一个整数,以-1结束:";cin >> n;}if (head != 0) //尾结点p2->next = 0;return(head);}//输出结点void PrintLinkList(const node *head){const node *p;p = head;while (p != NULL){cout <<" "<< (p->data);p = p->next;}cout << endl;}//升序排序void SortLinkList(node *head){node temp;node *p = NULL;node *q = NULL;//判断结点为空或者只有一个结点if (head == NULL || head->next == NULL){return;}//p->next!=NULL为链表倒数第2个结点for (p = head; p->next != NULL; p = p->next) {for (q = p->next; q != NULL; q = q->next){if (p->data > q->data) //升序{ //交换数据域temp.data = q->data;q->data = p->data;p->data = temp.data;}}}return;}//奇数结点和int OddSumLinkList(const node *head){int sum = 0;const node *p;p = head;while (p){//判断数值为是否奇数if (p->data % 2 != 0){sum = sum + p->data;}p = p->next;}return sum;}//偶数结点和int EvenSumLinkList(const node *head){int sum = 0;const node *p;p = head;while (p){//判断是否偶数if (p->data % 2 == 0){sum = sum + p->data; //偶数结点的数值累加}p = p->next;}return sum;}//释放链表void DeleteLinkList(node *head){node *p;while (head){p = head;head = head->next;delete p;}printf("释放成功\n");}void main(){node *head;head = NULL;int select;cout <<"************菜单************"<< endl;cout <<"输入对应选择,执行对应操作"<< endl;cout <<"1.创建一条含整数结点的无序链表"<< endl;cout <<"2.链表结点的输出"<< endl;cout <<"3.链表节点的升序排序"<< endl;cout <<"4.分别计算链表中奇数和偶数结点之和并输出"<< endl;cout <<"5.释放链表"<< endl;cout <<"0.退出"<< endl;while (1){cout <<"\n请输入选择:";cin >> select;switch (select) //判断选项,并执行对应的函数{case 1:{head = CreateLinkList();printf("无序链表创建完成\n");break;}case 2:{printf("输出链表中各结点数据:");PrintLinkList(head);break;}case 3:{SortLinkList(head);printf("升序后:");PrintLinkList(head);break;}case 4:{int oddsum;int evensum;oddsum = OddSumLinkList(head);evensum = EvenSumLinkList(head);printf("奇数和= %d,偶数和= %d\n", oddsum, evensum);break;}case 5:{DeleteLinkList(head);break;}case 0:{cout <<"退出"<< endl;exit(0);}default:{cout <<"输入选项有误,请重新输入:"<< endl;break;}}}}。
数据结构大作业

一、大作业设计题目以下题目中任选一个1.哈夫曼编码/译码器设计要求:针对字符集A及其各字符的频率值(可统计获得),给出其中字符的哈夫曼编码,并针对一段文本(定义在A上),进行编码和译码,实现哈夫曼编码/译码系统。
2.算术表达式求值设计要求:输入任意一个算术四则表达式,可求出其值。
3.一元多项式的代数运算设计要求:计算任意两个一元多项式的加法、减法和乘法。
4.最小生成树问题设计要求:在n个城市之间架设网络,只需保证连通即可,求最经济的架设方法。
二、大作业报告要求大作业报告的开头应给出题目、班级、姓名、学号和完成日期,并包括以下7个内容:1.需求分析以无歧义的陈述说明程序设计的任务,强调的是程序要做什么?并明确规定:(1) 输入的形式和输入值的范围;(2) 输出的形式;(3) 程序所能达到的功能;(4) 测试数据:包括正确的输入及其输出结果和含有错误的输入及其输出结果。
2.概要设计说明本程序中用到的所有抽象数据类型的定义、主程序的流程以及各程序模块之间的层次(调用)关系。
3.详细设计实现概要设计中定义的所有数据类型,对每个操作只需要写出伪码算法;对主程序和其他模块也都需要写出伪码算法(伪码算法达到的详细程度建议为:按照伪码算法可以在计算机键盘直接输入高级程序设计语言程序);画出函数和过程的调用关系图。
4.调试分析内容包括:a.调试过程中遇到的问题是如何解决的以及对设计与实现的回顾讨论和分析;b.算法的时空分析(包括基本操作和其他算法的时间复杂度和空间复杂度的分析)和改进设想;c.经验和体会等。
5.用户使用说明说明如何使用你编写的程序,详细列出每一步的操作步骤。
6.测试结果列出你的测试结果,包括输入和输出。
这里的测试数据应该完整和严格,最好多于需求分析中所列。
7.附录带注释的源程序。
如果提交源程序软盘,可以只列出程序文件名的清单。
数据结构(大作业)
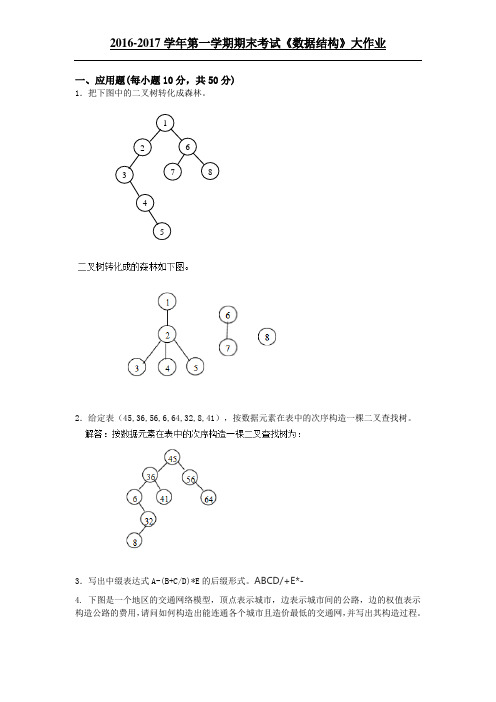
一、应用题(每小题10分,共50分)
1.把下图中的二叉树转化成森林。
2.给定表(45,36,56,6,64,32,8,41),按数据元素在表中的次序构造一棵二叉查找树。
3.写出中缀表达式A-(B+C/D)*E的后缀形式。
ABCD/+E*-
4. 下图是一个地区的交通网络模型,顶点表示城市,边表示城市间的公路,边的权值表示构造公路的费用,请问如何构造出能连通各个城市且造价最低的交通网,并写出其构造过程。
5. 已知数据序列为12,5,9,20,6,31,24,对该数据序列进行排序,试写出冒泡排序每趟的结果。
二、算法设计题(每小题50分,共25分)
1.判断单链表head(head 指向表头)是否是递增的。
2.设一棵二叉树以二叉链表为存储结构,试写一算法求该二叉树上度为2的结点个数。
则返回递归求左子树度为2节点个数。
情况3,则返回0算法步骤,如果r 既有左孩子又有右孩子,如果r 只有左孩子,则返回1 + 递归求左子树度为2节点个数+ 递归求右子树度为2节点个数,如果r 只有右孩子。
情况4。
情况2,则返回递归求右子树度为2节点个数。
情况1:
设根节点为r,如果r 既没有左孩子又没有右孩子。
数据结构大作业设计

作业要求:1)至少选择下面一个题目,完整实现。
2)对于下面问题,基本要求里面的功能一定要实现;同时,根据个人对于实际问题的理解,尽可能的完善解决问题的方法(提高要求里面给出了简单的进一步完善的方向)。
3)写出详细的设计文档:(不少于3000字)A.说明书格式(见《数据结构大作业说明书》)B.正文要分章节,正文为5号宋体,具体的章节可参考上面设计说明书格式。
C.正文内容:1)概述:开发环境及安装配置,项目的需求分析。
2)程序概要设计:程序的功能模块、程序的流程(可画出流程图),程序的文件结构分析。
3)程序详细设计:关键代码分析(要写详细),在设计中的疑难问题解决。
4)程序的发布和测试:程序发布过程,测试过程(必须有截图说明)5)分析程序的优点和不足,遇到的困难及解决的问题,总结自己的收获。
4)程序编写规范,使用C++语言进行编程。
5)代码编写要符合规范、简单明了,适当添加注释,总行数不得少于500行。
程序要求能够正常运行,并至少能实现基本功能要求。
完成扩展功能要求将得到较高的分数。
6)作业提交时间:开学后第4周周5前;提交打印版的程序设计说明书和电子版的程序代码(材料打包成一个文件夹,文件夹以学号+姓名的方式命名,根据说明书的内容确定答辩名单,不能体现设计过程的说明书均需要参加答辩。
答辩时间和地点另行通知。
)所有材料要保留到学期末(以备答辩)7)评分标准:程序50%,程序设计说明书50%(程序说明书不能说明问题的参考答辩情况)。
凡是没有按时交的、发现拷贝、抄袭的(无论抄与被抄者)均无法通过此课程;一定要将电子版程序设计说明书和源程序一起提交如果修改的,一定要把所有修改的资料都上传到ftp,不接受U盘;如果需要答辩的同学,可以自带电脑,但是也必须把所有的资料都先上传到ftp上面,否则不接受答辩。
8)学习委员收齐打印版文档后,于第4周周五前交到办公室B1-310。
要求:电子版上交地址:计算机科学与技术1班ftp://10.5.1.5/上传/数据结构大作业/ 13计算机1班,用户名:wang,密码:wang,个人文件夹请以学号姓名命名并压缩(使用rar或者zip压缩,不要使用其他的压缩工具),如200910012002张三。
数据结构大作业题目及要求

一、Josephu 问题Josephu 问题为:设编号为1,2,…n的n个人围坐一圈,约定编号为k(1<=k<=n)的人从1开始报数,数到m 的那个人出列,它的下一位又从1开始报数,数到m的那个人又出列,依次类推,直到所有人出列为止,由此产生一个出队编号的序列。
提示:用一个不带头结点的循环链表来处理Josephu 问题:先构成一个有n个结点的单循环链表,然后由k结点起从1开始计数,计到m时,对应结点从链表中删除,然后再从被删除结点的下一个结点又从1开始计数,直到最后一个结点从链表中删除算法结束。
二、稀疏矩阵的操作基本功能要求:稀疏矩阵采用三元组表示,求两个具有相同行列数的稀疏矩阵A和B的相加矩阵C,并输出C,求出A的转置矩阵D,输出D。
三、背包问题的求解:假设有一个能装入总体积为T的背包和n件体积分别为w1 , w2 , …, wn 的物品,能否从n件物品中挑选若干件恰好装满背包,即使w1 +w2 + …+ wn=T,要求找出所有满足上述条件的解。
例如:当T=10,各件物品的体积{1,8,4,3,5,2}时,可找到下列4组解:(1,4,3,2)(1,4,5)(8,2)(3,5,2)。
提示:可利用回溯法的设计思想来解决背包问题。
首先将物品排成一列,然后顺序选取物品装入背包,假设已选取了前i 件物品之后背包还没有装满,则继续选取第i+1件物品,若该件物品"太大"不能装入,则弃之而继续选取下一件,直至背包装满为止。
但如果在剩余的物品中找不到合适的物品以填满背包,则说明"刚刚"装入背包的那件物品"不合适",应将它取出"弃之一边",继续再从"它之后"的物品中选取,如此重复,,直至求得满足条件的解,或者无解。
由于回溯求解的规则规则是"后进先出"因此自然要用到栈。
四、n皇后问题问题描述:求出在一个n×n的棋盘上,放置n个不能互相捕捉的国际象棋"皇后"的所有布局要求:试编写程序实现将n个皇后放置在国际象棋棋盘的无冲突的位置上的算法,并给出所有的解。
数据结构大作业例子

数据结构大作业专业:班级:题目:最小生成树Kruskal算法学生姓名:目录1.任务与目标 (1)1.1课程设计内容 (1)1.2课程设计要求 (1)2.方案设计与论证 (2)2.1课设题目粗略分析 (2)2.2原理图介绍 (4)2.2.1 功能模块图 (4)2.2.2 流程图分析 (5)3.算法说明 (11)3.1存储结构 (11)3.2算法描述 (11)4.程序运行的测试与分析 (13)4.1调试过程 (13)1.2程序执行过程 (13)5.结论与心得 (16)6.参考文献 (16)7.附录(关键部分程序清单) (17)1.任务与目标1.1 课程设计内容编写算法能够建立带权图,并能够用Kruskal算法求该图的最小生成树。
最小生成树能够选择图上的任意一点做根结点。
最小生成树输出采用顶点集合和边的集合的形式。
1.2 课程设计要求1.顶点信息用字符串,数据可自行设定。
2.参考相应的资料,独立完成课程设计任务。
3.交规范课程设计报告和软件代码。
2.方案设计与论证2.1 课设题目粗略分析根据课设题目要求,拟将整体程序分为三大模块。
以下是三个模块的大体分析:1.要确定图的存储形式,通过对题目要求的具体分析。
发现该题的主要操作是路径的输出,因此采用边集数组(每个元素是一个结构体,包括起点、终点和权值)和邻接矩阵比较方便以后的编程。
2.Kruskal算法。
该算法设置了集合A,该集合一直是某最小生成树的子集。
在每步决定是否把边(u,v)添加到集合A中,其添加条件是A∪{(u,v)}仍然是最小生成树的子集。
我们称这样的边为A的安全边,因为可以安全地把它添加到A中而不会破坏上述条件。
3.Dijkstra算法。
算法的基本思路是:假设每个点都有一对标号(d j,p j),其中d是从起源点到点j的最短路径的长度(从顶点到其本身的最短路径是零路(没有弧的路),其长度等于零);p j则是从s到j 的最短路径中j点的前一点。
数据结构实验大作业
数据结构实验大作业大作业要求:请大家在暑假期间将数据结构实验大作业完成后,将代码粘贴在报告中,上传到网络学堂,作业在同一个班内不允许抄袭,截至日期为9月8日。
必须独立完成。
题目:一、Josephu问题Josephu问题为:设编号为1,2,…n的n个人围坐一圈,约定编号为k (1<=k<=n)的人从1开始报数,数到m 的那个人出列,它的下一位又从1开始报数,数到m的那个人又出列,依次类推,直到所有人出列为止,由此产生一个出队编号的序列。
提示:用一个不带头结点的循环链表来处理Josephu 问题:先构成一个有n个结点的单循环链表,然后由k结点起从1开始计数,计到m时,对应结点从链表中删除,然后再从被删除结点的下一个结点又从1开始计数,直到最后一个结点从链表中删除算法结束。
示意图:源代码:#include<stdio.h>struct Josephu_node{int node_nu;struct Josephu_node * pre;struct Josephu_node * next;};struct Josephu_node * Josephu_node_add(struct Josephu_node * head,int nu){struct Josephu_node * newnode;if(head == NULL){head= (struct Josephu_node *)malloc(sizeof(struct Josephu_node)); head->node_nu= 1;head->pre= head;head->next= head;printf("Creat Head:%d",head->node_nu);}else{newnode = (struct Josephu_node *)malloc(sizeof(structJosephu_node));newnode->node_nu = nu;newnode->pre = head->pre;newnode->next= head;head->pre->next= newnode;head->pre = newnode;printf(" ,%d",head->pre->node_nu);}return head;}struct Josephu_node *Joseph_node_del(struct Josephu_node * del_node) {struct Joseph_node * del_node_next=del_node->next;if(del_node != NULL){if(del_node->next != del_node){del_node->pre->next = del_node->next;del_node->next->pre = del_node->pre;}else{del_node_next = NULL;}printf(" %d,",del_node->node_nu);free(del_node);del_node = NULL;return del_node_next;}return NULL;}int main(int argc ,char ** argv){struct Josephu_node * head=NULL;struct Josephu_node * node_tmp;int nu_people=0;int out_nu =0;int i;printf("Please input the nu of the People : ");scanf("%d",&nu_people);printf("Please input the rule out nu: ");scanf("%d",&out_nu);for(i=0;i<nu_people;i++){head = Josephu_node_add(head,i+1);}printf("\n");i = 0;node_tmp = head;printf("Out of the table: ");while(node_tmp != node_tmp->pre){if(i == out_nu-1){node_tmp = Joseph_node_del(node_tmp);i=0;continue;}i++;node_tmp = node_tmp->next;}node_tmp = Joseph_node_del(node_tmp);printf("\n");return 0;}二、稀疏矩阵的操作基本功能要求:稀疏矩阵采用三元组表示,求两个具有相同行列数的稀疏矩阵A和B的相加矩阵C,并输出C,求出A的转置矩阵D,输出D。
数据结构大作业参考

[目录]一、实验目的二、具体实现三、程序片断四、运行结果[原文]1.向索引文件中插入一条记录的索引项;2.从索引文件中二分查找一条记录的索引项。
由上述分析可知,索引文件是有序文件,对索引文件的插入操作是在有序文件上进行的,操作后仍应是有序文件。
对有序文件通常按二进制方式进行操作,每次存取一个逻辑数据块,一个逻辑数据块可以包含一个或若干个记录。
一个逻辑数据块通常小于等于外存上一个物理数据块,而一个物理数据块的大小通常为1K至2K字节,它是进行一次外存访问操作的信息交换单位。
当从有序文件中顺序查找一个记录的插入位置时,不是使每个记录的关键字同给定关键字进行比较:而是使每个逻辑数据块中的最大关键字(即该块中最后一个记录的关键字)同给定关键字进行比较,若前者小于后者,则继续访问下一个数据块并比较,否则待插入的位置必然落在本块中。
[参考资料]数据结构最后一次的大作业数据结构:同时具有删除,添加,从大到小排序功能的链表(数字要可以键盘输入)#include<stdio.h>#include<stdlib.h>#define OK 1#define OVERFLOW -2#define ERROR 0typedef int ElemType;typedef int Status;typedef struct LNode{ElemType data;struct LNode *next;}LNode,*LinkList;void CreateList_L(LinkList &L,int n){ int i;LinkList p,rear;L=rear=(LinkList)malloc(sizeof(LNode)); L->next=NULL;for(i=1;i<=n;i++){printf("请输入第%d个元素:",i);p=(LinkList)malloc(sizeof(LNode)); scanf("%d",&p->data);p->next=NULL;rear->next=p;rear=p; }}Status ListInsert_L(LinkList &L,int i,ElemType e){ LinkList p,s;int j;p=L;j=0;while(p&&j<i-1){p=p->next;++j;}if(!p||j>i-1)return ERROR;s=(LinkList)malloc(sizeof(LNode));s->data=e;s->next=p->next;p->next=s;return OK;}Status ListDelete_L(LinkList &L,int i,ElemType &e){ LinkList p,q;int j;p=L;j=0;while(p->next&&j<i-1){p=p->next;++j;}if(!(p->next)||j>i-1)return ERROR;q=p->next;p->next=q->next;e=q->data;free(q);return OK;}Status ChangElem_L(LinkList &L,int i,ElemType e){ LinkList p;int j;p=L->next;j=1;while(p&&j<i){p=p->next;++j;}if(!p||j>i)return ERROR;p->data=e;return OK;}Status GetElem_L(LinkList L,int i,ElemType &e){ LinkList p;int j;p=L->next;j=1;while(p&&j<i){p=p->next;++j;}if(!p||j>i)return ERROR;e=p->data;return OK;}void SortList(LinkList head){LinkList p,q,large;int temp;for(p=head->next;p->next!=NULL;p=p->next) {large=p;for(q=p->next;q;q=q->next)if(q->data>large->data)large=q;if(large!=p){temp=p->data;p->data=large->data;large->data=temp;}}}void PrintList(LinkList L){LinkList p;p=L->next;do{printf("%d,",p->data);p=p->next; }while(p);printf("\n");}void main(){int n,e,i,flag;LinkList L;printf("请输入元素个数:");scanf("%d",&n);CreateList_L(L,n);printf("原始单链表:");PrintList(L);printf("\n请选择要进行的操作:\n1 增,2 删,3 改,4 查,5 排序\n输入选择序号:");scanf("%d",&flag);switch(flag){case 1:printf("请输入要插入的元素:");scanf("%d",&e);printf("请输入要插入的位置:");scanf("%d",&i);ListInsert_L(L,i,e);printf("改变后的单链表:");PrintList(L);break;case 2:printf("请输入要删除元素的位置:");scanf("%d",&i);ListDelete_L(L,i,e);printf("改变后的单链表:");PrintList(L);break;case 3:printf("请输入新的值:");scanf("%d",&e);printf("请输入要修改元素的位置:");scanf("%d",&i);ChangElem_L(L,i,e);printf("改变后的单链表:");PrintList(L);break;case 4:printf("请输入要查找元素的位置:");scanf("%d",&i);GetElem_L(L,i,e);printf("第%d个元素的值是:%d\n",i,e);break;case 5:SortList(L);printf("从大到小排序后的链表:\n"); PrintList(L);break; default:printf("你输入的选择不存在!\n"); break;}}能实现增删改查和排序我运行的时候没错误啊?能说一下是什么错误吗,VC++下面有提示的数据结构的问题---(1)查找单循环元素,链表中第i个,并输出其值.要求:i通过键盘输入.数据结构的问题(2)在单链表的第i个位置插入元素x。
《数据结构》大作业方案

《数据结构》大作业方案一.大作业成果上交时间,上交方法上交时间:17周四下午 2:00到2:30将所需要上交的部分交至工科大楼501。
上交方法:1.每个同学的"大作业计划安排"以E-mail 形式上交, wk1307@ ;2.最后成果上交要求有两部分,一是磁盘(可以以班为单位上交,每位同学建立一个名称为"姓名-学号"的文件夹),二是打印文档。
要求学生在上交时间前,应将所做的所有需要上交的内容压缩到.zip 或.rar 文件中,存储到一个磁盘中上交;以磁盘形式上交,要求学生目录清晰,磁盘中包含所有要求上交的内容,并及时主动与教师联系确认磁盘文件可以打开;其中"大作业报告"和"大作业总结"除了电子文档以外,还要以打印文稿的形式上交。
二.上交相关内容要求上交的成果的内容必须由以下四个部分组成,缺一不可。
1.上交源程序:学生按照大作业的具体要求所开发的所有源程序(应该放到一个文件夹中);2.上交程序的说明文件:(保存在.txt中)在说明文档中应该写明上交程序所在的目录,上交程序的主程序文件名,如果需要安装,要有程序的安装使用说明;3.大作业报告:(保存在word 文档中,文件名要求按照"姓名-学号-大作业报告"起名,如文件名为"张三-01-大作业报告".doc )按照大作业的具体要求建立的功能模块,每个模块要求按照如下几个内容认真完成;其中包括:a)需求分析:在该部分中叙述,每个模块的功能要求;b)概要设计在此说明每个部分的算法设计说明(可以是描述算法的流程图),每个程序中使用的存储结构设计说明(如果指定存储结构请写出该存储结构的定义。
c)详细设计各个算法实现的源程序,对每个题目要有相应的源程序(可以是一组源程序,每个功能模块采用不同的函数实现)源程序要按照写程序的规则来编写。
要结构清晰,重点函数的重点变量,重点功能部分要加上清晰的程序注释。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
数据结构大作业一、问题描述:单词检索现在有一个英文字典(每个单词都是由小写的'a'-'z'组成)单词量很大,达到120 多万的单词,而且还有很多重复的单词。
此外,我们现在还有一些Document,每个Document 包含一些英语单词。
针对这个问题,请你选择合适的数据结构,组织这些数据,使时间复杂度和空间复杂度尽可能低,并且解决下面的问题和分析自己算法的时间复杂度。
1)基本型问题(1)选择合适的数据结构,将所有的英文单词生成一个字典Dictionary。
(2)给定一个单词,判断这个单词是否在字典Dictionary中。
如果在单词库中,输出这个单词总共出现的次数。
否则输出NO 2)扩展型问题(3)给定一个单词,按字典序输出字典Dictionary 中所有以这个单词为前缀的单词。
例如,如果字典T={a,aa, aaa, b, ba}, 如果你输入a,那么输出应该为{a, aa, aaa}。
(4)给定一个单词,输出在Dictionary 中以这个单词为前缀的单词的出现频率最高的10 个单词,对于具有相同出现次数的情况,按照最近(即最后)插入的单词优先级比较高的原则输出。
(5)输出Dictionary 中出现次数最高的10个单词。
(6)现在我们有一些Document,每个Document 由一些单词组成,现在的问题就是给你一个word,检索出哪些Document包含这个word,输出这些Document 的DocumentID (就如同搜索引擎一样,即输入一些关键字,然后检索出和这些关键字相关的文档)。
(7)在第(6)问中,我们只考虑了一个word 在哪些Document 中的情况,我们进一步考虑2 个相邻word 的情况,检索出同时包含这两个相邻word 的DocumentID。
二、需求分析:对于(1)问,题目要求选择适当的数据结构将一百二十多万个英文单词生成一个字典。
我采用经典字典树结构进行构造,每个节点包括频度,时间,和后继二十六个指针。
其中频度为单词的频度,若该字母为单词的最后一个字母,则该字母的pin为该单词的频度,否则pin为零。
时间为单词最后一次出现的次序,为(4)问服务。
对于(2)问,题目要求在字典里查询指定单词,若在字典中则输出在字典中出现的次数,否则输出NO。
读入字母,根据字典树进行查找。
若在字典树中存在最后一个字母,且最后一个字母的频度不为零,则该单词存在,出现次数即为该字母频度。
否则,该单词不存在。
对于(3)问,题目要求查找以指定单词为前缀的所有单词,并输出所有单词,若不存在,什么也不输出。
我使用数组存储前缀和以此前缀为前缀的单词。
若在字典树中存在这样的前缀,则从此节点按照字典顺序遍历字典树,并输出所有以此为前缀的所有单词。
若不存在这样的前缀,则什么也不输出。
对于(4)问,题目要求查找以指定单词为前缀的频度最高的十个单词,并按频度高低顺序输出。
若频度相同,则按照最近(即最后)插入的单词优先级比较高的原则输出。
若不满十个则全部输出。
我采用Node T[10]存储频度最高的前十个单词,排序使用插入排序,对频度相同的单词,比较它们的time,若time比较大,则插到前面。
对于(5)问,题目要求输出字典中频度最高的十个单词。
我采用Node Top[10]存储频度最高的前十个单词,遍历字典树,按照插入排序进行排序。
对于(6)问,题目要求在若干Document中查找指定单词,若存在该单词,则输出所在Document的ID,要求输出所有存在的ID。
若不存在什么也不输出。
由于(6)(7)(8)问与前五问使用的文件不相同,我在编写程序时,就把前五问与后面几问分开了。
我同样采用了字典树结构进行存储Document中的单词,不过字母节点变成频度、坐标和二十六个后继指针。
其中坐标为单词所在Document的ID 和所在Document的第几个顺序。
在此问中,按照字典树查找指定单词,并输出单词所在Document的ID。
对于(7)问,题目要求在Document中查找两个单词组成的词组。
我先将读入的词组分成两个单词,分别在字典树中查找两个单词,得到两个单词的坐标。
先比较两个单词的ID,若ID相同,则比较在Document中的顺序,若前后两个单词的顺序,后一个单词比前一个单词顺序大1,则输出该ID。
否则不输出。
注:此题是我从网上搜的,原题一共八问,此处只做前七问.三、概要设计:1、节点设计:前五问:typedef struct TNode{struct TNode *point[26];int pin;int time;}TNode;//字典树节点,pin记录单词出现次数,time记录单词最后一次出现的次序typedef struct Node{char k[40];int flag;int time;}Node;//用来存前缀最高的十个单词六七问:typedef struct node{int pos;struct node *next1;}node;//存储单词在文件的位置typedef struct Node{int id;struct node *node1;struct Node *next;}Node;//存储单词在文件的IDtypedef struct TNode{struct TNode *point[26];int pin;struct Node *loc;}TNode;//字典树节点2、主函数:一至五问:void main(){int i;TNode *root;root=(struct TNode *)malloc(sizeof (struct TNode));for (i=0;i<26;i++){root->point[i]=NULL;}printf("程序开始运行\n\n打开文件“vocabulary.txt”开始生成字典\n");CreateTree(root);printf("生成字典成功\n第一问解决\n\n\n打开文件“SearchWordInVocabulary.txt”\n开始查找单词\n");Search(root);printf("查找结束\n结果保存在文件“SearchWordInVocabulary_Result.txt”\n第二问解决\n\n\n打开文件“TotPrefixWord.txt”\n开始查找前缀单词\n");Prefix(root);printf("查找结束\n结果保存在文件“TotPrefixWord_Result.txt”\n 第三问解决\n\n\n打开文件“PrefixFrequence.txt”\n开始查找前缀出现频率最高的十个单词\n");Prefixqueue(root);printf("查找结束\n结果保存在文件“PrefixFrequence_Result.txt”\n第四问解决\n\n\n开始查找频率最高的十个单词\n");MostFrequence(root);printf("查找结束\n结果保存在文件“MostFrequenceWord.txt”\n前五问解决\n\n\n");}六七问:void main(){int i;TNode *root;root=(struct TNode *)malloc(sizeof (struct TNode));for (i=0;i<26;i++){root->point[i]=NULL;}printf("程序开始运行\n\n\n打开文件“Document.txt”\n开始构造字典\n");Create(root);printf("字典构造结束\n打开文件“WordInDocument.txt\n开始在文件中查找单词\n");SearchWord(root);printf("查找结束\n结果保存在文件“WordInDocument_Result.txt”\n第六问解决\n\n\n打开文件“TwoWordInDocument.txt”\n开始在文件中查找连续的两个单词\n");SearchTwoWord(root);printf("查找结束\n结果保存在文件“TwoWordInDocument_Result.txt”\n第七问解决\n\n\n");}四、详细分析(对函数的一些注释)一至五问:(1)void CreateTree(TNode *root)注:(1)读入单词,构造字典树(2)void Search(TNode *root)注:(2)读入要查找的单词进行查找,若在字典中存在,则输出频度。
否则输出NO(3)void Printf(TNode *item,FILE *fp2,char *a,int k)(4)void Prefix(TNode *root)注:(4)查找指定前缀,若存在,则在(3)中进行输出以该单词为前缀的所有单词;若不存在,什么也不输出(5)void Printf1(TNode *item,char *a,int k,Node *T)(6)void Prefixqueue(TNode *root)注:(6)查找指定前缀,若存在,则在(5)中进行排序并输出频度最高的十个单词;否则什么也不输出(7)void Most(TNode *item,int i,Node *Top,char *a)(8)void MostFrequence(TNode *root)注:(7)(8)遍历整个字典树,将字典中频度最高的十个单词全部输出六七问:(1)void Create(TNode *root)注:(1)读入Document里面的单词,构建字典树(2)void SearchWord(TNode *root)注:(2)查找单词,若存在,则输出所有存在该单词的文件的ID,否则,什么也不输出(3)Node * Search(TNode *root,char *a)(4)void SearchTwoWord(TNode *root)注:(4)将词组分成两个单词,在(3)中分别进行查找,再对两个单词所在文件的ID求交,然后在相同的ID下判断位置是否相邻。
若相邻,则输出ID,否则什么也不输出五、使用说明:本函数运行环境为dos操作系统。
六、测试结果:第一问:第二问:第三问:第四问:第五问:第六问:第七问:- 11 -。