ZKNET数据库配置方法
数据库连接池的使用与配置方法

数据库连接池的使用与配置方法引言数据库是现代软件系统的重要组成部分,它负责存储和管理大量的数据。
在软件开发过程中,经常需要与数据库进行交互,而数据库连接则是实现这一过程的关键。
然而,大量的数据库连接请求可能会导致性能问题和资源浪费。
为了解决这个问题,数据库连接池应运而生。
本文将介绍数据库连接池的使用与配置方法,以提高数据库连接的效率和性能。
一、什么是数据库连接池数据库连接池是一种数据库连接管理机制,它维护一组数据库连接,以供应用程序复用。
连接池通过预先创建一定数量的数据库连接,并将其保存在池中;当应用程序需要连接数据库时,从池中取出一个连接并将其分配给应用程序使用。
在应用程序不再需要连接时,将释放连接并放回连接池,以供其他应用程序使用。
通过连接的复用和池的管理,数据库连接池可以有效地减少数据库连接的创建和销毁开销,提高应用程序的响应速度和资源利用率。
二、数据库连接池的优势1. 提高系统响应速度:通过复用连接,避免了频繁创建和销毁连接的开销,减少了与数据库建立连接的时间,从而提高了系统的响应速度。
2. 提高资源利用率:连接池提供了对连接的管理和复用,可以根据应用程序的需求动态调整连接数,有效地利用系统资源。
同时,连接池还可以对连接进行预处理和监控,进一步提高资源的利用效率。
3. 减轻数据库负载:连接池通过限制同时存在的连接数,可以有效地控制连接的并发数,从而减轻了数据库的负载,提高了数据库的吞吐量。
三、数据库连接池的配置1. 连接池参数设置:连接池的配置主要包括最大连接数、最小连接数、初始连接数、最大空闲连接数等参数。
最大连接数决定了连接池可以同时提供的最大连接数;最小连接数和初始连接数用于指定连接池的初始大小;最大空闲连接数用于控制连接池中保持空闲的最大连接数。
通过灵活配置这些参数,可以根据应用程序的需求进行调整,以达到最佳的性能和资源利用效果。
2. 连接超时设置:连接超时是指连接等待数据库响应的最大时间。
Weblogic 10 数据源配置操作手册范文

Weblogic 10 数据源配置操作手册第一步:登录Weblogic Service 控制登录台打开浏览器访问Weblogic Service 控制台
第二步:以weblogic用户登录
第三步:配置数据源
点击“锁定并编辑”(如下图所示)
出现下图
点击“服务”->“数据源”,出现下图
点击“新建”(如下图所示)
选择一般数据源,出现下图。
ds_rsmis为例(如下图所示)。
点击“下一步”,出现下图,可选择数据库驱动程序
点击“下一步”,出现下图
点击“下一步”,出现下图
填写数据库名称,主机名,端口,数据库用户名,口令,确认口令。
(如下图所示)
点击“下一步”,出现下图
查看无误后,点击“测试配置”,出现下图
点击“完成”,出现下图
完成数据源创建
二.修改数据源
双击数据源名称(如下图所示)
进入下图界面,可进行数据源多项的修改(如下图所示)
修改后,单击“保存”,即可完成修改。
三.删除数据源
选择数据源名称(如下图所示)
点击“删除”,出现下图
点击“是”,出现下图
完成数据源的删除。
ZKT系统使用手册系统帮助使用说明.

ZKT系统使用手册系统帮助使用说明左侧菜单操作:•⊕点击左侧一级菜单,即可展开/收起二级菜单;•⊕点击二级菜单,即可在右侧展示详细帮助页面。
快捷按钮操作:•⊕点击界面右下方的Top/Close快捷按钮即可回到页面顶部或者关闭页面。
•⊕如果您觉得快捷按钮影响了您的阅读,可点击快捷按钮上方的“∨”收起该快捷按钮。
此时上方变为“∧”,点击即可展开快捷按钮。
名词解释超级用户:即拥有系统全部操作权限的用户,可以在系统中分配新用户(如公司管理人员、登记员、门禁管理员等)并配置相应用户的角色。
角色:在日常使用过程中,超级用户需要分配一些具有不同权限级别的新用户,为避免对每个用户单独设置,可以在角色管理中设置一类具有特定权限的角色,在新增用户时直接将合适的角色分配给新用户即可。
门禁时间段:时间段用于门的时间设置,可以指定读头仅在指定门的有效时间段可用,其他时间段不可用,也可以用于设置门的常开时间段;时间段可以用于设置门禁权限,指定用户只能在指定时间段访问指定门(含门禁权限组和首卡常开设置)。
门磁延时:门被打开后延迟检查门磁的时间。
开门之后过一段时间才开始检测门磁,门在非“常开”时段,如果状态是打开的,开始计时,过了门磁延时时间则开始报警,门关闭时报警取消。
门磁延时须大于锁驱动时长。
闭门回锁:设置闭门之后是否锁门。
锁驱动时长:用来控制刷卡后开锁的延时时间。
首卡常开:在指定时间段内,当有首卡常开权限的人员第一次验证通过后,门将常开,有效时间段结束后门将自动恢复关闭。
多卡开门:某些特定门禁场合需要启用多卡开门功能:要求同一个开门组合中指定人数同时到场,依次验证通过后才能通过,在没通过验证前,不能插入其他人员(即便是该门其他组合的有效人员),否则要等待10秒后重新验证。
某个人单独到场验证不会开门。
互锁:可设置一个控制器上的两个(多个)门之间的互锁管制,当其中一个门开启时,其他对应的门都关闭,当要开启一个门时,其他对应的门必须都是关闭的,否则无法开门。
MycatZK配置文件详解

MycatZK配置⽂件详解1.1修订版。
ZK-Server记录了集群的信息,Mycat-eye、Mycat-Server等从ZK读取配置并协同⼯作。
Mycat安装包中提供⼀个zk-config.bat/sh⼯具,该⼯具从conf/zk-default.txt中加载zk路径到ZK-Server中去,完成ZK-Server数据的初始化过程。
然后Mycat-eye与LB可以⽤ZK来管理集群。
下图是Mycat 1.5 的多中⼼集群⽅案,分布于不同地域(Zone)内的⼀些Mycat Cluster 组成双中⼼多3中⼼⽅案,前提是这些不通中⼼中的Mycat Cluster可以以某种⽅式完成数据库端的数据同步机制。
每个中⼼都有⼀组Mycat负载均衡器LB,这些LB 与同⼀中⼼内的Cluster组成⼀对多关系,即⼀个LB可以服务⼀个中⼼内的所有Cluster的负载均衡请求,也可以是多个LB,每个负担不同的Cluster的流量。
此外建议是每⼀个LB都有⼀个Backup,平时并不连接Cluster,但监测到Master下线以后,就⽴即开始连接Cluster并开始⼯作。
下图是⼀个Mycat Cluster的组成部分,它是位于某个特定中⼼(Zone)的⼀个处理单元,包括,⼀个Mycatcluster包括如下信息:所属的中⼼(Zone),固定不可变的标⽰具有地理位置标⽰,⽐如北京联通机房11个或多个采⽤相同配置(引⽤同⼀个MyCat Schema配置)的Mycat ServerMySQL数据库服务器,是属于⼀个Zone内部的共享资源,不属于Cluster级别的,主要拥有以下关键信息:IP地址、端⼝和名称所在主机Host,为了区分数据迁移⽯时候是否需要复制⽂件MySQL群组,定义⼀组具备主从关系的MySQL服务器之间的关系管理员权限的⽤户名密码等,⽤于⾃动运维操作此外,配置管理部分,我们需要记录集群中所⽤的的主机的信息,包括账号密码等,hostId不可变化,可以理解为内部分配的⼀个编号(不同于主机名),在所有的Zone中保持唯⼀。
zk 查询命令用法

zk 查询命令用法ZooKeeper是一个分布式协调服务,用于管理分布式系统中的配置信息、同步服务和应用程序状态。
ZooKeeper提供了一个基于ZNode(节点)的数据模型,可以使用各种命令来操作ZNode和其属性。
以下是ZooKeeper的一些常用命令:1. 创建节点:create /path/to/node data2. 获取节点数据:get /path/to/node3. 设置节点数据:set /path/to/node data4. 获取子节点数:count2 /path/to/node5. 获取指定路径下的子节点数:count22 /path/to/node6. 获取指定路径下的子节点:ls /path/to/node7. 获取指定路径下的子节点和子节点数:ls2 /path/to/node8. 获取指定路径下的子节点和子节点数(包括指定路径):ls2 /path/to/node9. 获取指定路径下的子节点和子节点数(不包括指定路径):ls2 /path/to/node10. 获取指定路径下的子节点和子节点数(包括指定路径):count /path/to/node11. 获取指定路径下的子节点和子节点数(不包括指定路径):count /path/to/node12. 获取指定路径下的子节点和子节点数(包括指定路径):count /path/to/node13. 获取指定路径下的子节点和子节点数(不包括指定路径):count /path/to/node14. 获取指定路径下的子节点和子节点数(包括指定路径):count /path/to/node15. 获取指定路径下的子节点和子节点数(不包括指定路径):count /path/to/node16. 获取指定路径下的子节点和子节点数(包括指定路径):count /path/to/node17. 获取指定路径下的子节点和子节点数(不包括指定路径):count /path/to/node以上是一些常用的ZooKeeper命令,它们可以通过ZooKeeper的命令行界面(CLI)进行输入和执行。
NET数据库软件配置方法
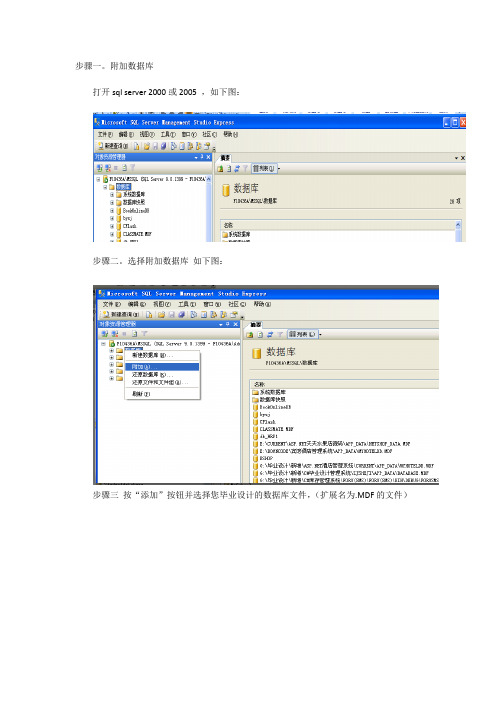
步骤一。
附加数据库打开sql server 2000或2005 ,如下图:步骤二。
选择附加数据库如下图:步骤三按“添加”按钮并选择您毕业设计的数据库文件,(扩展名为.MDF的文件)备注:如果您找不到您的数据库请找到类似如下图标的文件步骤四:打开visual studio 2005 或2008 并如下操作打开项目或者解决方案中请选择您毕业设计文件夹中的扩展名为.sln的文件图标如下:此时您可以按您键盘最上面的F5 按键来运行,如果成功,祝贺您!YOU ARE LUCKY!不成功不怕,接着做。
步骤五打开后您将会在右边看到解决方案资源管理器,如图一般来说都会有个app.config或者web.config 的文件存在您到app.config或者web.config 中找到一句话,这句话是配置数据库连接字符串的,有这句话才能和数据库连起来<add key="ConnectionString"value="DataSource=.\MSSQL;AttachDbFilename=|DataDirectory|\Database.mdf;Integrated Security=True;User Instance=False"/><add key="DatabaseConnectionString"value="Data Source=.\MSSQL;Initial Catalog=Database;Integrated Security=True;uid=sa;pwd=123456"/>看到Data Source=.\MSSQL;这几个字,看到了吗这.\MSSQL 您要改成.\这边是您的数据\后面的文字比如我这边是所以我就是 .\MSSQL 您改正后就可以按F5运行了。
如果还不行请找我。
Weblogic配置Oracle数据源

配置和管理 WebLogic JDBC配置 JDBC 数据源本部分包括以下信息:∙了解 JDBC 数据源∙创建 JDBC 数据源∙事务选项∙连接缓冲池功能∙设置数据库安全凭据∙调整数据源连接缓冲池选项∙在服务器和群集上部署数据源∙最大程度地减少由不响应的数据库引起的服务器启动暂停∙JDBC 数据源的安全∙JDBC 数据源工厂(不赞成使用)了解 JDBC 数据源在 WebLogic Server 中,可通过将数据源添加到您的 WebLogic 域来配置数据库连接。
WebLogic JDBC 数据源提供了数据库访问和数据库连接管理。
每个数据源都包含一个数据库连接缓冲池,其中的数据库连接是在创建数据源时和启动服务器时创建的。
应用程序会通过在 JNDI 树中或在本地应用程序上下文中查找数据源,然后调用 getConnection()来保留来自数据源的数据库连接。
完成连接后,应用程序应尽早调用 connection.close(),该方法会将数据库连接返回缓冲池以供其他应用程序使用。
数据源及其连接缓冲池可以提供有助于保持系统运行和性能的连接管理进程。
可以设置数据源中的选项以满足您的应用程序和您的环境的需要。
以下部分描述了这些选项以及如何启用这些选项。
创建 JDBC 数据源要在您的 WebLogic 域中创建 JDBC 数据源,可以使用管理控制台或 WebLogic 脚本工具 (WLST)。
有关详细信息,请参阅以下部分:∙"“管理控制台联机帮助”中的创建 JDBC 数据源∙"“WebLogic 脚本工具”中的创建 JDBC 资源注意:WLST 已取代了 weblogic.Admin 命令行实用工具。
WebLogic Server 示例(可选择将其随 WebLogic Server 一起安装)包含了可用来代替weblogic.Admin JDBC 命令的示例脚本。
如果已安装了上述示例,则这些示例脚本可从WL_HOME\samples\server\examples\src\examples\wlst\online 获得,其中,WL_HOME 指 WebLogic 主目录,如 C:\bea\weblogic91。
weblogic的安装与数据源配置
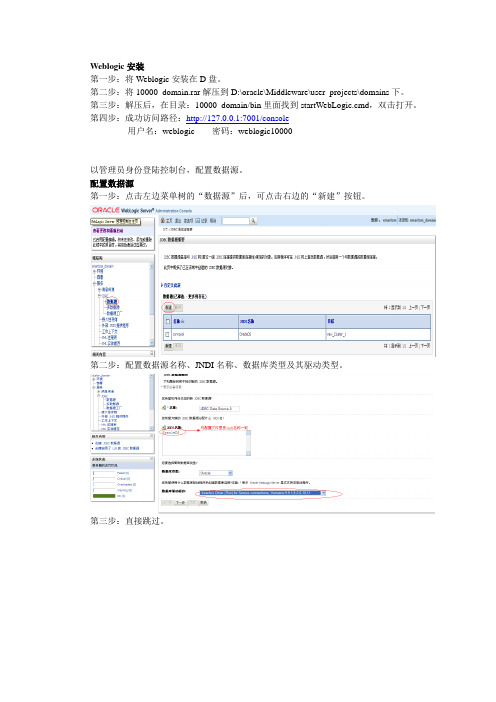
第四步:如下配置数据源的URL。
第五步:检查驱动类、数据库连接URL、用户名、密码无误后,点击“测试配置”按钮,连接成功后,在左上角有绿色提示:测试连接成功!
第六步:配置该数据源所属对象,我们要部署在如图所示选择c安装
第一步:将Weblogic安装在D盘。
第二步:将10000_domain.rar解压到D:\oracle\Middleware\user_projects\domains下。
第三步:解压后,在目录:10000_domain/bin里面找到startWebLogic.cmd,双击打开。
第四步:成功访问路径:http://127.0.0.1:7001/console
用户名:weblogic密码:weblogic10000
以管理员身份登陆控制台,配置数据源。
配置数据源
第一步:点击左边菜单树的“数据源”后,可点击右边的“新建”按钮。
第二步:配置数据源名称、JNDI名称、数据库类型及其驱动类型。
ZK简明教程
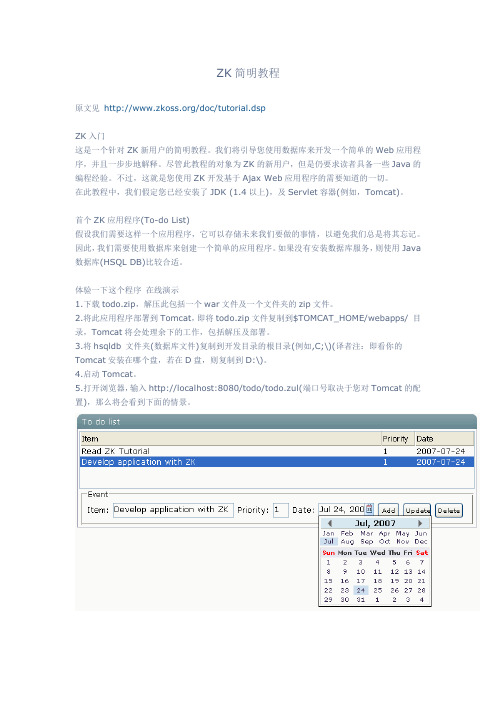
ZK简明教程原文见/doc/tutorial.dspZK入门这是一个针对ZK新用户的简明教程。
我们将引导您使用数据库来开发一个简单的Web应用程序,并且一步步地解释。
尽管此教程的对象为ZK的新用户,但是仍要求读者具备一些Java的编程经验。
不过,这就是您使用ZK开发基于Ajax Web应用程序的需要知道的一切。
在此教程中,我们假定您已经安装了JDK (1.4以上),及Servlet容器(例如,Tomcat)。
首个ZK应用程序(To-do List)假设我们需要这样一个应用程序,它可以存储未来我们要做的事情,以避免我们总是将其忘记。
因此,我们需要使用数据库来创建一个简单的应用程序。
如果没有安装数据库服务,则使用Java 数据库(HSQL DB)比较合适。
体验一下这个程序在线演示1.下载todo.zip,解压此包括一个war文件及一个文件夹的zip文件。
2.将此应用程序部署到Tomcat,即将todo.zip文件复制到$TOMCAT_HOME/webapps/ 目录,Tomcat将会处理余下的工作,包括解压及部署。
3.将hsqldb 文件夹(数据库文件)复制到开发目录的根目录(例如,C;\)(译者注:即看你的Tomcat安装在哪个盘,若在D盘,则复制到D:\)。
4.启动Tomcat。
5.打开浏览器,输入http://localhost:8080/todo/todo.zul(端口号取决于您对Tomcat的配置),那么将会看到下面的情景。
所有的情景某件事情的关键信息,点击Add按钮可以将新数据插入到数据库。
选中表中任一行来在相应的域中显示事件信息,以方便用户修改,点击Updata按钮后即可修改事件信息。
选中表中任一行,然后点击Delete按钮即可删除选中事件。
安装开发目录我们的首要任务是安装开发目录,包括将ZK的必须库文件引入到开发目录,并配置相关文件。
开发目录的结构在tomcat的Web应用程序目录下($TOMCAT_HOME/webapps )创建一个开发目录。
weblogic配置数据库连接

一、weblogic数据源配置进入到weblogic控制台,找到服务→jdbc→数据源,锁定并编辑后,新增数据源. 进入到新建页面,如下图:修改配置如下:注意,上面的jndi名称,需要在torConfig.xml配置文件中用到点击下一步(此步不需修改配置),再点击下一步,进入到如下页面:修改配置:数据库名称,即oracle的实例名(SID),主机名:可以输入oracle数据库所在机器的IP,端口号,根据实际情况输入,用户名和密码都根据实际生产环境的配置输入.以上配置,可以根据目前的torConfig.xml文件中的数据库连接方式把相应的配置录入到页面即可.如下图为我本机的配置:再点击下一步,出现如下图的页面:根据前一步数据库配置不同,有些数据与下图会不一样,点击测试配置,如果显示连接测试成功即表示配置成功:测试成功后,点击下一步,选择对应的运用服务,点击完成即可.(备注:每次修改保存后、都需要激活更改)激活以后,再次选择jdbc数据源,并点击“锁定并编辑”,选择对应的数据源,点击进入,会到以下页面:选择连接缓冲池,进入以下页面:调整初始容量为:30,最大容量为250(目前客户生产环境,设置的oracle最大连接数为300),容量增长为:15;语句缓存大小为:30;根据上面的配置调整后,激活更改,weblogic的数据源配置即可完成二、tor数据库连接配置把TORConfig.xml文件中目前的配置,如下代码,注释掉:<bean id="dataSource" class="org.logicalcobwebs.proxool.ProxoolDataSource" destroy-method="close"><property name="driver"><value>oracle.jdbc.driver.OracleDriver</value></property><property name="driverUrl"><value>jdbc:oracle:thin:gzldoa/*************.1.201:1521:ldoadev</value></property><property name="user"><value>gzldoa</value></property><property name="password"><value>toone</value></property><property name="alias"><value>gzwork</value></property><property name="houseKeepingSleepTime"><value>90000</value></property><property name="prototypeCount"><value>5</value></property><property name="maximumConnectionCount"><value>100</value></property><property name="minimumConnectionCount"><value>10</value></property><property name="trace"><value>true</value></property><property name="verbose"><value>true</value></property></bean>新增jndi连接方式配置:<bean id="dataSource" class="org.springframework.jndi.JndiObjectFactoryBean"> <property name="jndiName"><value>ldjoa</value></property></bean>后保存即可,注意需要把上面的ldjoa改成刚在weblogic控制台配置的jndi名称。
zrok用法

zrok用法
Zookeeper是一个分布式协调服务,主要用于管理大型分布式系统中的数据。
以下是Zookeeper的基本用法:
1. 创建顺序节点:在Zookeeper中,每一个节点都有一个唯一的路径,并且可以存储少量的数据。
Zookeeper会自动为每一个节点添加一个自增的编号,这个编号是用来标识节点的顺序的。
2. 获取和设置数据:Zookeeper允许你存储和获取节点的数据。
你可以使
用`get`命令获取节点的数据,使用`set`命令设置节点的数据。
3. 监控节点:Zookeeper允许你监控节点的变化。
你可以使用`watch`命令监控一个节点,当这个节点发生变化时,Zookeeper会通知你。
4. 获取指定路径下的子节点数:你可以使用`count`命令获取指定路径下的子节点数。
5. 获取指定路径下的子节点:你可以使用`ls`命令获取指定路径下的所有子节点。
6. 获取指定路径下的子节点数:你可以使用`count2`命令获取指定路径下的子节点数。
7. 获取指定路径下的子节点:你可以使用`ls2`命令获取指定路径下的所有子节点。
以上是Zookeeper的一些基本用法,你可以根据实际需要使用其他命令。
更多详细信息建议查询相关论坛或咨询技术人员。
ZKNet考勤管理系统

随着Internet的高速发展,以及企业现代化人事管理需求的不断增加,传统的考勤解决方案已经不再能够满足高端客户及大型企业的管理要求。
目前大型企业人事管理所面临的问题,不再单单是针对人员的管理,逐渐在向员工、考勤设备、卡的方向叠加管理过渡。
如何保障企业在使用大量考勤设备和管理众多员工的同时,对考勤设备、考勤数据高效、准确的管理,成为管理人员必须面对的一个管理难题!本系统正是顺应信息技术发展的潮流,以及广大客户的需求而开发出基于B/S架构的考勤管理系统,这种基于B/S架构的考勤系统必将为企业的办公自动化带来巨大变革。
本系统可在局域网、广域网内实现,方便企业考勤的异地管理,数据完全实现自动上传下载,管理人员无须太干预,实现真正的管理“无人值守”!二、本系统适用范围适用于:1、大型企业、连锁机构等需要异地管理的客户2、客户有基于B/S架构对考勤设备及人员的管理需求3、考勤数据的实时传输、4、公司全国范围内有专用网络的客户5、公司有可被外部访问的WEB地址的客户联系口口一五八六八五七一一六口口一零一二八七六七五八口口一五一八零一三八零一联系电++--话:一八零三九五六四六四八6.公司内部局域网无法架构三、系统架构说明四、系统操作流程1、安装:a.软件安装:在总部服务器上安装BS服务器考勤管理软件,并配置相关网络环境。
b.数据库安装:根据客户需求,在服务器上安装数据库,系统支持SQL Server、MySQL、PostgreSQL、SQLite、ORACLE等,同时可扩展至其他数据库。
我们的数据库协议是对外开放的,若公司有自己的OA系统,我们可以协助其兼容。
2、网络连接:a.系统采用HTTP协议,由考勤机主动发起向服务器连接和数据传送请求:b.支持复杂的网络接入方式:如ADSL/ISDN/远程Modem拨号接入、ISP专线等等c.支持广泛使用的Web访问方式:如路由、NAT、Http代理等等d.网络防火墙通常打开Web访问的HTTP协议端口,从而考勤机到服务器的访问几乎不受限制3、数据收集及人员信息上传下载:技术领先:A.员工考勤后,考勤数据自动上传到服务器B.新录入的员工指纹自动备份到服务器可设置为如下几种方式进行传送:(1)、实时上传到服务器;(2)、考勤机间隔一段时间(如5分钟)检查并传送新数据;(3)、设定几个时间定时检查并传送新数据;五、技术特点:1、数据自动上传下载,实现真正无人值守:如果网络暂时不能正常联接,在恢复连接后数据会自动重新传送数据通常是打包在一起成批传送的,从而降低网络连接的开销因为网络问题而传送失败的数据会重新被传送,直至成功为止数据上传下载不影响正常的考勤使用,只有在通过服务器大批量下发人员指纹到考勤机时,才会稍微减慢考勤的速度对考勤机进行远程控制,自动升级终端考勤机固件ü只传送新的数据,已经传送过的数据不会自动传送,但可以从服务器上要求重新传送ü2、数据可加密、压缩传送:?加密和压缩传送数据是一个可选项,同时进行,加密使得数据的传输更安全,压缩使得网络通信的带宽占用大大降低?加密和压缩采用专门的算法,其特点是速度快、效率高,基本不会给服务器和考勤机带来过大的开销?通常,20K的考勤记录数据可以压缩到6K在网络上进行传送4、依托强大的http服务器:a.支持Linux、Windows XP/2003及其以上版本b.支持Apache/IIS/Lighttpd/Nginx服务器软件c.利用HTTP服务器的高稳定、高可靠性和多进程管理能力,实现高并发连接数支持,从而可以同时连接数千台考勤机d.可根据考勤机数量、实时性和安全性要求等实际需要灵活布署多台服务器5、考勤终端特点:a.指纹可自动互相备份:?在一台机器上登记的用户和指纹可以自动传送到另一台机器上进行备份,从而一个地方多台考勤机的时,员工只需在其中一台上登记指纹就可以在另一台上比对;?一个考勤点多台机器,相互备份人员数据,除了提高使用效率,也降低其中一台意外损坏时的不能考勤的风险b.可在联网内的任意一台考勤机上进行考勤,是解决大规模(上万人)考勤的理想解决方案:可以按需要配置为:?在自己的默认考勤机上考勤时,直接按指纹即可;?在其他考勤机上考勤时,首先输入自己的ID号码,然后再按指纹;?在配置有读卡功能的机器上,输号码的方式可以用刷卡(ID卡/Mifare卡/HID卡)代替。
ZK配置文件

ZK配置⽂件The number of milliseconds of each tick, 最⼩时间单位,很多运⾏时的时间#间隔都是使⽤tickTime的倍数来表⽰的,例如initLimit=10就是tickTime的⼗倍等于2W毫秒tickTime=2000# The number of ticks that can pass between, sending a request and getting an acknowledgement# ⼼跳最⼤延迟时间,如果leader在规定的时间内⽆法获取到follow的⼼跳检测响应,则认为节点已脱离syncLimit=5# the directory where the snapshot is stored. do not use /tmp for storage, /tmp here is just. example sakes.# ⽤于存放内存数据库快照的⽂件夹,同时⽤于集群的myid⽂件也存在这个⽂件夹⾥dataDir=G:\\program-my\\zookeeper-3.4.9\\data# the port at which the clients will connect,ZK端⼝clientPort=2181# the maximum number of client connections. increase this if you need to handle more clients# 允许连接的客户端数⽬,0-不限制,通过 IP 来区分不同的客户端maxClientCnxns=60#将管理机器把事务⽇志写⼊到“ dataLogDir ”所指定的⽬录,⽽不是“ dataDir ”所指定的⽬录。
避免⽇志和快照之间的竞争#dataLogDir=/root/Hadoop-0.20.2/zookeeper-3.3.1/log/data_log# The number of snapshots to retain in dataDir#⽤于配置zookeeper在⾃动清理的时候需要保留的快照数据⽂件数量和对应的事务⽇志⽂件,最⼩值时三,如果⽐3⼩,会⾃动调整为3#autopurge.snapRetainCount=3# Purge task interval in hours. Set to "0" to disable auto purge feature#配套snapRetainCount使⽤,⽤于配置zk进⾏历史⽂件⾃动清理的频率,如果参数配置为0或者⼩于零,就表⽰不开启定时清理功能,默认不开启#autopurge.purgeInterval=1##集群配置# The number of ticks that the initial, synchronization phase can take# follow服务器在启动的过程中会与leader服务器建⽴链接并完成对数据的同步,leader服务器允许follow在initLimit时间内完成,默认时10.集群量增⼤时#同步时间变长,有必要适当的调⼤这个参数, 当超过设置倍数的 tickTime 时间,则连接失败initLimit=10#server.A=B:C:D:其中 A 数字,表⽰是第⼏号服务器. dataDir⽬录下必有⼀个myid⽂件,⾥⾯只存储A的值,ZK启动时读取此⽂件,与下⾯列表⽐较判断是哪个server # B 是服务器 ip ;C表⽰与 Leader 服务器交换信息的端⼝;D 表⽰的是进⾏选举时的通信端⼝。
Zookeeper 部署_配置_使用

Zookeeper 使用基础篇1. Zookeeper 基础概念2. Zookeeper 安装部署3. Zookeeper 常用命令4. Zookeeper 进阶说明TIPS:1 . 本示例所使用zookeeper版本为v3.4.10(2017.3.30版本)。
2 . 本示例所使用JDK版本为1.8.0_162。
3 . Zookeeper服务在本示例中简称 "zk"。
1 . Zookeeper 基础概念概念说明A . zk中所有节点只存在绝对路径,不存在相对路径。
B . zk可以在连接时指定初始化路径,那后续操作路径基于该初始化路径位置进行的操作。
C . zk中节点分为两种节点: 持久节点:该类型节点不会受会话断开而删除,该类节点下可以继续创建子节点。
临时节点:该类型节点在会话断开后会自动删除,且该类节点下无法再创建子节点。
D . zk中所有节点都有有序节点和无序节点两种状态。
无序节点会以路径名称作为节点名称进行创建。
有序节点会以路径加序号后缀的方式为节点命令进行创建。
E . zk中所有节点即可作为数据载体,即本身也可以存储少量数据,同时也可以作为全路径进行节点寻址判断使用。
F . zk中所有节点都可以添加观察者[watcher],zk中的[watcher]仅能触发一次,接收通知后即失效,所以必须采用循环注册方式来达到持续观察的效果。
G . zk中节点操作需要设置[ version ]属性。
可以选择直接使用[ -1 ]忽略版本属性,表示忽略操作哪个版本的节点,强制对所有版本节点生效。
同时,也可以选择指定版本号进行节点操作,实现类似乐观锁的效果。
H . zk中创建节点时必须指定节点值,如:[ create /foo "value" ]中[ "value" ]部分,如果不设置节点值则无法成功创建节点,zk中不能创建空值节点。
I . zk中观察者分两种,即数据观察者和节点观察者,详情参见后述 <观察者说明> 篇章。
weblogic配置Oracle数据库连接池

Weblogic中配置数据池应用服务器是:BEA WebLogic 10正式版数据库是:oracle 10g运行工具:myeclipse1、配置连接池启动weblogic服务器,通过http://localhost:7001/console进入管理控制台在左侧菜单中,依次进入:myserver(这里以自己的为准)--Services(服务)--JDBC--Connection Pools(连接缓冲池),点击“Configure a new JDBC Connection Pool(配置新的DBC Connection Pool)” Database Type(数据库类型): OracleDatabase Driver(数据库驱动): *Oracle's Driver (Thin) Versions:9.0.1,9.2.0,10点击“Continue(继续)”按钮,进入下一步:Name(名称):TestPool,此处根据实际应用填写名字。
Database Name(数据库名):testdb 这里注意是SID=testdbHost Name: 192.168.32.137 数据库所在的主机名或IPPort: 1521Databse User Name: system 数据库的登陆名Password: 123456 登陆密码点击“Continue”按钮,继续下一步。
点击“Test Driver Configuration”按钮,显示“Connection successful”.点击“Create and deploy”按钮,在新页面的列表中出现了"TestPool"项。
至此连接池配置完毕。
2、测试配置连接池在左侧的菜单中依次点击“myserver--services--JDBC--Connection Pools--TestPool”,在出现的页面中点击“Configuration”选项单--“Connections”选单,然后点击“高级选项”的“显示”。
中控改sql数据库方法
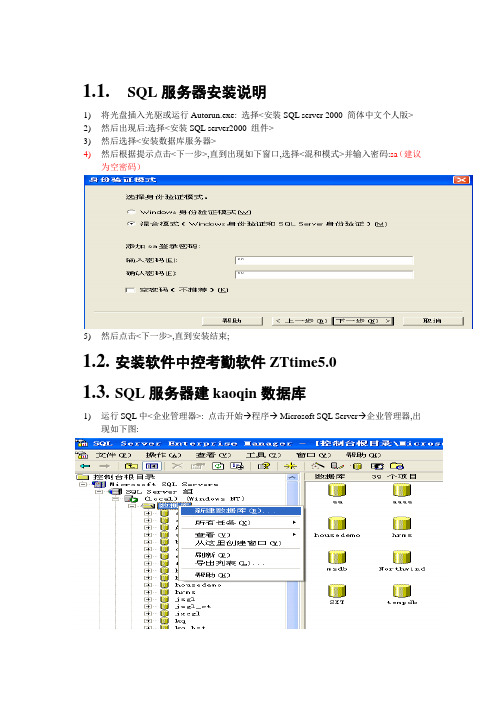
1.1. SQL服务器安装说明
1)将光盘插入光驱或运行Autorun.exe: 选择<安装SQL server 2000 简体中文个人版>
2)然后出现后:选择<安装SQL server2000 组件>
3)然后选择<安装数据库服务器>
4)然后根据提示点击<下一步>,直到出现如下窗口,选择<混和模式>并输入密码:sa(建议
为空密码)
5)然后点击<下一步>,直到安装结束;
1.2.安装软件中控考勤软件ZTtime5.0
1.3.SQL服务器建kaoqin数据库
1)运行SQL中<企业管理器>: 点击开始→程序→ Microsoft SQL Server→企业管理器,出
现如下图:
2)在数据库点击右键,出现如下图:输入数据库名称kaoqin,点击确定就可以了
1.4.SQL服务器建kaoqin数据库的表
1)运行<查询分析器>: 点击开始→程序→ Microsoft SQL Server→查询分析器,输入密码
后,出现如下图后选,在下拉列表中择数据库:kaoqin
2)打开建表的SQL文件: 点击菜单文件→打开→在弹出的文件对话框中选择考勤软件
安装目录下的sqlserver.SQL→打开
3)运行SQL文件: 点击菜单查询→执行→OK
运行中控考勤软件
1.4.1.配置数据库连接SQL数据库1)点击<维护设置> <数据库设置>出现如下窗口:
2)点击<下一步>出现如下窗口:
1)输入数据库服务器的IP地址,
2)输入用户名,密码,
3)选择允许保存密码,
4)选择在服务器上的数据库;。
力控NetDDEServer配置-推荐下载

力控实时数据库(DB)Net DDE Server配置A.概念动态数据交换(Dynamic Data Exchange,DDE)也是一种进程间通信形式。
它最早是随着Windows 3.1由美国微软公司(Microsoft)提出的。
当前大部分软件仍就支持DDE,但近10年间微软公司已经停止发展DDE技术,只保持对DDE技术给予兼容和支持。
但我们仍然可以利用DDE技术编写自己的数据交换程序。
B.通讯原理两个同时运行的程序间通过DDE方式交换数据时是客户/服务器关系,一旦客户和服务器建立起来连接关系,则当服务器中的数据发生变化后就会马上通知客户。
通过DDE方式建立的数据连接通道是双向的,即客户不但能够读取服务器中的数据,而且可以对其进行修改。
DDE和剪贴板一样既支持标准数据格式(如文本、位图等),又可以支持自定义的数据格式。
但它们的数据传输机制却不同,一个明显区别是剪贴板操作几乎总是用作对用户指定操作的一次性应答,如从菜单中选择粘贴命令。
尽管DDE也可以由用户启动,但它继续发挥作用,一般不必用户进一步干预。
DDE有三种数据交换方式,即:(1)冷连接(Cool Link):数据交换是一次性数据传输,与剪贴板相同。
当服务器中的数据发生变化后不通知客户,但客户可以随时从服务器读写数据;(2)温连接(Warm Link):当服务器中的数据发生变化后马上通知客户,客户得到通知后将数据取回;(3)热连接(Hot Link):当服务器中的数据发生变化后马上通知客户,同时将变化的数据直接送给客户。
DDE 客户程序向DDE 服务器程序请求数据时,它必须首先知道服务器的名称(即DDE Service名)、DDE主题名称(Topics名),还要知道请求哪一个数据项的项目名称(Items名)。
DDE Service名应该具有唯一性,否则容易产生混乱。
通常DDE Service就是服务器的程序名称,但不是绝对的,它是由程序设计人员在程序内部设定好的,并不是通过修改程序名称就可以改变的。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
指纹核心技术研发OEM/ODM 制造提供内联网及互联网在线身份认证
1ZKNET 数据库配置方法
ZKNET 系统支持Oracle,SQLServer,Sqlite,MySql 等各种数据库,对于各种数据库的连接,软件中自带了一个配置文件:attsite.ini.在文件中每个【DATABASE 】下面的内容针对一个数据库的连接配置,启用状态为【DATABASE 】,非启用状态为【DATABASE--】ENGINE :请保留默认
NAME:数据库名
USER:用户名
PASSWORD:密码
PORT:端口
HOST:数据库地址
软件连接数据库前,由于软件不能自动建立数据库,所以除软件自带MySql 外,其它需要手工建立一个空数据库,建库方法参照各数据库本身的文档。
库建好后可以用快速建表和数据库还原两种方法生成数据表。
(一)、快速建表
在软件安装目录内找到db.bat 文件,在保证配置文件保存正确后,双击这个文件即可。
在建表时会出现以下提示:
指纹核心技术研发OEM/ODM 制造提供内联网及互联网在线身份认证
2(二)、数据库还原
一.MySql
配置文件中的内容,这是软件默认的数据库
软件自带MySql 数据库,数据库会自动安装不需要额外的配置。
默认存放路径为软件安装后目录的mysql\data 内,如:软件默认安装在C:\iclockSvr ,则数据库为c:\iclockSvr\mysql\data 内,zknet 为数据库名,zknet
目录内为所有的表。
如图:
MySql 会在系统中创建一个服务,服务名为iclock-data;如图:
指纹核心技术研发OEM/ODM 制造提供内联网及互联网在线身份认证
3如果想对数据库进行备份,可以先关闭这个服务,然后对icdat 整个文件夹进行复制。
复制后要重新开启服务。
恢复时也要先关闭服务,把zknet 文件夹拷贝到原来的位置,然后开启服务即可。
卸载MySql :
命令行中输入
sc stop iclock-data
sc delete iclock-data
二.SQL Server 2005
配置文件中的内容:
(1)首先要在现有的SQL Server 2005中新建一个软件专用数据库
指纹核心技术研发OEM/ODM 制造提供内联网及互联网在线身份认证
4
调整数据库文件路径
右击新建的数据名称,选择【任务】--》【还原】--》【文件和文件组】
指纹核心技术研发OEM/ODM 制造提供内联网及互联网在线身份认证
5选择【源设备】---》【添加】;选择zknet.bak
存放的路径
勾选刚添加的文件:
在选择页中选择【选项】,在还原选项中选择【覆盖现有数据库】
指纹核心技术研发OEM/ODM 制造提供内联网及互联网在线身份认证
6
确定后会提示:
表示数据库已经恢复完成。
(2)或者直接在数据库根目录下右键菜单,选择【还原数据库】,不用新建数据库然后再还原,
直接在还原过程中创建数据库
指纹核心技术研发OEM/ODM 制造提供内联网及互联网在线身份认证
7还原的方法与(1)的还原方法相同
(3)如果在还原过程中出现如下错误提示可以使用另外一种方法进行还原:
在新建查询窗口中输入
restore database ZKNET from disk ='F:\ZKNET.bak'with replace ;
'F:\ZKNET.bak':为备份文件存放的位置
ZKNET :为新建数据库名称(要与备份文件同名)
指纹核心技术研发OEM/ODM 制造提供内联网及互联网在线身份认证
8或者把zknet.bak 文件拷贝到SQL Server2005默认的备份目录下\Microsoft SQL Server\MSSQL.1\MSSQL\Backup\,然后进行还原操作
三.ORACLE
配置文件中的内容:
注意:ORACLE 的端口号写法,要用双引号
首先要在现有的ORACLE 中新建一个软件专用数据库,以ORACLE10g
为例:
菜单中选择【Database Configuration Assistant 】来创建数据库,
9
指纹核心技术研发OEM/ODM制造提供内联网及互联网在线身份认证
10
指纹核心技术研发OEM/ODM制造提供内联网及互联网在线身份认证
11
指纹核心技术研发OEM/ODM制造提供内联网及互联网在线身份认证
12
指纹核心技术研发OEM/ODM制造提供内联网及互联网在线身份认证
指纹核心技术研发OEM/ODM 制造提供内联网及互联网在线身份认证
13
创建过程中都选择默认值即可。
数据库建立成功后,运行ORACLE 自带IMP 命令,导入已经有的zknet.dmp
如:
指纹核心技术研发OEM/ODM 制造提供内联网及互联网在线身份认证
14imp userid=system/ROOT@adms file=e:\zknet.dmp full=y
system:用户名
ROOT:密码
zknet :数据库名
E:\zknet.dmp:要导入的文件
注意:IMP 命令要在ORACLE 服务器端运行
四.SQLite
如果在配置文件中所有的【DATABASE 】,都为非启用状态【DATABASE--】,那软件会自动连接到SQLite 数据库。
它存放在安装后的目录iclockSvr\mysite 下,icdat.db
文件。