吉林大学IFE矩阵
eigen 四元数 变换矩阵-解释说明

eigen 四元数变换矩阵-概述说明以及解释1.引言1.1 概述概述概述部分将介绍本篇文章的主题以及提供对Eigen库、四元数和变换矩阵的基本理解。
本文主要关注于介绍Eigen库中四元数与变换矩阵的相关概念和实现方法,并提供一些应用实例。
在图形学和机器人学等领域,四元数和变换矩阵是非常重要的数学工具。
四元数是一种数学结构,可用于表示和操作三维旋转的姿态。
它们广泛应用于姿态估计、路径规划和机器人控制等领域。
变换矩阵则是用于在三维空间中表示和处理旋转、平移和缩放等变换的数学工具。
它们在计算机图形学中被广泛使用,用于模型变换、相机投影和场景渲染等应用。
Eigen库是一个C++模板库,提供了高性能的线性代数和数值计算功能。
它具有简洁的接口和高度优化的实现,使得它成为处理数学计算和矩阵运算的首选工具。
Eigen库广泛应用于机器人学、图像处理和物理模拟等领域。
本文将首先介绍Eigen库的基本概念和使用方法,以帮助读者快速上手。
接着,将详细介绍四元数的定义、运算规则和几何意义,以及它们与变换矩阵之间的关系。
最后,将展示如何在Eigen库中使用四元数和变换矩阵,并提供一些实际应用实例,以加深读者对这些概念的理解和应用能力。
总结起来,本文将提供一个关于Eigen库、四元数和变换矩阵的综合指南,旨在帮助读者理解和应用这些重要的数学工具。
阅读本文后,读者将能够在自己的项目中有效地使用Eigen库中的四元数和变换矩阵,并将它们应用于机器人、图形学和相关领域的实际问题中。
1.2 文章结构文章结构部分的内容包括了引言、正文和结论三个部分。
引言部分是整篇文章的开头,用于引入文章的主题和背景,并对文章的主要内容进行概述。
在本篇文章中,引言部分主要包括概述、文章结构、目的和总结四个小节。
概述部分用于简要介绍文章的主题,即Eigen四元数变换矩阵。
文章结构部分用于介绍整篇文章的组织结构和各个部分的内容安排。
目的部分用于说明撰写本文的目的是什么,可以是解决某个问题、讨论某个现象或者介绍某个知识点等。
移动机器人定位图像匹配的快速局部特征算法

(1)
对积分图像I∑(x,y)分别作尺寸为(2n–1)×n,n×(2n–1),和n×n的均值滤波,表示n×n的均值滤波器在x、y和xy方向的响应。再将这3个方向的响应进行尺寸归一化,记为Dxx、Dyy、Dxy,分别近似二阶Gaussian偏导数的运算结果。这样,Hessian矩阵的秩和迹可表示为:
(1 Department of Computer Science and Technology, Jilin University, Changchun 130012,China;2 Key Laboratory of Symbolic Computation and Knowledge Engineering, Ministry of Education, Jilin University, Changchun 130012, China)
(5)
式中:Neibor(x,y)是指点(x,y)的3×3邻域。
3描述子算法
3.1兴趣区域的划分
基于兴趣点的局部区域划分方式是建立不变性局部描述子的基础。为不失一般性,采用形状上下文[10]的方式以兴趣点为中心建立极坐标系,其中的半径坐标和角坐标的计算分别为:
(6)
(7)
在这样的极坐标系中,将兴趣区域划分为若干个不相交的子区域:R0,…,Rs。
基于局部不变性特征的图像匹配包含3个步骤:检测子、描述子以及匹配过程。局部特征检测子也可以称为兴趣点的检测。目前,使用最多的检测子算法还是角点检测算法[2-3]。为使角点检测算法具备尺度不变性,Lindeberg[4]运用自动尺度选择理论,在尺度空间中提取blob区域。Mikolajczyk等人[5]在此基础上,提出了更为鲁棒的尺度不变检测子算法称为Hessian-Laplace和Harris-Laplace。对已有的检测子算法进行性能分析得出结论[6]:基于Hessian的检测子算法比基于Harris的检测子算法更为稳定且重复性[6]更好。
非确定的公钥密码及其实现

CAOJie,SUJinxuan,ZHAO Yongzhe,QIU Zhiyang
(CollegeofComputerScienceandTechnology,JilinUniversity,Changchun130012,China)
公钥密码方案按用途主要分为两类:第一类用于加解密;第 二 类 用 于 数 字 签 名.对 第 一 类 公 钥 密 码,按由密文还原明文的角度,目前已提出的 方 案 都 是“完 备 的”,即 利 用 公 钥 对 任 意 明 文 加 密 后,用 对应的私钥对密文解密均可恢复正确的 明 文.显 然,对 于 保 密 通 讯,上 述 解 密 的 完 备 性 是 必 须 的.但 实 际 应 用 中 公 钥 密 码 很 少 直 接 用 于 对 消 息 的 加 解 密 ,而 是 用 于 约 定 会 话 密 钥 ,然 后 再 用 会 话 密 钥 和 对 称密码实现保密通迅.因此,设计第一类公钥密码方案的关键是如 何 实 现 密 钥 约 定.对 于 实 现 非 对 称 的 密 钥 约 定 ,公 钥 密 码 是 否 必 须 满 足 解 密 完 备 性 的 研 究 目 前 尚 未 见 文 献 报 道 ,本 文 研 究 该 问 题 .
首先引入非确 定 公 钥 密 码 (nondeterministicPKC,NPKC)及 确 定 公 钥 密 码 (deterministicPKC,
收 稿 日 期 :2018-09-19. 第一作者简介:曹 捷(1962—),男,汉族,硕士,工程师,从事 信 息 安 全 和 嵌 入 式 的 研 究,E-mail:caoj@.通 信 作 者 简 介 :赵 永 哲 (1961— ),男 ,汉 族 ,硕 士 ,教 授 ,从 事 信 息 安 全 和 密 码 学 的 研 究 ,E-mail:yongzhe@. 基 金 项 目 :“十 二 五 ”国 家 密 码 发 展 基 金 (批 准 号 :2011L014J00002).
一类特殊矩阵行列式的解法

一类特殊矩阵行列式的解法刘洪伟;徐屹【摘要】讨论了一类特殊矩阵行列式的解法.当方阵不可逆而特征值已知时,可先求出伴随矩阵的特征值,然后利用伴随矩阵的特征值计算出相应矩阵的行列式.我们给出了三种行之有效的求解方法.【期刊名称】《东北电力大学学报》【年(卷),期】2013(033)001【总页数】3页(P179-181)【关键词】伴随阵;奇异阵;特征值【作者】刘洪伟;徐屹【作者单位】东北电力大学理学院,吉林吉林132012;东北电力大学理学院,吉林吉林132012【正文语种】中文【中图分类】O151.21线性代数是工科专业学生必修的一门数学基础课程,也是考研时必考的一门课程,该课程属于比较抽象的理论课程,对于这些抽象的概念学生掌握起来比较困难。
矩阵是线性代数课程的基本概念,所讨论的问题都离不开它,判断方阵是否可逆这是一个重点,也是难点问题[1-2]。
方阵的行列式不等于零是判定方阵可逆的重要方法之一,掌握行列式的解法对本课程及其后继课程的学习都有重要意义。
然而行列式的计算方法种类繁多,灵活多样,没有统一定式。
我们可以采用归类的方式进行总结,不断积累一些好方法,方可提高计算水平。
1 问题提出在教学过程中,曾有同学请教如下两道填空题,两题具有一定代表性。
例1可以利用可逆矩阵来求解伴随矩阵。
对于例2其中涉及到奇异矩阵,对于这类问题,一般教材中没有给出相关的公式和求解方法。
本文总结了这类问题的解法。
对广大同学们来说也有重要的启示作用。
例1设,求A的伴随矩阵。
解析:我们不难发现A是可逆矩阵,可以利用可逆矩阵来求解伴随矩阵。
例2设3阶方阵A的特征值为1,0,-1,矩阵B=E-3A*,其中A*是A的伴随矩阵,求B。
解析:初看此题非常容易求解。
只要知道A*的特征值,便可得到B=E-3A*的特征值,则B就可以计算出来。
但仔细读题会发现A是奇异阵,这给计算A*的特征值带来困难,不能通过A来计算A*的特征值。
但R(A)=2,(R(A)表示矩阵A的秩),可知R(A*)=1,进一步可知矩阵A*有一个非零的特征值,而0是A*的二重特征值。
《企业市场竟争战略研究国内外文献综述》2900字

企业市场竟争战略研究国内外文献综述1 国外研究现状“战略管理”的概念最早是由美国学者提出的,随着“战略管理”在理论和实践中的不断发展,至今,“战略管理”已经成为企业管理中不可或缺的一部分。
目前,国外企业战略研究方向主要分为以下三个方面:其一是企业在未来的战略发展方向,这是企业在经营过程中面临战略选择时常常要探讨的,也是国外学者研究的重点。
目前学者们在研究中往往会选择一个具体的企业实例,然后分析这个企业在特定时间特定情境下的战略选择情况。
Ponomarev曾经以乌克兰电力公司为具体企业,采用案例分析法,利用SWOT矩阵、波特五力模型等分析工具,从企业的内部环境与外部环境、企业本身的优势与劣势来进行分析,并依据这些分析结果制定了乌克兰电力公司的企业战略。
Bandic等人则是从外部环境中的两个因素——政治环境与经济发展情况,探讨了克罗地亚的建筑公司要在激烈的竞争中站稳脚跟,该如何改变现状,重新制定新的公司运营方向。
其二是企业战略中的转型问题。
企业的战略不是一成不变的,而是会动态变化,不断改进的。
随着社会的不断发展,科技的不断进步,企业所面临的外部环境也是变化的越来越快,而企业要想在不断变化的市场环境中生存下来,就不得不做出战略转型来适应环境,适应世界的变化。
在信息技术不断发展的今天,柯达公司就因为没有顺应时代潮流,从而从世界上最大的胶卷生产商沦落到破产。
因此,企业顺应时代进行战略转型的重要性不言而喻。
企业进行战略转型的路径与方法,以及在转型过程中受到哪些因素影响、起到重要作用,这些也是国外学者研究的重点。
Heiser学者探索了领导者以及领导力在企业进行战略转型中的影响以及发挥的作用,认为在企业进行战略转型决策时,变革型的领导时最优的,能够带领企业积极探索,成功进行战略转型。
Oliver等学者则是选择了一家自媒体公司,探索了企业如何在数字技术不断发展的今天,成功抓住技术变革带来的新的机会,从而实现企业战略转型以应对市场变化。
东华理工大学IFE矩阵分析

3 2 2
0.15 0.4 0.2来自根据IFE矩阵可知,东华理工大学是优势大于劣势的, 所以东华理工大学应当采取积极主动,大力宣传其 优势和美誉的战略,提高知名度和竞争力。
东华理工大学IFE矩阵分析
关键内部因素 1. 学科优势:核工地质专 业处于全国领先地位 优势 权重 0.3 评分 4 3 加权分数 1.2 0.75 2. 搬去南昌后,处于省会 0.25 城市,有利于招生和吸引 人才 3. 科研投入在省内大学排 0.1 第三,拥有国家重点实验 室 4.校园绿化环境好 劣势 1.文理学科发展不平衡, 2. 学校由于长期在抚州, 受地域限制,不为大多数 人所知 合并 1 3.1 0.05 0.2 0.1 4 0.4
IFE矩阵_内部因素评价矩阵
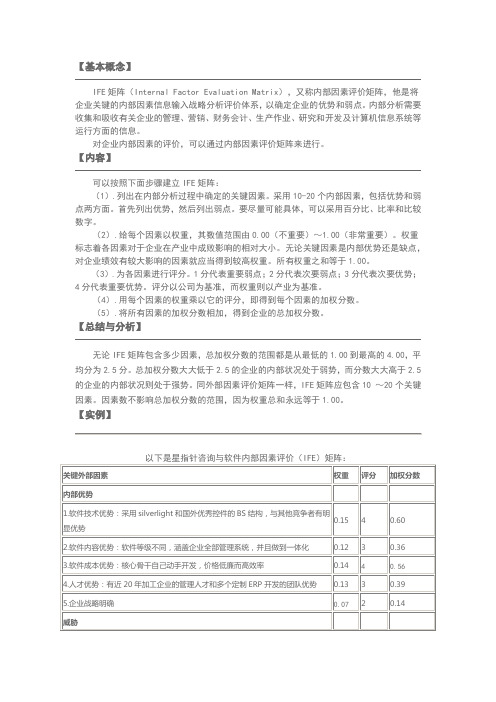
【基本概念】IFE矩阵(Internal Factor Evaluation Matrix),又称内部因素评价矩阵,他是将企业关键的内部因素信息输入战略分析评价体系,以确定企业的优势和弱点。
内部分析需要收集和吸收有关企业的管理、营销、财务会计、生产作业、研究和开发及计算机信息系统等运行方面的信息。
对企业内部因素的评价,可以通过内部因素评价矩阵来进行。
【内容】可以按照下面步骤建立IFE矩阵:(1).列出在内部分析过程中确定的关键因素。
采用10-20个内部因素,包括优势和弱点两方面。
首先列出优势,然后列出弱点。
要尽量可能具体,可以采用百分比、比率和比较数字。
(2).给每个因素以权重,其数值范围由0.00(不重要)~1.00(非常重要)。
权重标志着各因素对于企业在产业中成败影响的相对大小。
无论关键因素是内部优势还是缺点,对企业绩效有较大影响的因素就应当得到较高权重。
所有权重之和等于1.00。
(3).为各因素进行评分。
1分代表重要弱点;2分代表次要弱点;3分代表次要优势;4分代表重要优势。
评分以公司为基准,而权重则以产业为基准。
(4).用每个因素的权重乘以它的评分,即得到每个因素的加权分数。
(5).将所有因素的加权分数相加,得到企业的总加权分数。
【总结与分析】无论IFE矩阵包含多少因素,总加权分数的范围都是从最低的1.00到最高的4.00,平均分为2.5分。
总加权分数大大低于2.5的企业的内部状况处于弱势,而分数大大高于2.5的企业的内部状况则处于强势。
同外部因素评价矩阵一样,IFE矩阵应包含10 ~20个关键因素。
因素数不影响总加权分数的范围,因为权重总和永远等于1.00。
【实例】。
基于IFE 矩阵和EFE 矩阵的X 公司的发展战略研究

1引言当前,随着我国5G 应用推广的不断加速,软件和信息技术服务业呈现稳步向好趋势。
作为行业一员,X 公司自2009年起与国内领先的教育软件类上市公司达成战略合作协议,成为上述公司在江苏地区的核心伙伴,但是,自2019年以来面对复杂多变的国内外环境和因疫情影响不断加大的经济下行压力,X 公司同样面临困境,是否坚持推进转型升级,尝试不断拓展融合应用,以及如何主动加强产业链协作,整合上下游和跨领域资源,持续提升盈利能力和增强核心竞争力,都是X 公司需要思考的发展问题。
本文受江苏省高职院校青年教师企业实践培训项目资助,深入学习了解了X 公司现状,并基于IFE 矩阵、EFE 矩阵进行分析,尝试为X 公司发展献计献策,并希望为同类型的企业发展提供借鉴。
2X 公司的IFE 矩阵和EFE 矩阵分析2.1IFE 矩阵和EFE 矩阵概述IFE (Internal Factor Evaluation )矩阵,作为内部因素评价矩阵,主要通过对企业内部环境的优劣势分析寻找企业发展内因。
EFE (External Factor Evaluation )矩阵,作为外部因素评价矩阵,主要通过对企业外部存在的机会与威胁梳理,探讨外部环境对企业发展的影响。
针对X 公司的评价方法,可按以下五个步骤进行:①列出在内部(外部)分析过程中确定的关键因素;②为每个因素赋予权重;③为各因素评分;④用每个因素的权重乘以它的评分,即得到每个因素的加权分;⑤将所有因素的加权分相加,得到X 公司的总加权分。
2.2X 公司的IFE 矩阵分析结合五个步骤,X 公司管理层为公司10种不同内部影【基金项目】本论文得到江苏省高职院校青年教师企业实践培训项目资助(立项日期:2019-06)。
【作者简介】孙虹(1989-),女,江苏淮安人,讲师,从事管理学研究。
基于IFE 矩阵和EFE 矩阵的X 公司的发展战略研究Research on the Development Strategy of X CompanyBased on IFE Matrix and EFE Matrix孙虹(江苏旅游职业学院,江苏扬州225000)SUN Hong(Jiangsu College of Tourism,Yangzhou 225000,China)【摘要】随着市场需求的不断扩大,我国软件代理行业逐渐呈现竞争态势,并愈演愈烈。
吉林大学2020级工程数学A解答(0001)

工程数学试卷 A 评分标准适用专业: 考试日期:试卷类型:闭卷 考试时刻:120分钟 试卷总分:100分一. 填空题(每题3分,共计3⨯8=24分)一、设二次型()f x =222123232334x x x x x +++ ,那么二次型f 矩阵A =200032023⎡⎤⎢⎥⎢⎥⎢⎥⎣⎦二、设,9,3,A B A B ==三阶方阵有则1AB -= 33、设向量,101,121⎪⎪⎪⎭⎫ ⎝⎛=⎪⎪⎪⎭⎫ ⎝⎛=βα 那么T αβ⋅=101202101⎡⎤⎢⎥⎢⎥⎢⎥⎣⎦4、设向量111,0,11αβ⎛⎫⎛⎫⎪ ⎪== ⎪ ⎪ ⎪ ⎪⎝⎭⎝⎭那么内积[],αβ=2五、已知2BA B E =+,2112A ⎛⎫= ⎪-⎝⎭, 那么B = 2 六、设矩阵A =220210⎛⎫⎪⎝⎭ ,那么矩阵A 的秩为 27. 设A 为n 阶方阵,假设行列式50E A -=,那么A 必有一特点值为 5八、设123012111D =,那么111213A A A ++=二.选择题(3分⨯4=12分)1、 设α是矩阵A 对应于λ的特点向量,那么1P AP -对应的特点向量为( A )(A )1P α- (B )P α (C ) T P α(D ) α 2、 设n 阶矩阵A 可逆,以下说法错误的选项是( C )(A )存在B 使AB I = (B )0A ≠ (C )A 能相似于对角阵 (D) ()r A n =3、设四阶方阵A ,B 有秩()4,()3R A R B ==,那么()R AB =( C )。
(A ) 1 (B ) 2 (C ) 3 (D ) 44、设n 阶矩阵,A B 有0AB =,那么以下正确的有 ( D )(A )0A = (B )B=0 (C )()R A n = (D )()()R A R A n +≤三. 设矩阵方程25461321X -⎡⎤⎡⎤⋅=⎢⎥⎢⎥⎣⎦⎣⎦,求矩阵X (10分) 解:112535131246223,2108A A B AX B X A B ---⎡⎤⎡⎤=⇒=⎢⎥⎢⎥-⎣⎦⎣⎦--⎡⎤⎡⎤==⇒==⎢⎥⎢⎥⎣⎦⎣⎦………4分………6分四、设四元非齐次线性方程组AX b =的系数矩阵A 的秩()3R A =,且已知解123,,ηηη,其中1232132,4354ηηη⎛⎫⎛⎫⎪ ⎪ ⎪ ⎪=+= ⎪ ⎪ ⎪ ⎪⎝⎭⎝⎭, 求方程组AX b =的所有解 (10分)解:4,3n r ==,基础解系:取123342()56ξηηη⎛⎫⎪ ⎪=-+= ⎪ ⎪⎝⎭…………….6分方程组AX b =的所有解为13243,5465c c c R ξη⎛⎫⎛⎫ ⎪ ⎪ ⎪ ⎪+=+∈ ⎪ ⎪ ⎪ ⎪⎝⎭⎝⎭………………4分五、已知向量组123423240,1,1,22100αααα⎛⎫⎛⎫⎛⎫⎛⎫ ⎪ ⎪ ⎪ ⎪==== ⎪ ⎪ ⎪ ⎪ ⎪ ⎪ ⎪ ⎪⎝⎭⎝⎭⎝⎭⎝⎭,(1)求向量组的秩;(2)向量组的一个最大无关组;(3)将其余向量用最大无关组线性表示。
吉 林 大 学 硕 士 学 位 论 文

第四章 PSO 在求解聚类问题上的应用 ..................................... 25
4.1 聚类问题的数学描述 ..................................................................... 25 4.2 k-均值算法简介 ............................................................................. 26 4.3 基于粒子群的 k 均值算法的描述 ................................................. 26 4.3.1 算法描述 .............................................................................. 26 4.3.2 编码与适应度选择 .............................................................. 28 4.4 试验结果及分析 ............................................................................. 28
第二章 粒子群算法 ...................................................................... 5
第三章 改进算法及其在函数优化中的应用 .............................. 8
惯性权重 ........................................................................................... 8 约束因子 ........................................................................................... 8 杂交 PSO 算法 ................................................................................... 8 协同 PSO 算法 ................................................................................... 9 增加积分控制项和限制搜索空间 ................................................. 10 用适应度定标方法和重新定义全局极值 ..................................... 12 3.6.1 实验和结果分析 .................................................................. 13 3.7 用模拟退火策略的粒子群方法(PSOwSA) ..................................... 15 3.8 有分工策略的粒子群方法(PSOwDOW) ........................................... 18 3.9 加入后退算法和后期引入变异算子 ............................................. 21 3.10 随机 PSO 算法(SPSO) .................................................................. 22 3.10.1 SPSO 算法的收敛性分析 ................................................... 23 3.10.2 实例计算和结论分析 ........................................................ 24
基于DCT和SVD的图像检索算法

基于DCT和SVD的图像检索算法
许相莉;张利彪;于哲舟;周春光
【期刊名称】《吉林大学学报(理学版)》
【年(卷),期】2008(46)6
【摘要】提出一种在子块分割和区域划分的基础上, 利用离散余弦变换和奇异值分解对图像进行特征提取的检索算法.首先对图像进行子块分割, 利用离散余弦变换提取重要系数作为子块颜色特征, 进而对图像进行区域划分, 将每个区域中的子块颜色特征分量组成矩阵进行奇异值分解, 得到该区域的检索特征向量, 从而完成图像检索.实验结果表明, 该算法取得了较好的查全率和查准率, 具有较好的检索效果.【总页数】6页(P1125-1130)
【作者】许相莉;张利彪;于哲舟;周春光
【作者单位】吉林大学,计算机科学与技术学院,长春,130012;吉林大学,计算机科学与技术学院,长春,130012;吉林大学,计算机科学与技术学院,长春,130012;吉林大学,计算机科学与技术学院,长春,130012
【正文语种】中文
【中图分类】TP391
【相关文献】
1.基于DCT和SVD的图像哈希水印算法 [J], 徐伟; 刘颖; 朱婷鸽
2.基于DCT-SVD和标记矩阵的鲁棒可逆数字水印算法 [J], 阮涛;张学波
3.基于Fibonacci-DWT-DCT-SVD的音频数字水印算法 [J], 邱皓扬;郭现峰
4.基于LWT-SVD-DCT算法的水印技术 [J], 李伟;孙云娟
5.一种基于最优块的DWT-DCT-SVD的图像数字水印算法 [J], 黄根岭;刘成;黄海于
因版权原因,仅展示原文概要,查看原文内容请购买。
京东集团发展战略浅析——基于VRIO 框架

电子商务京东集团发展战略浅析——基于VRIO框架丘兆珊 东南大学成贤学院摘要:随着互联网的不断发展和各类新兴技术的涌现,企业正面临着愈发复杂且多变的竞争环境。
越来越多的新型产品与服务企业开始加入到电商行业领域中,市场更加细分化,因此在如今这种高度动态的环境下,如何应变电商不断发展,提高自身竞争力,占据该市场的更大份额,京东有必要制定和实施好发展战略,多方位多渠道发展,以更好地适应未来的竞争和发展。
本文将主要以京东为研究对象,对其发展战略进行浅析。
运用VRIO框架,主要针对京东的内部资源和能力进行浅析并运用IFE矩阵分析法对京东内部环境情况进行评价。
通过对京东发展问题与状况的了解,并根据京东战略的目标和定位,对其目前的战略选择进行了分析且给出意见与建议。
为京东集团未来的发展提供参考性建议,同时也为其他电商企业发展战略的制定和实施提供理论性参考。
关键词:京东;发展战略;VRIO框架;电子商务中图分类号:F240 文献识别码:A 文章编号:1001-828X(2019)010-0355-02一、引言我国近年来电商产业发展迅速,电商模式不断创新,影响力与日俱增。
据报告显示,2017年全国电商交易额达29.16万亿元,同比增长11.7%;网络零售市场交易规模达到7.18万亿元,同比增长32.2%,这些数据表明了我国电商交易额持续增长,增速进一步提高。
人们的生活水平也越来越高,需求越来越多样化,且产品更新速度明显加快,新旧技术不断更替,企业如何适应当前环境,抓住机遇,建立自身竞争优势,保证可持续化发展,值得我们去分析与思考。
二、研究的目的与意义我国电商发展优势已经进一步扩大,网络零售规模全球最大、产业创新活力世界领先。
在未来仍将呈现出规模不断扩大,结构不断优化、质量效益不断提升、产业渗透不断深化的发展态势。
因此京东作为我国一家众所周知的电商企业,它要如何应对当前的发展机遇与竞争挑战,继续前进发展,我们有意义进行分析。
基于边缘检测的深度图与单视图配准算法

基于边缘检测的深度图与单视图配准算法
张春彦;赵岩;陈贺新
【期刊名称】《吉林大学学报(信息科学版)》
【年(卷),期】2011(029)003
【摘要】为解决由单视点图像和相关深度数据所创建的立体图像部分存在的重影问题,提出基于边缘检测的深度图与单视图配准算法.对单视图和深度图进行边缘检测得到各自的边界后,以单视图的边界为基准,配准深度图的边界及其邻域的深度数据.实验结果表明,该算法与已有的算法相比,匹配质量明显提高,使在立体图像中的重影现象得到了缓解.
【总页数】6页(P175-180)
【作者】张春彦;赵岩;陈贺新
【作者单位】吉林大学通信工程学院,长春130012;吉林大学通信工程学院,长春130012;吉林大学通信工程学院,长春130012
【正文语种】中文
【中图分类】TN919.8
【相关文献】
1.基于SIFT图像特征匹配的多视角深度图配准算法 [J], 韦虎;张丽艳;刘胜兰;石春琴
2.基于遗传算法的深度图像配准方法研究 [J], 宋晓卿;齐和平
3.基于深度图像的激光点云配准算法 [J], 包竹;谢磊;陆楠楠;常吉亮
4.基于边缘检测的3D-HEVC深度图运动估计算法 [J], 谢晓燕; 辛晓斐; 朱筠; 王飞
龙; 刘阳
5.基于深度图正则化矩阵分解的多视图聚类算法 [J], 刘相男;丁世飞;王丽娟
因版权原因,仅展示原文概要,查看原文内容请购买。
基于遍历矩阵的公钥加密方案

基于遍历矩阵的公钥加密方案
裴士辉;赵永哲;赵宏伟
【期刊名称】《电子学报》
【年(卷),期】2010(038)008
【摘要】目前的公钥加密方案受到来自量子计算的威胁,研究在量子计算下安全的公开加密算法具有重要的意义.本文提出了遍历矩阵的概念,并给出了遍历矩阵的性质.同时提出了基于有限域上遍历矩阵的双侧幂乘问题(TEME:Two-side Ergodic Matrices Exponentiation),并证明了求解TEME问题是NP完全的.据此,本文提出了一个新的公钥加密方案,并在标准模型下,证明了该方案基于TEME问题的安全性,即该方案具有适应性选择密文攻击下的不可区分性.
【总页数】6页(P1908-1913)
【作者】裴士辉;赵永哲;赵宏伟
【作者单位】吉林大学计算机科学与技术学院,吉林长春,130012;浙江工业大学软件学院,浙江杭州,310032;吉林大学计算机科学与技术学院,吉林长春,130012;吉林大学计算机科学与技术学院,吉林长春,130012
【正文语种】中文
【中图分类】TP309.2
【相关文献】
1.基于遍历矩阵的公钥加密方案的安全性分析 [J], 古春生;景征骏;于志敏;吴访升
2.一种具有灵活公钥的自生成证书公钥加密方案(英文) [J],
3.一种具有灵活公钥的自生成证书公钥加密方案 [J], 赵彦慧; 徐茂智; 沈浔浔
4.Hyperledger Fabric中基于层级结构的公钥广播加密方案 [J], 黄宗敏;张大伟
5.基于SM2的多接收方公钥加密方案 [J], 赖俊祚;黄正安;翁健;吴永东
因版权原因,仅展示原文概要,查看原文内容请购买。
基于矩阵分解和聚类的协同过滤算法

基于矩阵分解和聚类的协同过滤算法董立岩;王宇;任怡;李永丽【摘要】基于矩阵分解和聚类提出一种协同过滤推荐算法.先利用交替最小二乘(ALS)算法进行矩阵分解,再利用改进的k-均值聚类算法弥补单一ALS算法在后期协同过滤阶段产生的大计算量问题,解决了由于减小原始矩阵高维度、高稀疏性带来的推荐准确度较低的问题,极大提高了计算速度和推荐精度.实验结果表明,改进算法在推荐准确性上有明显提高.【期刊名称】《吉林大学学报(理学版)》【年(卷),期】2019(057)001【总页数】6页(P105-110)【关键词】矩阵分解;聚类;协同过滤;推荐准确性【作者】董立岩;王宇;任怡;李永丽【作者单位】吉林大学计算机科学与技术学院,长春130012;吉林大学计算机科学与技术学院,长春130012;吉林大学计算机科学与技术学院,长春130012;东北师范大学信息科学与技术学院,长春130117【正文语种】中文【中图分类】TP301.6经典的协同过滤(CF)算法[1]具有较好的综合性能, 但由于该算法基于用户项目评分矩阵进行推荐, 因此矩阵的稀疏程度严重影响算法的精确度[2-5], 而且利用该算法计算目标用户最近邻集时需要遍历整个数据集, 产生大量不必要的计算. 交替最小二乘(ALS)矩阵分解算法能有效解决高维评分数据稀疏性的问题, 同时聚类算法在聚类模型构建完毕后将搜索最近邻的工作有效缩小在各簇类中, 提高了算法的效率, 但聚类算法在评分矩阵高维度、高稀疏性的情况下, 推荐的准确程度通常会降低. 本文针对上述问题对CF算法进行改进, 提出一种基于矩阵分解和聚类的协同过滤推荐算法[6]. 该算法通过ALS矩阵分解方法将原评分矩阵进行降维分解[7], 使得到的矩阵评分属性逼近原评分矩阵, 再利用构建聚类模型的方法对样本训练集上的用户进行分类划分. 模型构建完毕后, 对测试集中的用户, 首先找到该用户所在的聚类, 再在该聚类中进行协同过滤阶段、预测评分、选取Top-N、生成列表、产生推荐. 该算法既降低了原评分矩阵的稀疏程度, 又使最后产生的推荐结果更接近用户的真实评分数据, 减小了误差, 提高了算法的效率.1 算法描述1.1 基于ALS矩阵分解算法在ALS矩阵分解算法中, 矩阵R表示m个用户对n个项目的评分矩阵, 需要利用ALS算法求出一个低秩的矩阵X, 使X尽可能地接近原矩阵R. 其中X=UVT, U,V 为特征矩阵. 该算法的目标函数可表示为(1)其中: Rij表示原矩阵的评分值; Xij表示经过ALS矩阵分解后得到的评分; 目标函数L(x)表示两者的平方误差求和. 为了防止过拟合化, 需要在式(1)的基础上添加对应的二阶正则化相, 则可将目标函数的表达式改写为(2)其中λ为正则化因子. 该算法需要通过连续的交叉迭代, 计算并更新U和V, 直到结果收敛或运行到规定好的次数, 停止运算.首先固定V, 计算求解矩阵U:(3)其中: Ri表示用户i打分的向量; Vui表示用户i评分的特征向量矩阵; nui表示用户i评分的数量. 固定U, 计算更新矩阵V:(4)其中: Rj表示对j评过分用户的评分向量; Umj表示对j打过分用户的特征向量矩阵; nmj表示为j评分用户的数量; I表示单位矩阵. 反复迭代更新, 直到结果收敛或达到最大迭代次数为止. ALS算法如下.算法1 ALS算法.输入:训练数据集D和随机初始化特征矩阵U,V , 迭代最大次数k, 初始次数i=0; 输出:目标用户矩阵U*, 目标物品矩阵V*;步骤1) U*←U,V*←V//初始化步骤2) While i<k步骤3) for Ri←R //对每个用户更新步骤步骤5) end for步骤6) Update U*步骤7) for Rj←R //对每个物品更新步骤步骤9) end for步骤10) Update V*步骤11) end while步骤12) return U*,V*.1.2 改进的k-均值聚类算法在传统的k-均值聚类算法[8]中, 初始节点的选择对聚类的最终实现至关重要, 但该算法对中心点的选择是完全随机的, 会从完整的数据集中任意选择k个数据点作为最初的中心点, 这将导致原应属于同一个簇中的两个点, 在聚类刚开始的阶段被分别选择作为两个簇的中心, 使以后整个数据的聚类过程都出现明显偏差. 本文将最大距离原则融入到k-均值算法中, 将聚类最初的k个中心点之间的相互距离尽可能最大, 防止多个中心点出现在同一簇中. k-均值算法的主要思想如下:假设由n个数据对象组成的样本集合X={x1,x2,…,xi,…,xn}, 聚类中心的个数为k, 聚类中心集合center=φ;步骤1) 在输入的数据集中任意选取其中的一个点xi, 作为聚类模型构建时最初的中心点, 并将该点加入到中心聚合center中, 则center={c1};步骤2) 对于数据集中其他点xi, 依次计算各点与已选择好的中心点center之间的距离:∉center;(5)将距离最远的点作为新的中心, 并加入到集合center中;步骤3) 重复步骤2), 直至将k个中心点全部列举出, 最后形成的聚类中心集合为center={c1,c2,…,ck};步骤4) 依次统计计算数据集中的其他点xi(x=1,2,…,n)到中心cj(j=1,2,…,k)的距离, 并将每个点划分到其最近的簇中, 计算并更新该簇的中心;步骤5) 直至所有的节点均划分到相应的聚类中, 并且聚类的中心点不再出现任何改变时, 聚类结束.算法2 改进k-均值算法.输入:样本集合X={x1,x2,…,xi,…,xn}, 聚类中心的个数为k, 聚类中心集合center=φ;输出:簇划分center={c1,c2,…,ci,…,cn};步骤1) center={xi}//初始化步骤2) While i<k步骤3) for xn←xi //计算各点到center的距离步骤∉center步骤5) end for步骤6) Update center←max{D(xi,center)}步骤7) end while步骤8) return center.1.3 基于ALS和改进聚类的CF算法该算法将ALS模型与改进的k-均值算法相结合, 可很好地弥补互相间的不足, 使结果更精确. 该算法主要包括矩阵分解阶段、聚类模型构建阶段和协同过滤阶段. 1) 矩阵分解阶段:首先利用ALS算法将原矩阵分解[9]成两个低秩矩阵U和V, 对U和V分别进行迭代, 使两个矩阵进行计算后得到的预测值与原有矩阵的值差值最小, 即最小的损失函数;完成迭代, 通过A=UVT得到最后的相似矩阵A, 该矩阵不含缺省值.2) 构建聚类模型阶段:利用改进k-均值算法将用户分类, 最后形成k个聚类, 分别记为聚类1, 聚类2,…,聚类k;对于每个聚类中的不同用户, 两者之间具有良好的相似性, 而分布在不同聚类的用户, 两者之间相似程度较低.3) 协同过滤阶段:由于已经对训练集中的相关数据划分完毕, 当测试集中的用户加入到系统中时, 根据该用户对所有项目的评分向量与各簇中心质点的距离, 将其划到与其最近的簇类中, 并从该簇类中选取N个相似度较高的用户作为其最近邻集[10], 通过Pearson相似度公式[11]进行预测打分, 根据评估计算出结果, 将评分位于前列的N个项目, 生成最终的列表Top-N返回给该用户, 算法流程如图1所示. 图1 矩阵分解与聚类的协同过滤算法流程Fig.1 Flow chart of collaborative filtering algorithm based on matrix decomposition and clustering2 实验2.1 实验数据集实验使用的数据源于MovieLens 100K数据集[12], 该数据集包括943位用户, 1 682部电影, 用户给电影的评分共计100 000条, 本文实验主要运用3张信息表, 分别为u.item电影信息表、 u.data用户-电影评分表和er用户信息表.在该数据集中, 采用1~5分不等的评分制度, 分数越高表明用户对该类电影越喜欢, 反之, 分数越低表示用户对该类电影好感度越低, 其中0分表示未对电影作出任何评分. 同时, 该数据集还将涉及到的电影进行不同类别的分类, 共将其分为19个不同的类别[13], 包括爱情、喜剧、记录等题材, 每部电影可同时拥有一个或者多个不同的类别属性.2.2 评价指标本文采用平均绝对误差MAE和准确率(Precision)这两个指标评测协同过滤算法的性能优劣[14]. 平均绝对误差是通过系统中的已有评分和实验过程中的预测评分之间的差值大小反映预测评分的准确率, MAE的值越小, 表明系统的预测准确率越高, 定义为(6)其中: U表示测试集中所有用户构成的集合; I表示所有项目构成的集合; Pui表示经过该算法预测用户u对项目i的评分; Rui表示原评分矩阵的用户u对项目i的评分; n表示预测评分在实际测试集合中的命中次数.准确率表示系统在预测打分完毕后, 为用户推荐前N个评分最高的项目, 即Top-N 推荐列表, 其中能被真正用于推荐的项目占推荐结果的比例, 定义为(7)图2 不同个数聚类中心下的MAEFig.2 MAE under different number of clustering centers式中: R(u)表示系统为目标用户推荐所有项目的集合; T(u)表示用户在测试集上的行为列表. Precision值越大, 表明系统的推荐准确率越高, 推荐的结果适合用户的兴趣爱好.2.3 实验结果分析本文用两步实验对算法进行对比分析. 首先采用改进CF算法, 以MovieLens 100K 的数据作为实验数据集, 在其他条件相同的情况下, 观察不同个数的聚类中心对实验推荐结果的影响[15],如图2所示; 其次根据实验产生的最佳聚类中心个数作为实验初始条件, 并在其他条件相同的情况下, 对ALS矩阵分解算法[16]、 k-均值聚类算法以及本文改进算法进行对比实验, 考察不同算法对推荐结果的影响, 实验结果如图3所示.由图2可见, 当k<16时, MAE的值随着k值的增加呈现逐渐降低的趋势; 当k=16时, MAE的值达到最小值, 之后该值逐渐上升, 算法表现出较好的性能, 因此, 本文选取的聚类中心个数为16.当k=16时, 即共有16个用户聚类中心, 最近邻集合的个数选取为30, 在测试集上分别对ALS矩阵分解算法[17]、 k-均值聚类算法以及本文算法进行对比分析, 对比结果如图3所示. 由图3可见, 当聚类中心k=16, 最近邻集合个数为30时, 本文改进的聚类算法的MAE值明显好于其他算法, 整体性能得到提高.单一的MAE指标并不能很好说明改进算法有较好的性能[18], 因此, 本文用推荐准确率指标进一步对算法进行评估. 图4为ALS算法、 k-均值聚类算法和本文算法的推荐准确率分布结果.图3 不同算法下的MAEFig.3 MAE under different algorithms图4 不同算法下的准确率Fig.4 Precision under different algorithms由图4可见, 当聚类中心个数k=16, 最近邻集合的个数为30时, 选取预测评分Top-50的数据进行分析, 将本文算法与ALS算法、 k-均值聚类算法进行比较, 在准确率推荐方面, 本文算法的准确率数值明显高于其他算法, 因此, 本文算法推荐精度更高.综上所述, 为了避免由于数据稀疏带来的计算误差及协同过滤过程中带来大量的数据冗余, 提高推荐算法的效率和精度, 本文在CF算法的基础上, 提出了一种基于ALS矩阵分解和改进k-均值聚类的改进CF算法. 该算法先利用ALS矩阵分解技术对高维度、高稀疏性的矩阵进行降维填充, 减少了由于数据稀疏性带来的推荐误差; 然后利用改进的k-均值聚类算法对补全好的矩阵建立聚类模型, 再进行协同过滤处理; 最后通过对比实验验证了该算法的正确性和有效性, 在推荐准确率及算法时间复杂度上都明显优于传统CF算法.参考文献【相关文献】[1] CHEE S H S, HAN Jiawei, WANG Ke. RecTree: An Efficient Collaborative Filtering Method [C]//Proceedings of the International Conference on Data Warehousing and Knowledge Discovery. Heidelberg: Springer-Verlag, 2001: 141-151.[2] NAJAFABADI M K, MAHRIN M N, CHUPRAT S, et al. Improving the Accuracy of Collaborative Filtering Recommendations Using Clustering and Association Rules Mining on Implicit Data [J]. Computers in Human Behavior, 2017, 67(2): 113-128.[3] 黄贤英,熊李媛,李沁东. 基于改进协同过滤算法的个性化新闻推荐技术 [J]. 四川大学学报(自然科学版), 2018, 55(1): 49-55. (HUANG Xianying, XIONG Liyuan, LI Qindong. Personalized News Recommendation Technology Based on Improved Collaborative Filtering Algorithm [J]. Journal of Sichuan University (Natural Science Edition), 2018, 55(1): 49-55.)[4] 黄贤英,龙姝言,谢晋. 基于用户非对称相似性的协同过滤推荐算法 [J]. 四川大学学报(自然科学版), 2018, 55(3): 489-493. (HUANG Xianying, LONG Shuyan, XIE Jin. Collaborative Filtering Recommendation Algorithm Based on Asymmetrical Similarity of User [J]. Journal of Sichuan University (Natural Science Edition), 2018, 55(3): 489-493.)[5] 金玉,崔兰兰,孙界平, 等. 基于综合相似度迁移的协同过滤算法 [J]. 四川大学学报(自然科学版), 2018, 55(3): 477-482. (JIN Yu, CUI Lanlan, SUN Jieping, et al. Collaborative Filtering Algorithm Based on Integrated Similarity Transfer [J]. Journal of Sichuan University (Natural Science Edition), 2018, 55(3): 477-482.)[6] ORTEGA F, HERNANDO A, BOBADILLA J, et al. Recommending Items to Group of Users Using Matrix Factorization Based Collaborative Filtering [J]. Information Sciences, 2016, 345(16): 313-324.[7] HERNANDO A, ORTEGA F. A Non Negative Matrix Factorization for Collaborative Filtering Recommender Systems Based on a Bayesian Probabilistic Model [J]. Knowledge-Based Systems, 2016, 97: 188-202.[8] HIMEL M T, UDDIN M N, HOSSAIN M A, et al. Weight Based Movie Recommendation System Using K-Means Algorithm [C]//Proceedings of the International Conference on Information and Communication Technology Convergence. Piscataway, NJ: IEEE, 2017: 1302-1306.[9] CHEN Jing, FANG Jianbin, LIU Weifeng, et al. Efficient and Portable ALS Matrix Factorization for Recommender Systems [C]//Proceedings of the Parallel and Distributed Processing Symposium Workshops. Piscataway, NJ: IEEE, 2017: 409-418.[10] LIU Jianping, WANG Yong, YAN Fenghua. An Improved Collaborative Filtering Recommendation Algorithm [C]//Proceedings of the 1st International Conference on Networking and Distributed Computing. Piscataway, NJ: IEEE, 2010: 194-198.[11] LENG Yajun, LU Qing, LIANG Changyong. A Collaborative Filtering Similarity Measure Based on Potential Field [J]. Kybernetes, 2016, 45(3): 434-445.[12] HARPER F M, KONSTAN J A. The MovieLens Datasets [J]. ACM Transactions on Interactive Intelligent Systems, 2015, 5(4): 1-19.[13] NGUYEN H, DINH T. A Modified Regularized Non-negative Matrix Factorization for MovieLens [C]//IEEE Rivf International Conference on Computing and CommunicationTechnologies, Research, Innovation, and Vision for the Future. Piscataway, NJ: IEEE, 2012: 1-5.[14 V, CASTELLS P. Rank and Relevance in Novelty and Diversity Metrics for Recommender Systems [C]//Proceedings of the 5th ACM Conference on Recommender Systems. New York: ACM, 2011: 109-116.[15] PHORASIM P, YU Lasheng. Movies Recommendation System Using Collaborative Filtering and k-Means [J]. International Journal of Advanced Research in Computer Science, 2017, 7(29): 52-59.[16] WINLAW M, HYNES M B, CATERINI A, et al. Algorithmic Acceleration of Parallel ALS for Collaborative Filtering: Speeding Up Distributed Big Data Recommendation in Spark [C]//Proceedings of 21st International Conference on Parallel and Distributed Systems. Piscataway, NJ: IEEE, 2016: 682-691.[17] LEE H, KWON J. Improving the Scalability of ALS-Based Large Recommender Systems with Similar User Index [J]. International Journal of Software Engineering & Its Applications, 2015, 9(2): 189-200.[18] HERLOCKER J L. Evaluating Collaborative Filtering Recommender Systems [J]. ACM Transactions on Information Systems, 2004, 22(1): 5-53.。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
战略规划与咨询作业——
吉林大学IFE矩阵分析
1. 吉林大学简介
吉林大学(Jilin University ),简称吉大,坐落在吉林省省会长春市,始建于1946年。
是由中华人民共和国教育部直属的综合性全国重点大学。
系国家“211工程”、“985工程”、“2011计划”重点建设的著名学府。
学校学科门类齐全,涵盖哲学、经济学、法学、教育学、文学、历史学、理学、工学、农学、医学、管理学、军事学、艺术学等全部13大学科门类;有本科专业124个,一级学科硕士学位授权点59个,一级学科博士学位授权点44个。
截止2014年底,学校有教育部人文社会科学重点研究基地6个,新一轮“985工程”学科建设项目24个,国家工程实验室1个,国家重点实验室6个,教育部重点实验室11个,其他部委重点实验室23个。
是中国目前办学规模最大的高等学府,涵盖13大学科门类。
吉林大学已成为在国家和区域经济社会发展中具有重要地位的高素质创新人才培养、高水平科学研究和成果转化、高质量社会服务、先进文化引领的重要基地。
正朝着建设世界一流大学的宏伟目标迈进。
并且吉林大学连续多年进入中国大学排行榜前十名。
2.大学核心竞争力分析
核心竞争力定义
大学的核心竞争力 说明
由上面分析可知,一个大学的核心竞争力可以由科学研究、教学水平、办学资源、学校声誉、基本条件几项及其二级因素组成。
3.吉林大学核心竞争力分析
核心能力因素二级因素弱核心能力程度强
0 1 2 3 4 5 6 7 8 9
10
图表1.
由2部分分析可知,我们做出了这个吉林大学核心竞争力分析表,我们根据吉林大学官网上公布的相关资料,结合二级指标中应包含的因素对其核心能力程度打分,得出如图表1.所示。
我们认为吉林大学能位列中国大学前十名是因为其具有优秀的师资队伍以及较高的科研产出,其在科学研究方面
都处于较为领先的水平,这也是评价一所大学好坏的重要指标。
然后由于吉林大学地处吉林省长春市,相较于北上广深这类超一线城市,其相对不发达,经济相对较弱。
这直接影响学生对大学的选择、教师与学生的视野与职业的发展,这项因素对其影响很大,也导致其生源水平相对较弱,而且由于吉林大学过于庞大,蕴含学科过多,师生数量过于庞大,所以其效率与效益较低。
故我们认为地理位置、校园环境、生源水平、效率与效益是其内部劣势。
4.吉林大学优势与劣势分析
优势:
1.总体概况:吉林大学是教育部直属的全国重点综合性大学,坐落在吉林省长春市。
被列入“985 工程”,“211 工程国家重点建设的大学。
吉林大学学科门类齐全,下设43个学院,涵盖哲学、经济学、法学、教育学、文学、历史学、理学、工学、农学、医学、管理学、军事学、艺术学等全部13大学科门类;有本科专业125个,一级学科硕士学位授权点59个,一级学科博士学位授权点44个,硕士学位授权点302个,博士学位授权点242个,博士后科研流动站42个;有一级学科国家重点学科4个(覆盖17个二级学科),二级学科国家重点学科15个,国家重点(培育)学科4个。
多点位居中国大学排行榜前十名,在国外大学排榜中也屡获佳绩。
2.师资方面:吉林大学师资力量雄厚,有教师6568人,其中教授2058人,博士生指导教师1186人。
有中国科学院和中国工程院院士24人(双聘15人),哲学社会科学资深教授6人,国务院学位委员会委员2人,国务院学位委员会学科评议组成员18人,教育部社会科学委员会委员7人,教育部科学技术委员会委员2人,教育部科学技术委员会学部委员8人,国家教学名师奖获得者10人,“长江学者和创新团队发展计划”创新团队5个,“长江学者奖励计划”入选者29人,国家有突出贡献的中青年专家13人,国家杰出青年基金获得者28人,中央马克思理论研究和建设工程项目首席专家5人,国家“973”计划(含重大科学研究计划)项目首席科学家5人,国家社科基金重大项目首席专家4人,教育部跨世纪优秀人才32人,教育部新世纪优秀人才132人,百千万人才工程国家级人选16人,新世纪百千万人才工程国家级人选19人等一大批优秀人才和创新团队。
学校在师资队伍建设方面,一方面加强了教师的选留招聘工作,一方面积极做好人才引进和培养工作。
2004年,共有353人来校任教。
其中新引进1名双聘院士、2名诺贝尔奖得主的外籍院士、15名学术带头人和学术骨干,选留了73名博士研究生,使师资队伍进一步壮大。
对现有人员,学校积极创造条件,选拔派出
优秀教师出国或到其他高校进行学术交流或继续深造,加强培养。
3.学科建设方面,学校现有教育部人文社会科学重点研究基地6个,一流大学与一流学科建设项目52个,国家重点实验室5个,国家工程实验室1个,国家地方联合工程实验4个,国家工程技术研究中心1个,教育部重点实验室11个,其他部委重点实验室24个。
学校承担了大量国家级和省部级科研项目,产出了一批产业化前景好、技术含量高的高新技术成果。
学校对外交流广泛,校际合作紧密,已与美国、德国、韩国等39个国家和地区的236所高校、科研机构或国际学术组织建立了合作与交流关系。
近年来,先后与国外一流高校合作,建立了23个联合研究中心、实验室。
4.校园建设方面:吉林大学校园占地面积611万多平方米,校舍建筑面积363万平方米。
现有6个校区7个校园,分布在长春市的不同方位。
已建立计算机网络把所有校区连为一体,使网上办公、远程教育等更加便捷。
学校在珠海市建珠海校区,占地面积5000亩。
学校图书馆各类藏书743万册,已被确定为联合国教科文组织、联合国工业发展组织和世界银行的藏书馆。
经教育部批准建设在我校的CALIS东北地区中心为全国七大中心之一。
5.科研项目方面,吉林大学教师学术能力强、具有较强的科学创新精神,每年都能那大国家自然科学基金、国家社科基金、国家基础研究项目、以及吉林省的相关项目。
在项目研究数量与成果质量上排位居中国大学前列。
许多科研成果屡获国家级科技奖励、国家级社科奖励、专利进步奖、国家图书奖等。
6.学术研究方面,吉林大学2013年科学引文索引(SCIE)收录文献总数2960篇。
其中,论文2727篇,比去年增加418篇,高校排名第10位,在去年前进1 位的基础上又提高1位;2004——2013年期间,累计11854篇论文(根据SCI统计)被引126535次,高校排名第9位,比去年提高3位。
其中,科技论文数量在SCI收录中国化学领域排名第2位、材料学领域排名第11位、数学领域排名第13位、地学领域排名第14位、物理学领域排名第15位、生物领域排名第17位、医学领域排名第18位,在Medline数据库收录论文高校排名第13位。
7.人才培养方面,根据中国校友会发布《2012中国大学杰出校友排行榜》。
在总榜单前十位中,吉大位列第七,是吉林省唯一上榜的高校。
这一榜单共调研了我国政界、学界和商界三大领域的杰出人才共近8000人。
其中,政界1400多人,学界3600多人,包括两院院士2400多人、杰出人文社会科学家1200多人,商界2600多人。
毕业于吉大的政、学、商界杰出人才105人,与武汉大学并列第七,其中政界英才29人、两院院士30人、社科学家38人、亿万富豪8人。
而且,每年吉林大学都会有很多优秀的学生获得“挑战杯”、“数学建模”、“大学生科技挑战赛”等类比赛中获得优胜,硕果累累。
劣势:
1,地理位置,吉大各校区遍布长春各地,相对不发达,建筑相对较为久远,现代化程度也不高,并且气候干燥寒冷,这也直接影响到考生的择校。
2,生源水平,吉大在985高校里的排名属于中等,可是其录取分数相对于其他高校较低,吉大专业质量不一,普通专业与较差的专业可以差到几十分,这也是导致生源质量差的一个原因。
3,效率与效益,吉林大学校区众多,学生与教师数量庞大,致使内部运营不够流畅,效益与效率略低,这也是很难避免的。
4,校园环境,吉大各校区校园环境不一,中心校区即南区校园环境最优,四人寝室,拥有新建立的日新楼和建立不久的基础园区,校园环境不错,但是其他几个校区则没有如此待遇,校园环境整体并不算太好。
综上分析,吉林大学的优势众多、劣势分明。
根据我们列出的相关数为我们IFE矩阵的构建提供了理论支持与依据。
5.吉林大学IFE矩阵
注:权重总分为1分,每项评分满分为4分。
评分值涵义:1=弱,2=次弱,3=次强,4=强
6.评价及建议
矩阵评价的总分为分,处于中等偏上的得分水平。
通过IFE矩阵,我们可以直观的分析出,吉林大学的优势与劣势。
并且哪些优势指标是其核心竞争力。
总体来说,吉林大学是一所在各个方面发展的都处于相对不错状态的大学,但是其还有很多可以发展、强化的地方。
我们认为吉林大学可以通过提高研究生、博士生的学术水平与科研能力、加大与国外以及国内顶尖院校的交流,学习其优势等手段提升其成果质量、科研产出的数量和质量,将这些关键成功因素转化为其核心能力。
教师队伍是一个大学的灵魂,加大对优秀老师的鼓励力度以及吸纳更多的优秀教师来增加教师的整体水平,这样对吉林大学优势学科的构建有着推动作用。
吉林大学可以通过在北上广深这类较发达的城市建立分校的手段,弥补其地理位置所带来的劣势,在招生上多加大鼓励力度,吸引更加优秀的本科生和研究生,学生的能力对其人才的产出起着关键的作用。
吉林大学可以通过整合学科,精简一些具有发展优势的学科,除去一些相对处于劣势的学科,整合学校内的学科优势与资源,提高效率与效益。
把劣势化为优势,强化其优势,弥补其不足,相信吉林大学会在不久的将来成为世界级的名校。