一分钟查一个案例带你看看Oracle数据库到底有多牛逼性能难题
OracleSQL性能优化及案例分析

OracleSQL性能优化及案例分析标题:Oracle SQL性能优化及案例分析一、引言Oracle数据库作为全球最受欢迎的数据库之一,其性能优化问题一直是用户和开发者的焦点。
尤其是在处理大量数据或复杂查询时,性能问题可能会严重影响应用程序的响应时间和用户体验。
因此,对Oracle SQL进行性能优化及案例分析显得尤为重要。
二、Oracle SQL性能优化1、索引优化索引是提高Oracle SQL查询性能的重要工具。
通过创建合适的索引,可以大大减少查询所需的时间,提高数据库的响应速度。
然而,过多的索引可能会导致额外的存储空间和插入、更新、删除的性能损失。
因此,需要根据实际应用的需求,合理地选择需要索引的字段。
2、查询优化编写高效的SQL查询语句也是提高Oracle SQL性能的关键。
这包括选择正确的查询语句、避免在查询中使用复杂的子查询、使用连接(JOIN)代替子查询等。
还可以使用Oracle SQL Profiler来分析和优化查询语句的性能。
3、数据库参数优化Oracle数据库有许多参数可以影响SQL性能,如内存缓冲区、磁盘I/O参数等。
根据实际应用的需求和硬件环境,对这些参数进行合理的调整,可以提高Oracle SQL的性能。
三、案例分析1、案例一:索引优化问题描述:在一个电商系统中,用户在搜索产品时,使用全文本搜索功能时经常出现延迟。
解决方案:通过分析用户搜索的习惯和需求,对产品表的名称和描述字段创建全文索引。
同时,调整Oracle的全文搜索参数以提高搜索效率。
2、案例二:查询优化问题描述:在一个银行系统中,客户查询自己的贷款信息时,查询时间过长。
解决方案:通过使用Oracle SQL Profiler分析查询语句,发现查询中存在复杂的子查询。
将子查询改为连接(JOIN)方式,减少了查询时间。
3、案例三:数据库参数优化问题描述:在一个大型电商系统中,用户在访问高峰期经常遇到响应时间过长的问题。
数据库查询性能优化的经典案例分享

数据库查询性能优化的经典案例分享概述:随着互联网和大数据的发展,数据库成为了现代应用开发中的核心组成部分。
在应用程序中,大量的数据查询操作对数据库性能提出了巨大的挑战。
为了提高用户的体验和系统的响应速度,数据库查询性能优化变得至关重要。
本文将分享一些经典的案例,以展示常见的数据库查询性能优化技术。
案例一:索引优化索引是提高数据库查询性能的关键机制。
在一个大型的数据集中,使用索引可以大大减少查询所需的时间。
然而,不正确的索引设计可能会导致性能下降,甚至更糟糕的结果。
因此,我们需要仔细考虑索引的设计和使用。
案例二:查询重构查询的编写方式和查询的性能密切相关。
一些查询可能会导致全表扫描或使用不必要的临时表,这会导致性能下降。
通过对查询进行重构,优化关联条件、使用合适的连接方式、避免使用通配符等,可以有效减少查询的执行时间。
案例三:数据分区在处理大量数据时,数据分区技术可以将数据划分为多个分区,从而提高查询效率。
通过将数据分散存储在多个物理位置上,可以实现并行查询和负载均衡,改善数据库的性能。
同时,数据分区还可以减少索引的大小,加快索引的扫描速度。
案例四:内存优化内存是数据库查询性能优化的重要因素之一。
通过将常用的表和索引数据加载到内存中,可以降低磁盘I/O的使用,加快查询速度。
此外,调整数据库的内存配置参数,扩大内存缓冲区的大小,可以显著提高查询的性能。
案例五:性能监控与调优性能监控是优化数据库查询性能的关键步骤之一。
通过监控数据库的关键性能指标(如CPU使用率、磁盘I/O、响应时间等),可以及时发现性能瓶颈和潜在问题,并进行相应的调优。
使用性能监控工具和技术,可以帮助我们深入了解数据库的运行状况,以及查询的执行计划等信息。
案例六:合理的数据类型选择在数据库设计中,选择合适的数据类型可以极大地影响查询的性能。
使用整数类型替代字符类型、压缩存储数据、避免存储冗余数据等策略,都可以减少存储空间和提升查询效率。
Oracle数据库性能优化与案例分析

千里之行,始于足下。
Oracle数据库性能优化与案例分析Oracle数据库性能优化是指通过调整数据库的配置参数、优化SQL语句、增加索引等措施,以提升数据库的响应速度、减少资源消耗和提高系统的稳定性的过程。
下面是一个案例分析,介绍了一个实际的Oracle数据库性能优化案例。
案例分析:某公司使用Oracle数据库存储了大量的销售数据,随着数据量的增加,数据库的性能逐渐下降。
经过检查,发现以下问题:1. 缺少必要的索引:在数据库中存在大量的查询操作,但是缺少必要的索引导致查询效率低下。
解决方法:根据查询需求,为经常用到的列添加合适的索引,可以通过分析查询语句的执行计划来确定需要哪些索引。
同时,也要注意避免过多的索引导致性能下降。
2. SQL语句性能低下:存在一些复杂的SQL语句,执行时间较长。
解决方法:对于复杂的SQL语句,可以通过优化查询语句和重构查询逻辑来提升性能。
可以考虑使用JOIN操作替代子查询,避免使用全表扫描等。
3. 数据库参数设置不合理:数据库的一些配置参数没有进行调整,导致性能下降。
第1页/共2页锲而不舍,金石可镂。
解决方法:根据数据库的性能需求,适当调整一些关键的配置参数,如SGA和PGA的大小、缓冲区大小等。
4. 数据库统计信息过期:数据库的统计信息没有及时更新,导致查询优化器的估算不准确。
解决方法:定期收集和更新统计信息,可以使用Oracle提供的统计信息收集工具或者手动收集统计信息。
通过以上优化措施,可以显著提升Oracle数据库的性能,提高系统的响应速度和稳定性。
但需要注意,在进行性能优化时需要综合考虑多个因素,不能片面追求性能提升而导致其他问题的出现。
另外,性能优化也是一个持续的过程,需要定期检查和优化。
一分钟查一个案例带你看看Oracle数据库到底有多牛逼性能难题

一分钟查一个案例带你看看Oracle数据库到底有多牛逼性能难题问题来了电话响了,是一位证券客户 DBA 的来电,看来,问题没过两天,又出现了。
接起电话,果不其然。
“小y,前天那个问题又重现了。
重启后恢复正常,这次抓到了hangAnalyze,不过领导在身后一直催,所以没来得及抓取 systemstate dump 就重启了。
你尽快帮忙分析下吧,hanganalyze 的 trace 文件已经转到你邮箱了。
”就在 2 天前,该客户找到小 y, 他们有一套比较重要的系统出现了数据库无法登陆的情况,导致业务中断,重启后业务恢复,但原因未明,搞的他们压力很大。
可惜的是,他们是事后找过来,由于客户现场保护意识不足,最后也只能是巧妇难为无米之炊了…总的来说,小 y 还算是比较熟悉证券行业的。
毕竟,小 y 多年来一直在银行、证券、航空等客户提供数据库专家支持服务,这其中就包括了北京排名前 6 的所有证券公司。
简而言之,证券行业的要求就是快速恢复,快速恢复业务大于一切。
原因很简单,股价瞬息万变,作为股民,如果当时无法出售或者购买股票,甚至可能引发官司。
所以,证券核心交易系统如果中断时间超过 5 分钟,则可以算得上是严重故障了,一旦被投诉,则可能会被证监会通报,届时业务可能被降级,影响到证券公司的经营和收益。
结合这个特点,小 y 为客户制定了应急预案,看来收集 systemstate dump 是来不及了,只能先收集 hangAnalyze, 时间来得及的话则可以继续收集 systemstate dump。
收集 hangAnalyze 的命令很简单,照敲就是了,没什么技术含量。
$sqlplus –prelim “/as sysdba”SQL>oradebug setmypidSQL>oradebug hanganalyze 3.. 此处等上一会 ..SQL>oradebug hanganalyze 3 SQL>oradebugtracefile_name开启分析之旅1、hanganalyze 初体验打开附件,内容如下,中间部分太长了,所以用省略号代替。
Oracle数据库性能优化与案例分析

Oracle数据库性能优化与案例分析
性能优化探讨
• 原因:为什么? • 慢(响应时间) • 慢(吞吐量)
性能优化探讨
• 目的:为了什么? • 快(响应时间) • 快(吞吐量)
性能优化之案例分析
• 案例之方法论 • 案例之登录访问 • 案例之资源 • 案例之锁
性能优化方法论发展
• 登录输入指标测量 • Logons:= EndSnap. logons cumulative– StartSnap. logons
cumulative。 • Logons Per Second:= Logons / TimeInterval
案例之登录访问
登录输出指标测量:
Logon Response Time:= Network Response Time * 10 + Native TCP Logon :=Network Response Time * 10 + Listener Response Time + Native IPC Logon Time 。
案例之登录访问
• 例:
•
某医院HIS业务系统的账户登录操作异常缓慢,部分情况下
甚至会出现长时间的卡壳情况,业务影响主要发生在每天早上
的上班时刻。
案例之登录访问
优化过程: • 账户登录过程一般涉及到在账户表格以及对应日志表格上的冲
突,比如Buffer busy waits或者TX lock。AWR未体现该特征。 • AWR报告显示connection management call elapsed time时间偏长
成功率:98% 高 失败率:2% 低
失败人数:500*2%=10
数据库性能优化案例分析和优化数据库性能的实际案例

数据库性能优化案例分析和优化数据库性能的实际案例数据库作为管理和存储数据的重要工具,在现代信息系统中扮演着至关重要的角色。
然而,随着数据量的不断增长和业务的复杂化,数据库性能问题也随之而来。
为了解决这些问题,数据库性能优化成为了关注的焦点。
本文将通过分析实际案例,探讨数据库性能优化的方法和实践。
一、案例一:查询性能优化在一个电商平台的数据库中,查询操作占据了绝大部分的数据库负载。
客户在平台上进行商品搜索等操作时,查询的速度变慢,影响了用户体验和交易效率。
经过分析,我们发现以下几个问题:1. 没有适当的索引:索引是加速数据库查询的关键因素。
在该案例中,我们发现很多查询语句没有合适的索引,导致数据库需要进行全表扫描,严重影响了查询的速度。
解决方案:根据实际查询需求和数据表的特点,合理地创建索引,以提高查询效率。
但是需要注意的是,过多或者过少的索引都会对性能产生负面影响,需要做好平衡。
2. 查询语句优化:检查并优化查询语句,避免使用过于复杂的 SQL 语句,例如多重嵌套查询、不必要的关联等。
通过优化查询语句,减少数据库的负载,提高查询速度。
3. 数据库服务器性能不足:在高峰期,数据库服务器的性能出现瓶颈,无法满足用户的查询需求。
这可能是由于硬件配置不足或者数据库参数设置不合理等原因。
解决方案:可以考虑升级硬件设备,并对数据库参数进行调整,以提高数据库服务器的性能。
二、案例二:写入性能优化在一个订单管理系统的数据库中,写入操作频繁而且耗时较长,导致订单处理效率低下。
在分析问题原因后,发现以下几个关键问题:1. 锁冲突:在高并发情况下,多个写入操作会引发锁竞争,导致大量的阻塞和等待,进而降低数据库的写入性能。
解决方案:通过合理的事务隔离级别和锁调整,减少锁的粒度,降低锁冲突的可能性。
可以使用乐观锁或者行级锁来解决并发写入问题。
2. 数据库日志写入性能不足:数据库的写入操作通常需要将数据写入到日志中,以确保数据的持久性。
Oracle数据库常见的瓶颈问题与性能监测工具

内容摘要:数据库系统的性能最终了决定数据库的可用性和生命力。
大多数数据库系统在运行一段时间后都会存在一定的性能问题,主要涉及数据库硬件、数据库服务器、数据库内存、应用程序、操作系统、数据库参数等方面。
因此,基于数据库系统的性能调整与优化对于整个系统的正常运行起着至关重要的作用。
数据库性能调整与优化涉及到多个层面,通过统一规划、系统分析做出相应的调整,可以提高数据库的稳定性和可用性,保障系统高效地运行,解决系统瓶颈,节约系统开销,具有良好的应用价值,同时也对理论研究提供了一定的方法指导。
基于此,论文将Oracle 10g数据库的内存分配、磁盘I/O以及SQL语句等方面的性能调整与优化问题作为主要研究内容,对其进行了深入地分析和讨论,给出了一般情况下Oracle数据库应用系统的性能调整策略及优化方法。
关键词:Oracle 10g 数据库;体系结构;系统全局区;性能调整与优化AbstractAbstract: The performance of database systems eventually determines their availability and survivability. Most of them will bring about some performance problems more or less after running for a period of time, which mainly involve database hardware, database server, database memory, applications, operating systems and database parameters, etc. Therefore,performance tuning and optimization of database systems,which concern multiple aspects, are very vital to the normal running of the whole system. We can improve the stability and availability of database, guarantee its high running efficiency,solve system bottleneck, reduce system overhead, obtain considerable applicability and in them meanwhile, provide some guidelines for theoretical research through a unified plan and systematical analysis to make appropriate adjustment.Based on the above-mentioned idea, the paper principally pays attention to the research on the performance tuning and optimization problems of memory allocation of Oracle 10g, disc I/O, SQL statements, etc, and makes a further analysis and discuss. Besides, it provides some performance tuning strategies and optimization approaches of Oracle application system in general condition.Key Words: Oracle 10g Database不Architecture不System Global Area不 Adjustment and Optimization of Performance1 导言网格技术是本世纪初最新和最有吸引力的技术之一,数据库管理系统作为信息系统的基本支撑在信息化建设中扮演着重要的要色。
数据库性能优化方法&案例分析

开发、设计、运行维护各阶段 均可能导致性能问题
案例3:神奇的Oracle内部参数
• 内部参数列表
Parameter Name _b_tree_bitmap_plans _bump_highwater_mark_count _cursor_features_enabled _db_block_hash_buckets _db_block_hash_latches _db_block_numa _enable_NUMA_optimization _enqueue_hash_chain_latches _fix_control _in_memory_undo _index_join_enabled _optim_peek_user_binds _optimizer_mjc_enabled _sort_elimination_cost_ratio _sqlexec_progression_cost _table_lookup_prefetch_size _wait_for_sync Begin value FALSE 30 10 134217728 1048576 1 FALSE 256 5705630:ON, 5765456:3 TRUE FALSE FALSE FALSE 10 0 0 FALSE End value (if different)
的优化效果 80%的性能问题可以由20%的优 化技术所解决
应用开发技术运用策略
比较项目 操作特点 响应速度 吞吐量 并发访问量 联机业务 批处理业务 日常业务操作,尤其是包含 后台操作,例如统计报表、 大量前台操作 大批量数据加载 优先级最高,要求反应速度 要求速度高、吞吐量大 非常高 小 非常高 小 大 不高 大
自底向上
数据库性能管理的全面性
Oracle数据库性能优化与案例分析

千里之行,始于足下。
Oracle数据库性能优化与案例分析Oracle数据库是业界广泛使用的关系型数据库管理系统,它具有强大的数据处理能力和稳定性。
但是,在实际应用中,随着数据量的增大和业务需求的提升,数据库性能优化成为了一个非常重要的问题。
本文将从数据库性能优化的概念入手,介绍Oracle数据库性能优化的方法和常见案例分析。
数据库性能优化是指通过合理的配置、调整和优化数据库系统,以提高数据库的响应速度和吞吐量,减少资源占用和系统负载,从而提升应用性能和用户体验。
在进行数据库性能优化时,可以从以下几个方面入手:1. 硬件层面的优化:包括增加内存、加快硬盘访问速度、增加或优化网络带宽等。
通过提升硬件性能,可以减少数据库的响应时间和提高吞吐量。
2. 数据库配置的优化:包括合理设置数据库参数、调整存储结构、优化索引和分区等。
通过合理的配置和优化,可以减少数据库的资源占用和系统负载,提高查询和操作的效率。
3. SQL语句的优化:对于频繁执行的SQL语句,可以通过优化其执行计划、重写查询语句、添加合适的索引等,提高查询效率和执行速度。
4. 应用程序的优化:包括优化程序设计、减少对数据库的访问、合理使用连接池、缓存和异步处理等。
通过优化应用程序,可以减少对数据库的依赖和负载,提高整体性能。
下面以一个实际案例来分析数据库性能优化的具体实施过程。
第1页/共3页锲而不舍,金石可镂。
某企业的关键业务系统使用Oracle数据库存储大量的用户数据,并且有大量的查询和更新操作。
由于数据量增加和访问压力增大,系统的性能出现了明显下降。
为了解决这个问题,进行了如下的优化工作:1. 硬件层面的优化:- 增加内存:通过增加数据库服务器的内存,提高数据库的缓冲区大小,减少了磁盘访问的次数,提高了数据库的响应速度。
- 升级存储设备:将原来的磁盘阵列替换为更高速的固态硬盘,加快了数据库的读写速度。
- 优化网络带宽:增加网络带宽,减少了应用和数据库之间的数据传输时间。
oracle数据库故障处理案例

oracle数据库故障处理案例Oracle数据库是一种常见的关系数据库管理系统,它在企业应用中被广泛使用。
然而,由于各种原因,Oracle数据库可能会遇到各种故障和问题。
本文将列举一些常见的Oracle数据库故障处理案例,并提供解决方案。
1. 数据库无法启动:在某些情况下,Oracle数据库可能无法启动。
这可能是由于数据库文件损坏、数据库实例配置错误、内存不足等原因引起的。
解决此问题的方法包括修复数据库文件、重新配置数据库实例和增加内存容量。
2. 数据库性能下降:当Oracle数据库的性能下降时,可能会导致应用程序变慢或无响应。
这可能是由于数据库表空间过度使用、索引失效、SQL语句优化不当等原因引起的。
解决此问题的方法包括清理表空间、重新创建索引和优化SQL语句。
3. 数据库连接问题:有时候,应用程序无法连接到Oracle数据库。
这可能是由于网络问题、数据库实例未启动、监听器配置错误等原因引起的。
解决此问题的方法包括检查网络连接、启动数据库实例和检查监听器配置。
4. 数据库备份和恢复:数据库备份和恢复是保证数据安全和可用性的关键。
当数据库发生故障或数据丢失时,需要进行数据库恢复。
解决此问题的方法包括使用RMAN工具进行备份和恢复、使用闪回5. 数据库锁定和死锁:在多用户环境下,可能会发生数据库锁定和死锁问题。
这可能是由于事务并发操作引起的。
解决此问题的方法包括查找锁定和死锁的相关会话、释放锁定和解决死锁。
6. 数据库日志文件满:Oracle数据库的日志文件用于记录数据库操作和恢复信息。
当日志文件满时,可能会导致数据库无法继续进行操作。
解决此问题的方法包括增加日志文件大小、清理旧的日志文件和优化日志文件切换策略。
7. 数据库表空间不足:Oracle数据库的表空间用于存储数据和索引。
当表空间不足时,可能会导致无法插入新数据或创建新索引。
解决此问题的方法包括增加表空间大小、清理无效数据和重新分配表空间。
数据库性能调优的实践案例与技术分享

数据库性能调优的实践案例与技术分享数据库性能调优是指通过对数据库系统的配置和优化,提高数据库的执行效率和响应速度,以满足系统性能需求。
在实践中,我们可以根据不同的场景和问题,采取不同的优化策略和技术手段,来提高数据库的性能。
本文将分享几个实际案例,以及相关的技术方法和经验。
案例一:索引优化在一个电商平台的商品数据库中,查询常常出现性能瓶颈。
经过分析,发现其中一个常用的查询是根据商品名称进行模糊搜索,而该字段没有建立索引。
为了优化查询性能,我们选择为该字段建立全文索引。
通过在搜索引擎中设置适当的分词规则和权重,提高了搜索精确度和查询速度,大幅度减少了数据库的负载压力。
案例二:表分区技术对于一家银行来说,客户数据量巨大,且每天都有新数据插入。
在查询和统计报表时,常常需要扫描整个表格,导致查询速度缓慢。
为了解决这一问题,我们将该表按照时间周期进行分区。
通过按照数据的插入时间将表格分为多个子表,可以有效减少查询范围,提高查询性能。
同时,可以根据数据的更新频率,选择不同的分区策略,进一步优化数据库性能。
案例三:查询优化在一家物流公司的订单数据库中,某个复杂查询语句的执行时间过长,导致用户等待时间过长。
通过对查询语句的优化,我们发现其中存在多个不必要的关联查询和子查询。
通过重新设计查询语句,并合理利用数据库的索引和优化器,成功将查询时间从几分钟缩短至几秒钟。
同时,通过增加适当的缓存和调整系统参数,进一步提高了查询性能。
技术分享:除了以上案例中的具体优化方法外,还有一些常用的数据库性能优化技术值得分享。
首先是合理利用索引,根据查询的特点和数据分布情况选择合适的索引类型和索引字段。
其次是合理设计数据表结构,避免冗余字段和重复数据,减少磁盘空间占用和数据操作的复杂度。
另外,定期进行数据库维护和性能监控,及时发现和解决问题,也是保持数据库高性能的关键。
总结:通过实际案例和技术分享,我们可以看到数据库性能调优是一个复杂而重要的工作。
ORACLE数据库性能诊断分析案例
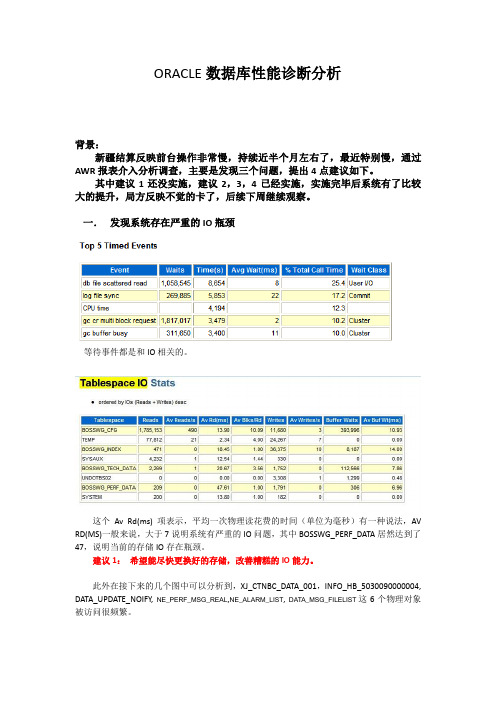
ORACLE数据库性能诊断分析背景:新疆结算反映前台操作非常慢,持续近半个月左右了,最近特别慢,通过AWR报表介入分析调查,主要是发现三个问题,提出4点建议如下。
其中建议1还没实施,建议2,3,4已经实施,实施完毕后系统有了比较大的提升,局方反映不觉的卡了,后续下周继续观察。
一.发现系统存在严重的IO瓶颈等待事件都是和IO相关的。
这个Av Rd(ms) 项表示,平均一次物理读花费的时间(单位为毫秒)有一种说法,AV RD(MS)一般来说,大于7说明系统有严重的IO问题,其中BOSSWG_PERF_DATA居然达到了47,说明当前的存储IO存在瓶颈。
建议1:希望能尽快更换好的存储,改善糟糕的IO能力。
此外在接下来的几个图中可以分析到,XJ_CTNBC_DATA_001,INFO_HB_5030090000004, DATA_UPDATE_NOIFY,NE_PERF_MSG_REAL,NE_ALARM_LIST,DATA_MSG_FILELIST这6个物理对象被访问很频繁。
建议2:对涉及到这6个表的代码做检查,另外争取能对这XJ_CTNBC_DATA_001,INFO_HB_5030090000004, DATA_UPDATE_NOIFY, NE_PERF_MSG_REAL,NE_ALARM_LIST, DATA_MSG_FILELIST 这6个表做瘦身。
方法:在不能建分区的情况下,先采delete部分数据,然后alter table XXX move ; 然后再rebuild所有索引的方法来进行瘦身。
这点目前也已基本做完,又有了一定的提升。
二.对SQL语句进行优化,对频繁访问对象进行瘦身同时也是CPU排名的前几名如下语句是执行频率超高的语句建议3:重点分析这三段代码(思路为索引和瘦身)b7yp8zh72tjmfbeginPKP_XJ_BUSI_MONITOR_UPDATE.UPDATE_XJ_CTNBC_DATA_001_HOUR('101, 104, 106, 108, 109, 110, 112'); end;f8wqpy51v6mfySELECT COUNT(*) FROM XJ_CTNBC_DATA_001 WHERE BUSI_CLASS = :B3 AND STAT_DATE = :B2 AND SOURCE_ID = :B1cqpqvrzhntqj5SELECT TICKET_CNT FROM XJ_CTNBC_DATA_001 WHERE BUSI_CLASS = :B3 AND SOURCE_ID = :B2 AND STAT_DATE = :B1chrkhspfq9xnuSELECT F.NE_NAME, F.NE_FLAG FROM NET_ELEMENT F WHERE F.NE_ID = :B1方法:1.组合索引create index idx_union_xj_ctnbcon XJ_CTNBC_DATA_001 (BUSI_CLASS,STAT_DATE,SOURCE_ID);create index idx_neid_name_flag on net_element (ne_id,ne_name,ne_flag);2.delete 部分数据,然后重组表如下alter table XJ_CTNBC_DATA_001 move;alter index 这个表的索引rebuild;这些基本已经完成,收效比较明显。
Oracle数据库教程 —— oracle11.2.0.3升级到11.2.0.4出现查询性能问题,分析处理

Oracle数据库教程—— oracl e11.2.0.3升级到11.2.0.4出现查询性能问题,分析处理在上次我们的博客中提到帮客户升级oda一体机,将数据库从oracle 11.2.0.3升级到oracle 11.2.0.4,顺利升级后,却出现了一些性能问题,比如说查询表空间的情况时,性能比以前下降了很多,执行时间较长,经过检查分析后发现是统计信息缺失所致,现在把整个过程记录下来与大家分享。
1、升级完成后,客户在执行这条语句时,相当慢SELECT a.tablespace_name,a.bytes total,b.bytes used,c.bytes free,(b.bytes * 100) / a.bytes "% USED ",(c.bytes * 100) / a.bytes "% FREE "FROM sys.sm$ts_avail a, sys.sm$ts_used b, sys.sm$ts_free cWHERE a.tablespace_name = b.tablespace_nameAND a.tablespace_name = c.tablespace_nameorder by a.tablespace_name;大概使用了好几分钟,根据我们以前的经验判断,怀疑可能是回收站可能有大量删除的对象所致所以直接对回站进行处理SQL> select count(*) from dba_recyclebin;COUNT(*)----------6455SQL> purge recyclebin;Recyclebin purged.处理好后,我们又重新执行那语句,但仍然非常慢,这个时候感觉奇怪了,于是我们对执行计划进行分析2、分析执行计划后,找到疑点PLAN_TABLE_OUTPUT--------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------| 40 | TABLE ACCESS FULL |TS$ | 12 | 312 | 5 (0)|| 41 | FIXED TABLE FIXED INDEX | X$KTFBFE (ind:1) | 7 | 273 | 0 (0)|| 42 | INDEX UNIQUE SCAN |I_FILE2 | 1 | 6 | 1 (0)|| 43 | NESTEDLOOPS | | 1| 136 | 16 (57)|| 44 | NESTEDLOOPS | | 1| 130 | 15 (60)|| 45 | MERGEJOIN | | 1| 65 | 7 (15)|| 46 | TABLE ACCESS BY INDEX ROWID| RECYCLEBIN$ | 1 | 39 | 1 (0)|| 47 | INDEX FULL SCAN |RECYCLEBIN$_TS | 1 | | 1 (0)|| 48 | SORTJOIN | | 12| 312 | 6 (17)|| 49 | TABLE ACCESS FULL |TS$ | 12 | 312 | 5 (0)|| 50 | FIXED TABLE FULL |X$KTFBUE |100000 | 6500K| 8 (100)|在这里,我们看到X$KTFBUE使用全表扫描。
Oracle数据库性能优化精解.ppt

ACOUG
李轶楠
Mail:ora-600@
13331192030
ITPUB
技术服务人生
SQL 调整:以前与现在的情况
情况:打包应用程序中的不良 SQL
以前
1. 检查系统使用情况
1.
2. 查看等待事件
2.
3. 查看数据库分散读取上的等待事件
4. 通过以下方法识别 SQL(难以操作)
3.
ACOUG
李轶楠
Mail:ora-600@
13331192030
ITPUB
技术服务人生
SQL Tuning Usage Scenarios
Automatic Selees
AWR
ADDM
Manual Selection
High-load SQL
Cursor Cache
3 表连接顺序:
ORDERED : 按照FROM中表名顺序连接 LEADING: 将选择的表作为连接驱动表.
ACOUG
李轶楠
Mail:ora-600@
13331192030
ITPUB
技术服务人生
一些典型的hints
4 连接:
USE_NL(tab) / NO_USE_NL(tab) :Use table 'tab' as the driving table in a Nested Loops join. If the driving row source is a combination of tables name one of the tables in the inner join and the NL should drive off the entire row-source. Does not work unless accompanied by an ORDERED hint.
数据库性能调优实践案例分享

数据库性能调优实践案例分享一、背景介绍数据库作为现代应用开发的重要组成部分,其性能对系统的运行效率和用户体验至关重要。
因此,数据库性能调优成为数据库管理员(DBA)和开发人员需要重点关注和解决的问题。
本文将分享一些数据库性能调优的实践案例,旨在帮助读者更好地理解和应用相关技术。
二、案例一:索引优化在数据库中,索引是提升查询效率的关键。
一家电商公司面临着用户订单查询响应慢的问题。
经过分析,发现该表中的索引设计不合理,无法满足查询需求。
针对该问题,DBA团队进行了索引重建和优化工作。
首先,使用数据库性能分析工具,应用程序调试,找到了经常进行查询的SQL语句。
然后,通过对表的字段进行分析和优化,根据查询需求选择合适的索引种类,并创建相关索引。
最终,通过监控和测试,发现订单查询响应时间明显缩短,用户体验得到了极大的改善。
三、案例二:查询优化一个社交媒体网站面临着用户关注查询耗时过长的问题。
经过对数据库查询语句进行审查,DBA团队发现存在多个复杂查询和未优化的连接查询。
在这种情况下,他们采取了以下措施进行优化。
首先,对复杂查询进行重构,利用数据库分区和缓存等技术对查询进行优化。
其次,通过优化连接查询语句,减少数据传输和计算量。
最后,他们还使用数据库查询缓存技术,将频繁查询的数据结果缓存到内存中,以加快查询速度。
经过调整和优化,查询耗时明显减少,用户关注功能得到了显著改善。
四、案例三:硬件优化某企业的数据库服务器频繁出现性能瓶颈,无法满足业务需求。
DBA团队对服务器性能进行了全面评估,发现服务器配置过低,容量已接近极限。
为了提升数据库性能,他们决定进行硬件升级。
首先,他们对服务器的内存、硬盘和网络进行扩展,以提供更好的资源支持。
其次,他们还将数据库迁移到新的高性能服务器上,以保证数据访问的稳定和快速。
最终,通过硬件优化,数据库的响应时间明显减少,系统性能得到了突破性的提升。
五、案例四:SQL语句优化一个电信运营商的数据库面临着频繁的死锁和性能下降的问题。
oracle数据库性能问题跟踪案例

oracle数据库性能问题跟踪案例一.现象在打开工单时忽然发现较平时慢了非常多,打开工单界面,需要刷新将近2分钟才正常载入。
网元视图也存在同样的情况。
影响用户工单的处理。
数据库环境简单介绍:1.RAC双机2.数据库主机物理内存分别为16G3.数据库主机CPU分别为16个4.两节点均为ORACLE 10.2.0.4.0版本,ORACLE 的SGA设置为6G二.分析过程2.1 传统方法,整体排查,空喜一场,暂无所获根据该情况,做了11点到12点的AWR采样报表进行分析(默认是一小时一个采样),并没有发现特别异常的情况,查看数据库告警日志,也并没发现异常情况。
接下来查看数据库监听日志情况,无意发现日志非常庞大,有1G左右,如此大的日志必然导致写入会比较缓慢,因此怀疑是监听日志太大导致前台连接缓慢。
当即及时清理了日志,发现前台立即恢复了正常。
当时以为问题解决了。
结果在当天的晚上19点多又出现问题了。
监听日志非常小,看来中午解决问题的方法是巧合,并没有真正解决问题。
继续做了19点到20点这时间段的AWR报表采样,看报表整体并不能发现数据库有啥问题。
不解的是,过了20点,再问现场人员,居然系统又恢复了,现场人员告知工单系统使用非常正常,再也不卡了。
28日上午又接连出现工单操作很卡,过一会儿又恢复正常的情况,电信局方对此很不满。
2.2即时定位,精确打击,苦尽甘来,终获突破2.2.1 问题再现时进行实施跟踪看来AWR默认的一小时一次的采样太泛了,无法准确定位出问题,因为前台觉得工单处理缓慢的时间一般不长,大致10来分钟,但是却频频发生。
看来方法应该改变了,应该采取工单处理缓慢时做AWR报表跟踪,这样才能突出重点。
于是我要求现场人员遇到问题时立即电话通知我在18点的时候,系统又出现这样的问题了,此时现场人员及时电话联系了我,当时安排如下操作步骤1.先登录数据库主机,sqlplus bosswg/bosswg登录后,执行如下:exec dbms_workload_repository.create_snapshot();步骤2.接下来,新疆前台人员操作前台界面(这个时候执行非常缓慢,需要2分钟才可以正常载入页面)步骤3.--2分钟后,执行如下:exec dbms_workload_repository.create_snapshot();步骤4.紧接着,执行如下跟踪@?/rdbms/admin/awrrpt.sql将开始和结束的这2分钟时间做一个短暂的AWR报表分析,看看系统主要等待事件2.2.2 分析即时AWR报表查询出主要等待事件观察AWR报表,我们可以看到,我们把时间范围缩短到非常精确的2分钟范围,具体如下在这个精确的基础上再观察AWR报表,终于观察到了,原先一小时的采样不能突出重点, T op 5 Timed Events 排在第一位的是CPU time,而现在情况变化了,我们可以翡翠明显的观察到一个等待事件read by other session ,说明数据库存在读的竞争,根据文档,这个事件的解释如下:This event occurs when a session requests a buffer that is currently being read into the buffer cache by another session. Prior to release 10.1, waits for this event were grouped with the other reasons for waiting for buffers under the'buffer busy wait' eventAWR报表,具体如下:2.2.3 根据AWR时段进一步分析ASH报表查找问题SQL到底是什么语句导致数据库在前台工单刷新缓慢的时候出现这个严重的read by other session的等待事件呢?这个时候观看ASH报表是一个非常好的方法,ASH可以很方便的定位到主要等待事件和具体哪个SQL有关系,是一个不可多得到ORACLE好工具。
Oracle数据库性能SQL优化案例
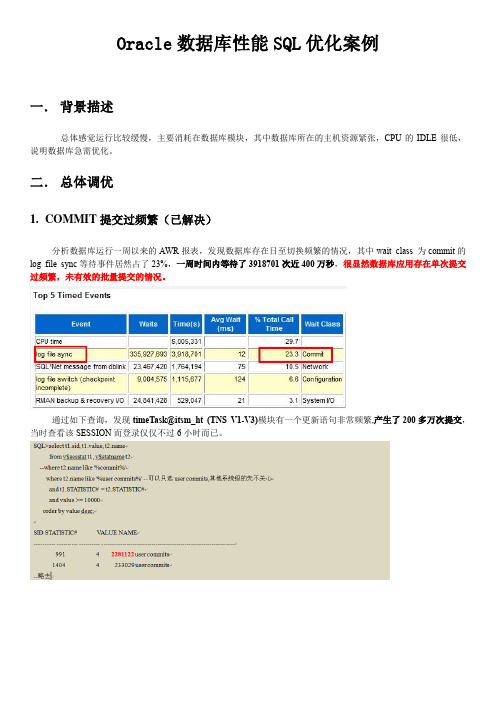
Oracle数据库性能SQL优化案例一.背景描述总体感觉运行比较缓慢,主要消耗在数据库模块,其中数据库所在的主机资源紧张,CPU的IDLE很低,说明数据库急需优化。
二.总体调优MIT提交过频繁(已解决)分析数据库运行一周以来的AWR报表,发现数据库存在日至切换频繁的情况,其中wait class 为commit的log file sync等待事件居然占了23%,一周时间内等待了3918701次近400万秒,很显然数据库应用存在单次提交过频繁,未有效的批量提交的情况。
通过如下查询,发现timeTask@itsm_ht (TNS V1-V3)模块有一个更新语句非常频繁,产生了200多万次提交,当时查看该SESSION而登录仅仅不过6小时而已。
效果:经过和后台开发人员沟通发现,这是后台程序的BUG,修正后,提交大幅度减少,数据库中COMMIT相关的log file sync等待得到极大的改善。
2.库的统计信息收集未开启(已解决)由于数据库总体运行缓慢,偶尔从同事的某些SQL的语句执行计划中发现驱动顺序明显错误得到启发,检查数据库的统计信息情况,发现居然返回了7431条,几乎占了bosswg和basedba用户的对象的全部!接下来发现,原来ORACLE 的自动收集统计信息的功能被关闭了,具体如下:开启自动收集exec dbms_scheduler.enable('GATHER_STATS_JOB');后,数据库统计信息得以正常收集3.手工收集统计信息含全局临时表(已解决)全局临时表是不能被收集统计信息的,否则容易出大问题,影响执行计划,当前调和模块的全局临时表RN_IDENTIFICATION_BATCH被收集了统计信息,如下:解决方法就是删除表的统计信息:EXEC dbms_stats.delete_table_stats(ownname => 'BOSSWG',tabname => 'RN_IDENTIFICATION_BATCH') ;当前已经解决(注:20121119完成这个回收全局临时表统计信息的改造)4.大量索引有并行属性(已解决)在随后的一小时的AWR报表分析中,发现PX的等待也非常明显,这是由于并行度设置在表或索引属性中引发的一种常见等待事件,如下所示,在一小时的采样中居然有近1万秒的PX等待:查看后发现索引居然有1334个设置有并行度属性,如下所示,略去大部分展现:SQL> select t.owner, t.table_name, index_name, degree, statusfrom dba_indexes twhere owner in ('BOSSWG', 'BASEDBA')and t.degree > '1';OWNER TABLE_NAME INDEX_NAME DEGREE STATUS--------- ------------------------------ ------------------------------ ---------- -------------------------------------------------------------------BOSSWG PERF_HOST_FILESYSTEM_HIS IDX_TEMP1 4 V ALIDBOSSWG PERF_WEBLOGIC_WEBMODULE_HIS IDX_TEMP2 4 V ALIDBOSSWG V3_REPLACE_CI_RELATION_LOG PK_V3_REPLACE_CI_RELATION_LOG 9V ALIDBOSSWG V3_REPLACE_CI_LOG PK_V3_REPLACE_CI_LOG 9V ALIDBOSSWG V3_REPLACE_CI_CLASS PK_V3_REPLACE_CI_CLASS 9 V ALIDBOSSWG IFACE_TODO_LIST PK_IFACE_TODO_LIST 9V ALIDBOSSWG IFACE_TODO PK_IFACE_TODO 9 V ALIDBOSSWG IFACE_STAFF PK_IFACE_STAFF 9 V ALID--以下略去1000多行1334 rows selected.效果:用如下方法,将这些并行取消后,数据库的PX等待事件从此消失了。
Oracle数据库性能

该视图记录数据库指标反映数据库当前的状态记录每分钟或每十五秒的值
数据库性能两大指标
QPS(Queries Per Second,每秒查询数) TPS(Transactions Per Second,每秒处理事务数)
Oracle数 据 库 性 能
具体案例 QPS --一分钟QPS select value from v$sysmetric where metric_name in ('Executions Per Sec') and group_id = 2 --15秒QPS select value from v$sysmetric where metric_name in ('Executions Per Sec') and group_id UE from v$sysmetric where metric_name in ('User Commits Per Sec')) + (select VALUE from v$sysmetric where metric_name in ('User Rollbacks Per Sec')) as TPS FROM DUAL
视图介绍 V$SYSMETRIC:该视图记录数据库指标,反映数据库当前的状态,记录每分钟或每十五秒的值。 V$SYSMETRIC_HISTORY: 是V$SYSMETRIC表的历史记录表,只是记录了最近一小时的数据 V$SYSMETRIC_SUMMARY: 是V$SYSMETRIC_HISTORY的汇总,记录最近一个小时最大值,最小值和平均值 V$SYSSTAT: 记录数据库指标自实例启动以来的累加值,
ORACLE数据库变得非常慢解决方案一例

ORACLE数据库变得非常慢解决方案一例最近在为一个项目做数据库优化,发现ORACLE数据库运行得特别慢,简直让人头大。
今天就来给大家分享一下我是如何一步步解决这个问题的,希望对你们有所帮助。
事情是这样的,那天老板突然过来,一脸焦虑地说:“小王,你看看这个数据库,查询速度怎么这么慢?客户都投诉了!”我二话不说,立刻开始分析原因。
我打开了数据库的监控工具,发现CPU和内存的使用率都很高,看来是数据库的压力确实很大。
然后,我开始查看慢查询日志,发现了很多执行时间很长的SQL语句。
这时,我意识到,问题的根源可能就在这些SQL语句上。
一、分析SQL语句1.对执行时间长的SQL语句进行优化。
我检查了这些SQL语句的写法,发现很多地方可以优化。
比如,有些地方使用了子查询,我尝试将其改为连接查询,以提高查询效率。
2.检查索引。
我发现有些表上没有合适的索引,导致查询速度变慢。
于是,我添加了合适的索引,以提高查询速度。
3.调整SQL语句的顺序。
有些SQL语句的执行顺序不当,导致查询速度变慢。
我调整了这些语句的顺序,使其更加合理。
二、调整数据库参数1.增加缓存。
我发现数据库的缓存设置比较低,导致查询时需要频繁读取磁盘。
我适当增加了缓存大小,以提高查询速度。
2.调整线程数。
我发现数据库的线程数设置较低,无法充分利用CPU资源。
我将线程数调整为合适的值,以提高数据库的处理能力。
3.优化数据库配置。
我对数据库的配置文件进行了调整,比如调整了日志文件的存储路径和大小,以及调整了数据库的备份策略等。
三、检查硬件资源1.检查CPU。
我查看了CPU的使用情况,发现CPU负载较高。
我建议公司采购更强大的CPU,以提高数据库的处理能力。
2.检查内存。
我发现内存的使用率也很高,于是建议公司增加内存容量。
3.检查磁盘。
我检查了磁盘的读写速度,发现磁盘的I/O性能较低。
我建议公司更换更快的磁盘,以提高数据库的读写速度。
四、定期维护1.定期清理数据库。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
一分钟查一个案例带你看看Oracle数据库到底有多牛逼性能难题问题来了电话响了,是一位证券客户 DBA 的来电,看来,问题没过两天,又出现了。
接起电话,果不其然。
“小y,前天那个问题又重现了。
重启后恢复正常,这次抓到了hangAnalyze,不过领导在身后一直催,所以没来得及抓取 systemstate dump 就重启了。
你尽快帮忙分析下吧,hanganalyze 的 trace 文件已经转到你邮箱了。
”就在 2 天前,该客户找到小 y, 他们有一套比较重要的系统出现了数据库无法登陆的情况,导致业务中断,重启后业务恢复,但原因未明,搞的他们压力很大。
可惜的是,他们是事后找过来,由于客户现场保护意识不足,最后也只能是巧妇难为无米之炊了…总的来说,小 y 还算是比较熟悉证券行业的。
毕竟,小 y 多年来一直在银行、证券、航空等客户提供数据库专家支持服务,这其中就包括了北京排名前 6 的所有证券公司。
简而言之,证券行业的要求就是快速恢复,快速恢复业务大于一切。
原因很简单,股价瞬息万变,作为股民,如果当时无法出售或者购买股票,甚至可能引发官司。
所以,证券核心交易系统如果中断时间超过 5 分钟,则可以算得上是严重故障了,一旦被投诉,则可能会被证监会通报,届时业务可能被降级,影响到证券公司的经营和收益。
结合这个特点,小 y 为客户制定了应急预案,看来收集 systemstate dump 是来不及了,只能先收集 hangAnalyze, 时间来得及的话则可以继续收集 systemstate dump。
收集 hangAnalyze 的命令很简单,照敲就是了,没什么技术含量。
$sqlplus –prelim “/as sysdba”SQL>oradebug setmypidSQL>oradebug hanganalyze 3.. 此处等上一会 ..SQL>oradebug hanganalyze 3 SQL>oradebugtracefile_name开启分析之旅1、hanganalyze 初体验打开附件,内容如下,中间部分太长了,所以用省略号代替。
朋友们,不妨自己停下来,耐心阅读一下,看看是否可以看的明白。
很快,根据这个 trace, 小 y 在一分钟找到了问题原因。
而这种问题,在其它数据库中属于很难查清的问题。
所以不得不说,Oracle 的 hangAnalyze 是如此的牛逼…问题原因就在后面,什么时候往下翻,由你决定…2、如何开始先看 trace 的第一部分,如下所示:上面的信息为出现异常时数据库的整体状态摘要,这些信息表示:1)共 76 个会话被 sid=494 的会话阻塞,原因是 sid=494 的会话本身申请 latch: shared pool资源时被其他会话阻塞。
2)共 22 个会话被 sid=496 的会话阻塞,原因是 sid=496 的会话本身申请 latch: shared pool资源时被其他会话阻塞。
3)共11个会话被sid=598的会话阻塞,”No Wait”表示sid=598的会话本身并未等待任何资源,即该进程在使用 CPU。
4)共 13 个会话被 sid=518 的会话阻塞,原因是 sid=518 的会话本身申请 latch: shared pool 资源时被其他会话阻塞。
用一张图来表示,如下所示:3、找到阻塞的源头会话 494、496、598、518 之间可能相互独立,也可能存在互相阻塞的关系。
小 y 带着大家继续往下梳理。
从抓取到的 hanganalyze 信息摘取上述会话信息的细节,如下所示 :在该信息中,关注 4 列的内容即可,其中:第 1 列为 oracle 给 trace 中每一个会话所取的唯一逻辑标识;第 3 列表示会话 sid;第 6 列表示操作系统进程号;第 10 列表示阻塞该会话的唯一逻辑标识,为空时表示无阻塞。
因此,从上述信息可知:1)sid=494 的会话被唯一逻辑标识为 597 的会话阻塞2)sid=496 的会话被唯一逻辑标识为 597 的会话阻塞3)sid=518 的会话被唯一逻辑标识为 597 的会话阻塞而唯一逻辑标识为 597 的会话信息为 :即唯一逻辑标识为 597 的会话的 sid=598, 操作系统进程号 553382,该行的第 10 列为空,即再也没有其他会话阻塞 sid=598 的会话。
也就是说,sid=598 的会话就是数据库异常时的会话获取资源时阻塞的源头。
如下图所示:4、陷入僵局?(阻塞的源头只是一个数字!)前面的分析,已经找到了源头是 SID=598 的会话。
那么 sid=598 的会话是什么用户什么程序什么机器发起,在执行什么 SQL,进程的 callstack 是什么呢?所有这些信息,我们都可以在systemstate dump 中可以找到,但可惜的是,客户虽然由于时间关系没有来得及抓取 systemstate dump,因此无法进一步获取该进程的信息。
悲剧了!难道要再一次陷入巧妇难为无米之炊的尴尬境地么?如果是你,你会怎么办,此处不妨思考几分钟…5、找到打开天堂大门的钥匙打开天堂之门的钥匙有很多把,但上帝总是会眷恋把握细节和用心的人。
难道因为缺少systemstatedump 就放弃了么?那客户怎么办?这里介绍其中一把钥匙,当然还有其他钥匙,如果你也找到了其他钥匙,不妨留言告诉小 y。
继续看阻塞源头的相关信息。
SID=598 的会话,在操作系统上的进程号是 553382。
一个进程要么是前台进程(服务进程),要么是后台进程。
如果是后台进程,则我们可以在 alert 日志中,找到操作系统上进程号是 553382 对应的后台进程到底是什么!打开 alert 日志,果然不出所料,凶手真的是他如下所示 :因此,造成数据库异常的源头就是数据库后台进程mman 进程 !即负责 ORACLE 内存动态调整的后台进程!该进程在数据库中负责SGA 内存在各个组件比如buffer cache 和shared pool 之间的动态调整。
通俗的来说,我们在配置数据库所使用的相关内存参数时,在 10g 版本之前,需要手工设置 buffer cache 和 shared pool 的大小,但是 10g 版本后,为了简化管理,可以只设置 buffer cache 和 shared pool 加起来的总内存大小,不需要关注单独为 buffercache和shared pool设置多大的内存,数据库后台进程mman进程可以在两者之间根据需要动态调整。
很多客户都默认地选择了这样一种智能但并不完美的内存管理方式。
那么整个系统中,是否有出现 SGA 内存动态调整的情况呢 ?摘取问题当天其他时段,例如 15 点到 16 点之间的 AWR 报告,观察该系统的情况。
(数据库重启后无法观察到问题时段 v$sga_resize_ops 了)从中可以看到,shared pool 在15 点时的大小为3584M,到了16 点就已经被动态调整到了1760M, 这些就是由后台mman 进程来完成的。
如此大幅度的下降,说明期间经历过多次的调整,不断的对shared pool 进程 shrink 操作。
那么到底是 sharedpool 中的哪部分内存被挪到了 buffercache 呢?从 AWR 报告的 SGA breakdown difference 可以看到:SQL AREA 从 2088M 降至 370M,被刷出了82% !SQLAREA 大量的内存被挪走,SQL 语句( 含登陆的递归 SQL) 必然被大量刷出,后续需要硬解析(hanganalyze 可以看到有latch:shared pool)。
6、进一步分析原因根据上述分析,有一个问题仍然需要确认 :那就是为什么 SGA 动态调整导致如此严重的问题?这明显与 ORACLE 的 BUG 相关。
当发现整个系统 buffer cache 命中率低、物理读高的时候,buffer cache 需要从sharedpool 中借走部分内存(由 MMAN 进程来负责完成动态调整)。
当需要借走的 granula 属于 shared pool 的SQL AREA, 但是由于 SQL 语句长时间在执行,SQL AREA 被 pin 住,MMAN 进程持有了 latch:shared pool 又不得不等,就容易导致其他进程无法获得 latch:shared pool 而引发问题。
当然,还有包括 ORACLE 内部实现动态机制的机制不够合理和高效等缺陷,也可能导致 SGA 动态调整引发问题。
实际上,小y的经验是,但凡涉及到内存动态调整的,不管是数据库,还是操作系统,都可能出现问题,例如操作系统的透明大页内存转换,就可能导致 kernel hang 。
如果想要查 BUG, 从上文的分析中可以知道,大概搜索的关键字是 MMAN 进程、latch Child shared pool 和 shrink 和 CPU, 以此为关键字在 ORACLE METALINK BUG 库中查找相关 BUG,与“ Bug 8211733- Shared pool latch contention when shared pool is shrinking [ID 8211733.8]”中的描述吻合,但缺少 systemstate dump, 无法核对 call stack, 因此无法完全确认。
但具体到该 CASE,核对 SGA 动态调整的具体 BUG 号的意义不大,因为 SGA 在各个版本中还是存在或多或少的问题,个别补丁不能完全预防隐患,最有效的解决办法时关闭 SGA 动态调整,使用手工管理的方式进行,同时为了避免关闭动态调整后的副作用,需要对应用进行对应的优化和调整。
7、头脑风暴之是否可以不关闭 SGA 动态调整来解决问题呢各位看官不妨也想一想这个问题?答案是当然可以,但是不知道能持续多长时间,因为应用可能在变,SQL 可能在变。
说可以,是因为,可以看到,该系统物理读高的SQL 有不少,并且很多 SQL 单次执行时间超过 100 秒!如果 SQL 语句优化后,buffercache 就几乎不需要动态调大了,同时SQL 优化后执行时间短了,需要 pin 的时间也短了,几个因素变好了,问题遇到的概率就小很多很多。
如果 SQL 语句短期无法优化和解决呢?如下图所示,物理读主要集中在两张表,并且表不大,因此可以通过 keep 到内存也可以解决物理读高导致动态调整的问题。
8、头脑风暴之如何避免关闭内存动态调整后的副作用单纯的关闭 SGA 动态调整,意味着 shared pool 没有自动增大的机会,可能因为内存碎片化导致ORA-4031 的几率增大,特别是对于硬解析较高的系统。