多元线性回归分析-研(精)
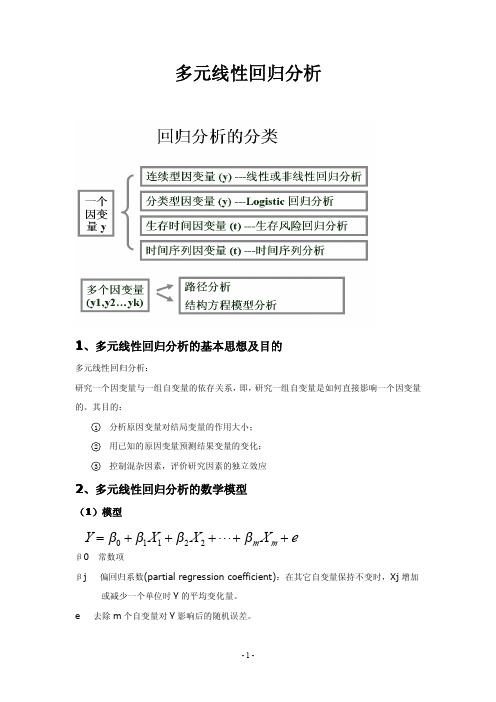
多元线性回归分析

3
二、多元线性回归模型的建立
由于二元线性回归方程是最典型的多元线性回归方程, 通过观察求解二元线性回归方程的参数的过程,就可了 解其他类型的多元线性回归方程参数的求解方法。设有 二元线性回归方程: yc a b1x1 b2 x2
统计学
一、多元线性回归分析的意义
粮食亩产量受播种量、施肥量、降雨量等 因素的影响;又如,彩电的销售额受彩电 价格、广告费支出、消费者购买力等因素 的影响;再如,企业产品成本受原材料价 格、原材料消耗、产量、质量、工艺技术 水平等因素的影响。
对于上述情况,如果只用一个自变量来进 行回归分析,分析的结果就存在问题,如 果将影响因变量的多个因素结合在一起进 行分析,则更能揭示现象内在的规律。
2
二、多元线性回归模型的建立
多元线性回归分析研究因变量和多个自变量间的线性关 系因,变这 量种 Y与线自性变关量系可用数学模型x来1, 之x表2,间x示3,存。,在设xn线因性变关量系为,Y,可 用多元线性回归方程来表示这种关系。设多元线性回归 方程为:yc a b1 x1 b2 x2 b3 x3 bn xn
要确定该回归方程,须先求解a、b1、b2三个参数。用最
小二乘法求解得x1方y y程a组nax如1 b1下b1:x1x12b2
x2 b2
x1x2
x2 y a
x2 b1
x1x2 b2
x22
4
统计学Biblioteka
多元线性回归分析

简介多元线性回归分析是一种统计技术,用于评估两个或多个自变量与因变量之间的关系。
它被用来解释基于自变量变化的因变量的变化。
这种技术被广泛用于许多领域,包括经济学、金融学、市场营销和社会科学。
在这篇文章中,我们将详细讨论多元线性回归分析。
我们将研究多元线性回归分析的假设,它是如何工作的,以及如何用它来进行预测。
最后,我们将讨论多元线性回归分析的一些限制,以及如何解决这些限制。
多元线性回归分析的假设在进行多元线性回归分析之前,有一些假设必须得到满足,才能使结果有效。
这些假设包括。
1)线性。
自变量和因变量之间的关系必须是线性的。
2)无多重共线性。
自变量之间不应高度相关。
3)无自相关性。
数据集内的连续观测值之间不应该有任何相关性。
4)同质性。
残差的方差应该在自变量的所有数值中保持不变。
5)正态性。
残差应遵循正态分布。
6)误差的独立性。
残差不应相互关联,也不应与数据集中的任何其他变量关联。
7)没有异常值。
数据集中不应有任何可能影响分析结果的异常值。
多重线性回归分析如何工作?多元线性回归分析是基于一个简单的数学方程,描述一个或多个自变量的变化如何影响因变量(Y)的变化。
这个方程被称为"回归方程",可以写成以下形式。
Y = β0 + β1X1 + β2X2 + ... + βnXn + ε 其中Y是因变量;X1到Xn是自变量;β0到βn是系数;ε是代表没有被任何自变量解释的随机变化的误差项(也被称为"噪音")。
系数(β0到βn)表示当所有其他因素保持不变时(即当所有其他自变量保持其平均值时),每个自变量对Y的变化有多大贡献。
例如,如果X1的系数为0.5,那么这意味着当所有其他因素保持不变时(即当所有其他独立变量保持其平均值时),X1每增加一单位,Y就会增加0.5单位。
同样,如果X2的系数为-0.3,那么这意味着当所有其他因素保持不变时(即所有其他独立变量保持其平均值时),X2每增加一个单位,Y就会减少0.3个单位。
多元线性回归分析的实例研究

多元线性回归分析的实例研究多元线性回归是一种经典的统计方法,用于研究多个自变量对一个因变量的影响关系。
在实际应用中,多元线性回归分析可以帮助我们理解多个因素对一些现象的综合影响,并通过构建模型来进行预测和决策。
本文将以一个假想的房价分析为例,详细介绍多元线性回归分析的步骤、数据解释以及结果分析。
假设我们想要研究一个城市的房价与面积、房龄和地理位置之间的关系。
我们收集了100个房源的数据,包括房价(因变量)、面积(自变量1)、房龄(自变量2)和地理位置(自变量3)。
下面是我们的数据:序号,房价(万元),面积(平方米),房龄(年),地理位置(距市中心距离,公里)----,------------,--------------,----------,--------------------------------1,150,120,5,22,200,150,8,63,100,80,2,104,180,130,10,55,220,160,12,3...,...,...,...,...100,250,180,15,1首先,我们需要对数据进行描述性统计分析。
通过计算平均值、标准差、最小值、最大值等统计量,可以初步了解数据的分布和变异程度。
然后,我们需要进行回归模型的拟合。
回归模型可以表示为:房价=β0+β1*面积+β2*房龄+β3*地理位置+ε其中,β0、β1、β2、β3是待估计的回归系数,ε是模型的误差项。
回归系数表示自变量对因变量的影响大小和方向。
为了估计回归系数,我们可以使用最小二乘法。
最小二乘法通过找到一组回归系数,使得实际观测值与模型预测值之间的平方误差最小化。
在本例中,我们可以使用统计软件进行回归模型的拟合和参数估计。
假设我们得到的回归模型如下:房价=100+1.5*面积-5*房龄+10*地理位置接着,我们需要对回归模型进行评价和解释。
首先,我们可以计算回归模型的决定系数(R^2),它表示因变量的变异中能够被模型解释的比例。
多元回归分析法的介绍及具体应用

多元回归分析法的介绍及具体应用————————————————————————————————作者: ————————————————————————————————日期:ﻩ多元回归分析法的介绍及具体应用在数量分析中,经常会看到变量与变量之间存在着一定的联系。
要了解变量之间如何发生相互影响的,就需要利用相关分析和回归分析。
回归分析的主要类型:一元线性回归分析、多元线性回归分析、非线性回归分析、曲线估计、时间序列的曲线估计、含虚拟自变量的回归分析以及逻辑回归分析等。
这里主要讲的是多元线性回归分析法。
1. 多元线性回归的定义说到多元线性回归分析前,首先介绍下医院回归线性分析,一元线性回归分析是在排除其他影响因素或假定其他影响因素确定的条件下,分析某一个因素(自变量)是如何影响另一事物(因变量)的过程,所进行的分析是比较理想化的。
其实,在现实社会生活中,任何一个事物(因变量)总是受到其他多种事物(多个自变量)的影响。
一元线性回归分析讨论的回归问题只涉及了一个自变量,但在实际问题中,影响因变量的因素往往有多个。
例如,商品的需求除了受自身价格的影响外,还要受到消费者收入、其他商品的价格、消费者偏好等因素的影响;影响水果产量的外界因素有平均气温、平均日照时数、平均湿度等。
因此,在许多场合,仅仅考虑单个变量是不够的,还需要就一个因变量与多个自变量的联系来进行考察,才能获得比较满意的结果。
这就产生了测定多因素之间相关关系的问题。
研究在线性相关条件下,两个或两个以上自变量对一个因变量的数量变化关系,称为多元线性回归分析,表现这一数量关系的数学公式,称为多元线性回归模型。
多元线性回归模型是一元线性回归模型的扩展,其基本原理与一元线性回归模型类似,只是在计算上更为复杂,一般需借助计算机来完成。
2. 多元回归线性分析的运用具体地说,多元线性回归分析主要解决以下几方面的问题。
(1)、确定几个特定的变量之间是否存在相关关系,如果存在的话,找出它们之间合适的数学表达式;(2)、根据一个或几个变量的值,预测或控制另一个变量的取值,并且可以知道这种预测或控制能达到什么样的精确度;(3)、进行因素分析。
多元线性回归模型分析

L(ˆ,2) P(y1, y2,, yn)
1 212 (yi (ˆ0ˆ1x1i ˆ2x2i ˆkxki))2
e n
2
n
(2)
1
n
(2 )2
e212 (YXˆ )(YXˆ )
n
多元线性回归模型分析
▪ 对数似然函数为
L*Ln(L)
nLn( 2)212(YX )'(YX )
▪ 参数的极大似然估计
xn2
x1K
T
y1
x2K y2
xnK
yn
ห้องสมุดไป่ตู้
上述矩阵方程的第一个方程可以表示为:
n
n
yˆi yi
i1
i1
则有: yˆ y
多元线性回归模型分析
附录:极大似然估计
多元线性回归模型分析
回忆一元线性回归模型
对于一元线性回归模型:
Yi 0 1Xi i
i=1,2,…n
随机抽取n组样本观测值Yi,Xi (i=1,2,…n),假如模型的参数
β ( X X )1 X Y 多元线性回归模型分析
▪ 注:这只是得到了求极值的必要条件。到目 前为止,仍不能确定这一极值是极大还是极 小。接下来考察求极值充分条件。
多元线性回归模型分析
注意到上述条件只是极小化问题的必要条件,为了 判断充分性,我们需要求出目标函数的Hessian矩阵 :
2Q(ˆ ) ˆ ˆ
投影和投影矩阵 分块回归和偏回归 偏相关系数
多元线性回归模型分析
一、参数的OLS估计
▪ 普通最小二乘估计原理:使样本残差平方和最小
我们的模型是:
Y= x11 + x22 +…+ xk k +
多元线性回归分析

多元线性回归分析预测法概述在市场的经济活动中,经常会遇到某一市场现象的发展和变化取决于几个影响因素的情况,也就是一个因变量和几个自变量有依存关系的情况。
而且有时几个影响因素主次难以区分,或者有的因素虽属次要,但也不能略去其作用。
例如,某一商品的销售量既与人口的增长变化有关,也与商品价格变化有关。
这时采用一元回归分析预测法进行预测是难以奏效的,需要采用多元回归分析预测法。
多元回归分析预测法,是指通过对两上或两个以上的自变量与一个因变量的相关分析,建立预测模型进行预测的方法。
当自变量与因变量之间存在线性关系时,称为多元线性回归分析。
[编辑]多元线性回归的计算模型[1]一元线性回归是一个主要影响因素作为自变量来解释因变量的变化,在现实问题研究中,因变量的变化往往受几个重要因素的影响,此时就需要用两个或两个以上的影响因素作为自变量来解释因变量的变化,这就是多元回归亦称多重回归。
当多个自变量与因变量之间是线性关系时,所进行的回归分析就是多元性回归。
设y 为因变量,为自变量,并且自变量与因变量之间为线性关系时,则多元线性回归模型为:其中,b 0为常数项,为回归系数,b 1为固定时,x1每增加一个单位对y 的效应,即x 1对y 的偏回归系数;同理b 2为固定时,x 2每增加一个单位对y 的效应,即,x 2对y 的偏回归系数,等等。
如果两个自变量x 1,x 2同一个因变量y 呈线相关时,可用二元线性回归模型描述为:其中,b 0为常数项,为回归系数,b 1为固定时,x 2每增加一个单位对y 的效应,即x 2对y 的偏回归系数,等等。
如果两个自变量x 1,x 2同一个因变量y 呈线相关时,可用二元线性回归模型描述为: y = b 0 + b 1x 1 + b 2x 2 + e建立多元性回归模型时,为了保证回归模型具有优良的解释能力和预测效果,应首先注意自变量的选择,其准则是:(1)自变量对因变量必须有显著的影响,并呈密切的线性相关;(2)自变量与因变量之间的线性相关必须是真实的,而不是形式上的;(3)自变量之彰应具有一定的互斥性,即自变量之彰的相关程度不应高于自变量与因变量之因的相关程度;(4)自变量应具有完整的统计数据,其预测值容易确定。
卫生统计学课件12多重线性回归分析(研)

多重线性回归分析的步骤
(一)估计各项参数,建立多重线性回归方程模型 (二)对整个模型进行假设检验,模型有意义的前提 下,再分别对各偏回归系数进行假设检验。 (三)计算相应指标,对模型的拟合效果进行评价。
多重线性回归方程的建立
Analyze→Regression→Linear Dependent :Y Independent(s):X1、X2、X3 Method:Enter OK
Mo del S um mary
Model 1
Std. Error of
R R Square Adju sted R Square the E stimate
.8 84a .7 81
.7 40 216.0570 680
a. Predictors: (Constant), X3, X2, X1
R (复相关系数)
(二)偏回归系数的假设检验及其评价
各偏回归系数的t检验
C oe fficien tas
Unstand ardized Co efficients
St an d ard ized Co efficients
Model
B
Std. Error
Bet a
1
(Constant) -2262.081 1081 .870
(三)有关评价指标
R (复相关系数)
0.884
R Square (决定系数)
0.781
Adj R-Sq (校正决定系数)
0.740
Std.Error of the Estimate (剩余标准差)
216.0570680
Std.Error of the Estimate (剩余标准差)
SY ,12...m
多元回归分析

则: F Lb
b L1 F
多元回归的应用-本构方程
选择“最优”回归方程的方法
在多元线性回归研究中 , 总设想把对 y 变量影 响显著的自变量因子引入回归方程 , 引入得越多 越好 ( 反映更加全面 ); 而把对 y 变量影响不显著的
因子剔除掉 , 剩余得越少越好 ( 方程更加简单 ), 建
其残差平方和Q:
Q(b0 , b1 , b2 ) et 2
i 1 n
n
ˆt ) 2 ( yi y
i 1 n
[ yi (b0 b1 xi1 b2 xi 2 )]2
i 1
显然:
Q(b0 , b1, b2 ) 0
由极值原理:
由(1)得:
由(2)(3)得:
b0 y (b1 x1 b2 x2 )
*
L11b1 L12b2 L10 L21b1 L22b2 L20
解该方程得:
L10 L22 L20 L21 b 1 L L L L 11 22 12 21 b L20 L11 L10 L21 2 L11 L22 L12 L21
多元线性回归模型包含多个变量,多个解释变量 同时对被解释变量发生作用,若要考察其中一个 解释变量对的影响就必须假设其它解释变量保持 不变来进行分析。
因此多元线性回归模型中的回归系数为偏回归系 数,即反映了当模型中的其它变量不变时,其中 一个解释变量对因变量的均值的影响。
最简单的多元线性回归模型是二元线性回归模型。
逐步回归方程的基本思想
根据自变量对因变量的重要性,把它们逐个地选 入到回归方程。 1. 从建立值包含一个自变量的回归方程开始, 接着是建立两个自变量的回归方程。 2. 反复进行两个步骤(1)对已经进入回归方程 的自变量进行显著性检验,显著的保留,最 不显著的剔除;(2)对不在回归方程中的自 变量挑选最显著的引入回归方程。直到留在 方程中的所有自变量均对y有显著影响,方程 外的自变量对y均无显著性影响。
多元线性回归分析

多元线性回归模型(二)
设因变量为y,自变量为xi(i= 1,….,m),m元线 性回归方程为: ŷ=a+b1*x1+b2*x2+….+bm*xm, 或y=ŷ+e。 ŷ 是y的估计值或预测值; e是残差,不能由现有的自变量决定的部分; a为常数项或截距; bi为样本偏回归系数,即在其它自变量固定不变 情况下,xi改变一个单位,因变量平均改变bi 个单 位。对应的总体偏回归系数为βi,若βi =0,则该 自变量xi与因变量y之间无线性关系,即xi对因变 量y无影响 。
自变量的贡献(一)
偏回归系数反映了自变量对应变量的作用大小;但在多元 回归方程中,偏回归系数是随自变量所带单位的不同而改 变。所以,要比较不同自变量对应变量的作用大小,不能 直接比较它们的偏回归系数大小,必须将其标准化,使之 成为无量纲的标准偏回归系数,直接比较大小。 bi’:标准化偏回归系数,比较度量衡单位不同的自变量对 因变量的贡献大小。 bi’ = bi *(ιii1/2 / ιyy1/2 )。 标准偏回归系数反映的是自变量对因变量y的直接作用。
回归分析的步骤
1、建立线性回归方程; 2、回归方程的假设检验; 3、偏回归系数的假设检验与区间估计; 4、比较自变量对因变量的作用大小; 5、因变量的区间估计; 6、残差分析。 Analyze→Regression → Linear
建立线性回归方程(一)
即计算截距a和回归系数bi ,应用最小二乘 法原理,即要求残差平方和达到最小。 以 PAN.sav为例,作身高、体重对肺活量影 响的多元线性回归分析。 选择变量的方法有强迫引入法(系统默认)、 强迫剔除法、向前引入法、向后剔除法、 逐步回归法。
回归方程有统计学意义,并不等于方程中每个变 量都有统计学意义,因此要分别检验每个偏回归 系数是否均为0,用t检验: H0: βi =0 ,H1: βi≠0 ;α = 0.05。 t i= bi / s bi ,得P值大小,若P≤ 0.05,则拒绝H0, 接受H1,说明该变量有统计学意义;若P> 0.05, 则不拒绝H0,说明该变量无统计学意义。 对应SPSS的结果中标题为“Coefficients”的表格, 经t检验,身高变量无统计学意义,而体重变量有 统计学意义。
多元线性回归分析

多元线性回归分析多元线性回归分析是一种常用的统计方法,用于研究多个自变量与因变量之间的关系。
它可以帮助我们理解多个因素对于一个目标变量的影响程度,同时也可以用于预测和解释因变量的变化。
本文将介绍多元线性回归的原理、应用和解读结果的方法。
在多元线性回归分析中,我们假设因变量与自变量之间存在线性关系。
具体而言,我们假设因变量是自变量的线性组合,加上一个误差项。
通过最小二乘法可以求得最佳拟合直线,从而获得自变量对因变量的影响。
多元线性回归分析的第一步是建立模型。
我们需要选择一个合适的因变量和若干个自变量,从而构建一个多元线性回归模型。
在选择自变量时,我们可以通过领域知识、经验和统计方法来确定。
同时,我们还需要确保自变量之间没有高度相关性,以避免多重共线性问题。
建立好模型之后,我们需要对数据进行拟合,从而确定回归系数。
回归系数代表了自变量对因变量的影响大小和方向。
通过最小二乘法可以求得使残差平方和最小的回归系数。
拟合好模型之后,我们还需要进行模型检验,以评估模型拟合的好坏。
模型检验包括对回归方程的显著性检验和对模型的拟合程度进行评估。
回归方程的显著性检验可以通过F检验来完成,判断回归方程是否显著。
而对模型的拟合程度进行评估可以通过判断决定系数R-squared的大小来完成。
解读多元线性回归结果时,首先需要看回归方程的显著性检验结果。
如果回归方程显著,说明至少一个自变量对因变量的影响是显著的。
接下来,可以观察回归系数的符号和大小,从中判断自变量对因变量的影响方向和相对大小。
此外,还可以通过计算标准化回归系数来比较不同自变量对因变量的相对重要性。
标准化回归系数表示自变量单位变化对因变量的单位变化的影响程度,可用于比较不同变量的重要性。
另外,决定系数R-squared可以用来评估模型对观测数据的拟合程度。
R-squared的取值范围在0到1之间,越接近1说明模型对数据的拟合越好。
但需要注意的是,R-squared并不能反映因果关系和预测能力。
多元线性回归分析
' j
=
X
j
− X Sj
j
标准化回归方程
标准化回归系数 bj ’ 的绝对值用来比较各个自变量 Xj 对 Y 的影响程度大小; 绝对值越大影响越大。标准化回归方程的截距为 0。 标准化回归系数与一般回归方程的回归系数的关系:
b 'j = b j
l jj l YY
⎛ Sj ⎞ = b j⎜ ⎜S ⎟ ⎟ ⎝ Y⎠
R = R2
^
�
说明所有自变量与 Y 间的线性相关程度。即 Y 与 Y 间的相关程度。联系了回归和相关
-5-
�
如果只有一个自变量,此时
R=r 。
3) 剩余标准差( Root MSE )
SY |12... p =
∑ (Y − Yˆ )
2
/( n − p − 1)
= SS 残 (n − p − 1 ) = MS 残 = 46.04488 = 6.78564 反映了回归方程的精度,其值越小说明回归效果越好
(SS 残) p Cp = − [n − 2(p + 1)] ( MS 残) m p≤m
2
P 为方程中自变量个数。 最优方程的 Cp 期望值是 p+1。应选择 Cp 最接近 P+1 的回归方程为最优。
5、决定模型好坏的常用指标和注意事项:
• 决定模型好坏的常用指标有三个:检验总体模型的 p-值,确定系数 R2 值和检验每一 个回归系数 bj 的 p-值。 • 这三个指标都是样本数 n、模型中参数的个数 k 的函数。样本量增大或参数的个数增 多,都可以引起 p-值和 R2 值的变化。但由于受到自由度的影响,这些变化是复杂 的。 • 判断一个模型是否是一个最优模型,除了评估各种统计检验指标外,还要结合专业知 识全面权衡各个指标变量系数的实际意义,如符号,数值大小等。 • 对于比较重要的自变量,它的留舍和进入模型的顺序要倍加小心。
12多重线性回归分析(研)

AIC越小越好
(二)逐步选择法
1. 前进法(forward selection) 2. 后退法(backward elimination) 3. 逐步回归法(stepwise regression)
➢ 向前引入法:由一个自变量开始,每次引入一个 有统计学意义的自变量,由少到多,直到无自变 量可以引入为止。此法建立的方程有时不够精炼
➢ 逐步筛选法:取上述两种方法的优点,引入和剔 除交替进行,直到无变量可以引入,同时也无自 变量可以剔除为止。目前比较常用
SPSS操作
Analyze→Regression→Linear Dependent :Y Independent(s):X1、X2、X3 Method:Stepwise OK
(一)回归方程的方差分析
H0:所有回归系数为0 H1:至少有一个回归系数不为0
ANO VbA
Mo d el
Su m o f Squ ares d f Mean Squ are F
1
Reg re2ss6i6o4n4 8 4 .4 9 4
838 8 16 1 .49 8 1 9 .0 2 6
Resid u a7l4 6 89 0 .50 6
X2
3 8. 55 0
1 3. 34 6
.444 2.889
X3
104.585
7 4. 36 1
.260 1.406
a. Dep en den t Variab le: Y
多元线性回归分析

求解后得 b1 0.1424 , b2 0.3515 , b3 0.2706 , b4 0.6382
各变量均值分别为: X1 5.8126 , X 2 2.8407 , X 3 6.1467 , X 4 9.1185 ,Y 11.9259 , 则常数项:
b0 11.9259 0.1424 5.8126 0.3515 2.8407 0.2706 6.1467 0.6382 9.1185
sY 123 m 表示。
公式为: sY123 m
MS剩余
SS剩余 n m 1
剩余标准差越小,说明回归效果越好
3、剩余标准差
剩余标准差除与剩余平方和有关外,还与自由度 有关,因此剩余标准差与决定系数对回归效果优 劣的评价结果有时不一致。研究者通常希望用尽 可能少的自变量来最大限度地解释因变量的变异, 从这个意义上来说,用剩余标准差作为评价回归 效果的指标比决定系数更好。
对 Y 变异的影响。 SS剩余 SS总 SS回归
1、对模型的假设检验—F检验
SS总=lyy=222.5519;ν总=n-1=26 SS剩余= SS总- SS回归=222.5519-133.7107=88.8412 ν剩余=n-m-1=22
= = MS回归 SS回归/ν回归; MS剩余 SS剩余/ν剩余;
标准化偏回归系数b’j
0.07758 0.30931 -0.33948 0.39774
bj b j
l jj lYY
bj
l jj /(n 1) lYY /(n 1)
bj
Sj SY
偏回归系数
偏回归系 数标准误
标准偏回归系数
(三)计算相应指标,对模型的拟合效果进行评价
多元线性回归解析

本次实验的数据个数 n=13 自变量因素 m=4 置信度为95% 在MATLAB下输入 finv(0.95,4,8)
求得统计参数F的临界值F4,8(0.05)=3.84
F计
n-m-1=8
参考文献 《基础化学计量学及其应用》 张立国等 《多元线性回归分析》 陆健 《常用多变量统计方法简介》 王淑康
i 1
i 1
式中Q为误差平方和,亦即误差的方差。
多元线性回归分析的目标就是找出最佳β值使Q达到最小。
通过回归得到的最小Q值称为剩余平方和或残余方差。
表 15-2 27 名糖尿病人的血糖及有关变量的测量结果
序号 i
总胆固醇 甘油三酯 胰岛素 糖化血红蛋白 血糖
(mmol/L) (mmol/L) (U/ml)
(%)
(mmol/L)
X1
X2
X3
X4
Y
1
5.68
1.90
4.53
8.2
11.2
2
3.79
1.64
7.32
6.9
8.8
3
6.02
3.56
6.95
10.8
12.3
27
3.84
1.20
6.45
9.6
10.4
• 各变量的离均差
• L =(X X +X X + X X )-(X X )(X +X )/27 (1,2)
多元线性回归模型的检验
• 1.复相关系数的检验 (检验方程)
• 多重相关系数R
R R2 SSR SST
相关系数越接近1,则模型非常准确。
决定系数 R2 R2=1- S残/LYY=S回/LYY
(S残=Q)
多元线性回归分析报告

多元线性回归分析报告1. 研究背景在数据科学和统计学领域,多元线性回归是一种常用的分析方法。
它用于探究多个自变量与一个因变量之间的关系,并且可以用于预测和解释因变量的变化。
本文将通过多元线性回归分析来研究一个特定问题,探讨自变量对因变量的影响程度和统计显著性。
2. 数据收集和准备在进行多元线性回归分析之前,需要收集和准备相关的数据。
数据的收集可以通过实验、调查问卷或者从已有的数据集中获得。
在本次分析中,我们使用了一个包含多个自变量和一个因变量的数据集。
首先,我们导入数据集,并进行数据的初步观察和预处理。
这些预处理步骤包括去除缺失值、处理异常值和标准化等。
经过数据准备之后,我们可以开始进行多元线性回归分析。
3. 回归模型建立在多元线性回归分析中,我们建立一个数学模型来描述自变量和因变量之间的关系。
假设我们有p个自变量和一个因变量,可以使用以下公式表示多元线性回归模型:Y = β0 + β1X1 + β2X2 + … + βpXp + ε其中,Y表示因变量,X1, X2, …, Xp分别表示自变量,β0, β1, β2, …, βp表示模型的系数,ε表示模型的误差项。
4. 模型拟合和参数估计接下来,我们使用最小二乘法来估计模型的参数。
最小二乘法通过最小化观测值与模型预测值之间的差异来确定最佳拟合线。
通过估计模型的系数,我们可以得到每个自变量对因变量的影响程度和显著性。
在进行参数估计之前,我们需要检查模型的假设前提,包括线性关系、多重共线性、正态性和异方差性等。
如果模型的假设不成立,我们需要采取相应的方法进行修正。
5. 模型评估和解释在完成模型的参数估计后,我们需要对模型进行评估和解释。
评估模型的好坏可以使用多个指标,如R方值、调整R方值、F统计量和t统计量等。
这些指标可以帮助我们判断模型的拟合程度和自变量的显著性。
解释模型的结果需要注意解释模型系数的大小、符号和显著性。
系数的大小表示自变量对因变量的影响程度,符号表示影响的方向,显著性表示结果是否具有统计意义。
《应用回归分析 》---多元线性回归分析实验报告

《应用回归分析》---多元线性回归分析实验报告
二、实验步骤:
1、计算出增广的样本相关矩阵
2、给出回归方程
Y=-65.074+2.689*腰围+(-0.078*体重)3、对所得回归方程做拟合优度检验
4、对回归方程做显著性检验
5、对回归系数做显著性检验
三、实验结果分析:
1、计算出增广的样本相关矩阵相关矩阵
2、给出回归方程
回归方程:Y=-65.074+2.689*腰围+(-0.078*体重)
3、对所得回归方程做拟合优度检验
由表可知x与y的决定性系数为r2=0.800,说明模型的你和效果一般,x与y 线性相关系数为R=0.894,说明x与y有较显著的线性关系,当F=33.931,显著性Sig.p=0.000,说明回归方程显著
4、对回归方程做显著性检验
5、对回归系数做显著性检验
Beta的t检验统计量t=-6.254,对应p的值接近0,说明体重和体内脂肪比重对腰围数据有显著影响
6、结合回归方程对该问题做一些基本分析
从上面的分析过程中可以看出腰围和脂肪比重以及腰围和体重的相关性都是很大的,通过检验可以看出回归方程、回归系数也很显著。
其次可以观察到腰围、脂肪比重、体重的数据都是服从正态分布的。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
RUN;
10
例15.1:P210 SPSS的分析结果
Coefficientsa Unstandardized Coefficients B Std. Error 8.429 .607 .126 .096 .044 .008 .057 .009 .032 .006 -.017 .013 Standardized Coefficients Beta .112 .476 .434 .431 -.105
23
三、选择最优回归方程的方法
1.最优回归方程 : 1)对y的作用有统计学意义的自变量,全部
选入回归方程
2)对y的作用没有统计学意义的自变量,一 个也不引入回归方程
24
2.方法: 1)最优子集回归法:又称全局择优法,求出所 有可能的回归模型(共有2m-1个)选取最优 者 2)向后剔除法(backward selection)
l11b1 l12b2 l1mbm l1Y
l21b1 l22 b2 l2 m bm l2Y lm1b1 lm2b2 lmm bm lmY
b0 Y (b1 X1 b2 X 2 bm X m)
9
方程的求解过程复杂,可借助于SPSS、SAS 等统计软件来完成 SPSS:Analyze→Regression→Linear regression→dependent:y independent:x1-x5 SAS程序:PROC REG DATA=mr15-1;
1.根据样本数据求得模型参数的估计值,得到 应变量与自变量数量关系的表达式:
ˆ b0 b1 x1 b2 x2 ...... bm xm y
此公式称为多元线性回归方程
2.对回归方程及各自变量作假设检验,并对方 程的拟和效果及各自变量的作用大小作出评价
8
多元线性回归方程的建立:
利用最小二乘法原理估计模型的参数: (使残差平方和最小)
12
1.多元线性回归方程的假设检验: 方差分析法:SS总 = SS回 + SS残
H 0 : 1 2 H1 : i (i 1, 2,
m 0 , m)不全为0 bmlmY
SS回 b1l1Y b2l2Y SS残 SS总 SS回
SS回 / m MS回 F SS残 ( / n m 1 ) MS残
13
ANOVAb Model 1 Sum of Squares 48.750 7.888 56.637 df 5 34 39 Mean Square 9.750 .232 F 42.028 Sig . .000a
Reg ression Residual Total
a. Predictors: (Constant), x5, x3, x1, x2, x4 b. Dependent Variable: y
a. Dependent Variable: y
30
d Model Summary
Model 1 2 3
R .676a .846b .919c
R Sq uare .456 .716 .845
Adjusted R Sq uare .442 .700 .832
Std. Error of the Estimate .90018 .65967 .49326
R
2 adj
n 1 1 (1 R ) n m 1
2
22
b Model Summary
Model 1
R .928a
R Sq uare .861
Adjusted R Sq uare .840
Std. Error of the Estimate .48165
a. Predictors: (Constant), x 5, x3, x1, x2, x4 b. Dependent Variable: y
多元线性回归模型的应用条件:
1.线性趋势:Y与Xi间具有线性关系
2.独立性:应变量Y的取值相互独立
3.正态性:对任意一组自变量取值,因变量Y 服从正态分布 4.方差齐性:对任意一组自变量取值,因变 量y的方差相同 后两个条件等价于:残差ε服从均数为0、 方差为σ2的正态分布
7
多元线性回归的分析步骤:
lii si b bi bi l yy sy
' i
在有统计学意义的前提下,标准化偏回归系数绝对值 的大小可直接进行比较,以衡量自变量对应变量的作 用大小
例:见P213
20
4.复相关系数
复相关系数:multiple correlation coefficient
衡量因变量y与回归方程内所有自变量线性组合 间相关关系的密切程度,也即Y与Y之间的相关 系数。R
Model 1
(Constant) x1 x2 x3 x4 x5
t 13.893 1.305 5.693 6.491 5.048 -1.318
Sig . .000 .201 .000 .000 .000 .196
a. Dependent Variable: y
19
3.标准化偏回归系数 对各数据进行标准化后求得的回归方程即标准 化回归方程,其相应的偏回归系数即标准化偏 回归系数。 标准化偏回归系数和偏回归系数的关系:
5
一、多元线性回归模型
一般形式为: Y=β0+β1X1 +β2X2 +…+βmXm +ε β0 :常数项,又称为截距
β1,β2,…,βm: 偏 回 归 系 数 (Partial regression coefficient) 简称回归系数,在 其它自变量保持不变时 Xi(i=1,2,…,m) 每改变 一个单位时,应变量Y的平均变化量 ε:去除m个自变量对Y的影响后的随机误差, 又称残差 6
x2
.
2
x3
.
3
x4
.
a. Dependent Variable: y
29
Coefficientsa Unstandardized Coefficients B Std. Error 12.546 .252 .063 .011 8.000 .804 .064 .008 .067 .011 8.202 .602 .048 .007 .060 .009 .029 .005 Standardized Coefficients Beta .676 .685 .509 .521 .457 .399
表1 27名糖尿病人的血糖及有关变量的测量结果
总胆固醇 序号 (mmol/L) i X1 1 2 3 27 5.68 3.79 6.02 3.84 甘油三酯 胰岛素 糖化血红蛋白 (%) X4 8.2 6.9 10.8 9.6 血糖 (mmol/L) Y 11.2 8.8 12.3 10.4
X1 X3 X4 X5 X1 X2 X4 X5
X1 X2 X3 X5
SS-2ቤተ መጻሕፍቲ ባይዱSS-3
SS-4
SS总- SS-2 SS总- SS3
SS总- SS4
X1 X2 X3 X4
SS-5
SS总- SS5
17
2.偏回归系数的假设检验 t检验法:
bi ti sbi
n-m-1
18
SPSS的结果
Coefficientsa Unstandardized Coefficients B Std. Error 8.429 .607 .126 .096 .044 .008 .057 .009 .032 .006 -.017 .013 Standardized Coefficients Beta .112 .476 .434 .431 -.105
,则剔除Xi,同时再对Xj进行检验。若Xj依然
有意义则继续选择下一个偏回归平方和最大者
并进行检验。重复此过程。
26
逐步回归法
每引入或剔除一个自变量后都要重新对已进 入方程中的自变量进行检验,直到方程外没
有有意义的自变量可引入、方程内也没有无
意义的自变量可剔除为止 。
27
逐步回归法
双向筛选 ;引入一个有意义变量(前进法)
Model 1 2
3
(Constant) x2 (Constant) x2 x3 (Constant) x2 x3 x4
t 49.858 5.648 9.953 7.818 5.810 13.621 7.230 6.904 5.493
Sig . .000 .000 .000 .000 .000 .000 .000 .000 .000
3)向前引入法(forward selection)
4)逐步回归法(stepwise regression)
25
逐步回归法
自变量回归平方和最大的Xi首先进入方程,在 Xi进入方程的基础上计算其余m-1个自变量分
别进入回归方程时的偏回归平方和,其中最大
者记为SSj,对Xj进行检验,若有意义则进入方
程,并重新对Xi进行检验。若Xi退化为无意义
和的减少量,或者在m-1个自变量的基础上增
加一个自变量后回归平方和的增加量。
注意:m-1个自变量对y的回归平方和由m-1个
自变量对y重新建立回归方程后计算得到,而 不能简单的在整个方程的基础上把biliy去掉后 得到。
16
各偏回归平方和SS(Xi)及残差的计算 回归方程中包含的自 变量 X1 X2 X3 X4 X5 X2 X3 X4 X5 SS回 SS总 SS-1 SS(Xi) - SS总- SS-1
的同时,剔除无意义的变量(后退法)
“先剔除后选入”原则 α入和α出可等可不等 注意,引入变量的检验水准要小于或等于 剔除变量的检验水准。
28
Variables Entered/Removeda Model 1 Variables Entered Variables Removed Method Stepwise (Criteria: Probabilit y-ofF-to-enter <= .050, Probabilit y-ofF-to-remo ve >= . 100). Stepwise (Criteria: Probabilit y-ofF-to-enter <= .050, Probabilit y-ofF-to-remo ve >= . 100). Stepwise (Criteria: Probabilit y-ofF-to-enter <= .050, Probabilit y-ofF-to-remo ve >= . 100).