数据结构8排序
数据结构实验报告八-快速排序

实验8 快速排序1.需求分析(1)输入的形式和输入值的范围:第一行是一个整数n,代表任务的件数。
接下来一行,有n个正整数,代表每件任务所用的时间。
中间用空格或者回车隔开。
不对非法输入做处理,及假设用户输入都是合法的。
(2)输出的形式:输出有n行,每行一个正整数,从第一行到最后一行依次代表着操作系统要处理的任务所用的时间。
按此顺序进行,则使得所有任务等待时间最小。
(3)程序所能达到的功能:在操作系统中,当有n 件任务同时来临时,每件任务需要用时ni,输出所有任务等待的时间和最小的任务处理顺序。
(4)测试数据:输入请输入任务个数:9请输入任务用时:5 3 4 2 6 1 5 7 3输出任务执行的顺序:1 2 3 3 4 5 5 6 72.概要设计(1)抽象数据类型的定义:为实现上述程序的功能,应以整数存储用户的第一个输入。
并将随后输入的一组数据储存在整数数组中。
(2)算法的基本思想:如果将任务按完成时间从小到大排序,则在完成前一项任务时后面任务等待的时间总和最小,即得到最小的任务处理顺序。
采取对输入的任务时间进行快速排序的方法可以在相对较小的时间复杂度下得到从小到大的顺序序列。
3.详细设计(1)实现概要设计中定义的所有数据类型:第一次输入的正整数要求大于零,为了能够存储,采用int型定义变量。
接下来输入的一组整数,数据范围大于零,为了排序需要,采用线性结构存储,即int类型的数组。
(2)实现程序的具体步骤:一.程序主要采取快速排序的方法处理无序数列:1.在序列中根据随机数确定轴值,根据轴值将序列划分为比轴值小和比轴值大的两个子序列。
2.对每个子序列采取从左右两边向中间搜索的方式,不断将值与轴值比较,如果左边的值大于轴值而右边的小于轴值则将二者交换,直到左右交叉。
3.分别对处理完毕的两个子序列递归地采取1,2步的操作,直到子序列中只有一个元素。
二.程序各模块的伪代码:1、主函数int main(){int n;cout<<"请输入任务个数:";cin>>n;int a[n];cout<<"请输入任务用时:";for(int i=0;i<n;i++) cin>>a[i];qsort(a,0,n-1); //调用“快排函数”cout<<"任务执行的顺序:";for(int i=0;i<n;i++) cout<<a[i]<<" "; //输出排序结果}2、快速排序算法:void qsort(int a[],int i,int j){if(j<=i)return; //只有一个元素int pivotindex=findpivot(a,i,j); //调用“轴值寻找函数”确定轴值swap(a,pivotindex,j); //调用“交换函数”将轴值置末int k=partition(a,i-1,j,a[j]); //调用“分割函数”根据轴值分割序列swap(a,k,j);qsort(a,i,k-1); //递归调用,实现子序列的调序qsort(a,k+1,j);}3、轴值寻找算法://为了保证轴值的“随机性”,采用时间初始化种子。
8排序

16
【时间效率】
确定插入位置所进行的折半查找,定位一个关键码的位 置需要比较次数至多为 间复杂度为O (nlog2n)。
log 2 (n 1)次,所以比较次数时
相对直接插入排序,折半插入排序只能减少关键字间的 比较次数,而移动记录的次数和直接插入排序相同,故时间 复杂度仍为O(n2)。 折半插入排序是一个稳定的排序方法。
2019/2/7
数据结构
6
8.2.1 直接插入排序
直接插入排序是一种简单的插入排序方法,基本 思想为:在 R[1] 至 R[i-1] 长度为 i-1 的子表已经有序 的情况下,将R[i]插入,得到R[1]至R[i]长度为i 的 子表有序,这样通过 n-1 趟( i=2..n )之后, R[1] 至 R[n]有序。
65 5
97 0
76 4
49 8
38 1
49 3
6
2019/2/7
数据结构
25
0
i=4 j=(1)、 6 i=5 j=8 i=6 j=(3)、 7
MAXINT
1
13 (6) 13
6
2
27 (7) 27
3
38 (7) 38
4
97
0
5
76
4
6
49 8 97
7
65 5 65
8
49
3
MAXINT
49
76
49
j 1 1 2) n(n 1) 2n n 2 2 4 4
(
j 1
n 1
由此,直接插入排序的时间复杂度为O(n2)。
直接插入排序是一个稳定的排序方法。
直接插入排序也可以在链式结构上实现。
(完整word版)数据结构 第八章排序

第八章排序:习题习题一、选择题1.在所有排序方法中,关键字比较的次数与记录的初始排列次序无关的是( )。
A.希尔排序B.冒泡排序C.插入排序D.选择排序2.设有1000个无序的记录,希望用最快的速度挑选出其中前10个最大的记录,最好选用( )排序法。
A.冒泡排序B.快速排序C.堆排序D.基数排序3.在待排序的记录序列基本有序的前提下,效率最高的排序方法是( )。
A.插入排序B.选择排序C.快速排序D.归并排序’4.不稳定的排序方法是指在排序中,关键字值相等的不同记录的前后相对位置( )。
A.保持不变B.保持相反C.不定D.无关5.内部排序是指在排序的整个过程中,全部数据都在计算机的( )中完成的排序。
A. 内存储器B.外存储器C.内存储器和外存储器D.寄存器6.用冒泡排序的方法对n个数据进行排序,第一趟共比较( )对记录。
A.1B.2C.n-lD.n7.直接插入排序的方法是从第( )个记录开始,插入前边适当位置的排序方法。
A.1B.2C.3D.n8.用堆排序的方法对n个数据进行排序,首先将n个记录分成( )组。
A.1B.2C.n-lD.n9.归并排序的方法对n个数据进行排序,首先将n个记录分成( )组,两两归并。
A.1B.2C.n-lD.n10.直接插入排序的方法要求被排序的数据( )存储。
A.必须是顺序B.必须是链表C.顺序或链表D.二叉树11.冒泡排序的方法要求被排序的数据( )存储。
A.必须是顺序B.必须是链表C.顺序或链表D.二叉树12.快速排序的方法要求被排序的数据( )存储。
A.必须是顺序B.必须是链表C.顺序或链表D.二叉树13.排序方法中,从未排序序列中依次取出记录与已排序序列(初始时为空)中的记录进行比较,将其放入已排序序列的正确位置上的方法,称为( )。
A.希尔排序B.冒泡排序C.插入排序D.选择排序14.每次把待排序的记录划分为左、右两个子序列,其中左序列中记录的关键字均小于等于基准记录的关键字,右序列中记录的关键字均大于基准记录的关键字,则此排序方法叫做( )。
《数据结构(C语言版 第2版)》(严蔚敏 著)第八章练习题答案

《数据结构(C语言版第2版)》(严蔚敏著)第八章练习题答案第8章排序1.选择题(1)从未排序序列中依次取出元素与已排序序列中的元素进行比较,将其放入已排序序列的正确位置上的方法,这种排序方法称为()。
A.归并排序B.冒泡排序C.插入排序D.选择排序答案:C(2)从未排序序列中挑选元素,并将其依次放入已排序序列(初始时为空)的一端的方法,称为()。
A.归并排序B.冒泡排序C.插入排序D.选择排序答案:D(3)对n个不同的关键字由小到大进行冒泡排序,在下列()情况下比较的次数最多。
A.从小到大排列好的B.从大到小排列好的C.元素无序D.元素基本有序答案:B解释:对关键字进行冒泡排序,关键字逆序时比较次数最多。
(4)对n个不同的排序码进行冒泡排序,在元素无序的情况下比较的次数最多为()。
A.n+1B.n C.n-1D.n(n-1)/2答案:D解释:比较次数最多时,第一次比较n-1次,第二次比较n-2次……最后一次比较1次,即(n-1)+(n-2)+…+1=n(n-1)/2。
(5)快速排序在下列()情况下最易发挥其长处。
A.被排序的数据中含有多个相同排序码B.被排序的数据已基本有序C.被排序的数据完全无序D.被排序的数据中的最大值和最小值相差悬殊答案:C解释:B选项是快速排序的最坏情况。
(6)对n个关键字作快速排序,在最坏情况下,算法的时间复杂度是()。
A.O(n)B.O(n2)C.O(nlog2n)D.O(n3)答案:B解释:快速排序的平均时间复杂度为O(nlog2n),但在最坏情况下,即关键字基本排好序的情况下,时间复杂度为O(n2)。
(7)若一组记录的排序码为(46,79,56,38,40,84),则利用快速排序的方法,以第一个记录为基准得到的一次划分结果为()。
A.38,40,46,56,79,84B.40,38,46,79,56,84C.40,38,46,56,79,84D.40,38,46,84,56,79答案:C(8)下列关键字序列中,()是堆。
(19)第八章 排序

21 21
i=2
0 25
1 21 21
2 25 25 25 25 25
3 49 49 49 49 49
4 5 25* 16 25* 16 25* 16 25* 16 25* 16
6 08 08 08 08 08
i=3
49
21 21
i=4
25*
21
21
25
25*
49
16
08
9
i=3
49
21 21
25 25 25 25 25
排序的时间开销: 排序的时间开销是衡量算法好 坏的最重要的标志。排序的时间开 销主要取决于算法执行中的数据比 较次数与数据移动次数。
4
内部排序分类
依排序的实现方法进行分类 插入排序、交换排序、选择排序、 归并排序、和基数排序等。 依算法的执行效率进行分类 简单排序---时间复杂度O(n2) 先进排序方法---时间复杂度O(n log2n)
25* 16 49 16
08
08 08
7
i=4
25*
21 21
i=2
0 25
1 21
21
2 25
25 25
3 49
49 49
4 5 25* 16
25* 16 25* 16
6 08
08 08
i=3
49
21
21
25
25 25
49
49 25*
25* 16
25* 16 49 16
08
08 08
8
i=4
25*
15
折半插入排序的算法 注意,最后折半结束
后有: higt+1=low void BinInsSort ( SqList &L ) { int low, high; for ( int i = 2; i < =L.length; i++) { //L.r[0]空闲无用 low = 1; high = i-1; L.r[0].key = L.r[i].key; while ( low <= high ) { //折半查找插入位置 int mid = ( low + high )/2; if ( L.r[0].key < L.r[mid].key ) high = mid - 1; else low = mid + 1; } for ( int j = i-1; j >= high+1; j-- ) L.r[j+1]= L.r[j]; //记录后移 L.r[high+1] = L.r[0]; //插入
数据结构实验8 查找与排序

注意事项:在磁盘上创建一个目录,专门用于存储数据结构实验的程序。
因为机房机器有还原卡,请同学们将文件夹建立在最后一个盘中,以学号为文件夹名。
实验八查找和排序一、实验目的掌握运用数据结构两种基本运算查找和排序,并能通过其能解决应用问题。
二、实验要求1.掌握本实验的算法。
2.上机将本算法实现。
三、实验内容为宿舍管理人员编写一个宿舍管理查询软件, 程序采用交互工作方式,其流程如下:建立数据文件,数据结构采用线性表,存储方式任选(建议用顺序存储结构),数据元素是结构类型(学号,姓名,性别,房号),元素的值可从键盘上输入,可以在程序中直接初始化。
数据文件按关键字(学号、姓名、房号)进行排序(排序方法任选一种),打印排序结果。
(注意字符串的比较应该用strcmp(str1,str2)函数)查询菜单: (查找方法任选一种)1. 按学号查询2. 按姓名查询3. 按房号查询打印任一查询结果(可以连续操作)。
参考:typedef struct {char sno[10];char sname[2];int sex; //以0表示女,1表示男int roomno;}ElemType;struct SqList{ElemType *elem;int length;};void init(SqList &L){L.elem=(ElemType *)malloc(MAXSIZE*sizeof(ElemType));L.length=0;}void printlist(SqList L){ int i;cout<<" sno name sex roomno\n";for(i=0;i<L.length;i++)cout<<setw(7)<<L.elem[i].sno<<setw(10)<<L.elem[i].sname<<setw(3)<<L.elem[i].sex<<setw(6) <<L.elem[i].roomno<<endl;}。
数据结构第八章_排序

49 38 65 97 76
三趟排序:4 13 27 38 48 49 55 65 76 97
算法描述
#define T 3 int d[]={5,3,1};
例 13 48 97 55 76 4 13 49 27 38 65 49 27 38 65 48 97 55 76 4 j j j
j
j
i
例 初始: 49 38 65 97 76 13 27 48 55 4 取d1=5 49 38 65 97 76 13 27 48 55 4 一趟分组:
一趟排序:13 27 48 55 4 取d2=3 13 27 48 55 4 二趟分组:
49 38 65 97 76 49 38 65 97 76
二趟排序:13 4 48 38 27 49 55 65 97 76 取d3=1 13 27 48 55 4 三趟分组:
初始时令i=s,j=t
首先从j所指位置向前搜索第一个关键字小于x的记录,并和rp
交换 再从i所指位置起向后搜索,找到第一个关键字大于x的记录, 和rp交换 重复上述两步,直至i==j为止 再分别对两个子序列进行快速排序,直到每个子序列只含有 一个记录为止
快速排序演示
算法描述
算法评价
例
38 49 49 38 65 76 97 13 97 76 97 27 13 30 97 27 97 30 初 始 关 键 字
38 49 65 13 76 27 76 13 30 76 27 76 30 97 第 一 趟
38 49 13 65 27 65 13 30 65 27 65 30
38 13 49
时间复杂度
最好情况(每次总是选到中间值作枢轴)T(n)=O(nlog2n) 最坏情况(每次总是选到最小或最大元素作枢轴)
C语言八大排序算法
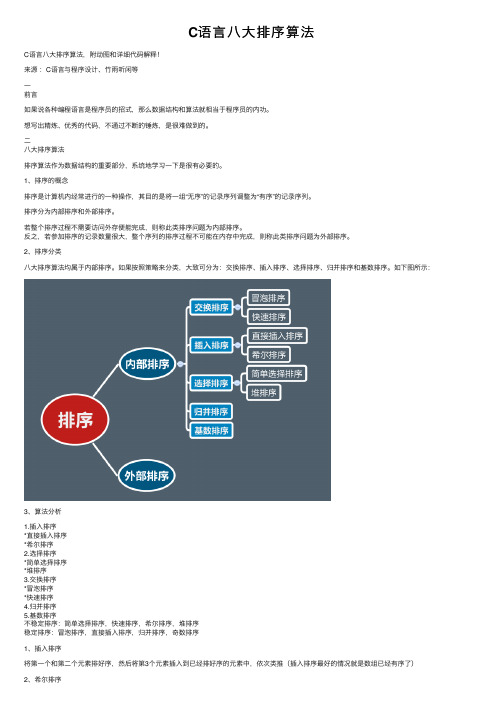
C语⾔⼋⼤排序算法C语⾔⼋⼤排序算法,附动图和详细代码解释!来源:C语⾔与程序设计、⽵⾬听闲等⼀前⾔如果说各种编程语⾔是程序员的招式,那么数据结构和算法就相当于程序员的内功。
想写出精炼、优秀的代码,不通过不断的锤炼,是很难做到的。
⼆⼋⼤排序算法排序算法作为数据结构的重要部分,系统地学习⼀下是很有必要的。
1、排序的概念排序是计算机内经常进⾏的⼀种操作,其⽬的是将⼀组“⽆序”的记录序列调整为“有序”的记录序列。
排序分为内部排序和外部排序。
若整个排序过程不需要访问外存便能完成,则称此类排序问题为内部排序。
反之,若参加排序的记录数量很⼤,整个序列的排序过程不可能在内存中完成,则称此类排序问题为外部排序。
2、排序分类⼋⼤排序算法均属于内部排序。
如果按照策略来分类,⼤致可分为:交换排序、插⼊排序、选择排序、归并排序和基数排序。
如下图所⽰:3、算法分析1.插⼊排序*直接插⼊排序*希尔排序2.选择排序*简单选择排序*堆排序3.交换排序*冒泡排序*快速排序4.归并排序5.基数排序不稳定排序:简单选择排序,快速排序,希尔排序,堆排序稳定排序:冒泡排序,直接插⼊排序,归并排序,奇数排序1、插⼊排序将第⼀个和第⼆个元素排好序,然后将第3个元素插⼊到已经排好序的元素中,依次类推(插⼊排序最好的情况就是数组已经有序了)因为插⼊排序每次只能操作⼀个元素,效率低。
元素个数N,取奇数k=N/2,将下标差值为k的数分为⼀组(⼀组元素个数看总元素个数决定),在组内构成有序序列,再取k=k/2,将下标差值为k的数分为⼀组,构成有序序列,直到k=1,然后再进⾏直接插⼊排序。
3、简单选择排序选出最⼩的数和第⼀个数交换,再在剩余的数中⼜选择最⼩的和第⼆个数交换,依次类推4、堆排序以升序排序为例,利⽤⼩根堆的性质(堆顶元素最⼩)不断输出最⼩元素,直到堆中没有元素1.构建⼩根堆2.输出堆顶元素3.将堆低元素放⼀个到堆顶,再重新构造成⼩根堆,再输出堆顶元素,以此类推5、冒泡排序改进1:如果某次冒泡不存在数据交换,则说明已经排序好了,可以直接退出排序改进2:头尾进⾏冒泡,每次把最⼤的沉底,最⼩的浮上去,两边往中间靠16、快速排序选择⼀个基准元素,⽐基准元素⼩的放基准元素的前⾯,⽐基准元素⼤的放基准元素的后⾯,这种动作叫分区,每次分区都把⼀个数列分成了两部分,每次分区都使得⼀个数字有序,然后将基准元素前⾯部分和后⾯部分继续分区,⼀直分区直到分区的区间中只有⼀个元素的时候,⼀个元素的序列肯定是有序的嘛,所以最后⼀个升序的序列就完成啦。
数据结构(8).ppt

冒泡排序算法描述
viod Bubblesort(Sqlist *L) { ElemType temp; int i,j,flag for (i= L->length-1;i>0; --i) { flag=0; for (j=0;j<i;++j) if (L->data[j].key>L.data[j+1].key) { temp=L->data[j];L->data[j]=L->data[j+1]; L->data[j+1]=temp; //交换数据元素 flag=1; //置标识 } if (!flag) break; } }
冒泡排序(续1)
结束标志:若某遍处理无数据交换,说明已排序 好,可提前结束。 若为正序,则只需进行一趟排序,只进行n-1次关 键字比较,无记录移动。 若为逆序,则需进行n-1趟排序,需进行n(n-1)/2次 比较,并做等数量级的记录移动,算法时间复杂度为 O(n2)。 算法中可设置一标志变量flag,每一遍处理开始时, 令其为0,该遍若有数据交换,则置成1。
直接插入排序--算法分析
空间分析:需要一个记录的辅助空间。 时间分析: 1、若记录关键字已按非递减排列,每趟排序插入,只需 进行一次关键字比较,则总的比较次数为n-1。算法时间复杂 度为O(n)。 2、若关键字已按非递增排列,则对第i个记录进行查找插 入时,要比较i次,移动i+1个记录。则总的比较次数为: ∑i=(n+2)(n-1)/2=(n2+n-2)/2 (i=2..n) 移动记录数为∑(i+1)=(n+4)(n-1)/2=(n2+3n-4)/2 平均比较次数=((n2+n-2)/2+n-1)/2=n2/4+3n/4-1≈n2/4 平均移动次数=((n2+3n-4)/2)/2 =n2/2+7n/2-1≈n2/2 则直接插入排序的时间复杂度为O(n2) 直接插入排序为稳定排序。
(完整版)数据结构与算法第8章答案

第8 章排序技术课后习题讲解1. 填空题⑴排序的主要目的是为了以后对已排序的数据元素进行()。
【解答】查找【分析】对已排序的记录序列进行查找通常能提高查找效率。
⑵对n个元素进行起泡排序,在()情况下比较的次数最少,其比较次数为()。
在()情况下比较次数最多,其比较次数为()。
【解答】正序,n-1,反序,n(n-1)/2⑶对一组记录(54, 38, 96, 23, 15, 72, 60, 45, 83)进行直接插入排序,当把第7个记录60插入到有序表时,为寻找插入位置需比较()次。
【解答】3【分析】当把第7个记录60插入到有序表时,该有序表中有2个记录大于60。
⑷对一组记录(54, 38, 96, 23, 15, 72, 60, 45, 83)进行快速排序,在递归调用中使用的栈所能达到的最大深度为()。
【解答】3⑸对n个待排序记录序列进行快速排序,所需要的最好时间是(),最坏时间是()。
【解答】O(nlog2n),O(n2)⑹利用简单选择排序对n个记录进行排序,最坏情况下,记录交换的次数为()。
【解答】n-1⑺如果要将序列(50,16,23,68,94,70,73)建成堆,只需把16与()交换。
【解答】50⑻对于键值序列(12,13,11,18,60,15,7,18,25,100),用筛选法建堆,必须从键值为()的结点开始。
【解答】60【分析】60是该键值序列对应的完全二叉树中最后一个分支结点。
2. 选择题⑴下述排序方法中,比较次数与待排序记录的初始状态无关的是()。
A插入排序和快速排序B归并排序和快速排序C选择排序和归并排序D插入排序和归并排序【解答】C【分析】选择排序在最好、最坏、平均情况下的时间性能均为O(n2),归并排序在最好、最坏、平均情况下的时间性能均为O(nlog2n)。
⑵下列序列中,()是执行第一趟快速排序的结果。
A [da,ax,eb,de,bb] ff [ha,gc]B [cd,eb,ax,da] ff [ha,gc,bb]C [gc,ax,eb,cd,bb] ff [da,ha]D [ax,bb,cd,da] ff [eb,gc,ha]【解答】A【分析】此题需要按字典序比较,前半区间中的所有元素都应小于ff,后半区间中的所有元素都应大于ff。
数据结构——排序——8种常用排序算法稳定性分析

数据结构——排序——8种常⽤排序算法稳定性分析⾸先,排序算法的稳定性⼤家应该都知道,通俗地讲就是能保证排序前2个相等的数其在序列的前后位置顺序和排序后它们两个的前后位置顺序相同。
在简单形式化⼀下,如果Ai = Aj, Ai原来在位置前,排序后Ai还是要在Aj位置前。
其次,说⼀下稳定性的好处。
排序算法如果是稳定的,那么从⼀个键上排序,然后再从另⼀个键上排序,第⼀个键排序的结果可以为第⼆个键排序所⽤。
基数排序就是这样,先按低位排序,逐次按⾼位排序,低位相同的元素其顺序再⾼位也相同时是不会改变的。
另外,如果排序算法稳定,对基于⽐较的排序算法⽽⾔,元素交换的次数可能会少⼀些(个⼈感觉,没有证实)。
回到主题,现在分析⼀下常见的排序算法的稳定性,每个都给出简单的理由。
(1)冒泡排序冒泡排序就是把⼩的元素往前调或者把⼤的元素往后调。
⽐较是相邻的两个元素⽐较,交换也发⽣在这两个元素之间。
所以,如果两个元素相等,我想你是不会再⽆聊地把他们俩交换⼀下的;如果两个相等的元素没有相邻,那么即使通过前⾯的两两交换把两个相邻起来,这时候也不会交换,所以相同元素的前后顺序并没有改变,所以冒泡排序是⼀种稳定排序算法。
(2)选择排序选择排序是给每个位置选择当前元素最⼩的,⽐如给第⼀个位置选择最⼩的,在剩余元素⾥⾯给第⼆个元素选择第⼆⼩的,依次类推,直到第n-1个元素,第n个元素不⽤选择了,因为只剩下它⼀个最⼤的元素了。
那么,在⼀趟选择,如果当前元素⽐⼀个元素⼩,⽽该⼩的元素⼜出现在⼀个和当前元素相等的元素后⾯,那么交换后稳定性就被破坏了。
⽐较拗⼝,举个例⼦,序列5 8 5 2 9,我们知道第⼀遍选择第1个元素5会和2交换,那么原序列中2个5的相对前后顺序就被破坏了,所以选择排序不是⼀个稳定的排序算法。
(3)插⼊排序插⼊排序是在⼀个已经有序的⼩序列的基础上,⼀次插⼊⼀个元素。
当然,刚开始这个有序的⼩序列只有1个元素,就是第⼀个元素。
数据结构课后习题答案第八章

第八章排序(参考答案)本章所用数据结构#define N 待排序记录的个数typedef struct{ int key;ElemType other;}rectype;rectype r[n+1]; // r为结构体数组8.2稳定排序有:直接插入排序、起泡排序、归并排序、基数排序不稳定排序有:希尔排序、直接选择排序、堆排序希尔排序例:49,38,49,90,70,25直接选择排序例:2,2,1堆排序例:1,2,28.3void StlinkedInsertSort(s , n);// 对静态链表s[1..n]进行表插入排序,并调整结果,使表物理上排序{ #define MAXINT 机器最大整数typedef struct{ int key;int next;}rec;rec s[n+1]; // s为结构体数组s[0].key=maxint; s[1].next=0; //头结点和第一个记录组成循环链表i=2; //从第2个元素开始,依次插入有序链表中while (i<=n){q=0; p=s[0].next; // p指向当前最小元素,q是p的前驱while (p!=0 && s[p].key<s[i].key) // 查找插入位置{ q=p; p=s[p].next; }s[i].next=p; s[q].next=i; // 将第个元素链入i++;} // while(i<=n) 静态链表的插入// 以下是重排静态链表,使之物理有序i=1; p=s[0].next;while (i<=n){WHILE (p<i) p=s[p].next;q=s[p].next;if (i!=p){ s[i] s[p]; s[i].next=p;p=q;i++;}}}//算法结束8.4void TwoWayBubbleSort( rectype r[n+1]; int n)// 对r[1..n]进行双向冒泡排序。
北京林业大学《数据结构与算法》课件PPT 第8章 排序

Typedef struct {
//定义每个记录(数据元素)的结构
KeyType key ;
//关键字
InfoType otherinfo; //其它数据项
}RedType ;
Typedef struct {
//定义顺序表的结构
RedType r [ MAXSIZE +1 ]; //存储顺序表的向量
北京林业大学信息学院
(21,25,49,25*,16,08)
*表示后一个25 将序列存入顺序表L中,将L.r[0]作为哨兵
初态:
完成!
210暂存568*
021816
21516
2425591*
2459*
214569*
49 08
0 123456
i=2 i=3 i=4 i=5 i=6
北京林业大学信息学院
插入排序的基本思想:
有序序列R[1..i-1]
无序序列 R[i..n]
R[i]
有序序列R[1..i] 无序序列 R[i+1..n]
北京林业大学信息学院
插入排序的基本步骤:
1.在R[1..i-1]中查找R[i]的插入位置, R[1..j].key R[i].key< R[j+1..i-1].key; 2.将R[ j+1..i-1]中的所有记录均后移一个位置; 3.将R[i] 插入到R[j+1]的位置上。
//r[0]一般作哨兵或缓冲区
int length ; //顺序表的长度
}SqList ;
北京林业大学信息学院
排序算法分类
规则不同
插入排序 交换排序 选择排序 归并排序
时间复杂度不同
简单排序O(n2) 先进排序O( nlog2n )
8.排序

(1)对n个记录的文件排序所需比较关 键字的次数; (2)对n个记录的文件排序所需移动记 录的次数; (3)排序过程中所需要的辅助存贮空间 的大小。
2014-7-9 数据结构(C语言)wh 7
排序算法其执行的时间不仅依赖于问题 的规模,还取决于输入数据的状态(顺序), 因此,对排序的算法我们将讨论其最好、最 坏和平均三种情况的时间复杂度。
2014-7-9 数据结构(C语言)wh 25
8.3
交换排序
交换排序的基本思想是两两比较待排 序记录的关键字,当发现两个记录的次 序相反时即进行交换,直到没有反序的 记录为止。本节将介绍两种交换排序方 法:冒泡排序和快速排序。
2014-7-9 数据结构(C语言)wh 16
折半插入排序
直接插入排序的基本操作是向当前有序表中插 入一个记录,插入位置的确定通过对有序表中 记录按关键字逐个比较得到的。平均情况下总 比较次数约为n2/4。既然是在当前有序表中确 定插入位置,可以不断二分当前有序表来确定 插入位置,即一次比较,通过待插入记录与有 序表居中的记录按关键字比较,将有序表一分 为二,下次比较在其中一个有序子表中进行, 将子表又一分为二,这样继续下去,直到要比 较的子表中只有一个记录时,比较一次便确定 了插入位置。
第
8
章
排 序
2014-7-9
数据结构(C语言)wh
1
排序(Sort)是这样一种操作,它 将待处理的信息按照某种次序排列, 使之有序。
2014-7-9
数据结构(C语言)wh
2
8.1基本概念
我们假定被排序的对象是由一组记录组成的 文件。每个记录由若干个数据项组成,其中每 个数据项均称为一个关键字项,该数据项的值 称为关键字的值。关键字可用来作为排序的依 据,它们既可是数字类型,也可是字符类型, 字符串类型等。至于选取记录中的哪一项作为 关键字,这应根据问题的要来确定。
数据结构(C语言)第八章 排序

直接插入排序过程
0 21 1 25 2 49 3 4 25* 16 5 08 temp
i=1
0 21
21
1 25
25 25
2 49
49 49
3 4 25* 16
25* 16 25* 16
5 08
08 08
temp 25
i=2
21
49
21
25
25 25
49
49 25*
25* 16
25* 16 49 16
希尔排序 (Shell Sort)
基本思想设待排序对象序列有 n 个对象, 首 先取一个整数 gap < n 作为间隔, 将全部对 象分为 gap 个子序列, 所有距离为 gap 的对 象放在同一个子序列中, 在每一个子序列中 分别施行直接插入排序。然后缩小间隔 gap, 例如取 gap = gap/2,重复上述的子序列划 分和排序工作。直到最后取 gap == 1, 将所 有对象放在同一个序列中排序为止。 希尔排序方法又称为缩小增量排序。
第八章 排序
概述
插入排序
交换排序 选择排序 归并排序 基数排序 各种内排方法比较
概 述
排序: 将一个数据元素的任意序列,重新
排列成一个按关键字有序的序列。
数据表(datalist): 它是待排序数据对象的
有限集合。
主关键字(key): 数据对象有多个属性域,
即多个数据成员组成, 其中有一个属性域可用 来区分对象, 作为排序依据,称为关键字。也 称为关键字。
直接插入排序 (Insert Sort)
基本思想 当插入第i (i 1) 个对象时, 前面的 R[0], R[1], …, R[i-1]已经排好序。这时, 用 R[i]的关键字与R[i-1], R[i-2], …的关键字顺 序进行比较, 找到插入位臵即将R[i]插入, 原 来位臵上的对象向后顺移。
数据结构 排序

集合来说,如果关键字满足数据元素值不同时该关键字的值也 一定不同,这样的关键字称为主关键字。不满足主关键字定义
的关键字称为次关键字。
学生成绩表
序号 0 1 2 3
...
学号 1004 1002 1012 1008
...
姓名 Wang Yun Zhang Pen Li Cheng Chen Hong
常用的选择排序算法:
(1)直接选择排序
(2)堆排序
8.3.1直接选择排序
1、其基本思想
每经过一趟比较就找出一个最小值,与待排序列最前 面的位置互换即可。 (即从待排序的数据元素集合中选取关键字最小的数据元 素并将它与原始数据元素集合中的第一个数据元素交换位 置;然后从不包括第一个位置的数据元素集合中选取关键 字最小的数据元素并将它与原始数据集合中的第二个数据 元素交换位置;如此重复,直到数据元素集合中只剩一个 数据元素为止。)
例4:有序列T1=(08, 25, 49, 46, 58, 67)和序列 T2=(91, 85, 76, 66, 58, 67, 55),判断它们是否 “堆”? 0 0 91 08 1 1 2 2 85 76 25 49 6 3 4 5 3 4 5 66 58 67 55 46 58 67
d=5 d=3 d=1
第2趟
076,301,129,256,438,694,742,751,863,937
第3趟 076,129,256,301,438,694,742,75本思想是:每次从待排序的数据元
素集合中选取关键字最小(或最大)的数据元素放到 数据元素集合的最前(或最后),数据元素集合不断 缩小,当数据元素集合为空时选择排序结束。
数据结构之——八大排序算法

数据结构之——⼋⼤排序算法排序算法⼩汇总 冒泡排序⼀般将前⾯作为有序区(初始⽆元素),后⾯作为⽆序区(初始元素都在⽆序区⾥),在遍历过程中把当前⽆序区最⼩的数像泡泡⼀样,让其往上飘,然后在⽆序区继续执⾏此操作,直到⽆序区不再有元素。
这块是对⽼式冒泡排序的⼀种优化,因为当某次冒泡结束后,可能数组已经变得有序,继续进⾏冒泡排序会增加很多⽆⽤的⽐较次数,提⾼时间复杂度。
所以我们增加了⼀个标识变量flag,将其初始化为1,外层循环还是和⽼式的⼀样从0到末尾,内存循环我们改为从最后⾯向前⾯i(外层循环所处的位置)处遍历找最⼩的,如果在内存没有出现交换,说明⽆序区的元素已经变得有序,所以不需要交换,即整个数组已经变得有序。
(感谢@站在远处看童年在评论区的指正)#include<iostream>using namespace std;void sort(int k[] ,int n){int flag = 1;int temp;for(int i = 0; i < n-1 && flag; i++){flag = 0;for(int j = n-1; j > i; j--){/*下⾯这⾥和i没关系,注意看这块,从下往上travel,两两⽐较,如果不合适就调换,如果上来后⼀次都没调换,说明下⾯已经按顺序拍好了,上⾯也是按顺序排好的,所以完美!*/if(k[j-1] > k[j]){temp = k[j-1];k[j-1] = k[j];k[j] = temp;flag = 1;}}}}int main(){int k[3] = {0,9,6};sort(k,3);for(int i =0; i < 3; i++)printf("%d ",k[i]);}快速排序(Quicksort),基于分治算法思想,是对冒泡排序的⼀种改进。
快速排序由C. A. R. Hoare在1960年提出。
数据结构 ds_8

大小插入到前面已排序表中的适当位置,直到全部插
入完为止。
8.2.1
8.2.2
直接插入排序
二分法插入排序
8.2.3
8.2.4
表插入排序
Shell排序
8.2.1
直接插入排序 Straight Insert Sort
假设待排序的n个记录{R0,R1,…,Rn-1}存放 在数组中,直接插入法在插入记录Ri(i=1,2…n-1) 时,记录集合被划分为两个区间[R0,Ri-1 ]和 [Ri,Rn-1 ],其中,前一个子区间已经排好序, 后一个子区间是当前未排序的部分,将排序码Ki 与Ki-1,Ki-2,…,K0依次比较,找出应该插入 的位置,将记录Ri插入,原位置的记录向后顺移。 直接插入排序采用顺序存储结构。
若将和此序列对应的一维数组看成是一个完全二 叉树,则堆的含义表明,完全二叉树中所有非终端结 点的值均不大于(或不小于)其左右孩子结点的值。 由此,若序列 {k1,k2,…,kn} 是堆,则堆顶元素必为 序列中n个元素的最小值(或最大值)。如果在输出 堆顶的最小值后,使得剩余n-1个元素的序列重又建 成一个堆,则得到次小值。反复执行便能得到所有记 录的有序序列,这个过程称为堆排序。 现在剩下两个问题: (1)如何由一个无序序列建成一个堆; (2)如何在输出堆顶元素后,调整剩余元素为 一个新的堆。
算法分析:
• 空间效率:只需要一个记录的辅助空间。 • 时间效率: 比较记录的次数: 最小: n-1次;最大: n(n-1)/2次 移动记录的次数: 最小: n-1 最大: (n+4)(n-1)/2
pjcj =(1/i)(j+1) =(i+1)/2
j=0 j=0
i-1
i-1
8排序

排序
39
5
4
3
1
2
扫描下面3个气泡: 上、下两个气泡, 若大的在下面,则交换
排序
40
5
4
3
1
2
扫描下面2个气泡: 上、下两个气泡, 若大的在下面,则交换
排序
41
5
4
3
2
1
扫描下面2个气泡: 上、下两个气泡, 若大的在下面,则交换
排序
42
更一般的例子:
2
4
1
上、下两个气泡, 若大的在下面,则交换
数据结构
8 排序
排序 1
主要内容
• 什么是排序 • 内部排序
– 插入式排序:直接插入排序法、希尔排序法 – 交换式排序:气泡法、快速排序法 – 选择式排序:直接选择排序法、堆排序 – 归并排序
• 各种内部排序方法的比较
排序
2
什么是排序
• 排序:按照一定的规则,对一系列数据进行排列 • 数据表:待排序的数据对象的有限集合
25
i j
第一趟排序后
08
16
21
25* 49
– 开始时gap的值较大,子序列中的元素较 少,排序速度较快 – 随着排序进展,gap值逐渐变小,子序列 中元素个数变多,但是由于前面工作的 基础,大多数元素已基本有序,所以排 序速度仍然很快
排序 25
希尔排序
• Gap的取法
– 最初Shell提出取gap = n/2,gap = gap/2,...,直到gap = 1 – Knuth提出取gap = gap/3 + 1 – 还有人提出都取奇数为好 – 也有人提出各gap互质为好
5 0 2 9 4 3 7 1 4 6
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
改进直接插入排序算法
INSERTSORT(DataType R[],int n) i,j; { int i,j; 循环n 循环n-1次 (i=2 i<=n; for (i=2;i<=n;i++) 暂存 R[0 R[i]; { R[0]=R[i]; j=i-1; 比较 (R[0 key<R[j]. while (R[0].key<R[j].key) R[j+1 R[jR[j+1]=R[j- -]; 先后移, 先后移,再j-1 R[j+1 R[0 R[j+1]=R[0]; 插入 } }
25* 25* 25* 25* 49] 49] 25* 25
16 16 16 16 16 49] 49] 25*
8 8 8 8 8 8 49] 49]
25 49 25* 16 8
2011-12-14
12
算法步骤: 算法步骤:
设已排序部分(R1,R2...Ri-1), 已排序部分(R1,R2...Ri ...Ri未排序部分(Ri,Ri+1,...Rn), 未排序部分(Ri,Ri+1,...Rn), (1). R0=Ri (2). R0.key与 Rj.key (j=i-1,i-2...)进行比较; R0.key与 (j=i-1,i-2...)进行比较 进行比较; (3).若 (3).若R0 .key < Rj .key, 则Rj后移一位, j--, .key, Rj后移一位 j-后移一位, --, 再执行(2); 再执行(2); (4).若 (4).若R0 .key >=Rj .key, 则将R0插入Rj+1位置, .key, 则将R0插入Rj+1位置, R0插入Rj+1位置 执行(1) 执行(1)
2011-12-14
9
直接插入排序举例
i (0) temp (1) (2) (3) (4) (5)
21 [21] 21] 25 1 [21 [21 49 2 [21 [21 25* 3 [21 [21 16
2011-12-14
25 25 25] 25] 25 25
49 49 49
25* 16 25* 16 25* 16
直接插入排序的稳定性
直接插入排序是一种稳定的排序方法。 直接插入排序是一种稳定的排序方法。 稳定的排序方法 原理:关键字相同的两个对象,在整个排序过程中, 原理:关键字相同的两个对象,在整个排序过程中, 不会通过比较而相互交换。 不会通过比较而相互交换。
2011-12-14 17
希尔排序
由D.L. Shell提出,又称缩小增量排序,即先小范围排序. Shell提出 又称缩小增量排序,即先小范围排序. 提出, 基本思想: 基本思想: 先将待排序记录序列分割成若干个“较稀疏的”子序列, 先将待排序记录序列分割成若干个“较稀疏的”子序列, 分别进行直接插入排序。经过上述粗略调整, 分别进行直接插入排序。经过上述粗略调整, 整个序列中的记 录已经基本有序,最后再对全部记录进行一次直接插入排序。 录已经基本有序,最后再对全部记录进行一次直接插入排序。 (1) 取一个整数 d1(d1<n 又称增量),将全部 n 个记录分为 又称增量) 若干个组, 倍数的记录放在同一个组中。 若干个组, 将所有距离为 d1 倍数的记录放在同一个组中。 (2) 在每一个组内进行直接插入排序。 在每一个组内进行直接插入排序。 (3) 取d2<d1,重复上述的分组和排序,…..直到最后取di=1 d2<d1,重复上述的分组和排序,…..直到最后取 直到最后取di=1 为止。 为止。 可以看出:希尔排序是分组概念上的直接插入排序. 可以看出:希尔排序是分组概念上的直接插入排序.
i=1 移动次数最大值:∑(i+2)=(n移动次数最大值:∑(i+2)=(n-1)(n+4)/2 n-1 i=1
T(n)=O(n2) T(n)=O(n2)
随机情况:若初始时关键字随机排列。 随机情况:若初始时关键字随机排列。 比较次数的期望值为: 比较次数的期望值为: n2/4 移动次数的期望值为: 移动次数的期望值为: n2/4 原始数据集合越接近有序,直接插入排序的时间效率越高. 原始数据集合越接近有序,直接插入排序的时间效率越高. 其效率: O(n)---O(n 其效率: O(n)---O(n2)
排序(Sorting): 排序(Sorting):
简单地说, 简单地说,排序就是将一组杂乱无章的数据按 一定的规律排列起来(递增或递减)。 一定的规律排列起来(递增或递减)。 排序是计算机中经常遇到的操作。 排序是计算机中经常遇到的操作。
2011-12-14
3
排序的几个基本概念
数据表(Data 数据表(Data List): 待排序的数据对象的有限集合。 待排序的数据对象的有限集合。 关键字(Key): 作为排序依据的数据对象中的属性域。 作为排序依据的数据对象中的属性域。 主关键字 :不同的数据对象若关键字互不相同,则这种 不同的数据对象若关键字互不相同 关键字互不相同,
概述 插入排序 选择排序 交换排序 归并排序 基数排序 比较
2011-12-14 1
总体内容: 总体内容:
排序的概念和有关知识 常用几种排序方法的基本思想、排序过程和 常用几种排序方法的基本思想、 实现算法。 实现算法。 分析各种算法的时间复杂度
2011-12-14
2
8.1、 8.1、排序的概述
2011-12-14
8
直接插入排序( 直接插入排序(Insert Sort) Sort)
基本思想: 基本思想:
R[0]---R[iR[0]---R[i-1] ---R[i
有序区
R[i]---R[nR[i]---R[n-1] ---R[n
无序区
当插入第i个对象时,前面的(R[0],R[1], ,R[i当插入第i个对象时,前面的(R[0],R[1],…,R[i (R[0],R[1], ,R[i1])已经排好序 此时, R[i]的关键字与R[i已经排好序, 的关键字与R[i 1])已经排好序,此时,用R[i]的关键字与R[i-1], R[i-2],…的关键字顺序进行比较 的关键字顺序进行比较, R[i-2], 的关键字顺序进行比较,找到插入位置即将 R[i]插入 原来位置上对象向后顺移。 插入, R[i]插入,原来位置上对象向后顺移。
8 8 8 8 8
10
49] 49] 25* 16 25* 49] 49] 16
直接插入排序算法
InsertSort(DataType R[],int n) i,j; { int i,j; temp; DataType temp; (i=0 i<n//nfor (i=0;i<n-1;i++) //n-1次 temp=R[i+1 { temp=R[i+1]; j=i; while(j>temp.key<R[j]. while(j>-1 && temp.key<R[j].key) R[j+1 R[jR[j+1]=R[j- -]; R[j+1 temp; R[j+1]=temp; } }
2011-12-14 7
8.2、 8.2、插入排序
基本原理: 基本原理:
在一个已排好序的记录子集的基础上, 在一个已排好序的记录子集的基础上,每一步将 下一个待排序的记录有序地插入到已排好序的记录子 集中,直到将所有待排记录全部插入为止。 集中,直到将所有待排记录全部插入为止。
分类: 分类: 直接插入排序( Sort) 直接插入排序(Insert Sort) 希尔排序( 希尔排序(Shell Sort) Sort)
i≠j), 若在排序前的序列中Ri领先于Rj( i<j), Ri领先于Rj(即 i≠j), 若在排序前的序列中Ri领先于Rj(即i<j),经过 排序后得到的序列中Ri仍领先于Rj, 排序后得到的序列中Ri仍领先于Rj, 则称所用的排序方 Ri仍领先于Rj 法是稳定的;反之, 法是稳定的;反之,当相同关键字的领先关系在排序过程 中发生变化,则称所用的排序方法是不稳定的。 中发生变化,则称所用的排序方法是不稳定的。 如:2, 2*,1,排序后若为1, 2*, 2 则该排序方法是 2*,1,排序后若为1, 不稳定的。在应用排序的某些场合,如选举和比赛等,对 不稳定的。在应用排序的某些场合,如选举和比赛等, 排序的稳定性是有特殊要求的。 排序的稳定性是有特殊要求的。
2011-12-14 11
改进: 改进:
R(1) R(0)
R(2)
R(3) R(4)
R(5) R(6)
i 2 3 4 5 6
21 [21] [21] [21 [21 [21 [21 [21 [21 [16 [16 [ 8
25 25 25] 25] 25 25 21 16
49 49 49 49] 49] 25* 25 21
2011-12-14 14
R[0]有两个作用 有两个作用: 有两个作用
其一: 是进入查找循环之前, 其一: 是进入查找循环之前,保存 R[i] 的副本,使之 的副本, 不至于因记录的后移而丢失R[i]中的内容; R[i]中的内容 不至于因记录的后移而丢失R[i]中的内容; 其二: 其二 是在 while 循环时,“监视”下标变量 j 是 循环时, 监视” 否越界, 越界(j<1),R[0]自动控制while循环的 自动控制while 否越界,一旦 越界(j<1),R[0]自动控制while循环的 结束, 从而避免了在while 结束, 从而避免了在while 循环内的每一次都要检测 是否越界( 即省略了循环条件j j 是否越界( 即省略了循环条件j > -1)。 因此, 称为“监视哨” 因此,把 R[0] 称为“监视哨”。