金融数据库——SAS数据处理应用题
sas期末考试试题

sas期末考试试题SAS期末考试试题一、选择题(每题2分,共20分)1. 在SAS中,以下哪个命令用于创建数据集?A. PROC SORTB. DATASETSC. SETD. INPUT2. 下列哪个选项不是SAS数据集中的变量属性?A. 长度B. 格式C. 标签D. 颜色3. SAS中的PROC FREQ过程用于:A. 描述性统计分析B. 频率分布分析C. 回归分析D. 时间序列分析4. 以下哪个命令用于在SAS中生成随机数?A. RANDB. RANDOMC. RNDD. UNIVARIATE5. 在SAS中,如何使用PROC GPLOT创建图形?A. 使用PLOT语句B. 使用SGPLOT过程C. 使用GPLOT语句D. 使用GRAPH语句二、简答题(每题10分,共30分)1. 解释SAS中的宏语言及其用途。
2. 描述如何使用SAS进行数据清洗的基本步骤。
3. 简述SAS中PROC UNIVARIATE过程的功能和应用场景。
三、编程题(每题25分,共50分)1. 编写SAS程序,从一个名为“sales_data”的数据集中提取出所有销售额超过平均销售额的产品,并计算这些产品的总销售额。
```sasdata sales_data;set sales_data;if sales > mean(sales);run;proc means data=sales_data mean;var sales;output out=avg_sales mean=avg_sales;run;data top_sales;set sales_data;where sales > avg_sales.avg_sales;run;proc sql;select sum(sales) into: total_salesfrom top_sales;quit;```2. 编写SAS程序,使用PROC REG过程对一个名为“education_data”的数据集进行线性回归分析,预测学生的考试成绩(变量名为“score”)基于其学习时间(变量名为“study_hours”)。
sas试题A

考生注意:舞弊万莫做,那样要退学,自爱当守诺,最怕错上错,若真不及格,努力下次过。
开 试题成绩课程名称 应用统计软件(A ) 考试时间 年 11月19日8时 00分至10时 00分 教 研 室 统计 开卷 闭卷 适用专业班级 统计061 提前 期末 班 级 姓名 学号一、填空题(每空1分,共20分):1.SAS 的三个基本窗口是 , 及 。
2.SAS 程序每一数据步以 开始,而过程步以 开始,整个程序以 语句结束。
3.每个语句常以开始的关键词称呼,用 表示语句的结束。
4.运行存在错误的程序后,在 窗口中会出现红色错误提示;可通过按 键或在命令栏中发布 命令或从 菜单中选Recall Last Submit ,将程序重新调入PGM 窗口进行修改。
5.调用SAS/INSIGHT 可在命令行中键入命令 。
6.SAS/INSIGHT 的功能主要有:通过多窗口连动的图象和分析结果,对数据进行探索;分析 分布;用 和 研究多变量间的关系;用 和 说明、拟合变量间关系的模型。
7.调用分析员应用可在命令行中键入命令 。
8.分析员通过选择 的不同选项可完成各种基本分析功能和绘图功能;完成每项任务后,能立即显示相应的结果,而且保留相应的 ;在分析过程中可随时调出有关的图形和结果进行显示。
----------------------------------------------------------------------装--------------------订--------------------线-------------------------------------------------------------试 题 共 3 页 第 1 页run;A. d:\B. d:\sasdataC.c:\D.不确定 4.下列程序读入外部文件的模式是( )Data dst; Infile 'd:\lecsas\basev8\dst\imptdt01.dat' firstobs=2 obs=3; Input ID Age Actlevel $ Sex $; Run;A. 按列输入模式B.格式化输入模式C.列举输入模式D.其它模式 5.列举模式读入分隔符缺省为( )A.Tab 键B.逗号C.空格符D.任意符号都可以 6.提交下列SAS 程序,那种说法是正确的( )proc sort data = work.test; by fname descending salary; run;A. 数据集work.test 先按照fname 降序排列,再按照salary 降序排列B. 数据集work.test 先按照fname 升序排列,再按照salary 降序排列C. 数据集work.test 先按照salary 降序排列,再按照fname 降序排列D. 数据集work.test 先按照salary 降序排列,再按照fname 升序排列 7.提交下列程序,得到的回归方程为( ) data tem; set sasuser. admit; a2=age*age; a3=a2*age;a4=a3*age;run;proc glm data=tem;model fee=age a2 a3 a4/ss1; run;A .fee=age+b1*age 2+b2*age 3+b3*age 4命题负责人: 教研室主任:。
sas完整
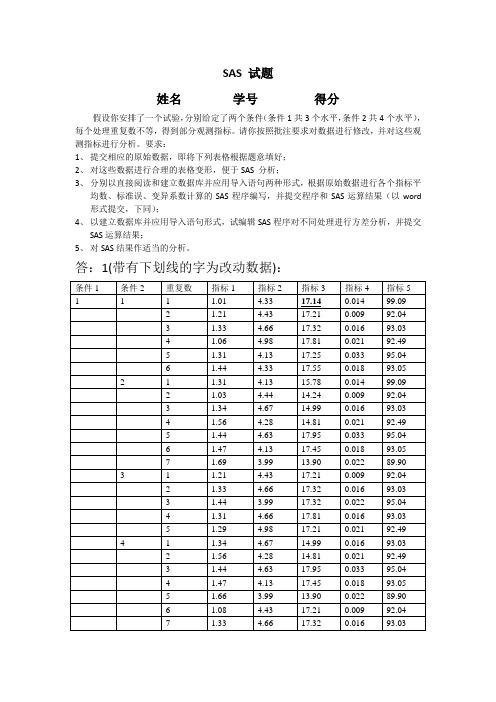
SAS 试题姓名学号得分假设你安排了一个试验,分别给定了两个条件(条件1共3个水平,条件2共4个水平),每个处理重复数不等,得到部分观测指标。
请你按照批注要求对数据进行修改,并对这些观测指标进行分析。
要求:1、提交相应的原始数据,即将下列表格根据题意填好;2、对这些数据进行合理的表格变形,便于SAS 分析;3、分别以直接阅读和建立数据库并应用导入语句两种形式,根据原始数据进行各个指标平均数、标准误、变异系数计算的SAS程序编写,并提交程序和SAS运算结果(以word 形式提交,下同);4、以建立数据库并应用导入语句形式,试编辑SAS程序对不同处理进行方差分析,并提交SAS运算结果;5、对SAS结果作适当的分析。
答:1(带有下划线的字为改动数据):2:变形后的数据:21 1.31 4.1317.250.033 95.04 21 1.82 4.4317.210.009 92.04 21 1.47 4.1317.450.018 93.05 21 1.23 4.9817.210.021 92.49 21 1.21 4.4317.210.009 92.0421 1.31 4.1317.250.033 95.0422 1.5 4.2814.810.021 92.49 22 1.1 3.9913.90.022 89.9 22 1.2 4.1317.450.018 93.05 22 1.66 3.9913.90.022 89.9 22 1.56 4.2814.810.021 92.4922 1.44 4.6317.950.033 95.0423 1.33 4.6617.320.016 93.03 23 1.44 3.9917.320.022 95.04 23 1.31 4.6617.810.016 93.03 23 1.47 4.1317.450.018 93.05 23 1.66 3.9913.90.022 89.9 23 1.82 4.4317.210.009 92.0423 1.33 4.6617.320.016 93.0324 1.33 4.6617.320.016 93.03 24 1.06 4.9817.810.021 92.49 24 1.31 4.1317.250.033 95.04 24 1.44 4.3317.550.018 93.05 24 1.31 4.1315.780.014 99.09 24 1.23 4.4414.240.009 92.04 24 1.34 4.6714.990.016 93.03 31 1.56 4.2814.810.021 92.49 31 1.44 4.6317.950.033 95.04 31 1.47 4.1317.450.018 93.05 31 1.66 3.9913.90.022 89.9 31 1.56 4.2814.810.021 92.4931 1.8 4.6317.950.033 95.0432 1.33 4.6617.320.016 93.03 32 1.44 3.9917.320.022 95.04 32 1.11 4.6617.810.016 93.03 32 1.47 4.1317.450.018 93.05 32 1.66 3.9913.90.022 89.932 1.22 4.4317.210.009 92.0433 1.47 4.1317.450.018 93.05 33 1.23 4.9817.210.021 92.49 33 1.81 4.4317.210.009 92.04 33 1.31 4.1317.250.033 95.04 33 1.56 4.2814.810.021 92.4933 1.47 4.1317.450.018 93.0534 1.66 3.9913.90.022 89.934 1.47 4.1317.450.018 93.0534 1.93 4.9817.210.021 92.4934 1.21 4.4317.210.009 92.0434 1.31 4.1317.250.033 95.0434 1.16 4.2814.810.021 92.4934 1.69 3.9913.90.022 89.934 1.47 4.1317.450.018 93.053、程序:直接阅读数据:data x;input TJ1 TJ2 ZB1 ZB2 ZB3 ZB4 ZB5 @@;output;cards;1 1 1.01 4.33 17.14 0.014 99.09 1 1 1.21 4.43 17.210.009 92.041 1 1.33 4.66 17.32 0.016 93.03 1 1 1.06 4.98 17.810.021 92.491 1 1.31 4.13 17.25 0.033 95.04 1 1 1.44 4.33 17.550.018 93.051 2 1.31 4.13 15.78 0.014 99.09 1 2 1.03 4.44 14.240.009 92.041 2 1.34 4.67 14.99 0.016 93.03 1 2 1.56 4.28 14.810.021 92.491 2 1.44 4.63 17.95 0.033 95.04 1 2 1.47 4.13 17.450.018 93.051 2 1.69 3.99 13.9 0.022 89.9 1 3 1.21 4.43 17.210.009 92.041 3 1.33 4.66 17.32 0.016 93.03 1 3 1.44 3.99 17.320.022 95.041 3 1.31 4.66 17.81 0.016 93.03 1 3 1.29 4.98 17.210.021 92.491 4 1.34 4.67 14.99 0.016 93.03 1 4 1.56 4.28 14.810.021 92.491 4 1.44 4.63 17.95 0.033 95.04 1 4 1.47 4.13 17.450.018 93.051 4 1.66 3.99 13.9 0.022 89.9 1 4 1.08 4.43 17.210.009 92.041 4 1.33 4.66 17.32 0.016 93.03 2 1 1.31 4.13 17.250.033 95.040.018 93.052 1 1.23 4.98 17.21 0.021 92.49 2 1 1.21 4.43 17.210.009 92.042 1 1.31 4.13 17.25 0.033 95.04 2 2 1.5 4.28 14.810.021 92.492 2 1.1 3.99 13.9 0.022 89.9 2 2 1.2 4.13 17.450.018 93.052 2 1.66 3.99 13.9 0.022 89.9 2 2 1.56 4.28 14.810.021 92.492 2 1.44 4.63 17.95 0.033 95.04 2 3 1.33 4.66 17.320.016 93.032 3 1.44 3.99 17.32 0.022 95.04 2 3 1.31 4.66 17.810.016 93.032 3 1.47 4.13 17.45 0.018 93.05 2 3 1.66 3.99 13.90.022 89.92 3 1.82 4.43 17.21 0.009 92.04 2 3 1.33 4.66 17.320.016 93.032 4 1.33 4.66 17.32 0.016 93.03 24 1.06 4.98 17.810.021 92.492 4 1.31 4.13 17.25 0.033 95.04 2 4 1.44 4.33 17.550.018 93.052 4 1.31 4.13 15.78 0.014 99.09 2 4 1.23 4.44 14.240.009 92.042 4 1.34 4.67 14.99 0.016 93.03 3 1 1.56 4.28 14.810.021 92.493 1 1.44 4.63 17.95 0.033 95.04 3 1 1.47 4.13 17.450.018 93.053 1 1.66 3.99 13.9 0.022 89.9 3 1 1.56 4.28 14.810.021 92.493 1 1.8 4.63 17.95 0.033 95.04 3 2 1.33 4.66 17.320.016 93.033 2 1.44 3.99 17.32 0.022 95.04 3 2 1.11 4.66 17.810.016 93.033 2 1.47 4.13 17.45 0.018 93.05 3 2 1.66 3.99 13.90.022 89.93 2 1.22 4.43 17.21 0.009 92.04 3 3 1.47 4.13 17.450.018 93.053 3 1.23 4.98 17.21 0.021 92.49 3 3 1.81 4.43 17.210.009 92.043 3 1.31 4.13 17.25 0.033 95.04 3 3 1.56 4.28 14.810.021 92.493 3 1.66 3.99 13.9 0.022 89.9 3 3 1.47 4.13 17.450.018 93.050.018 93.053 4 1.93 4.98 17.21 0.021 92.49 3 4 1.21 4.43 17.210.009 92.043 4 1.31 4.13 17.25 0.033 95.04 3 4 1.16 4.28 14.810.021 92.493 4 1.69 3.99 13.9 0.022 89.9 3 4 1.47 4.13 17.450.018 93.05;proc MEANS MEAN STDERR CV MAXDEC=3;CLASS TJ1 TJ2;var ZB1 ZB2 ZB3 ZB4 ZB5;run;建立数据库并导入数据:PROC IMPORT OUT= WORK.SHUJUDATAFILE= "C:\Users\ZZY\Desktop\SAS数据.txt"DBMS=TAB REPLACE;GETNAMES=YES;DATAROW=2;RUN;DATA Y;SET SHUJU;proc MEANS MEAN STDERR CV MAXDEC=3;CLASS TJ1 TJ2;var ZB1 ZB2 ZB3 ZB4 ZB5;run;结果(1:电脑系统时间已改;2:TJ1、TJ2、ZB1、ZB2、ZB3、ZB4、ZB5分别代表条件1、条件2、指标1、指标2、指标3、指标4、指标5;3:删除部分空格,使表格对齐):SAS 系统 2009年11月19日星期四下午02时00分16秒 1MEANS PROCEDURETJ1 TJ2 观测的个数变量均值标准误差变异系数-------------------------------------------------------------------------------1 1 6 ZB1 1.227 0.068 13.550ZB3 17.380 0.103 1.457 ZB4 0.019 0.003 44.146 ZB5 94.123 1.078 2.8052 7 ZB1 1.406 0.079 14.938 ZB2 4.324 0.099 6.086 ZB3 15.589 0.592 10.045 ZB4 0.019 0.003 39.852 ZB5 93.520 1.093 3.0913 5 ZB1 1.316 0.037 6.303 ZB2 4.544 0.164 8.063 ZB3 17.374 0.112 1.438 ZB4 0.017 0.002 30.757 ZB5 93.126 0.513 1.2324 7 ZB1 1.411 0.071 13.245 ZB2 4.399 0.103 6.224 ZB3 16.233 0.609 9.926 ZB4 0.019 0.003 38.304 ZB5 92.654 0.580 1.6562 1 6 ZB1 1.392 0.093 16.451 ZB2 4.372 0.136 7.601 ZB3 17.263 0.038 0.542 ZB4 0.021 0.004 52.696 ZB5 93.283 0.576 1.5122 6 ZB1 1.410 0.088 15.349 ZB2 4.217 0.098 5.703 ZB3 15.470 0.727 11.517 ZB4 0.023 0.002 22.743 ZB5 92.145 0.807 2.1443 7 ZB1 1.480 0.073 13.044 ZB2 4.360 0.120 7.263 ZB3 16.904 0.506 7.920 ZB4 0.017 0.002 26.087 ZB5 92.731 0.581 1.6594 7 ZB1 1.289 0.045 9.176 ZB2 4.477 0.118 6.989 ZB3 16.420 0.533 8.582ZB5 93.967 0.924 2.6033 1 6 ZB1 1.582 0.054 8.353ZB2 4.323 0.107 6.035ZB3 16.145 0.749 11.362ZB4 0.025 0.003 26.728ZB5 93.002 0.784 2.0662 6 ZB1 1.372 0.080 14.237ZB2 4.310 0.129 7.312ZB3 16.835 0.593 8.630ZB4 0.017 0.002 28.159ZB5 92.682 0.685 1.8113 7 ZB1 1.501 0.075 13.212ZB2 4.296 0.126 7.735ZB3 16.469 0.556 8.933ZB4 0.020 0.003 35.056ZB5 92.580 0.577 1.6494 8 ZB1 1.488 0.093 17.658ZB2 4.258 0.115 7.658ZB3 16.148 0.579 10.138ZB4 0.021 0.002 32.252ZB5 92.245 0.602 1.845-------------------------------------------------------------------------------4、程序:PROC IMPORT OUT= WORK.QUANBUDATAFILE= "C:\Users\ZZY\Desktop\SAS数据.txt"DBMS=TAB REPLACE;GETNAMES=YES;DATAROW=2;RUN;data Y;SET QUANBU;PROC ANOVA DATA=Y;CLASS TJ1 TJ2;MODEL ZB1 ZB2 ZB3 ZB4 ZB5=TJ1 TJ2 TJ1*TJ2;RUN;结果(1:电脑系统时间已改;2:TJ1、TJ2、ZB1、ZB2、ZB3、ZB4、ZB5分别代表条件1、条件2、指标1、指标2、指标3、指标4、指标5;3:删除部分空格,使表格对齐):SAS 系统 2009年11月19日星期四下午02时11分46秒 1 The ANOVA ProcedureClass Level InformationClass Levels ValuesTJ1 3 1 2 3TJ2 4 1 2 3 4Number of Observations Read 78Number of Observations Used 78SAS 系统 2009年11月19日星期四下午02时11分46秒 2The ANOVA ProcedureDependent Variable: ZB1Sum ofSource DF Squares Mean Square F Value Pr > FModel 11 0.67771810 0.06161074 1.67 0.1011Error 66 2.44068190 0.03698003Corrected Total 77 3.11840000R-Square Coeff Var Root MSE ZB1 Mean0.217329 13.63843 0.192302 1.410000Source DF Anova SS Mean Square F Value Pr > FTJ1 2 0.26679052 0.13339526 3.61 0.0326TJ2 3 0.03048421 0.01016140 0.27 0.8434TJ1*TJ2 6 0.38044336 0.06340723 1.71 0.1314SAS 系统 2009年11月19日星期四下午02时11分46秒 3The ANOVA ProcedureDependent Variable: ZB2Sum ofSource DF Squares Mean Square F Value Pr > F Model 11 0.62629062 0.05693551 0.61 0.8111 Error 66 6.12832476 0.09285341Corrected Total 77 6.75461538R-Square Coeff Var Root MSE ZB2 Mean0.092720 6.991425 0.304719 4.358462Source DF Anova SS Mean Square F Value Pr > FTJ1 2 0.22610437 0.11305219 1.22 0.3025TJ2 3 0.13619773 0.04539924 0.49 0.6912TJ1*TJ2 6 0.26398852 0.04399809 0.47 0.8254SAS 系统 2009年11月19日星期四下午02时11分46秒 4The ANOVA ProcedureDependent Variable: ZB3Sum ofSource DF Squares Mean Square F Value Pr > F Model 11 28.2458789 2.5678072 1.32 0.2345 Error 66 128.5673890 1.9479907Corrected Total 77 156.8132679R-Square Coeff Var Root MSE ZB3 Mean0.180124 8.465985 1.395704 16.48603Source DF Anova SS Mean Square F Value Pr > FTJ1 2 0.45027037 0.22513519 0.12 0.8910TJ2 3 12.97947231 4.32649077 2.22 0.0939TJ1*TJ2 6 14.81613622 2.46935604 1.27 0.2844SAS 系统 2009年11月19日星期四下午02时11分46秒 5The ANOVA ProcedureDependent Variable: ZB4Sum ofSource DF Squares Mean Square F Value Pr > F Model 11 0.00037867 0.00003442 0.70 0.7309 Error 66 0.00323051 0.00004895Corrected Total 77 0.00360918R-Square Coeff Var Root MSE ZB4 Mean0.104917 35.76053 0.006996 0.019564Source DF Anova SS Mean Square F Value Pr > FTJ1 2 0.00005818 0.00002909 0.59 0.5549TJ2 3 0.00008803 0.00002934 0.60 0.6176TJ1*TJ2 6 0.00023245 0.00003874 0.79 0.5798SAS 系统 2009年11月19日星期四下午02时11分46秒 6 The ANOVA ProcedureDependent Variable: ZB5Sum ofSource DF Squares Mean Square F Value Pr > FModel 11 28.6945646 2.6085968 0.69 0.7463Error 66 250.7465033 3.7991894Corrected Total 77 279.4410679R-Square Coeff Var Root MSE ZB5 Mean0.102686 2.096101 1.949151 92.98936Source DF Anova SS Mean Square F Value Pr > FTJ1 2 7.40891360 3.70445680 0.98 0.3825TJ2 3 5.62022255 1.87340752 0.49 0.6883TJ1*TJ2 6 15.66542847 2.61090474 0.69 0.66065、从以上结果中可以看出,除指标1的P<0.05以外,其他的均为P>0.05,所以可以得出结论:⑴条件1水平的改变对指标1有显著的影响,条件2对指标1的影响不显著;⑵条件1与条件2对其他指标均无显著的影响;⑶条件1与条件2在各指标中均无互做作用。
SAS综合练习题的(答案)

SAS金融数据处理综合练习题1.创建一包含10000个变量(X1-X10000),100个观测值的SAS数据集。
分别用DATA步,DATA步数组语句和IML过程实现。
(1)用data步实现data test1a;informat x1-x10000 9.2; /*创建100个变量,规定输出格*/do i=1to100; /*做循环*/output;/*每一次循环,输出所有的变量,包括i*/drop i;/*去掉i*/end;run;或者data test1a;format x1-x10000 best12.; /*创建10000个变量x1-x10000,但未有初始化*/do i=1to100; /*创建100个观测*/output;/*且每一个观测都输出到数据集test1a*/end;drop i;run;(2)用data步数组语句实现data test1b;array t{10000} x1-x10000 ;/*创建数组变量*/do i =1to100;/*每个变量有100个观测*/output;/*每一次循环,输出所有的变量,包括i*/drop i;/*去掉i*/end;/*循环结束*/data test1c;array t{10000} x1-x10000;do j=1to100;/*100次观测的循环*/do i = 1to10000;t{i}=i;/*第i个变量等于i*/end;output;/*输出第i次观测的i个变量的值*/end;drop i j;/*去掉i和j*/run;或者data test1b;array t{10000} x1-x10000;do j=1to100;/*100次观测的循环*/do i = 1to10000;t{i}=i;/*第i个变量等于i*/end;output;/*输出第i次观测的i个变量的值*/end;drop i j;/*去掉i和j*/run;(3)用IML过程实现proc iml;/*启用iml环境*/x='x1':'x10000';/*定义数组x1-x10000*/t= j(100,10000,1) ;/*创建100行10000列的. 同元素矩阵*/print t x;/*打印两个矩阵察看*/create test1d from t[colname=x];/*创建数据集c,变量数为列数,观测数为行数,列名更改为变量名,默认逻辑库为临时*/append from t; /*将t中的值填充的数据集中*/show datasets;show contents;/*显示数据集的一些7788的属性*/close test1d;run;quit;或者proc iml;x='x1':'x10000';t= shape(1,100,10000) ;/*shape和j不太一样,顺序是元素,行,列,j的顺序为行,列,元素*/print t x;create test1d from t[colname=x];append from t;show datasets;show contents;close test1d;run;quit;(4)用宏实现%macro names(name,number,obs);data a;%do i=1%to &obs;%do n=1%to &number;&name&n=1;%end;output;%end;run;%mend names;%names(x, 10000,100);2.多种方法创建包含变量X的10000个观测值的SAS数据集。
SPSS金融分析软件 习题及答案

第 3 周习题:转置、生产序列号
1、对于下表中的数据,请你采用 SPSS 的 Transpose 和 Compute 功能计算拉斯贝 尔产量指数、派许价格指数和总指数,计算公式分别为:
Kq
q p q p
1 0
0 0
;
Kp
q p q p
1
1 1 0
;K
q p q p
0
1 1 0
COMPUTE k = q1p1 / q0p0 . EXECUTE . 2、请你打开 SPSS 自带的数据文件“voter . sav” ,先对文件中的年龄(age)从
小到大排序(Sort cases) ,然后采用 SPSS 的某项功能(说明是哪一项?)生成 一列序号变量,变量名为“id” ,变量名标签为“选民的序号” ,最后填写下表中 相应 id 号(采用 go to case 功能定位)的选民信息: id pres92 age agecat educ degree sex 55 Clinton 29 lt 35 13 high school female 109 Clinton 47 45 - 64 16 bachelor male 239 Perot 83 65 + 12 high school female 1211 Clinton 74 65 + 12 high school female 1485 Bush 73 65 + 12 high school male 1778 Perot 43 35 - 44 16 bachelor female 说 明 : 生 成 一 列 序 号 变 量 , 采 用 SPSS 菜 单 ___Data_____ 下 的 __define datas_______,选择其中的___days_______或___years_______。
SAS参考答案

SAS参考答案SAS参考答案在当今信息爆炸的时代,人们对于获取知识的需求也越来越迫切。
无论是学生们的功课辅导,还是企业中的数据分析,都需要一种高效而可靠的工具来帮助他们解决问题。
而SAS(Statistical Analysis System)作为一种全球领先的数据分析软件,提供了一系列强大的功能和工具,为用户提供了解决问题的参考答案。
SAS作为一种统计分析软件,可以帮助用户处理和分析大规模的数据集。
它提供了一套完整的数据处理和分析工具,包括数据清洗、数据管理、数据可视化、统计分析等功能。
无论是学术研究还是商业决策,SAS都可以为用户提供准确和全面的数据分析结果。
首先,SAS在数据清洗方面发挥着重要作用。
数据清洗是数据分析的第一步,它涉及到对数据进行筛选、去重、填充缺失值等操作,以确保数据的准确性和完整性。
SAS提供了丰富的数据处理函数和语句,可以帮助用户快速清洗数据,减少错误和噪声的干扰,从而得到更可靠的分析结果。
其次,SAS在数据管理方面也具备强大的功能。
在处理大规模数据集时,数据管理变得尤为重要。
SAS提供了灵活的数据存储和查询方式,可以高效地管理和检索数据。
用户可以通过SAS的数据集和数据视图来组织和管理数据,同时还可以使用SQL语句进行复杂的数据查询和操作。
这些功能使得用户能够轻松地处理和管理庞大的数据集,提高工作效率。
此外,SAS还具备出色的数据可视化能力。
数据可视化是将数据转化为图表、图形等可视化形式,以便用户更好地理解和分析数据。
SAS提供了多种数据可视化工具,如图形绘制、统计图表生成等,用户可以根据自己的需求选择合适的可视化方式。
通过直观的数据可视化,用户可以更清晰地把握数据的规律和趋势,从而做出更准确和有针对性的决策。
最后,SAS作为一种统计分析软件,自然也具备强大的统计分析能力。
无论是描述性统计还是推断性统计,SAS都可以提供全面而准确的分析结果。
它支持各种统计方法和模型,如回归分析、方差分析、聚类分析等,用户可以根据自己的需求选择合适的方法进行分析。
SAS基础与金融计算4

SAS基础与金融计算4引言本文档旨在介绍SAS(Statistical Analysis System)及其在金融计算中的基础应用。
SAS是一种广泛使用的统计分析软件,其功能强大,能够进行数据的处理、分析和可视化。
在金融领域,SAS被广泛应用于风险管理、投资组合分析、量化交易等方面。
本文将介绍SAS的一些基础知识,并结合金融计算的实例进行说明。
第一部分:SAS基础知识1. SAS语言基础SAS语言是一种类似于英语的编程语言,用于描述数据的处理和分析过程。
以下是一些基础的SAS语言元素:•数据集(Data Set):SAS中的数据存储在数据集中,每个数据集由变量和观测组成。
•数据步(Data Step):数据步是SAS程序中用来对数据进行处理的基本单位,包括数据导入、数据转换等操作。
•过程(Procedure):过程是SAS程序中用来进行数据分析的模块,比如描述统计、线性回归等。
•语句(Statement):语句是SAS程序的最小执行单位,每个语句以分号结尾。
2. SAS数据集操作SAS提供了丰富的数据集操作函数,可以对数据集进行增删改查等操作。
以下是一些常用的数据集操作:•创建数据集:使用data语句可以创建一个新的数据集,并定义其中的变量。
•导入数据:使用import语句可以从外部文件导入数据到SAS中的数据集。
•数据过滤:使用where语句可以对数据进行条件过滤,只选择满足条件的观测。
•数据排序:使用sort语句可以对数据集按照指定的变量进行排序。
•数据合并:使用merge语句可以将两个或多个数据集按照共有的变量合并成一个数据集。
3. SAS统计分析SAS提供了各种统计分析的过程,可用于探索数据的特征、分析数据之间的关系等。
以下是一些常用的统计分析过程:•描述统计:使用proc means过程可以计算数据的基本统计量,比如均值、方差等。
•数据分组:使用proc freq过程可以对数据按照指定的变量进行分组统计。
SAS数据分析应用实例及相关程序
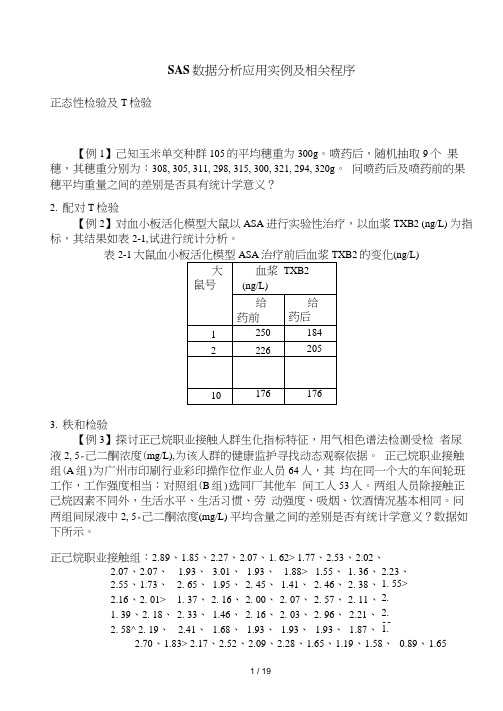
SAS数据分析应用实例及相关程序正态性检验及T检验【例1】己知玉米单交种群105的平均穗重为300g。
喷药后,随机抽取9个果穗,其穗重分别为:308, 305, 311, 298, 315, 300, 321, 294, 320g。
问喷药后及喷药前的果穗平均重量之间的差别是否具有统计学意义?2.配对T检验【例2】对血小板活化模型大鼠以ASA进行实验性治疗,以血浆TXB2 (ng/L) 为指标,其结果如表2-1,试进行统计分析。
表2-1大鼠血小板活化模型ASA治疗前后血浆TXB2的变化(ng/L)3.秩和检验【例3】探讨正己烷职业接触人群生化指标特征,用气相色谱法检测受检者尿液2, 5-己二酮浓度(mg/L),为该人群的健康监护寻找动态观察依据。
正己烷职业接触组(A组)为广州市印刷行业彩印操作位作业人员64人,其均在同一个大的车间轮班工作,工作强度相当:对照组(B组)选同厂其他车间工人53人。
两组人员除接触正己烷因素不同外,生活水平、生活习惯、劳动强度、吸烟、饮酒情况基本相同。
问两组间尿液中2, 5-己二酮浓度(mg/L) 平均含量之间的差别是否有统计学意义?数据如下所示。
正己烷职业接触组:2.89、1.85、2.27、2.07、1. 62> 1.77、2.53、2.02、2.07、2.07、 1.93、3.01、1.93、 1.88> 1.55、1. 36、2.23、2.55、1.73、 2. 65、1.95、2. 45、1.41、2. 46、2. 38、1. 55>2.16、2. 01> 1. 37、2. 16、2. 00、2. 07、2. 57、2. 11、2.37、1. 39、2. 18、2. 33、1.46、2. 16、2. 03、2. 96、2.21、2.00、2. 58^ 2. 19、 2.41、1.68、1.93、1.93、1.93、1.87、1.74、2.70、1.83> 2.17、2.52、2.09、2.28、1.65、1.19、1.58、0.89、1.65对照组:0.27、0.36、0.26、0.16、0.49、0.58、0.16、0.45、0.22、0.25、0. 66> 0. 05、0.31 >0.12、0.51、0.30、0. 37> 0.14、0. 28> 0.33、0.36、0.51、0.37、0.36、0.47、0.34、0. 72、0. 39> 0. 55、0. 17> 0. 27、0. 33、0. 30、0. 26、0. 50、0. 17、0. 22、0. 18、0. 17>0.62、0. 27> 0.26、0.34、0.17、0.61、0.42、0.39、0.28、0. 36> 0.43、0.24、0. 15、0. 194.两独立正态总体的检验【例4】一个小麦新品种经过6代选育,从第5代(A组)中抽出10株,株高为:66、65、66、68、62、65> 63、66、68、62 (cm),又从第6代(B组)中抽出10株,株高为:64、61、57、65、65、63、62、63、64、60 (cm), 问株高性状是否己经达到稳定?5.单因素K (KM3)水平方差分析【例5】从津丰小麦4个品系中分別随机抽取10株,测量其株高(cm),数据如下所示,问不同品系津丰小麦的平均株高之间的差别是否具有统计学意义?品系0-3-1: 63、65、64、61、68 > 65、65、63、64品系0-3-2: 56、54、58、57、57、60、59、63、62品系0-3-3: 61、61、67、62、60、67> 66、63、65品系0-3-4: 53、58、60、55、60、59、61、60、596.双因素无重复试验的方差分析【例6】某医生欲研究回心草各单体成分对试验性心肌缺血血流动力学的影响,选取健康新西兰家兔若干只,体重(2.0±0.3)畑,雌雄不计,将其随机分成9组:胡椒碱高剂量组(100MO〃L)、胡椒碱中剂量组(10mo〃L)、胡椒碱低剂量组(1MO〃L)、胡椒酸甲酯高剂量组(100沏?刃/L)、胡椒酸甲酯中剂量组(10MO〃L)、胡椒酸甲酯低剂量组(lmo〃L)、咖啡酸甲酯高剂量组(100沏zo〃L)、咖啡酸甲酯中剂量组(10mo〃L)、咖啡酸甲酯低剂量组(lmo〃L) o所有家兔处死后,造缺血缺氧的离体心脏模型,给以各试验组相应种类及浓度的药物进行试验,记录各组试验家兔血流动力学指标的平均值,结果见表4-2。
SAS 2 例题和习题数据

第2章描述性统计例题数据[例]某小麦品种的每穗小穗数为例,随机采取100个麦穗,计数每穗小穗数,未加整理的资料列成表3-1。
18 15 17 19 16 15 20 18 19 1717 18 17 16 18 20 19 17 16 1817 16 17 19 18 18 17 17 17 1818 15 16 18 18 18 17 20 19 1817 19 15 17 17 17 16 17 18 1817 19 19 17 19 17 18 16 18 1717 19 16 16 17 17 17 15 17 1618 19 18 18 19 19 20 17 16 1918 17 18 20 19 16 18 19 17 1615 16 18 17 18 17 17 16 19 17[例] 100行水稻试验的产量。
表3-4 140行水稻产量(单位:克)177 215 197 97 123 159 245 119 119 131 149 152 167 104161 214 125 175 219 118 192 176 175 95 136 199 116 165214 95 158 83 137 80 138 151 187 126 196 134 206 13798 97 129 143 179 174 159 165 136 108 101 141 148 168163 176 102 194 145 173 75 130 149 150 161 155 111 158131 189 91 142 140 154 152 163 123 205 149 155 131 209183 97 119 181 149 187 131 215 111 186 118 150 155 197116 254 239 160 172 179 151 198 124 179 135 184 168 169173 181 188 211 197 175 122 151 171 166 175 143 190 213192 231 163 159 158 159 177 147 194 227 141 169 124 159[例]某水稻杂种第二代植株米粒性状的分离情况,归于表3-7。
sas练习题

SAS练习题一、基础操作类1. 如何在SAS中创建一个数据集?2. 请写出SAS中读取外部数据文件的语句。
3. 如何在SAS中查看数据集的结构?4. 如何在SAS中对数据集进行排序?5. 请写出SAS中合并两个数据集的语句。
6. 如何在SAS中删除一个数据集?7. 请简述SAS中变量的命名规则。
8. 如何在SAS中修改数据集的属性?9. 请写出SAS中创建临时数据集和永久数据集的语句。
10. 如何在SAS中导入和导出Excel文件?二、数据处理类1. 如何在SAS中对缺失值进行处理?2. 请写出SAS中计算变量总和、平均数、最大值和最小值的语句。
3. 如何在SAS中进行条件筛选?4. 请简述SAS中日期和时间的处理方法。
5. 如何在SAS中实现数据的分组汇总?6. 请写出SAS中创建新变量的语句。
7. 如何在SAS中进行数据类型转换?8. 请写出SAS中替换变量值的语句。
9. 如何在SAS中实现数据的横向连接和纵向连接?10. 请简述SAS中数组的使用方法。
三、统计分析类1. 如何在SAS中进行单因素方差分析?2. 请写出SAS中进行t检验的语句。
3. 如何在SAS中计算相关系数?4. 请简述SAS中回归分析的基本步骤。
5. 如何在SAS中进行主成分分析?6. 请写出SAS中进行聚类分析的语句。
7. 如何在SAS中实现时间序列分析?8. 请简述SAS中生存分析的基本概念。
9. 如何在SAS中进行非参数检验?10. 请简述SAS中多重响应分析的方法。
四、图形绘制类1. 如何在SAS中绘制直方图?2. 请写出SAS中绘制散点图的语句。
3. 如何在SAS中绘制饼图?4. 请简述SAS中绘制箱线图的方法。
5. 如何在SAS中绘制条形图?6. 请写出SAS中绘制折线图的语句。
7. 如何在SAS中设置图表的颜色和样式?8. 请简述SAS中绘制雷达图的方法。
9. 如何在SAS中实现图表的交互功能?10. 请简述SAS中图表导出的方法。
SAS练习题及程序答案

1.随机取组有无重复试验的两种本题是无重复DATA PGM15G;DO A=1TO4; /*A为窝别*/DO B=1TO3; /*B为雌激素剂量*/INPUT X @@; /*X为子宫重量*/OUTPUT;END;END;CARDS;106 116 14542 68 11570 111 13342 63 87;RUN;ods html; /*将结果输出成网页格式,SAS9.0以后版本可用*/ PROC GLM DATA=PGM15G;CLASS A B;MODEL X=A B / SS3;MEANS A B; /*给出因素A、B各水平下的均值和标准差*/MEANS B / SNK; /*对因素B(即剂量)各水平下的均值进行两两比较*/ RUN;ODS HTML CLOSE;2.2*3析因设计两因素完全随机统计方法2*3析因设计tiff =f的开方DATA aaa;DO zs=125,200;DO repeat=1TO2; /*每种试验条件下有2次独立重复试验*/do js=0.015,0.030,0.045;INPUT cl @@;OUTPUT;END;END;END;CARDS;2.70 2.45 2.602.78 2.49 2.722.83 2.85 2.862.86 2.80 2.87;run;PROC GLM;CLASS zs js;MODEL cl=zs js zs*js / SS3;MEANS zs*js;LSMEANS zs*js / TDIFF PDIFF; /*对 zs和js各水平组合而成的试验条件进行均数进行两两比较*/RUN;ODS HTML CLOSE;练习一:2*2横断面研究列链表方法:卡方矫正卡方FISHERDATA PGM19A;DO A=1TO2;DO B=1TO2;INPUT F @@;OUTPUT;END;END;CARDS;2 268 21;run;PROC FREQ;WEIGHT F;TABLES A*B / CHISQ;RUN;样本大小= 57练习二:对裂列连表结果变量换和不换三部曲1横断面研究P《0.05 RDATA PGM19B;DO A=1TO2;DO B=1TO2;INPUT F @@;OUTPUT;END;END;CARDS;40 34141 19252;run;ods html;PROC FREQ;WEIGHT F;TABLES A*B / CHISQ cmh;RUN;ods html close;样本大小= 57练习三:病例对照2*2 病例组中有何没有那个基因是正常的3.8倍,则有可能导致痴呆要做前瞻性研究用对裂DATA PGM20;DO A=1TO2;DO B=1TO2;INPUT F @@;OUTPUT;END;END;CARDS;240 60360 340;run;ods html;PROC FREQ;WEIGHT F;TABLES A*B / CHISQ cmh;RUN;ods html close;总样本大小= 1000练习四:配对设计隐含金标准2*2 MC卡方检验34和0在总体上(B+C《40 用矫正卡方)是否相等则可得甲培养基优于乙培养基一般都用矫正因卡方为近似计算DATA PGM19F;INPUT b c;chi=(ABS(b-c)-1)**2/(b+c);p=1-PROBCHI(chi,1);求概率 1减掉从左侧积分到卡方的值chi=ROUND(chi, 0.001);IF p>0.0001THEN p=ROUND(p,0.0001);FILE PRINT;PUT(打印在输出床口) #2 @10'Chisq' @30'P value'(#表示行)#4 @10 chi @30 p;CARDS;34 0;run;ods html close;练习五:双向有序R*C列连表用KPA data aaa;do a=1to3;do b=1to3;input f @@;output;end;end;cards;58 2 31 42 78 9 17;run;ods html;*简单kappa检验;proc freq data=aaa;weight f;(频数)tables a*b;test kappa;run;*加权kappa检验;proc freq;weight f;tables a*b;test wtkap;run;SASFREQ 过程a *b 表的统计量对称性检验指总体上主对角线的上三角数相加是否与下三角三个数相加对称性检验与KPA 检验是否一致是否一个可以代替另一个检验Pe理论观察一致率独立假设性基础上计算的相互独立总体的KPA 是否为0 KPA 大于0两种方法的一致性有统计学意义 小于0 不一致性有统计学意义置信区间不包括0 拒绝H0 但要看专业要求达到多少才可以 观测一致率达到多少才可以代替 样本大小 = 147FREQ 过程a *b 表的统计量对加权的KPA检验与简单的(利用对角线上的数据分析)加权还要利用对角线以外的数据分析样本大小= 147练习六:双向无序R*C 列连表用卡方理论频数小于5没有超过五分之一,一般用卡方实在不行用FISHER检验超过用KPA 两种血型都是按小中大排列相互不影响独立的接受H0 不一致行与列变量相互不影响DATA PGM20A;DO A=1TO4;DO B=1TO3;INPUT F @@;OUTPUT;END;END;CARDS;431 490 902388 410 800495 587 950137 179 325;run;ods html;PROC FREQ;WEIGHT F;TABLES A*B / CHISQ;*exact;RUN;ods html close;样本大小= 6094练习七:单向有序R*C 秩和检验*方法1;(单因素非参数 HO三个药物疗效相同 H1不完全相等)DATA PGM20C;DO A=1TO4;DO B=1TO3;INPUT F @@;OUTPUT;END;END;CARDS;15 4 149 9 1531 50 455 22 24;run;ods html;PROC NPAR1WAY WILCOXON;FREQ F;CLASS B;VAR A;RUN;*方法2;(FIQ CHIM)proc freq data=PGM20C;weight f;tables b*a/cmh scores=rank;run;ods html close;总样本大小= 270练习八:双向有序属性不同R*C 4种目的4种方法SPEARMAN秩相关分析DATA PGM20E;DO A=1TO3;DO B=1TO3;INPUT F @@;OUTPUT;END;END;CARDS;215 131 14867 101 12844 63 132;run;ods html;PROC CORR SPEARMAN;VAR A B;FREQ F;RUN;ods html close;统计分析与SAS实现第1次上机实习题一、定量资料上机实习题要求:(1)先判断定量资料所对应的实验设计类型;(2)假定资料满足参数检验的前提条件,请选用相应设计的定量资料的方差分析,并用SAS软件实现统计计算;(3)摘录主要计算结果并合理解释,给出统计学结论和专业结论。
SAS和金融数据处理

• 每一行命令都以分号结束 • 最后需要加run;表示程序告一段落,可以开始运行 • 运行的方式是通过鼠标选定需要运行的命令段(被 颜色覆盖),然后点击菜单栏的“运行”命令,或 者按键盘的F3键。
窗口介绍
• 一些小习惯
• 把sas code和相应的sas data保存在同一个文件夹 • 对于一些经常用到的sas code可以保存下来,方便以 后取用 • 通过google和SAS global forum了解一些sas的处理技 巧
数据的合并
• 横向的合并:merge
– 按照相同的某个变量合并(如股票代码、年份)
PROC SORT DATA=data; BY stkcd; PROC SORT DATA=inddata; BY stkcd; RUN;
DATA data1; MERGE data inddata; BY stkcd; RUN;
经济、金融和会计研究中,SAS和Stata使用比较广泛
窗口介绍
结果输出窗口 保存数据的逻 辑库 数据处理和程序检 查的日志(记录)
SAS运行程序
窗口介绍
Work是默认的逻辑 库,此逻辑库下的 数据在关闭sas程序 后不能保存
窗口介绍
• 逻辑库
– 普通逻辑库
• 好比电脑的文件夹,可以保存数据 • 新建逻辑库需要制定存储路径 • 引用数据时,表达格式为:逻辑库名.数据文件名(比如 ds.data1)
• 保留变量
Data test1; set test; keep var1 var2; Run;
变量
• 更改变量名称
Data test;set test; Rename var1=var1_n var2=var2_n; Label var1=‘var1_n’ var2=‘var2_n’; Run;
金融数据库——SAS数据处理应用题

SAS数据处理应用题_2005以下练习题选自《SAS数据处理综合练习》,解决这些题目原则上需要学完《SAS编程技术与金融数据》前18章内容。
1. 创建一包含10000个变量(X1-X10000),100个观测值的SAS数据集。
分别用DATA 步,DA TA步数组语句和IML过程实现。
2. 创建包含日期变量DA TE的SAS数据集,日期值从1900年1月1日到2000年1月1日。
3. 多种方法创建包含变量X的10000个观测值的SAS数据集。
4. 利用随机数函数RANUNI对某数据集设计返回抽样方案?5. 利用随机数函数RANUNI对某数据集设计不返回抽样方案?6. 数据集A中日期变量DATE包含有缺失值,创建包含日期变量DATE的数据集B,并填充开始到结束日之间的所有日期值。
7. 创建组标识变量GROUP,将数据集A中的观测等分为10组,观测值不能整除10时,前余数组各多加一个观测值。
8. 数据集A有一个变量n,5个观测值1,2,3,4,5。
数据A1由下面程序2产生,同样有一个变量n,5个观测值1,2,3,4,5。
试分析下面两段程序中,PUT语句在Log窗口输出结果的差异,为什么?程序1:Data a; Set a; Put n=; Run; 程序2: data a1;do n=1 to 5; output; end;put n=; run;9. 假设数据集A中的变量logdate为如下形式的字符格式:1998-12-21999-8-61999-8-10将其转换为日期格式变量date。
如果字符格式的数据为:199812021999080619990810又怎样转换为日期格式变量。
10. 数据集fdata. Calendar包含一个日期变量,fdata. bond_price包含一个债券代码、一个日期变量与其它相应的价格。
合并两个数据集,用Calendar中的日期数据替代bond_price 数据集中每支债券中的日期数据。
金融数据库——SAS编程与数据处理2-18章复习题

金融数据库——SAS编程与数据处理2-18章复习题SAS编程与数据处理2-18章复习题朱世武著.《SAS编程技术与金融数据处理》.清华大学出版社. 2003.7第2章SAS系统快速入门1.SAS系统的特点。
2.简述SAS的三类功能与相应的模块举例。
3.SAS技术水平的三个层次.4.缺省情况下SAS系统的五个功能窗口及各自的作用是什么?怎样定义激活这些窗口的快捷键?5.SAS程序的一般特点。
6.SAS日志窗口的信息构成。
7.会使用工具菜单的options选项。
8.在显示管理系统下,切换窗口和完成各种特定的功能等,有四种发布命令的方式:即,在命令框直接键入命令;使用下拉菜单;使用工具栏;按功能键。
试举例说明这些用法。
9.理解SAS逻辑库、临时库和永久库的概念。
会用菜单方式新建SAS永久库。
10.说明下面SAS命令的用途:keys, dlglib, libname, dir, var, options, submit, recall.11.怎样增加和删除SAS工具?12.会用菜单方式导入(Import)和导出SAS数据集(Export)。
13.会用菜单方式创建查询。
14.会用SAS的INSIGHT模块进行简单的数据分析。
15.简述SAS逻辑库的作用。
第3章数据步创建SAS数据集1.理解SAS语句的信息构成。
举例说明。
2.SAS名的种类及命名规则。
什么是SAS关键词?3.理解Data步的Proc步。
4.SAS变量的类型和属性。
举例说明SAS自动变量。
5.理解SAS程序。
SAS程序的书写规则。
给一个简单SAS 程序的例子,适当应用SAS的注释语句。
6.SAS数据集中变量列表时,X1-Xn表示什么?特殊SAS变量列表_numeric_, _character_和_all_的含义。
7.怎样提交SAS程序?程序执行过程中,LOG窗口显示的信息结构。
8.怎样查看SAS程序的输出结果。
9.SAS表达式定义及其构成元素。
[课件]SAS数据步练习题PPT
![[课件]SAS数据步练习题PPT](https://img.taocdn.com/s3/m/bae317e62cc58bd63186bda8.png)
的相关公司数据。
练习
对sashelp里的GNP数据进行如下分析: 1 ) 计 算 各 年 份 的 gnp 、 consump 、 invest 、 exports 、 govt 总 合 , 保 存 所 获 得 的 数 据 集 为 gnpsum; 2 )将数据集 gnpsum 和 gnp 进行合并,要求总合数 据出现在每年的最后一个季度,产生新的数据集为 gnpsum2;
练习
1. 计算标准正态分布在x=-3,-2,-1, 0,1,2,3时的 分布函数F(x)和密度函数(x)的值;
2. 设随机变量T~t(n),计算t分布的分位数tp(n),
其中n=1,5,10,20; p=0.10,0.90, 0.95, 0.975; 3. 当日期值date=’14JUL2007’d时,试问这一天是星 期几?
山本美智子 87/01/18 623.3 id=003 sex=女 张美萍 85/04/30 589.6 id=018 sex=女 王晓刚 84/09/11 578 id=021 sex=男 杨英 82/11/19 587.9 id=034 sex=女
练习
通过DATA步内编程来建立一个由姓名(name)、生 日( birthday )、性别( sex )、积分( score1score3 )、工资 (wage) 、百分比 (percent) 组成的 SAS 数据集,并输出数据集。原始数据(不能改变 其格式)如下:
1 ) 在 company 数 据 集 基 础 上 产 生 新 的 数 据 集
08-09第二学期试题(A)SAS

2008~2009学年第二学期《SAS统计分析》研究生试题(A)一、选择题(16分,每题2分)1.SAS的三个窗口中,C可以显示统计计算结果。
A.EditorB.LogC.OutputD.ExplorerE.Results2.以下数值变量名哪几个是合法的?A B DA.ABB.AB5C.AB-5D.AB_6E.2AB3.将两个数据集横向合并,使用DATA步中的哪几条语句?AA.mergeB.setC.inputD.sumE.keep4.SAS程序的每条语句必须以什么符号结束?BA ,B ;C @@D $E :5.下面data步程序运行后,数据集中变量为AData a; do l=l to 3; do c=l to 2; input x y @@; xl=log(x); rename y=y1; output; end; end; cards;2 3 4 4 3 6 7 5 3 4 5 6;run;A. 4B. 3C. 5D. 6E. 26.设数据集a中已有变量x1、x2、x3、x4,执行下面程序后,新数据集b中有C 个变量。
Data b;set a; rename x1=y1; x2= log(x2); if x3>0 then x3g=1; else x3g=0; run;A. x1,x2,x3,x4,x3g.y1, log(x2)B. x1,x2,x3,x4,x3g,y1C. y1,x2,x3,x4,x3gD. y1,x2,x4,x3g7.两因素析因方差分析中,变量为x,a和b分别代表两个因素,试作方差分析,以下SAS 过程步D 是对的。
A. proc anova;class a b;model a b a*b=x; run;B. proc anova;model x=a b a*b; class a b;run;C. proc anova;class a b;model x=a b ; run;D. proc anova;class a b;model x= a b a*b; run;8.比较A、B两种疗法的疗效,搜集接受这两种疗法治疗的若干病人的生存时间的数据,可考虑用SAS程序A 分析。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
SAS数据处理应用题_2005以下练习题选自《SAS数据处理综合练习》,解决这些题目原则上需要学完《SAS编程技术与金融数据》前18章内容。
1. 创建一包含10000个变量(X1-X10000),100个观测值的SAS数据集。
分别用DATA 步,DA TA步数组语句和IML过程实现。
2. 创建包含日期变量DA TE的SAS数据集,日期值从1900年1月1日到2000年1月1日。
3. 多种方法创建包含变量X的10000个观测值的SAS数据集。
4. 利用随机数函数RANUNI对某数据集设计返回抽样方案?5. 利用随机数函数RANUNI对某数据集设计不返回抽样方案?6. 数据集A中日期变量DATE包含有缺失值,创建包含日期变量DATE的数据集B,并填充开始到结束日之间的所有日期值。
7. 创建组标识变量GROUP,将数据集A中的观测等分为10组,观测值不能整除10时,前余数组各多加一个观测值。
8. 数据集A有一个变量n,5个观测值1,2,3,4,5。
数据A1由下面程序2产生,同样有一个变量n,5个观测值1,2,3,4,5。
试分析下面两段程序中,PUT语句在Log窗口输出结果的差异,为什么?程序1:Data a; Set a; Put n=; Run; 程序2: data a1;do n=1 to 5; output; end;put n=; run;9. 假设数据集A中的变量logdate为如下形式的字符格式:1998-12-21999-8-61999-8-10将其转换为日期格式变量date。
如果字符格式的数据为:199812021999080619990810又怎样转换为日期格式变量。
10. 数据集fdata. Calendar包含一个日期变量,fdata. bond_price包含一个债券代码、一个日期变量与其它相应的价格。
合并两个数据集,用Calendar中的日期数据替代bond_price 数据集中每支债券中的日期数据。
11. 当股票的分配事件分两次完成,且第一次分配在节假日或该股票的停牌日,第二次分配在下一个交易日时,一般的数据库会有如下表所示的观测值存贮方式。
写程序将停牌日(即没有收盘价的那个观测值)中的分配事件合到下一个观测中。
注:…表示有数据值,.表示缺失值。
编程变量名参考:股票代码Hstkcd,日期Dt,收盘价Closepr,送股比例Stkdrate,转增比例Capissurate,配股比例Rigoffrate,配股价Rigoffpr,增发比例Snirate,增发价格Snipr,现金红利Dividend。
12.现有一个数据流:a 2 b 3 c d 4 6,按下面要求创建SAS数据集。
用语句input id $ no; 变量id取值上面数据流里的a,b,c,d,变量no取值2,3,4,6。
但是这个数据流存在问题:如有的id没有no,有的no没有id。
创建SAS数据集,删除只有id 没有no或者只有no没有id的观测,即把上面的c和6去掉,最后得到三个观测,a 2, b 3与d 4。
更一般情况。
现有一个数据流:a23 223 bc4 36 3c5 11d 400 620,按下面要求创建SAS数据集。
用语句input id $ no; 变量id取值上面数据流里的a23, bc4, 11d ,变量no取值233,36,400。
但是这个数据流存在问题:如有的id没有no,有的no没有id。
创建SAS数据集,删除只有id没有no或者只有no没有id的观测,即把上面的3c5和620去掉,最后得到三个观测:a23 223bc4 3611d 40013. 假设股票市场的股本数据如下表,对每支股票,按如下要求设计填充总股本和流通股股本数据的SAS程序:以该股票前面的股本数据填充后面的缺失值,如果某支股票上市交易时就缺失股本数据,则用该股票上市后的第一个股本数据向前填充。
注:…表示有数据值,.表示缺失值。
编程变量名参考:股票代码Hstkcd,日期Dt, 收盘价Closepr, 股本变动日Capchgdt, 总股本Fullshr, 流通股trdshr, 总股本Fullshr./* 创建样本数据集*/data test;infile datalines missover ;informat hstkcd $8. dt yymmdd10. closepr 8.2 capchgdt yymmdd10. fullshr Trdshr 20. ;input hstkcd $ dt closepr capchgdt fullshr Trdshr;format hstkcd $8. dt yymmdd10. closepr 8.2 capchgdt yymmdd10. fullshr Trdshr 20.;cards;11600000 2003-1-20 9.94 2003-1-20 3915000000 90000000011600000 2003-1-21 9.6811600000 2003-1-22 9.6611600000 2003-1-23 9.611600000 2003-1-24 9.8811600000 2003-1-27 10.0711600000 2003-1-28 10.1711600000 2003-1-29 10.3111600000 2003-2-10 10.0911600000 2003-2-11 10.211600000 2003-2-12 10.3111600000 2003-2-13 10.1311600001 2000-5-29 8.13 2000-5-2911600001 2000-5-30 8.1411600001 2000-5-31 8.6511600001 2000-6-1 8.9311600001 2000-6-2 9.1111600001 2000-6-5 9.02 2000-6-5 1486553100 49000000011600001 2000-6-6 8.6311600001 2000-6-7 8.5211600001 2000-6-8 8.5511600001 2000-6-9 8.311600001 2000-6-12 8.34;Run;进一步调试程序时,请索要电子档试题与数据。
14.用线性插值法填充缺失数据。
以下面的实际数据为基础,完成相关SAS程序的设计。
银行间债券市场的回购行情如下表,对于一个月、二个月和三个月的债券回购利率,按如下要求设计填充回购利率的月底缺失数据。
从所给数据集中识别出一个月、二个月和三个月的债券回购利率,建立一个仅包括日期dt(2004年1月到2004年5月)、一个月债券回购利率R1M、二个月债券回购利率R2M和三个月债券回购利率R3M的数据集,对于不同期限的回购利率分别取每个月最后一天的回购利率,如果在月底当日没有交易,则采用该月最后一次交易与下月第一次交易的数据进行注:…表示有数据值,.表示缺失值。
编程变量名参考:交易日期dt, 债券代码code, 收盘价closepr, 一个月债券回购利率R1M,二个月债券回购利率R2M,三个月债券回购利率R3M./* 创建样本数据集*/data test;informat dt yymmdd10. code$8.closepr;input dt: code $ closepr;format dt yymmdd10. code $8.closepr;cards;2004-01-02 R1M 0.0252004-01-05 R1M 0.02552004-01-05 R2M 0.0244………………(该题解答有全部数据,同学可索要电子档)2004-06-01 R1M 0.0312004-06-01 R2M 0.03192004-06-01 R3M 0.0335;15.当股票发生分配事件时,可以根据相应的分配和股本数据计算股价的调整因子。
为了检验数据的正确性,有必要根据股价调整因子来计算当天股价的变动是否合理。
如下表所示,可以算得除权日股票涨跌的绝对值为:|10.00-5.20*2.00| = 0.40,相对于当时的股价5.20来说,这个变动值是在合理的范围内的。
设计程序,对于不同的股票(永久性代码不同),计算分配日股票涨跌(=分配前股票价格–分配日股票价格*股价调整因子)的绝对值。
只要求保留分配日的观测(即股价调整因编程变量名参考:永久性代码Permno,日期Dt,收盘价Closepr,股价调整因子Facpr16. 控制权价值研究中的数据处理问题。
计算每只股票相应DT前30个交易日的平均收盘价格。
股票代码Hstkcd与日期DT的数据集由下面SAS程序给出。
data stkdt;input Hstkcd $6. dt ;informat dt yymmdd10.;format dt yymmdd10.;cards;000024 20010405000510 20011020……….(该题解答有全部数据,同学可索要电子档)600262 20021228600277 20020904;17. 某商业银行为了进行内部成本核算,需要统计每个储户当前存款余额的平均期限。
平均期限计算方法如下:假设该银行有一储户6天内进行了6笔存取款业务。
如下表所示。
业务种类金额余额第1天开户+100元+100元第2天存款+100元+200元第3天取款-150元+50元第4天存款+200元+250元第5天存款+100元+350元第6天取款-100元+250元第1天,开户存入100元,计期开始。
第2天,存入100元,此时该储户持有100元×1天,100元×0天,所以平均期限为(100*1+100*0)/(100+100)天。
第3天,取出第一天的100元和第2天的50元(遵循先进先出法),此时持有第2天的50元,期限为(50*1)/50=1天。
第4天,存入200元,此时余额为250元,平均期限为(50*2+200*0)/(50+200)天。
第5天,存入100元,此时余额为350元,平均期限为(50*3+200*1+100*0)/(50+200+100)天。
第6天,取出了第2天的50元,第4天的50元,余额为250元,平均期限(150*2+100*1)/(150+100)天。
该银行储户历史数据集如下表所示,包括所有储户开户至今的全部存取款数据。
请分别计算每个储户存款金额的平均期限。
id datetime credit debit 000001 01JAN2000:10:00:01100 .000002 01JAN2000:11:00:01200 .000002 02JAN2000:13:00:01. 80000001 03JAN2000:10:00:01. 50000002 03JAN2000:12:00:01100 .000003 05JAN2000:16:00:01100 .000002 10JAN2000:09:00:01. 150000005 15JAN2000:10:00:01200 .000006 18JAN2000:13:00:01100 .000003 21JAN2000:12:00:0150 .000002 21JAN2000:15:00:01. 20000001 25JAN2000:09:00:01. 30000003 25JAN2000:12:00:01. 120……本题的实际意义:可作商业银行进行内部成本核算的指标吗?中国建设银行曾计划进行成本核算,委托麦肯锡给其设计如何计算存款的成本。