《形式语言与自动机》(王柏、杨娟编著)课后习题答案
形式语言与自动机ch4.2

可致空符号(nullable symbol)
对于 CFG G = (N, T, P , S ),称符号 A N 是可致 空的,当且仅当 A .
(3)消除 G 中的 无用符号.
注意 以上简化步骤的次序. 结论 设 CFG G 的语言至少包含一个非 的字符串,通 过上述步骤从 G 构造 G1 ,则有 L(G1)= L(G) - {}.
College of Computer Science & Technology, BUPT
22
§ 4.2 上下文无关文法的变换
CFG 的简化 消无用符号 消 产生式 消单产生式 对生成式形式进行标准化
College of Computer Science & Technology, BUPT
1
生成式的标准形式
Chomsky范式 (CNF - Chomsky Normal Form) 生成式形式为A→BC, A→a, A, B, C∈N , a∈T (后 面将证明, 每个上下文无关文法都有一个CNF文法)
College of Computer Science & Technology, BUPT 6
算法1: 找出有用非终结符(图示)
N''= N0∪{B|B→α 且α ∈(T∪N ')* } N' = { A | A→ω 且 ω ∈T*}
B
1
A
1
N0 = 空
A
2
A
3
2
B
一层层向外扩展,直至最外两层相等为止。所得集合
作业参考答案8

形式语言与自动机作业参考答案第八次作业:(课本P182,183第6题,第8题,第9题,第10题)6.设文法G=({S,T,F},{0,1},P,S),其中生成式P如下:S -> 0C | 1DD -> 0 | 0S | 1DDC -> 1 | 1S | 0CC对于字符串0001110011,找出(1)一个最左推导。
(2)一个最右推导。
(3)一棵推导树。
答:(1) 最左推导:S => 0C => 00CC => 000CCC => 0001CC => 00011C => 000111S=> 0001110C => 00011100CC => 000111001C => 0001110011(2) 最右推导:S => 0C => 00CC => 00C1S => 00C10C => 00C100CC => 00C100C1=> 00C10011 => 000CC10011 => 000C110011 => 0001110011(3) 推导树如下:S0 C0 C C0 C C 1 S1 1 0 C1 18. 把下列文法G1和G2,分别变换为没有无用符号,且与其等价的上下文无关文法。
(1)G1:S -> DC | EDC -> CE | DCD -> aE -> aC | b(2)G2:S -> D | CD -> aC | bS | bC -> DC | CaE -> DS | b答:(1)G1:根据算法1得出的有用符号N1 = {S, D, E},在此基础上用算法2得到最终的有用符号N1 = {S, D, E},T1 = {a, b}。
所以不含无用符号的与原文法等价的文法为:G = ({S, D, E}, {a, b}, P, S),其中P如下:S -> EDD -> aE -> b(2)G2:根据算法1得出的有用符号N1 = {S, D, E},在此基础上用算法2得到最终的有用符号N1 = {S, D},T1 = {b}。
完整版形式语言与自动机课后习题答案部分.ppt

• pp.84:习题 7(1)
用自然语言描述下列文法定义的语言
G: AaaA|aaB
BBcc|D#cc
DbbbD|#
• 解题思路
– 观察每个产生式及其组合产生的子语言的特点; – 根据开始符的产生式将它们并起来就是整个文法产生的语言;
• 解答
(1) D产生式:DbbbD|# – 使用DbbbD可产生句型:(bbb)mD (m1); – 进一步使用D#可得:L(D)={(bbb)m#| m0}
• A|0A|1A;
– 产生语言{0x|x{0, 1}*}的文法
• S0A;
– G: S0A
A|0A|1A
精心整理
11
G FH
课后作业二 (cont.)
• 习题8(3)的解答
– 分析:语言的特点
• {11x11|x*}{111, 11};
– 产生语言{x|x{0, 1}*}的文法
• A|0A|1A;
– 习题 22 --- 前/后缀
– 习题 23 --- 前/后缀
– 习题 28(1)(2)(10) --- L的描述
精心整理
3
G FH
课后作业一 (cont.)
• pp.40:习题 21
– 判断集合是否字母表的依据
• 非空性
• 有穷性
• 可区分性:字母表中的字符两两互不相同
• 整体性或不可分性
– 解答:(1)、(2) 和(6) 是字母表,其它不是
– 产生子语言{11x11|x*}的文法
• S11A11 ;
– 产生子语言{111, 11}的文法
• S111|11;
– G: S11A11|111|11
A|0A|1A
其它答案 (1) G: S11A|111|11
形式语言与自动机Chapter7练习参考解答

Chapter 7 练习参考解答Exercise 7.1.3 从以下文法出发:S → 0A0 | 1B1 | BBA → CB → S | AC → S | εa) 有没有无用符号?如果有的话去除它们。
b) 去除ε-产生式。
c) 去除单位产生式。
d) 把该文发转化为乔姆斯基范式。
参考解答:a)没有无用符.b) 所有符号S,A,B,C都是可致空的,消去ε-产生式后得到新的一组产生式:S → 0A0 | 1B1 | BB | B | 00 | 11A → CB → S | AC → Sc) 单元偶对包括:(A,A),(B,B),(C,C),(S,S),(A,C),(A,S),(A,B),(B,A),(B,C),(B,S),(C,A),(C,B),(C,S),(S,A),(S,B),(S,C),消去单元产生式后得到新的一组产生式S → 0A0 | 1B1 | BB | B | 00 | 11A → CB → S | AC → SS → 0A0 | 1B1 | BB | 00 | 11A → 0A0 | 1B1 | BB | 00 | 11B → 0A0 | 1B1 | BB | 00 | 11C → 0A0 | 1B1 | BB | 00 | 11d)先消去无用符号C,得到新的一组产生式:S → 0A0 | 1B1 | BB | 00 | 11A → 0A0 | 1B1 | BB | 00 | 11B → 0A0 | 1B1 | BB | 00 | 11引入非终结符C,D,增加产生式C → 0和D → 1,得到新的一组产生式:S → CAC | DBD | BB | CC | DDA → CAC | DBD | BB | CC | DDB → CAC | DBD | BB | CC | DDC → 0D → 1引入非终结符E,F,增加产生式E → CA和F → DB,得到满足Chomsky范式的一组产生式:S → EC | FD | BB | CC | DDA → EC | FD | BB | CC | DDB → EC | FD | BB | CC | DDE → CAF → DBC → 0D → 1Exercise 7.2.1(b)用CFL泵引理来证明下面的语言都不是上下文无关的:b) {a n b n c i | i ≤n}。
形式语言与自动机ch4.1

v
E
(
E O
)
E
v
v (v+d)
(5) (4) (1)
+
d
v (v+E)
(6)
(1) (2) (3) (4) (5) (6)
E EOE E (E) Ev Ed O + O
(3)
vO(v+E)
(3)
vO(E+E)
vO(EOE)
vO(E)
(2)
vOE
EOE
(1)
E
12
College of Computer Science & Technology, BUPT 18
二义性
定义: 2型文法是二义的,当且仅当对于句子ω∈L(G),存在两棵不 同的具有边缘为ω的推导树。 (即:如果文法是二义的, 那么它所产生的某个句子必然能从 不同的最左(右)推导推出)。 例: (书P124 例1) 句子(a*a+a)有二棵不同的推导树. (相当于一个先算乘法,一 个先算加法.) 注意: 可有二个文法,一个有二义,一个无二义,但产生相同的语言. 可否通过变换消除二义性? —— 无一般的算法!
v (v+d)
(5) (4)
v (v+E) vO(E)
(2)
(6)
vO(v+E)
(3)
(3)
vO(E+E) E
5
vO(EOE)
(1)
vOE
EOE
(1)
College of Computer Science & Technology, BUPT
归约与推导
推导过程举例
对于CFG Gexp = ({E,O}, { (, ),+, , v, d }, P , E ) ,P 为
《形式语言与自动机》(王柏、杨娟编著)课后习题答案
形式语言与自动机课后习题答案第二章4.找出右线性文法,能构成长度为1至5个字符且以字母为首的字符串。
答:G={N,T,P,S}其中N={S,A,B,C,D} T={x,y} 其中x∈{所有字母} y∈{所有的字符} P如下: S→x S→xA A→y A→yBB→y B→yC C→y C→yD D→y6.构造上下文无关文法能够产生L={ω/ω∈{a,b}*且ω中a的个数是b的两倍}答:G={N,T,P,S}其中N={S} T={a,b} P如下:S→aab S→aba S→baaS→aabS S→aaSb S→aSab S→SaabS→abaS S→abSa S→aSba S→SabaS→baaS S→baSa S→bSaa S→Sbaa7.找出由下列各组生成式产生的语言(起始符为S)(1)S→SaS S→b(2)S→aSb S→c(3)S→a S→aE E→aS答:(1)b(ab)n /n≥0}或者L={(ba)n b/n≥0}(2) L={a n cb n /n≥0}(3)L={a2n+1 /n≥0}第三章1.下列集合是否为正则集,若是正则集写出其正则式。
(1)含有偶数个a和奇数个b的{a,b}*上的字符串集合(2)含有相同个数a和b的字符串集合(3)不含子串aba的{a,b}*上的字符串集合答:(1)是正则集,自动机如下(2) 不是正则集,用泵浦引理可以证明,具体见17题(2)。
(3) 是正则集先看L’为包含子串aba的{a,b}*上的字符串集合显然这是正则集,可以写出表达式和画出自动机。
(略)则不包含子串aba的{a,b}*上的字符串集合L是L’的非。
根据正则集的性质,L也是正则集。
4.对下列文法的生成式,找出其正则式(1)G=({S,A,B,C,D},{a,b,c,d},P,S),生成式P如下:S→aA S→BA→abS A→bBB→b B→cCC→D D→bBD→d(2)G=({S,A,B,C,D},{a,b,c,d},P,S),生成式P如下:S→aA S→BA→cC A→bBB→bB B→aC→D C→abBD→d答:(1) 由生成式得:S=aA+B ①A=abS+bB ②B=b+cC ③C=D ④D=d+bB ⑤③④⑤式化简消去CD,得到B=b+c(d+bB)即B=cbB+cd+b =>B=(cb)*(cd+b) ⑥将②⑥代入①S=aabS+ab(cb)*(cd+b)+(cb)*(cd+b) =>S=(aab)*(ab+ε)(cb)*(cd+b) (2) 由生成式得:S=aA+B ①A=bB+cC ②B=a+bB ③C=D+abB ④D=dB ⑤由③得 B=b*a ⑥将⑤⑥代入④ C=d+abb*a=d+ab+a ⑦将⑥⑦代入② A=b+a+c(d+b+a) ⑧将⑥⑧代入① S=a(b+a+c(d+ab+a))+b*a=ab+a+acd+acab+a+b*a5.为下列正则集,构造右线性文法:(1){a,b}*(2)以abb结尾的由a和b组成的所有字符串的集合(3)以b为首后跟若干个a的字符串的集合(4)含有两个相继a和两个相继b的由a和b组成的所有字符串集合答:(1)右线性文法G=({S},{a,b},P,S)P: S→aS S→bS S→ε(2) 右线性文法G=({S},{a,b},P,S)P: S→aS S→bS S→abb(3) 此正则集为{ba*}右线性文法G=({S,A},{a,b},P,S)P: S→bA A→aA A→ε(4) 此正则集为{{a,b}*aa{a,b}*bb{a,b}*, {a,b}*bb{a,b}*aa{a,b}*}右线性文法G=({S,A,B,C},{a,b},P,S)P: S→aS/bS/aaA/bbBA→aA/bA/bbCB→aB/bB/aaCC→aC/bC/ε7.设正则集为a(ba)*(1)构造右线性文法(2)找出(1)中文法的有限自 b动机答:(1)右线性文法G=({S,A},{a,b},P,S)P: S→aA A→bS A→ε(2)自动机如下:(p2是终结状态)9.对应图(a)(b)的状态转换图写出正则式。
形式语言与自动机Chapter5练习参考解答

Chapter 5 练习参考解答Exercise 5.1.2 (c) 下面的文法产生了正则表达式0*1(0+1)*的语言:εε|1|0|01B B B A A BA S →→→试给出下列串的最左推导和最右推导:c) 00011。
参考解答:一个最左推导:S ⇒lm A1B ⇒lm 0A1B ⇒lm 00A1B ⇒lm 000A1B ⇒lm 0001B ⇒lm 00011B ⇒lm 00011一个最右推导:S ⇒rm A1B ⇒rm A11B ⇒rm A11 ⇒rm 0A11⇒rm 00A11⇒rm 000A11 ⇒rm 00011! Exercise 5.1.3 证明任何正则语言都是上下文无关语言。
提示:通过对正则表达式中的运算符的数目进行归纳的方法来构造CFG 。
参考解答:对于任何正规表达式R ,归纳于R 中算符的数目n 构造如下产生式集合P(R),相应的开始符号为S(R):基础:n=0.(1)R 为ε,则任选非终结符A ,令P(R)只包含A →ε,以及S(R)为A ;(2)R 为φ,令P(R) 为空集;(3)R 为a ,则任选非终结符A ,令P(R)只包含A →a ,以及S(R)为A ; 基础:n>0.(1)R为R1+R2,则适修改非终结符的名字,使得P(R1)与P(R2)中的所有非终结符没有重名,任选不出现在P(R1)⋃P(R2)中的非终结符A,令P(R)= P(R1) ⋃P(R2)⋃{ A→ S(R1), A→ S(R2) },并且,令S(R)为A;(2)R为R1R2,则适修改非终结符的名字,使得P(R1)与P(R2)中的所有非终结符没有重名,任选不出现在P(R1)⋃P(R2)中的非终结符A,令P(R)= P(R1) ⋃P(R2)⋃{ A→ S(R1)S(R2) };并且,令S(R)为A;(3)R为R1*,任选不出现在P(R1) 中的非终结符A,令P(R)= P(R1) ⋃{ A→ AS(R1) , A→ε };并且,令S(R)为A.设L为正规语言,R为正规表达式,且有L=L(R). 令上下文无关文法G 的产生式集合为上述归纳过程所得到的P(R),以及G的开始符号为S(R). 可以归纳证明L(G)=L(R)=L.! Exercise 5.1.4 (选做)如果一个CFG的每个产生式的体都最多只有一个变元,并且该变元总在最右端,那么该CFG称做右线性的。
《形式语言与自动机》第二版英文版课后题答案

Exercise 2.3.1Here are the sets of NFA states represented by each of the DFA states A through H: A = {p}; B = {p,q}; C = {p,r}; D = {p,q,r}; E = {p,q,s}; F = {p,q,r,s}; G = {p,r,s}; H = {p,s}.Exercise 2.3.4(a)The idea is to use a state qi, for i= 0,1,...,9 to represent the idea that we have seen an input i and guessed that this is the repeated digit at the end. We also have state qs, the initial state, and qf, the final state. We stay in state qs all the time; itSolutions for Section 2.4Exercise 2.4.1(a)We'll use q0 as the start state. q1, q2, and q3 will recognize abc; q4, q5, and q6 will recognize abd, and q7 through q10 will recognize aacd. The transition table is:Exercise 2.4.2(a)The subset construction gives us the following states, each representing the subset of the NFA states indicated: A = {q0}; B = {q0,q1,q4,q7}; C = {q0,q1,q4,q7,q8}; D = {q0,q2,q5}; E = {q0,q9}; F = {q0,q3}; G = {q0,q6}; H = {q0,q10}. Note that F, G and H can be combined into one accepting state, or we can use these three state to signal the recognition of abc, abd, and aacd, respectively.Solutions for Section 2.5Exercise 2.5.1For part (a): the closure of p is just {p}; for q it is {p,q}, and for r it is {p,q,r}.For (b), begin by noticing that a always leaves the state unchanged. Thus, we can think of the effect of strings of b's and c's only. To begin, notice that the only ways to get from p to r for the first time, using only b, c, and ε-transitions are bb, bc, and c. After getting to r, we can return to r reading either b or c. Thus, every string of length 3 or less, consisting of b's and c's only, is accepted, with the exception of the string b. However, we have to allow a's as well. When we try to insert a's in these strings, yet keeping the length to 3 or less, we find that every string of a's b's, and c's with at most one a is accepted. Also, the strings consisting of one c and up to 2 a's are accepted; other strings are rejected.There are three DFA states accessible from the initial state, which is the ε closure of p, or {p}. Let A = {p}, B = {p,q}, and C = {p,q,r}. Then the transition table is:Solutions for Section 3.1Exercise 3.1.1(a)The simplest approach is to consider those strings in which the first a precedes the first b separately from those where the opposite occurs. The expression:c*a(a+c)*b(a+b+c)* + c*b(b+c)*a(a+b+c)*Exercise 3.1.2(a)(Revised 9/5/05) The trick is to start by writing an expression for the set of strings that have no two adjacent 1's. Here is one such expression: (10+0)*(ε+1)To see why this expression works, the first part consists of all strings in which every 1 is followed by a 0. To that, we have only to add the possibility that there is a 1 at the end, which will not be followed by a 0. That is the job of (ε+1).Now, we can rethink the question as asking for strings that have a prefix with no adjacent 1's followed by a suffix with no adjacent 0's. The former is the expression we developed, and the latter is the same expression, with 0 and 1 interchanged. Thus, a solution to this problem is (10+0)*(ε+1)(01+1)*(ε+0). Note that the ε+1 term in the middle is actually unnecessary, as a 1 matching that factor can be obtained from the (01+1)* factor instead.Exercise 3.1.4(a)This expression is another way to write ``no adjacent 1's.'' You should compare it with the different-looking expression we developed in the solution to Exercise 3.1.2(a). The argument for why it works is similar. (00*1)* says every 1 is preceded by at least one 0. 0*at the end allows 0's after the final 1, and (ε+1) at the beginning allows an initial 1, which must be either the only symbol of the string or followed by a 0.Exercise 3.1.5The language of the regular expression ε. Note that ε* denotes the language of strings consisting of any number of empty strings, concatenated, but that is just the set containing the empty string.Solutions for Section 3.2Exercise 3.2.1Part (a): The following are all R0expressions; we list only the subscripts. R11 = ε+1; R12 = 0; R13 = phi; R21 = 1; R22 = ε; R23 = 0; R31 = phi; R32 = 1; R33 = ε+0.Part (b): Here all expression names are R(1); we again list only the subscripts. R11 = 1*; R12 = 1*0; R13 = phi; R21 = 11*; R22 = ε+11*0; R23 = 0; R31 = phi; R32 = 1; R33 = ε+0.Part (e): Here is the transition diagram:If we eliminate state q2 we get:Applying the formula in the text, the expression for the ways to get from q1 to q3 is: [1 + 01 +00(0+10)*11]*00(0+10)*Exercise 3.2.4(a)Exercise 3.2.6(a)(Revised 1/16/02) LL* or L+.Exercise 3.2.6(b)The set of suffixes of strings in L.Exercise 3.2.8Let R(k)ijm be the number of paths from state i to state j of length m that go through no state numbered higher than k. We can compute these numbers, for all states i and j, and for m no greater than n, by induction on k.Basis: R0ij1 is the number of arcs (or more precisely, arc labels) from state i to state j. R0ii0 = 1, and all other R0ijm's are 0.Induction: R(k)ijm is the sum of R(k-1)ijm and the sum over all lists (p1,p2,...,pr) of positive integers that sum to m, of R(k-1)ikp1 * R(k-1)kkp2 *R(k-1)kkp3 *...* R(k-1)kkp(r-1) * R(k-1)kjpr. Note r must be at least 2.The answer is the sum of R(k)1jn, where k is the number of states, 1 is the start state, and j is any accepting state.Solutions for Section 3.4Exercise 3.4.1(a)Replace R by {a} and S by {b}. Then the left and right sides become {a} union {b} = {b} union {a}. That is, {a,b} = {b,a}. Since order is irrelevant in sets, both languages are the same: the language consisting of the strings a and b.Exercise 3.4.1(f)Replace R by {a}. The right side becomes {a}*, that is, all strings of a's, including the empty string. The left side is ({a}*)*, that is, all strings consisting of the concatenation of strings of a's. But that is just the set of strings of a's, and is therefore equal to the right side.Exercise 3.4.2(a)Not the same. Replace R by {a} and S by {b}. The left side becomes all strings of a's and b's (mixed), while the right side consists only of strings of a's (alone) and strings of b's (alone). A string like ab is in the language of the left side but not the right.Exercise 3.4.2(c)Also not the same. Replace R by {a} and S by {b}. The right side consists of all strings composed of zero or more occurrences of strings of the form a...ab, that is, one or more a's ended by one b. However, every string in the language of the left side has to end in ab. Thus, for instance, ε is in the language on the right, but not on the left.Solutions for Section 4.1Exercise 4.1.1(c)Let n be the pumping-lemma constant (note this n is unrelated to the n that is a local variable in the definition of the language L). Pick w = 0n10n. Then when we write w = xyz, we know that |xy| <= n, and therefore y consists of only 0's. Thus, xz, which must be in L if L is regular, consists of fewer than n0's, followed by a 1 and exactly n0's. That string is not in L, so we contradict the assumption that L is regular.Exercise 4.1.2(a)Let n be the pumping-lemma constant and pick w = 0n2, that is, n2 0's. When we write w = xyz, we know that y consists of between 1 and n 0's. Thus, xyyz has length between n2 + 1 and n2 + n. Since the next perfect square after n2 is (n+1)2 = n2 + 2n + 1, we know that the length of xyyz lies strictly between the consecutive perfect squares n2 and (n+1)2. Thus, the length of xyyz cannot be a perfect square. But if the language were regular, then xyyz would be in the language, which contradicts the assumption that the language of strings of 0's whose length is a perfect square is a regular language.Exercise 4.1.4(a)We cannot pick w from the empty language.Exercise 4.1.4(b)If the adversary picks n = 3, then we cannot pick a w of length at least n.Exercise 4.1.4(c)The adversary can pick an n > 0, so we have to pick a nonempty w. Since w must consist of pairs 00 and 11, the adversary can pick y to be one of those pairs. Then whatever i we pick, xy i z will consist of pairs 00 and 11, and so belongs in the language.Solutions for Section 4.2Exercise 4.2.1(a)aabbaa.Exercise 4.2.1(c)The language of regular expression a(ab)*ba.Exercise 4.2.1(e)Each b must come from either 1 or 2. However, if the first b comes from 2 and the second comes from 1, then they will both need the a between them as part of h(2) and h(1), respectively. Thus, the inverse homomorphism consists of the strings {110, 102, 022}.Exercise 4.2.2Start with a DFA A for L. Construct a new DFA B, that is exactly the same as A, except that state q is an accepting state of B if and only if δ(q,a) is an accepting state of A. Then B accepts input string w if and only if A accepts wa; that is, L(B) = L/a.Exercise 4.2.5(b)We shall use D a for ``the derivative with respect to a.'' The key observation is that if epsilon is not in L(R), then the derivative of RS will always remove an a from the portion of a string that comes from R. However, if epsilon is in L(R), then the string might have nothing from R and will remove a from the beginning of a string in L(S) (which is also a string in L(RS). Thus, the rule we want is:If epsilon is not in L(R), then D a(RS) = (D a(R))S. Otherwise, D a(RS) = D a(R)S + D a(S).Exercise 4.2.5(e)L may have no string that begins with 0.Exercise 4.2.5(f)This condition says that whenever 0w is in L, then w is in L, and vice-versa. Thus, L must be of the form L(0*)M for some language M (not necessarily a regular language) that has no string beginning with 0.In proof, notice first that D0(L(0*)M = D0(L(0*))M union D0(M) = L(0*)M. There are two reasons for the last step. First, observe that D0 applied to the language of all strings of 0's gives all strings of 0's, that is, L(0*). Second, observe that because M has no string that begins with 0, D0(M) is the empty set [that's part (e)].We also need to show that every language N that is unchanged by D0is of this form. Let M be the set of strings in N that do not begin with 0. If N is unchanged by D0, it follows that for every string w in M, 00...0w is in N; thus, N includes all the strings of L(0*)M. However, N cannot include a string that is not in L(0*)M. If x were such a string, then we can remove all the 0's at the beginning of x and get some string y that is also in N. But y must also be in M.Exercise 4.2.8Let A be a DFA for L. We construct DFA B for half(L). The state of B is of the form [q,S], where:∙q is the state A would be in after reading whatever input B has read so far.∙S is the set of states of A such that A can get from exactly these states to an accepting state by reading any input string whose length is the same as the length of the string B has read so far.It is important to realize that it is not necessary for B to know how many inputs it has read so far; it keeps this information up-to-date each time it reads a new symbol. The rule that keeps things up to date is: δB([q,S],a) = [δA(q,a),T], where T is the set of states p of A such that there is a transition from p to any state of S on any input symbol. In this manner, the first component continues to simulate A, while the second component now represents states that can reach an accepting state following a path that is one longer than the paths represented by S.To complete the construction of B, we have only to specify:∙The initial state is [q0,F], that is, the initial state of A and the accepting states of A. This choice reflects the situation when A has read 0 inputs: it is still in its initial state, and the accepting states are exactly the ones that can reach anaccepting state on a path of length 0.∙The accepting states of B are those states [q,S] such that q is in S. The justification is that it is exactly these states that are reached by some string of length n, and there is some other string of length n that will take state q to an accepting state.Exercise 4.2.13(a)Start out by complementing this language. The result is the language consisting of all strings of 0's and 1's that are not in 0*1*, plus the strings in L0n1n. If we intersect with 0*1*, the result is exactly L0n1n. Since complementation and intersection with a regular set preserve regularity, if the given language were regular then so would be L0n1n. Since we know the latter is false, we conclude the given language is not regular.Exercise 4.2.14(c)Change the accepting states to be those for which the first component is an accepting state of A L and the second is a nonaccepting state of A M. Then the resulting DFA accepts if and only if the input is in L - M.Solutions for Section 4.3Exercise 4.3.1Let n be the pumping-lemma constant. Test all strings of length between n and 2n-1 for membership in L. If we find even one such string, then L is infinite. The reason is that the pumping lemma applies to such a string, and it can be ``pumped'' to show an infinite sequence of strings are in L.Suppose, however, that there are no strings in L whose length is in the range n to 2n-1. We claim there are no strings in L of length 2n or more, and thus there are only a finite number of strings in L. In proof, suppose w is a string in L of length at least 2n, and w is as short as any string in L that has length at least 2n. Then the pumping lemma applies to w, and we can write w = xyz, where xz is also in L. How long could xz be? It can't be as long as 2n, because it is shorter than w, and w is as short as any string in L of length 2n or more. n, because xz is at most n shorter than w. Thus, xz is of length between n and 2n-1, which is a contradiction, since we assumed there were no strings in L with a length in that range.Solutions for Section 4.4Exercise 4.4.1Revised 10/23/01.B|xC|x xD|x x xE|x x xF|x x x xG| x x x x xH|x x x x x x x---------------A B C D E F GNote, however, that state H is inaccessible, so it should be removed, leaving the first four states as the minimum-state DFASolutions for Section 5.1Exercise 5.1.1(a)S -> 0S1 | 01Exercise 5.1.1(b)S -> AB | CDA -> aA | εB -> bBc | E | cDC -> aCb | E | aAD -> cD | εE -> bE | bTo understand how this grammar works, observe the following:∙A generates zero or more a's.∙D generates zero or more c's.∙E generates one or more b's.∙B first generates an equal number of b's and c's, then produces either one or more b's (via E) or one or more c's (via cD).That is, B generates strings in b*c* with an unequal number of b's and c's.∙Similarly, C generates unequal numbers of a's then b's.∙Thus, AB generates strings in a*b*c* with an unequal numbers of b's and c's, while CD generates strings in a*b*c* with an unequal number of a's and b's.Exercise 5.1.2(a)Leftmost: S => A1B => 0A1B => 00A1B => 001B => 0010B => 00101B => 00101Rightmost: S => A1B => A10B => A101B => A101 => 0A101 => 00A101 => 00101Exercise 5.1.5S -> S+S | SS | S* | (S) | 0 | 1 | phi | eThe idea is that these productions for S allow any expression to be, respectively, the sum (union) of two expressions, the concatenation of two expressions, the star of an expression, a parenthesized expression, or one of the four basis cases of expressions: 0, 1, phi, and ε.Solutions for Section 5.2Exercise 5.2.1(a)S/ | \A 1 B/ | / |0 A 0 B/ | / |0 A 1 B| |e eIn the above tree, e stands for ε.Solutions for Section 5.3Exercise 5.3.2B -> BB | (B) | [B] | εExercise 5.3.4(a)Change production (5) to:ListItem -> <LI> Doc </LI>Solutions for Section 5.4Exercise 5.4.1Here are the parse trees:S S/ | / / | \a S a Sb S/ | \ \ | \ |a Sb S a S e| | |e e eThe two leftmost derivations are: S => aS => aaSbS => aabS => aab and S => aSbS => aaSbS => aabS => aab. The two rightmost derivations are: S => aS => aaSbS => aaSb => aab and S => aSbS => aSb => aaSb => aab. Exercise 5.4.3The idea is to introduce another nonterminal T that cannot generate an unbalanced a. That strategy corresponds to the usual rule in programming languages that an ``else'' is associated with the closest previous, unmatched ``then.'' Here, we force a b to match the previous unmatched a. The grammar:S -> aS | aTbS | εT -> aTbT | εExercise 5.4.6Alas, it is not. We need to have three nonterminals, corresponding to the three possible ``strengths'' of expressions:1. A factor cannot be broken by any operator. These are the basis expressions, parenthesized expressions, and theseexpressions followed by one or more *'s.2. A term can be broken only by a *. For example, consider 01, where the 0 and 1 are concatenated, but if we follow it bya *, it becomes 0(1*), and the concatenation has been ``broken'' by the *.3.An expression can be broken by concatenation or *, but not by +. An example is the expression 0+1. Note that if weconcatenate (say) 1 or follow by a *, we parse the expression 0+(11) or 0+(1*), and in either case the union has been broken.The grammar:E -> E+T | TT -> TF | FF -> F* | (E) | 0 | 1 | phi | eSolutions for Section 6.1Exercise 6.1.1(a)(q,01,Z0) |- (q,1,XZ0) |- (q,ε,XZ0) |- (p,ε,Z0)|- (p,1,Z0) |- (p,ε,ε)Solutions for Section 6.2Exercise 6.2.1(a)We shall accept by empty stack. Symbol X will be used to count the 0's on the input. In state q, the start state, where we have seen no 1's, we add an X to the stack for each 0 seen. The first X replaces Z0, the start symbol. When we see a 1, we go to state p, and then only pop the stack, one X for each input 1. Formally, the PDA is ({q,p},{0,1},{X,Z0},δ,q,Z0). The rules:1.δ(q,0,Z0) = {(q,X)}2.δ(q,0,X) = {(q,XX)}3.δ(q,1,X) = {(p,ε)}4.δ(p,1,X) = {(p,ε)}Exercise 6.2.2(a)Revised 6/20/02.Begin in start state q0, with start symbol Z0, and immediately guess whether to check for:1.i=j=0 (state q1).2.i=j>0 (state q2).3.j=k (state q3).We shall accept by final state; as seen below, the accepting states are q1 and q3. The rules, and their explanations:∙δ(q0,ε,Z0) = {(q1,Z0), (q2,Z0), (q3,Z0)}, the initial guess.∙δ(q1,c,Z0) = {(q1,Z0)}. In case (1), we assume there are no a's or b's, and we consume all c's. State q1 will be one of our accepting states.∙δ(q2,a,Z0) = {(q2,XZ0)}, and δ(q2,a,X) = {(q2,XX)}. These rules begin case (2). We use X to count the number of a's read from the input, staying in state q2.∙δ(q2,b,X) = δ(q4,b,X) = {(q4,ε)}. When b's are seen, we go to state q4 and pop X's against the b's.∙δ(q4,ε,Z0) = {(q1,Z0)}. If we reach the bottom-of-stack marker in state q4, we have seen an equal number of a's and b's.We go spontaneously to state q1, which will accept and consume all c's, while continuing to accept.∙δ(q3,a,Z0) = {(q3,Z0)}. This rule begins case (3). We consume all a's from the input. Since j=k=0 is possible, state q3 must be an accepting state.∙δ(q3,b,Z0) = {(q5,XZ0)}. When b's arrive, we start counting them and go to state q5, which is not an accepting state.∙δ(q5,b,X) = {(q5,XX)}. We continue counting b's.∙δ(q5,c,X) = δ(q6,c,X) = {(q6,ε)}. When c's arrive, we go to state q6 and match the c's against the b's.∙δ(q6,ε,Z0) = {(q3,ε)}. When the bottom-of-stack marker is exposed in state q6, we have seen an equal number of b's and c's. We spontaneously accept in state q3, but we pop the stack so we cannot accept after reading more a's.Exercise 6.2.4Introduce a new state q, which be comes the initial state. On input ε and the start symbol of P, the new PDA has a choice of popping the stack (thus accepting ε), or going to the start state of P.Exercise 6.2.5(a)Revised 6/6/06.(q0,bab,Z0) |- (q2,ab,BZ0) |- (q3,b,Z0) |- (q1,b,AZ0) |- (q1,ε,Z0) |- (q0,ε,Z0) |- (f,ε,ε)Exercise 6.2.8Suppose that there is a rule that (p,X1X2...X k) is a choice in δ(q,a,Z). We create k-2 new states r1,r2,...,r k-2 that simulate this rule but do so by adding one symbol at a time to the stack. That is, replace (p,X1X2...X k) in the rule by (r k-2,X k-1X k. Then create new rules δ(r k-2,ε,X k-1) = {(r k-3,X k-2X k-1)}, and so on, down to δ(r2,ε,X3) = {(r1,X2X3)} and δ(r1,X2) = {(p,X1X2)}.Solutions for Section 6.3Exercise 6.3.1({q},{0,1),{0,1,A,S},δ ,q ,S) where δ is defined by:1.δ(q,ε,S) = {(q,0S1), (q,A)}2.δ(q,ε,A) = {(q,1A0), (q,S), (q,ε)}3.δ(q,0,0) = {(q,ε)}4.δ(q,1,1) = {(q,ε)}Exercise 6.3.3In the following, S is the start symbol, e stands for the empty string, and Z is used in place of Z0.1.S -> [qZq] | [qZp]The following four productions come from rule (1).2.[qZq] -> 1[qXq][qZq]3.[qZq] -> 1[qXp][pZq]4.[qZp] -> 1[qXq][qZp]5.[qZp] -> 1[qXp][pZp]The following four productions come from rule (2).6.[qXq] -> 1[qXq][qXq]7.[qXq] -> 1[qXp][pXq]8.[qXp] -> 1[qXq][qXp]9.[qXp] -> 1[qXp][pXp]The following two productions come from rule (3).10.[qXq] -> 0[pXq]11.[qXp] -> 0[pXp]The following production comes from rule (4).12.[qXq] -> eThe following production comes from rule (5).13.[pXp] -> 1The following two productions come from rule (6).14.[pZq] -> 0[qZq]15.[pZp] -> 0[qZp]Exercise 6.3.6Convert P to a CFG, and then convert the CFG to a PDA, using the two constructions given in Section 6.3. The result is a one-state PDA equivalent to P.Solutions for Section 6.4Exercise 6.4.1(b)Not a DPDA. For example, rules (3) and (4) give a choice, when in state q, with 1 as the next input symbol, and with X on top of the stack, of either using the 1 (making no other change) or making a move on ε input that pops the stack and going to sta te p.Exercise 6.4.3(a)Suppose a DPDA P accepts both w and wx by empty stack, where x is not ε (i.e., N(P) does not have the prefix property). Then (q0,wxZ0) |-* (q,x,ε) for some state q, where q0 and Z0 are the start state and symbol of P. It is not possible that (q,x,ε) |-* (p,ε,ε) for some state p, because we know x is not ε, and a PDA cannot have a move with an empty sta ck. This observation contradicts the assumption that wx is in N(P).Exercise 6.4.3(c)Modify P' in the following ways to create DPDA P:1.Add a new start state and a new start symbol. P, with this state and symbol, pushes the start symbol of P' on top of thestack and goes to the start state of P'. The purpose of the new start symbol is to make sure P doesn't accidentally accept by empty stack.2.Add a new ``popping state'' to P. In this state, P pops every symbol it sees on the stack, using ε input.3.If P' enters an accepting state, P enters the popping state instead.As long as L(P') has the prefix property, then any string that P' accepts by final state, P will accept by empty stack.Solutions for Section 7.1Exercise 7.1.1A and C are clearly generating, since they have productions with terminal bodies. Then we can discover S is generating because of the production S->CA, whose body consists of only symbols that are generating. However,B is not generating. Eliminating B, leaves the grammarS -> CAA -> aC -> bSince S, A, and C are each reachable from S, all the remaining symbols are useful, and the above grammar is the answer to the question.Exercise 7.1.2Revised 6/27/02.a)Only S is nullable, so we must choose, at each point where S occurs in a body, to eliminate it or not. Since there is no body that consists only of S's, we do not have to invoke the rule about not eliminating an entire body. The resulting grammar:S -> ASB | ABA -> aAS | aA | aB -> SbS | bS | Sb | b | A | bbb)The only unit production is B -> A. Thus, it suffices to replace this body A by the bodies of all the A-productions. The result:S -> ASB | ABA -> aAS | aA | aB -> SbS | bS | Sb | b | aAS | aA | a | bbc)Observe that A and B each derive terminal strings, and therefore so does S. Thus, there are no useless symbols.d)Introduce variables and productions C -> a and D -> b, and use the new variables in all bodies that are not a single terminal:S -> ASB | ABA -> CAS | CA | aB -> SDS | DS | SD | b | CAS | CA | a | DDC -> aD -> bFinally, there are bodies of length 3; one, CAS, appears twice. Introduce new variables E, F, andG to split these bodies, yielding the CNF grammar:S -> AE | ABA -> CF | CA | aB -> SG | DS | SD | b | CF | CA | a | DDC -> aD -> bE -> SBF -> ASG -> DSExercise 7.1.10It's not possible. The reason is that an easy induction on the number of steps in a derivation shows that every sentential form has odd length. Thus, it is not possible to find such a grammar for a language as simple as {00}.To see why, suppose we begin with start symbol S and try to pick a first production. If we pick a production with a single terminal as body, we derive a string of length 1 and are done. If we pick a body with three variables, then, since there is no way for a variable to derive epsilon, we are forced to derive a string of length 3 or more.Exercise 7.1.11(b)The statement of the entire construction may be a bit tricky, since you need to use the construction of part (c) in (b), although we are not publishing the solution to (c). The construction for (b) is by induction on i, but it needs to be of the stronger statement that if an A i-production has a body beginning with A j, then j > i (i.e., we use part (c) to eliminate the possibility that i=j).Basis: For i = 1 we simply apply the construction of (c) for i = 1.Induction: If there is any production of the form A i -> A1..., use the construction of (a) to replace A1. That gives us a situation where all A i production bodies begin with at least A2 or a terminal. Similarly, replace initial A2's using (a), to make A3 the lowest possible variable beginning an A i-production. In this manner, we eventually guarantee that the body of each A i-production either begins with a terminal or with A j, for some j >= i. A use of the construction from (c) eliminates the possibility that i = j.Exercise 7.1.11(d)As per the hint, we do a backwards induction on i, that the bodies of A i productions can be made to begin with terminals.Basis: For i = k, there is nothing to do, since there are no variables with index higher than k to begin the body.Induction: Assume the statement for indexes greater than i. If an A i-production begins with a variable, it must be A j for some j > i. By the induction hypothesis, the A j-productions all have bodies beginning with terminals now. Thus, we may use the construction (a) to replace the initial A j, yielding only A i-productions whose bodies begin with terminals.After fixing all the A i-productions for all i, it is time to work on the B i-productions. Since these have bodies that begin with either terminals or A j for some j, and the latter variables have only bodies that begin with terminals, application of construction (a) fixes the B j's.Solutions for Section 7.2Exercise 7.2.1(a)Let n be the pumping-lemma constant and consider string z = a n b n+1c n+2. We may write z = uvwxy, where v and x, may be ``pumped,'' and |vwx| <= n. If vwx does not have c's, then uv3wx3y has at least n+2a's or b's, and thus could not be in the language.If vwx has a c, then it could not have an a, because its length is limited to n. Thus, uwy has n a's, but no more than 2n+2b's and c's in total. Thus, it is not possible that uwy has more b's than a's and also has more c's than b's. We conclude that uwy is not in the language, and now have a contradiction no matter how z is broken into uvwxy.Exercise 7.2.1(d)Let n be the pumping-lemma constant and consider z = 0n1n2. We break Z = uvwxy according to the pumping lemma. If vwx consists only of 0's, then uwy has n2 1's and fewer than n 0's; it is not in the language. If vwx has only 1's, then we derive a contradiction similarly. If either v or x has both 0's and 1's, then uv2wx2y is not in 0*1*, and thus could not be in the language.Finally, consider the case where v consists of 0's only, say k 0's, and x consists of m 1's only, where k and m are both positive. Then for all i, uv i+1wx i+1y consists of n + ik 0's and n2 + im 1's. If the number of 1's is always to be the square of the number of 0's, we must have, for some positive k and m: (n+ik)2 = n2+ im, or 2ink + i2k2= im. But the left side grows quadratically in i, while the right side grows linearly, and so this equality for all i is impossible. We conclude that for at least some i, uv i+1wx i+1y is not in the language and have thus derived a contradiction in all cases.Exercise 7.2.2(b)It could be that, when the adversary breaks z = uvwxy, v = 0k and x = 1k. Then, for all i, uv i wx i y is in the language.Exercise 7.2.2(c)The adversary could choose z = uvwxy so that v and x are single symbols, on either side of the center. That is, |u| = |y|, and w is either epsilon (if z is of even length) or the single, middle symbol (if z is of odd length). Since z is a palindrome, v and x will be the same symbol. Then uv i wx i y is always a palindrome.。
自然语言理解(03)形式语言与自动机

3.3自动机理论
q 线性带限自动机所接受的语言
3.3自动机理论
q 定理
定理 3.5:如果 L 是一个前后文有关语言,则 L 由一个不 确定的线性带限自动机所接受。反之,如果 L 被一个线性带 限自动机所接受,则 L 是一个前后文有关语言。
各类自动机的区别与联系
主要区别:各类自动机的主要区别是它们能够使用的信 息存储空间的差异:有限状态自动机只能用状态来存储信息; 下推自动机除了可以用状态以外,还可以用下推存储器 (栈);线性带限自动机可以利用状态和输入/输出带本身。 因为输入/输出带没有“先进后出”的限制,因此其功能大于 栈;而图灵机的存储空间没有任何限制。 识别语言的能力:有限自动机等价于正则文法;下推自 动机等价于上下文无关文法;线性带限自动机等价于上下文 有关文法,图灵机等基于 0 型文法。
3.2 形式语言
q 关于语言的定义
按照一定规律构成的句子和符号串的有限或无限的集合。
- Chomsky
语言可以被看成一个抽象的数学系统。(吴蔚天,1994)
语言描述的三种途径
v 穷举法 — — 只适合句子数目有效的语言。 v 语法描述 — — 生成语言中合格的句子。
v 自动机 — — 对输入的句子进行检验,区别哪些是语 言中的句子,哪些不是语言中的句子。
3.4自动机在自然语言处理中的应用
• 3.4.1 单词拼写检查 • 3.4.2单词形态分析 • 3.4.3 词性消歧
3.4自动机在自然语言处理中的应用
q 有限自动机用于英语单词拼写检查
[Oflazer, 1996] 设 X 为拼写错误的字符串,其长度为 m,Y 为 X 对应的正 确的单词(答案),其长度为 n。则 X 和 Y 的编辑距离 ed(X[m], Y[n])为:从字符串 X 转换到 Y 需要的插入、删除、 替换和交换两个相邻的基本单位(字符)的最小个数。如: ed (recoginze, recognize) = 1 ed (sailn, failing) = 3
形式语言与自动机 形式语言与自动机理论-蒋宗礼-第三章参考答案

形式语言与自动机形式语言与自动机理论-蒋宗礼-第三章参考答案导读:就爱阅读网友为您分享以下“形式语言与自动机理论-蒋宗礼-第三章参考答案”的资讯,希望对您有所帮助,感谢您对的支持!因此我们只需要证明对任何的2NFA M1?(Q1,?,?1,F1,q0),都存在FAM2?(Q2,?,?2,F2,q0)与之等价。
对于任何的2NFA M1?(Q1,?,?1,F1,q0),构造FA M2?(Q2,?,?2,F2,q0),按三个方式构造?2:1.如果q?Q1,a??,?1(q,a)?{p,R},则?2(q,a)?p;2.如果q?Q1,a??,?1(q,a)?{p,S},则如果??1(p,a)?{o,R},则?2(q,a)?o;如果??1(p,a)?{o,S},则重复第二步;如果??1(p,a)?{o,L},则对于集合A = {r|b?Q1,?1(r,b)?(o,R)},?2(q,a)?r,r?A。
3.如果q?Q1,a??,?1(q,a)?{p,L},则设集合 A = {r|b?Q1,?1(r,b)?(p,R)},?2(q,a)?r,r?A*************************************************** ****************************28.证明定理3-8:Moore机与Mealy机等价(郭会02282015)证明:不妨设Moore机M1=(Q1,?,?,?1,?1,q01),Mealy机M2=(Q2,?,?,?2,?2,q02),则根据Moore机和Mealy机等价的定义知,必须证明:T1(x)??1(q0)T2(x),其中T1(x)和T2(x)分别表示M1和M2关于x的输出。
??Moore机M1,?Mealy机M2,使M2与M1等价(1)构造M2,?2??1,q02?q01,Q2?Q1?q?Q1?{q01},?1(q)?a,?q'?Q1且?b??,?1(q',b)=q,就构造?2(q',b)=a(2)证明?x??*,?1(q0)T2(x)?T1(x)不妨设x?x1x2……xn,则?i?N,(i?1,2……n)则M1的输出为:T1(x)??1(q0)?1(?1(q0,x1))……?1(?1((…?1(q0,x1),x2)…),xn)由题意可知?1(q0,x1),?1(?1(q0,x1),x2),…,?1(……?1 (?1(q0,x1),x2) xn) 均为Moore机中的状态,由(1)中的构造假设知,M2的输出为:T2(x)??2(q0,x1)?2(?2(q0,x1),x2)…?2(……?2(?2(q0,x1),x2) ? ?1(q0,x1)?1(?1(q0,x1),x2)…?1(……?1(?1(q0,x1),x2) xn) xn) ?T1(x)??1(q0)T2(x)??Mealy机M2,?Moore机M1,使M1与M2等价(1)构造M1,q01?q02Q1?Q2?{qij|??2(qi,a)?qj,其中qi,qj?Q2,a??}?1?{?|?(qi,a)?qij,?(qij,?)?qj其中?2(qi,a)?qj}?1?{?|?1(qi,a)?qij,?1(qij,?)?qj,?(qij)??2(qi,a) }(2)证明?x??*,T1(x)=?1(q0)T2(x)不妨设x?x1x2……xn,则?i?N,(i?1,2……n)则M1的输出为:T2(x)??2(?2(q0,x1))……?2(?2((…?2(q0,x1),x2)…),xn) 由题意可知?2(q0,x1),?2(?2(q0,x1),x2),…,?2(……?2 (?2(q0,x1),x2) xn) 均为Mealy机中的状态,由(1)中的构造假设知,M1的输出为:T1(x)??1(q0)?1(?2(q0,x1))?1(?1(q0,x1),x2)…?1(……?1(?1(q 0,x1),x2) xn)??1(q0)?2(?2(q0,x1))……?2(?2((…?2(q0,x1),x2)…),xn) ?T1(x)??1(q0)T2(x)综上所述,Moore机与Mealy机等价第三章作业答案1.已知DFA M1与M2如图3-18所示。
形式语言与自动机 习题答案(部分)
a)语言{ww:w∈{a,b}*}的文法G=(V,∑,R,S)如下: V={S,a,b,A,B,C,Ta,Tb,Tc} ∑={a,b} R={ S -> CC, C -> AC | BC | Tc BTc -> Tcb ATc -> Tca Tc -> e } 或 文法G[S]: S→CD Ab→bA C→aCA Ba→aB C→bCB Bb→bB AD→aD C→ε BD→bD D→ε Aa→bD 或 S→aAS|bBS|aAE|bBE Aa→aA Ab→bA Ba→aB AE→Ea|a BE→Eb|b L(G)={ww|w∈{a,b}*}
4331把两个带头分别移动第一个带头向左移动到带头第二个带头向右移动直到发现空格为2向右移动第一个带头记录下字符的值
2.2.3
2.2.9
2.3.4
3.5.14
• (a):是上下文相关的,因为m,n,p之间必存在二者 相等的情况,如果a的个数确定了,则b或者c的个 数也是确定的。 • (b):是上下文相关的,因为当a的个数确定时,b和 c的个数是不能和a相同的,即n和p的取值有了限 制。 • (c):是上下文相关的,a的个数限定了b和c的个数。 • (d):是上下文相关的,当a和b的个数相等的情况下, 则限定了c的个数不能和a,b相同。 • (e):是上下文相关的,若要满足 |w1|=|w2|…..=|wn|>=2,则|w|的值限定了必须是可 被整除的数(素数)。
4.1.10
• 功能是: • 首先找到第二个和第三个字符,要求不能 是空格,然后记录下,再分别填入之后的 第一个空格和第二个空格所位置。
4.3.3
• (1)把两个带头分别移动,第一个带头向左移动 到带头,第二个带头向右移动,直到发现空格为 止。 • (2)向右移动第一个带头,记录下字符的值。判 断有没有遇到空格,若遇到空格,则跳至(), 否则,跳至(3)。 • (3)向右移动第二个带头,并复制下已记录的字 符,再跳至(2)。 • (4)第一个带头遇到空格,说明w已经复制完, 故停机。
《形式语言与自动机》期末复习题及答案(一)

形式语言与自动机期末复习题及答案(一)1.有图灵机 M=(Q, ∑, Γ, δ,q 0 , B , F) 接受语言{w t w│w ∈{a, b}*},按照下图说明其接受过程。
(本题15分 )[q 1[q 6,B]答:abtab 的分析过程:[q 1,B]abtab├a [q 2,a]btab├ab [q 2,a]tab├abt [q 3,a]ab├ ab [q 4,B]tab├a [q 5,B]btab├[q 6,B]abtab├a [q 1,B]btab ├ab [q 2,b]tab├abt [q 3,b]ab ├abta [q 3,b]b ├abt [q 4,B]ab├a [q 5,B]btab ├ab [q 7,B]tab ├abt [q 8,B]ab├abta [q 8,B]b ├abtab [q 8,B]B├abta [q 9,B]b 接受abtab√√√√√√√√√√√√√√√√√√√√√√√√√√√√√√√√√√√√√√√√√√√√√√√√2.简述《形式语言与自动机》课程的主要内容。
(本题10分)答:语言的文法描述;RL (RG 、FA 、RE 、RL 的性质 );CFL (CFG(CNF 、GNF)、PDA 、CFL 的性质);TM (基本TM 、构造技术、TM 的修改);CSL (CSG 、LBA )。
3.简述《形式语言与自动机》课程的学习目的和基本要求。
(本题10分) 答:本专业人员4种基本的专业能力:计算思维能力、算法的设计与分析能力、程序设计和实现能力、计算机软硬件系统的认知、分析、设计与应用能力。
其中计算思维能力包括:逻辑思维能力和抽象思维能力、构造模型对问题进行形式化描述、理解和处理形式模型。
本课程应使学生掌握如下知识:正则语言、下文无关语言的文法、识别模型及其基本性质、图灵机的基本知识。
锻炼培养如下能力:形式化描述和抽象思维能力、了解和初步掌握“问题、形式化描述、自动化(计算机化)”这一最典型的计算机问题求解思路。
形式语言与自动机课后习题答案部分PPT69页

16、自己选择的路、跪着也要把它走 完。 17、一般情况下)不想三年以后的事, 只想现 在的事 。现在 有成就 ,以后 才能更 辉煌。
18、敢于向黑暗宣战的人,心里必须 充满光 明。 19、学习的关键--重复。
20、懦弱的人只会裹足不前,莽撞的 人只能 引为烧 身,只 有真正 勇敢的 人才能 所向披 靡。
拉
60、生活的道路一旦选定,就要勇敢地 走到底 ,决不 回头。 ——左
56、书不仅是生活,而且是现在、过 去和未 来文化 生活的 源泉。 ——库 法耶夫 57、生命不可能有两次,但许多人连一 次也不 善于度 过。— —吕凯 特 58、问渠哪得清如许,为有源头活水来 。—— 朱熹 59、我的努力求学没有得到别的好处, 只不过 是愈来 愈发觉 自己的 无知。 ——笛 卡儿
作业参考答案9

形式语言与自动机作业参考答案第九次作业:(课本P183,184,185页第11,15,20,21,22题)11.设2型文法G=({S,A,B,C,D,E,F},{a,b,c},P,S)其中P:S -> ASB | ε; A -> aAS | a; B ->SBS | A | bb试将G变换为无ε生成式,无单生成式,没有无用符号的文法,再将其转换为Chomsky范式。
答:G变换为无为无ε生成式,无单生成式,没有无用符号的等价文法G1如下:G1 = ({S1,S,A,B},{a,b},P1,S1),其中P1如下:S1 -> ASB | AB | εS -> ASB | ABA -> aAS | aA | aB -> SBS | SB | BS | aAS | aA | a | bb转化为Chomsky范式为:G2 = ({S1,S,A,B,C,D,E,F},{a,b},P2,S1),其中P2如下:S1 -> ε| AC | ABS -> AC | ABA -> ED | EA | aB -> CS | SB | BS | ED | EA | a | FFC -> SBD -> ASE -> aF -> b15.将下列文法变换为等价的Greibach范式文法:(1)S -> DD | aD -> SS | b(2)A1 -> A3b | A2aA2 -> A1b | A2A2a | bA3 -> A1a | A3A3b | a答:(1)1)先化为chomsky范式:由于文法本身已经是chomsky范式,所以不用化。
2)再对非终结符给一个排序:对本题给给排序为S,D。
3)对最高位,通过迭代使第一个字符化为它自己或者终结符:本题用S -> DD | a代入D生成式的第一个字符,得,D -> DDS | aS | b4)消除左递归,得D -> aS | b | aSD1 | bD1D1 -> DS | DSD15)逐步迭代化为Greibach范式得,所求Greibach范式为,G1 = ({S,D,D1},{a,b},P1,S),其中P1如下:S -> aSD | bD | aSD1D | bD1D | aD -> aS | b | aSD1 | bD1D1 -> aSS | bS | aSD1S | bD1S | aSSD1 |bSD1 | aSD1SD1 | bD1SD1(2)基本方法跟(1)相同,从略。
《形式语言与自动机》(王柏、杨娟编著)课后习题答案

形式语言与自动机课后习题答案第二章4.找出右线性文法,能构成长度为1至5个字符且以字母为首得字符串。
答:G={N,T,P,S}其中N={S,A,B,C,D} T={x,y} 其中x∈{所有字母} y∈{所有得字符} P如下: S→x S→xA A→y A→yBB→y B→yC C→y C→yD D→y6.构造上下文无关文法能够产生L={ω/ω∈{a,b}*且ω中a得个数就是b得两倍}答:G={N,T,P,S}其中N={S} T={a,b} P如下:S→aab S→aba S→baaS→aabS S→aaSb S→aSab S→SaabS→abaS S→abSa S→aSba S→SabaS→baaS S→baSa S→bSaa S→Sbaa7.找出由下列各组生成式产生得语言(起始符为S)(1)S→SaS S→b(2)S→aSb S→c(3)S→a S→aE E→aS答:(1)b(ab)n /n≥0}或者L={(ba)n b/n≥0}(2) L={a n cb n /n≥0}(3)L={a2n+1 /n≥0}第三章1.下列集合就是否为正则集,若就是正则集写出其正则式。
(1)含有偶数个a与奇数个b得{a,b}*上得字符串集合(2)含有相同个数a与b得字符串集合(3)不含子串aba得{a,b}*上得字符串集合答:(1)就是正则集,自动机如下题(2)。
(3) 就是正则集先瞧L’为包含子串aba得{a,b}*上得字符串集合显然这就是正则集,可以写出表达式与画出自动机。
(略)则不包含子串aba得{a,b}*上得字符串集合L就是L’得非。
根据正则集得性质,L也就是正则集。
4.对下列文法得生成式,找出其正则式(1)G=({S,A,B,C,D},{a,b,c,d},P,S),生成式P如下:S→aA S→BA→abS A→bBB→b B→cCC→D D→bBD→d(2)G=({S,A,B,C,D},{a,b,c,d},P,S),生成式P如下:S→aA S→BA→cC A→bBB→bB B→aC→D C→abBD→d答:(1) 由生成式得:S=aA+B ①A=abS+bB ②B=b+cC ③C=D ④D=d+bB ⑤③④⑤式化简消去CD,得到B=b+c(d+bB)即B=cbB+cd+b =>B=(cb)*(cd+b) ⑥将②⑥代入①S=aabS+ab(cb)*(cd+b)+(cb)*(cd+b) =>S=(aab)*(ab+ε)(cb)*(cd+b) (2) 由生成式得:S=aA+B ①A=bB+cC ②B=a+bB ③C=D+abB ④D=dB ⑤由③得 B=b*a ⑥将⑤⑥代入④ C=d+abb*a=d+ab+a ⑦将⑥⑦代入② A=b+a+c(d+b+a) ⑧将⑥⑧代入① S=a(b+a+c(d+ab+a))+b*a=ab+a+acd+acab+a+b*a5、为下列正则集,构造右线性文法:(1){a,b}*(2)以abb结尾得由a与b组成得所有字符串得集合(3)以b为首后跟若干个a得字符串得集合(4)含有两个相继a与两个相继b得由a与b组成得所有字符串集合答:(1)右线性文法G=({S},{a,b},P,S)P: S→aS S→bS S→ε(2) 右线性文法G=({S},{a,b},P,S)P: S→aS S→bS S→abb(3) 此正则集为{ba*}右线性文法G=({S,A},{a,b},P,S)P: S→bA A→aA A→ε(4) 此正则集为{{a,b}*aa{a,b}*bb{a,b}*, {a,b}*bb{a,b}*aa{a,b}*}右线性文法G=({S,A,B,C},{a,b},P,S)P: S→aS/bS/aaA/bbBA→aA/bA/bbCB→aB/bB/aaCC→aC/bC/ε7、设正则集为a(b a)*(1)构造右线性文法(2)找出(1)中文法得有限自b动机答:(1)右线性文法G=({S,A},{a,b},P,S)P: S→aA A→bS A→ε(2)自动机如下:)9、对应图(a)(b)得状态转换图写出正则式。
形容性格的词语及形式语言与自动机理论第二章参考答案

形容性格的词语性格:外向善良开朗活泼好动轻松愉快热情可亲豁达稳重幽默真诚豪爽耿直成熟独立果断健谈机敏深沉坚强兴奋热情率直毅力友爱风趣沉静谨慎忠诚友善严肃忠心乐观坦率勇敢自信自立沉著执著容忍体贴满足积极有趣知足勤劳和气无畏务实轻浮冲动幼稚自私依赖任性自负拜金暴躁倔强虚伪孤僻刻薄武断浮躁莽撞易怒轻率善变狡猾易怒多疑懒惰专横顽固猜疑挑衅冷漠虚荣冷淡反覆跋扈自负逆反怨恨鲁莽放任贫乏固执内向脆弱自卑害羞敏感迟钝柔弱畏缩顺从胆小安静寡言保守被动忍让抑郁谨慎胆怯温和老实平和顺服含蓄迁就羞涩忸怩缓慢乏味散漫迟缓罗嗦耐性悲观消极拖延烦躁妥协唠叨好交际善组织有韧性可依赖规范型好心肠善交际无异议竞争性自控性受尊重激励性重秩序有条理聆听者无拘束领导者受欢迎神经质糊涂虫有惰性易兴奋好批评不专注好争吵无目标不宽恕无热忱易激动难预测不合群不灵活喜操纵情绪化大嗓门统治欲强迫性好表现适应能力强工作有效率能克服困难办事认真细心严守秩序有条理善于体察别人常为小事而动感情完美主义者轻率不踏实易见异思迁易轻率作决定语言动作迟缓不易暴露内心活动执拗不灵活适应能力差显得落落寡合不圆滑老练不善言谈交际善解人意井井有条意志坚定自我牺牲考虑周到雷历风行适应力强喜好娱乐善于说服坚持不懈善于分析专心致志一丝不苟令人信服生气勃勃惹人喜爱外交手腕令人高兴瞻前顾后循规蹈矩善于社交不怕困难性情平和理想主义无攻击性感情外露勇敢正义聪明好学实事求是务实实际一本正经使人振作反应敏捷文化修养贯彻始终快言快语爱管闲事追求刺激豪放不羁积极负责埋头工作果敢坚持富有朝气表情丰富反应敏捷兴趣广泛随波逐流精力充沛喜交朋友活力充沛活泼开朗能说会道温柔体贴不拘小节交际广泛风趣幽默处事洒脱淡泊名利助人为乐瞻前顾后乐天达观成熟稳重幼稚调皮温柔体贴活泼可爱普普通通内向害羞外向开朗心地善良循规蹈矩聪明伶俐善解人意风趣幽默思想开放积极进取正义正直处事洒脱异想天开淡泊名利小心谨慎敢作敢当乐观向上诚实坦白圆滑老练急性子喋喋不休无同情心胆小怕事言语不清无安全感优柔寡断不善表达不受欢迎难以琢磨小肚鸡肠排斥异己不善交际不懂幽默慢条斯理婆婆妈妈重色轻友胆小怕事老实守旧老实巴交脾气暴躁贪小便宜见异思迁水性扬花多愁善感情绪多变狡猾善变悲观失意见利忘义情绪不佳暴力倾向损人利己附庸风雅时喜时悲患得患失沉默寡言生活紊乱小心翼翼逆来顺受悲观消极郁郁寡欢缺乏耐力按部就班过分敏感杂乱无章脾气暴躁情绪低落信心受挫烦躁粗心萎蘼不振犹豫不决缺乏自信忧心忡忡难于取悦慢条斯理好吃懒做疑神疑鬼形容个性:爱财如命,安分守己,安贫乐道,安如泰山,傲慢不逊,傲血欺霜,八面玲珑,白璧无瑕,百折不挠,饱食终日,暴殄天物,卑躬屈膝,表里如一,别具匠心,别具一格,彬彬有礼,冰清玉洁,博闻强识,博古通今,博学多才,不学无术,临危不惧......2.1回答下面的问题:(周期律02282067)(1)在文法中,终极符号和非终极符号各起什么作用?✓终结符号是一个文法所产生的语言中句子的中出现的字符,他决定了一个文法的产生语言中字符的范围。
形式语言与自动机复习总结

形式语言与自动机复习总结适合《形式语言与自动机》(第2版)、杨娟,石川,王柏主编1.形式语言:形式化描述的字母表上的字符串集合,是一种公认的符号和表达式所描述的一种语言,是通用的语言。
2.自动机:具有离散的输入输出模型。
a)状态:一个标识,能区分自动机在不同时刻的状况。
b)自动机本质:根据输入和规则决定下一个状态。
c)部分常见的自动机:i.有限自动机:具有读头的有限控制器和一条写有字符的输入带组成。
ii.下推自动机:由一个输入带,一个有限控制器和一个下推栈组成。
iii.图灵机:一个具有读写头的有限控制器和一条无限带组成。
3.部分术语a)字母表:字符的有限集合,记为。
b)字符串:由字母表中的字符构成的序列。
Note: 一般字符串常用来表示,单个字符常用来表示。
c)字(串):字母表上的字符串。
d)空串:不包含任何字符的字符串,用表示。
e)长度:字符串上的字符个数,用表示。
f)连接:设为串,且,,那么和的连接定义为。
性质:i.ii.iii.g)字符串的逆:字符串的倒置,用或表示,其中。
h)幂运算:设为字母表,为任意自然数,定义:i.ii.设,则iii.中的元素由i和ii生成i)闭包:j)闭包:Note:4.语言:设为字母表,则任何集合是字母表上的一个语言。
a)语言的积:和的积表示为,表示由和的字符串连接所构成的字符串的集合。
Note:b)语言的幂:。
Note: 字符串和语言的关系可以类比集合的元素和集合的关系。
5.文法:定义语言的数学模型。
a)列举法:表示有限集合。
b)文化产生系统:由定义的文法规则产生语言。
c)机器识别系统:当一个字符串能被识别系统接受,则这个字符串是语言的一个句子。
d)BNF:讨论某种程序设计语言语法的元语言<数字><字母><标识符> <字母>|<标识符><字母>|<标识符><数字>“定义为”, “或者”, <>: “必须的部分”6.Chomsky文法体系:将BNF中的“”用“”代替,用字符代替汉字包含两个不同的有限符号的集合:非终结符和终结符,形式规则的有限集,起始符,文法,的集合,, 。
形式语言与自动机理论--第三章参考答案
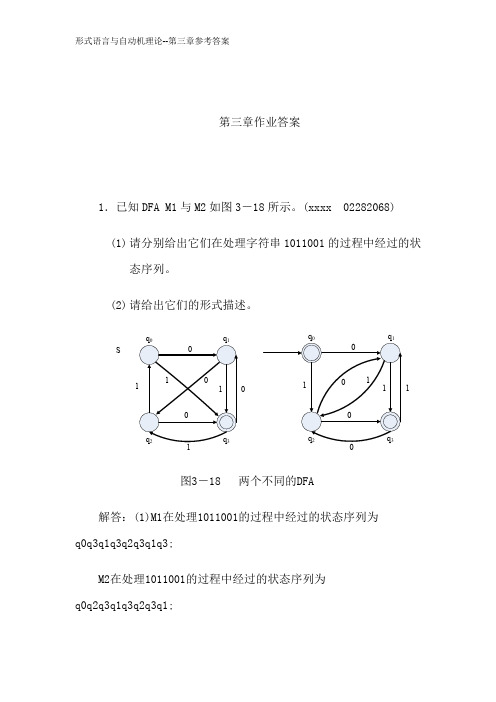
第三章作业答案1.已知DFA M1与M2如图3-18所示。
(xxxx 02282068) (1) 请分别给出它们在处理字符串1011001的过程中经过的状态序列。
(2) 请给出它们的形式描述。
Sq q1q q图3-18 两个不同的DFA解答:(1)M1在处理1011001的过程中经过的状态序列为q0q3q1q3q2q3q1q3;M2在处理1011001的过程中经过的状态序列为q0q2q3q1q3q2q3q1;(2)考虑到用形式语言表示,用自然语言似乎不是那么容易,所以用图上作业法把它们用正则表达式来描述:M1: [01+(00+1)(11+0)][11+(10+0)(11+0)]* M2: (01+1+000){(01)*+[(001+11)(01+1+000)]*} *******************************************************************************2.构造下列语言的DFA( xx02282085 ) (1){0,1}*,1(2){0,1}+,1(3){x|x{0,1}+且x 中不含00的串}(设置一个陷阱状态,一旦发现有00的子串,就进入陷阱状态)(4){ x|x{0,1}*且x中不含00的串}(可接受空字符串,所以初始状态也是接受状态)(5){x|x{0,1}+且x中含形如10110的子串}(6){x|x{0,1}+且x中不含形如10110的子串}(设置一个陷阱状态,一旦发现有00的子串,就进入陷阱状态)(7){x|x{0,1}+且当把x看成二进制时,x模5和3同余,要求当x为0时,|x|=1,且x0时,x的首字符为1 }1.以0开头的串不被接受,故设置陷阱状态,当DFA在启动状态读入的符号为0,则进入陷阱状态2.设置7个状态:开始状态qs,q0:除以5余0的等价类,q1:除以5余1的等价类,q2:除以5余2的等价类,q3:除以5余3的等价类,q4:除以5余4的等价类,接受状态qt3.状态转移表为(8){x|x{0,1}+且x的第十个字符为1}(设置一个陷阱状态,一旦发现x的第十个字符为0,进入陷阱状态)(9){x|x{0,1}+且x以0开头以1结尾}(设置陷阱状态,当第一个字符为1时,进入陷阱状态)(10){x|x{0,1}+且xxx至少含有两个1}(11){x|x{0,1}+且如果x以1结尾,则它的xx为偶数;如果x以0结尾,则它的xx为奇数}可将{0,1}+的字符串分为4个等价类。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
形式语言与自动机课后习题答案第二章4.找出右线性文法,能构成长度为1至5个字符且以字母为首的字符串。
答:G={N,T,P,S}其中N={S,A,B,C,D} T={x,y} 其中x∈{所有字母} y∈{所有的字符} P如下: S→x S→xA A→y A→yBB→y B→yC C→y C→yD D→y6.构造上下文无关文法能够产生L={ω/ω∈{a,b}*且ω中a的个数是b的两倍}答:G={N,T,P,S}其中N={S} T={a,b} P如下:S→aab S→aba S→baaS→aabS S→aaSb S→aSab S→SaabS→abaS S→abSa S→aSba S→SabaS→baaS S→baSa S→bSaa S→Sbaa7.找出由下列各组生成式产生的语言(起始符为S)(1)S→SaS S→b(2)S→aSb S→c(3)S→a S→aE E→aS答:(1)b(ab)n /n≥0}或者L={(ba)n b/n≥0}(2) L={a n cb n /n≥0}(3)L={a2n+1 /n≥0}第三章1.下列集合是否为正则集,若是正则集写出其正则式。
(1)含有偶数个a和奇数个b的{a,b}*上的字符串集合(2)含有相同个数a和b的字符串集合(3)不含子串aba的{a,b}*上的字符串集合答:(1)是正则集,自动机如下(2) 不是正则集,用泵浦引理可以证明,具体见17题(2)。
(3) 是正则集先看L’为包含子串aba的{a,b}*上的字符串集合显然这是正则集,可以写出表达式和画出自动机。
(略)则不包含子串aba的{a,b}*上的字符串集合L是L’的非。
根据正则集的性质,L也是正则集。
4.对下列文法的生成式,找出其正则式(1)G=({S,A,B,C,D},{a,b,c,d},P,S),生成式P如下:S→aA S→BA→abS A→bBB→b B→cCC→D D→bBD→d(2)G=({S,A,B,C,D},{a,b,c,d},P,S),生成式P如下:S→aA S→BA→cC A→bBB→bB B→aC→D C→abBD→d答:(1) 由生成式得:S=aA+B ①A=abS+bB ②B=b+cC ③C=D ④D=d+bB ⑤③④⑤式化简消去CD,得到B=b+c(d+bB)即B=cbB+cd+b =>B=(cb)*(cd+b) ⑥将②⑥代入①S=aabS+ab(cb)*(cd+b)+(cb)*(cd+b) =>S=(aab)*(ab+ε)(cb)*(cd+b) (2) 由生成式得:S=aA+B ①A=bB+cC ②B=a+bB ③C=D+abB ④D=dB ⑤由③得 B=b*a ⑥将⑤⑥代入④ C=d+abb*a=d+ab+a ⑦将⑥⑦代入② A=b+a+c(d+b+a) ⑧将⑥⑧代入① S=a(b+a+c(d+ab+a))+b*a=ab+a+acd+acab+a+b*a5.为下列正则集,构造右线性文法:(1){a,b}*(2)以abb结尾的由a和b组成的所有字符串的集合(3)以b为首后跟若干个a的字符串的集合(4)含有两个相继a和两个相继b的由a和b组成的所有字符串集合答:(1)右线性文法G=({S},{a,b},P,S)P: S→aS S→bS S→ε(2) 右线性文法G=({S},{a,b},P,S)P: S→aS S→bS S→abb(3) 此正则集为{ba*}右线性文法G=({S,A},{a,b},P,S)P: S→bA A→aA A→ε(4) 此正则集为{{a,b}*aa{a,b}*bb{a,b}*, {a,b}*bb{a,b}*aa{a,b}*}右线性文法G=({S,A,B,C},{a,b},P,S)P: S→aS/bS/aaA/bbBA→aA/bA/bbCB→aB/bB/aaCC→aC/bC/ε7.设正则集为a(b a)*(1)构造右线性文法(2)找出(1)中文法的有限自b动机答:(1)右线性文法G=({S,A},{a,b},P,S)P: S→aA A→bS A→ε(2)自动机如下:9.对应图(a)(b)的状态转换图写出正则式。
(图略)(1)由图可知q0=aq0+bq1+a+εq1=aq2+bq1q0=aq0+bq1+a=>q1=abq1+bq1+aaq0+aa=(b+ab) q1+aaq0+aa=(b+ab) *( aaq0+aa)=>q0=aq0+b(b+ab) *( aaq0+aa ) +a+ε= q0(a+b (b+ab) *aa)+ b(b+ab) *aa+a+ε=(a+b (b+ab) *aa) *((b+ab) *aa+a+ε)=(a+b (b+ab) *aa) *(3)q0=aq1+bq2+a+bq1=aq0+bq2+bq0=aq1+bq0+a=>q1=aq0+baq1+bbq0+ba+b=(ba)*(aq0 +bbq0+ba+b)=>q2=aaq0+abq2+bq0+ab+a=(ab)*(aaq0 +bq0+ ab+a)=>q0=a(ba)*(a+bb) q0 + a(ba)*(ba+b)+b(ab)*(aa+b)q0+ b(ab)*(ab+a)+a+b =[a(ba)*(a+bb) +b(ab)*(aa+b)]* (a(ba)*(ba+b)+ b(ab)*(ab+a)+a+b)10.设字母表T={a,b},找出接受下列语言的DFA:(1)含有3个连续b的所有字符串集合(2)以aa为首的所有字符串集合(3)以aa结尾的所有字符串集合14构造DFA M1等价于NFA M,NFA M如下:(1)M=({q0,q1 q2,q3},{a,b},σ,q0,{q3}),其中σ如下:σ(q0,a)={q0,q1} σ(q0,b)={q0}σ(q1,a)={q2} σ(q1,b)= {q2 }σ(q2,a)={q3} σ(q2,b)=Φσ(q3,a)={q3} σ(q3,b)= {q3 }(2)M=({q0,q1 q2,q3},{a,b},σ,q0,{ q1,q2}),其中σ如下:σ(q0,a)={q1,q2} σ(q0,b)={q1}σ(q1,a)={q2} σ(q1,b)= {q1,q2 }σ(q2,a)={q3} σ(q2,b)= {q0}σ(q3,a)=Φσ(q3,b)= {q0}答:(1)DFA M1={Q1, {a,b},σ1, [q0],{ [q0,q1,q3],[q0,q2,q3],[q0, q1,q2,q3]}其中Q1 ={[q0],[q0,q1], [q0,q1,q2],[ q0,q2],[ q0,q1, q2,q3],[ q0,q1, q3],[ q0,q2, q3],[ q0,q3]}(2)DFA M1={Q1, {a,b},σ1, [q0],{ [q1],[q3], [q1,q3],[q0,q1,q2],[q1,q2] ,[q1,q2,q3],[q2,q3]} 其中Q1 ={[q0],[q1,q3], [q1],[q2],[ q0,q1,q2],[q1,q2],[q3], [q1,q2,q3],[q2,q3]}(2)将此ε-NFA转换为没有ε的NFA答:(1)可被接受的的串共23个,分别为aac, abc, acc, bac, bbc, bcc, cac, cbc, ccc, caa, cab, cba, cbb, cca, ccb, bba, aca, acb, bca, bcb, bab, bbb, abb(2)ε-NFA:M=({p,q,r},{a,b,c},σ,p,r) 其中σ如表格所示。
因为ε-closure(p)= Φ则设不含ε的NFA M1=({p,q,r},{a,b,c},σ1,p,r)σ1(p,a)=σ’(p,a)=ε-closure(σ(σ’(p,ε),a))={p}σ1(p,b)=σ’(p,b)=ε-closure(σ(σ’(p,ε),b))={p,q}σ1(p,c)=σ’(p,c)=ε-closure(σ(σ’(p,ε),c))={p,q,r}σ1(q,a)=σ’(q,a)=ε-closure(σ(σ’(q,ε),a))={p,q}σ1(q,b)=σ’(q,b)=ε-closure(σ(σ’(q,ε),b))={p,q,r}σ1(q,c)=σ’(q,c)=ε-closure(σ(σ’(q,ε),c))={p,q,r}σ1(r,a)=σ’(r,a)=ε-closure(σ(σ’(r,ε),a))={p,q,r}σ1(r,b)=σ’(r,b)=ε-closure(σ(σ’(r,ε),b))={p,q,r}σ1(r,c)=σ’(r,c)=ε-closure(σ(σ’(r,ε),c))={p,q,r}图示如下:(r为终止状态)b,ca,b,ca,b,c a,b,c16.设NFA M=({q 0,q 1},{a,b},σ,q 0,{q 1}),其中σ如下:σ(q 0,a)={q 0,q 1} σ(q 0,b)={q 1}σ(q 1,a)= Φ σ(q 1,b)= {q 0, q 1}构造相应的DFA M 1,并进行化简答:构造一个相应的DFA M 1={Q 1, {a,b},σ1, [q 0],{ [q 1],[q 0,q 1]}其中Q 1 ={[q 0],[q 1],[q 0,q 1]}17.使用泵浦引理,证明下列集合不是正则集:(1) 由文法G 的生成式S →aSbS/c 产生的语言L(G)(2) {ω/ω∈{a,b}*且ω有相同个数的a 和b}(3) {a k ca k /k ≥1}(4) {ωω/ω∈{a,b}*}证明:(1)在L(G)中,a 的个数与b 的个数相等假设L(G)是正则集,对于足够大的k 取ω= a k (cb)k c令ω=ω1ω0ω2因为|ω0|>0 |ω1ω0|≤k 存在ω0使ω1ω0i ω2∈L所以对于任意ω0只能取ω0=a n n ∈(0,k)则ω1ω0i ω2= a k –n (a n )i (cb)k c 在i 不等于0时不属于L与假设矛盾。
则L(G)不是正则集(2)假设该集合是正则集,对于足够大的k 取ω= a k bk 令ω=ω1ω0ω2因为|ω0|>0 |ω1ω0|≤k 存在ω0使ω1ω0i ω2∈L所以对于任意ω0只能取ω0=a n n ∈(0,k)则ω1ω0i ω2= a k –n (a n )i b k 在i 不等于0时a 与b 的个数不同,不属于该集合 与假设矛盾。
则该集合不是正则集(3)假设该集合是正则集,对于足够大的k 取ω= a k ca k令ω=ω1ω0ω2因为|ω0|>0 |ω1ω0|≤k 存在ω0使ω1ω0i ω2∈L所以对于任意ω0只能取ω0=a n n ∈(0,k)则ω1ω0i ω2= a k –n (a n )i ca k 在i 不等于0时c 前后a 的个数不同,不属于该集合 与假设矛盾。