java html内容生成word文件实现代码
java使用POI操作XWPFDocument生成Word实战(一)

java使⽤POI操作XWPFDocument⽣成Word实战(⼀)注:我使⽤的word 2016功能简介:(1)使⽤jsoup解析html得到我⽤来⽣成word的⽂本(这个你们可以忽略)(2)⽣成word、设置页边距、设置页脚(页码),设置页码(⽂本)⼀、解析htmlDocument doc = Jsoup.parseBodyFragment(contents);Element body = doc.body();Elements es = body.getAllElements();⼆、循环Elements获取我需要的html标签boolean tag = false;for (Element e : es) {//跳过第⼀个(默认会把整个对象当做第⼀个)if(!tag) {tag = true;continue;}//创建段落:⽣成word(核⼼)createXWPFParagraph(docxDocument,e);}三、⽣成段落/*** 构建段落* @param docxDocument* @param e*/public static void createXWPFParagraph(XWPFDocument docxDocument, Element e){XWPFParagraph paragraph = docxDocument.createParagraph();XWPFRun run = paragraph.createRun();run.setText(e.text());run.setTextPosition(35);//设置⾏间距if(e.tagName().equals("titlename")){paragraph.setAlignment(ParagraphAlignment.CENTER);//对齐⽅式run.setBold(true);//加粗run.setColor("000000");//设置颜⾊--⼗六进制run.setFontFamily("宋体");//字体run.setFontSize(24);//字体⼤⼩}else if(e.tagName().equals("h1")){addCustomHeadingStyle(docxDocument, "标题 1", 1);paragraph.setStyle("标题 1");run.setBold(true);run.setColor("000000");run.setFontFamily("宋体");run.setFontSize(20);}else if(e.tagName().equals("h2")){addCustomHeadingStyle(docxDocument, "标题 2", 2);paragraph.setStyle("标题 2");run.setBold(true);run.setColor("000000");run.setFontFamily("宋体");run.setFontSize(18);}else if(e.tagName().equals("h3")){addCustomHeadingStyle(docxDocument, "标题 3", 3);paragraph.setStyle("标题 3");run.setBold(true);run.setColor("000000");run.setFontFamily("宋体");run.setFontSize(16);}else if(e.tagName().equals("p")){//内容paragraph.setAlignment(ParagraphAlignment.BOTH);//对齐⽅式paragraph.setIndentationFirstLine(WordUtil.ONE_UNIT);//⾸⾏缩进:567==1厘⽶run.setBold(false);run.setColor("001A35");run.setFontFamily("宋体");run.setFontSize(14);//run.addCarriageReturn();//回车键}else if(e.tagName().equals("break")){paragraph.setPageBreak(true);//段前分页(ctrl+enter)}四、设置页边距/*** 设置页边距 (word中1厘⽶约等于567)* @param document* @param left* @param top* @param right* @param bottom*/public static void setDocumentMargin(XWPFDocument document, String left,String top, String right, String bottom) {CTSectPr sectPr = document.getDocument().getBody().addNewSectPr();CTPageMar ctpagemar = sectPr.addNewPgMar();if (StringUtils.isNotBlank(left)) {ctpagemar.setLeft(new BigInteger(left));}if (StringUtils.isNotBlank(top)) {ctpagemar.setTop(new BigInteger(top));}if (StringUtils.isNotBlank(right)) {ctpagemar.setRight(new BigInteger(right));}if (StringUtils.isNotBlank(bottom)) {ctpagemar.setBottom(new BigInteger(bottom));}}五、创建页眉/*** 创建默认页眉** @param docx XWPFDocument⽂档对象* @param text 页眉⽂本* @return返回⽂档帮助类对象,可⽤于⽅法链调⽤* @throws XmlException XML异常* @throws IOException IO异常* @throws InvalidFormatException ⾮法格式异常* @throws FileNotFoundException 找不到⽂件异常*/public static void createDefaultHeader(final XWPFDocument docx, final String text){CTP ctp = CTP.Factory.newInstance();XWPFParagraph paragraph = new XWPFParagraph(ctp, docx);ctp.addNewR().addNewT().setStringValue(text);ctp.addNewR().addNewT().setSpace(SpaceAttribute.Space.PRESERVE);CTSectPr sectPr = docx.getDocument().getBody().isSetSectPr() ? docx.getDocument().getBody().getSectPr() : docx.getDocument().getBody().addNewSectPr(); XWPFHeaderFooterPolicy policy = new XWPFHeaderFooterPolicy(docx, sectPr);XWPFHeader header = policy.createHeader(STHdrFtr.DEFAULT, new XWPFParagraph[] { paragraph });header.setXWPFDocument(docx);}}六、创建页脚/*** 创建默认的页脚(该页脚主要只居中显⽰页码)** @param docx* XWPFDocument⽂档对象* @return返回⽂档帮助类对象,可⽤于⽅法链调⽤* @throws XmlException* XML异常* @throws IOException* IO异常*/public static void createDefaultFooter(final XWPFDocument docx) {// TODO 设置页码起始值CTP pageNo = CTP.Factory.newInstance();XWPFParagraph footer = new XWPFParagraph(pageNo, docx);CTPPr begin = pageNo.addNewPPr();begin.addNewPStyle().setVal(STYLE_FOOTER);begin.addNewJc().setVal(STJc.CENTER);pageNo.addNewR().addNewFldChar().setFldCharType(STFldCharType.BEGIN);pageNo.addNewR().addNewInstrText().setStringValue("PAGE \\* MERGEFORMAT");pageNo.addNewR().addNewFldChar().setFldCharType(STFldCharType.SEPARATE);CTR end = pageNo.addNewR();CTRPr endRPr = end.addNewRPr();endRPr.addNewNoProof();endRPr.addNewLang().setVal(LANG_ZH_CN);end.addNewFldChar().setFldCharType(STFldCharType.END);CTSectPr sectPr = docx.getDocument().getBody().isSetSectPr() ? docx.getDocument().getBody().getSectPr() : docx.getDocument().getBody().addNewSectPr(); XWPFHeaderFooterPolicy policy = new XWPFHeaderFooterPolicy(docx, sectPr);policy.createFooter(STHdrFtr.DEFAULT, new XWPFParagraph[] { footer });}七、⾃定义标题样式(这个在我另⼀篇word基础中也有提及)* 增加⾃定义标题样式。
java实现word文件转html(图片用base64转化)

java实现word⽂件转html(图⽚⽤base64转化)1.添加需要的jar包:<dependency><groupId>fr.opensagres.xdocreport</groupId><artifactId>fr.opensagres.xdocreport.document</artifactId><version>2.0.1</version></dependency><dependency><groupId>org.apache.poi</groupId><artifactId>poi</artifactId><version>3.15</version></dependency><dependency><groupId>org.apache.poi</groupId><artifactId>poi-scratchpad</artifactId><version>3.15</version></dependency><dependency><groupId>fr.opensagres.xdocreport</groupId><artifactId>fr.opensagres.poi.xwpf.converter.xhtml</artifactId><version>2.0.1</version></dependency>2.来⼀个⼩demo吧。
对于该demo,描述⼏个我觉得需要注意的点:2.1:不知道有没有⼩伙伴发⽣了jar包冲突的现象呢,可以考虑修改⼀下jar包版本号哦,基本上应该没什么问题呢;2.2:word⽂档的后缀有.doc和.docx,需要知道转换的⽅法不是⼀样的。
java使用模板生成word文件
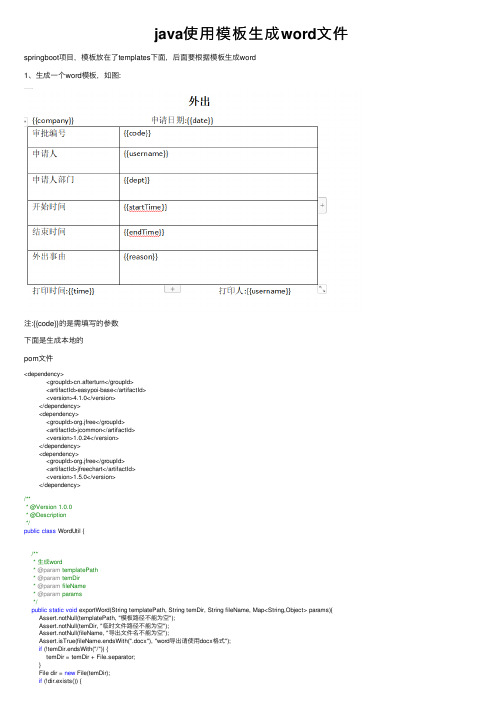
java使⽤模板⽣成word⽂件springboot项⽬,模板放在了templates下⾯,后⾯要根据模板⽣成word1、⽣成⼀个word模板,如图:注:{{code}}的是需填写的参数下⾯是⽣成本地的pom⽂件<dependency><groupId>cn.afterturn</groupId><artifactId>easypoi-base</artifactId><version>4.1.0</version></dependency><dependency><groupId>org.jfree</groupId><artifactId>jcommon</artifactId><version>1.0.24</version></dependency><dependency><groupId>org.jfree</groupId><artifactId>jfreechart</artifactId><version>1.5.0</version></dependency>/*** @Version 1.0.0* @Description*/public class WordUtil {/*** ⽣成word* @param templatePath* @param temDir* @param fileName* @param params*/public static void exportWord(String templatePath, String temDir, String fileName, Map<String,Object> params){Assert.notNull(templatePath, "模板路径不能为空");Assert.notNull(temDir, "临时⽂件路径不能为空");Assert.notNull(fileName, "导出⽂件名不能为空");Assert.isTrue(fileName.endsWith(".docx"), "word导出请使⽤docx格式");if (!temDir.endsWith("/")) {temDir = temDir + File.separator;}File dir = new File(temDir);if (!dir.exists()) {dir.mkdirs();}try {XWPFDocument doc = WordExportUtil.exportWord07(templatePath, params);String tmpPath = temDir + fileName;FileOutputStream fos = new FileOutputStream(tmpPath);doc.write(fos);fos.flush();fos.close();} catch (Exception e) {e.printStackTrace();}}}/*** @Version 1.0.0* @Description*/public class WordDemo {public static void main(String[] args) {Map<String,Object> map = new HashMap<>();map.put("username", "张三");map.put("company","xx公司" );map.put("date","2020-04-20" );map.put("dept","IT部" );map.put("startTime","2020-04-20 08:00:00" );map.put("endTime","2020-04-20 08:00:00" );map.put("reason", "外出办公");map.put("time","2020-04-22" );WordUtil.exportWord("templates/demo.docx","D:/" ,"⽣成⽂件.docx" ,map );}}2、下⾯是下载word⽂件/*** 导出word形式* @param response*/@RequestMapping("/exportWord")public void exportWord(HttpServletResponse response){Map<String,Object> map = new HashMap<>();map.put("username", "张三");map.put("company","杭州xx公司" );map.put("date","2020-04-20" );map.put("dept","IT部" );map.put("startTime","2020-04-20 08:00:00" );map.put("endTime","2020-04-20 08:00:00" );map.put("reason", "外出办公");map.put("time","2020-04-22" );try {response.setContentType("application/msword");response.setCharacterEncoding("utf-8");String fileName = URLEncoder.encode("测试","UTF-8" );//String fileName = "测试"response.setHeader("Content-disposition","attachment;filename="+fileName+".docx" ); XWPFDocument doc = WordExportUtil.exportWord07("templates/demo.docx",map); doc.write(response.getOutputStream());} catch (Exception e) {e.printStackTrace();}//WordUtil.exportWord("templates/demo.docx","D:/" ,"⽣成⽂件.docx" ,map );} 。
JAVA不使用POI,用PageOffice动态导出Word文档

JAVA不使用POI,用PageOffice动态导出Word文档很多情况下,软件开发者需要从数据库读取数据,然后将数据动态填充到手工预先准备好的Word模板文档里,这对于大批量生成拥有相同格式排版的正式文件非常有用,这个功能应用PageOffice的基本动态填充功能即可实现。
但若是用户想动态生成一个没有固定模版的公文时,换句话说,没有办法事先准备一个固定格式的模板时,就需要开发人员在后台用代码实现Word文档的从零到图文并茂的动态生成功能了。
这里的“零”指的是Word空白文档。
那如何实现Word文档的从无到有呢,下面我就把自己实现这一功能的过程介绍一下。
例如,我想打开一个Word文档,里面的内容为:标题(粗体、黑体、字体大小为20、居中显示)、第一段内容(内容(略)、字体倾斜、字体大小为10、中文“楷体”、英文“Times New Roman”、红色、最小行间距、左对齐、首行缩进)、第二段内容(内容(略)、字体大小为12、黑体、1.5倍行间距、左对齐、首行缩进、插入图片)、第三段内容(内容(略)、字体大小为14、华文彩云、2倍行间距、左对齐、首行缩进)第一步:请先安装PageOffice的服务器端的安装程序,之后在WEB项目下的“WebRoot/WEB-INF/lib”路径中添加pageoffice.cab和pageoffice.jar(在网站的“下载中心”中可下载相应的压缩包,解压之后直接将pageoffice.cab和pageoffice.jar文件拷贝到该目录下就可以了)文件。
第二步:修改WEB项目的配置文件,将如下代码添加到配置文件中:<!-- PageOffice Begin --><servlet><servlet-name>poserver</servlet-name><servlet-class>com.zhuozhengsoft .pageoffice.poserver.Server</servlet-class></servlet><servlet-mapping><servlet-name>poserver</servlet-name><url-pattern>/poserver.do</url-pattern></servlet-mapping><servlet-mapping><servlet-name>poserver</servlet-name><url-pattern>/pageoffice.cab</url-pattern></servlet-mapping><servlet-mapping><servlet-name>poserver</servlet-name><url-pattern>/popdf.cab</url-pattern></servlet-mapping><servlet-mapping><servlet-name>poserver</servlet-name><url-pattern>/sealsetup.exe</url-pattern></servlet-mapping><servlet><servlet-name>adminseal</servlet-name><servlet-class>com.zhuozhengsoft.pageoffice.poserver.AdminSeal </servlet-class></servlet><servlet-mapping><servlet-name>adminseal</servlet-name><url-pattern>/adminseal.do</url-pattern></servlet-mapping><servlet-mapping><servlet-name>adminseal</servlet-name><url-pattern>/loginseal.do</url-pattern></servlet-mapping><servlet-mapping><servlet-name>adminseal</servlet-name><url-pattern>/sealimage.do</url-pattern></servlet-mapping><mime-mapping><extension>mht</extension><mime-type>message/rfc822</mime-type></mime-mapping><context-param><param-name>adminseal-password</param-name><param-value>123456</param-value></context-param><!-- PageOffice End -->第三步:在WEB项目的WebRoot目录下添加文件夹存放word模板文件,在此命名为“doc”,将要打开的空白Word文件拷贝到该文件夹下,我要打开的Word文件为“test.doc”。
Java实现word文档在线预览,读取office(word,excel,ppt)文件

Java实现word⽂档在线预览,读取office(word,excel,ppt)⽂件想要实现word或者其他office⽂件的在线预览,⼤部分都是⽤的两种⽅式,⼀种是使⽤openoffice转换之后再通过其他插件预览,还有⼀种⽅式就是通过POI读取内容然后预览。
⼀、使⽤openoffice⽅式实现word预览主要思路是:1.通过第三⽅⼯具openoffice,将word、excel、ppt、txt等⽂件转换为pdf⽂件2.通过swfTools将pdf⽂件转换成swf格式的⽂件3.通过FlexPaper⽂档组件在页⾯上进⾏展⽰我使⽤的⼯具版本:openof:3.4.1swfTools:1007FlexPaper:这个关系不⼤,我随便下的⼀个。
推荐使⽤1.5.1JODConverter:需要jar包,如果是maven管理直接引⽤就可以操作步骤:1.office准备下载openoffice:从过往⽂件,其他语⾔中找到中⽂版3.4.1的版本下载后,解压缩,安装然后找到安装⽬录下的program ⽂件夹在⽬录下运⾏soffice -headless -accept="socket,host=127.0.0.1,port=8100;urp;" -nofirststartwizard如果运⾏失败,可能会有提⽰,那就加上 .\ 在运⾏试⼀下这样openoffice的服务就开启了。
2.将flexpaper⽂件中的js⽂件夹(包含了flexpaper_flash_debug.js,flexpaper_flash.js,jquery.js,这三个js⽂件主要是预览swf⽂件的插件)拷贝⾄⽹站根⽬录;将FlexPaperViewer.swf拷贝⾄⽹站根⽬录下(该⽂件主要是⽤在⽹页中播放swf⽂件的播放器)项⽬结构:页⾯代码:fileUpload.jsp<%@ page language="java" contentType="text/html; charset=UTF-8"pageEncoding="UTF-8"%><!DOCTYPE html PUBLIC "-//W3C//DTD HTML 4.01 Transitional//EN" "/TR/html4/loose.dtd"><html><head><meta http-equiv="Content-Type" content="text/html; charset=UTF-8"><title>⽂档在线预览系统</title><style>body {margin-top:100px;background:#fff;font-family: Verdana, Tahoma;}a {color:#CE4614;}#msg-box {color: #CE4614; font-size:0.9em;text-align:center;}#msg-box .logo {border-bottom:5px solid #ECE5D9;margin-bottom:20px;padding-bottom:10px;}#msg-box .title {font-size:1.4em;font-weight:bold;margin:0 0 30px 0;}#msg-box .nav {margin-top:20px;}</style></head><body><div id="msg-box"><form name="form1" method="post" enctype="multipart/form-data" action="docUploadConvertAction.jsp"><div class="title">请上传要处理的⽂件,过程可能需要⼏分钟,请稍候⽚刻。
JAVA生成word文档代码加说明

import java.io.ByteArrayOutputStream;import java.io.File;import java.io.FileInputStream;import java.io.FileNotFoundException;import java.io.FileOutputStream;import java.io.IOException;import java.io.OutputStream;import java.util.Iterator;import java.util.Map;import javax.servlet.http.HttpServletResponse;import org.apache.poi.hwpf.HWPFDocument;import org.apache.poi.hwpf.model.FieldsDocumentPart;import ermodel.Field;import ermodel.Fields;import ermodel.Range;import ermodel.Table;import ermodel.TableIterator;import ermodel.TableRow;publicclass WordUtil {publicstaticvoid readwriteWord(String filePath, String downPath, Map<String, String> map, int[] num, String downFileName) { //读取word模板FileInputStream in = null;try {in = new FileInputStream(new File(filePath));} catch (FileNotFoundException e1) {e1.printStackTrace();}HWPFDocument hdt = null;try {hdt = new HWPFDocument(in);} catch (IOException e1) {e1.printStackTrace();}Fields fields = hdt.getFields();Iterator<Field> it = fields.getFields(FieldsDocumentPart.MAIN) .iterator();while (it.hasNext()) {System.out.println(it.next().getType());}//读取word表格内容try {Range range = hdt.getRange();//得到文档的读取范围TableIterator it2 = new TableIterator(range);//迭代文档中的表格int tabCount = 0;while (it2.hasNext()) {//System.out.println(" 第几个表格 "+tabCount);//System.out.println(num[tabCount] +" 行");Table tb2 = (Table) it2.next();//迭代行,默认从0开始for (int i = 0; i < tb2.numRows(); i++) {TableRow tr = tb2.getRow(i);// System.out.println(" fu "+num[tabCount] +" 行");if (num[tabCount] < i && i < 7) {tr.delete();}} //end fortabCount++;} //end while//替换word表格内容for (Map.Entry<String, String> entry : map.entrySet()) { range.replaceText("$"+ entry.getKey().trim() + "$", entry.getValue());}// System.out.println("替换后------------:"+range.text().trim());} catch (Exception e) {e.printStackTrace();}//System.out.println("--------------------------------------------------------------------------------------");ByteArrayOutputStream ostream = new ByteArrayOutputStream();String fileName = downFileName;fileName += ".doc";String pathAndName = downPath + fileName;File file = new File(pathAndName);if (file.canRead()) {file.delete();}FileOutputStream out = null;out = new FileOutputStream(pathAndName, true);} catch (FileNotFoundException e) {e.printStackTrace();}try {hdt.write(ostream);} catch (IOException e) {e.printStackTrace();}//输出字节流try {out.write(ostream.toByteArray());} catch (IOException e) {e.printStackTrace();}try {out.close();} catch (IOException e) {e.printStackTrace();}try {ostream.close();} catch (IOException e) {e.printStackTrace();}}/***实现对word读取和修改操作(输出文件流下载方式)*@param response响应,设置生成的文件类型,文件头编码方式和文件名,以及输出*@param filePathword模板路径和名称*@param map待填充的数据,从数据库读取*/publicstaticvoid readwriteWord(HttpServletResponse response, String filePath, Map<String, String> map) {//读取word模板文件//String fileDir = newFile(base.getFile(),"//.. /doc/").getCanonicalPath();//FileInputStream in = new FileInputStream(newFile(fileDir+"/laokboke.doc"));FileInputStream in;HWPFDocument hdt = null;in = new FileInputStream(new File(filePath));hdt = new HWPFDocument(in);} catch (Exception e1) {e1.printStackTrace();}Fields fields = hdt.getFields();Iterator<Field> it = fields.getFields(FieldsDocumentPart.MAIN) .iterator();while (it.hasNext()) {System.out.println(it.next().getType());}//替换读取到的word模板内容的指定字段Range range = hdt.getRange();for (Map.Entry<String, String> entry : map.entrySet()) { range.replaceText("$" + entry.getKey() + "$",entry.getValue());}//输出word内容文件流,提供下载response.reset();response.setContentType("application/x-msdownload");String fileName = "" + System.currentTimeMillis() + ".doc";response.addHeader("Content-Disposition", "attachment;filename="+ fileName);ByteArrayOutputStream ostream = new ByteArrayOutputStream();OutputStream servletOS = null;try {servletOS = response.getOutputStream();hdt.write(ostream);servletOS.write(ostream.toByteArray());servletOS.flush();servletOS.close();} catch (Exception e) {e.printStackTrace();}}}注:以上代码需要poi包, 可以下载。
Freemarker+xml实现Java导出word
Freemarker+xml实现Java导出word前⾔最近做了⼀个调查问卷导出的功能,需求是将维护的题⽬,答案,导出成word,参考了⼏种⽅案之后,选择功能强⼤的freemarker+固定格式之后的wordxml实现导出功能。
导出word的代码是可以直接复⽤的,于是在此贴出,并进⾏总结,⽅便⼤家拿⾛。
实现过程概览先在word上,调整好⾃⼰想要的样⼦。
然后存为xml⽂件。
保存为freemarker模板,以ftl后缀结尾。
将需要替换的变量使⽤freemarker的语法进⾏替换。
最终将数据准备好,和模板进⾏渲染,⽣成⽂件并返回给浏览器流。
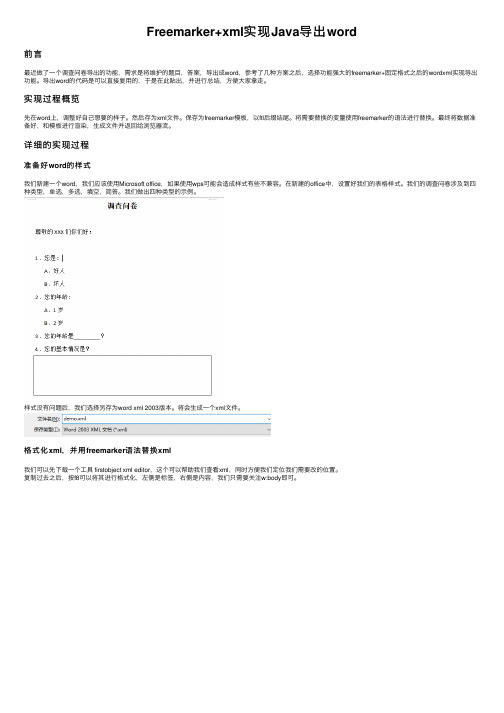
详细的实现过程准备好word的样式我们新建⼀个word,我们应该使⽤Microsoft office,如果使⽤wps可能会造成样式有些不兼容。
在新建的office中,设置好我们的表格样式。
我们的调查问卷涉及到四种类型,单选,多选,填空,简答。
我们做出四种类型的⽰例。
样式没有问题后,我们选择另存为word xml 2003版本。
将会⽣成⼀个xml⽂件。
格式化xml,并⽤freemarker语法替换xml我们可以先下载⼀个⼯具 firstobject xml editor,这个可以帮助我们查看xml,同时⽅便我们定位我们需要改的位置。
复制过去之后,按f8可以将其进⾏格式化,左侧是标签,右侧是内容,我们只需要关注w:body即可。
像右侧的调查问卷这个就是个标题,我们实际渲染的时候应该将其进⾏替换,⽐如我们的程序数据map中,有title属性,我们想要这⾥展⽰,我们就使⽤语法${title}即可。
freemarker的具体语法,可以参考freemarker的问题,在这⾥我给出⼏个简单的例⼦。
⽐如我们将所有的数据放置在dataList中,所以我们需要判断,dataList是不是空,是空,我们不应该进⾏下⾯的逻辑,不是空,我们应该先循环题⽬是必须的,答案是需要根据类型进⾏再次循环的。
Aspose.wordsJava基于模板生成word之纯文本内容
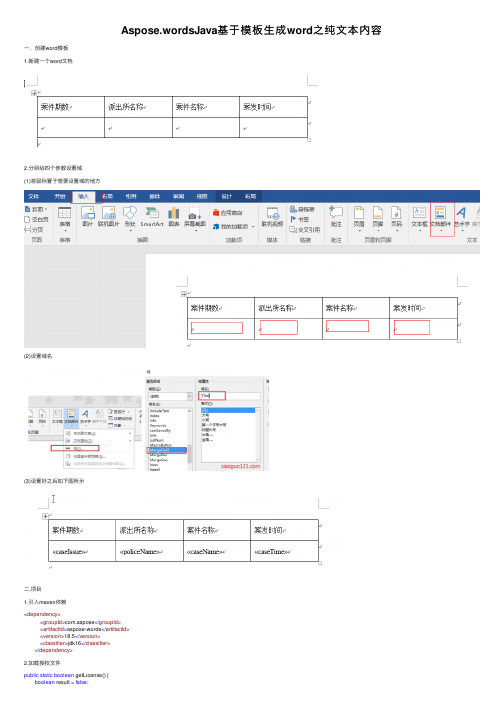
Aspose.wordsJava基于模板⽣成word之纯⽂本内容⼀,创建word模板1.新建⼀个word⽂档2.分别给四个参数设置域(1)将⿏标置于想要设置域的地⽅(2)设置域名(3)设置好之后如下图所⽰⼆,项⽬1,引⼊maven依赖<dependency><groupId>com.aspose</groupId><artifactId>aspose-words</artifactId><version>18.5</version><classifier>jdk16</classifier></dependency>2,加载授权⽂件public static boolean getLicense() {boolean result = false;try {InputStream is = AsposeToWordTest.class.getClassLoader().getResourceAsStream("license-word.xml"); License aposeLic = new License();aposeLic.setLicense(is);result = true;} catch (Exception e) {e.printStackTrace();}return result;}3,获取值以及插⼊到模板中并⽣成新的⽂档public static void main(String[] args) throws Exception {// 验证Licenseif (!getLicense()) {return;}//模板wordString template = "E:\\test\\temp.docx";//⽬标wordString destdoc = "E:\\test\\edit.docx";//定义⽂档接⼝Document doc = new Document(template);//⽂本域String[] Flds = new String[]{"caseIssue","policeName", "caseName", "caseTime"};String caseIssue = "001";String policeName = "XX派出所";String caseName = "0727电动车盗窃案";String caseTime = "2018-07-26 12:20:22";//值Object[] Vals = new Object[]{caseIssue,policeName, caseName, caseTime};//调⽤接⼝doc.getMailMerge().execute(Flds, Vals);doc.save(destdoc);System.out.println("完成");}4,结果。
java 根据word模板生成word文件

java 根据word模板生成word文件Java可以使用Apache POI库来生成Word文件,并且也可以使用freemarker等模板引擎来实现根据Word模板生成Word 文件的功能。
下面是一个简单的示例代码,可以帮助您快速入门。
模板制作:offer,wps都行,我使用wps进行操作第一步制作模板CTRL+f9生成域------》鼠标右键编辑域------》选择邮件合并-----》在域代码后面加上英文${跟代码内的一致}。
这样模板就创建好了。
首先需要引入POI和freemarker的依赖:<!-- Apache POI --><dependency><groupId>fr.opensagres.xdocreport</groupId><artifactId>fr.opensagres.xdocreport.core</artifactId><version>2.0.2</version></dependency><dependency><groupId>fr.opensagres.xdocreport</groupId><artifactId>fr.opensagres.xdocreport.document< /artifactId><version>2.0.2</version></dependency><dependency><groupId>fr.opensagres.xdocreport</groupId><artifactId>fr.opensagres.xdocreport.template< /artifactId><version>2.0.2</version></dependency><dependency><groupId>fr.opensagres.xdocreport</groupId><artifactId>fr.opensagres.xdocreport.document.docx</artifactId><version>2.0.2</version></dependency><dependency><groupId>fr.opensagres.xdocreport</groupId><artifactId>fr.opensagres.xdocreport.template.freemarker</artifactId><version>2.0.2</version></dependency>接下来是一个简单的示例代码:public class WordGenerator {public static void main(String[] args) throws IOException, TemplateException {// 读取Word模板try {= null;//wordInputStream in = new (new File("模板文件.docx"));//注册xdocreport实例并加载FreeMarker模板引擎IXDocReport r = XDocReportRegistry.getRegistry().loadReport(in, TemplateEngineKind.Freemarker);// 生成Word文件//创建xdocreport上下文对象IContext context =r.createContext();//将需要替换的数据数据添加到上下文中//其中key为word模板中的域名,value是需要替换的值User user = new User("zhangsan", 18, "福建泉州");context.put("uesrname",user.getUsername());context.put("age", user.getAge()); context.put("address",user.getAddress());out = new (newFile("D://xxx.docx"));//处理word文档并输出r.process(context, out);} catch (IOException e) {e.printStackTrace();} finally {if (in != null) {try {in.close();} catch (IOException e) {e.printStackTrace();}}if (out != null) {try {out.close();} catch (IOException e) {e.printStackTrace();}}}}}在这个示例代码中,我们读取了名为模板文件.docx的Word 模板,然后准备了一些数据,利用Freemarker模板引擎将数据填充到模板中,最后生成了一个名为xxx.docx的Word文件。
java将html转为word导出(富文本内容导出word)

java将html转为word导出(富⽂本内容导出word)业务:将富⽂本内容取出⽣成本地word⽂件参考百度的⽅法word本⾝是可以识别html标签,所以通过poi写⼊html内容即可import com.util.WordUtil;import org.springframework.web.bind.annotation.PostMapping;import javax.servlet.http.HttpServletRequest;import javax.servlet.http.HttpServletResponse;public class SysAnnouncementController {@PostMapping(value = "/exportAccidentExampleWord")public void exportAccidentExampleWord(HttpServletRequest request, HttpServletResponse response) throws Exception {String s = "<p><strong>第⼀⾏要加粗</strong></p>\n" +"<p><em><strong>第⼆⾏要倾斜</strong></em></p>\n" +"<p style=\"text-align: center;\"><em><strong>第三⾏要居中</strong></em></p>";StringBuffer sbf = new StringBuffer();sbf.append("<html " +"xmlns:v=\"urn:schemas-microsoft-com:vml\" xmlns:o=\"urn:schemas-microsoft-com:office:office\" xmlns:w=\"urn:schemas-microsoft-com:office:word\" xmlns:m=\"/office/2004/12/omml\" xmlns=\"http://w ">");//缺失的⾸标签sbf.append("<head>" +"<!--[if gte mso 9]><xml><w:WordDocument><w:View>Print</w:View><w:TrackMoves>false</w:TrackMoves><w:TrackFormatting/><w:ValidateAgainstSchemas/><w:SaveIfXMLInvalid>false</w:SaveIfXMLInvalid><w:IgnoreMixedCo "</head>");//将版式从web版式改成页⾯试图sbf.append("<body>");//缺失的⾸标签sbf.append(s);//富⽂本内容sbf.append("</body></html>");//缺失的尾标签try{WordUtil.exportWord(request,response,sbf.toString(),"wordName");}catch (Exception e){System.out.println(e.getMessage());}}}⼯具类import javax.servlet.ServletOutputStream;import javax.servlet.http.HttpServletRequest;import javax.servlet.http.HttpServletResponse;import java.io.ByteArrayInputStream;import java.io.OutputStream;public class WordUtil {public static void exportWord(HttpServletRequest request, HttpServletResponse response, String content, String fileName) throws Exception {byte[] b = content.getBytes("GBK"); //这⾥是必须要设置编码的,不然导出中⽂就会乱码。
Javafreemarker生成word模板文件(如合同文件)及转pdf文件方法
Javafreemarker⽣成word模板⽂件(如合同⽂件)及转pdf⽂件⽅法Java freemarker⽣成word模板⽂件(如合同⽂件)及转pdf⽂件⽅法创建模板⽂件ContractTemplate.docxContractTemplate.xml导⼊的Jar包compile("junit:junit")compile("org.springframework:spring-test")compile("org.springframework.boot:spring-boot-test")testCompile 'org.springframework.boot:spring-boot-starter-test'compile 'org.freemarker:freemarker:2.3.28'compile 'fakepath:aspose-words:19.5jdk'compile 'fakepath:aspose-cells:8.5.2'Java⼯具类 xml⽂档转换 Word XmlToDocx.javapackage com.test.docxml.utils;import java.io.File;import java.io.FileInputStream;import java.io.FileOutputStream;import java.io.InputStream;import java.util.Enumeration;import java.util.zip.ZipEntry;import java.util.zip.ZipFile;import java.util.zip.ZipOutputStream;/*** xml⽂档转换 Word*/public class XmlToDocx {/**** @param documentFile 动态⽣成数据的docunment.xml⽂件* @param docxTemplate docx的模板* @param toFilePath 需要导出的⽂件路径* @throws Exception*/public static void outDocx(File documentFile, String docxTemplate, String toFilePath,String key) throws Exception { try {File docxFile = new File(docxTemplate);ZipFile zipFile = new ZipFile(docxFile);Enumeration<? extends ZipEntry> zipEntrys = zipFile.entries();FileOutputStream fileOutputStream = new FileOutputStream(toFilePath);ZipOutputStream zipout = new ZipOutputStream(fileOutputStream);int len = -1;byte[] buffer = new byte[1024];while (zipEntrys.hasMoreElements()) {ZipEntry next = zipEntrys.nextElement();InputStream is = zipFile.getInputStream(next);// 把输⼊流的⽂件传到输出流中如果是word/document.xml由我们输⼊zipout.putNextEntry(new ZipEntry(next.toString()));if ("word/document.xml".equals(next.toString())) {InputStream in = new FileInputStream(documentFile);while ((len = in.read(buffer)) != -1) {zipout.write(buffer, 0, len);}in.close();} else {while ((len = is.read(buffer)) != -1) {zipout.write(buffer, 0, len);}is.close();}}zipout.close();} catch (Exception e) {e.printStackTrace();}}}Java⼯具类 word⽂档转换 PDF WordToPdf.javapackage com.test.docxml.utils;import com.aspose.cells.*;import com.aspose.cells.License;import com.aspose.words.*;import java.io.ByteArrayInputStream;import java.io.File;import java.io.FileOutputStream;import java.io.InputStream;/*** word⽂档转换 PDF*/public class WordToPdf {/*** 获取license许可凭证* @return*/private static boolean getLicense() {boolean result = false;try {String licenseStr = "<License>\n"+ " <Data>\n"+ " <Products>\n"+ " <Product>Aspose.Total for Java</Product>\n"+ " <Product>Aspose.Words for Java</Product>\n"+ " </Products>\n"+ " <EditionType>Enterprise</EditionType>\n"+ " <SubscriptionExpiry>20991231</SubscriptionExpiry>\n"+ " <LicenseExpiry>20991231</LicenseExpiry>\n"+ " <SerialNumber>23dcc79f-44ec-4a23-be3a-03c1632404e9</SerialNumber>\n"+ " </Data>\n"+ " <Signature>0nRuwNEddXwLfXB7pw66G71MS93gW8mNzJ7vuh3Sf4VAEOBfpxtHLCotymv1PoeukxYe31K441Ivq0Pkvx1yZZG4O1KCv3Omdbs7uqzUB4xXHlOub4VsTODzDJ5MWHqlRCB1HHcGjlyT2sVGiovLt0Grvqw5+QXBuin + "</License>";InputStream license = new ByteArrayInputStream(licenseStr.getBytes("UTF-8"));License asposeLic = new License();asposeLic.setLicense(license);result = true;} catch (Exception e) {e.printStackTrace();}return result;}/*** word⽂档转换为 PDF* @param inPath 源⽂件* @param outPath ⽬标⽂件*/public static File doc2pdf(String inPath, String outPath) {//验证License,获取许可凭证if (!getLicense()) {return null;}//新建⼀个PDF⽂档File file = new File(outPath);try {//新建⼀个IO输出流FileOutputStream os = new FileOutputStream(file);//获取将要被转化的word⽂档Document doc = new Document(inPath);// 全⾯⽀持DOC, DOCX,OOXML, RTF HTML,OpenDocument,PDF, EPUB, XPS,SWF 相互转换doc.save(os, com.aspose.words.SaveFormat.PDF);os.close();} catch (Exception e) {e.printStackTrace();}return file;}public static void main(String[] args) {doc2pdf("D:/1.doc", "D:/1.pdf");}}Java单元测试类 XmlDocTest.javapackage com.test.docxml;import com.test.docxml.utils.WordToPdf;import com.test.docxml.utils.XmlToDocx;import freemarker.template.Configuration;import freemarker.template.Template;import org.junit.Test;import org.junit.runner.RunWith;import org.springframework.boot.test.context.SpringBootTest;import org.springframework.core.io.ClassPathResource;import org.springframework.core.io.Resource;import org.springframework.test.context.junit4.SpringJUnit4ClassRunner;import org.springframework.test.context.web.WebAppConfiguration;import java.io.File;import java.io.PrintWriter;import java.io.Writer;import java.nio.charset.Charset;import java.util.HashMap;import java.util.Locale;import java.util.Map;/*** 本地单元测试*/@RunWith(SpringJUnit4ClassRunner.class)//@RunWith(SpringRunner.class)@SpringBootTest(classes= TemplateApplication.class)@WebAppConfigurationpublic class XmlDocTest {//短租@Testpublic void testContract() throws Exception{String contractNo = "1255445544";String contractCorp = "银河宇宙⽆敌测试soft";String contractDate = "2022-01-27";String contractItem = "房地产交易中⼼";String contractContent = "稳定发展中的⽂案1万字";//doc xml模板⽂件String docXml = "ContractTemplate.xml"; //使⽤替换内容//xml中间临时⽂件String xmlTemp = "tmp-ContractTemplate.xml";//⽣成⽂件的doc⽂件String toFilePath = contractNo + ".docx";//模板⽂档String docx = "ContractTemplate.docx";//⽣成pdf⽂件String toPdfFilePath = contractNo + ".pdf";;String CONTRACT_ROOT_URL = "/template";Resource contractNormalPath = new ClassPathResource(CONTRACT_ROOT_URL + File.separator + docXml);String docTemplate = contractNormalPath.getURI().getPath().replace(docXml, docx);//设置⽂件编码(注意点1)Writer writer = new PrintWriter(new File(xmlTemp),"UTF-8");Configuration configuration = new Configuration(Configuration.VERSION_2_3_28);configuration.setEncoding(Locale.CHINESE, Charset.forName("UTF-8").name());//设置配置(注意点3)configuration.setDefaultEncoding("UTF-8");String filenametest = contractNormalPath.getURI().getPath().replace(docXml, "");System.out.println("filenametest=" + filenametest);configuration.setDirectoryForTemplateLoading(new File(filenametest));// Template template = configuration.getTemplate(ContractConstants.CONTRACT_NORMAL_URL+orderType+type+".xml"); //设置模板编码(注意点2)Template template = configuration.getTemplate(docXml,"UTF-8"); //绝对地址Map paramsMap = new HashMap();paramsMap.put("contractCorp",contractCorp);paramsMap.put("contractDate",contractDate);paramsMap.put("contractNo",contractNo);paramsMap.put("contractItem",contractItem);paramsMap.put("contractContent",contractContent);template.process(paramsMap, writer);XmlToDocx.outDocx(new File(xmlTemp), docTemplate, toFilePath, null);System.out.println("do finish");//转成pdfWordToPdf.doc2pdf(toFilePath,toPdfFilePath);}}创建成功之后的⽂件如下:。
Java实现用Freemarker完美导出word文档(带图片)

Java实现⽤Freemarker完美导出word⽂档(带图⽚)前⾔最近在项⽬中,因客户要求,将页⾯内容(如合同协议)导出成word,在⽹上翻了好多,感觉太乱了,不过最后还是较好解决了这个问题。
准备材料1.word原件2.编辑器(推荐Firstobject free XML editor)实现步骤1.⽤Microsoft Office Word打开word原件;2.把需要动态修改的内容替换成***,如果有图⽚,尽量选择较⼩的图⽚⼏⼗K左右,并调整好位置;3.另存为,选择保存类型Word 2003 XML ⽂档(*.xml)【这⾥说⼀下为什么⽤Microsoft Office Word打开且要保存为Word2003XML,本⼈亲测,⽤WPS找不到Word 2003XML选项,如果保存为Word XML,会有兼容问题,避免出现导出的word⽂档不能⽤Word 2003打开的问题】;4.⽤Firstobject free XML editor打开⽂件,选择Tools下的Indent【或者按快捷键F8】格式化⽂件内容。
左边是⽂档结构,右边是⽂档内容;5. 将⽂档内容中需要动态修改内容的地⽅,换成freemarker的标识。
其实就是Map<String, Object>中key,如${landName};6.在加⼊了图⽚占位的地⽅,会看到⼀⽚base64编码后的代码,把base64替换成${image},也就是Map<String, Object>中key,值必须要处理成base64;代码如:<w:binData w:name="wordml://⾃定义.png" xml:space="preserve">${image}</w:binData>注意:“>${image}<”这尖括号中间不能加任何其他的诸如空格,tab,换⾏等符号。
Java如何实现读取txt文件内容并生成Word文档

Java如何实现读取txt⽂件内容并⽣成Word⽂档⽬录导⼊Jar包1. Maven仓库下载导⼊2. ⼿动导⼊读取txt⽣成Word注意事项本⽂将以Java程序代码为例介绍如何读取txt⽂件中的内容,⽣成Word⽂档。
在编辑代码前,可参考如下代码环境进⾏配置:IntelliJ IDEAFree Spire.Doc for JavaTxt⽂档导⼊Jar包两种⽅法可在Java程序中导⼊jar⽂件1. Maven仓库下载导⼊在pom.xml中配置如下:<repositories><repository><id>com.e-iceblue</id><url>https:///repository/maven-public/</url></repository></repositories><dependencies><dependency><groupId>e-iceblue</groupId><artifactId>spire.doc.free</artifactId><version>3.9.0</version></dependency></dependencies>2. ⼿动导⼊需先下载jar包到本地,解压,找到lib路径下的jar⽂件。
然后在Java程序中打开“Project Structure”窗⼝,然后执⾏如下步骤导⼊:找到本地路径下的jar⽂件,添加到列表,然后导⼊:读取txt⽣成Word代码⼤致步骤如下:1. 实例化Document类的对象。
然后通过Document.addSection()⽅法和Section.addParagraph()⽅法添加节和段落。
2. 读取txt⽂件:创建InputStreamReader类的对象,构造⽅法中传递输⼊流和指定的编码表名称。
java导出word的6种方式(复制来的文章)

java导出word的6种⽅式(复制来的⽂章)来⾃:最近做的项⽬,需要将⼀些信息导出到word中。
在⽹上找了好多解决⽅案,现在将这⼏天的总结分享⼀下。
⽬前来看,java导出word⼤致有6种解决⽅案:1:Jacob是Java-COM Bridge的缩写,它在Java与微软的COM组件之间构建⼀座桥梁。
使⽤Jacob⾃带的DLL动态链接库,并通过JNI的⽅式实现了在Java平台上对COM程序的调⽤。
DLL动态链接库的⽣成需要windows平台的⽀持。
该⽅案只能在windows平台实现,是其局限性。
2:Apache POI包括⼀系列的API,它们可以操作基于MicroSoft OLE 2 Compound Document Format的各种格式⽂件,可以通过这些API在Java中读写Excel、Word等⽂件。
他的excel处理很强⼤,对于word还局限于读取,⽬前只能实现⼀些简单⽂件的操作,不能设置样式。
3:Java2word是⼀个在java程序中调⽤ MS Office Word ⽂档的组件(类库)。
该组件提供了⼀组简单的接⼝,以便java程序调⽤他的服务操作Word ⽂档。
这些服务包括:打开⽂档、新建⽂档、查找⽂字、替换⽂字,插⼊⽂字、插⼊图⽚、插⼊表格,在书签处插⼊⽂字、插⼊图⽚、插⼊表格等。
填充数据到表格中读取表格数据,1.1版增强的功能:指定⽂本样式,指定表格样式。
如此,则可动态排版word⽂档。
是⼀种不错的解决⽅案。
4:iText是著名的开放源码的站点sourceforge⼀个项⽬,是⽤于⽣成PDF⽂档的⼀个java类库。
通过iText不仅可以⽣成PDF或rtf的⽂档,⽽且可以将XML、Html⽂件转化为PDF⽂件。
功能强⼤。
5:JSP输出样式,该⽅案实现简单,但是处理样式有点缺陷,简单的导出可以使⽤。
6:⽤XML做就很简单了。
Word从2003开始⽀持XML格式,⼤致的思路是先⽤office2003或者2007编辑好word的样式,然后另存为xml,将xml翻译为FreeMarker模板,最后⽤java来解析FreeMarker模板并输出Doc。
JAVA+根据WORD模板生成WORD+文档

/** * 把选定内容替换为设定文本 * @param selection Dispatch 选定内容 * @param newText String 替换为文本 */ public void replace(Dispatch selection,String newText) {
//设置替换文本 Dispatch.put(selection,"Text",newText); }
/* * 传入数据为 HashMap 对象,对象中的 Key 代表 word 模板中要替换的字段,Value 代表用来替换的值。 * word 模板中所有要替换的字段(即 HashMap 中的 Key)以特殊字符开头和结尾,如:$code$、$date$……, 以免执行错误的替换。 * 所有要替换为图片的字段,Key 中需包含 image 或者 Value 为图片的全路径(目前只判断文件后缀名 为:.bmp、 .jpg、.gif)。 * 要替换表格中的数据时,HashMap 中的 Key 格式为“table$R@N”,其中:R 代表从表格的第 R 行开始 替换,N 代表 word 模板中的第 N 张表格;Value 为 ArrayList 对象,ArrayList 中包含的对象统一为 String[],一条 String[] 代 表一行数据,ArrayList 中第一条记录为特殊记录,记录的是表格中要替换的列号,如:要替换第一列、第 三列、 第五列的数据,则第一条记录为 String[3] {“1”,”3”,”5”}。 */
for(int i = 0;i < count;i ++) {
Dispatch.call(selection,"MoveLeft"); } }
/** * 把选定内容或插入点向右移动 * @param selection Dispatch 要移动的内容 * @param count int 移动的距离 */ public void moveRight(Dispatch selection,int count) {
java使用POI实现html和word相互转换

java使⽤POI实现html和word相互转换项⽬后端使⽤了springboot,maven,前端使⽤了ckeditor富⽂本编辑器。
⽬前从html转换的word为doc格式,⽽图⽚处理⽀持的是docx格式,所以需要⼿动把doc另存为docx,然后才可以进⾏图⽚替换。
⼀.添加maven依赖主要使⽤了以下和poi相关的依赖,为了便于获取html的图⽚元素,还使⽤了jsoup:<dependency><groupId>org.apache.poi</groupId><artifactId>poi</artifactId><version>3.14</version></dependency><dependency><groupId>org.apache.poi</groupId><artifactId>poi-scratchpad</artifactId><version>3.14</version></dependency><dependency><groupId>org.apache.poi</groupId><artifactId>poi-ooxml</artifactId><version>3.14</version></dependency><dependency><groupId>fr.opensagres.xdocreport</groupId><artifactId>xdocreport</artifactId><version>1.0.6</version></dependency><dependency><groupId>org.apache.poi</groupId><artifactId>poi-ooxml-schemas</artifactId><version>3.14</version></dependency><dependency><groupId>org.apache.poi</groupId><artifactId>ooxml-schemas</artifactId><version>1.3</version></dependency><dependency><groupId>org.jsoup</groupId><artifactId>jsoup</artifactId><version>1.11.3</version></dependency>⼆.word转换为html在springboot项⽬的resources⽬录下新建static⽂件夹,将需要转换的word⽂件temp.docx粘贴进去,由于static是springboot的默认资源⽂件,所以不需要在配置⽂件⾥⾯另⾏配置了,如果改成其他名字,需要在application.yml进⾏相应配置。
javapoi实现word导出(包括word模板的使用、复制表格、复制行、插入图片的使用)

/** * 功能描述:word下载 * * @param response * @param patientMap * @param list * @param itemList * @param file * @see [相关类/方法](可选) * @since [产品/模块版本](可选) */ public static final void DownloadWord(HttpServletResponse response, Map<String, Object> patientMap, List<Map<String, Object>> list, List<List<String>> itemList, String file) {
博客园 用户登录 代码改变世界 密码登录 短信登录 忘记登录用户名 忘记密码 记住我 登录 第三方登录/注册 没有账户, 立即注册
javapoi实现 word导出(包括 word模板的使用、复制表格、复制 行、插入图片的使用)
java poi实现数据的word导出(包括word模板的使用、复制表格、复制行、插入图片的使用) 1.实现的效果 实现病人基本信息、多条病历数据、多项检查项图片的动态插入(网络图片)
/** * 功能描述:复制段落,从source到target * * @param target * @param source * @param index * @see [相关类/方法](可选) * @since [产品/模块版本](可选) */ public static void copyParagraph(XWPFParagraph target, XWPFParagraph source, Integer index) { // 设置段落样式 target.getCTP().setPPr(source.getCTP().getPPr()); // 移除所有的run for (int pos = target.getRuns().size() - 1; pos >= 0; pos--) { target.removeRun(pos); } // copy 新的run for (XWPFRun s : source.getRuns()) { XWPFRun targetrun = target.createRun(); copyRun(targetrun, s, index); } }
JAVA操作WORD

JAVA操作WORDJava操作Word主要有两种方式:一种是使用Apache POI库进行操作,另一种是使用XML模板进行操作。
下面将详细介绍如何通过XML模板实现Java操作Word。
1.准备工作:2. 创建Word模板:首先,创建一个空的Word文档,将其保存为XML格式,作为Word的模板。
可以在Word中添加一些标记或占位符,用于后续替换。
3.导入POI和相关依赖:在Java项目中,导入以下依赖:```xml<dependency><groupId>org.apache.poi</groupId><artifactId>poi-ooxml</artifactId><version>4.1.2</version></dependency><dependency><groupId>org.apache.xmlbeans</groupId><artifactId>xmlbeans</artifactId><version>3.1.0</version></dependency>```4.读取模板文件:使用POI库读取Word模板文件,将其转换为XML格式的字符串,并保存为`template.xml`文件中。
```javaimport ermodel.XWPFDocument;import java.io.FileOutputStream;public class WordTemplateReaderpublic static void main(String[] args) throws ExceptionXWPFDocument document = new XWPFDocument(new FileInputStream("template.docx"));FileOutputStream out = new FileOutputStream("template.xml");document.write(out);out.close(;document.close(;}}```5.数据替换:读取template.xml文件,使用Java中的字符串替换功能,将模板中的占位符替换为实际的数据。
javaweb页面导出word

javaweb页⾯导出word①我做了⼀个word模板,定义好了书签为listyd,书签是在⼀个表格中,在书签位置动态的⽣成表格,例⼦代码如下:var ole = new ActiveXObject("Word.Application");var url=c:\nsqktzs_fm.doc"var doc =ole.documents.open(url,false,false);ole.V isible = true;ole.selection.find.forward =true;var rg=ole.selection.goto(true,0,0,"listyd");var tab=doc.Tables.Add(rg, 2,2) ;for(var i=1;i<=2;i++){for(var j=1;j<=2;j++){var rgcell=tab.Cell(i,j).Range;rgcell.InsertAfter(i+j);}}⽣成的表格嵌套在以前的表格中,很难看,如何能让⽣成的表格和外边的表格看上去是⼀个整体。
rgcell.InsertAfter(i+j);可以⽤insertBefore么。
也可以考虑⽤java语⾔做word模板。
③.⼩弟最近在做JSP页⾯内容导出到Word,但遇到了很多困难,望各位⼤侠急救需求:1.将JSP页⾯中的内容导出到Word⽂件中。
2.JSP页⾯中包含图⽚,图⽚的数据是从数据库中加载出来,实时⽣成的。
⼩弟在⽹上看过N个例⼦,也测试了,就是⽆法解决,问题如下:1.通过window.document.location.href='test.action'的链接⽅式,访问加⼀个JSP页⾯,⽂件头为:<%@ page contentType="application/msword;charset=gbk"%>当点击“导出”按钮时,可以⽣成Word⽂件,但是图⽚⽆法在Word中⽣成.2.直接在页⾯中加JS脚本:var oWD = new ActiveXObject("Word.Application");oWD.WindowState = 2;var oDC = oWD.Documents.Add("",0,1);var oRange =oDC.Range(0,1);var sel = document.body.createTextRange();sel.moveToElementText(PrintA);sel.select();sel.execCommand("Copy");oRange.Paste();oWD.Application.Visible = true;在我的电脑上可以导出Word(我的office版本是2007)⽂件,并且可以显⽰图⽚。
java实现的导出word文档

java实现的导出word⽂档之前没有做过类似的功能,所以第⼀次接触的时候费了我⼀天的时间来完成这个功能。
先说⼀下原理,其实就是通过修改后缀来完成的。
需要先⽤office2013做⼀个word模板,就是你想要⽣成的word的模板,保存为xml格式。
然后在线格式化⼀下,这样⽣成的代码⽐较规范,然后将后缀修改为ftl,内容为⼀下格式:、我使⽤的⽅法是通过Action跳转的⽅法来进⾏调⽤的,Action⽅法如下,[java] view plain copy print?1. public String exportProWorkOrder(){2.3. /** 取出参数**/4.5. /** 输出审批 **/6. Template t=null;7. PrintWriter wt = null;8.9. try {10. /** 查询数据 **/11. ProjectWorkOrder pwo = consultingProjectBo.findPWOMessage(18);12.13. Map<String,Object> dataMap=new HashMap<String,Object>();14.15. //getData(dataMap);16. /** 放置数据 **/17. consultingProjectBo.makeExportProWorkOrderData(pwo,dataMap);18. String fn = makeFileName(pwo);19.20. //FTL⽂件所存在的位置21. t = freeMarkerConfiguration.getTemplate("export_proworkorder.ftl"); //⽂件名22.23.24. //配置 Response 参数25. getResponse().setContentType(26. "application/msword; charset=UTF-8");27. getResponse().setHeader(28. "Content-Disposition",29. "Attachment;filename= "30. + new String(fn.toString().getBytes(31. //"UTF-8"),"UTF-8"));32. "gb2312"), "ISO8859_1"));//20151030 改为UTF-8 需要兼容性测试33. wt = getResponse().getWriter();34. t.process(dataMap, wt);34. t.process(dataMap, wt);35.36. } catch (IOException e) {37. e.printStackTrace();38. } catch (Exception e) {39. e.printStackTrace();40. } finally {41. if(wt!=null){42. wt.flush();43. wt.close();44. }45. }46. return null;47. }48.49. protected String makeFileName(ProjectWorkOrder pwo) {50. if(pwo==null){51. return "⽂件不存在";52. }53.54. String filename = "";55. if(pwo.getProjectTitle()!=null){56. filename = pwo.getProjectTitle() + "⼯程造价咨询项⽬⼯作交办单" + ".doc";57. }else{58. filename = "⼯程造价咨询项⽬⼯作交办单"+".doc";59. }60.61. return filename;62. }跳转进⼊⽅法中,期中放置数据的⽅法如下,[java] view plain copy print?1. public ProjectWorkOrder findPWOMessage(Integer projectId){2. SimpleDateFormat sdf = new SimpleDateFormat( "yyyy-MM-dd HH:mm:ss" );3. Project project = null;4. List<ProjectDepartment> list = null;5. ProjectEngineering pe = null;6. project = projectBo.findFull(projectId);7. list = projectDepartmentBo.findPDByProjectId(projectId);8. pe = projectEngineeringBo.findPEByProjectId(projectId);9. ProjectWorkOrder pwo = new ProjectWorkOrder();10. if(projectId != null){11. pwo.setProjectId(projectId);12. }13. if(project.getProject_title() != null){14. pwo.setProjectTitle(project.getProject_title());15. }16. if(project.getBegin_date() != null){17. pwo.setBeginDate(sdf.format(project.getBegin_date()));18. }19. if(project.getEnd_date() != null){20. pwo.setEndDate(sdf.format(project.getEnd_date()));21. }22. if(project.getProject_target() != null){23. pwo.setProjecTarget(project.getProject_target());24. }24. }25. if(project.getMember_id() != null){26. Member member = memberBo.getCacheMember(project.getMember_id());27. pwo.setMemberId(member.getMember_name());28. }29. if(pe.getPlan_no() != null){30. pwo.setPlanNu(pe.getPlan_no());31. }32. if(pe.getIncrement() != null){33. pwo.setInvestment(pe.getIncrement());34. }35. if(pe.getDo_item() != null){36. pwo.setDoItem(pe.getDo_item());37. }38. if(pe.getKey_point() != null){39. pwo.setKeyPoint(pe.getKey_point());40. }41. if(list != null){42. pwo.setChild(addtypePlus(list));43. }44. return pwo;45. }46. /**47. *将⼯程造价咨询项⽬⼯作交办单导出为word48. */49. @Override50. public void makeExportProWorkOrderData(ProjectWorkOrder pwo, Map<String, Object> dataMap) {51. if(pwo==null){52. return;53. }54. if(pwo.getProjectTitle() != null){55. dataMap.put("ptitle",pwo.getProjectTitle());//项⽬名称56. }else{57. dataMap.put("ptitle","⽆");58. }59. if(pwo.getProjectId() != null){60. dataMap.put("pid", pwo.getProjectId());//⼯程id61. }else{62. dataMap.put("pid", "0");63. }64. if(pwo.getBeginDate() != null){65. dataMap.put("begindate", pwo.getBeginDate());//项⽬开始时间66. }else{67. dataMap.put("begindate", "⽆");68. }69. if(pwo.getEndDate() != null){70. dataMap.put("endate", pwo.getEndDate());//结束⽇期71. }else{72. dataMap.put("endate", "⽆");73. }74. if(pwo.getProjecTarget() != null){75. dataMap.put("ptarget", pwo.getProjecTarget());//⽬标76. }else{77. dataMap.put("ptarget", "⽆");78. }79. if(pwo.getMemberId() != null){80. dataMap.put("pmemberid", pwo.getMemberId());//负责⼈81. }else{81. }else{82. dataMap.put("pmemberid", "⽆");83. }84. if(pwo.getPlanNu() != null){85. dataMap.put("plano", pwo.getPlanNu());//计划编号86. }else{87. dataMap.put("plano", "⽆");88. }if(pwo.getInvestment() != null){89. dataMap.put("investment", pwo.getInvestment());//总投资90. }else{91. dataMap.put("investment", "⽆");92. }93. if(pwo.getDoItem() != null){94. dataMap.put("doitem", pwo.getDoItem());//事项95. }else{96. dataMap.put("doitem", "⽆");97. }98. if(pwo.getKeyPoint() != null){99. dataMap.put("keypoint", pwo.getKeyPoint());//重点100. }else{101. dataMap.put("keypoint", "⽆");102. }103. if(pwo.getChild() != null){104. dataMap.put("list", pwo.getChild());//联系⼈列表105. }else{106. dataMap.put("list", "⽆");107. }108. SimpleDateFormat tempDate = new SimpleDateFormat("yyyy年MM⽉dd⽇"); 109. String datetime = tempDate.format(DateTimeUtil.getCurrDate());110. dataMap.put("datetime", datetime);111. }112. /**113. * 将单位类型数字转换为对应的字符114. */115. private List<ProjectDepartment> addtypePlus(List<ProjectDepartment> list){116. for (ProjectDepartment projectDepartment : list) {117. if(projectDepartment.getType() == 1){projectDepartment.setTypePlus("委托单位");} 118. if(projectDepartment.getType() == 2){projectDepartment.setTypePlus("建设单位");} 119. if(projectDepartment.getType() == 3){projectDepartment.setTypePlus("施⼯单位");} 120. if(projectDepartment.getType() == 4){projectDepartment.setTypePlus("监理单位");} 121. if(projectDepartment.getType() == 5){projectDepartment.setTypePlus("设计单位");} 122. if(projectDepartment.getType() == 6){projectDepartment.setTypePlus("编制单位");} 123. }124. return list;125. }配置⽂件的信息这⾥就不在多说了,同时需要修改ftl中的参数,修改⽅法如下,[html] view plain copy print?1. <w:r wsp:rsidRPr="002C3578">2. <w:rPr>3. <w:rFonts w:ascii="宋体" w:h-ansi="宋体" w:hint="fareast"/>4. <wx:font wx:val="宋体"/>5. <w:sz-cs w:val="21"/>6. </w:rPr>7. <w:t><![CDATA[${doitem}]]></w:t>7. <w:t><![CDATA[${doitem}]]></w:t>8. </w:r>与jsp中的⽅法基本⼀致,处理list,如果遇到循环的话,使⽤如下的⽅法,[html] view plain copy print?1. <#list list as bean><!-- Start 循环体 -->2. <w:tr wsp:rsidR="002C3578" wsp:rsidRPr="002C3578" wsp:rsidTr="002C3578">3. <w:trPr>4. <w:trHeight w:val="427"/>5. </w:trPr>6. <w:tc>7. <w:tcPr>8. <w:tcW w:w="534" w:type="dxa"/>9. <w:vmerge/>10. <w:shd w:val="clear" w:color="auto" w:fill="auto"/>11. </w:tcPr>12. <w:p wsp:rsidR="0068277C" wsp:rsidRPr="002C3578" wsp:rsidRDefault="0068277C" wsp:rsidP="002C3578">13. <w:pPr>14. <w:jc w:val="center"/>15. <w:rPr>16. <w:rFonts w:ascii="宋体" w:h-ansi="宋体" w:hint="fareast"/>17. <wx:font wx:val="宋体"/>18. <w:sz-cs w:val="21"/>19. </w:rPr>20. </w:pPr>21. </w:p>22. </w:tc>23. <w:tc>24. <w:tcPr>25. <w:tcW w:w="1596" w:type="dxa"/>26. <w:shd w:val="clear" w:color="auto" w:fill="auto"/>27. </w:tcPr>28. <w:p wsp:rsidR="0068277C" wsp:rsidRPr="002C3578" wsp:rsidRDefault="0068277C" wsp:rsidP="002C3578">29. <w:pPr>30. <w:spacing w:line="360" w:line-rule="auto"/>31. <w:jc w:val="center"/>32. <w:rPr>33. <w:rFonts w:ascii="宋体" w:h-ansi="宋体" w:hint="fareast"/>34. <wx:font wx:val="宋体"/>35. <w:sz-cs w:val="21"/>36. </w:rPr>37. </w:pPr>38. <w:r wsp:rsidRPr="002C3578">39. <w:rPr>40. <w:rFonts w:ascii="宋体" w:h-ansi="宋体" w:hint="fareast"/>41. <wx:font wx:val="宋体"/>42. <w:sz-cs w:val="21"/>43. </w:rPr>44. <w:t><![CDATA[${bean.typePlus}]]></w:t>45. </w:r>46. </w:p>47. </w:tc>48. <w:tc>48. <w:tc>49. <w:tcPr>50. <w:tcW w:w="2130" w:type="dxa"/>51. <w:shd w:val="clear" w:color="auto" w:fill="auto"/>52. </w:tcPr>53. <w:p wsp:rsidR="0068277C" wsp:rsidRPr="002C3578" wsp:rsidRDefault="0068277C" wsp:rsidP="002C3578">54. <w:pPr>55. <w:spacing w:line="360" w:line-rule="auto"/>56. <w:jc w:val="center"/>57. <w:rPr>58. <w:rFonts w:ascii="宋体" w:h-ansi="宋体" w:hint="fareast"/>59. <wx:font wx:val="宋体"/>60. <w:sz-cs w:val="21"/>61. </w:rPr>62. </w:pPr>63. <w:r wsp:rsidRPr="002C3578">64. <w:rPr>65. <w:rFonts w:ascii="宋体" w:h-ansi="宋体" w:hint="fareast"/>66. <wx:font wx:val="宋体"/>67. <w:sz-cs w:val="21"/>68. </w:rPr>69. <w:t><![CDATA[${bean.department_name}]]></w:t>70. </w:r>71. </w:p>72. </w:tc>73. <w:tc>74. <w:tcPr>75. <w:tcW w:w="2131" w:type="dxa"/>76. <w:shd w:val="clear" w:color="auto" w:fill="auto"/>77. </w:tcPr>78. <w:p wsp:rsidR="0068277C" wsp:rsidRPr="002C3578" wsp:rsidRDefault="0068277C" wsp:rsidP="002C3578">79. <w:pPr>80. <w:spacing w:line="360" w:line-rule="auto"/>81. <w:jc w:val="center"/>82. <w:rPr>83. <w:rFonts w:ascii="宋体" w:h-ansi="宋体" w:hint="fareast"/>84. <wx:font wx:val="宋体"/>85. <w:sz-cs w:val="21"/>86. </w:rPr>87. </w:pPr>88. <w:r wsp:rsidRPr="002C3578">89. <w:rPr>90. <w:rFonts w:ascii="宋体" w:h-ansi="宋体" w:hint="fareast"/>91. <wx:font wx:val="宋体"/>92. <w:sz-cs w:val="21"/>93. </w:rPr>94. <w:t><![CDATA[${bean.linkman}]]></w:t>95. </w:r>96. </w:p>97. </w:tc>98. <w:tc>99. <w:tcPr>100. <w:tcW w:w="2131" w:type="dxa"/>101. <w:shd w:val="clear" w:color="auto" w:fill="auto"/>102. </w:tcPr>103. <w:p wsp:rsidR="0068277C" wsp:rsidRPr="002C3578" wsp:rsidRDefault="0068277C" wsp:rsidP="002C3578"> 104. <w:pPr>104. <w:pPr>105. <w:spacing w:line="360" w:line-rule="auto"/>106. <w:jc w:val="center"/>107. <w:rPr>108. <w:rFonts w:ascii="宋体" w:h-ansi="宋体" w:hint="fareast"/>109. <wx:font wx:val="宋体"/>110. <w:sz-cs w:val="21"/>111. </w:rPr>112. </w:pPr>113. <w:r wsp:rsidRPr="002C3578">114. <w:rPr>115. <w:rFonts w:ascii="宋体" w:h-ansi="宋体"/>116. <wx:font wx:val="宋体"/>117. <w:sz-cs w:val="21"/>118. </w:rPr>119. <w:t><![CDATA[${bean.phone}]]></w:t>120. </w:r>121. </w:p>122. </w:tc>123. </w:tr>124. </#list><!-- End 循环体 -->这样就能导出想要的word⽂档,⼀定要记住,使⽤office2013,我试着⽤WPS,但是⽣成内容让我很懵逼,全是xml代码。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
java html内容生成word文件实现代码
编辑:kepeer 来源:转载
处理HTML标签我用的是Jsoup组件,生成word文档这方面我用的是Jacob组件。
有兴趣的朋友可以去Google搜索一下这两个组件。
大致思路如下:
先利用jsoup将得到的html代码“标准化”(Jsoup.parse(String html))方法,然后利用FileWiter 将此html内容写到本地的template.doc文件中,此时如果文章中包含图片的话,template.doc 就会依赖你的本地图片文件路径,如果你将图片更改一个名称或者将路径更改,再打开这个template.doc,图片就会显示不出来(出现一个叉叉)。
为了解决此问题,利用jsoup组件循环遍历html文档的内容,将img元素替换成${image_自增值}的标识,取出img元素中的src
此时你的html内容会变成如下格式:(举个示例)
代码如下复制代码
<html>
<head></head>
<body>
<p>测试消息1</p>
<p>${image_1}<p>
<table>
<tr>
<td> <td>
</tr>
</table>
<p>测试消息2</p>
<a href=><p>${image_2}</p></a>
<p>测试消息3</p>
</body>
</html>
保存到本地文件以后,利用MSOfficeGeneratorUtils类(工具类详见下面,基于开源组件Jacob)打开你保存的这个template.doc,调用replaceText2Image,将上面代码的图片标识替换为图片,这样就消除了本地图片路径的问题。
然后再调用copy方法,复制整篇文档,关闭template.doc
文件,新建一个doc文件(createDocument),调用paste方法粘贴你刚复制的template.doc 里的内容,保存。
基本上就ok了。
关于copy整个word文档的内容,也会出现一个隐式问题。
就是当复制的内容太多时,关闭word程序的时候,会谈出一个对话框,问你是否将复制的数据应用于其它的程序。
对于这个问题解决方法很简单,你可以在调用quit(退出word程序方法)之前,新建一篇文档,输入一行字,然后调用copy方法,对于复制的数据比较少时,关闭word程序时,它不会提示你的。
见如下代码
//复制一个内容比较少的*.doc文档,防止在关闭word程序时提示有大量的copy内容在内存中,是否应用于其它程序对话框,。