SQL SERVER利用分区对大数据表处理操作手册
sql server 分区注意事项-概述说明以及解释

sql server 分区注意事项-概述说明以及解释1.引言1.1 概述SQL Server是一种关系型数据库管理系统,具有强大的数据处理和存储能力。
在处理大规模数据时,为了提高查询性能和维护数据的效率,我们可以使用分区技术来对数据库进行划分。
分区是将数据库表或索引按某种规则划分成多个逻辑上相互独立的部分,每个部分称为一个分区。
每个分区可以单独进行管理和维护,使得数据的访问和处理更加高效快速。
在使用SQL Server分区技术时,需要注意以下几点:首先,分区设计需要根据具体的业务需求进行合理的划分。
不同的业务场景可能需要不同的分区策略,如按照时间、地域或其他特定的业务属性进行分区。
合理的分区设计可以提高查询性能,并提供更好的数据管理能力。
其次,分区键的选择非常重要。
分区键是指用于划分分区的列或列集合,可以是表中的任意列。
选择一个适合的分区键可以提高查询性能和数据加载的效率。
通常,选择具有高选择性的列作为分区键会得到较好的效果。
另外,分区表的维护和管理也需要特别关注。
由于分区表的数据分布在不同的分区中,因此需要针对每个分区进行独立的维护工作,如备份、索引维护和数据迁移等。
同时,需要注意监控每个分区的使用情况,及时进行分区的调整或优化。
最后,使用分区功能可能涉及到一些限制和注意事项。
例如,分区表的设计需要遵循一些特定的规则和限制,如每个分区的大小应该合理控制,避免某个分区过大或过小。
此外,分区表的查询和删除操作也需要特别注意,以确保操作的正确性和效率。
总之,SQL Server分区技术可以提高数据库的性能和数据管理的灵活性,但在使用分区功能时需要注意以上几点,以确保分区设计的合理性和分区表的正常运行。
1.2 文章结构本文将按照以下结构进行讨论和介绍sql server 分区的注意事项:1. 引言:首先,我们会在引言部分简要介绍sql server 分区的概述,包括其定义、作用和应用场景。
同时,我们还会说明本文的目的,即为读者提供一些有关sql server 分区的注意事项,以帮助他们在使用和设计分区时避免一些常见的问题和错误。
SQL Server 数据库分离与附加操作手册

SQL Server 数据库分离与附加操作手册门禁软件和考勤软件都可以使用SQL数据库,本文介绍如何对SQL数据库进行分离和附加,以便安装和备份门禁数据。
一、概述SQL Server提供了“分离/附加”数据库、“备份/还原”数据库、复制数据库等多种数据库的备份和恢复方法。
这里介绍一种学习中常用的“分离/附加”方法,类似于大家熟悉的“文件拷贝”方法,即把数据库文件(.MDF)和对应的日志文件(.LDF)拷贝到其它磁盘上作备份,然后把这两个文件再拷贝到任何需要这个数据库的系统之中。
但由于数据库管理系统的特殊性,需要利用SQL Server 提供的工具才能完成以上工作,而直接的文件拷贝是行不通的。
这个方法涉及到SQL Server分离数据库和附加数据库这两个互逆操作工具。
1、分离数据库就是将某个数据库(如AXDate)从SQL Server数据库列表中删除,使其不再被SQL Server管理和使用,但该数据库的文件(.MDF)和对应的日志文件(.LDF)完好无损。
分离成功后,我们就可以把该数据库文件(.MDF)和对应的日志文件(.LDF)拷贝到其它磁盘中作为备份保存。
2、附加数据库就是将一个备份磁盘中的数据库文件(.MDF)和对应的日志文件(.LDF)拷贝到需要的计算机,并将其添加到某个SQL Server数据库服务器中,由该服务器来管理和使用这个数据库。
二、分离数据库1. 在启动SSMS并连接到数据库服务器后,在对象资源管理器中展开服务器节点。
在数据库对象下找到需要分离的数据库名称,这里以AXDate数据库为例。
右键单击AXDate数据库,在弹出的快捷菜单中选择属性。
2:在分离数据库前,你不妨先查看一下数据文件的物理位置,如下图:3.右键单击该数据库名称,在快捷菜单中选择“任务”的二级菜单项“分离”。
出现下图所示的“分离数据库”窗口。
4.如果有使用数据库,将出现连接数量不是0 ,需要清除,才能分离。
MS SQL Server分区表、分区索引详解

MS SQL Server:分区表、分区索引详解1. 分区表简介使用分区表的主要目的,是为了改善大型表以及具有各种访问模式的表的可伸缩性和可管理性。
⌝大型表:数据量巨大的表。
⌝访问模式:因目的不同,需访问的不同的数据行集,每种目的的访问可以称之为一种访问模式。
分区一方面可以将数据分为更小、更易管理的部分,为提高性能起到一定的作用;另一方面,对于如果具有多个CPU的系统,分区可以是对表的操作通过并行的方式进行,这对于提升性能是非常有帮助的。
注意:只能在SQL Server Enterprise Edition 中创建分区函数。
只有SQL Server Enterprise Edition 支持分区。
2. 创建分区表或分区索引的步骤可以分为以下步骤:1. 确定分区列和分区数2. 确定是否使用多个文件组3. 创建分区函数4. 创建分区架构(Schema)5. 创建分区表6. 创建分区索引下面详细描述的创建分区表、分区索引的步骤。
2.1. 确定分区列和分区数在开始做分区操作之前,首先要确定待分区表的访问模式,该模式决定了什么列适合做分区键。
例如,对于销售数据,一般会先根据日期把数据范围限定在一个范围内,然后在这个基础上做进一步的查询,这样,就可以把日期作为分区列。
确定了分区列之后,需要进一步确定分区数,亦即分区表中需要包含多少数据,每个分区的数据应该限定在哪个范围。
2.2. 确定是否使用多个文件组为了有助于优化性能和维护,应该使用文件组分离数据。
一般情况下,如果经常对分区的整个数据集操作,则文件组数最好与分区数相同,并且这些文件组通常应该位于不同的磁盘上,再配合多个CPU,则SQL Server 可以并行处理多个分区,从而大大缩短处理大量复杂报表和分析的总体时间。
2.3. 创建分区函数分区函数用于定义分区的边界条件,创建分区函数的语法如下:CREATE PARTITION FUNCTION partition_function_name ( input_parameter_type ) AS RANGE [ LEFT | RIGHT ]FOR VALUES ( [ boundary_value [ ,...n ] ] )[ ; ]参数说明:⌝ partition_function_name是分区函数的名称。
SQL Server表分区操作详解

SQL Server 表分区操作详解SQL Server 2005 引入的表分区技术,让用户能够把数据分散存放到不同的物理磁盘中,提 高这些磁盘的并行处理性能以优化查询性能……【IT 专家网独家】你是否在千方百计优化 SQL Server 数据库的性能?如果你 的数据库中含有大量的表格, 把这些表格分区放入独立的文件组可能会让你受益 匪浅。
SQL Server 2005 引入的表分区技术,让用户能够把数据分散存放到不同 的物理磁盘中,提高这些磁盘的并行处理性能以优化查询性能。
SQL Server 数据库表分区操作过程由三个步骤组成: 1. 创建分区函数 2. 创建分区架构 3. 对表进行分区 下面将对每个步骤进行详细介绍。
步骤一: 步骤一:创建一个分区函数 此分区函数用于定义你希望 SQL Server 如何对数据进行分区的参数值 ([u]how[/u])。
这个操作并不涉及任何表格,只是单纯的定义了一项技术来分割 数据。
我们可以通过指定每个分区的边界条件来定义分区。
例如,假定我们有一份 Customers 表,其中包含了关于所有客户的信息,以一一对应的客户编号(从 1 到 1,000,000)来区分。
我们将通过以下的分区函数把这个表分为四个大小相同 的分区: CREATE PARTITION FUNCTION customer_partfunc (int) AS RANGE RIGHT FOR VALUES (250000, 500000, 750000) 这些边界值定义了四个分区。
第一个分区包括所有值小于 250,000 的数据, 第二个分区包括值在 250,000 到 49,999 之间的数据。
第三个分区包括值在 500,000 到 7499,999 之间的数据。
所有值大于或等于 750,000 的数据被归入第 四个分区。
请注意,这里调用的"RANGE RIGHT"语句表明每个分区边界值是右界。
SqlServer2005对现有数据进行分区具体步骤
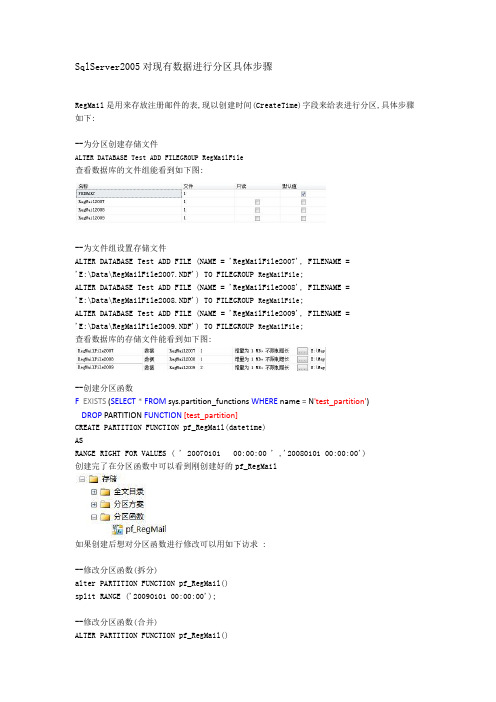
SqlServer2005对现有数据进行分区具体步骤RegMail是用来存放注册邮件的表,现以创建时间(CreateTime)字段来给表进行分区,具体步骤如下:--为分区创建存储文件ALTER DATABASE Test ADD FILEGROUP RegMailFile查看数据库的文件组能看到如下图:--为文件组设置存储文件ALTER DATABASE Test ADD FILE (NAME = 'RegMailFile2007', FILENAME ='E:\Data\RegMailFile2007.NDF') TO FILEGROUP RegMailFile;ALTER DATABASE Test ADD FILE (NAME = 'RegMailFile2008', FILENAME ='E:\Data\RegMailFile2008.NDF') TO FILEGROUP RegMailFile;ALTER DATABASE Test ADD FILE (NAME = 'RegMailFile2009', FILENAME ='E:\Data\RegMailFile2009.NDF') TO FILEGROUP RegMailFile;查看数据库的存储文件能看到如下图:--创建分区函数F EXISTS (SELECT*FROM sys.partition_functions WHERE name = N'test_partition')DROP PARTITION FUNCTION[test_partition]CREATE PARTITION FUNCTION pf_RegMail(datetime)ASRANGE RIGHT FOR VALUES ( ' 20070101 00:00:00 ' ,'20080101 00:00:00')创建完了在分区函数中可以看到刚创建好的pf_RegMail如果创建后想对分区函数进行修改可以用如下访求 :--修改分区函数(拆分)alter PARTITION FUNCTION pf_RegMail()split RANGE ('20090101 00:00:00');--修改分区函数(合并)ALTER PARTITION FUNCTION pf_RegMail()MERGE RANGE ('20080101 00:00:00');--创建分区方案/*看分区方案是否存在,若存在先drop掉*/IF EXISTS (SELECT*FROM sys.partition_schemes WHERE name = N'test_scheme') DROP PARTITION SCHEME test_schemeCREATE PARTITION SCHEME ps_RegMailAS PARTITION pf_RegMail TO (RegMail2007,RegMail2008,RegMail2009)CREATE PARTITION SCHEME MonthDateRangeSchemeASPARTITION MonthDateRangeALL TO ([PRIMARY])如果想去分区方案进行修改--修改分区方案ALTER PARTITION SCHEME ps_RegMailNEXT USED RegMail2010;--创建分区表CREATE TABLE [dbo].[PARTITIONERegMail]([id] [int] IDENTITY(1,1) NOT NULL,[CreateTime] [datetime] NOT NULLCONSTRAINT [PK_PARTITIONERegMail] PRIMARY KEY NONCLUSTERED([id] ASC)WITH (IGNORE_DUP_KEY = OFF) ON [PRIMARY]) ON [ps_RegMail]([CreeateTime])--此为关键步骤,将现有数据存入上面所建的文件中ALTER TABLE [dbo].[RegMail]WITH NOCHECK ADDCONSTRAINT [PK_RegMail] PRIMARY KEY CLUSTERED([CreateTime]) ON [ps_RegMail]([CreateTime])--如果原来的表里有主键哪就要执行下面语句:alter table RegEmail drop constraint PK_RegEmail--将表的主键删除--4. --对已经存在的表进行分区设置ALTER TABLE dbo.d_depot_inoutDROP CONSTRAINT PK_d_depot_inoutWITH(MOVE TO ps_d_depot_inout(statdate))ALTER TABLE d_depot_inoutADDPRIMARY KEY NONCLUSTERED(depot,statdate,itemno)ON ps_d_depot_inout(statdate)GO--查寻数据所在文件组--最后看看结果。
SqlServer数据库分区分表实例分享(有详细代码和解释)

SqlServer数据库分区分表实例分享(有详细代码和解释)数据库单表数据量太⼤可能会导致数据库的查询速度⼤⼤下降(感觉都是千万级以上的数据表了),可以采取分区分表将⼤表分为⼩表解决(当然这只是其中⼀种⽅法),⽐如数据按⽉、按年分表,最后可以使⽤视图将⼩表重新并为总的虚拟表,其实并不影响上层程序的使⽤(程序也许都不知道分表了)。
主要步骤:1、新建⽂件组,将数据表⽂件保存路径指向相应⽂件组(应将⽂件组和⽂件放⼊不同的磁盘中,甚⾄不同服务器形成分布式数据库,因为数据的读取瓶颈很⼤程度在于磁盘的的读写速度,多个磁盘存放⼀个表可以负载均衡)2、设置分区函数(声明分区的标准)3、设置分区⽅案(即哪些区域使⽤哪个分区函数,形成完整的分区⽅案)4、给新表或现有表设置分区⽅案5、建⽴视图详细步骤(看需求可选):⼀、数据库状态备份和恢复USE master-- 备份BACKUP DATABASE AdventureWorksTO DISK = 'AdventureWorks.bak'WITH FORMAT---- 恢复RESTORE DATABASE AdventureWorksFROM DISK = 'AdventureWorks.bak'WITH REPLACEGO⼆、⽂件组和⽂件操作添加⽂件组USE [master]GOALTER DATABASE ZHH ADD FILEGROUP [⽂件组名称]Go添加⽂件并把其指向指定⽂件组USE master;GOALTER DATABASE 数据库名ADD FILE(NAME=N'⽂件名',FILENAME='存放路径', //如:E:\201109.NDF(精确到⽂件名)⽂件组存放与不同磁盘可以提⾼IO读写效率(多个磁头并发)SIZE=3MB,MAXSIZE=100MB,FILEGROWTH=5MB)TO FILEGROUP [⽂件组名]Go修改⽂件(可选)USE master;GOALTER DATABASE 数据库名MODIFY FILE(NAME = ⽂件名,SIZE = 20MB); //可以修改所有属性,列举即可GO删除⽂件(可选)ALTER DATABASE 数据库名 REMOVE FILE [⽂件组名]三、分区函数和分区⽅案分区函数⽤于规范如何分区的标准,如已哪列进⾏为标准分区、分区的⽅式(按时间、ID等)、分区的具体界限(⼀般来说,界限指标数要⽐分区数少1,⼀⼑则有两段)USE 数据库名GOCREATE PARTITION FUNCTION 分区函数名 (指标列的数据类型) //如:datetime、intAS RANGE RIGHT //右边界切分,默认为LEFTFOR VALUES (划分界限) //如时间划分('2003/01/01', '2004/01/01'),两个时间界限可划分出三个分区GO分区⽅案⽤于将已经建⽴好的分区函数组织成完整的⽅案,为每个分区分配存储位置Use 数据库名gocreate partition scheme 分区⽅案名as partition 分区函数to(⽂件组1,⽂件组2,⽂件组3,...) //注意分区数要与实际分区⼀致go在原有的基础上添加分区(可选)use 数据库名goalter partition scheme ps_OrderDate next used [FG4] //修改分区⽅案ps_OrderDate,定义新新分区使⽤FG4⽂件组alter partition function pf_OrderDate() split range('2005/01/01') //修改分区函数pf_OrderDate,在末尾添加界限'2005/01/01'go为现有表设置分区⽅案(可选)//为AutoBench表的InsertTime列创建新聚集索引,并绑定Scheme_DateTime分区⽅案CREATE CLUSTERED INDEX IX_CreateDate ON AutoBench (InsertTime)ON Scheme_DateTime (InsertTime)注:如原来主键有聚众索引要将其改为⾮聚集索引,才可添加新聚众索引//删除原主键上的聚集索引PK_ProductALTER TABLE Product DROP CONSTRAINT PK_Product//重新创建主键⾮聚集索引PK_ProductALTER TABLE Product ADD CONSTRAINT PK_Product PRIMARY KEY NONCLUSTERED (ProductID ASC)上⾯语句也可直接在索引属性中将聚集改为⾮聚集为新建表设置分区⽅案(可选)//创建表格Order,并设置Scheme_DateTime分区⽅案,指标列为OrderDateCREATE TABLE [Order](OrderID INT IDENTITY(1,1) NOT NULL,UserID INT NOT NULL,TotalAmount DECIMAL(18,2) NULL,OrderDate DATETIME NOT NULL) ON Scheme_DateTime (OrderDate)查询分区数据四、其他操作查询分区数据$partition函数--为任何指定的分区函数返回分区号,⼀组分区列值将映射到该分区号中语法: [ database_name. ] $PARTITION.partition_function_name(expression)参数: database_name 包含分区函数的数据库的名称。
sqlserver中partition用法

sqlserver中partition用法在SQL Server中,分区(Partition)是一种将表的数据分布在多个物理位置的技术,以便更有效地管理数据和访问速度。
通过分区,可以将表拆分为较小的逻辑部分,以便更方便地执行查询和管理操作。
以下是SQL Server中分区的一些常见用法:1、创建分区表:在创建分区表时,需要定义分区的数量和每个分区包含的列。
以下是一个创建分区表的示例:sqlCREATE TABLE PartitionedTable(Column1 INT,Column2 VARCHAR(50),...)WITH (DATA_COMPRESSION = PAGE)ON PartitionScheme (PartitionColumn) =(PARTITION_Scheme1 (01, 02, 03),PARTITION_Scheme2 (04, 05, 06),...);在上面的示例中,PartitionedTable 是要创建的分区表的名称,Column1 和Column2 是表中的列。
WITH (DATA_COMPRESSION = PAGE) 指定了使用页压缩来压缩数据。
ON PartitionScheme 指定了分区方案,其中PartitionColumn 是用于分区的列,而PARTITION_Scheme1 和PARTITION_Scheme2 是定义分区的方案和范围。
2、查询分区表:查询分区表时,可以使用分区键的值来确定要查询的分区。
以下是一个查询分区表的示例:sqlSELECT *FROM PartitionedTableWHERE PartitionColumn = '01'; --根据分区键的值筛选数据在上面的示例中,PartitionedTable 是已分区的表,PartitionColumn 是用于分区的列。
通过在WHERE 子句中使用适当的分区键值,可以仅查询特定的分区。
SQL Server数据库技术手册

目录一、数据库简介 (3)1、数据库系统概述 (3)数据库技术的发展 (3)数据库系统组成 (4)2、数据库体系结构 (5)什么是模式 (5)三级模式结构 (5)3、数据模型 (7)数据模型的分类 (7)E-R 模型 (7)层次模型 (9)网状模型 (11)关系模型 (12)4、常见数据库 (13)Access (13)SQL Server (14)Oracle (15)5、数据库分类 (17)二、SQL Server 2016 (17)1、简介 (17)2、特点 (18)新的组件功能 (18)混合云技术 (19)3、安装SQL Server 2016 (20)安装必备 (20)SQL Server 2016 的安装 (22)SQL Server 2016 的卸载 (45)使用SQL Server 2016 帮助 (48)三、数据库操作 (49)1、数据库概述 (49)1.1 数据库基本概念 (49)1.2 数据库常用对象 (51)1.3 数据库的组成 (52)2、数据表概述 (54)2.1 SQL Server 2016 基本数据类型 (54)2.2 用户自定义数据类型 (58)2.3 使用管理器管理数据表 (62)3、SQL 语言的构成 (74)4、数据库语句操作 (74)4.1 创建数据库 (74)4.2 删除数据库 (102)4.3 创建数据表 (106)4.4 创建视图 (108)4.5 删除视图 (109)4.6 建立索引 (109)4.7 删除索引 (109)4.8 使用管理器修改数据库 (110)4.9 修改数据库属性 (113)4、SQL Server 的命名规则 (119)4.1 标识符 (120)4.2 对象命名规则 (120)4.3 实例命名规则 (121)三、数据库数据操控语句 (122)1、查询语句 (122)1.1 一般查询 (122)1.2 带条件查询 (122)1.3 模糊查询 (123)1.4 ORDER BY用法 (123)1.5 TOP 用法 (124)1.6 IN 用法 (124)1.7 别名的用法 (125)1.8 多表查询 (125)1.9 JOIN用法 (126)1.10 UNION用法 (127)1.11 UNION ALL 用法 (128)1.12 临时表 (128)2、插入语句 (132)3、更新语句 (133)4、删除语句 (133)5、合并语句 (134)三、数据库数据类型 (134)1、数据类型类别 (135)4、日期数据类型 (136)5、混合型数据类型 (136)5.1 BINARY和BIT (136)5.2 大对象数据类型 (137)5.3CURSOR (137)5.4UNIQUEIDENTIFIER (137)5.5SQL_VARTANT (137)5.6TABLE (137)5.7XML (143)5.8Geography(地理空间类型) (144)5.9HIERARCHYID (145)5.10 TIMESTAMP (145)5.11 自定义数据类型 (146)6、附带有VARDECIMAL的DECIMAL存储类型 (146)7、类型转换 (146)CAST 和CONVERT (146)一、数据库简介数据库是依照某种数据模型组织起来并存放在二级存储器中的数据集合,可以将其视为电子化的文件柜。
【IT专家】SQL Server表分区详解

本文由我司收集整编,推荐下载,如有疑问,请与我司联系SQL Server表分区详解转载收藏于:cnblogs/knowledgesea/p/3696912.html 什么是表分区一般情况下,我们建立数据库表时,表数据都存放在一个文件里。
但是如果是分区表的话,表数据就会按照你指定的规则分放到不同的文件里,把一个大的数据文件拆分为多个小文件,还可以把这些小文件放在不同的磁盘下由多个cpu进行处理。
这样文件的大小随着拆分而减小,还得到硬件系统的加强,自然对我们操作数据是大大有利的。
因此大数据量的数据表,对分区的需要还是必要的,因为它可以提高select效率,还可以对历史数据经行区分存档等。
但是数据量少的数据就不要凑这个热闹啦,因为表分区会对数据库产生不必要的开销,除啦性能还会增加实现对象的管理费用和复杂性。
跟着做,分区如此简单先跟着做一个分区表(分为11个分区),去除神秘的面纱,然后咱们再逐一击破各个要点要害。
分区是要把一个表数据拆分为若干子集合,也就是把把一个数据文件拆分到多个数据文件中,然而这些文件的存放可以依托一个文件组或这多个文件组,由于多个文件组可以提高数据库的访问并发量,还可以把不同的分区配置到不同的磁盘中提高效率,因此创建时建议分区跟文件组个数相同。
1.创建文件组 可以点击数据库属性在文件组里面添加 T-sql语法: alter database 数据库名add filegroup 文件组名---创建数据库文件组alter database testSplit add filegroup ByIdGroup1alter database testSplit add filegroup ByIdGroup2alter database testSplit add filegroup ByIdGroup3alter database testSplit add filegroup ByIdGroup4alter database testSplit add filegroup ByIdGroup5alter database testSplit add filegroup ByIdGroup6alter database testSplit add filegroup ByIdGroup7alter database testSplit add filegroup ByIdGroup8alter database testSplit add filegroup。
SQL Server 常用操作手册

SQL Server 常用操作手册目录一、建库操作 (1)二、建表操作 (1)三、设主键操作 (2)四、设外键操作 (3)五、备份数据库操作 (4)六、还原数据库操作 (5)七、导入/导出数据操作 (6)一、建库操作1、打开企业管理器2、选中数据库节点,进行新建二、建表操作1、打开企业管理器2、选中数据库节点,新建数据库3、选中新建数据库文件,单击右键出现新建下拉框,在出现的菜单中打开所有任务,找到表选项三、设主键操作1、打开企业管理器2、选中新建数据库文件,单击右键出现新建下拉框,在出现的菜单中打开所有任务,找到表选项,进行新建表3、将新建好的表打开后,单击图表空白处单击右键出现下拉框,单击要设置主键名称4、置成功的主键钱会有一个钥匙的形状四、设外键操作1、打开企业管理器2、选择表,在表表上右键菜单中选择设计表3、然后我们就可以在属性前鼠标右键,选择索引/键4、在属性对话框中选择关系,在类型中我们选择新建按钮,然后设置我们需要的外键1、打开企业管理器2、找到我们需要备份的数据库,点击备份数据库3、在备份中我们可以选择完全备份或差异备份,备份到的地址我们通过添加完成4、写入要备份的文件名及地址,确定后就可以完成备份操作了1、打开企业管理器2、找到我们需要还原的数据库,点击还原数据库3、在还原数据库中,我们在还原中选择从设备,然后点击选择设备4、点击添加按钮来选择要还原的数据库,添加完成后点击确定后就可以完成还原操作了七、导入/导出数据操作1、打开企业管理器2、找到我们要导入/导出的数据库3、出现转换服务导入/导出向导的对话框,我们点击下一步4、我们选择数据源下边的QL Server身份验证,在数据库后边的下拉框中我们选择要导入/导出的数据库,然后点击下一步5、我们看到又弹出了一个跟上面一样的对话框,我们继续选择数据源下边的QL Server身份验证,在数据库后边的下拉框中我们选择要导入/导出的数据库,然后点击下一步6、我们选择要导入/导出的数据库文件,点击下一步7、点击下一步8、我们看到完成了数据库之间的导入/导出,点击完成按钮9、数据库之间的导入/导出操作完成。
sqlserver数据库分区分表
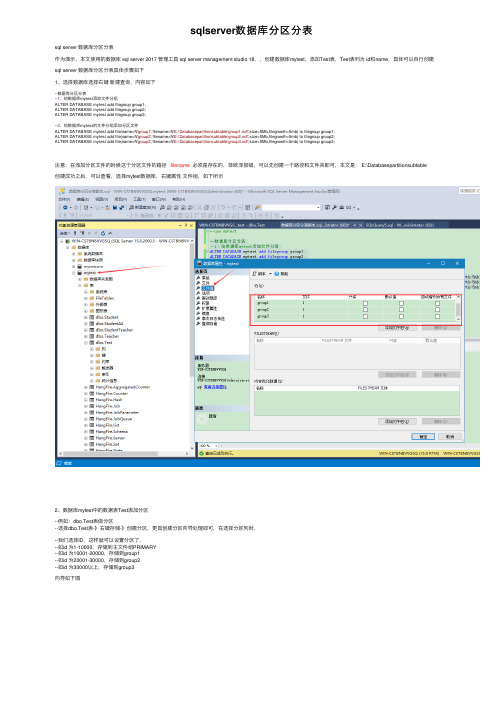
sqlserver数据库分区分表sql server 数据库分区分表作为演⽰,本⽂使⽤的数据库 sql server 2017 管理⼯具 sql server management studio 18,,创建数据库mytest,添加Test表,Test表列为 id和name,具体可以⾃⾏创建sql server 数据库分区分表具体步骤如下1、选择数据库选择右键新建查询,内容如下--数据库分区分表--1、给数据库mytest添加⽂件分组ALTER DATABASE mytest add filegroup group1;ALTER DATABASE mytest add filegroup group2;ALTER DATABASE mytest add filegroup group3;--2、给数据库mytest的⽂件分组添加分区⽂件ALTER DATABASE mytest add file(name=N'group1',filename=N'E:\Databasepartitionsubtable\group1.ndf',size=5Mb,filegrowth=5mb) to filegroup group1;ALTER DATABASE mytest add file(name=N'group2',filename=N'E:\Databasepartitionsubtable\group2.ndf',size=5Mb,filegrowth=5mb) to filegroup group2;ALTER DATABASE mytest add file(name=N'group3',filename=N'E:\Databasepartitionsubtable\group3.ndf',size=5Mb,filegrowth=5mb) to filegroup group3;注意:在添加分区⽂件的时候这个分区⽂件的路径filename 必须是存在的,菲欧泽报错,可以先创建⼀个路径和⽂件夹即可,本⽂是: E:\Databasepartitionsubtable创建成功之后,可以查看,选择mytest数据库,右键属性⽂件组,如下所⽰2、数据库mytest中的数据表Test添加分区--例如:dbo.Test表做分区--选择dbo.Test表-》右键存储-》创建分区,更具创建分区向导处理即可,在选择分区列时,--我们选择ID,这样就可以设置分区了,--如id 为1-10000,存储到主⽂件组PRIMARY--如id 为10001-20000,存储到group1--如id 为20001-30000,存储到group2--如id 为30000以上,存储到group3向导如下图下⾯分区的范围,左边界和右边界意思就是,分界值存储在房钱分组还是下⼀个分组选择左边界--我们选择ID,这样就可以设置分区了,--如id 为1-10000,存储到主⽂件组PRIMARY--如id 为10001-20000,存储到group1--如id 为20001-30000,存储到group2--如id 为30000以上,存储到group3上述操作完成以后,我们的数据库分区分表就完成了,查看表的分区存储情况选择Test表右键属性-》存储可以看到分区和⽂件组选择myest数据库右键属性-》⽂件,可以看到分区⽂件、⽂件组注意:⼀盘数据库分区分表建议不要进⾏全表扫描,可以使⽤条件查询,这个性能更好,本⽂只是问了演⽰做了id来警醒分区分表存储的,其实如果Table中时间字段的话,并且有按照年分来使⽤的话,那么可以⼀句这个书简字段分进⾏分区分表存储,例如销售数据,2010-12-31,2011-12-31,2012-12-31,2013-12-31等等来进⾏分区分表。
sql server操作手册

SQL Server操作手册一、简介SQL Server是由微软公司开发的关系数据库管理系统,广泛应用于企业级数据管理和处理。
本手册旨在为用户提供SQL Server的操作指南,帮助用户熟练掌握SQL Server的基本操作和高级功能。
二、安装和配置1. 下载SQL Server安装包用户可以从微软冠方全球信息站下载SQL Server的安装程序,选择适用于自己系统的版本进行下载。
2. 安装SQL Server双击安装程序,按照指引进行安装。
在安装过程中,用户需要选择安装的组件、配置数据库实例、设置管理员账号等信息。
3. 配置SQL Server安装完成后,用户需要进行SQL Server的配置工作,包括设置数据库连接、调整性能参数、配置备份策略等。
三、基本操作1. 连接数据库用户可以使用SQL Server Management Studio(SSMS)等工具连接到数据库实例,输入正确的服务器名、用户名和密码进行连接。
2. 创建数据库通过SSMS或者T-SQL语句,用户可以创建新的数据库,指定数据库的名称、文件路径、文件大小等参数。
3. 创建表在数据库中创建表格,定义表格的字段、数据类型、约束等信息,为数据存储做准备。
4. 插入数据使用INSERT语句向数据库表格中插入数据,确保数据的完整性和正确性。
5. 查询数据使用SELECT语句查询数据库表格中的数据,根据条件筛选出符合要求的数据。
6. 更新和删除数据使用UPDATE和DELETE语句更新和删除数据库表格中的数据,确保数据的实时性和准确性。
四、高级功能1. 存储过程用户可以使用T-SQL语句创建存储过程,实现对数据库的一系列操作逻辑的封装和复用。
2. 触发器使用触发器可以在数据库表格发生特定事件时自动执行特定的操作,实现数据的自动化处理和监控。
3. 索引优化通过合理地创建各种类型的数据库索引,可以提高数据库的查询性能和数据检索速度。
4. 备份恢复制定定期备份数据库的策略,并了解如何灵活、高效地进行数据库的恢复操作。
sql-server-分区方案

s q l-s e r v e r-分区方案(总11页) --本页仅作为文档封面,使用时请直接删除即可----内页可以根据需求调整合适字体及大小--什么是表分区一般情况下,我们建立数据库表时,表数据都存放在一个文件里。
但是如果是分区表的话,表数据就会按照你指定的规则分放到不同的文件里,把一个大的数据文件拆分为多个小文件,还可以把这些小文件放在不同的磁盘下由多个cpu进行处理。
这样文件的大小随着拆分而减小,还得到硬件系统的加强,自然对我们操作数据是大大有利的。
所以大数据量的数据表,对分区的需要还是必要的,因为它可以提高select效率,还可以对历史数据经行区分存档等。
但是数据量少的数据就不要凑这个热闹啦,因为表分区会对数据库产生不必要的开销,除啦性能还会增加实现对象的管理费用和复杂性。
跟着做,分区如此简单先跟着做一个分区表(分为11个分区),去除神秘的面纱,然后咱们再逐一击破各个要点要害。
分区是要把一个表数据拆分为若干子集合,也就是把把一个数据文件拆分到多个数据文件中,然而这些文件的存放可以依托一个文件组或这多个文件组,由于多个文件组可以提高数据库的访问并发量,还可以把不同的分区配置到不同的磁盘中提高效率,所以创建时建议分区跟文件组个数相同。
1.创建文件组可以点击数据库属性在文件组里面添加T-sql语法:alter database<数据库名>add filegroup <文件组名>---创建数据库文件组alter database testSplit add filegroup ByIdGroup1alter database testSplit add filegroup ByIdGroup2alter database testSplit add filegroup ByIdGroup3alter database testSplit add filegroup ByIdGroup4alter database testSplit add filegroup ByIdGroup5alter database testSplit add filegroup ByIdGroup6alter database testSplit add filegroup ByIdGroup7alter database testSplit add filegroup ByIdGroup8alter database testSplit add filegroup ByIdGroup9alter database testSplit add filegroup ByIdGroup102.创建数据文件到文件组里面可以点击数据库属性在文件里面添加T-sql语法:alter database<数据库名称>add file<数据标识>to filegroup <文件组名称>--<数据标识> (name:文件名,fliename:物理路径文件名,size:文件初始大小kb/mb/gb/tb,filegrowth:文件自动增量kb/mb/gb/tb/%,maxsize:文件可以增加到的最大大小kb/mb/gb/tb/unlimited)alter database testSplit add file(name=N'ById1',filename=N'J:\Work\数据库\data\',size=5Mb,filegrowth=5mb)to filegroup ByIdGroup1alter database testSplit add file(name=N'ById2',filename=N'J:\Work\数据库\data\',size=5Mb,filegrowth=5mb)to filegroup ByIdGroup2alter database testSplit add file(name=N'ById3',filename=N'J:\Work\数据库\data\',size=5Mb,filegrowth=5mb)to filegroup ByIdGroup3alter database testSplit add file(name=N'ById4',filename=N'J:\Work\数据库\data\',size=5Mb,filegrowth=5mb)to filegroup ByIdGroup4alter database testSplit add file(name=N'ById5',filename=N'J:\Work\数据库\data\',size=5Mb,filegrowth=5mb)to filegroup ByIdGroup5alter database testSplit add file(name=N'ById6',filename=N'J:\Work\数据库\data\',size=5Mb,filegrowth=5mb)to filegroup ByIdGroup6alter database testSplit add file(name=N'ById7',filename=N'J:\Work\数据库\data\',size=5Mb,filegrowth=5mb)to filegroup ByIdGroup7alter database testSplit add file(name=N'ById8',filename=N'J:\Work\数据库\data\',size=5Mb,filegrowth=5mb)to filegroup ByIdGroup8alter database testSplit add file(name=N'ById9',filename=N'J:\Work\数据库\data\',size=5Mb,filegrowth=5mb)to filegroup ByIdGroup9alter database testSplit add file(name=N'ById10',filename=N'J:\Work\数据库\data\',size=5Mb,filegrowth=5mb)to filegroup ByIdGroup10执行完成后,右键数据库看文件组跟文件里面是不是多出来啦这些文件组跟文件。
SQLServer表分区的操作

SQLServer表分区的操作背景:⼤多数项⽬开发中都会有⼏个⽇志表⽤于记录⽤户操作或者数据变更的信息,往往这些表数据数据量⽐较庞⼤,每次对这些表数据进⾏操作都⽐较费时,这个时候就考虑⽤表分区对表进⾏切分到不同物理磁盘进⾏存储,从⽽提⾼运⾏效率。
表分区优点:1.性能提升:最⼤的好处应该是把表数据分割到不同的磁盘存储,充分利⽤多cpu对数据⽂件同步处理带来的数据操作效率的提升2.数据管理:分区表进⾏数据备份的时候可以单独备份需要的指定分区⽂件进⾏备份,不需要对整个表数据进⾏备份3.可⽤性:⼀个分区⽂件遭到破坏不会影响其他⽂件的正常使⽤实战:项⽬中有⼀个⽇志表因为每⽇记录数据量太⼤(3个⽉数据2000W)需要只保留最近三个⽉的数据,这样就要求每⽉初把3个⽉前的数据给删掉,同时这个表要进⾏分页查询和数据汇总,这样就考虑到将这张表进⾏分区操作,操作数据库是SQL Server2012(只有专业版才⽀持分区)第⼀步:创建⽂件组和分组⽂件alter database Test add filegroup LoginLog1alter database Test add filegroup LoginLog2alter database Test add filegroup LoginLog3alter database Test add filegroup LoginLog4Test是⽤来测试的数据库名称,我们先创建4个⽂件组接下来创建分组⽂件alter database Test add file(Name=N'LoginLog1',filename='G:\练习\表分区测试\group\LoginLog1.ndf',size=10mb,maxsize=200Mb,filegrowth=5mb)to filegroup LoginLog1alter database Test add file(Name=N'LoginLog2',filename='G:\练习\表分区测试\group\LoginLog2.ndf',size=10mb,maxsize=200Mb,filegrowth=5mb)to filegroup LoginLog2alter database Test add file(Name=N'LoginLog3',filename='G:\练习\表分区测试\group\LoginLog3.ndf',size=10mb,maxsize=200Mb,filegrowth=5mb)to filegroup LoginLog3alter database Test add file(Name=N'LoginLog4',filename='G:\练习\表分区测试\group\LoginLog4.ndf',size=10mb,maxsize=200Mb,filegrowth=5mb)to filegroup LoginLog4第⼆步创建分区函数我们当前⽤时间作为分区字段,以便于⽇志表根据添加时间做分区create partition function Login_Log_CreateTime (datetime)as range right for values ('2017-04-01','2017-05-01','2017-06-01')这⾥我们⽤三个⽇期把整个时间轴划分为4块:2017-04-01以前的数据、2017-04-01⾄2017-04-30的数据、2017-05-01⾄2017-05-31的数据、2017-06-01⾄2017-06-30的数据注意range right的left和right的作⽤是决定临界点值得归属,⼀开始我这⾥⽤的是left导致分区划分为4、5、6和6⽉份以后的数据,这样导致我在下次添加新的分区的时候没办法添加2017-07-01的分割点,只能添加>=2017-08-01的时间点。
大型数据库技术第05章SQL Server查询处理和表数据编辑

2014年10月16日4时53分
» 7
第5章 SQL Server查询处理和表数据编辑
大型数据库 SQL Server 2005
(3)查询计算列
• 也可以查询由常量、变量和函数构成的表达式
【例5-3】将累计学分降低10%后显示出来
SELECT FROM 姓名, 累计学分, 累计学分- 累计学分*0.1 学生表
第5章 SQL Server查询处理和表数据编辑
大型数据库 SQL Server 2005
(5) 空值判断
返回
• 查询条件: exp IS [NOT] NULL • exp 是由常量、变量、函数构成的表达式。 • 含义:exp的值(不)为空值,则条件为真,否则为假。 【例5-17】查询没有成绩的学号和开课计划编号。 SELECT 学号, 开课号 FROM 选课表 WHERE 成绩 IS NULL • 注意“IS”不能用“=”代替。 【例5-18】查询有成绩的学号和开课计划编号。 SELECT 学号, 开课号 FROM 选课表 WHERE 成绩 IS NOT NULL • 注意“IS NOT”不能用“!=”或“<>”代替。
返回
• 模式字符串除了包含普通字符外,还包含下列特殊字符(称为通配 符): % 匹配任意长度的字符串(长度可以为 0) 【例5-15 5-13 】查询姓名中第二个字为“鹏”的学生学号和姓名。 【例 1”和“ 3 5-14】查询学号最后一位既不是“ 】查询学号长度不等于 7,或者学号后 6”,也不是 位含有非数字 “ 字符的学生学号和姓名。 _ 9”的学生学号和姓名。 匹配任意一个字符 SELECT 学号 ,姓名 FROM 学生表 SELECT 学号 , 姓名 FROM 学生表 SELECT 学号 , 姓名 学生表 c , c , …, c WHERE 姓名 LIKE 鹏 [c1c2… cn] 匹配字符 c1, c2'_ ,FROM …, cn%' 中的一个。当 1 2 n WHERE 学号 '%[^139]' WHERE 学号 LIKE NOT 连续时可简化为 [c1-cLIKE n] 'S[0-9][0-9][0-9][0-9][0-9][0-9]' ESCAPE短语 : 使模式串中的某个通配符恢复原来的含义。 [^c1c2…cn] 匹配除c1, c2, …, cn外的一个字符。当c1, c2, …, 【例5-16 】查询课程名以“DB_”开头的课程信息。 cn连续时可简化为[^c1-cn] SELECT * FROM 课程表 • 含义:若s1(不)与s2相匹配,则条件为真,否则为假。 2014 年10月16日 4时53分 LIKE 'DB\_%' ESCAPE '\' » 16 WHERE 课名
sql大数据量的分表操作

sql⼤数据量的分表操作-- 建⽴⽂件组:use OwnMSDBgoalter database OwnMSDB add filegroup filegroup1alter database OwnMSDB add filegroup filegroup2alter database OwnMSDB add filegroup filegroup3alter database OwnMSDB add filegroup filegroup4go-- 在⽂件组中添加⽂件,⼀个⽂件组可以包含多个⽂件,每个⽂件代表的是某个表的分表,最好放到不同的磁盘下,可以充分发挥IO的操作速度use OwnMSDBgoalter database OwnMSDB add file(name=N'TextDataFile',filename=N'C:\sql file group1\TextDataFile1.ndf',size=3072kb,filegrowth=1024KB) to filegroup filegroup1 -- and so on--表分区步骤-- 如果数据库含有⼤量表格,则把表格分区是很好的优化性能的⽅法--1 ,创建⼀个分区函数 how-- 定义⼀个分区的函数,来把不同编号的客户区分出来create partition function customer_partfunc(int)as range rightfor values(250000,500000,750000)--分区为>=250000 ,250000< >=500000,50000< <=750000,750000<--2,创建⼀个分区架构,将分区连接到指定的到指定的⽂件组就⾏了use OwnMSDBgocreate partition scheme customer_partschemeas partition customer_partfuncto(filegroup1,filegroup2,filegroup3,filegroup4)--3,对⼀个表分区create table Customer1(firstname varchar(100),lastname varchar(100),customerid int)on customer_partscheme(customerid)。
SqlServer性能优化——Partition(管理分区)

SqlServer性能优化——Partition(管理分区)Sql Server性能优化——Partition(管理分区)作者: 拖鞋不脱来源: 博客园发布时间: 2010-09-01 14:59 阅读: 4 次原文链接全屏阅读 [收藏]编辑点评:正如文章"SqlServer 性能优化——Partition(创建分区)"中所述,分区并不是一个一劳永逸的操作,对一张表做好分区仅仅是开始,接下来可能需要频繁的变更分区,管理分区。
在企业管理器中,虽然有“管理分区”的菜单,里面的内容却可能与你的预想不同,这里并没有提供直接对分区进行操作的方法,所以一些普通的操作,比如“增加分区”、“删除分区”之类的操作就需要通过脚本实现了。
增加分区(Split Partition)“增加分区”事实上就是将现有的分区分割开,基于此,在SQL Server中应用的是Split操作。
在分离分区的时候,不仅仅要在Partition Function上指定分割的分界点,同样需要在Partition Scheme上指定新分区应用的文件组:--指定下一个分区应用文件组PRIMARYALTER PARTITION SCHEME [MyPartitionSchema]NEXT USED [PRIMARY]--指定分区分界点为5000ALTER PARTITION FUNCTION MyPartitionFunction()SPLIT RANGE (5000)需要注意的一点是,新增的分区中非聚簇索引的压缩模式会被置为None。
删除分区(Merge Partition)“删除分区”同样可以认为是将原来分离的分区合并在一起,所以对应的是Merge操作,而且由于并没有新增的分区,Partition Scheme并不需要改变:ALTER PARTITION FUNCTION MyPartitionFunction ()MERGE RANGE (5000)切换分区(Switch Partition)“切换分区”可能是一个比看上去会应用的更频繁的操作,它的意义在于将一个分区的数据从一张表切换到另一张表中。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
SQL SERVER 2005利用分区对大数据表处理操作手册超大型数据库的大小常常达到数百GB,有时甚至要用TB来计算。
而单表的数据量往往会达到上亿的记录,并且记录数会随着时间而增长。
这不但影响着数据库的运行效率,也增大数据库的维护难度。
除了表的数据量外,对表不同的访问模式也可能会影响性能和可用性。
这些问题都可以通过对大表进行合理分区得到很大的改善。
当表和索引变得非常大时,分区可以将数据分为更小、更容易管理的部分来提高系统的运行效率。
如果系统有多个CPU或是多个磁盘子系统,可以通过并行操作获得更好的性能。
所以对大表进行分区是处理海量数据的一种十分高效的方法。
本文通过一个具体实例,介绍如何创建和修改分区表,以及如何查看分区表。
SQL Server 2005是微软在推出SQL Server 2000后时隔五年推出的一个数据库平台,它的数据库引擎为关系型数据和结构化数据提供了更安全可靠的存储功能,使用户可以构建和管理用于业务的高可用和高性能的数据应用程序。
此外SQL Server 2005结合了分析、报表、集成和通知功能。
这使企业可以构建和部署经济有效的BI解决方案,帮助团队通过记分卡、Dashboard、Web Services 和移动设备将数据应用推向业务的各个领域。
无论是开发人员、数据库管理员、信息工作者还是决策者,SQL Server 2005都可以提供出创新的解决方案,并可从数据中获得更多的益处。
它所带来的新特性,如T-SQL的增强、数据分区、服务代理和与.NetFramework的集成等,在易管理性、可用性、可伸缩性和安全性等方面都有很大的增强。
表分区的具体实现方法:表分区分为水平分区和垂直分区。
水平分区将表分为多个表。
每个表包含的列数相同,但是行更少。
例如,可以将一个包含十亿行的表水平分区成12个表,每个小表表示特定年份内一个月的数据。
任何需要特定月份数据的查询只需引用相应月份的表。
而垂直分区则是将原始表分成多个只包含较少列的表。
水平分区是最常用分区方式,本文以水平分区来介绍具体实现方法。
水平分区常用的方法是根据时期和使用对数据进行水平分区。
例如本文例子,一个短信发送记录表包含最近一年的数据,但是只定期访问本季度的数据。
在这种情况下,可考虑将数据分成四个区,每个区只包含一个季度的数据。
以下是创建过程:一、最基本,最重要的一步就是创建分区函数。
创建分区函数首先要确定分区键--既按照哪字段来进行分区。
在这里,使用记录的时间来作为分区键,由于数据量的问题,最终决定每个月的数据放一个单独的分区。
CREATE PARTION FUNCTION FiveYearDateRangePFN(datetime)ASRANGE LEFT FOR VALUES (' 23:59:59.997',--2006年9月' 23:59:59.997',--2006年10月' 23:59:59.997',--2006年11月' 23:59:59.997',--2006年12月' 23:59:59.997',--2007年1月' 23:59:59.997',--2007年2月' 23:59:59.997',--2007年3月' 23:59:59.997',--2007年4月' 23:59:59.997',--2007年5月' 23:59:59.997',--2007年6月'200731 23:59:59.997',-- 2007年7月' 23:59:59.997',--2007年8月' 23:59:59.997',--2007年9月' 23:59:59.997',--2007年10月' 23:59:59.997',--2007年11月' 23:59:59.997',--2007年12月.......}GO二、上一步是完成一个概念上的分区,接下来要完成一个物理的构建,使得属于不同分区的数据存储到不同的物理文件上去.a.创建文件组创建多个文件组主要是为了获得好的I/O 平衡。
一般情况下,文件组数最好与分区数相同,并且这些文件组通常位于不同的磁盘上。
每个文件组可以由一个或多个文件构成,而每个分区必须映射到一个文件组。
一个文件组可以由多个分区使用。
为了更好地管理数据(例如,为了获得更精确的备份控制),对分区表应进行设计,以便只有相关数据或逻辑分组的数据位于同一个文件组中。
使用ALTER DATABASE,添加逻辑文件组名:--File group for 2006ALTER DATABASE MES ADD FILEGROUP [Teaching200609]ALTER DATABASE MES ADD FILEGROUP [Teaching200610]ALTER DATABASE MES ADD FILEGROUP [Teaching200611]ALTER DATABASE MES ADD FILEGROUP [Teaching200612]--File group for 2007ALTER DATABASE MES ADD FILEGROUP [Teaching200701]ALTER DATABASE MES ADD FILEGROUP [Teaching200702]ALTER DATABASE MES ADD FILEGROUP [Teaching200703]ALTER DATABASE MES ADD FILEGROUP [Teaching200704]ALTER DATABASE MES ADD FILEGROUP [Teaching200705]ALTER DATABASE MES ADD FILEGROUP [Teaching200706]ALTER DATABASE MES ADD FILEGROUP [Teaching2007]ALTER DATABASE MES ADD FILEGROUP [Teaching200708]ALTER DATABASE MES ADD FILEGROUP [Teaching200709]ALTER DATABASE MES ADD FILEGROUP [Teaching200710]ALTER DATABASE MES ADD FILEGROUP [Teaching200711]ALTER DATABASE MES ADD FILEGROUP [Teaching200712]......b.创建物理文件,在这里,为了方便起见,把每个物理文件放到了一个单独的文件组里面.--Add file for 2006ALTER DATABASE MESADD FILE(NAME=N'Teaching200609',FILENAME =N'D:\MyData\MyLu\Teaching200609.ndf',SIZE =5MB,MAXSIZE =100MB,FILEGROWTH = 5MB)TO FILEGROUP [Teaching200609]ALTER DATABASE MESADD FILE(NAME=N'Teaching200610',FILENAME =N'D:\MyData\MyLu\Teaching200610.ndf',SIZE =5MB,MAXSIZE =100MB,FILEGROWTH = 5MB)TO FILEGROUP [Teaching200610]ALTER DATABASE MESADD FILE(NAME=N'Teaching200611',FILENAME =N'D:\MyData\MyLu\Teaching200611.ndf',SIZE =5MB,MAXSIZE =100MB,FILEGROWTH = 5MB)TO FILEGROUP [Teaching200611]......三、创建完分区函数,接下来就要建立分区架构,用来将概念上的分区和文件组(物理文件)关联起来。
创建分区函数后,必须将其与分区方案相关联,以便将分区指向至特定的文件组。
就是定义实际存放数据的媒体与各数据块的对应关系。
多个数据表可以共用相同的数据分区函数,一般不共用相同的数据分区方案。
可以通过不同的分区方案,使用相同的分区函数,使不同的数据表有相同的分区条件,但存放在不同的媒介上。
创建分区方案的代码如下:CREATE PARTION SCHEME [FiveYearDateRangePScheme]ASPARTION FiveYearDateRangePFN TO( [Teaching200609],[Teaching200610],[Teaching200611],[Teaching200612],[Teaching200701],[Teaching200702],[Teaching200703],[Teaching200704],[Teaching200705],[Teaching200706],[Teaching2007],[Teaching200708],[Teaching200709],[Teaching200710],[Teaching200711],[Teaching200712],......[PRIMARY] )GO四、分区表的基础架构到此就完成了,接下来就要对原有的数据表建立分区了。
分区表是通过定义分区键值和分区方案相联系的。
插入记录时,SQLSERVER会根据分区键值的不同,通过分区函数的定义将数据放到相应的分区。
从而把分区函数、分区方案和分区表三者有机的结合起来。
创建分区表的代码如下:ALTER TABLE REPORT_ITEMVALUESADDPRIMARY KEY NONCLUSTERED(reportid,rq,itemid)ON FiveYearDateRangePScheme(rq)GO五、维护分区分区的维护主要设计分区的添加、减少、合并和在分区间转换。
可以通过ALTER PARTION FUNCTION的选项SPLIT,MERGE和ALTER TABLE的选项SWITCH 来实现。
SPLIT会多增加一个分区,而MEGRE会合并或者减少分区,SWITCH则是逻辑地在组间转换分区。
在建立分区表的时候注意一下分区键的选择。
接下来呢,就可以往分区表里面插入数据,SQL SERVER会根据分区键的不同将数据放到相应的分区,我们可以通过如下语句来查看数据存在那个分区中:select $partion.FiveYearDateRangePFN(teachingdate),teachingdate,*from objteaching aorder by a.teachingdate asc结束语对海量数据的处理一直是一个令人头痛的问题。