机器学习_BCPreddataset(BCPred数据集).
使用机器学习算法进行时间序列聚类的步骤详解

使用机器学习算法进行时间序列聚类的步骤详解时间序列聚类是一种将时间序列数据按照相似性进行分组的方法。
它可以帮助我们在海量的数据中发现潜在的模式和关联规律。
而机器学习算法是一种可以自动学习和改善的方法,可以帮助我们有效地进行时间序列聚类。
本文将详细介绍使用机器学习算法进行时间序列聚类的步骤。
首先,我们需要准备好我们的数据集。
时间序列数据通常包含一系列按时间顺序排列的数据点,例如股票价格、气温、销售量等。
我们需要将这些数据整理成适合机器学习算法输入的格式,通常是一个二维数组,其中每一行代表一个时间序列,每一列代表一个时间点。
接下来,我们需要选择合适的机器学习算法。
时间序列聚类常用的机器学习算法包括K-means算法、层次聚类算法和DBSCAN算法等。
每个算法都有其独特的特点和适用性,我们可以根据实际需求选择合适的算法。
然后,我们需要对数据进行特征工程。
特征工程是为了提取和选择能够反映时间序列相似性的特征。
常见的特征提取方法包括统计特征(如平均值、标准差、最大值、最小值等)、频域特征(如傅里叶变换、小波变换等)和时域特征(如自回归模型、移动平均等)。
我们可以通过计算这些特征来表示每一个时间序列。
接着,我们需要选择合适的相似性度量方法。
相似性度量方法用于度量两个时间序列之间的相似程度。
常用的相似性度量方法有欧氏距离、动态时间规整(DTW)距离和相关系数等。
我们需要根据具体情况选择合适的相似性度量方法。
在确定了相似性度量方法之后,我们可以使用机器学习算法进行时间序列聚类。
对于K-means算法和层次聚类算法,我们需要选择合适的聚类数目。
为了找到最优的聚类数目,我们可以使用肘部法则、轮廓系数等方法进行评估。
对于DBSCAN算法,我们需要选择合适的邻域大小和密度阈值。
这些参数的选择会直接影响聚类的结果,因此需要多次实验和验证。
最后,我们需要对聚类结果进行评估和解释。
评估聚类结果的常用指标包括轮廓系数、互信息、F-度量等。
双重机器学习代码

双重机器学习代码
双重机器学习方法相对于传统的倾向匹配、双重差分、断点回归等因果推断方法,有非常多的优点,包括但不限于适用于高维数据(传统的计量方法在解释变量很多的情况下不便使用),目不需要预设协变量的函数形式(可能协变量与Y是非线性关系)。
2018年有学者将双重机器学习方法应用在了平均处理效应、局部处理效应和部分线性IV模型等中。
他们通过三个案例,包括失业保险对失业持续时间的影响、401(k)养老金参与资格对于净金融资产的影响、制度对经济增长的长期影响,拓展了双重机器学习在政策评估中的应用场景。
双重机器学习假设所有混淆变量都可以被观测,其正则化过程能够达到高维变量选择的目的,与Frisch-Waugh-Lovell定理相似,模型通过正交化解决正则化带来的偏差。
除了上面所描述的,还有一些问题待解决,比如在ML模型下存在偏差和估计有效性的问题,这个时候可以通过Sample Splitting和Cross Fitting的方式来解决,具体做法是我们把数据分成一个训练集和估计集,在讥练集上我们分别使用机器学习来拟合影响,在估计集上我们根据拟合得到的函数来做残差的估计,通过这种方法,可以对偏差进行修正。
在偏差修正的基础上,我们可以对整个估计方法去构造一个moment condition,得到置信区间的推断,从而得到一个有良好统计的估计。
catboostclassifier predict -回复

catboostclassifier predict -回复CatBoostClassifier是一个强大的机器学习算法模型,它在分类问题中表现出色。
本文将通过一步一步回答问题的方式,深入探讨CatBoostClassifier predict方法的原理和应用。
首先,我们来了解一下CatBoostClassifier是什么。
CatBoostClassifier 是Yandex(俄罗斯最大的搜索引擎)开发的一种梯度提升决策树算法模型。
它是基于Boosting算法的一种实现,能够处理各种类型的数据,包括类别型和数值型。
接下来,我们来解释一下CatBoostClassifier predict方法的作用。
在机器学习中,我们通常将数据集划分为训练集和测试集。
通过训练模型,我们可以建立模型之间特定的关系和规律,然后利用测试集来评估模型的性能。
而predict方法就是通过该模型对测试集中的样本进行分类预测,即预测样本属于哪个类别。
那么,CatBoostClassifier的predict方法是如何工作的呢?首先,它会利用训练阶段学到的决策树模型,对测试集中的每个样本进行特征提取。
特征提取是将原始数据映射到新的特征空间的过程,以便更好地表示样本的特征。
接下来,CatBoostClassifier会将测试样本输入到决策树模型中,根据决策树的节点和分支规则,将样本分配到某个叶子节点。
最后,CatBoostClassifier根据叶子节点的条件概率分布,确定测试样本属于哪个类别。
那么,我们该如何使用CatBoostClassifier的predict方法呢?首先,我们需要将训练好的模型加载到内存中。
可以通过以下代码实现:pythonfrom catboost import CatBoostClassifier# 加载模型model = CatBoostClassifier()model.load_model('model.cbm') #将模型文件加载到内存中接下来,我们需要将测试集中的样本传递给模型的predict方法,进行分类预测。
B细胞表位预测研究进展

B细胞表位预测研究进展羊红光; 张立佳; 成彬【期刊名称】《《河北省科学院学报》》【年(卷),期】2019(036)003【总页数】7页(P21-27)【关键词】B细胞表位; 表位鉴定; 表位预测; 计算方法【作者】羊红光; 张立佳; 成彬【作者单位】河北省科学院应用数学研究所河北石家庄 050018; 河北省科学院河北石家庄 050081; 河北省信息安全认证工程技术研究中心河北石家庄050018【正文语种】中文【中图分类】R392.9许多微生物菌株对抗生素的耐药性日益增加,化疗药物的副作用日益严重,使得人们需要寻找有效的诊断方法和新的预防策略,特别是通过接种疫苗进行预防。
理解表位/抗体相互作用是构建有效疫苗和有效诊断的关键。
B细胞表位定位是鉴定微生物主要抗原决定簇的一种有前途的方法,特别是不连续构象的决定簇。
基于表位的疫苗比传统疫苗具有显著的优势,因为它们具有特异性,能够避免不良免疫反应,能产生更持久的免疫保护[1]。
“表位”一词在20世纪60年代开始普遍使用[2],是指“抗体与其抗原结合的地方”。
B细胞表位由抗原的一组氨基酸残基组成,这些残基与属于抗体的残基直接接触。
从结构上看,B细胞表位分为线性表位(也称为连续表位)和构象性表位(也非线性称为或不连续表位)[3]。
线性表位由抗原序列的单个连续片段组成,在蛋白质变性后或在小肽片段中持续存在。
构象表位仅存在于正确折叠的蛋白质或大的折叠片段中。
1 表位的鉴定与预测表位的认识严格来讲,分为鉴定和预测两种方式。
鉴定是准确确定表位的方法,预测是为鉴定表位提供可能的结果的方法,是一种表位筛选方法。
目前,表位鉴定有多种方法可以实现,这些方法有各自的优势,也存在自身的缺点。
下面简要的介绍一下这几种方法[4]。
(1)基于结晶学的方法。
该方法能够检测连续的线性表位,但是复杂和昂贵,因为它需要大量高纯度的、已知结构的蛋白单克隆抗体(单克隆抗体)复合物。
在这种技术中,首先需要获得高度纯化的抗原,并使其与相应的抗体共结晶。
用python实现鸢尾花数据集的朴素贝叶斯算法

用python实现鸢尾花数据集的朴素贝叶斯算法Python是一种功能强大的编程语言,广泛应用于数据科学和机器学习领域。
朴素贝叶斯算法是一种常见的建模方法,可以用于分类问题。
在这篇文章中,我们将使用Python实现朴素贝叶斯算法来处理鸢尾花数据集。
首先,我们需要导入一些必要的库。
在Python中,有很多强大的数据处理和机器学习库可供选择,例如NumPy、Pandas和Scikit-Learn。
这些库可以帮助我们加载和处理数据,以及构建机器学习模型。
我们首先导入NumPy和Pandas库,用于数据处理和分析。
pythonimport numpy as npimport pandas as pd接下来,我们将使用Pandas库加载鸢尾花数据集。
鸢尾花数据集是一个常用的机器学习数据集,其中包含150个样本,每个样本有四个特征:花萼长度、花萼宽度、花瓣长度和花瓣宽度。
鸢尾花数据集由三个类别组成:Setosa、Versicolor和Virginica。
我们可以使用Pandas库的read_csv函数从CSV文件中加载数据集。
pythondata = pd.read_csv('iris.csv')数据集加载完成后,我们可以使用head()函数查看前几行数据,确保数据正确加载。
pythonprint(data.head())现在,我们已经成功加载了鸢尾花数据集。
接下来,我们将进行数据预处理,以准备数据用于训练朴素贝叶斯分类器。
首先,我们需要将数据集拆分为特征和目标变量。
特征是我们用来预测目标变量的变量,而目标变量是我们希望预测的变量。
pythonX = data.drop('species', axis=1)y = data['species']在实施朴素贝叶斯算法之前,我们需要将特征进行标准化处理。
标准化可以确保数据具有相似的范围和分布,有助于提高算法的性能。
我们可以使用Scikit-Learn库中的StandardScaler进行标准化处理。
机器学习建模实验报告(3篇)

第1篇一、实验背景随着大数据时代的到来,机器学习技术在各个领域得到了广泛应用。
本实验旨在通过实际操作,掌握机器学习建模的基本流程,包括数据预处理、特征选择、模型选择、模型训练和模型评估等步骤。
通过实验,我们将深入理解不同机器学习算法的原理和应用,提高解决实际问题的能力。
二、实验目标1. 熟悉Python编程语言,掌握机器学习相关库的使用,如scikit-learn、pandas等。
2. 掌握数据预处理、特征选择、模型选择、模型训练和模型评估等机器学习建模的基本步骤。
3. 熟悉常见机器学习算法,如线性回归、逻辑回归、决策树、支持向量机、K最近邻等。
4. 能够根据实际问题选择合适的机器学习算法,并优化模型参数,提高模型性能。
三、实验环境1. 操作系统:Windows 102. 编程语言:Python3.83. 机器学习库:scikit-learn 0.24.2、pandas 1.3.4四、实验数据本实验使用鸢尾花数据集(Iris dataset),该数据集包含150个样本,每个样本有4个特征(花瓣长度、花瓣宽度、花萼长度、花萼宽度)和1个标签(类别),共有3个类别。
五、实验步骤1. 数据导入与预处理首先,使用pandas库导入鸢尾花数据集,并对数据进行初步查看。
然后,对数据进行标准化处理,将特征值缩放到[0, 1]范围内。
```pythonimport pandas as pdfrom sklearn import datasets导入鸢尾花数据集iris = datasets.load_iris()X = iris.datay = iris.target标准化处理from sklearn.preprocessing import StandardScalerscaler = StandardScaler()X = scaler.fit_transform(X)```2. 特征选择使用特征重要性方法进行特征选择,选择与标签相关性较高的特征。
matlab逻辑斯蒂回归多分类

MATLAB逻辑斯蒂回归多分类简介逻辑斯蒂回归(Logistic Regression)是一种经典的机器学习算法,主要用于处理二分类问题。
然而,在实际应用中,我们常常遇到多分类问题,即需要将样本分为多个类别。
本文将介绍如何使用MATLAB进行逻辑斯蒂回归的多分类任务。
数据准备在进行多分类任务之前,我们需要准备好训练数据和测试数据。
假设我们有一个包含多个特征的数据集,每个样本都属于三个类别之一。
我们可以使用MATLAB内置的数据集fisheriris作为示例数据集。
load fisheririsX = meas; % 特征矩阵Y = species; % 类别标签在这个示例中,X是一个150x4的矩阵,表示150个样本的四个特征。
Y是一个150x1的向量,表示每个样本的类别标签。
数据预处理在进行逻辑斯蒂回归之前,我们需要对数据进行预处理。
常见的预处理步骤包括特征缩放、特征选择和数据分割等。
特征缩放特征缩放是将不同特征的取值范围映射到相同的尺度上,以防止某些特征对模型的影响过大。
常用的特征缩放方法有标准化和归一化。
X = zscore(X); % 标准化在上述代码中,我们使用zscore函数对特征矩阵X进行标准化处理。
数据分割为了评估模型的性能,我们需要将数据集划分为训练集和测试集。
训练集用于训练模型,测试集用于评估模型在新数据上的预测性能。
cv = cvpartition(Y, 'HoldOut', 0.2); % 80%训练集,20%测试集X_train = X(cv.training,:);Y_train = Y(cv.training,:);X_test = X(cv.test,:);Y_test = Y(cv.test,:);在上述代码中,我们使用cvpartition函数将数据集按照80:20的比例划分为训练集和测试集。
多分类模型训练在MATLAB中,可以使用fitcecoc函数来训练逻辑斯蒂回归的多分类模型。
基于决策树的算法分析与应用示例

基于决策树的算法分析与应用示例在机器学习领域,决策树是一个经典的算法,它可以在面对大量数据时进行快速且可靠的分类或回归。
本文将介绍决策树算法的原理与应用,并通过一个具体的案例来展示其实际应用价值。
一、什么是决策树算法决策树是一种树形结构的分类模型,它的构建过程就像是一次“递归”的决策过程。
假设我们有一组数据,每个数据点都有若干个特征(即不同的属性),我们要根据这些特征来决定其类别(如是/否、高/中/低等)。
而决策树的生成就是一个逐步“分治”的过程,将原始数据分成不同子集,并根据不同特征来分别处理,最终得到一棵带有判定条件的树形结构。
决策树的构建过程可以分为三个步骤:特征选择、决策树生成和决策树剪枝。
其中,特征选择是指从所有特征中选出一个最佳特征来作为当前的分类依据;决策树生成是指利用选定的特征对数据进行划分,生成一棵完整的决策树;决策树剪枝是指对已经生成的决策树进行优化,去除一些不必要的节点和分枝,以避免过拟合等问题。
除了常见的二叉树决策树外,还有多叉树、CART树、C4.5树、ID3树等多种类型的决策树算法。
它们在特征选择、剪枝等方面有所不同,但本质上都是基于“树形结构”来完成分类或回归任务的。
二、决策树算法的应用示例决策树算法有许多实际应用,如金融风险评估、医学诊断、信用卡反欺诈等。
这里我们以一个简单的基于决策树的鸢尾花分类为例来说明决策树的应用过程。
鸢尾花数据集是机器学习中常用的一个数据集,它包含了150条记录,每条记录都有四个特征:花萼长度、花萼宽度、花瓣长度、花瓣宽度。
根据这些特征,我们需要判断鸢尾花属于哪种类型:山鸢尾(Iris-setosa)、变色鸢尾(Iris-versicolor)或维吉尼亚鸢尾(Iris-virginica)。
以下是如何用Python和sklearn库来实现这一任务:```python# 引入相关库和数据集from sklearn.datasets import load_irisfrom sklearn.tree import DecisionTreeClassifierfrom sklearn.model_selection import train_test_splitiris = load_iris()X_train, X_test, y_train, y_test = train_test_split(iris.data, iris.target, test_size=0.3, random_state=42)# 构建决策树模型并进行训练clf = DecisionTreeClassifier(criterion='entropy', max_depth=10, random_state=42)clf.fit(X_train, y_train)# 预测并评估模型准确率y_pred = clf.predict(X_test)score = clf.score(X_test, y_test)print(score)```上述代码首先引入了相关的Python库和鸢尾花数据集,并将数据集分为训练集和测试集。
机器学习算法如何处理缺失数据

机器学习算法如何处理缺失数据在当今的数据驱动时代,机器学习算法被广泛应用于各个领域,从预测股票市场的走势到医疗诊断,从推荐系统到智能交通管理。
然而,数据往往并不完美,其中一个常见的问题就是缺失数据。
缺失数据可能由于各种原因产生,比如数据收集过程中的错误、某些属性难以测量、被调查者未回答等。
处理缺失数据是机器学习中的一个重要任务,因为它可能会对模型的性能和准确性产生显著影响。
首先,我们需要了解一下缺失数据的类型。
一般来说,缺失数据可以分为完全随机缺失(Missing Completely At Random,MCAR)、随机缺失(Missing At Random,MAR)和非随机缺失(Missing Not At Random,MNAR)。
完全随机缺失意味着数据的缺失与数据本身以及其他任何观察到或未观察到的变量都无关。
例如,在一个问卷调查中,某些问题的答案缺失仅仅是因为被调查者随机选择不回答。
随机缺失则是指数据的缺失与已观察到的变量有关,但与未观察到的变量无关。
比如,在医疗数据中,患者的某些症状信息缺失可能与他们的年龄、性别等已记录的特征相关,但与未记录的疾病严重程度等无关。
非随机缺失是最复杂的情况,数据的缺失与未观察到的变量有关。
例如,在一项关于收入的调查中,高收入人群可能更不愿意报告他们的准确收入,导致这部分数据的缺失。
那么,机器学习算法是如何应对这些不同类型的缺失数据呢?一种常见的方法是删除包含缺失值的数据行或列。
这种方法被称为删除法,简单直接,但也存在明显的缺点。
如果缺失数据的比例较大,大量删除可能会导致数据量急剧减少,从而丢失很多有价值的信息。
而且,如果缺失数据不是完全随机的,删除可能会引入偏差。
另一种方法是填充缺失值。
常见的填充方法包括使用均值、中位数或众数来填充。
对于数值型数据,通常使用均值或中位数;对于分类型数据,使用众数。
这种方法的优点是简单快捷,但也有局限性。
它没有考虑数据的分布和相关性,可能会导致数据的方差减小,影响模型的准确性。
机器学习实验报告代码

一、实验目的1. 理解K-means聚类算法的基本原理。
2. 掌握K-means聚类算法的Python实现方法。
3. 通过实验验证K-means聚类算法在不同数据集上的效果。
二、实验环境1. 操作系统:Windows 102. 编程语言:Python3. 数据分析库:NumPy、Matplotlib、Scikit-learn三、实验内容1. 数据准备2. K-means聚类算法实现3. 聚类结果可视化4. 聚类效果评估四、实验步骤1. 数据准备本实验采用二维数据集,数据集包含100个样本,每个样本有两个特征。
```pythonimport numpy as np# 生成二维数据集data = np.random.rand(100, 2)```2. K-means聚类算法实现```pythondef kmeans(data, k):"""K-means聚类算法实现:param data: 输入数据集:param k: 聚类个数:return: 聚类中心、聚类标签"""# 随机初始化聚类中心centroids = data[np.random.choice(data.shape[0], k, replace=False)]while True:# 计算每个样本与聚类中心的距离,并分配到最近的聚类中心distances = np.sqrt(((data - centroids[:,np.newaxis])2).sum(axis=2))labels = np.argmin(distances, axis=0)# 计算新的聚类中心new_centroids = np.array([data[labels == i].mean(axis=0) for i in range(k)])# 判断聚类中心是否收敛if np.allclose(new_centroids, centroids):breakcentroids = new_centroidsreturn centroids, labels```3. 聚类结果可视化```pythonimport matplotlib.pyplot as plt# 绘制聚类结果def plot_clusters(data, centroids, labels):plt.scatter(data[:, 0], data[:, 1], c=labels, cmap='viridis')plt.scatter(centroids[:, 0], centroids[:, 1], s=300, c='red', marker='x')plt.xlabel('Feature 1')plt.ylabel('Feature 2')plt.title('K-means Clustering Results')plt.show()# 调用函数进行聚类centroids, labels = kmeans(data, 3)# 绘制聚类结果plot_clusters(data, centroids, labels)```4. 聚类效果评估为了评估K-means聚类算法的效果,我们可以计算轮廓系数(Silhouette Coefficient)。
使用Scikit-learn进行机器学习模型评估

使用Scikit-learn进行机器学习模型评估机器学习模型评估是机器学习任务中非常重要的一环,它可以帮助我们评估模型的性能,找出模型存在的问题并对模型进行调优。
在进行机器学习模型评估时,我们可以使用Scikit-learn库来实现。
本文将介绍如何使用Scikit-learn对机器学习模型进行评估,并对常用的评估指标进行详细的讲解。
Scikit-learn是一个用于机器学习的开源库,包含多种机器学习算法和工具,方便用户快速构建模型、进行数据预处理和模型评估。
在Scikit-learn中,有多种评估指标可以帮助我们评估模型性能,比如准确率、精确率、召回率、F1值等。
在接下来的部分,我们将分别介绍这些评估指标,并讲解如何使用Scikit-learn进行评估。
1.准确率(Accuracy)准确率是模型预测结果中正确的样本数占总样本数的比例,是常用的模型评估指标之一。
在Scikit-learn中,可以使用`accuracy_score`函数来计算模型的准确率,其用法如下:```pythonfrom sklearn.metrics import accuracy_scoreaccuracy = accuracy_score(y_true, y_pred)```其中`y_true`是真实的标签,`y_pred`是模型预测的标签。
`accuracy`即为模型的准确率。
在实际使用中,我们可以将模型的预测结果和真实标签传入`accuracy_score`函数中,即可得到模型的准确率。
2.精确率(Precision)精确率是指模型正确预测为正例的样本数占预测为正例的样本总数的比例。
在Scikit-learn中,可以使用`precision_score`函数来计算模型的精确率:```pythonfrom sklearn.metrics import precision_scoreprecision = precision_score(y_true, y_pred)```与准确率类似,`y_true`和`y_pred`分别表示真实的标签和模型的预测标签,`precision`为模型的精确率。
机器学习-数据预处理、降维、特征提取及聚类
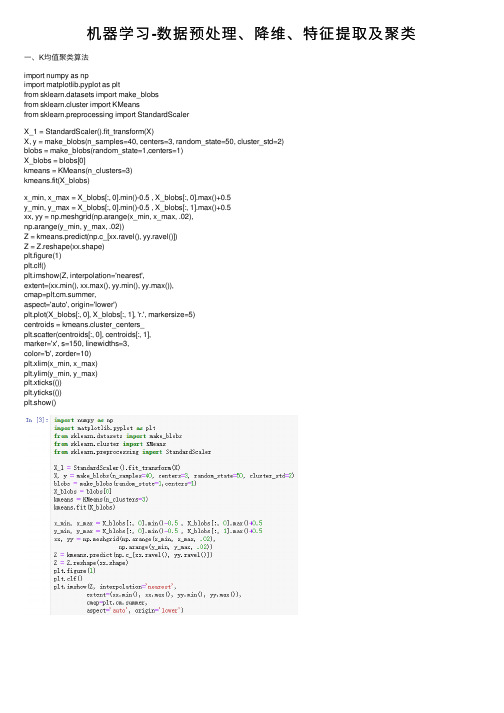
机器学习-数据预处理、降维、特征提取及聚类⼀、K均值聚类算法import numpy as npimport matplotlib.pyplot as pltfrom sklearn.datasets import make_blobsfrom sklearn.cluster import KMeansfrom sklearn.preprocessing import StandardScalerX_1 = StandardScaler().fit_transform(X)X, y = make_blobs(n_samples=40, centers=3, random_state=50, cluster_std=2)blobs = make_blobs(random_state=1,centers=1)X_blobs = blobs[0]kmeans = KMeans(n_clusters=3)kmeans.fit(X_blobs)x_min, x_max = X_blobs[:, 0].min()-0.5 , X_blobs[:, 0].max()+0.5y_min, y_max = X_blobs[:, 0].min()-0.5 , X_blobs[:, 1].max()+0.5xx, yy = np.meshgrid(np.arange(x_min, x_max, .02),np.arange(y_min, y_max, .02))Z = kmeans.predict(np.c_[xx.ravel(), yy.ravel()])Z = Z.reshape(xx.shape)plt.figure(1)plt.clf()plt.imshow(Z, interpolation='nearest',extent=(xx.min(), xx.max(), yy.min(), yy.max()),cmap=plt.cm.summer,aspect='auto', origin='lower')plt.plot(X_blobs[:, 0], X_blobs[:, 1], 'r.', markersize=5)centroids = kmeans.cluster_centers_plt.scatter(centroids[:, 0], centroids[:, 1],marker='x', s=150, linewidths=3,color='b', zorder=10)plt.xlim(x_min, x_max)plt.ylim(y_min, y_max)plt.xticks(())plt.yticks(())plt.show()⼆、凝聚聚类算法⼯作原理展⽰from scipy.cluster.hierarchy import dendrogram, wardlinkage = ward(X_blobs)dendrogram(linkage)ax = plt.gca()plt.show()三、DBSCAN算法对make_blobs数据集的聚类结果from sklearn.cluster import DBSCANdb = DBSCAN(min_samples = 20)clusters = db.fit_predict(X_blobs)plt.scatter(X_blobs[:, 0], X_blobs[:, 1], c=clusters, cmap=plt.cm.cool, s=60,edgecolor='k')plt.xlabel("Feature 0")plt.ylabel("Feature 1")plt.show()。
基于机器学习的RNA编辑位点预测方法综述

基于机器学习的RNA编辑位点预测方法综述冷嘉承;吴凌云【摘要】RNA编辑是一个十分重要的生物细胞分子机制.作为转录后修饰的一步,它可以增加蛋白质组学多样性,改变转录产物的稳定性,调节基因表达等.RNA编辑失调会导致各种疾病,包括神经疾病和癌症.在动物中,腺苷到肌苷(A-to-I)的编辑是最普遍的.高通量测序技术的进步大大提高了在全局范围内检测和量化RNA编辑的能力,使得RNA编辑的大规模全基因组分析变得可行,产生了一系列基于高通量测序技术的RNA编辑位点预测方法.通过对这些方法进行介绍、总结和分析,为RNA 编辑的进一步研究提供一些思路.【期刊名称】《生物信息学》【年(卷),期】2019(017)001【总页数】8页(P1-8)【关键词】RNA编辑;高通量测序;A-to-I;机器学习【作者】冷嘉承;吴凌云【作者单位】中国科学院数学与系统科学研究院应用数学研究所,管理、决策与信息系统重点实验室,国家数学与交叉科学中心,北京100190;中国科学院大学数学科学学院,北京100049;中国科学院数学与系统科学研究院应用数学研究所,管理、决策与信息系统重点实验室,国家数学与交叉科学中心,北京100190;中国科学院大学数学科学学院,北京100049【正文语种】中文【中图分类】Q522+.6RNA合成、加工、行使功能和降解是细胞生存的关键,并在许多不同的层面进行着调控[1]。
RNA合成是基因表达的第一步,转录因子调控RNA聚合酶II(Pol II)与启动子结合[2],通过一套非常复杂的操作步骤将DNA转录为前体RNA[3]。
前体RNA随后被加工产生成熟mRNA、功能性tRNA和rRNA[4]。
RNA的加工包括(1)加帽:将7-甲基鸟苷酸(m7G)添加到5’末端[5];(2)聚腺苷酸化:在3’末端添加poly-A尾巴[6];(3)剪接:去除内含子之后拼接外显子[7];(4)RNA编辑:修改RNA分子序列并导致蛋白质多样性[4, 8]。
Spark大数据处理系列之Machine Learning

Spark大数据处理系列之Machine Learning超人学院——机器学习和数据科学机器学习是从已经存在的数据进行学习来对将来进行数据预测,它是基于输入数据集创建模型做数据驱动决策。
数据科学是从海里数据集(结构化和非结构化数据)中抽取知识,为商业团队提供数据洞察以及影响商业决策和路线图。
数据科学家的地位比以前用传统数值方法解决问题的人要重要。
以下是几类机器学习模型:∙监督学习模型∙非监督学习模型∙半监督学习模型∙增强学习模型下面简单的了解下各机器学习模型,并进行比较:∙监督学习模型:监督学习模型对已标记的训练数据集训练出结果,然后对未标记的数据集进行预测;监督学习又包含两个子模型:回归模型和分类模型。
∙非监督学习模型:非监督学习模型是用来从原始数据(无训练数据)中找到隐藏的模式或者关系,因而非监督学习模型是基于未标记数据集的;∙半监督学习模型:半监督学习模型用在监督和非监督机器学习中做预测分析,其既有标记数据又有未标记数据。
典型的场景是混合少量标记数据和大量未标记数据。
半监督学习一般使用分类和回归的机器学习方法;∙增强学习模型:增强学习模型通过不同的行为来寻找目标回报函数最大化。
下面给各个机器学习模型举个列子:∙监督学习:异常监测;∙非监督学习:社交网络,语言预测;∙半监督学习:图像分类、语音识别;∙增强学习:人工智能(AI)。
机器学习项目步骤开发机器学习项目时,数据预处理、清洗和分析的工作是非常重要的,与解决业务问题的实际的学习模型和算法一样重要。
典型的机器学习解决方案的一般步骤:∙特征工程∙模型训练∙模型评估图1原始数据如果不能清洗或者预处理,则会造成最终的结果不准确或者不可用,甚至丢失重要的细节。
训练数据的质量对最终的预测结果非常重要,如果训练数据不够随机,得出的结果模型不精确;如果数据量太小,机器学习出的模型也不准确。
使用案例:业务使用案例分布于各个领域,包括个性化推荐引擎(食品推荐引擎),数据预测分析(股价预测或者预测航班延迟),广告,异常监测,图像和视频模型识别,以及其他各类人工智能。
【机器学习】异常检测算法速览(Python代码)

【机器学习】异常检测算法速览(Python代码)正文共: 8636字 8图预计阅读时间: 22分钟一、异常检测简介异常检测是通过数据挖掘方法发现与数据集分布不一致的异常数据,也被称为离群点、异常值检测等等。
1.1 异常检测适用的场景异常检测算法适用的场景特点有:(1)无标签或者类别极不均衡;(2)异常数据跟样本中大多数数据的差异性较大;(3)异常数据在总体数据样本中所占的比例很低。
常见的应用案例如:金融领域:从金融数据中识别”欺诈用户“,如识别信用卡申请欺诈、信用卡盗刷、信贷欺诈等;安全领域:判断流量数据波动以及是否受到攻击等等;电商领域:从交易等数据中识别”恶意买家“,如羊毛党、恶意刷屏团伙;生态灾难预警:基于天气指标数据,判断未来可能出现的极端天气;医疗监控:从医疗设备数据,发现可能会显示疾病状况的异常数据;1.2 异常检测存在的挑战异常检测是热门的研究领域,但由于异常存在的未知性、异质性、特殊性及多样性等复杂情况,整个领域仍有较多的挑战:•1)最具挑战性的问题之一是难以实现高异常检测召回率。
由于异常非常罕见且具有异质性,因此很难识别所有异常。
•2)异常检测模型要提高精确度(precision)往往要深度结合业务特征,否则效果不佳,且容易导致对少数群体产生算法偏见。
二、异常检测方法按照训练集是否包含异常值可以划分为异常值检测(outlier detection)及新颖点检测(novelty detection),新颖点检测的代表方法如one class SVM。
按照异常类别的不同,异常检测可划分为:异常点检测(如异常消费用户),上下文异常检测(如时间序列异常),组异常检测(如异常团伙)。
按照学习方式的不同,异常检测可划分为:有监督异常检测(Supervised Anomaly Detection)、半监督异常检测(Semi-Supervised Anomaly Detection)及无监督异常检测(Unsupervised Anomaly Detection)。
加权核范数代码

加权核范数代码加权核范数是一种用于特征选择和模型优化的技术。
它将特征的重要性考虑在内,并在模型中引入正则化项,以防止过拟合。
加权核范数代码实现了这个技术,可以应用于各种机器学习问题。
一、什么是加权核范数?1.1 定义加权核范数是指对于一个带有权重的特征向量,通过对其进行L1或L2正则化来获得其稀疏性和平滑性的一种方法。
1.2 作用加权核范数在特征选择和模型优化中都有广泛应用。
它能够筛选出最重要的特征,并且可以防止模型过拟合。
二、如何实现加权核范数代码?2.1 加权核范数公式加权核范数公式如下:$J(w)=\frac{1}{n}\sum_{i=1}^{n}l(y_i,w^Tx_i)+\lambda\sum_{j=1} ^{m}\omega_j||w_j||_p$其中,$l(y_i,w^Tx_i)$为损失函数,$w$为参数向量,$\lambda$为正则化系数,$\omega_j$为第$j$个特征的权重,$m$为特征数量,$p=1$时为L1正则化,$p=2$时为L2正则化。
2.2 代码实现加权核范数的代码实现可以使用Python语言和机器学习库来完成。
以下是一个使用scikit-learn库的示例代码:```from sklearn.linear_model import LogisticRegressionfrom sklearn.datasets import load_digitsfrom sklearn.model_selection import train_test_splitfrom sklearn.metrics import accuracy_score# 加载数据集digits = load_digits()X_train, X_test, y_train, y_test = train_test_split(digits.data,digits.target, test_size=0.3)# 创建模型并训练clf = LogisticRegression(penalty='l1')clf.fit(X_train, y_train)# 预测并评估模型y_pred = clf.predict(X_test)score = accuracy_score(y_test, y_pred)print('Accuracy:', score)```在上面的代码中,我们使用了Logistic回归模型,并指定了L1正则化。
tf里prebatch格式解析

tf里prebatch格式解析TensorFlow(TF)中的PreBatch 格式是一种用于处理批量数据的前处理方法。
在深度学习训练过程中,通常需要将数据进行批量处理,以提高计算效率。
PreBatch 格式就是在这个过程中对批量数据进行解析和处理的格式。
PreBatch 格式主要包括以下几个部分:1. 数据集划分:将原始数据集划分为多个批次(batch)。
每个批次的样本数量可以根据实际情况进行设置,通常情况下,批次越大,计算效率越高,但过大的批次可能导致内存不足。
2. 数据预处理:对每个批次的数据进行预处理,如归一化、标准化等。
这有助于减少数据之间的差异,使模型更容易学习。
3. 数据增强(Optional):对批次内的数据进行增强,如旋转、缩放等。
数据增强可以提高模型的泛化能力,防止过拟合。
4. 标签处理:将批次内的标签进行处理,如one-hot 编码、softmax 等。
这有助于模型更好地理解和识别数据。
5. 批次构建:将处理后的数据和标签构建为TensorFlow 的数据结构,如Dataset、Queue 等。
这些数据结构可以方便地被模型读取和处理。
在实际应用中,PreBatch 格式可以根据具体需求进行调整和优化。
以下是一个简单的Python 示例,展示了如何使用TensorFlow 读取和处理批量数据:```pythonimport tensorflow as tf# 读取数据dataset = tf.data.Dataset.from_tensor_slices((x_train, y_train))# 数据预处理dataset = dataset.map(lambda x, y: (x / 255.0, tf.one_hot(y, num_classes)))# 数据增强(示例:旋转)dataset = dataset.map(lambda x, y: (tf.image.rotate(x, angle=90), y))# 划分批次batch_size = 32dataset = dataset.batch(batch_size)# 创建一个会话来读取和处理数据with tf.Session() as sess:for epoch in range(num_epochs):iterator = dataset.make_one_shot_iterator()next_batch = iterator.get_next()while True:try:x_batch, y_batch = sess.run(next_batch)# 在这里使用x_batch 和y_batch 进行模型训练except tf.errors.OutOfRangeError:break```在这个示例中,我们首先读取了原始数据和标签,然后对数据进行了预处理和增强。
机器学习_BCPreddataset(BCPred数据集).

attribute Seq string
attribute class {0,1}
Reference
EL-Manzalawy Y, Dobbs D, Honavar V (2008 Predicting linear B-cell epitopes using string kernels. J. Mol. Recognit. 21: 243-255.
中文关键词:
机器学习,线性B细胞,抗原,Binear B-cell,Antigen,BCPred,
数据格式:
TEXT
数据用途:
The data can be used for prediction and analysis.
数据详细介绍:
BCPred dataset
∙Abstract
Five homology-reduced datasets (BCP20, BCP18, BCP16, BCP14, and BCP12 which have been used to evaluate and build the BCPred method for predicting linear B-cell epitopes.
数据预览:
点此下载完整数据集
机器学习bcpreddatasetbcpred数据集机器学习数据集机器学习实战数据集机器学习数据集下载机器学习机器学习实战机器学习算法机器学习与数据挖掘机器学习实战pdf机器学习pdf
BCPred dataset(BCPred数据集
数据摘要:
Five homology-reduced datasets (BCP20, BCP18, BCP16, BCP14, and BCP12 which have been used to evaluate and build the BCPred method for predicting linear B-cell epitopes.
域适应数据集

域适应数据集域适应数据集在机器学习和深度学习中的应用非常广泛,尤其在图像分类、目标检测和语音识别等领域中。
在这些任务中,我们通常需要训练一个模型来将输入数据映射到对应的标签。
然而,在现实世界中,由于不同领域之间的差异,我们很难直接使用从其他领域收集到的数据集来训练模型。
这时候,域适应数据集就派上了用场。
通过使用域适应数据集,我们可以将模型在源域上训练得到的知识迁移到目标域上,从而提高模型在目标域上的性能。
域适应数据集的研究主要涉及到两个方面:特征对齐和标签对齐。
特征对齐是指通过一些方法,使得源域和目标域的特征分布尽可能地接近。
常用的方法包括最大均值差异(Maximum Mean Discrepancy,简称MMD)和深度特征对齐(Deep Feature Alignment)等。
标签对齐是指通过一些方法,使得源域和目标域的标签分布尽可能地接近。
常用的方法包括自训练(Self-Training)和领域对抗神经网络(Domain Adversarial Neural Network,简称DANN)等。
关于域适应数据集的研究已经取得了一些重要的成果。
例如,在图像分类任务中,通过使用域适应数据集,研究人员可以将模型在ImageNet等大规模数据集上训练得到的知识迁移到其他小规模数据集上,从而显著提高模型的性能。
在目标检测任务中,通过使用域适应数据集,研究人员可以将模型在COCO等大规模数据集上训练得到的知识迁移到其他小规模数据集上,从而提高模型在目标检测任务上的性能。
除了图像分类和目标检测,域适应数据集在语音识别、文本分类和推荐系统等领域中也得到了广泛应用。
在语音识别任务中,通过使用域适应数据集,研究人员可以将模型在TIMIT等数据集上训练得到的知识迁移到其他语音识别任务上,从而提高模型的性能。
在文本分类任务中,通过使用域适应数据集,研究人员可以将模型在大规模文本数据集上训练得到的知识迁移到其他小规模数据集上,从而提高模型在文本分类任务上的性能。