SPSS对主成分回归实验报告
SPSS之回归分析10-1(主成分分析)(1)

Descriptives:描述统计量 ➢ Statistics:输出基本统计量
Univariate descriptives :输出各个变量的基本 描述统计量 Initial solution:因子分析的初始解 ➢ Correlation Matrix:相关矩阵及其检验
步骤
Extration:指定提取因子的方法 ➢ Method:提取因子的方法 ➢ Analyze:分析矩阵 ➢ Extract:确定因子的数目 ➢ Display:输出与因子提取相关的信息 Unrotated factor solution:输出未旋转的因子 提取结果 Scree plot:输出因子的碎石图
因子旋转
因子旋转的方法: 1.varimax:方差最大旋转。简化对因子的解释 2.direct oblimin:直接斜交旋转。允许因子之间具有相
关性。 3.quartmax:四次最大正交旋转。简化对变量的解释 4.equamax:平均正交旋转。 5.promax:斜交旋转方法。
实例分析
例1续:各地区年平均收入数据, 进行因子分析,要求
主成分分析
主成分分析是考察多个数值变量间相关性 的一种多元统计方法,它是研究如何通过 少数几个主成分来解释多变量的方差—协 方差结构。
导出几个主成分,使它们尽可能多地保留 原始变量的信息,且彼此间不相关。
数学原理
对原有变量作坐标变换,
z1 u11x1 u21x2 ... u p1xp z2 u12 x1 u22 x2 ... u p2 xp ...... z p u1p x1 u2 p x2 ... u pp xp
步骤
Rotation:选择因子旋转方法 ➢ Method:旋转方法 ➢ Display:输出与因子旋转有关的信息 Rotated Solution:输出旋转后的因子分析结果 Loading plots:旋转后的因子载荷散点图
SPSS学习系列27.回归分析报告

27. 回归分析回归分析是研究一个或多个变量(因变量)与另一些变量(自变量)之间关系的统计方法。
主要思想是用最小二乘法原理拟合因变量与自变量间的最佳回归模型(得到确定的表达式关系)。
其作用是对因变量做解释、控制、或预测。
回归与拟合的区别:拟合侧重于调整曲线的参数,使得与数据相符;而回归重在研究两个变量或多个变量之间的关系。
它可以用拟合的手法来研究两个变量的关系,以及出现的误差。
回归分析的步骤:(1)获取自变量和因变量的观测值;(2)绘制散点图,并对异常数据做修正;(3)写出带未知参数的回归方程;(4)确定回归方程中参数值;(5)假设检验,判断回归方程的拟合优度;(6)进行解释、控制、或预测。
(一)一元线性回归一、基本原理一元线性回归模型:Y=0+1X+ε其中 X 是自变量,Y 是因变量, 0, 1是待求的未知参数, 0也称为截距;ε是随机误差项,也称为残差,通常要求ε满足:① ε的均值为0; ② ε的方差为 2;③ 协方差COV(εi , εj )=0,当i≠j 时。
即对所有的i≠j, εi 与εj 互不相关。
二、用最小二乘法原理,得到最佳拟合效果的01ˆˆ,ββ值: 1121()()ˆ()niii nii x x yy x x β==--=-∑∑, 01ˆˆy x ββ=- 三、假设检验1. 拟合优度检验计算R 2,反映了自变量所能解释的方差占总方差的百分比,值越大说明模型拟合效果越好。
通常可以认为当R 2大于0.9时,所得到的回归直线拟合得较好,而当R 2小于0.5时,所得到的回归直线很难说明变量之间的依赖关系。
2. 回归方程参数的检验回归方程反应了因变量Y 随自变量X 变化而变化的规律,若 1=0,则Y 不随X 变化,此时回归方程无意义。
所以,要做如下假设检验:H 0: 1=0, H 1: 1≠0; (1) F 检验若 1=0为真,则回归平方和RSS 与残差平方和ESS/(N-2)都是 2的无偏估计,因而采用F 统计量:来检验原假设β1=0是否为真。
SPSS数据的主成分分析报告

2019/9/10
4
zf
多个指标的问题:
1、指标与指标可能存在相关关系 信息重叠,分析偏误
2、指标太多,增加问题的复杂性和分析难度
如何避免?
2019/9/10
5
zf
主成分分析的基本思想
一项十分著名的工作是美国的统计学家斯通(stone)在 1947年关于国民经济的研究。他曾利用美国1929一1938 年各年的数据,得到了17个反映国民收入与支出的变量 要素,例如雇主补贴、消费资料和生产资料、纯公共支 出、净增库存、股息、利息外贸平衡等等。
运用主成分得分系数矩阵解释主成分:
王冬《我国外汇储备增长因素主成分分析》,《北京工商大学学报》, 2006年4期。
田波平等《主成分分析在中国上市公司综合评价中的作用》,《数学 的实践与认识》,2004年4期
2019/9/10
25
zf
主成分解释的案例分析
基于相关系数矩阵的主成分分析。对美国纽约上市的有关化学产业的三支股票 (Allied Chemical, du Pont, Union Carbide)和石油产业的2支股票(Exxon and Texaco )做了100周的收益率调查(1975年1月-1976年10月)。
F1
F2
F3
i
i
t
F1
1
F201源自F3001
i 0.995 -0.041 0.057 l
Δi -0.056 0.948 -0.124 -0.102 l
t -0.369 -0.282 -0.836 -0.414 -0.112 1
2019/9/10
7
zf
主成分分析:将原来具有相关关系的多个指标简化为少数几个 新的综合指标的多元统计方法。
SPSS进行主成分分析

欢呼词语的近义词有哪些欢呼词语的意思是什么呢?如何使用欢呼词语造句呢?关于欢呼词语的近义词有哪些呢?小编给大家收集了关于表达欢呼词语的解释呢,希望能帮助大家,欢迎大家学习参考!欢呼词语解释欢呼的近义词:欢庆、呐喊、呼喊、欢叫、欢乐、欢畅、喝彩基本信息拼音:huānhū释义:形容一种欢乐而振臂高呼的激情场面。
基本解释[hail;cheer;acclaim;applaud] 欢乐地喊叫他作为英雄而受到欢呼这场战争尚未正式结束,民众已在欢呼引证解释1. 欢乐地喊叫。
《东观汉记·王霸传》:“贼众欢呼,雨射营中。
” 唐元稹《辨日旁瑞气状》:“其日三将同升,万姓欢呼,四方来贺。
” 元萨都剌《将至太平驿》诗:“到驿欢呼如到家,明日舟行复如此。
” 明冯梦龙《东周列国志》第七十一回:“(齐)景公大悦,于是解衣卸冠,与梁邱据欢呼于丝竹之间,鸡鸣而返。
”毛泽东《中国人民站起来了》:“我们的革命已经获得全世界广大人民的同情和欢呼,我们的朋友遍于全世界。
”2. 懽呼:欢乐地呼喊。
唐薛用弱《集异记·李钦瑶》:“举军懽呼,声振山谷。
” 明张居正《贺瑞雪表》五:“懽呼敢效乎虫鸣,踊跃岂殊於兽舞!” 康有为《将至桂林望诸石峰》诗:“昔游燕吴读园记,每见叠石辄懽呼。
”关于欢呼造句1, 在荣誉的桂冠下面,在欢呼声的背后,便是孤独,我们的孤独!2, 收到大学录取通知书,她立刻欢呼雀跃起来。
3, 首先是50米跑,运动员们都摩拳擦脚,准备一举夺下桂冠。
随着一声令下,运动员像脱了弦的箭似的飞了出去,同学们不断为自己的班级喝彩加油打气。
观众席上欢呼声拍掌声此起彼伏,久久不断。
4, 最后一个敌人在血泊里倒下,战争胜利了,满目疮痍的战场上响起了震耳欲聋的欢呼声,只是那命悬一线的惊心动魄始终萦绕在每个人的心头。
5, 每个人都有自己的梦,都有自己的偶像,都有自己的爱好,都有自己的个性……生命中有很多事情,可能没人在乎,但说不定会有谁为你而欢呼。
SPSS学习系列27.回归分析报告
27. 回归分析回归分析是研究一个或多个变量(因变量)与另一些变量(自变量)之间关系的统计方法。
主要思想是用最小二乘法原理拟合因变量与自变量间的最佳回归模型(得到确定的表达式关系)。
其作用是对因变量做解释、控制、或预测。
回归与拟合的区别:拟合侧重于调整曲线的参数,使得与数据相符;而回归重在研究两个变量或多个变量之间的关系。
它可以用拟合的手法来研究两个变量的关系,以及出现的误差。
回归分析的步骤:(1)获取自变量和因变量的观测值;(2)绘制散点图,并对异常数据做修正;(3)写出带未知参数的回归方程;(4)确定回归方程中参数值;(5)假设检验,判断回归方程的拟合优度;(6)进行解释、控制、或预测。
(一)一元线性回归一、基本原理一元线性回归模型:Y=0+1X+ε其中 X 是自变量,Y 是因变量, 0, 1是待求的未知参数, 0也称为截距;ε是随机误差项,也称为残差,通常要求ε满足:① ε的均值为0; ② ε的方差为 2;③ 协方差COV(εi , εj )=0,当i≠j 时。
即对所有的i≠j, εi 与εj 互不相关。
二、用最小二乘法原理,得到最佳拟合效果的01ˆˆ,ββ值: 1121()()ˆ()niii nii x x yy x x β==--=-∑∑, 01ˆˆy x ββ=- 三、假设检验1. 拟合优度检验计算R 2,反映了自变量所能解释的方差占总方差的百分比,值越大说明模型拟合效果越好。
通常可以认为当R 2大于0.9时,所得到的回归直线拟合得较好,而当R 2小于0.5时,所得到的回归直线很难说明变量之间的依赖关系。
2. 回归方程参数的检验回归方程反应了因变量Y 随自变量X 变化而变化的规律,若 1=0,则Y 不随X 变化,此时回归方程无意义。
所以,要做如下假设检验:H 0: 1=0, H 1: 1≠0; (1) F 检验若 1=0为真,则回归平方和RSS 与残差平方和ESS/(N-2)都是 2的无偏估计,因而采用F 统计量:来检验原假设β1=0是否为真。
统计分析软件应用SPSS-主成分分析实验报告

本科学生综合性、设计性实验报告实验课程名称统计分析软件应用开课学期2010至2011学年下学期上课时间2011 年4 月25 日辽宁师范大学教务处编印、实验方案、实验目的:掌握主成分分析的思想和具体步骤。
掌握SPSS实现主成分分析的具体操作,并对处理结果做出解释。
5、参考文献:[1]卢纹岱.SPSS for Window銃计分析[M].电子工程出版社,2006[2]郭显光.如何用SPS歎件进行主成分分析[J].统计与信息论坛,1998, (2)[3]何晓群.现代统计分析方法与应用[M].中国人民大学出版社,1998[4]余建英、何旭宏.数据统计分析与SPSS^用[M].人民邮电出版社,2003、实验报告1、 实验目的、设备与材料、理论依据、实验方法步骤见实验设计方案2、 实验现象、数据及结果表1描述性统计量表表2主成分因子荷载矩阵表表3相关系数矩阵表表4公因子方差表Descriptive Statistics图1碎石图Component U 刨乡至拜占,3 GQmponenls extrudedCommunalitiesExtraction Method: Principal Component Analysis.表总方差分解表Total Variance ExplainedCompoiieint initial EigenvaluesExtraction Sums of Squared Loadings Tota J cf Variance Cumulabv? % Total % of '/a™nee Cumulative %1 3&14 48.929 +£.929 3.914 4S929 48.92921 312 23.BSS 723271.912 23B96 72 S2? 3■1.430 17.9911.43917 曲■!&G.S1B4 S79 7.335 SB.'353 5,1441,797 9^.3506.012150 100.000 76 13E-Q13 7.66E-017 1Q0JO0S-4.2E-016-4.25E-015IQO.OOQExtraction Method: Prkicipal Component AnalysisInitial Extraction赔付率1.000 .964 净收入与总收入之比 1.000 .993 投资收益率 1.000 .923 再保险率 1.000 .968 总资产报酬率 1.000 .919 两年保费收入收益率 1.000 .659 保费收入变化率 1.000 .961 流动性比率 1.000.879Plolb1= *X1+*X2+**X4+*X5+***X8b2=*X1+**X3+***X6+*X7+*X8 b3=*X1+*X2+*X3+***X6+**X8表7Y1= *x1+*x2+**x4+*x5+***x8 Y2=*xi+*x2- **x4+*x5+***x8 Y3=*x1+*x2+*x3+*x4+**x6+**x8加权:输出结果,并从高到低进行排序:表81:人保2:平安3:太平洋4:大众5:华泰6:永安7:华安 Z 主成分综合得分Num 1 Z 主成分综合得分 | Num华泰1:人保可以如上所述计算主成分得分,还可以通过综合评价函数计算综合得分综合评价函数:Z=%*Y1+%*Y2+%*Y34、结论:表8中,综合得分出现负值,这只表明该保险公司的综合水平处于平均水平之下。
主成分分析、因子分析实验报告--SPSS

主成分分析、因子分析实验报告--SPSS主成分分析、因子分析实验报告SPSS一、实验目的主成分分析(Principal Component Analysis,PCA)和因子分析(Factor Analysis,FA)是多元统计分析中常用的两种方法,旨在简化数据结构、提取主要信息和解释变量之间的关系。
本次实验的目的是通过使用 SPSS 软件对给定的数据集进行主成分分析和因子分析,深入理解这两种方法的原理和应用,并比较它们的结果和差异。
二、实验原理(一)主成分分析主成分分析是一种通过线性变换将多个相关变量转换为一组较少的不相关综合变量(即主成分)的方法。
这些主成分是原始变量的线性组合,且按照方差递减的顺序排列。
主成分分析的主要目标是在保留尽可能多的数据信息的前提下,减少变量的数量,从而简化数据分析和解释。
(二)因子分析因子分析则是一种探索潜在结构的方法,它假设观测变量是由少数几个不可观测的公共因子和特殊因子线性组合而成。
公共因子解释了变量之间的相关性,而特殊因子则代表了每个变量特有的部分。
因子分析的目的是找出这些公共因子,并估计它们对观测变量的影响程度。
三、实验数据本次实验使用了一份包含多个变量的数据集,这些变量涵盖了不同的领域和特征。
数据集中的变量包括具体变量 1、具体变量 2、具体变量 3等,共X个观测样本。
四、实验步骤(一)主成分分析1、打开 SPSS 软件,导入数据集。
2、选择“分析”>“降维”>“主成分分析”。
3、将需要分析的变量选入“变量”框。
4、在“抽取”选项中,选择主成分的提取方法,如基于特征值大于1 或指定提取的主成分个数。
5、点击“确定”,运行主成分分析。
(二)因子分析1、同样在 SPSS 中,选择“分析”>“降维”>“因子分析”。
2、选入变量。
3、在“描述”选项中,选择相关统计量,如 KMO 检验和巴特利特球形检验。
4、在“抽取”选项中,选择因子提取方法,如主成分法或主轴因子法。
SPSS回归分析实验报告

中国计量学院现代科技学院实验报告实验课程:应用统计学实验名称:回归分析班级:学号:姓名:实验日期: 2012.05.23 实验成绩:指导教师签名:一.实验目的一元线性回归简单地说是涉及一个自变量的回归分析,主要功能是处理两个变量之间的线性关系,建立线性数学模型并进行评价预测。
本实验要求掌握一元线性回归的求解和多元线性回归理论与方法。
二.实验环境中国计量学院现代科技学院机房310三.实验步骤与内容1打开应用统计学实验指导书,新建excel表地区供水管道长度(公里)全年供水总量(万平方米)北京15896 128823 天津6822 64537 河北10771.2 160132 山西5669.3 77525 内蒙古5635.5 59276 辽宁21999 280510 吉林6384.9 159570 黑龙江9065.9 153387 上海22098.8 308309 江苏36632.4 380395 浙江24126.9 235535 安徽7389.4 204128 福建6270.4 118512 江西5094.7 143240 山东26073.9 259782 河南11405.6 185092 湖北15668.6 257787 湖南9341.8 262691 广东35728.8 568949 广西6923.1 134412 海南1726.7 20241 重庆6082.7 71077 四川12251.3 165632 贵州3275.3 45198 云南5208.5 52742 西藏364.9 5363陕西4270 73580甘肃5010 62127青海893 14390宁夏1538.2 22921新疆3670.2 766852.打开SPSS,将数据导入3.打开分析,选择回归分析再选择线性因变量选全年供水总量,自变量选供水管道长度统计里回归系数选估计,再选择模型拟合按继续再按确定会出来分析的结果对以上结果进行分析:(1)回归方程为:y=28484.712+11.610X(X是自变量供水管道长度,Y是因变量全年供水总量)(2)检验1)拟合效果检验根据表2可知,R2=0.819,即拟合效果好,线性成立。
SPSS进行主成分分析报告
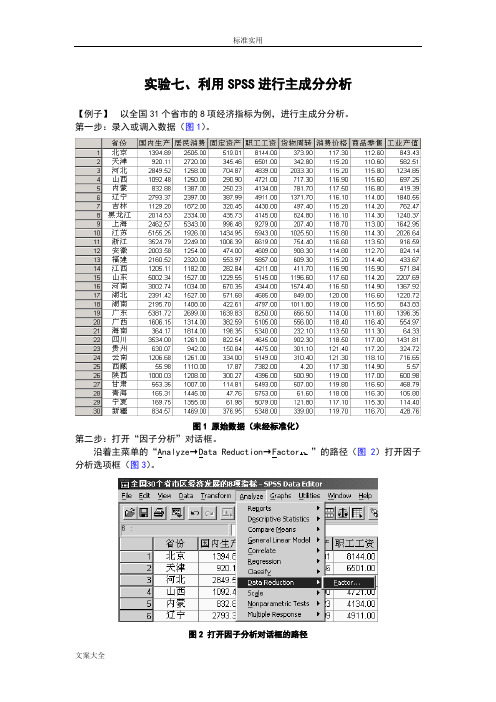
实验七、利用SPSS进行主成分分析【例子】以全国31个省市的8项经济指标为例,进行主成分分析。
第一步:录入或调入数据(图1)。
图1 原始数据(未经标准化)第二步:打开“因子分析”对话框。
沿着主菜单的“Analyze→Data Reduction→Factor ”的路径(图2)打开因子分析选项框(图3)。
图2 打开因子分析对话框的路径图3 因子分析选项框第三步:选项设置。
首先,在源变量框中选中需要进行分析的变量,点击右边的箭头符号,将需要的变量调入变量(Variables)栏中(图3)。
在本例中,全部8个变量都要用上,故全部调入(图4)。
因无特殊需要,故不必理会“Value ”栏。
下面逐项设置。
图4 将变量移到变量栏以后⒈设置Descriptives描述选项。
单击Descriptives按钮(图4),弹出Descriptives对话框(图5)。
图5 描述选项框在Statistics 统计 栏中选中Univariate descriptives 复选项,则输出结果中将会给出原始数据的抽样均值、方差和样本数目(这一栏结果可供检验参考);选中Initial solution 复选项,则会给出主成分载荷的公因子方差(这一栏数据分析时有用)。
在Correlation Matrix 栏中,选中Coefficients 复选项,则会给出原始变量的相关系数矩阵(分析时可参考);选中Determinant 复选项,则会给出相关系数矩阵的行列式,如果希望在Excel 中对某些计算过程进行了解,可选此项,否则用途不大。
其它复选项一般不用,但在特殊情况下可以用到(本例不选)。
设置完成以后,单击Continue 按钮完成设置(图5)。
⒉ 设置Extraction 选项。
打开Extraction 对话框(图6)。
因子提取方法主要有7种,在Method 栏中可以看到,系统默认的提取方法是主成分(Principal Components ),因此对此栏不作变动,就是认可了主成分分析方法。
SPSS的线性回归分析实验报告

农业总产值(亿元)
农业劳动力(万人)
灌溉面积(万公顷)
化肥用量(万吨)
户均固定资产(元)
农机动力(万马力)
北京
19.61
90.1
33.84
7.5
394.3
435.3
天津
14.4
95.2
34.95
3.9
567.5
450.7
河北
149.9
1639
357.26
92.4
706.89
2712.6
山西
55.07
需求量/万台
价格/千元
家庭平均收入/千元
3.0
4.0
6.0
5.0
4.5
6.8
6.5
3.5
8.0
7.0
3.0
10.0
8.5
3.0
16.0
7.5
3.5
20
10.0
2.5
22
9.0
3.0
24
11
2.5
26
12.5
2.0
28
2、一般认为,一个地区的农业总产值与该地区的农业劳动力、灌溉面积、化肥用量、农户固定资产、农业机械化水平等因素有关。下表为某年我国北方地区12个省市的相关数据。试建立我国北方地区的农业产出线性回归模型,分析影响农业产出的主要因素,并说明理由。
第一题
实验结果:拟合优度系数接近1说明拟合好。回归方程的p值<0.05,说明显著线性。回归系数p值<0.05,说明显著线性。
线性回归方程:y=11.167+0.17x1-1.903x2
第二题
实验结果分析:拟合优度系数接近1,说明拟合度好。存在多重线性。化肥用量p值<0.05.说明线性显著。线性回归方程:y=19.501+1.526x
SPSS回归分析实验报告

中国计量学院现代科技学院实验报告实验课程:应用统计学实验名称: 回归分析_____________ 班级:___________________________ 学号:______________________________ 姓名:__________________________ 实验日期:2012.05.23 ____________实验成绩:________________ 指导教师签名: __________________实验目的一元线性回归简单地说是涉及一个自变量的回归分析个变量之间的线性关系,建立线性数学模型并进行评价预测一元线性回归的求解和多元线性回归理论与方法。
二. 实验环境中国计量学院现代科技学院机房310三. 实验步骤与内容1打开应用统计学实验指导书,新建excel表,主要功能是处理两本实验要求掌握新疆 3670.2 766852 •打开SPSS,将数据导入3 •打开分析,选择回归分析再选择线性因变量选全年供水总量,自变量选供水管道长度 统计里回归系数选估计,再选择模型拟合空旧I 圖囤 丨_ |韵虫| 叮鬥 口圭|冃 钥10 11 12 13 14 15W 17 1R19 2021232425 26 272831地区|供水管道|全年供水 天肄 1J 西对蒙古黒龙江:工芯 晰江 安徵 江西闕北云甫宁裏var var var var var var1ESS E6S22 W771 5669 5&36 21999 E385906G' 22099j 3663'f 24127627011406 15669 3572969231727 6063 12251 3275 5209 365 42705010393 T&39 367C120323165632 45198527425363 735S06212714390^921 76685-SP5S Data Editor訳肋(囲恚 E ■ T -S i.U64537 160132 110512 143240568949 134412 202417107777525 5^276 2田7氐185C92257787彳胎狞■!235535 20412B 230610 159570 153367 308309^ 360395"按继续再按确定会出来分析的结果7EB■* b |\M> Ww & Vslife Vtowfi2iZ736^91却朋134412 2W*i 71(177FE£EZ2第I*口川 鼻州出常-* MKlt "Ell“ f j. |4iJI+ Regressionbth De pe n den tVa rt attie'(万平方米)a. Predictors: (ConstamtJ.ft^Xa. Predittnrs: (Ccnstant ),ftzKr®Iff Io. Dcpen dent Vari at>le :(万平右米)3DependentVariabie'对以上结果进行分析:(1)回归方程为:y=28484.712+11.610X (X 是自变量供水管道长度,丫是因 变量全年供水总量)(2)检验1) 拟合效果检验根据表2可知,R2=0.819 ,即拟合效果好,线性成立。
SPSS进行主成分分析报告

实验七、利用SPSS进行主成分分析【例子】以全国31个省市得8项经济指标为例,进行主成分分析.第一步:录入或调入数据(图1)。
图1原始数据(未经标准化)第二步:打开“因子分析”对话框。
沿着主菜单得“Analyze→Data Reduction→Factor”得路径(图2)打开因子分析选项框(图3)。
图2 打开因子分析对话框得路径图3因子分析选项框第三步:选项设置。
首先,在源变量框中选中需要进行分析得变量,点击右边得箭头符号,将需要得变量调入变量(Variables)栏中(图3)。
在本例中,全部8个变量都要用上,故全部调入(图4).因无特殊需要,故不必理会“Value”栏。
下面逐项设置。
图4 将变量移到变量栏以后⒈设置Descriptives描述选项。
单击Descriptives按钮(图4),弹出Descriptives对话框(图5).图5描述选项框在Statistics 统计栏中选中Univariate descriptives复选项,则输出结果中将会给出原始数据得抽样均值、方差与样本数目(这一栏结果可供检验参考);选中Initial solution复选项,则会给出主成分载荷得公因子方差(这一栏数据分析时有用)。
在CorrelationMatrix栏中,选中Coefficients复选项,则会给出原始变量得相关系数矩阵(分析时可参考);选中Determinant复选项,则会给出相关系数矩阵得行列式,如果希望在Excel中对某些计算过程进行了解,可选此项,否则用途不大。
其它复选项一般不用,但在特殊情况下可以用到(本例不选)。
设置完成以后,单击Continue按钮完成设置(图5)。
⒉设置Extraction选项。
打开Extraction对话框(图6).因子提取方法主要有7种,在Method栏中可以瞧到,系统默认得提取方法就是主成分(Principal ponents),因此对此栏不作变动,就就是认可了主成分分析方法。
spss回归分析报告怎么写

SPSS回归分析报告怎么写引言回归分析是一种重要的统计方法,可用于探索变量之间的关系,并预测因变量的数值。
SPSS是一种常用的统计软件,能够进行回归分析并生成相应的报告。
本文将介绍如何撰写SPSS回归分析报告,包括报告的结构、内容和格式。
报告结构一个完整的SPSS回归分析报告通常包括以下几个部分:1. 标题在报告的开头,应写上简明扼要的标题,概括研究的主题和目的。
2. 引言在引言中,介绍研究的背景和目的。
说明为什么选择回归分析方法,并列出研究所使用的自变量和因变量。
还可以介绍一下所使用的数据集和样本情况。
3. 方法在方法部分,详细描述回归分析所使用的方法和步骤。
包括数据的预处理、变量的选择和模型的建立。
还可说明所使用的统计假设和显著性水平。
4. 结果结果部分应该以清晰明了的方式呈现回归分析的结果。
可以包括相关系数矩阵、回归方程、参数估计值和统计显著性等。
同时,还可以使用可视化工具如柱状图、散点图或折线图来展示数据。
5. 讨论在讨论部分,对回归分析的结果进行解释和分析。
可以讨论自变量对因变量的影响程度、显著性以及变量之间的相互作用关系。
还可以比较不同模型的效果,讨论模型的优劣之处,并与已有的研究进行对比。
6. 结论在结论部分,总结回归分析的结果,并回答研究的问题。
可以强调研究的重要性和结果对实际应用的意义。
7. 参考文献在报告的最后,列出所有引用的参考文献。
确保引用格式符合规范,如APA格式。
报告内容和格式在撰写SPSS回归分析报告时,要注意以下几点:1. 清晰明了的语言使用简洁明了的语言,避免使用过于专业的术语,使报告易于理解。
2. 表格和图表的使用使用表格和图表来展示数据和结果,使报告更具可读性。
表格和图表应有清晰的标题和标注,便于读者理解。
3. 结果解释对回归分析的结果进行详细解释,包括回归方程的含义、参数估计值的解释和显著性的判断。
4. 讨论和分析在讨论和分析部分,对结果进行深入的探讨,解释自变量对因变量的影响机制、模型的合理性以及其他可能的解释。
SPSS进行主成分分析报告
实验七、利用SPSS进行主成分分析【例子】以全国31个省市得8项经济指标为例,进行主成分分析.第一步:录入或调入数据(图1)。
图1原始数据(未经标准化)第二步:打开“因子分析”对话框。
沿着主菜单得“Analyze→Data Reduction→Factor”得路径(图2)打开因子分析选项框(图3)。
图2 打开因子分析对话框得路径图3因子分析选项框第三步:选项设置。
首先,在源变量框中选中需要进行分析得变量,点击右边得箭头符号,将需要得变量调入变量(Variables)栏中(图3)。
在本例中,全部8个变量都要用上,故全部调入(图4).因无特殊需要,故不必理会“Value”栏。
下面逐项设置。
图4 将变量移到变量栏以后⒈设置Descriptives描述选项。
单击Descriptives按钮(图4),弹出Descriptives对话框(图5).图5描述选项框在Statistics 统计栏中选中Univariate descriptives复选项,则输出结果中将会给出原始数据得抽样均值、方差与样本数目(这一栏结果可供检验参考);选中Initial solution复选项,则会给出主成分载荷得公因子方差(这一栏数据分析时有用)。
在CorrelationMatrix栏中,选中Coefficients复选项,则会给出原始变量得相关系数矩阵(分析时可参考);选中Determinant复选项,则会给出相关系数矩阵得行列式,如果希望在Excel中对某些计算过程进行了解,可选此项,否则用途不大。
其它复选项一般不用,但在特殊情况下可以用到(本例不选)。
设置完成以后,单击Continue按钮完成设置(图5)。
⒉设置Extraction选项。
打开Extraction对话框(图6).因子提取方法主要有7种,在Method栏中可以瞧到,系统默认得提取方法就是主成分(Principal ponents),因此对此栏不作变动,就就是认可了主成分分析方法。
主成分分析、因子分析实验报告 SPSS

一、实验目的及要求:1、目的用SPSS软件实现主成分分析、因子分析及其应用。
2、内容及要求用SPSS对2009年我国88个房地产上市公司做因子分析,并做出相关解释。
二、仪器用具:三、实验方法与步骤:准备工作:把实验所用数据从Word文档复制到Excel,并进一步导入到SPSS 数据文件中,以备后续分析。
四、实验结果与数据处理:在因子分析的SPSS操作中所用到的部分选项的设置如下面四个图所示,其余为软件默认的选项,因此不再列示,具体的分析如这些表之后所示。
图一图二图三图四分析结果:由表1可知,巴特利特球度检验统计量的观测值为398.287,相应的概率p值接近0,小于显著性水平 (取0.05),所以应拒绝原假设,认为相关系数矩阵与单位矩阵有显著差异。
同时,KMO值为0.637,根据Kaiser给出的KMO度量标准(0.9以上表示非常适合;0.8表示适合;0.7表示一般;0.6表示不太适合;0.5以下表示极不适合)可知原有变量不算特别适合进行因子分析。
表2为公因子方差,即因子分析的初始解,显示了所有变量的共同度数据。
第一列是因子分析初始解下的变量共同度,它表明,对原有10个变量如果采用主成分分析方法提取所有特征根(10个),那么原有变量的所有方差都可被解释,变量的共同度均为1(原有变量标准化后的方差为1)。
事实上,因子个数小于原有变量的个数才是因子分析的目标,所以不可提取全部特征根;第二列是在按指定提取条件(这里为特征根大于1)提取特征根时的共同度。
可以看到,总资产报酬率、成交量、流通市值、总市值的绝大部分信息可被因子解释,这些变量的信息丢失较少。
但毛利率这一变量的信息丢失相当严重(近70%),净资产收益率、应收应付比率两个变量的信息丢失较为严重(近40%)。
因此本次因子提取的总体效果并不理想。
表3展示了特征根及累积贡献率情况,按照特征根大于1的原则,选入了4个公共因子,其累积方差贡献率为72.343%,同时也可以看出,因子旋转后,累计方差比并没有改变,也就是没有影响原有变量的共同度,但却重新分配了各个因子解释原有变量的方差,改变了各因子的方差贡献,使各因子更易于解释。
SPSS对主成分回归实验报告

SPSS对主成分回归实验报告一、实验目的本实验的目的是利用SPSS软件对主成分回归进行分析,通过降维处理建立回归模型,并对模型结果进行解释和评估。
二、实验数据本实验使用的数据为一个假设情景中的模拟数据,包含自变量x1、x2、x3和因变量y。
数据集共有100个样本,样本量较小,主成分回归的效果可以更好地展示。
三、分析方法及步骤1.导入数据首先,在SPSS软件中导入实验数据,并进行必要的数据预处理,例如检查数据的缺失情况和异常值,并进行处理。
2.主成分分析使用PCA方法对自变量进行降维处理。
在SPSS软件中,选择“分析”菜单下的“尺度分析”选项,选择需要进行主成分分析的自变量,并设置合适的选项参数,例如保留主成分的方差解释比例。
3.主成分得分计算利用主成分分析得到的特征值和特征向量信息,对样本数据集进行主成分得分计算,得到降维后的自变量。
4.主成分回归通过主成分得分和因变量之间的回归分析,建立主成分回归模型。
在SPSS软件中,选择“分析”菜单下的“回归”选项,将主成分得分作为自变量,因变量作为被解释变量,进行回归分析。
通过观察回归模型的系数、显著性检验和拟合优度等指标,对主成分回归模型进行评估。
5.结果解释和模型选择根据主成分回归的结果,解释模型中各个主成分的影响程度和对因变量的贡献。
通过模型评估指标和领域知识的综合考虑,选择合适的主成分回归模型。
四、结果分析通过SPSS软件分析主成分回归模型后,得到了以下结果:1.主成分分析的解释方差比为0.785,表示保留的主成分能够解释原始变量78.5%的方差。
2.主成分得分的系数表明,对于因变量y的预测,主成分1和主成分3具有显著正向影响,而主成分2则具有显著负向影响。
3.模型的拟合优度(例如R方)为0.602,说明主成分回归模型可以解释因变量y的60.2%变异。
综合以上结果,我们可以得出结论:在这个假设情景中,使用主成分回归对于因变量y的预测具有一定的效果,但存在一些主成分对因变量y的贡献不显著的情况。
《2024年如何正确应用SPSS软件做主成分分析》范文

《如何正确应用SPSS软件做主成分分析》篇一一、引言主成分分析(Principal Component Analysis, PCA)是一种强大的统计工具,用于数据降维和解释多变量数据集。
在社会科学、生物学、经济学等多个领域,它都发挥着重要的作用。
本文将详细介绍如何正确应用SPSS软件进行主成分分析,包括数据的准备、主成分分析的步骤、结果解读及后续的讨论。
二、数据准备1. 数据清洗:在进行主成分分析之前,首先需要对数据进行清洗,包括去除缺失值、异常值,处理重复数据等。
2. 数据标准化:为了使每个变量在主成分分析中具有相同的权重,需要对数据进行标准化处理。
3. 确定分析变量:根据研究目的选择合适的变量进行分析。
三、SPSS主成分分析步骤1. 打开SPSS软件,导入数据。
2. 选择“分析”菜单,点击“降维”中的“主成分分析”。
3. 在弹出的对话框中,选择需要进行主成分分析的变量。
4. 设置提取主成分的数量。
这通常基于特征值的大小或解释的方差比例来确定。
5. 选择合适的旋转方法,如最大方差法或直接斜交法等。
6. 点击“运行”开始进行主成分分析。
四、结果解读1. 解释性方差矩阵表:这个表格列出了每个主成分所解释的方差比例。
可以根据此表格判断所提取的主成分数量是否合理。
2. 主成分矩阵图:也称为成分图或负载图,它显示了每个原始变量在主成分上的负载值。
这可以帮助我们理解每个主成分的含义和来源。
3. 旋转后的主成分矩阵图:经过旋转后,主成分的负载值可能会发生变化,但总体上可以更清晰地解释原始变量的含义。
4. 主成分得分图:显示了每个样本在各个主成分上的得分情况,可以用于进一步分析样本之间的关系和差异。
五、结果讨论与后续步骤1. 根据主成分分析的结果,可以提取出几个主要因素来解释原始变量的变化情况。
这些主要因素可以用于进一步的研究和分析。
2. 结合其他统计方法(如回归分析、聚类分析等)对主成分分析的结果进行深入探讨,以获取更全面的研究结果。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
《多元统计分析分析》实验报告
2012 年月日学院经贸学院姓名学号
实验
实验成绩名称
一、实验目的
(一)利用SPSS对主成分回归进行计算机实现.
(二)要求熟练软件操作步骤,重点掌握对软件处理结果的解释.
二、实验内容
以教材例题为实验对象,应用软件对例题进行操作练习,以掌握多元统计分析方法的应用
三、实验步骤(以文字列出软件操作过程并附上操作截图)
1、数据文件的输入或建立:(文件名以学号或姓名命名)
将表数据输入spss:点击“文件”下“新建”——“数据”见图1:
图1
点击左下角“变量视图”首先定义变量名称及类型:见图2:
图2:
然后点击“数据视图”进行数据输入(图3):
图3
完成数据输入
2、具体操作分析过程:
(1)首先做因变量Y与自变量X1-X3的普通线性回归:
在变量视图下点击“分析”菜单,选择“回归”-“线性”(图4):
图4
将因变量Y调入“因变量”栏,将x1-x3调入“自变量”栏(图5):
然后选择相关要输出的结果:①点击右上角“统计量(s)”:“回归系数”下选择“估计”;“残差”下选择“”;在右上角选择输出“模型拟合度”、“部分相关和偏相关”“共线性诊断”(后两项是做多重共线性检验)。
选完后点击“继续”(见图6)②如果需要对因变量与残差进行图形分析则需要在“绘制”下选择相关项目(图7),一般不需要则继续③如果需要将相关结果如因变量预测值、残差等保存则点击“保存”(图8),选择要保存的项目④如果是逐步回归法或者设置不带常数项的回归模型则点击“选项”(图9)
其他选项按软件默认。
最后点击“确定”,运行线性回归,输出相关结果(见表1-3)
图5图6
图7
图8
图9
回归分析输出结果:
表1
模型汇总b
1表示提取的因子或主成分至少代表1个单位标准差的变量信息,因为标准化后的变量方差为1,因子或者主成分作为提取的综合变量应该至少代表1个变量的信息),也可以自选提取的因子个数(即第二项),本例中做主成分回归,选择提取全部可能的3个主成分,所以自选个数填3。
选完后点击“继续”进行下一步;③点击“旋转”(图14),按默认的“方法”下不旋转(注意,主成分分析不能旋转!)其他不用选,点击“继续”进行下一步;④点击“得分”,计算不旋转的初始因子得分(图15),选中“保存为变量”,“方法”下按默认,其他不修改,点击“继续”进行下一步。
⑤“选项”下可以不选按默认(选项里主要针对缺失值和系数显示格式,不影响分析结果)
最后点击“确定”,运行因子分析。
图10
图11
图12
图13
图14
图15
由运行结果计算主成分:
表4、描述统计量
均值标准差分析N
x111
x211
x311
表5、相关矩阵
x1x2x3
相关x1.026.997
x2.026.036
x3.997.036
Sig.(单侧)x1.470.000
x2.470.459
x3.000.459
表6、KMO 和Bartlett 的检验
取样足够度的Kaiser-Meyer-Olkin 度量。
.492
Bartlett 的球形度检验近似卡方
df3
Sig..000
表7、解释的总方差
成份初始特征值提取平方和载入
合计方差的%累积%合计方差的%累积% 1
2.998.998
3.003.090.003.090
提取方法:主成份分析。
表8、成份矩阵a
成份
123
x1.999.037
x2.062.998.000
x3.999
提取方法:主成份。
a. 已提取了3 个成份。
由表5、6可知适合做主成分或因子分析(KMO检验通过),表7知前两个主成分(初始因子)贡献率已达%,提取前两个主成分用于分析。
由表8(初始因子载荷阵)和表7可计算前两个特征向量,用表8前两列分别除以前两个特征值的平方根得前两个主成分表达式:
F1=*+*+*(式1)
F2=*+**(式2)
其中X1*-X3*表示为标准化变量(这是因为在进行主成分分析时是以标准化变量进行分析的,是从相关阵出发分析的,见图13的选项)。
由于主成分互不相关,可以用提取的主成分代替自变量进行回归分析,因此需要计算主成分得分来代替自变量X1-X3。
主成分的计算:依据式1和2中两个主成分的表达式,对各自变量标准化后带入就可以计算出每个样品的主成分得分。
但是在spss中,由因子分析提取时是用主成分法提取的,根据初始因子与主成分的关系,未旋转的初始因子等于主成分除以特征根的平方根,因此主成分得分等于因子得分乘以特征根的平方根,因此可以由因子得分计算主成分得分。
前面在因子分析选项中保存了因子得分(见图15),因此计算两个主成分得分:点击“转换”—“计算变量”(图16):在弹出的窗口分别定义主成分F1=第一因子得分*第一特征根的平方根(图17)和F2=第二因子得分*第二特征根的平方根。
(3)主成分回归过程:
要做主成分回归,需要用标准化的因变量(因为自变量经过标准化处理做主成分分析,因变量需要对应做标准化)与主成分做回归,对因变量Y做标准化处理,点击“分析”—“描述统计”—“描述”(见图18),在弹出窗口中将Y调入变量,并选中“将标准化得分另存为变量”(图19)后确定完成Y的标准化。
点击“分析”---“回归”---“线性”(图20)在弹出窗口(图21)中将Zscore(y)调入因变量,F1和F2调入自变量,其他选项同前面图6-9,然后点击“确定”运行主成分回归,相关输出结果见表9
图16
图17
图18图19
图20
图21
主成分回归结果:
表9、模型汇总
模型R R 方调整R 方标准估计的误
差
1.994a.988.985.
a. 预测变量: (常量), F1, F2。
表10、Anova b。