sqlserver表操作
SQLServer的表数据简单操作(表数据查询)

SQLServer的表数据简单操作(表数据查询)--表数据查询----数据的基本查询----数据简单的查询--select * | 字段名[,字段名2, ...] from 数据表名 [where 条件表达式]例:use商品管理数据库goselect*from商品信息表select商品编号,商品名称,产地from商品信息表selelct *from商品信息表where产地='辽宁沈阳'理解例⼦--关键字辅助查询----1)distinct关键字(⽤来消除查询结果中的重复⾏,使⽤时紧跟在select命令后)--select distinct * | 字段名[,字段名2, ...] from 数据表名 [where 条件表达式]例:use商品管理数据库goselect distinct产地from商品信息表理解例⼦--2)top关键字(⽤来查找结果中前n条或前n%条记录,⽤法:top n | n percent,使⽤时紧跟在select命令后)--select top n | n percent * | 字段名[,字段名2, ...] from 数据表名 [where 条件表达式]例:use 商品管理数据库goselect top 3 * from 商品信息表 --查询结果的前3条记录select top 30 percent * from 商品信息表 --查询结果的30%条记录--3)between...and...关键字(⽤来查找结果在⼀定范围内的记录,使⽤时放于where后⾯,作为筛选条件)--字段名[not] between 低值 and ⾼值 --加"not"表⽰对满⾜between...and...关键字的查找结果取反值例:use 商品管理数据库goselelct * from 库存信息表 where 库存数量 between 100 and 200 --查询"库存信息表"中"库存数量"在100到200之间的记录--4)in 关键字(⽤来查找结果为指定值的记录,使⽤时放于where后⾯,作为筛选条件)--字段名[not] int (值1,值2,值3,...) --加"not"表⽰对满⾜in关键字的查找结果取反值例:use 商品管理数据库goselelct * from 库存信息表 where 库存数量 in(100,200) --查询"库存信息表"中"库存数量"为100或者200的记录--5)like 关键字(⽤来实现表⽰⼀定范围的模糊查询,主要⽤于字符型字段,使⽤时放于where后⾯,作为筛选条件)--字段名 [not] like '<字符表达式>' --加"not"表⽰对满⾜like关键字的查找结果取反值例:use 商品管理数据库goselect * from 客户信息表 where 客户姓名 like '_⼩%' --查询"客户信息表"中"客户姓名"满⾜筛选条件'_⼩%'的记录--6)in null 关键字(⽤来查询字段中是否包含空值,使⽤时放在where后⾯,作为条件筛选)--字段名 is null --is不可以⽤"="代替,null也不能⽤"0"或空格等代替例:use 商品管理数据库goselelct * from 客户信息表 where 邮箱 is null--数据的统计查询---- 聚合函数查询--count( * | 字段名) --统计数据表中的数据总数sum( 表达式 | 字段名) --计算表达式或字段名中数据的和,表达式或字段名的数据类型要求是数值型avg( 表达式 | 字段名) --计算表达式或字段名中数据的平均值,表达式或字段名的数据类型要求是数值型max( 表达式 | 字段名) --求出表达式或字段名中数据的最⼤值,表达式或字段名的数据类型可以是数值型、字符型或⽇期时间型min( 表达式 | 字段名) --求出表达式或字段名中数据的最⼩值,表达式或字段名的数据类型可以是数值型、字符型或⽇期时间型--为查询结果重命名的3种⽅法:--原字段名 '新字段名'原字段名 as '新字段名''新字段名'=原字段名例:use 商品管理数据库goselect COUNT(*),SUM(进货数量),AVG(进货⾦额),MAX(进货⾦额),MIN(进货⾦额) from 进货信息表select COUNT(*)as'总记录',SUM(进货数量)as'进货数量和',AVG(进货⾦额) '进货⾦额平均数',MAX(进货⾦额) '进货⾦额最⼤值','进货⾦额最⼩值'=MIN(进货⾦额) from 进货信息表--查询结果排序(order by 语句⽤于实现排序操作,可以出现在from或者where语句的后⾯)--order by 字段名1 [,字段名2, ...] [asc | desc] --加asc表⽰升序,加desc表⽰降序,默认升序,关键字asc可以省略例:use 商品管理数据库goselect*from 进货信息表 order by 进货数量 desc --查询进货信息表中的所有字段,并将进货数量进⾏降序排序--查询结果分组⼩计----1)group by...语句 --使⽤时可出现在from语句或者where语句后⾯group by 字段名列表 [ having 条件表达式] --"字段名列表"表⽰按该字段分组。
sqlserver如何使用sql语句创建表

sqlserver如何使⽤sql语句创建表--使⽤masteruse mastergo--判断数据库HR是否存在if exists(select 1 from sysdatabases where name='HR')begin--如果存在则删除数据库HRdrop database HRendgo--创建数据库HRcreate database HRgo--使⽤数据库HRuse HRgo----------------------------------------------------------------------------------------在数据库HR中创建JOBS表存储公司中职位的信息--判断JOBS表是否存在if exists(select 1 from sysobjects where name='JOBS')begin--如果表存在则删除JOBS表drop table JOBSendgo--创建JOBS表create table JOBS(JOB_ID varchar(10) not null primary key,--职位编号JOB_TITLE nvarchar(20) not null, --职位名称MIN_SALARY money not null, --职位最低薪资,不⼩于1000元MAX_SALARY money not null --职位最⾼薪资,不⼩于最低薪资)go---------添加JOBS表中的约束条件-------------检查MIN_SALARY不⼩于1000元alter table JOBSadd constraint CH_MIN_SALARY check(MIN_SALARY>=1000)--检查MAX_SALARY不⼩于不⼩于最低薪资alter table JOBSadd constraint CH_MAX_SALARY check(MAX_SALARY>=MIN_SALARY)go--向表JOBS中添加测试数据insert into JOBS values(1001,'经理',1200,1300)--insert into JOBS values(1002,'经理1', 200,1300)错误,职位最低薪资⼩于1000元go--显⽰JOBS中的所有的信息select * from JOBSgo------------------------------------------------------------------------------------------------------------------------------------------------------------------------------在数据库HR中创建DEPARTMENTS表存储公司中部门的信息--判断表DEPARTMENTS是否存在if exists(select 1 from sysobjects where name='DEPARTMENTS')begin--如果存在则删除drop table DEPARTMENTSendgo--创建表DEPARTMENTScreate table DEPARTMENTS(DEPARTMENT_ID int identity(1001,1) primary key not null,--部门编号,主键,⾃增DEPARTMENT_NAME nvarchar(30) not null, --部门名称MANAGER_ID int --部门主管编号,外键,引⽤EMPLOYEES表的EMPLOYEE_ID)go--向表中添加测试数据insert into DEPARTMENTS values('管理部门',null)go--显⽰表DEPARTMENTS中的所有的信息select * from DEPARTMENTSgo------------------------------------------------------------------------------------------------------------------------------------------------------------------------------在数据库HR中创建EMPLOYEES表存储公司中职员的信息--判断表EMPLOYEES是否存在if exists(select 1 from sysobjects where name='EMPLOYEES')begin--如果EMPLOYEES表中存在则删除表drop table EMPLOYEESendgo--创建表EMPLOYEEScreate table EMPLOYEES(EMPLOYEE_ID int primary key identity(100,1) not null, --职员编号,主键,⾃增(起始值为100,每次增1)FIRST_NAME nvarchar(4) not null, --职员名称LAST_NAME nvarchar(4) not null,--职员姓⽒EMAIL varchar(25) not null,--职员邮件PHONE_NUMBER varchar(20) not null,--职员电话HIRE_DATE datetime default(getdate()),--职员⼊职时间JOB_ID varchar(10) not null,--职员职位编号,外键,引⽤JOBS表的JOB_IDSALARY money ,--职员薪资,⼤于0MANAGER_ID int ,--职员主管编号,外键,引⽤EMPLOYEES表的EMPLOYEE_IDDEPARTMENT_ID int ,--职员部门编号,外键,引⽤DEPARTMENTS表的DEPARTMENT_ID)go----------向表中添加约束条件----------------- 职员职位编号,外键,引⽤JOBS表的JOB_IDalter table EMPLOYEESadd constraint FK_JOB_ID foreign key(JOB_ID) references JOBS(JOB_ID)--职员薪资,⼤于0alter table EMPLOYEESadd constraint CH_SALARY check(SALARY>0)--职员主管编号,外键,引⽤EMPLOYEES表的EMPLOYEE_IDalter table EMPLOYEESadd constraint FK_EMPLOYEE_ID foreign key(EMPLOYEE_ID) references EMPLOYEES(EMPLOYEE_ID)-- 职员部门编号,外键,引⽤DEPARTMENTS表的DEPARTMENT_IDalter table EMPLOYEESadd constraint FK_DEPARTMENT_ID foreign key(DEPARTMENT_ID) references DEPARTMENTS(DEPARTMENT_ID) go--向表EMPLOYEES中添加测试数据insert into EMPLOYEES values('李四','李','821670983@','180123266',default,'1001',2000,100,1001)go--显⽰表EMPLOYEES中的所有的信息select * from EMPLOYEESgo---------------------------------------------------------------------------------------------------扩展练习-------------------------------------------------------------------------------------------------------------在数据库HR中,创建任职历史记录表distory--判断HR中的表distory是否存在if exists (select 1 from sysobjects where name='distory')begin--如果表存在则删除该表drop table distoryendgo--创建表distorycreate table distory(EMPLOYEE_ID int not null,--职员编号,主键START_DATE datetime not null,--开始时间,主键END_DATE datetime not null,--结束时间默认为getdate()JOB_ID varchar(10) not null,--职员职位编号,外键,引⽤JOBS表的JOB_IDDEPARTMENT_ID int --职员部门编号,外键,引⽤DEPARTMENTS表的DEPARTMENT_ID)go----------向表中添加约束条件-----------------职员编号,主键alter table distoryadd constraint PK_EMPLOYEE_ID primary key(EMPLOYEE_ID)--开始时间,主键alter table distoryadd constraint PK_START_DATE unique(START_DATE)--结束时间默认为getdate()alter table distoryadd constraint DF_END_DATE default(getdate()) for END_DATE--职员职位编号,外键,引⽤JOBS表的JOB_IDalter table distoryadd constraint FK_JOB_ID1 foreign key(JOB_ID) references JOBS(JOB_ID)--职员部门编号,外键,引⽤DEPARTMENTS表的DEPARTMENT_IDalter table distoryadd constraint FK_DEPARTMENT_ID1 foreign key(DEPARTMENT_ID) references DEPARTMENTS(DEPARTMENT_ID) go--向表distory中添加测试数据insert into distory values(100001,'2012.12.12',default,'1001',1001)insert into distory values(100002,'2015. 2. 2',default,'1001',1001)go--查询表distory中的所有的信息select * from distorygo--------------------------------------------------------------------------------------。
sqlserver数据库导出表结构说明

sqlserver数据库导出表结构说明要在SQL Server中导出表结构说明,你可以使用多种方法,包括使用SQL Server Management Studio (SSMS) 或查询系统表。
下面是两种常见的方法:方法 1: 使用 SQL Server Management Studio (SSMS)1. 打开 SQL Server Management Studio 并连接到你的数据库实例。
2. 在“对象资源管理器”中,展开你想要导出表结构的数据库。
3. 右键点击“表”,选择“编写表脚本为” -> “CREATE 到” -> “新查询编辑器窗口”。
4. 这将为所选的每个表生成一个 CREATE TABLE 语句,其中包含表结构、索引、触发器等。
5. 你可以复制这些语句并保存到文件中,或者直接在新的查询编辑器窗口中执行它们。
方法 2: 使用系统表查询你也可以通过查询系统表来获取表结构信息,并将结果保存到文件中。
例如,下面的查询可以用于获取表结构信息:```sqlSELECTTABLE_NAME,COLUMN_NAME,DATA_TYPE,IS_NULLABLE,COLUMN_DEFAULT,CHARACTER_MAXIMUM_LENGTH,NUMERIC_PRECISION,NUMERIC_SCALEFROMINFORMATION_WHERETABLE_NAME = 'YourTableName' -- 替换为你的表名ORDER BYORDINAL_POSITION;```你可以将上述查询的结果导出到文件,或者将其复制到其他工具或应用程序中。
注意:以上两种方法都是基于SQL Server的,并且假设你有足够的权限来访问和导出这些信息。
SQLServer表的创建与操作

binary[(n)], varbinary[(n)], varbinary(MAX) Image
date, datetime, smalldatetime, datetime2, datetimeoffset, time timestamp geometry, geography sql_variant, uniqueidentifier, xml, hierarchyid
8.日期时间型:date,datetime,smalldatetime,datetime2,
datetimeoffset,time
备注
提前修完《数据结构》 班长
下面简单介绍与表有关的几个概念。 (1)表结构。组成表的各列的名称及数据类型,统称为表结构。 (2)记录。每个表包含若干行数据,它们是表的“值”,表中的一行称为一个 记录。 (3)字段。每个记录由若干个数据项构成,将构成记录的每个数据项称为字段。 例如,表3.1中的表结构为(学号,姓名,性别,出生时间,专业,总学分,备注), 包含7个字段,由5个记录组成。 (4)空值。空值(NULL)通常表示未知、不可用或将在以后添加的数据。若 一个列允许为空值,则向表中输入记录值时可不为该列给出具体值;而一个列若不允 许为空值,则在输入时必须给出具体值。 (5)关键字。若表中记录的某一字段或字段组合能唯一标识记录,则称该字段 或字段组合为候选关键字(Candidate key)。
263~2631 19
存储字节 4
2 1 8
2.精确数值型:decimal,numeric 精确数值型数据由整数部分和小数部分构成,其所有的数字都是有效位,能够以 完整的精度存储十进制数。decimal 和 numeric在功能上完全等价。 格式:numeric | decimal(p[,s]),其中p为精度,s为小数位数,s<p, 默认值为0。 存储–1038+1~1038–1的固定精度和小数位的数字数据。
sqlserver几种建表方式

sqlserver几种建表方式SQL Server是一种关系型数据库管理系统,它提供了多种建表方式,以满足不同的需求和场景。
本文将介绍SQL Server中几种常见的建表方式。
第一种建表方式是使用SQL Server Management Studio(SSMS)图形界面。
SSMS是SQL Server的官方管理工具,它提供了一个直观的图形界面,可以通过拖拽和点击来创建表。
在SSMS中,我们可以选择数据库,右键点击“表”文件夹,然后选择“新建表”选项。
接下来,我们可以在表设计器中定义表的结构,包括列名、数据类型、约束等。
最后,点击保存按钮即可创建表。
第二种建表方式是使用Transact-SQL(T-SQL)语句。
T-SQL是SQL Server的扩展语言,它可以用于管理数据库对象、执行查询和修改数据等操作。
通过编写T-SQL语句,我们可以创建表并定义其结构。
例如,下面的代码演示了如何使用T-SQL语句创建一个名为“students”的表:```CREATE TABLE students (id INT PRIMARY KEY,name VARCHAR(50),age INT,gender VARCHAR(10));```在上述代码中,我们使用CREATE TABLE语句创建了一个名为“students”的表,该表包含了id、name、age和gender四个列,分别定义了它们的数据类型和约束。
第三种建表方式是使用SQL Server Integration Services(SSIS)。
SSIS是SQL Server的一种数据集成工具,它可以用于将数据从不同的源导入到SQL Server中。
在SSIS中,我们可以使用“导入和导出向导”来创建表并定义其结构。
通过选择源和目标数据库,以及映射源和目标列,我们可以轻松地创建表并将数据导入其中。
第四种建表方式是使用SQL Server Data Tools(SSDT)。
sqlserver 2017 创建数据表使用步骤

sqlserver 2017 创建数据表使用步骤
在 SQL Server 2017 中,创建数据表的步骤如下:
1. 打开 SQL Server Management Studio (SSMS)。
2. 连接到 SQL Server 数据库引擎。
3. 在 "对象资源管理器" 窗口中找到你想要创建数据表的数据库,展开该数据库。
4. 右键单击 "表" 文件夹,然后选择 "新建表"。
5. 在 "新建表" 对话框中,输入数据表的名称。
6. 在 "设计" 窗口中,选择并定义数据表的列。
- 单击 "列名" 单元格,输入列的名称。
- 在 "数据类型" 列选择合适的数据类型。
- 在 "长度/值" 列中指定列的长度。
- 可以为每一列选择是否允许空值、是否自增等属性。
7. 单击 "保存" 图标,或使用 "Ctrl + S" 快捷键保存数据表的设计。
8. 关闭 "设计" 窗口,数据表会自动保存到指定的数据库中。
完成上述步骤后,你就成功地在 SQL Server 2017 中创建了一个数据表。
sqlserver几种建表方式

sqlserver几种建表方式摘要:1.SQL Server 简介2.建表的基本概念3.创建表的语法4.几种建表方式及其示例5.建表的注意事项正文:1.SQL Server 简介SQL Server 是由Microsoft 公司开发的一款关系型数据库管理系统,广泛应用于企业级数据存储和管理。
SQL Server 提供了丰富的功能和高效的性能,可以满足各种不同类型的业务需求。
2.建表的基本概念在建立数据库时,我们需要创建表来存储数据。
表是数据库中的一种基本对象,它可以看作是一个数据容器,用于存储具有相同属性的数据记录。
在SQL Server 中,建表是指创建一个新的表,并定义其结构和属性。
3.创建表的语法在SQL Server 中,创建表的语法如下:```sqlCREATE TABLE 表名(列名1 数据类型,列名2 数据类型,列名3 数据类型,...);```其中,表名是我们为新表起的名字,列名1、列名2、列名3 等是用于存储数据的列,数据类型表示该列存储的数据类型,如int、varchar、datetime 等。
4.几种建表方式及其示例(1) 使用单个CREATE TABLE 语句创建表```sqlCREATE TABLE Employees (EmployeeID int PRIMARY KEY,FirstName varchar(50),LastName varchar(50),Email varchar(100),Phone varchar(20));```(2) 使用ALTER TABLE 语句创建表如果数据库中已经存在一个表,我们可以使用ALTER TABLE 语句来修改表结构,增加新的列。
```sqlALTER TABLE EmployeesADD Email varchar(100);ALTER TABLE EmployeesADD Phone varchar(20);```(3) 使用CREATE TABLE AS SELECT 语句创建表如果我们想根据现有表的数据创建一个新表,可以使用CREATE TABLE AS SELECT 语句。
SQLServer表的创建和操作

3.浮点型:real,float 浮点型不能精确表示数据的精度,用于处理取值范围非常大且对精确度要求不太 高的数值量。
类型 数范围 real –3.40E+38~3.40E+38 float –1.79E+308~1.79E+308 定义长度(n) 1~24 25~53 精度 7 15 字节 4 8
4.货币型:money,smallmoney 用十进制数表示货币值。
类型 money smallmoney 数范围 263~2631 –231~2311 小数位数 4 4 精度 19 10 字节 8 4
5.位型:bit
它只存储0和1。当为bit类型数据赋0时,其值为0,而赋非0时,其值为1。字符串值TRUE 转换为1,FALSEห้องสมุดไป่ตู้换为0。
(1)日期部分的表示形式常用的格式如下:
年月日 年日月 月 日[,]年 月年日 日 月[,]年 日年月 年(4位数) 年月日 月/日/年 月-日-年 月.日.年 2001 Jan 20、2001 January 20 2001 20 Jan Jan 20 2001、Jan 20,2001、Jan 20,01 Jan 2001 20 20 Jan 2001、20 Jan,2001 20 2001 Jan 2001表示2001年1月1日 20010120、010120 01/20/01、1/20/01、01/20/2001、1/20/2001 01-20-01、1-20-01、01-20-2001、1-20-2001 01.20.01、1.20.01、01.20.2001、1.20.2001
8
默认值 默认值 12 默认值 500
×
√ √ √ √ √
无
1 无 无 0 无
SQLserver命令创建、修改、删除数据表
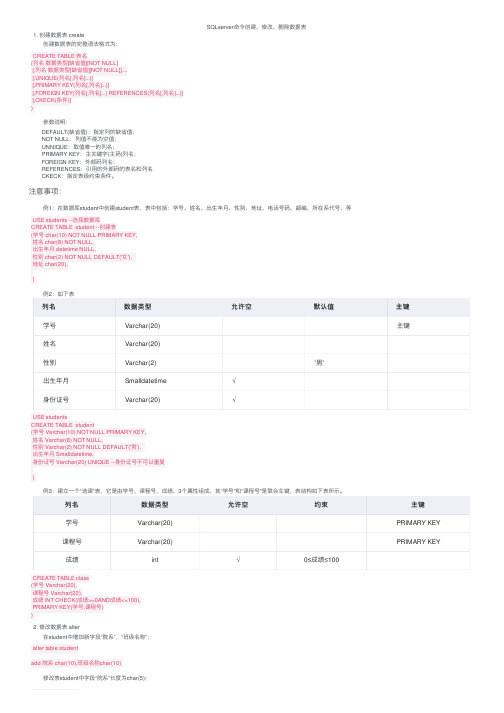
SQLserver命令创建、修改、删除数据表1. 创建数据表 create创建数据表的完整语法格式为:CREATE TABLE 表名(列名数据类型[缺省值][NOT NULL][,列名数据类型[缺省值][NOT NULL]]....[,UNIQUE(列名[,列名]...)][,PRIMARY KEY(列名[,列名]...)][,FOREIGN KEY(列名[,列名]...) REFERENCES(列名[,列名]...)][,CKECK(条件)])参数说明:DEFAULT(缺省值):指定列的缺省值;NOT NULL:列值不能为空值;UNNIQUE:取值唯⼀的列名;PRIMARY KEY:主关键字(主码)列名;FOREIGN KEY:外部码列名;REFERENCES:引⽤的外部码的表名和列名CKECK:指定表级约束条件。
注意事项:例1:在数据库student中创建student表,表中包括:学号、姓名、出⽣年⽉、性别、地址、电话号码、邮编、所在系代号、等USE students --选择数据库CREATE TABLE student --创建表(学号 char(10) NOT NULL PRIMARY KEY,姓名 char(8) NOT NULL,出⽣年⽉ datetime NULL,性别 char(2) NOT NULL DEFAULT('⼥'),地址 char(20),)例2:如下表列名数据类型允许空默认值主键学号Varchar(20)主键姓名Varchar(20)性别Varchar(2)'男'出⽣年⽉Smalldatetime√⾝份证号Varchar(20)√USE studentsCREATE TABLE student(学号 Varchar(10) NOT NULL PRIMARY KEY,姓名 Varchar(8) NOT NULL,性别 Varchar(2) NOT NULL DEFAULT('男'),出⽣年⽉ Smalldatetime,⾝份证号 Varchar(20) UNIQUE --⾝份证号不可以重复)例3:建⽴⼀个“选课”表,它是由学号、课程号、成绩、3个属性组成,其“学号”和“课程号”是联合主键,表结构如下表所⽰。
sqlserver exec 返回 table

SQL Server 是一种关系型数据库管理系统,它允许用户通过执行 SQL 查询来访问和操纵数据库中的数据。
在 SQL Server 中,exec 关键字用于执行存储过程或函数。
当执行存储过程时,有时需要将结果作为表返回,这就涉及到使用 exec 返回表的操作。
在 SQL Server 中,使用 exec 返回表的操作可以通过以下步骤来实现:1. 创建一个存储过程2. 在存储过程中定义要返回的表结构3. 使用 INSERT 语句向表中插入数据4. 使用 SELECT 语句从表中检索数据并返回接下来,我们将逐步介绍如何在 SQL Server 中使用 exec 返回表的操作。
第一步:创建一个存储过程我们需要创建一个存储过程,以便在其中定义要返回的表结构,并编写插入数据和检索数据的逻辑。
我们可以使用以下语法来创建存储过程:```sqlCREATE PROCEDURE proc_nameASBEGIN-- 在这里定义要执行的逻辑END```在上面的语法中,proc_name 是存储过程的名称,我们可以根据实际情况进行命名。
在 BEGIN 和 END 之间可以编写实际的逻辑代码。
第二步:定义要返回的表结构在存储过程中,我们需要使用 CREATE TABLE 语句来定义要返回的表结构。
我们可以使用以下语法来定义一个包含 ID 和 Name 两个字段的表:```sqlCREATE TABLE #tempTable(ID INT,Name NVARCHAR(50))```在上面的语法中,#tempTable 是表的临时名称,ID 和 Name 是表的两个字段,分别表示编号和名称。
我们可以根据实际需求来定义更复杂的表结构。
第三步:插入数据在存储过程中,我们可以使用 INSERT 语句向表中插入数据。
我们可以使用以下语法来向上面定义的表中插入一条数据:```sqlINSERT INTO #tempTable (ID, Name)VALUES (1, 'John')```在上面的语法中,我们向 #tempTable 表中插入了一条数据,其 ID 为 1,名称为 John。
sqlserver常用命令

sqlserver常用命令SQLServer是一种关系型数据库管理系统,被广泛应用于各种企业级应用程序中。
它提供了一系列的命令,用于管理数据库、表、视图、存储过程等对象。
本文将介绍SQL Server中常用的命令及其使用方法,帮助读者快速掌握SQL Server的基本操作。
一、数据库管理命令1. 创建数据库CREATE DATABASE database_name;该命令用于创建一个新的数据库,其中database_name为要创建的数据库名称。
使用该命令时,需要确保具有足够的权限。
2. 删除数据库DROP DATABASE database_name;该命令用于删除指定的数据库,其中database_name为要删除的数据库名称。
使用该命令时,需要确保具有足够的权限,并且要谨慎操作,以免误删数据。
3. 修改数据库ALTER DATABASE database_name SET options;该命令用于修改指定的数据库,其中options为要修改的选项。
常用的选项包括修改数据库的名称、修改数据库的文件路径、修改数据库的恢复模式等。
二、表管理命令1. 创建表CREATE TABLE table_name (column_name1 data_type1, column_name2 data_type2, …);该命令用于创建一个新的表,其中table_name为要创建的表名称,column_name为要创建的列名称,data_type为要创建的列数据类型。
使用该命令时,需要确保具有足够的权限。
2. 删除表DROP TABLE table_name;该命令用于删除指定的表,其中table_name为要删除的表名称。
使用该命令时,需要确保具有足够的权限,并且要谨慎操作,以免误删数据。
3. 修改表ALTER TABLE table_name ADD column_name data_type;该命令用于向指定的表中添加一列,其中table_name为要修改的表名称,column_name为要添加的列名称,data_type为要添加的列数据类型。
SQLServer快速掌握创建和修改表格

本⽂将介绍数据库定义语⾔(DDL)⽤于创建数据库和表格以及修改表格结果的指令。
当你使⽤这些指令时⼀定要⼩⼼——它很容易删去你的数据库中的主要结构令您丢失数据。
所以,在您开始修改数据库之前,您需要知道数据库是什么。
数据库之间的差异 本⽂中的样品查询系统遵循SQL92 ISO标准。
并不是所有的数据库都遵循该标准,有些数据库做了改进,这会产⽣不可预料的结果。
创建数据库 为了创建表格,你⾸先需要需要创建⼀个可以容纳表格的数据库。
SQL⽤于创建数据库的基本语句是: 以下是引⽤⽚段:CREATE DATABASE dbname; 你的数据库⽤户必须有建⽴数据库的适当权限。
如果与你有关的⽤户不能发出⽤于创建新数据库的命令,要求数据库管理员为你建⽴数据库,你也作为管理员登录然后建⽴数据库并设置权限。
举个例⼦,⽤CREATE指令为⼀个应⽤程序建⽴⼀个数据库⽤于显⽰⼀个⽬录: 以下是引⽤⽚段:CREATE DATABASE Catalog; 这给你⼀个⽤于在查询时与其它表格区分的表格名字。
下⼀步是创建⽤于输⼊它的表格。
创建表格 如你所知,表格是有若⼲个栏⽬所组成。
当创建表格时,你可以定义栏⽬并分配字段属性。
表格建⽴后,可以⽤ALTER 表格指令来修改它,我们稍后将提到这⼀点。
你可以⽤下⾯这条指令来创建数据库,命令⾏的参数为表格名字、栏⽬名字,还有每⼀栏的数据类型。
以下是引⽤⽚段:CREATE TABLE table_name (column1 data_type, column2 data_type, column3 data_type); 不同的数据库提供商的标准差别很⼤。
你的帮助⽂档中应该有⼀段详细说明如何使⽤每⼀种数据、接受何种参数。
以下是引⽤⽚段:Char Char(8) 它包含了⼀个固定长度的字符串,其值常常是字符串长度。
Varchar Varchar(128) 它包含了⼀个长度不⼤于指定值的长度可变的字符串。
sqlserver建表语句带中文注释

标题:SQL Server建表语句带中文注释一、引言在SQL Server数据库中,建表语句是非常重要的,它决定了数据库中表的结构和属性。
建表语句的编写需要遵循一定的规范和标准,同时也需要适当的注释来方便其他人阅读和理解。
本文将介绍如何使用SQL Server建表语句,并给出带中文注释的示例。
二、SQL Server建表语句的基本语法SQL Server建表语句的基本语法如下:```sqlCREATE TABLE 表名(列名1 数据类型1,列名2 数据类型2,...列名N 数据类型N);```在上面的语法中,CREATE TABLE是创建表的关键字,后面跟着表的名称。
括号中包含了表的列名和数据类型。
在每一行中,列名和数据类型之间使用空格分隔,不同的列之间使用逗号分隔。
三、示例:使用SQL Server建表语句创建学生表下面我们将以学生表为例,展示如何使用SQL Server建表语句,并在注释中说明每个字段的含义。
```sql-- 创建学生表CREATE TABLE 学生(学号 VARCHAR(10), -- 学号尊称 NVARCHAR(20), -- 尊称性别 NVARCHAR(2), -- 性别生日 DATE, -- 生日入学年份 INT -- 入学年份);```在上面的示例中,我们使用CREATE TABLE语句创建了一个名为“学生”的表。
表中包含了5个字段,分别是学号、尊称、性别、生日和入学年份。
每个字段后面的注释说明了该字段的含义,方便其他人阅读和理解表结构。
四、SQL Server建表语句的注意事项在使用SQL Server建表语句时,需要注意以下几点:1. 数据类型的选择:根据实际需求选择合适的数据类型,例如VARCHAR、NVARCHAR、INT、DATE等。
2. 主键和外键:如果需要设置主键和外键,需要在建表语句中加入相应的约束。
3. 索引:根据查询需求,为表中的字段添加索引以提高查询效率。
sqlserver 教程

sqlserver 教程SQL Server 是一种关系型数据库管理系统(RDBMS),它被广泛用于存储和管理大量数据。
本教程将指导您如何使用SQL Server 进行各种数据库操作。
1. 安装 SQL Server:- 下载 SQL Server 安装程序并运行它。
- 按照安装向导的指示进行操作,选择所需的选项,例如安装位置和实例名称。
- 完成安装后,启动 SQL Server。
2. 创建数据库:- 使用 SQL Server Management Studio(SSMS)或 Transact-SQL(T-SQL)语句来创建数据库。
- 使用 CREATE DATABASE 语句创建数据库。
例如:```sqlCREATE DATABASE MyDatabase;```3. 创建表:- 在数据库中创建表来存储数据。
- 使用 CREATE TABLE 语句创建表,并定义列的名称和数据类型。
例如:```sqlCREATE TABLE Employees (ID INT PRIMARY KEY,Name VARCHAR(50),Age INT,Department VARCHAR(50));```4. 插入数据:- 使用 INSERT INTO 语句将数据插入表中。
例如:```sqlINSERT INTO Employees (ID, Name, Age, Department) VALUES (1, 'John Doe', 30, 'IT');```5. 查询数据:- 使用 SELECT 语句从表中检索数据。
例如:```sqlSELECT * FROM Employees;```6. 更新数据:- 使用 UPDATE 语句更新表中的数据。
例如:```sqlUPDATE EmployeesSET Age = 35WHERE ID = 1;```7. 删除数据:- 使用 DELETE FROM 语句删除表中的数据。
sqlserver建库建表(数据库和数据表的常用操作)

sqlserver建库建表(数据库和数据表的常⽤操作)数据库和数据表(开发常⽤操作)⼀,数据库的创建⼀个SQLServer 是由两个⽂件组成的:数据⽂件(mdf) 和⽇志⽂件(ldf),所以我们创建数据库就是要为其指定数据库名、数据⽂件和⽇志⽂件。
a) create database 数据库名;例:create database mydb;数据⽂件和⽇志⽂件存放在默认⽂件夹数据库⽂件名为mydb.mdf,⽇志⽂件的名字为mydb.ldfb) 创建数据库的完整语句(⾃⼰定义数据⽂件和⽇志⽂件的位置)create database mydbon(name='mydb123',filename='C:\mydb.mdf',--数据⽂件保存位置size=10,--数据库初始⼤⼩以M 为单位maxsize=50,--数据库⼤⼩的最⼤值filegrowth=5 --当数据库数据⼤⼩超过默认值,每次增长的⼤⼩)log on(name='mydb_ldf',filename='C:\mydb_log.ldf',size=5,maxsize=50,filegrowth=5);2) 使⽤数据库use 数据库名;3) 删除数据库drop database数据库名;1. 数据库的备份:将数据库⽂件⽣成⼀个本份⽂件(dat⽂件)backup database 数据库名 to disk=’路径’;backup database mydb to disk='D:\mmm.dat' with format;2. 数据库的还原:根据备份⽂件恢复数据库a) 查看备份⽂件的信息restore filelistonly from disk='D:\mmm.dat';b) 将数据库⽂件还原到备份前的位置restore database mydb from disk='D:\mmm.dat';c) 将数据库⽂件还原到指定位置restore database mydb from disk='D:\mmm.dat'with move 'mydb' to 'F:\mydb.mdf',move 'mydb_log' to 'F:\mydb_log.ldf';三,模式(命名空间)1. 创建模式create schema 模式名 authorization 登录名;例:create schema model01 authorization sa;2. 删除模式a) 级联删除:如果模式中有表,先删除表再删除模式。
SQLserver2008R2操作数据库表命令

SQLserver2008R2操作数据库表命令1.修改数据表字段长度语句:ALTER TABLE tableName(表名) ALTER COLUMN columnName(字段名) VARCHAR(n(长度))2.DROP,TRUNCATE和DELETE的区别。
使⽤这3个命令时⼀定要谨慎,都是删除表数据的命令。
按删除实⼒分:第⼀、DROP;第⼆、TRUNCATE;第三、DELETE⽆条件时都是删除表中的全部数据‘。
TRUNCATE⽐DELECTE速度快,占⽤系统资源少。
以下是详细区分:DROP:命令DROP TABLE tableName(表名)------删除内容和定义,释放空间。
即删除整个表,包括表结构,数据,定义。
⽆法回滚,恢复,要恢复只能重新新建⼀个表。
⾮常暴⼒。
TRUNCATE:命令 TRUNCATE TABLE tableName(表名)------删除内容,释放空间但不删除定义结构,只清空表数据。
保留表结构(字段),属性。
所谓释放空间就是删除表的ID标识列,在插⼊数据时,标识列(ID)重新从1开始,DELETE是做不到的。
a.TRUNCATE不能删除⾏数据,要删就清空整张表。
b.删除数据速度来说,TRUNCATE三者中最快,属于DDL语⾔,将被隐式提交时若有ROLLBACK(回滚)命令, TRUNCATE不会被撤销(回滚),但DELETE可以。
c.重新设置⾼⽔平线和所有的索引。
在对整张表和索引进⾏完全浏览时,经过TRUNCATE操作后的表⽐DELETE操作后的表要快很多。
d.TRUNCATE不能清空⽗表,不能触发任何DELETE触发器,当表被清空后表与表的索引将重新设置成初始⼤⼩,⽽DELETE则不能。
DELETE:命令DELETE TABLE tableName(表名)------也可以删除整个表数据,但是⾮常慢,系统是⼀⾏⼀⾏删除,效率低。
后⾯可以跟条件,如:DELETE TABLE tableName(表名) WHERE (条件) 。
SqlServer新建表操作DDL

SqlServer新建表操作DDL创建新表:1,五要素2,not null3,默认值4,字段注释,表名称5,索引6,指定约束名称-- ------------------------------ Table structure for Table-- ----------------------------IF EXISTS (SELECT * FROM sys.all_objects WHERE object_id = OBJECT_ID(N'[dbo].[TableName]') AND type IN ('U')) DROP TABLE [dbo].[TableName]CREATE TABLE [dbo].[TableName] ([CreatedUserID] int DEFAULT ((0)) NOT NULL,[CreatedTime] datetime DEFAULT (getdate()) NOT NULL,[ModifiedUserID] int DEFAULT ((0)) NOT NULL,[ModifiedTime] datetime DEFAULT (getdate()) NOT NULL,[IsDelete] int DEFAULT ((1)) NOT NULL)--指定属性名称EXEC sp_addextendedproperty'MS_Description', N'创建⼈','SCHEMA', N'dbo','TABLE', N'TableName','COLUMN', N'CreatedUserID'EXEC sp_addextendedproperty'MS_Description', N'创建时间','SCHEMA', N'dbo','TABLE', N'TableName','COLUMN', N'CreatedTime'EXEC sp_addextendedproperty'MS_Description', N'修改⼈','SCHEMA', N'dbo','TABLE', N'TableName','COLUMN', N'ModifiedUserID'EXEC sp_addextendedproperty'MS_Description', N'修改时间','SCHEMA', N'dbo','TABLE', N'TableName','COLUMN', N'ModifiedTime'EXEC sp_addextendedproperty'MS_Description', N'是否有效,1:有效,0:⽆效','SCHEMA', N'dbo','TABLE', N'TableName','COLUMN', N'IsDelete'EXEC sp_addextendedproperty'MS_Description', N'表名称','SCHEMA', N'dbo','TABLE', N'TableName'--指定默认值(缺省)、指定约束名称(不指定会⽣成随机名称,不利于维护)ALTER TABLE [dbo].[tableName] ADD CONSTRAINT [DF_tableName_CreatedUserId] DEFAULT ((0)) FOR [CreatedUserId] ALTER TABLE [dbo].[tableName] ADD CONSTRAINT [DF_tableName_CreatedTime] DEFAULT (getdate()) FOR [CreatedTime]ALTER TABLE [dbo].[tableName] ADD CONSTRAINT [DF_tableName_ModifiedUserId] DEFAULT ((0)) FOR [ModifiedUserId] ALTER TABLE [dbo].[tableName] ADD CONSTRAINT [DF_tableName_ModifiedTime] DEFAULT (getdate()) FOR [ModifiedTime] ALTER TABLE [dbo].[tableName] ADD CONSTRAINT [DF_tableName_IsDelete] DEFAULT ((1)) FOR [IsDelete]-- ------------------------------ Indexes structure for table Table-- ----------------------------CREATE NONCLUSTERED INDEX [IX_Table_xxxID]ON [dbo].[Table] ([xxxID] ASC)-- ------------------------------ Primary Key structure for table Table-- ----------------------------ALTER TABLE [dbo].[Table] ADD CONSTRAINT [PK_Table] PRIMARY KEY CLUSTERED ([xxxOOOID])WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, IGNORE_DUP_KEY = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON)ON [PRIMARY]。
sqlserver基本操作

SQL Server基本操作SQL Server是一种关系型数据库管理系统(RDBMS),它提供了用于管理和操作数据库的丰富功能,常用于企业级应用程序。
一些SQL Server的基本操作(SQL语句)如下:1. 创建数据库:CREATE DATABASE database_name;2. 删除数据库:DROP DATABASE database_name;3. 创建表:CREATE TABLE table_name (column1 datatype constraint,column2 datatype constraint,...);4. 删除表:DROP TABLE table_name;5. 插入数据:INSERT INTO table_name (column1, column2, ...)VALUES (value1, value2, ...);6. 更新数据:UPDATE table_nameSET column1 = value1, column2 = value2, ...WHERE condition;7. 删除数据:DELETE FROM table_name WHERE condition;8. 查询数据:SELECT column1, column2, ...FROM table_nameWHERE condition;9. 条件查询:SELECT column1, column2, ...FROM table_nameWHERE column1 > value;10. 排序查询(升序|降序):SELECT column1, column2, ...FROM table_nameORDER BY column1 ASC|DESC;11. 连接查询:SELECT column1, column2, ...FROM table1INNER JOIN table2 ON table1.column = table2.column;12. 聚合函数:SELECT COUNT(column) FROM table;SELECT SUM(column) FROM table;SELECT AVG(column) FROM table;SELECT MAX(column) FROM table;SELECT MIN(column) FROM table;13. 创建索引:CREATE INDEX index_name ON table_name (column1, column2, ...);14. 删除索引:DROP INDEX index_name ON table_name;15. 修改表:ALTER TABLE table_name ADD column_name datatype;ALTER TABLE table_name DROP COLUMN column_name;ALTER TABLE table_name ALTER COLUMN column_name datatype;16. 创建视图:CREATE VIEW view_name ASSELECT column1, column2, ...FROM table_nameWHERE condition;17. 删除视图:DROP VIEW view_name;18. 创建存储过程:CREATE PROCEDURE procedure_name@parameter1 datatype,@parameter2 datatype,...ASBEGINSELECT column1, column2, ...FROM table_nameWHERE condition;END;19. 执行存储过程:EXEC procedure_name @parameter1 = value1, @parameter2 = value2, ...;20. 创建触发器:CREATE TRIGGER trigger_nameON table_nameFOR INSERT, UPDATE, DELETEASBEGIN-- trigger actionEND;21. 备份数据库:BACKUP DATABASE database_name TO disk = 'backup_file_path';22. 恢复数据库:RESTORE DATABASE database_name FROM disk = 'backup_file_path'; 23. 查询当前数据库版本:SELECT @@VERSION;。
SQLServer表分区的操作

SQLServer表分区的操作背景:⼤多数项⽬开发中都会有⼏个⽇志表⽤于记录⽤户操作或者数据变更的信息,往往这些表数据数据量⽐较庞⼤,每次对这些表数据进⾏操作都⽐较费时,这个时候就考虑⽤表分区对表进⾏切分到不同物理磁盘进⾏存储,从⽽提⾼运⾏效率。
表分区优点:1.性能提升:最⼤的好处应该是把表数据分割到不同的磁盘存储,充分利⽤多cpu对数据⽂件同步处理带来的数据操作效率的提升2.数据管理:分区表进⾏数据备份的时候可以单独备份需要的指定分区⽂件进⾏备份,不需要对整个表数据进⾏备份3.可⽤性:⼀个分区⽂件遭到破坏不会影响其他⽂件的正常使⽤实战:项⽬中有⼀个⽇志表因为每⽇记录数据量太⼤(3个⽉数据2000W)需要只保留最近三个⽉的数据,这样就要求每⽉初把3个⽉前的数据给删掉,同时这个表要进⾏分页查询和数据汇总,这样就考虑到将这张表进⾏分区操作,操作数据库是SQL Server2012(只有专业版才⽀持分区)第⼀步:创建⽂件组和分组⽂件alter database Test add filegroup LoginLog1alter database Test add filegroup LoginLog2alter database Test add filegroup LoginLog3alter database Test add filegroup LoginLog4Test是⽤来测试的数据库名称,我们先创建4个⽂件组接下来创建分组⽂件alter database Test add file(Name=N'LoginLog1',filename='G:\练习\表分区测试\group\LoginLog1.ndf',size=10mb,maxsize=200Mb,filegrowth=5mb)to filegroup LoginLog1alter database Test add file(Name=N'LoginLog2',filename='G:\练习\表分区测试\group\LoginLog2.ndf',size=10mb,maxsize=200Mb,filegrowth=5mb)to filegroup LoginLog2alter database Test add file(Name=N'LoginLog3',filename='G:\练习\表分区测试\group\LoginLog3.ndf',size=10mb,maxsize=200Mb,filegrowth=5mb)to filegroup LoginLog3alter database Test add file(Name=N'LoginLog4',filename='G:\练习\表分区测试\group\LoginLog4.ndf',size=10mb,maxsize=200Mb,filegrowth=5mb)to filegroup LoginLog4第⼆步创建分区函数我们当前⽤时间作为分区字段,以便于⽇志表根据添加时间做分区create partition function Login_Log_CreateTime (datetime)as range right for values ('2017-04-01','2017-05-01','2017-06-01')这⾥我们⽤三个⽇期把整个时间轴划分为4块:2017-04-01以前的数据、2017-04-01⾄2017-04-30的数据、2017-05-01⾄2017-05-31的数据、2017-06-01⾄2017-06-30的数据注意range right的left和right的作⽤是决定临界点值得归属,⼀开始我这⾥⽤的是left导致分区划分为4、5、6和6⽉份以后的数据,这样导致我在下次添加新的分区的时候没办法添加2017-07-01的分割点,只能添加>=2017-08-01的时间点。
SQLServer数据库循环表操作每一条数据(游标的使用)

SQLServer数据库循环表操作每⼀条数据(游标的使⽤)DECLARE@FunctionCode VARCHAR(20)--声明游标变量DECLARE curfuntioncode CURSOR FOR SELECT FunctionalityCode FROM dbo.SG_Functionality WHERE Type=2ORDER BY TimeStamp--创建游标OPEN curfuntioncode --打开游标FETCH NEXT FROM curfuntioncode INTO@FunctionCode--给游标变量赋值WHILE@@FETCH_STATUS=0--判断FETCH语句是否执⾏执⾏成功BEGINPRINT@FunctionCode--打印数据(对每⼀⾏数据进⾏操作)FETCH NEXT FROM curfuntioncode INTO@FunctionCode--下⼀个游标变量赋值ENDCLOSE curfuntioncode --关闭游标DEALLOCATE curfuntioncode --释放游标⽰例CREATE PROC USP_AddPermissions_Admin ( @usercode NVARCHAR(50) ) ASDECLARE@UserID UNIQUEIDENTIFIERBEGINSET@UserID=(SELECT UserID FROM dbo.SG_User WHERE UserCode=@usercode)DECLARE@FunctionCode VARCHAR(20)DECLARE curfuntioncode CURSOR FOR SELECT FunctionalityCode FROM dbo.SG_Functionality WHERE Type=2ORDER BY TimeStampOPEN curfuntioncode FETCH NEXT FROM curfuntioncode INTO@FunctionCodeWHILE@@FETCH_STATUS=0BEGININSERT INTO SG_UserFunctionality (UserFunctionalityID,UserID,FunctionalityCode,Type)VALUES(NEWID(),@UserID,@FunctionCode ,2)FETCH NEXT FROM curfuntioncode INTO@FunctionCodeENDCLOSE curfuntioncodeDEALLOCATE curfuntioncodeEND操作多个字段版本DECLARE coupon CURSOR FOR select CouponID,BatchMakeCouponID from CRM_Coupon WHERE CouponType='9'and State=4and IssueDate<=GETDATE() --创建游标OPEN coupon --打开游标DECLARE@CouponID UNIQUEIDENTIFIER,@BatchMakeCouponID UNIQUEIDENTIFIER--声明游标变量FETCH NEXT FROM coupon INTO@CouponID,@BatchMakeCouponID--给游标变量赋值--开始循环WHILE@@FETCH_STATUS=0BEGINif (select StartDate from CRM_BatchMakeCoupon WHERE BatchMakeCouponID =@BatchMakeCouponID) is null--开始时间为空beginupdate CRM_Coupon set State =0, IssueBy =null, IssueDate =null, MemberID =null, MemberNO =null , StartDate =null, EndDate =null, UpdateBy =null, UpdateDate=null where CouponID=@CouponID endelsebeginupdate CRM_Coupon set State =0, IssueBy =null, IssueDate =null, MemberID =null, MemberNO =null , UpdateBy =null, UpdateDate=null where CouponID=@CouponIDendFETCH NEXT FROM coupon INTO@CouponID, @BatchMakeCouponIDENDCLOSE coupon --关闭游标DEALLOCATE coupon --释放游标。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
(column_name1[, column_name2,…,column_name16])
各参数说明如下:
constraint_name
指定约束的名称约束的名称。在数据库中应是惟一的。如果不指定,则系统会自动生成一个约束名。
删除一个表和它的所有子表的监查约束:
ALTER TABLE distributors DROP CONSTRAINT zipchk;
向表中增加一个外键约束:
ALTER TABLE distributors ADD CONSTRAINT distfk FOREIGN KEY (address) REFERENCES addresses(address) MATCH FULL;
对现存字段改名:
ALTER TABLE distributors RENAME COLUMN address TO city;
更改现存表的名字:
ALTER TABLE distributors RENAME TO suppliers;
给一个字段增加一个非空约束:
ALTER TABLE distributors ALTER COLUMN street SET NOT NULL;
constraint pk_order_id primary key (order_id) ,
foreign key(p_id, p_name) references products(p_id, p_name)
) on [primary]
注意:临时表不能指定外关键字约束。
惟一性约束
修改表中字段的类型:
alter table SPMS_TEACH_OUTLINE alter column to_teachOutline text
使用一个 USING 子句, 把一个包含 UNIX 时间戳的 integer 字段转化成 timestamp with time zone:
从一个字段里删除一个非空约束:
ALTER TABLE distributors ALTER COLUMN street DROP NOT NULL;
给一个表增加一个检查约束:
ALTER TABLE distributors ADD CONSTRAINT zipchk CHECK (char_length(zipcode) = 5);
alter table stuInfo
add constraint FK_stuNo foreign key(stuNo)references stuinfo(stuNo)
约束(Constraint)是Microsoft SQL Server 提供的自动保持数据库完整性的一种方法,定义了可输入表或表的单个列中的数据的限制条件(有关数据完整性的介绍请参见第9 章)。在SQL Server 中有5 种约束:主关键字约束(Primary Key Constraint)、外关键字约束(Foreign Key Constraint)、惟一性约束(Unique Constraint)、检查约束(Check Constraint)和缺省约束(Default Constraint)。
CLUSTERED | NONCLUSTERED
指定索引类别,CLUSTERED 为缺省值。其具体信息请参见下一章。
column_name
指定组成主关键字的列名。主关键字最多由16 个列组成。
例7-3: 创建一个产品信息表,以产品编号和名称为主关键字
create table products (
) on [primary]
2 外关键字约束
外关键字约束定义了表之间的关系。当一个表中的一个列或多个列的组合和其它表中的主关键字定义相同时,就可以将这些列或列的组合定义为外关键字,并设定它适合哪个表中哪些列相关联。这样,当在定义主关键字约束的表中更新列值,时其它表中有与之相关联的外关键字约束的表中的外关键字列也将被相应地做相同的更新。外关键字约束的作用还体现在,当向含有外关键字的表插入数据时,如果与之相关联的表的列中无与插入的外关键字列值相同的值时,系统会拒绝插入数据。与主关键字相同,不能使用一个定义为 TEXT 或IMAGE 数据类型的列创建外关键字。外关键字最多由16 个列组成。
p_id char(8) not null,
p_name char(10) not null ,
price money default 0.01 ,
quantity smallint null ,
constraint pk_p_id primary key (p_id, p_name)
修改SQL-SERVER数据库表结构的SQL命令
向表中增加一个 address 列:
ALTER TABLE distributors ADD address varchar(30);
从表中删除一个字段:
ALTER TABLE distributors DROP COLUMN address RESTRICT;
定义外关键字约束的语法如下:
CONSTRAINT constraint_name
FOREIGN KEY (column_name1[, column_name2,…,column_name16])
REFERENCES ref_table [ (ref_column1[,ref_column2,…, ref_column16] )]
1.—-添加主键约束(将stuNo作为主键)
alter table stuInfo
add constraint PK_stuNo primary key (stuNo)
2.—-添加唯一约束(身份证号唯一,因为每个人的都不一样)
alter table stuInfo
add constraint UQ_stuID unique(stuID)
emp_name char(10) ,
emp_cardid char(18),
constraint pk_emp_id primary key (emp_id),
constraint uk_emp_cardid unique (emp_cardid)
) on [primary]
UNIQUE [CLUSTERED | NONCLUSTERED]
(column_name1[, column_name2,…,column_name16])
例7-5:定义一个员工信息表,其中员工的身份证号具有惟一性。
create table employees (
emp_id char(8),
7.2.4 检查约束
检查约束对输入列或整个表中的值设置检查条件,以限制输入值,保证数据库的数据完整性。可以对每个列设置符合检查。
3.—-添加默认约束(如果地址不填 默认为“地址不详”)
alter table stuInfo
add constraint DF_stuAddress default (‘地址不详’) for stuAddress
4.—-添加检查约束 (对年龄加以限定 15-40岁之间)
alter table stuInfo
ALTER TABLE foo
ALTER COLUMN foo_timestamp TYPE timestamp with time zone
USING
timestamp with time zone 'epoch' + foo_timestamp * interval '1 second';
add constraint CK_stuAge check (stuAge between 15 and 40)
alter table stuInfo
add constraint CK_stuSex check (stuSex=’男’ or stuSex=’女′)
5.—-添加外键约束 (主表stuInfo和从表stuMarks建立关系,关联字段stuNo)
3.—-检查约束 (Check Counstraint) 对该列数据的范围、格式的限制(如:年龄、性别等)
4.—-默认约束 (Default Counstraint) 该数据的默认值
5.—-外键约束 (Foreign Key Counstraint) 需要建立两表间的关系并引用主表的列
五大约束的语法示例
[ ON DELETE { CASCADE | NO ACTION } ]
[ ON UPDATE { CASCADE | NO ACTION } ] ]
[ NOT FOR REPLICATION ]
各参数说明如下:
REFERENCES
指定要建立关联的表的信息。
ref_table
指定要建立关联的表的名称。
ref_column
指定要建立关联的表中的相关列的名称。
ON DELETE {CASCADE | NO ACTION}
指定在删除表中数据时,对关联表所做的相关操作。在子表中有数,则在删除父表数据行时会将子表中对应的数据行删除;如果指定的是NO ACTION,则SQL Server 会产生一个错误,并将父表中的删除操作回滚。NO ACTION 是缺省值。
惟一性约束指定一个或多个列的组合的值具有惟一性,以防止在列中输入重复的值。惟一性约束指定的列可以有NULL 属性。由于主关键字值是具有惟一性的,因此主关键字列不能再设定惟一性约束。惟一性约束最多由16 个列组成。
定义惟一性约束的语法如下:
CONSTRAINT constraint_name