Mysql my.ini文件配置详解
MySQL配置文件mysql.ini参数详解、MySQL性能优化

#key_buffer_size指定用于索引的缓冲区大小,增加它可得到更好的索引处理性能。对于内存在4GB左右的服务器该参数可设置为256M或384M。注意:该参数值设置的过大反而会是服务器整体效率降低!
max_allowed_packet = 4M
show variables like '%innodb%'; # 查看innodb相关配置参数
show status like '%innodb%'; # 查看innodb相关的运行时参数(比如当前正在打开的表的数量,当前已经打开的表的数量)
show global status like 'open%tables'; # 查看全局的运行时参数,加上global是对当前mysql服务器中运行的所有数据库实例进行统计。不加global则只对当前数据库实例进行统计。
back_log = 384
#back_log参数的值指出在MySQL暂时停止响应新请求之前的短时间内多少个请求可以被存在堆栈中。 如果系统在一个短时间内有很多连接,则需要增大该参数的值,该参数值指定到来的TCP/IP连接的侦听队列的大小。不同的操作系统在这个队列大小上有它自己的限制。 试图设定back_log高于你的操作系统的限制将是无效的。默认值为50。对于Linux系统推荐设置为小于512的整数。
innodb_log_file_size=53M # 每一个InnoDB事务日志的大小。一般设为innodb_buffer_pool_size的25%到100%
innodb_thread_concurrency=9 # InnoDB内核最大并发线程数。
在Apache, PHP, MySQL的体系架构中,MySQL对于性能的影响最大,也是关键的核心部分。对于Discuz!论坛程序也是如此,MySQL的设置是否合理优化,直接影响到论坛的速度和承载量!同时,MySQL也是优化难度最大的一个部分,不但需要理解一些MySQL专业知识,同时还需要长时间的观察统计并且根据经验进行判断,然后设置合理的参数。 下面我们了解一下MySQL优化的一些基础,MySQL的优化我分为两个部分,一是服务器物理硬件的优化,二是MySQL自身(f)的优化。
MySQL的my.ini11配置参数详解

MySQL的my.ini配置参数详解:port=3306;端口号basedir=d:/MySQL;MySQL安装目录log-error=d:/logs/mysql_error.log;日志文件datadir=d:/MySQL/data;数据库所在目录=================================1. back_log指定MySQL可能的连接数量。
当MySQL主线程在很短的时间内得到非常多的连接请求,该参数就起作用,之后主线程花些时间(尽管很短)检查连接并且启动一个新线程。
back_log参数的值指出在MySQL暂时停止响应新请求之前的短时间内多少个请求可以被存在堆栈中。
如果系统在一个短时间内有很多连接,则需要增大该参数的值,该参数值指定到来的TCP/IP连接的侦听队列的大小。
不同的操作系统在这个队列大小上有它自己的限制。
试图设定back_log高于你的操作系统的限制将是无效的。
当观察MySQL进程列表,发现大量264084 | unauthenticated user | xxx.xxx.xxx.xxx | NULL | Connect | NULL | login | NULL 的待连接进程时,就要加大back_log 的值。
back_log默认值为50。
2. basedirMySQL主程序所在路径,即:–basedir参数的值。
3. bdb_cache_size分配给BDB类型数据表的缓存索引和行排列的缓冲区大小,如果不使用DBD类型数据表,则应该在启动MySQL时加载–skip-bdb 参数以避免内存浪费。
4.bdb_log_buffer_size分配给BDB类型数据表的缓存索引和行排列的缓冲区大小,如果不使用DBD类型数据表,则应该将该参数值设置为0,或者在启动MySQL时加载–skip-bdb 参数以避免内存浪费。
5.bdb_home参见–bdb-home 选项。
6. bdb_max_lock指定最大的锁表进程数量(默认为10000),如果使用BDB类型数据表,则可以使用该参数。
Windows下mysql-5.7.28下载、安装、配置教程图文详解
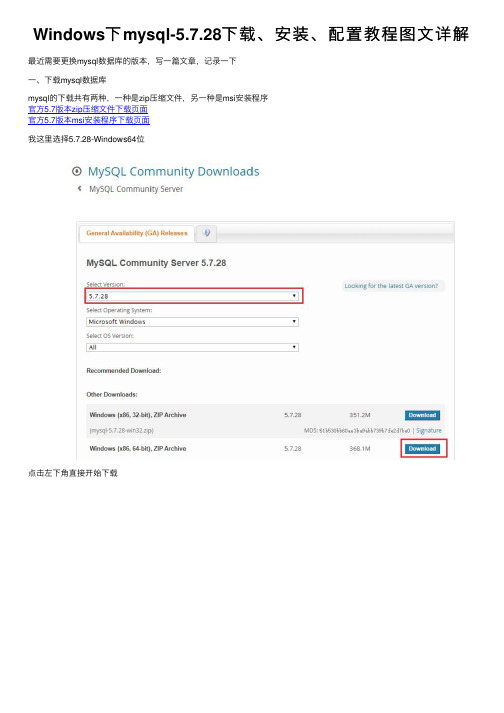
Windows下mysql-5.7.28下载、安装、配置教程图⽂详解最近需要更换mysql数据库的版本,写⼀篇⽂章,记录⼀下⼀、下载mysql数据库mysql的下载共有两种,⼀种是zip压缩⽂件,另⼀种是msi安装程序官⽅5.7版本zip压缩⽂件下载页⾯官⽅5.7版本msi安装程序下载页⾯我这⾥选择5.7.28-Windows64位点击左下⾓直接开始下载使⽤迅雷或者IDM等下载器,下载会快⼀点下载完成之后的两种⽂件⼆、安装mysql数据库我这⾥使⽤zip压缩⽂件安装,这是免安装的,配置的内容多⼀点1.解压缩安装⽂件注意:解压缩的路径⾥⾯不要出现中⽂2.配置mysql双击进⼊到能看到bin的⽬录中新建data⽂件夹然后再新建⽂本⽂件,重命名为my.ini(注意电脑可能未显⽰⽂件拓展名,my.ini⽂件不要放在data⽂件夹⾥)使⽤⽂本编辑器打开my.ini⽂件,将下⾯的配置⽂本内容复制到my.ini⽂件中修改为⾃⼰电脑的配置内容(⼀定要删除所有的中⽂⽂字所在⾏内容)保存并关闭编辑器[mysqld]# 设置服务端使⽤的字符集为utf-8character-set-server=utf8# 绑定IPv4地址bind-address = 0.0.0.0# 设置mysql的端⼝号port = 3306# 设置mysql的安装⽬录(能看到bin即可)basedir=D:\Applocations\64_mysql\mysql-5.7.28-winx64# 设置mysql数据库的数据的存放⽬录(能看到my.ini⽂件的⽬录)datadir=D:\Applocations\64_mysql\mysql-5.7.28-winx64\data# 允许最⼤连接数max_connections=2000# 创建新表时将使⽤的默认存储引擎default-storage-engine=INNODB# 设置mysql以及数据库的默认编码[mysql]default-character-set=utf8[mysql.server]default-character-set=utf8# 设置客户端默认字符集[client]default-character-set=utf83.安装mysql进⼊到bin/⽬录下在地址栏输⼊cmd,然后回车打开cmd命令⾏终端地址路径不能含有中⽂,如果前⾯没注意,可将mysql安装⽂件剪切到纯英⽂路径下在cmd终端⾥执⾏安装命令# 安装命令mysqld --install# 卸载命令mysqld --remove提⽰安装成功4.初始化mysql继续在终端执⾏初始化命令(你可以初始化多次,但是每次必须清空data⽂件夹)# mysql数据库初始化mysqld --initialize --user=root --console执⾏完成之后,会给mysql的root⽤户分配随机密码,如图5.登陆mysql在终端通过命令启动mysql服务# 启动mysql服务net start mysql# 停⽌mysql服务net stop mysql使⽤命令连接mysql注:这个密码就是前⾯初始化mysql⽣成的随机密码mysql -uroot -p密码mysql -uroot -p6.修改mysql的密码默认随机密码也可以使⽤,但是太难记了,可以设置⼀个简单的密码执⾏下⾯的命令设置mysql的密码# 设置mysql的密码set password = password('密码');# 退出mysql数据库exit7.配置mysql的环境变量以此'此电脑'-->'属性'-->'⾼级系统设置'-->'环境变量'在系统变量下新建系统变量变量名:MYSQL_HOME变量值:D:\Applocations\64_mysql\mysql-5.7.28-winx64(能看到bin⽬录的mysql解压路径)在path下新增环境变量复制代码代码如下:%MYSQL_HOME%\bin重新随意打开cmd终端,使⽤命令加修改的密码,就可以直接连接mysql了三、mysql数据库添加⽤户root⽤户是mysql数据库的超级⽤户,权限⽐较⾼,使⽤起来不安全,推荐新建⽤户,当然不新建也可以的在终端⾥使⽤以下命令新建⽤户并授予权限# 格式说明grant 权限 on 数据库.表 to ⽤户名@连接的ip地址 identified by'密码';# 实例,给密码是1234的test⽤户所有数据库的所有表的所有权限grant all on *.* to test@'%' identified by'1234';到此为⽌mysql安装完成,可以使⽤navicat连接数据库了总结以上所述是⼩编给⼤家介绍的Windows下mysql-5.7.28下载、安装、配置教程图⽂详解,希望对⼤家有所帮助,如果⼤家有任何疑问请给我留⾔,⼩编会及时回复⼤家的。
windows下mysql配置,my.ini配置文件

windows下mysql配置,my.ini配置⽂件 2019.9.20更新mysql5.7以上和5.7以下的版本存在参数配置不同5.7以上报不存在的字段有unknown variable 'innodb_additional_mem_pool_size=2M'解决:移除这个配置innodb_additional_mem_pool_size 和 innodb_use_sys_malloc 在 MySQL 5.7.4 中移除。
#unknown variable 'log-slow-queries'解决:mysql5.6版本以上,取消了参数log-slow-queries,更改为slow-query-log-file还需要加上 slow_query_log = on 否则,还是没⽤#log-slow-queries = /home/db/madb/log/slow-query.logslow_query_log = onslow-query-log-file = /home/db/madb/log/slow-query.loglong_query_time = 15.7以上版本使⽤ character_set_server=utf8 代替default-character-set = utf8#unknown variable myisam_max_extra_sort_file_size=100G5.7版本没有上⾯参数,去除基本配置,这个配置可以直接复制到mysql根⽬录下了my.ini⽂件中,[client]port=3306[mysql]no-beep# default-character-set=[mysqld]port=3306# mysql根⽬录basedir="D:\AppServ\mysql5.7\"# 放所有数据库的data⽬录datadir=D:\AppServ\mysql5.7\data# character-set-server=# 默认存储引擎innoDBdefault-storage-engine=INNODB# Set the SQL mode to strictsql-mode="STRICT_TRANS_TABLES,NO_AUTO_CREATE_USER,NO_ENGINE_SUBSTITUTION"#⽇志输出为⽂件log-output=FILE# 是否开启sql执⾏结果记录,必须要设置general_log_file参数,⽇志的路径地址# 即⽇志跟踪,1为开启,0为关闭general-log=0general_log_file="execute_sql_result.log"# 配置慢查询,5.7版本默认为1slow-query-log=1slow_query_log_file="user-slow.log"long_query_time=10#默认不开启⼆进制⽇志#log-bin=mysql-log#错误信息⽂件设置,会将错误信息放在data/mysql.err⽂件下log-error=mysql.err# Server Id.数据库服务器id,这个id⽤来在主从服务器中标记唯⼀mysql服务器server-id=1#lower_case_table_names:此参数不可以动态修改,必须重启数据库#lower_case_table_names = 1 表名存储在磁盘是⼩写的,但是⽐较的时候是不区分⼤⼩写#lower_case_table_names=0 表名存储为给定的⼤⼩和⽐较是区分⼤⼩写的#lower_case_table_names=2, 表名存储为给定的⼤⼩写但是⽐较的时候是⼩写的lower_case_table_names=1#限制数据的导⼊导出都只能在Uploads⽂件中操作,这个是在sql语句上的限制。
Windows下MySQL5.6查找my.ini配置文件的方法

Windows下MySQL5.6查找my.ini配置⽂件的⽅法
记录⼀笔,防⽌以后忘了可以过来看看。
问题描述:
今天做个⼩实验需要修改MySQL的配置⽂件,我电脑上安装的是MySQL5.6,由于安装时间太久忘了安装在哪个⽬录下了,所以⾸先查了⼀下安装在本机上的MySQL的⽬录位置。
在DOS命令⾏窗⼝登录MySQL,输⼊如下命令查看MySQL的安装⽬录和数据存放⽬录,MySQL的配置⽂件就在数据存放⽬录下:
另外⼀种⽅法:
在“开始→所有程序→ MySQL”下⾯找到MySQL的命令⾏客户端⼯具,右键选择该命令⾏⼯具查看“属性”,在“⽬标”⾥⾯也可以看到MySQL使⽤的配置⽂件位置。
注意:ProgramData⽬录可能是“隐藏”的,如果在显⽰的分区中看不到的话就修改⼀下系统设置,让隐藏⽂件/⽂件夹可见。
或者直接将ProgramData/MySQL/MySQL Server 5.6⽬录复制下来直接粘贴到⽂件夹的⽬录窗⼝中也可以。
以上这篇Windows下MySQL5.6查找my.ini配置⽂件的⽅法就是⼩编分享给⼤家的全部内容了,希望能给⼤家⼀个参考,也希望⼤家多多⽀持。
MySQL免安装版配置

MySQL免安装版配置1.下载MySQL 免安装版2.将MySQL 解压到待安装目录,使用%MYSQL_HOME%表示3.打开文件my-huge.ini另存为my.ini,在my.ini文件中加入如下配置,再放到C:/windows 下[mysqld]basedir=E:/share/mysqldatadir=E:/share/mysql/data4.在环境变量中设置MYSQL_HOME,把%MYSQL_HOME%\bin 加入到path5.在命令行运行mysqld 即可启动MySQL 数据库可以执行下列操作,将mysql安装为winsow服务1、执行命令:mysqld-nt.exe --install (安装到windows的服务)2、执行命令:net start mysql一般情况下,这样操作后,mysql安装完成。
注:1、如果以前系统存在mysql。
则进入以前系统存在的mysql目录,执行mysqld-nt.exe --remove(先从系统中移除mysql服务)在开始执行上面第4步。
设置MySQL中文字符集(MySQL正常显示中文)1).配置服务器端,修改my.ini文件,使用中文字符集存储记录,同时用中文排序比较方式。
[mysqld]# set character setdefault-character-set=gbk# set character collationdefault-collation=gbk_chinese_ci2). 如果要在中文环境的服务器端使用mysql命令行,改变my.ini文件中mysql的默认字符集。
[mysql]# set character setdefault-character-set=gbk文章出处:DIY部落(/course/7_databases/mysql/myxl/20081213/153727.html)使用mysql 免安装版我比较喜欢免安装版(非安装版)的mysql,下载如:mysql-noinstall-5.0.45-win32.zip把它解压到如:E:/mysql-5.0.45,当然可以任意位置。
MySQL8.0.20安装教程及其安装问题详细教程

MySQL8.0.20安装教程及其安装问题详细教程官⽹下载MySQL的安装包1.下载链接如下:其他版本:2.MySQL8.0.20版本压缩包解压后如下图所⽰:添加并配置my.ini⽂件在原解压根⽬录下添加my.ini⽂件:新建⽂本⽂件,也就是记事本⽂件,并命名为my.ini (也就是拓展名为ini格式)。
如果更改不了拓展名,。
在my.ini⽂件写⼊如下的基本配置:[mysqld]# 设置3306端⼝port=3306# 设置mysql的安装⽬录basedir=D:\\Program Files\\MySQL# 设置mysql数据库的数据的存放⽬录#datadir=D:\\Program Files\\MySQL\\Data# 允许最⼤连接数max_connections=200# 允许连接失败的次数。
max_connect_errors=10# 服务端使⽤的字符集默认为utf8mb4character-set-server=utf8mb4# 创建新表时将使⽤的默认存储引擎default-storage-engine=INNODB# 默认使⽤“mysql_native_password”插件认证#mysql_native_passworddefault_authentication_plugin=mysql_native_password[mysql]# 设置mysql客户端默认字符集default-character-set=utf8mb4[client]# 设置mysql客户端连接服务端时默认使⽤的端⼝port=3306default-character-set=utf8mb43.配置⽂件处理完后根⽬录下⽂件的情况如下图:4.注意事项:MySQL8.0.18版本⼀下的需要⼿动配置Data⽂件夹(把我注释掉的 datadir 哪⼀⾏最前⾯把#号去掉,如下⾯样式)所填路径为你MySQL要安装的路径位置!datadir=D:\\Program Files\\MySQL\\Data配置系统变量并初始化MySQL1.创建MySQL的安装位置:在D盘创建Program Files⽂件夹,在其⽂件夹下创建MySQL⽂件夹,然后把刚刚解压的MySQL⽂件连同刚刚添加的my.ini⽂件复制到此⽂件夹下,效果如下(安装在其他磁盘处也是可以的,但是要注意my.ini⽂件中配置⽂件的路径):2.配置系统的环境变量Pathpath变量中新增bin⽂件夹的路径,然后全部保存并退出,。
MySQL配置文件-my.ini

MySQL配置⽂件-my.ini 原⽂链接下⾯允许我介绍⼀下MySQL的my.ini配置⽂件:my.ini是什么? my.ini是MySQL数据库中使⽤的配置⽂件,修改这个⽂件可以达到更新配置的⽬的。
my.ini存放在哪⾥? my.ini存放在MySql安装的根⽬录,如图所⽰:my.ini的具体内容介绍:1 # CLIENT SECTION2 # ----------------------------------------------------------------------3 #4 # The following options will be read by MySQL client applications.5 # Note that only client applications shipped by MySQL are guaranteed6 # to read this section. If you want your own MySQL client program to7 # honor these values, you need to specify it as an option during the8 # MySQL client library initialization.9 #10 [client]1112 port=33061314 [mysql]1516 default-character-set=gb2312上⾯显⽰的是客户端的参数,[client]和[mysql]都是客户端,下⾯是参数简介: 1.port参数表⽰的是MySQL数据库的端⼝,默认的端⼝是3306,如果你需要更改端⼝号的话,就可以通过在这⾥修改。
2.default-character-set参数是客户端默认的字符集,如果你希望它⽀持中⽂,可以设置成gbk或者utf8。
3.这⾥还有⼀个password参数,在这⾥设置了password参数的值就可以在登陆时不⽤输⼊密码直接进⼊1 # SERVER SECTION2 # ----------------------------------------------------------------------3 #4 # The following options will be read by the MySQL Server. Make sure that5 # you have installed the server correctly (see above) so it reads this6 # file.7 #8 [mysqld]910 # The TCP/IP Port the MySQL Server will listen on11 port=3306121314 #Path to installation directory. All paths are usually resolved relative to this.15 basedir="E:/Java/Mysql/"1617 #Path to the database root18 datadir="C:/ProgramData/MySQL/MySQL Server 5.5/Data/"1920 # The default character set that will be used when a new schema or table is21 # created and no character set is defined22 character-set-server=gb23122324 # The default storage engine that will be used when create new tables when25 default-storage-engine=INNODB2627 # Set the SQL mode to strict28 sql-mode="STRICT_TRANS_TABLES,NO_AUTO_CREATE_USER,NO_ENGINE_SUBSTITUTION"2930 # The maximum amount of concurrent sessions the MySQL server will31 # allow. One of these connections will be reserved for a user with32 # SUPER privileges to allow the administrator to login even if the33 # connection limit has been reached.34 max_connections=1003536 # Query cache is used to cache SELECT results and later return them37 # without actual executing the same query once again. Having the query38 # cache enabled may result in significant speed improvements, if your39 # have a lot of identical queries and rarely changing tables. See the40 # "Qcache_lowmem_prunes" status variable to check if the current value41 # is high enough for your load.42 # Note: In case your tables change very often or if your queries are43 # textually different every time, the query cache may result in a44 # slowdown instead of a performance improvement.45 query_cache_size=04647 # The number of open tables for all threads. Increasing this value48 # increases the number of file descriptors that mysqld requires.49 # Therefore you have to make sure to set the amount of open files50 # allowed to at least 4096 in the variable "open-files-limit" in51 # section [mysqld_safe]52 table_cache=2565354 # Maximum size for internal (in-memory) temporary tables. If a table55 # grows larger than this value, it is automatically converted to disk56 # based table This limitation is for a single table. There can be many57 # of them.58 tmp_table_size=35M596061 # How many threads we should keep in a cache for reuse. When a client62 # disconnects, the client's threads are put in the cache if there aren't63 # more than thread_cache_size threads from before. This greatly reduces64 # the amount of thread creations needed if you have a lot of new65 # connections. (Normally this doesn't give a notable performance66 # improvement if you have a good thread implementation.)67 thread_cache_size=86869 #*** MyISAM Specific options7071 # The maximum size of the temporary file MySQL is allowed to use while72 # recreating the index (during REPAIR, ALTER TABLE or LOAD DATA INFILE.73 # If the file-size would be bigger than this, the index will be created74 # through the key cache (which is slower).75 myisam_max_sort_file_size=100G7677 # If the temporary file used for fast index creation would be bigger78 # than using the key cache by the amount specified here, then prefer the79 # key cache method. This is mainly used to force long character keys in80 # large tables to use the slower key cache method to create the index.81 myisam_sort_buffer_size=69M8283 # Size of the Key Buffer, used to cache index blocks for MyISAM tables.84 # Do not set it larger than 30% of your available memory, as some memory85 # is also required by the OS to cache rows. Even if you're not using86 # MyISAM tables, you should still set it to 8-64M as it will also be87 # used for internal temporary disk tables.88 key_buffer_size=55M8990 # Size of the buffer used for doing full table scans of MyISAM tables.91 # Allocated per thread, if a full scan is needed.92 read_buffer_size=64K93 read_rnd_buffer_size=256K9495 # This buffer is allocated when MySQL needs to rebuild the index in96 # REPAIR, OPTIMZE, ALTER table statements as well as in LOAD DATA INFILE97 # into an empty table. It is allocated per thread so be careful with98 # large settings.99 sort_buffer_size=256K上⾯是服务器断参数,⼀下是参数的简介: 1.port参数也是表⽰数据库的端⼝。
my.ini文件详解

my.ini⽂件详解优化思路:数据库异步同步三点:幕等时序延迟按照我的理解⼜分为以下⼏个⽅⾯的层级传输阶段:⽤户连接⾄应⽤服务器,应⽤服务器访问数据库服务器;硬件层:物理机器设备,硬盘的转速,CPU的主频,内存的⼤⼩,⽹卡速率;硬件层之上:read卡,bios,双⽹卡绑定;操作系统的优化:ulimit,tcp握⼿包的调试,selinux等;数据库配置⽂件的调试:my.ini 主配置⽂件;数据库表结构的调试;SQL语句的优化;以下整理搬运学弟的,让⾃⼰在优化及调整的时候更⽅便,选择⽤到的,满⾜需求就好。
MySQL配置⽂件优化[client]port = 3306 #客户端端⼝号为3306socket =/data/3306/mysql.sock #default-character-set = utf8 #客户端字符集,(控制character_set_client、character_set_connection、character_set_results)[mysql]no-auto-rehash #仅仅允许使⽤键值的updates和deletes[mysqld] #组包括了mysqld服务启动的参数,它涉及的⽅⾯很多,其中有MySQL的⽬录和⽂件,通信、⽹络、信息安全,内存管理、优化、查询缓存区,还有MySQL⽇志设置等。
user = mysql #mysql_safe脚本使⽤MySQL运⾏⽤户(编译时--user=mysql指定),推荐使⽤mysql⽤户。
port = 3306 #MySQL服务运⾏时的端⼝号。
建议更改默认端⼝,默认容易遭受攻击。
socket =/data/3306/mysql.sock #socket⽂件是在Linux/Unix环境下特有的,⽤户在Linux/Unix环境下客户端连接可以不通过TCP/IP⽹络⽽直接使⽤unix socket连接MySQL。
basedir = /application/mysql #mysql程序所存放路径,常⽤于存放mysql启动、配置⽂件、⽇志等datadir = /data/3306/data #MySQL数据存放⽂件(极其重要)character-set-server = utf8 #数据库和数据库表的默认字符集。
win10安装zip版MySQL8.0.19的教程详解

win10安装zip版MySQL8.0.19的教程详解⽬录⼀. 下载后解压到想安装的⽬录⼆. 在安装⽬录中添加配置⽂件my.ini三. 配置环境变量,将mysql的bin⽬录添加到path中五. 安装数据库六.修改root密码七.创建远程⽤户并授予权限⼋.删除数据库⼀. 下载后解压到想安装的⽬录⼆. 在安装⽬录中添加配置⽂件my.ini[mysqld]# 设置3306端⼝port=3306# 设置mysql的安装⽬录basedir=D:\DevTool\MySQL-8.0.19# 设置mysql数据库的数据的存放⽬录datadir=D:\DevTool\MySQL-8.0.19\data# 允许最⼤连接数max_connections=200# 允许连接失败的次数。
这是为了防⽌有⼈从该主机试图攻击数据库系统max_connect_errors=10# 服务端使⽤的字符集默认为UTF8character-set-server=utf8mb4# 创建新表时将使⽤的默认存储引擎default-storage-engine=INNODB# 默认使⽤“mysql_native_password”插件认证default_authentication_plugin=mysql_native_password[mysql]# 设置mysql客户端默认字符集default-character-set=utf8mb4[client]# 设置mysql客户端连接服务端时默认使⽤的端⼝和字符集port=3306default-character-set=utf8mb4其中datadir不需要⾃⼰建⽂件夹,初始化数据库时会⾃动建的三. 配置环境变量,将mysql的bin⽬录添加到path中四. 初始化数据库以管理员⾝份打开命令窗⼝并执⾏mysqld --initialize --user=mysql --console红⾊框中是root⽤户和密码,之后登陆的时候会⽤到五. 安装数据库在命令⾏窗⼝中执⾏ mysqld -install 出现Service successfully installed.则证明安装成功!⽤ net start mysql启动服务⽤ mysql -u root -p 命令登录mysql 需要输⼊之前初始化数据库时的密码六.修改root密码⽤ alter user 'root'@'localhost' identified by 'password'; 修改root密码其中password是你想⽤的密码可以⽤exit命令退出mysql之后⽤新密码重新登录七.创建远程⽤户并授予权限创建⽤户: create user 'username'@'%' identified by 'password';授予权限: grant all privileges on *.* to 'username'@'%' with grant option;刷新权限: flush privileges;⼋.删除数据库net stop mysql 关闭服务,mysqld -remove 或 sc delete mysql 删除mysql服务删除mysql⽂件⽬录即可总结以上所述是⼩编给⼤家介绍的win10安装zip版MySQL8.0.19的教程详解,希望对⼤家有所帮助,也⾮常感谢⼤家对⽹站的⽀持!。
mysql配置文件详解

MySQL的主要配置文件是f(在Windows系统中为my.ini)。
这个文件包含了MySQL服务器和客户端的各种设置选项。
下面我们详细介绍f文件的结构、主要配置项及其作用:1文件位置在Linux系统中,f文件通常位于以下位置之一:•/etc/f•/etc/mysql/f•$MYSQL_HOME/f•~/f在Windows系统中,my.ini文件通常位于MySQL安装目录下。
2文件结构f文件由多个配置组(section)组成,每个组以方括号[]包围的标题开始。
主要的配置组包括:[mysqld] - MySQL服务器配置 [mysql] - MySQL命令行客户端配置 [client] - 所有MySQL客户端程序的通用配置 [mysqldump] - mysqldump工具的配置3主要配置项[mysqld] 部分的重要配置项:a. 基本设置port = 3306 # MySQL服务器监听端口bind-address = 127.0.0.1 # 绑定的IP地址datadir = /var/lib/mysql # 数据目录socket = /tmp/mysql.sock # Unix套接字文件位置b. 连接设置max_connections = 151 # 最大并发连接数max_allowed_packet = 16M # 最大允许的数据包大小c. 缓冲区和缓存设置key_buffer_size = 16M # 索引缓冲区大小innodb_buffer_pool_size = 128M # InnoDB缓冲池大小query_cache_size = 16M # 查询缓存大小d. 日志设置log_error = /var/log/mysql/error.log # 错误日志文件slow_query_log = 1 # 开启慢查询日志slow_query_log_file = /var/log/mysql/slow.log # 慢查询日志文件long_query_time = 2 # 定义慢查询的阈值(秒)e. InnoDB设置innodb_file_per_table = 1 # 每个表使用单独的表空间文件innodb_flush_log_at_trx_commit = 1 # 事务提交时刷新日志innodb_log_file_size = 48M # 日志文件大小f. 字符集和排序规则character-set-server = utf8mb4 # 服务器默认字符集collation-server = utf8mb4_general_ci # 服务器默认排序规则4[mysql] 和 [client] 部分这些部分通常包含客户端程序的配置,如:[mysql]auto-rehashdefault-character-set = utf8mb4[client]port = 3306socket = /tmp/mysql.sock5性能优化相关配置根据服务器硬件和工作负载,可能需要调整以下参数:innodb_buffer_pool_size = 4G # 根据可用内存调整innodb_log_buffer_size = 16Minnodb_read_io_threads = 8innodb_write_io_threads = 8innodb_flush_method = O_DIRECT6注意事项•修改配置文件后需要重启MySQL服务才能生效。
MySQL my.ini 中文详细说明

[mysqld]port = 3306socket = /tmp/mysql.sock# 设置mysql的安装目录basedir=F:\\Hzq Soft\\MySql Server 51GA# 设置mysql数据库的数据的存放目录,必须是data,或者是\\xxx-data datadir=F:\\Hzq Soft\\MySql Server 51GA\\data#innodb_log_arch_dir 默认datadir#innodb_log_group_home_dir 默认datadir# 设置mysql服务器的字符集,默认编码default-character-set=utf8#连接数的操作系统监听队列数量,如果经常出现“拒绝连接”错误可适当增加此值back_log = 50#不使用接听TCP / IP端口方法,mysqld通过命名管道连接#skip-networking# 最大连接数量max_connections = 100#打开表的线程数量限定,最大4096,除非用mysqld_safe打开限制table_open_cache = 2048#MySql 服务接收针对每个进程最大查询包大小max_allowed_packet = 16M#作用于SQL查询单笔处理使用的内存缓存,如果一笔操作的二进制数据超过了限定大小,将会在磁盘上开辟空间处理,一般设为 1-2M即可,默认1Mbinlog_cache_size = 2M#单个内存表的最大值限定max_heap_table_size = 64M#为每个线程分配的排序缓冲大小sort_buffer_size = 8M#join 连表操作的缓冲大小,根据实际业务来设置,默认8Mjoin_buffer_size = 32M#操作多少个离开连接的线程的缓存thread_cache_size = 8#并发线程数量,默认为8,可适当增加到2倍以内。
mysql系统配置表结构设计

MySQL的系统配置通常存储在f或my.ini文件中,这个文件包含了各种配置选项,这些选项可以影响MySQL服务器的运行方式。
不过,从MySQL 5.7开始,MySQL引入了一个新的系统表performance_schema,它用于存储服务器运行时的性能数据。
如果你想设计一个结构来更集中地管理这些配置或性能数据,你可以考虑以下的表结构设计:1. 服务器配置表(server_configurations)id: 主键,自增。
name: 配置项名称,例如"max_connections"。
value: 配置项的值。
description: 对配置项的描述。
2. 性能数据表(performance_data)id: 主键,自增。
event_name: 事件的名称,例如"table_open"。
count: 该事件发生的次数。
start_time: 事件开始的时间戳。
end_time: 事件结束的时间戳。
hostname: 发生该事件的服务器的主机名。
... 其他相关的性能指标字段。
3. 历史性能数据表(performance_history)除了包含performance_data的所有字段外,还可以加入时间戳字段来记录数据的时间。
4. 用户权限表(user_permissions)id: 主键,自增。
username: 用户名。
permission: 权限名称,例如"SELECT"、"INSERT"等。
status: 权限状态,例如"GRANT"、"REVOKE"等。
5. 服务器状态表(server_status)id: 主键,自增。
status_name: 状态名称,例如"ONLINE"、"OFFLINE"。
status_value: 状态的值或描述。
mysql 最大连接数参数

mysql 最大连接数参数
MySQL 的最大连接数参数是 max_connections。
在 MySQL 配置文件 f 或者 my.ini 中,可以通过配置max_connections 参数来设置 MySQL 的最大连接数。
该参数决定了 MySQL 可以同时处理的最大连接数。
默认情况下,max_connections 参数的值为 151。
但是这个值可能会根据服务器的硬件配置和应用程序的需求进行调整。
要修改 max_connections 参数,可以按照以下步骤进行:
1. 打开 f 或者 my.ini 文件。
2. 在 [mysqld] 部分中找到 max_connections 参数。
3. 修改 max_connections 参数的值为所需的最大连接数。
4. 保存并关闭文件。
5. 重新启动 MySQL 服务,使新的参数生效。
需要注意的是,增加 max_connections 参数的值会增加服务器的内存消耗,因此应根据服务器的实际硬件情况和应用程序的需求进行设置,以避免出现内存不足或性能下降等问题。
关于MySQL5.6配置文件my-default.ini不生效问题

关于MySQL5.6配置⽂件my-default.ini不⽣效问题⼀、问题描述 ⾸先,由于⼯作要求,需使⽤MySQL5.6版本(绿⾊版),从解压到修改root密码,⼀切都很顺利,但是在我要修改mysql的最⼤连接数的时候,出现问题了,配置不⽣效。
完蛋。
还好有万能的百度,把my-default.ini改成my.ini,重启服务,nice,⽣效了,还有修改注册表的⽅法,两种⽅法都有效(两种⽅法详细操作在下⾯均有详细说明)。
使⽤msi⽂件安装的MySQL配置⽂件⼀般在C:\ProgramData⽬录下,修改这个⽬录下的my.ini就完事了。
以下是详细说明:注:MySQL是前段时间安装的,并⾮是写博客的时候装好的,但是问题重现是正常的。
⼆、问题截图1、下图是未修改过的m-default.ini⽂件。
2、查看这个时候MySQL最⼤连接数,显⽰为151,下图可以直接使⽤mysql -u -p登录是因为配置过环境变量的原因。
3、开始修改,修改内容:max_connections=200,并重启MySQL服务4、重新登录MySQL,并查看最⼤连接数,如下图所⽰,⽤sql语句查出来的最⼤连接数并没有变成配置⾥⾯的200还是之前的151。
三、解决⽅案1、修改配置⽂件名称1.1、将my-default.ini修改为my.ini1.2、重启服务并重新登录查看配置。
由下图,直接修改⽂件名⽅法可⾏。
2、修改注册表2.1、为了得到较为准确的结果。
⾸先,把my.ini改回my-default.ini,然后查看最⼤连接数是否由200变回151其实修改注册表之后,就是改这个可执⾏⽂件的路径2.2、修改注册表步骤:win + R 输⼊regedit,回车win+R---->regedit---->HKEY_LOCAL_MACHINE---->SYSTEM---->CurrentControlSet---->Services---->MySQL根据路径找到ImagePath,双击,就会弹出这个编辑字符串,把这个修改⼀下,加上下⾯这⾏内容,注意“ -- ”前⾯有空格--defaults-file="C:\Program Files\mysql\mysql-5.6.44\my-default.ini"下⾯是修改后的内容"C:\Program Files\mysql\mysql-5.6.44\bin\mysqld.exe" --defaults-file="C:\Program Files\mysql\mysql-5.6.44\my-default.ini" MySQL2.3、重启MySQL服务然后重新使⽤dos登录MySQL,查看结果修改注册表并重启服务之后,很明显的看到MySQL服务⾥的可执⾏⽂件的路径有变化。
Mysqlmy.ini配置文件详解

Mysqlmy.ini配置⽂件详解Mysql my.ini 配置⽂件详解#BEGIN CONFIG INFO#DESCR: 4GB RAM, 只使⽤InnoDB, ACID, 少量的连接, 队列负载⼤#TYPE: SYSTEM#END CONFIG INFO## 此mysql配置⽂件例⼦针对4G内存# 主要使⽤INNODB#处理复杂队列并且连接数量较少的mysql服务器## 将此⽂件复制到/etc/f 作为全局设置,# mysql-data-dir/f 作为服务器指定设置# (@localstatedir@ for this installation) 或者放⼊# ~/f 作为⽤户设置.## 在此配置⽂件中, 你可以使⽤所有程序⽀持的长选项.# 如果想获悉程序⽀持的所有选项# 请在程序后加上"--help"参数运⾏程序.## 关于独⽴选项更多的细节信息可以在⼿册内找到### 以下选项会被MySQL客户端应⽤读取.# 注意只有MySQL附带的客户端应⽤程序保证可以读取这段内容.# 如果你想你⾃⼰的MySQL应⽤程序获取这些值# 需要在MySQL客户端库初始化的时候指定这些选项#[client]#password = [your_password]port = @MYSQL_TCP_PORT@socket = @MYSQL_UNIX_ADDR@# *** 应⽤定制选项 ***## MySQL 服务端#[mysqld]# ⼀般配置选项port = @MYSQL_TCP_PORT@socket = @MYSQL_UNIX_ADDR@# back_log 是操作系统在监听队列中所能保持的连接数,# 队列保存了在MySQL连接管理器线程处理之前的连接.# 如果你有⾮常⾼的连接率并且出现"connection refused" 报错,# 你就应该增加此处的值.# 检查你的操作系统⽂档来获取这个变量的最⼤值.# 如果将back_log设定到⽐你操作系统限制更⾼的值,将会没有效果back_log = 50# 不在TCP/IP端⼝上进⾏监听.# 如果所有的进程都是在同⼀台服务器连接到本地的mysqld,# 这样设置将是增强安全的⽅法# 所有mysqld的连接都是通过Unix sockets 或者命名管道进⾏的.# 注意在windows下如果没有打开命名管道选项⽽只是⽤此项# (通过 "enable-named-pipe" 选项) 将会导致mysql服务没有任何作⽤!#skip-networking# MySQL 服务所允许的同时会话数的上限# 其中⼀个连接将被SUPER权限保留作为管理员登录.# 即便已经达到了连接数的上限.max_connections = 100# 每个客户端连接最⼤的错误允许数量,如果达到了此限制.# 这个客户端将会被MySQL服务阻⽌直到执⾏了"FLUSH HOSTS" 或者服务重启# ⾮法的密码以及其他在链接时的错误会增加此值.# 查看 "Aborted_connects" 状态来获取全局计数器.max_connect_errors = 10# 所有线程所打开表的数量.# 增加此值就增加了mysqld所需要的⽂件描述符的数量# 这样你需要确认在[mysqld_safe]中 "open-files-limit" 变量设置打开⽂件数量允许⾄少4096table_cache = 2048# 允许外部⽂件级别的锁. 打开⽂件锁会对性能造成负⾯影响# 所以只有在你在同样的⽂件上运⾏多个数据库实例时才使⽤此选项(注意仍会有其他约束!)# 或者你在⽂件层⾯上使⽤了其他⼀些软件依赖来锁定MyISAM表#external-locking# 服务所能处理的请求包的最⼤⼤⼩以及服务所能处理的最⼤的请求⼤⼩(当与⼤的BLOB字段⼀起⼯作时相当必要)# 每个连接独⽴的⼤⼩.⼤⼩动态增加max_allowed_packet = 16M# 在⼀个事务中binlog为了记录SQL状态所持有的cache⼤⼩# 如果你经常使⽤⼤的,多声明的事务,你可以增加此值来获取更⼤的性能.# 所有从事务来的状态都将被缓冲在binlog缓冲中然后在提交后⼀次性写⼊到binlog中# 如果事务⽐此值⼤, 会使⽤磁盘上的临时⽂件来替代.# 此缓冲在每个连接的事务第⼀次更新状态时被创建binlog_cache_size = 1M# 独⽴的内存表所允许的最⼤容量.# 此选项为了防⽌意外创建⼀个超⼤的内存表导致永尽所有的内存资源.max_heap_table_size = 64M# 排序缓冲被⽤来处理类似ORDER BY以及GROUP BY队列所引起的排序# 如果排序后的数据⽆法放⼊排序缓冲,# ⼀个⽤来替代的基于磁盘的合并分类会被使⽤# 查看 "Sort_merge_passes" 状态变量.# 在排序发⽣时由每个线程分配sort_buffer_size = 8M# 此缓冲被使⽤来优化全联合(full JOINs 不带索引的联合).# 类似的联合在极⼤多数情况下有⾮常糟糕的性能表现,# 但是将此值设⼤能够减轻性能影响.# 通过 "Select_full_join" 状态变量查看全联合的数量# 当全联合发⽣时,在每个线程中分配join_buffer_size = 8M# 我们在cache中保留多少线程⽤于重⽤# 当⼀个客户端断开连接后,如果cache中的线程还少于thread_cache_size,# 则客户端线程被放⼊cache中.# 这可以在你需要⼤量新连接的时候极⼤的减少线程创建的开销# (⼀般来说如果你有好的线程模型的话,这不会有明显的性能提升.)thread_cache_size = 8# 此允许应⽤程序给予线程系统⼀个提⽰在同⼀时间给予渴望被运⾏的线程的数量.# 此值只对于⽀持 thread_concurrency() 函数的系统有意义( 例如Sun Solaris).# 你可可以尝试使⽤ [CPU数量]*(2..4) 来作为thread_concurrency的值thread_concurrency = 8# 查询缓冲常被⽤来缓冲 SELECT 的结果并且在下⼀次同样查询的时候不再执⾏直接返回结果.# 打开查询缓冲可以极⼤的提⾼服务器速度, 如果你有⼤量的相同的查询并且很少修改表.# 查看 "Qcache_lowmem_prunes" 状态变量来检查是否当前值对于你的负载来说是否⾜够⾼.# 注意: 在你表经常变化的情况下或者如果你的查询原⽂每次都不同,# 查询缓冲也许引起性能下降⽽不是性能提升.query_cache_size = 64M# 只有⼩于此设定值的结果才会被缓冲# 此设置⽤来保护查询缓冲,防⽌⼀个极⼤的结果集将其他所有的查询结果都覆盖.query_cache_limit = 2M# 被全⽂检索索引的最⼩的字长.# 你也许希望减少它,如果你需要搜索更短字的时候.# 注意在你修改此值之后,# 你需要重建你的 FULLTEXT 索引ft_min_word_len = 4# 如果你的系统⽀持 memlock() 函数,你也许希望打开此选项⽤以让运⾏中的mysql在在内存⾼度紧张的时候,数据在内存中保持锁定并且防⽌可能被swapping out# 此选项对于性能有益#memlock# 当创建新表时作为默认使⽤的表类型,# 如果在创建表⽰没有特别执⾏表类型,将会使⽤此值default_table_type = MYISAM# 线程使⽤的堆⼤⼩. 此容量的内存在每次连接时被预留.# MySQL 本⾝常不会需要超过64K的内存# 如果你使⽤你⾃⼰的需要⼤量堆的UDF函数# 或者你的操作系统对于某些操作需要更多的堆,# 你也许需要将其设置的更⾼⼀点.thread_stack = 192K# 设定默认的事务隔离级别.可⽤的级别如下:# READ-UNCOMMITTED, READ-COMMITTED, REPEATABLE-READ, SERIALIZABLEtransaction_isolation = REPEATABLE-READ# 内部(内存中)临时表的最⼤⼤⼩# 如果⼀个表增长到⽐此值更⼤,将会⾃动转换为基于磁盘的表.# 此限制是针对单个表的,⽽不是总和.tmp_table_size = 64M# 打开⼆进制⽇志功能.# 在复制(replication)配置中,作为MASTER主服务器必须打开此项# 如果你需要从你最后的备份中做基于时间点的恢复,你也同样需要⼆进制⽇志.log-bin=mysql-bin# 如果你在使⽤链式从服务器结构的复制模式 (A->B->C),# 你需要在服务器B上打开此项.# 此选项打开在从线程上重做过的更新的⽇志,# 并将其写⼊从服务器的⼆进制⽇志.#log_slave_updates# 打开全查询⽇志. 所有的由服务器接收到的查询 (甚⾄对于⼀个错误语法的查询)# 都会被记录下来. 这对于调试⾮常有⽤, 在⽣产环境中常常关闭此项.#log# 将警告打印输出到错误log⽂件. 如果你对于MySQL有任何问题# 你应该打开警告log并且仔细审查错误⽇志,查出可能的原因.#log_warnings# 记录慢速查询. 慢速查询是指消耗了⽐ "long_query_time" 定义的更多时间的查询.# 如果 log_long_format 被打开,那些没有使⽤索引的查询也会被记录.# 如果你经常增加新查询到已有的系统内的话. ⼀般来说这是⼀个好主意,log_slow_queries# 所有的使⽤了⽐这个时间(以秒为单位)更多的查询会被认为是慢速查询.# 不要在这⾥使⽤"1", 否则会导致所有的查询,甚⾄⾮常快的查询页被记录下来(由于MySQL ⽬前时间的精确度只能达到秒的级别).long_query_time = 2# 在慢速⽇志中记录更多的信息.# ⼀般此项最好打开.# 打开此项会记录使得那些没有使⽤索引的查询也被作为到慢速查询附加到慢速⽇志⾥log_long_format# 此⽬录被MySQL⽤来保存临时⽂件.例如,# 它被⽤来处理基于磁盘的⼤型排序,和内部排序⼀样.# 以及简单的临时表.# 如果你不创建⾮常⼤的临时⽂件,将其放置到 swapfs/tmpfs ⽂件系统上也许⽐较好# 另⼀种选择是你也可以将其放置在独⽴的磁盘上.# 你可以使⽤";"来放置多个路径# 他们会按照roud-robin⽅法被轮询使⽤.#tmpdir = /tmp# *** 复制有关的设置# 唯⼀的服务辨识号,数值位于 1 到 2^32-1之间.# 此值在master和slave上都需要设置.# 如果 "master-host" 没有被设置,则默认为1, 但是如果忽略此选项,MySQL不会作为master⽣效.server-id = 1# 复制的Slave (去掉master段的注释来使其⽣效)## 为了配置此主机作为复制的slave服务器,你可以选择两种⽅法:## 1) 使⽤ CHANGE MASTER TO 命令 (在我们的⼿册中有完整描述) -# 语法如下:## CHANGE MASTER TO MASTER_HOST=<host>, MASTER_PORT=<port>,# MASTER_USER=<user>, MASTER_PASSWORD=<password> ;## 你需要替换掉 <host>, <user>, <password> 等被尖括号包围的字段以及使⽤master的端⼝号替换<port> (默认3306). ## 例⼦:## CHANGE MASTER TO MASTER_HOST='125.564.12.1', MASTER_PORT=3306,# MASTER_USER='joe', MASTER_PASSWORD='secret';## 或者## 2) 设置以下的变量. 不论如何, 在你选择这种⽅法的情况下, 然后第⼀次启动复制(甚⾄不成功的情况下,# 例如如果你输⼊错密码在master-password字段并且slave⽆法连接),# slave会创建⼀个 ⽂件,并且之后任何对于包含在此⽂件内的参数的变化都会被忽略# 并且由 ⽂件内的内容覆盖, 除⾮你关闭slave服务, 删除 并且重启slave 服务.# 由于这个原因,你也许不想碰⼀下的配置(注释掉的) 并且使⽤ CHANGE MASTER TO (查看上⾯) 来代替## 所需要的唯⼀id号位于 2 和 2^32 - 1之间# (并且和master不同)# 如果master-host被设置了.则默认值是2# 但是如果省略,则不会⽣效#server-id = 2## 复制结构中的master - 必须#master-host = <hostname>## 当连接到master上时slave所⽤来认证的⽤户名 - 必须#master-user = <username>## 当连接到master上时slave所⽤来认证的密码 - 必须#master-password = <password>## master监听的端⼝.# 可选 - 默认是3306#master-port = <port># 使得slave只读.只有⽤户拥有SUPER权限和在上⾯的slave线程能够修改数据.# 你可以使⽤此项去保证没有应⽤程序会意外的修改slave⽽不是master上的数据#read_only#*** MyISAM 相关选项# 关键词缓冲的⼤⼩, ⼀般⽤来缓冲MyISAM表的索引块.# 不要将其设置⼤于你可⽤内存的30%,# 因为⼀部分内存同样被OS⽤来缓冲⾏数据# 甚⾄在你并不使⽤MyISAM 表的情况下, 你也需要仍旧设置起 8-64M 内存由于它同样会被内部临时磁盘表使⽤. key_buffer_size = 32M# ⽤来做MyISAM表全表扫描的缓冲⼤⼩.# 当全表扫描需要时,在对应线程中分配.read_buffer_size = 2M# 当在排序之后,从⼀个已经排序好的序列中读取⾏时,⾏数据将从这个缓冲中读取来防⽌磁盘寻道.# 如果你增⾼此值,可以提⾼很多ORDER BY的性能.# 当需要时由每个线程分配read_rnd_buffer_size = 16M# MyISAM 使⽤特殊的类似树的cache来使得突发插⼊# (这些插⼊是,INSERT ... SELECT, INSERT ... VALUES (...), (...), ..., 以及 LOAD DATA# INFILE) 更快. 此变量限制每个进程中缓冲树的字节数.# 设置为 0 会关闭此优化.# 为了最优化不要将此值设置⼤于 "key_buffer_size".# 当突发插⼊被检测到时此缓冲将被分配.bulk_insert_buffer_size = 64M# 此缓冲当MySQL需要在 REPAIR, OPTIMIZE, ALTER 以及 LOAD DATA INFILE 到⼀个空表中引起重建索引时被分配. # 这在每个线程中被分配.所以在设置⼤值时需要⼩⼼.myisam_sort_buffer_size = 128M# MySQL重建索引时所允许的最⼤临时⽂件的⼤⼩ (当 REPAIR, ALTER TABLE 或者 LOAD DATA INFILE).# 如果⽂件⼤⼩⽐此值更⼤,索引会通过键值缓冲创建(更慢)myisam_max_sort_file_size = 10G# 如果被⽤来更快的索引创建索引所使⽤临时⽂件⼤于制定的值,那就使⽤键值缓冲⽅法.# 这主要⽤来强制在⼤表中长字串键去使⽤慢速的键值缓冲⽅法来创建索引.myisam_max_extra_sort_file_size = 10G# 如果⼀个表拥有超过⼀个索引, MyISAM 可以通过并⾏排序使⽤超过⼀个线程去修复他们.# 这对于拥有多个CPU以及⼤量内存情况的⽤户,是⼀个很好的选择.myisam_repair_threads = 1# ⾃动检查和修复没有适当关闭的 MyISAM 表.myisam_recover# 默认关闭 Federatedskip-federated# *** BDB 相关选项 ***# 如果你运⾏的MySQL服务有BDB⽀持但是你不准备使⽤的时候使⽤此选项. 这会节省内存并且可能加速⼀些事.skip-bdb# *** INNODB 相关选项 ***# 如果你的MySQL服务包含InnoDB⽀持但是并不打算使⽤的话,# 使⽤此选项会节省内存以及磁盘空间,并且加速某些部分#skip-innodb# 附加的内存池被InnoDB⽤来保存 metadata 信息# 如果InnoDB为此⽬的需要更多的内存,它会开始从OS这⾥申请内存.# 由于这个操作在⼤多数现代操作系统上已经⾜够快, 你⼀般不需要修改此值.# SHOW INNODB STATUS 命令会显⽰当先使⽤的数量.innodb_additional_mem_pool_size = 16M# InnoDB使⽤⼀个缓冲池来保存索引和原始数据, 不像 MyISAM.# 这⾥你设置越⼤,你在存取表⾥⾯数据时所需要的磁盘I/O越少.# 在⼀个独⽴使⽤的数据库服务器上,你可以设置这个变量到服务器物理内存⼤⼩的80%# 不要设置过⼤,否则,由于物理内存的竞争可能导致操作系统的换页颠簸.# 注意在32位系统上你每个进程可能被限制在 2-3.5G ⽤户层⾯内存限制,# 所以不要设置的太⾼.innodb_buffer_pool_size = 2G# InnoDB 将数据保存在⼀个或者多个数据⽂件中成为表空间.# 如果你只有单个逻辑驱动保存你的数据,⼀个单个的⾃增⽂件就⾜够好了.# 其他情况下.每个设备⼀个⽂件⼀般都是个好的选择.# 你也可以配置InnoDB来使⽤裸盘分区 - 请参考⼿册来获取更多相关内容innodb_data_file_path = ibdata1:10M:autoextend# 设置此选项如果你希望InnoDB表空间⽂件被保存在其他分区.# 默认保存在MySQL的datadir中.#innodb_data_home_dir = <directory># ⽤来同步IO操作的IO线程的数量. This value is# 此值在Unix下被硬编码为4,但是在Windows磁盘I/O可能在⼀个⼤数值下表现的更好.innodb_file_io_threads = 4# 如果你发现InnoDB表空间损坏, 设置此值为⼀个⾮零值可能帮助你导出你的表.# 从1开始并且增加此值知道你能够成功的导出表.#innodb_force_recovery=1# 在InnoDb核⼼内的允许线程数量.# 最优值依赖于应⽤程序,硬件以及操作系统的调度⽅式.# 过⾼的值可能导致线程的互斥颠簸.innodb_thread_concurrency = 16# 如果设置为1 ,InnoDB会在每次提交后刷新(fsync)事务⽇志到磁盘上,# 这提供了完整的ACID⾏为.# 如果你愿意对事务安全折衷, 并且你正在运⾏⼀个⼩的⾷物, 你可以设置此值到0或者2来减少由事务⽇志引起的磁盘I/O # 0代表⽇志只⼤约每秒写⼊⽇志⽂件并且⽇志⽂件刷新到磁盘.# 2代表⽇志写⼊⽇志⽂件在每次提交后,但是⽇志⽂件只有⼤约每秒才会刷新到磁盘上.innodb_flush_log_at_trx_commit = 1# 加速InnoDB的关闭. 这会阻⽌InnoDB在关闭时做全清除以及插⼊缓冲合并.# 这可能极⼤增加关机时间, 但是取⽽代之的是InnoDB可能在下次启动时做这些操作.#innodb_fast_shutdown# ⽤来缓冲⽇志数据的缓冲区的⼤⼩.# 当此值快满时, InnoDB将必须刷新数据到磁盘上.# 由于基本上每秒都会刷新⼀次,所以没有必要将此值设置的太⼤(甚⾄对于长事务⽽⾔)innodb_log_buffer_size = 8M# 在⽇志组中每个⽇志⽂件的⼤⼩.# 你应该设置⽇志⽂件总合⼤⼩到你缓冲池⼤⼩的25%~100%# 来避免在⽇志⽂件覆写上不必要的缓冲池刷新⾏为.# 不论如何, 请注意⼀个⼤的⽇志⽂件⼤⼩会增加恢复进程所需要的时间.innodb_log_file_size = 256M# 在⽇志组中的⽂件总数.# 通常来说2~3是⽐较好的.innodb_log_files_in_group = 3# InnoDB的⽇志⽂件所在位置. 默认是MySQL的datadir.# 你可以将其指定到⼀个独⽴的硬盘上或者⼀个RAID1卷上来提⾼其性能#innodb_log_group_home_dir# 在InnoDB缓冲池中最⼤允许的脏页⾯的⽐例.# 如果达到限额, InnoDB会开始刷新他们防⽌他们妨碍到⼲净数据页⾯.# 这是⼀个软限制,不被保证绝对执⾏.innodb_max_dirty_pages_pct = 90# InnoDB⽤来刷新⽇志的⽅法.# 表空间总是使⽤双重写⼊刷新⽅法# 默认值是 "fdatasync", 另⼀个是 "O_DSYNC".#innodb_flush_method=O_DSYNC# 在被回滚前,⼀个InnoDB的事务应该等待⼀个锁被批准多久.# InnoDB在其拥有的锁表中⾃动检测事务死锁并且回滚事务.# 如果你使⽤ LOCK TABLES 指令, 或者在同样事务中使⽤除了InnoDB以外的其他事务安全的存储引擎# 那么⼀个死锁可能发⽣⽽InnoDB⽆法注意到.# 这种情况下这个timeout值对于解决这种问题就⾮常有帮助.innodb_lock_wait_timeout = 120[mysqldump]# 不要在将内存中的整个结果写⼊磁盘之前缓存. 在导出⾮常巨⼤的表时需要此项quickmax_allowed_packet = 16M[mysql]no-auto-rehash# 仅仅允许使⽤键值的 UPDATEs 和 DELETEs .#safe-updates[isamchk]key_buffer = 512Msort_buffer_size = 512Mread_buffer = 8Mwrite_buffer = 8M[myisamchk]key_buffer = 512Msort_buffer_size = 512Mread_buffer = 8Mwrite_buffer = 8M[mysqlhotcopy]interactive-timeout[mysqld_safe]# 增加每个进程的可打开⽂件数量.# 警告: 确认你已经将全系统限制设定的⾜够⾼!# 打开⼤量表需要将此值设⾼open-files-limit = 8192。
Mysql5.7在windows7下my.ini文件加载路径及数据位置修改方法

Mysql5.7在windows7下my.ini⽂件加载路径及数据位置修改⽅法因为要将公司线上数据库传输到本地做测试,捣⿎了半天本地mysql的data位置修改,⽹上资料也有很多介绍,重复的不赘述,写⾃⼰遇到的问题供⼤家参考。
mysql版本:5.7os:windows7(不同的mysql版本在安装路径 data路径和my.ini的启动配置⽂件路径上可能有差异,不做研究)更改mysql的数据位置,除了⽹络上资料讲的:(1)关闭mysql服务;(2)修改my.ini的datadir(路径"\"还是"/",整个路径名是不是要双引号包括⼤家⾃⼰尝试吧,怎么⾛得通怎么来,我是不⽤双引号正反斜杠都可以);(3)然后迁移整个data⽂件夹(这个data⽂件夹根据版本和系统可能在不同⽂件夹下,⽐如可能在c:\Program Files\MySQL 或者c:\ProgramData\MySQL下,推荐⽤everything这个软件⾃⼰找找)到修改后的⽬录下;(4)最后重启。
这4个基本步骤之外,还要注意MySQL使⽤的启动⽂件my.ini是哪个。
这个要以mysql在windows注册表⾥的信息为准,具体操作:开始-运⾏-regedit-回车,进⼊windows注册表,然后找到[HKEY_LOCAL_MACHINE\SYSTEM\CurrentControlSet\Services\MySql](注意这是在win7和mysql5.7下的注册路径,其他版本可能不⼀样),修改其中“ImagePath”⾥⾯“--defaults-file=”后⾯的路径⽂件就好,这个⽂件才是mysql启动时读取的配置⽂件,并不⼀定放在mysql安装⽬录下或者是data⽬录下的就⼀定是使⽤的配置⽂件。
总结以上所述是⼩编给⼤家介绍的Mysql5.7在windows7下my.ini⽂件加载路径及数据位置修改,希望对⼤家有所帮助,如果⼤家有任何疑问请给我留⾔,⼩编会及时回复⼤家的。
MySQL配置文件详解

MySQL配置⽂件详解# 客户端设置,即客户端默认的连接参数[client]# 默认连接端⼝port = 3306# ⽤于本地连接的socket套接字socket = /usr/local/mysql/data/mysql.sock# 字符集编码default-character-set = utf8mb4# 服务端基本设置[mysqld]# MySQL监听端⼝port = 3306# 为MySQL客户端程序和服务器之间的本地通讯指定⼀个套接字⽂件socket = /usr/local/mysql/data/mysql.sock# pid⽂件所在⽬录pid-file = /usr/local/mysql/data/mysql.pid# 使⽤该⽬录作为根⽬录(安装⽬录)basedir = /usr/local/mysql# 数据⽂件存放的⽬录datadir = /usr/local/mysql/database# MySQL存放临时⽂件的⽬录tmpdir = /usr/local/mysql/data/tmp# 服务端默认编码(数据库级别)character_set_server = utf8mb4# 服务端默认的⽐对规则,排序规则collation_server = utf8mb4_bin# MySQL启动⽤户。
如果是root⽤户就配置root,mysql⽤户就配置mysqluser = root# 错误⽇志配置⽂件(configure file)log-error=/usr/local/mysql/data/error.logsecure-file-priv = null# 开启了binlog后,必须设置这个值为1.主要是考虑binlog安全# 此变量适⽤于启⽤⼆进制⽇志记录的情况。
它控制是否可以信任存储函数创建者,⽽不是创建将导致# 要写⼊⼆进制⽇志的不安全事件。
如果设置为0(默认值),则不允许⽤户创建或更改存储函数,除⾮⽤户具有# 除创建例程或更改例程特权之外的特权log_bin_trust_function_creators = 1# 性能优化的引擎,默认关闭performance_schema = 0# 开启全⽂索引# ft_min_word_len = 1# ⾃动修复MySQL的myisam引擎类型的表#myisam_recover# 明确时间戳默认null⽅式explicit_defaults_for_timestamp# 计划任务(事件调度器)event_scheduler# 跳过外部锁定;External-locking⽤于多进程条件下为MyISAM数据表进⾏锁定skip-external-locking# 跳过客户端域名解析;当新的客户连接mysqld时,mysqld创建⼀个新的线程来处理请求。
my.ini 规则

my.ini 规则`my.ini`是 MySQL 数据库的配置文件,用于存储 MySQL 服务器的配置信息。
下面是一些常见的`my.ini`规则:1. [client]- 设置客户端的配置选项。
- `port`:指定 MySQL 客户端连接服务器时使用的端口号。
- `socket`:指定 MySQL 客户端连接服务器时使用的套接字文件路径。
- `default-character-set`:指定客户端默认使用的字符集。
2. [mysqld]- 设置 MySQL 服务器的配置选项。
- `port`:指定 MySQL 服务器监听的端口号。
- `socket`:指定 MySQL 服务器使用的套接字文件路径。
- `basedir`:指定 MySQL 服务器的安装目录。
- `datadir`:指定 MySQL 服务器的数据目录。
- `character-set-server`:指定服务器默认使用的字符集。
- `collation-server`:指定服务器默认使用的排序规则。
3. [mysql]- 设置 MySQL 客户端程序的行为。
- `no-auto-rehash`:禁用自动重新哈希功能。
- `default-character-set`:指定 MySQL 客户端默认使用的字符集。
4. [safe]- 配置 MySQL 的安全相关选项。
- `socket`:指定安全套接字文件的路径。
这只是`my.ini`文件中的一些常见规则,实际上,它可能包含更多的配置选项和规则,具体取决于你的需求和使用情况。
在修改`my.ini`文件时,请务必小心,并根据你的实际情况进行配置。
如果你需要更详细的信息或特定的规则,请提供更多上下文,我将尽力帮助你。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
# 另一种选择是你也可以将其放置在独立的磁盘上. # 你可以使用";"来放置多个路径 # 他们会按照 roud-robin 方法被轮询使用. #tmpdir = /tmp
# *** 复制有关的设置
# 唯一的服务辨识号,数值位于 1 到 2^32-1 之间. # 此值在 master 和 slave 上都需要设置. # 如果 "master-host" 没有被设置,则默认为 1, 但是如果忽略此选项,MySQL 不会作为 master 生效. server-id = 1 # 复制的 Slave (去掉 master 段的注释来使其生效) # # 为了配置此主机作为复制的 slave 服务器,你可以选择两种方法: # # 1) 使用 CHANGE MASTER TO 命令 (在我们的手册中有完整描述) # 语法如下: # # CHANGE MASTER TO MASTER_HOST=<host>, MASTER_PORT=<port>, # MASTER_USER=<user>, MASTER_PASSWORD=<password> ; # # 你需要替换掉 <host>, <user>, <password> 等被尖括号包围的字段以及使用 master 的端口 号替换<port> (默认 3306). # # 例子: # # CHANGE MASTER TO MASTER_HOST='125.564.12.1', MASTER_PORT=3306, # MASTER_USER='joe', MASTER_PASSWORD='secret'; # # 或者 # # 2) 设置以下的变量. 不论如何, 在你选择这种方法的情况下, 然后第一次启动复制(甚至 不成功的情况下, # 例如如果你输入错密码在 master-password 字段并且 slave 无法连接), # slave 会创建一个 文件,并且之后任何对于包含在此文件内的参数的变化都会 被忽略 # 并且由 文件内的内容覆盖, 除非你关闭 slave 服务, 删除 并且重 启 slave 服务. # 由于这个原因,你也许不想碰一下的配置(注释掉的) 并且使用 CHANGE MASTER TO (查看 上面) 来代替 # # 所需要的唯一 id 号位于 2 和 2^32 - 1 之间 # (并且和 master 不同)
# 如果排序后的数据无法放入排序缓冲, # 一个用来替代的基于磁盘的合并分类会被使用 # 查看 "Sort_merge_passes" 状态变量. # 在排序发生时由每个线程分配 sort_buffer_size = 8M # 此缓冲被使用来优化全联合(full JOINs 不带索引的联合). # 类似的联合在极大多数情况下有非常糟糕的性能表现, # 但是将此值设大能够减轻性能影响. # 通过 "Select_full_join" 状态变量查看全联合的数量 # 当全联合发生时,在每个线程中分配 join_buffer_size = 8M # 我们在 cache 中保留多少线程用于重用 # 当一个客户端断开连接后,如果 cache 中的线程还少于 thread_cache_size, # 则客户端线程被放入 cache 中. # 这可以在你需要大量新连接的时候极大的减少线程创建的开销 # (一般来说如果你有好的线程模型的话,这不会有明显的性能提升.) thread_cache_size = 8 # 此允许应用程序给予线程系统一个提示在同一时间给予渴望被运行的线程的数量. # 此值只对于支持 thread_concurrency() 函数的系统有意义( 例如 Sun Solaris). # 你可可以尝试使用 [CPU 数量]*(2..4) 来作为 thread_concurrency 的值 thread_concurrency = 8 # 查询缓冲常被用来缓冲 SELECT 的结果并且在下一次同样查询的时候不再执行直接返回 结果. # 打开查询缓冲可以极大的提高服务器速度, 如果你有大量的相同的查询并且很少修改表. # 查看 "Qcache_lowmem_prunes" 状态变量来检查是否当前值对于你的负载来说是否足够 高. # 注意: 在你表经常变化的情况下或者如果你的查询原文每次都不同, # 查询缓冲也许引起性能下降而不是性能提升. query_cache_size = 64M # 只有小于此设定值的结果才会被缓冲 # 此设置用来保护查询缓冲,防止一个极大的结果集将其他所有的查询结果都覆盖. query_cache_limit = 2M # 被全文检索索引的最小的字长. # 你也许希望减少它,如果你需要搜索更短字的时候. # 注意在你修改此值之后, # 你需要重建你的 FULLTEXT 索引 ft_min_word_len = 4 # 如果你的系统支持 memlock() 函数,你也许希望打开此选项用以让运行中的 mysql 在在内 存高度紧张的时候,数据在内存中保持锁定并且防止可能被 swapping out # 此选项对于性能有益 #memlock # 当创建新表时作为默认使用的表类型, # 如果在创建表示没有特别执行表类型,将会使用此值 default_table_type = MYISAM
Mysql myBiblioteka ini 配置文件详解#BEGIN CONFIG INFO #DESCR: 4GB RAM, 只使用 InnoDB, ACID, 少量的连接, 队列负载大 #TYPE: SYSTEM #END CONFIG INFO # # 此 mysql 配置文件例子针对 4G 内存 # 主要使用 INNODB #处理复杂队列并且连接数量较少的 mysql 服务器 # # 将此文件复制到/etc/f 作为全局设置, # mysql-data-dir/f 作为服务器指定设置 # (@localstatedir@ for this installation) 或者放入 # ~/f 作为用户设置. # # 在此配置文件中, 你可以使用所有程序支持的长选项. # 如果想获悉程序支持的所有选项 # 请在程序后加上"--help"参数运行程序. # # 关于独立选项更多的细节信息可以在手册内找到 # # # 以下选项会被 MySQL 客户端应用读取. # 注意只有 MySQL 附带的客户端应用程序保证可以读取这段内容. # 如果你想你自己的 MySQL 应用程序获取这些值 # 需要在 MySQL 客户端库初始化的时候指定这些选项 # [client] #password = [your_password] port = @MYSQL_TCP_PORT@ socket = @MYSQL_UNIX_ADDR@ # *** 应用定制选项 *** # # MySQL 服务端 # [mysqld] # 一般配置选项 port = @MYSQL_TCP_PORT@ socket = @MYSQL_UNIX_ADDR@ # back_log 是操作系统在监听队列中所能保持的连接数, # 队列保存了在 MySQL 连接管理器线程处理之前的连接. # 如果你有非常高的连接率并且出现"connection refused" 报错,
# 你就应该增加此处的值. # 检查你的操作系统文档来获取这个变量的最大值. # 如果将 back_log 设定到比你操作系统限制更高的值,将会没有效果 back_log = 50 # 不在 TCP/IP 端口上进行监听. # 如果所有的进程都是在同一台服务器连接到本地的 mysqld, # 这样设置将是增强安全的方法 # 所有 mysqld 的连接都是通过 Unix sockets 或者命名管道进行的. # 注意在 windows 下如果没有打开命名管道选项而只是用此项 # (通过 "enable-named-pipe" 选项) 将会导致 mysql 服务没有任何作用! #skip-networking # MySQL 服务所允许的同时会话数的上限 # 其中一个连接将被 SUPER 权限保留作为管理员登录. # 即便已经达到了连接数的上限. max_connections = 100 # 每个客户端连接最大的错误允许数量,如果达到了此限制. # 这个客户端将会被 MySQL 服务阻止直到执行了"FLUSH HOSTS" 或者服务重启 # 非法的密码以及其他在链接时的错误会增加此值. # 查看 "Aborted_connects" 状态来获取全局计数器. max_connect_errors = 10 # 所有线程所打开表的数量. # 增加此值就增加了 mysqld 所需要的文件描述符的数量 # 这样你需要确认在[mysqld_safe]中 "open-files-limit" 变量设置打开文件数量允许至少 4096 table_cache = 2048 # 允许外部文件级别的锁. 打开文件锁会对性能造成负面影响 # 所以只有在你在同样的文件上运行多个数据库实例时才使用此选项(注意仍会有其他约 束!) # 或者你在文件层面上使用了其他一些软件依赖来锁定 MyISAM 表 #external-locking # 服务所能处理的请求包的最大大小以及服务所能处理的最大的请求大小(当与大的 BLOB 字段一起工作时相当必要) # 每个连接独立的大小.大小动态增加 max_allowed_packet = 16M # 在一个事务中 binlog 为了记录 SQL 状态所持有的 cache 大小 # 如果你经常使用大的,多声明的事务,你可以增加此值来获取更大的性能. # 所有从事务来的状态都将被缓冲在 binlog 缓冲中然后在提交后一次性写入到 binlog 中 # 如果事务比此值大, 会使用磁盘上的临时文件来替代. # 此缓冲在每个连接的事务第一次更新状态时被创建 binlog_cache_size = 1M # 独立的内存表所允许的最大容量. # 此选项为了防止意外创建一个超大的内存表导致永尽所有的内存资源. max_heap_table_size = 64M # 排序缓冲被用来处理类似 ORDER BY 以及 GROUP BY 队列所引起的排序