LIBSVM使用方法
libsvm使用详细文档2

LIBSVM软件包简介简介LIBSVM是台湾大学林智仁(Chih-Jen Lin) 博士等开发设计的一个操作简单、易于使用、快速有效的通用SVM 软件包。
可以解决分类问题(包括C- SVC 、n - SVC )回归问题(包括e - SVR 、n - SVR )分布估计(one-class-SVM )等问题提供了四种常用的核函数供选择线性、多项式、径向基和S形函数可以有效地解决多类问题、交叉验证选择参数、对不平衡样本加权、多类问题的概率估计等。
LIBSVM 是一个开源的软件包,需要者都可以免费的从作者的个人主页.tw/~cjlin/ 处获得。
他不仅提供了LIBSVM 的C++ 语言的算法源代码,还提供了Python 、Java 、R 、MATLAB 、Perl 、Ruby 、LabVIEW以及C#.net 等各种语言的接口,可以方便的在Windows 或UNIX 平台下使用,也便于科研工作者根据自己的需要进行改进(譬如设计使用符合自己特定问题需要的核函数等)。
另外还提供了WINDOWS 平台下的可视化操作工具SVM-toy ,并且在进行模型参数选择时可以绘制出交叉验证精度的等高线图。
SVM进行函数估计是有监督学习,进行概率密度估计是非监督学习自从版本2.8以后libsvm采用SMO算法安装环境下载文件下载Libsvm2.88、Python2.4(默认安装在D:)和Gnuplot配置文件的路径Python2.4文件路径如下:Gnuplot路径设置Gnuplot不是安装文件,直接放在tmp目录即可另一个工具就是gnuplot.exe,下载不是安装文件:安装完上面的软件还不能运行,还要修改easy.py,grid.py的设置.,以写字板的格式打开easy.py:如下:将他们对应的代码" gnuplot_exe = r"c:\tmp\gnuplot\bin\pgnuplot.exe""都改为你的pgnuplot.exe 所在的路径,比如我的文件在当前目录的上一级目录,就是和tools文件夹在同一级目录,那么我的设置应该为" gnuplot_exe = r"..\gnuplot\bin\pgnuplot.exe"".本人使用的上边一种方法(测试通过),事实上也符合下面的方式,为了保险起见。
libsvm使用说明

Libsvm是一个简单,易于使用和高效的SVM软件分类和回归。
它解决了C-SVM分类,nu-SVM分类,一类SVM,ε-SVM回归和nu-SVM回归。
它还提供了一个自动模型选择工具C-SVM分类。
本文档介绍了libsvm的使用。
Libsvm可在.tw/~cjlin/libsvm在使用libsvm之前,请先阅读COPYRIGHT文件。
目录=================- 快速开始- 安装和数据格式- `svm-train'用法- `svm-predict'用法- `svm-scale'用法- 实用技巧- 例子- 预先计算的内核- 图书馆使用- Java版本- 构建Windows二进制文件- 附加工具:子采样,参数选择,格式检查等- MATLAB / OCTAVE接口- Python接口- 附加信息快速开始===========如果您是SVM的新手,如果数据不大,请转到`tools'目录,并在安装后使用easy.py。
它是一切都是自动的- 从数据缩放到参数选择。
用法:easy.py training_file [testing_file]有关参数选择的更多信息,请参见`工具/自述文件'。
安装和数据格式============================在Unix系统上,键入`make'来构建`svm-train'和`svm-predict'程式。
运行他们没有参数,以显示他们的用法。
在其他系统上,请参阅“Makefile”来构建它们(例如,在此文件中构建Windows二进制文件)或使用预构建的二进制文件(Windows二进制文件位于目录“windows”中)。
培训和测试数据文件的格式是:<label> <index1>:<value1> <index2>:<value2> ...。
libsvm参数说明

libsvm参数说明【原创版】目录1.概述2.安装与配置3.参数说明4.应用实例5.总结正文1.概述LIBSVM 是一个开源的支持向量机(SVM)算法库,它可以在多种平台上运行,包括 Windows、Linux 和 Mac OS。
LIBSVM 提供了一系列用于解决分类和回归问题的工具和算法,它的核心是基于序列最小化算法的支持向量机。
2.安装与配置在使用 LIBSVM 之前,需要先安装它。
在 Windows 平台上,可以直接下载LIBSVM 的二进制文件,然后设置环境变量。
对于 Linux 和 Mac OS 平台,需要先安装相应的依赖库,然后编译并安装 LIBSVM。
在安装完成后,需要配置 LIBSVM 的参数,包括选择核函数、设置惩罚参数等。
这些参数对于支持向量机的性能至关重要,需要根据实际问题进行调整。
3.参数说明LIBSVM 的参数主要包括以下几个方面:- 核函数:LIBSVM 支持多种核函数,包括线性核、多项式核、径向基函数(RBF)核和 Sigmoid 核。
核函数的选择取决于问题的性质,需要根据实际问题进行选择。
- 惩罚参数:惩罚参数用于控制模型的复杂度,避免过拟合。
惩罚参数的取值范围是 0 到 1,取值越小,模型的复杂度越高,过拟合的风险也越高。
- 迭代次数:迭代次数用于控制算法的收敛速度,取值越大,收敛速度越快,但可能会影响模型的精度。
- 随机种子:随机种子用于生成随机数,影响模型的初始化和迭代过程。
在实际应用中,建议设置随机种子,以保证模型的可重复性。
4.应用实例LIBSVM 在实际应用中可以用于多种问题,包括分类、回归和排序等。
例如,在人脸检测、车牌识别和文本分类等问题中,可以使用 LIBSVM 来实现支持向量机算法。
5.总结LIBSVM 是一个功能强大的支持向量机库,它提供了多种核函数和参数设置,可以用于解决多种实际问题。
第1页共1页。
libsvm安装教程matlab中使用(详细版)
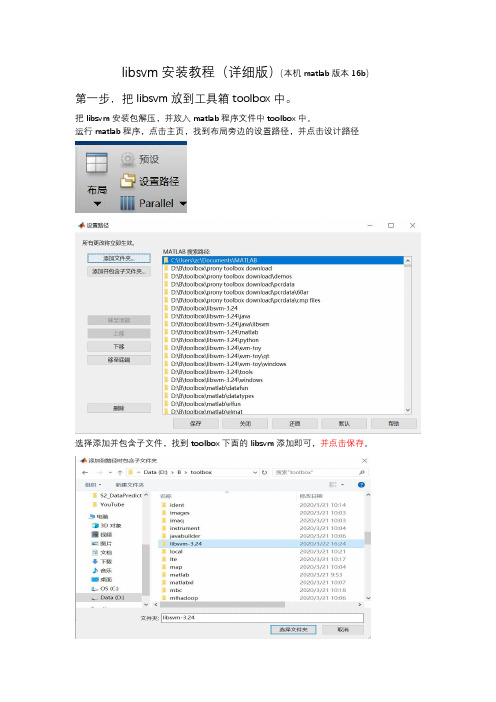
libsvm安装教程(详细版)(本机matlab版本16b)第一步,把libsvm放到工具箱toolbox中。
把libsvm安装包解压,并放入matlab程序文件中toolbox中。
运行matlab程序,点击主页,找到布局旁边的设置路径,并点击设计路径选择添加并包含子文件,找到toolbox下面的libsvm添加即可,并点击保存。
第二步更新工具箱找到布局旁边的预测按钮,并点击预设按钮。
找到常规,选择更新工具箱路径缓存,并点击应用,最后点击确定。
第三步,更改libsvm文件在matlab文件行,打开如下地址:D:\B\toolbox\libsvm-3.24\matlab打开make.m文件,将make.m中的CFLAGS改为COMPFLAGS。
注:因为matlab中有自带的svm,为了防止libsvm和自带的svm发生冲突,所以将D:\B\toolbox\libsvm-3.24\matlab中将svmtrian.c和svmpredic.c前面加入lib,相应的make.m文件中也做修改第四步,安装编译器编译器采用最新版tdm64-gcc-9.2.0,安装教程很简单选择Creat,保存路径直接选择C盘即可,C:\TDM-GCC-64。
第五步,使用matlab读取C语言程序。
Matlab文件行调整到此目录下D:\B\toolbox\libsvm-3.24\matlab 并在命令行窗口输入:setenv('MW_MINGW64_LOC','C:\TDM-GCC-64')make点击回车,当命令行窗口出现:使用'MinGW64 Compiler (C)' 编译。
MEX 已成功完成。
使用'MinGW64 Compiler (C)' 编译。
MEX 已成功完成。
使用'MinGW64 Compiler (C)' 编译。
MEX 已成功完成。
libsvm使用说明

libSVM的使用文档11. 程序介绍和环境设置windows下的libsvm是在命令行运行的Console Program。
所以其运行都是在windows的命令行提示符窗口运行(运行,输入cmd)。
运行主要用到的程序,由如下内容组成:libsvm-2.9/windows/文件夹中的:svm-train.exesvm-predict.exesvm-scale.exelibsvm-2.9/windows/文件夹中的:checkdata.pysubset.pyeasy.pygrid.py另外有:svm-toy.exe,我暂时知道的是用于演示svm分类。
其中的load按钮的功能,是否能直接载入数据并进行分类还不清楚,尝试没有成功;python文件夹及其中的svmc.pyd,暂时不清楚功能。
因为程序运行要用到python脚本用来寻找参数,使用gnuplot来绘制图形。
所以,需要安装python和Gnuplot。
(Python v3.1 Final可从此下载:/detail/33/320958.shtml)(gnuplot可从其官网下载:)为了方便,将gnuplot的bin、libsvm-2.9/windows/加入到系统的path中,如下:gnuplot.JPGlibsvm.JPG这样,可以方便的从命令行的任何位置调用gnuplot和libsvm的可执行程序,如下调用svm-train.exe:pathtest.JPG出现svm-train程序中的帮助提示,说明path配置成功。
至此,libsvm运行的环境配置完成。
下面将通过实例讲解如何使用libsvm进行分类。
2. 使用libsvm进行分类预测我们所使用的数据为UCI的iris数据集,将其类别标识换为1、2、3。
然后,取3/5作为训练样本,2/5作为测试样本。
使用论坛中“将UCI数据转变为LIBSVM使用数据格式的程序”一文将其转换为libsvm所用格式,如下:训练文件tra_iris.txt1 1:5.4 2:3.4 3:1.7 4:0.21 1:5.1 2:3.7 3:1.5 4:0.41 1:4.6 2:3.6 3:1 4:0.21 1:5.1 2:3.3 3:1.7 4:0.51 1:4.8 2:3.4 3:1.9 4:0.2……2 1:5.9 2:3.2 3:4.8 4:1.82 1:6.1 2:2.8 3:4 4:1.32 1:6.3 2:2.5 3:4.9 4:1.52 1:6.1 2:2.8 3:4.7 4:1.22 1:6.4 2:2.9 3:4.3 4:1.3……3 1:6.9 2:3.2 3:5.7 4:2.33 1:5.6 2:2.8 3:4.9 4:23 1:7.7 2:2.8 3:6.7 4:23 1:6.3 2:2.7 3:4.9 4:1.83 1:6.7 2:3.3 3:5.7 4:2.13 1:7.2 2:3.2 3:6 4:1.8……测试文件tes_iris.txt1 1:5.1 2:3.5 3:1.4 4:0.21 1:4.9 2:3 3:1.4 4:0.21 1:4.7 2:3.2 3:1.3 4:0.21 1:4.6 2:3.1 3:1.5 4:0.21 1:5 2:3.6 3:1.4 4:0.21 1:5.4 2:3.9 3:1.7 4:0.4……2 1:7 2:3.2 3:4.7 4:1.42 1:6.4 2:3.2 3:4.5 4:1.52 1:6.9 2:3.1 3:4.9 4:1.52 1:5.5 2:2.3 3:4 4:1.32 1:6.5 2:2.8 3:4.6 4:1.5……3 1:6.3 2:3.3 3:6 4:2.53 1:5.8 2:2.7 3:5.1 4:1.93 1:7.1 2:3 3:5.9 4:2.13 1:6.3 2:2.9 3:5.6 4:1.83 1:6.5 2:3 3:5.8 4:2.2……libsvm的参数选择一直是令人头痛的问题。
如何使用MATLAB-LIBSVM
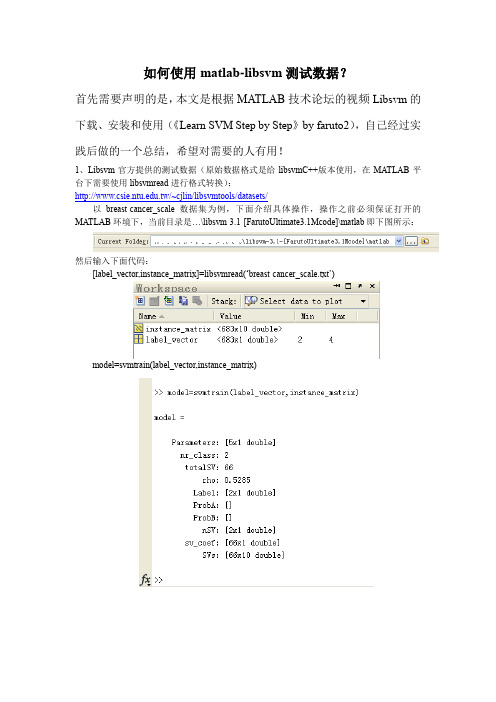
如何使用matlab-libsvm测试数据?首先需要声明的是,本文是根据MA TLAB技术论坛的视频Libsvm的下载、安装和使用(《Learn SVM Step by Step》by faruto2),自己经过实践后做的一个总结,希望对需要的人有用!1、Libsvm官方提供的测试数据(原始数据格式是给libsvmC++版本使用,在MA TLAB平台下需要使用libsvmread进行格式转换):.tw/~cjlin/libsvmtools/datasets/以breast-cancer_scale数据集为例,下面介绍具体操作,操作之前必须保证打开的MA TLAB环境下,当前目录是…\libsvm-3.1-[FarutoUltimate3.1Mcode]\matlab即下图所示:然后输入下面代码:[label_vector,instance_matrix]=libsvmread(‘breast-cancer_scale.txt’)model=svmtrain(label_vector,instance_matrix)[plabel,accuracy]=svmpredict(label_vector,instance_matrix,model)2、UCI数据库:/ml/datasets.html下面以wine_data数据集为例,介绍具体操作:先将下载好的wine.data数据集放在…\libsvm-3.1-[FarutoUltimate3.1Mcode]\matlab文件夹下面,必须保证打开的MA TLAB环境下,当前目录如下图所示:然后在打开的MA TLAB环境下,File->Import Data…->文件类型(all files)->选择wine.data,接下来输入下面代码:wine_label=wine(:,1)结果如图所示wine_data=wine(:,2:end)结果如图所示savewinedata.mat结果如图所示loadwinedata结果如图所示modelw=svmtrain(wine_label,wine_data)结果如图所示[plabelw,accuracyw]=svmpredict(wine_label,wine_data,modelw) 结果如图所示。
libsvm函数库使用说明

libsvm函数库使用说明本文大部分来自Felomeng的翻译,原文是《Felomeng翻译:libsvm2.88之函数库的使用》。
2.88版本的README文件和libsvm3.0的README文件差不多,3.0版本的README见这里:/4001-libsvm3.0_READMELibrary Usage=============这些函数和结构都在头文件“svm.h”中有声名。
你需要在你的C/C++源文件中添加#include “svm.h”语句,在连接时需要将你的程序与svm.cpp连接。
具体使用方法可以参考“svm-train.c”和“svm-predict.c”的使用示例。
在文件svm.h中使用LIBSVM_VERSION定义了版本号,以便读者查阅。
在对测试数据进行分类之前,需要先使用训练数据建立一个支持向量模型。
模型可以以文件的形式存储以备以后使用。
一旦建立好了支持向量机模型,就可以用它来对新的数据进行分类了。
-函数:struct svm_model *svm_train(const struct svm_problem *prob, const struct svm_parameter *param);这个函数根据给定的参数和训练数据构建并返回一个支持向量机模型。
结构体svm_problem将问题形式化:struct svm_problem{int l;double *y;struct svm_node **x;};其中“l”表示训练数据的实例数,而“y”是一个数组,用于存放它们的目标值。
(类型值用整型数据,回归值用实数)“x”是一个数组指针,每一个指针指向一个稀疏的训练向量(即一个svm_node数组)。
例如,如果我们有如下的训练数据:LABEL ATTR1 ATTR2 ATTR3 ATTR4 ATTR5----- ----- ----- ----- ----- -----1 0 0.1 0.2 0 02 0 0.1 0.3 -1.2 01 0.4 0 0 0 02 0 0.1 0 1.4 0.53 -0.1 -0.2 0.1 1.1 0.1于是svm_problem的构成如下:l = 5y -> 1 2 1 2 3x -> [ ] -> (2,0.1) (3,0.2) (-1,?)[ ] -> (2,0.1) (3,0.3) (4,-1.2) (-1,?)[ ] -> (1,0.4) (-1,?)[ ] -> (2,0.1) (4,1.4) (5,0.5) (-1,?)[ ] -> (1,-0.1) (2,-0.2) (3,0.1) (4,1.1) (5,0.1) (-1,?)其中(索引,值)存储在结构“svm_node”中:struct svm_node{int index;double value;};当索引为-1时表示已经到达向量的末端。
libsvm的原理及使用方法介绍

LibSVM学习目录LibSVM学习 (1)初识LibSVM (1)第一次体验libSvm (3)LibSVM使用规范 (5)1. libSVM的数据格式 (5)2. svmscale的用法 (5)3. svmtrain的用法 (6)4. svmpredict 的用法 (7)逐步深入LibSVM (7)分界线的输出 (11)easy.py和grid.py的使用 (13)1. grid.py使用方法 (13)2. easy.py使用方法 (14)参考 (16)LibSVM学习初识LibSVMLibSVM是台湾林智仁(Chih-Jen Lin's) 教授2001年开发的一套支持向量机的库,这套库运算速度还是挺快的,可以很方便的对数据做分类或回归。
由于libSVM程序小,运用灵活,输入参数少,并且是开源的,易于扩展,因此成为目前国内应用最多的SVM的库。
这套库可以从林智仁的home page上免费获得,目前已经发展到3.0版。
下载.zip格式的版本,解压后可以看到,主要有5个文件夹和一些c++源码文件。
Java ——主要是应用于java平台的源码和libsvm.jar包;Python ——是用来参数优选的工具,稍后介绍;svm-toy ——一个可视化的工具,用来展示训练数据和分类界面,里面是源码,其编译后的程序在windows文件夹下;tools ——主要包含四个python文件,用来数据集抽样(subset.py),参数优选(grid.py),集成测试(easy.py), 数据检查(checkdata.py);windows ——包含libSVM四个exe程序包,我们所用的库和程序就是它们。
其他.h和.cpp文件都是程序的源码,可以编译出相应的.exe文件。
其中,最重要的是svm.h 和svm.cpp文件,svm-predict.c、svm-scale.c和svm-train.c(还有一个svm-toy.cpp在svm-toy\qt 文件夹中)都是调用的这个文件中的接口函数,编译后就是windows下相应的四个exe程序。
LIBSVM 使用方法简介

LIBSVM 使用方法简介LIBSVM 在给出源代码的同时还提供了Windows操作系统下的可执行文件,包括:进行支持向量机训练的svmtrain.exe;根据已获得的支持向量机模型对数据集进行预测的svmpredict.exe;以及对训练数据与测试数据进行简单缩放操作的svmscale.exe。
它们都可以直接在DOS 环境中使用。
如果下载的包中只有C++的源代码,则也可以自己在VC等软件上编译生成可执行文件。
LIBSVM 使用的一般步骤是:1)按照LIBSVM软件包所要求的格式准备数据集;2)对数据进行简单的缩放操作;3)考虑选用RBF 核函数2 K(x,y) e x y = -g - ;4)采用交叉验证选择最佳参数C与g ;5)采用最佳参数C与g 对整个训练集进行训练获取支持向量机模型;6)利用获取的模型进行测试与预测。
一. LIBSVM 使用的数据格式LIBSVM使用的训练数据和测试数据文件格式如下:::< value2> …其中是训练数据集的目标值,对于分类,它是标识某类的整数(支持多个类);对于回归,是任意实数。
是以1 开始的整数,表示特征的序号;为实数,也就是我们常说的特征值或自变量。
当特征值为0 时,特征序号与特征值value都可以同时省略,即index可以是不连续的自然数。
与第一个特征序号、前一个特征值与后一个特征序号之间用空格隔开。
测试数据文件中的label 只用于计算准确度或误差,如果它是未知的,只需用任意一个数填写这一栏,也可以空着不填。
例如:+1 1:0.708 2:1 3:1 4:-0.320 5:-0.105 6:-1 8:1.21二. svmscale 的用法对数据集进行缩放的目的在于:1)避免一些特征值范围过大而另一些特征值范围过小;2)避免在训练时为了计算核函数而计算内积的时候引起数值计算的困难。
因此,通常将数据缩放到[ -1,1]或者是[0,1]之间。
matlab下的LIBSVM的使用

执行文件,还提供了源代码,方便改进、修改以及 在其它操作系统上应用 – 且对SVM所涉及的参数调节相对比较少,提供了很 多的默认参数,利用这些默认参数可以解决很多问 题 – 并提供了交互检验(Cross Validation)的功能
Company Logo
该软件包可在 .tw/~cjlin/ 免费获得。 该软件可以解决C-SVM、ν-SVM、ε-SVR和 ν-SVR等问题,包括基于一对一算法的多类模 式识别问题。
Company Logo
使用
参数设置 主要函数
Company Logo
主要参数设置
-s(默认0)——SVM类型选择
– 0--CSVC – – – –
(分类问题) 1--nu-SVC (分类问题,引入一个新的参数nu) 2--one-class SVM(做分布估计) 3--epsilon-SVR (回归问题) 4--nu-SVR
Company Logo
安装
下载之后设置路径
– FILE——Set Path——Add with subfoders——选择所在
文件夹
Company Logo
选择编译器
libsvm的原始版本使用C++写的,为了在 matlab平台下使用,需要用C++编译器编译, 生成类似于.m文件的.mexw32文件。 这里要说明matlab自带一个C编译器 Lcc_win32C,但此处需要C++编译器。 matlab支持的编译器列表: /support/compi lers/R2011a/win32.html
Company Logo
测试数据及格式
测试数据集
– libsvm官方提供的测试数据格式是C++版本使用
LibSVM在matlab中的使用

LibSVM 在matlab 中的使⽤搞了⼀天,看了很多资料,终于搞好了matlab 中调⽤⼤⽜写好的svm 库,将结果告诉⼤家避免以后⾛弯路。
1. 参考⽹站:2. 操作流程:请注意:详细操作流程请参考上⾯的“详解”⽹站,这⾥只说⼤框架和详解⾥没有提到的问题。
A.设置pathFile->set path ->add with subfolders->加⼊libsvm-3.11⽂件夹的路径B. 在matlab 中编译⽬的:将libsvm-3.11\matlab 中 libsvmwrite.c 等 C++⽂件编译成 libsvmread.mexw32 等matlab ⽂件,这样就可以在command window 中被直接调⽤了。
注意:在最外⾯的Readme 中有提到已经有编译好的⽂件,⽐如在libsvm-3.11\windows 中也会看到libsvmread.mexw32,但这⾥不要被误导!还是需要你⾃⼰再编译⼀遍的!(还有如果matlab 版本太低,如matlab 7.0是不能⽤VS 作为编译器的,只能⽤VC++ 6.0,这是我劝你给matlab 升级吧!别装vc 了~我就是这样,升级到Matlab 2011b 就可以⽤VS2008做编译器了)C.加载数据集就是这⾥搞了我⼀下午!加载数据集有两个数据集,⼀个是C++的, ⼀个是matlab 的。
libsvm 库中下载的是C++数据,所以matlab 加载我们下载的heart_scale 是会报错的:<这就是视频中遗漏的⼩问题>这时怎么办?法2、⽤libsvmread ⽽⾮load ,就是这⾥这样就可以加载数据集了,完成该步骤后发现Workspace 中出现了heart_scale_inst 和 heart_scale_label,说明正确。
ok ,下⼀步我们来测试svm 的训练和predictD.train & predict可以看到结果:=========================MAC 版如何在matlab 中使⽤libsvm=========================下⾯说下mac 怎么⽤libsvm ,这⾥的问题是mex -setup 的问题,需要安装⼀个补丁。
libsvm使用详细说明

libsvm使⽤详细说明⼀,简介LibSVM是台湾林智仁(Chih-Jen Lin)教授2001年开发的⼀套⽀持向量机的库,这套库运算速度还是挺快的,因此成为⽬前国内应⽤最多的SVM的库。
详细的使⽤说明及博主博客见下链接:Java——主要是应⽤于java平台;Python——是⽤来参数优选的⼯具svm-toy——⼀个可视化的⼯具,⽤来展⽰训练数据和分类界⾯,⾥⾯是源码,其编译后的程序在windows⽂件夹下;tools——主要包含四个python⽂件,⽤来数据集抽样(subset),参数优选(grid),集成测试(easy),数据检查(checkdata);windows——包含libSVM四个exe程序包,我们所⽤的库就是他们,⾥⾯还有个heart_scale,是⼀个样本⽂件,可以⽤记事本打开,⽤来测试⽤的。
⼆,我的使⽤⼼得:使⽤windows 下的⼯具:1. 打开cmd 命令⾏,定位到windows⽂件夹的⽬录下。
2. 进⾏libsvm训练,输⼊命令 svm-train[参数的选择] file_name。
参数的选择:根据你的任务,选择分类或者回归模型等,命令⾏中有提⽰。
file_name,是训练的⽂件名称,⽂件格式如下:Label 1:value 2:value ….Label:是类别的标识,⽐如上节train.model中提到的1 -1,你可以⾃⼰随意定,⽐如-10,0,15。
当然,如果是回归,这是⽬标值,就要实事求是了。
Value:就是要训练的数据,从分类的⾓度来说就是特征值,数据之间⽤空格隔开⽐如: -15 1:0.708 2:1056 3:-0.3333需要注意的是,如果特征值为0,特征冒号前⾯的(姑且称做序号)可以不连续。
如:-15 1:0.708 3:-0.3333我采⽤4w维的向量做训练,libsvm 速度还可以,⽀持向量的稀疏表⽰。
训练结束后,可以看到原来训练⽂件⽬录下,多了个model ⽂件,记录了训练后的结果。
LIBSVM使用方法

LIBSVM使用方法LIBSVM使用方法1 LIBSVM简介2 LIBSVM使用方法LibSVM是以源代码和可执行文件两种方式给出的。
如果是Windows系列操作系统,可以直接使用软件包提供的程序,也可以进行修改编译;如果是Unix类系统,必须自己编译,软件包中提供了编译格式文件,我们在SGI工作站(操作系统IRIX6.5)上,使用免费编译器GNU C++3.3编译通过。
2.1 LIBSVM 使用的一般步骤:1) 2) 3) 4) 5) 6) 按照LIBSVM软件包所要求的格式准备数据集;对数据进行简单的缩放操作;考虑选用RBF 核函数;采用交叉验证选择最佳参数C与g;采用最佳参数C与g 对整个训练集进行训练获取支持向量机模型;利用获取的模型进行测试与预测。
2.2 LIBSVM使用的数据格式该软件使用的训练数据和检验数据文件格式如下:: : ...其中是训练数据集的目标值,对于分类,它是标识某类的整数(支持多个类);对于回归,是任意实数。
是以1开始的整数,可以是不连续的;为实数,也就是我们常说的自变量。
检验数据文件中的label只用于计算准确度或误差,如果它是未知的,只需用一个数填写这一栏,也可以空着不填。
在程序包中,还包括有一个训练数据实例:heart_scale,方便参考数据文件格式以及练习使用软件。
可以编写小程序,将自己常用的数据格式转换成这种格式。
2.3 Svmtrain和Svmpredict的用法Svmtrain(训练建模)的用法:svmtrain [options] training_set_file [model_file]Options:可用的选项即表示的涵义如下-s svm类型:SVM设置类型(默认0)0 -- C-SVC1 --v-SVC2 –一类SVM3 -- e -SVR4 -- v-SVR-t 核函数类型:核函数设置类型(默认2)0 –线性:u'v1 –多项式:(r*u'v + coef0)^degree2 – RBF函数:exp(-r|u-v|^2)3 –sigmoid:tanh(r*u'v + coef0)-d degree:核函数中的degree设置(默认3)-g r(gama):核函数中的?函数设置(默认1/ k)-r coef0:核函数中的coef0设置(默认0)-c cost:设置C-SVC,? -SVR和?-SVR的参数(默认1)-n nu:设置?-SVC,一类SVM和?- SVR的参数(默认0.5)-p e:设置? -SVR 中损失函数?的值(默认0.1)-m cachesize:设置cache内存大小,以MB为单位(默认40)-e ε:设置允许的终止判据(默认0.001)-h shrinking:是否使用启发式,0或1(默认1)-wi weight:设置第几类的参数C为weight?C(C-SVC中的C)(默认1)-v n: n-fold交互检验模式其中-g选项中的k是指输入数据中的属性数。
libsvm参数说明

libsvm参数说明(实用版)目录1.LIBSVM 简介2.LIBSVM 参数说明3.LIBSVM 的使用方法4.LIBSVM 的应用场景5.总结正文1.LIBSVM 简介LIBSVM 是一个开源的支持向量机(Support Vector Machine,简称SVM)算法库,它可以帮助我们解决分类和回归问题。
支持向量机是一种非常强大和有效的机器学习算法,它可以在各种领域中得到广泛的应用,如人脸检测、车牌识别等。
2.LIBSVM 参数说明在使用 LIBSVM 时,我们需要了解一些基本的参数,这些参数可以影响模型的性能。
以下是一些常用的 LIBSVM 参数及其说明:- -train:训练数据文件- -test:测试数据文件- -model:模型文件- -param:参数文件- -predict:预测数据文件此外,还有一些其他参数,如-v(显示详细信息)、-n(核函数的阶数)、-c(惩罚参数)等。
通过调整这些参数,我们可以优化模型的性能。
3.LIBSVM 的使用方法使用 LIBSVM 的过程可以分为以下几个步骤:(1)准备数据:将数据分为训练集和测试集,确保数据是线性可分的。
(2)训练模型:使用训练集和相应的参数训练 SVM 模型。
(3)预测结果:使用测试集和训练好的模型进行预测。
(4)评估性能:评估模型的性能,并根据需要调整参数以优化性能。
4.LIBSVM 的应用场景LIBSVM 可以广泛应用于各种分类和回归问题中,如人脸检测、车牌识别、文本分类、图像分类等。
在实际应用中,我们需要根据具体问题选择合适的核函数(如线性核、多项式核、径向基函数等)并调整相关参数,以获得最佳的模型性能。
5.总结总之,LIBSVM 是一个功能强大的支持向量机库,可以帮助我们解决各种分类和回归问题。
python libsvm 实例

python libsvm 实例Pythonlibsvm是一个基于C++编写的支持向量机(SVM)库,可以在Python中调用。
它提供了各种不同的内核函数、参数优化方式和模型选择工具,使得使用者可以灵活地进行SVM的分类、回归和异常检测等任务。
本文将通过实例介绍Python libsvm的使用方法。
1. 安装Python libsvmPython libsvm可以通过pip安装:```pip install -U libsvm```2. 导入数据在本例中,我们将使用UCI Machine Learning Repository的Iris Dataset作为样本数据。
该数据集包含3种不同的鸢尾花,每种花有50个样本,共计150个样本。
每个样本包含4个特征:花萼长度、花萼宽度、花瓣长度和花瓣宽度。
我们将使用这些特征来预测鸢尾花的种类。
首先,我们需要导入数据。
在本例中,我们将使用pandas库来加载CSV文件,并将其转换为NumPy数组。
代码如下:```import pandas as pdimport numpy as np# 加载数据data = pd.read_csv('iris.csv')# 将数据转换为NumPy数组x = np.array(data.iloc[:, :-1])y = np.array(data.iloc[:, -1])```在上面的代码中,我们首先使用pandas库加载Iris Dataset的CSV文件。
然后,我们将数据转换为NumPy数组。
x数组包含所有样本的特征,y数组包含所有样本的类别标签。
3. 数据预处理在使用SVM进行分类任务之前,我们需要对数据进行一些预处理。
首先,我们将使用sklearn库的train_test_split函数将数据分为训练集和测试集。
我们将70%的数据用于训练,30%的数据用于测试。
代码如下:```from sklearn.model_selection import train_test_split# 将数据分为训练集和测试集x_train, x_test, y_train, y_test = train_test_split(x, y, test_size=0.3)```其次,我们需要对数据进行标准化处理。
使用libsvm

支持向量机(SVM,Support Vector Machine)是一种基于统计学习理论的模式识别方法,在解决小样本、高维度及非线性的分类问题中应用非常广泛。
LIBSVM是一个由台湾大学林智仁(Lin Chih-Jen)教授等开发的SVM模式识别与回归的软件包,使用简单,功能强大,本文主要介绍其在Matlab中的使用。
4. 添加路径为了以后使用的方便,建议把LIBSVM的编译好的文件所在路径(如C:\libsvm-3.17\matlab)添加到Matlab的搜索路径中。
具体操作为:(中文版Matlab对应进行)HOME -> Set Path -> Add Folder -> 加入编译好的文件所在的路径(如C:\libsvm-3.17\ma tlab)当然也可以把那4个编译好的文件复制到想要的地方,然后再把该路径添加到Matlab的搜索路径中。
LIBSVM软件包中自带有测试数据,为软件包根目录下的heart_scale文件,可以用来测试L IBSVM是否安装成功。
这里的heart_scale文件不能用Matlab的load进行读取,需要使用l ibsvmread读取。
进入LIBSVM的根目录运行以下代码(因为heart_scale文件没有被添加进搜索路径中,其他路径下无法访问这个文件):如果LIBSVM安装正确的话,会出现以下的运行结果,显示正确率为86.6667%。
使用SVM前首先得了解SVM的工作原理,简单介绍如下。
SVM(Support Vector Machine,支持向量机)是一种有监督的机器学习方法,可以学习不同类别的已知样本的特点,进而对未知的样本进行预测。
SVM本质上是一个二分类的算法,对于n维空间的输入样本,它寻找一个最优的分类超平面,使得两类样本在这个超平面下可以获得最好的分类效果。
这个最优可以用两类样本中与这个超平面距离最近的点的距离来衡量,称为边缘距离,边缘距离越大,两类样本分得越开,SVM就是寻找最大边缘距离的超平面,这个可以通过求解一个以超平面参数为求解变量的优化问题获得解决。
matlab下的LIBSVM的使用

相关参数
-c(默认1,范围(0,+ ))
-n(默认0.5,范围(0,1]) -n(默认0.5,范围(0,1])
-c(默认1,(0, + )) -p(默认0.1,(0, + ))
-c(默认1,(0, + ))
-n(默认0.5,(0,1])
Company Logo
主要参数设置
-t(默认2)——选择核函数
Company Logo
测试数据及格式
测试数据集
– libsvm官方提供的测试数据格式是C++版本使用 的,需要使用libsvmread进行格式转换
– UCI数ቤተ መጻሕፍቲ ባይዱ集 –等
格式
– 标签 属性编号1:属性值1 属性编号2: 属性值2 – 如:+1 1:0.78 2:1 3:1 ........
如如modelsvmtrainlabeldatac1w12w105companylogo标签1的样本惩罚参数为2标签为1的样本惩罚参数为05主要参数设置?v一般选择5或10交叉检验参数必须大于2当使用此参数时返回的结果不再是一个结构体model分类问题返回的是交叉检验下的平均分类准且率回归问题回归问题返回的是交叉检验下的平均均方差误差返回的是交叉检验下的平均均方差误差companylogo测试数据及格式?测试数据集libsvm官方提供的测试数据格式是c版本使用的需要使用libsvmread进行格式转换uci数据集等companylogo?格式标签属性编号1
Company Logo
编译
make 命令
– 编译后文件夹中会出现多个svmtrain.mexw32、 svmpredict.mexw32等文件。
– .mexw32文件是加密文件,打开为乱码。 – 运行help对这些函数无效
libsvm用法

离散分类-s svm_type : set type of SVM (default 0)0 -- C-SVC c支持向量机1 -- nu-SVC nu向量机2 -- one-class SVM 0,1,2用于离散的分类,分2类最好3 -- epsilon-SVR4 -- nu-SVR 连续的,连续映射-t kernel_type : set type of kernel function (default 2) 核函数0 -- linear: u'*v 线性的1 -- polynomial: (gamma*u'*v + coef0)^degree 多项式2 -- radial basis function: exp(-gamma*|u-v|^2) 指数的3 -- sigmoid: tanh(gamma*u'*v + coef0) 反tan cot-d degree : set degree in kernel function (default 3)-g gamma : set gamma in kernel function (default 1/num_features)-r coef0 : set coef0 in kernel function (default 0)-c cost : set the parameter C of C-SVC, epsilon-SVR, and nu-SVR (default 1)C of C-SVC, epsilon-SVR, and nu-SVR 才采用-c-n nu : set the parameter nu of nu-SVC, one-class SVM, and nu-SVR (default 0.5)-p epsilon : set the epsilon in loss function of epsilon-SVR (default 0.1)-m cachesize : set cache memory size in MB (default 100)-e epsilon : set tolerance of termination criterion (default 0.001)-h shrinking: whether to use the shrinking heuristics, 0 or 1 (default 1)-b probability_estimates: whether to train a SVC or SVR model for probability estimates, 0 or 1 (default 0)-wi weight: set the parameter C of class i to weight*C, for C-SVC (default 1)load heart_scalemodel = svmtrain(heart_scale_label,heart_scale_inst);[predict_label] = svmpredict(heart_scale_label,heart_scale_inst,model)model = svmtrain(heart_scale_label,heart_scale_inst,' -s 0 -c 10 -t 1 -g 1 -r 1 -d 3');-s 0 -c 10 -t 1 -g 1 -r 1 -d 3');[predict_label] = svmpredict(heart_scale_label,heart_scale_inst,model)连续预测load mpgForSvm[Y,PS] = mapminmax(mpg_label')model = svmtrain(Y',mpg_inst,'-s 3 -t 2 -c 4096.0 -g 0.001 -p 0.001 -h 0');-c,-p,-g这三个是最要命的。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
LIBSVM1 LIBSVM简介LIBSVM是台湾大学林智仁(Lin Chih-Jen)副教授等开发设计的一个简单、易于使用和快速有效的SVM模式识别与回归的软件包,他不但提供了编译好的可在Windows 系列系统的执行文件,还提供了源代码,方便改进、修改以及在其它操作系统上应用;该软件还有一个特点,就是对SVM所涉及的参数调节相对比较少,提供了很多的默认参数,利用这些默认参数就可以解决很多问题;并且提供了交互检验(Cross -SVM回归等问题,包括基于一对一算法的多类模式识别问题。
SVM用于模式识别或回归时,SVM方法及其参数、核函数及其参数的选择,目前国际上还没有形成一个统一的模式,也就是说最优SVM算法参数选择还只能是凭借经验、实验对比、大范围的搜寻或者利用软件包提供的交互检验功能进行寻优。
ν-SVM回归和ε-SVM分类、νValidation)的功能。
该软件包可以在.tw/~cjlin/免费获得。
该软件可以解决C-SVM分类、-SVM回归等问题,包括基于一对一算法的多类模式识别问题。
SVM用于模式识别或回归时,SVM方法及其参数、核函数及其参数的选择,目前国际上还没有形成一个统一的模式,也就是说最优SVM算法参数选择还只能是凭借经验、实验对比、大范围的搜寻或者利用软件包提供的交互检验功能进行寻优。
2 LIBSVM使用方法LibSVM是以源代码和可执行文件两种方式给出的。
如果是Windows系列操作系统,可以直接使用软件包提供的程序,也可以进行修改编译;如果是Unix类系统,必须自己编译,软件包中提供了编译格式文件,我们在SGI工作站(操作系统IRIX6.5)上,使用免费编译器GNU C++3.3编译通过。
2.1 LIBSVM 使用的一般步骤:1) 按照LIBSVM软件包所要求的格式准备数据集;2) 对数据进行简单的缩放操作;3) 考虑选用RBF 核函数;4) 采用交叉验证选择最佳参数C与g;5) 采用最佳参数C与g 对整个训练集进行训练获取支持向量机模型;6) 利用获取的模型进行测试与预测。
2.2 LIBSVM使用的数据格式该软件使用的训练数据和检验数据文件格式如下:<label> <index1>:<value1> <index2>:<value2> ...其中<label> 是训练数据集的目标值,对于分类,它是标识某类的整数(支持多个类);对于回归,是任意实数。
<index> 是以1开始的整数,可以是不连续的;<value>为实数,也就是我们常说的自变量。
检验数据文件中的label只用于计算准确度或误差,如果它是未知的,只需用一个数填写这一栏,也可以空着不填。
在程序包中,还包括有一个训练数据实例:heart_scale,方便参考数据文件格式以及练习使用软件。
可以编写小程序,将自己常用的数据格式转换成这种格式。
2.3 Svmtrain和Svmpredict的用法Svmtrain(训练建模)的用法:svmtrain [options] training_set_file [model_file]Options:可用的选项即表示的涵义如下-s svm类型:SVM设置类型(默认0)0 -- C-SVC1 --v-SVC2 – 一类SVM3 -- e -SVR4 -- v-SVR-t 核函数类型:核函数设置类型(默认2)0 – 线性:u'v1 – 多项式:(r*u'v + coef0)^degree2 – RBF函数:exp(-r|u-v|^2)3 –sigmoid:tanh(r*u'v + coef0)-d degree:核函数中的degree设置(默认3)-g r(gama):核函数中的?函数设置(默认1/ k)-r coef0:核函数中的coef0设置(默认0)-c cost:设置C-SVC,? -SVR和?-SVR的参数(默认1)-n nu:设置?-SVC,一类SVM和?- SVR的参数(默认0.5)-p e:设置? -SVR 中损失函数?的值(默认0.1)-m cachesize:设置cache内存大小,以MB为单位(默认40)-e ε:设置允许的终止判据(默认0.001)-h shrinking:是否使用启发式,0或1(默认1)-wi weight:设置第几类的参数C为weight?C(C-SVC中的C)(默认1)-v n: n-fold交互检验模式其中-g选项中的k是指输入数据中的属性数。
option -v 随机地将数据剖分为n部分并计算交互检验准确度和均方根误差。
以上这些参数设置可以按照SVM的类型和核函数所支持的参数进行任意组合,如果设置的参数在函数或SVM类型中没有也不会产生影响,程序不会接受该参数;如果应有的参数设置不正确,参数将采用默认值。
training_set_file是要进行训练的数据集;model_file是训练结束后产生的模型文件,文件中包括支持向量样本数、支持向量样本以及Lagrange系数等必须的参数;该参数如果不设置将采用默认的文件名,也可以设置成自己惯用的文件名。
2.4 Svmpredict的用法Svmpredict(使用已有的模型进行预测)的用法:svmpredict test_file model_file output_filemodel_file是由svmtrain产生的模型文件;test_file是要进行预测的数据文件;Output_file是svmpredict的输出文件。
svm-predict没有其它的选项。
svmtrain -s 0 -c 1000 -t 1 -g 1 -r 1 -d 3 data_file训练一个由多项式核(u'v+1)^3和C=1000组成的分类器。
svmtrain -s 1 -n 0.1 -t 2 -g 0.5 -e 0.00001 data_file在RBF核函数exp(-0.5|u-v|^2)和终止允许限0.00001的条件下,训练一个?-SVM (? = 0.1)分类器。
svmtrain -s 3 -p 0.1 -t 0 -c 10 data_file以线性核函数u'v和C=10及损失函数?= 0.1求解SVM回归。
LIBSVM使用笔记1 程序准备:C:\Python25 //需要安装python2.5E:\svm\libsvm-2.83 //解压缩libsvm-2.83E:\svm\libsvm-2.83\gp373w32 //画图工具gnuplotE:\svm\libsvm-2.83\python //SVM, cross validationE:\svm\libsvm-2.83\tools //easy.py, grid.py, subset.pyE:\svm\libsvm-2.83\tools1 //生成所需格式的数据,两种方式:matlab 或 excelE:\svm\libsvm-2.83\windows //windows 下面的4个可执行程序2 修改E:\svm\libsvm-2.83\tools\easy.py:程序开始加入以下两句:svmpath = "E:\svm\libsvm-2.83\windows" // easy需要调用svm可执行程序pythonpath = "E:\svm\libsvm-2.83\tools" // easy需要调用grid.pygnuplot_exe = r"c:\tmp\gnuplot\bin\pgnuplot.exe" 改为:gnuplot_exe = r"..\gp373w32\pgnuplot.exe"grid_py = r".\grid.py" 改为:grid_py = r"..\tools\grid.py"3 修改E:\svm\libsvm-2.83\tools\grid.py:程序开始加入以下两句:svmpath = "E:\svm\libsvm-2.83\windows" // grid需要调用svm可执行程序gnuplotpath = "E:\svm\libsvm-2.83\gp373w32" // grid需要调用画图工具gnuplot_exe = r"c:\tmp\gnuplot\bin\pgnuplot.exe" 改为:gnuplot_exe = r"..\gp373w32\pgnuplot.exe"4 数据准备:1、使用excel宏手工转换数据格式,可以通过excel文件FormatDataLibsvm.xls打开包含数据的文本文件,然后用宏将数据转换为libsvm格式。
也可以用宏将libsvm格式的数据转换回来。
2、使用matlabFormatSplitBat.m是一个批量将以Tab或者空格分隔的数据转换为libsvm格式,并且分成占全部数据比例为p的训练集和1-p的测试集,然后调用easy.py的例子。
//摘自Libsvm-2_6.mht修改程序中的三处路径与本机实际存储情况一致,并确保easy.py的第28行能够正确调用grid.py,之后将fileList.txt文件中写入要转换格式的文件列表。
这些文件名都在当前路径(E:\svm\libsvm-2.83\data)之下。
运行E:\svm\libsvm-2.83\Tools1\FormatSplitBat.m,程序自动将fileList.txt中提到的文件名的数据内容按照概率p进行随机划分,本程序p为0.5,则有一半划分到train,一半划分到test。
另外,本程序划分是循环10次,可以按照自己的要求进行调整。
每次循环将每个原数据文档在文件夹E:\svm\libsvm-2.83\data中生成4个文件,分别是:file_i.train, file_i.te st, file_iL.train, file_iL.test. 其中,L表示标示变量在左边,为libsvm能够使用的文件。
运行过程中,每一次循环程序都要调用easy.py,grid.py默认采用5倍交叉验证,对c 采用的搜索范围和步长分别为[-10, 15]和1,g的为[10, -15]和-1,可根据需要自行修改gri d.py。
运行完grid.py,在..\tools1\中每两个有L的文件(train, test)生成了7个文件,分别是t rain5个,test2个。