spss简明教程检验和t检验
依据调查问卷,进行单样本T检验SPSS操作步骤

依据调查问卷,进行单样本T检验SPSS
操作步骤
本文档将介绍如何使用SPSS进行单样本T检验,以便根据调查问卷数据进行统计分析。
步骤一:准备数据
1. 打开SPSS软件并导入数据文件。
2. 确保数据文件中包含了需要分析的目标变量。
步骤二:进行单样本T检验
1. 点击菜单栏中的"分析(Analyse)"选项。
3. 将目标变量拖动到"因变量"栏中,并将参照组变量(在这里通常是一个常数)拖动到"因子"栏中。
4. 点击"确定(OK)"按钮。
步骤三:查看结果
1. 在SPSS输出窗口中,查找单样本T检验的结果。
2. 结果中将显示均值、标准误差、95%置信区间、T值和P值
等统计信息。
请注意,进行单样本T检验前需要确保数据满足一些前提条件,例如正态分布和同方差性。
如果数据不满足这些条件,可能需要使
用非参数测试方法进行分析。
以上是依据调查问卷进行单样本T检验的SPSS操作步骤。
希
望本文档能够帮助您进行统计分析。
spss单一样本的T检验

spss单一样本的T检验SPSS是一款广泛使用的统计软件,可以用于各种统计分析,包括单一样本的T 检验。
下面是关于如何使用SPSS进行单一样本的T检验的详细步骤和解释。
一、目的单一样本的T检验主要用于比较一个样本的平均值与已知的或预设的数值,或者用于比较一个样本与已知的或预设的数值之间的差异。
这种检验通常用于检验一个样本是否显著地不同于已知的或预设的数值。
二、步骤1.打开SPSS软件,点击“分析”菜单,然后选择“比较平均值”>“独立样本T检验”。
2.在弹出的对话框中,将左侧的“独立样本T检验”选项卡中的“变量”字段拖到右侧的“变量”框中。
3.在“独立样本T检验”选项卡下方的“组”字段中输入已知的或预设的数值。
4.点击“确定”按钮,SPSS将计算并显示T检验的结果。
三、结果解释单一样本的T检验的结果通常包括T值和p值。
T值是计算出的统计量,而p 值是观察到的数据与零假设之间的不一致程度。
如果p值小于选择的显著性水平(通常为0.05),则可以拒绝零假设,认为样本平均值与已知的或预设的数值之间存在显著差异。
四、注意事项1.单一样本的T检验的前提是数据符合正态分布。
如果数据不符合正态分布,可以使用非参数检验,例如Mann-Whitney U检验或Wilcoxon符号秩检验。
2.在使用单一样本的T检验时,需要明确知道或预设的数值是什么,以及为什么要比较这个数值。
如果不知道或预设的数值是什么,或者比较的目的不明确,那么这种检验可能会没有意义或者导致错误的结论。
3.单一样本的T检验只能告诉我们一个样本的平均值与已知的或预设的数值之间的差异是否显著,但不能告诉我们这种差异的实际意义或影响。
因此,在解释结果时需要谨慎,并考虑实际应用背景。
4.在进行单一样本的T检验时,需要确保数据的质量和准确性。
如果数据存在缺失、异常值或错误,将会对结果产生影响。
在进行统计分析前,需要对数据进行清洗和预处理。
5.在进行单一样本的T检验时,需要考虑变量的类型和测量尺度。
SPSS检验步骤总结

检验步骤总结:1、t检验2、方差分析3、卡方检验4、秩和检验5、相关分析6、线性回归1、t检验(要求数据来自正态总体,可能需要先做正态检验)(1)单一样本t检验数据特征:单一样本变量均数与某固定已知均数进行比较方法:ANALYZE-COMPARE MEANS-ONE SAMPLE t TEST(2)独立样本t检验数据特征:两个独立、没有配对关系的样本(有专门变量表示组数)方法:ANALYZE-COMPARE MEANS-INDEPENDENT SAMPLES t TEST注意观察方差分析结果,判断查看的数据是哪一行!(3)配对样本t检验数据特征:两个不独立的,有配对关系的样本(没有专门变量表示组数)方法:ANALYZE-COMPARE MEANS-PAIRED SAMPLES t TEST不需要方差分析结果检验步骤:(1)正态性检验1(有同学推荐,老师没有强调,但依据理论应进行)(2)建立假设(H0:。
来自同一样本。
H1:。
不来自同一样本)(3)确定检验水准(4)计算统计量(依据上面不同样本类型选择检验方法,注意独立样本t检验要先注明方差分析结果)(5)确定概率值P(6)得出结论2、方差分析(要求数据来自正态总体,可能需要先做正态检验)(1)单因素方差分析数据特征:相互独立、来自正态总体、随机、方差齐性的多样本(有专门变量表示组数,且组数大于2)方法:ANALYZE-COMPARE MEANS-ONE WAY ANOVA注意需要在options 里面选择homogeneity variance test 做方差分析符合方差齐性才可以得出结论!(>0.1)(2)双因素方差分析1正态性检验方法:analyze-explore-plot里面选择normality test数据特征:有三列数据,1列是主要研究因素,1列是配伍组因素,1列是研究数据。
方法:GENERAL LINEAR MODEL-UNIVARIATE (注意选择model里的custom,type是main effect,注意把两个因素选择为fixed factor)检验步骤:(1)正态性检验(有同学推荐,老师没有强调,但依据理论应进行)(2)建立假设(H0:。
Spss统计软件操作2-t检验

标准株(11人) 100 200 400 400 400 400 800 1600 1600 1600 3200 水生株(9人) 100 100 100 200 200 200 200
Analyze—Compare Means—Independent-Samples T Test
Thanks
计量资料的统计推断
目的要求
掌握:假设检验的基本步骤、均数假设检验的
常见类型及公式计算
学会:使用SPSS操作及对输出结果做恰当解释
假设检验的基本步骤
1.建立检验假设,确定检验水准
H0:(无效假设) µ =µ 0;μ1=μ2 H1:(备择假设) µ >µ 0或μ<μ0 ( µ≠µ0 ) μ1>μ2 或μ1<μ2 (μ1≠μ2)
检验水准 α=0.05 单、双侧检验的选择: (1)根据专业知识
事先不知道会出现什么结果 事先知道只能出现某种结果 双侧 单侧
(2)问题的提法
*通常用双侧(除非有充足的理由选用单侧之外, 一般选用 保守的双侧较稳妥)
2.选定检验方法或计算统计量
根据研究设计的类型、资料类型及分析目的
选用适当的检验方法。如样本均数与总体均数的
比较、配对资料的比较、成组设计两个样本均数
的比较等。
3.确定P值,做出统计推断
P值的含义:P值是在H0成立的条件下推断出的现 有统计量(第2步中计算出的统计量)的概率或更 极端的概率(尾部概率) 确定P值大小的方法:用公式求出的t值与 查表查出的t0.05, 比较
P
P=0.05 t
t0.05,ν
4.做出推断结论
(推断的结论=统计结论+专业结论)
P>0.05,按α=0.05检验水准,不拒绝H0,差异无统 计学意义,还不能认为……不同或不等。 P<0.05 ,按α=0.05检验水准,拒绝H0,接受H1设检验的注意问题
SPSST检验方法教程

实习三数值变量资料的统计推断(一)第185~199页一、均数的抽样误差及总体均数可信区间的估计(一)均数的抽样误差1.定义在抽样研究中,由于抽样造成的样本均数与总体均数之间的差异或者样本均数之间的差异,称为均数的抽样误差(sampling error)。
抽样误差是不可避免的,造成抽样误差的根本原因是个体变异的客观存在。
(一)均数的抽样误差2.计算一、均数的抽样误差及总体均数置信区间的估计3.性质(1)抽样误差的大小,即标准误,与标准差成正比,与样本含量的平方根成反比。
(2)在实际工作中,减小抽样误差的有效方法是增大样本含量。
标准误的精确值标准误的估计值(二)t分布一、均数的抽样误差及总体均数置信区间的估计(二)t分布2.性质一组与自由度ν有关的曲线,随着自由度ν的增大接近标准正态分布。
一、均数的抽样误差及总体均数置信区间的估计(三)总体均数95%置信区间的估计二、数值变量资料的假设检验(t 检验和z 检验)(一)假设检验的目的推断两个总体均数是否相等(双侧检验:μ1=μ2?,单侧检验:μ1>μ2?或者μ1< μ2?)(二)假设检验方法的选择¾根据σ是否已知以及n的大小,选择t检验或z检验。
¾根据不同的研究设计类型,选择不同的方法。
¾注意单侧、双侧检验的选择*资料中σ已知时,可以用σ代替公式中相应的s 。
t 检验和z检验的应用条件和计算公式(二)假设检验方法的选择二、数值变量资料的假设检验(t 检验和z 检验)二、数值变量资料的假设检验(t 检验和z 检验)(二)假设检验方法的选择完全随机设计的两样本均数的t检验¾假设检验的P 值不能反映总体均数差别的大小。
P 值越小,越有理由(越有把握)认为两总体均数不相等。
¾假设检验的结论具有概率性。
H 0原本正确, 但P ≤0.05,拒绝H 0:第一类错误(α)H 0原本不正确,但P >0.05,不拒绝H 0:第二类错误(β)α为事先指定的检验水平(一般取0.05),β未知;α越小,β越大;α越大,β越小;增大样本量n ,可以同时减小α和β。
T检验简易教程-SPSS

速度知觉实验数据处理之SPSS简易教程配对样本T检验T检验是做什么的?T检验是对组与组之间平均水平的比较。
什么是配对样本T检验?配对样本是指样本x1,x2,…x n,与y1,y2,…y n ,不可以独立颠倒顺序,如果顺序颠倒,就会改变问题的性质。
比如要考察一项培训的效果,培训前和培训后分别对每个学生进行测试,得到两组分数,要比较培训前后的分数有无显著差异,就需要使用配对样本T检验。
如果顺序颠倒,将A学生培训前的分数与B学生培训后的分数相比较,是没有意义的。
对于本实验来说,需要分别比较(1)快速和慢速情况下速度知觉差别阈限是否有显著差异;(2)远距离和近距离情况下速度知觉差别阈限是否有显著差异。
步骤一,输入数据(图中所有数据均为随机虚拟!)。
打开SPSS,输入数据。
SPSS的主体页面和Excel是相似的,直接将数据输入表格中即可。
将所有快速(慢速)条件下的数据输入“快速”(慢速)一栏(不区分距离远近),但必须注意的是,横向的两个数据是同一位被试的数据(配对!)。
步骤二,统计分析点击分析→比较均值→配对样本T检验,如图单击之后,出现下面的界面:然后把左边的“快速”“慢速”“远距离”“近距离”放到右边,方法是点击中间的蓝色箭头,放置结果如下,单击确定,之后会弹出输出结果的界面,可以找到T检验的结果,最重要的是红框里面的结果,Sig代表显著性,如果小于0.05,则认为两组平均水平具有显著差异,如果小于0.01,则是极其显著的差异。
(图中的结果表示不显著,由于数据完全是随机虚拟,此结果没有任何意义!)注意:在最后的结果呈现中,请将均值,标准差,T,df,Sig,这几项结果放在三线表中,请勿直接将SPSS的结果黏贴到实验报告中。
用SPSS进行T检验

用SPSS进行T检验什么是T检验?T检验是统计学中的常用方法之一,用于检验两组样本的均值是否有显著差异。
它是通过计算样本的t值来确定两组样本均值差异是否显著。
因此,如果两组样本的t值越大,则它们之间的差异就越明显。
在进行T检验之前,我们首先需要明确两组样本是否满足正态分布的要求。
如果样本呈正态分布,则我们可以使用独立样本T检验或配对样本T检验进行检验。
如果不符合正态分布条件,我们需要使用非参数检验方法,例如Wilcoxon符号秩检验或Mann-Whitney U检验。
如何用SPSS进行T检验?下面我们将演示如何使用SPSS进行独立样本T检验和配对样本T检验。
独立样本T检验独立样本T检验用于检验两个独立样本的均值是否有差异。
例如,我们想知道男性和女性在身高上是否有显著差异,则可以使用独立样本T检验来验证。
我们使用一个示例数据集来展示如何进行独立样本T检验。
该数据集包含两组样本:一组是男子的身高,另一组是女子的身高。
在SPSS中,我们可以按照以下步骤进行独立样本T检验:1.打开SPSS软件并载入数据集。
2.单击菜单栏中的“分析”(Analyze),然后选择“比较均值”(CompareMeans),再选“独立样本T检验”(Independent-Samples T Test)。
3.在“独立样本T检验”对话框中,将男性身高和女性身高变量分别放到“变量1”和“变量2”框中。
4.点击“OK”按钮,SPSS将自动计算并输出T检验的结果和描述性统计数据。
下面是一个示例的SPSS的输出:执行男子控制女子均值174.609 161.164标准差 6.971 6.098标准误差均值 1.760 1.53595% CI(下限)171.023 158.126T 17.915df 38Sig。
(双尾).000T检验结果显示,在本例中,男性和女性的身高之间存在显著差异。
T值为17.915,df值为38,Sig值小于0.05,表明这两组数据的差异不是由于随机因素导致的,而是由于不同的性别所导致的。
独立样本t检验spss的步骤

独立样本t检验spss的步骤独立样本t检验SPSS的步骤概述:独立样本t检验(Independent Samples t-test)是一种常见的统计方法,用于比较两组独立样本的均值是否存在显著差异。
在SPSS (Statistical Package for the Social Sciences)软件中进行独立样本t检验是一项相对简单而又方便的任务。
本文将详细介绍如何使用SPSS进行独立样本t检验的步骤。
步骤一:准备数据和SPSS环境在进行独立样本t检验之前,首先需要准备好需要进行比较的两组数据以及将其输入到SPSS软件中。
确保数据的格式正确,即每一组数据都应该是一个单独的变量。
打开SPSS软件,并在数据编辑器中将这两组数据输入到不同的变量列中。
步骤二:指定假设在进行独立样本t检验之前,需要明确要比较的两组数据的假设。
独立样本t检验有一对假设需要检验,分别是零假设(H0)和备择假设(H1)。
零假设(H0):两组数据的均值相等。
备择假设(H1):两组数据的均值不相等。
步骤三:进行独立样本t检验在SPSS软件中,进行独立样本t检验需要使用“Analyze”和“Compare Means”菜单。
按照以下步骤进行操作:1. 选择菜单栏中的“Analyze”。
2. 选择“Compare Means”。
3. 在“Compare Means”菜单下,选择“Independent-Samples T Test”。
在弹出的对话框中,将需要比较的两组数据变量选择到“Test Variables”框中。
点击“箭头”按钮将其移至“Grouping Variable”框中。
点击“OK”按钮,SPSS将自动为你进行独立样本t检验,并生成相应的结果报告。
步骤四:解读结果SPSS生成的独立样本t检验结果报告包含了一些关键的统计信息。
以下是一些常见的结果:1. “Mean Difference”(平均数差异):表示两组数据均值之间的差异。
SPSS简明教程X检验和T检验

SPSS简明教程(X检验和T检验)————————————————————————————————作者:————————————————————————————————日期:SPSS最适用的统计学方法(X2检验和T检验)1.SPSS的启动(1)在windows[开始]→[程序]→[spss20],进入SPSS for Windows对话框,2.创建一个数据文件三个步骤:(1)选择菜单【文件】→【新建】→【数据】新建一个数据文件。
(2)单击左下角【变量视窗】标签进入变量视图界面,定义每个变量类型。
(3)单击【数据视窗】标签进入数据视窗界面,录入数据库单元格内。
3.读取外部数据当前版本的SPSS可以很容易地读取Excel数据,步骤如下:(1)按【文件】→【打开】→【数据】的顺序使用菜单命令调出打开数据对话框,在文件类型下拉列表中选择数据文件,如图2.2所示。
图2.2 Open File对话框(2)选择要打开的Excel文件,单击“打开”按钮,调出打开Excel数据源对话框,如图2.3所示。
对话框中各选项的意义如下:工作表下拉列表:选择被读取数据所在的Excel工作表。
范围输入框:用于限制被读取数据在Excel工作表中的位置。
图2.3 Open Excel Data Source对话框4.数据编辑在SPSS中,对数据进行基本编辑操作的功能集中在Edit和Data菜单中。
5.SPSS数据的保存SPSS数据录入并编辑整理完成以后应及时保存,以防数据丢失。
保存数据文件可以通过【文件】→【保存】或者【文件】→【另存为】菜单方式来执行。
在数据保存对话框(如图2.5所示)中根据不同要求进行SPSS数据保存。
图2.5 SPSS数据的保存5. 数据分析在SPSS中,数据整理的功能主要集中在【数据】和【分析】两个主菜单下6.语言切换:编辑(E)—选项(N)--用户界面-语言--简体中文第六章:描述性统计分析(X2检验)完成计数资料和等级资料的统计描述和一般的统计检验,我们常用的X2检验也在其中完成。
SPSS统计分析简明教程

3 SPSS统计描述
差异量数
在统计分析中经常应用的是标准差,其公式如下:
人物生平 文学成就
S
xi x2
di2
n
n
其中, di xi X
为每个学生的得分与平均分的离差。
23
3 SPSS统计描述
差异量数
标准分数,又称Z分数,是以标准差为单位表示一个分人文物学生成平就 数在团队分数中所处的位置。其计算公式为:
人物生平 文学成就
可生成数十种基本图和交互图,例如条形图、面积图 、饼图、直方图、交互点形图、交互带形图等,这些 图形生成后可以进行编辑。
与其它软件的衔接
能打开Excel、Access、Foxbase、文本编辑器等生成 的数据文件。
SPSS生成的图形可保存为多种图形格式。
9
1 SPSS统计软件介绍
20 3 SPSS统计描述
正态分布
10
人物生平 文学成就
Std. Dev = 7.21
Mean = 79.4
0
N = 100.00
60.0 65.0 70.0 75.0 80.0 85.0 90.0 95.0
62.5 67.5 72.5 77.5 82.5 87.5 92.5
32
¿¼ ÊÔ ³É ¼¨
Insert Variable、Delete—在列上进行操作 Insert Case-----在行上进行操作
11
2 SPSS统计软件基本功能
SPSS统计分析的基本过程
2 数据的预分析
人物生平 文学成就
在原始数据录入完毕后,要对数据进行必要的预分析 ,如数据分组、排序、分布图、平均数、标准差的描 述等。
最新SPSS应用:t检验及方差齐性检验、正态性检验

→ok
正态性检验有两种结果:
未转换数据(的方差齐性检验)
Shapiro-Wilk:W检验(小样本)
Kolmogorov-Smirnov:D检验(大样本)
“Paste”按钮的使用
此课件下载可自行编辑修改,仅供参考! 感谢您的支持,我们努力做得更好!谢谢
→ok 例3-7:
五.正态性检验和方差齐性检验:
Analyze → descriptive statistics→ Explore(探索性分析)
→ dependent list:分析变量 factor:分组变量
正态性检验
plots:normality test
untransformed →continue
→paried variables:配对的两个变量
→ok 例3-6:
四.t检验:两样本均数的比较 analyze→compare means →independent-samples t test
→test variable:分析变量 →grouping variable:分组变量
→define groups:分组变量的值
SPSS应用:t检验及方差齐性检 验、正态性检验
二.t检验:样本均数与总体均e-sample t test
→test variable:分析变量 →test value:总体均数的值
→ok 例3-5:
三.t检验:配对t检验 analyze→compare means →paried-samples t test
SPSS简明教程X检验和T检验

S P S S最适用的统计学方法(X 2检验和T检验)1.SPSS的启动(1)在windows[开始]→[程序]→[spss20],进入SPSS for Windows对话框,2.创建一个数据文件三个步骤:(1)选择菜单【文件】→【新建】→【数据】新建一个数据文件。
(2)单击左下角【变量视窗】标签进入变量视图界面,定义每个变量类型。
(3)单击【数据视窗】标签进入数据视窗界面,录入数据库单元格内。
3.读取外部数据当前版本的SPSS可以很容易地读取Excel数据,步骤如下:(1)按【文件】→【打开】→【数据】的顺序使用菜单命令调出打开数据对话框,在文件类型下拉列表中选择数据文件,如图所示。
图 Open File对话框(2)选择要打开的Excel文件,单击“打开”按钮,调出打开Excel数据源对话框,如图所示。
对话框中各选项的意义如下:工作表下拉列表:选择被读取数据所在的Excel工作表。
范围输入框:用于限制被读取数据在Excel工作表中的位置。
图 Open Excel Data Source对话框4.数据编辑在SPSS中,对数据进行基本编辑操作的功能集中在Edit和Data菜单中。
5.SPSS数据的保存SPSS数据录入并编辑整理完成以后应及时保存,以防数据丢失。
保存数据文件可以通过【文件】→【保存】或者【文件】→【另存为】菜单方式来执行。
在数据保存对话框(如图所示)中根据不同要求进行SPSS数据保存。
图 SPSS数据的保存5. 数据分析在SPSS中,数据整理的功能主要集中在【数据】和【分析】两个主菜单下6.语言切换:编辑(E)—选项(N)--用户界面-语言--简体中文第六章:描述性统计分析(X2检验)完成计数资料和等级资料的统计描述和一般的统计检验,我们常用的X2检验也在其中完成。
6.1.1界面说明界面如下所示:分析—描述统计—频率用于定义需要计算的其他描述统计量。
现将各部分解释如下:Percentile Values复选框组定义需要输出的百分位数,可计算1.四分位数(Quartiles)、2.每隔指定百分位输出当前百分位数(Cut points for equal groups)3.直接指定某个百分位数(Percentiles),如直接和o Central tendency复选框组用于定义描述集中趋势的一组指标:均数(Mean)、中位数(Median)、众数(Mode)、总和(Sum)。
SPSS简易分析流程详解
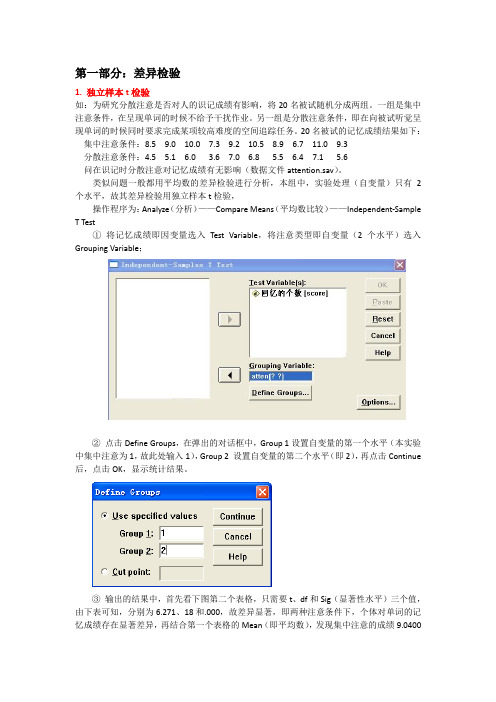
第一部分:差异检验1. 独立样本t检验如:为研究分散注意是否对人的识记成绩有影响,将20名被试随机分成两组。
一组是集中注意条件,在呈现单词的时候不给予干扰作业。
另一组是分散注意条件,即在向被试听觉呈现单词的时候同时要求完成某项较高难度的空间追踪任务。
20名被试的记忆成绩结果如下:集中注意条件:8.5 9.0 10.0 7.3 9.2 10.5 8.9 6.7 11.0 9.3分散注意条件:4.5 5.1 6.0 3.6 7.0 6.8 5.5 6.4 7.1 5.6问在识记时分散注意对记忆成绩有无影响(数据文件attention.sav)。
类似问题一般都用平均数的差异检验进行分析,本组中,实验处理(自变量)只有2个水平,故其差异检验用独立样本t检验,操作程序为:Analyze(分析)——Compare Means(平均数比较)——Independent-Sample T Test①将记忆成绩即因变量选入Test Variable,将注意类型即自变量(2个水平)选入Grouping Variable;②点击Define Groups,在弹出的对话框中,Group 1设置自变量的第一个水平(本实验中集中注意为1,故此处输入1),Group 2 设置自变量的第二个水平(即2),再点击Continue 后,点击OK,显示统计结果。
③输出的结果中,首先看下图第二个表格,只需要t、df和Sig(显著性水平)三个值,由下表可知,分别为6.271、18和.000,故差异显著,即两种注意条件下,个体对单词的记忆成绩存在显著差异,再结合第一个表格的Mean(即平均数),发现集中注意的成绩9.0400大于分散注意的成绩5.4600,故集中注意的记忆效果显著高于分散注意。
2. 相关样本t检验基本过程与独立样本t检验类似,操作程序为:Analyze(分析)——Compare Means(平均数比较)——Paired-Sample T Test例题:从某小学三年级随机抽取20名儿童做样本,分别在学期初和学期末进行了推理测验,结果如下(数据文件:Test.sav):学生编号 1 2 3 4 5 6 7 8 9 10学期初 12 13 12 11 10 13 14 15 15 11学期末 14 14 11 15 11 14 14 17 15 14学生编号 11 12 13 14 15 16 17 18 19 20学期初 13 12 11 10 13 14 15 15 11 12学期末 14 14 11 15 14 14 16 18 15 14①分两次分别点击“学期初成绩”和“学期末成绩”两个变量,如下图所示,Current Selections 显示两个变量后,点击中间的小三角选入Paired Variables后点击OK,显示结果;②输出结果的理解和分析与独立样本t检验相同。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
S P S S最适用的统计学方法(X2检验和T检验)1.SPSS的启动(1)在windows[开始]→[程序]→[spss20],进入SPSSforWindows对话框,2.创建一个数据文件三个步骤:(1)选择菜单【文件】→【新建】→【数据】新建一个数据文件。
(2)单击左下角【变量视窗】标签进入变量视图界面,定义每个变量类型。
(3)单击【数据视窗】标签进入数据视窗界面,录入数据库单元格内。
3.读取外部数据当前版本的SPSS可以很容易地读取Excel数据,步骤如下:(1)按【文件】→【打开】→【数据】的顺序使用菜单命令调出打开数据对话框,在文件类型下拉列表中选择数据文件,如图2.2所示。
图2.2OpenFile对话框(2)选择要打开的Excel文件,单击“打开”按钮,调出打开Excel数据源对话框,如图2.3所示。
对话框中各选项的意义如下:工作表下拉列表:选择被读取数据所在的Excel工作表。
范围输入框:用于限制被读取数据在Excel工作表中的位置。
图2.3OpenExcelDataSource对话框4.数据编辑在SPSS中,对数据进行基本编辑操作的功能集中在Edit和Data菜单中。
5.SPSS数据的保存SPSS数据录入并编辑整理完成以后应及时保存,以防数据丢失。
保存数据文件可以通过【文件】→【保存】或者【文件】→【另存为】菜单方式来执行。
在数据保存对话框(如图2.5所示)中根据不同要求进行SPSS数据保存。
图2.5SPSS数据的保存5.数据分析在SPSS中,数据整理的功能主要集中在【数据】和【分析】两个主菜单下6.语言切换:编辑(E)—选项(N)--用户界面-语言--简体中文第六章:描述性统计分析(X2检验)完成计数资料和等级资料的统计描述和一般的统计检验,我们常用的X2检验也在其中完成。
6.1.1界面说明界面如下所示:分析—描述统计—频率用于定义需要计算的其他描述统计量。
现将各部分解释如下:PercentileValues复选框组定义需要输出的百分位数,可计算1.四分位数(Quartiles)、2.每隔指定百分位输出当前百分位数(Cutpointsforequalgroups)3.直接指定某个百分位数(Percentiles),如直接P2.5和P97.5o Centraltendency复选框组用于定义描述集中趋势的一组指标:均数(Mean)、中位数(Median)、众数(Mode)、总和(Sum)。
o Dispersion复选框组用于定义描述离散趋势的一组指标:标准差(Std.deviation)、方差(Variance)、全距(Range)、最小值(Minimum)、最大值(Maximum)、标准误。
o Distribution复选框组用于定义描述分布特征的两个指标:偏度系数(Skewness)和峰度系数(Kurtosis)。
o Valuesaregroupmidpoints复选框当你输出的数据是分组频数数据,并且具体数值是组中值时,选中该复选框以通知SPSS,免得它犯错误。
【Charts钮】弹出Charts对话框,用于设定所做的统计图。
o Charttype单选钮组定义统计图类型,有四种选择:无、条图(Barchart)、圆图(Piechart)、直方图Histogram),其中直方图还可以选择是否加上正态曲线(Withnormalcurve)。
例:许根友要求统计的。
丙氨酸氨基转移酶(ALT)调查,男性244人有50人异常,女性255人有6人结果异常,结果是否有统计学意义。
X2卡方值是41.777,P<0.0016.1.2分析实例例6.1某地101例健康男子血清总胆固醇值测定结果如下,请绘制频数表、直方图,计算均数、标准差、变异系数CV、中位数M、p2.5和p97.5(卫统第三版p2331.1题)。
4.773.376.143.953.564.234.314.715.694.124.564.375.396.305.217.225.543.935. 214.125.185.774.795.125.205.104.704.743.504.694.384.896.255.324.504.633.61 4.444.434.254.035.854.093.354.084.795.304.973.183.975.165.105.864.795.344. 244.324.776.366.384.885.553.044.553.354.874.175.855.165.094.524.384.314.58 5.726.554.764.614.174.034.473.403.912.704.604.095.965.484.404.555.383.894. 604.473.644.345.186.143.244.903.05解:为节省篇幅,这里只给出精确频数表的做法,假设数据已经输好,变量名为X,具体解法如下:1.Analyze==>DescriptiveStatistics==>Frequencies(分析—描述统计—频率--)2.Variables(变量)框:选入X3.单击Statistics(统计量)钮:4.选中Mean(均数)、Std.deviation(标准差)、Median(中位数)复选框5.单击Percentiles(百分位数):输入2.5:单击Add(添加):输入97.5:单击Add:6.单击Continue钮7.单击Charts(图表)钮:8.选中Barcharts(条形图)9.单击Continue钮10.单击OK得出结果后手工计算出CV。
6.1.3结果解释上题除直方图外的的输出结果如下:Frequencies统计量XN 有效101缺失0均值 4.6995中值 4.6100标准差.86162百分位数25 3.045597.5 6.4565最上方为表格名称,左上方为分析变量名,可见样本量N为101例,缺失值0例,均数Mean=4.69,中位数Median=4.61,标准差STD=0.8616,P2.5=3.04,P97.5=6.45。
系统对变量x作频数分布表(此处只列出了开头部分),Vaild右侧为原始值,Frequency 为频数,Percent为各组频数占总例数的百分比(包括缺失记录在内),Validpercent 为各组频数占总例数的有效百分比,CumPercent为各组频数占总例数的累积百分比。
§6.2Descriptives过程最上方为表格名称,左上方为分析变量名,可见样本量N为101例,缺失值0例,均数Mean=4.69,中位数Median=4.61,标准差STD=0.8616,P2.5=3.04,P97.5=6.45。
X频率百分比有效百分比累积百分比有效2.70 1 1.0 1.0 1.03.04 1 1.0 1.0 2.0 3.05 1 1.0 1.0 3.0 3.18 1 1.0 1.04.0 3.24 1 1.0 1.05.0 3.35 2 2.0 2.06.9 3.37 1 1.0 1.07.9 3.40 1 1.0 1.08.9 3.50 1 1.0 1.09.9 3.56 1 1.0 1.0 10.9 3.61 1 1.0 1.0 11.9 3.64 1 1.0 1.0 12.9 3.89 1 1.0 1.0 13.9 3.91 1 1.0 1.0 14.9 3.93 1 1.0 1.0 15.8 3.95 1 1.0 1.0 16.83.97 1 1.0 1.0 17.84.03 2 2.0 2.0 19.8 4.08 1 1.0 1.0 20.8 4.09 2 2.0 2.0 22.8 4.12 2 2.0 2.0 24.8 4.17 2 2.0 2.0 26.74.23 1 1.0 1.0 27.74.24 1 1.0 1.0 28.74.25 1 1.0 1.0 29.74.31 2 2.0 2.0 31.74.32 1 1.0 1.0 32.74.34 1 1.0 1.0 33.74.37 1 1.0 1.0 34.74.38 2 2.0 2.0 36.64.40 1 1.0 1.0 37.64.43 1 1.0 1.0 38.64.44 1 1.0 1.0 39.64.47 2 2.0 2.0 41.64.50 1 1.0 1.0 42.64.52 1 1.0 1.0 43.6系统对变量x作频数分布表(此处只列出了开头部分),Vaild右侧为原始值,Frequency 为频数,Percent为各组频数占总例数的百分比(包括缺失记录在内),Validpercent 为各组频数占总例数的有效百分比,CumPercent为各组频数占总例数的累积百分比。
6.2Descriptives过程(描述性统计分析)以上面的题为例,分析—统计描述—描述—选项—均值、标准差、方差、最小值、最大值、均值的标准误、变量例表---继续---确定。
§6.4Crosstabs过程(交叉表)Crosstabs过程用于对计数资料和有序分类资料进行统计描述和简单的统计推断。
在分析时可以产生二维至n维列联表,并计算相应的百分数指标。
统计推断则包括了我们常用的X2检验、Kappa值,分层X2(X2)。
如果安装了相应模块,还可计算n维列联表的M-H确切概率(Fisher'sExactTest)值。
6.4.2分析实例例6.2某医生用国产呋喃硝胺治疗十二指肠溃疡,以甲氰咪胍作对照组,问两种方法行变量、列变量和指示每个格子中频数的变量,然后用WeightCases对话框指定频数变量,最后调用Crosstabs过程进行X2检验。
假设三个变量分别名为R、C和W,则数也可以这样在变量视图—在变量视图—药物的值中标签(1=呋喃硝胺,2=甲氰咪胍)在变量视图—治疗情况、药物、X的类型全为数值一、1.Data==>WeightCases(数据==>加权个案)2.WeightCasesby单选框:选中加权个案单选框3.FreqencyVariable(频率变量):选入X4.单击OK钮(单击确定按钮)二、5.Analyze==>DescriptiveStatistics==>Crosstabs(分析==>描述统计==>交叉表)6.Rows(行)框:选入药物、7.Columns(列)框:选入治疗情况8.Statistics(统计量)钮:Chi-square(卡方)复选框:选中:单击Continue(继续)钮9.单击OK(确定)钮6.4.3结果解释上题的结果如下:首先是处理记录缺失值情况报告,可见126例均为有效值。